Machine Vision System for Counting Small Metal Parts in Electro-Deposition Industry





Abstract
Featured Application
Abstract

1. Introduction
- m = mass deposited on electrode [g];
- M = molar mass of the material to be deposited [g/mol];
- I = current intensity (A);
- t = time (s);
- Z = valence of material’s ions;
- F = Faraday’s constant (96485.33 C mol−1).
- n = number of items to be electroplated;
- s = surface of a single item;
- T= coating thickness;
- = material mass density.
2. Materials and Methods
2.1. Literature Methods
2.2. Image Acquisition Requirements
- Frontal lighting with a black uniform background;
- Lighted white background;
- Light rear-projection.
2.3. Light Settings
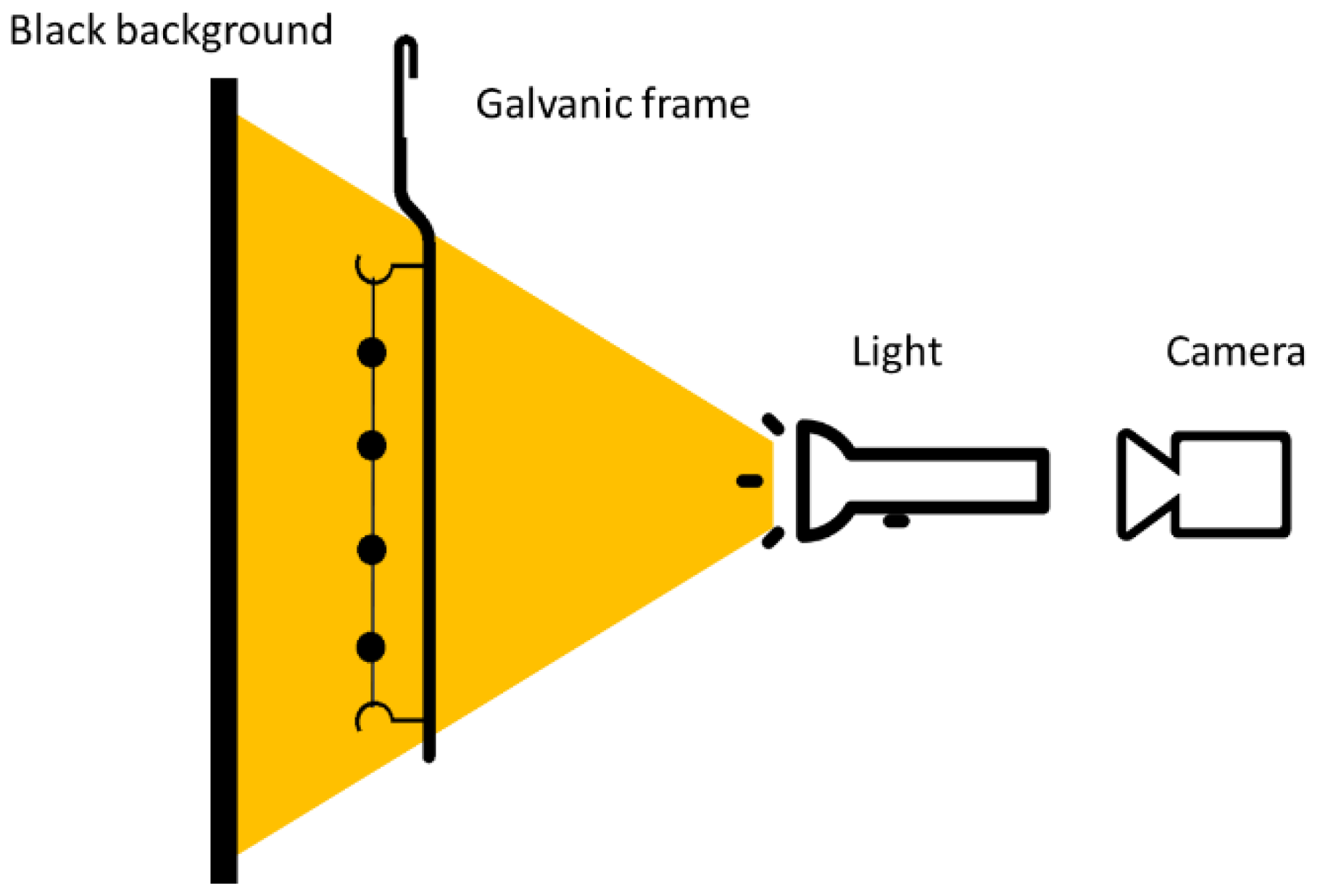
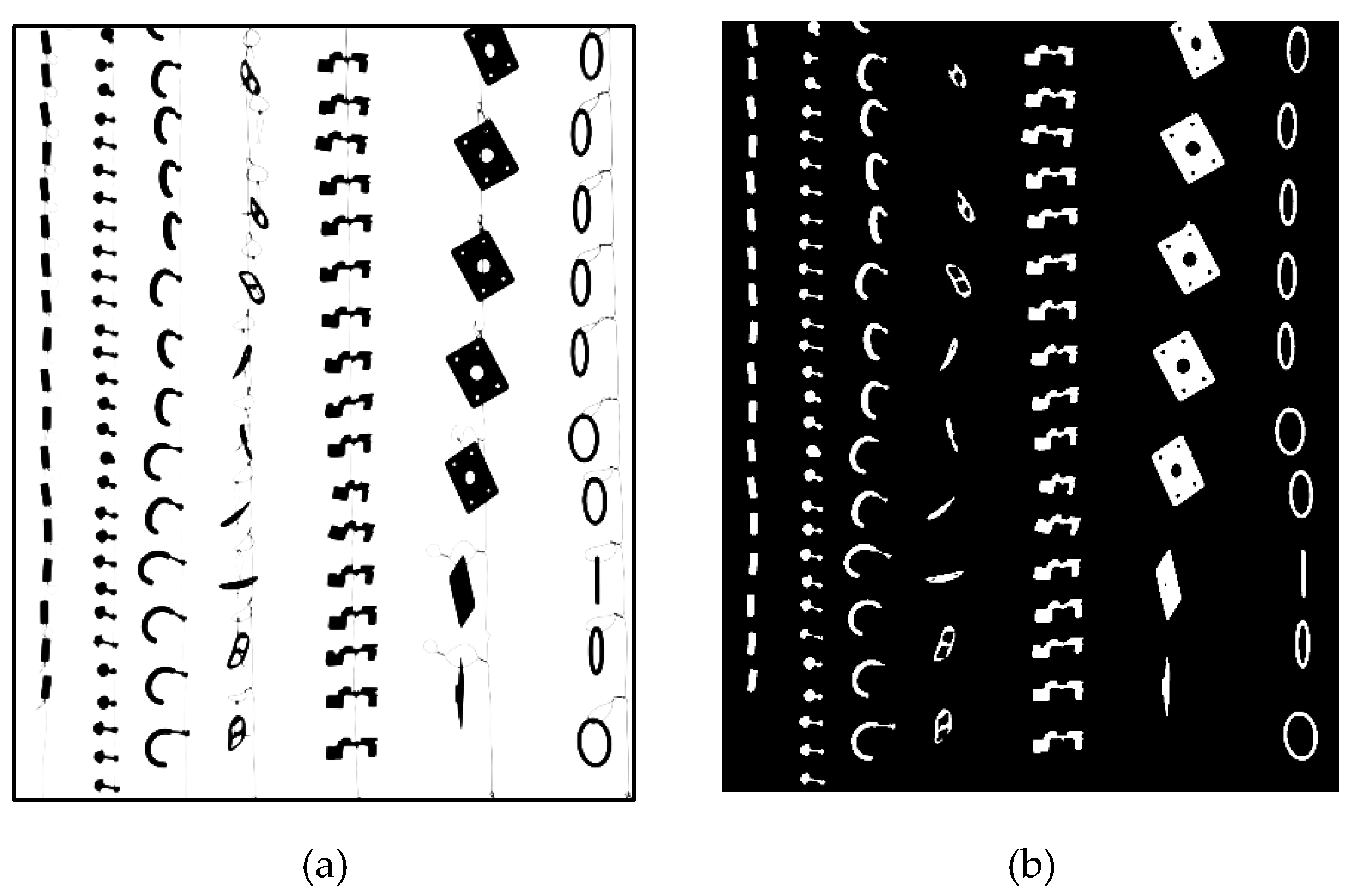
2.3.1. Frontal Light with Black Uniform Background
- Items and background pixels may be incorrectly detected/assigned;
- The wire and item brightness are similar and thus difficult to separate.
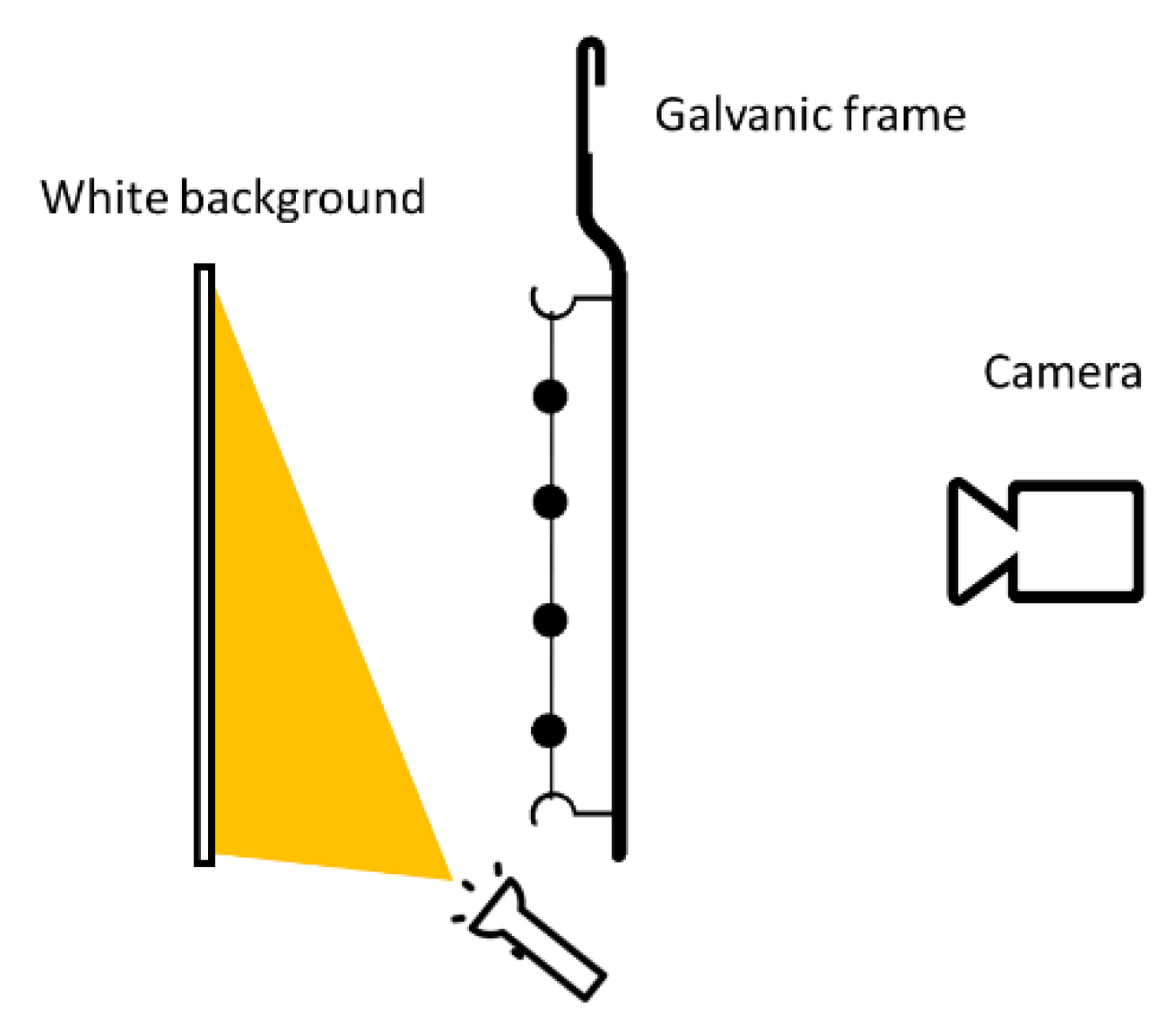
2.3.2. Lighted Background
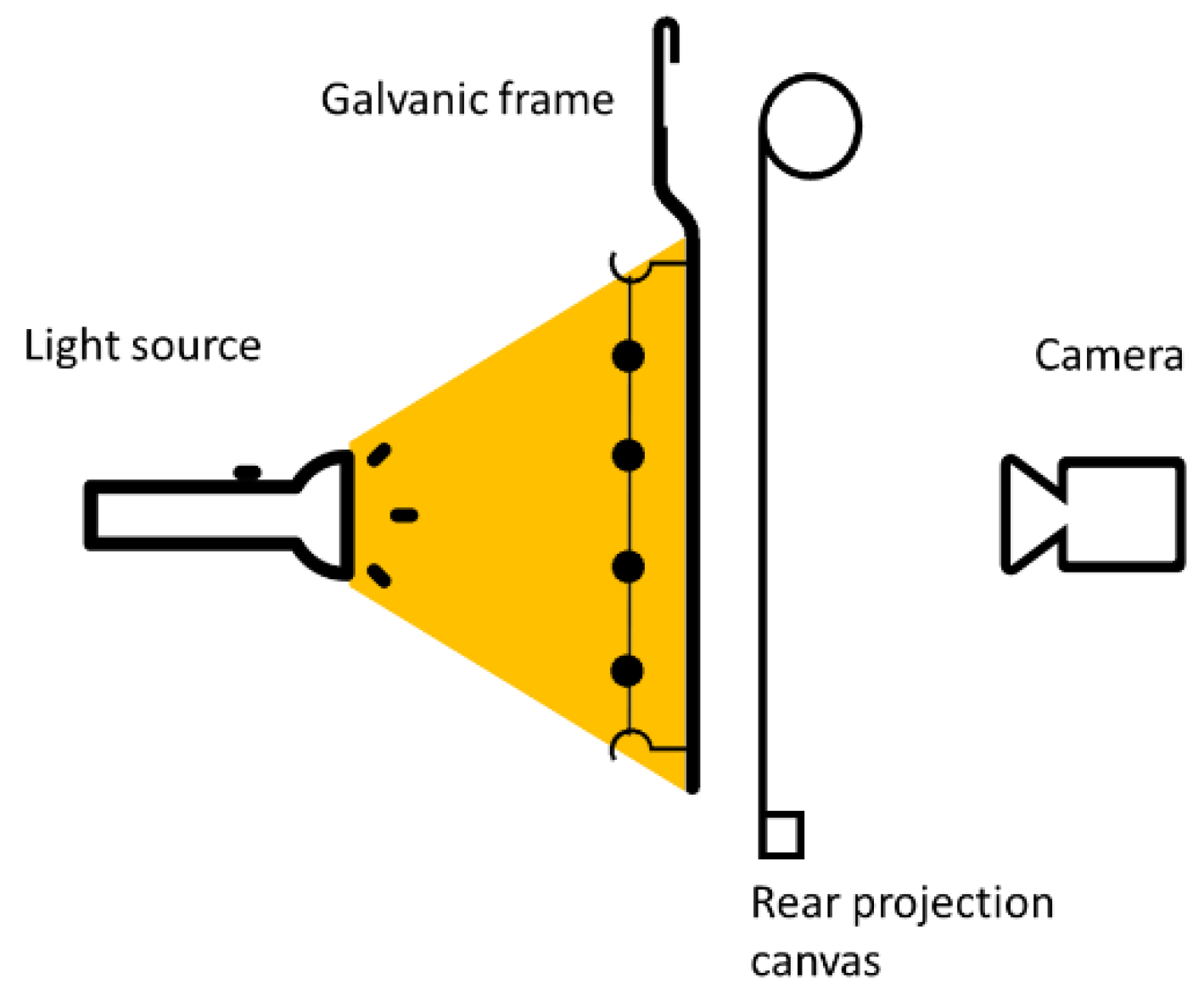
2.3.3. Rear Projection
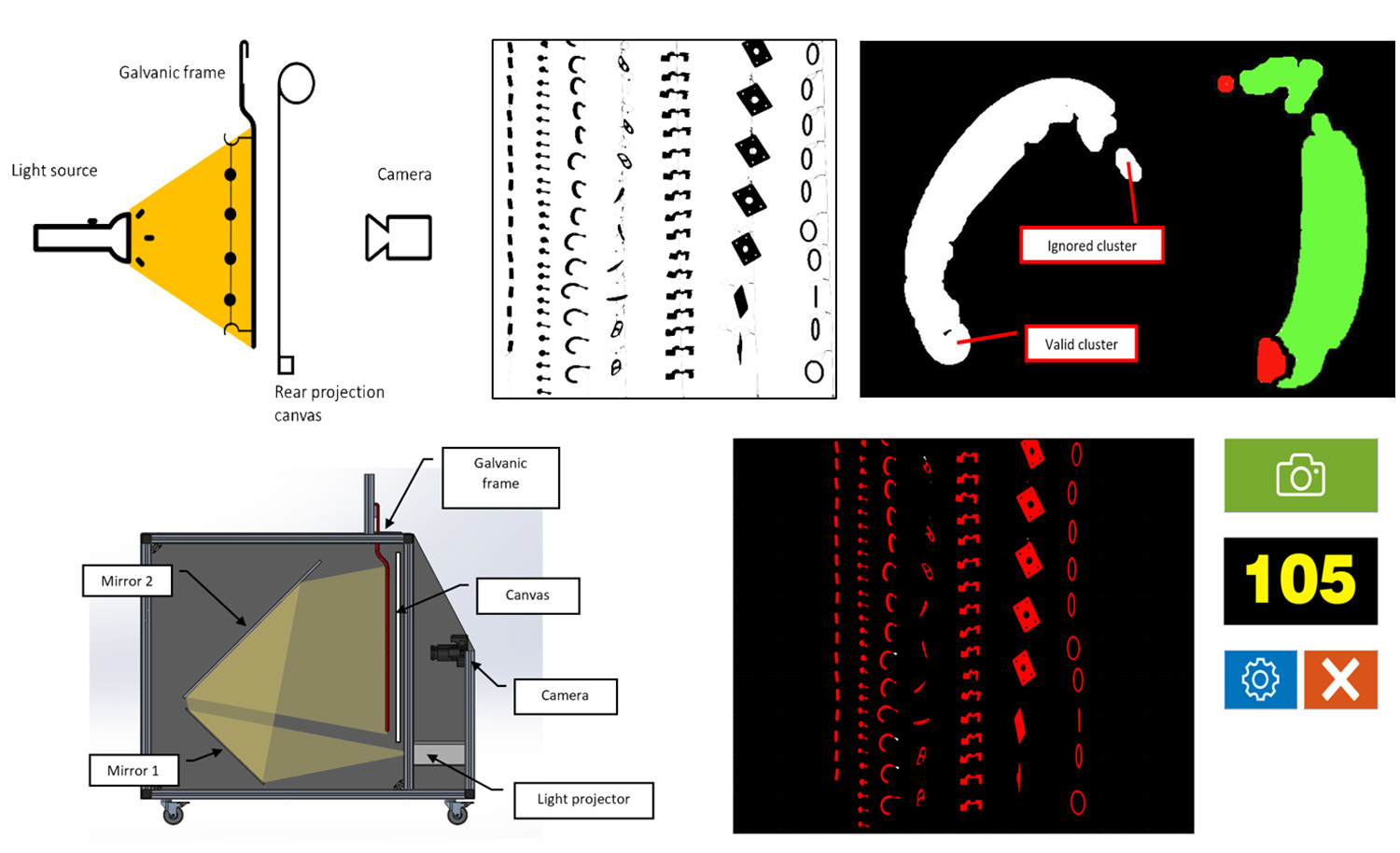
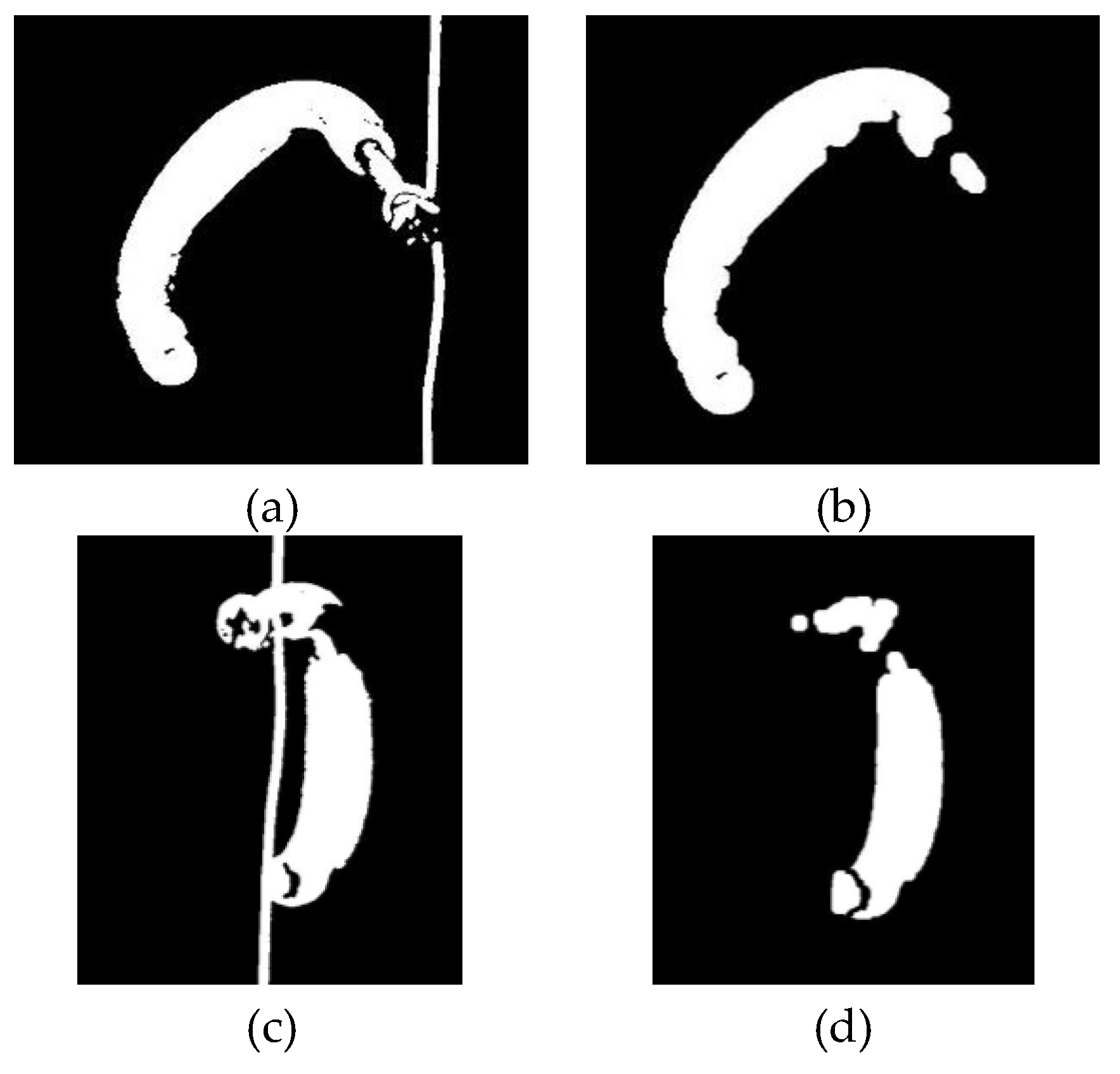
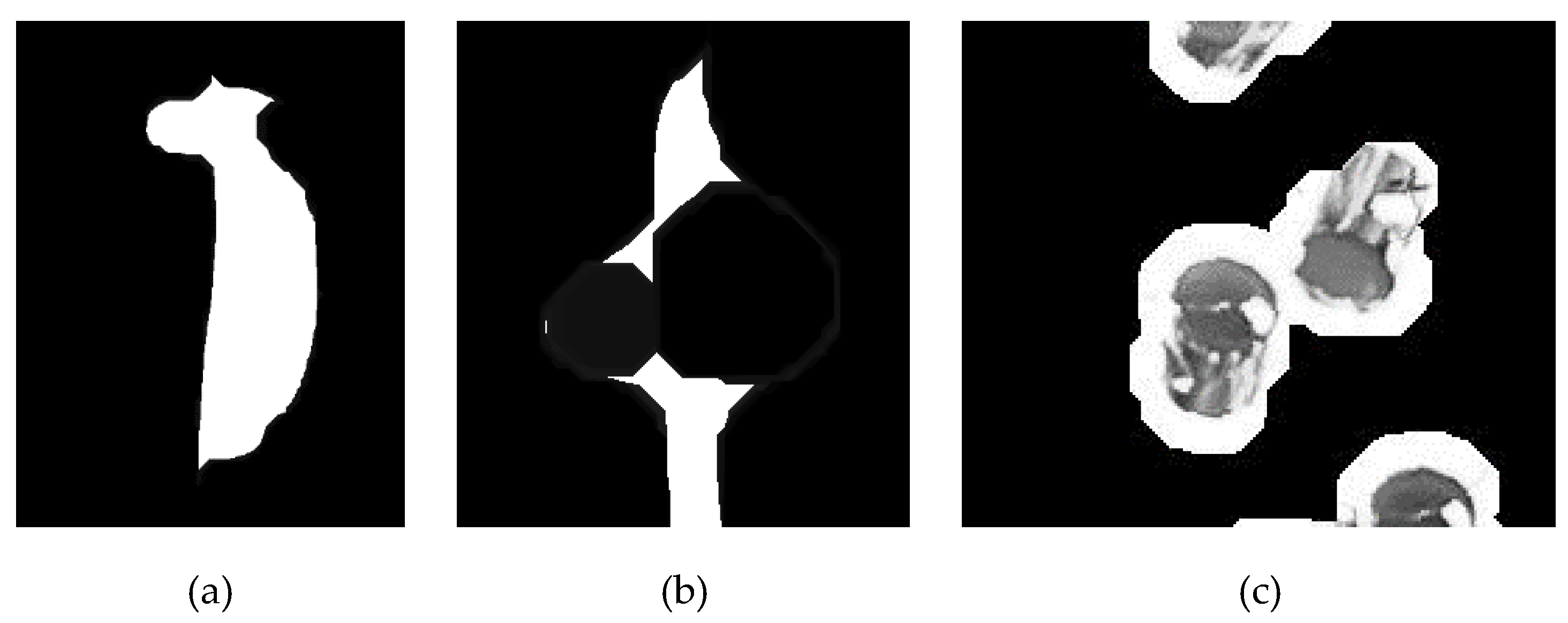
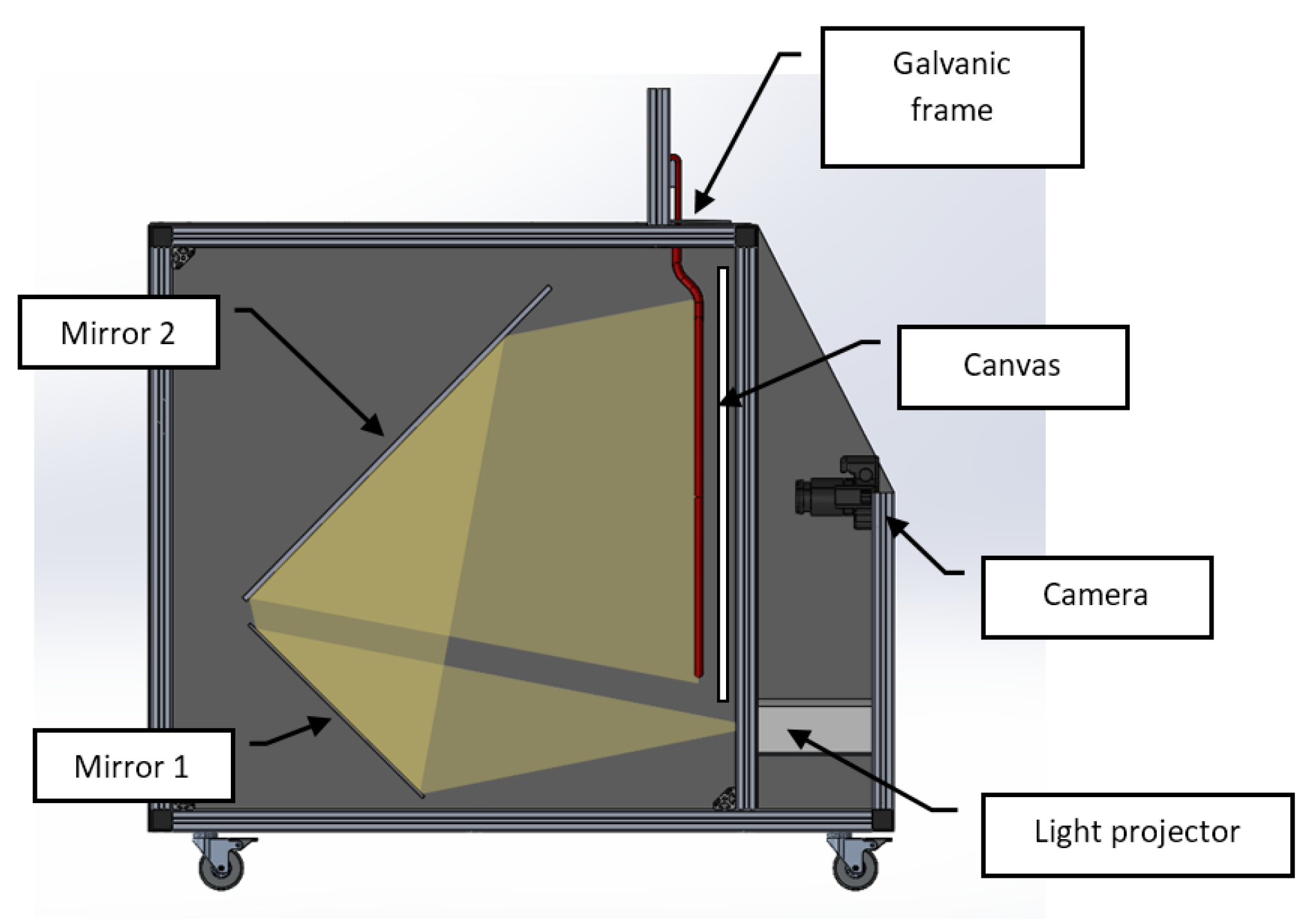
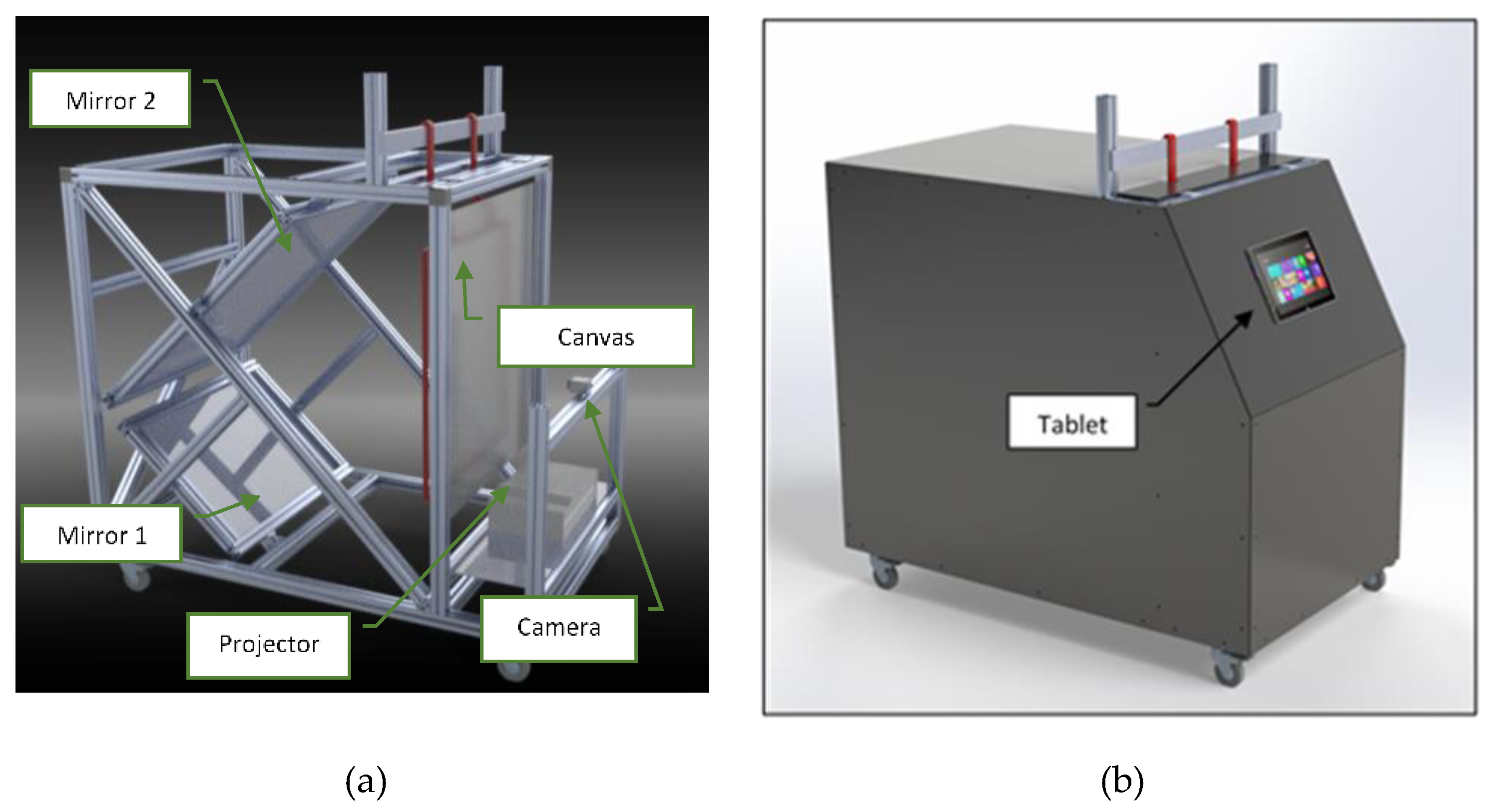
3. Rear Projection-Based Counting Machine Prototype
- -
- An image acquisition device (industrial monochrome camera IDS UI 3200-SE-M with a 6 mm lens with 12-megapixel resolution (4104 × 3006 pixels);
- -
- An LCD overhead light projector, to assure uniform lighting;
- -
- A couple of orientable mirrors (used to extend the light path up to the 1.8 m, mentioned in Section 3). Such mirrors are used to reduce the overall dimensions of the counting machine, which must not exceed 1.5 × 1.0 × 1.0 m, in order to not to be excessively cumbersome for an industrial environment;
- -
- An enclosure system, to assure the environmental light does not affect the scene.
4. Discussion and Conclusions
Author Contributions
Funding

Conflicts of Interest
References
- Bard, A.J.; Faulkner, L.R. Electrochemical Methods: Fundamentals and Applications; Wiley: Hoboken, NJ, USA, 1980; p. 718. [Google Scholar]
- Barker, D.; Walsh, F.C. Applications of Faraday’s Laws of Electrolysis in Metal Finishing. Trans. IMF 1991, 69, 158–162. [Google Scholar] [CrossRef]
- Phromlikhit, C.; Cheevasuvit, F.; Yimman, S. Tablet counting machine base on image processing. In Proceedings of the 5th 2012 Biomedical Engineering International Conference, Ubon Ratchathani, Thailand, 5–7 December 2012. [Google Scholar]
- Nudol, C. Automatic jewel counting using template matching. In Proceedings of the IEEE International Symposium on Communications and Information Technology 2004 (ISCIT 2004), Sapporo, Japan, 26–29 October 2004; Volume 2. [Google Scholar]
- Sokkarie, A.; Osborne, J. Object counting and sizing. In Proceedings of the SoutheastCon’94, Miami, FL, USA, USA, 10–13 April 1994. [Google Scholar]
- Courshee, R.J. Testing a counting machine. Br. J. Appl. Phys. 1954, 5. [Google Scholar] [CrossRef]
- Barbedo, J.G.A. A Review on Methods for Automatic Counting of Objects in Digital Images. IEEE Latin Am. Trans. 2012, 10, 5. [Google Scholar]
- Chauhan, V.; Joshi, K.D.; Surgenor, B. Machine Vision for Coin Recognition with ANNs: Effect of Training and Testing Parameters. In Proceedings of the Engineering and Applications of Neural Networks: 18th International Conference, Athens Greece, 25–27 August 2017. [Google Scholar]
- Bremananth, R.; Balaji, B.; Sankari, M.; Chitra, A. A New Approach to Coin Recognition using Neural Pattern Analysis. In Proceedings of the 2005 Annual IEEE India Conference-Indicon, Chennai, India, 11–13 December 2005. [Google Scholar]
- Furferi, R.; Governi, L. Prediction of the spectrophotometric response of a carded fiber composed by different kinds of coloured raw materials: An artificial neural network-based approach. Color Res. Appl. 2011, 36, 179–191. [Google Scholar] [CrossRef]
- Sharma, T.; Rajurkar, S.D.; Molangur, N.; Verma, N.K.; Salour, A. Multi-faced Object Recognition in an Image for Inventory Counting. Adv. Intell. Syst. Comput. 2019, 799, 333–346. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Peduzzi, P.; Concato, J.; Kemper, E.; Holford, T.R.; Feinstein, A.R. A simulation study of the number of events per variable in logistic regression analysis. J. Clin. Epidemiol. 1996, 49, 1373–1379. [Google Scholar] [CrossRef]
- van den Boomgaard, R.; van Balen, R. Methods for fast morphological image transforms using bitmapped binary images. CVGIP: Graph. Models Image Process. 1992, 54, 252–258. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Richard, R.E.; Woods, E.; Eddins, S.L. Digital Image Processing Using MATLAB; Dorsing Kindersley: London, UK, 2004; p. 620. [Google Scholar]
- Haralick, R.M.; Shapiro, L.G. Computer and Robot Vision; Addison-Wesley Pub Co.: Boston, MA, USA, 1992. [Google Scholar]
- Wang, J.; Wu, X.; Zhang, C. Support vector machines based on K-means clustering for real-time business intelligence systems. Int. J. Bus. Intell. Data Min. 2005, 1, 54–64. [Google Scholar] [CrossRef]
- Furferi, R.; Governi, L.; Volpe, Y. Modelling and simulation of an innovative fabric coating process using artificial neural networks. Text. Res. J. 2012, 82, 1282–1294. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test # | Actual # of Items | Minimum Item Dimension (mm) | Frontal Light* (# of items) | Lighted Background (# of items) | Rear Projection (# of items) |
|---|---|---|---|---|---|
| 1 | 60 | 100 | 62 | 61 | 60 |
| 2 | 120 | 40 | 124 | 124 | 120 |
| 3 | 40 | 200 | 40 | 40 | 40 |
| 4 | 100 | 30 | 104 | 105 | 100 |
| 5 | 20 | 300 | 20 | 20 | 20 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Furferi, R.; Governi, L.; Puggelli, L.; Servi, M.; Volpe, Y. Machine Vision System for Counting Small Metal Parts in Electro-Deposition Industry. Appl. Sci. 2019, 9, 2418. https://doi.org/10.3390/app9122418
Furferi R, Governi L, Puggelli L, Servi M, Volpe Y. Machine Vision System for Counting Small Metal Parts in Electro-Deposition Industry. Applied Sciences. 2019; 9(12):2418. https://doi.org/10.3390/app9122418
Chicago/Turabian StyleFurferi, Rocco, Lapo Governi, Luca Puggelli, Michaela Servi, and Yary Volpe. 2019. "Machine Vision System for Counting Small Metal Parts in Electro-Deposition Industry" Applied Sciences 9, no. 12: 2418. https://doi.org/10.3390/app9122418
APA StyleFurferi, R., Governi, L., Puggelli, L., Servi, M., & Volpe, Y. (2019). Machine Vision System for Counting Small Metal Parts in Electro-Deposition Industry. Applied Sciences, 9(12), 2418. https://doi.org/10.3390/app9122418