1. Introduction
Software Defect Prediction (SDP) models are built using software metrics which based on data collected from the previous developed system or similar software projects [
1]. Using such a model, the defect-proneness of the software modules under development can be predicted. The goal of SDP is to achieve high software quality and reliability with the effective use of available limited resources. In other words, SDP involves identifying software modules or components that are prone to defects. This will avail software engineers to prioritize the utilization of inhibited resources during each phase of the software development [
2,
3]. Consequently, reliability and quality for the software assessment, in addition to software quality assurance, are guaranteed [
4,
5]. Software metrics which includes software source code complexity and development history are typically used to analyze the efficiency of the software process, quality, and reliability of the software products. In addition, software engineers use these software metrics for risk assessment and they are used for defect prediction to identify and improve the quality of software products [
6,
7,
8]. Specifically, McCabe and Halstead Metrics, Procedural Metrics, Process Metrics, etc. are types of engineered software metrics used to determine the quality and reliability level of a software system [
6,
9]. A software module or component unit contains a set of features (metrics) and a class label. The class label depicts the state of the software module, either as defective or non-defective, while the derived features are used to develop SDP models [
10,
11]. That is, SDP uses historical data extracted from software repositories to determine the quality and reliability of the software modules or components [
12,
13].
SDP can be regarded as a classification task that involves categorizing software modules either as defective or non-defective, based on historical data and software metrics or features [
14,
15,
16]. Software features or metrics reflect the characteristics of software modules. However, the numbers of metrics generated are usually high. This is due to various different types of software metric mechanisms used to determine the quality and reliability of a software system. The proliferation of these mechanisms consequently generates a large number of metric values, leading to a high-dimensionality problem when many feature values are generated. In addition, some of these features (metrics) may be more relevant to the class (defective or non-defective) than others, and some may be redundant or irrelevant [
17,
18].
Feature selection (FS) can be used to select high uncorrelated features from the high dimensional features. In other words, it can select those features that are more relevant and irredundant to the class label of the dataset among the features. Therefore, introducing FS methods into SDP can solve the high dimensionality problem [
17,
18,
19]. FS is a vital data pre-processing step in classification processes as it improves the quality of data and consequently improves the predictive performance of the prediction models. Existing research has shown that irrelevant features, along with redundant features, can severely affect the accuracy of the defect predictors [
20,
21,
22,
23]. Thus, there is a need for finding an efficient feature selection method which can identify and remove as much irrelevant and redundant information as possible, thereby leading to good predictive performance with low computational cost [
24,
25]. Supervised feature selection techniques evaluate the available feature’s characteristics and derive a set of pertinent characteristics based on labeled datasets. The criteria used to determine the useful feature characteristics depend on the underlining computational characteristics of the technique utilized. Filter feature-ranking (FFR) methods which are types of supervised FS methods depend on the computational characteristics of each feature by certain critical factors, and then the analyst culls some features that are congruous with a particular dataset. On the other hand, filter feature subset selection (FSS) methods (another type of supervised FS methods) search for a subset of features that have good predictive capability collectively. In this study, a comparative performance analysis of FFR and FSS methods based on different search methods are investigated to determine their respective efficacy in culling a germane set of features.
Recent studies have compared the impact of FS methods on the performance of SDP [
26,
27,
28,
29,
30,
31,
32]. Some studies conclude that some of the FS methods are better than others [
27,
28,
30,
31], while some studies claimed that there is no significant difference between the performances of FS methods in SDP [
26,
29,
32]. This contradiction and inconsistency in results by existing studies may be due to the choice of search mechanism used in FS methods.
In this study, four different FFR methods (Information Gain (IG), ReliefF (RFA), Gain Ratio (GR), and Clustering Variation (CV)) based on Ranker Search method and two FFS methods: Correlation-based Feature Subset Selection (CFS) and Consistency Feature Subset Selection (CNS) based on two different search approaches: Exhaustive Search (Best First Search (BFS) and Greedy Stepwise Search (GSS) methods) and Heuristic Search (Genetic Search (GS), Bat Search (BAT), Ant Search (AS), Fire-Fly Search (FS), and Particle Swarm Optimization (PSO) method). Four classification techniques: Naïve Bayes (NB), Decision Tree (DT), Logistic Regression (LR), and K-Nearest Neighbor (KNN) were used to evaluate the effectiveness of these FS methods. The respective models were used on five software defects dataset from the NASA repository and their predictive performances were measured comparatively based on accuracy.
From our experimental results, the application of FS improves the predictive performance of the prediction models and the performance of FS methods varies across datasets and prediction models. IG recorded the best improvement on prediction models over other FFR methods, while CNS based on BFS had the best influence on prediction models based on FSS methods. Further analysis showed that prediction models based on FFR are more stable in terms of performance accuracy than other FS methods.
The rest of this paper is structured as follows.
Section 2 presents a literature review and analysis of existing related works.
Section 3 presents the various FS methods including the search methods, classifiers, datasets, and the performance metric considered in the experimental works of this study.
Section 4 highlights the experimental procedure, experimental results, and discussion of our findings for the experimental works.
Section 5 presents the threats to the validity of this study.
Section 6 concludes the comparative study and summarizes future work.
2. Related Works
A major problem associated with SDP is the dilemma of having a large number of metrics (features). In other words, using all software metrics in training an SDP model can end up negatively affecting the predictive performance of the model. As such, many FS approaches have been proposed in addressing the selection of optimal software metrics. Some studies went to the extent on comparing these methods in order to identify the best method. However, most of these studies yielded contradictory and inconsistent conclusions on the effect of FS methods in SDP [
26,
29,
32].
Ghotra et al. [
28] performed a large scale impact analysis of twenty-eight FS methods on twenty-one commonly used classifiers. Their experiment was based on software defect datasets from the NASA and the PROMISE repositories. They concluded that correlation-based filter-FS method based on the BF search method outperforms other FS methods across the datasets. This is a good indicator that their experiment covered a large number of FS methods, classification techniques, and datasets. However, they only considered BF and GA search methods as search mechanisms for the FSS methods. There are other heuristics and meta-heuristic search methods such as BAT, AS, FS, etc. that may perform better than BF and GS in this context.
Afzal and Torkar [
26] conducted a benchmark study by empirically comparing state-of-the-art FS methods. They have considered, IG, RF, Principal Component Analysis (PCA), CFS, CNS and wrapper subset evaluation (WRP). NB and DT were deployed on Five software defect datasets and the predictive models were evaluated based on Area Under Curve (AUC). Their results showed that FS is beneficial to SDP but there was no individual best FS method for SDP. This could be partly due to the number and type of software defect datasets been considered and the choice of search mechanisms in the case of the FSS and WRP FS methods.
Gao et al. [
27], regarded feature selection as a search problem in software engineering. Their study was concerned with software quality estimation and they proposed a hybrid FS approach which was based on Kolmogorov–Smirnov statistic and automatic hybrid search (AHS). Their results showed that AHS was superior to other methods, and that an elimination of 85% of software metrics may affect performances of SDP models positively or remain constant.
Akintola et al. [
18] performed a comparative analysis of classifiers based on FFS on SDP and their results gave credit to the usage of FFS, but there can still be further analysis using other FS methods. It has been proven empirically that wrappers obtain subsets with better performance than filter feature selection because the subsets were evaluated using a real modeling algorithm [
33,
34]. Rodriguez et al. [
35] have also conducted comparative experiments on FS methods based on three different FFR and WRP models on four software defect datasets. Their results showed that smaller data sets generally maintain predictability with fewer features than the original data sets.
From the aforementioned studies, only a handful of comparative performance studies have been carried out to evaluate the efficacy of FS methods based on different search mechanisms. Therefore, there is a need to have a vital comparative evaluation of FS methods based on different search mechanisms in SDP. This is to create a better understanding of FS methods characteristics and guide researchers and analysts on the selection of search methods in FS based for SDP. In this paper, a comparative performance analysis of eighteen FS methods in SDP is presented. Each FS methods was used with four different classifiers selected based on performance and heterogeneity. The respective SDP models were tested with five software defect datasets from NASA repository and evaluated based on prediction accuracy. The performance stability of each prediction model based on FS methods was further evaluated via the coefficient of variation for each prediction models.
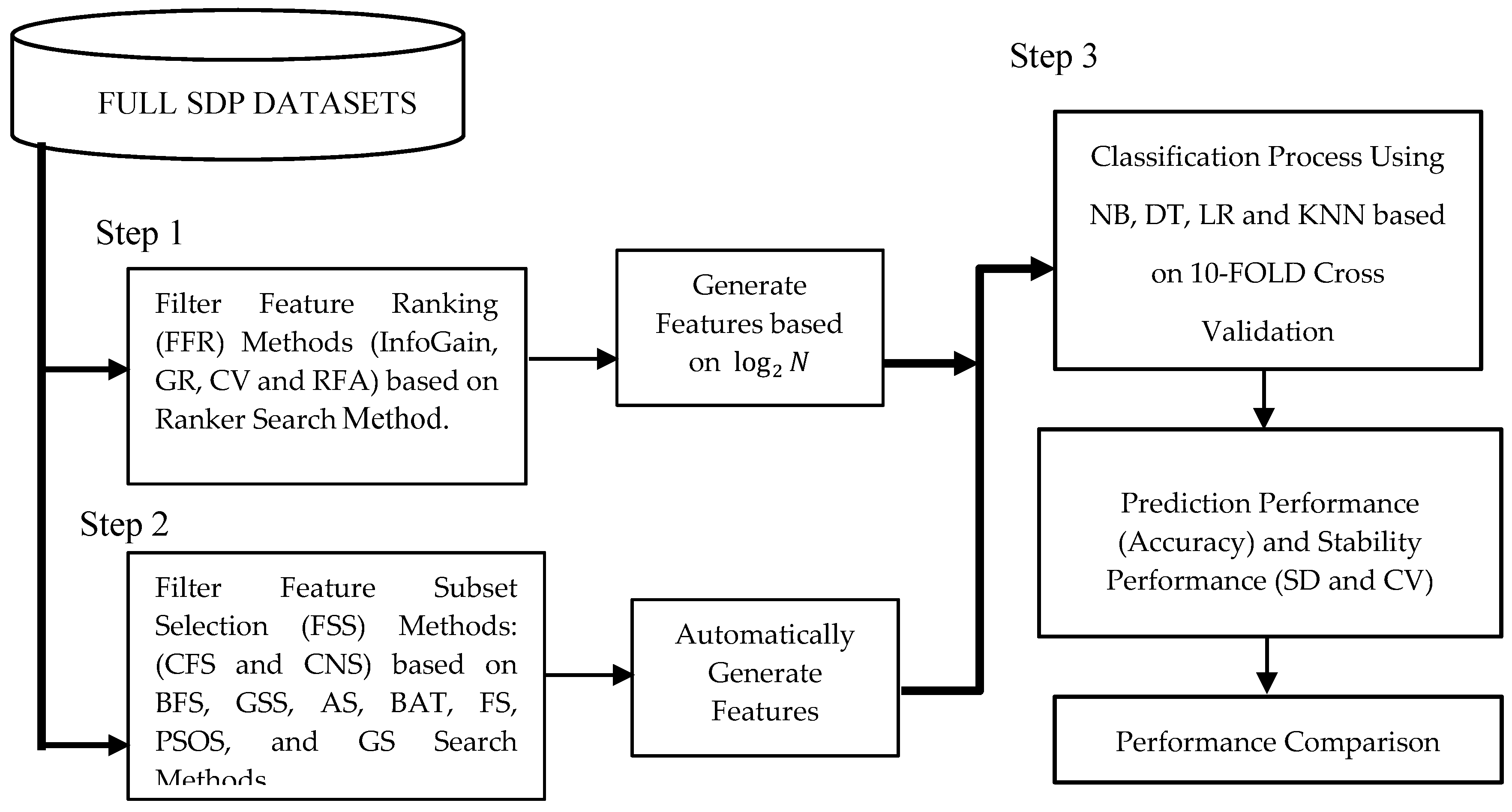
4. Experimental Results
This section presents the experimental results based on the experimental procedure (See
Figure 1). The performances of each prediction models were analyzed based on accuracy and the results were compared on two cases (with and without application of FS methods). The parameter settings for each classifier and search method are as shown in
Table 3 and
Table 4. All prediction models were built based on the WEKA machine learning tool [
41]. For replication of this study, all models and datasets used in this study are readily available in [
42].
As mentioned previously, four FFR and fourteen FSS methods were applied one after the other to five software defect datasets. Four classifiers based on the selected and full features of the datasets were used to develop the SDP models.
Table 6,
Table 7,
Table 8 and
Table 9 present the accuracy values of the four classifiers on the software defect datasets. These accuracy values were from two scenarios (With FS methods and Without FS methods). Specifically, in each of the tables, the accuracy performance value of each classifier on the individual datasets (full and reduced) is shown. The search methods for the FSS (CFS and CNS) were further grouped into two (i.e. Heuristic method and Exhaustive method). This is to show the distinction of how the respective search methods behaved when used as subset evaluation methods in FSS. The average performance of these classifiers (NB, DT, LR, and KNN) across all datasets were computed and the variation of the average performance of each prediction models with FS (FFR and FSS) methods to the average performance of each prediction model without FS methods were also computed. This is to show how significant the effectiveness of the application of FS methods in SDP. As shown in
Table 6,
Table 7,
Table 8 and
Table 9, it is observed that the accuracy performance of the prediction models based on FS methods, in this case, FFR and FSS were better than when no FS methods are applied. This further strengthens the evidence that FS methods can improve the performance of prediction models in SDP.
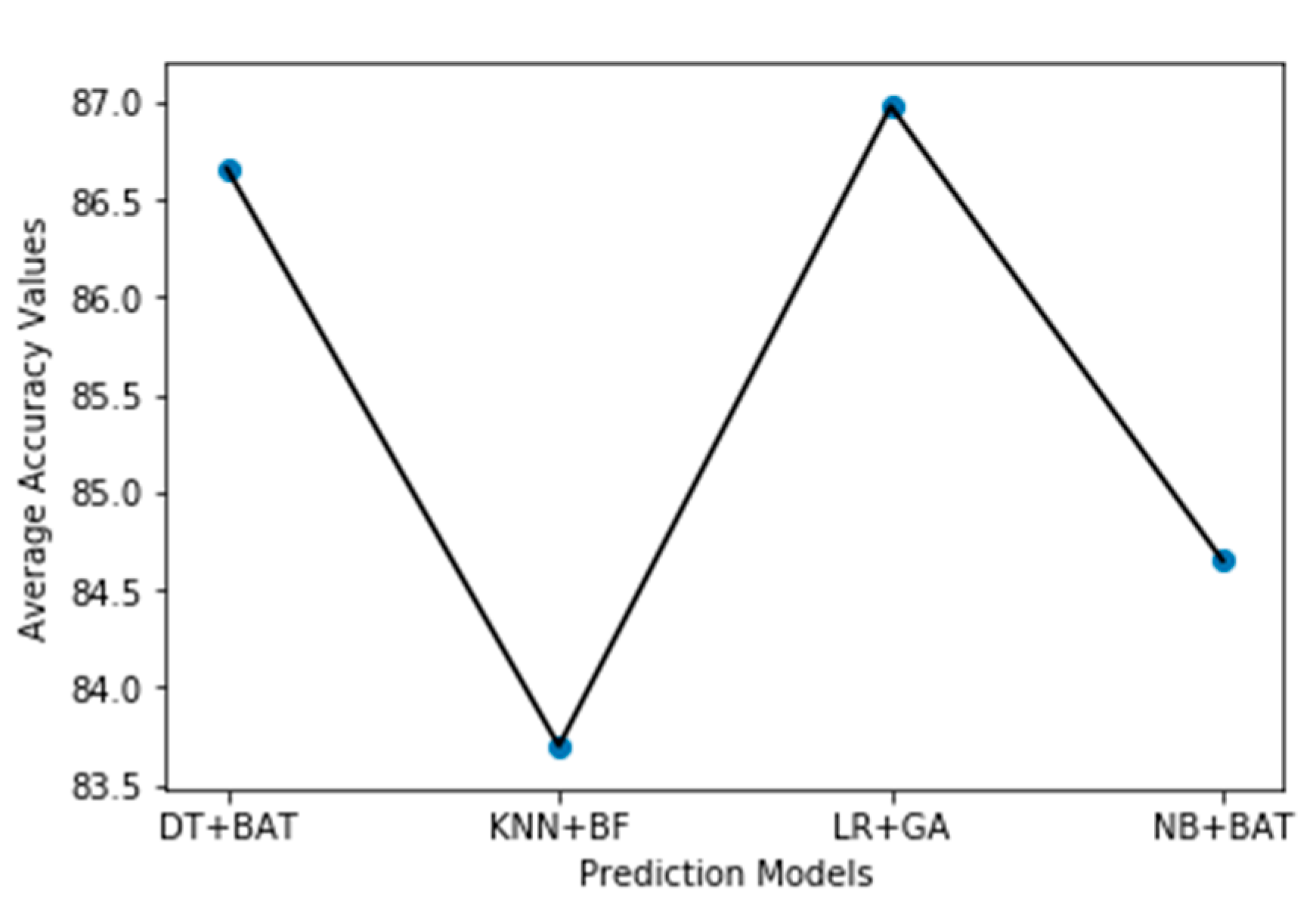
Specifically, considering the average accuracy performance value of prediction models based on NB classifier as shown in
Table 6, NB with CFS using BAT heuristic search method had the highest average accuracy value, i.e., 84.65%. This accuracy value is better than when no FS methods are used with the NB model (81.14%) by 4.33%. The same goes to prediction models based on DT classifier, as shown in
Table 7. DT with CFS using BAT heuristic search method had the best average accuracy value of 86.66%. Compared with when no FS methods on DT (84.50%), a variation of 2.33% increment was observed. In the case of LR classifier, as presented in
Table 8, LR with CNS based on GS had the highest average accuracy value of 86.98% with a positive variation of 1.22% when compared with when no FS methods are used on LR (85.93%). From
Table 9, KNN with CNS based on BFS had the highest average accuracy value of 83.70% with a positive variation of 3.92% when compared with no FS methods. It was also observed that LR with CNS based on GS had the highest average accuracy value (85.93%) across all prediction models and NB with CFS based on BAT heuristic search had the highest positive variation (4.33%). This clearly shows that FS methods have a positive effect on the prediction models as the average accuracy values based on each classifier without FS methods are less than when FS methods are applied. Our findings on the positive effect of FS methods on prediction models are in accordance with research outcomes from existing empirical studies. Ghotra et al. [
28], Afzal and Torkar [
26], and Akintola et al. [
18] in their respective studies also reported that FS methods had a positive effect on prediction models in SDP. However, our study explored the effect of FS methods on prediction models based on the search method which is different from existing empirical studies.
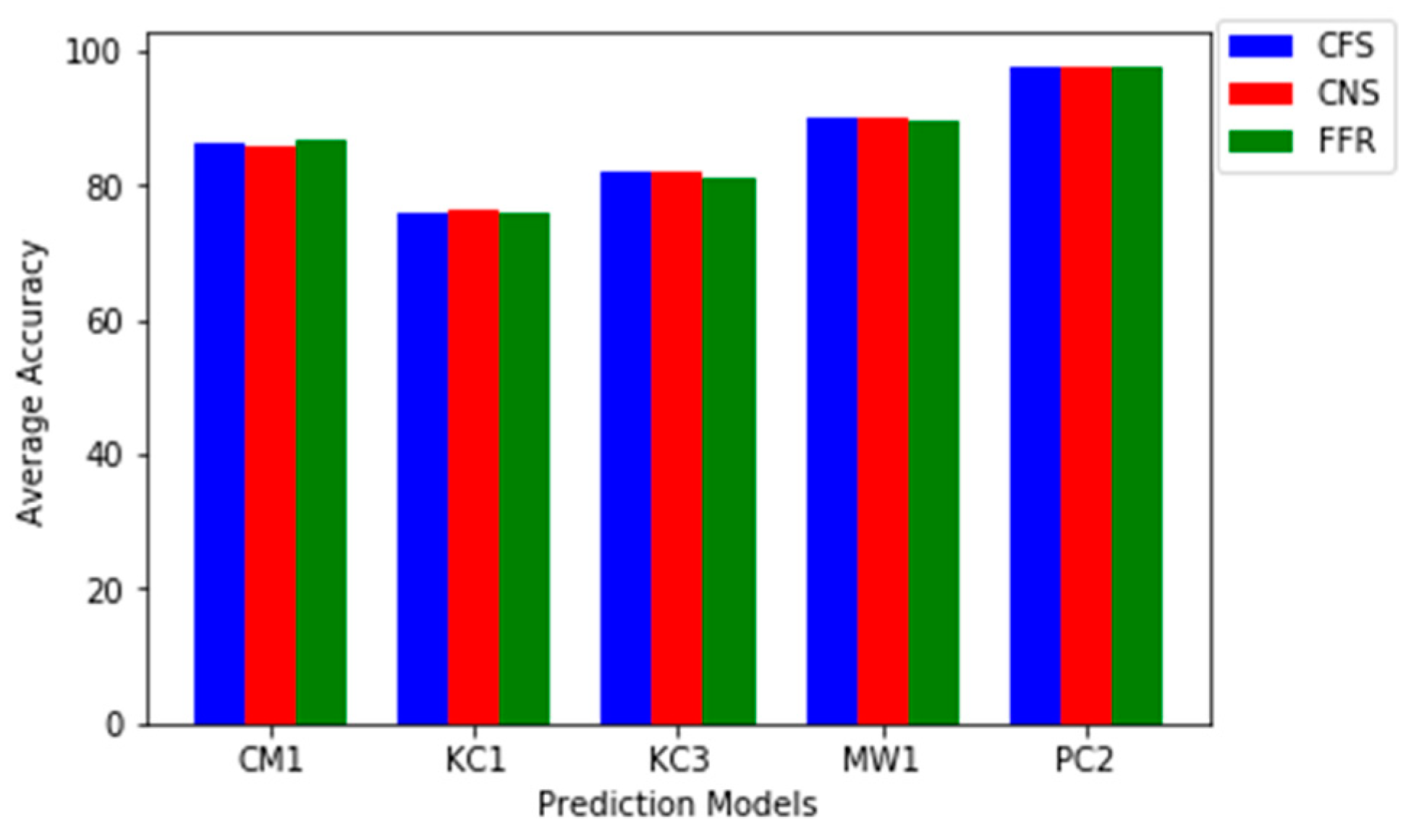
Furthermore, assessing the accuracy performance of each prediction model on each of the dataset will showcase how these prediction models perform based on different FS methods.
Table 10,
Table 11,
Table 12,
Table 13 and
Table 14 present the comparisons of FS (FFR and FSS) methods on each of the five datasets respectively. Considering the number of features generated by FS methods, FFR features are pre-calculated based on
(where
N is the number of features). The number of features for FSS methods are based on the search methods used (Heuristic or Exhaustive). Across all datasets and FS methods used in this study, the number of features generated by CFS is less than CNS. On the CM1 dataset, with respect to CFS, LR with PSO search method and DT with BAT search method had an accuracy value of 87.16% with (LR+CFS+PSO) selecting eight features and the (DT+CFS+BAT) had five features. Same also was observed for CNS, LR with GA search, DT with GSS search, and LR with BF search had accuracy value of 87.16%. LR with GA search had more features (twelve) and LR with BF selected just one feature. However, based on the FFR method, DT with CV based on Ranker search had the highest accuracy value of 87.46% which means the FFR method gave the best performance on CM1 dataset as presented in
Table 10. From
Table 11, LR with CNS based on AS (77.11%) out-performs all prediction models on the KC1 dataset. The prediction model was built on seventeen features as selected by AS. Other FS methods on KC1 selected smaller features but their respective prediction model had lower accuracy performance. In addition, on dataset KC3 as presented in
Table 12, DT with CFS based on BAT and GA search had the highest accuracy value of 82.99% with two features selected while LR with CFS based on BAT search in
Table 13 had the best accuracy value on MW1 dataset. In
Table 14, DT and LR with CFS based on BAT and AS respectively had an accuracy value of 97.78% on PC2 dataset. The FFR methods also had similar accuracy value on PC2 based on DT with RFA, GR, and CV. Clearly, there was no significant difference in the performance of the FS methods, as their respective performance and effect varies from dataset to dataset and the choice of classification algorithm. This research outcome is related to the findings from Xu et al. [
29], Kondo et al. [
31] and Muthukumaran et al. [
30]. Although on average, FSS methods proved to be better than FFR methods.
From the aforementioned results, it is clear that there is no significant difference in the performance accuracy values of the FS methods. That is, the performance of FS methods depends largely on the dataset as the best subset of features that varied from one dataset to another. In addition, it was also observed that based on the FSS (CFS and CNS) methods, a varying number of features were selected. This presents a very interesting case on how the small number of features affects the performance of prediction models. Some studies argued that the lesser the features, the better the performance [
26,
37,
43]. However, in this study, it was observed that the number of features selected depends largely on the FS method used. CNS often selects more features and the prediction models based on CNS outperforms other FS methods. In addition, as presented in
Table 15, considering the FFR methods, IG had the best influence on the prediction models over other FFR methods. While considering the FSS, CNS based on BFS had the best influence on the prediction models. However, CFS based on BS had the best improvement on the performance of NB and DT and CNS based on GS and BF improved the performance of LR and KNN best, respectively.
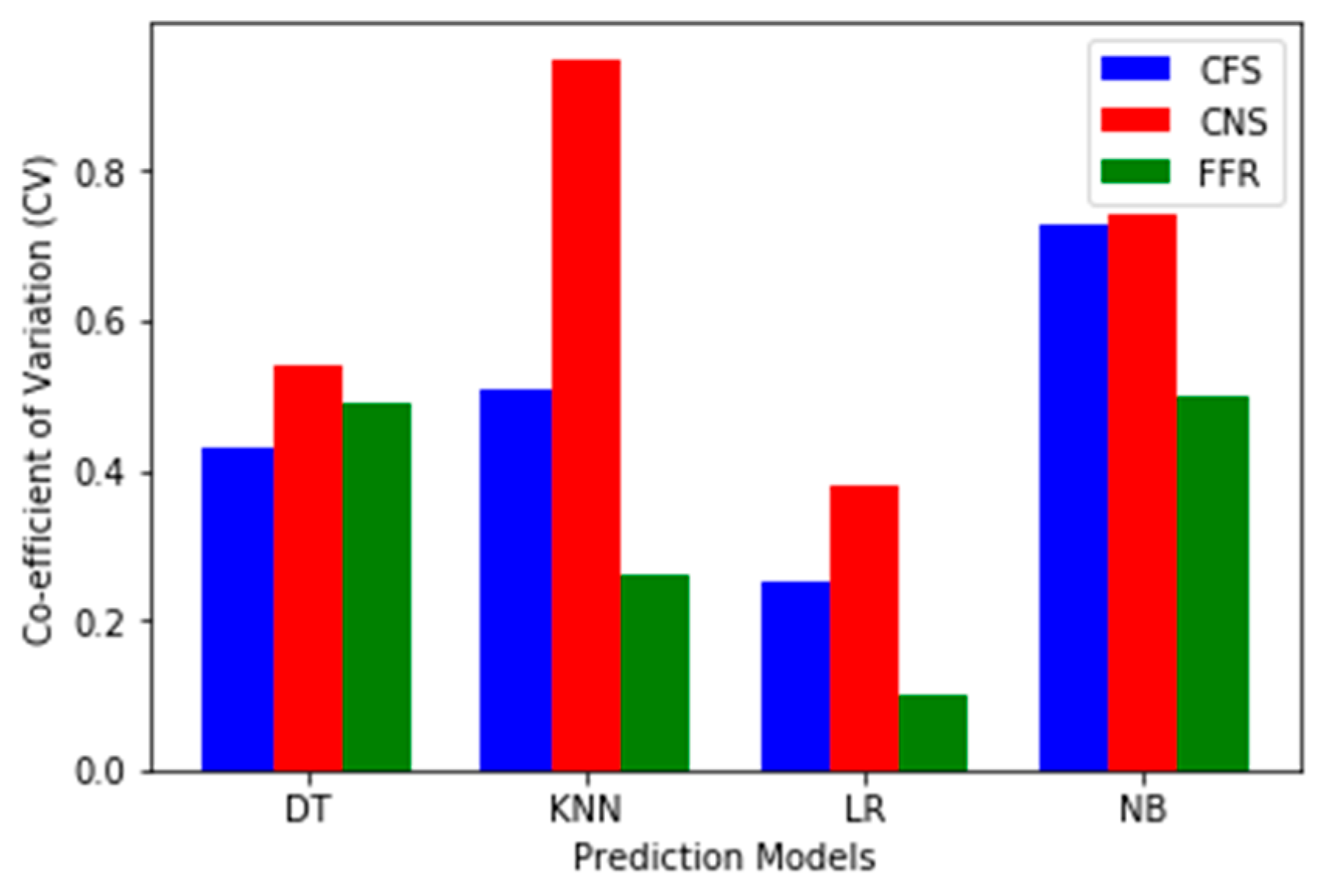
Furthermore, we conducted a stability test on the FS methods based on different prediction models using the average accuracy values from the experimental results. We calculated the Standard Deviation (SD) and the Co-efficient of Variation (CV) as presented in
Appendix A Table A1. FFR methods produced more stable results in terms of accuracy across the prediction models as compared with the FSS methods. Consequently, even if there is no significant difference for the prediction models based on a variety of FS methods considered in this study, FFR proves to be more stable than FSS methods having lower CV values. The best prediction model developed using each classifier is illustrated in
Figure 2. In
Table 15, prediction models with FS methods outperform models developed without features selection. This indicates the importance of FS methods while developing the SDP model regardless of which family (characteristics) the classification algorithm belongs.
Figure 3 shows the positive gain, that is, the variation of the prediction models with FS methods to prediction models without FS methods.
Figure 4 and
Figure 5 show the performance stability of prediction models developed with FS methods respectively. Both figures depict the standard deviation (SD) and Co-efficient of Variation (CV) values for each FS method. Lastly,
Figure 6 pictorially presents the performance FS method based on average accuracy values on each dataset.
In conclusion, listed below are a summary of our findings from this comparative study:
FS methods are very important and useful as it improves the performance of prediction models.
Based on the individual performance accuracy values, FS methods had the highest improvement on the predictive performance of NB classifier.
CFS based on (AS, BAT, GS, FS, PSO, BFS, and GSS) selects (automatically) the minimum number of features.
On the average as presented in
Table 15, CFS based on BAT had the highest positive variation on NB and DT while CNS based on GS and BFS had the highest positive variation value on LR and KNN.
FFR had the lowest C.V. values which make it more stable than other FSS methods (See
Table A1 in
Appendix A).
5. Threat to Validity
This section discusses the threats to the validity of our comparative study. According to Wohlin et al. [
44], empirical software engineering is becoming relevant and a vital factor of any empirical study is to analyze and mitigate threats to the validity of the experimental results.
External validity: This validity mainly bothers on the ability to generalize the experimental study. Five software defects datasets which have been extensively utilized in defect prediction were used in this study. Although these datasets differs in their characteristics (number of instances and attributes) and are from the commonly used corpora (NASA), we cannot generalize conclusions of this study on other software defect datasets. However, this study provided a comprehensive experimental setup, with applicable parameter tuning and settings, which makes it possible for researchers to replicate on other software defect datasets.
Internal validity: This validity stresses on the choice of prediction models and feature selection methods. Gao et al. [
45] stated that factors such as choice of software applications, classification algorithm selection, and noisy datasets affect the internal validity of SDP. In this study, we selected 4 classificationn algorithms based on performance and heterogeneity (See:
Table 4) and these classification algorithms are well used in SDP. Specifically, 18 methods based on two FS techniques with seven search methods were used in this study. Nonetheless, future studies can consider other FS techniques and new search methods.
Construct validity: This validity focuses on the choice of performance metrics used to evaluate the performance of prediction models. In this study, accuracy which measures the percentage of the correctly classified instances was employed and Co-efficient of Variation (C.V) was applied to the results of the prediction models to determine the performance stability of prediction models. However, other performance metrics such as Area under Curve (AUC) and F-Measure may also be applicable.
6. Conclusions and Future Work
SDP can assist software engineers in identifying defect-prone modules in a software system and consequently streamline the deployment of limited resources in Software Development Life Cycle (SDLC) during software development. However, the performance of SDP depends on the quality of software defect datasets which suffers from high dimensionality. Hence, the selection of relevant and irredundant features from software defect datasets is imperative to achieve a strong prediction model in SDP. This study conducted a comparative performance analysis via the investigation of eighteen FS methods on five software defect datasets from NASA repository with four classification algorithms. The FS methods were grouped into two Filter subset selections (FSS) (CFS and CNS) with seven different search methods (BFS, BAT, FS, AS, GSS, PSOS, and GS) and four Feature Filter Rank (FFR) (IG, RFA, GR, and CV) methods based on ranker search method. From the experimental results, IG recorded the best improvement on the prediction models over other FFR methods while CNS based on BFS had the best influence on the prediction models based on FSS methods. In addition, further analysis showed that prediction models based on FFR are more stable than other FS methods. It was conclusively discovered that the performance of FS methods varied across the dataset and that some classifiers behaved differently. This may be due to the class imbalance which is a primary data quality problem in data science. In the future, we intend to look at how other data quality problems, such as class imbalance and outliers, affect FS methods in SDP.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





