1. Introduction
The research and development of virtual reality (VR) and augmented reality (AR) have made significant progress over the last several decades. For the successful realization of VR/AR systems, it has been known that spatial sound or three-dimensional (3D) sound is an important component for enhancing the immersive quality of the systems when combined with video [
1].
To generate such spatial sound, spatial cues from the human auditory system have been studied. The principle of spatial hearing is based on binaural and monaural cues [
2]. Binaural cues imply the differences between two ears, including the time difference of arrival and the intensity difference between two ears, which are respectively referred to as the interaural time difference (ITD) and the interaural level difference (ILD). These binaural cues are related to the perceiving horizontal direction of a sound source. However, monaural cues contain the effects of the head, body, and pinna. They modify the magnitude spectrum of a sound source and are strongly related to perceiving the vertical direction of sound sources [
3]. Another monaural cue is the reverberant factor, which is defined as the amount of reflection and reverberation relative to the direct sound and is primarily related to perceiving the distance of a sound source [
4].
To date, audio rendering, which is a spatial audio processing technique, has been used to localize a sound source to an arbitrary position in 3D space. Thus, a listener perceives a sound produced from a localized position virtually. The audio rendering can be conducted in either the binaural or transaural configuration [
1]. In a binaural configuration through headphones, research on spatial sound has focused primarily on finding the relationship between the position of a given sound source and the listener’s ears. The relationship between such a sound source and the listener is typically called the head-related transfer function (HRTF), through which spatial sound is produced. The HRTF can be measured using a dummy head that mimics the human eardrum [
5]. This measurement represents the effects of the head, body, and pinna and the pathway from a given source position to a dummy head. Therefore, HRTFs differ from person to person because sound propagation varies due to the head, torso, and eardrums of each person [
6]. Applying measured HRTFs from a dummy head or other people to a specific person can degrade the performance of immersive sound effects due to the variance in personal characteristics. Therefore, HRTFs should be individually designed or measured to obtain localization performance.
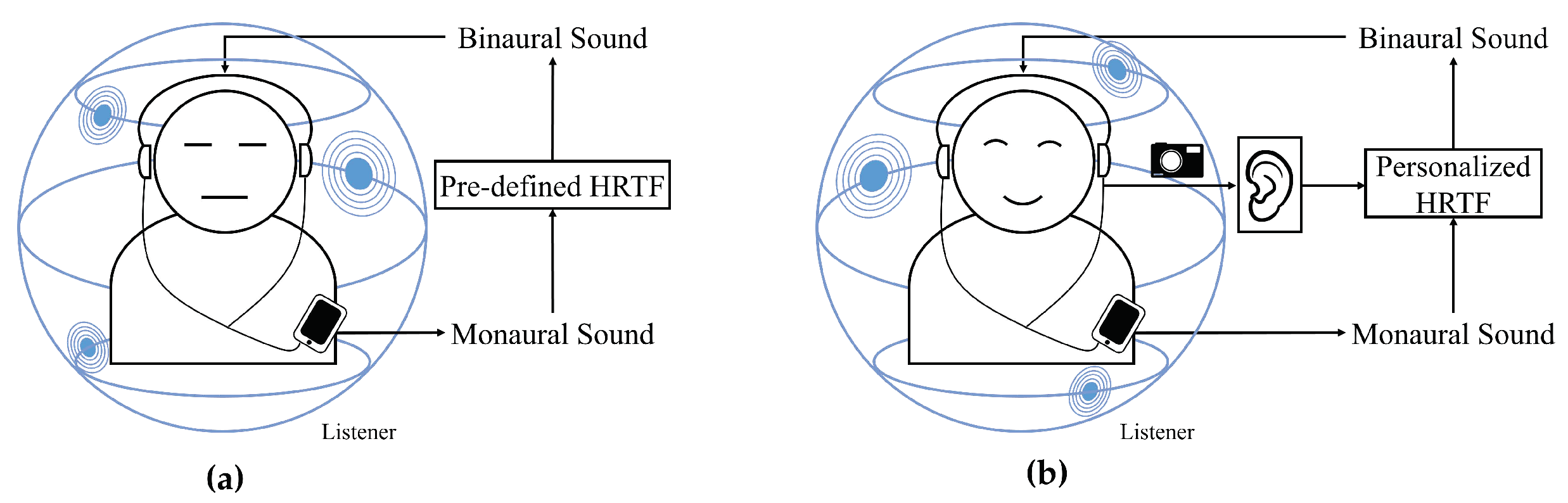
Figure 1 shows a possible application of the personalized HRTF when playing sound in a binaural configuration. As shown in
Figure 1a, a traditional approach to generating binaural sound from monaural sound is using a pre-defined HRTF, but the proposed method shown in
Figure 1b enables us to provide better sound quality to a listener with HRTF that is personalized to the listener.
As HRTFs vary according to anthropometric measurements, HRTFs have been designed using statistical methods to create standard human head models [
5]. However, since HRTFs are sensitive to individual characteristics, the spatial sound generated by an average HRTF model cannot be expected to produce faultless effects [
6]. Therefore, it is necessary to measure the HRTF that suits the individual, but the measurement cost and time pose difficulties. To overcome these shortcomings, mathematical design methods based on measured HRTFs have also been studied in Reference [
7,
8,
9]. Recently, artificial neural networks have shown meaningful results in various applications, such as temperature estimation and control [
10,
11], machinery fault diagnosis [
12,
13], material property prediction [
14,
15], load forecasting [
16], handwritten digit recognition [
17], and wind-speed forecasting [
18]. In particular, based on biometric information, breast cancer classification [
19] and corneal power estimation [
20] showed good performance. A deep learning approach has also been applied to explore the complex relationship between anthropometric measurements and HRTFs [
21,
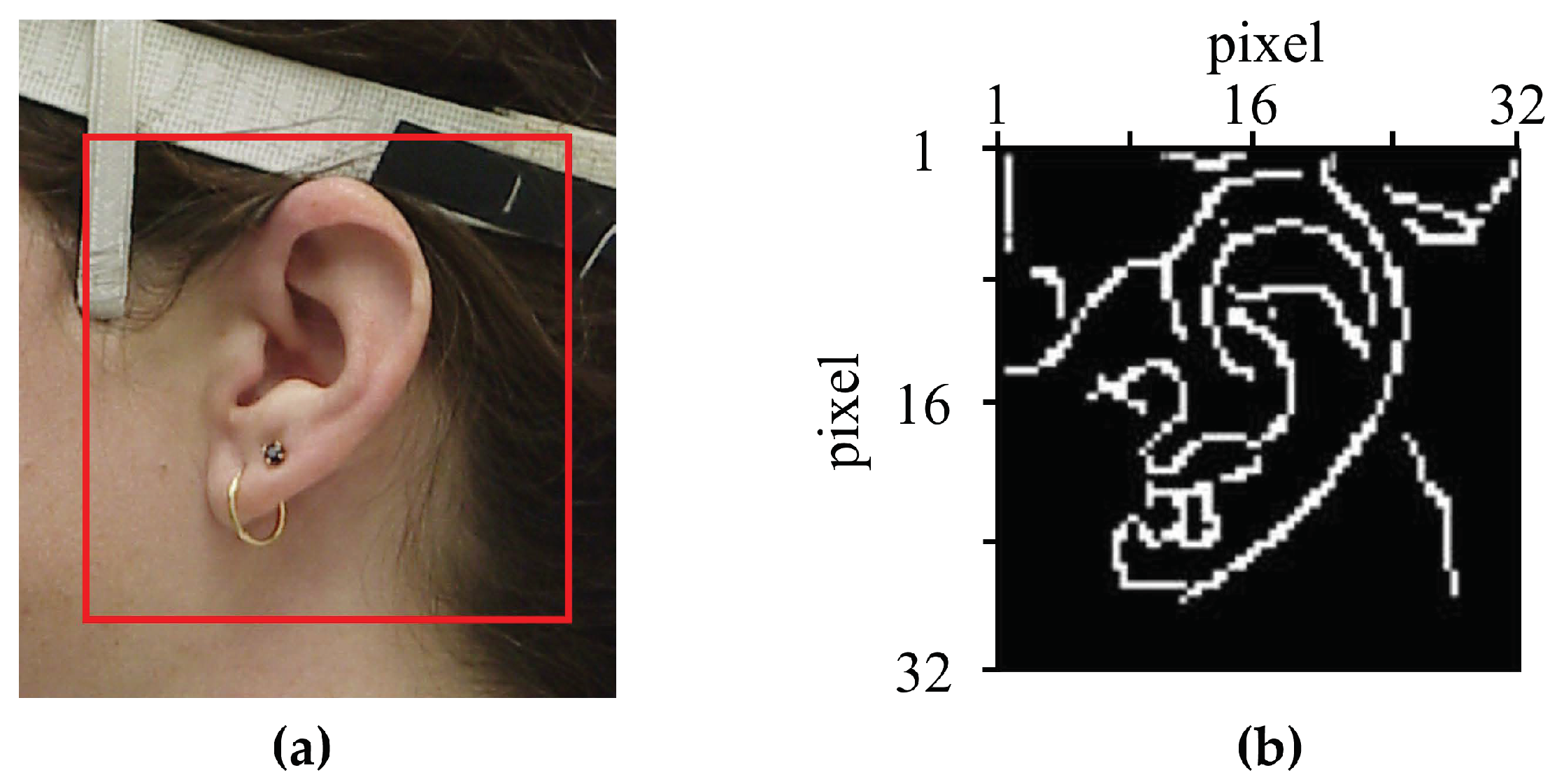
22], where anthropometric measurements including detailed measurements of the head, shoulders, and ears were used as the input features for a deep neural network (DNN). However, the performance of this approach was limited because ear-related measurements were difficult to obtain in real life. Instead of directly measuring anthropometric pinna measurements, we proposed a feature extraction method for ear images using an auto-encoder based on a convolutional neural network (CNN) [
23] where the bottleneck features were extracted to represent personalized anthropometric data.
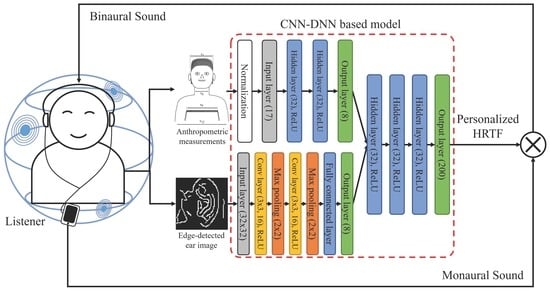
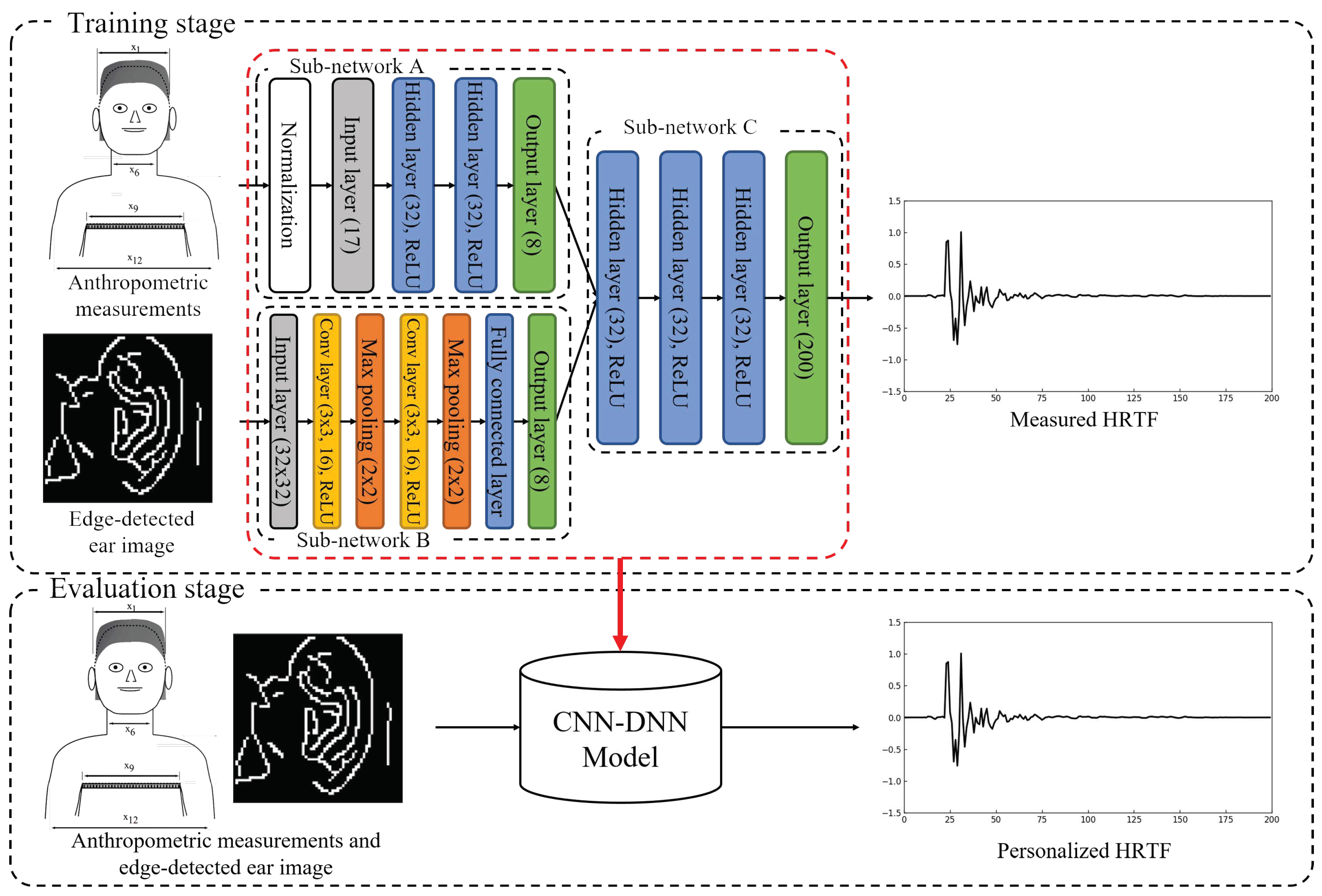
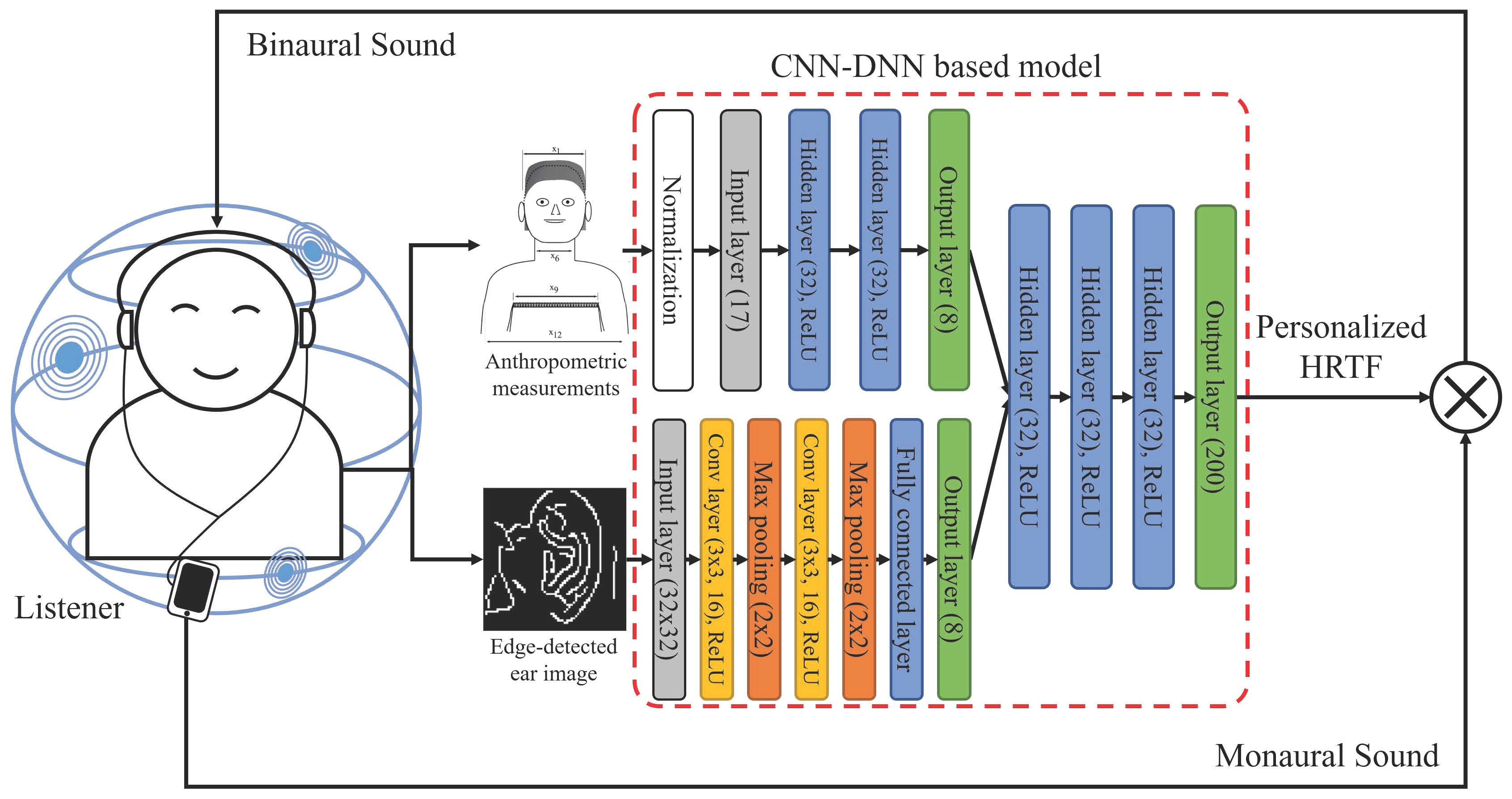
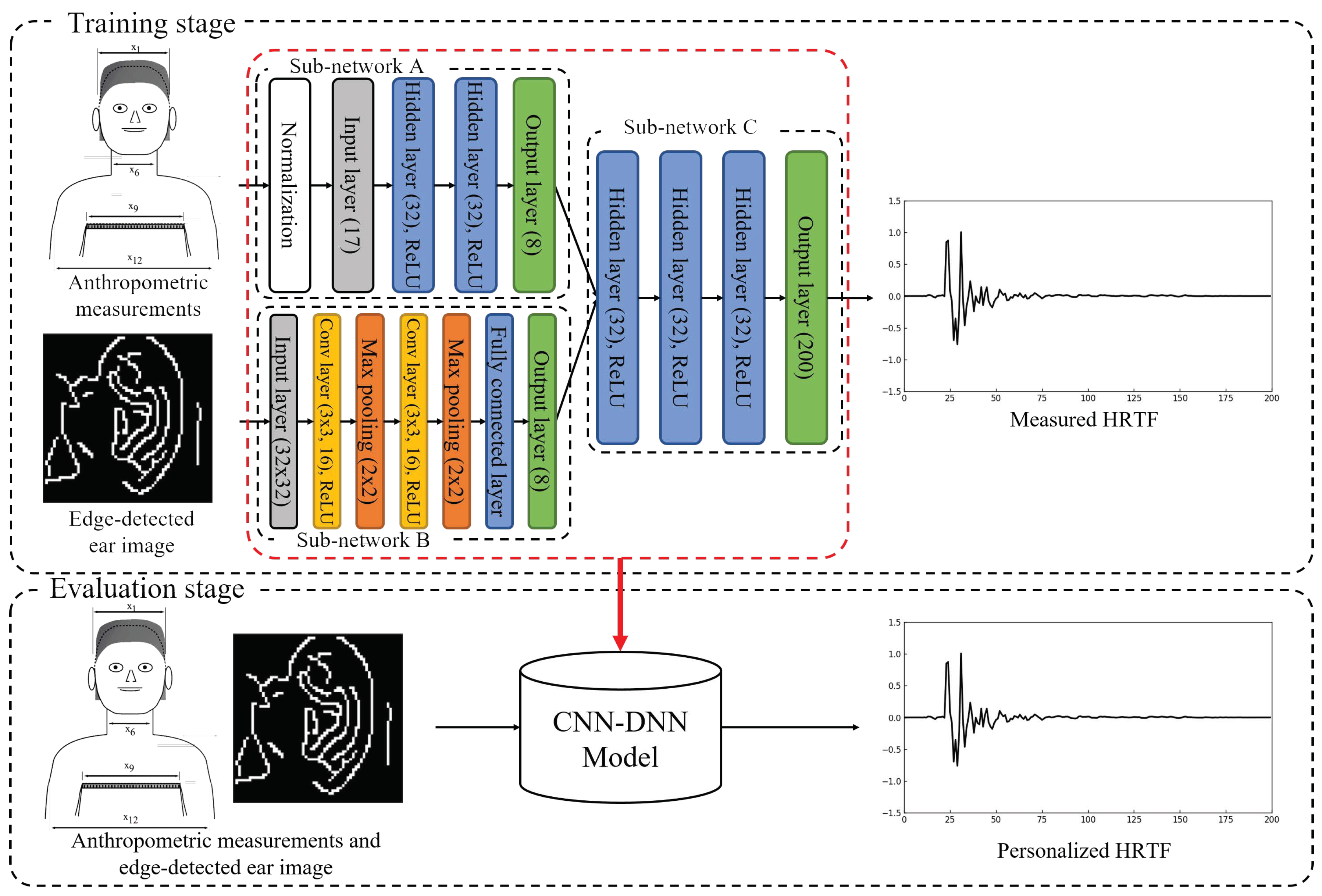
In this paper, our previous approach is extended to estimate a personalized HRTF using ear images instead of ear-related anthropometric measurements. The proposed neural network for the personalized HRTF estimation is composed of three sub-networks, the first of which is a feed-forward DNN that uses anthropometric measurements as input features to represent information on the relationship between anthropometric measurements and HRTFs [
22]. The second sub-network tries to represent the personalized anthropometric measurements from ear images and is designed using a CNN, which enables us to obtain bottleneck features as proposed in Reference [
23]. Lastly, the two different internal features obtained from the anthropometric measurements and ear images are combined using another DNN to estimate personalized HRTFs. The performance of the proposed method is evaluated objectively and subjectively. As objective measures, the root-mean-square error (RMSE) and log-spectral distortion (LSD) between the reference and estimated HRTF are calculated. In addition, the distance perceived by listeners after applying the estimated HRTF to a sound source is used as a subjective measure. Next, the performance of the proposed method is compared with that of HRTF estimation methods using the average [
6] and estimated HRTF by a DNN trained with anthropometric measurements [
22].
The remainder of this paper is organized as follows:
Section 2 briefly reviews deep learning-based personalized HRTF estimation using whole anthropometric measurements.
Section 3 proposes a personalized HRTF estimation method using a neural network that combines a DNN and a CNN in parallel applied to anthropometric measurements and ear images, respectively.
Section 4 evaluates the performance of the proposed method and compares it with those of HRTF estimation methods using the average HRTF and the estimated HRTF by the DNN trained with anthropometric measurements. Finally,
Section 5 concludes this paper.
2. Review of HRTF Modeling Using Anthropometrics
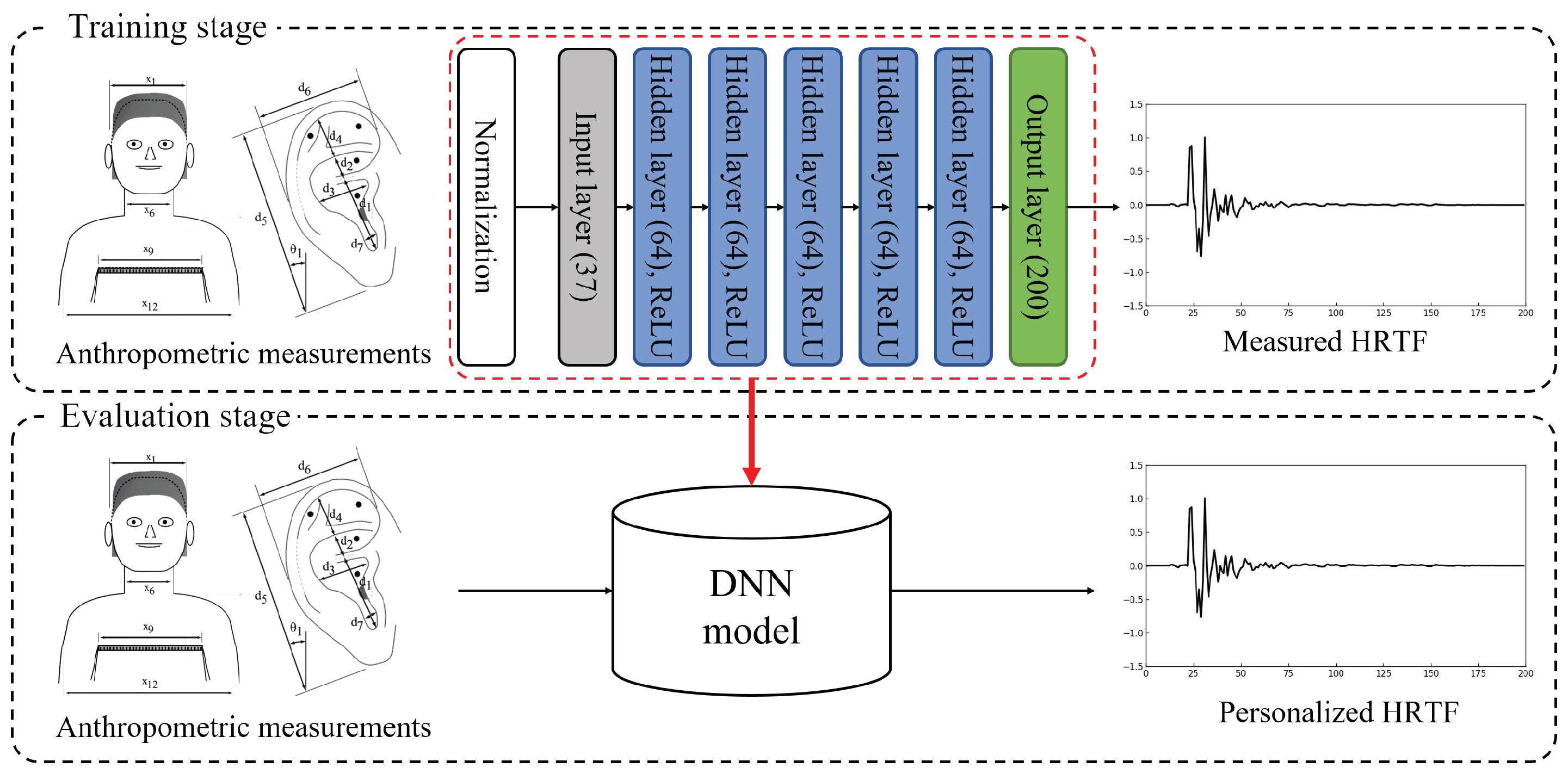
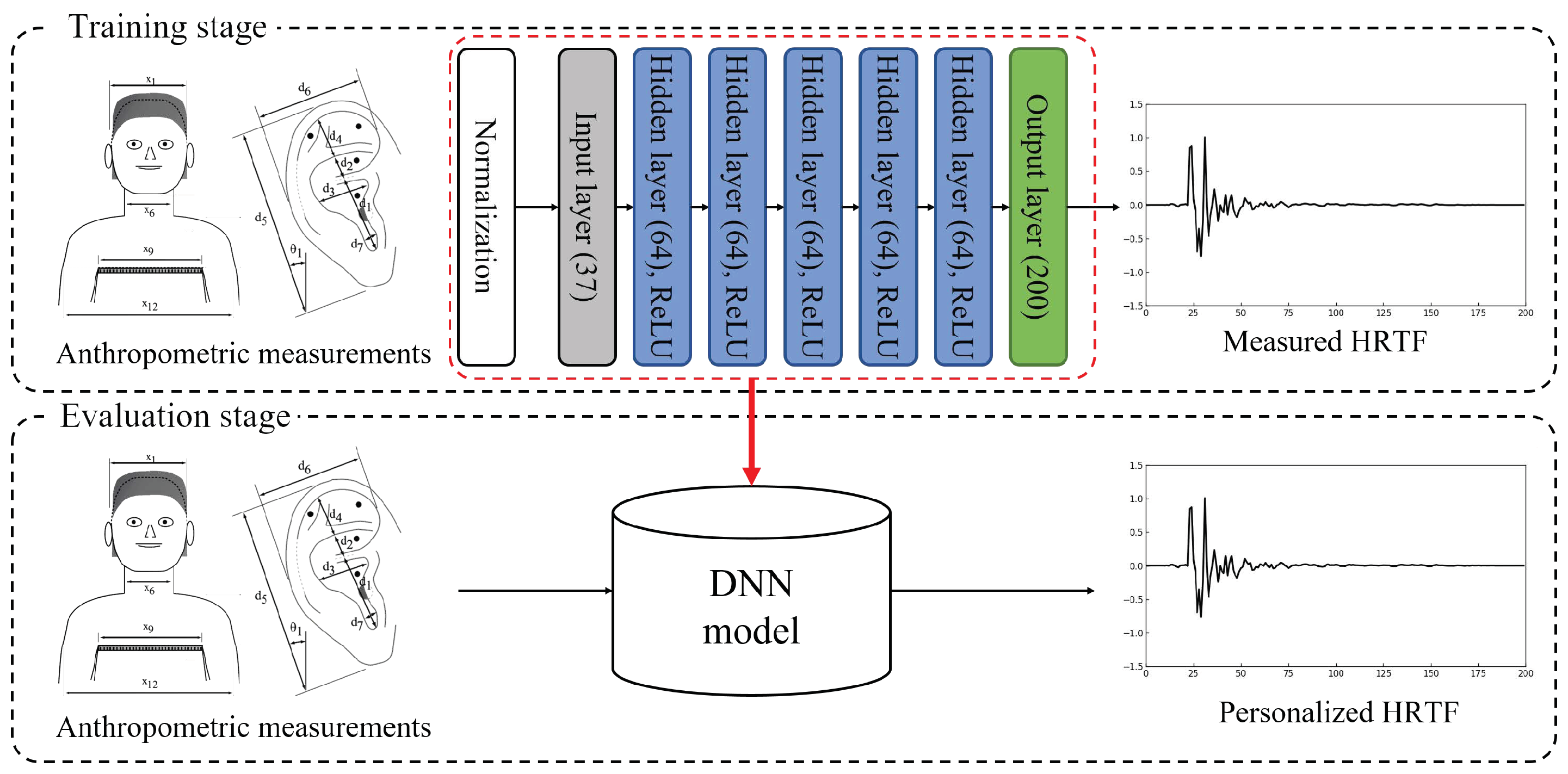
In this section, we briefly review a method for generating personalized HRTFs based on DNNs using anthropometric measurements, as shown in
Figure 2 [
22]. In the process of designing personalized HRTFs, the public HRTF database was provided by the Center for Image Processing and Integrated Computing (CIPIC) of the University of California at Davis [
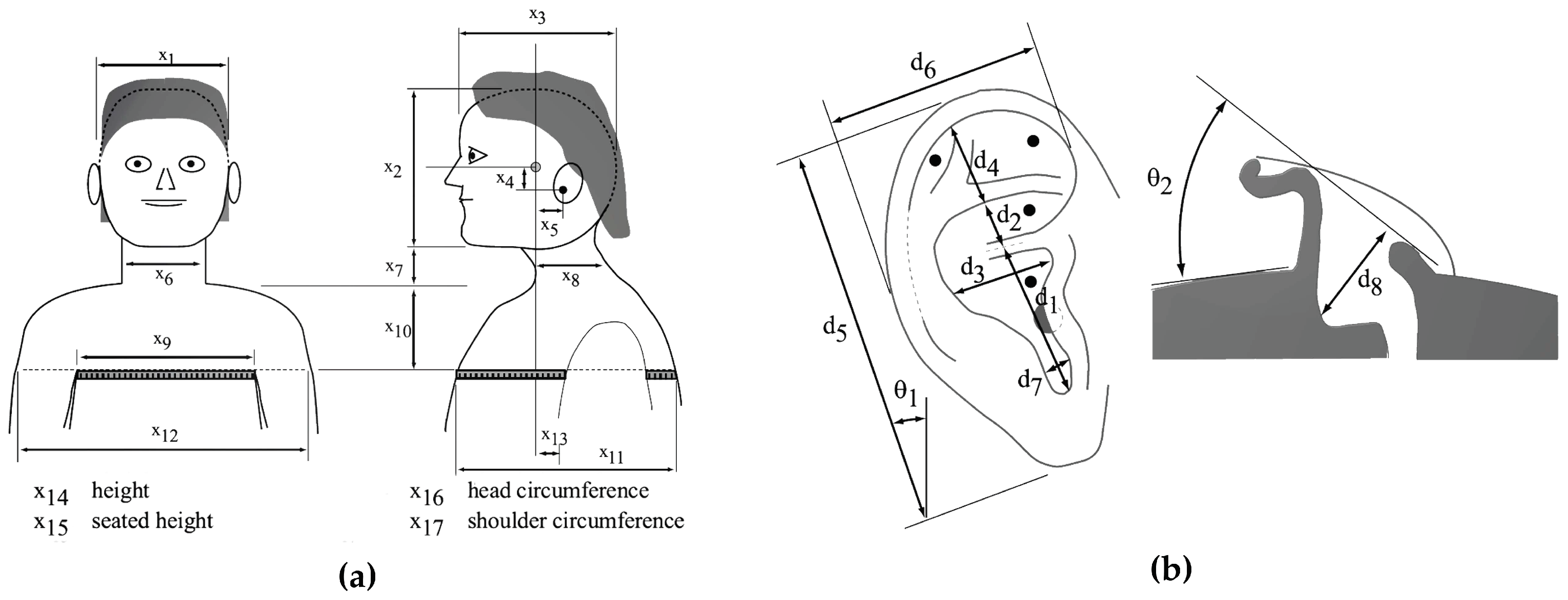
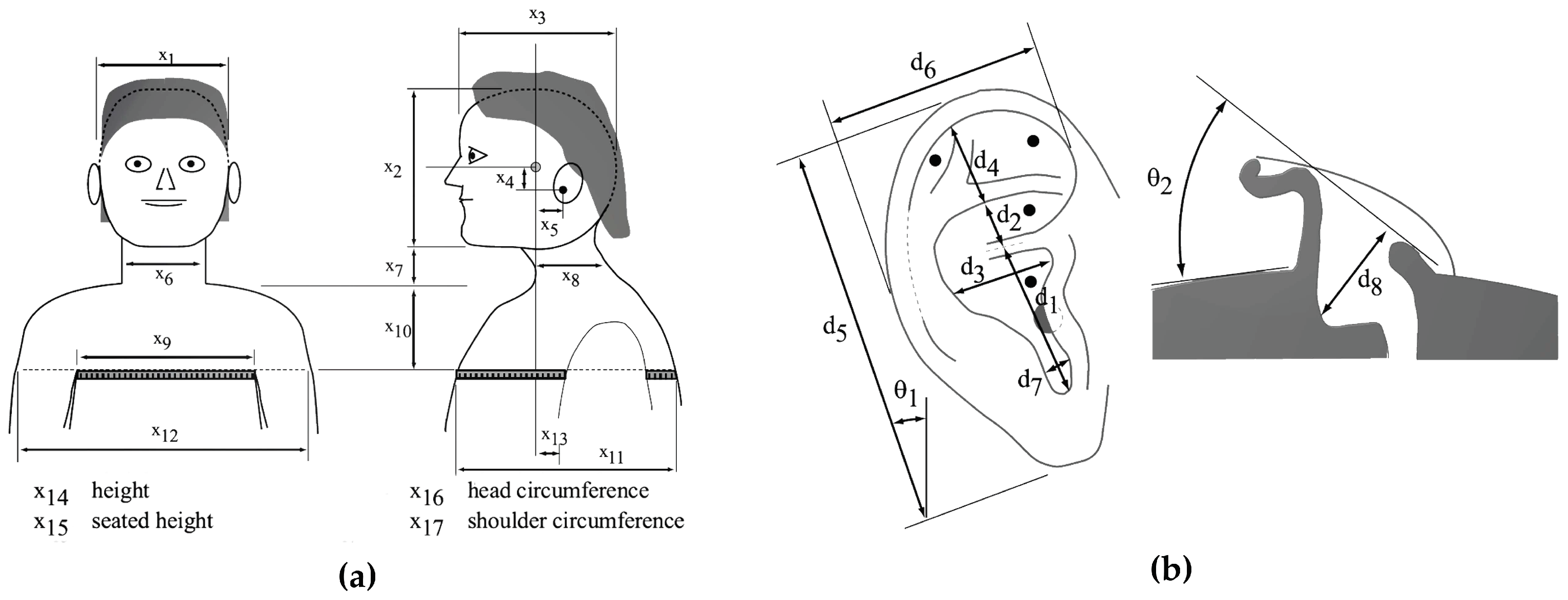
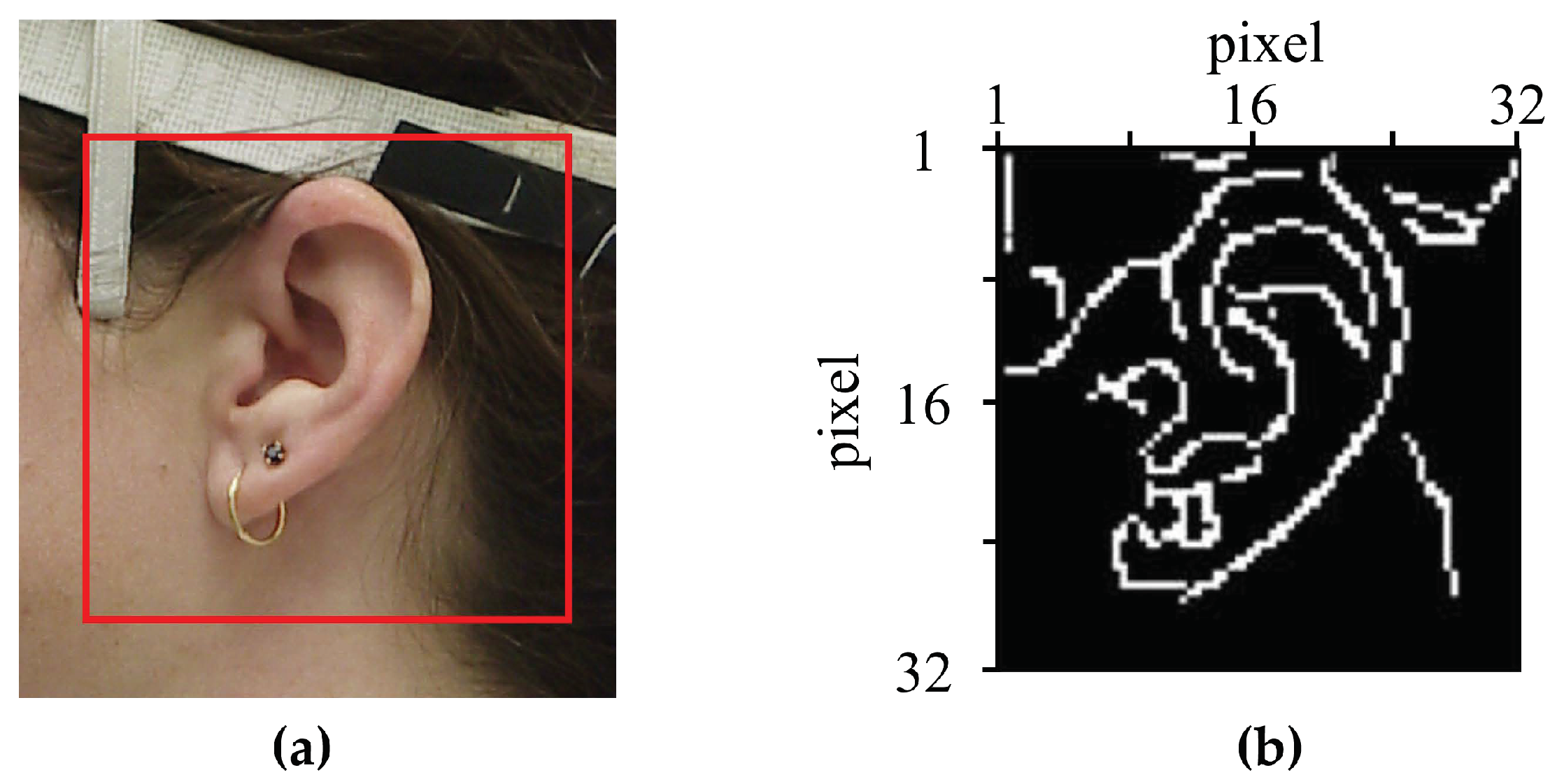
24]. This database included head-related impulse responses (HRIRs), another representation of HRTFs, for 45 subjects at 25 different azimuths and 50 different elevations with anthropometric measurements and ear images of each subject. The specifications of the anthropometric measurements included in the database are as shown in
Figure 3 and
Table 1. In the CIPIC database, there were 17 parameters for head and torso measurements and 10 for pinna measurements. In particular, elevation and azimuth were sampled using a head-centered polar coordinate system. The elevations were uniformly sampled at intervals of 5.625° from −45° to 230.625° while the azimuths were sampled at 25 different angles from −80° to 80° with different steps of 5° to 15°. There were 1250 HRTFs of length 200 samples, corresponding to a duration of approximately 4.5 msec at a sampling rate of 44.1 kHz.
To compare the performance of our proposed method in
Section 3 with the neural network model described in this section, a DNN is constructed as shown at the upper block of
Figure 2. The DNN model here is composed of one input layer, five hidden layers, and one output layer. There are 37 input units (17 parameters for the height and circumference measurements and 20 for the pinna measurements for both ears), as described in
Table 1, and the number of output nodes is set to 200, corresponding to the length of the HRTFs. In addition, the number of each hidden layer’s nodes is set to 64 and the rectified linear unit (ReLU) is applied as an activation function for each layer because the ReLU activation function is known to be effective for solving gradient-vanishing problems [
25]. Moreover, since the range of anthropometric measurement is different between measurements, a measurement with a small range may not influence learning. Thus, each input feature for the DNN is normalized using the mean and variance for all training data without regard for the subjects, such as
where
and
are the
i-th component of the input and normalized feature vector, respectively, and
and
are the mean and standard deviation of all the training data, respectively. Note that
could be
or
in
Table 1.
For training the DNN, Xavier initialization is utilized for the initial weights of the configured model, and the biases are initialized at zero [
26]. The mean square error (MSE) between the original target and the estimate target is selected as a cost function [
27]. The adaptive moment estimation (Adam) optimization is utilized for the backpropagation algorithm and the first- and second-moment decay rates are set to 0.9 and 0.999, respectively, with a learning rate of 0.001 [
28]. In addition, the dropout technique is utilized with the keep probability of 0.9 [
29]. Finally, the model was trained for 20,000 epochs. The performance of the DNN described thus far will be discussed in
Section 4.
4. Performance Evaluation
In this section, the performance of the proposed personalized HRTF estimation method was evaluated in terms of both objective and subjective tests. For objective tests, the RMSE and LSD between the reference and estimated HRTF were measured. For the subjective test, a sound localization experiment was performed, and the distance perceived by listeners after applying the estimated HRTF to a sound source was measured. Subsequently, the performance of the proposed method was compared to those of the following other HRTF estimation methods: (1) an HRTF estimation method using average HRTF, referred to as “Average HRTF”; (2) the estimated HRTF by a DNN trained with anthropometric measurements in
Section 2 [
11], referred to as “DNN(37) HRTF” because there were 37 anthropometric measurements including ear measurements; (3) the estimated HRTF by a DNN trained with only 17 head and torso measurements, referred to as “DNN(17) HRTF.” Henceforth, the proposed method is referred to as “CNN–DNN HRTF.” Note that since it was difficult to obtain anthropometric measurements of the pinna for a test subject, the performance of the DNN in
Section 2 was only evaluated using objective measures.
All methods were implemented in MATLAB with a version of R2013b using Tensorflow whose version was r1.1.0 with Python 3.5.2. In this paper, 30 subjects and one subject of the CIPIC database were used for training and testing each neural network, respectively. Then, 31 cross-validations were performed and measurements were averaged over all cross-validations. Note here that the average HRTF method took an average over the HRTFs of all 31 subjects. In addition, since there were 1250 different environments (25 azimuths and 50 elevations), both the proposed method and the DNN-based methods were constructed in each different environment, resulting in 1250 CNN–DNN HRTFs, 1250 DNN(37) HRTFs, and 1250 DNN(17) HRTFs.
4.1. Objective Evaluation
As mentioned earlier, there were two objectives measured here. One was the RMSE between the reference HRTF
and the estimated HRTF
which was defined as
where
N (=200) was the total length of the HRTF. In addition, the LSD was defined as
where
and
were obtained by applying a fast Fourier transform (FFT) to
and
, respectively, and
M (=512) was half the size of the FFT.
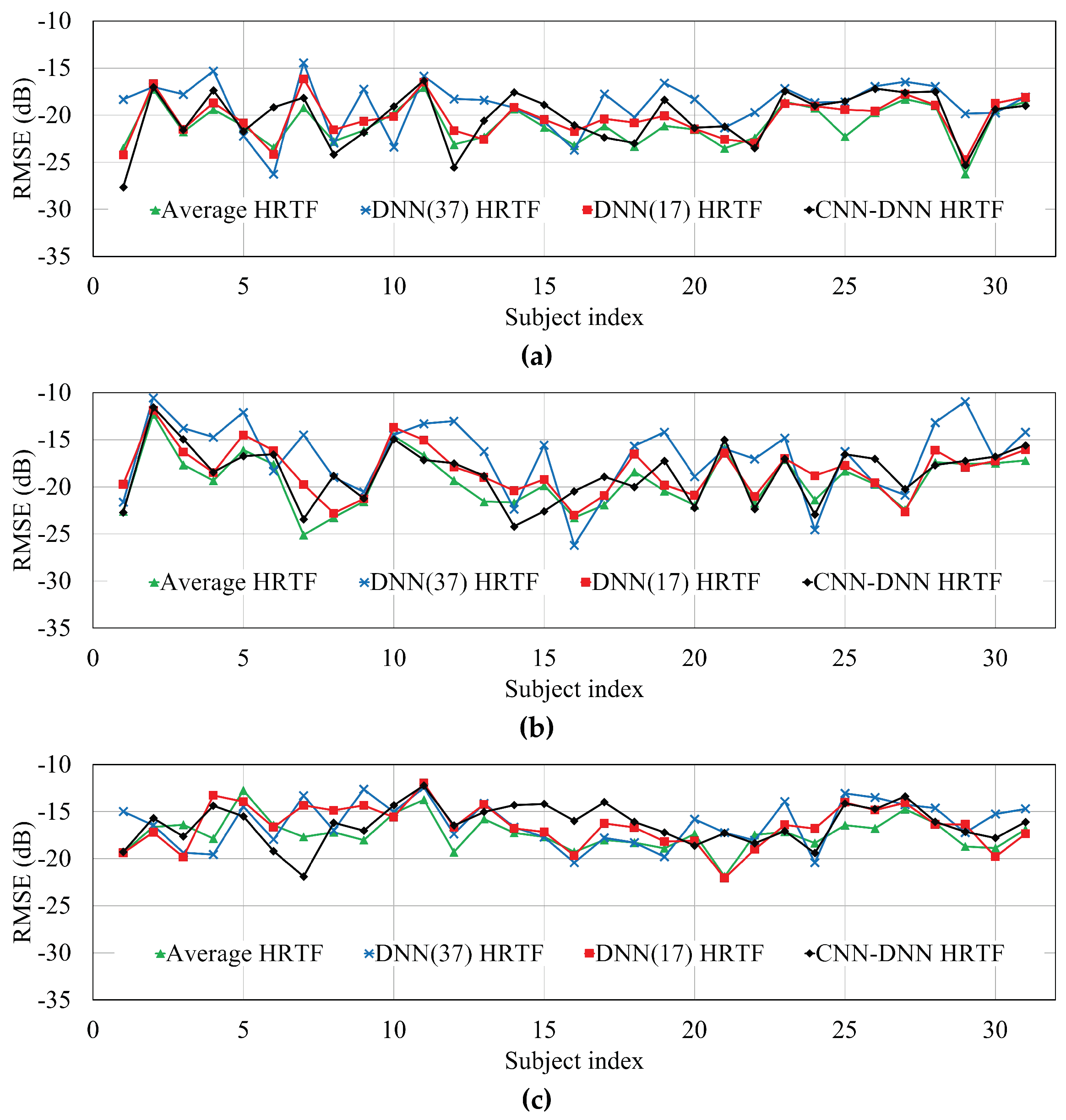
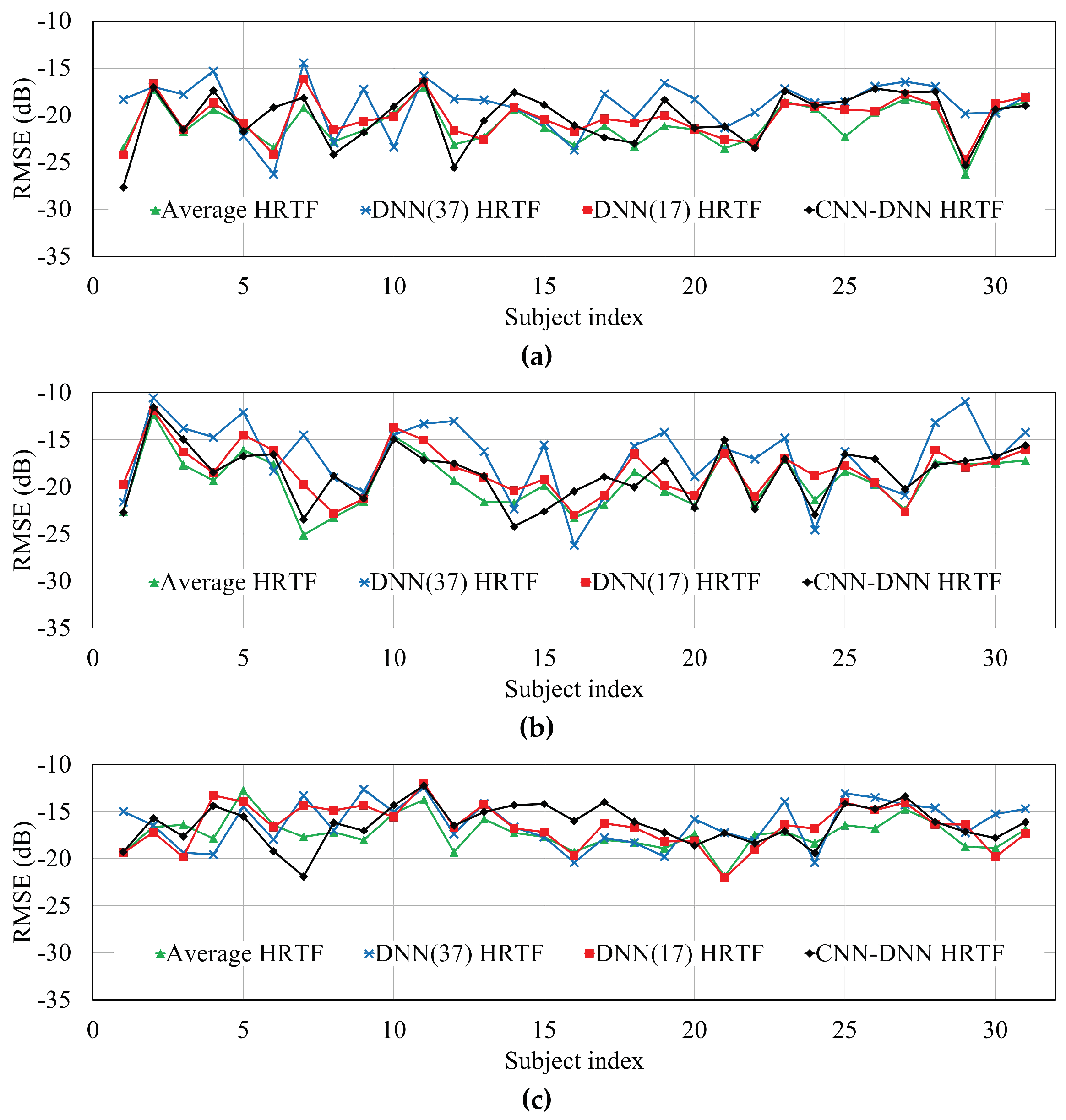
Figure 6 compares the RMSEs of the individual subject according to different HRTF estimation methods, measured at −135°, −80°, and −45°. Note that the performances of the HRTFs at 135°, 80°, and 45° were identical to those at −135°, −80°, and −45°, respectively. In addition,
Table 2 compares the average HRTF over all the HRTFs in the CIPIC database, measured at −135°, −80°, and −45°. As shown in
Figure 6 and
Table 2, the DNN-based method (DNN(37) HRTF) and the proposed method provided RMSEs that were 1.91 and 0.88 dB higher than the average HRTF method, respectively. Even though the average HRTF had the lowest RMSE because this was obtained from exact pinna measurements, it was actually hard to get pinna measurement data from live human ears. Without such pinna measurements, the DNN-based method increased RMSE by 0.02 dB. Thus, the RMSE of the estimated HRTF by the proposed method was lowered than that estimated by the DNN(17) HRTF.
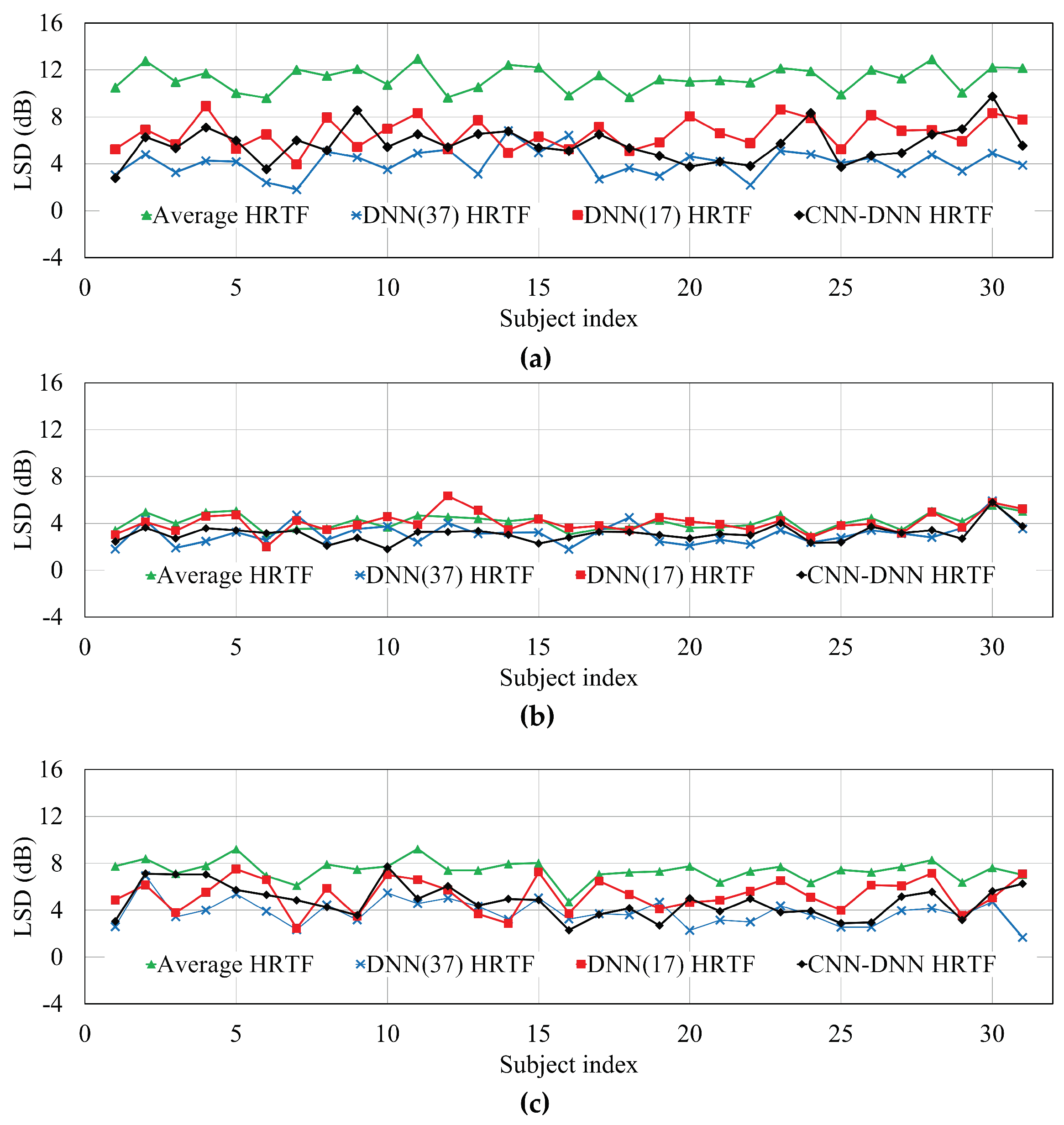
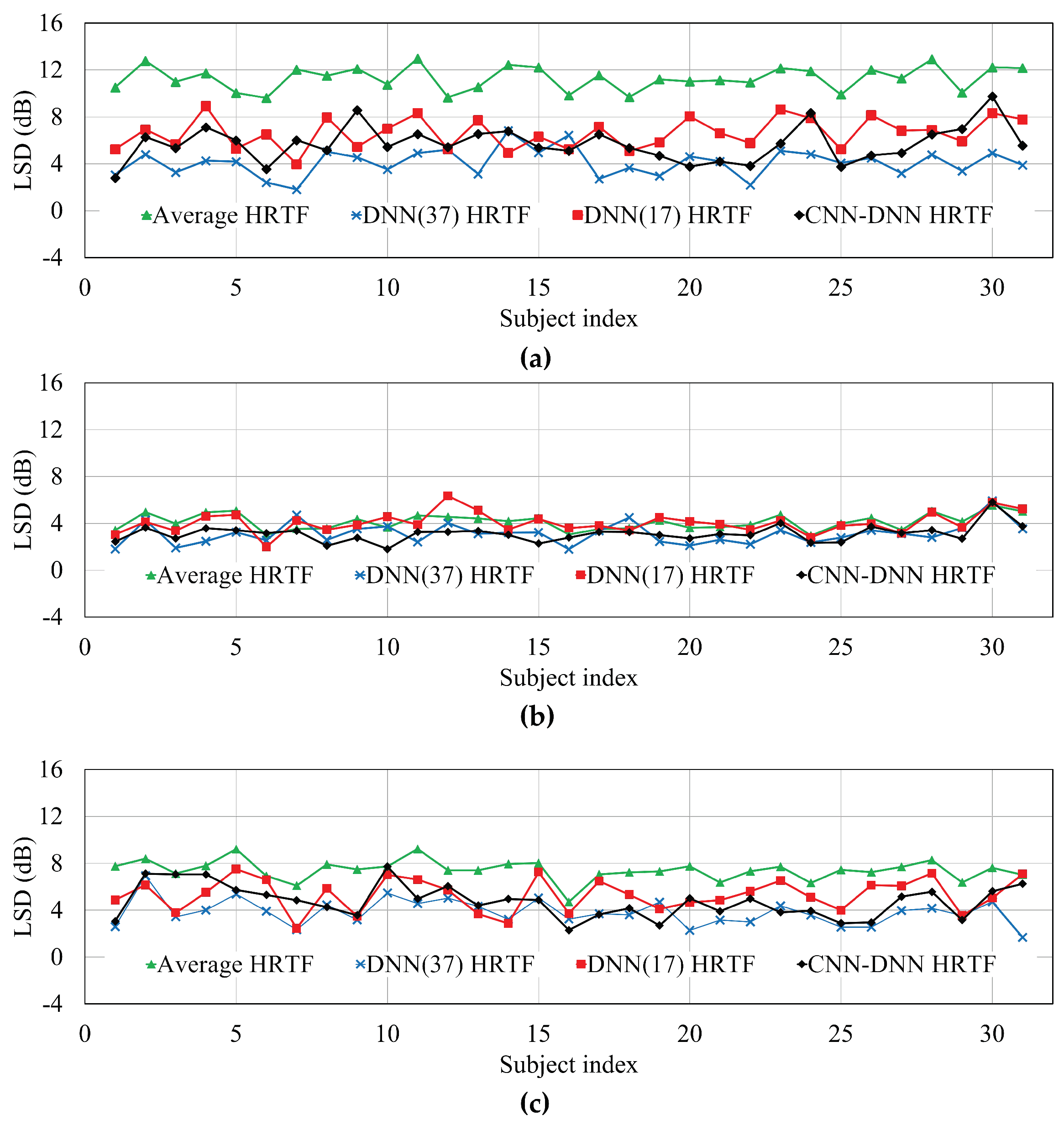
Next, the LSD was computed between the reference HRTF and its estimated HRTF for each of the four different HRTF estimation methods.
Figure 7 and
Table 3 compare the LSDs of the individual subject and the average LSD according to different HRTF estimation methods, measured at −135°, −80°, and −45°, respectively. As shown in the figure and table, the average LSD measured from the DNN(37) HRTFs was lowest among the methods. However, similar to the RMSE described above, the average LSD of the HRTFs estimated by the proposed method was lower by 0.85 dB compared to that by DNN(17) HRTFs. In particular, the LSDs for the HRTFs estimated by both neural network-based methods were greatly reduced compared to the average HRTF method.
4.2. Subjective Evaluation
In this subsection, we carried out a subjective evaluation of the localization experiment in which five listeners (three males and two females) without any auditory disease participated. This experiment was performed using Microsoft Surface Pro 4, which was manufactured by Pegatron Corporation, Taipei, Taiwan, with Sennheiser HD 650 headphones.
Table 4 shows the anthropometric measurements of each listener, where male and female listeners are denoted as M1–3 and F1–2, respectively, and
are head and torso measurements, as described in
Table 1. Both these anthropometric measurements and each listener’s ear images were used as input features for the proposed method. Then, each personalized HRTF was estimated in an environment for each specific listener by the proposed method and the DNN-based method using only head and torso measurements. Next, the estimated HRTFs and average HRTF at a given environment were applied to a speech signal of 10-s duration at a sampling rate of 44.1 kHz. In other words, each HRTF was convoluted with the speech signal. Here, the environments selected in this paper were at eight different azimuths (0°, ±45°, ±80°, ±135°, and 180°) with an elevation of 0°. For the evaluation, each participant listened to a pair of speech signals that were convolved with average HRTF, DNN(17) HRTF, or CNN–DNN HRTF, and then he/she judged the azimuth at which each speech signal was assumed to be directed.
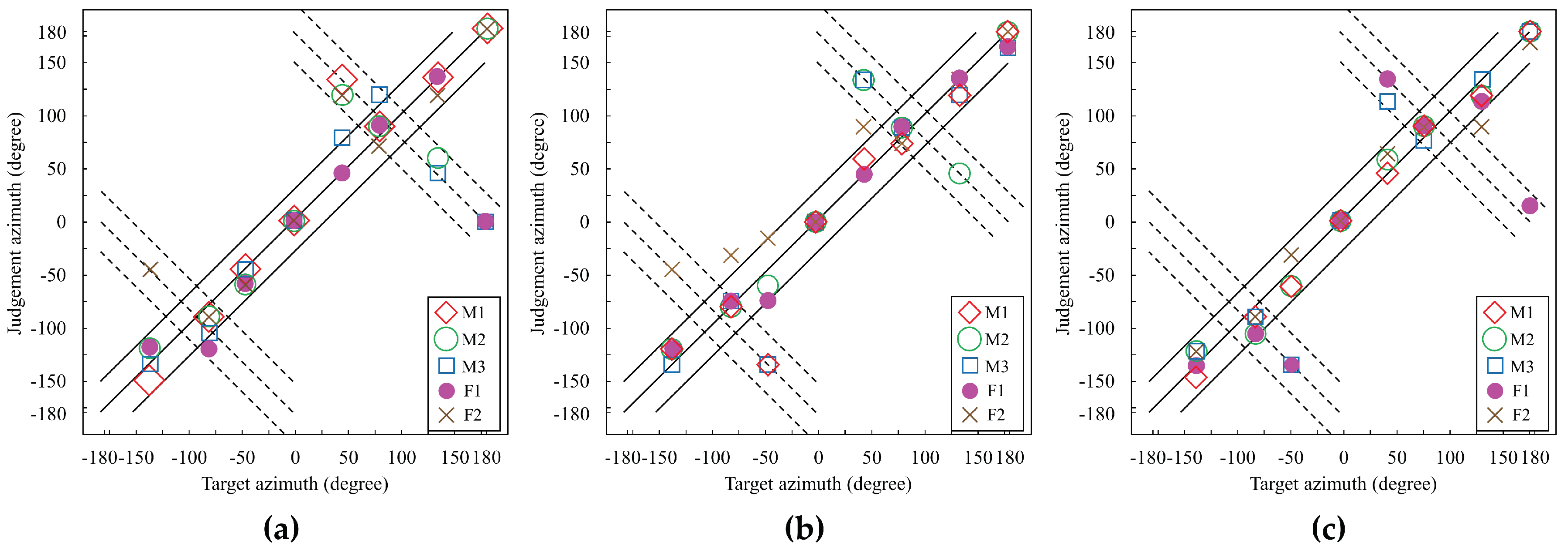
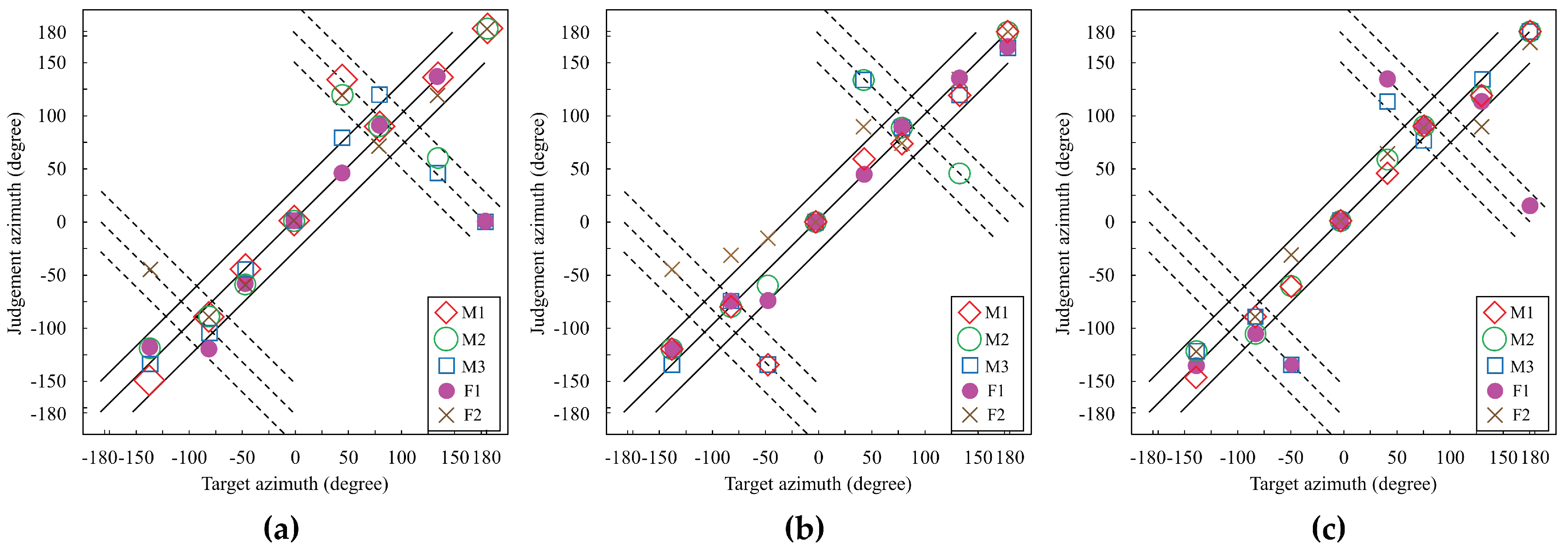
Figure 8 illustrates the sound localization performance to show the azimuths judged by the participants versus the target azimuth when average HRTF, DNN(17) HRTF, and CNN–DNN HRTF were used. In the figure, the main diagonal solid line indicates correct judgment, and the upper and lower off-diagonal solid lines indicate ±30° margin of error. On the one hand, if a sound is judged on or near the dashed lines, this corresponds to front/back confusion. For example, when the target azimuth was set to 50°, the sound should be located in the front-right direction. However, the sound seemed to be heard in the back-right direction if the azimuth was judged at 130°. In addition, two dotted lines parallel to the dashed lines means that the margins of errors are ±30°. As shown in the figure, judged azimuths when using the proposed method were clustered better than when using average HRTFs or DNN(17) HRTFs.
Table 5 compares the accuracies within specific margins, such as ±15° and ±30°, and the front/back confusion rate of the localization experiment between the average HRTF and the proposed method. As shown in the table, the proposed CNN–DNN-based HRTF estimation method achieved higher accuracies of 10% and 12.5% than the average HRTF method for the ±15° and ±30° margins, respectively. In addition, the accuracy of the proposed method was improved by 10% and 2.5%, compared to the average HRTF method and the DNN(17)-based method, respectively. Moreover, the front/back confusion rate of the proposed method was reduced by 12.5% and 2.5%, compared to the average HRTF method and the DNN(17)-based method, respectively.
4.3. Performance Comparison with Data Augmentation
The number of ear images in the CIPIC database seems so small that the deep learning model could be overfitted to the training data [
30]. Data augmentation can be an alternative to prevent this problem. In this paper, data augmentation techniques, such as zero-phase component analysis (ZCA) [
35] and/or image shifting [
36], were applied to 30 ear images; thus, the total numbers of training data were increased to 60 after applying ZCA and 90 after applying ZCA combined with image shifting, respectively.
Table 6 and
Table 7 compare the RMSEs and LSDs for individual subjects according to the proposed HRTF estimation method with and without data augmentation, respectively, as measured at −135°, −80°, and −45°. As shown in
Table 6, the average RMSE went a little higher as the amount of augmentation data increased. In other words, the average RMSE of ZCA + Image Shift-CNN–DNN HRTF was increased by 0.45 dB compared to that of CNN–DNN HRTF. Meanwhile, the average LSD was decreased as the amount of data augmentation increased.
Table 7 showed that the ZCA+Image Shift-CNN–DNN HRTF could reduce the average LSD by 0.29 dB compared to CNN–DNN HRTF.
5. Conclusions
In this paper, a personalized HRTF estimation method has been proposed on the basis of deep neural networks using anthropometric measurements and ear images. In particular, while a conventional DNN-based method aimed to estimate HRTFs using the anthropometric data including head, torso, and pinna measurements, the proposed method replaced pinna measurements with ear images due to the difficulty of obtaining pinna measurements for live human ears. Thus, the neural network in the proposed method was composed of three sub-networks. The first one was a DNN to represent the head and torso measurements and the second one was a CNN for extracting pinna measurements from edge-detected ear images instead of actually measured pinna data. The two sub-networks were then merged into another DNN to estimate a personalized HRTF.
The performance of the proposed personalized HRTF estimation method was evaluated in terms of both objective and subjective tests. For the objective tests, the RMSEs and LSDs between the reference and estimated HRTFs were measured. For the subjective test, a sound localization experiment was performed, and the distance perceived by listeners after applying the estimated HRTF to a sound source was measured. After that, the performance of the proposed method was compared with those of HRTF estimation methods using average HRTF, the estimated HRTF by a DNN trained with anthropometric measurements, and the estimated HRTF by a DNN trained with only head and torso measurements. Consequently, it was shown from the objective evaluation that the proposed method decreased the RMSE and LSD by 0.02 and 0.85 dB, respectively, compared to the DNN-based method using anthropometric data without pinna measurements. In addition, it was shown form the subjective evaluation that the proposed method provided higher localization accuracy of 6% than the DNN-based method. In addition, the front/back confusion rate for the proposed method was reduced by 2.5% compared to the DNN-based method. Next, data augmentation was performed to increase the training data by applying zero-phase component analysis (ZCA) and image shifting. Thus, it was shown that after data augmentation, the proposed method could increase the RMSE but reduce the LSD by 0.29 dB, compared to only using ear images from the CIPIC HRTF database.
In future work, to improve the performance of the proposed CNN–DNN HRTF estimation method, different model structures need to be studied, such as a residual network [
37] or a dense network [
38]. Moreover, the CIPIC HRTF database is too small to train deep learning models. Even though data augmentation has been performed in this paper, further sophisticated investigation of the effect of data augmentation on the performance of the proposed method, particularly the RMSE, will be studied.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}