1. Introduction
Digital topographic data are indispensable for modern modelling needs in many science branches (e.g., environmental planning, forestry, geology, hydrology, climate change, etc.). Airborne Laser Scanner (ALS) systems record terrain elevation, terrain structure lines, buildings, vegetation and, in general, any feature present in the field and that can be detected by its resolution. One type of product of great importance that is derived from ALS are digital terrain models (DTM). DTM generation using only LiDAR data present limitation to simultaneously distinguish complicated terrain situations (e.g., discontinuities and shape ridges), highly fragmented landscapes, and a variety of objects ([
1]). The vertical accuracy of LiDAR-derived DTM for uncovered and vegetated areas is assessed in [
2]. By means of 193 check-points measured with GNSS-RTK, the mean vertical accuracy reached 0.091 m, while the RMSE was 0.115 m. Related to volume changing (DEM comparison), in [
3], the vertical difference of ALS data for vegetated and no vegetated area of a landslide is reported 0.3 and 0.125 m respectively. In the case of the errors caused by the forest vegetation structure, the presence of leaf-on vegetation causes significant errors (RMSE > 1 m), in contrast with the leaf-off conditions (RMSE = 0.22 m) according to the results presented by [
4]. In [
5], the influence of factors such as forest structure, slope, off-nadir angle, understory vegetation and filtration and interpolation algorithm on ALS-derived DTM accuracy in mixed mountainous forests was evaluated. The RMSE and the mean error ranged from 0.19 to 0.23 m, and from 0.13 to 0.16 m, respectively, being the slope and the undergrowth vegetation the most important factors influencing DTM accuracy. In [
6], as part of a multitemporal study of an alpine rock glacier, the signed discrepancy for stable areas yielded a standard deviation of 0.23 m for a time span of 5 years. LiDAR precision is also evaluated for physical features, as for example in [
7], where the LiDAR error for dimensional features of a bridge and several fence posts reach up to 23.5%.
The best way to assess or control positional accuracy is by applying standardized methods. Some of them are the National Standard for Spatial Data Accuracy [
8], the Engineering Map Accuracy Standard [
9], the Standardization Agreement 2215 [
10], the Positional Accuracy Standards for Digital Geospatial Data [
11] and the European Spatial Data Research (EuroSDR) through its proposal of accuracy measures for digital surface models based on parametric approaches [
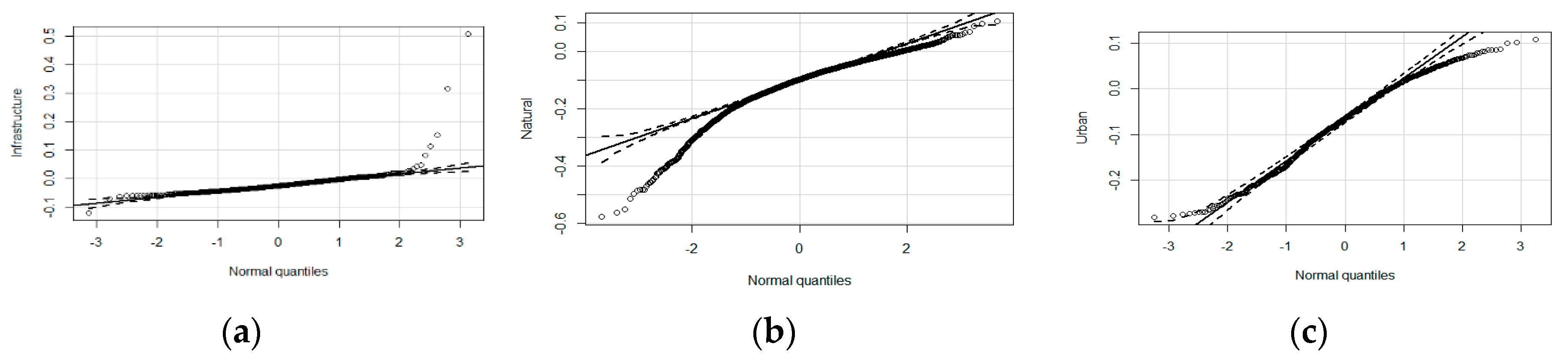
12]. More precisely, EuroSDR proposes the use of the relative vertical accuracy, the absolute vertical accuracy, and the relation pointed out between them. Ariza-López and Atkinson-Gordo [
13] presented an analysis of the main features of some of these methods, and in many cases, they are based on the assumption of the normality of the errors. However, many authors [
14,
15,
16,
17,
18,
19] indicate that positional errors are not normally distributed.
The normal distribution is a suitable distribution for representing real-valued random variables. Therefore, the situation described above regarding positional errors leads to three important questions: (1) why may error data be non-normally distributed? (2) how does non-normality affect the methods based on the assumption of normally distributed data? and finally, (3) how can we work with non-normal data?
For the first question, and from a general point of view, six main causes of the non-normality of errors can be considered: (i) the presence of too many extreme values (i.e., outliers), (ii) the overlap of two or more processes, (iii) insufficient data discrimination (e.g., round-off errors, poor resolution), (iv) the elimination of data from the sample, (v) the distribution of values close to zero or the natural limit, and (vi) data following a different distribution (e.g., Weibull, Gamma, etc.). Additionally, some of these causes can appear together.
With regards to the second question and working with methods based on the normality assumption, the non-normality of the data can have various consequences depending on the degree of non-normality of the data and the robustness of the method applied. In this case, the non-normality violates a basic assumption of the method, and this violation is important from a strict perspective. For instance, the minimum quadratic estimators are not efficient, and the confidence intervals and hypothesis tests of parameters can only be approximated. Although it is possible that the results of a method can be considered valid if the non-normality is slight, the results may be completely incorrect if the non-normality is significant [
20]. As an example of the above, if the error data contain a few outliers, their elimination from the analysis to achieve normality can give an acceptable result, but if the number of outliers is very large, this elimination is no longer possible.
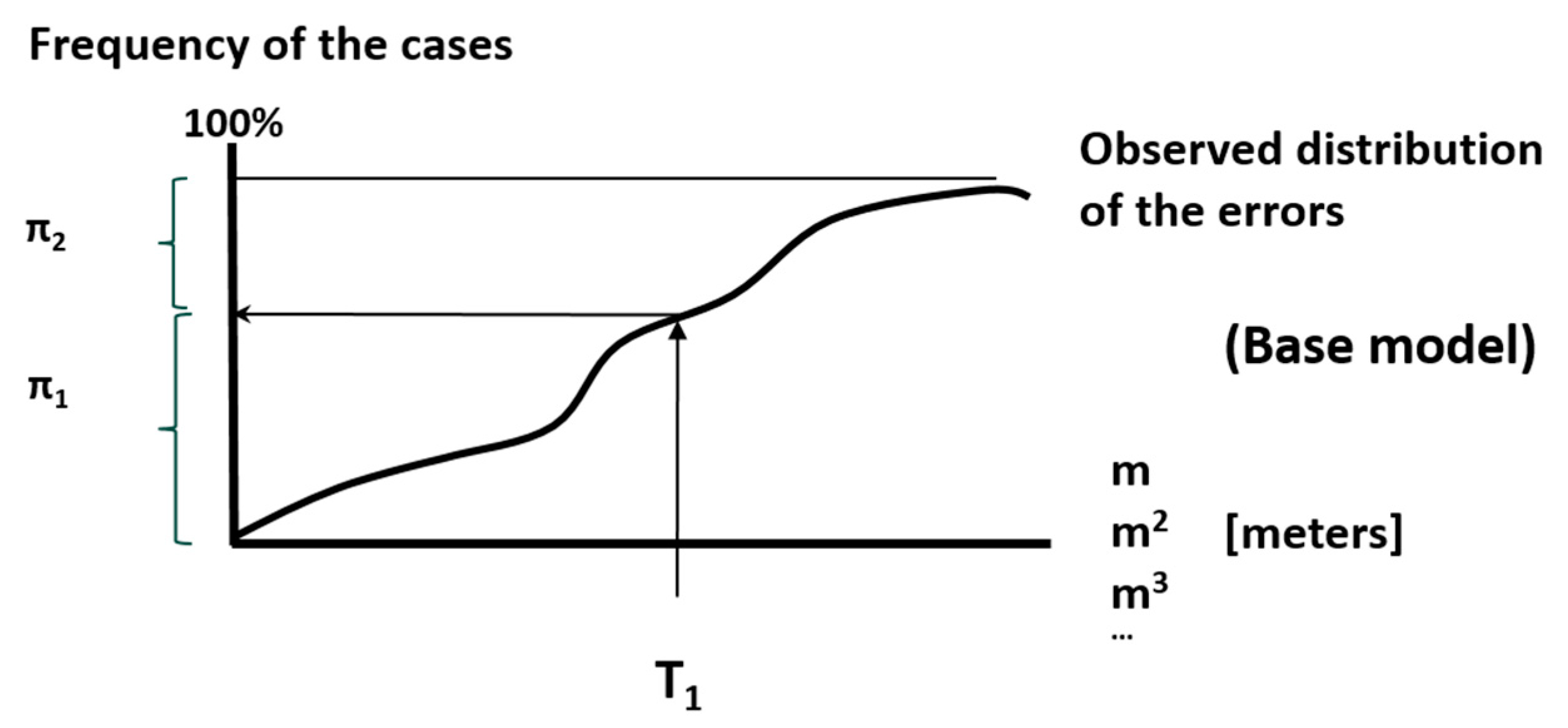
Finally, to answer the third question, it is necessary to consider two very different situations: (a) data are not normally distributed but are distributed following another parametric distribution function (e.g., Weibull, Gamma, etc.), (b) data do not follow a distribution. In both cases, methods based on normal data are inadequate, but if a parametric distribution can be applied, the properties and parameters of such a distribution can help us work with these data. If the data are freely distributed, an observed distribution function is required for the analysis. Working with observed distributions is more complicated than working with parametric models, but this circumstance does not prevent estimation and decision-making (quality control) within a probabilistic framework [
21].
Positional accuracy assessment methods based on free-distributed data are scarce. Following the analysis of Ariza-López & Rodríguez-Avi [
22], the National Map Accuracy Standard [
23] can be considered a method with capabilities to work with free-distributed data. In addition, it is possible to use percentiles when working with this type of error data, but the proposals for the use of percentiles, such as that of Maune [
14], are merely descriptive, in the statistical sense, and no method for quality control is given. Error counting is the statistical technique that is used to cope with these cases. Following this idea, several methods exist: Cheok et al. [
24] describe a method that allows the control of building plans; Ariza-López & Rodríguez-Avi [
25] propose a method for positional accuracy control of line strings; the Spanish standard for positional accuracy control [
26] proposes the use of the defect counting method established by the International Standard ISO 2859 [
27]. All of these methods are able to work with free-distributed error data but are very limited by the statistical model that is applied (i.e., the binomial distribution function).
The objective of this paper is to propose a new and general statistical method for positional accuracy control that can be applied to any kind of data without the need for any underlying statistical hypothesis, e.g., ALS error data, and in general, for any free-distributed error data or non-normally distributed data. The motivation of this work is twofold: to have a method of quality control that is not subject to the need for normal positional errors and, on the other hand, the possibility of controlling the observed error distribution as much as desired.
3. Results and Discussion
In this section, some examples of the proposed method are presented using the data described in
Section 2. In particular, three different test bed sites (study cases) in terms of roughness and slope (infrastructure, urban and natural) were used to validate the positional accuracy of the ALS. The examples are developed for 1D and 3D cases, but the methods for handling of any other cases are similar (e.g., 2D). For simplicity, all the examples are developed using two metric tolerances:
and
.
is linked to a 50% proportion of error cases, and
is linked to a 90% proportion of error cases.
To demonstrate the validity of the proposed method, two analyses are performed: the first one is focused on the type I error (risked by the producer/the significance of the test) and the second on the type II error (risked by the user/ the power of the test. For additional information see [
38]). For the type I error analysis, three different quality controls are presented to show that the acceptance of the null hypothesis performs well. For the type II error analysis, small modifications are introduced to the tolerances to observe the null hypothesis rejection behavior of the method.
For the analysis of each quality control case, several sample sizes are used, and a simulation procedure is applied to demonstrate the proposed method. Five sampling sizes (20, 50, 100, 200, 500) were considered. These sample sizes are in the range of values that have been used in other simulation studies [
39,
40] on the behavior of positional accuracy control methods. For each sample size, 10,000 iterations were performed. In general, the larger the number of iterations, the more the overall results of the simulation are stable. According to [
41], 10,000 iterations is a suitable number for simulations of this type. For each iteration, the proposed method was applied, and the test’s behavior was analyzed. For each quality control case and sample size, the proportion of times in which the corresponding null hypothesis has been rejected is presented as the main result. When the hypothesis is true, the percentage of rejections must be close to the value of the significance that is considered (type I error). When the hypothesis is false, the percentage of rejections is the power of the test (type II error).
3.1. Type I Error Analysis
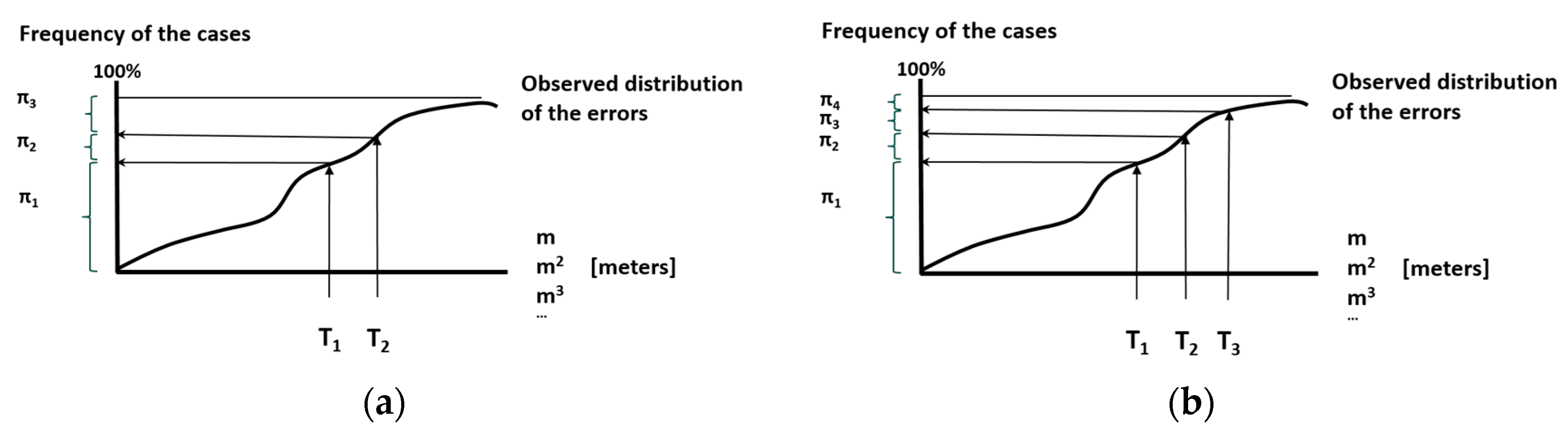
Three different cases of quality controls are presented (QC1, QC2, QC3) to show that the method can be applied in different situations. The first two situations address the adoption of control tolerances derived from models based on normal data. The third case is based on quantiles, so its distribution is free. The proposed quality controls are as follows:
QC1. The data are considered to be unbiased, and intervals are defined around the zero value (signed errors are considered).
QC2. The data are considered to have bias. The bias (expressed by the median) is taken into account, and intervals are defined around the median.
QC3. The observed quantiles are used.
For each quality control case, the metric tolerances (thresholds) are defined based on
Table 5. In all cases, tolerances define three categories of errors (CoE1, CoE2, CoE3) and account for the number of errors in each of these categories (
). In all cases, the null hypothesis
to be tested is:
The population probabilities for CoE1, CoE2 and CoE3 are, respectively
Against the alternative hypothesis
the true probabilities are worse than .
3.1.1. Quality Control #1
The data are considered to be unbiased, and intervals are defined around the zero value (signed errors are considered). This situation is ideal because it is desirable that no bias is present, and it is equivalent to taking the absolute values of errors. As a guide, the tolerances are established in relation to the Gaussian model. In this situation, it is mandatory to distinguish between 1D (infrastructure) and 3D (urban and natural) cases. The tolerance values are as follows:
For the 1D study case (infrastructure sample), since the errors were computed according to the Z discrepancies, the NMAD value is ±0.02 m. The values are derived as follows: m and m
For the two 3D study cases (urban and natural samples) where the error was computed according to a 3D signed distance, a unique reference value is used via the arithmetic mean of both the NMAD (±0.088 and ±0.064 m), which is ±0.075 m, and the values derived as follows: m and m
Consequently, three categories of errors (CoE1..3) are defined as follows:
The results obtained by the simulation following the process described at the beginning of this section are shown in
Table 7. The situation is very clear, and the controls on the infrastructure data usually result in a rejection of the null hypothesis (i.e., the null hypothesis not accepted), even with small sample sizes. This finding implies that the proposed limits are very restrictive or, in other words, that the data do not verify the specifications. Otherwise, for the remaining two cases of study, the test always results in the acceptance of the null hypothesis. This finding implies that true limits of the errors are narrower than the specifications being considered.
3.1.2. Quality Control #2
Now, data are considered to have bias (expressed by the median, see
Table 5). Intervals are built as:
, where the tolerances are the same as for the QC1 case.
Consequently, three categories of errors are defined:
Infrastructure study case. The tolerances for the 1D case define the following intervals:
- -
CoE1: .
- -
CoE2: OR .
- -
CoE3: OR
Urban study case. The tolerances for the 3D case define the following intervals:
- -
CoE1: .
- -
CoE2: OR .
- -
CoE3: OR .
Natural study case. The tolerances for the 3D case define the following intervals:
- -
CoE1: .
- -
CoE2: OR .
- -
CoE3: OR .
The results obtained by the simulation following the process described at the beginning of this section are shown in
Table 8. Here, the situation is somewhat different from QC1. Study cases 2 and 3 behave almost as they did in QC1 and the null hypothesis is always accepted. Study case 1 reduces its rejection noticeably because when including the bias in the calculations, there are more error cases within the tolerances. For this study case, the rejection values are close to the significance level (5%), and this is logical since the values of the tolerances for this case are very close to the quantiles of the observed distribution (
Table 5).
3.1.3. Quality Control #3
Because it has been demonstrated (see
Section 2.1) that data are not normally distributed, tolerances in direct relation to quantiles can be used for quality control. In the QC3 case, the quantiles from the same error distribution function were used, which means that a high acceptance is expected. In this quality control case, the three err*or categories are determined as follows:
CoE1:
CoE2: OR
CoE3: OR
Where the quantiles actuating as tolerances are those presented in
Table 4.
The results obtained by the simulation following the process described at the beginning of this section are shown in
Table 9.
For the three study cases and sample sizes, the proportion of times that the null hypothesis is rejected when it actually is true is close to the significance value (α = 5%) and does not depend on the sampling size. The tolerances used in this base case of QC3 come from the observed distribution (
Table 5), so that the distribution being used is its own observed probabilistic model, and therefore its probability of acceptance and the rejection level approximately equals the significance value of the hypothesis test.
In short, the interpretation of the three controls (QC1, QC2, and QC3) performed to know the type I error when the new proposed method is applied are conclusive: the proposed method allows to control this type error effectively. This is what happens in the case QC # 3, which is based on the determination of tolerances from the observed data (remember that errors do not follow a normal distribution). This situation is very different from those shown in QC1 and QC2 because in these cases, the adopted base model for deriving the tolerances was based on a Gaussian model. The QC1 and QC2 cases are a clear example that tolerances must be well established to be neither too permissive nor too restrictive in relation to the type I error. The best is that the tolerances are based on the behavior of the observed data, not on models that are supposed to follow that data (usually this is not checked). The method allows us to perfectly adjust the risk of the producer (type I error or the significance), which is an appropriate behavior with respect to the data under analysis and to the interest of quality controls. The statistical behavior of the proposed method is as expected; the observed data only show and confirm its applicability to the use case.
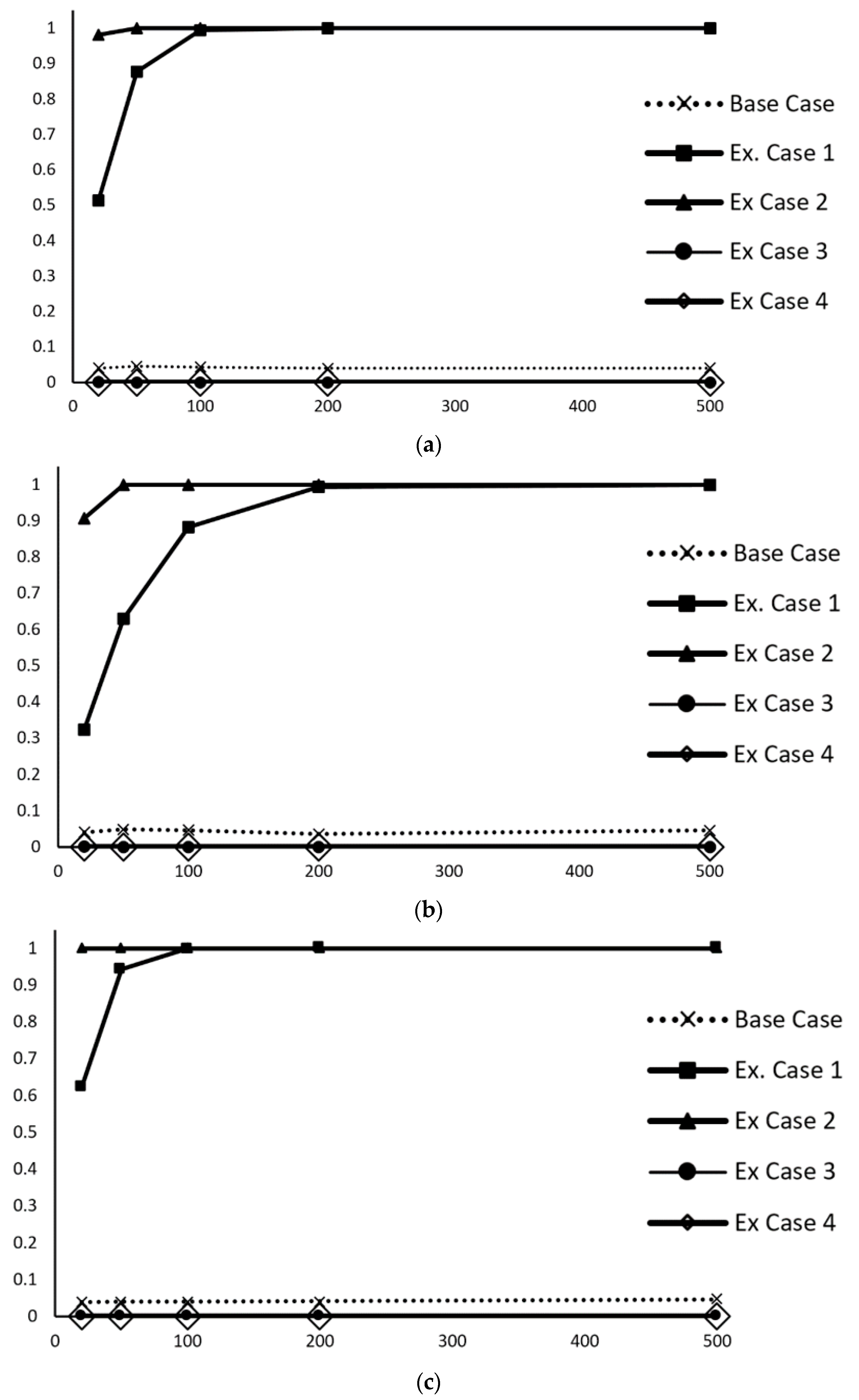
3.2. Type II Error Analysis
Now, we will study how the method behaves when the null hypothesis is not true; we will study the power of the statistical test. Since our proposal is specially designed for non-normal data, it is necessary to analyze the sensitivity of this method based on error counting when modifying tolerances. Considering the same situation as for QC3 (based on the observed data), we work with four extensions of the case in which the probability limits have been modified with respect to limits specified in the base case (QC3). The first two extended cases (ExC1 and ExC2) are more restrictive than the base case (QC3), and the last two extended cases (ExC3 and ExC4) are less restrictive than the base case (QC3). The newly proposed control limits of
(in meters) appear in
Table 10 for
.
For infrastructure data, the limits are modified by ±0.5 cm and ±1 cm in relation to the base case, and for urban and natural data, the limits are modified by ±2 cm and ±4 cm in relation to the base case. Different values are considered for the infrastructure data (0.5 cm and 1 cm) and the urban/natural data (2 cm and 4 cm) since the distribution of the error data for the first case is narrower than the other cases. In all the extended cases, the three error categories are determined as follows:
CoE1:
CoE2: OR
CoE3: OR
The results of this sensitivity analysis for the three study cases are shown in
Figure 5. Additionally, for comparison, the base case for QC3 is included in each data category. The curves are very similar for the three study cases. In the two extended cases (ExC1 and ExC2), which are more restrictive than the base case of QC3, the null hypothesis is widely rejected even with small sample sizes (see the upper curves), whereas in the two extended cases (ExC3 and ExC4), which are less restrictive than the base case of QC3, the null hypothesis is always accepted. The curve of the base case of QC3 has been added, and it can be observed that this curve is almost horizontal, with a value of approximately 5%. This sensitivity analysis clearly shows that the method works well against variations in tolerances (statistical power or type II error). If the tolerances are more restrictive, the null hypothesis is rejected with great probability even for small sample sizes. If the tolerances are more generous, the null hypothesis is always accepted.
In conclusion, the behavior of the proposed control method is expected for a statistical contrast with respect to type II error. In addition, the example shown can guide users of the new method to test with their data and evaluate the power of the statistical contrast they are applying in their specific case.
4. Conclusions
In this paper, a new statistical method for positional accuracy quality control has been proposed, which can be applied to non-normal errors and to any number of dimensions.
The new control method is based on the use of a multinomial distribution that categorizes the cases of errors according to metric tolerances. This method of defining a quality control is very versatile and allows the control of positional errors in 1D, 2D, and 3D cases. In addition, depending on the number of tolerances considered, a greater degree of similarity could be established between the observed distribution of errors and any desired probabilistic model. The major advantages of this method are as follows:
(1) it can be applied to any kind of error model (parametric or nonparametric),
(2) it can be applied to a mix of error models (e.g., in a 3D case, the X and Y errors can be normally distributed and the Z errors can be non-normally distributed),
(3) it can be applied to any kind of geometry (e.g., points, line strings, etc.),
(4) it can be applied to cases of any dimension (1D, 2D, 3D, …nD),
(5) the method allows quantitative and qualitative aspects to be jointly controlled by means of proportions in established categories.
The method has been proposed in a generic way and has been developed for the case of two tolerances (three categories of errors). The most complex aspect of the method is that it is an exact test, so the calculation of the p-value is not done by means of approximations but by calculating the sum of a finite set of solutions. In the appendix, an example is presented to show how to calculate the p-value using the R statistical program. This test is very flexible because the specification limits, the probabilities for each category and even the dimension number can be established by the user.
To demonstrate the applicability, ALS data from three different study cases (infrastructure, urban and natural) have been used, and 1D and 3D errors have been considered. Three quality controls with different tolerances were applied. In two of the quality control cases, the tolerances were defined from a Gaussian model (with and without bias), and in the third quality control case, the tolerances were defined from the quantiles of the observed error distribution.
The results of the three study cases and of the three quality controls show that if tolerances are well established for in the control of positional accuracy, problems of excess rejection or of excess acceptance can occur. For the case of non-normal data, the use of quantiles is suggested to establish the values of the metric tolerances. The quality controls developed by simulation for the three study cases and for different sample sizes show that this method is capable of ensuring the desired significance level. In addition, the sensitivity analysis carried out by modifying the tolerances indicates that the statistical power of the new proposed control method is adequate since correct results are obtained, and they are quite stable for sample sizes greater than 100.
Taking into account the results according to the variability of the study cases, the proposed method is very promising to improve the quality control of ALS data and other non-normally distributed spatial datasets, which is the usual case when we deal with in geotechnologies, such as terrestrial laser scanning or photogrammetry.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




