Deep Homography Estimation and Its Application to Wall Maps of Wall-Climbing Robots


Abstract
:Featured Application
Abstract
1. Introduction
2. Related Work
3. Homography Estimation for a Center-Aligned Image Pair
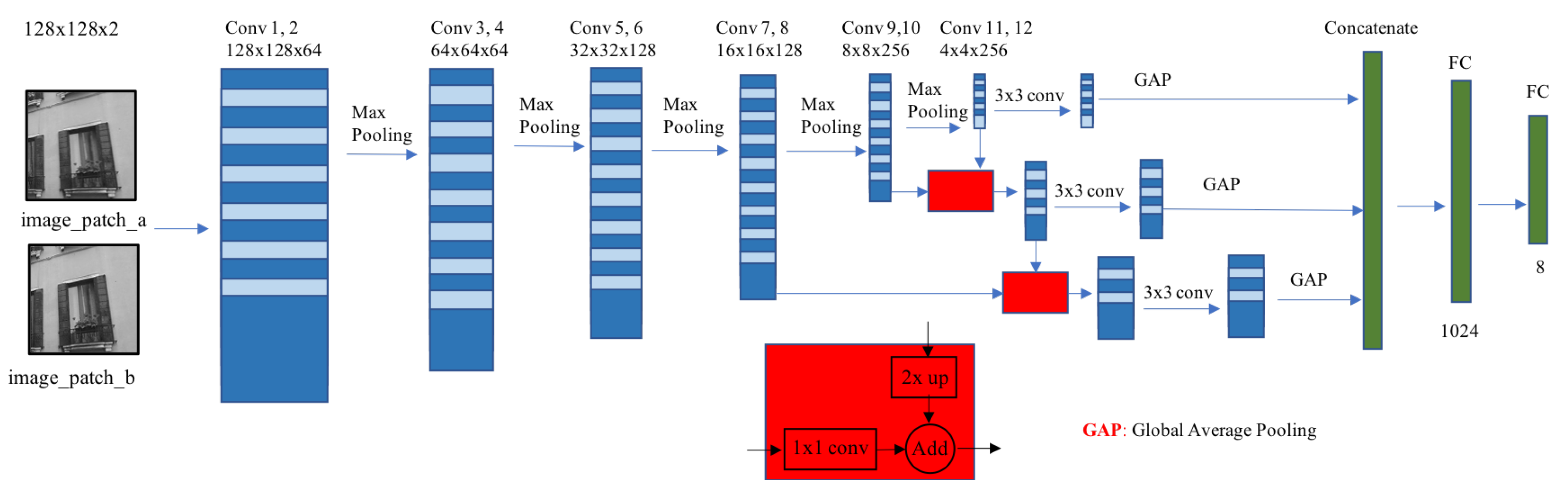
3.1. HomographyFpnNet Structure
3.2. Dataset of the Center-Aligned Image Pair
3.3. Training and Results
4. Homography Estimation for a Non-Center-Aligned Image Pair
4.1. Dataset of Non-Center-Aligned Image Pair
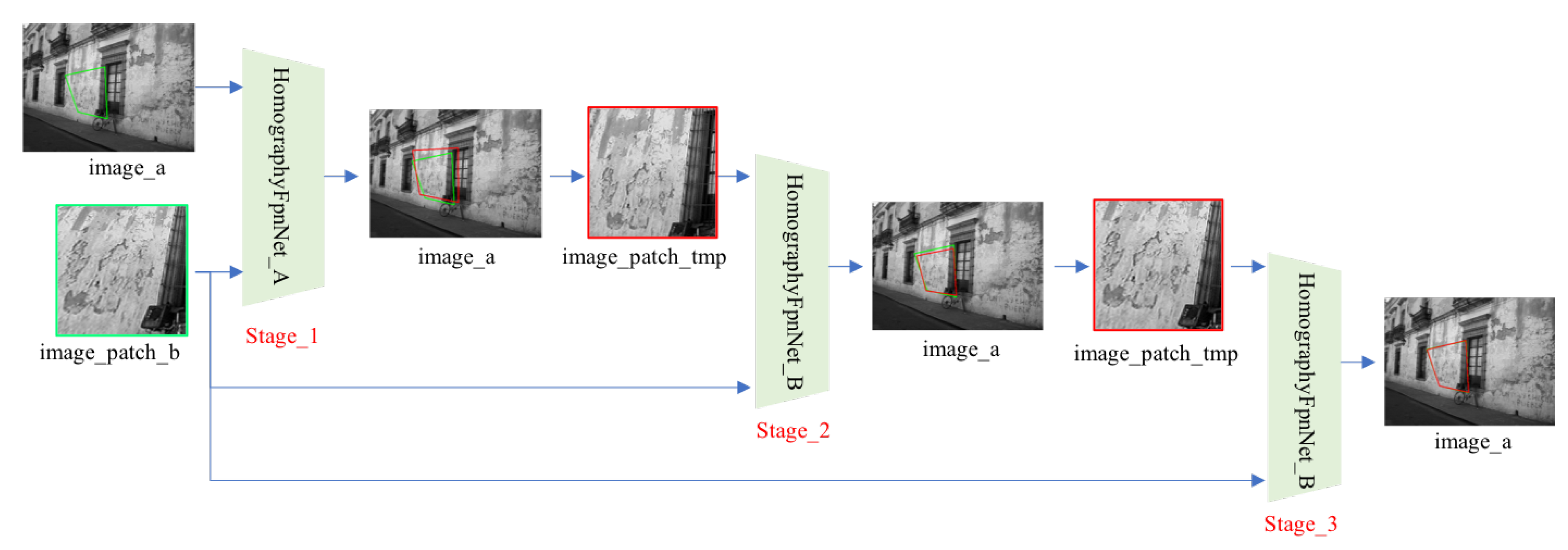
4.2. Hierarchical Homography Estimation
4.3. Training
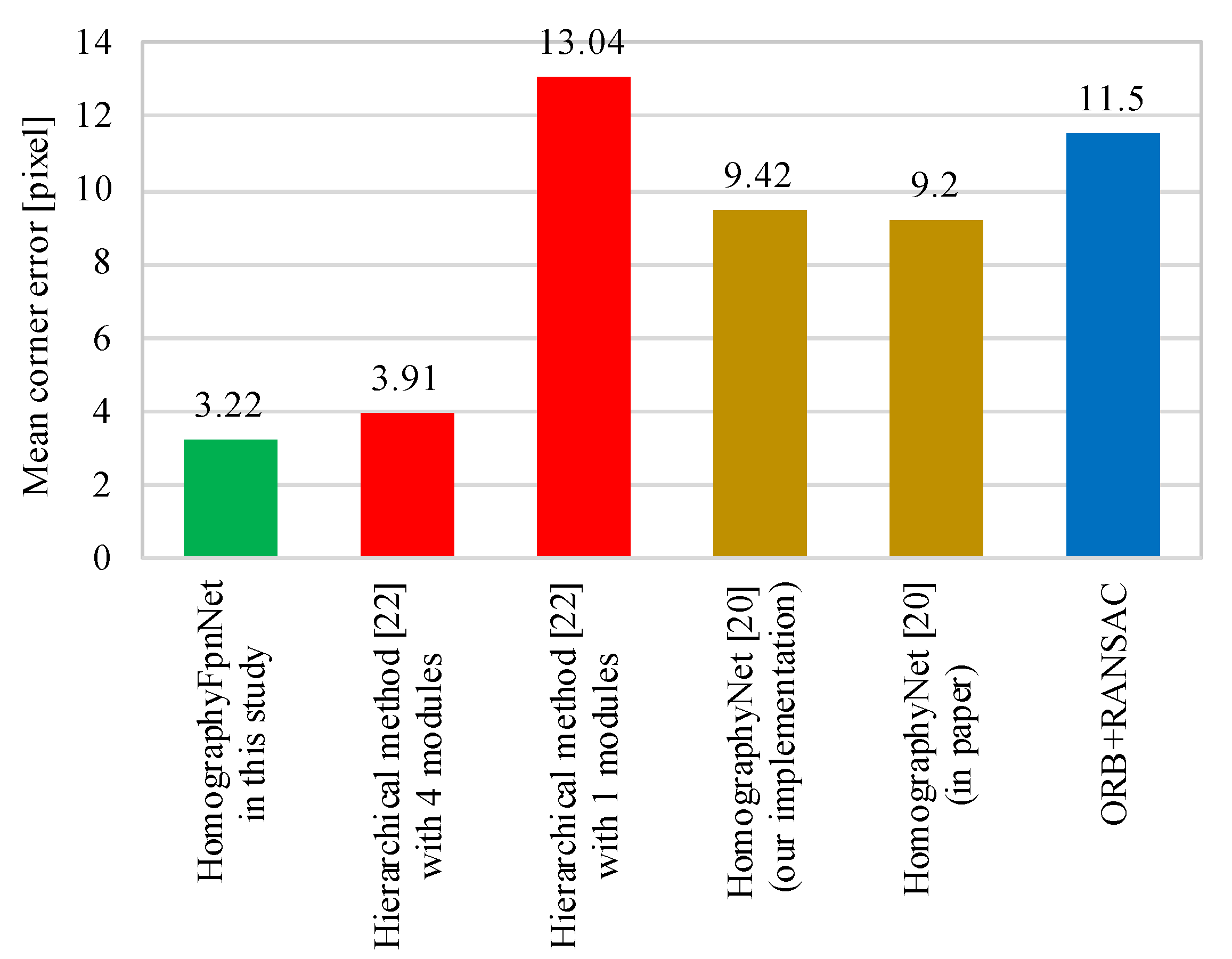
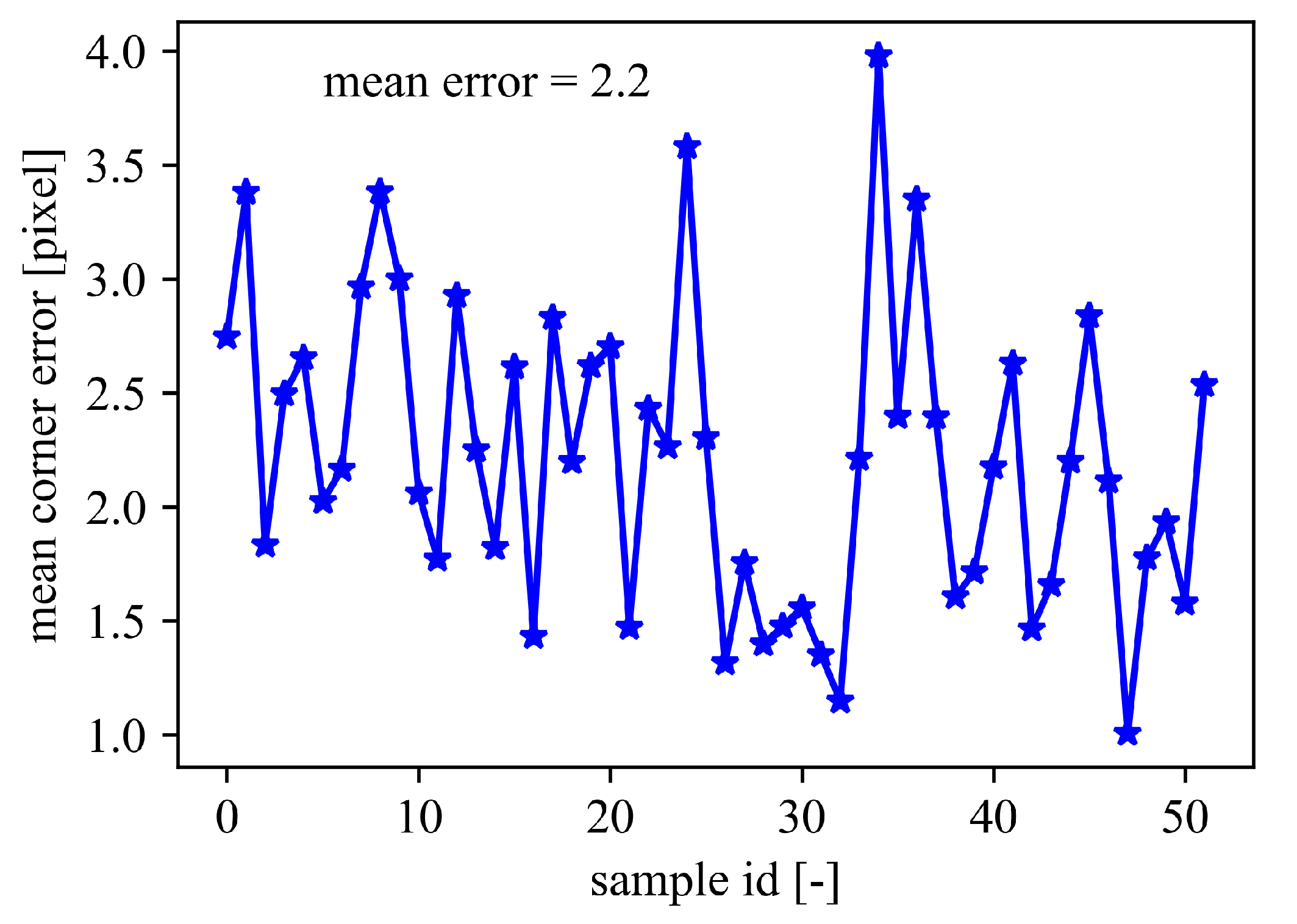
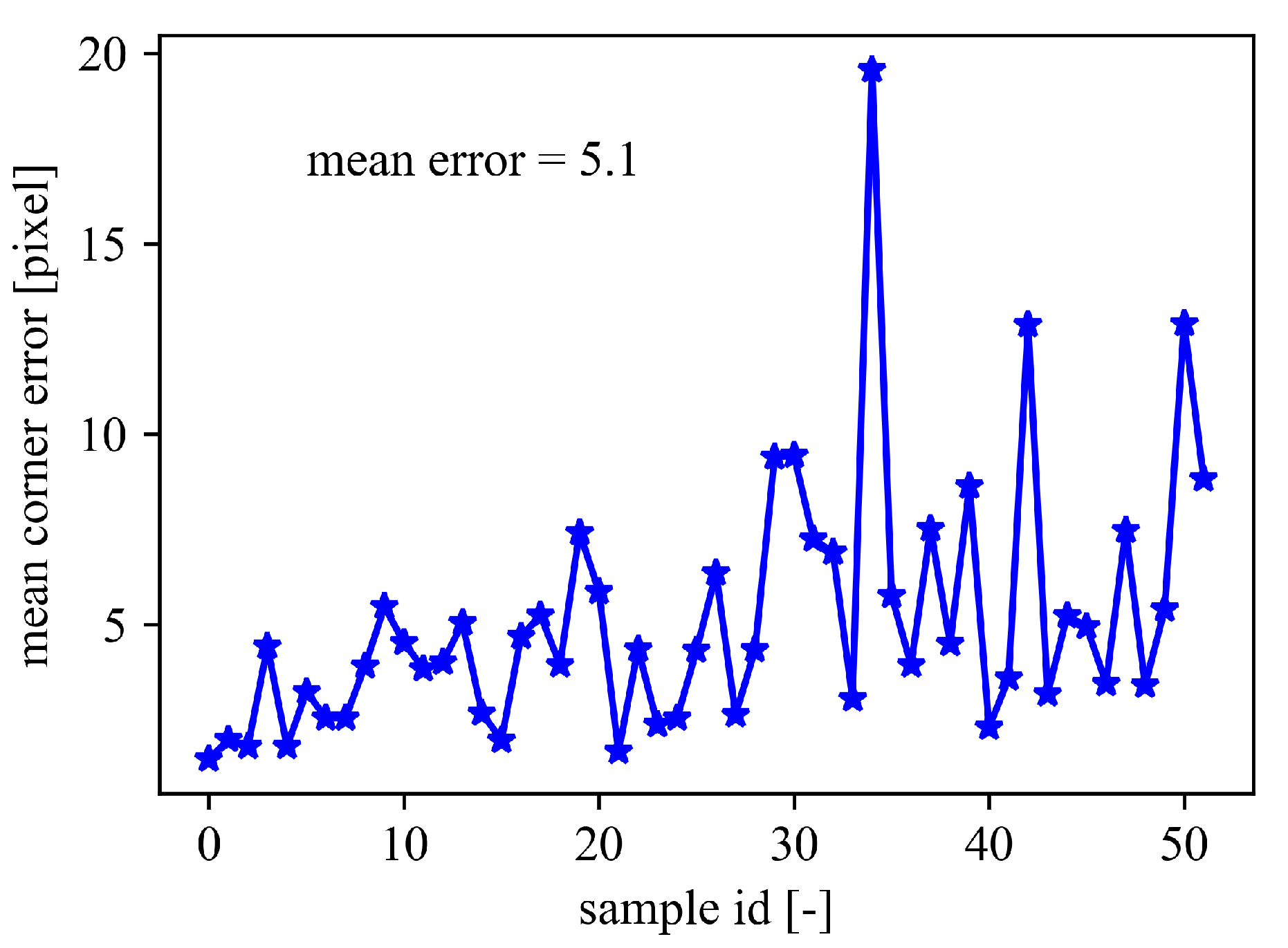
4.4. Results and Discussion
4.5. Time Consumption Analysis
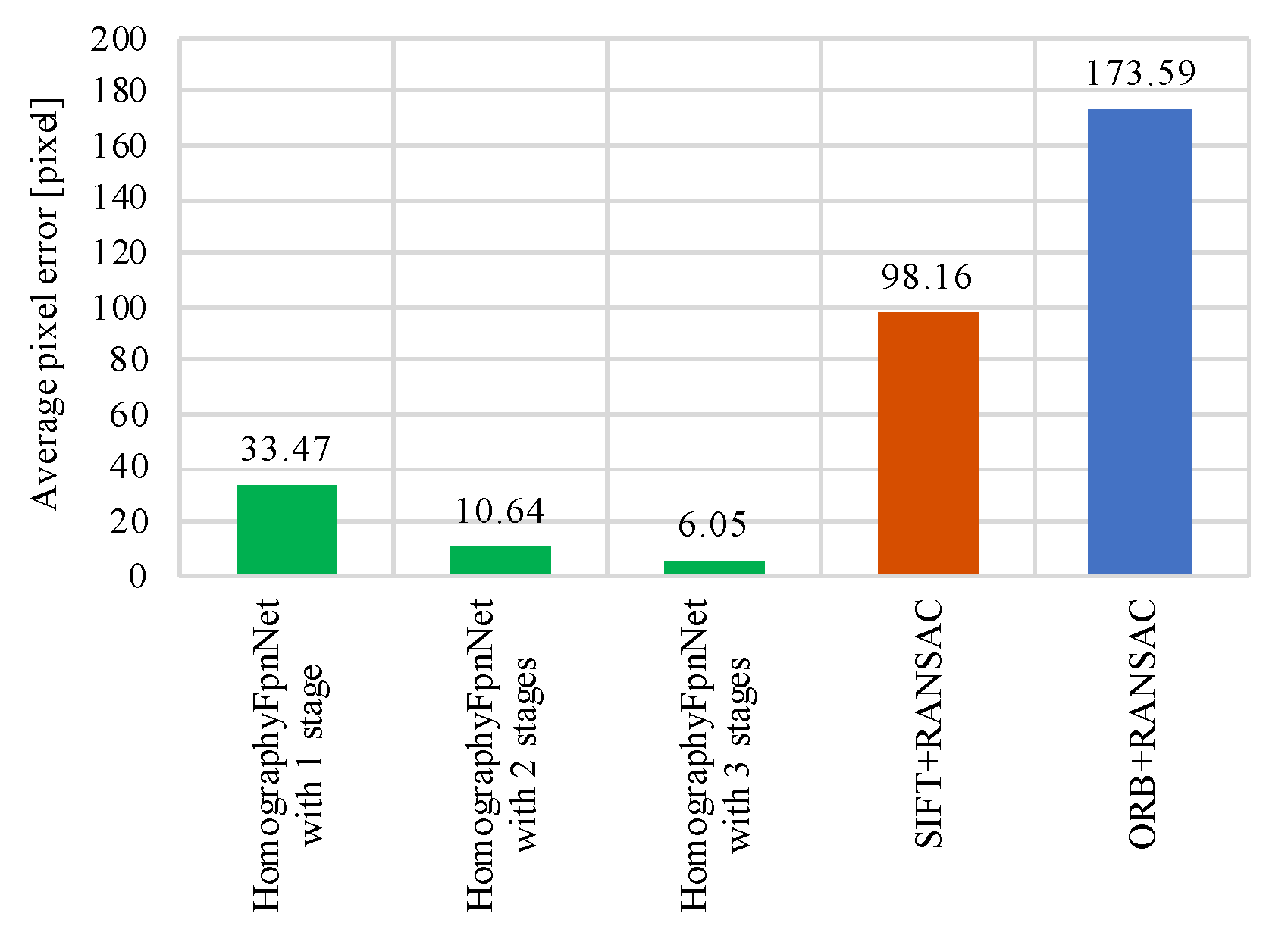
5. Experiment on Wall Images
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Armada, M.; Prieto, M.; Akinfiev, T.; Fernandez, R.; González, P.; García, E.; Montes Coto, H.J.; Nabulsi, S.; Ponticelli, R.; Sarria, J.; et al. On the design and development of climbing and walking robots for the maritime industries. J. Marit. Res. 2005, 2, 9–31. [Google Scholar]
- Armada, M.; de Santos, P.G. Climbing, walking and intervention robots. Ind. Robot Int. J. 1997, 24, 158–163. [Google Scholar] [CrossRef]
- Akinfiev, T.; Armada, M.; Nabulsi, S. Climbing cleaning robot for vertical surfaces. Ind. Robot Int. J. 2009, 36, 352–357. [Google Scholar] [CrossRef]
- Zhou, Q.; Li, X. Experimental comparison of drag-wiper and roller-wiper glass-cleaning robots. Ind. Robot Int. J. 2016, 43, 409–420. [Google Scholar] [CrossRef]
- Kim, T.Y.; Kim, J.H.; Seo, K.C.; Kim, H.M.; Lee, G.U.; Kim, J.W.; Kim, H.S. Design and Control of a Cleaning Unit for a Novel Wall-Climbing Robot. Appl. Mech. Mater. 2014, 541–542, 1092–1096. [Google Scholar] [CrossRef]
- Huang, H.; Li, D.; Xue, Z.; Chen, X.; Liu, S.; Leng, J.; Wei, Y. Design and performance analysis of a tracked wall-climbing robot for ship inspection in shipbuilding. Ocean Eng. 2017, 131, 224–230. [Google Scholar] [CrossRef]
- Sayab, M.; Aerden, D.; Paananen, M.; Saarela, P. Virtual Structural Analysis of Jokisivu Open Pit Using `Structure-from-Motion’ Unmanned Aerial Vehicles (UAV) Photogrammetry: Implications for Structurally-Controlled Gold Deposits in Southwest Finland. Remote Sens. 2018, 10, 1296. [Google Scholar] [CrossRef]
- Arai, Y.; Sekiai, M. Absolute position measurement system for mobile robot based on incident angle detection of infrared light. In Proceedings of the 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003) (Cat. No.03CH37453), Las Vegas, NV, USA, 27–31 October 2003. [Google Scholar]
- Yan, C.; Zhan, Q. Real-time multiple mobile robots visual detection system. Sens. Rev. 2011, 31, 228–238. [Google Scholar] [CrossRef]
- Wang, C.; Fu, Z. A new way to detect the position and orientation of the wheeled mobile robot on the image plane. In Proceedings of the 2014 IEEE International Conference on Robotics and Biomimetics (ROBIO 2014), Bali, Indonesia, 5–10 December 2014. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Fischer, P.; Dosovitskiy, A.; Ilg, E.; Häusser, P.; Hazırbaş, C.; Golkov, V.; van der Smagt, P.; Cremers, D.; Brox, T. FlowNet: Learning Optical Flow with Convolutional Networks. arXiv 2015, arXiv:1504.06852. [Google Scholar]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Deep Image Homography Estimation. arXiv 2016, arXiv:1606.03798. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Nowruzi, F.E.; Laganiere, R.; Japkowicz, N. Homography Estimation from Image Pairs with Hierarchical Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C. Lawrence Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Time Consumption on a GPU (ms) |
|---|---|
| One-stage hierarchical HomographyFpnNet | 3.48 |
| Two-stage hierarchical HomographyFpnNet | 7.03 |
| Three-stage hierarchical HomographyFpnNet | 10.8 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Q.; Li, X. Deep Homography Estimation and Its Application to Wall Maps of Wall-Climbing Robots. Appl. Sci. 2019, 9, 2908. https://doi.org/10.3390/app9142908
Zhou Q, Li X. Deep Homography Estimation and Its Application to Wall Maps of Wall-Climbing Robots. Applied Sciences. 2019; 9(14):2908. https://doi.org/10.3390/app9142908
Chicago/Turabian StyleZhou, Qiang, and Xin Li. 2019. "Deep Homography Estimation and Its Application to Wall Maps of Wall-Climbing Robots" Applied Sciences 9, no. 14: 2908. https://doi.org/10.3390/app9142908
APA StyleZhou, Q., & Li, X. (2019). Deep Homography Estimation and Its Application to Wall Maps of Wall-Climbing Robots. Applied Sciences, 9(14), 2908. https://doi.org/10.3390/app9142908