1. Introduction
The use of machine learning techniques in optical communication networks is currently a popular research topic [
1]. Among the various algorithms for machine learning the support vector machine (SVM) can provide a powerful way of learning nonlinear functions. Besides noise, optical data transmission is also affected by linear and nonlinear impairments. Using coherent detection at the receiver, linear effects like chromatic dispersion can be successfully post-compensated by digital signal processing (DSP). Compensation can be done through a finite impulse response filter, also known as feed-forward equalizer (FFE). In case of long transmission distances, a separate electronic dispersion compensation (EDC) [
2] is usually implemented, since otherwise too many coefficients for the adaptive FFE structure are required. With an increasing launch power, nonlinear effects additionally occur. For single-carrier transmission self-phase modulation (SPM), caused by the Kerr effect and nonlinear phase noise (NLPN), which results from the interaction between the amplified spontaneous emission (ASE) noise of inline optical amplifiers and SPM can be regarded as the most limiting nonlinear distortions [
3]. These impairments cannot be compensated with conventional FFE structures. Previous approaches for the compensation of these nonlinear impairments focused on replacing the FFE by a nonlinear Volterra equalizer (NLVE) [
4] or, if the fiber parameters are known, to replace the EDC with a digital backpropagation algorithm to compensate for linear and nonlinear effects simultaneously [
5]. After using these methods, a signal detection with conventional linear decision thresholds takes place. Another approach for the compensation of nonlinear effects is an extended signal detection where the decision thresholds are adjusted to the disturbed constellations. In other words, the equalization problem is defined as a classification task. To solve this problem suitable algorithms such as expectation maximization (EM) [
6,
7], k-means algorithm (KMA) [
8,
9], neural network [
10] or SVM [
11] can be found in the large field of machine learning algorithms.
The advantage of extended signal detection by SVM is already emphasized in references [
3,
12,
13,
14]. In order to investigate exclusively the influence of nonlinearities such as NLPN or SPM, the influence of dispersion has been neglected deliberately in the past [
3,
12]. The absence of dispersion means that the interaction between dispersion and nonlinearities is not investigated. Thus, it should be examined whether these equalization techniques work equally well in dispersion influenced transmission.
In this paper we apply the SVM algorithm to a 64-QAM based coherent optical data center interconnect transmission system to mitigate nonlinear impairments after 100 km transmission distance, including the influence of dispersion. We numerically investigate, for the first time of our knowledge, the impact of different combinations of equalizer (FFE, NLVE) with various detection structures (SVM, KMA). Additionally, we show that the combination of SVM and NLVE can reduce the computational complexity of the NLVE and that this combination allows a more accurate compensation of the impairments that arise in an optical transmission system that is operated in the nonlinear regime.
3. Simulation Setup
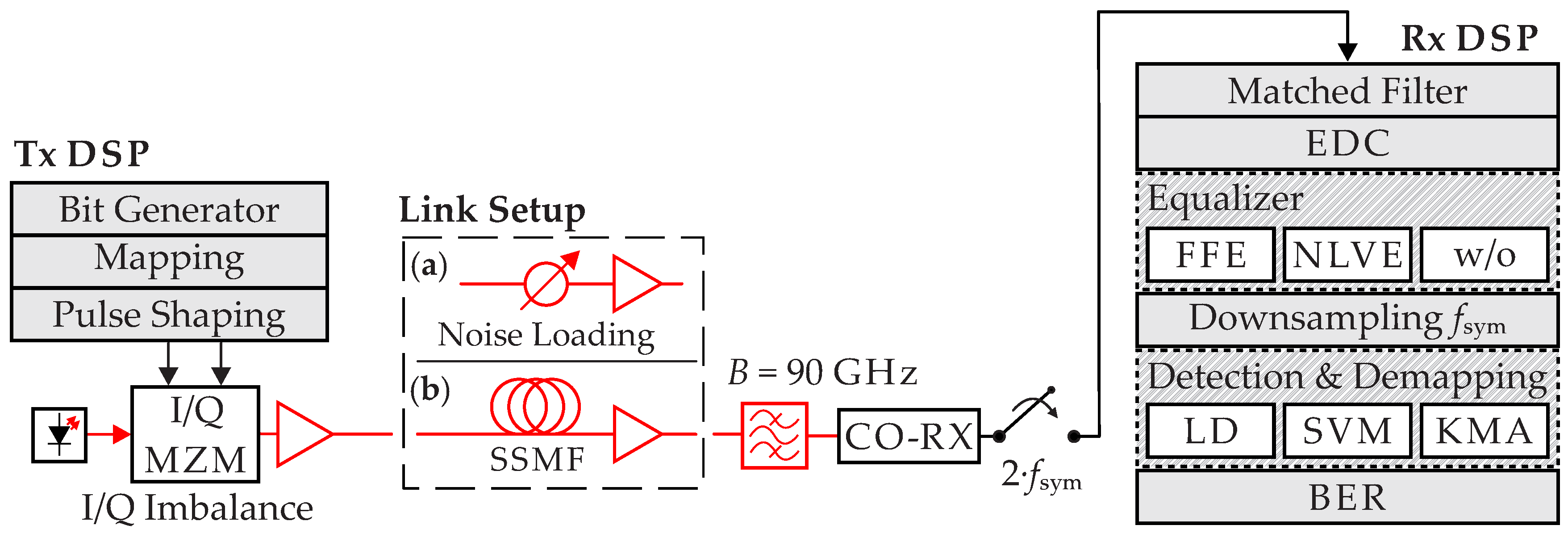
The proposed techniques are subsequently thoroughly evaluated in numerical simulations for a 64 GBd 64-QAM system. For simulation purposes we will initially restrict ourselves to a single-polarization system but it can be extended straight forward to a dual-polarization system. A schematic of the general setup is given in
Figure 3. A
randomly generated bit sequence, using the MATLAB R2018a (9.4.0.813654) rand function, is mapped to the 64-QAM symbols. The digital to analog conversion is modelled as a root-raised cosine pulse shaping filter with roll-off factor
. The symbols are modulated on the carrier (wavelength
nm) via an I/Q MZ-modulator. The linewidth of the laser is set to zero. The modulated optical signal is coupled into the fiber after it is amplified by the erbium doped fiber amplifier (EDFA) with a noise figure (NF) of 5 dB.
In order to investigate the performance of the enhanced detection algorithms, two types of communication systems are modeled. The link setup (
a) is used to test a back-to-back (B2B) scenario, that is, no transmission link was simulated. The setup (
b) is used to examine a dispersion uncompensated link, where the dispersion is compensated by DSP at the end of the transmission. The parameters for the SSMF are given by the attenuation coefficient
= 0.2 dB/km, the dispersion coefficient
ps/(nm·km), dispersion slope
ps/(nm
·km) and the nonlinear coefficient
(W·km)
. For a complete compensation of span loss an EDFA (NF
dB) is applied. After transmission a Gaussian optical filter with 90 GHz bandwidth is used to reduce ASE noise. The received signal is detected by a coherent receiver and downsampled to 128 GS/s. After matched filtering an ideal EDC is used to compensate for dispersion. After the equalization stage, which consists of either an FFE, an NLVE or no equalizer at all (w/o), the signal is downsampled to symbol frequency and detected. Detection and demodulation is performed either linear by using conventional linear decision thresholds and demapping, here called linear detection (LD), or by machine learning algorithms such as SVM or KMA [
8,
9]. System performance is evaluated by BER. The hard-decision forward error correction (HD-FEC) limit is assumed to be
. We examine the suitability of the SVM as a classifier and combine the mentioned equalizer schemes with the SVM to achieve the maximum gain of the machine learning algorithm.
Since more coefficients require more training symbols, increasing the number of coefficients without adjusting the number of training symbols might decrease the performance. Thus, for a correct adjustment of the Volterra equalizer it is necessary to determine the optimal number of coefficients and training symbols. For the further investigations the training length of 2048 symbols and memory lengths of NLVE[4,2,5] was determined after optimization.
4. Results and Discussion
Initially the behavior of SVM against I/Q imbalances was examined. In an I/Q modulator, the ideal phase shift between the I- and Q-branch is 90°. Due to physical imperfections of the system components and the non-perfect tuning of the
/2 phase shift, amplitudes and phase mismatches may occur. These I/Q imbalances may considerably disturb the signal constellation [
21]. We investigate the I/Q imbalances in a B2B scenario according to
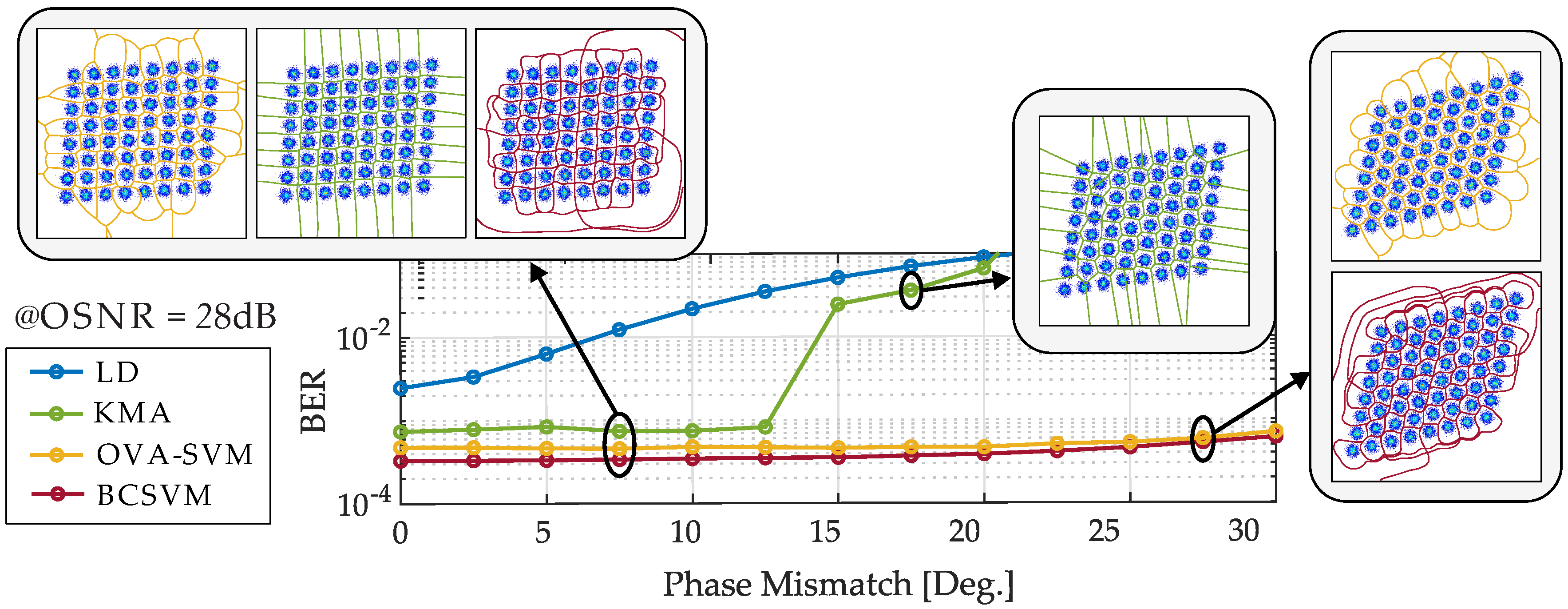
Figure 3a at an optical signal-to-noise ratio (OSNR) of 28 dB, where the signal is disturbed at the transmitter side. The amplitude mismatch is set to 0.125 and the phase mismatch is varied between 0° and 30°. To cope with these imperfections, we examine the performance of the BCSVM and the OVA-SVM and compare them to LD. In order to compare the SVM with other enhanced detection techniques, the KMA is added to this comparison. The training length of the respective SVMs and KMA is set to 1024 symbols. Moreover, the number of iterations for KMA is set to 5.
Figure 4 shows the performance of the various detection methods depending on the transmitter I/Q imbalances. As expected, detection by machine learning algorithms is more robust against I/Q imbalances compared to LD. For low phase mismatch, the performance of the two enhanced detection techniques seems similar. However, above 12° phase mismatch the KMA’s performance rapidly deteriorates. For SVM a decline in performance can be observed above 20° phase mismatch. Compared with OVA-SVM, the BCSM achieves slightly better performance, which is in the range of 1 × 10
.
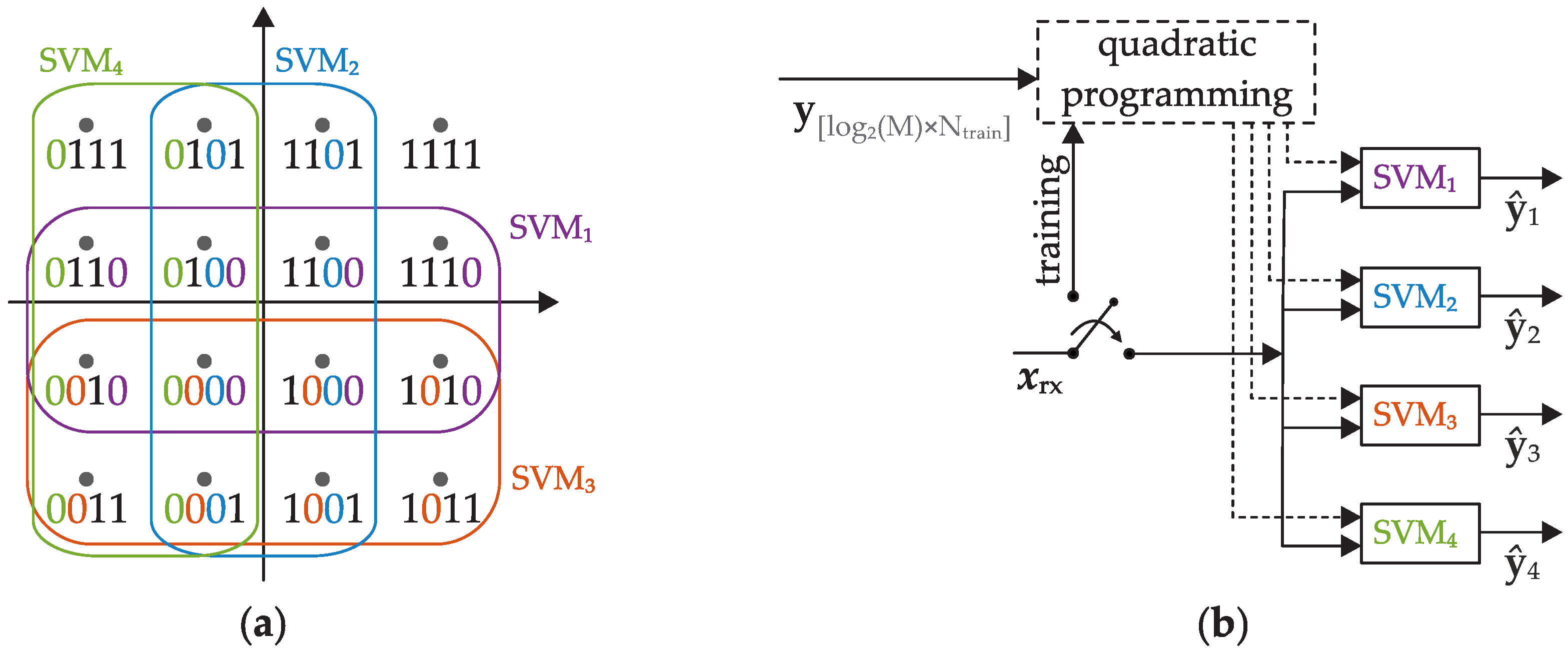
It should be mentioned that SVM and KMA are two completely different procedures. The SVM has already been introduced as classification algorithm in
Section 2.1. The KMA, in contrast, belongs to a cluster-based detection. The training of KMA is iterative and unsupervised, while the training of the SVM is supervised. The KMA is initialized with the centers of the cluster. Therefore, it is necessary to know how many clusters are present and where the centers are approximately expected. If the actual cluster is too far away from the expected cluster, the KMA is no longer able to separate the clusters correctly. This can be seen for example in the constellation of the KMA at 17.5° phase mismatch, where the field at the top right has been assigned to about two full constellation points. Although the centers of the clusters are updated in each iteration. This effect may also occur in case of a phase rotation induced by SPM. Furthermore, the KMA is only a linear algorithm in essence, while the SVM is a nonlinear classifier due to the usage of kernels. Accordingly, the KMA is unsuitable for highly complex and nonlinear data distributions and is therefore no longer used as comparison in the following investigations.
Regarding the visualization of the decision thresholds, the different working principles of the algorithms can be observed. Based on the RBF kernel, the SVM calculates significantly rounder and softer decision thresholds than the KMA. Additionally, a difference between the multi-class methods of the SVM can be seen. Therefore, we would like to point out at this point that besides the selection of the kernel also the choice of the SVM multi-class method may have a more or less significant influence on the results.
Next, we include the fiber in our simulations. To evaluate the ability of the SVM to compensate nonlinear impairments in the 100 km setup for different launch powers, we compare the nonlinear detection by SVM with an FFE and an NLVE. To distort the 64-QAM constellation we set the modulation depth of the modulator to and generated an I/Q imbalance with 5% phase deviation from 90°. The number of training symbols for SVM is set to 1024.
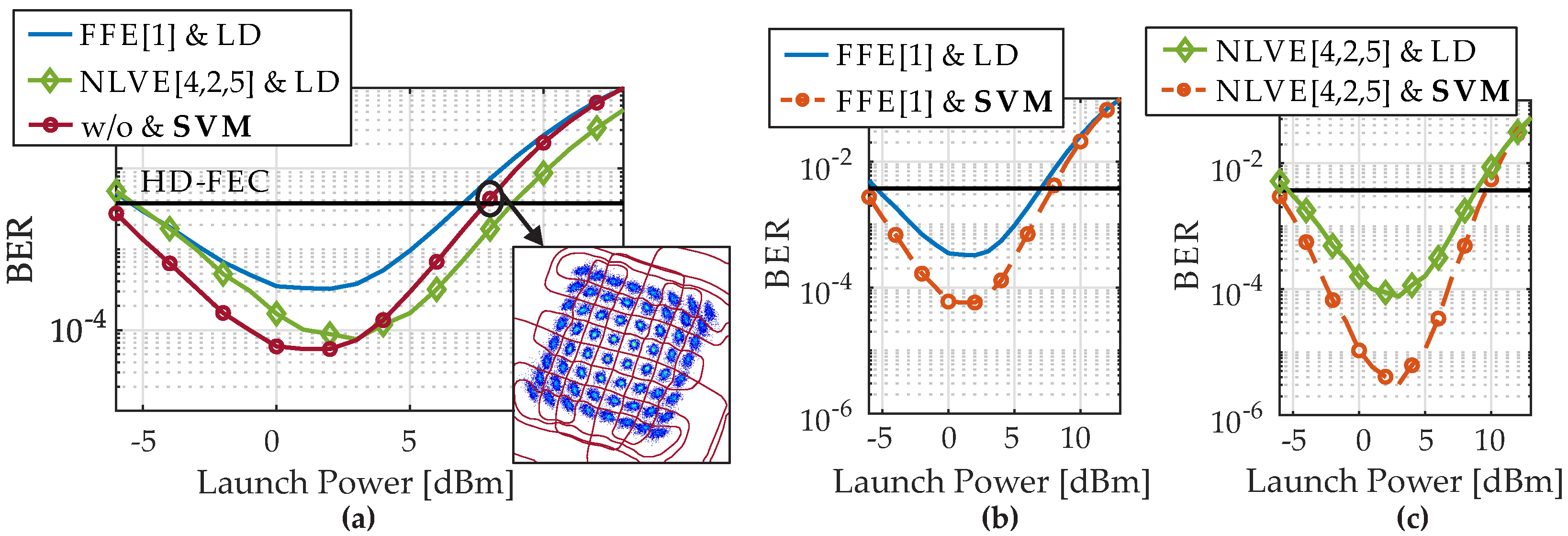
The BER as a function of the launch power after 100 km dispersion uncompensated transmission is shown in
Figure 5. The launch power of the 64-QAM signal ranges from −6 to +12 dBm. We investigate different combinations of equalizers and detection techniques.
Figure 5a first presents the results for FFE[1] and NLVE[4,2,5] in conjunction with LD. In addition, the red curve shows a detection based on SVM only without any previously inserted equalizer. It can be seen that a nonlinear detection with SVM only is already quite powerful. Here, the lowest BER is achieved by SVM at 3 dBm launch power, which is about six times lower than the BER using the FFE. Up to 4 dBm the best results can be achieved with SVM detection. Above 4 dBm nonlinear effects dominate and the optimally configured NLVE shows the best performance while the SVM is not as good as the NLVE but still better than the FFE. The launch power to stay below HD-FEC can be increased by 2 dB, if NLVE[4,2,5] is used and by 1 dB if the SVM is used compared to FFE[1]. If an FFE[1] or NLVE[4,2,5] is now added before the SVM, the overall system performance can be improved significantly, as shown in
Figure 5b,c. Especially the combination of NLVE[4,2,5] and SVM further minimizes the BER significantly as can be seen in
Figure 5c at 3 dBm launch power, where the BER is reduced from 7.7
to 3.1
by SVM.
The optimum setting for the NLVE is given by NLVE[4,2,5]. So, the total number of NLVE coefficients sums up to
, according to Equation (
8). The majority of coefficients belongs to the third order of the NLVE. Therefore, in our further investigations we have reduced the number of delay elements in the third order to
. Consequently, the number of coefficients is decreased from 75 to 18 (74%).
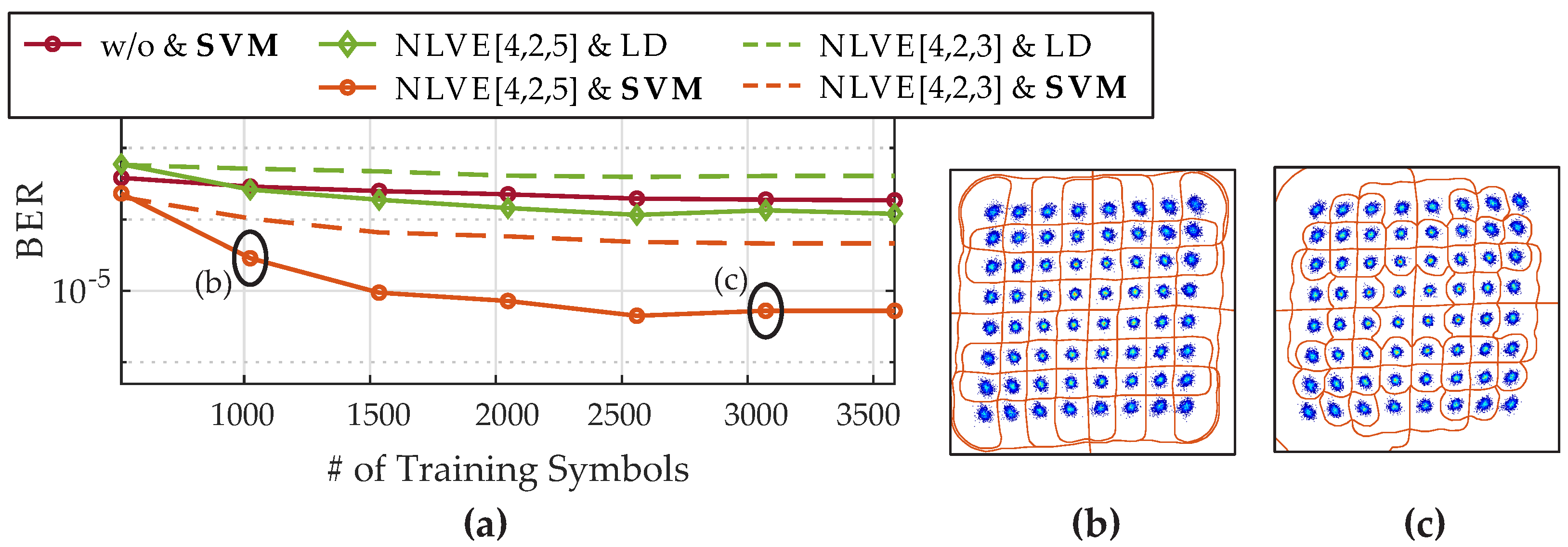
Figure 6 shows the obtained BER as a function of the launch power for the optimal and reduced NLVE. The SVM is trained with 1024 and the NLVE with 2048 symbols. It can be seen that further reducing the coefficients of the NLVE leads to a decline of the overall system performance. To stay below the HD-FEC, the launch power is reduced by 1 dB in case of NLVE[3,2,3] and LD compared to the NLVE[4,2,5] and LD. Furthermore, NLVE[4,2,3] is continuously worse than a detection by SVM only. By combining the reduced NLVE[4,2,3] and the SVM, it can be observed that better results are achieved compared to the optimally adjusted NLVE[4,2,5] and LD. At 3 dBm launch power, the BER of NLVE[4,2,3] and LD (green dashed line) is 1.2
and can be reduced to 1
by SVM (orange dashed line).
Finally, we examined the impact of the number of training symbols on the performance of the NLVE and the SVM. The obtained results are presented in
Figure 7 including the investigations for the NLVE with optimal and reduced coefficients in combination with LD and SVM based nonlinear detection plus a single detection only by SVM. We increased the number of training symbols from 512 to 3584 at 5 dBm launch power. The main improvement is observed after an increase from 512 to 1024 symbols for all investigated structures.
The training of the SVM is based on the classes that are included in the classification task. To ensure that the SVM can learn and capture link properties from ony a small amount of training data [
12], it is important, that besides a sufficient number of training symbols all classes are uniformly distributed in the training set. For example, with the amount of 512 training symbols and 64 different classes it is not guaranteed that each class is included in the training data, if a randomly generated training sequence is used. Concerning the NLVE, the training is based on the amount of inter symbol interference which is independent on the training data itself. Here, a certain number of symbols is necessary to estimate the coefficients correctly. In case of the NLVE[4,2,5], the training length of 512 is not sufficient to determine the coefficients correctly. However, if a certain number of training symbols is used, the channel estimation of the NLVE can improve its performance barely, even if more training data is used as it can be seen for the reduced NLVE[4,2,3]. While the plain NLVE and SVM structures saturated fast, the results with combined NLVE and SVM based detection are quite remarkable.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






