Figure 1.
An example transcription equivalent in modern notation (bottom image) based on a neume notation (upper image). A neume consisting of graphical connected note components (NCs) (a) is visualised by a slur, each new neume starts with an increased space (b), logical connected NCs are notated with small note space (c). The modern notation maintains the relevant information for performing the historical neume notation. The example image is taken from our corpus introduced in
Section 3.
Figure 1.
An example transcription equivalent in modern notation (bottom image) based on a neume notation (upper image). A neume consisting of graphical connected note components (NCs) (a) is visualised by a slur, each new neume starts with an increased space (b), logical connected NCs are notated with small note space (c). The modern notation maintains the relevant information for performing the historical neume notation. The example image is taken from our corpus introduced in
Section 3.
Figure 2.
Each page represents parts 1, 2, and 3, respectively. The bottom images provide a zoomed view on the upper pages. While the first page is very clean, both other pages suffer from bleeding and fainter writing. The staff lines in the first and second part are very straight most certainly due to usage of a ruler, whereas the staff lines of the third part are freehand drawn.
Figure 2.
Each page represents parts 1, 2, and 3, respectively. The bottom images provide a zoomed view on the upper pages. While the first page is very clean, both other pages suffer from bleeding and fainter writing. The staff lines in the first and second part are very straight most certainly due to usage of a ruler, whereas the staff lines of the third part are freehand drawn.
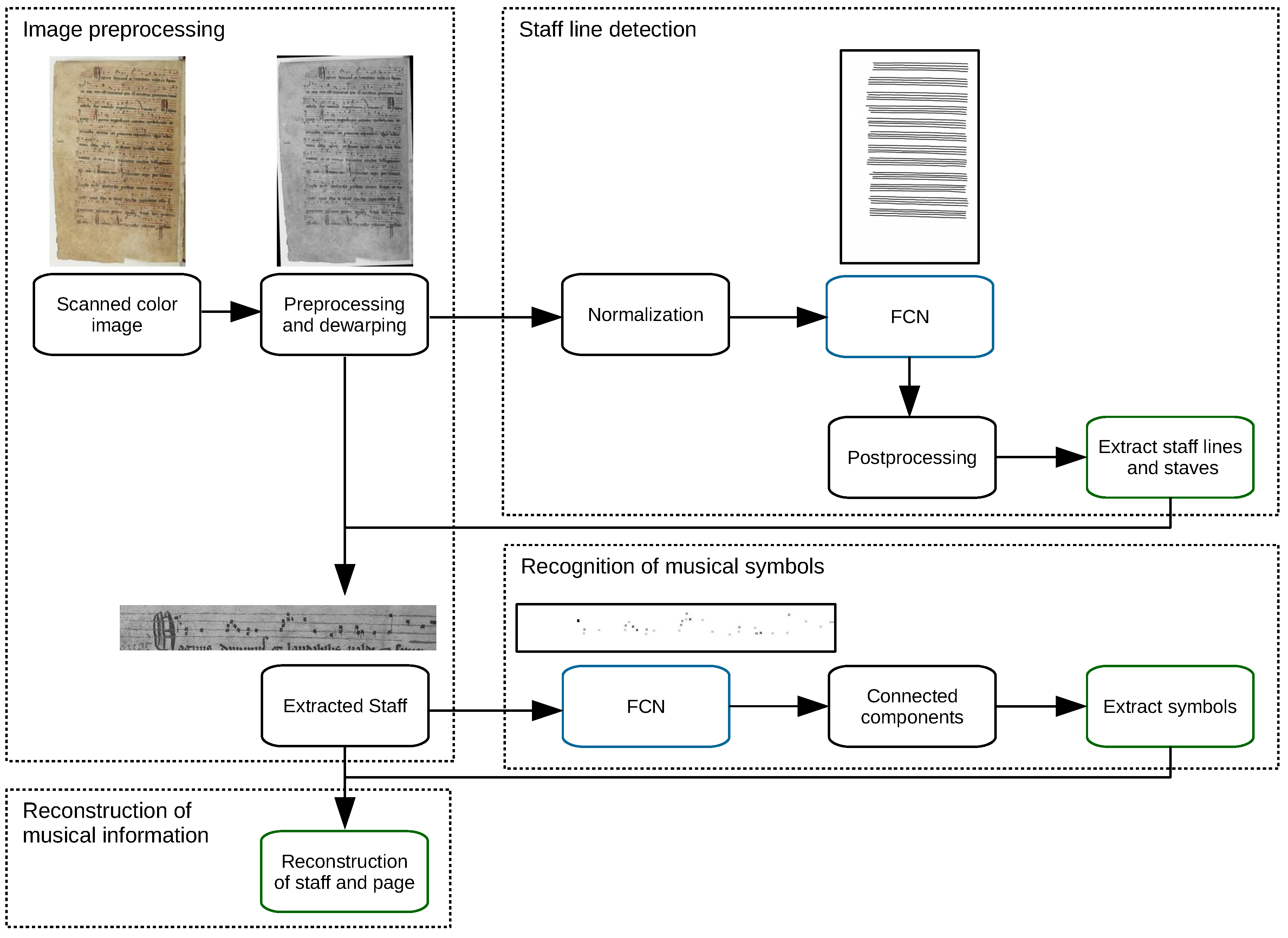
Figure 3.
Schematic view of the workflow of the staff line and symbol detection. The small images show the original image and the input and output of the respective Fully Convolutional Network (FCN).
Figure 3.
Schematic view of the workflow of the staff line and symbol detection. The small images show the original image and the input and output of the respective Fully Convolutional Network (FCN).
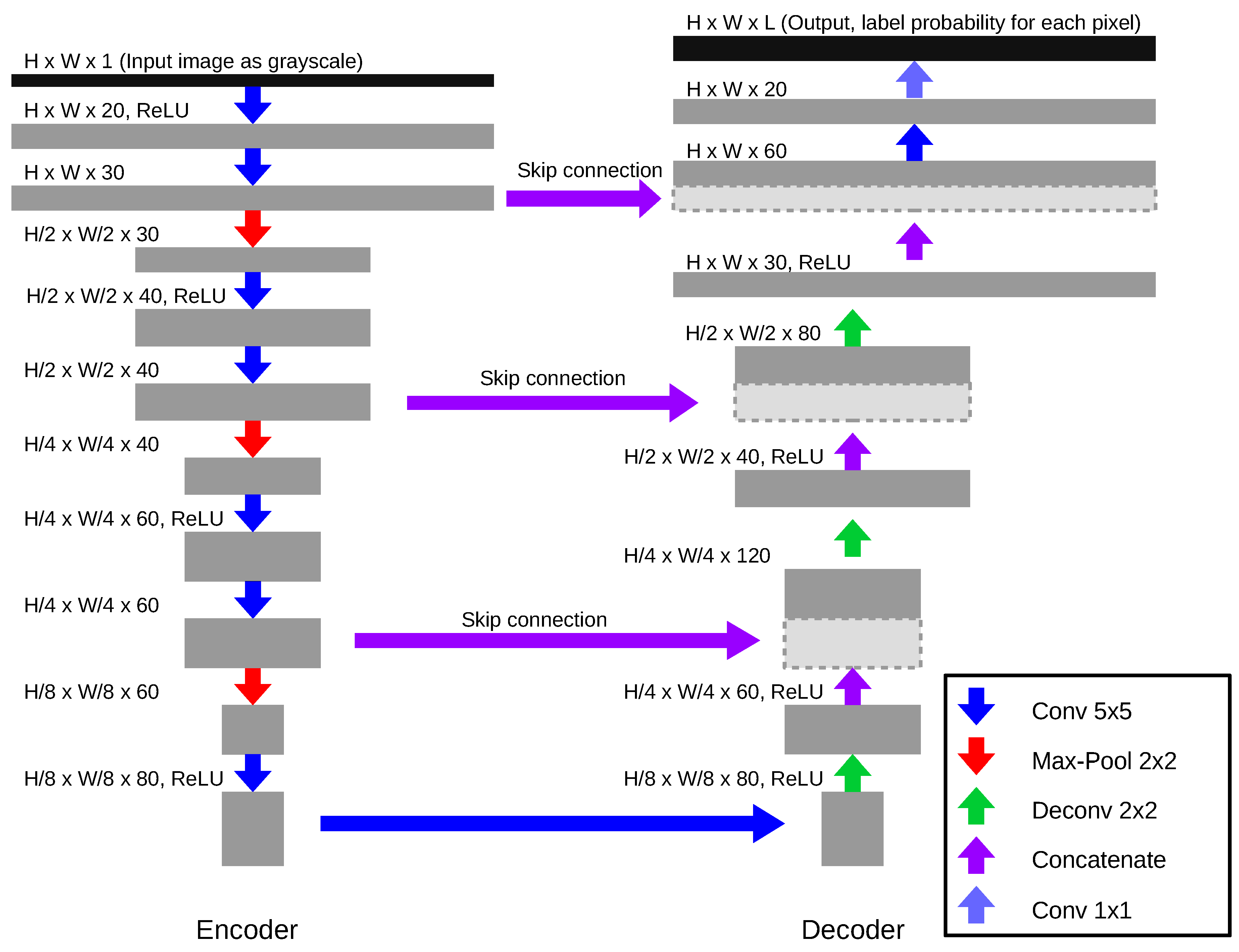
Figure 4.
FCN network architecture used for the staff line detection and symbol detection. Both the type and the dimension of each layer is shown.
Figure 4.
FCN network architecture used for the staff line detection and symbol detection. Both the type and the dimension of each layer is shown.
Figure 5.
GT pairs of input and target for training the FCN. The upper box shows an example for the staff line detection where the FCN acts on the full page. The staff lines in the GT are drawn as black lines in the target binary image. The symbol detection, instead, expects an image of a single line as input. The different grey levels of the target represent the symbol classes, for example the darkest level indicates a F-clef, while the brightest level marks a NC which is the start of a neume.
Figure 5.
GT pairs of input and target for training the FCN. The upper box shows an example for the staff line detection where the FCN acts on the full page. The staff lines in the GT are drawn as black lines in the target binary image. The symbol detection, instead, expects an image of a single line as input. The different grey levels of the target represent the symbol classes, for example the darkest level indicates a F-clef, while the brightest level marks a NC which is the start of a neume.
Figure 6.
Staff line detection steps including the application of the FCN and the postprocessing. The example images show the output of the respective step. In step (f–h) the resulting polylines indicating staff lines are drawn, while in the other steps (a–e) the output is a matrix. The run-length encoding (RLE) scale of 6 px relative to the output and the dimension of is shown as reference in gray.
Figure 6.
Staff line detection steps including the application of the FCN and the postprocessing. The example images show the output of the respective step. In step (f–h) the resulting polylines indicating staff lines are drawn, while in the other steps (a–e) the output is a matrix. The run-length encoding (RLE) scale of 6 px relative to the output and the dimension of is shown as reference in gray.
Figure 7.
The first line shows the cut off original input image. The next one is the target mask for the FCN in which notes and clefs are marked. The next three lines show the dewarped, padded and an augmented version of the original image.
Figure 7.
The first line shows the cut off original input image. The next one is the target mask for the FCN in which notes and clefs are marked. The next three lines show the dewarped, padded and an augmented version of the original image.
Figure 8.
Each column shows cropped instances of the seven classes to be recognised by the symbol detection, respectively for each data set part. The central pixel position defines the type.
Figure 8.
Each column shows cropped instances of the seven classes to be recognised by the symbol detection, respectively for each data set part. The central pixel position defines the type.
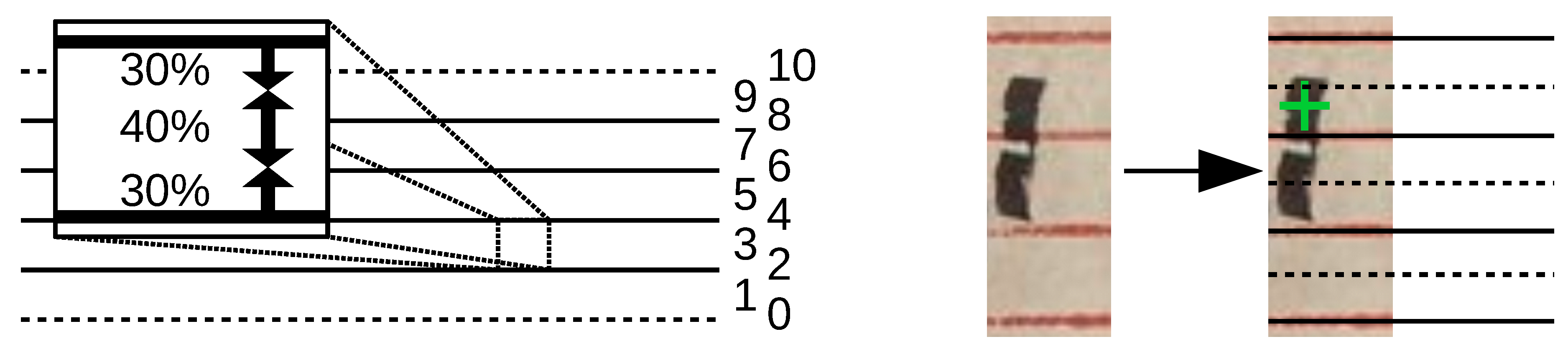
Figure 9.
The left image shows the relative staff line positions shown on the right. The zoomed window marks the area sizes that are assigned as line or space, while the dashed lines indicate ledger lines. The right image is an example for a NC (green mark) that is visually closer to the space (dashed) however actually a NC on a line (solid).
Figure 9.
The left image shows the relative staff line positions shown on the right. The zoomed window marks the area sizes that are assigned as line or space, while the dashed lines indicate ledger lines. The right image is an example for a NC (green mark) that is visually closer to the space (dashed) however actually a NC on a line (solid).
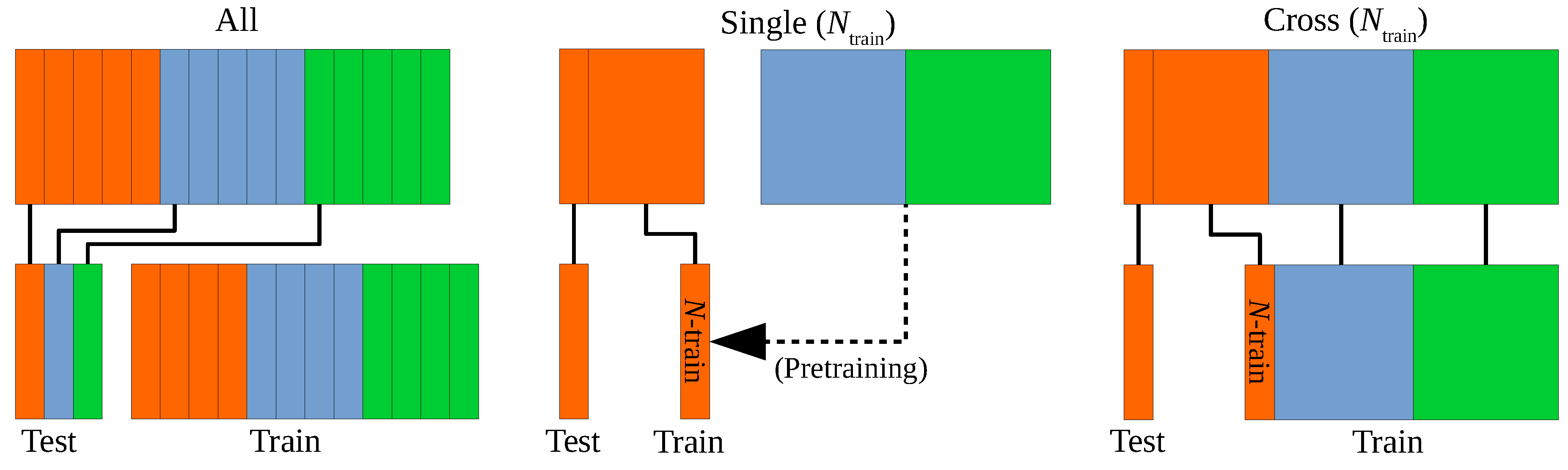
Figure 10.
Scheme of the used cross fold training. Each color represents a part that is split into a five fold (smaller boxes). Depending on the experiment different sections are chosen for training and testing. Optionally, a pretrained model on remaining data is used. For the cross-part scheme can be set to zero to only train on other parts.
Figure 10.
Scheme of the used cross fold training. Each color represents a part that is split into a five fold (smaller boxes). Depending on the experiment different sections are chosen for training and testing. Optionally, a pretrained model on remaining data is used. For the cross-part scheme can be set to zero to only train on other parts.
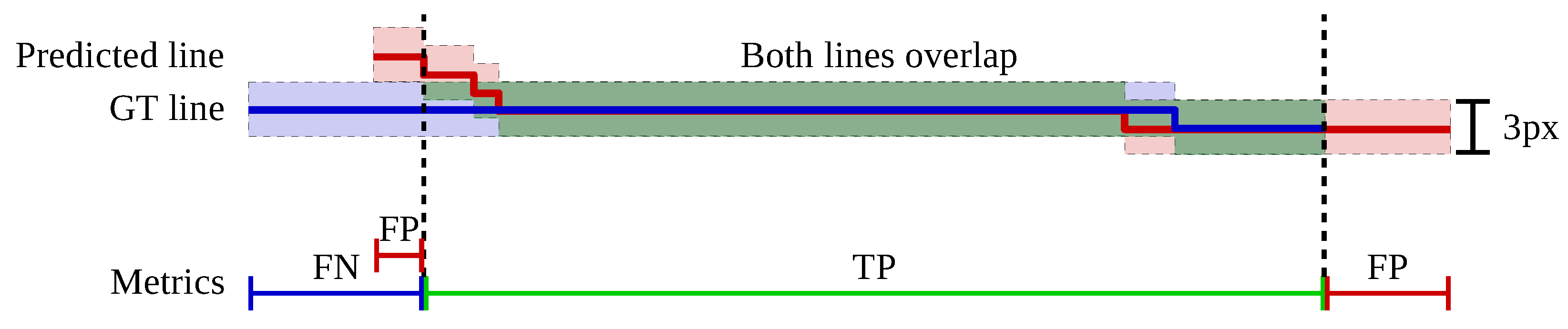
Figure 11.
Visualisation of the metric used to evaluate the staff line detection. The blue and red solid lines in the upper image denote the GT and prediction of a single staff line, respectively. The colored area is the allowed space of 3 px where lines must overlap to be counted as a match. If at least one vertical pixel is green it is counted as correct. The bottom line shows the intervals which are counted as false negative (FN), true positive (TP) and false positive (FP). The deviation in the first part counts both as FN and FP.
Figure 11.
Visualisation of the metric used to evaluate the staff line detection. The blue and red solid lines in the upper image denote the GT and prediction of a single staff line, respectively. The colored area is the allowed space of 3 px where lines must overlap to be counted as a match. If at least one vertical pixel is green it is counted as correct. The bottom line shows the intervals which are counted as false negative (FN), true positive (TP) and false positive (FP). The deviation in the first part counts both as FN and FP.
Figure 12.
The left image shows typical errors during the staff line detection. Green pixels indicate TPs, red FPs, blue FNs. Either all lines in a staff are too long (third staff) or bled background is recognised (last staff). The right image shows a page with weak bleeding. In this image all staff lines are detected correctly. The zoomed sub images focus on the start and end of a staff.
Figure 12.
The left image shows typical errors during the staff line detection. Green pixels indicate TPs, red FPs, blue FNs. Either all lines in a staff are too long (third staff) or bled background is recognised (last staff). The right image shows a page with weak bleeding. In this image all staff lines are detected correctly. The zoomed sub images focus on the start and end of a staff.
Figure 13.
The page visualises the full prediction of the staff line and symbol detection. Encoded staff lines are drawn as blue lines on top of the red staff lines of the original manuscript, the green dashed lines mark the bounding boxes of single staves. The vertical dashed lines separate neumes whose NCs are drawn as yellow boxes. Graphical connection withing a neume are indicated by a black stroke between two NCs. The reading order is represented by a thin dotted line that connects all NCs withing a staff. Small crosses inside of the yellow box of a NCs mark the discrete location of the symbol relative to the staff lines. The cyan symbols mark clefs.
Figure 13.
The page visualises the full prediction of the staff line and symbol detection. Encoded staff lines are drawn as blue lines on top of the red staff lines of the original manuscript, the green dashed lines mark the bounding boxes of single staves. The vertical dashed lines separate neumes whose NCs are drawn as yellow boxes. Graphical connection withing a neume are indicated by a black stroke between two NCs. The reading order is represented by a thin dotted line that connects all NCs withing a staff. Small crosses inside of the yellow box of a NCs mark the discrete location of the symbol relative to the staff lines. The cyan symbols mark clefs.
Figure 14.
The three lines exemplarily show typical errors of the symbol detection algorithm. Refer to
Table 9 for the definition of the numbers indicating different groups. The yellow boxes mark single NCs, solid lines between two NCs indicate that the second note is graphically connected to the previous. The dashed vertical lines separate single neumes and therefore represent logical connections. The cyan symbols denote clefs. The connecting thin dotted line represents the reading order of the symbols.
Figure 14.
The three lines exemplarily show typical errors of the symbol detection algorithm. Refer to
Table 9 for the definition of the numbers indicating different groups. The yellow boxes mark single NCs, solid lines between two NCs indicate that the second note is graphically connected to the previous. The dashed vertical lines separate single neumes and therefore represent logical connections. The cyan symbols denote clefs. The connecting thin dotted line represents the reading order of the symbols.
Table 1.
Overview of the data set statistics. The data set is split manually into three groups that share similarities in layout or handwriting.
Table 1.
Overview of the data set statistics. The data set is split manually into three groups that share similarities in layout or handwriting.
| Part | Pages | Staves | S.-Lines | Symbols | Notes | Clefs | Accid. |
|---|
| 1 | 14 | 125 | 500 | 3911 | 3733 | 153 | 25 |
| 2 | 27 | 313 | 1252 | 10,794 | 10,394 | 361 | 39 |
| 3 | 8 | 72 | 288 | 1666 | 1581 | 84 | 1 |
| Total | 49 | 510 | 2040 | 16,371 | 15,708 | 598 | 65 |
Table 2.
Staff line detection and length metrics with and without data augmentation. The last column combines the two individual measures by multiplication.
Table 2.
Staff line detection and length metrics with and without data augmentation. The last column combines the two individual measures by multiplication.
| | Line Detection | Length Fit | |
|---|
| Model | Prec. | Rec. | | Prec. | Rec. | | Total |
|---|
| Default | 0.996 | 0.998 | 0.997 | 0.977 | 0.995 | 0.985 | 0.982 |
| Data aug. | 0.987 | 0.991 | 0.989 | 0.972 | 0.995 | 0.983 | 0.972 |
Table 3.
Staff detection and the number of recognised lines in a detected staff with and without data augmentation. The last column combines the two individual measures by multiplication.
Table 3.
Staff detection and the number of recognised lines in a detected staff with and without data augmentation. The last column combines the two individual measures by multiplication.
| | Staff Detection | Hit Lines | |
|---|
| Model | Prec. | Rec. | | Prec. | Rec. | | Total |
|---|
| Default | 0.996 | 0.998 | 0.997 | 1.000 | 1.000 | 1.000 | 0.997 |
| Data aug. | 0.988 | 0.992 | 0.990 | 0.999 | 0.999 | 0.999 | 0.989 |
Table 4.
Comparing staff line detection using cross data set training: Two parts are chosen for training while the remainder is chosen as the test data set. The training data is split into five cross folds (four folds training, one for validation) of which the average scores are shown. The total score is computed as the product of the individual -scores. The lower half of the table shows the results when using data augmentation.
Table 4.
Comparing staff line detection using cross data set training: Two parts are chosen for training while the remainder is chosen as the test data set. The training data is split into five cross folds (four folds training, one for validation) of which the average scores are shown. The total score is computed as the product of the individual -scores. The lower half of the table shows the results when using data augmentation.
| | | | Detection | Length Fit | |
|---|
| | Train | Test | Prec. | Rec. | | Prec. | Rec. | | Total |
|---|
| Def. | 2, 3 | 1 | 1.000 | 1.000 | 1.000 | 0.977 | 0.990 | 0.983 | 0.983 |
| 1, 3 | 2 | 0.986 | 0.993 | 0.990 | 0.982 | 0.995 | 0.988 | 0.978 |
| 1, 2 | 3 | 1.000 | 0.978 | 0.988 | 0.990 | 0.990 | 0.990 | 0.978 |
| | Mean | | | 0.993 | | | 0.987 | 0.980 |
| Aug. | 2, 3 | 1 | 1.000 | 1.000 | 1.000 | 0.976 | 0.993 | 0.984 | 0.984 |
| 1, 3 | 2 | 0.959 | 0.978 | 0.968 | 0.968 | 0.997 | 0.982 | 0.951 |
| 1, 2 | 3 | 0.989 | 0.967 | 0.977 | 0.988 | 0.995 | 0.991 | 0.969 |
| | Mean | | | 0.982 | | | 0.986 | 0.968 |
Table 5.
Evaluation how the number of training instances influence the accuracy of pages with an unknown layout. All results are the averages of a five fold of each data set part. Only
pages are chosen for actual training. The major row grouping shows if pages of the remaining parts are included during training: Either no data is used (Default), a pretrained model on the data is used (PT), a large data set comprising all other data which is extended by
is used (Inc.) The first row shows the cross-training (CT.) results of
Table 4 without any data of the target layout. The two major column sections show the results with and without data augmentation on the training data. The best values for each
are marked bold.
Table 5.
Evaluation how the number of training instances influence the accuracy of pages with an unknown layout. All results are the averages of a five fold of each data set part. Only
pages are chosen for actual training. The major row grouping shows if pages of the remaining parts are included during training: Either no data is used (Default), a pretrained model on the data is used (PT), a large data set comprising all other data which is extended by
is used (Inc.) The first row shows the cross-training (CT.) results of
Table 4 without any data of the target layout. The two major column sections show the results with and without data augmentation on the training data. The best values for each
are marked bold.
| | | No Data Augmentation | Data Augmentation |
|---|
| | | | | Tot. | | | Tot. |
|---|
| CT. | 0 | 0.993 | 0.987 | 0.980 | 0.982 | 0.986 | 0.968 |
| Default | 1 | 0.983 | 0.969 | 0.953 | 0.991 | 0.980 | 0.971 |
| 2 | 0.986 | 0.976 | 0.962 | 0.990 | 0.985 | 0.975 |
| 4 | 0.994 | 0.979 | 0.973 | 0.994 | 0.984 | 0.978 |
| All | 0.989 | 0.984 | 0.974 | 0.994 | 0.986 | 0.979 |
| PT | 1 | 0.992 | 0.980 | 0.972 | 0.988 | 0.985 | 0.973 |
| 2 | 0.992 | 0.981 | 0.973 | 0.993 | 0.984 | 0.977 |
| 4 | 0.999 | 0.983 | 0.982 | 0.993 | 0.987 | 0.980 |
| All | 0.995 | 0.984 | 0.980 | 0.998 | 0.986 | 0.984 |
| Inc. | 1 | 0.992 | 0.988 | 0.980 | 0.985 | 0.988 | 0.973 |
| 2 | 0.992 | 0.987 | 0.979 | 0.985 | 0.984 | 0.969 |
| 4 | 0.994 | 0.986 | 0.980 | 0.986 | 0.986 | 0.972 |
| All | 0.994 | 0.988 | 0.982 | 0.988 | 0.986 | 0.974 |
Table 6.
Metrics of various hyperparameter settings for the symbol detection. All experiments were conducted using a cross-fold of size five using all available data. The best values for each metric are highlighted.
Table 6.
Metrics of various hyperparameter settings for the symbol detection. All experiments were conducted using a cross-fold of size five using all available data. The best values for each metric are highlighted.
| | Detection | Type | Position in Staff | Sequence |
|---|
| | | | | | | | | hSAR | dSAR |
|---|
| 0.926 | 0.936 | 0.523 | 0.929 | 0.925 | 0.963 | 0.992 | 0.834 | 0.792 |
| 0.953 | 0.961 | 0.655 | 0.944 | 0.911 | 0.968 | 0.994 | 0.877 | 0.844 |
| 0.956 | 0.964 | 0.693 | 0.949 | 0.897 | 0.970 | 0.990 | 0.885 | 0.856 |
| 0.956 | 0.965 | 0.673 | 0.950 | 0.911 | 0.970 | 0.995 | 0.884 | 0.856 |
| Pad | 0.962 | 0.966 | 0.829 | 0.949 | 0.982 | 0.967 | 0.990 | 0.893 | 0.866 |
| Dewarp | 0.952 | 0.959 | 0.708 | 0.946 | 0.873 | 0.969 | 0.987 | 0.877 | 0.845 |
| Aug. | 0.959 | 0.968 | 0.671 | 0.953 | 0.912 | 0.970 | 0.992 | 0.889 | 0.862 |
| Pad, Aug. | 0.964 | 0.969 | 0.818 | 0.952 | 0.982 | 0.971 | 0.992 | 0.898 | 0.871 |
Table 7.
Symbol detection scores when testing on one and training on the remaining parts. The upper and lower rows show the results without and with data augmentation, respectively. Padding and a line height of 80px are used for all experiments.
Table 7.
Symbol detection scores when testing on one and training on the remaining parts. The upper and lower rows show the results without and with data augmentation, respectively. Padding and a line height of 80px are used for all experiments.
| | | | Detection | Type | Position in Staff | Sequence |
|---|
| | Test | Train | | | | | | | | hSAR | dSAR |
|---|
| Def. | 1 | 2, 3 | 0.956 | 0.965 | 0.782 | 0.914 | 1.000 | 0.981 | 0.993 | 0.906 | 0.860 |
| 2 | 1, 3 | 0.912 | 0.916 | 0.638 | 0.928 | 0.975 | 0.955 | 0.990 | 0.797 | 0.757 |
| 3 | 1, 2 | 0.950 | 0.952 | 0.907 | 0.958 | 0.968 | 0.981 | 1.000 | 0.895 | 0.867 |
| Mean | 0.939 | 0.944 | 0.776 | 0.933 | 0.981 | 0.972 | 0.994 | 0.866 | 0.828 |
| Aug. | 1 | 2, 3 | 0.958 | 0.964 | 0.822 | 0.914 | 1.000 | 0.980 | 0.990 | 0.907 | 0.862 |
| 2 | 1, 3 | 0.939 | 0.945 | 0.699 | 0.947 | 0.975 | 0.965 | 0.990 | 0.848 | 0.817 |
| 3 | 1, 2 | 0.943 | 0.945 | 0.901 | 0.959 | 0.956 | 0.981 | 1.000 | 0.886 | 0.859 |
| Mean | 0.946 | 0.951 | 0.807 | 0.940 | 0.977 | 0.976 | 0.993 | 0.881 | 0.846 |
Table 8.
Symbol detection scores when varying the number of training examples. The first line is the average of the cross-part training (CT.) experiment of
Table 7 where no pages of the target part are used. The next rows (Default) only use
of the target data set for training. Afterwards, a pretrained model is used (PT.) or the additional part data is included (Inc.).
Table 8.
Symbol detection scores when varying the number of training examples. The first line is the average of the cross-part training (CT.) experiment of
Table 7 where no pages of the target part are used. The next rows (Default) only use
of the target data set for training. Afterwards, a pretrained model is used (PT.) or the additional part data is included (Inc.).
| | | Detection | Type | Position in Staff | Sequence |
|---|
| | | | | | | | | | hSAR | dSAR |
|---|
| CT. | 0 | 0.946 | 0.951 | 0.807 | 0.940 | 0.977 | 0.976 | 0.993 | 0.881 | 0.846 |
| Default | 1 | 0.846 | 0.854 | 0.533 | 0.862 | 0.963 | 0.954 | 0.986 | 0.730 | 0.661 |
| 2 | 0.899 | 0.905 | 0.706 | 0.901 | 0.989 | 0.962 | 0.998 | 0.806 | 0.749 |
| 4 | 0.926 | 0.930 | 0.775 | 0.927 | 0.982 | 0.970 | 0.990 | 0.846 | 0.804 |
| All | 0.954 | 0.958 | 0.861 | 0.945 | 0.987 | 0.977 | 0.998 | 0.897 | 0.867 |
| PT. | 1 | 0.925 | 0.929 | 0.760 | 0.907 | 0.978 | 0.956 | 0.992 | 0.834 | 0.777 |
| 2 | 0.939 | 0.942 | 0.796 | 0.928 | 0.981 | 0.966 | 0.999 | 0.862 | 0.821 |
| 4 | 0.953 | 0.956 | 0.871 | 0.944 | 0.987 | 0.972 | 0.996 | 0.890 | 0.858 |
| All | 0.969 | 0.971 | 0.910 | 0.950 | 0.989 | 0.975 | 0.997 | 0.916 | 0.888 |
| Inc. | 1 | 0.948 | 0.953 | 0.808 | 0.936 | 0.982 | 0.977 | 0.997 | 0.882 | 0.846 |
| 2 | 0.952 | 0.958 | 0.793 | 0.939 | 0.978 | 0.976 | 0.997 | 0.887 | 0.854 |
| 4 | 0.959 | 0.964 | 0.817 | 0.948 | 0.980 | 0.976 | 0.996 | 0.900 | 0.870 |
| All | 0.961 | 0.966 | 0.846 | 0.950 | 0.979 | 0.977 | 0.996 | 0.905 | 0.878 |
Table 9.
Error analysis: The relative amount of errors of the output sequence is categorised.
Table 9.
Error analysis: The relative amount of errors of the output sequence is categorised.
| | Group | Error |
|---|
| False Negatives | 51.7% |
| 1. | Missing Note | 21.2% |
| 2. | Wrong Connection | 10.8% |
| 3. | Wrong Location | 14.3% |
| 4. | Missing Clef | 3.5% |
| 5. | Missing Accidental | 1.9% |
| False Positives | 48.3% |
| 6. | Additional Note | 20.6% |
| 2. | Wrong Connection | 10.8% |
| 3. | Wrong Location | 14.3% |
| 7. | Additional Clef | 2.6% |
| 8. | Additional Accidental | 0.0% |
| | Total | 100% |
Table 10.
Prediction and training times in seconds. For the staff line detection the numbers denote the time to process a whole page, while for the symbol detection the reference is a single staff. Prediction includes pre- and postprocessing; however, training only refers to a single iteration.
Table 10.
Prediction and training times in seconds. For the staff line detection the numbers denote the time to process a whole page, while for the symbol detection the reference is a single staff. Prediction includes pre- and postprocessing; however, training only refers to a single iteration.
| | Staff Line | Symbols |
|---|
| | GPU | CPU | GPU | CPU |
|---|
| Predict | 3.5 | 3.7 | 0.15 | 0.12 |
| Train | 0.12 | 3.6 | 0.04 | 0.42 |
Table 11.
Overview of the main results of this paper.
Table 11.
Overview of the main results of this paper.
| Task | Score |
|---|
| -scores of staff line & staff detection | >99% |
| -score of detected Symbols | >96% |
| Diplomatic sequence accuracy (dSAR) | ≈87% |

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}