1. Introduction
Three-dimensional (3D) content has been steadily increasing in popularity because of its excellent lifelike appearance. With the recent development of 3D display technology, many new 3D applications have appeared to maximize realism, such as head-mounted displays, 360° virtual reality and ultra-high definition 3D content. Consequently, interest in 3D content and in the 3D market itself have both increased greatly.
Methods of representing 3D content are divided into stereo image recording (SIR) and depth-image-based rendering (DIBR). SIR stores the left and right views (as human eyes do) and provides a high-quality immersive view; however, this has many limitations, including a large data size, fixed depth, high cost and difficulty with multiple camera settings. Meanwhile, DIBR is a rendering method that creates various virtual viewpoint images using center and depth images [
1,
2,
3,
4]. The DIBR method has two main advantages: (1) the DIBR system is able to easily save and transmit 3D content, because it requires less data compared to SIR; (2) the DIBR system can provide various viewpoints, since it allows us to adjust the 3D configuration. These advantages have led to DIBR technology being employed in 2D-to-3D conversion [
5,
6,
7,
8,
9,
10] and auto-stereo [
11,
12] and multi-view stereo [
13,
14,
15,
16,
17], which provide various viewpoints depending on the user’s position
Copyright protection techniques for DIBR content have received considerable attention due to DBIR’s important role and significant 3D content market growth. A typical copyright protection technique is watermarking, but many conventional two-dimensional (2D) watermarking techniques are difficult to apply to DIBR content. In the DIBR system, center image pixels are partially moved along the horizontal axis with distance depending on the depth image, using a process called non-linear geometric distortion. Watermarks inserted in the center image are strongly distorted and cannot be extracted.
Hence, several watermarking methods have been proposed as being robust to the DIBR process. Lin et al. proposed a method of embedding watermarks by predicting pixels’ moving distance [
18]. Protecting the center image and both the left and right images required superimposing and embedding three watermarks. This method has a low bit error rate (BER) against the DIBR process and common distortions, such as JPEG or additive noise. However, this method is vulnerable when the depth information is modified, such as in depth image preprocessing or the change of baseline distance, since the moving distance for pixels during the DIBR process is predicted with unmodified depth information. Additionally, this method is vulnerable to geometric attacks due to the characteristics of the discrete cosine transform (DCT) domain.
Franco-Contreras et al. proposed a method of averaging the luminance of an image in the horizontal direction and then inserting a watermark in the averaged vector [
19]. This method is robust against DIBR and signal processing attacks, but has the disadvantage of not considering geometric transformations.
Kim et al. suggested a watermarking method that employed quantization on dual tree complex wavelet transform (DT-CWT) domain coefficients [
20]. The method used directional coefficients that were not significantly changed by the DIBR process. Row-wise quantization was performed to provide robustness to horizontal pixel shifts. The method showed robustness to DIBR; JPEG compression; image scaling; and DIBR configuration adjustments, such as depth image preprocessing and baseline distance changes. However, it was vulnerable to noise addition and geometric distortions.
Wang et al. [
21], Miao et al. [
22] and Cui et al. [
23] proposed a DIBR watermarking method that used the scale-invariant feature transform (SIFT). The SIFT based-watermarking systems found similar parts between the center image and the synthesized image using a SIFT descriptor and then inserted the watermark into those parts. Because of the object matching with SIFT, these methods were robust to DIBR distortion. Additionally, the methods showed high robustness to both general signal distortions and geometric distortions. However, SIFT-based DIBR watermarking methods need SIFT descriptors during watermark extraction. These methods cannot extract watermarks blindly; therefore, SIFT-based watermarking methods are less practical than full-blind watermarking systems.
Rana et al. defined a dependent view region, which is a common area of the left and right eye images, and inserted a watermark using the DC coefficients of the DCT in the dependent view region [
24]. This method achieved robustness against DIBR, JPEG compression and various noise attacks. Rana et al. also proposed a 3D video watermarking technique [
25]. This method exploits the shift invariance and the directional property of the 2D DT-DWT to insert a watermark. This technique showed high invisibility and high robustness against 3D-high efficiency video coding compression, as well as DIBR attacks. However, neither of these methods consider geometric distortions.
Asikuzzaman et al. proposed a DT-CWT-based video watermarking method using color channels [
26,
27]. The method inserted a watermark into the U channel of the YUV color space and inserted the same watermark rotated 180° into the V channel. They showed that the method was robust to DIBR, due to the DT-CWT domain characteristics; and geometric attacks, such as scaling and rotation, since the U and V channels suffer the same geometric transformation. However, if the image center were changed due to attacks such as crop or translation, the watermark could not be detected, and under geometric distortion, it could only determine whether a watermark had been inserted or not, i.e., an on/off switch. Therefore, its application was somewhat limited.
Various templates have been proposed that are robust against geometric attacks [
28,
29,
30,
31]. However, these are only designed to be robust to linear distortions, such as affine transforms, and so are not robust to DIBR, which is a non-linear distortion, as discussed above.
The results of previous works show that blind watermarks have great difficulty surviving in geometrically-distorted DIBR images, because the watermark must be robust to both DIBR and geometric attacks, as shown in
Figure 1. The combination of non-linear and linear deformation severely damages most watermarking domains. Therefore, it is desirable to solve this problem by combining two watermarking methods that have different characteristics, rather than using a single watermarking method.
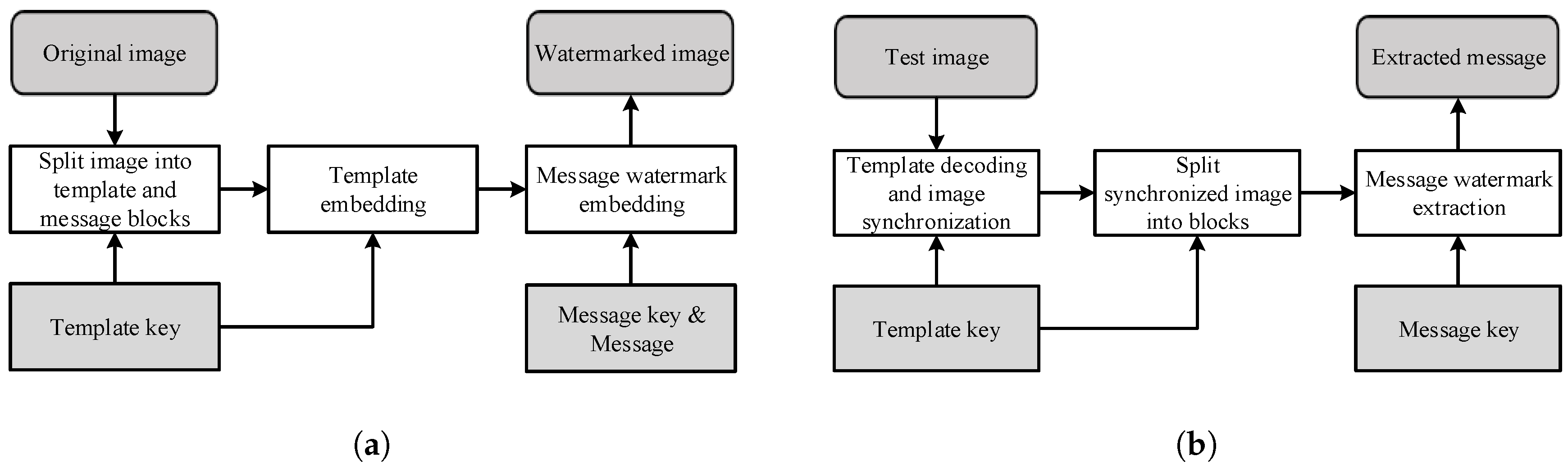
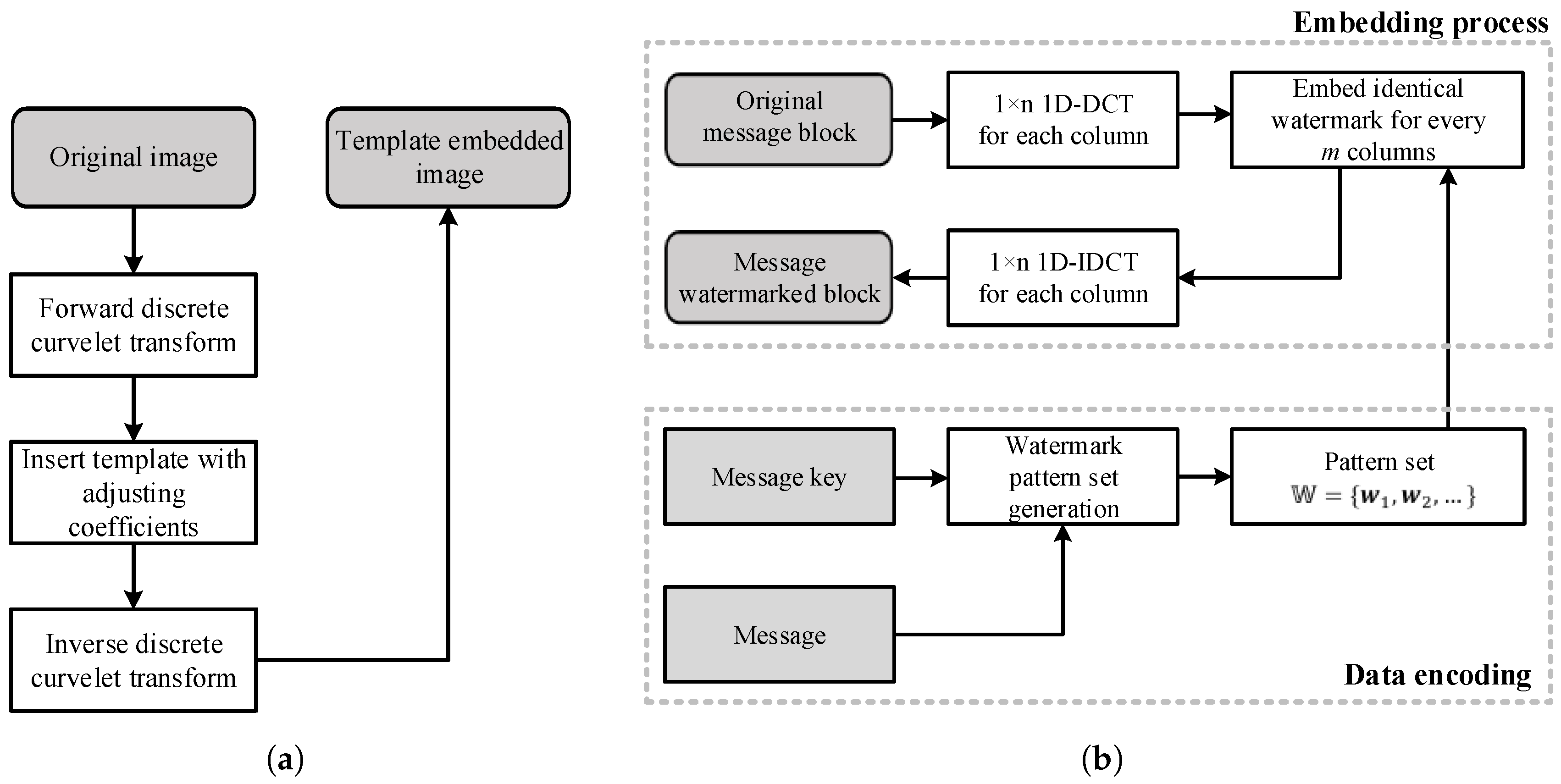
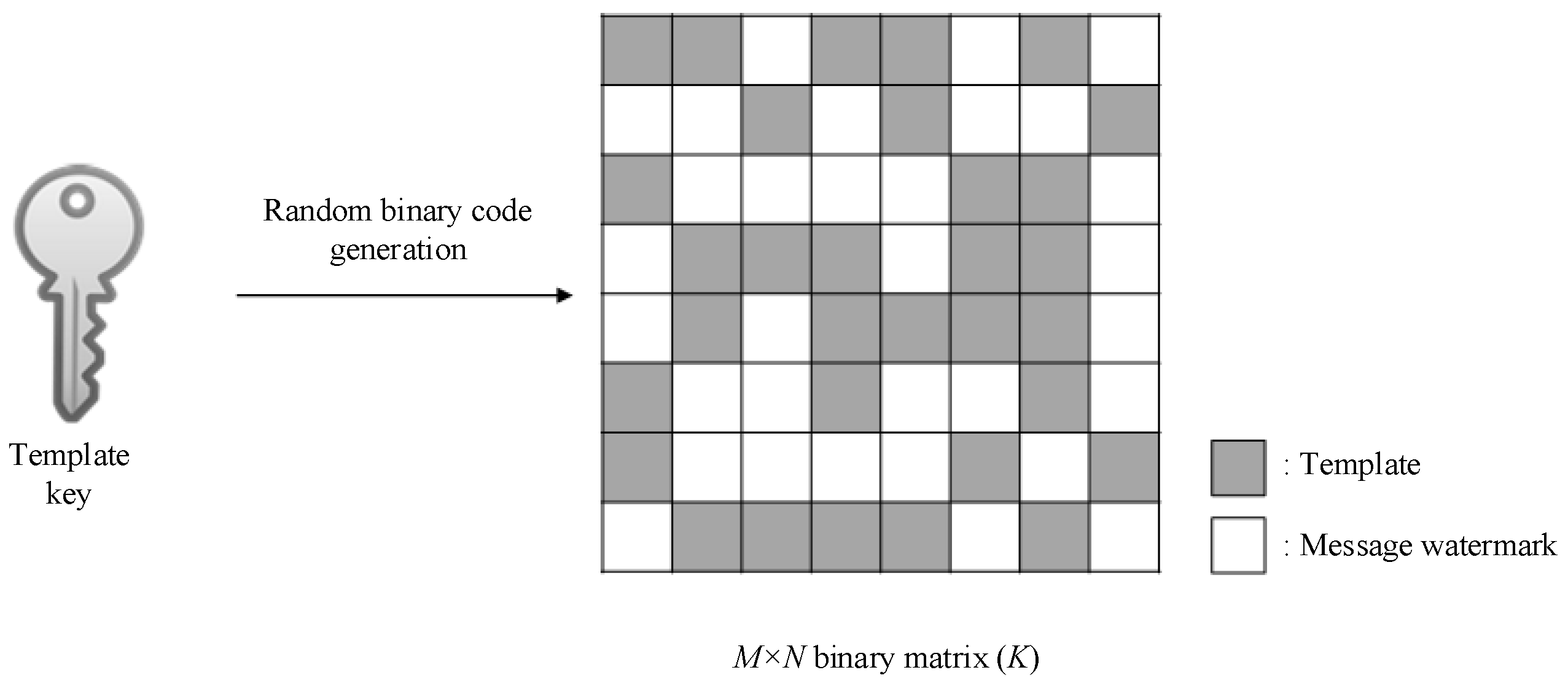
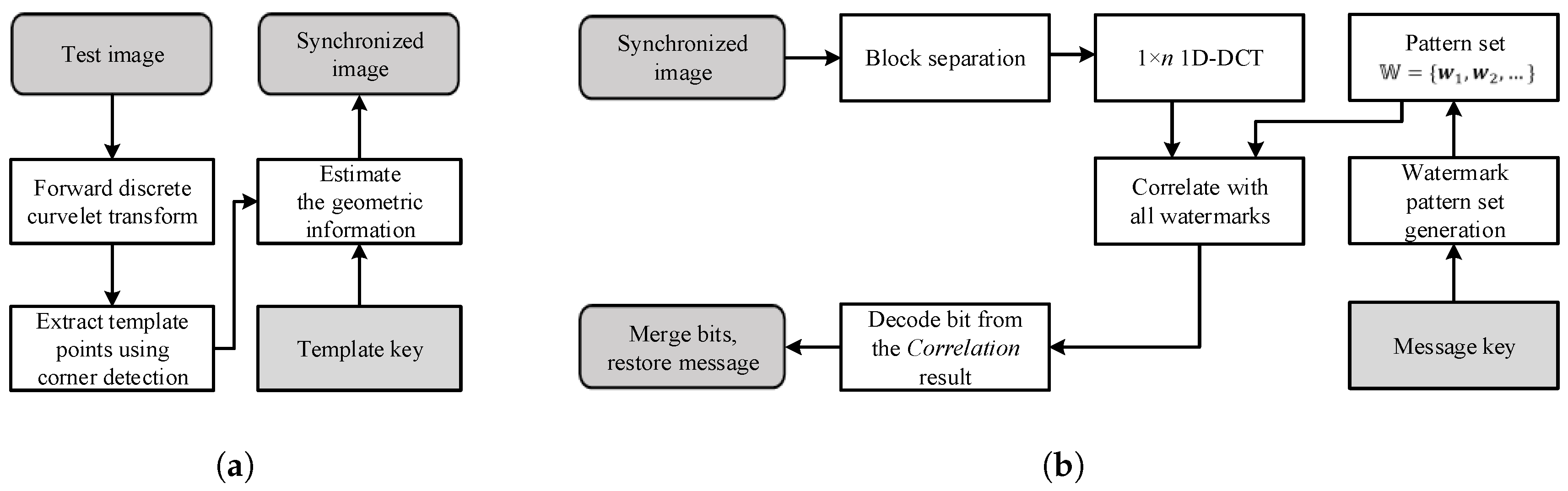
This paper proposes a blind template-based watermarking system combining templates and message watermarks. The role of the template is to restore geometric distortion without being destroyed by the DIBR attack. The template is inserted into the curvelet domain in the form of peak points, and geometric distortion is estimated using the modified iterative closest point (ICP) method. The message watermark inserts and detects messages in the DIBR image. The proposed message watermark is inserted into the 1D-DCT domain, and the message is extracted from the DIBR image after geometric distortion recovery using the proposed template. The message watermark inserts the same information along the horizontal direction in the 1D-DCT domain, and the inserted message watermark is invariant to DIBR due to 1D-DCT linearity.
Experimental results showed that the proposed method has both high invisibility and robustness against various attacks. It achieved excellent scores in visual quality tests and low BER for common signal distortions, such as noise addition and JPEG compression. The watermarking system also exhibited good robustness against geometric distortions, a point of vulnerability in previous approaches, and excellent robustness against DIBR attacks and DIBR configuration adjustments.
This paper is organized as follows.
Section 2 describes the DIBR system and curvelet transform, which are fundamental techniques for the proposed scheme.
Section 3.1 demonstrates the main idea of the proposed watermarking method. The watermark embedding and extraction processes are presented in
Section 3.2 and
Section 3.3, respectively, and the experimental results and conclusion are given in
Section 4 and
Section 5, respectively.
2. Background
This section presents DIBR and the curvelet transform, fundamental techniques of the proposed watermarking system. First, the DIBR process is briefly introduced and DIBR analysis presented, and then, we provide an introduction to and analysis of the curvelet transform.
2.1. DIBR Process
The whole DIBR process is shown in
Figure 2. DIBR consists of three steps: depth image preprocessing, pixel location warping and hole-filling.
Depth image preprocessing, the first step, improves the quality of the rendered image by reducing the number of holes [
32,
33,
34]. When the viewpoint is moved by the DIBR, an area where no pixel information exists is generated. These areas, referred to as holes, are the main cause of 3D image quality degradation. Holes occur mainly when the depth difference between two adjacent pixels is large. Hence, the image quality can be improved by reducing the number of holes through depth image smoothing.
Pixel location warping, the second step, changes the position of pixels along the horizontal direction, allowing users to feel a 3D effect. The warping equation is as follows,
where
is the pixel position on the
x-axis of the center image,
and
are the pixel positions on the
x-axis of the left view and the right view, respectively,
is the baseline distance, which means the distance from the center axis to the left and right,
f is the focal length and
Z is the value of the depth image. During warping, two or more pixels can overlap in one position. In this situation, the highest
Z value of a pixel has to be selected to prevent an unnatural image.
The last step is hole-filling, which creates pixel values in holes caused by pixel location warping. There are several hole-filling techniques, such as interpolation and inpainting. This is a field that is constantly studied in pursuit of a more natural image [
4,
35,
36].
2.2. Analysis of DIBR Attack
In the DIBR process, pixels are only translated horizontally, where the translation magnitude is determined by the depth. Similar to the cover model being considered as random, the depth image is also close to a random signal [
37]; hence, the pixel’s moving distance can also be assumed to be random. Consequently, the pixels move irregularly, unlike in common translation. Thus, the 2D transformed domain coefficients are distorted by DIBR.
The watermark damage caused by DIBR can be confirmed by the average energy change of the middle frequency at which the watermark is inserted, since the average energy is the basis of the watermark embedding energy.
Table 1 shows the average energy change between center and synthesized DIBR image coefficients. DIBR parameters used in this test were as recommended by [
3], and average energy change was defined as:
where
O and
S are the transformed domain’s coefficients for the original and synthesized images, respectively; and MSE is mean squared error. The various transform domain coefficients’ energy is severely impaired by DIBR. Therefore, the watermark energy, inserted into the transform domain’s coefficients, is also damaged, and watermarks damaged by more than 40% are difficult to detect.
However, the average energy change of the Haar discrete wavelet transform (DWT) is reduced to 4% if the distorted coefficients are matched with the undistorted coefficients using the depth image. This is because the wavelet series represent the frequency information of the small spatial block, such as 2 × 2, 4 × 4, ⋯.
If the image is divided into small blocks, some of these will be undistorted, since the depth is similar between adjacent pixels within an object. If all depth values are the same in the block, pixel moving distances are all the same. DIBR is treated like a common translation for this case. A smaller block size implies a greater percentage of uncorrupted blocks, as shown in
Table 2 for the example of 1800 synthesized DIBR images. Similar to the previous average energy change test, this test also used the recommended DIBR parameters from [
3].
Since DCT and discrete Fourier transform (DFT) express a global frequency that does not include spatial information, the amount of average energy change after matching is still high. In other words, it can be seen that the magnitude of the coefficients is damaged in DCT and DFT, but the magnitude of the coefficients is maintained in DWT.
In summary, the following two properties of DIBR can be identified: (1) the pixel is moved only in the horizontal direction, and the moving distance is determined by the depth; (2) the percentage of undistorted blocks is high with a small block size. Due to the second property, the wavelet series are robust to DIBR.
2.3. Curvelet Transform
The curvelet transform is a multi-scale decomposition-like wavelet transform, and the curvelet represents the curve shape for the various directions in the spatial domain [
38,
39,
40,
41]. The curvelet transform is developed to improve the limitation of wavelet-based transforms and can represent edges more efficiently than conventional wavelet-based transforms. Moreover, curvelet bases cover all frequencies in contrast to other directional multi-scale transforms, such as the Gabor and ridgelet transforms [
42]. The curvelet transform is expressed as follows,
In (
3),
C is the curvelet coefficient,
is the scale parameter,
l is the rotation parameter and
is the translation parameter.
is a “wedge”-shaped frequency window represented in (
4).
is the rotation operator, and
. In (
4),
W and
V are the radial and angular windows, respectively.
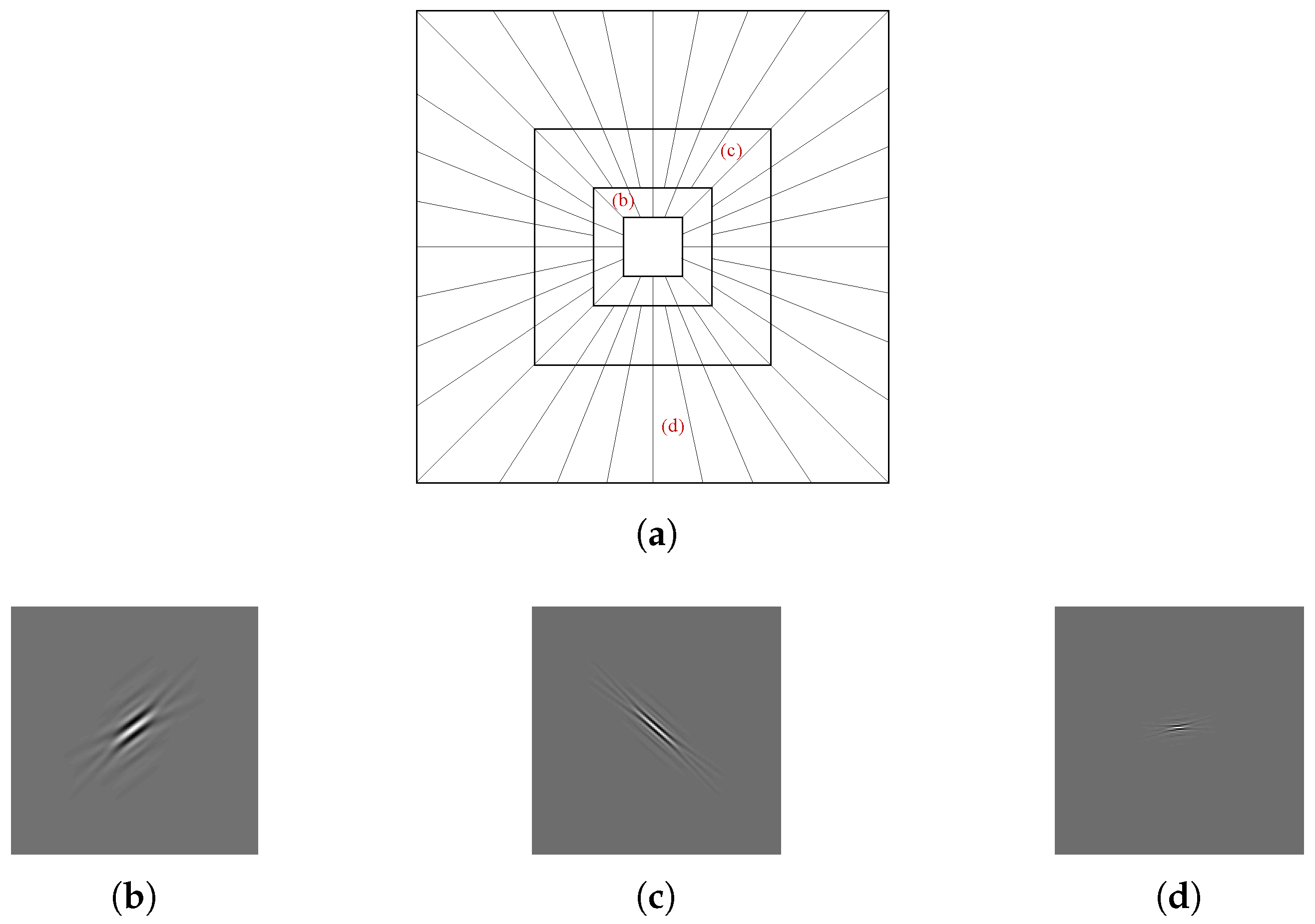
The curvelet is illustrated in
Figure 3.
Figure 3a illustrates the tiling of the curvelet in the frequency domain, and the curvelet shape in several directions and scales in the spatial domain is shown in
Figure 3b–d.
As shown in Equation (
3) and
Figure 3, the curvelet represents frequency information of a small spatial block similarly, so the curvelet is also not distorted by DIBR. In addition, energy conservation is better with the curvelet transform than with conventional Haar DWT when image rotation occurs [
43]. For example, when the image rotates 10 degrees, the energy inserted into Haar DWT is reduced to 50%, but that inserted into the curvelet is maintained up to 85%. In the case of scaling attack, energy is well maintained in most DWT.
In summary, the curvelet transform is suitable for use as a template due to its robustness to DIBR and geometric transform.
4. Experimental Results
This section evaluates the proposed method’s performance in terms of imperceptibility and robustness to various distortions. The proposed method was compared with other blind DIBR image watermarking systems, specifically Lin’s method [
18] and Kim’s method [
20]. The bit capacity of all methods was set to 64.
4.1. Experiment Setting
The test image sets were obtained from Heinrich Hertz Institute [
2], Middlebury [
47,
48,
49,
50] and Microsoft Research 3D Video Datasets [
51].
Figure 10 shows pairs of center and depth images of the test image sets. They have various resolutions from 900 × 720–1800 × 1500. The total number of images used in the experiment was about 1800.
The DIBR parameters are set to focal length and baseline distance of the image width, which are the recommended values for comfortable viewing conditions. Linear interpolation is used as hole-filling for simplicity and without loss of generality.
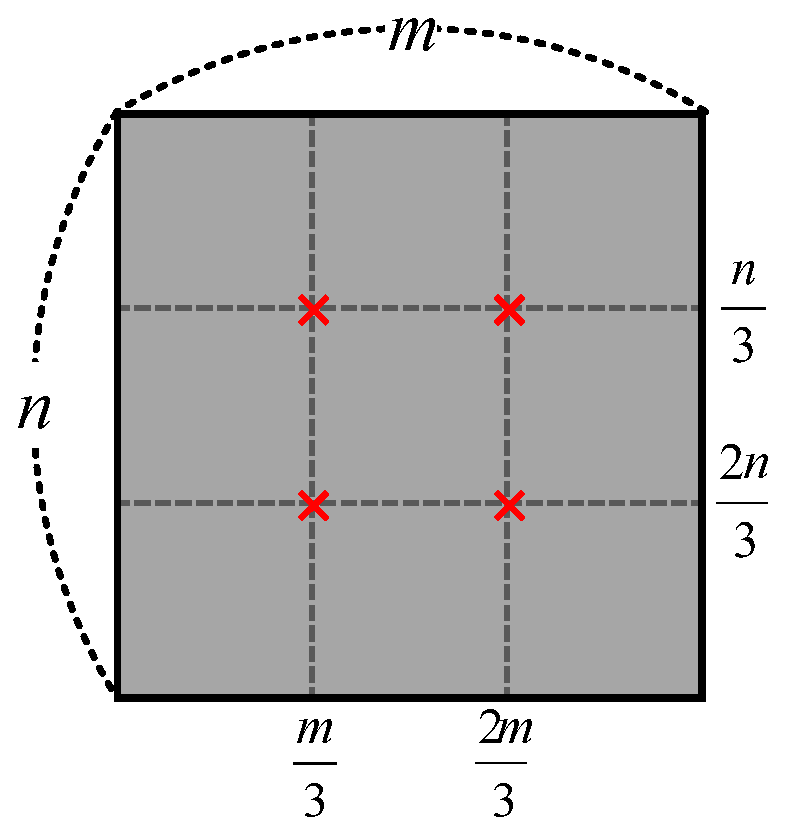
For Lin’s method, block size was set from 100 × 100–200 × 200 to match embedding capacity with other methods. Watermark strength was set as = 1; watermark pattern length = 5120; and the beginning of the embedding position is the 250th coefficient of the zigzag scan order in the DCT domain.
For Kim’s method, block size was set to (
w/8) × (
h/8). The weighting factor for coefficient magnitude was set as
= 450, maximum quantization level
= 2 and minimum difference between paired coefficients
= 8. These values are demonstrated in [
20].
In the proposed method, the size of each block is set set to (w/8) × (h/8). In the template embedding process, the template strengths and are set to five and 50, experimentally. In the message watermark embedding process, is set to 0.5; the length of the watermark pattern is 40; and the start of the embedding position is the 45th coefficient of 1D-DCT.
4.2. Image Quality
As shown in
Figure 11, the quality degradation of the watermarked image is not noticeable. For more accurate image quality measurements, the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) [
52] were measured. The average PSNR and SSIM are shown in
Table 4.
Lin’s method has a lower PSNR despite it exploiting a spread spectrum-based watermarking method that is similar to the proposed method. Since the 2D-DCT is not invariant to DIBR, Lin’s method must insert three watermarks in a superimposed manner in order to protect the left, right and center image. For this reason, the inserted watermark energy is very large.
In Kim’s method, the images are seriously blurred, because this method cuts the coefficient off excessively. As a result, both the PSNR and SSIM values were low.
The proposed method increases imperceptibility by taking advantage of the curvelet and 1D-DCT, which are robust against DIBR. Due to this robustness, the proposed method does not require excessive insertion of the watermark. In particular, the message watermark using the 1D-DCT does not require watermark insertion in a superimposed manner, so the insertion energy can be reduced to about one-third as compared with the 2D-DCT. In addition, since the template and the message can be inserted into different blocks after dividing the block, it is possible to prevent the invisibility degradation caused by the overlapping of templates and message watermarks. For these reasons, PSNR outperforms the other methods and shows similar performance to the best methods according to SSIM.
4.3. Robustness against DIBR
Table 5 shows the results of a DIBR attack. All three methods have low BER against the DIBR attack. Since Lin’s method inserts multiple watermarks, the BER is slightly higher on the right image. The previously inserted watermark (right watermark) was disturbed by the later inserted watermarks (left and center watermarks).
The major advantage of the DIBR process is that DIBR configurations can be adjusted to suit a user’s needs. As described in
Section 2.1, the user can preprocess the depth image to increase the rendered image quality.
Table 6 shows robustness results for synthesized images with a preprocessed depth image. Unlike other methods, Lin’s method raised the BER. This result shows that Lin’s method is susceptible to the shift distance of the pixel, because the left and right watermarks were inserted by predicting the shift distance of the pixels.
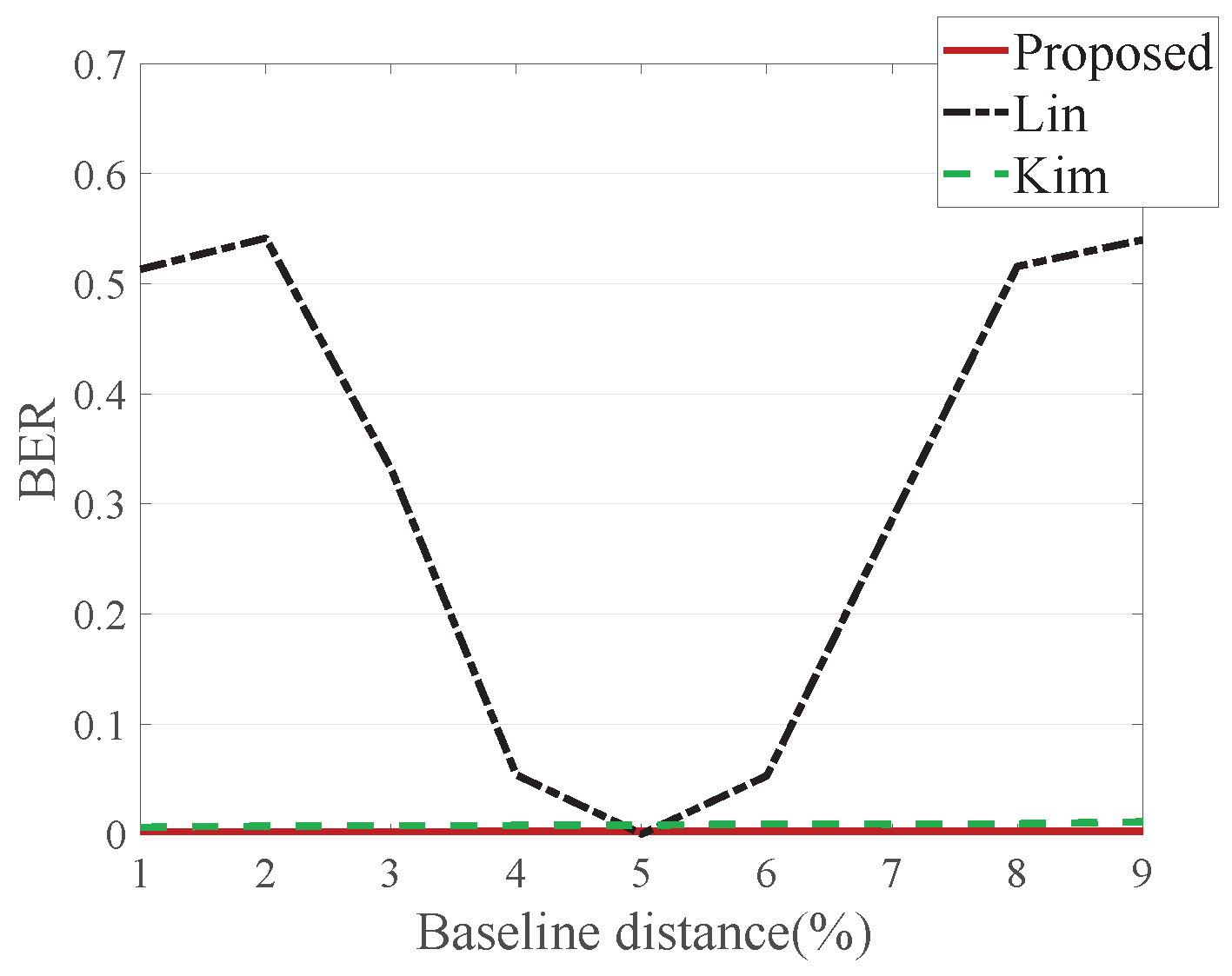
Baseline distance is another DIBR configuration aspect. Various viewpoints of an image can be synthesized depending on the baseline distance change.
Figure 12 shows average BER where the baseline distance is adjusted from 1–10%. Lin’s method increases BER for the same reason as in depth image preprocessing, whereas Kim’s and the proposed method do not increase BER in the baseline distance adjustment.
4.4. Robustness against Signal Distortion
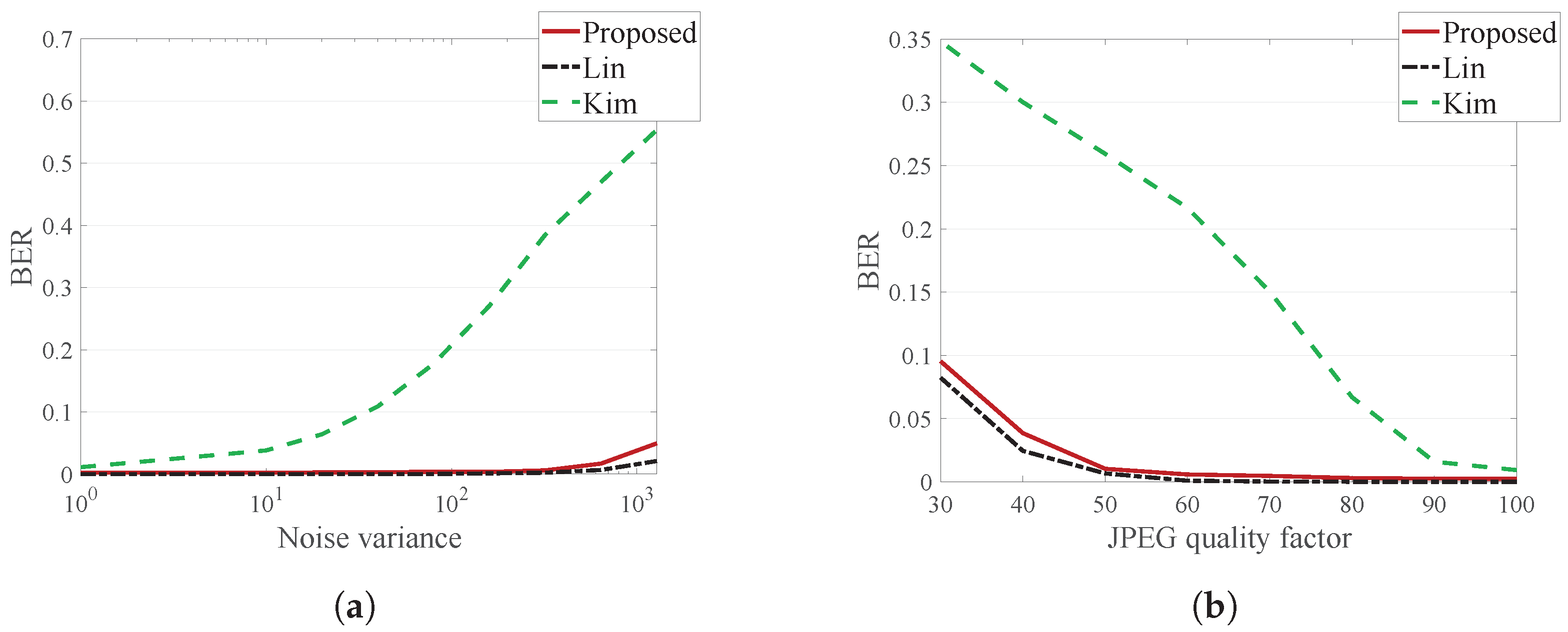
Table 7 and
Table 8 show the average BER for the signal distorted center, left and right images, and
Figure 13 illustrates the average BER for the signal distorted right image.
For additive noise, Lin’s method has the best performance, and the proposed method has a slightly higher BER than Lin’s method. However, additive Gaussian noise with a variance of 2000 is a very severe attack, and such a large amount of noise barely occurs. Considering this, the proposed method is robust enough to additive noise.
For JPEG compression, the proposed method has a slightly higher BER than Lin’s method. However, since the proposed method exhibits error <0.1 for a JPEG quality factor of 30, which is very large compression, it can be considered sufficiently strong against a JPEG attack.
Meanwhile, Kim’s method is more vulnerable to signal distortion than the other methods, since the quantized DT-CWT coefficients are greatly affected by the signal distortion.
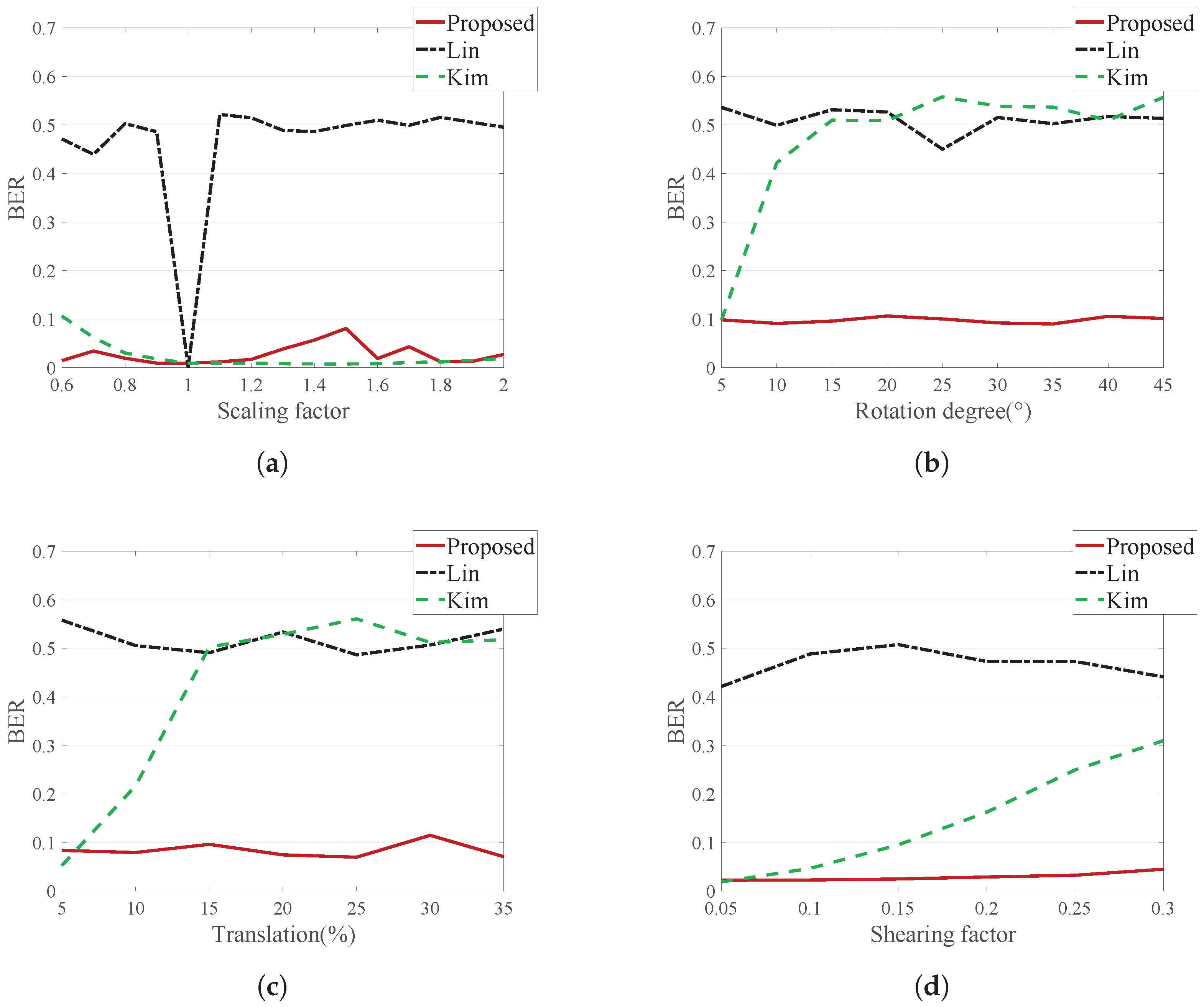
4.5. Robustness against Geometric Distortion
A robustness test against geometric distortion was also conducted with the center, left and right images. We did not consider the case where a geometric attack occurred before the DIBR attack. If a geometric attack takes place before a DIBR attack, the image becomes unnatural. For example, depth is measured horizontally, so if the DIBR is applied after the image is rotated, pixel warping will occur in an unintended direction.
Table 9,
Table 10,
Table 11 and
Table 12 show the average BER for the geometrically-distorted center, left and right images, and
Figure 14 illustrates the average BER for the geometrically-distorted right image.
Lin’s method does not show good results against geometric distortion, because this method embeds the watermark in the DCT domain, which is vulnerable to geometric distortion.
Kim’s method shows good performance against scaling, but is weak to rotation, translation and shearing. This method does not lose synchronization information in scaling. However, the rotation, translation and shearing attacks break the block synchronization. This is because the block size is specified as the ratio of the image, such as .
The proposed method shows good performance on this test, because it utilizes a template robust to geometric attacks. Since the images were recovered from geometric distortion using this template, the message watermark has a low error.
Experiments were also conducted on the combination of geometric distortion in the proposed method. This experiments were conducted by combining two of rotation, translation and scaling, and the results are shown in
Table 13. Rotation with translation and scaling with translation show good results. However, when rotation and scaling occur at the same time, the watermark signal is greatly weakened, so the error is higher than with other geometric combination attacks.
5. Conclusions
Due to the advent of new 3D applications, DIBR has taken on an important role in 3D content. To protect the copyright of such content, this paper proposed a template-based DIBR watermarking system. Ensuring robustness against geometric attacks in rendered images requires that watermarks should be robust to both DIBR and geometric attacks. In order to have robustness to a combination of linear and non-linear attacks, a watermarking system was designed by combining two methods: template and message watermark. Inserting a template into the curvelet domain robust to DIBR allowed this method to restore the geometrically-distorted image. Then, the message was extracted using a 1D-DCT message watermarking method that was invariant to the DIBR. In the experimental results, the proposed method showed high image quality. In terms of robustness, it had low BER to DIBR configuration adjustment, as well as standard configured DIBR. Additionally, the results showed that the proposed method is very robust against noise addition and JPEG compression. For geometric distortion, such as scaling, rotation, translation and shearing, good performance was also demonstrated. However, this method still does not consider the robustness of video coding, which is often used in 3D video, such as high efficiency video coding (HEVC). Therefore, future work will focus on extending this method to 3D videos. In addition, since the proposed method does not use message encryption, we could further improve the security of the message by using encryption. In the future, we will investigate various other types of attack, such as copy-and-paste or transplantation.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}