A Text-Generated Method to Joint Extraction of Entities and Relations



Abstract
:1. Introduction
- (1)
- We completely convert the entity-relation extraction to the text generation task, and use a unified decoding method to generate entities and relational expressions as target text to realize the joint extraction of entities and relations.
- (2)
- Based on the text generation framework, the model is designed to generate multiple groups of relational triplets. Entities can be repeated in multiple triplets to solve the problem of overlapped multiple relational tuples.
- (3)
- We conduct experiments on NYT10 and NYT11 public datasets, and the experimental results show that we proposed method outperforms state-of-the-art with 4.7% and 11.4% improvements in F1 score, respectively.
2. Related Work
3. Materials and Methods
3.1. Problem Formulation
3.2. Model Description
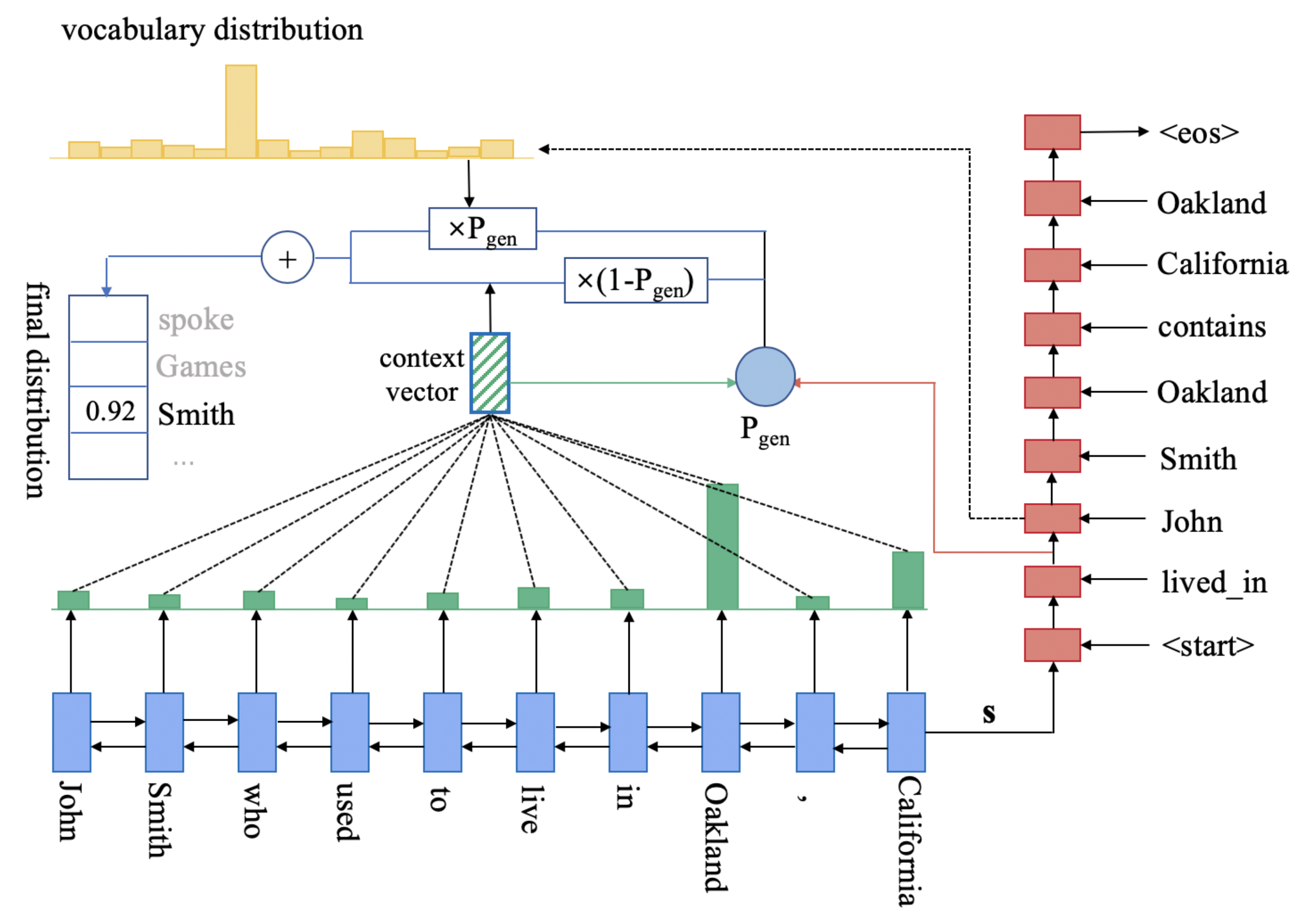
3.2.1. Encoder
3.2.2. Decoder
3.2.3. Training and Decoding
4. Experimental Setup
4.1. Dataset
4.2. Settings
4.3. Baseline and Evaluation Metrics
- CoType [24]: a domain-independent framework by jointly embedding entity mentions, relation mentions, text features, and type labels into representations, which formulates extraction as a global embedding problem.
- SPTree [7]: an end-to-end relation extraction model that represents both word sequence and dependency tree structures using bidirectional sequential and tree-structured LSTM-RNNs.
- Noveltagging [8]: an approach that treats joint extraction as a sequential labeling problem using a tagging schema where each tag encodes entity mentions and relation types at the same time to achieve joint extraction of entities and relations.
- MultiDecoder [9]: a sequence-to-sequence learning framework with a copy mechanism for joint extraction, where multiple decoders are applied to generate triples to handle overlapping relations, completing the extraction of a relational triple every three steps. This method is the first time to solve the overlapping problem of multi-relational extraction.
5. Results
Model Performance
6. Discussion
6.1. Comparison of Overall Performance
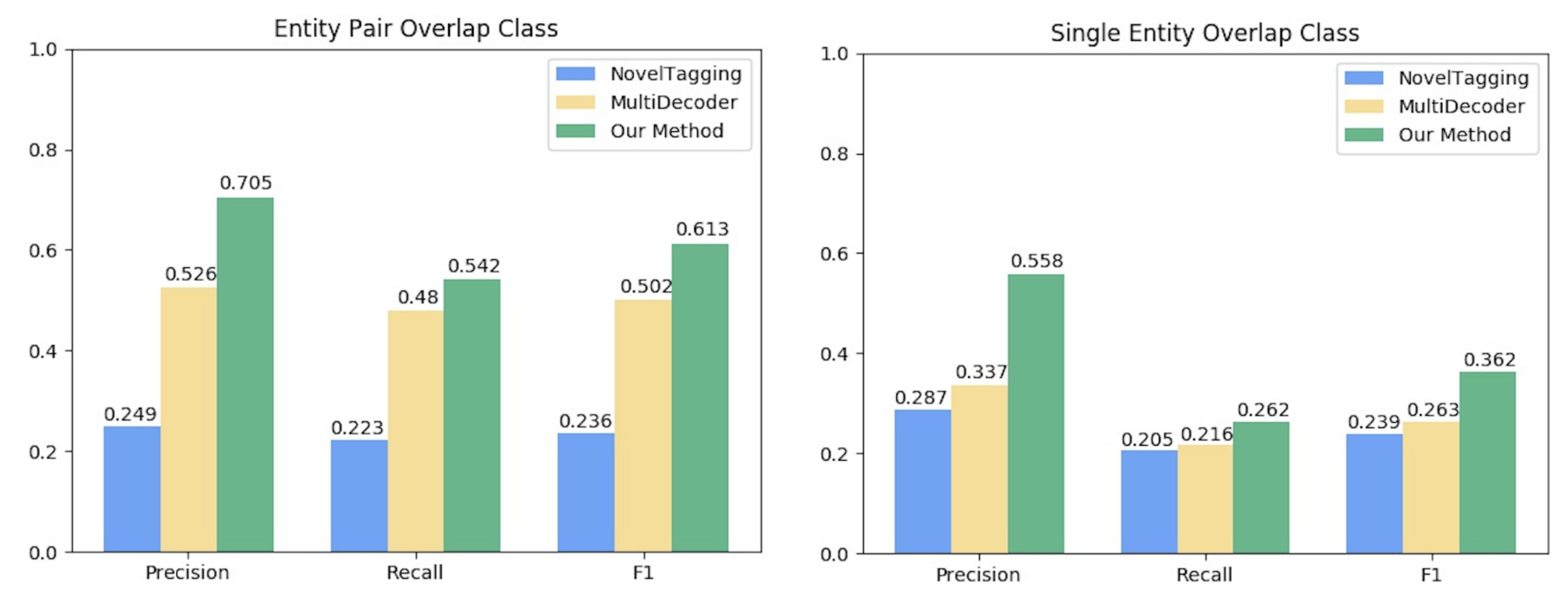
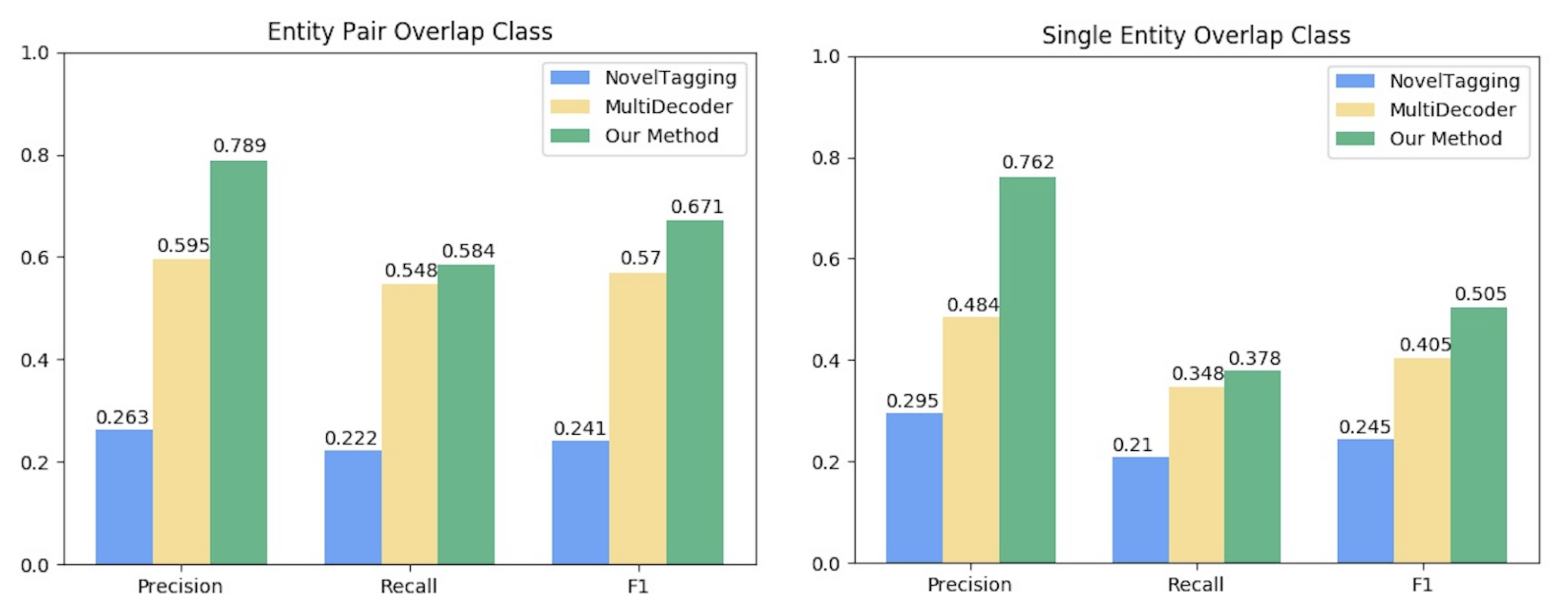
6.2. Comparison of Overlapped Multi-Relations Extraction Performance
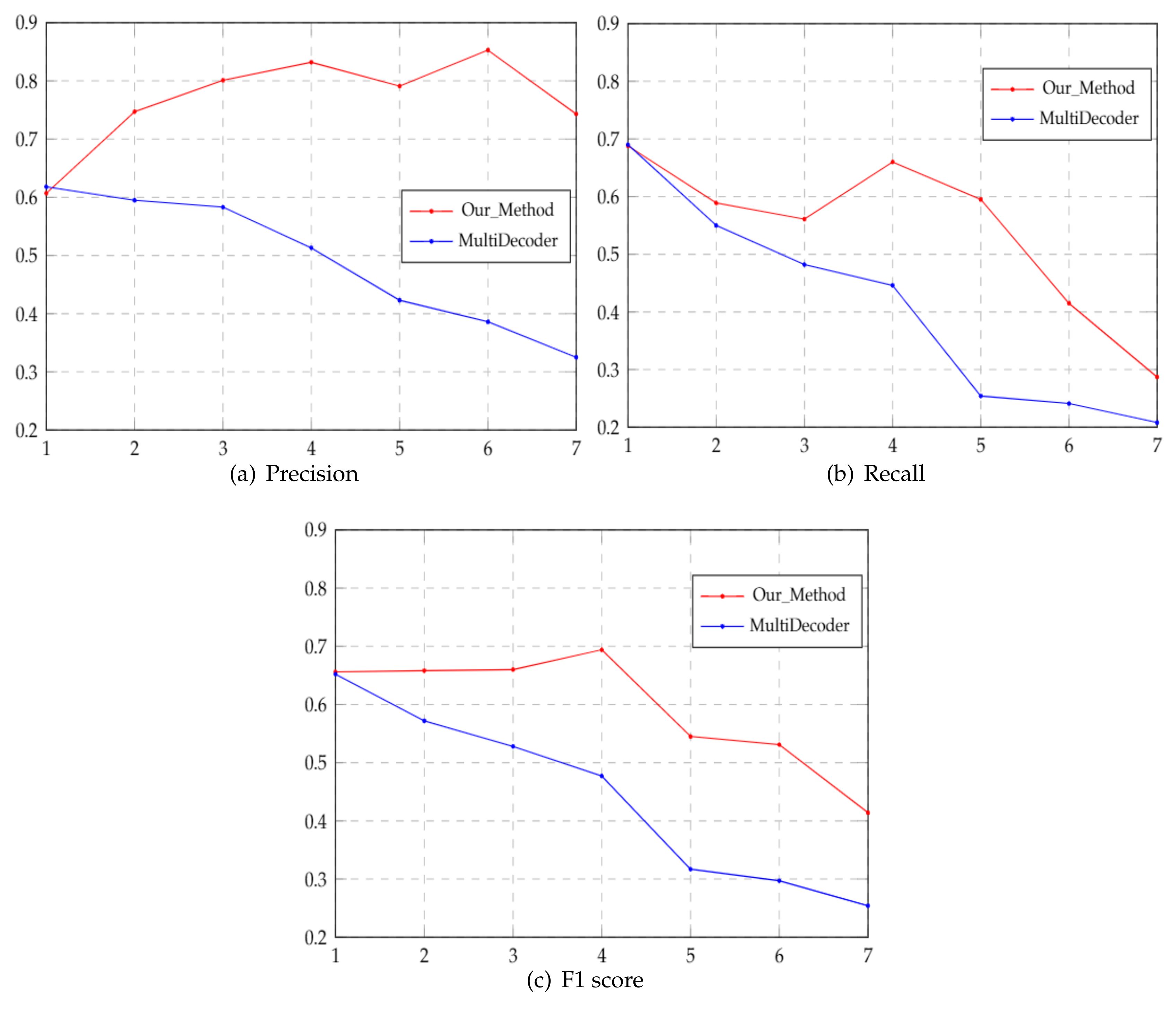
6.3. Comparison of the Multiple Relational Triples Extraction Performance
6.4. Case Study
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| RC | Relation Classification |
| NER | Named Entity Recognition |
| LSTM | Long Short-Term Memory |
| RNN | Recurrent Neural Network |
| CNN | Convolutional Neural Network |
References
- Zhao, M.; Wang, H.; Guo, J.; Liu, D.; Xie, C.; Liu, Q.; Cheng, Z. Construction of an Industrial Knowledge Graph for Unstructured Chinese Text Learning. Appl. Sci. 2019, 9, 2720. [Google Scholar] [CrossRef]
- Cai, R.; Zhang, X.; Wang, H. Bidirectional recurrent convolutional neural network for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; Volume 1, pp. 756–765. [Google Scholar]
- Hashimoto, K.; Miwa, M.; Tsuruoka, Y.; Chikayama, T. Simple customization of recursive neural networks for semantic relation classification. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1372–1376. [Google Scholar]
- Zeng, D.; Liu, K.; Lai, S.; Zhou, G.; Zhao, J. Relation classification via convolutional deep neural network. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 2335–2344. [Google Scholar]
- Katiyar, A.; Cardie, C. Investigating lstms for joint extraction of opinion entities and relations. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; Volume 1, pp. 919–929. [Google Scholar]
- Katiyar, A.; Cardie, C. Going out on a limb: Joint extraction of entity mentions and relations without dependency trees. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 917–928. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-end relation extraction using lstms on sequences and tree structures. arXiv 2016, arXiv:1601.00770. [Google Scholar]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint extraction of entities and relations based on a novel tagging scheme. arXiv 2017, arXiv:1706.05075. [Google Scholar]
- Zeng, X.; Zeng, D.; He, S.; Liu, K.; Zhao, J. Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 506–514. [Google Scholar]
- Christopoulou, F.; Miwa, M.; Ananiadou, S. A Walk-based Model on Entity Graphs for Relation Extraction. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Melbourne, Australia, 15–20 July 2018; Volume 2, pp. 81–88. [Google Scholar]
- Wang, S.; Zhang, Y.; Che, W.; Liu, T. Joint Extraction of Entities and Relations Based on a Novel Graph Scheme. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 4461–4467. [Google Scholar]
- Nallapati, R.; Zhai, F.; Zhou, B. Summarunner: A recurrent neural network based sequence model for extractive summarization of documents. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Zhang, Y.; Li, D.; Wang, Y.; Fang, Y.; Xiao, W. Abstract Text Summarization with a Convolutional Seq2seq Model. Appl. Sci. 2019, 9, 1665. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Cheng, Y.; Yang, Q.; Liu, Y.; Sun, M.; Xu, W. Joint training for pivot-based neural machine translation. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the point: Summarization with pointer-generator networks. arXiv 2017, arXiv:1704.04368. [Google Scholar]
- Socher, R.; Huval, B.; Manning, C.D.; Ng, A.Y. Semantic compositionality through recursive matrix-vector spaces. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; pp. 1201–1211. [Google Scholar]
- Xu, K.; Feng, Y.; Huang, S.; Zhao, D. Semantic relation classification via convolutional neural networks with simple negative sampling. arXiv 2015, arXiv:1506.07650. [Google Scholar]
- Santos, C.N.D.; Xiang, B.; Zhou, B. Classifying relations by ranking with convolutional neural networks. arXiv 2015, arXiv:1504.06580. [Google Scholar]
- Xu, Y.; Mou, L.; Li, G.; Chen, Y.; Peng, H.; Jin, Z. Classifying relations via long short term memory networks along shortest dependency paths. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1785–1794. [Google Scholar]
- Yu, X.; Lam, W. Jointly Identifying Entities and Extracting Relations in Encyclopedia Text via A Graphical Model Approach. In Proceedings of the International Conference on Coling, Beijing, China, 23–27 August 2010. [Google Scholar]
- Zheng, S.; Hao, Y.; Lu, D.; Bao, H.; Xu, J.; Hao, H.; Xu, B. Joint entity and relation extraction based on a hybrid neural network. Neurocomputing 2017, 257, 59–66. [Google Scholar] [CrossRef]
- Riedel, S.; Yao, L.; McCallum, A. Modeling relations and their mentions without labeled text. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2010; pp. 148–163. [Google Scholar]
- Ren, X.; Wu, Z.; He, W.; Qu, M.; Voss, C.R.; Ji, H.; Abdelzaher, T.F.; Han, J. Cotype: Joint extraction of typed entities and relations with knowledge bases. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1015–1024. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Sentence | Relation Triples |
|---|---|---|
| Normal | S1: Chicago is in the United States. | <The United States, contains, Chicago> |
| Entity Pair Overlap | S2: News of the list’s existence unnerved officials in Khartoum, Sudan’s capital. | <Sudan, contains, Khartoum> <Sudan, capital, Khartoum> |
| Single Entity Overlap | S3: John, 23, who lives in Los Angeles, California. | <John, placelived, Los Angeles> <California, contains, Los Angeles> |
| NYT10 | NYT11 | |
|---|---|---|
| Relation types | 29 | 24 |
| Training set | 66,828 | 58,356 |
| Training tuples | 84,166 | 98,393 |
| Test set | 4000 | 4998 |
| Test tuples | 5010 | 8226 |
| Model | NYT10 | NYT11 | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | |
| CoType | - | - | - | 0.417 | 0.320 | 0.362 |
| SPTree | 0.464 | 0.591 | 0.519 | 0.493 | 0.634 | 0.555 |
| Noveltagging | 0.563 | 0.334 | 0.419 | 0.622 | 0.341 | 0.440 |
| MultiDecoder | 0.543 | 0.530 | 0.536 | 0.586 | 0.574 | 0.580 |
| Our Method | 0.592 | 0.533 | 0.561 | 0.702 | 0.598 | 0.646 |
| 1 | 2 | 3 | >=4 | Percentage | |
|---|---|---|---|---|---|
| sentences containing 2 relation triples | 514 | 943 | - | - | 0.647 |
| sentences containing 3 relation triples | 210 | 72 | 182 | - | 0.547 |
| sentences containing 4 relation triples | 70 | 71 | 12 | 194 | 0.800 |
| Input | Output of Our Model |
|---|---|
| Kevin Steurer is helping complete arrangements for a family trip to Houston, America. | contains , America , Houston . |
| You can take the train from many cities in Italy to Lecce , which is about 45 min from Otranto by car. | contains, Italy, Lecce. contains, Italy, Otranto. |
| The real power at Microsoft resides with its longtime leaders—Bill Gates, the co-founder and chairman. | work_in, Bill Gates, Microsoft . founder, Microsoft, Bill Gates. |
| Somerset County has experienced disaster, with the crash of flight and nine coal miners trapped at Quecreek. | contains, County, Quecreek |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
E, H.; Xiao, S.; Song, M. A Text-Generated Method to Joint Extraction of Entities and Relations. Appl. Sci. 2019, 9, 3795. https://doi.org/10.3390/app9183795
E H, Xiao S, Song M. A Text-Generated Method to Joint Extraction of Entities and Relations. Applied Sciences. 2019; 9(18):3795. https://doi.org/10.3390/app9183795
Chicago/Turabian StyleE, Haihong, Siqi Xiao, and Meina Song. 2019. "A Text-Generated Method to Joint Extraction of Entities and Relations" Applied Sciences 9, no. 18: 3795. https://doi.org/10.3390/app9183795
APA StyleE, H., Xiao, S., & Song, M. (2019). A Text-Generated Method to Joint Extraction of Entities and Relations. Applied Sciences, 9(18), 3795. https://doi.org/10.3390/app9183795