Improving Lossless Image Compression with Contextual Memory



Abstract
:1. Introduction
2. Related Work
3. PAQ8PX Algorithm for Lossless Image Compression in Detail
3.1. Introduction
3.2. General Aspects
3.3. Modeling
3.4. Image Compression
3.4.1. Direct Modeling
3.4.2. Indirect Modeling
3.4.3. Least Squares Modeling
3.4.4. Correlations
3.4.5. Grayscale 8 bpp
3.5. Context Mixing
3.6. Adaptive Probability Maps
3.7. Other Considerations
4. The Proposed Method–Contextual Memory
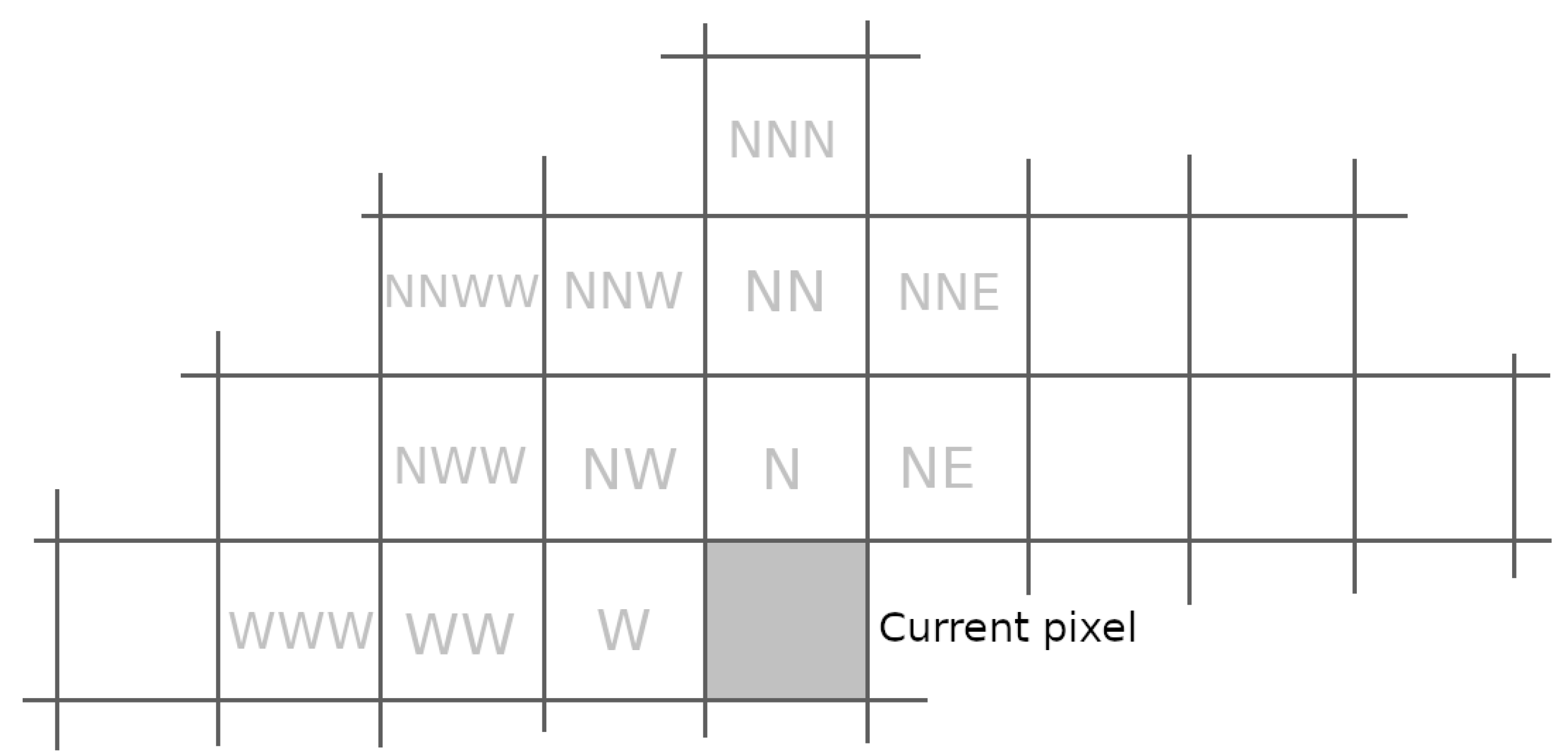
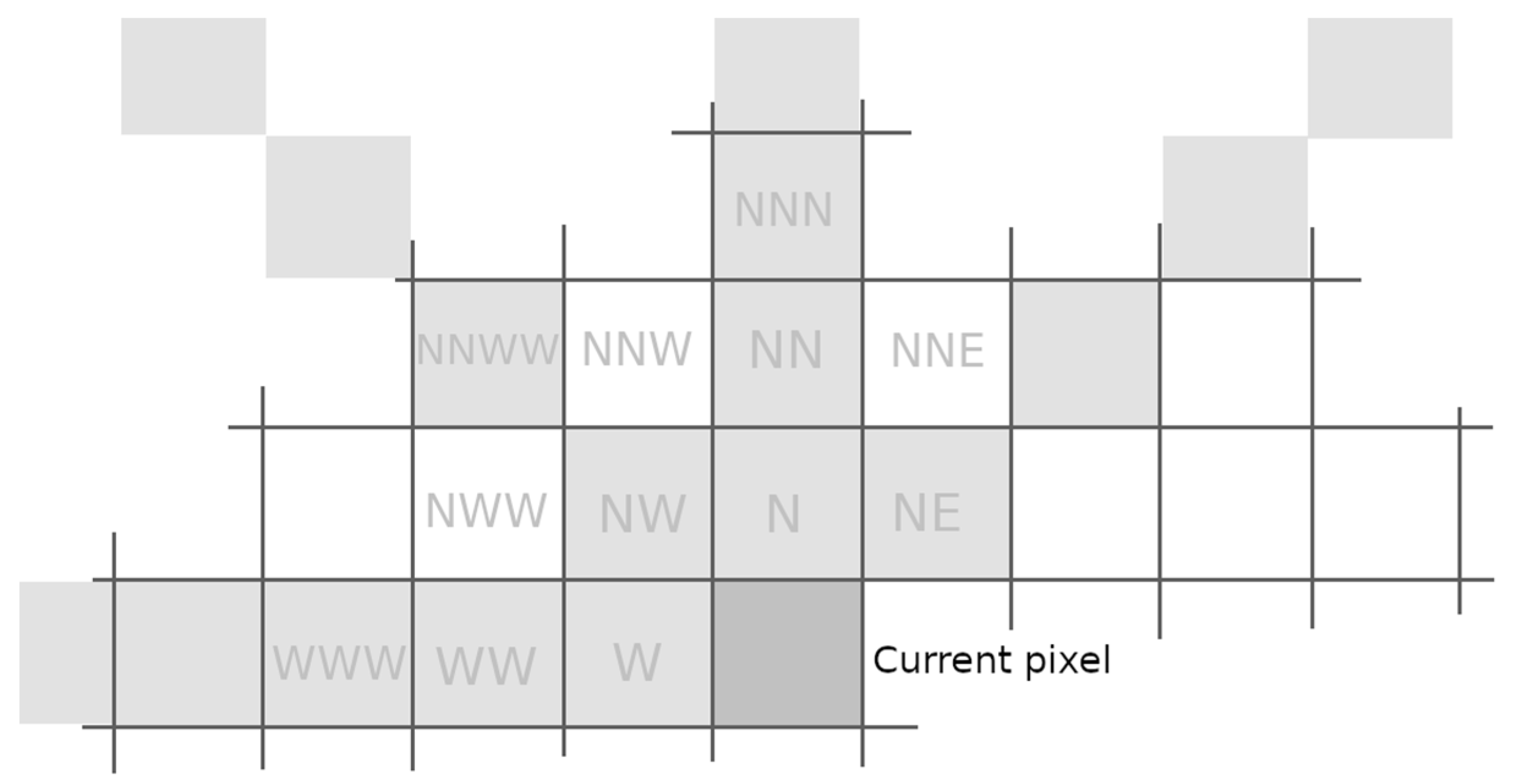
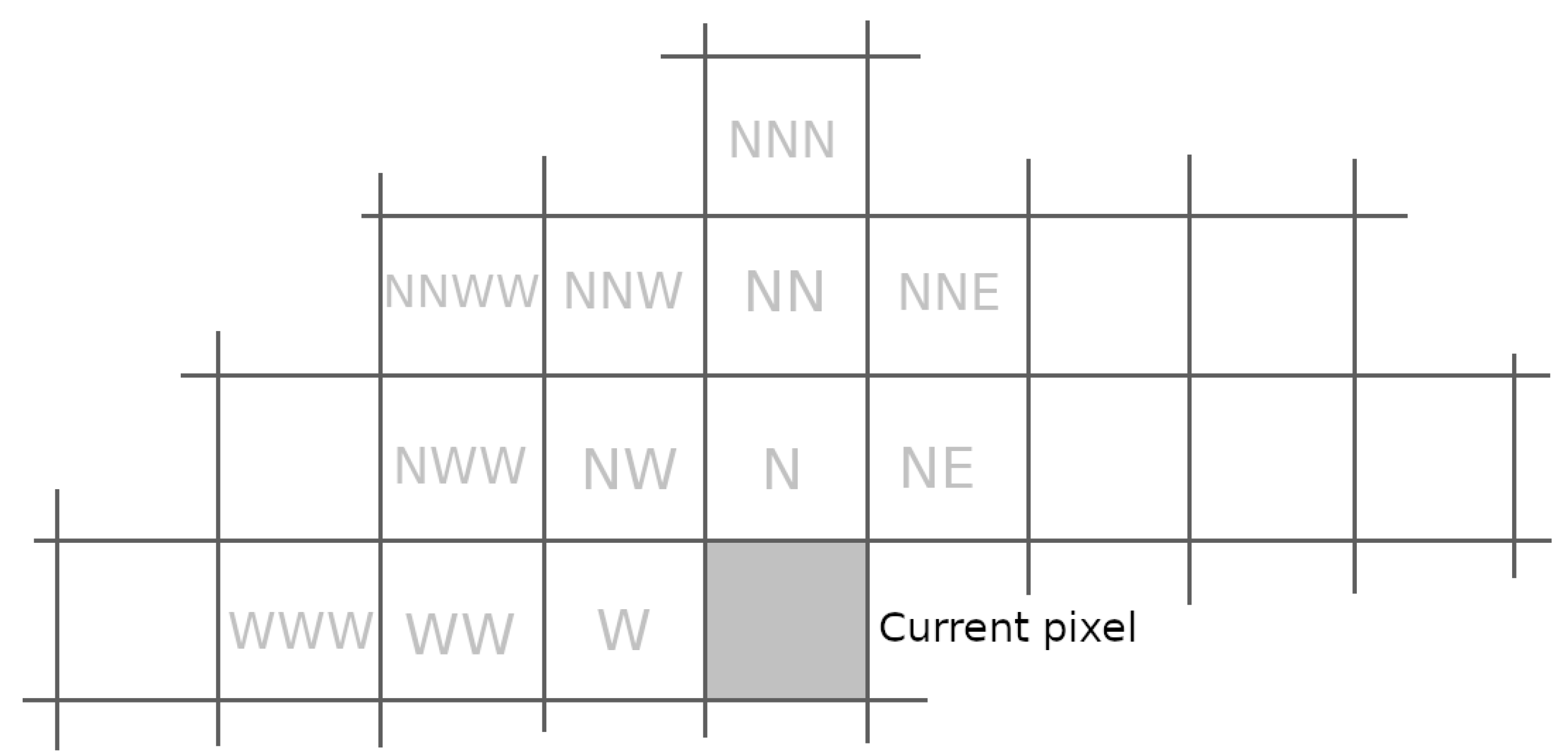
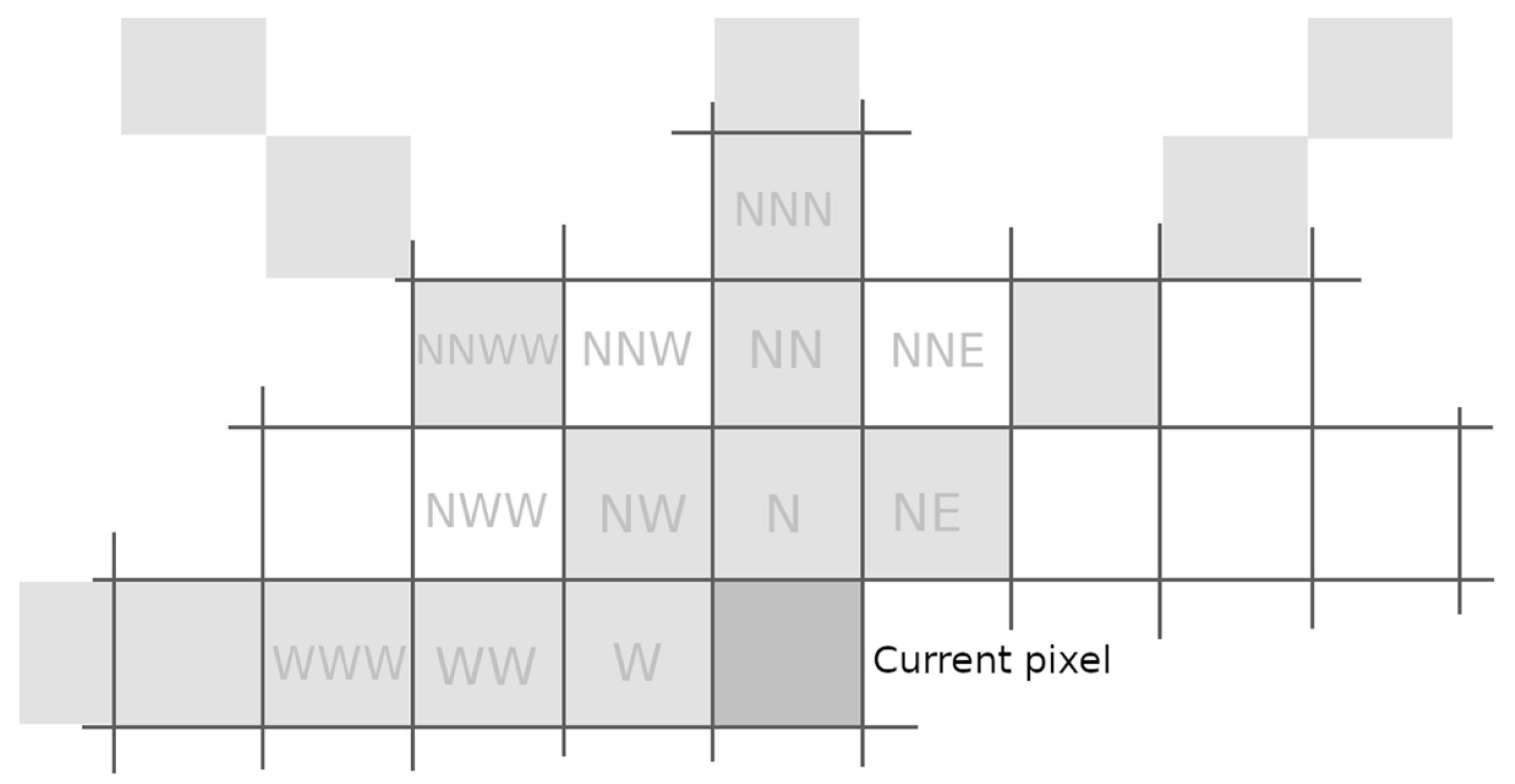
4.1. Context Modeling
4.2. Description of the Contextual Prediction
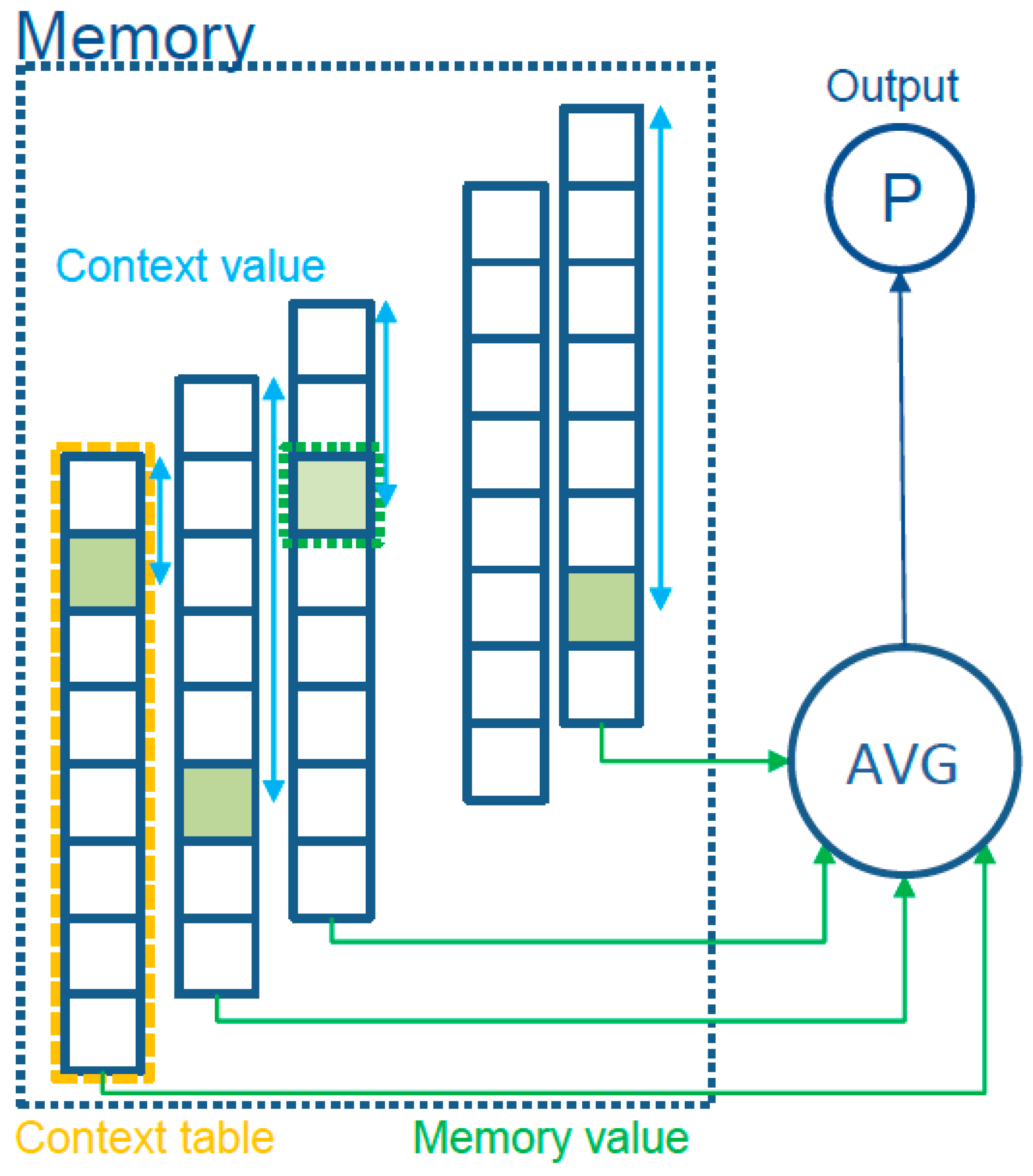
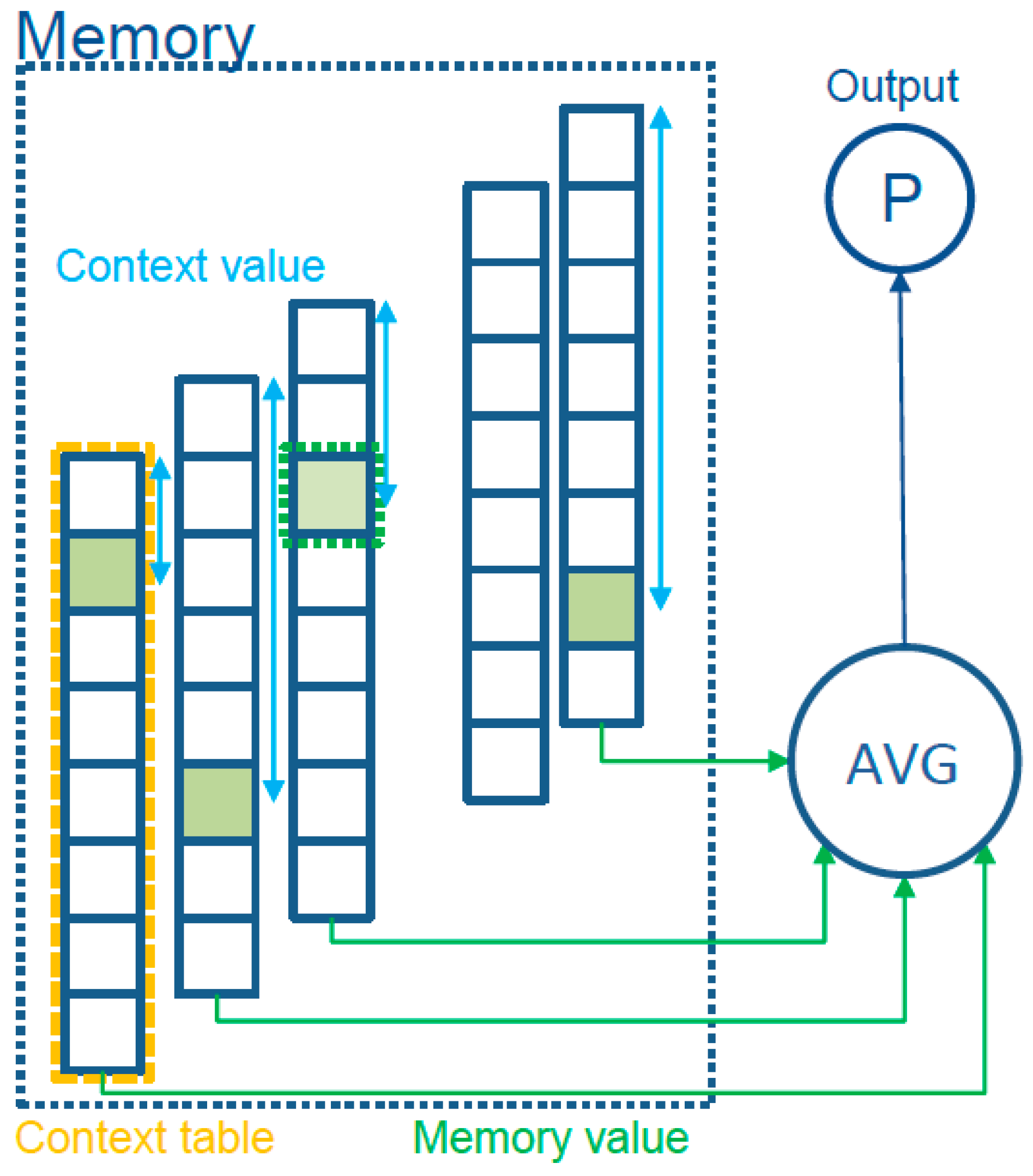
4.2.1. Model Prediction
- We obtain a value from the memory for each context. One way to do that is to index the hash of the “context value” in a table
- We average all the obtained “memory values”
- Convert the average into a probability using the sigmoid function
4.2.2. Interpretation of Values
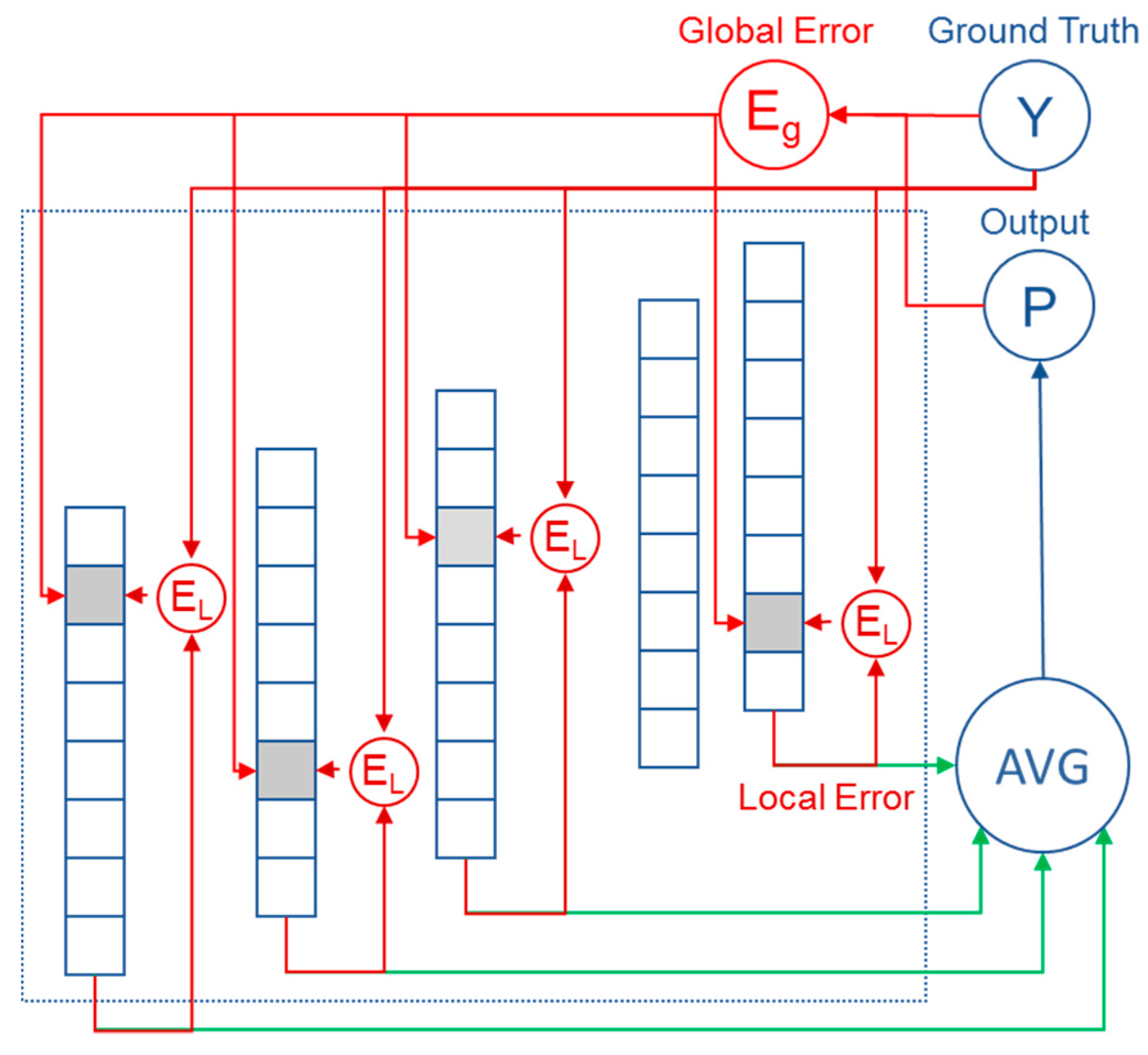
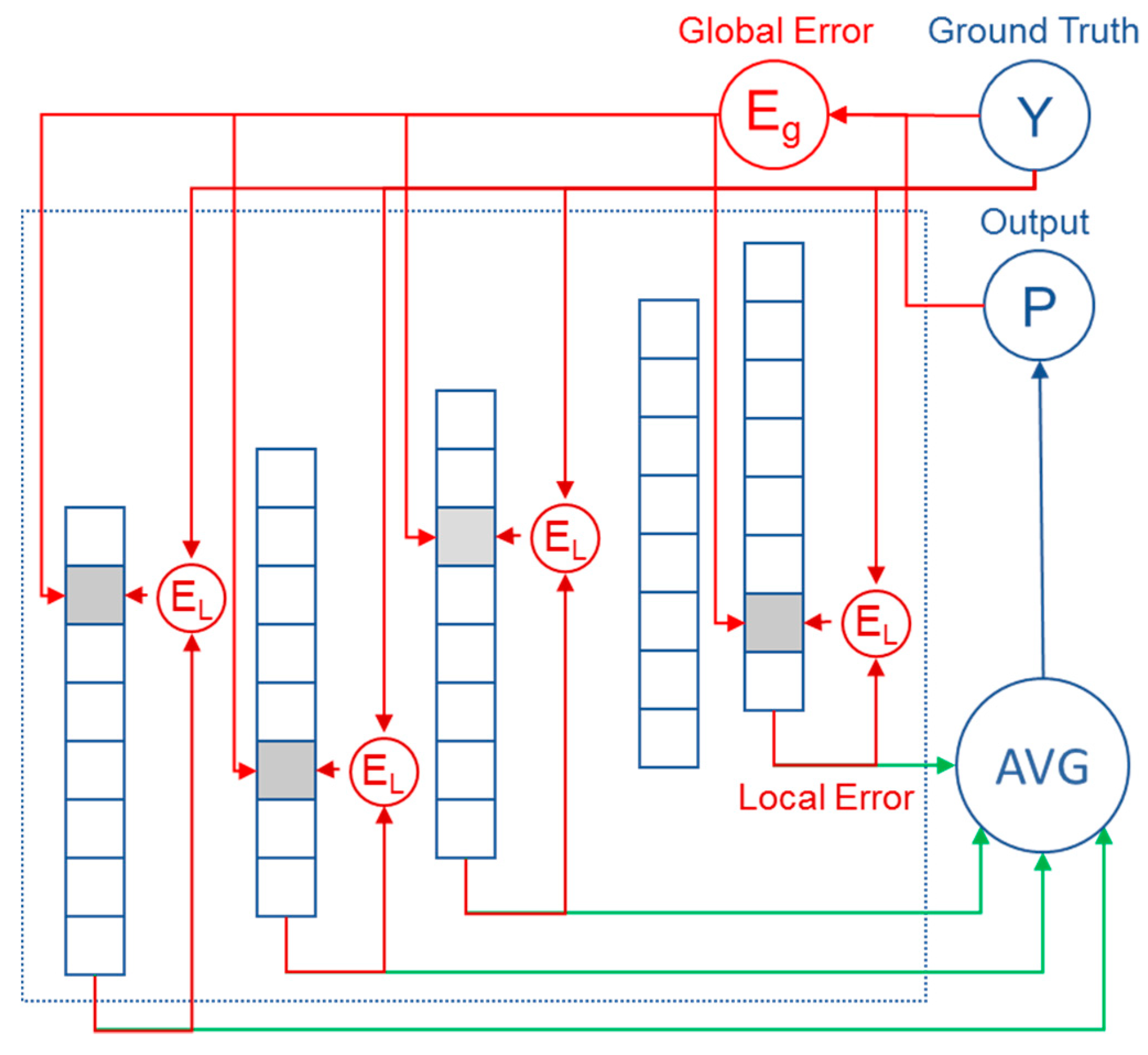
4.2.3. Updating the Model
- In respect to the output of the network–global error
- In respect to the output of the individual nodes (side predictions)–local error
4.3. Memory Implementation and Variations
- simple lookup–we ignore the potential collisions and average the memory values, multiply the result by an ad-hoc constant, and then apply the sigmoid function,where n is the number of contexts and k is an ad-hoc constant. Once the number of contexts becomes known, c becomes a constant and can be computed only once.
- tagged lookup–for each memory value a small tag is added that is computed by taking the higher order bits of the context value. If a table address size is less than 32 bits, the remaining bits still can bring value to the indexing. If the tag matches, we can use the value for the average.where nt is the number of tag matches. In an empirical study we concluded that instead of simply averaging the values, we can get better results by dividing the sum by the average of the number of contexts and the number of tag matches. The formula becomesThis is an approximate weighting of the confidence of the output based on how many inputs participate in the result.On update, we update the tag of the location where it does not match. The value of the location can be reset to zero or the old value can be kept and the regular updated formula used. Keeping the old value sometimes gives better results and we believe this is because the collisions generated by noise can reset a very biased context value. This method uses more memory and has a more complex update rule, but gives better results than the simple lookup with the cost of improved computing complexity.
- bucket lookup–the context value indexes a bucket with an array of tagged values. The selection of the memory value is done by searching the bucket for a matching tag. In this way, we can implement complex replacement rules for the values inside the bucket. We provide a “least bias” eviction rule when no tag is matched in the bucket. This means kicking the location with the value closest to zero. In this way, we keep the values that can bring benefits to the compression. Computing the output and the update rules are the same as in tagged lookup. If the bucket size is kept small (4 to 8 entries), the linear search is done in the same cache line, making the speed comparable to the tagged lookup.
5. Experimental Results
5.1. PAQ8PX Contextual Memory Implementation Details
5.2. Evaluation on the Benchmarks
5.3. Discussion on the Results
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, D.; Li, Y.; Zhang, H.; Gao, W. Invertible update-then-predict integer lifting wavelet for lossless image compression. EURASIP J. Adv. Signal Process. 2017, 2017, 8–17. [Google Scholar] [CrossRef]
- Khan, A.; Khan, A.; Khan, M.; Uzair, M. Lossless image compression: Application of Bi-level Burrows Wheeler Compression Algorithm (BBWCA) to 2-D data. Multimed. Tools Appl. 2017, 76, 12391–12416. [Google Scholar] [CrossRef]
- Feng, W.; Hu, C.; Wang, Y.; Zhang, J.; Yan, H. A Novel Hierarchical Coding Progressive Transmission Method for WMSN Wildlife Images. Sensors 2019, 19, 946. [Google Scholar] [CrossRef] [PubMed]
- Schiopu, I.; Munteanu, A. Residual-error prediction based on deep learning for lossless image compression. Electron. Lett. 2018, 54, 1032–1034. [Google Scholar] [CrossRef]
- Hosseini, S.M.; Naghsh-Nilchi, A.-R. Medical ultrasound image compression using contextual vector quantization. Comput. Biol. Med. 2012, 42, 743–750. [Google Scholar] [CrossRef] [PubMed]
- Eben Sophia, P.; Anitha, J. Contextual Medical Image Compression using Normalized Wavelet-Transform Coefficients and Prediction. IETE J. Res. 2017, 63, 671–683. [Google Scholar] [CrossRef]
- Borusyak, A.V.; Vasin, Y.G. Development of an algorithm for adaptive compression of indexed images using contextual simulation. Pattern Recognit. Image Anal. 2016, 26, 4–8. [Google Scholar] [CrossRef]
- Strutz, T. Context-Based Predictor Blending for Lossless Color Image Compression. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 687–695. [Google Scholar] [CrossRef]
- Knezovic, J.; Kovac, M.; Mlinaric, H. Classification and Blending Prediction for Lossless Image Compression. In Proceedings of the MELECON 2006–2006 IEEE Mediterranean Electrotechnical Conference, Benalmadena, Spain, 16–19 May 2006; pp. 486–489. [Google Scholar] [CrossRef]
- Strizic, L.; Knezovic, J. Optimization of losless image compression method for GPGPU. In Proceedings of the 18th Mediterranean Electrotechnical Conference (MELECON), Lemesos, Cyprus, 18–20 April 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Weinlich, A.; Amon, P.; Hutter, A.; Kaup, A. Probability Distribution Estimation for Autoregressive Pixel-Predictive Image Coding. IEEE Trans. Image Process. 2016, 25, 1382–1395. [Google Scholar] [CrossRef] [PubMed]
- Biadgie, Y.; Kim, M.; Sohn, K.-A. Multi-resolution Lossless Image Compression for Progressive Transmission and Multiple Decoding Using an Enhanced Edge Adaptive Hierarchical Interpolation. Ksii Trans. Internet Inf. Syst. 2017, 11, 6017–6037. [Google Scholar] [CrossRef]
- Biadgie, Y. Edge Adaptive Hierarchical Interpolation for Lossless and Progressive Image Transmission. Ksii Trans. Internet Inf. Syst. 2011, 5, 2068–2086. [Google Scholar] [CrossRef]
- Song, X.; Huang, Q.; Chang, S.; He, J.; Wang, H. Lossless medical image compression using geometry-adaptive partitioning and least square-based prediction. Med Biol. Eng. Comput. 2018, 56, 957–966. [Google Scholar] [CrossRef] [PubMed]
- Lucas, L.F.R.; Rodrigues, N.M.M.; da Silva Cruz, L.A.; de Faria, S.M.M. Lossless Compression of Medical Images Using 3-D Predictors. IEEE Trans. Med. Imaging 2017, 36, 2250–2260. [Google Scholar] [CrossRef] [PubMed]
- Shen, H.; Jiang, Z.; Pan, W. Efficient Lossless Compression of Multitemporal Hyperspectral Image Data. J. Imaging 2018, 4, 142. [Google Scholar] [CrossRef]
- Consultative Committee for Space Data Systems CCSDS Recommended Standard for Image Data Compression. 2017. Available online: https://public.ccsds.org/Pubs/122x0b2.pdf (accessed on 29 June 2019).
- Knoll, B.; De Freitas, N. A Machine Learning Perspective on Predictive Coding with PAQ8. In Proceedings of the 2012 Data Compression Conference, Snowbird, UT, USA, 10–12 April 2012; pp. 377–386. [Google Scholar] [CrossRef]
- Mahoney, M.V. Adaptive Weighing of Context Models for Lossless Data Compression; The Florida Institute of Technology: Melbourne, FL, USA, 2005; Volume 6. [Google Scholar]
- Data Compression Explained. Available online: http://mattmahoney.net/dc/dce.html#Section_43 (accessed on 11 May 2019).
- Paq8px thread. Available online: https://encode.ru/threads/342-paq8px (accessed on 11 May 2019).
- Chartier, M. MCM File Compressor. Available online: https://github.com/mathieuchartier/mcm (accessed on 29 June 2019).
- Veness, J.; Lattimore, T.; Bhoopchand, A.; Grabska-Barwinska, A.; Mattern, C.; Toth, P. Online Learning with Gated Linear Networks. arXiv 2017, arXiv:1712.01897 [cs, math]. [Google Scholar]
- Mattern, C. Mixing Strategies in Data Compression. In Proceedings of the 2012 Data Compression Conference, Snowbird, UT, USA, 10–12 April 2012; pp. 337–346. [Google Scholar] [CrossRef]
- Mattern, C. Linear and Geometric Mixtures-Analysis. In Proceedings of the 2013 Data Compression Conference, Snowbird, UT, USA, 20–22 March 2013; pp. 301–310. [Google Scholar] [CrossRef]
- Mattern, C. On Statistical Data Compression. Ph.D. Thesis, Technische Universität Ilmenau, Ilmenau, Germany, 2016. [Google Scholar]
- Fowler–Noll–Vo Hash Functions. Available online: http://www.isthe.com/chongo/tech/comp/fnv/index.html (accessed on 11 May 2019).
- Dorobanţiu, A.; Brad, R. A novel contextual memory algorithm for edge detection. Pattern Anal. Appl. 2019, 1–13. [Google Scholar] [CrossRef]
- Alexandru Dorobanțiu-GitHub. Available online: https://github.com/AlexDorobantiu (accessed on 11 May 2019).
- Dorobanțiu, A. Paq8px167ContextualMemory. Available online: https://github.com/AlexDorobantiu/Paq8px167ContextualMemory (accessed on 13 May 2019).
- Image Repository of the University of Waterloo. Available online: http://links.uwaterloo.ca/Repository.html (accessed on 11 May 2019).
- Garg, S. The New Test Images-Image Compression Benchmark. Available online: http://imagecompression.info/test_images/ (accessed on 11 May 2019).
- Squeeze Chart Lossless Data Compression Benchmarks. Available online: http://www.squeezechart.com/ (accessed on 11 May 2019).
- 7-cpu. Available online: https://www.7-cpu.com/utils.html (accessed on 13 June 2019).
- Dorobanțiu, A. Compute Bits Per Pixel for Compressed Images. Available online: https://github.com/AlexDorobantiu/BppEvaluator (accessed on 29 June 2019).
- Mahoney, M. The ZPAQ Open Standard Format for Highly Compressed Data-Level 2. 2016. Available online: http://www.mattmahoney.net/dc/zpaq206.pdf (accessed on 29 June 2019).
- Aiazzi, B.; Alparone, L.; Baronti, S. Context modeling for near-lossless image coding. IEEE Signal Process. Lett. 2002, 9, 77–80. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Set | JPEG 2000 | JPEG-LS | MRP | ZPAQ | VanilcWLS D | Paq8px167 | Paq8px167+CM (proposed) |
|---|---|---|---|---|---|---|---|
| bird | 3,6300 | 3,4710 | 3,2380 | 4,0620 | 2,7490 | 2,6073 | 2,6077 |
| bridge | 6,0120 | 5,7900 | 5,5840 | 6,3680 | 5,5960 | 5,5074 | 5,5037 |
| camera | 4,5700 | 4,3140 | 3,9980 | 4,7660 | 3,9950 | 3,8176 | 3,8173 |
| circles11 | 0,9280 | 0,1530 | 0,1320 | 0,2300 | 0,0430 | 0,0281 | 0,0282 |
| crosses1 | 1,0660 | 0,3860 | 0,0510 | 0,2120 | 0,0160 | 0,0176 | 0,0171 |
| goldhill1 | 5,5160 | 5,2810 | 5,0980 | 5,8210 | 5,0900 | 5,0220 | 5,0197 |
| horiz11 | 0,2310 | 0,0940 | 0,0160 | 0,1220 | 0,0150 | 0,0139 | 0,0140 |
| lena1 | 4,7550 | 4,5810 | 4,1890 | 5,6440 | 4,1230 | 4,1302 | 4,1293 |
| montage1 | 2,9830 | 2,7230 | 2,3530 | 3,3350 | 2,3630 | 2,1505 | 2,1501 |
| slope1 | 1,3420 | 1,5710 | 0,8590 | 1,5040 | 0,9600 | 0,7186 | 0,7194 |
| squares1 | 0,1630 | 0,0770 | 0,0130 | 0,1770 | 0,0070 | 0,0129 | 0,0128 |
| text1 | 4,2150 | 1,6320 | 3,1750 | 0,4960 | 0,6210 | 0,1053 | 0,1052 |
| Average | 2,9510 | 2,5060 | 2,3920 | 2,7280 | 2,1310 | 2,0109 | 2,0103 |
| Set | JPEG2000 | JPEG-LS | MRP | ZPAQ | VanilcWLS D | Paq8px167 | Paq8px167+CM (proposed) |
|---|---|---|---|---|---|---|---|
| barb | 4,6690 | 4,7330 | 3,9100 | 5,6720 | 3,8710 | 3,9319 | 3,9297 |
| boat | 4,4150 | 4,2500 | 3,8720 | 4,9650 | 3,9280 | 3,8165 | 3,8145 |
| france1 | 2,0350 | 1,4130 | 0,6030 | 0,4220 | 1,1590 | 0,0992 | 0,0966 |
| frog | 6,2670 | 6,0490 | _2 | 3,3560 | 5,1060 | 2,4656 | 2,4581 |
| goldhill2 | 4,8470 | 4,7120 | 4,4650 | 5,2830 | 4,4630 | 4,4227 | 4,4214 |
| lena2 | 4,3260 | 4,2440 | 3,9230 | 5,0660 | 3,8680 | 3,8608 | 3,8604 |
| library1 | 5,7120 | 5,1010 | 4,7650 | 4,4870 | 4,9110 | 3,3253 | 3,3200 |
| mandrill | 6,1190 | 6,0370 | 5,6790 | 6,3690 | 5,6780 | 5,6364 | 5,6339 |
| mountain | 6,7120 | 6,4220 | 6,2210 | 4,4930 | 5,2150 | 4,0799 | 4,0744 |
| peppers2 | 4,6290 | 4,4890 | 4,1960 | 5,0950 | 4,1740 | 4,1493 | 4,1470 |
| washsat | 4,4410 | 4,1290 | 4,1470 | 2,2900 | 1,8900 | 1,7478 | 1,7466 |
| zelda | 4,0010 | 4,0050 | 3,6320 | 4,9200 | 3,6330 | 3,6437 | 3,6435 |
| Average | 4,8480 | 4,6320 | 4,3680 | 3,9910 | 3,4316 | 3,4288 |
| Set | JPEG2000 | JPEG-LS | MRP | ZPAQ | GraLIC | VanilcWLS D | Paq8px167 | Paq8px167+CM (proposed) |
|---|---|---|---|---|---|---|---|---|
| artificial1 | 1,1970 | 0,7980 | 0,5170 | 0,6730 | 0,4464 | 0,6820 | 0,3188 | 0,3186 |
| big_building | 3,6550 | 3,5920 | _2 | 4,3350 | 3,1777 | 3,2430 | 3,1250 | 3,1216 |
| big_tree | 3,8050 | 3,7320 | _2 | 4,4130 | 3,4080 | 3,4680 | 3,3823 | 3,3803 |
| Bridge | 4,1930 | 4,1480 | _2 | 4,7250 | 3,8700 | 3,8420 | 3,7958 | 3,7953 |
| cathedral | 3,7100 | 3,5700 | 3,2600 | 4,2390 | 3,1900 | 3,3020 | 3,1539 | 3,1519 |
| Deer | 4,5820 | 4,6590 | _2 | 4,7280 | 4,3116 | 4,3760 | 4,1788 | 4,1750 |
| fireworks | 1,6540 | 1,4650 | 1,3010 | 1,5550 | 1,2500 | 1,3640 | 1,2324 | 1,2325 |
| flower_foveon | 2,1980 | 2,0380 | _2 | 2,4640 | 1,7761 | 1,7470 | 1,6944 | 1,6943 |
| hdr | 2,3440 | 2,1750 | 1,8540 | 2,5890 | 1,9197 | 1,8730 | 1,8330 | 1,8327 |
| leaves_iso_200 | 4,0830 | 3,8200 | 3,4000 | 4,7430 | 3,2630 | 3,5370 | 4,0509 | 4,0473 |
| leaves_iso_1600 | 4,6810 | 4,4860 | 4,1860 | 5,2600 | 4,0720 | 4,2430 | 3,2168 | 3,2130 |
| nightshot_iso_100 | 2,3000 | 2,1300 | 1,8390 | 2,5760 | 1,8240 | 1,8750 | 1,7811 | 1,7805 |
| nightshot_iso_1600 | 4,0380 | 3,9710 | 3,7430 | 4,2680 | 3,6610 | 3,7820 | 3,6295 | 3,6272 |
| spider_web | 1,9080 | 1,7660 | 1,3490 | 2,3640 | 1,4441 | 1,4220 | 1,3498 | 1,3502 |
| zone_plate1 | 5,7550 | 7,4290 | 2,8340 | 5,9430 | 0,8620 | 0,9110 | 0,1257 | 0,1257 |
| Average | 3,3400 | 3,3190 | 3,6580 | 2,5650 | 2,6500 | 2,4579 | 2,4564 |
| Set | MRP | cmix v14f | GraLIC | Paq8px167 | Paq8px167+CM (proposed) |
|---|---|---|---|---|---|
| blood8 | 2,1670 | 2,1600 | 2,3200 | 2,1308 | 2,1304 |
| cathether8 | 1,5350 | 1,5351 | 1,6580 | 1,5382 | 1,5380 |
| fetus | 4,0650 | 3,9730 | 4,1310 | 3,8236 | 3,8225 |
| shoulder | 2,8660 | 2,9080 | 3,1130 | 2,8697 | 2,8676 |
| sigma8 | 2,6870 | 2,6290 | 2,7200 | 2,6266 | 2,6263 |
| Average | 2,6640 | 2,6410 | 2,7880 | 2,5978 | 2,5970 |
| Image | MRP | JPEG 2000 | JPEG-LS | GraLIC | Paq8px167 | Paq8px167+CM (proposed) |
|---|---|---|---|---|---|---|
| lena2 | 258 s | 0.04 s | 0.02 s | 0.25 s | 12 s | 24 s |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dorobanțiu, A.; Brad, R. Improving Lossless Image Compression with Contextual Memory. Appl. Sci. 2019, 9, 2681. https://doi.org/10.3390/app9132681
Dorobanțiu A, Brad R. Improving Lossless Image Compression with Contextual Memory. Applied Sciences. 2019; 9(13):2681. https://doi.org/10.3390/app9132681
Chicago/Turabian StyleDorobanțiu, Alexandru, and Remus Brad. 2019. "Improving Lossless Image Compression with Contextual Memory" Applied Sciences 9, no. 13: 2681. https://doi.org/10.3390/app9132681
APA StyleDorobanțiu, A., & Brad, R. (2019). Improving Lossless Image Compression with Contextual Memory. Applied Sciences, 9(13), 2681. https://doi.org/10.3390/app9132681