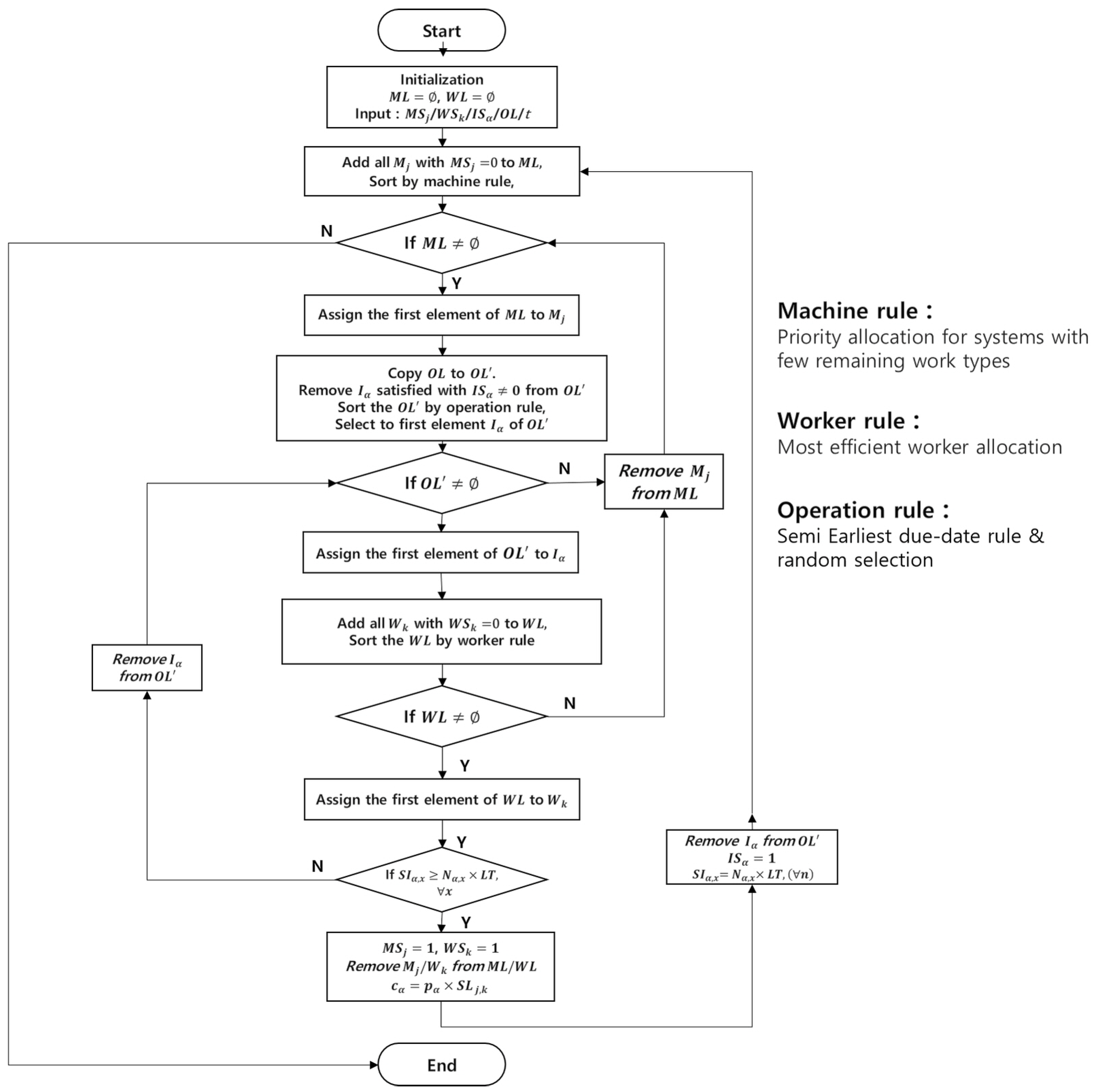
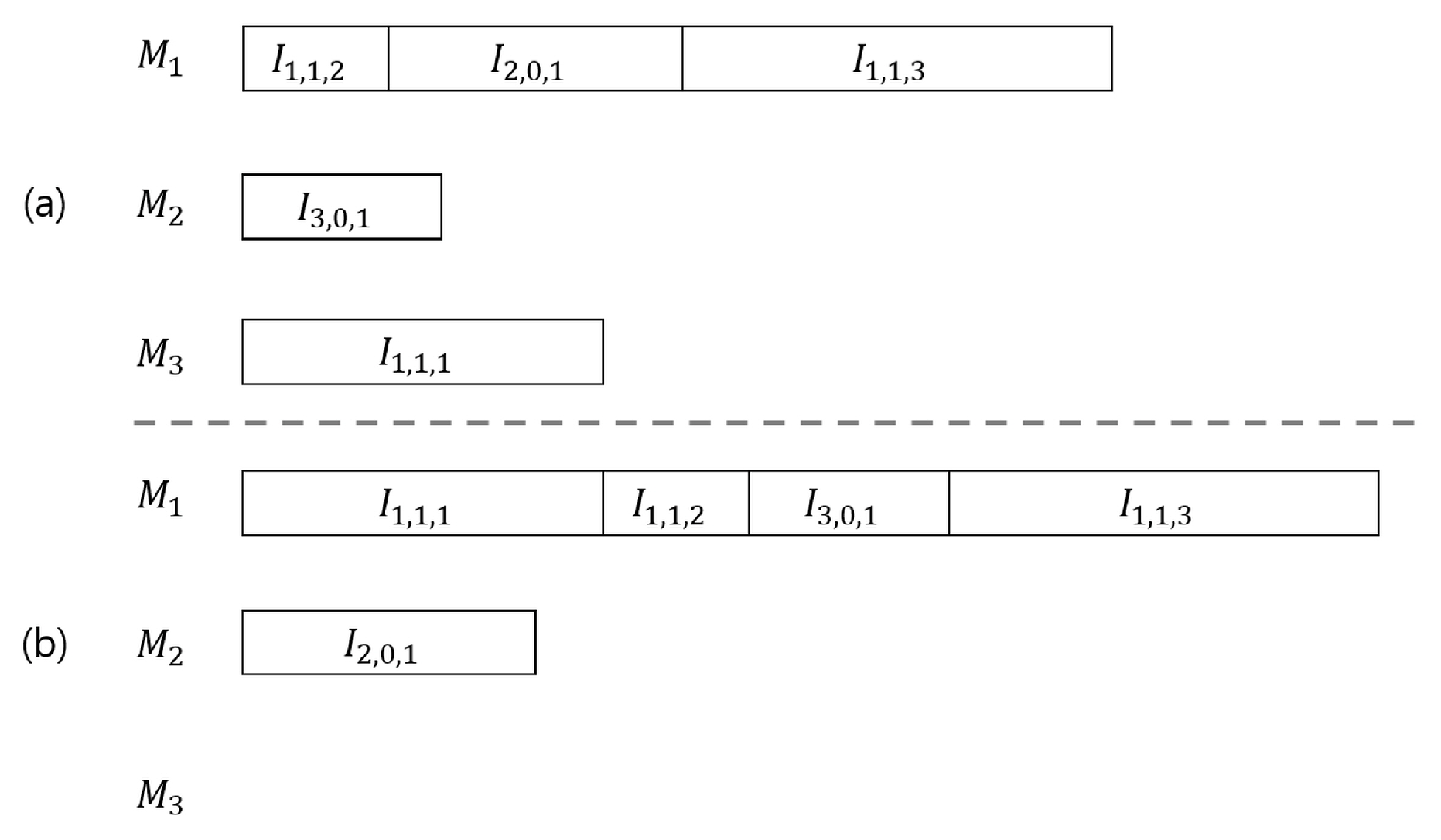
1. Introduction
Several changes have occurred with the onset of the mass customization era following the traditional mass production era. Additionally, multipurpose machines and manufacturing processes have been adapted to flexible production systems producing a batch of small quantity [
1]. In response to this trend, scheduling studies have focused on flexible manufacturing processes and have actively been conducted to solve the flexible job-shop scheduling problem (FJSP). In the FJSP research, various constraints, such as sequence dependent setup time [
2,
3,
4], learning effect [
5], and dual resource constraint [
6,
7,
8], are considered depending on the manufacturing environment. This study deals with the dual resource constrained flexible job-shop scheduling problem (DRCFJSP) under the consideration of the worker’s skill level for machines and multilevel product structures (MLPS).
Research on the complexity of processes has been conducted, but there has been little research to reflect the complexity of product structures. The majority of the literature assumes a product structure composed of simple sequential operations for a job, which is very different from the bill of materials (BOM) structure that is widely used in manufacturing industries, especially for products requiring assembly processes. In several advanced planning and scheduling (APS) studies, the product complexity was reflected through the concept of MLPS. MLPS is a hierarchical tree that expresses the product structure and is essential for products requiring assembly processes. The top node of tree is a final product. Each child node of the tree represents a component or part of the product. With the MLPS, the operations for all the child nodes associated with the parent node must be performed, and then the operation for the parent node can be conducted. Chen et al. [
9] developed a mixed integer programming model, which reflected the MLPS as a constraint; however, they only solved small-size problems with two orders. Dayou et al. [
10] solved a multiobjective APS problem using a genetic algorithm (GA). To solve the structural problem of an MLPS, two chromosomes were constructed for the operation priority and machine assignment, respectively. The priority was randomly assigned through the operation priority chromosome, and the solution was constructed by assigning a feasible solution with the highest priority to a machine through the machine assignment chromosome. The performance and efficiency of the algorithm have been proven by experiments in 5 orders, 50 operations, and 20 machines. Chansombat et al. [
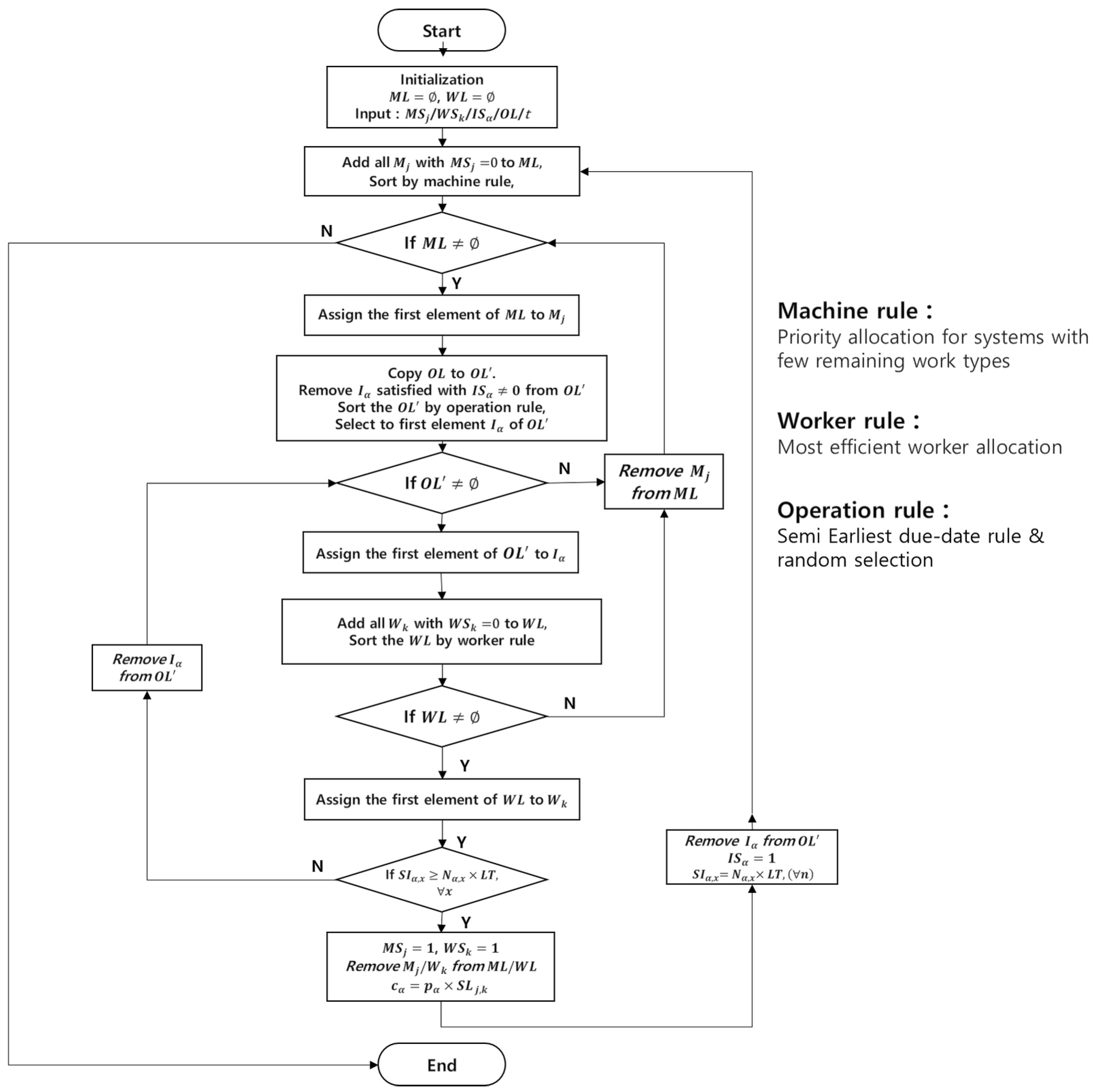
11] focused on the determination of the operation sequence using the Bat algorithm. To solve the structural problems of the MLPS, the operation sequence was first determined and the solution feasibility was derived by correcting the misplacement of the items. In this study, unlike previous studies that separately determined the operation sequence and machine assignment, we propose a time-based integrated initial solution algorithm that allocates feasible operations and available resources (machine and worker), based on the priority rules that maintain solution feasibility and local search algorithms that narrow the search space using the earliest possible start time (EPST) and latest possible start time (LPST). In addition, previous studies determined the batch size based on the individual order quantity without considering the inventory level of the subparts and machine-dependent batch size, which is not suitable in environments where inventories exist and the batch size is required for the machine efficiency. Therefore, we combine the quantity of the subcomponents required for each order and generate the operations based on the inventory level and batch size.
The majority of the literature on scheduling considers only the machine as a constrained resource and ignores the constraints of worker availability required for the operations [
12]. However, considering that the number of workers is limited in some manufacturing industries, scheduling without considering workers may be significantly different from the shop floor [
6]. Studies have been conducted to solve the problem of co-considering the workers and machines as the dual resource constrained (DRC) scheduling problem. In particular, the dual resource constraints are investigated in the job shop and flexible job shop environments. The DRCFJSP has been studied using metaheuristic algorithms, such as GA [
12,
13], variable neighborhood search (VNS) algorithm [
6,
8], artificial bee colony algorithm [
14], and memetic algorithm [
15], because DRCFJSP adds another subproblem of worker assignment, which makes the problem complex, in addition to the machine assignment and operation sequence determination [
16]. For example, EIMaraghy et al. [
12] proposed a GA algorithm to solve the DRCFJSP in an environment with equal skill level of the workers. The allocation of the operations, machines, and workers was expressed as three chromosomes, and the superiority of the algorithm was proved by comparing it with the dispatching rules. Gong et al. [
15] proposed a memetic algorithm for the DRCFJSP with multiobjective functions. The aim of the proposed algorithm was to minimize the makespan and workload of the machine and worker under the consideration of different worker skill levels. Lei et al. [
8] proposed an efficient algorithm for solving the DRCFJSP by applying VNS. They demonstrated the performance of their algorithms in comparison with the GA. Wu et al. [
6] proposed a hybrid algorithm combining the VNS and GA to solve the DRCFJSP considering worker’s learning ability. The VNS was applied to the populations, exhibiting a good performance. They demonstrated that the GA-VNS exhibits a better performance and lower relative percentage deviation than those of the GA and hybrid discrete particle swarm optimization.
The aforementioned metaheuristic algorithms are at risk of being isolated to the local optima due to the characteristics of the algorithm. Therefore, most metaheuristic algorithms prevent the solution from being isolated by introducing a wide variety of diversification, rather than concentrating on the intensification, to compensate for the weaknesses of the regional search algorithm. However, it is difficult to determine a feasible solution with many complicated constraints, and even intuitive improvements focused on intensification within a limited time are difficult due to the problem complexity. Therefore, exploring the solution space with a poor performance within the given computation time weakens the algorithm’s performance. Previous studies on the DRCFJSP were conducted by mitigating some constraints, such as worker skill, batch size, and complex product structure. In particular, the majority of the studies have developed algorithms for a simple product structure, and the metaheuristic algorithms demonstrated good performances. In this study, to deal with more complex problems with additional constraints, we propose a new local search algorithm that identifies a good search space and focuses on the intensification of a more likely space to compensate for the problem of diversification. In addition, the simple exchange of the operation sequence used in most scheduling algorithms in MLPS requires the process of solution repair for the feasibility. This results in heavy modification of the solution and increased computation time. Therefore, we use the priority rules to create a reliable initial solution for the time-based integrated initial solution algorithm, rather than the existing operation sequence expression, and derive an optimal schedule through the local search algorithm that limits the exploration space. To the best of our knowledge, our study is the first to propose an algorithm to solve the DRCFJSP that reflects the MLPS.
The remainder of this paper is organized as follows.
Section 2 describes the environment and assumptions for the problem.
Section 3 explains the proposed algorithm. In
Section 4, we discuss the results based on the numerical experiments. Finally, some insights are discussed along with the conclusion and future research directions in
Section 5.
2. Problem Description
The DRCFJSP can be applied in various industries including automobile industry, equipment industry [
6] and electromechanical industry [
17]. We consider DRCFJSP with an MLPS to deal with the scheduling problem of manufacturing systems with assembly lines. There is a set of orders,
; a set of final products
; a set of machines
; and a set of workers
. An order,
, denotes a production request for the final products,
, within the due date,
. MLPS is a hierarchical tree that expresses the BOM structure for a final product and subcomponents. To produce each upper element, various types of child components are required. In
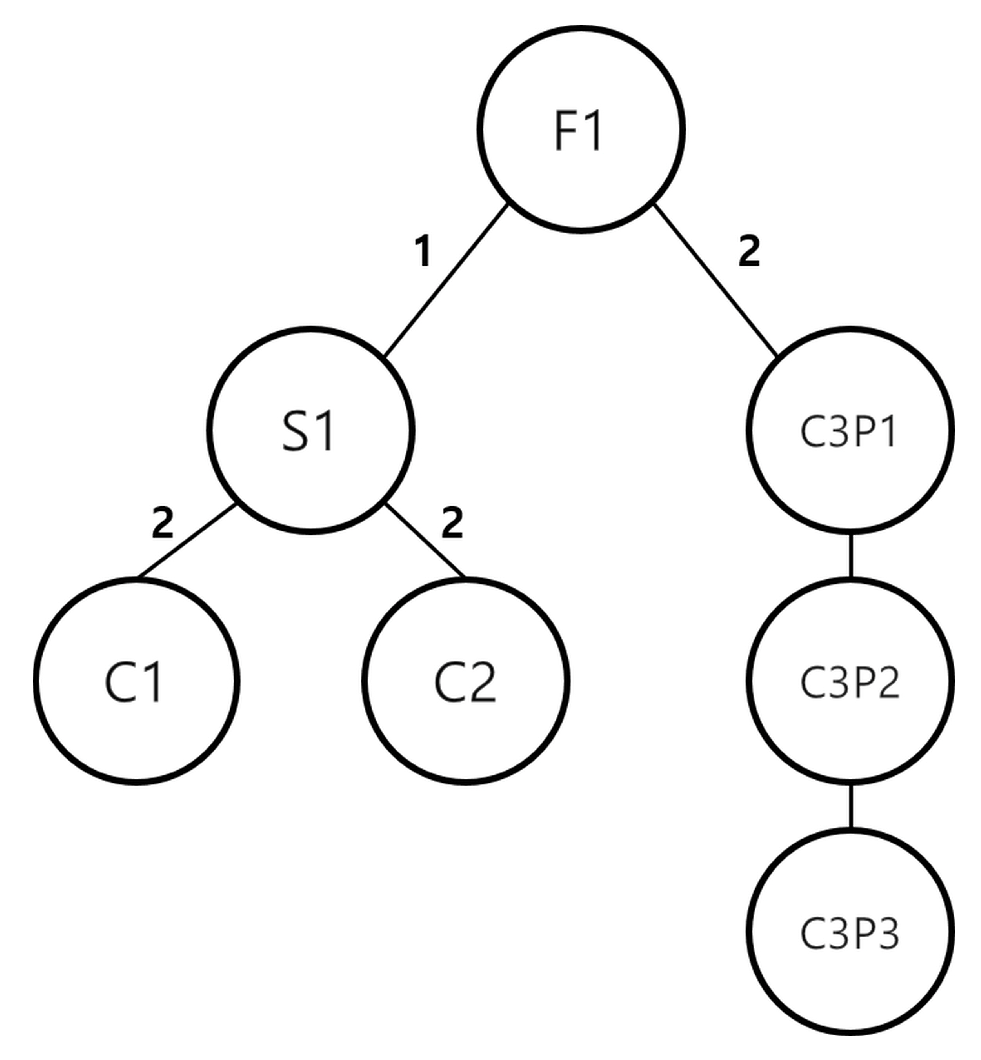
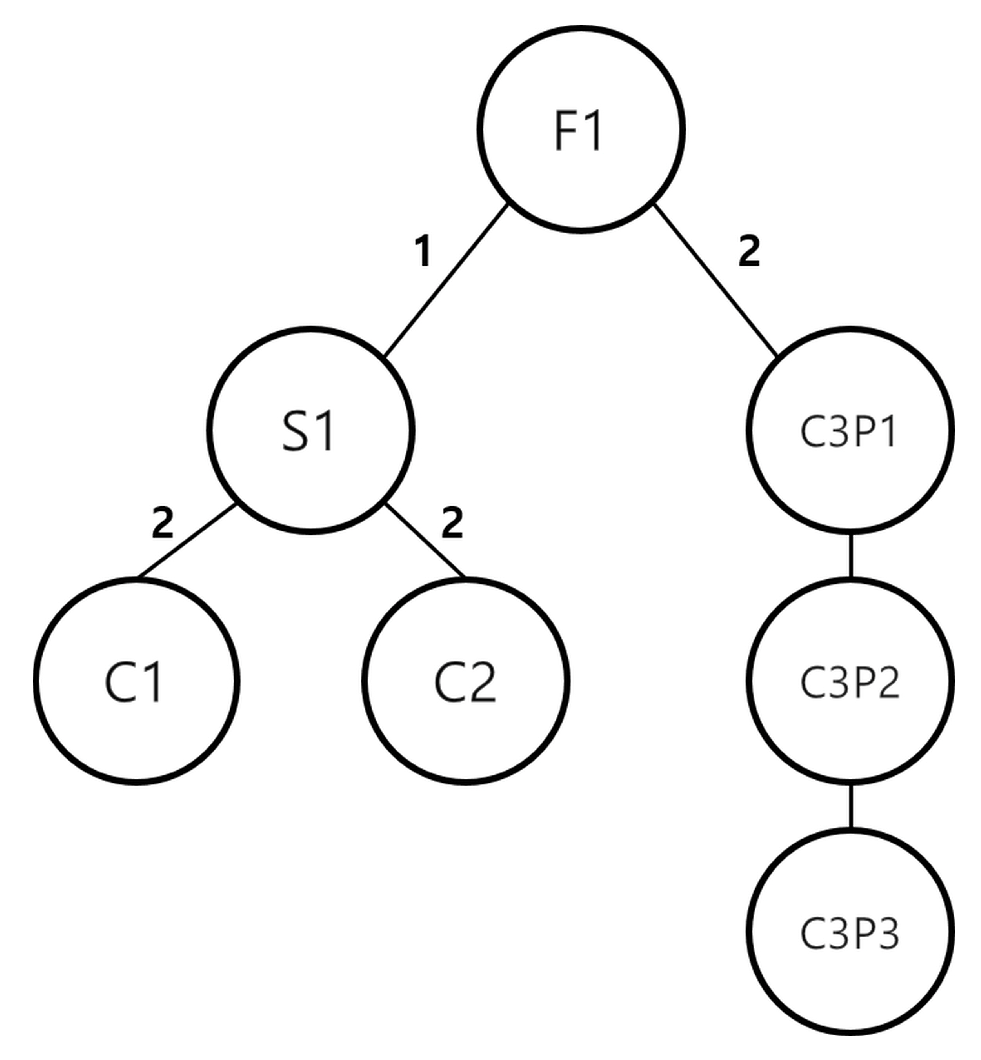
Figure 1, the numbers on the arcs connecting each node represent the number of child components required to produce the parent node.
Figure 1 illustrates an example of the MLPS for a final product, F1, in Chen et al. [
9]. F1 is produced by assembling one component S1 and two C1s, and C3 requires three successive processes, namely, P1, P2, and P3. When more than one process is required to produce a component, the process name is written along with the component name in the node. For example, in
Figure 1, C3P1, C3P2, and C3P3 imply that the component C3 is processed in P1, P2, and P3, respectively.
Several constraints are considered for an environment of DRCFJSP with MLPS. First, MLPS must be considered to determine the schedule, i.e., a sequence of operations according to MLPS. For example, in
Figure 1, the operations for C1 and C2 must be executed before S1. Second, each item and subitem can be processed only in the designated machines, and each worker can work on all machines. The processing time of an item depends on the assigned machine and the skill level of the worker. Third, each machine and worker cannot simultaneously perform more than two operations. The same type of item cannot be worked on machines at the same time. Finally, the production quantity is determined based on the lot size and the total demand. It must be greater than the demand and must be an integer multiple of the lot size.
In addition to the constraints, the following assumptions are made for the parameter values.
The raw materials required for the operation of the items are sufficient.
The operation setup time is small enough to be ignored.
The lot-size of each operation is fixed.
There is a difference in the skill level of each worker according to the machine; however, the improvement in the worker’s skill level because of the learning effect is small enough to ignore.
This study aims to minimize the lateness, makespan, and maximum deviation of the workload in the machines. Among these objective functions, lateness minimization has the highest priority, followed by makespan minimization and workload balance; the function with the highest priority is the most preferred. Equation (
1) represents the objective function for lateness. Delays in delivery are one of the most important factors in the manufacturing environment, because frequent delivery violations and lateness cause financial damage by lowering the corporate trust and resulting in long-term declines in orders. Equation (
2) minimizes the makespan, which is used in many scheduling studies as a measure of process productivity. Equation (
3) represents the objective function for minimizing the deviation of workload between machines, and is used to prevent the imbalance of workload between machines. The notations used in this paper are summarized in
Table A1 4. Numerical Experiments
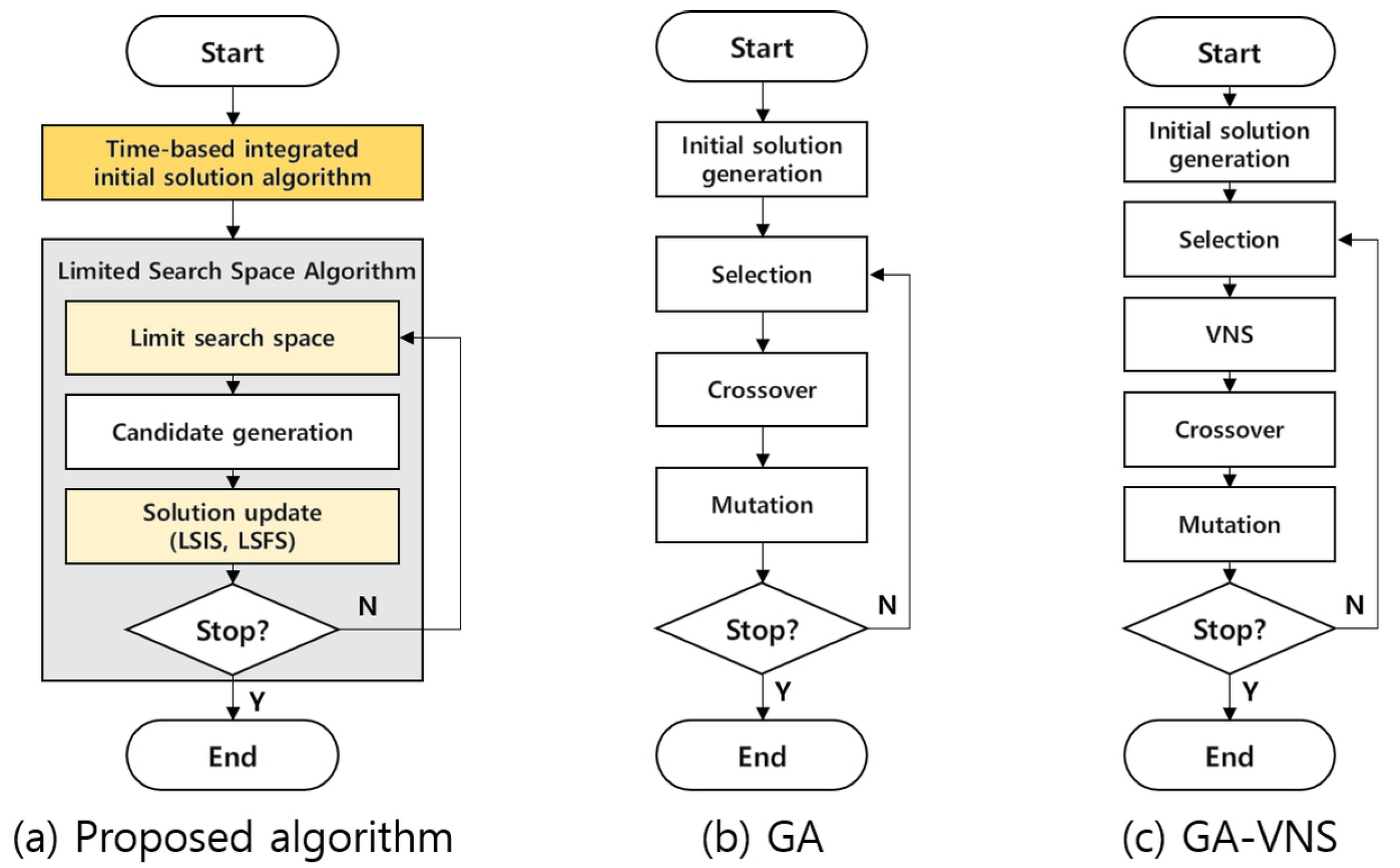
The superiority of the proposed algorithm is demonstrated through its comparison with the GA and GA-VNS. The overall algorithm structure of GA and GA-VNS is based on the previous study by Wu et al. [
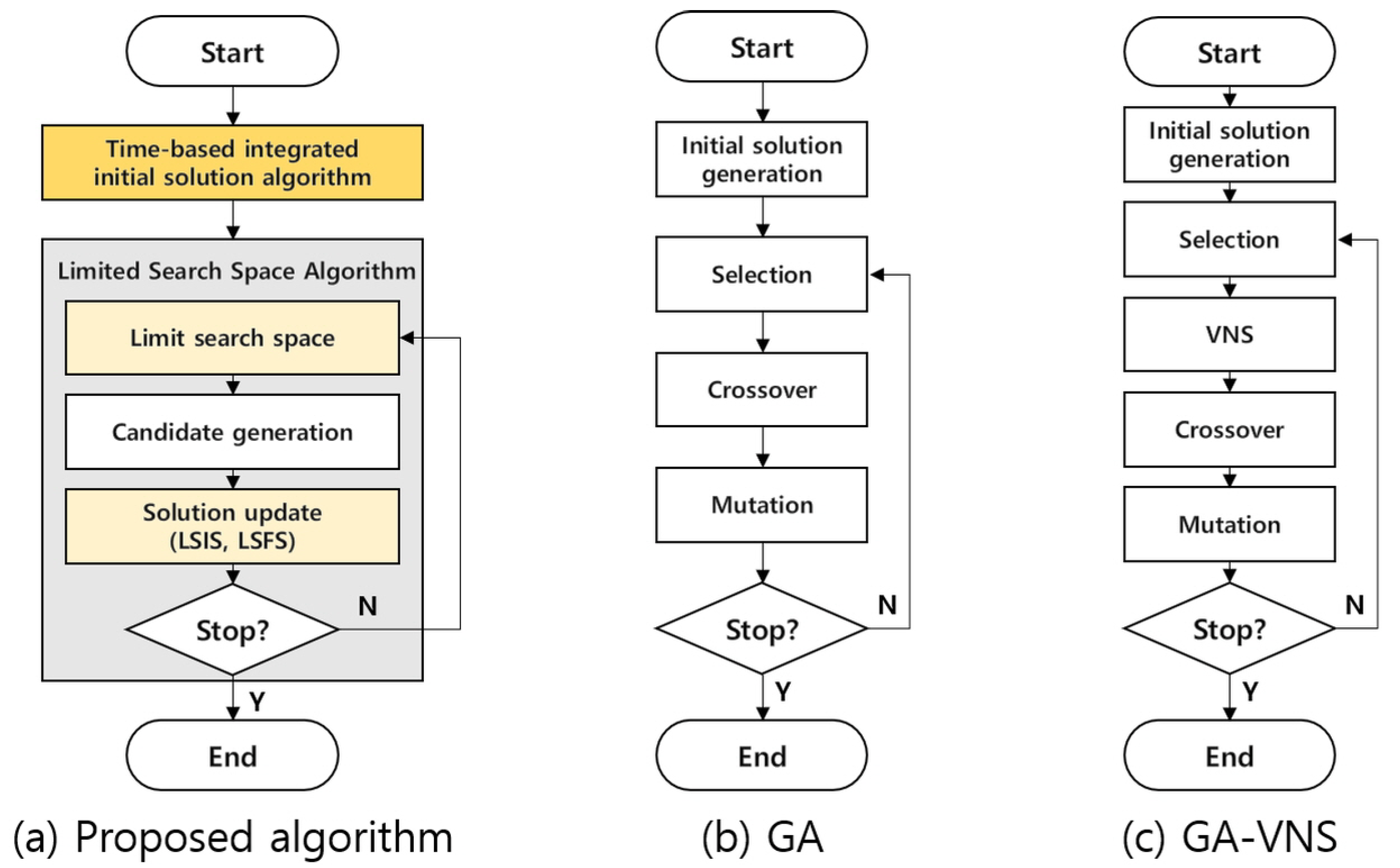
6]. As shown in
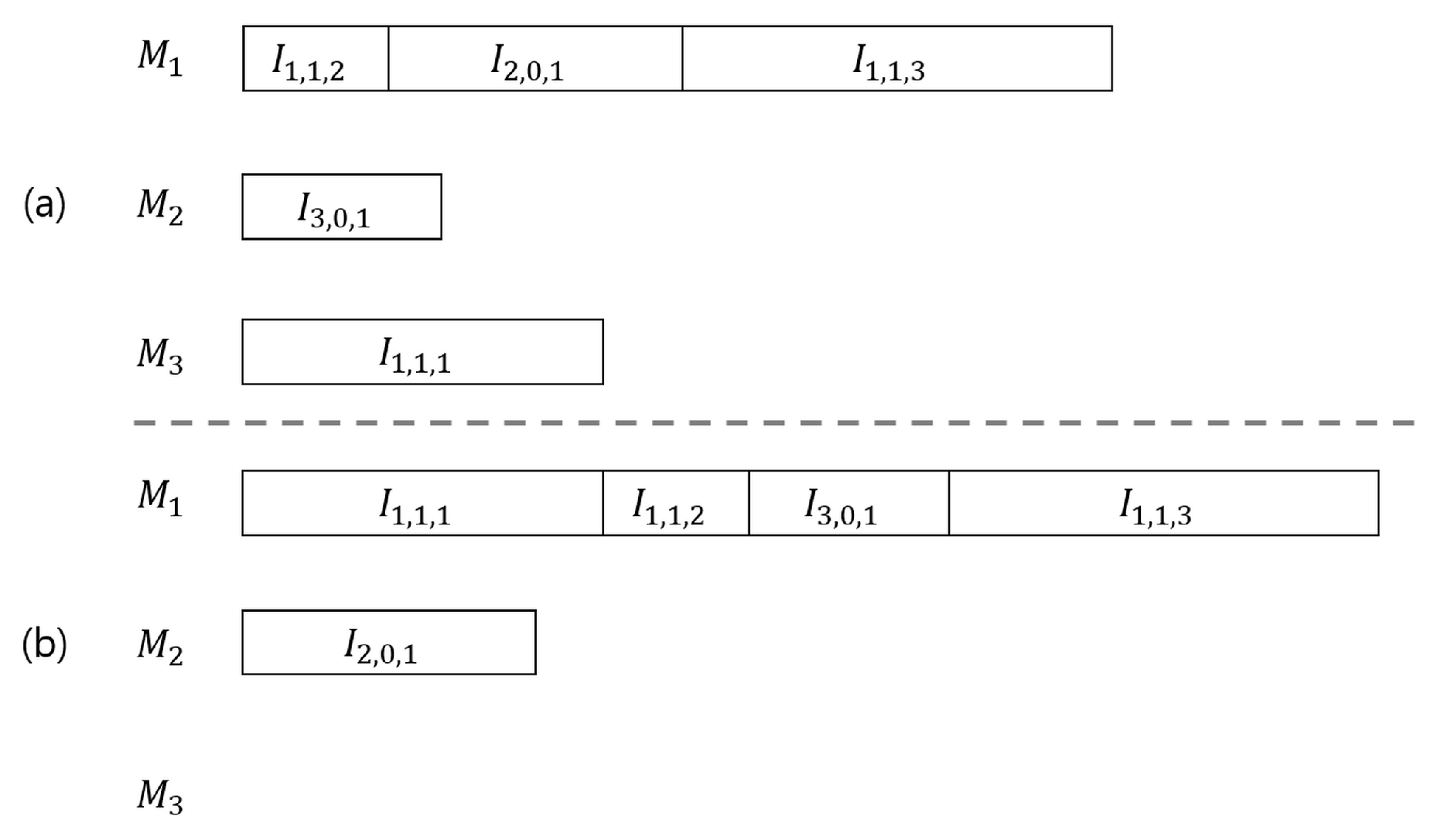
Figure 2, GA proceeds through the procedures of initialization, selection, crossover, and mutation. The algorithm proposed by Wu et al. [
6] was partially modified because it is not suitable for MLPS. In their problem, a final item requires a simple sequence of operations, and the order for a final item occurs only once. Therefore, it is easy to construct an operation sequence chromosome based on the final item. However, this is not appropriate when we consider MLPS and multiple orders for each item. The representation of the operation sequence chromosome based on the final item has a problem of uniqueness. Therefore, the decoding process is modified to consider the MLPS. The feasible suboperations required for the final product are selected based on the MLPS, and the sequence of suboperations is randomly selected if there are multiple feasible suboperations. The encoding and other parameter settings, such as crossover, mutation, elite, and tournament, are the same as those in the algorithm proposed by Wu et al. [
6]. In particular, selection is performed through the elite tournament, and VNS is applied to the top 50% of the candidate s in the case of GA-VNS.
4.1. Evaluation of the Initial Solution Algorithm
To verify the effectiveness of the initial solution algorithm, we solve small scale problems. The experiment environment is described as follows.
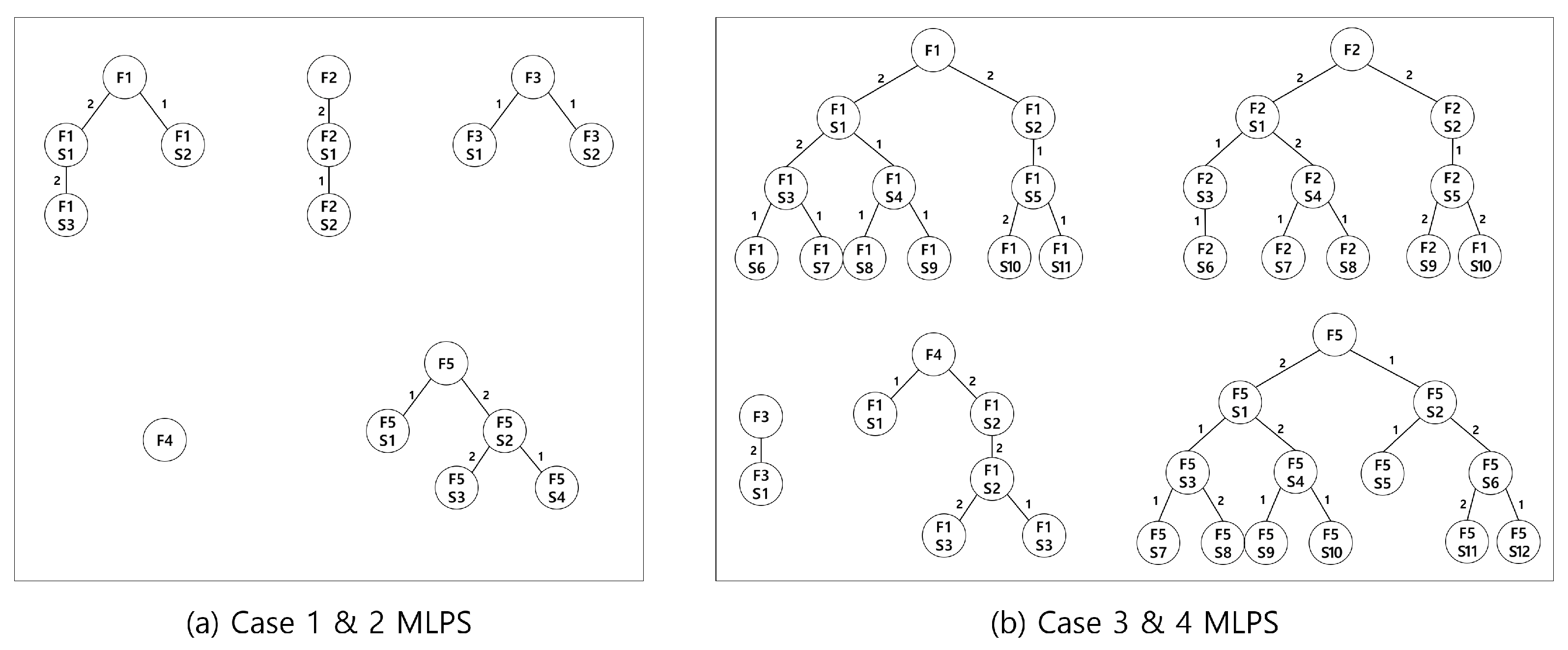
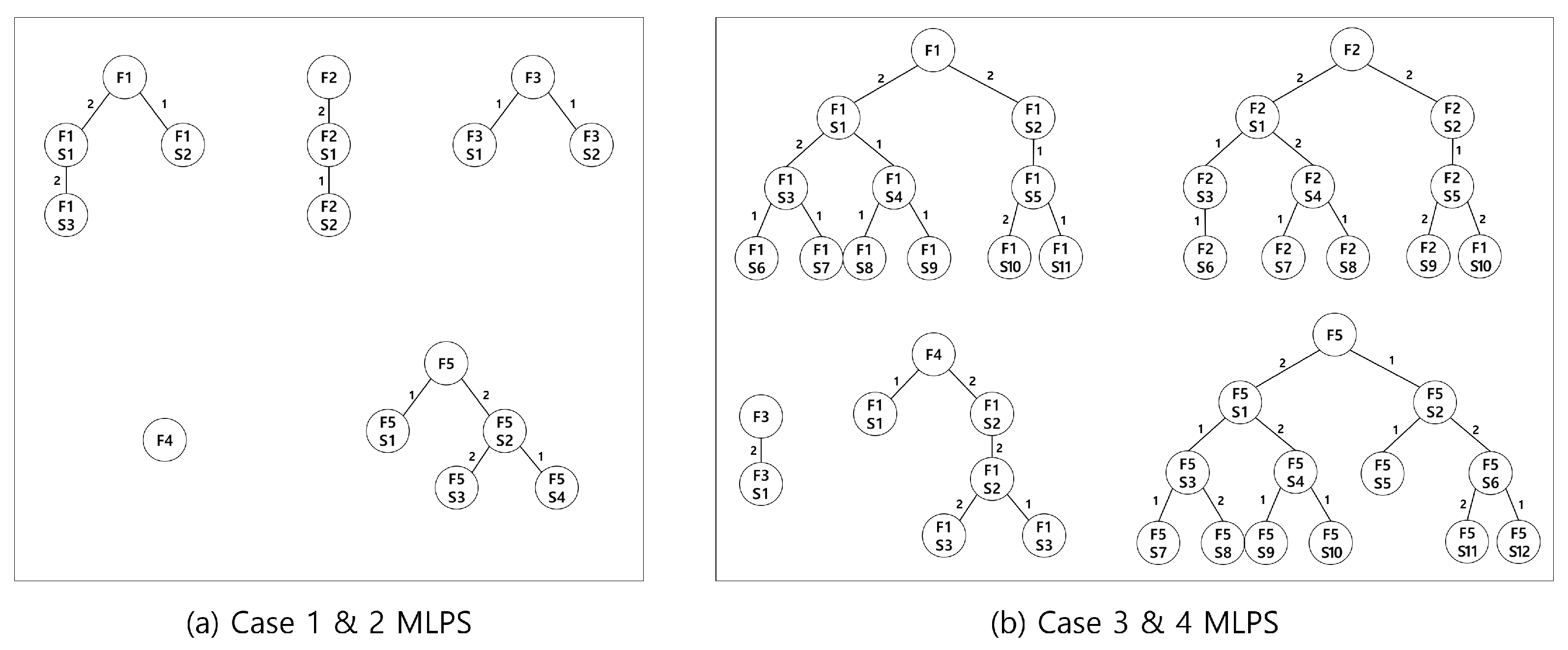
The number of final items is five, and they have the BOM structure in
Figure 6. In cases 1 and 2, a BOM can have up to two subparts for the upper part. In cases 3 and 4, the BOM structure is extended up to four levels.
The time horizon is composed of seven time buckets, and the number of finished product s required in each time bucket can be up to 30.
The processing time of each operation is randomly generated within a range from 1 to 15 time units.
The number of machines is five. On an average, each machine can work on processing 30% items, and designated machines are randomly assigned.
Capacity is either low or high. In the case of low capacity, the available time unit per day is 2000, and in the case of high capacity, 4500 units per day are available.
The number of workers is three. The skill level of each worker is randomly generated within a range from 50 to 100%.
Initial inventory level is zero.
The lot size is 30.
Table 1 and
Table 2 show numerical results with simple a BOM structure, as shown in
Figure 6a. Order data is randomly generated within a range from 1 to 30, and other data remain the same. The performances of LSFS and LSIS are compared with those of GA, GA-VNS, and LSFS without initial solution algorithm, and LSIS without initial solution algorithm. In addition, the performance measures used are the objective function values (G1, G2, and G3) explained in
Section 2 and computation time.
The results show that LSFS and LSIS with the initial solution algorithm are better than other algorithms. In particular, the performance gap between the algorithm with initial solution and without initial solution algorithm is quite large. As mentioned in the previous section, the main concept of the proposed algorithm is to begin with a relatively good starting point and improve the solution within the limited search space. It is also interesting that the computation time of LSIS and LSFS becomes shorter when the initial solution algorithm is applied. In other words, the performance of LSS-based algorithms is heavily dependent on the initial starting point, and the proposed initial solution algorithm plays a critically important role in achieving good performance. In addition, the performance of LSFS and LSIS is even worse than GA-based algorithms when the initial algorithm is not applied. Different from GA-based algorithms, the proposed algorithm does not use a mutation operator, and it can be worse than GA-based algorithms. The difference in the performances of LSFS and LSIS is not large. However, in terms of computation time, LSIS tends to be slightly superior to LSFS.
Next, we consider a more complex BOM structure shown in
Figure 6b. We note that the proposed algorithm is terminated after 7200 seconds because it requires more computation time because of the complex BOM structure.
Table 3 and
Table 4 summarize the results. In most cases, LSFS and LSIS perform better than the other algorithms, but GA performs well in case 3 with low capacity. Because of the nature of a small-size problem, in some cases, GA can be better than the strategy limiting the search space and requiring efforts in the local search, which is less efficient than randomly searching for a larger solution space. In both cases, the initial solution algorithm improves the performance of the algorithm.
4.2. Extended Experiments
The FJSP can be categorized into total FJSP and partial FJSP according to the machine compatibility. Cases 5 and 6 represent the partial FJSP, where each operation can be processed only on some machines [
18], whereas case 7 represents the total FJSP, where each operation can be processed on all the machines. For extended experiments, we used a simple BOM structure, as in
Figure 6a, and increased the problem size including the numbers of final items, machines, and workers.
In case 5, the data used for the experiments are same as those used in the previous section except for order data. In the cases of GA and GA-VNS, 10 iterations were performed with 20 populations due to the limitations in the computational time, unlike in previous studies that performed more than 20 iterations with over 100 populations. The other parameters are similar to those in the study conducted by Wu et al. [
6] (ratio of crossover: 0.5; ratio of mutation: 0.5; ratio of elite: 0.2; ratio of VNS: 0.5).
Table 5 presents the results of a numerical experiment in case 5. In this case, GA exhibits the best performance, as presented in
Table 5.
Case 6 represents a larger problem in comparison with case 5, with 20 final items, 10 workers, and 10 machines. The environment contains more flexible processes, and the machines can process an average of 50% of the items. Due to the practical constraints on the computation time, the experiment was conducted by reducing the scale to 10 populations and 10 iterations. Additionally, the proposed algorithm was terminated after 7200 s.
Table 6 summarizes the results of the numerical experiment in case 6. As the problem becomes larger, the strategy limiting the search space becomes more efficient, which is different from the results of case 5. The LSS algorithm with LSFS and the LSS with LSIS are better than the GA-based algorithms in terms of all performance measures. The results demonstrate a good performance with a significant difference in terms of lateness in a shorter computation time. For example, at low capacities, the total delayed time units was 9 for the LSFS and LSIS with a computation time of 7200 s. However, the total delayed time units was 70 and 52 for the GA and GA-VNS, respectively, with a computation time of over 9000 s. At high capacities, the lateness is reduced in all algorithms; however, the LSS-based algorithms perform better than the GA-based algorithms.
Case 7 assumes the most flexible environment, in which all the machines can operate at all items. The number of final items, workers, and machines are 30, 10, and 10, respectively. Experiments are conducted under the same conditions as those of case 6.
Table 7 presents the results of a numerical experiment in case 7. The result of case 7 is similar to that of case 6. Both LSS-based algorithms outperform the GA-based algorithms in a shorter time. LSIS is more efficient than LSFS even in an environment with low capacity, which explores more search space in a shorter time as the problem becomes more complicated. Although the search space is limited, LSFS determines all the possible candidate solutions at each iteration. Therefore, it takes a longer time and does not perform well for more complex problems.
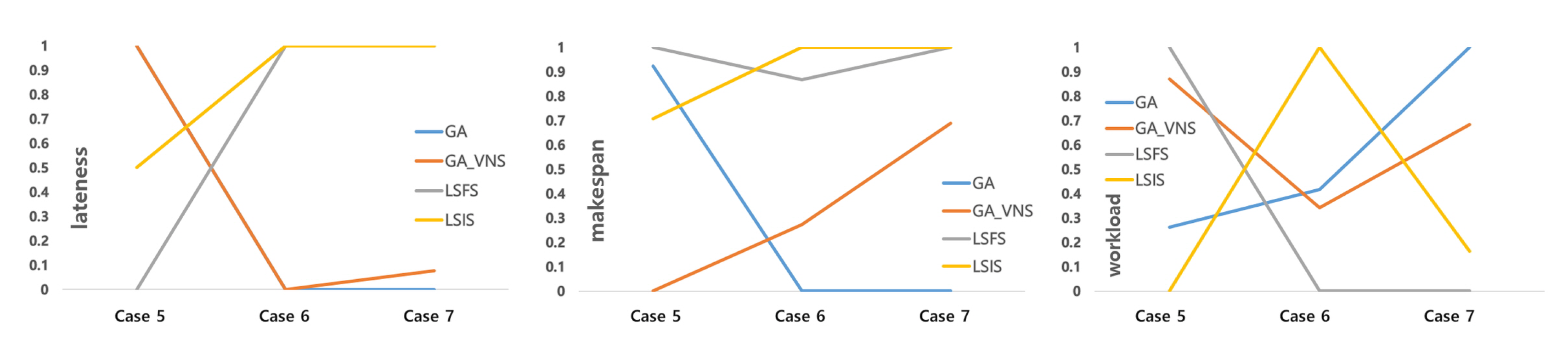
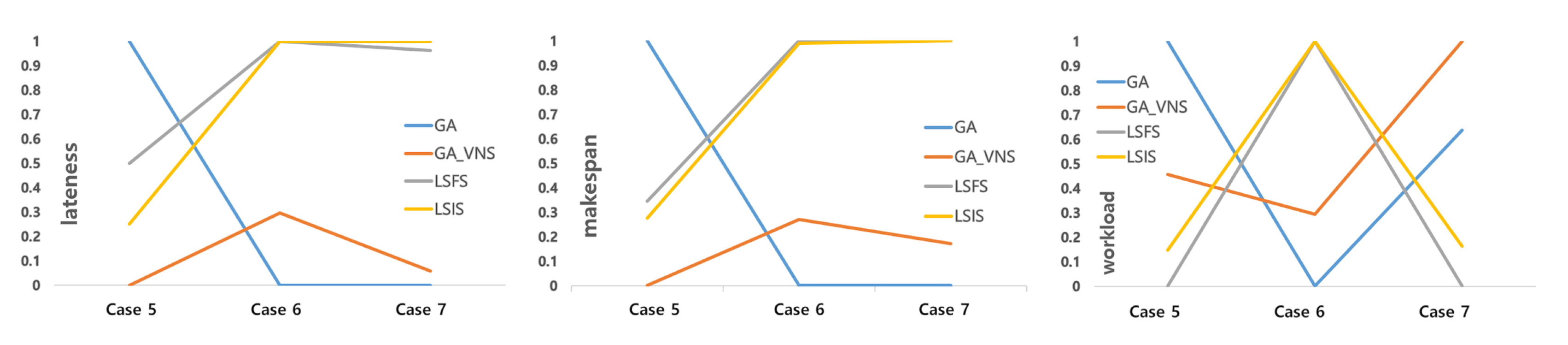
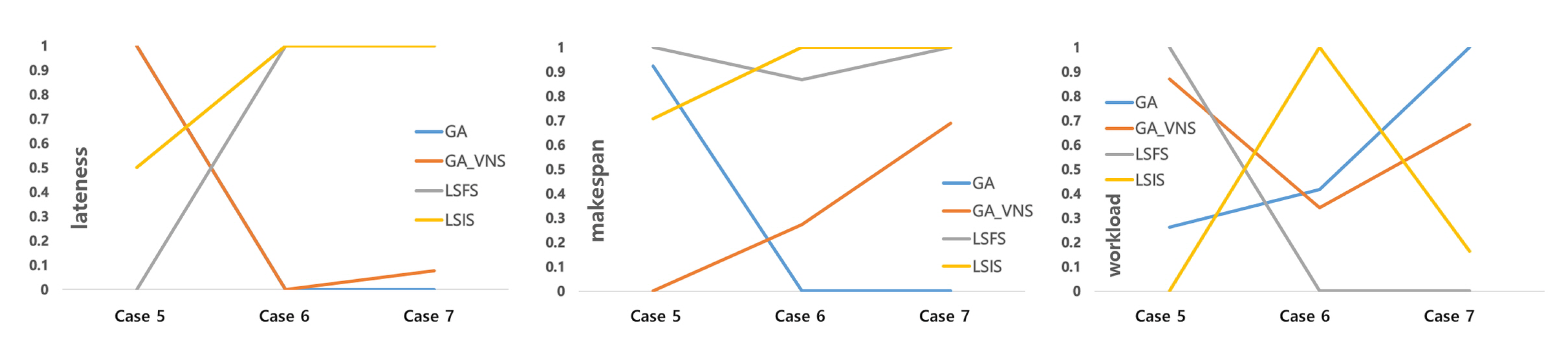
Figure 7 and
Figure 8 illustrate the relative performance in comparison with the best solution, as the problem size increases in each capacity condition. The relative performance is calculated using Equation (
4). The objective function values are normalized, and the best and worst solutions become 1 and 0, respectively. In terms of lateness, the objective function with the highest priority, the GA algorithm generates the best solution when the problem size is small, and the performance of LSIS is not the worst. However, as the problem size increases, LSIS generates the best solution or one that is very close to the best solution, and the performance of the GA algorithm becomes the worst. The performance of GA-VNS is similar to that of GA for cases 6 and 7. With respect to the makespan, the trend of the result is similar to that of the lateness, when the capacity is low. At high capacities, the LSS-based algorithms generate the best solutions or those that are very close to the best solution in all the cases. As for the third objective function, none of the algorithms outperform the others because this study considers a preemptive multiobjective approach, wherein the performance depends on the first and second objective functions.
5. Conclusions
This study addressed the DRCFJSP under the consideration of worker’s skill and the MLPS. Due to the complexity of the problem, we proposed an efficient algorithm, limiting the search space to solve the complex DRCFJSP with three objective functions to minimize lateness, makespan, and machine workload distribution, which were improved sequentially. The algorithm was composed of a time-based integrated initial solution algorithm and LSS algorithm. The time-based integrated initial solution algorithm was tailored to the problem domain and modified the existing encoding method due to the unique characteristics of the MLPS. The LSS algorithm used the concept of EPST and LSPT to restrict the movement in the solution space, such that the previous solution was not considerably changed. In the limited search algorithm, the solution was updated using LSFS or LSIS.
Numerical experiments demonstrated that the proposed algorithm has an advantage for a complex problem when compared to the GA-based algorithms in terms of time and performance. In particular, when the problem size was small, the proposed algorithm was not always better than GA. In some cases, GA performed better than the proposed algorithm. However, for large-sized problems, we obtained better solutions in a shorter computation time by limiting the search space.
Further research is needed to develop extended models and algorithms considering additional constraints and uncertainties in the production system, such as the learning effect. The workers’ skill levels can be improved as the same work is repeated, and thus the efficiency can be changed. Various types of uncertainties must also be considered in future works. Because the actual manufacturing environment has various uncertainties, this research can be expanded to reflect the uncertain processing time, demand fluctuation, and machine failure. To overcome these issues, robust optimization and stochastic programming approaches can be applied.
The authors declare no conflicts of interest.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}