Self-Interaction Attention Mechanism-Based Text Representation for Document Classification


Abstract
:1. Introduction
- To the best of our knowledge, ours is the first attempt to model the interactions between source elements in a document;
- We propose a Self-interaction Attention Mechanism (TextSAM) to produce the interaction representation in a document for classification.
- We introduce three aggregated strategies to integrate the interaction into a hierarchical structure, generating three models for document classification, i.e., TextSAMAVE, TextSAMMAX and TextSAMATT, respectively.
- We conduct comprehensive experiments on two large-scale public datasets (Yelp 2016 and Amazon Reviews (Electronics)) for document classification. We find that our proposals significantly outperform the state-of-the-art baselines, achieving an improvement ranging from to in terms of accuracy.
2. Related work
2.1. Statistical Classification
2.2. Neural Classification
2.3. Attention Mechanism
3. Methods
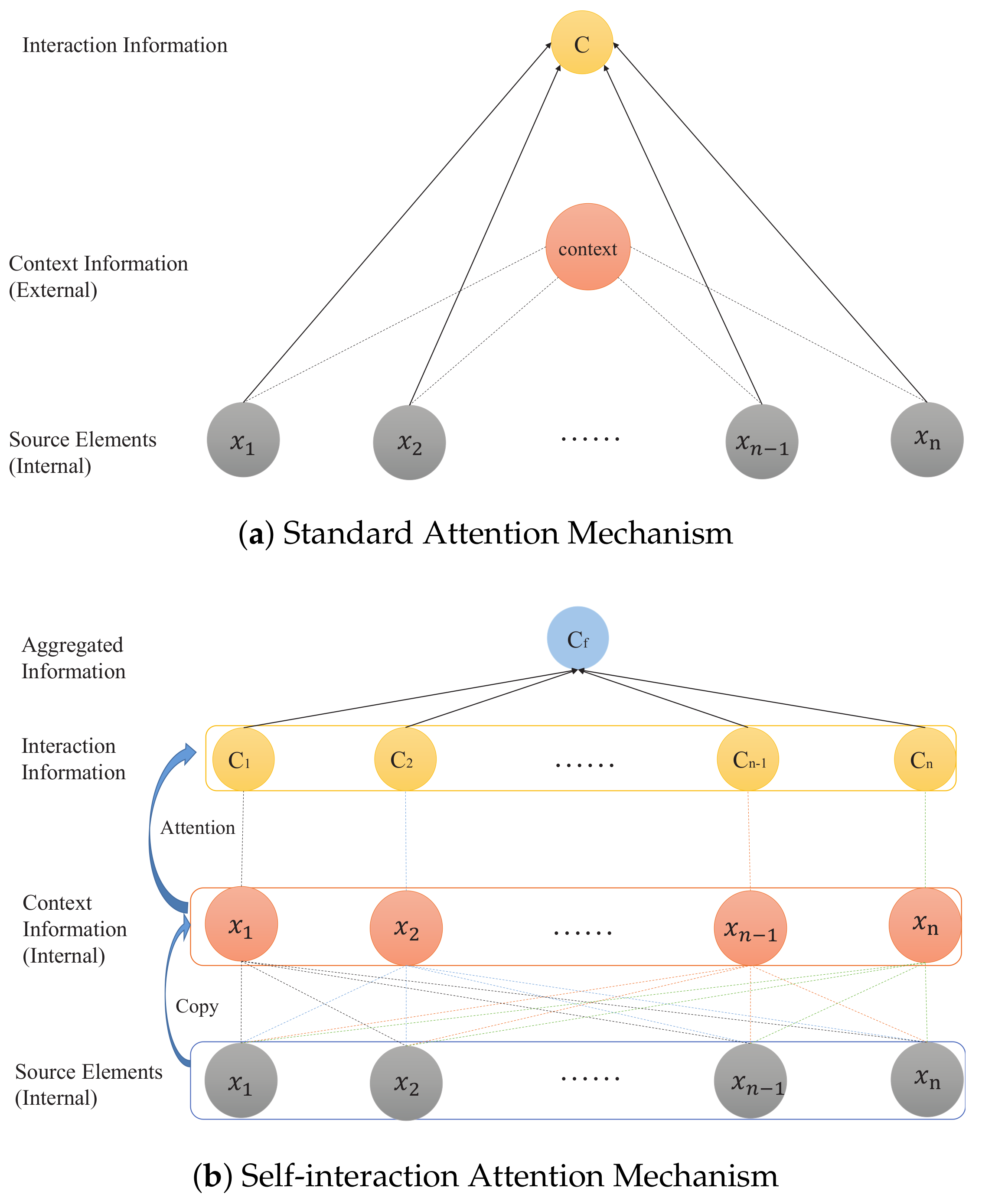
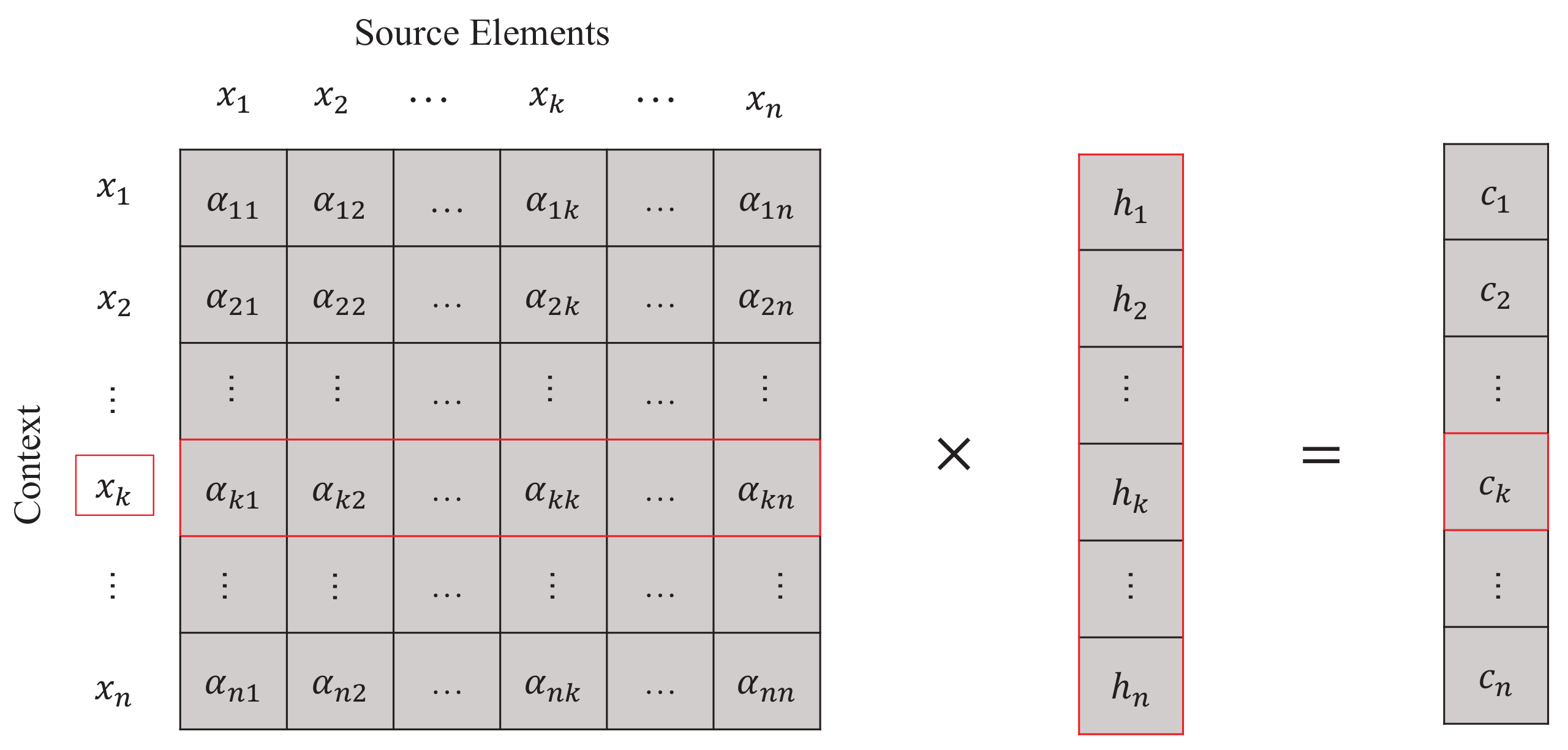
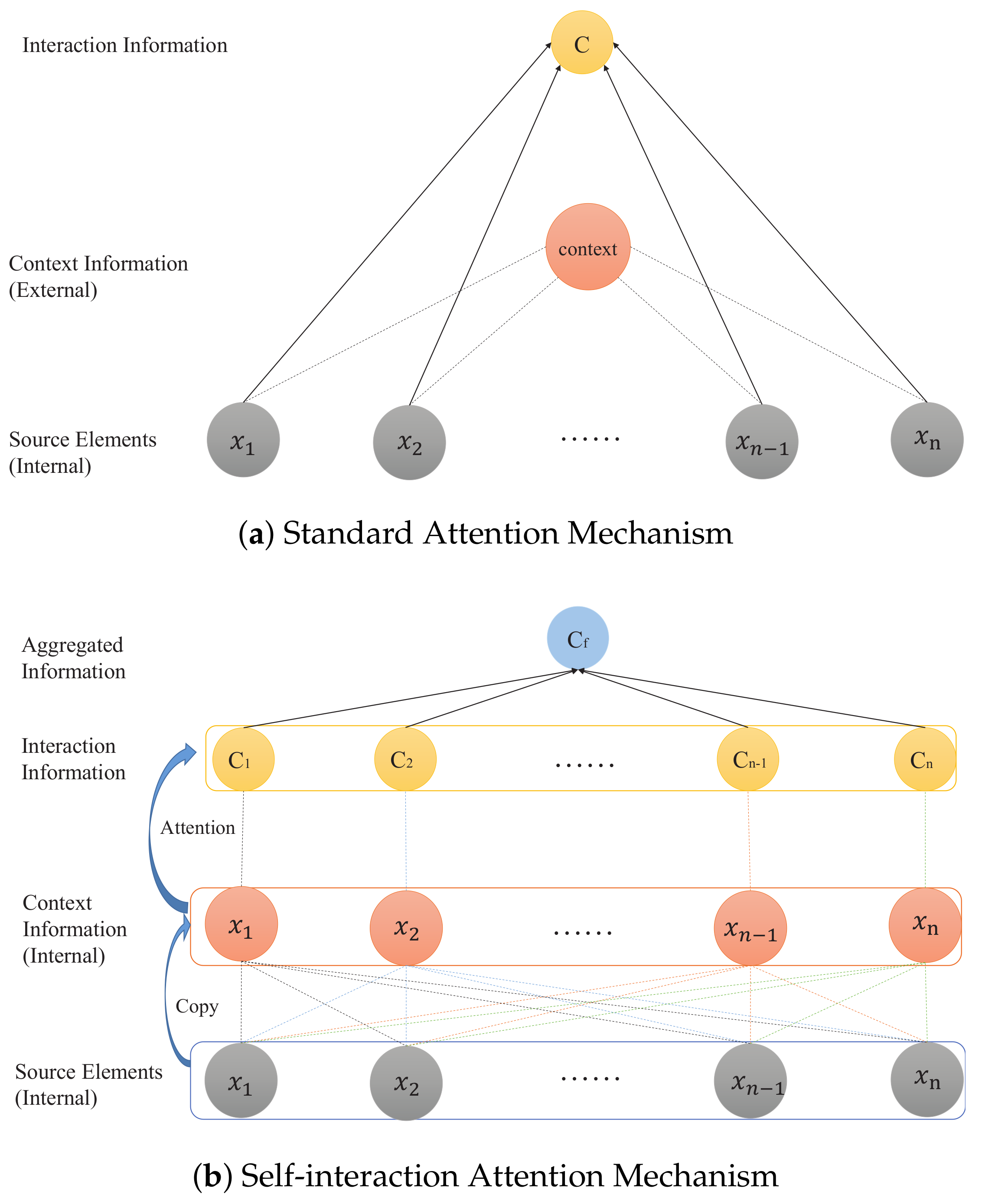
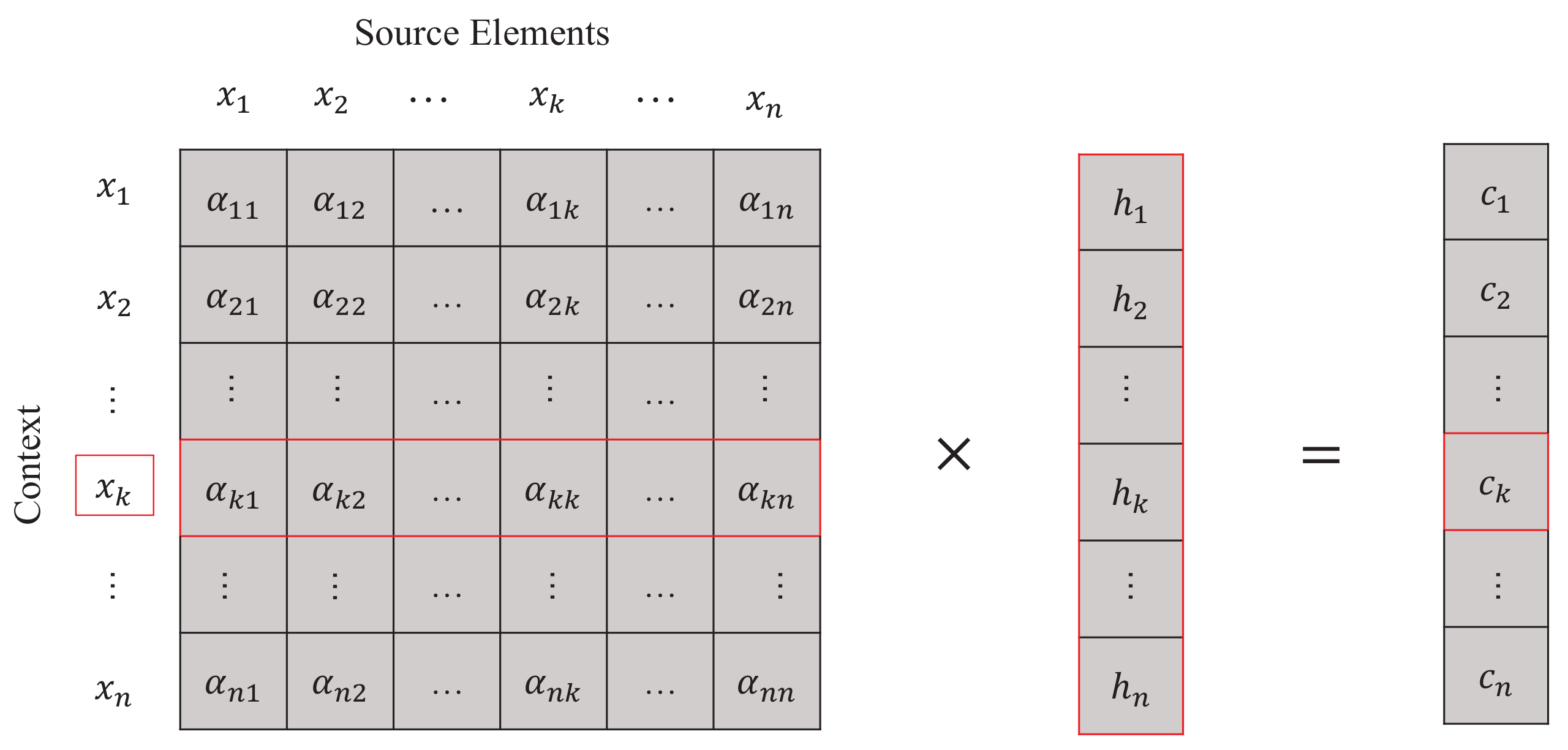
3.1. Self-Interaction Attention Mechanism
3.1.1. One-Way Action
3.1.2. Interaction Representation
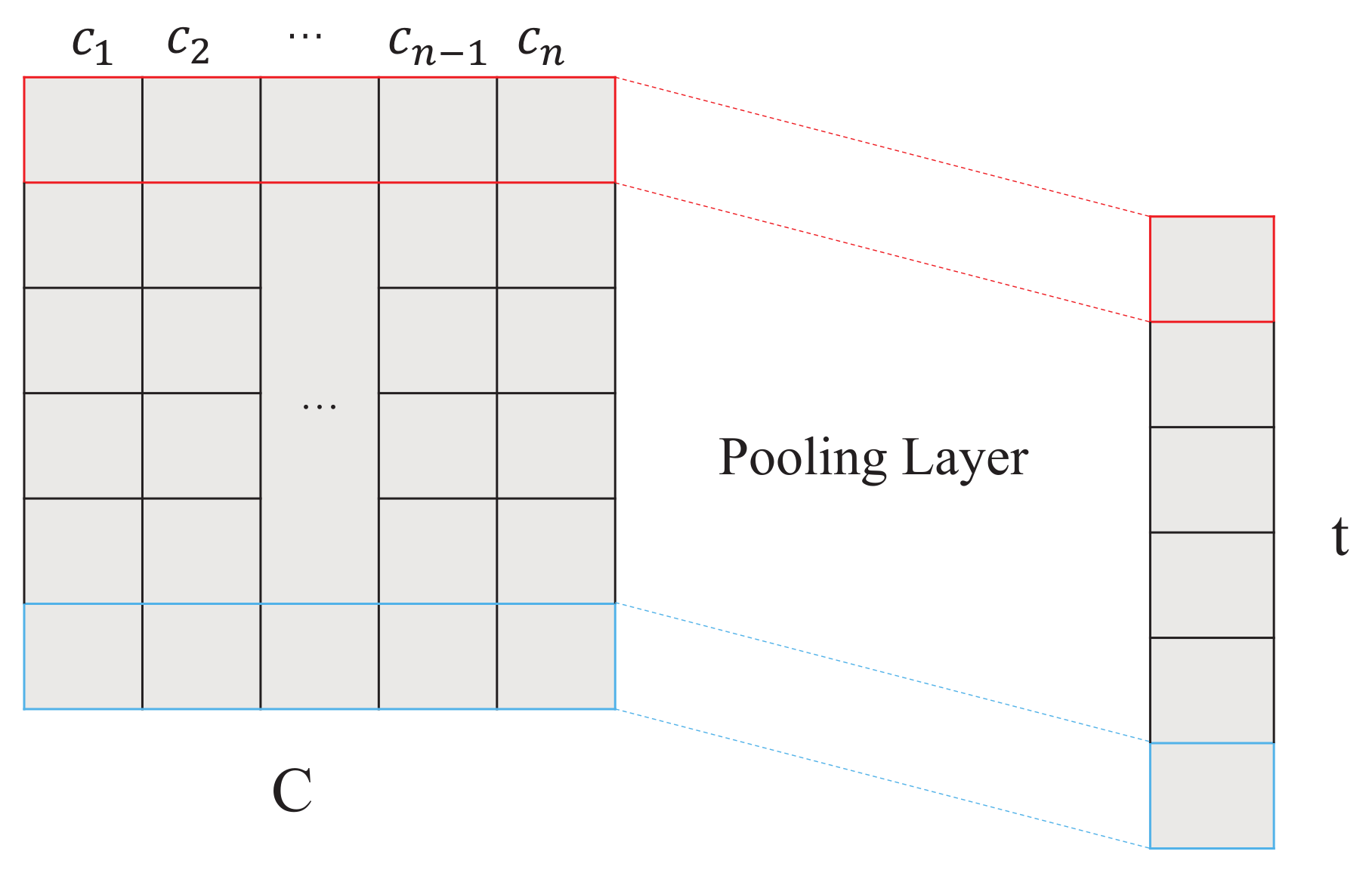
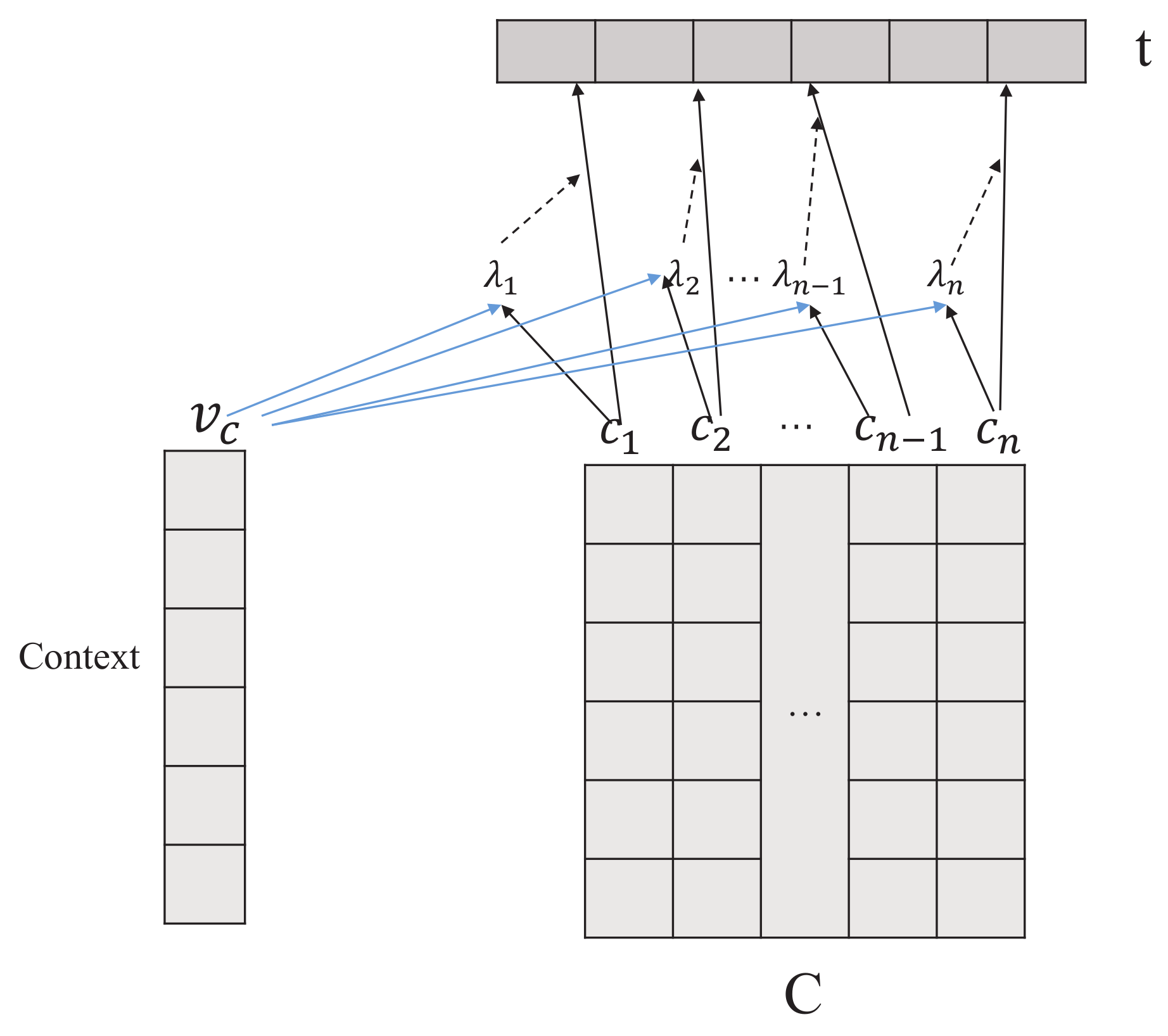
3.2. Aggregated Strategy
3.2.1. Pooling Proces
3.2.2. One-Way Action-Again Process
3.3. Document Classification
4. Experiments
4.1. Model Summary
4.2. Datasets and Evaluation Metrics
- Yelp 2016 is obtained from the Yelp Dataset Challenge in 2016 (https://www.yelp.com/dataset/challenge), which has five levels of ratings from 1 to 5. In other words, we can classify the documents into five classes.
- Amazon Reviews (Electronics) are obtained from Amazon products data (http://jmcauley.ucsd.edu/data/amazon/). This dataset contains the product reviews and the metadata from Amazon from May 1996 to July 2014. Similarly, five levels of ratings from 1 to 5 are given to product reviews.
4.3. Model Configuration
4.4. Research Question
- RQ 1
- Does the self-interaction attention mechanism incorporated in the document representation model help to improve the performance for classification?
- RQ 2
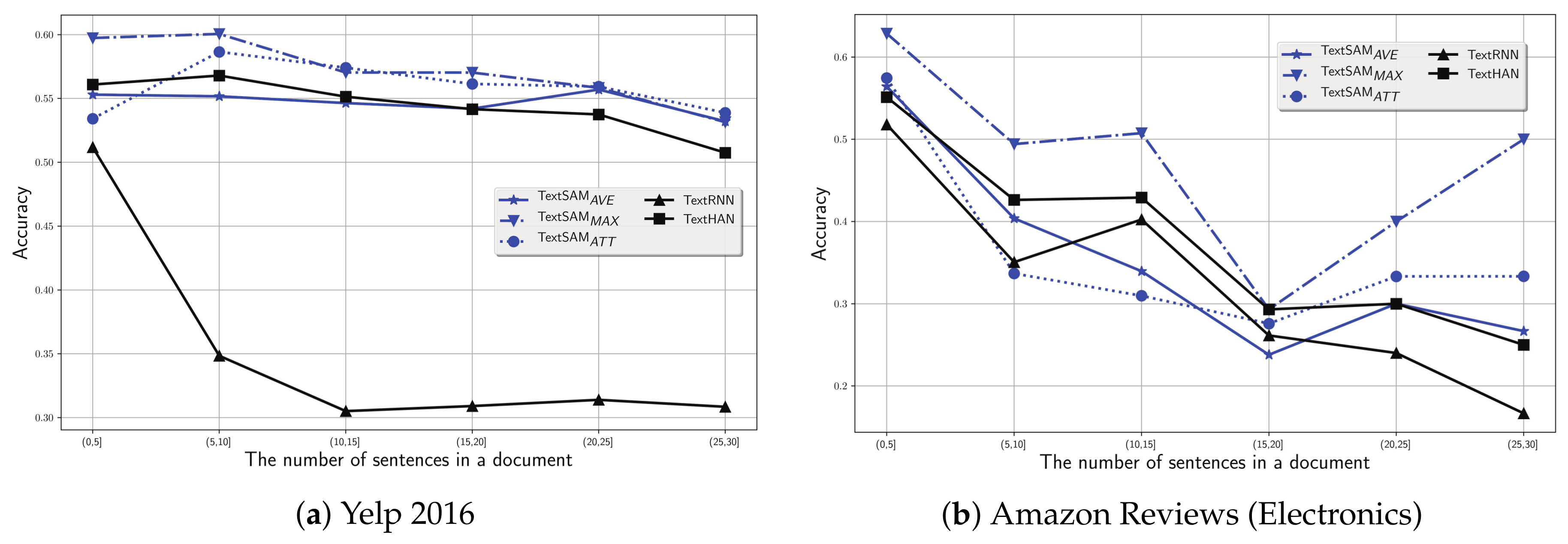
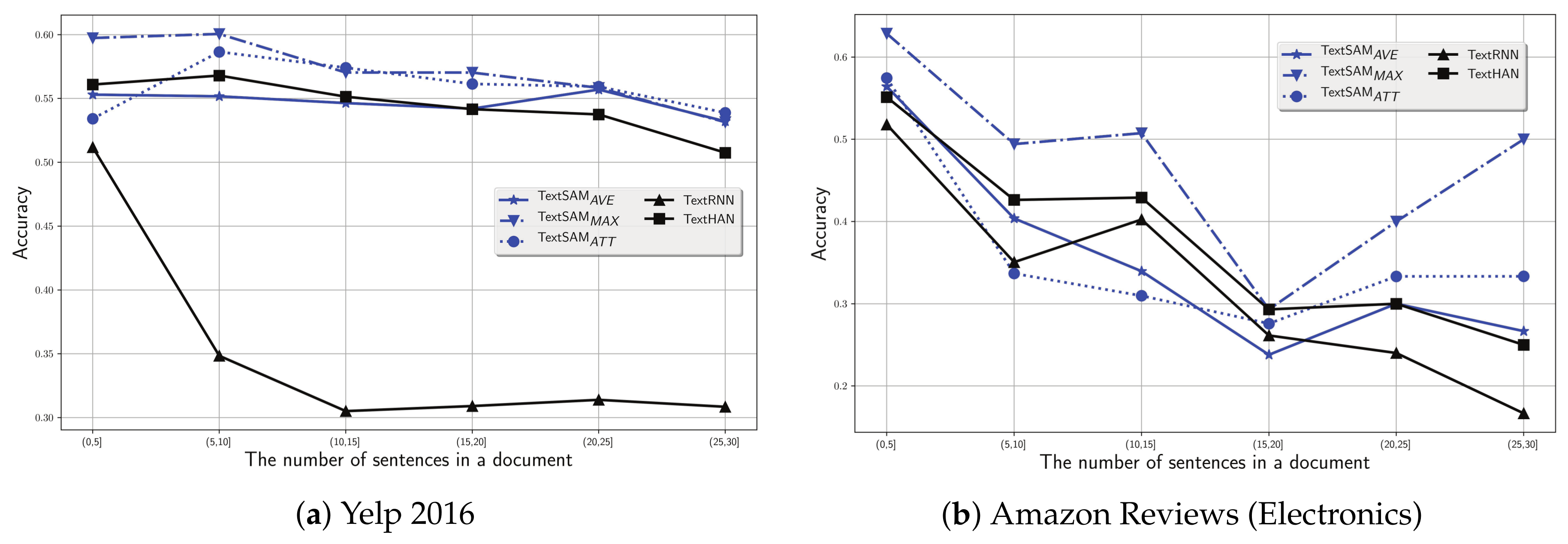
- Since the self-interaction attention mechanism is only built on the sentence level, what is the impact on performance of the number of sentences in a document?
5. Results and Analysis
5.1. Performance Comparison
5.1.1. Holdout Method
5.1.2. K-Fold Cross-Validation
5.2. Impact of the Number of Sentences
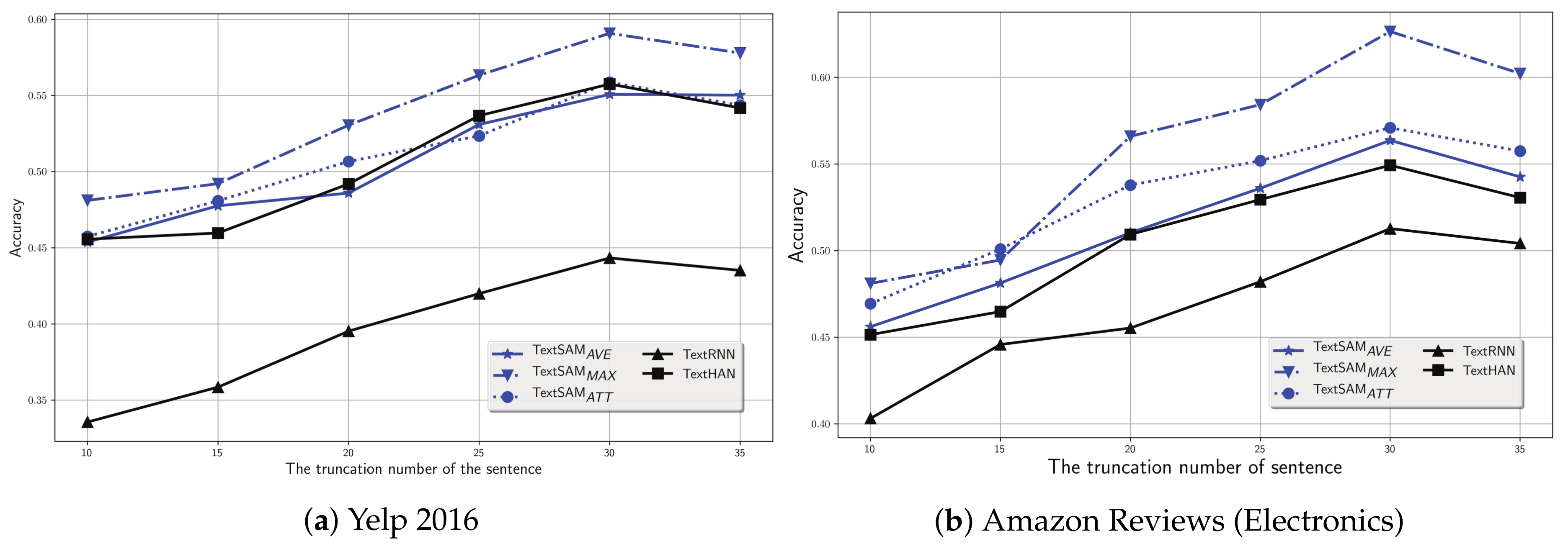
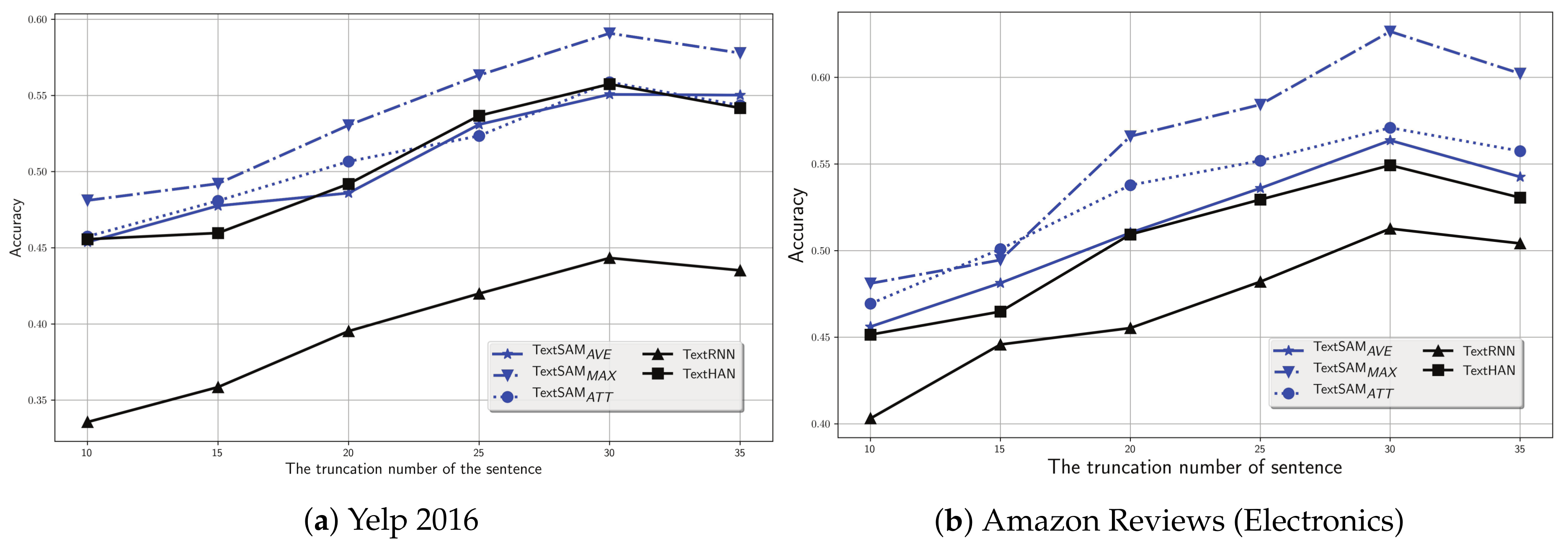
5.3. Parameters Analysis
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
| Algorithm A1 Self-interaction attention mechanism for document classification |
| Input: The embedding matrix for each word in vocabulary, ; the sentence sequence in document d, ; the word sequence in each sentence, e.g., . |
Output: The class label of document d.
|
References
- Moraes, R.; Valiati, J.A.F.; Neto, W.P.G.A. Document-level sentiment classification: An empirical comparison between SVM and ANN. Expert Syst. Appl. 2013, 40, 621–633. [Google Scholar] [CrossRef]
- Tang, D.; Qin, B.; Liu, T. Document Modeling with Gated Recurrent Neural Network for Sentiment Classification. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1422–1432. [Google Scholar]
- Wang, M.; Liu, M.; Feng, S.; Wang, D.; Zhang, Y. A Novel Calibrated Label Ranking-based Method for Multiple Emotions Detection in Chinese Microblogs. In Natural Language Processing and Chinese Computing; Springer: Berlin/Heidelberg, Germany, 2014; pp. 238–250. [Google Scholar]
- Santini, M.; Rosso, M. Testing a genre-enabled application: A preliminary assessment. In Proceedings of the Bcs Irsg Conference on Future Directions in Information Access, London, UK, 22 September 2008; p. 7. [Google Scholar]
- Wang, S.; Manning, C.D. Baselines and bigrams: Simple, good sentiment and topic classification. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers, Jeju Island, Korea, 8–14 July 2012; pp. 90–94. [Google Scholar]
- Joachims, T. Text categorization with Support Vector Machines: Learning with many relevant features. In Proceedings of the European Conference on Machine Learning, Chemnitz, Germany, 21–23 April 1998; pp. 137–142. [Google Scholar]
- Zhang, X.; Zhao, J.; Lecun, Y. Character-level Convolutional Networks for Text Classification. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; pp. 649–657. [Google Scholar]
- Robertson, S. Understanding inverse document frequency: On theoretical arguments for IDF. J. Doc. 2004, 60, 503–520. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3 April 2017; pp. 427–431. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent neural network for text classification with multi-task learning. In Proceedings of the International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2873–2879. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Jun, Z. Recurrent Convolutional Neural Networks for Text Classification. In Proceedings of the Association for the Advancement of Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2267–2273. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the International Conference on Learning Representation, Rossland, BC, Canada, 7–9 May 2015. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the International Conference on Learning Representations, Scottsdale, Arizona, 2–4 May 2013. [Google Scholar]
- Lewis, D.D. An evaluation of phrasal and clustered representations on a text categorization task. In Proceedings of the 15th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Copenhagen, Denmark, 21–24 June 1992; pp. 37–50. [Google Scholar]
- Post, M.; Bergsma, S. Explicit and Implicit Syntactic Features for Text Classification. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; pp. 866–872. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-Based Models for Speech Recognition. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Hermann, K.M.; Kočiský, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching machines to read and comprehend. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Kim, Y.; Denton, C.; Hoang, L.; Rush, A.M. Structured Attention Networks. In Proceedings of the International Conference on Learning Representation, Toulon, France, 24–26 April 2017. [Google Scholar]
- Lin, Z.; Feng, M.; Santos, C.N.D.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A Structured Self-attentive Sentence Embedding. In Proceedings of the International Conference on Learning Representation, Toulon, France, 24–26 April 2017. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Ranzato, M.A.; Boureau, Y.L.; Lecun, Y. Sparse feature learning for deep belief networks. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 1185–1192. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.J.; Mcclosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training Recurrent Neural Networks. Comput. Sci. 2012, 52, III–1310. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Graves, A. Long Short-Term Memory; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1735–1780. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Description |
|---|---|
| TextRNN ∘ | A recurrent neural network-based approach [11]. |
| TextHAN ∘ | A hierarchical attention network-based approach [14]. |
| TextSAMAVE ★ | A self-interaction attention mechanism-based approach with averaging the interaction. |
| TextSAMMAX ★ | A self-interaction attention mechanism-based approach with maximizing the interaction. |
| TextSAMATT ★ | A self-interaction attention mechanism-based approach with one more attention on interaction. |
| Dataset | Yelp 2016 | Amazon Reviews (Electronics) |
|---|---|---|
| # classes | 5 | 5 |
| # documents | 4,153,150 | 1,689,188 |
| # average sentences/document | 8.11 | 6.88 |
| # average words/sentence | 17.02 | 7.65 |
| # average words/document | 138.02 | 136.97 |
| # maximal sentences in document | 166 | 416 |
| # maximal words in document | 1431 | 7488 |
| # words in vocabulary | 155,498 | 66,551 |
| Model | Yelp 2016 | Amazon Reviews (Electronics) |
|---|---|---|
| TextRNN [11] | 0.4433 | 0.5127 |
| TextHAN [14] | 0.5575 | 0.5493 |
| TextSAMAVE | 0.5507 | 0.5636 |
| TextSAMAMX | 0.5908 | 0.6265 |
| TextSAMATT | 0.5587 | 0.5709 |
| Model | Yelp 2016 | Amazon Reviews (Electronics) |
|---|---|---|
| TextRNN [11] | 0.4532 | 0.5211 |
| TextHAN [14] | 0.5537 | 0.5435 |
| TextSAMAVE | 0.5543 | 0.5632 |
| TextSAMAMX | 0.5919 | 0.6293 |
| TextSAMATT | 0.5602 | 0.5726 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, J.; Cai, F.; Shao, T.; Chen, H. Self-Interaction Attention Mechanism-Based Text Representation for Document Classification. Appl. Sci. 2018, 8, 613. https://doi.org/10.3390/app8040613
Zheng J, Cai F, Shao T, Chen H. Self-Interaction Attention Mechanism-Based Text Representation for Document Classification. Applied Sciences. 2018; 8(4):613. https://doi.org/10.3390/app8040613
Chicago/Turabian StyleZheng, Jianming, Fei Cai, Taihua Shao, and Honghui Chen. 2018. "Self-Interaction Attention Mechanism-Based Text Representation for Document Classification" Applied Sciences 8, no. 4: 613. https://doi.org/10.3390/app8040613
APA StyleZheng, J., Cai, F., Shao, T., & Chen, H. (2018). Self-Interaction Attention Mechanism-Based Text Representation for Document Classification. Applied Sciences, 8(4), 613. https://doi.org/10.3390/app8040613