1. Introduction
Natural language processing (NLP) relies on word embeddings as input for machine learning or deep learning algorithms. For decades, NLP solutions were restricted to machine learning approaches that trained on handcrafted, high dimensional and sparse features [
1]. Nowadays, the trend is neural networks [
2], which use dense vector representations. Hence, the superior results on NLP tasks is attributed to word embeddings [
3,
4] and deep learning methods [
5]. Therefore, as observed by the authors of [
6,
7,
8,
9], improved performance of downstream NLP tasks is achieved by learning vector representation of words in language models. Quality word vectors are expected to capture syntactic and semantic similarities among words by addressing the similarities in surface form of words and the context [
8]. This has motivated the transition from the conventional one-hot word representation to word representation [
10] based on words and sub-word information (characters and morphemes). Despite Mikolov et al.’s [
4] contribution of distributed word representation, the urge for even better word representation has led to composition of word embeddings from sub-word information such as characters [
8,
11,
12], character n-gram [
13] and morphemes [
7,
14,
15].
However, with all these developments, deep learning is yet to be utilized in processing low resource languages [
16,
17], particularly the syllabic based languages, such as Swahili, Xhosa, Luhya, Shona, Kikuyu and Mijikenda. In fact, the East Africa integration initiative by the respective countries has encountered language barrier as a challenge in the quest for a common language [
18], a problem that could be overcome by automated language systems. A probable solution is automating Swahili using deep learning models that can learn its syllabic alphabet to effectively represent the Swahili words, which are highly agglutinative [
19]. To the best of our knowledge, no study has considered learning word representation from constituent syllables of words in syllabic-based languages. We are inspired by the Swahili language teaching methodology, which first introduces syllables, then two-syllable words, and lastly complex words and sentences [
20]. For this reason, we propose syllabic based word embeddings (WEFSE) to match Swahili’s complex word morphology, as opposed to using characters or morphemes. This study generated word embeddings from syllable embeddings (WEFSE) but differently from Assylbekov et al. [
21], who used an external hyphenator to segment the words into syllables. We hypothesize that learning word representations from syllabic alphabets captures both semantic meaning of words and handles new words. We attribute this to the fact that the syllables in Swahili are the smallest meaningful semantic unit and are a subset of the morphemes [
22]. Consider the following Swahili verbs:
anapojitakia (when he/she wants it for himself/herself);
aliandika (he wrote); and
atakikamata (he will catch it).
From these examples we note that Swahili is highly agglutinative, as it starts with a root word and creates a new word by adding syllables such as “a”, “na”, “po”, “ji”, “ki”, “li", “ndi”, “ka”, “ta” and “ma”. This indicates that the ultimate meaning of the verb anapojitakia is a culmination of the subject prefix (“a”), tense prefix (“na”), relative prefix (“po”), object prefix (“ji”), root (“taka”) and extension (“ia”). The position of each syllable in the word also bears syntactic and semantic meaning. For example, the second syllable “na”, “li” and “ta” in Examples 1, 2 and 3 connote present, past and future tenses, respectively. Intuitively, words with the same syllables have a similar context. The study’s objective was to effectively represent Swahili words by capturing the compositional and contextual aspects.
There is a trend in NLP of optimizing performance of downstream tasks through high quality vectors for word representation [
6,
23]. Classical language models [
23] use contextual word information from a large corpus to generate word embeddings, however these models were deficient in representing rare words and new words [
24]. This led to compositional models, in particular, character-aware models [
6,
8,
11,
12,
13,
25,
26] aimed at mitigating the data sparsity problem. Although these models address the rare word problem, characters carry no inherent semantic meaning. Alternatively, the compositional models based on morphemes [
7,
14,
15,
27,
28,
29] address the semantic meaning deficiency in character models. However, external fragmentation of words into morphemes propagate errors into the models, affecting the quality of the word embeddings [
29]. Our work is similar to those of Assylbekov et al., Yu et al. and Mikolov et al. [
9,
21,
30] on the basis of learning syllable and word representation. However, we utilized a defined syllabic alphabet instead of an external hyphenation algorithm to divide the words into syllables, which we hypothesize that may introduce errors.
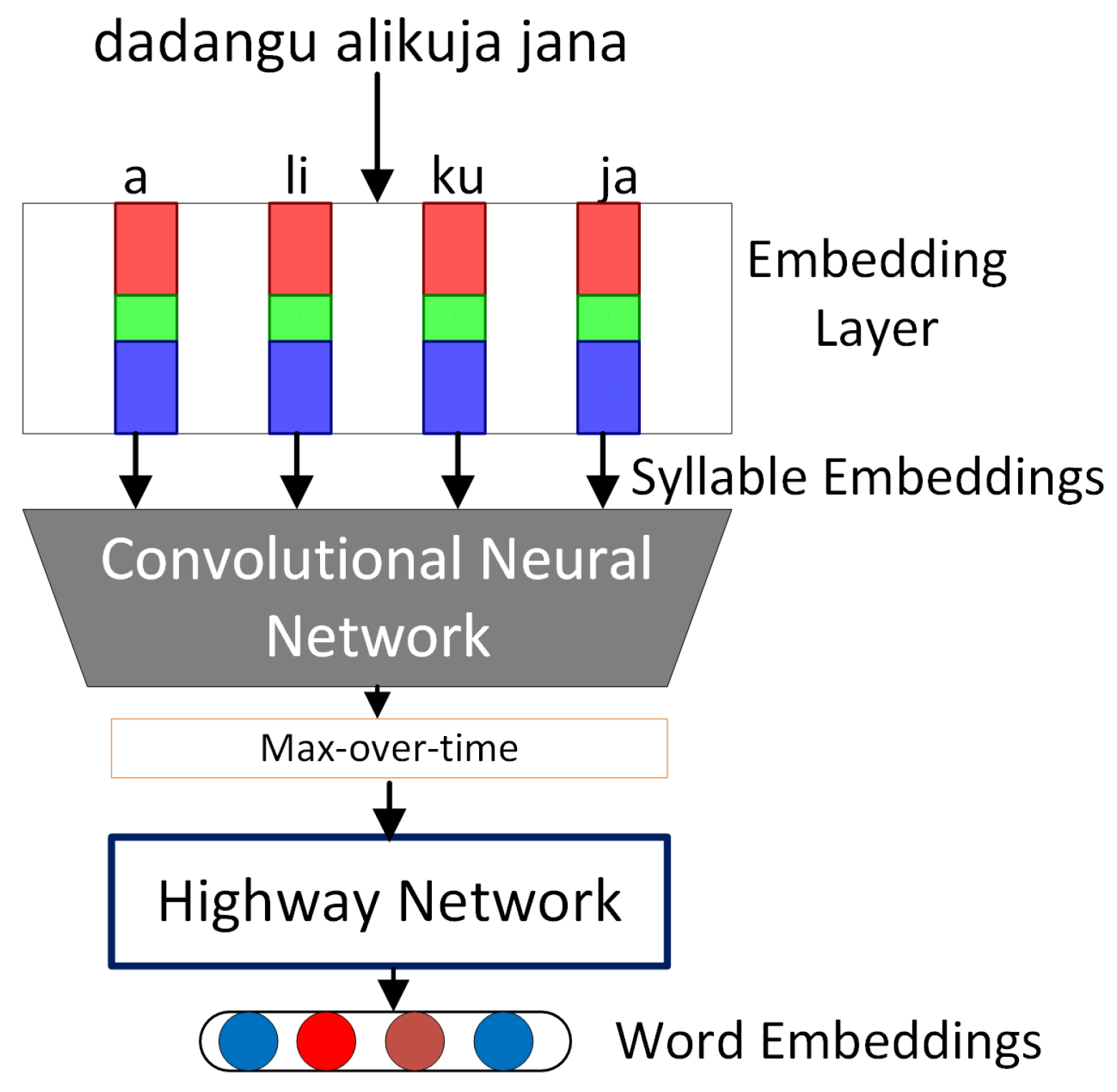
The architecture of our model resembles that of Assylbekov et al. [
21]. Both models apply a convolutional neural network [
31] to extract features and compose the word embeddings, a highway network [
32] to model interactions among the syllables and finally a recurrent neural network language model [
3]. Our model is different in terms of how the words are encoded to syllables. It takes syllables as input and then extracts feature maps using a convolutional neural network to form the word embeddings. Then, the language model, which is made of a long short term memory [
33], predicts the target words given the contextual words. The model has the potential to generalize unseen words and apply existing knowledge on new words because it is learning from a standard finite syllabic alphabet, which is the basis of all Swahili words. We chose Swahili as the main language for the experiments because of its syllabic structure, agglutinative and polysemous features, and its popularity in East and Central Africa [
17,
19]. For comparison purposes, we performed experiments on Xhosa and Shona, which are syllabic but with limited scope. The quality of the generated word embeddings (WEFSE) is demonstrated by the perplexity values of the syllable-aware language model on both small and medium datasets developed by Gelas et al. [
34]. The perplexity values are very competitive with the existing state-of-the-art models and outperform the character-aware counterparts. We further evaluated our word embeddings using the word analogy task to verify the quality of the word embeddings.
The main contributions of our study are as follows:
syllable alphabet;
word embeddings from syllable embeddings (WEFSE) (to the best of our knowledge, the first attempt to use syllabic alphabet);
syllable-aware language model; and
Swahili word analogy dataset.
The remaining sections of the paper are organized as follows.
Section 2 discusses the Swahili language structure and introduces the syllabic alphabet.
Section 3 reviews the previous works and
Section 4 provides the details of the proposed model. We outline the experiments in
Section 5 and discuss results and word analogy task in
Section 6. We conclude in
Section 7 and provide more details of the experiments in the
Appendix A.
2. Swahili Language Structure
Swahili is one of the Bantu languages widely spoken in East and Central Africa, with two main dialects being Unguja (which is spoken in Zanzibar) and Mvita (which spoken in Mombasa) [
35]. It is influenced by languages such as Arabic, Persian, German, Portuguese, English and French [
35]. This explains the presence of a couple of loan words such as
shukrani (thanks) and
polisi (police). Swahili is also very contextual with high agglutinative and polysemous features [
19,
36]. The following two sentences demonstrate the polysemy feature of the word
panda:
The Swahili morphology depends on prefixes and suffixes, which are syllables. It has a large noun class system with distinctive singular and plural forms [
37], which is achieved by using syllable pairs, for example,
mtu (person) and
watu (people), or
kitabu (book) and
vitabu (books). In fact, Ng’ang’a [
38] observed that synthetic and functional information can be derived from these connotation bearing affixes attached to nouns. However, verbs, pronouns, adjectives and demonstrations must match with the noun class to guarantee effective Swahili communication. In addition, Swahili verbs are very agglutinative, and may consist of subject, tense, relative and object prefixes in addition to roots and extensions. The following list provides a few examples of the verbal agglutinative components:
subject prefix: a, m, ni, wa, tu, si, hatu;
tense prefix: na, ta, li, me, ngeli, ja, singali;
relative: po, ko, o, cho, mo, yo, vyo, lo;
object prefix: wa, ni, ji, ku, i, ya, vi, zi;
root: sema, kuja, ahidi, acha, aga, ajiri; and
extension: ia, iwa, lia, shwa, ana, isha, kia.
Swahili Syllabic Alphabet
This section briefly introduces the finite Swahili syllabic alphabet, which forms the basis of all Swahili words. Swahili uses the English alphabet letters with the exception of x and q. The vowels a, e, i, o, and u count as syllables and constitute the smallest syllabic unit [
35]. Swahili syllables are derived from vowels and consonants of the alphabet, with a syllable normally consisting of a vowel preceded by one to three consonants. In special cases, the syllable is a single vowel or consonant. For example, in the words
mtu (person) and
anakula (he is eating), the starting letters “m” and “a” are special syllables. It is imperative that the position of the syllable in a word be preserved to maintain the syntactic and functional information. The following are the rules for Swahili syllabification [
35,
39]:
a consonant or a vowel preceded by a vowel is the start of a syllable;
a consonant (other than a semi-vowel) preceded by a consonant is the start of a syllable (for n, m and loan words);
all syllables end at the beginning of the next syllable or at the end of the word;
where a pre-consonantal nasal functions as a syllabic peak, a syllable is formed by a combination of two sounds;
a cluster of a consonant and a semi-vowel together with a vowel can also form a syllable; and
a segment of clusters of three with a vowel can form a syllable.
To derive the syllabic alphabet, we apply the above rules, appropriately combine the consonants with the vowels based on the list of letters provided by Masengo [
40] and add the list of special syllables. It is important to note that new words or loan words can be generated from the alphabet. For example, before a proper Swahili word for television (
runinga) was coined, it was and is still referred to as
televisheni whose syllables can be found in the alphabet.
Table 1 outlines the Swahili syllabic alphabet.





{kind=link}
{kind=link}
{kind=link}