An Integrated Wildlife Recognition Model Based on Multi-Branch Aggregation and Squeeze-And-Excitation Network


Abstract
Featured Application
Abstract
1. Introduction
2. Related Work
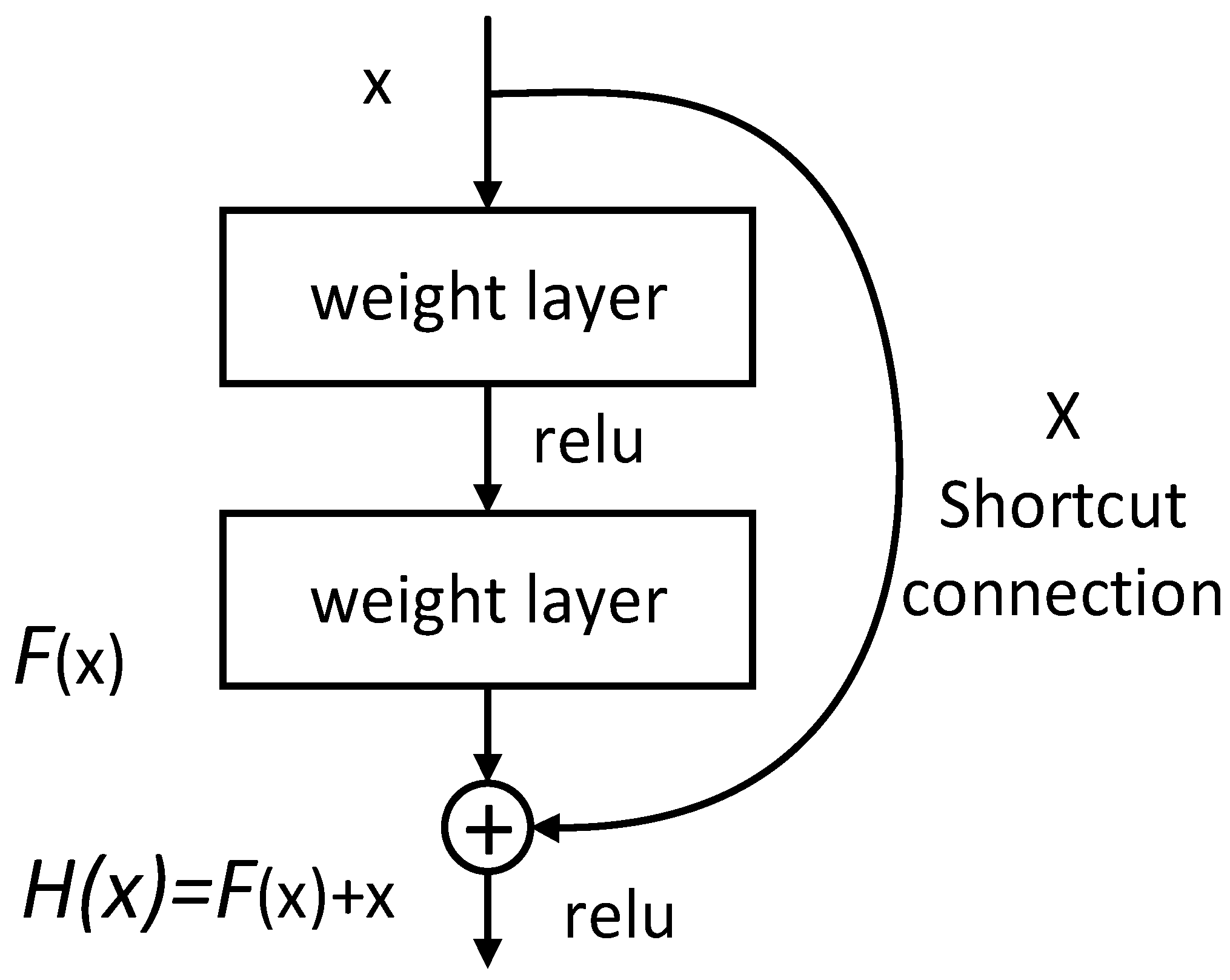
2.1. The Construction of Residual Block
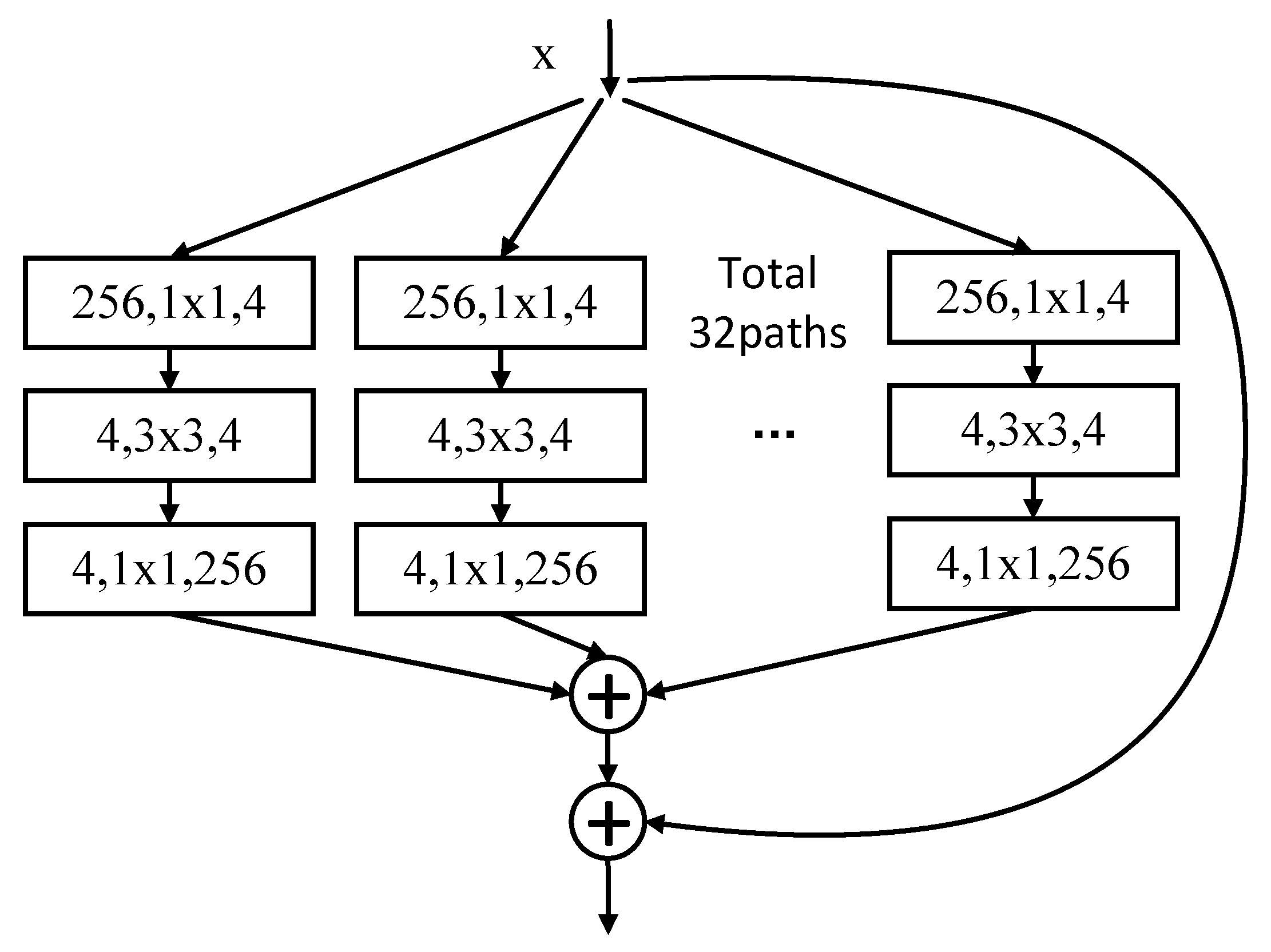
2.2. Multi-Branch Aggregation Transformation Residual Network
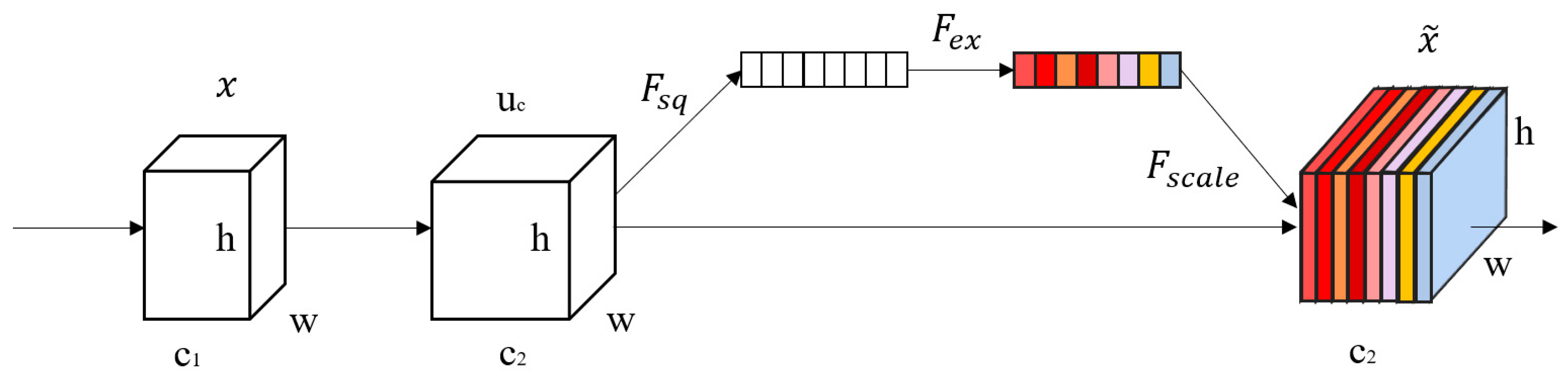
2.3. SENet
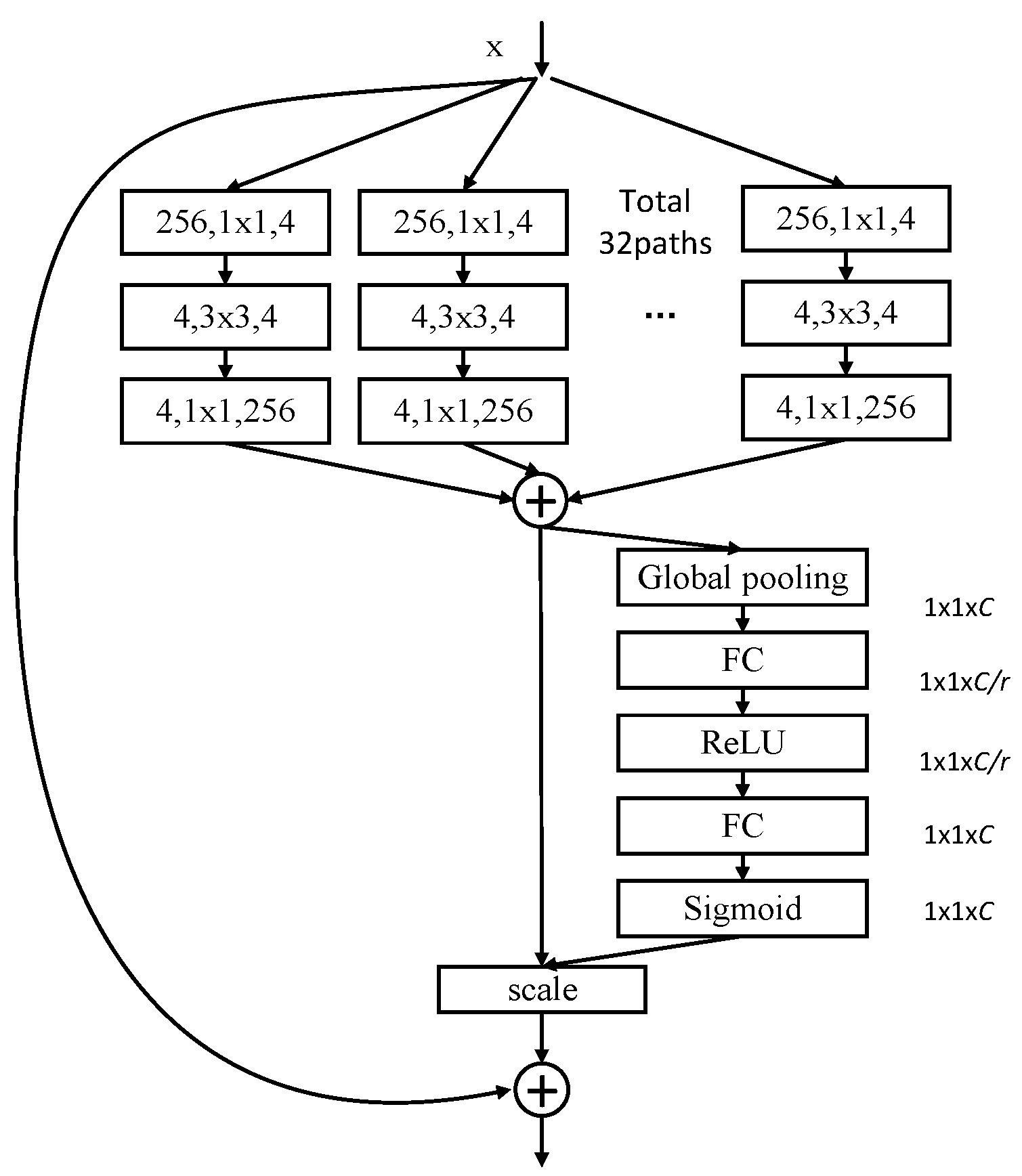
3. The Design of SE-ResNeXt
4. Results and Discussion
4.1. Comparative Experiments of Different Models on our Own Dataset
4.1.1. Our Own Dataset
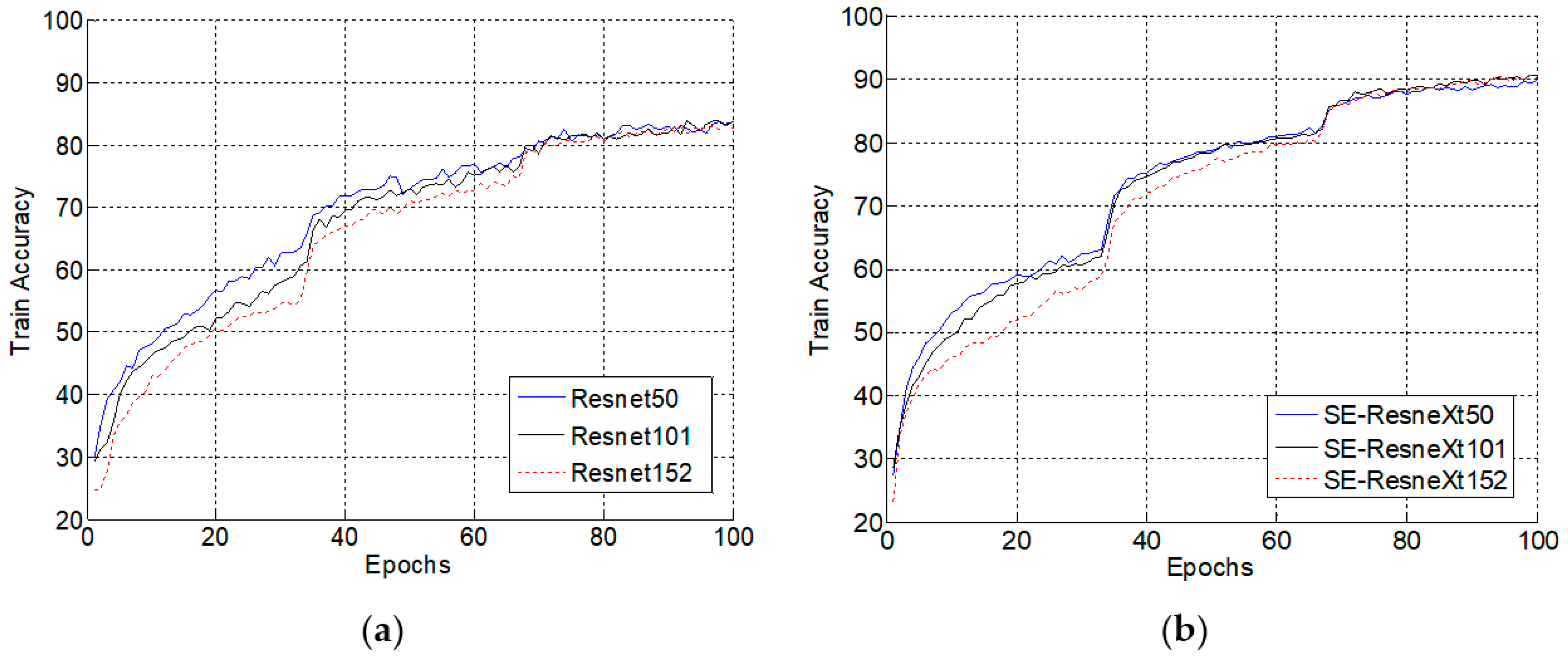
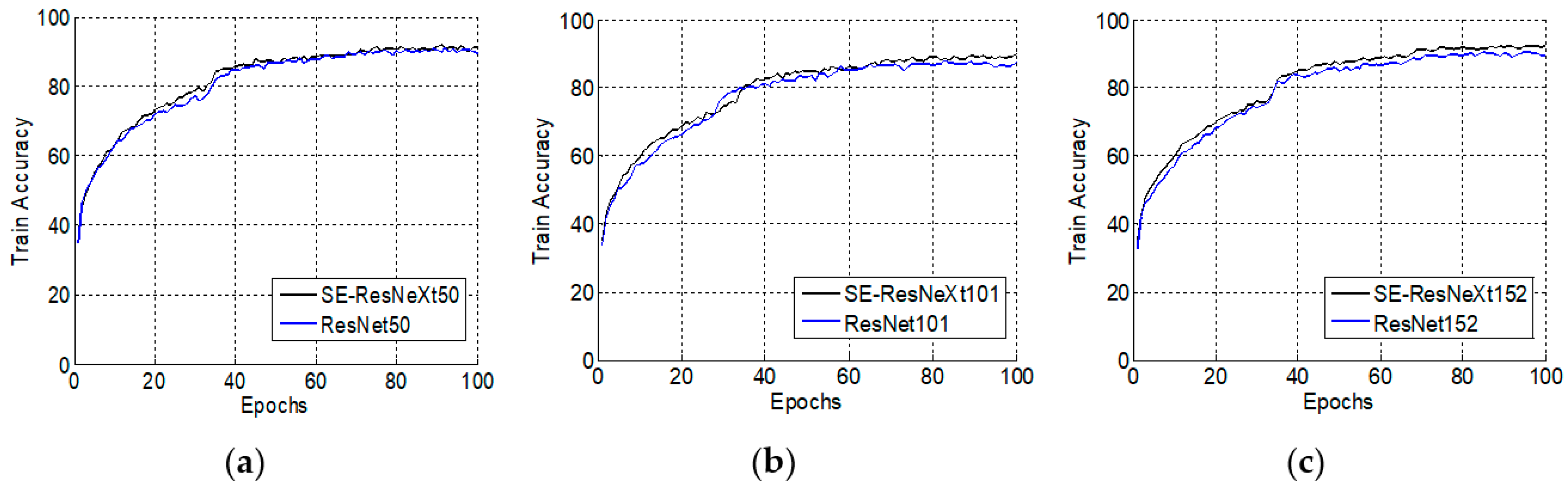
4.1.2. Comparison Experiments of ResNet and SE-ResNeXt in Different Numbers of Layers
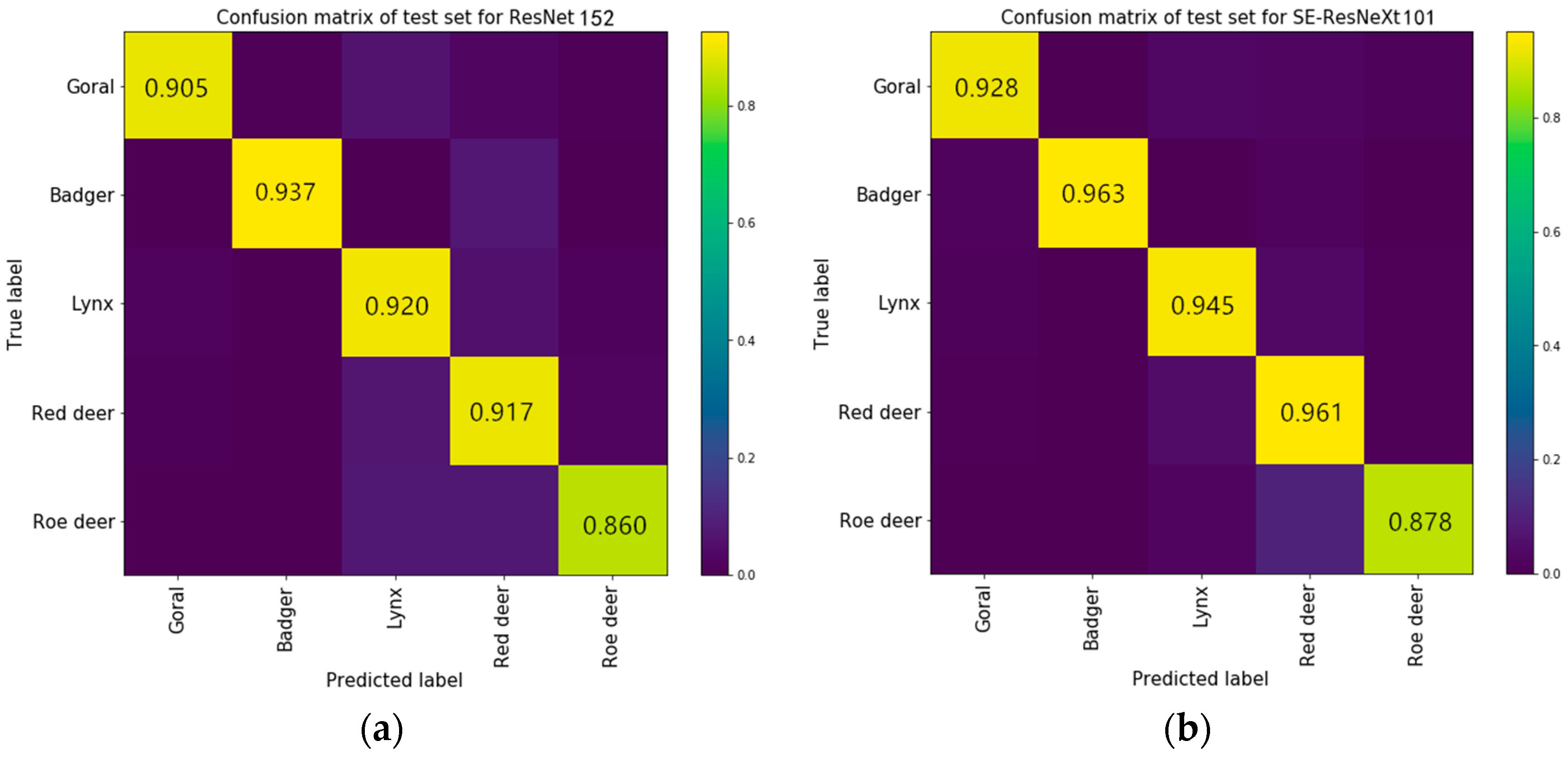
4.1.3. Comparison Experiments of Accuracy for Each Category
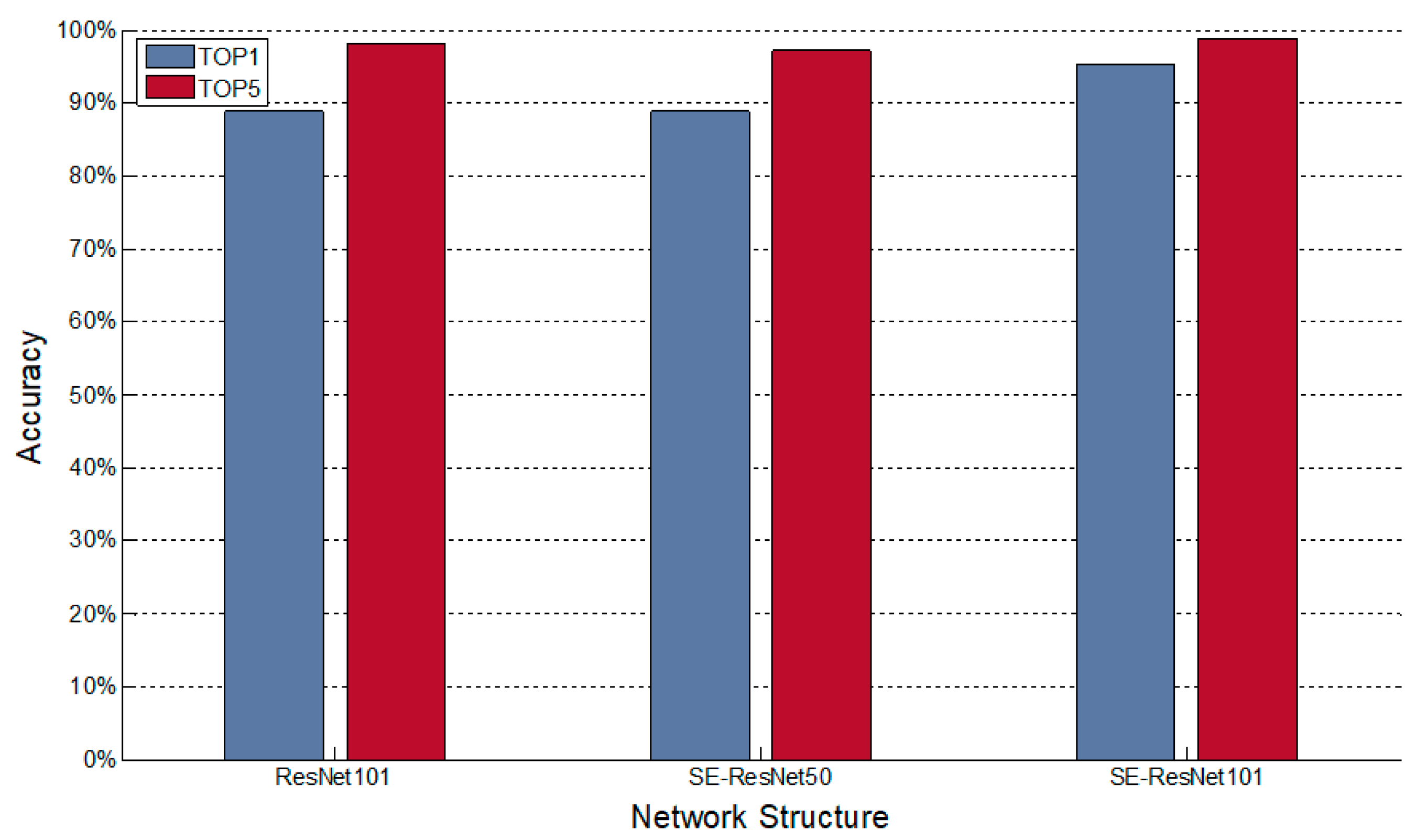
4.2. Comparative Experiment with Existing ROI-CNN Algorithm
4.3. Comparative Experiments with Snapshot Serengeti Dataset
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- O’Connell, A.F.; Nichols, J.D.; Karanth, K.U. Camera Traps in Animal Ecologym; Springer: Tokyo, Japan, 2011. [Google Scholar]
- Jiang, J.; Xu, H.; Zhang, S. Object Detection Algorithm Based on Multiheaded Attention. Appl. Sci. 2019, 9, 1829. [Google Scholar] [CrossRef]
- Kamencay, P.; Trnovszky, T.; Benco, M.; Hudec, R.; Sykora, P.; Satnik, A. Accurate wild animal recognition using PCA, LDA and LBPH. In Proceedings of the 2016 IEEE ELEKTRO, Strbske Pleso, Slovakia, 16–18 May 2016; pp. 62–67. [Google Scholar]
- Okafor, E.; Pawara, P.; Karaaba, F. Comparative Study Between Deep Learning and Bag of Visual Words for Wild-Animal Recognition. In Proceedings of the IEEE Symposium Series on Computational Intelligence, Athens, Greece, 6–9 December 2016; pp. 1–8. [Google Scholar]
- Tang, Y.; Wang, J.; Gao, B.; Dellandréa, E.; Gaizauskas, R.; Chen, L. Large scale semi-supervised object detection using visual and semantic knowledge transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2119–2128. [Google Scholar]
- Owoeye, K.; Hailles, S. Online Collective Animal Movement Activity Recognition. In Proceedings of the Workshop on Modeling and Decision-Making in the Spatiotemporal Domain. 32nd Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7 December 2018. [Google Scholar]
- Manohar, N.; Subrahmanya, S.; Bharathi, R.K.; YH, S.K.; Kumar, H. Recognition and classification of animals based on texture features through parallel computing. In Proceedings of the 2016 Second International Conference on Cognitive Computing and Information Processing, Mysore, India, 12–13 August 2016; pp. 1–5. [Google Scholar]
- Zhang, X.; Xiong, H.; Zhou, W.; Lin, W.; Tian, Q. Picking deep filter responses for fine-grained image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1134–1142. [Google Scholar]
- Liu, W.; Li, A.; Zhang, J. Automatic identification of terrestrial wildlife in Saihanwula National Nature Reserve based on ROI-CNN. J. Beijing For. Univ. 2018, 40, 124–131. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Mcallister, P.; Zheng, H.; Bond, R. Combining deep residual network features with supervised machine learning algorithms to classify diverse food image datasets. Comput. Biol. Med. 2018, 95, 217–233. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Zhang, H.; Zhou, H. Zebrafish Embryo Vessel Segmentation Using a Novel Dual ResUNet Model. Comput. Intell. Neurosci. 2019, 2019, 8214975. [Google Scholar] [CrossRef]
- Martinel, N.; Foresti, G.L.; Micheloni, C. Wide-slice residual networks for food recognition. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 567–576. [Google Scholar]
- Peng, M.; Wang, C.; Chen, T. Attention Based Residual Network for Micro-Gesture Recognition. In Proceedings of the IEEE International Conference on Automatic Face & Gesture Recognition, Xi’an, China, 15–19 May 2018; pp. 790–794. [Google Scholar]
- Nigati, K.; Shi, Q.; Liu, S.; Biloli, Y.; Li, H. Automatic classification method of oasis plant community in desert hinterland based on VGGNet and ResNet model. J. Agric. Mach. 2019, 50, 217–225. [Google Scholar]
- Koné, I.; Boulmane, L. Hierarchical ResNeXt Models for Breast Cancer Histology Image Classification. In Proceedings of the International Conference Image Analysis and Recognition, Póvoa de Varzim, Portugal, 27–29 June 2018; pp. 796–803. [Google Scholar]
- Tang, Y.; Wang, X.; Dellandréa, E. Weakly supervised learning of deformable part-based models for object detection via region proposals. IEEE Trans. Multimed. 2016, 19, 393–407. [Google Scholar] [CrossRef]
- Yunlong, Y.; Fuxian, L. A Two-Stream Deep Fusion Framework for High-Resolution Aerial Scene Classification. Comput. Intell. Neurosci. 2018, 2018, 8639367. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 7132–7141. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Chen, S.; Hu, C.; Zhang, J. Design of Wildlife Image Monitoring System Based on Wireless Sensor Networks. Mod. Manuf. Technol. Equip. 2017, 3, 64–66. [Google Scholar]
- Na, L. Nature Monitoring on Wildlife Biodiversity at Saihanwula National Nature Reserve; Beijing Forestry University: Beijing, China, 2011. [Google Scholar]
- Swanson, A.; Kosmala, M.; Lintott, C. Snapshot Serengeti, high-frequency annotated camera trap images of 40 mammalian species in an African savanna. Sci. Data 2015, 2, 150026. [Google Scholar] [CrossRef] [PubMed]
- Villa, A.G.; Salazar, A.; Vargas, F. Towards automatic wild animal monitoring: Identification of animal species in camera-trap images using very deep convolutional neural networks. Ecol. Inform. 2017, 41, 24–32. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Massachusetts Institute of Technology Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 2015 International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Output | ResNet-50 a | SE-ResNeXt-50 a |
|---|---|---|
| 112 × 112 | Conv b, 7 × 7, 64, stride 2 | |
| 56 × 56 | Max pool, 3 × 3, stride 2 | |
| 28 × 28 | ||
| 14 × 14 | ||
| 7 × 7 | ||
| 1 × 1 | Global average pool, 1000-d fc, softmax | |
| Species | Red Deer | Goral | Roe Deer | Lynx | Badger |
|---|---|---|---|---|---|
| Daytime | 2822 | 1027 | 1698 | 301 | 292 |
| Dark | 1782 | 639 | 839 | 120 | 146 |
| Number of Images | 4604 | 1666 | 2537 | 421 | 438 |
| Layers | 50 | 101 | 152 | |||
|---|---|---|---|---|---|---|
| Model | ResNet [10] | SE-ResNeXt | ResNet [10] | SE-ResNeXt | ResNet [10] | SE-ResNeXt |
| lr = 0.01 | 0.906 | 0.935 | 0.898 | 0.935 | 0.908 | 0.921 |
| lr = 0.1 | 0.879 | 0.919 | 0.899 | 0.929 | 0.881 | 0.925 |
| Model | ROI-CNN [9] | ResNet-50 [10] | ResNet-101 [10] | ResNet-152 [10] | SE-50 * | SE-101 | SE-152 |
|---|---|---|---|---|---|---|---|
| Test acc | 0.912 | 0.902 | 0.870 | 0.835 | 0.906 | 0.902 | 0.914 |
| Species | # Images | Species | # Images |
|---|---|---|---|
| Wildebeest | 212,973 | Lion, female and cub | 8773 |
| Zebra | 181,043 | Eland | 7395 |
| Thomson’s gazelle | 116,421 | Topi | 6247 |
| Buffalo | 34,684 | Baboon | 4618 |
| Human | 26,557 | Reedbuck | 4141 |
| Elephant | 25,294 | Dik dik | 3364 |
| Guinea fowl | 23,023 | Cheetah | 3354 |
| Giraffe | 22,439 | Hippopotamus | 3231 |
| Impala | 22,281 | Lion male | 2413 |
| Warthog | 22,041 | Kori Bustard | 2042 |
| Grants gazelle | 21,340 | Ostrich | 1945 |
| Hartebeest | 15,401 | Secretary bird | 1302 |
| Spotted hyena | 10,242 | Jackal | 1207 |
| Species | SE-ResNeXt101 | ResNet-101 | Species | SE-ResNeXt101 | ResNet-101 |
|---|---|---|---|---|---|
| Wildebeest | 91.7 | 93.1 | Lion, female and cub | 92.8 | 83.3 |
| Zebra | 96.3 | 99.5 | Eland | 97.5 | 87.5 |
| Thomson’s gazelle | 94.5 | 71.6 | Topi | 93.1 | 95.8 |
| Buffalo | 97.7 | 83.3 | Baboon | 94.8 | 98.3 |
| Human | 99.8 | 99.1 | Reedbuck | 93.3 | 95.0 |
| Elephant | 96.8 | 90.4 | Dik dik | 94.6 | 75.8 |
| Guinea fowl | 94.1 | 99.5 | Cheetah | 94.7 | 97.0 |
| Giraffe | 94.8 | 96.6 | Hippopotamus | 97.6 | 94.1 |
| Impala | 98.3 | 92.0 | Lion male | 93.5 | 77.0 |
| Warthog | 95.0 | 98.0 | Kori Bustard | 94.9 | 97.9 |
| Grants gazelle | 96.2 | 65.0 | Ostrich | 92.4 | 94.1 |
| Hartebeest | 93.8 | 97.5 | Secretary bird | 92.9 | 95.4 |
| Spotted hyena | 98.9 | 85.4 | Jackal | 97.8 | 92.4 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, J.; Li, A.; Zhang, J.; Cheng, Z. An Integrated Wildlife Recognition Model Based on Multi-Branch Aggregation and Squeeze-And-Excitation Network. Appl. Sci. 2019, 9, 2794. https://doi.org/10.3390/app9142794
Xie J, Li A, Zhang J, Cheng Z. An Integrated Wildlife Recognition Model Based on Multi-Branch Aggregation and Squeeze-And-Excitation Network. Applied Sciences. 2019; 9(14):2794. https://doi.org/10.3390/app9142794
Chicago/Turabian StyleXie, Jiangjian, Anqi Li, Junguo Zhang, and Zhean Cheng. 2019. "An Integrated Wildlife Recognition Model Based on Multi-Branch Aggregation and Squeeze-And-Excitation Network" Applied Sciences 9, no. 14: 2794. https://doi.org/10.3390/app9142794
APA StyleXie, J., Li, A., Zhang, J., & Cheng, Z. (2019). An Integrated Wildlife Recognition Model Based on Multi-Branch Aggregation and Squeeze-And-Excitation Network. Applied Sciences, 9(14), 2794. https://doi.org/10.3390/app9142794