An Approach to Participatory Business Process Modeling: BPMN Model Generation Using Constraint Programming and Graph Composition


Abstract
1. Introduction
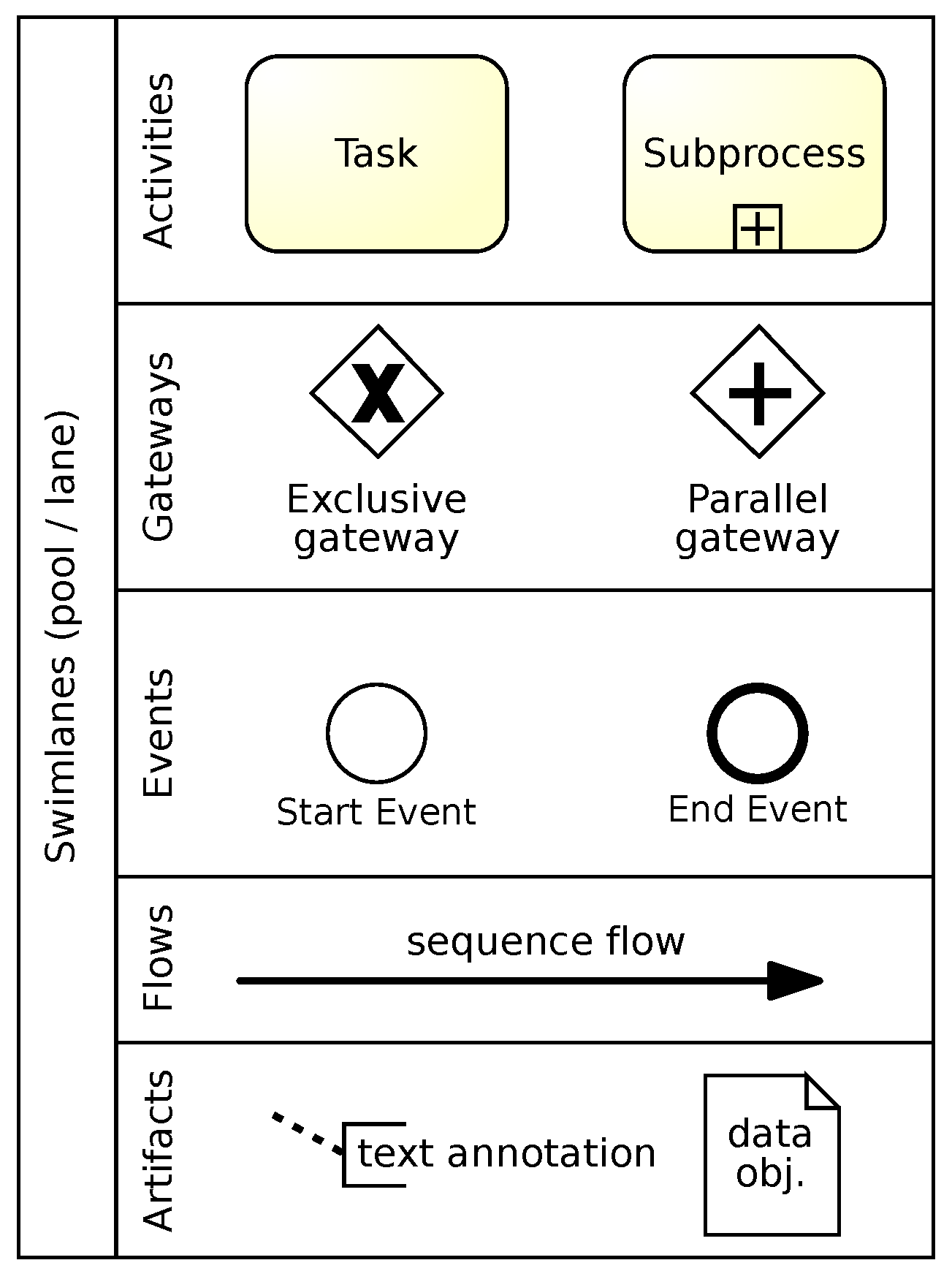
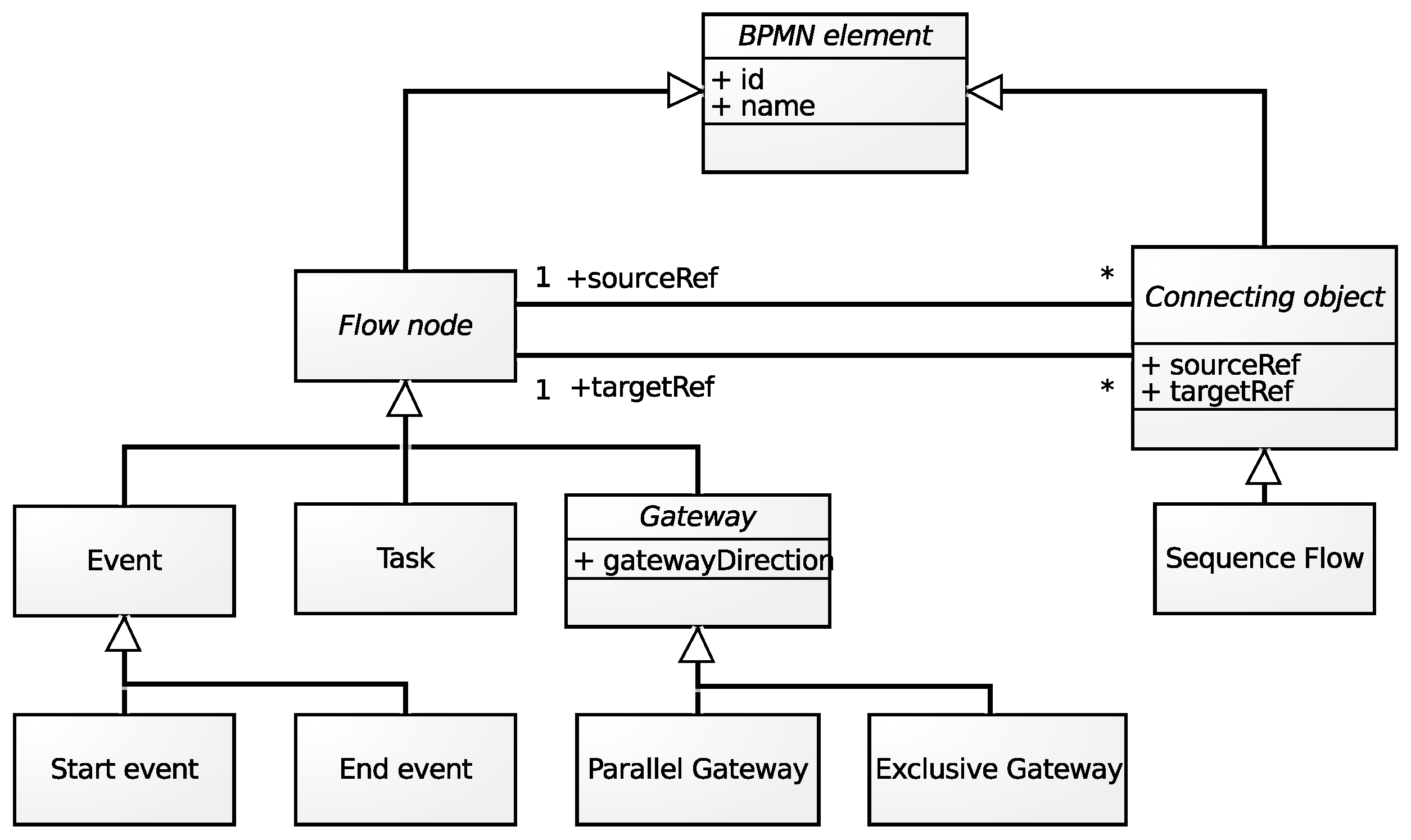
2. Business Process Modeling with BPMN
- Sequence: simple succession of activities.
- Parallel split: split in a single thread of control into multiple threads that can execute in parallel.
- Synchronization: synchronization of multiple parallel branches into a single thread.
- Exclusive choice: representation of a decision point in a process where one of several branches is chosen.
- Simple merge: a point in a process where two or more alternative branches come together without synchronization.
- is the set of flow objects,
- is the set of sequence flows.
- : a non-empty set of tasks (),
- : a non-empty set of start and end events (),
- : a set of gateways that split or merge the flow,
3. Related Works
3.1. Generating Models from Text Description
3.2. Generating Models from Other Models
3.3. Generating Process Models from Data Models
3.4. Generating Imperative Process Models from Declarative Models
3.5. Analyzing Workflow Logs
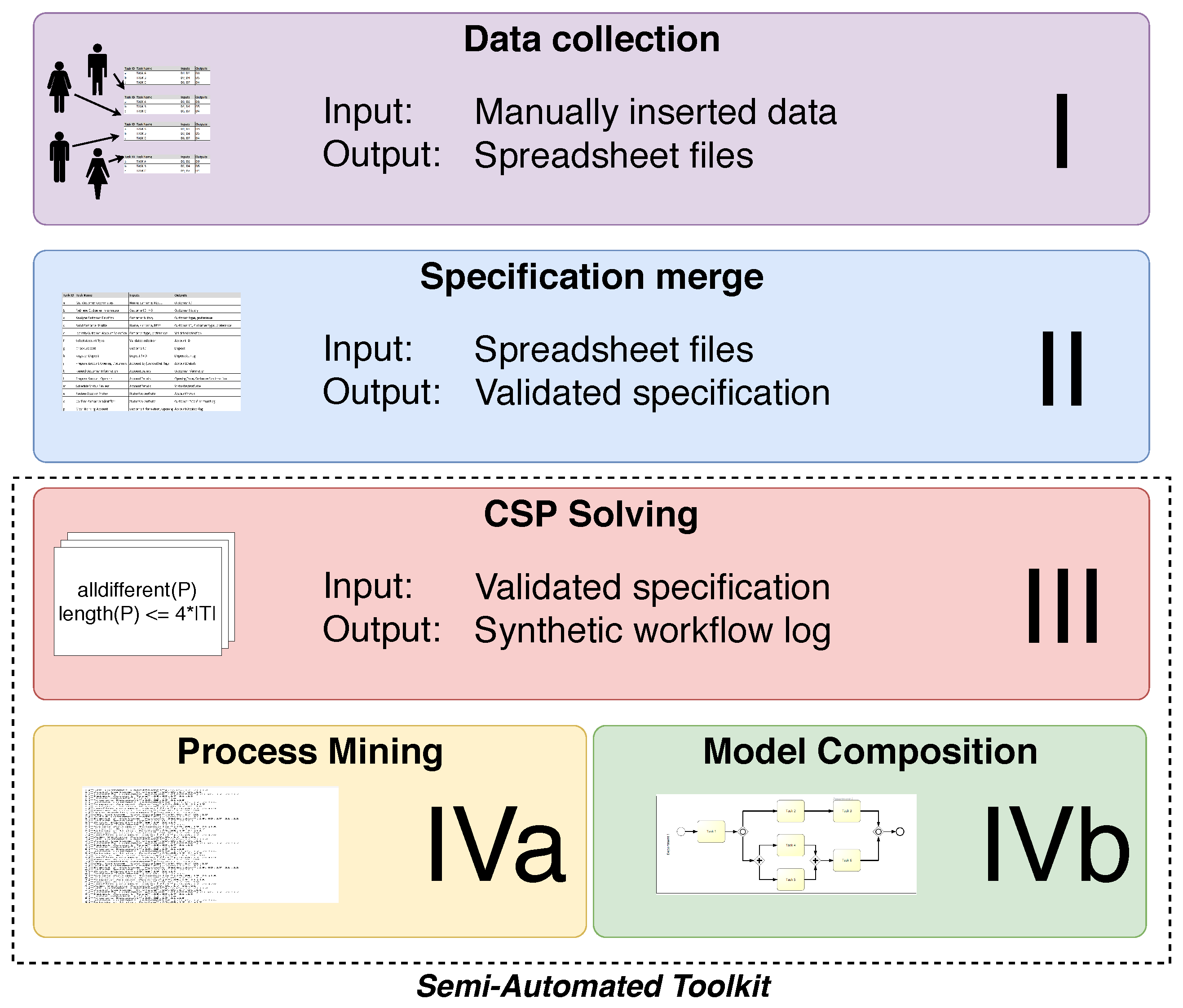
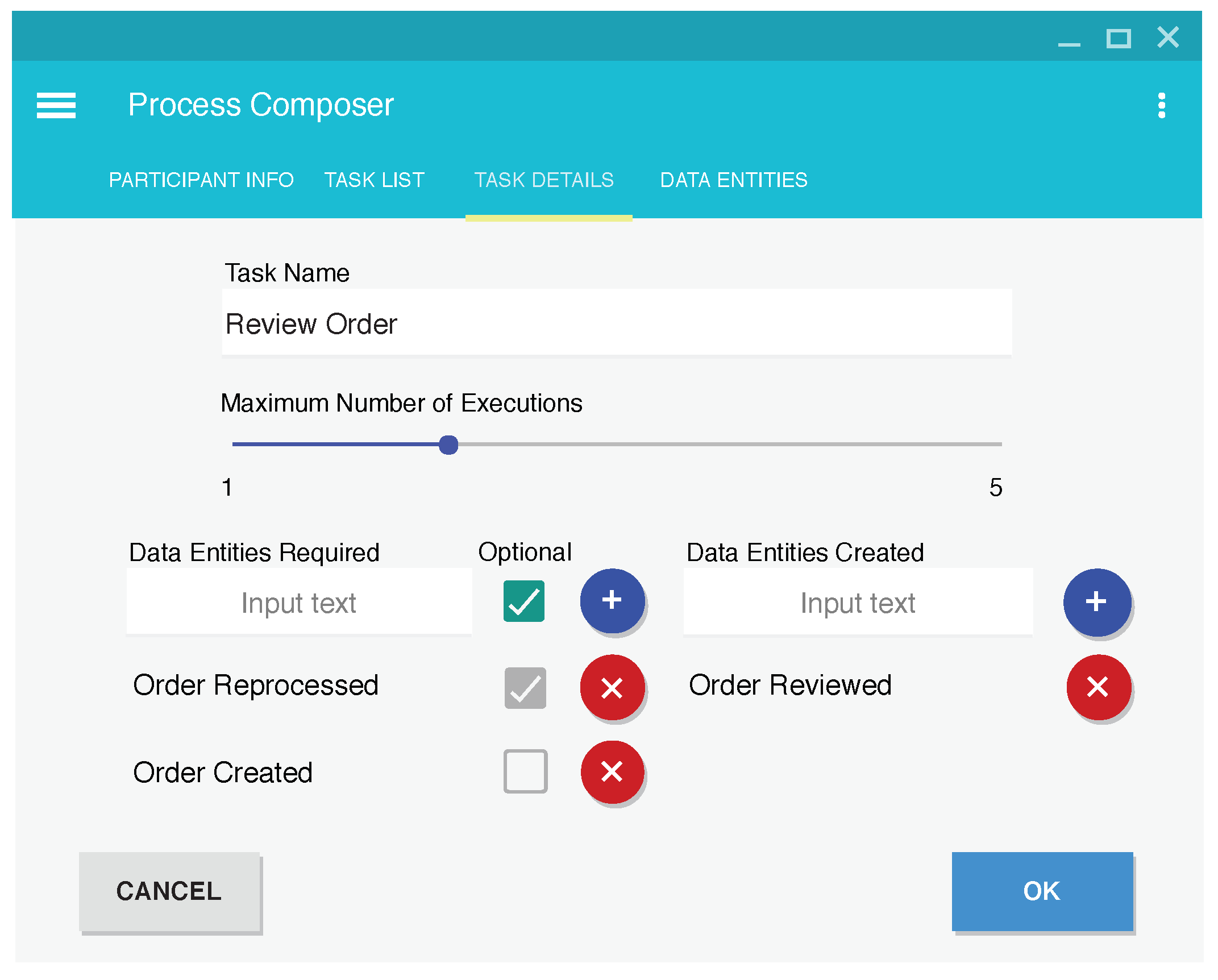
4. Collecting Process Data
- data entities that are required or are optional for execution,
- data entities created after execution,
- maximum number of repetitions.
- If requested goods are available in the warehouse, then there is no need for purchase order; then inventory checked is the only data entity required. All data related to purchase order processing should not exist.
- Otherwise, the expected goal is a completed purchase order, which corresponds to the order completed data entity.
5. Constraint-Based Model
5.1. Formal Process Data Structures
- : for conditions needed for a task to be executed,
- : for effects caused by the execution of a task.
5.2. Generation of a Workflow Log
- Search space: finite sequences of tasks.
- Decision variables: workflow trace, process state matrix.
- Constraints over variables: determined by the input data, as well as a set of predefined formulae.
- State satisfies requirements (based on Formula (4)).

- State satisfies set of requirements.



- The global limit of executions for all tasks is a constant value and denoted as .

- The number of executions for each task should be lower than or equal to the corresponding value in vector or to the global limit.

- The maximum length of the workflow trace is equal to .

- The input state of the first executed task should be equal to .

- Every non-empty task should change the current state.

- The process should end when the desired goal state is achieved.

- The last state of the process should satisfy one of the goal states.

- A task can be executed only if the current state satisfies its input conditions.









- the model file .mzn, which contains definitions of decision variables, predicates and constraints,
- the data file .dzn, where all the input information such as matrices , , and initial state vector are defined.
6. Composition of a BPMN Diagram
- The mining-driven approach.
- The process composition based on activity graphs.
6.1. Mining-Driven Approach
- Abstraction-based (also known as -series): consists of three phases: abstraction, induction and construction. In such an algorithm, ordering relations between tasks are identified, and the final workflow net is constructed based on predefined rules.
- Heuristic-based: consider the frequency of ordering relations appearing in workflow traces, and filter out the potential noise.
- Search-based: use genetic algorithms to discover process models that represent the most frequent behavior in a workflow log.
- Language-based: assume that each activity in a trace is a letter in an alphabet and each trace is a word. One of the approaches [63] uses Integer Linear Programming (ILP) to discover control flows.
- Inductive: filter the most frequent activities, and produce a process tree. The generated model is then enriched with frequency information for each task and the information about how the generated model deviates from the input log.
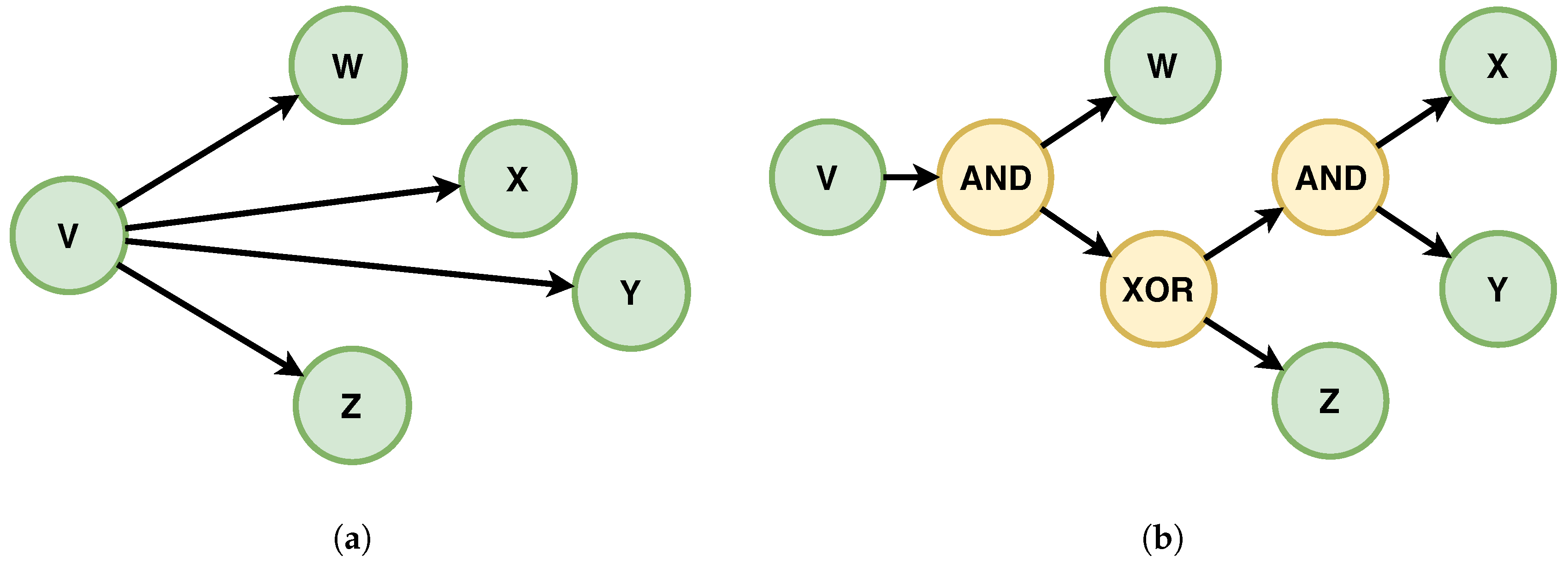
6.2. Process Composition Based on Activity Graphs
- is a finite set of vertices representing process activities,
- E is a set of directed edges,
- determines the number of incoming edges for a vertex, and stands for non-negative integers,
- determines the number of outgoing edges for a vertex.
- chain response: if A occurs, then it is directly followed by B,
- chain precedence: if B occurs, then it is directly preceded by A,
- chain succession: A occurs if and only if B occurs directly afterwards.

- There exists a directed edge leading from A to B and one from B to A.
- There exists a workflow trace where the number of occurrences for A and B is equal.
- There exist two workflow traces such that A occurs first before the first occurrence of B in and B occurs first before the first occurrence of A in .

- Create the process file structure.
- For each vertex and its attributes, create an element corresponding to the type of flow object.
- For each directed edge, create a sequenceFlow element.

7. Evaluation
7.1. Generation of Workflow Traces
- Each activity generates one data entity.
- Each activity requires data entities generated by its predecessors. If it is preceded by an exclusive gateway, then an artificial data entity is created to represent the alternative.
- The initial state of the process is a zero vector.
- The goal state of the process requires data entities produced by its predecessors.
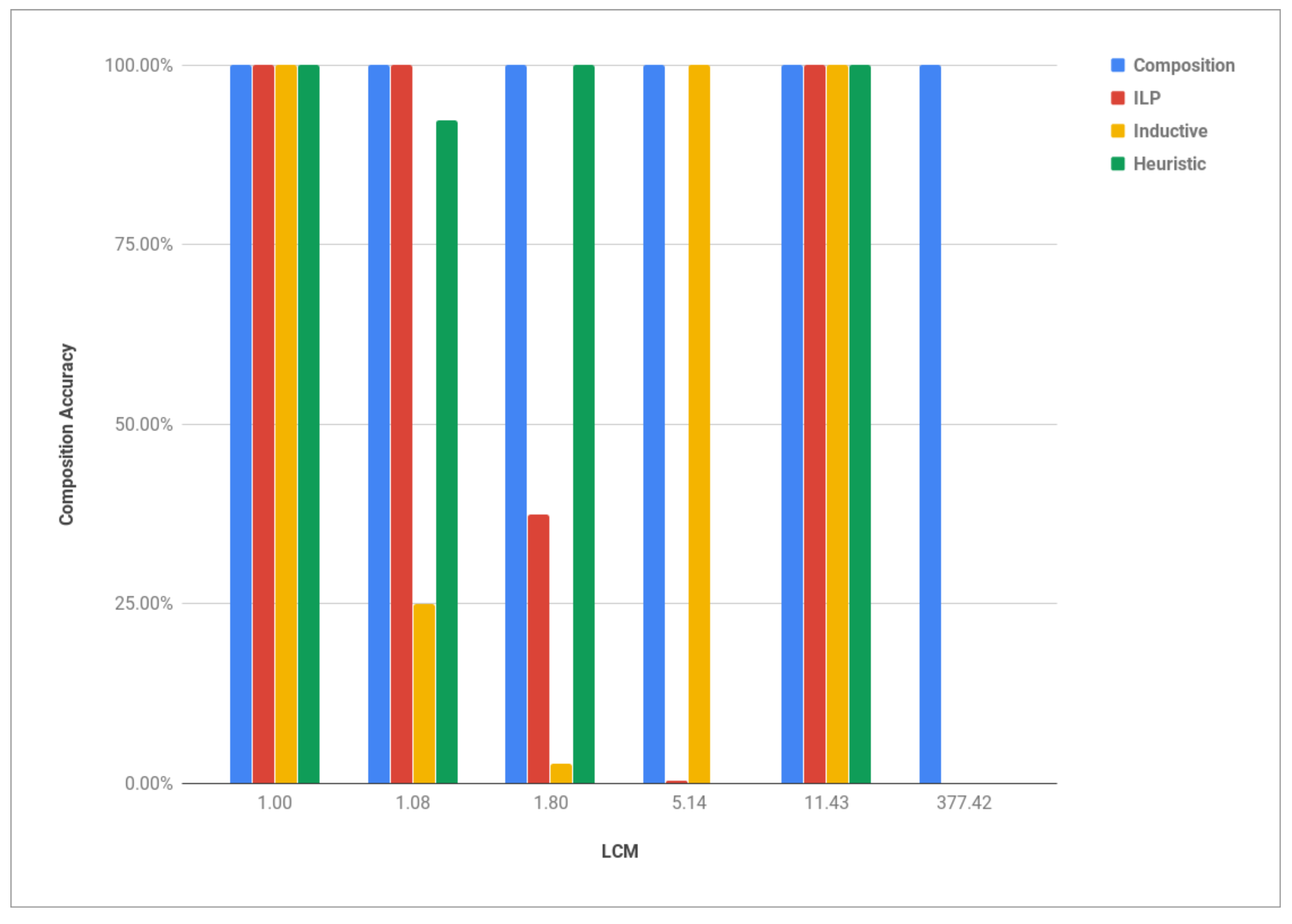
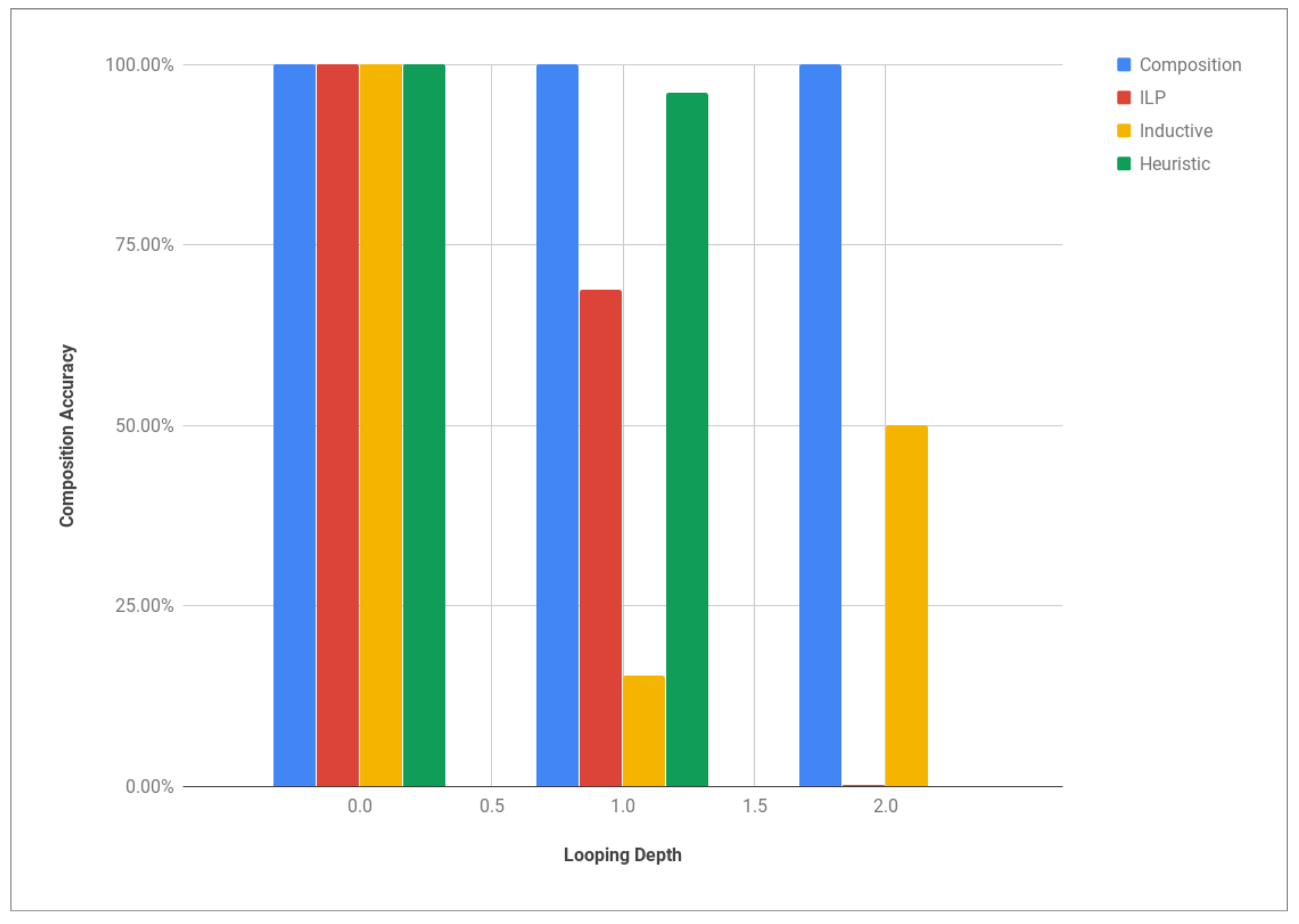
7.2. Graph-Based Model Composition
- model fitness: the percentage of traces from the original log, which were generated based on the composed model,
- execution precision: the percentage of generated workflow traces that are allowed in the original log.
7.3. Limitations
8. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Object Management Group (OMG). Business Process Model and Notation (BPMN): Version 2.0 Specification; Technical Report Formal/2011-01-03; Object Management Group: Needham, MA, USA, 2011. [Google Scholar]
- Object Management Group (OMG). Decision Model and Notation, Version 1.0.; Technical Report Formal/2015-09-01; Object Management Group: Needham, MA, USA, 2015. [Google Scholar]
- Miller, J.; Mukerji, J. MDA Guide Version 1.0.1; Object Management Group (OMG): Needham, MA, USA, 2003. [Google Scholar]
- Weske, M. Business Process Management: Concepts, Languages, Architectures, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Lawrence, P. (Ed.) Workflow Handbook; John Wiley & Sons, Inc.: New York, NY, USA, 1997. [Google Scholar]
- Van der Aalst, W. Business process management: A personal view. Bus. Process Manag. J. 2004, 10. [Google Scholar] [CrossRef]
- Lindsay, A.; Dawns, D.; Lunn, K. Business Processes—Attempts to Find a Definition. Inf. Softw. Technol. 2003, 45, 1015–1019. [Google Scholar] [CrossRef]
- Kluza, K.; Wiśniewski, P.; Jobczyk, K.; Ligęza, A.; Mroczek, A.S. Comparison of selected modeling notations for process, decision and system modeling. In Proceedings of the 2017 Federated Conference on IEEE Computer Science and Information Systems (FedCSIS), Prague, Czech Republic, 3–6 September 2017; pp. 1095–1098. [Google Scholar]
- Chinosi, M.; Trombetta, A. BPMN: An introduction to the standard. Comput. Stand. Interfaces 2012, 34, 124–134. [Google Scholar] [CrossRef]
- Kluza, K.; Jobczyk, K.; Wiśniewski, P.; Ligęza, A. Overview of Time Issues with Temporal Logics for Business Process Models. In Proceedings of the 2016 Federated Conference on Computer Science and Information Systems, Gdansk, Poland, 11–14 September 2016; Ganzha, M., Maciaszek, L., Paprzycki, M., Eds.; IEEE: Piscataway, NJ, USA, 2016; Volume 8, pp. 1115–1123. [Google Scholar] [CrossRef]
- Arevalo, C.; Escalona, M.; Ramos, I.; Domínguez-Muñoz, M. A metamodel to integrate business processes time perspective in BPMN 2.0. Inf. Softw. Technol. 2016, 77, 17–33. [Google Scholar] [CrossRef]
- Pillat, R.M.; Oliveira, T.C.; Alencar, P.S.; Cowan, D.D. BPMNt: A BPMN extension for specifying software process tailoring. Inf. Softw. Technol. 2015, 57, 95–115. [Google Scholar] [CrossRef]
- Gómez-López, M.T.; Reina Quintero, A.M.; Parody, L.; Pérez Álvarez, J.M.; Reichert, M. An Architecture for Querying Business Process, Business Process Instances, and Business Data Models. In Business Process Management Workshops; Teniente, E., Weidlich, M., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 757–769. [Google Scholar]
- Yousfi, A.; Bauer, C.; Saidi, R.; Dey, A.K. uBPMN: A BPMN extension for modeling ubiquitous business processes. Inf. Softw. Technol. 2016, 74, 55–68. [Google Scholar] [CrossRef]
- Wohed, P.; van der Aalst, W.M.P.; Dumas, M.; ter Hofstede, A.H.M.; Russell, N. On the Suitability of BPMN for Business Process Modelling. In Business Process Management, Proceedings of the 4th International Conference, BPM 2006, Vienna, Austria, 5–7 September 2006; Dustdar, S., Fiadeiro, J.L., Sheth, A.P., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 161–176. [Google Scholar] [CrossRef]
- Lodhi, A.; Küppen, V.; Saake, G. An Extension of BPMN Meta-model for Evaluation of Business Processes. Sci. J. Riga Tech. Univ. 2011, 43, 27–34. [Google Scholar] [CrossRef]
- Ligęza, A. BPMN—A logical model and property analysis. Decis. Mak. Manuf. Serv. 2011, 5, 57–67. [Google Scholar]
- Meyer, A.; Pufahl, L.; Fahland, D.; Weske, M. Modeling and Enacting Complex Data Dependencies in Business Processes. In Business Process Management, Proceedings of the 11th International Conference, BPM 2013, Beijing, China, 26–30 August 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 171–186. [Google Scholar]
- Friedrich, F.; Mendling, J.; Puhlmann, F. Process Model Generation from Natural Language Text. In Advanced Information Systems Engineering; Lecture Notes in Computer Science; Mouratidis, H., Rolland, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6741, pp. 482–496. [Google Scholar]
- Reijers, H.A.; Limam, S.; van der Aalst, W.M.P. Product-based workflow design. J. Manag. Inf. Syst. 2003, 20, 229–262. [Google Scholar]
- Kluza, K.; Honkisz, K. From SBVR to BPMN and DMN models. proposal of translation from rules to process and decision models. In International Conference on Artificial Intelligence and Soft Computing; Springer: Cham, Switzerland, 2016; pp. 453–462. [Google Scholar]
- Milani, F.; Dumas, M.; Matulevičius, R. Decomposition driven consolidation of process models. In International Conference on Advanced Information Systems Engineering; Springer: Berlin/Heidelberg, Germany, 2013; pp. 193–207. [Google Scholar]
- Nawrocki, J.R.; Nedza, T.; Ochodek, M.; Olek, L. Describing Business Processes with Use Cases; BIS: Klagenfurt, Austria, 2006; pp. 13–27. [Google Scholar]
- Lubke, D.; Schneider, K.; Weidlich, M. Visualizing Use Case Sets as BPMN Processes. In Proceedings of the 2008 Requirements Engineering Visualization (REV ’08), Barcelona, Spain, 8 September 2008; pp. 21–25. [Google Scholar]
- Zafar, U.; Bhuiyan, M.; Prasad, P.; Haque, F. Integration of use case models and BPMN using Goal-Oriented requirements engineering. J. Comput. 2018, 13, 212–222. [Google Scholar]
- Suchenia, A.; Kluza, K.; Jobczyk, K.; Wiśniewski, P.; Wypych, M.; Ligęza, A. Supporting BPMN Process Models with UML Sequence Diagrams for Representing Time Issues and Testing Models. In International Conference on Artificial Intelligence and Soft Computing; Springer: Cham, Switzerland, 2017; pp. 589–598. [Google Scholar]
- Hasic, F.; De Smedt, J.; Vanthienen, J. Towards assessing the theoretical complexity of the decision model and notation (DMN). In Proceedings of the 8th International Workshop on Enterprise Modeling and Information Systems Architectures (EMISA), Essen, Germany, 12–13 June 2017; pp. 64–71. [Google Scholar]
- Nešković, S.; Kirchner, K. Using Context Information and CMMN to Model Knowledge-Intensive Business Processes. In Proceedings of the 6th International Conference on Information Society and Technology ICIST 2016, Kopaonik, Serbia, 28 February – 2 March 2016; pp. 17–21. [Google Scholar]
- Van der Aalst, W. On the automatic generation of workflow processes based on product structures. Comput. Ind. 1999, 39, 97–111. [Google Scholar] [CrossRef]
- Vanderfeesten, I.; Reijers, H.; Aalst, W. Case Handling Systems as Product Based Workflow Design Support. In Enterprise Information Systems; Lecture Notes in Business Information Processing; Filipe, J., Cordeiro, J., Cardoso, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 12, pp. 187–198. [Google Scholar]
- Vanderfeesten, I.; Reijers, H.; Aalst, W.; Vogelaar, J. Automatic Support for Product Based Workflow Design: Generation of Process Models from a Product Data Model. In On the Move to Meaningful Internet Systems: OTM 2010 Workshops; Lecture Notes in Computer Science; Meersman, R., Dillon, T., Herrero, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6428, pp. 665–674. [Google Scholar]
- Vanderfeesten, I.; Reijers, H.A.; van der Aalst, W.M.P. Product-based workflow support. Inf. Syst. 2011, 36, 517–535. [Google Scholar] [CrossRef]
- Van der Aa, H.; Reijers, H.A.; Vanderfeesten, I. Composing workflow activities on the basis of data-flow structures. In Business Process Management; Springer: Berlin/Heidelberg, Germany, 2013; pp. 275–282. [Google Scholar]
- Vanderfeesten, I.; Reijers, H.A.; van der Aalst, W.M.P. Product based workflow support: Dynamic workflow execution. In Advanced Information Systems Engineering; Springer: Berlin/Heidelberg, Germany, 2008; pp. 571–574. [Google Scholar]
- Li, S.; Shao, X.; Zhang, Z.; Chang, J. Dynamic Workflow Modeling Based on Product Structure Tree. Appl. Math. 2012, 6, 751–757. [Google Scholar]
- Li, S.; Shao, X.D.; Chang, J.T. Dynamic workflow modeling oriented to product design process. Comput. Integr. Manuf. Syst. 2012, 18, 1136–1144. [Google Scholar]
- Wu, F.; Priscilla, L.; Gao, M.; Caron, F.; Roover, W.; Vanthienen, J. Modeling Decision Structures and Dependencies. In On the Move to Meaningful Internet Systems: OTM 2012 Workshops; Lecture Notes in Computer Science; Herrero, P., Panetto, H., Meersman, R., Dillon, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7567, pp. 525–533. [Google Scholar]
- Roover, W.; Vanthienen, J. On the Relation between Decision Structures, Tables and Processes. In On the Move to Meaningful Internet Systems: OTM 2011 Workshops; Lecture Notes in Computer Science; Meersman, R., Dillon, T., Herrero, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 7046, pp. 591–598. [Google Scholar]
- Kluza, K.; Nalepa, G.J. A method for generation and design of business processes with business rules. Inf. Softw. Technol. 2017, 91, 123–141. [Google Scholar] [CrossRef]
- Gómez-López, M.T.; Pérez-Álvarez, J.M.; Varela-Vaca, A.J.; Gasca, R.M. Guiding the Creation of Choreographed Processes with Multiple Instances Based on Data Models. In Business Process Management Workshops; Dumas, M., Fantinato, M., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 239–251. [Google Scholar]
- Goedertier, S.; Vanthienen, J.; Caron, F. Declarative business process modelling: Principles and modelling languages. Enterp. Inf. Syst. 2015, 9, 161–185. [Google Scholar] [CrossRef]
- De Giacomo, G.; Dumas, M.; Maggi, F.M.; Montali, M. Declarative Process Modeling in BPMN. In Advanced Information Systems Engineering, Proceedings of the 27th International Conference, CAiSE 2015, Stockholm, Sweden, 8–12 June 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 84–100. [Google Scholar] [CrossRef]
- Reijers, H.A.; Slaats, T.; Stahl, C. Declarative modeling—An academic dream or the future for BPM? In Business Process Management; Springer: Berlin/Heidelberg, Germany, 2013; pp. 307–322. [Google Scholar]
- Prescher, J.; Di Ciccio, C.; Mendling, J. From Declarative Processes to Imperative Models. In Proceedings of the Fourth International Symposium on Data-driven Process Discovery and Analysis SIMPDA 2014, Milan, Italy, 19–21 November 2014; pp. 162–173. [Google Scholar]
- Mrasek, R.; Mülle, J.; Böhm, K. Automatic generation of optimized process models from declarative specifications. In International Conference on Advanced Information Systems Engineering; Springer: Cham, Switzerland, 2015; pp. 382–397. [Google Scholar]
- Jiménez-Ramírez, A.; Weber, B.; Barba, I.; Del Valle, C. Generating optimized configurable business process models in scenarios subject to uncertainty. Inf. Softw. Technol. 2015, 57, 571–594. [Google Scholar] [CrossRef]
- Parody, L.; Gómez-López, M.T.; Gasca, R.M. Hybrid business process modeling for the optimization of outcome data. Inf. Softw. Technol. 2016, 70, 140–154. [Google Scholar] [CrossRef]
- Tang, Y.; Mackey, I.; Su, J. Querying workflow logs. Information 2018, 9, 25. [Google Scholar] [CrossRef]
- Arriagada-Benítez, M.; Sepúlveda, M.; Munoz-Gama, J.; Buijs, J.C. Strategies to automatically derive a process model from a configurable process model based on event data. Appl. Sci. 2017, 7, 1023. [Google Scholar] [CrossRef]
- Chesani, F.; Ciampolini, A.; Loreti, D.; Mello, P. Abduction for Generating Synthetic Traces. In International Conference on Business Process Management; Springer: Cham, Switzerland, 2017; pp. 151–159. [Google Scholar]
- Rossi, F.; Van Beek, P.; Walsh, T. Handbook of Constraint Programming; Elsevier: Boston, MA, USA, 2006. [Google Scholar]
- Wiśniewski, P.; Kluza, K.; Ślażyński, M.; Ligęza, A. Constraint-Based Composition of Business Process Models. In Business Process Management Workshops; BPM 2017; Lecture Notes in Business Information Processing; Springer: Cham, Switzerland, 2018; Volume 308, pp. 133–141. [Google Scholar]
- Weijters, A.; van Der Aalst, W.M.; De Medeiros, A.A. Process mining with the heuristics miner-algorithm. TU Eindhoven. Tech. Rep. WP 2006, 166, 1–34. [Google Scholar]
- Gaaloul, W.; Baïna, K.; Godart, C. A bottom-up workflow mining approach for workflow applications analysis. In Data Engineering Issues in E-Commerce and Services; Springer: Berlin/Heidelberg, Germany, 2006; pp. 182–197. [Google Scholar]
- Chenouard, R.; Granvilliers, L.; Soto, R. Model-driven constraint programming. In Proceedings of the 10th International ACM SIGPLAN Conference on Principles and Practice of Declarative Programming, Valencia, Spain, 15–17 July 2008; ACM: New York, NY, USA, 2008; pp. 236–246. [Google Scholar]
- Nethercote, N.; Stuckey, P.J.; Becket, R.; Brand, S.; Duck, G.J.; Tack, G. MiniZinc: Towards a Standard CP Modelling Language. In Principles and Practice of Constraint Programming—CP 2007, Proceedings of the 13th International Conference, Providence, RI, USA, 23–27 September 2007; Bessière, C., Ed.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 529–543. [Google Scholar] [CrossRef]
- Schulte, C.; Stuckey, P.J. Efficient Constraint Propagation Engines. ACM Trans. Program. Lang. Syst. 2008, 31, 2:1–2:43. [Google Scholar] [CrossRef]
- Van der Aalst, W. Process Mining Software. In Process Mining: Data Science in Action; Springer: Berlin/Heidelberg, Germany, 2016; pp. 325–352. [Google Scholar]
- Van der Aalst, W.M.; van Dongen, B.F.; Günther, C.W.; Rozinat, A.; Verbeek, E.; Weijters, T. ProM: The process mining toolkit. BPM (Demos) 2009, 489, 2. [Google Scholar]
- Van Der Aalst, W.; Adriansyah, A.; De Medeiros, A.K.A.; Arcieri, F.; Baier, T.; Blickle, T.; Bose, J.C.; van den Brand, P.; Brandtjen, R.; Buijs, J.; et al. Process mining manifesto. In International Conference on Business Process Management; Springer: Berlin/Heidelberg, Germany, 2011; pp. 169–194. [Google Scholar]
- Van Dongen, B.F.; De Medeiros, A.A.; Wen, L. Process mining: Overview and outlook of petri net discovery algorithms. In Transactions on Petri Nets and Other Models of Concurrency II; Springer: Berlin/Heidelberg, Germany, 2009; pp. 225–242. [Google Scholar]
- Leemans, S.J.; Fahland, D.; van der Aalst, W.M. Exploring processes and deviations. In International Conference on Business Process Management; Springer: Cham, Switzerland, 2014; pp. 304–316. [Google Scholar]
- Van der Werf, J.M.E.; van Dongen, B.F.; Hurkens, C.A.; Serebrenik, A. Process discovery using integer linear programming. In International Conference on Applications and Theory of Petri Nets; Springer: Berlin/Heidelberg, Germany, 2008; pp. 368–387. [Google Scholar]
- Kalenkova, A.A.; van der Aalst, W.M.; Lomazova, I.A.; Rubin, V.A. Process mining using BPMN: Relating event logs and process models. Softw. Syst. Model. 2017, 16, 1019–1048. [Google Scholar] [CrossRef]
- Kundu, D.; Samanta, D. A Novel Approach to Generate Test Cases from UML Activity Diagrams. J. Object Technol. 2009, 8, 65–83. [Google Scholar] [CrossRef]
- Maggi, F.M.; Mooij, A.J.; van der Aalst, W.M. User-guided discovery of declarative process models. In Proceedings of the 2011 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Paris, France, 11–15 April 2011; pp. 192–199. [Google Scholar]
- Van der Aalst, W.; Weijters, T.; Maruster, L. Workflow mining: Discovering process models from event logs. IEEE Trans. Knowl. Data Eng. 2004, 16, 1128–1142. [Google Scholar] [CrossRef]
- Alves de Medeiros, A.; Van Dongen, B.; Van Der Aalst, W.; Weijters, A. Process Mining: Extending the Alpha-Algorithm to Mine Short Loops; Technical Report, BETA Working Paper Series; Eindhoven University of Technology: Eindhoven, The Netherlands, 2004. [Google Scholar]
- Nielsen, M.; Plotkin, G.; Winskel, G. Petri nets, event structures and domains. In Semantics of Concurrent Computation; Springer: Berlin/Heidelberg, Germany, 1979; pp. 266–284. [Google Scholar]
- Armas-Cervantes, A.; García-Bañuelos, L.; Dumas, M. Event structures as a foundation for process model differencing, part 1: Acyclic processes. In International Workshop on Web Services and Formal Methods; Springer: Berlin/Heidelberg, Germany, 2012; pp. 69–86. [Google Scholar]
- Wiśniewski, P.; Ligęza, A. Constraint-Based Identification of Complex Gateway Structures in Business Process Models. In International Conference on Artificial Intelligence and Soft Computing; Springer: Berlin/Heidelberg, Germany, 2018; pp. 788–798. [Google Scholar]
- Meyer, B. Self-organizing graphs—A neural network perspective of graph layout. In International Symposium on Graph Drawing; Springer: Berlin/Heidelberg, Germany, 1998; pp. 246–262. [Google Scholar]
- Crosmarie, G.; Salatge, N.; EasyBPMN. EasyBPMN Toolbox—A Powerful Java Library for BPMN 2.0. Available online: https://research.linagora.com/display/easybpmn/ (accessed on 2 May 2018).
- Bazhenova, E.; Buelow, S.; Weske, M. Discovering decision models from event logs. In International Conference on Business Information Systems; Springer: Cham, Switzerland, 2016; pp. 237–251. [Google Scholar]
- Bonnet, F.; Decker, G.; Dugan, L.; Kurz, M.; Misiak, Z.; Ringuette, S. Making BPMN a true lingua franca. BPM Trends. 2014. Available online: http://www.bptrends.com/making-bpmn-a-true-lingua-franca/ (accessed on 2 August 2018).
- Kluza, K.; Nalepa, G.J.; Lisiecki, J. Square complexity metrics for business process models. In Advances in Business ICT; Springer: Cham, Switzerland, 2014; pp. 89–107. [Google Scholar]
- Lassen, K.B.; van der Aalst, W.M.P. Complexity metrics for Workflow nets. Inf. Softw. Technol. 2009, 51, 610–625. [Google Scholar] [CrossRef]
- Wiśniewski, P. Decomposition of business process models into reusable sub-diagrams. ITM Web Conf. 2017, 15, 01002. [Google Scholar] [CrossRef]
- Buijs, J.C.; Van Dongen, B.F.; van Der Aalst, W.M. On the role of fitness, precision, generalization and simplicity in process discovery. In OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”; Springer: Berlin/Heidelberg, Germany, 2012; pp. 305–322. [Google Scholar]
- Zur Muehlen, M.; Recker, J. How Much Language Is Enough? Theoretical and Practical Use of the Business Process Modeling Notation. In Advanced Information Systems Engineering, Proceedings of the 20th International Conference, CAiSE 2008 Montpellier, France, 16–20 June 2008; Bellahsène, Z., Léonard, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 465–479. [Google Scholar] [CrossRef]
- Zur Muehlen, M.; Recker, J. We Still Don’t Know How Much BPMN Is Enough, But We Are Getting Closer. In Seminal Contributions to Information Systems Engineering: 25 Years of CAiSE; Bubenko, J., Krogstie, J., Pastor, O., Pernici, B., Rolland, C., Sølvberg, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 445–451. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task Name | Required DEs | Created DEs | Executions |
|---|---|---|---|
| Check Inventory | Goods Request | Inventory Checked | 1 |
| Receive Packing Slip | Order Sent | Packing Slip | 1 |
| Record Packing Slip | Packing Slip | Packing Slip Record | 1 |
| Task Name | Required DEs | Created DEs | Executions |
|---|---|---|---|
| Reserve Funds | Order Reviewed | Funds Reserved | 1 |
| Receive Invoice | Order Sent | Invoice | 1 |
| Record Invoice | Invoice | Invoice Record | 1 |
| Release Funds | Invoice Record | Funds Released | 1 |
| Packing Slip Record | |||
| Issue Payment | Funds Released | Order Completed | 1 |
| Task Name | Required DEs | Created DEs | Executions |
|---|---|---|---|
| Create Order | Inventory Checked | Order Created | 1 |
| Reprocess Order | Order Reviewed | Order Reprocessed | 1 |
| Task Name | Required DEs | Created DEs | Executions |
|---|---|---|---|
| Review Order | Order Created | Order Reviewed | 2 |
| (Order Reprocessed) | |||
| Send Order | Funds Reserved | Order Sent | 1 |
| ID | Name | Type |
|---|---|---|
| 01 | Goods Request | Text/JSON |
| 02 | Inventory Checked | Boolean |
| 03 | Order Sent | Boolean |
| 04 | Packing Slip | Text/JSON |
| 05 | Packing Slip Record | Integer |
| 06 | Order Reviewed | Boolean |
| 07 | Funds Reserved | Boolean |
| 08 | Invoice | Text/JSON |
| 09 | Invoice Record | Integer |
| 10 | Funds Released | Boolean |
| 11 | Order Completed | Boolean |
| 12 | Order Created | Boolean |
| 13 | Order Reprocessed | Boolean |
| Value | ||||
|---|---|---|---|---|
| not relevant | unchanged | not relevant | — | |
| 0 | forbidden | deleted | forbidden | forbidden |
| 1 | required | created | required | required |
| Feature | Algorithm | Heuristic Miner | ILP Miner | Inductive Miner |
|---|---|---|---|---|
| Type | abstraction | heuristic | language | inductive |
| Construct discovery | ◐ | ● | ● | ◐ |
| Fitness tendency | overfitting | underfitting | overfitting | overfitting |
| Generalization | ◐ | ● | ◐ | ● |
| Advantage | simplicity | control flow | high fitness | high fitness |
| discovery | ||||
| Inconvenience | low quality | high generalization | complex use | block division |
| Recommended | ✓ | ✓✓ | ✓✓✓ | ✓ |
| Element Name | Attributes |
|---|---|
| startEvent | id, name |
| endEvent | id, name |
| task | id, name |
| parallelGateway | id, name, gatewayDirection |
| exclusiveGateway | id, name, gatewayDirection |
| sequenceFlow | id, name, sourceRef, targetRef |
| Process Model | LCM | LD | CFC | ||
|---|---|---|---|---|---|
| Liability Insurance | 6 | 6 | 1 | 0 | 1 |
| Supply Management | 12 | 13 | 1.08 | 1 | 7 |
| Student Project Evaluation | 5 | 9 | 1.8 | 1 | 9 |
| Employee Hiring | 7 | 36 | 5.14 | 2 | 7 |
| Bank Account Opening | 14 | 160 | 11.43 | 0 | 8 |
| Intricate Example | 31 | 10,700 | 345.16 | 2 | 25 |
| Element Type | Support |
|---|---|
| Sequence Flow | ● |
| Task | ● |
| End Event | ● |
| Start Event | ● |
| Pool | ◐ |
| Data-based XOR | ● |
| Start Message | ◐ |
| Text Annotation | ○ |
| Message Flow | ○ |
| Parallel Split/join | ● |
| Lanes | ◐ |
| Association | ○ |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wiśniewski, P.; Kluza, K.; Ligęza, A. An Approach to Participatory Business Process Modeling: BPMN Model Generation Using Constraint Programming and Graph Composition. Appl. Sci. 2018, 8, 1428. https://doi.org/10.3390/app8091428
Wiśniewski P, Kluza K, Ligęza A. An Approach to Participatory Business Process Modeling: BPMN Model Generation Using Constraint Programming and Graph Composition. Applied Sciences. 2018; 8(9):1428. https://doi.org/10.3390/app8091428
Chicago/Turabian StyleWiśniewski, Piotr, Krzysztof Kluza, and Antoni Ligęza. 2018. "An Approach to Participatory Business Process Modeling: BPMN Model Generation Using Constraint Programming and Graph Composition" Applied Sciences 8, no. 9: 1428. https://doi.org/10.3390/app8091428
APA StyleWiśniewski, P., Kluza, K., & Ligęza, A. (2018). An Approach to Participatory Business Process Modeling: BPMN Model Generation Using Constraint Programming and Graph Composition. Applied Sciences, 8(9), 1428. https://doi.org/10.3390/app8091428