Speech Enhancement Using Generative Adversarial Network by Distilling Knowledge from Statistical Method

Abstract
:1. Introduction
2. Related Work
2.1. Speech Enhancement Using Generative Adversarial Networks
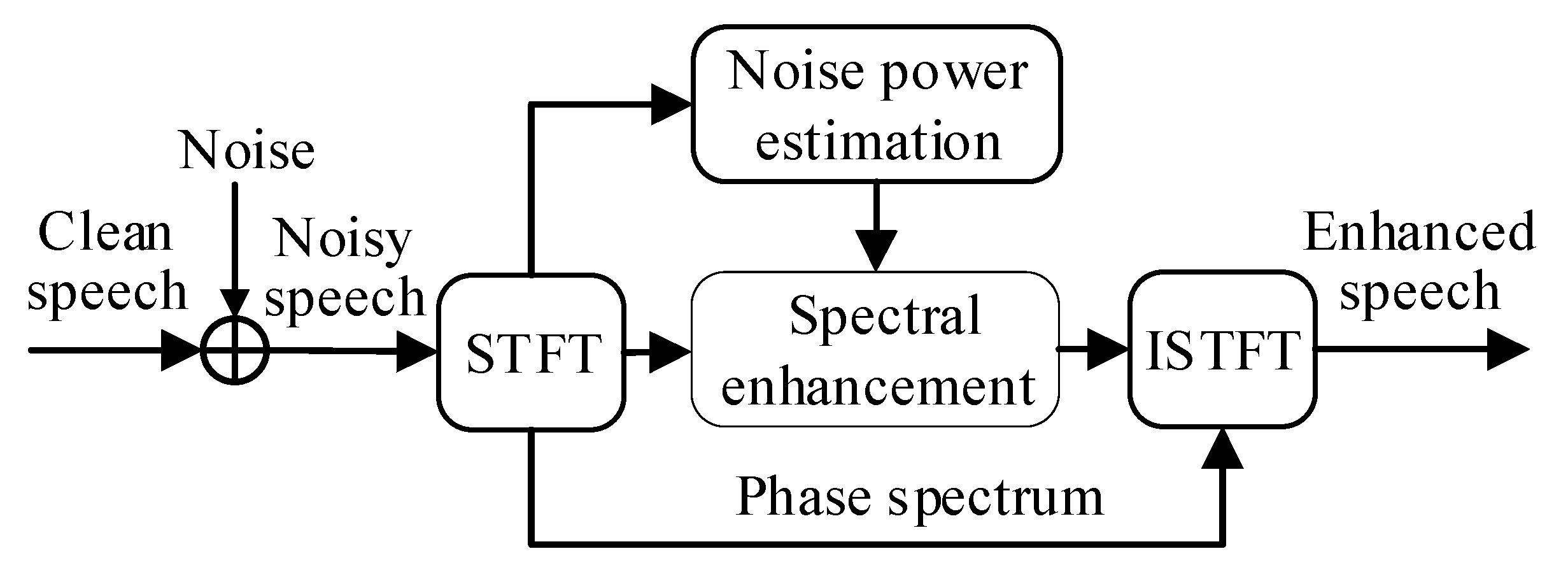
2.2. Statistical-Based Speech Enhancement
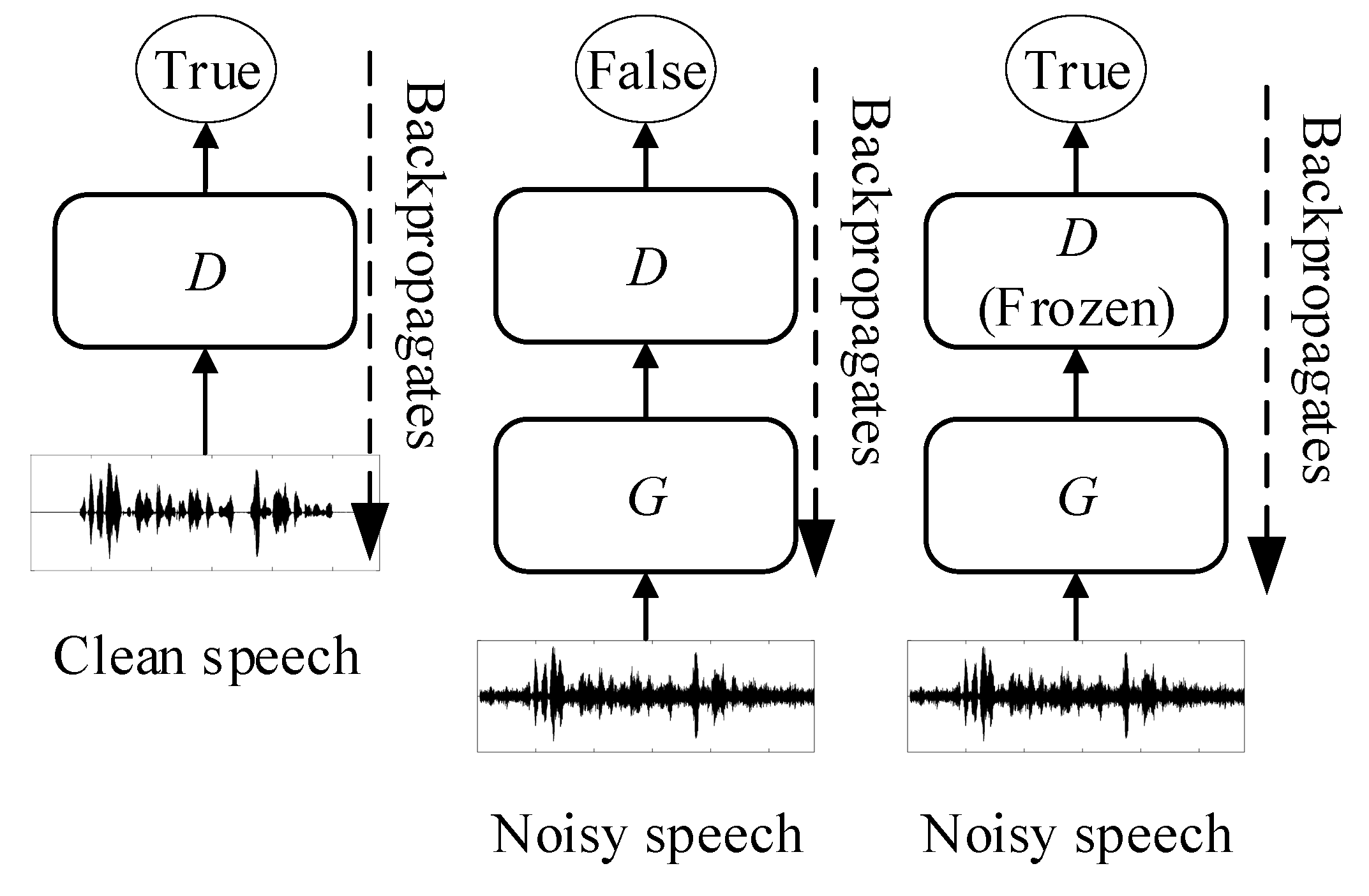
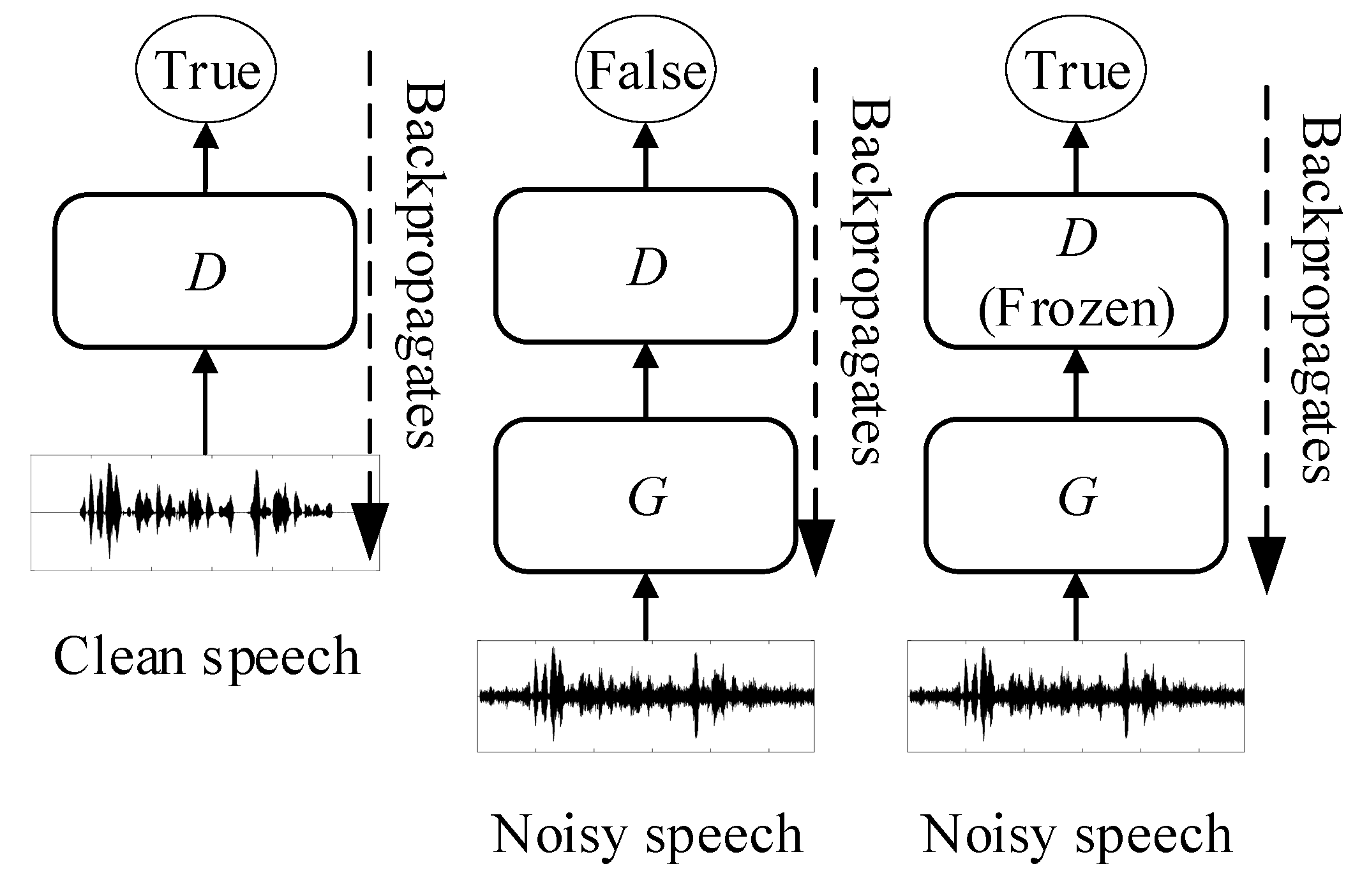
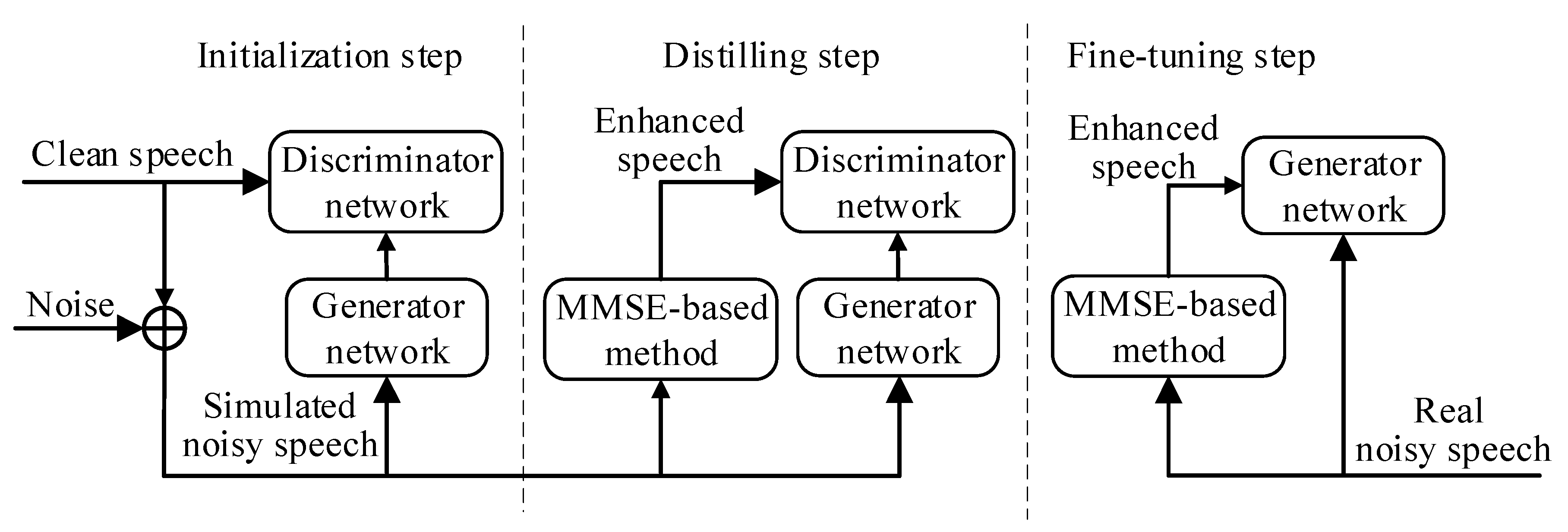
3. Adversarial Network with Distilled Knowledge from Statistical Method
3.1. Proposed Architecture
3.2. Network Initialization Using Adversarial Learning
3.3. Distilling Knowledge from MMSE-Based Speech Enhancement Algorithm
3.4. Fine-Tuning the Generator Network for Speech Enhancement
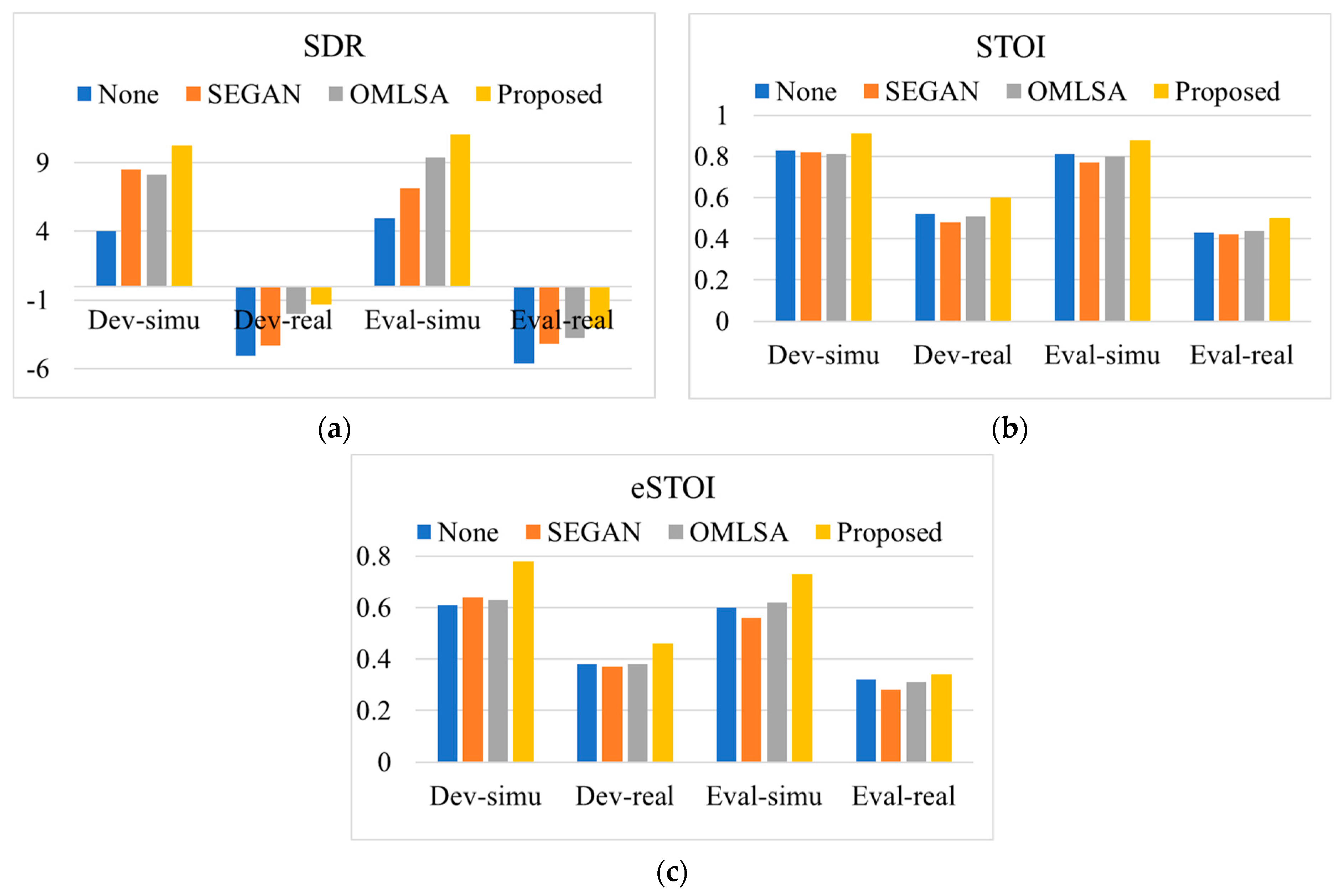
4. Experimental Results
4.1. Setup
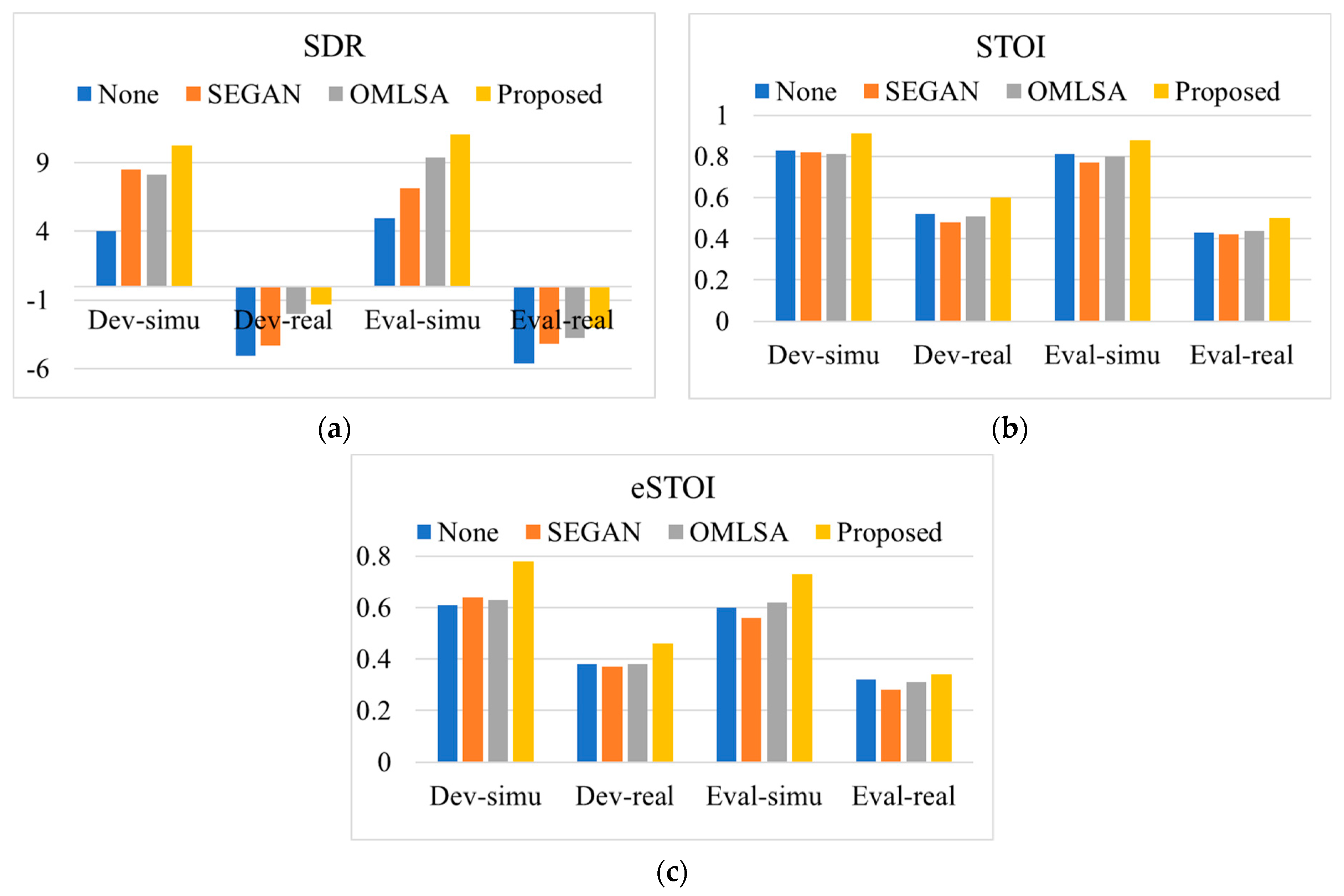
4.2. Evaluation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ephraim, Y.; Malah, D. Speech enhancement using minimum mean square log spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal. Process. 1985, 33, 443–445. [Google Scholar] [CrossRef]
- Cohen, I.; Gannot, S. Spectral enhancement methods. In Springer Handbook of Speech Processing; Benesty, J., Sondhi, M.M., Huang, Y., Eds.; Springer: Berlin, Germany, 2008; pp. 873–901. [Google Scholar]
- Loizou, P.C. Speech Enhancement: Theory and Practice, 2nd ed.; CRC: Boca Raton, FL, USA, 2013. [Google Scholar]
- Rosenkranz, T.; Henning, P. Improving robustness of codebook-based noise estimation approaches with delta codebooks. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 1177–1188. [Google Scholar] [CrossRef]
- Veisi, H.; Hossein, S. Speech enhancement using hidden Markov models in Mel-frequency domain. Speech Commun. 2013, 55, 205–220. [Google Scholar] [CrossRef]
- Xu, Y.; Du, J.; Dai, L.-R.; Lee, C.-H. A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 71–79. [Google Scholar]
- Narayanan, A.; Wang, D.L. Ideal ratio mask estimation using deep neural networks for robust speech recognition. In Proceedings of the ICASSP, Vancouver, BC, Canada, 26–31 May 2013; pp. 7092–7096. [Google Scholar]
- Yuxuan, W.; DeLiang, W. Towards scaling up classification-based speech separation. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 1381–1390. [Google Scholar] [CrossRef]
- Pascual, S.; Antonio, B.; Serrà, J. SEGAN: Speech Enhancement Generative Adversarial Network. Proc. Interspeech 2017, 2017, 36423–36646. [Google Scholar]
- Hinton, G.; Oriol, V.; Jeff, D. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Mehdi, M.; Simon, O. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- ITU-T. Perceptual Evaluation of Speech Quality (PESQ): An Objective Method for End-to-End Speech Quality Assessment of Narrow-Band Telephone Networks and Speech Codecs; International. Telecommun; Union-Telecommun. Stand Sector: Geneva, Switzerland, 2001; p. 862. [Google Scholar]
- Barker, J.; Marxer, R.; Vincent, E.; Watanabe, S. The third ’CHiME’ speech separation and recognition challenge: Dataset, task and baselines. In Proceedings of the IEEE 2015 Automatic Speech Recognition and Understanding Workshop (ASRU), Scottsdale, AZ, USA, 13–17 December 2015. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An algorithm for intelligibility prediction of time–frequency weighted noisy speech. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Jensen, J.; Taal, C.H. An algorithm for predicting the intelligibility of speech masked by modulated noise maskers. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 2009–2022. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Environment | Dev-Simu | Dev-Real | Eval-Simu | Eval-Real |
|---|---|---|---|---|---|
| None | BUS | 2.15 | 2.03 | 2.16 | 2.17 |
| CAF | 1.87 | 2.18 | 1.88 | 2.37 | |
| PED | 2.12 | 2.33 | 1.93 | 2.35 | |
| STR | 1.95 | 2.11 | 1.97 | 2.38 | |
| SEGAN | BUS | 2.08 | 1.96 | 2.10 | 1.98 |
| CAF | 1.96 | 2.01 | 1.89 | 2.26 | |
| PED | 2.03 | 2.20 | 2.03 | 2.21 | |
| STR | 1.88 | 2.03 | 1.91 | 2.32 | |
| OMLSA | BUS | 2.18 | 2.06 | 2.21 | 2.19 |
| CAF | 1.91 | 2.21 | 1.92 | 2.32 | |
| PED | 2.32 | 2.40 | 2.32 | 2.42 | |
| STR | 2.02 | 2.27 | 2.02 | 2.46 | |
| Proposed | BUS | 2.20 | 2.03 | 2.32 | 2.28 |
| CAF | 2.08 | 2.30 | 2.08 | 2.51 | |
| PED | 2.36 | 2.45 | 2.48 | 2.43 | |
| STR | 2.08 | 2.26 | 2.13 | 2.50 |
| Method | Eval-Simu | Eval-Real | Ave |
|---|---|---|---|
| SEGAN | 15.3% | 12.7% | 14.0% |
| OMLSA | 12.6% | 16.9% | 14.8% |
| Proposed | 72.1% | 70.4% | 71.3% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Hua, Y.; Yang, S.; Qin, H.; Qin, H. Speech Enhancement Using Generative Adversarial Network by Distilling Knowledge from Statistical Method. Appl. Sci. 2019, 9, 3396. https://doi.org/10.3390/app9163396
Wu J, Hua Y, Yang S, Qin H, Qin H. Speech Enhancement Using Generative Adversarial Network by Distilling Knowledge from Statistical Method. Applied Sciences. 2019; 9(16):3396. https://doi.org/10.3390/app9163396
Chicago/Turabian StyleWu, Jianfeng, Yongzhu Hua, Shengying Yang, Hongshuai Qin, and Huibin Qin. 2019. "Speech Enhancement Using Generative Adversarial Network by Distilling Knowledge from Statistical Method" Applied Sciences 9, no. 16: 3396. https://doi.org/10.3390/app9163396
APA StyleWu, J., Hua, Y., Yang, S., Qin, H., & Qin, H. (2019). Speech Enhancement Using Generative Adversarial Network by Distilling Knowledge from Statistical Method. Applied Sciences, 9(16), 3396. https://doi.org/10.3390/app9163396