A Systematic Literature Review on Image Captioning

Abstract
1. Introduction
2. SLR Methodology
2.1. Search Sources
- ArXiv
- IEEE Xplore
- Web of Science—WOS (previously known as Web of Knowledge)
2.2. Search Questions
- What techniques have been used in image caption generation?
- What are the challenges in image captioning?
- How does the inclusion of novel image description and addition of semantics improve the performance of image captioning?
- What are the newest researches on image captioning?
2.3. Search Query
3. Results
- Year
- ○
- 2016;
- ○
- 2017;
- ○
- 2018;
- ○
- 2019;
- Feature extractors:
- ○
- AlexNet;
- ○
- VGG-16 Net;
- ○
- ResNet;
- ○
- GoogleNet (including all nine Inception models);
- ○
- DenseNet;
- Language models:
- ○
- LSTM;
- ○
- RNN;
- ○
- CNN;
- ○
- cGRU;
- ○
- TPGN;
- Methods:
- ○
- Encoder-decoder;
- ○
- Attention mechanism;
- ○
- Novel objects;
- ○
- Semantics;
- Results on datasets:
- ○
- MS COCO;
- ○
- Flickr30k;
- Evaluation metrics:
- ○
- BLEU-1;
- ○
- BLEU-2;
- ○
- BLEU-3;
- ○
- BLEU-4;
- ○
- CIDEr;
- ○
- METEOR;
4. Discussion
4.1. Model Architecture and Computational Resources
4.1.1. Encoder—CNN
4.1.2. Decoder—LSTM
4.1.3. Attention Mechanism
4.2. Datasets
4.3. Human-Like Feeling
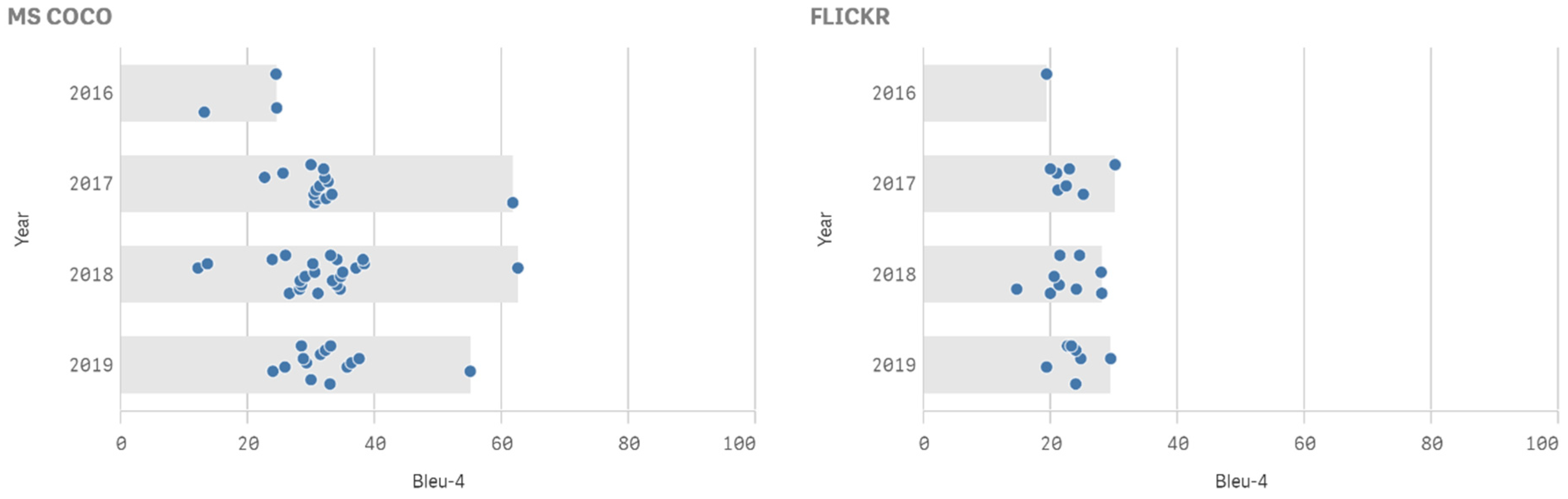
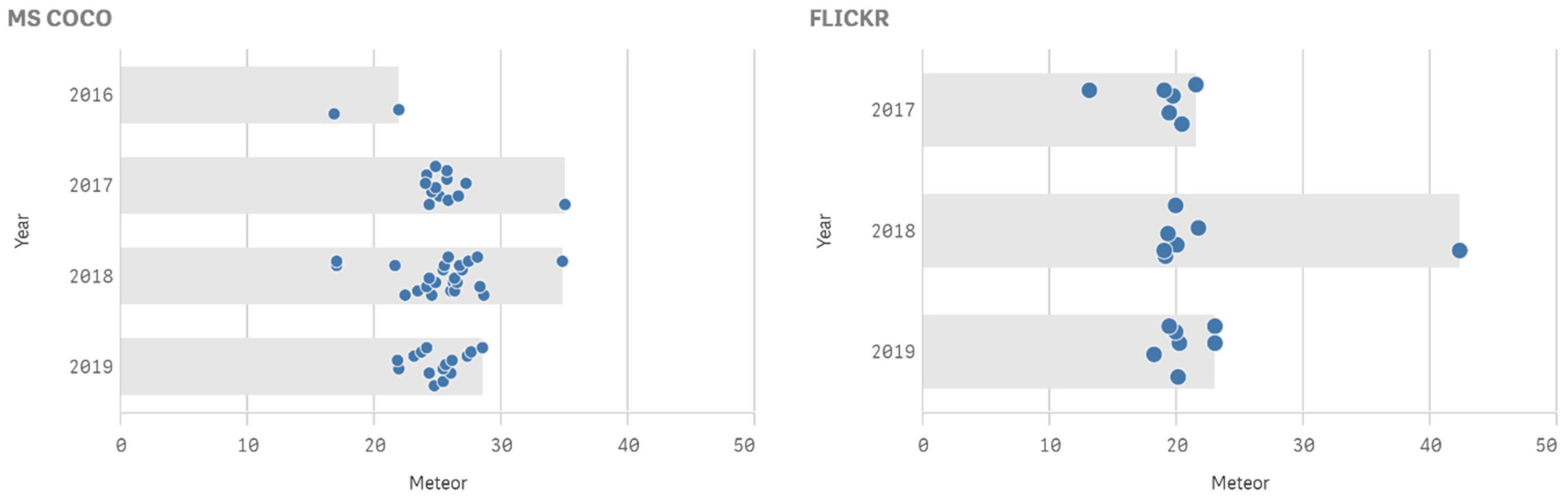
4.4. Comparison of Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Encoder | Image Decoder | Method | MS COCO | Flickr30k | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Year | Citation | AlexNet | VGGNet | GoogleNet | ResNet | DenseNet | LSTM | RNN | CNN | cGRU | TPGN | Encoder-Decoder | Attention | Novel Objects | Semantics | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | CIDEr | Meteor | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | CIDEr | Meteor | ||||||
| 2016 | [10] | x | x | Lifelog Dataset | |||||||||||||||||||||||||||||
| 2016 | [11] | x | x | x | x | 67.2 | 49.2 | 35.2 | 24.4 | 62.1 | 42.6 | 28.1 | 19.3 | ||||||||||||||||||||
| 2016 | [12] | x | x | x | x | 50.0 | 31.2 | 20.3 | 13.1 | 61.8 | 16.8 | ||||||||||||||||||||||
| 2016 | [13] | x | x | x | x | 71.4 | 50.5 | 35.2 | 24.5 | 63.8 | 21.9 | ||||||||||||||||||||||
| 2017 | [14] | x | x | ||||||||||||||||||||||||||||||
| 2017 | [15] | x | x | x | x | 63.8 | 44.6 | 30.7 | 21.1 | ||||||||||||||||||||||||
| 2017 | [16] | x | x | CUB-Justify | |||||||||||||||||||||||||||||
| 2017 | [17] | x | x | x | 27.2 | ||||||||||||||||||||||||||||
| 2017 | [18] | x | x | x | 66.9 | 46 | 32.5 | 22.6 | |||||||||||||||||||||||||
| 2017 | [19] | x | x | x | x | 70.1 | 50.2 | 35.8 | 25.5 | 24.1 | 67.9 | 44 | 29.2 | 20.9 | 19.7 | ||||||||||||||||||
| 2017 | [20] | x | x | Visual Genome Dataset | |||||||||||||||||||||||||||||
| 2017 | [21] | x | x | x | 19.9 | 13.7 | 13.1 | ||||||||||||||||||||||||||
| 2017 | [22] | x | x | x | x | ||||||||||||||||||||||||||||
| 2017 | [23] | x | x | x | x | 70.9 | 53.9 | 40.6 | 30.5 | 90.9 | 24.3 | ||||||||||||||||||||||
| 2017 | [24] | x | 31.1 | 93.2 | |||||||||||||||||||||||||||||
| 2017 | [25] | x | x | x | x | 71.3 | 53.9 | 40.3 | 30.4 | 93.7 | 25.1 | ||||||||||||||||||||||
| 2017 | [26] | x | x | x | x | 30.7 | 93.8 | 24.5 | |||||||||||||||||||||||||
| 2017 | [27] | x | x | x | x | x | x | 72.4 | 55.5 | 41.8 | 31.3 | 95.5 | 24.8 | 64.9 | 46.2 | 32.4 | 22.4 | 47.2 | 19.4 | ||||||||||||||
| 2017 | [28] | x | x | x | x | 73.4 | 56.7 | 43 | 32.6 | 96 | 24 | ||||||||||||||||||||||
| 2017 | [29] | x | x | x | 32.1 | 99.8 | 25.7 | 66 | |||||||||||||||||||||||||
| 2017 | [30] | x | x | x | 42 | 31.9 | 101.1 | 25.7 | 32.5 | 22.9 | 44.1 | 19 | |||||||||||||||||||||
| 2017 | [31] | x | x | x | 39.3 | 29.9 | 102 | 24.8 | 37.2 | 30.1 | 76.7 | 21.5 | |||||||||||||||||||||
| 2017 | [32] | x | x | x | x | x | x | 91 | 83.1 | 72.8 | 61.7 | 102.9 | 35 | ||||||||||||||||||||
| 2017 | [33] | x | x | x | x | 73.1 | 56.7 | 42.9 | 32.3 | 105.8 | 25.8 | ||||||||||||||||||||||
| 2017 | [34] | x | x | x | x | 74.2 | 58 | 43.9 | 33.2 | 108.5 | 26.6 | 67.7 | 49.4 | 35.4 | 25.1 | 53.1 | 20.4 | ||||||||||||||||
| 2018 | [35] | x | x | Recall Evaluation metric | |||||||||||||||||||||||||||||
| 2018 | [36] | x | x | OI, VG, VRD | |||||||||||||||||||||||||||||
| 2018 | [37] | x | x | X | X | 71.6 | 51.8 | 37.1 | 26.5 | 24.3 | |||||||||||||||||||||||
| 2018 | [38] | x | x | APRC, CSMC | |||||||||||||||||||||||||||||
| 2018 | [39] | x | x | x | x | F-1 score metrics | 21.6 | ||||||||||||||||||||||||||
| 2018 | [40] | x | x | x | x | x | |||||||||||||||||||||||||||
| 2018 | [41] | x | x | x | x | 72.5 | 51 | 36.2 | 25.9 | 24.5 | 68.4 | 45.5 | 31.3 | 21.4 | 19.9 | ||||||||||||||||||
| 2018 | [42] | x | x | x | x | 74 | 56 | 42 | 31 | 26 | 73 | 55 | 40 | 28 | |||||||||||||||||||
| 2018 | [43] | x | x | x | x | x | 63 | 42.1 | 24.2 | 14.6 | 25 | 42.3 | |||||||||||||||||||||
| 2018 | [44] | x | x | x | x | 74.4 | 58.1 | 44.3 | 33.8 | 26.2 | |||||||||||||||||||||||
| 2018 | [45] | x | x | x | x | IAPRTC-12 | |||||||||||||||||||||||||||
| 2018 | [46] | x | x | x | x | ||||||||||||||||||||||||||||
| 2018 | [47] | x | x | x | x | x | R | ||||||||||||||||||||||||||
| 2018 | [48] | x | x | x | x | x | x | 50.5 | 30.8 | 19.1 | 12.1 | 60 | 17 | ||||||||||||||||||||
| 2018 | [49] | x | x | x | x | x | 51 | 32.2 | 20.7 | 13.6 | 65.4 | 17 | |||||||||||||||||||||
| 2018 | [50] | x | x | x | x | x | x | 66.7 | 23.8 | 77.2 | 22.4 | ||||||||||||||||||||||
| 2018 | [51] | x | x | x | x | 68.8 | 51.3 | 37 | 26.5 | 83.9 | 23.4 | 60.7 | 42.5 | 29.2 | 19.9 | 39.5 | 19.1 | ||||||||||||||||
| 2018 | [52] | x | x | x | 71 | 53.7 | 39.1 | 28.1 | 89 | 24.1 | |||||||||||||||||||||||
| 2018 | [53] | x | x | x | 70.8 | 53.6 | 39.1 | 28.4 | 89.8 | 24.8 | 61.5 | 43.8 | 30.5 | 21.3 | 46.4 | 20 | |||||||||||||||||
| 2018 | [54] | x | x | x | 39.5 | 28.2 | 90.7 | 24.3 | |||||||||||||||||||||||||
| 2018 | [55] | x | x | 72 | 54.7 | 40 | 29 | 91.7 | 62.7 | 43.5 | 29.6 | 20.5 | 19.3 | ||||||||||||||||||||
| 2018 | [56] | x | x | x | x | 57.1 | 30.5 | 98 | 25.4 | ||||||||||||||||||||||||
| 2018 | [57] | x | x | X | x | 74.0 | 56.7 | 43.3 | 31.3 | 98.3 | 25.5 | 64.6 | 43.8 | 31.9 | 22.4 | 39.6 | 19.2 | ||||||||||||||||
| 2018 | [58] | x | x | x | x | 91.6 | 83.6 | 73.4 | 62.5 | 99 | 34.8 | ||||||||||||||||||||||
| 2018 | [59] | x | x | x | x | 30.2 | 101.8 | 25.8 | |||||||||||||||||||||||||
| 2018 | [60] | x | x | x | x | 34 | 103.6 | 26.3 | |||||||||||||||||||||||||
| 2018 | [61] | x | x | x | x | x | 74.2 | 57.7 | 43.8 | 33 | 105.8 | 66.3 | 48.1 | 34.4 | 24.5 | 52.9 | |||||||||||||||||
| 2018 | [62] | x | x | x | x | x | 44.3 | 34.5 | 105.9 | 26.5 | 33.4 | 24 | 44.2 | 19 | |||||||||||||||||||
| 2018 | [63] | x | x | x | x | 44.3 | 34 | 106.0 | 26.3 | ||||||||||||||||||||||||
| 2018 | [64] | x | x | x | x | 73 | 56.9 | 43.6 | 33.3 | 108.1 | |||||||||||||||||||||||
| 2018 | [65] | x | x | x | 75 | 34.6 | 108.2 | 26.9 | |||||||||||||||||||||||||
| 2018 | [66] | x | x | x | x | x | 76.1 | 58.1 | 44.9 | 34.9 | 109.1 | 26.7 | 73.1 | 54 | 38.6 | 27.9 | 59.4 | 21.7 | |||||||||||||||
| 2018 | [67] | x | x | x | x | x | x | 76.4 | 60.4 | 47.9 | 37 | 112.5 | 27.4 | ||||||||||||||||||||
| 2018 | [68] | X | X | X | X | X | x | 79.4 | 63.1 | 48.2 | 36.1 | 119.6 | 28.1 | 72.1 | 48.7 | 36.9 | 21.2 | 53.6 | 20.5 | ||||||||||||||
| 2018 | [69] | x | x | x | x | 38.3 | 123.2 | 28.6 | |||||||||||||||||||||||||
| 2018 | [70] | x | x | x | x | 38.1 | 126.1 | 28.3 | |||||||||||||||||||||||||
| 2019 | [71] | x | x | x | x | 71.9 | 52.9 | 38.7 | 28.4 | 24.3 | 69.4 | 45.7 | 33.2 | 22.6 | 23 | ||||||||||||||||||
| 2019 | [72] | x | x | x | x | 21.9 | |||||||||||||||||||||||||||
| 2019 | [73] | x | x | x | x | 12.6 | |||||||||||||||||||||||||||
| 2019 | [74] | x | x | x | x | 67.1 | 48.8 | 34.3 | 23.9 | 73.3 | 21.8 | ||||||||||||||||||||||
| 2019 | [75] | x | x | x | x | x | x | 66.6 | 48.9 | 35.5 | 25.8 | 82.1 | 23.1 | 61.5 | 42.1 | 28.6 | 19.3 | 39.9 | 18.2 | ||||||||||||||
| 2019 | [76] | x | x | x | x | 70.6 | 53.4 | 39.5 | 29.2 | 88.1 | 23.7 | ||||||||||||||||||||||
| 2019 | [77] | x | x | x | x | x | 69.5 | 52.1 | 38.6 | 28.7 | 91.9 | 24.1 | 66.6 | 48.4 | 34.6 | 24.7 | 52.4 | 20.2 | |||||||||||||||
| 2019 | [78] | x | x | x | x | x | 72.1 | 55.1 | 41.5 | 31.4 | 95.6 | 24.7 | |||||||||||||||||||||
| 2019 | [79] | x | x | x | x | 73.4 | 56.6 | 42.8 | 32.2 | 99.9 | 25.4 | 65.2 | 47.1 | 33.6 | 23.9 | 19.9 | |||||||||||||||||
| 2019 | [80] | x | x | x | x | x | 73.9 | 57.1 | 43.3 | 33 | 101.6 | 26 | 66.1 | 47.2 | 33.4 | 23.2 | 19.4 | ||||||||||||||||
| 2019 | [81] | x | x | x | 73.5 | 56.9 | 43.3 | 32.9 | 103.3 | 25.4 | 67.1 | 48.7 | 34.9 | 23.9 | 53.3 | 20.1 | |||||||||||||||||
| 2019 | [82] | x | x | x | 73.1 | 54.9 | 40.5 | 29.9 | 107.2 | 25.6 | |||||||||||||||||||||||
| 2019 | [83] | x | x | x | x | x | x | x | 55 | 110.1 | 26.1 | ||||||||||||||||||||||
| 2019 | [84] | x | x | x | 75.8 | 59.6 | 46 | 35.6 | 110.5 | 27.3 | |||||||||||||||||||||||
| 2019 | [85] | x | x | x | x | x | x | 79.2 | 63.2 | 48.3 | 36.3 | 120.2 | 27.6 | ||||||||||||||||||||
| 2019 | [86] | x | x | x | x | x | x | 79.9 | 37.5 | 125.6 | 28.5 | 73.8 | 55.1 | 40.3 | 29.4 | 66.6 | 23 | ||||||||||||||||
| 2019 | [87] | x | x | x | x | x | x | 38.6 | 28.3 | 126.3 | |||||||||||||||||||||||
References
- Kiros, R.; Salakhutdinov, R.; Zemel, R. Multimodal neural language models. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 595–603. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Yan, S.; Xie, Y.; Wu, F.; Smith, J.S.; Lu, W.; Zhang, B. Image captioning based on a hierarchical attention mechanism and policy gradient optimization. J. Latex Cl. Files 2015, 14, 8. [Google Scholar]
- Karpathy, A.; Li, F.-F. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; Volume 39, pp. 3128–3137. [Google Scholar] [CrossRef]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the 32nd International Conference on Machine Learning (ICML’15), Lille, France, 6–11 July 2015. [Google Scholar]
- Hossain, M.Z.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A comprehensive survey of deep learning for image captioning. ACM Comput. Surv. (CSUR) 2019, 51, 118. [Google Scholar] [CrossRef]
- Bai, S.; An, S. A survey on automatic image caption generation. Neurocomputing 2018, 311, 291–304. [Google Scholar] [CrossRef]
- Shabir, S.; Arafat, S.Y. An image conveys a message: A brief survey on image description generation. In Proceedings of the 2018 1st International Conference on Power, Energy and Smart Grid (ICPESG), Azad Kashmir, Pakistan, 9–10 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Jenisha, T.; Purushotham, S. A survey of neural network algorithms used for image annotation. IIOAB J. 2016, 7, 236–252. [Google Scholar]
- Fan, C.; Crandall, D.J. DeepDiary: Automatic caption generation for lifelogging image streams. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 459–473. [Google Scholar] [CrossRef]
- Wang, C.; Yang, H.; Bartz, C.; Meinel, C. Image captioning with deep bidirectional LSTMs. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 988–997. [Google Scholar] [CrossRef]
- Mathews, A.P.; Xie, L.; He, X. Senticap: Generating image descriptions with sentiments. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Sugano, Y.; Bulling, A. Seeing with humans: Gaze-assisted neural image captioning. arXiv 2016, arXiv:1608.05203. [Google Scholar]
- Venugopalan, S.; Anne Hendricks, L.; Rohrbach, M.; Mooney, R.; Darrell, T.; Saenko, K. Captioning images with diverse objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5753–5761. [Google Scholar]
- He, X.; Shi, B.; Bai, X.; Xia, G.-S.; Zhang, Z.; Dong, W. Image caption generation with part of speech guidance. Pattern Recognit. Lett. 2017, 119, 229–237. [Google Scholar] [CrossRef]
- Vedantam, R.; Bengio, S.; Murphy, K.; Parikh, D.; Chechik, G. Context-aware captions from context-agnostic supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 251–260. [Google Scholar] [CrossRef]
- Shetty, R.; Rohrbach, M.; Anne Hendricks, L.; Fritz, M.; Schiele, B. Speaking the same language: Matching machine to human captions by adversarial training. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4135–4144. [Google Scholar]
- Xin, M.; Zhang, H.; Yuan, D.; Sun, M. Learning discriminative action and context representations for action recognition in still images. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 757–762. [Google Scholar] [CrossRef]
- Yuan, A.; Li, X.; Lu, X. FFGS: Feature fusion with gating structure for image caption generation. In Proceedings of the Computer Vision, Tianjin, China, 11–14 October 2017; Springer: Singapore, 2017; pp. 638–649. [Google Scholar] [CrossRef]
- Yang, L.; Tang, K.; Yang, J.; Li, L.J. Dense captioning with joint inference and visual context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2193–2202. [Google Scholar] [CrossRef]
- Kilickaya, M.; Akkus, B.K.; Cakici, R.; Erdem, A.; Erdem, E.; Ikizler-Cinbis, N. Data-driven image captioning via salient region discovery. IET Comput. Vis. 2017, 11, 398–406. [Google Scholar] [CrossRef]
- Shah, P.; Bakrola, V.; Pati, S. Image captioning using deep neural architectures. In Proceedings of the 2017 International Conference on Innovations in Information, Embedded and Communication Systems (ICIIECS), Coimbatore, India, 17–18 March 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Huang, Q.; Smolensky, P.; He, X.; Deng, L.; Wu, D. Tensor product generation networks for deep NLP modeling. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), New Orleans, LA, USA, 1–6 June 2018; pp. 1263–1273. [Google Scholar] [CrossRef]
- Liu, C.; Sun, F.; Wang, C. MAT: A multimodal translator for image captioning. In Proceedings of the Artificial Neural Networks and Machine Learning, Pt II, Alghero, Italy, 11–14 September 2017; Lintas, A., Rovetta, S., Verschure, P., Villa, A.E.P., Eds.; Springer International Publishing Ag: Cham, Switzerland, 2017; Volume 10614, p. 784. [Google Scholar]
- Ren, Z.; Wang, X.; Zhang, N.; Lv, X.; Li, L.-J. Deep reinforcement learning-based image captioning with embedding reward. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 290–298. [Google Scholar]
- Pedersoli, M.; Lucas, T.; Schmid, C.; Verbeek, J. Areas of attention for image captioning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1242–1250. [Google Scholar]
- Fu, K.; Jin, J.; Cui, R.; Sha, F.; Zhang, C. Aligning where to see and what to tell: Image captioning with region-based attention and scene-specific contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2321–2334. [Google Scholar] [CrossRef]
- Yao, T.; Pan, Y.; Li, Y.; Qiu, Z.; Mei, T. Boosting image captioning with attributes. In Proceedings of the IEEE Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4894–4902. [Google Scholar] [CrossRef]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: Lessons learned from the 2015 MSCOCO image captioning challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 652–663. [Google Scholar] [CrossRef]
- Xu, K.; Wang, H.; Tang, P. Image captioning with deep LSTM based on sequential residual. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 361–366. [Google Scholar] [CrossRef]
- Dai, B.; Fidler, S.; Urtasun, R.; Lin, D. Towards diverse and natural image descriptions via a conditional GAN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2970–2979. [Google Scholar] [CrossRef]
- Dai, B.; Lin, D. Contrastive learning for image captioning. In Advances in Neural Information Processing Systems; MIT Press: London, UK, 2017; pp. 898–907. [Google Scholar]
- Liu, C.; Sun, F.; Wang, C.; Wang, F.; Yuille, A. MAT: A multimodal attentive translator for image captioning. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 4033–4039. [Google Scholar] [CrossRef]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 375–383. [Google Scholar]
- Nguyen, D.-K.; Okatani, T. Multi-task learning of hierarchical vision-language representation. arXiv 2018, arXiv:1812.00500. [Google Scholar]
- Zhang, J.; Shih, K.; Tao, A.; Catanzaro, B.; Elgammal, A. An interpretable model for scene graph generation. arXiv 2018, arXiv:1811.09543. [Google Scholar]
- Yan, S.; Wu, F.; Smith, J.S.; Lu, W.; Zhang, B. Image captioning using adversarial networks and reinforcement learning. In Proceedings of the 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 248–253. [Google Scholar] [CrossRef]
- Liu, D.; Fu, J.; Qu, Q.; Lv, J. BFGAN: Backward and forward generative adversarial networks for lexically constrained sentence generation. arXiv 2018, arXiv:1806.08097. [Google Scholar]
- Wu, Y.; Zhu, L.; Jiang, L.; Yang, Y. Decoupled novel object captioner. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; ACM: New York, NY, USA, 2018; pp. 1029–1037. [Google Scholar] [CrossRef]
- Wang, W.; Ding, Y.; Tian, C. A novel semantic attribute-based feature for image caption generation. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 3081–3085. [Google Scholar] [CrossRef]
- Chang, Y.-S. Fine-grained attention for image caption generation. Multimed. Tools Appl. 2018, 77, 2959–2971. [Google Scholar] [CrossRef]
- Wu, Q.; Shen, C.; Wang, P.; Dick, A.; van den Hengel, A. Image captioning and visual question answering based on attributes and external knowledge. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1367–1381. [Google Scholar] [CrossRef]
- Baig, M.M.A.; Shah, M.I.; Wajahat, M.A.; Zafar, N.; Arif, O. Image caption generator with novel object injection. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, Australia, 10–13 December 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Chen, F.; Ji, R.; Sun, X.; Wu, Y.; Su, J. GroupCap: Group-based image captioning with structured relevance and diversity constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1345–1353. [Google Scholar]
- Kinghorn, P.; Zhang, L.; Shao, L. A region-based image caption generator with refined descriptions. Neurocomputing 2018, 272, 416–424. [Google Scholar] [CrossRef]
- Cornia, M.; Baraldi, L.; Cucchiara, R. Show, control and tell: A framework for generating controllable and grounded captions. arXiv 2018, arXiv:1811.10652. [Google Scholar]
- Huang, F.; Zhang, X.; Li, Z.; Zhao, Z. Bi-directional spatial-semantic attention networks for image-text matching. IEEE Trans. Image Process. 2018, 28, 2008–2020. [Google Scholar] [CrossRef]
- Chen, T.; Zhang, Z.; You, Q.; Fang, C.; Wang, Z.; Jin, H.; Luo, J. “Factual” or “emotional”: Stylized image captioning with adaptive learning and attention. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 527–543. [Google Scholar] [CrossRef]
- You, Q.; Jin, H.; Luo, J. Image captioning at will: A versatile scheme for effectively injecting sentiments into image descriptions. arXiv 2018, arXiv:1801.10121. [Google Scholar]
- Mathews, A.; Xie, L.; He, X. SemStyle: Learning to generate stylised image captions using unaligned text. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8591–8600. [Google Scholar] [CrossRef]
- Wang, Q.; Chan, A.B. CNN+CNN: Convolutional decoders for image captioning. arXiv 2018, arXiv:1805.09019. [Google Scholar]
- Aneja, J.; Deshpande, A.; Schwing, A. Convolutional image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5561–5570. [Google Scholar]
- Cornia, M.; Baraldi, L.; Serra, G.; Cucchiara, R. Paying more attention to saliency: Image captioning with saliency and context attention. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2018, 14, 48. [Google Scholar] [CrossRef]
- Shi, H.; Li, P. Image captioning based on deep reinforcement learning. In Proceedings of the 10th International Conference on Internet Multimedia Computing and Service, Nanjing, China, 17–19 August 2018; p. 45. [Google Scholar]
- Fan, Y.; Xu, J.; Sun, Y.; He, B. Long-term recurrent merge network model for image captioning. In Proceedings of the 2018 IEEE 30th International Conference on Tools with Artificial Intelligence (ICTAI), Volos, Greece, 5–7 November 2018; pp. 254–259. [Google Scholar] [CrossRef]
- Shen, K.; Kar, A.; Fidler, S. Lifelong learning for image captioning by asking natural language questions. arXiv 2018, arXiv:1812.00235. [Google Scholar]
- Yu, N.; Song, B.; Yang, J.; Zhang, J. Topic-oriented image captioning based on order-embedding. IEEE Trans. Image Process. 2019, 28, 2743–3754. [Google Scholar] [CrossRef]
- Kim, B.; Lee, Y.H.; Jung, H.; Cho, C. Distinctive-attribute extraction for image captioning. Eur. Conf. Comput. Vis. 2018, 133–144. [Google Scholar] [CrossRef]
- Delbrouck, J.-B.; Dupont, S. Bringing back simplicity and lightliness into neural image captioning. arXiv 2018, arXiv:1810.06245. [Google Scholar]
- Sow, D.; Qin, Z.; Niasse, M.; Wan, T. A sequential guiding network with attention for image captioning. arXiv 2018, arXiv:1811.00228. [Google Scholar]
- Zhu, X.; Li, L.; Liu, J.; Li, Z.; Peng, H.; Niu, X. Image captioning with triple-attention and stack parallel LSTM. Neurocomputing 2018, 319, 55–65. [Google Scholar] [CrossRef]
- Fang, F.; Wang, H.; Chen, Y.; Tang, P. Looking deeper and transferring attention for image captioning. Multimed. Tools Appl. 2018, 77, 31159–31175. [Google Scholar] [CrossRef]
- Fang, F.; Wang, H.; Tang, P. Image captioning with word level attention. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018. [Google Scholar] [CrossRef]
- Zhu, X.; Li, L.; Liu, J.; Peng, H.; Niu, X. Captioning transformer with stacked attention modules. Appl. Sci. 2018, 8, 739. [Google Scholar] [CrossRef]
- Wang, F.; Gong, X.; Huang, L. Time-dependent pre-attention model for image captioning. In Proceedings of the 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 3297–3302. [Google Scholar] [CrossRef]
- Ren, L.; Hua, K. Improved image description via embedded object structure graph and semantic feature matching. In Proceedings of the IEEE International Symposium on Multimedia (ISM), Taichung, Taiwan, 10–12 December 2018; pp. 73–80. [Google Scholar] [CrossRef]
- Jiang, W.; Ma, L.; Jiang, Y.G.; Liu, W. Recurrent fusion network for image captioning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 499–515. [Google Scholar]
- Yang, M.; Zhao, W.; Xu, W.; Feng, Y.; Zhao, Z.; Chen, X.; Lei, K. Multitask learning for cross-domain image captioning. IEEE Trans. Multimed. 2018, 21, 1047–1061. [Google Scholar] [CrossRef]
- Chen, C.; Mu, S.; Xiao, W.; Ye, Z.; Wu, L.; Ju, Q. Improving image captioning with conditional generative adversarial nets. arXiv 2018, arXiv:1805.07112. [Google Scholar]
- Du, J.; Qin, Y.; Lu, H.; Zhang, Y. Attend more times for image captioning. arXiv 2018, arXiv:1812.03283. [Google Scholar]
- Yuan, A.; Li, X.; Lu, X. 3G structure for image caption generation. Neurocomputing 2019, 330, 17–28. [Google Scholar] [CrossRef]
- Kim, D.-J.; Choi, J.; Oh, T.-H.; Kweon, I.S. Dense relational captioning: Triple-stream networks for relationship-based captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Mishra, A.; Liwicki, M. Using deep object features for image descriptions. arXiv 2019, arXiv:1902.09969. [Google Scholar]
- Xu, N.; Liu, A.-A.; Liu, J.; Nie, W.; Su, Y. Scene graph captioner: Image captioning based on structural visual representation. J. Vis. Commun. Image Represent. 2019, 58, 477–485. [Google Scholar] [CrossRef]
- Tan, Y.H.; Chan, C.S. Phrase-based image caption generator with hierarchical LSTM network. Neurocomputing 2019, 333, 86–100. [Google Scholar] [CrossRef]
- Tan, J.H.; Chan, C.S.; Chuah, J.H. COMIC: Towards a compact image captioning model with attention. IEEE Trans. Multimed. 2019. [Google Scholar] [CrossRef]
- He, C.; Hu, H. Image captioning with text-based visual attention. Neural Process. Lett. 2019, 49, 177–185. [Google Scholar] [CrossRef]
- Li, J.; Ebrahimpour, M.K.; Moghtaderi, A.; Yu, Y.-Y. Image captioning with weakly-supervised attention penalty. arXiv 2019, arXiv:1903.02507. [Google Scholar]
- He, X.; Yang, Y.; Shi, B.; Bai, X. VD-SAN: Visual-densely semantic attention network for image caption generation. Neurocomputing 2019, 328, 48–55. [Google Scholar] [CrossRef]
- Zhao, D.; Chang, Z.; Guo, S. A multimodal fusion approach for image captioning. Neurocomputing 2019, 329, 476–485. [Google Scholar] [CrossRef]
- Wang, W.; Hu, H. Image captioning using region-based attention joint with time-varying attention. Neural Process. Lett. 2019, 1–13. [Google Scholar] [CrossRef]
- Zhou, Y.; Sun, Y.; Honavar, V. Improving image captioning by leveraging knowledge graphs. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 283–293. [Google Scholar] [CrossRef]
- Ren, L.; Qi, G.; Hua, K. Improving diversity of image captioning through variational autoencoders and adversarial learning. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 263–272. [Google Scholar] [CrossRef]
- Zhang, M.; Yang, Y.; Zhang, H.; Ji, Y.; Shen, H.T.; Chua, T.-S. More is better: Precise and detailed image captioning using online positive recall and missing concepts mining. IEEE Trans. Image Process. 2019, 28, 32–44. [Google Scholar] [CrossRef]
- Li, X.; Jiang, S. Know more say less: Image captioning based on scene graphs. IEEE Trans. Multimed. 2019. [Google Scholar] [CrossRef]
- Gao, L.; Li, X.; Song, J.; Shen, H.T. Hierarchical LSTMs with adaptive attention for visual captioning. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Zha, Z.J.; Liu, D.; Zhang, H.; Zhang, Y.; Wu, F. Context-aware visual policy network for fine-grained image captioning. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- KOUSTUBH. ResNet, AlexNet, VGGNet, Inception: Understanding Various Architectures of Convolutional Networks. Available online: https://cv-tricks.com/cnn/understand-resnet-alexnet-vgg-inception/ (accessed on 24 May 2019).
- He, S.; Tavakoli, H.R.; Borji, A.; Pugeault, N. A synchronized multi-modal attention-caption dataset and analysis. arXiv 2019, arXiv:1903.02499. [Google Scholar]
- Plummer, B.A.; Wang, L.; Cervantes, C.M.; Caicedo, J.C.; Hockenmaier, J.; Lazebnik, S. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2641–2649. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Ordonez, V.; Han, X.; Kuznetsova, P.; Kulkarni, G.; Mitchell, M.; Yamaguchi, K.; Stratos, K.; Goyal, A.; Dodge, J.; Mensch, A.; et al. Large scale retrieval and generation of image descriptions. Int. J. Comput. Vis. 2016, 119, 46–59. [Google Scholar] [CrossRef]
- Agrawal, H.; Desai, K.; Chen, X.; Jain, R.; Batra, D.; Parikh, D.; Lee, S.; Anderson, P. Nocaps: Novel object captioning at scale. arXiv 2018, arXiv:1812.08658. [Google Scholar]
- Tariq, A.; Foroosh, H. A context-driven extractive framework for generating realistic image descriptions. IEEE Trans. Image Process. 2017, 26, 619–632. [Google Scholar] [CrossRef]
- Zhang, H.; Shang, X.; Luan, H.; Wang, M.; Chua, T.-S. Learning from collective intelligence: Feature learning using social images and tags. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2017, 13, 1. [Google Scholar] [CrossRef]
- Sharma, S.; Suhubdy, D.; Michalski, V.; Kahou, S.E.; Bengio, Y. ChatPainter: Improving text to image generation using dialogue. arXiv 2018, arXiv:1802.08216. [Google Scholar] [CrossRef]






| 1Q | ArXiv | IEEE | WOS |
|---|---|---|---|
| Found | 29 | 9 | 18 |
| Relevant | 11 | 6 (1) | 10(6) |
| 2Q | ArXiv | IEEE | WOS |
|---|---|---|---|
| Found | 48 | 19 | 78 |
| Relevant | 16 (3) | 3 (6) | 12 (11) |
| 3Q | ArXiv | IEEE | WOS |
|---|---|---|---|
| Found | 26 | 28 | 42 |
| Relevant | 6 (4) | 8 (6) | 2 (10) |
| 4Q | ArXiv | IEEE | WOS |
|---|---|---|---|
| Found | 38 | 20 | 25 |
| Relevant | 8 (3) | 5 (3) | 7 (3) |
| Image Encoder | Image Decoder | Method | MS COCO | Flickr30k | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Year | Citation | AlexNet | VGGNet | GoogleNet | ResNet | DenseNet | LSTM | RNN | CNN | cGRU | TPGN | Encoder-Decoder | Attention | Novel objects | Semantics | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | CIDEr | Meteor | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | CIDEr | Meteor |
| 2016 | [13] | x | x | x | x | 71.4 | 50.5 | 35.2 | 24.5 | 63.8 | 21.9 | ||||||||||||||||
| 2016 | [12] | x | x | x | x | 50.0 | 31.2 | 20.3 | 13.1 | 61.8 | 16.8 | ||||||||||||||||
| 2016 | [11] | x | x | x | x | 67.2 | 49.2 | 35.2 | 24.4 | 62.1 | 42.6 | 28.1 | 19.3 | ||||||||||||||
| Image Encoder | Image Decoder | Method | MS COCO | Flickr30k | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Year | Citation | AlexNet | VGGNet | GoogleNet | ResNet | DenseNet | LSTM | RNN | CNN | cGRU | TPGN | Encoder-Decoder | Attention | Novel Objects | Semantics | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | CIDEr | Meteor | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | CIDEr | Meteor |
| 2017 | [34] | x | x | x | x | 74.2 | 58 | 43.9 | 33.2 | 108.5 | 26.6 | 67.7 | 49.4 | 35.4 | 25.1 | 53.1 | 20.4 | ||||||||||
| 2017 | [33] | x | x | x | x | 73.1 | 56.7 | 42.9 | 32.3 | 105.8 | 25.8 | ||||||||||||||||
| 2017 | [32] | x | x | x | x | x | x | 91 | 83.1 | 72.8 | 61.7 | 102.9 | 35 | ||||||||||||||
| 2017 | [31] | x | x | x | 39.3 | 29.9 | 102 | 24.8 | 37.2 | 30.1 | 76.7 | 21.5 | |||||||||||||||
| 2017 | [30] | x | x | x | 42 | 31.9 | 101.1 | 25.7 | 32.5 | 22.9 | 44.1 | 19 | |||||||||||||||
| Image Encoder | Image Decoder | Method | MS COCO | Flickr30k | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Year | Citation | AlexNet | VGGNet | GoogleNet | ResNet | DenseNet | LSTM | RNN | CNN | cGRU | TPGN | Encoder-Decoder | Attention | Novel Objects | Semantics | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | CIDEr | Meteor | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | CIDEr | Meteor |
| 2018 | [70] | x | x | x | x | 38.1 | 126.1 | 28.3 | |||||||||||||||||||
| 2018 | [69] | x | x | x | x | 38.3 | 123.2 | 28.6 | |||||||||||||||||||
| 2018 | [68] | X | X | X | X | X | x | 79.4 | 63.1 | 48.2 | 36.1 | 119.6 | 28.1 | 72.1 | 48.7 | 36.9 | 21.2 | 53.6 | 20.5 | ||||||||
| 2018 | [67] | x | x | x | x | x | x | 76.4 | 60.4 | 47.9 | 37 | 112.5 | 27.4 | ||||||||||||||
| 2018 | [66] | x | x | x | x | x | 76.1 | 58.1 | 44.9 | 34.9 | 109.1 | 26.7 | 73.1 | 54 | 38.6 | 27.9 | 59.4 | 21.7 | |||||||||
| Image Encoder | Image Decoder | Method | MS COCO | Flickr30k | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Year | Citation | AlexNet | VGGNet | GoogleNet | ResNet | DenseNet | LSTM | RNN | CNN | cGRU | TPGN | Encoder-Decoder | Attention | Novel Objects | Semantics | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | CIDEr | Meteor | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | CIDEr | Meteor |
| 2019 | [87] | x | x | x | x | x | x | 38.6 | 28.3 | 126.3 | |||||||||||||||||
| 2019 | [86] | x | x | x | x | x | x | 79.9 | 37.5 | 125.6 | 28.5 | 73.8 | 55.1 | 40.3 | 29.4 | 66.6 | 23 | ||||||||||
| 2019 | [85] | x | x | x | x | x | x | 79.2 | 63.2 | 48.3 | 36.3 | 120.2 | 27.6 | ||||||||||||||
| 2019 | [84] | x | x | x | 75.8 | 59.6 | 46 | 35.6 | 110.5 | 27.3 | |||||||||||||||||
| 2019 | [83] | x | x | x | x | x | x | x | 55 | 110.1 | 26.1 | ||||||||||||||||
| Encoder/Decoder | Year | LSTM | RNN | CNN | cGRU | TPGN |
|---|---|---|---|---|---|---|
| AlexNet | 2016 | [11] | ||||
| 2017 | [22] | [45] | [21] | |||
| 2018 | ||||||
| 2019 | ||||||
| VGG Net | 2016 | [10,11,13] | ||||
| 2017 | [14,15,16,19,20,25,30,31,32] | [26,32] | [21] | |||
| 2018 | [40,41,42,43,47,48,49,54,61] | [51,52] | ||||
| 2019 | [71,72,73,74,75,77,83] | |||||
| Google Net | 2016 | [12] | ||||
| 2017 | [17,18,28,29] | |||||
| 2018 | [43,57,60,62,67] | [50] | ||||
| 2019 | [76,77,80] | |||||
| ResNet | 2016 | |||||
| 2017 | [23,27,30,32,33,34] | [32] | [23] | |||
| 2018 | [37,39,43,46,48,49,53,55,58,61,70] | [56,59] | ||||
| 2019 | [78,83,84,85,86,87] | [81] | ||||
| DenseNet | 2016 | |||||
| 2017 | ||||||
| 2018 | ||||||
| 2019 | [79] |
| Year/Method | Encoder-Decoder | Attention Mechanism | Novel Objects | Semantics |
|---|---|---|---|---|
| 2016 | [11,12,13] | [13] | [12] | |
| 2017 | [15,17,19,22,23,25,26,27,28,29,31,32,33,34] | [19,21,22,26,27,32,33,34] | [15,18,25,27] | [27,28] |
| 2018 | [35,37,39,40,41,42,44,45,46,48,50,51,52,54,56,57,59,60,61,62,63,64,66,67,68,69,70] | [36,37,38,40,41,46,47,48,49,50,51,53,56,59,60,61,62,63,64,65,66,67,68,69,70] | [39,40,43,44,45,47,48,49,50,58,67,68] | [36,42,44,47,50,57,58,66,68] |
| 2019 | [71,72,73,75,76,78,82,83,85,86,87] | [71,74,75,76,77,78,79,80,81,83,85,86,87] | [72,73,74,75,77,78,79,80,83,85,86,87] | [75,80,82,83,84,85,86,87] |
| CONVOLUTIONAL NEURAL NETWORKS ARCHITECTURES | |||||
|---|---|---|---|---|---|
| Architecture | #Params | #Multiply-Adds | Top-1 Accuracy | Top-5 Accuracy | Year |
| Alexnet | 61M | 724M | 57.1 | 80.2 | 2012 |
| VGG | 138M | 15.5B | 70.5 | 91.2 | 2013 |
| Inception-V1 | 7M | 1.43B | 69.8 | 89.3 | 2013 |
| Resnet-50 | 25.5M | 3.9B | 75.2 | 93 | 2015 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Staniūtė, R.; Šešok, D. A Systematic Literature Review on Image Captioning. Appl. Sci. 2019, 9, 2024. https://doi.org/10.3390/app9102024
Staniūtė R, Šešok D. A Systematic Literature Review on Image Captioning. Applied Sciences. 2019; 9(10):2024. https://doi.org/10.3390/app9102024
Chicago/Turabian StyleStaniūtė, Raimonda, and Dmitrij Šešok. 2019. "A Systematic Literature Review on Image Captioning" Applied Sciences 9, no. 10: 2024. https://doi.org/10.3390/app9102024
APA StyleStaniūtė, R., & Šešok, D. (2019). A Systematic Literature Review on Image Captioning. Applied Sciences, 9(10), 2024. https://doi.org/10.3390/app9102024