Structure Preserving Convolutional Attention for Image Captioning

Abstract
:1. Introduction
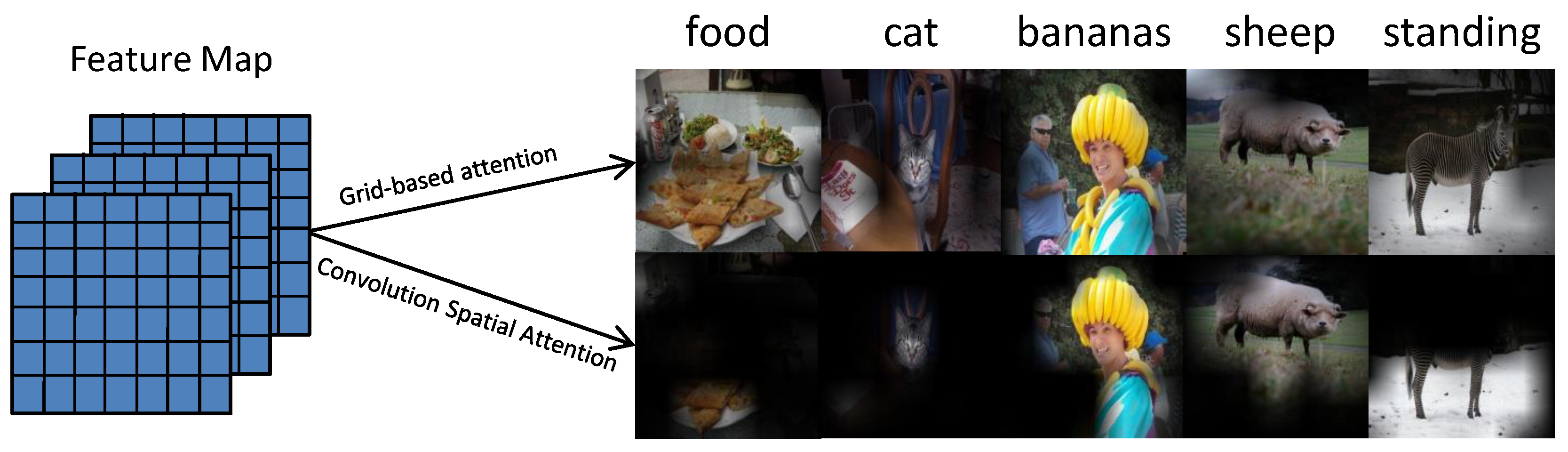
- We propose a convolutional spatial attention for preserving spatial structures in the attention map.
- Two attention components, namely cross-channel attention and convolutional spatial attention, are designed to adaptively determine ‘what’ and ‘where’ to focus on when predicting each word.
2. Related Work
2.1. Image Captioning
2.2. Attention Mechanism in Captioning
2.3. 2D-Latent-State LSTM
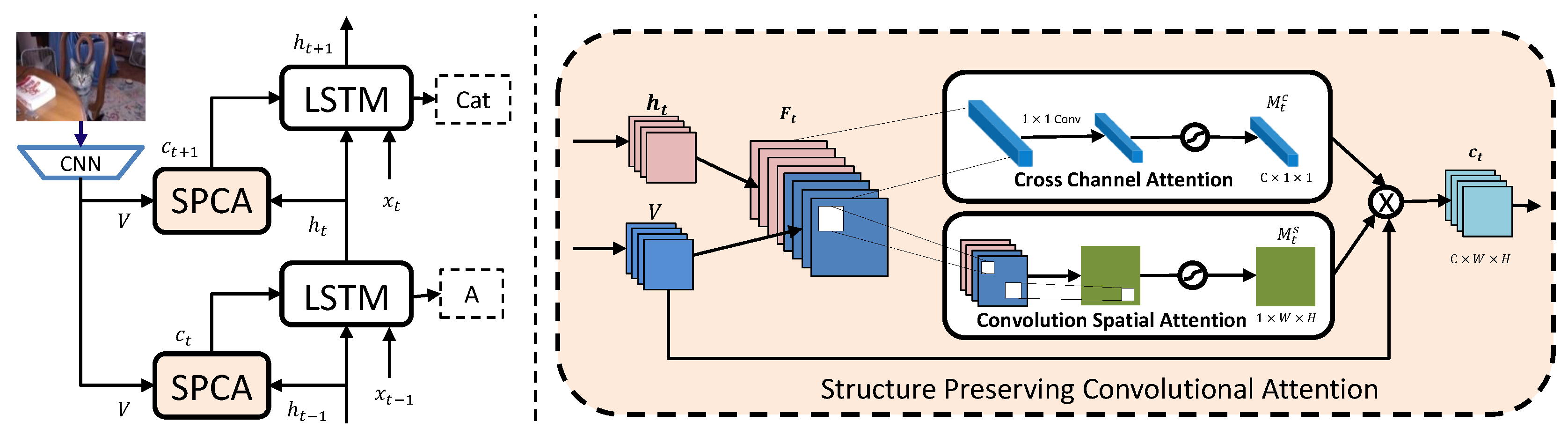
3. Proposed Method
3.1. Overview
3.2. Structure Preserving Convolutional Attention
3.2.1. Convolutional Spatial Attention
3.2.2. Cross Channel Attention
4. Experiments
4.1. Dataset and Evalution
4.2. Implementation Details
4.3. Performance and Analysis
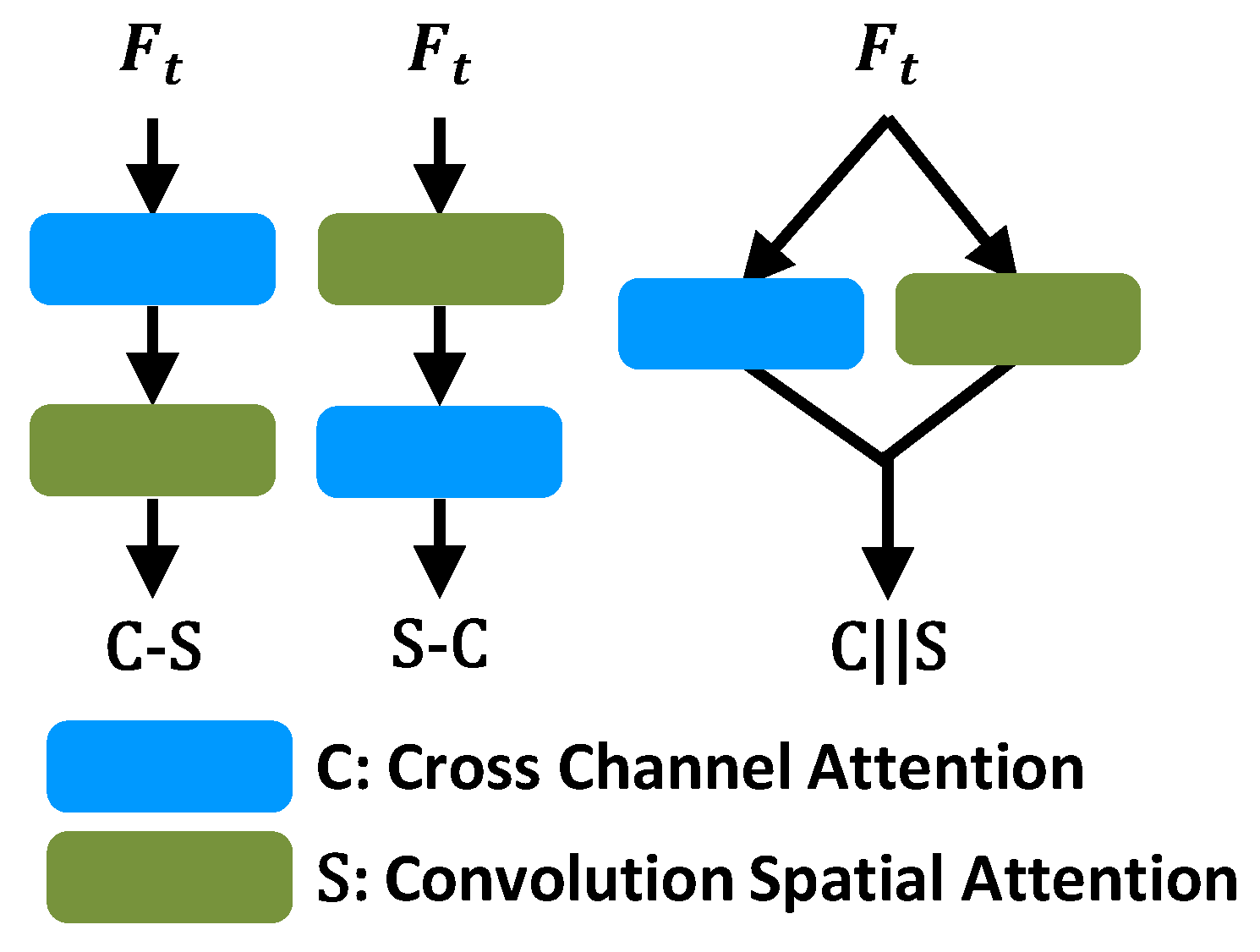
4.3.1. Attention Structure Selection
4.3.2. Convolution Kernel Size
4.3.3. Performance Comparisons
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fang, H.; Gupta, S.; Iandola, F.; Srivastava, R.K.; Deng, L.; Dollár, P.; Gao, J.; He, X.; Mitchell, M.; Platt, J.C.; et al. From captions to visual concepts and back. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1473–1482. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Mao, J.; Xu, W.; Yang, Y.; Wang, J.; Huang, Z.; Yuille, A. Deep Captioning with Multimodal Recurrent Neural Networks (m-RNN). arXiv 2014, arXiv:1412.6632. [Google Scholar]
- Socher, R.; Karpathy, A.; Le, Q.V.; Manning, C.D.; Ng, A.Y. Grounded compositional semantics for finding and describing images with sentences. Trans. Assoc. Comput. Linguist. 2014, 2, 207–218. [Google Scholar] [CrossRef]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Graves, A. Generating sequences with recurrent neural networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- Wu, Z.; Cohen, R. Encode, review, and decode: Reviewer module for caption generation. arXiv 2016, arXiv:1605.07912. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 6, p. 2. [Google Scholar]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6298–6306. [Google Scholar]
- Gan, Z.; Gan, C.; He, X.; Pu, Y.; Tran, K.; Gao, J.; Carin, L.; Deng, L. Semantic Compositional Networks for Visual Captioning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, S.; Zhu, Z.; Ye, N.; Guadarrama, S.; Murphy, K. Improved image captioning via policy gradient optimization of spider. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; Volume 3, p. 3. [Google Scholar]
- Ren, Z.; Wang, X.; Zhang, N.; Lv, X.; Li, L.J. Deep reinforcement learning-based image captioning with embedding reward. arXiv 2017, arXiv:1704.03899. [Google Scholar]
- Bengio, S.; Vinyals, O.; Jaitly, N.; Shazeer, N. Scheduled sampling for sequence prediction with recurrent neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 1171–1179. [Google Scholar]
- Yang, Z.; Yuan, Y.; Wu, Y.; Cohen, W.W.; Salakhutdinov, R.R. Review networks for caption generation. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016; pp. 2361–2369. [Google Scholar]
- Dai, B.; Ye, D.; Lin, D. Rethinking the form of latent states in image captioning. Work 2018, 8, 10–13. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y. Rouge: A Package for Automatic Evaluation of Summaries; Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization; Association for Computational Linguistics: Ann Arbor, MI, USA, 2005; pp. 65–72. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Graves, A. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Rennie, S.J.; Marcheret, E.; Mroueh, Y.; Ross, J.; Goel, V. Self-critical Sequence Training for Image Captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Param | Millisecond/Image |
|---|---|---|
| Soft-Attention [5] | 248.8 M | 57.6 ± 0.7 |
| 1D-LSTM + SPCA | 264.8 M | 70.95 ± 0.9 |
| 2D-latent state [19] | 205.7 M | 55.7 ± 0.4 |
| 2D-latent-LSTM + SPCA | 223.9 M | 64.7 ± 0.3 |
| Dataset | Method | B4 | MT | RG | CD |
|---|---|---|---|---|---|
| Baseline | 22.6 | 19.6 | 44.5 | 42.2 | |
| S | 22.2 | 19.3 | 44.5 | 44.3 | |
| Flickr_30K | C | 22.9 | 19.8 | 45 | 46.9 |
| C-S | 23.8 | 20.1 | 45.4 | 47.5 | |
| S-C | 23.4 | 19.9 | 45.1 | 46.9 | |
| S‖C | 23.7 | 20.3 | 45.6 | 49.9 | |
| Baseline | 30.1 | 24.9 | 52.8 | 94.8 | |
| S | 30.5 | 24.6 | 52.3 | 91.2 | |
| MS-COCO | C | 31.9 | 24.7 | 52.6 | 96 |
| C-S | 33.1 | 25.2 | 53.3 | 96.9 | |
| S-C | 32.5 | 25 | 53 | 96.5 | |
| S‖C | 32.4 | 25.8 | 53.9 | 99.3 |
| Dataset | Kernel Size | B4 | MT | RG | CD |
|---|---|---|---|---|---|
| 1 × 1 | 23.9 | 20.2 | 45.6 | 48.7 | |
| Flickr-30K | 3 × 3 | 23.7 | 20.3 | 45.6 | 49.9 |
| 5 × 5 | 23.6 | 20.3 | 45.5 | 49.3 | |
| 1 × 1 | 31.9 | 25.4 | 53.2 | 97.3 | |
| MS-COCO | 3 × 3 | 32.4 | 25.8 | 53.9 | 99.3 |
| 5 × 5 | 31.8 | 25.6 | 53.6 | 98.4 |
| Model | Flikr-30K | MS-COCO | ||||||
|---|---|---|---|---|---|---|---|---|
| B4 | MT | RG | CD | B4 | MT | RG | CD | |
| Google NIC [6] | - | - | - | - | 24.6 | - | - | - |
| Soft-Attention [5] | 19.1 | 18.5 | - | - | 24.3 | 23.9 | - | - |
| Soft-Attention* | 22.2 | 19.7 | 45.0 | 47.0 | 33.4 | 26.1 | 54.2 | 101.1 |
| Hard-Attention [5] | 19.9 | 18.5 | - | - | 25 | 23 | - | - |
| SCA-CNN [13] | 22.3 | 19.5 | - | - | 31.1 | 25 | 52.4 | 91.2 |
| ATT2in [27] | - | - | - | - | 31.3 | 26.0 | 54.3 | 101.3 |
| 2D-latent state [19] | 22 | - | 44.4 | 42.7 | 31.9 | - | 53.8 | 99.4 |
| 2D-latent state* | 22.6 | 19.6 | 44.5 | 42.2 | 30.1 | 24.9 | 52.8 | 94.8 |
| 1D-LSTM + SPCA | 23.4 | 20.2 | 46.2 | 50.0 | 33.9 | 26.4 | 55.1 | 106.3 |
| 2D-latent-LSTM + SPCA | 23.7 | 20.3 | 45.6 | 49.9 | 32.1 | 25.8 | 53.9 | 99.3 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, S.; Hu, R.; Liu, J.; Guo, L.; Zheng, F. Structure Preserving Convolutional Attention for Image Captioning. Appl. Sci. 2019, 9, 2888. https://doi.org/10.3390/app9142888
Lu S, Hu R, Liu J, Guo L, Zheng F. Structure Preserving Convolutional Attention for Image Captioning. Applied Sciences. 2019; 9(14):2888. https://doi.org/10.3390/app9142888
Chicago/Turabian StyleLu, Shichen, Ruimin Hu, Jing Liu, Longteng Guo, and Fei Zheng. 2019. "Structure Preserving Convolutional Attention for Image Captioning" Applied Sciences 9, no. 14: 2888. https://doi.org/10.3390/app9142888
APA StyleLu, S., Hu, R., Liu, J., Guo, L., & Zheng, F. (2019). Structure Preserving Convolutional Attention for Image Captioning. Applied Sciences, 9(14), 2888. https://doi.org/10.3390/app9142888