Next, we analyse the minimum values and their corresponding location reported by the benchmark functions considered. Additionally, we present the results obtained with our metaheuristic along with the respective analysis.
6.1. Benchmark Functions
VLE was tested using 15 mathematical benchmark functions frequently used by many researchers, Equations (
19)–(
33) [
20,
24,
30,
34,
42], and 6 composite benchmark functions selected from the Technical Report of the CEC 2017 Special Session [
43], as described in Table 6. The first set of benchmark functions includes four unimodal functions, Equations (
19)–(
22), five multimodal functions, Equations (
23)–(
27), and six multimodal functions with fix dimensions, Equations (
28)–(
33). Functions
to
, i.e., Equations (
19)–(
27), are high-dimensional problems. Functions
to
, i.e., Equations (
23)–(
27), are a very difficult group of problems for optimization algorithms. In these problems, the number of local minima increases exponentially as the number of dimensions increases [
20]. This set of multimodal functions is very important because it reflects the ability of startup from local optima and continues the search in another place in the search space. The number of dimensions is
in Equations (
19)–(
27). The minimum values of all these functions and the corresponding solutions are given in
Table 3.
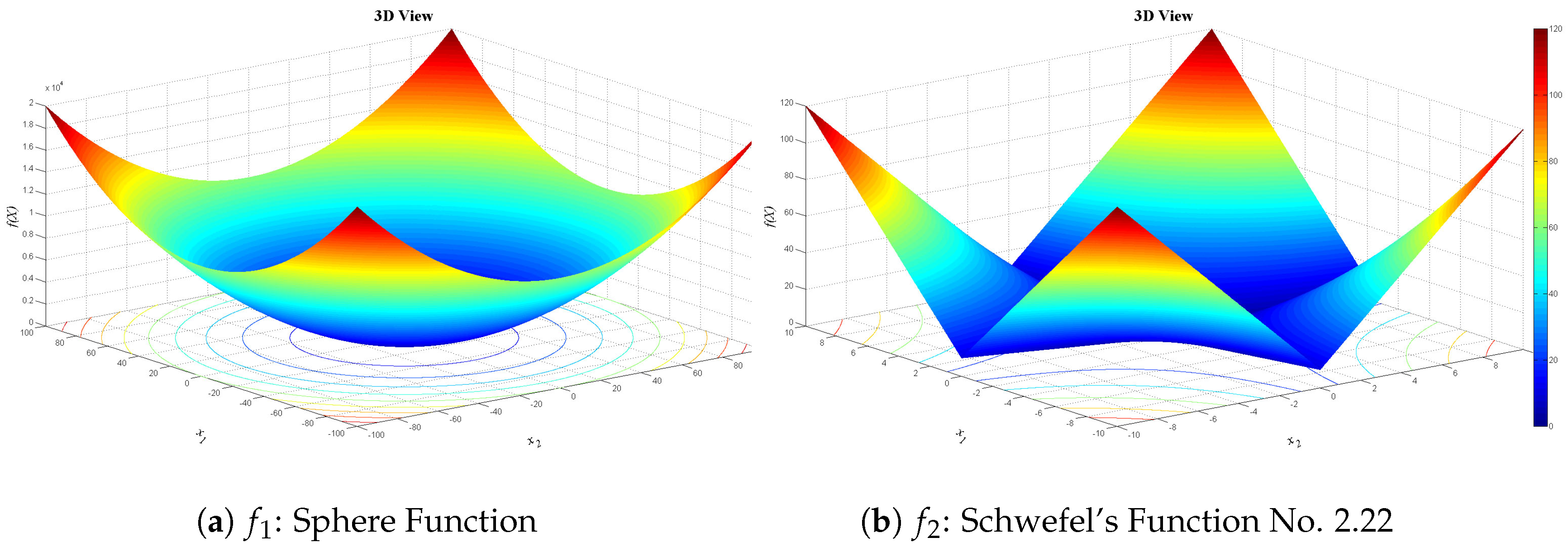
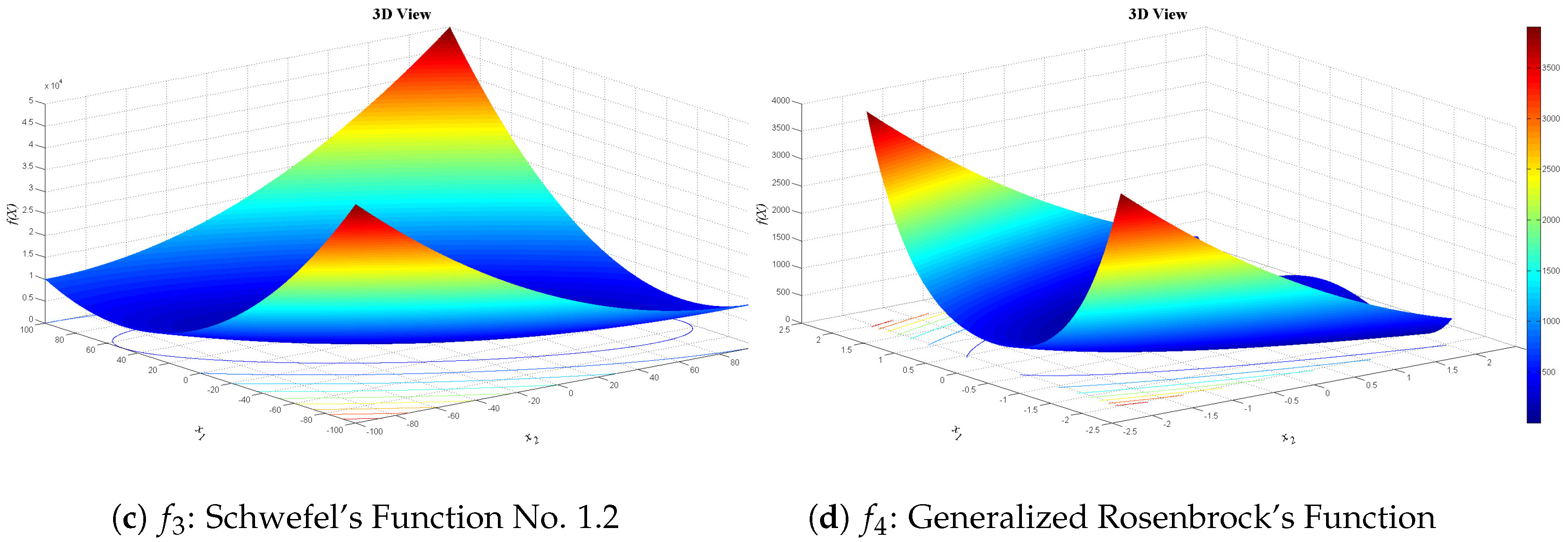
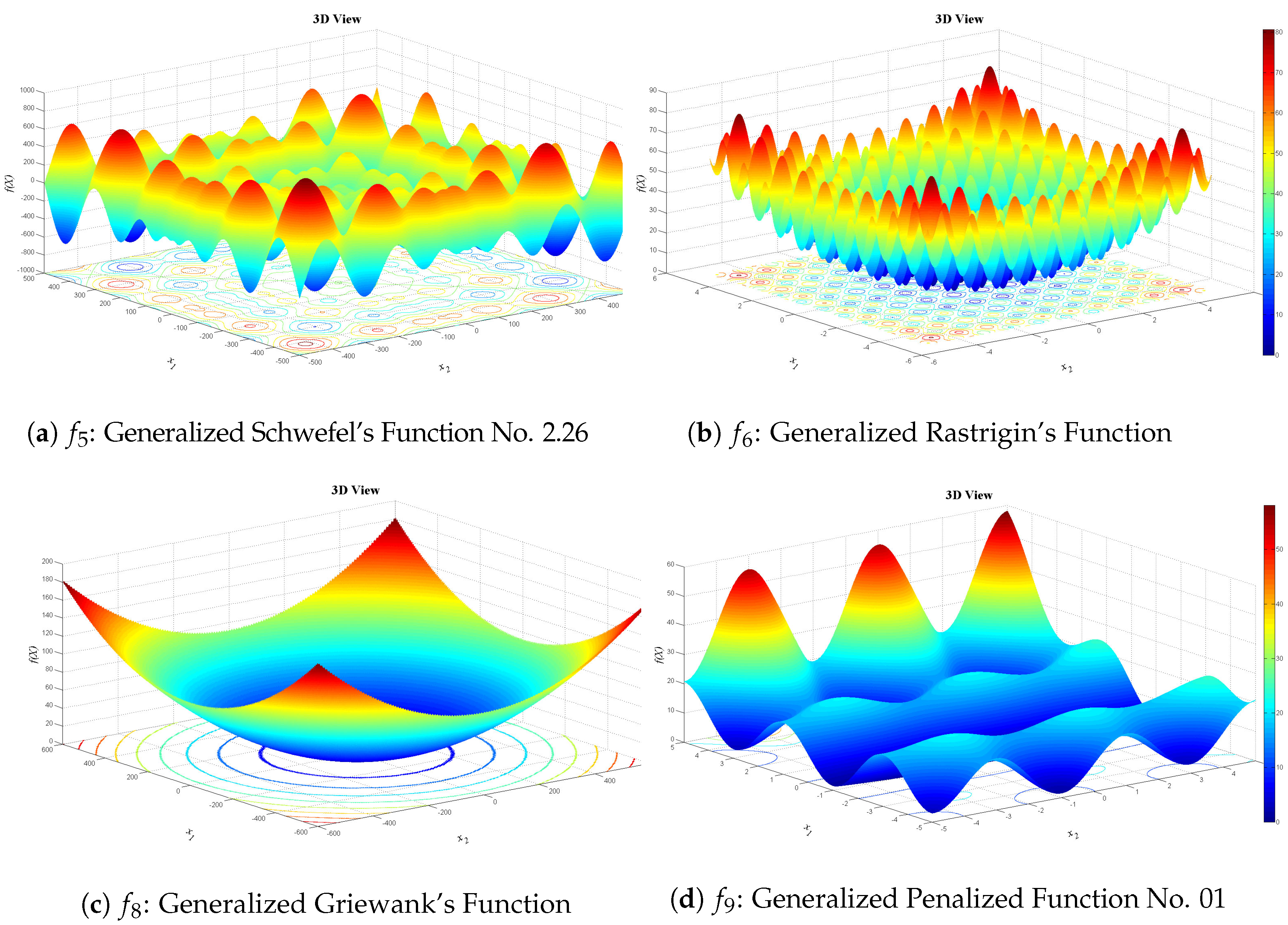
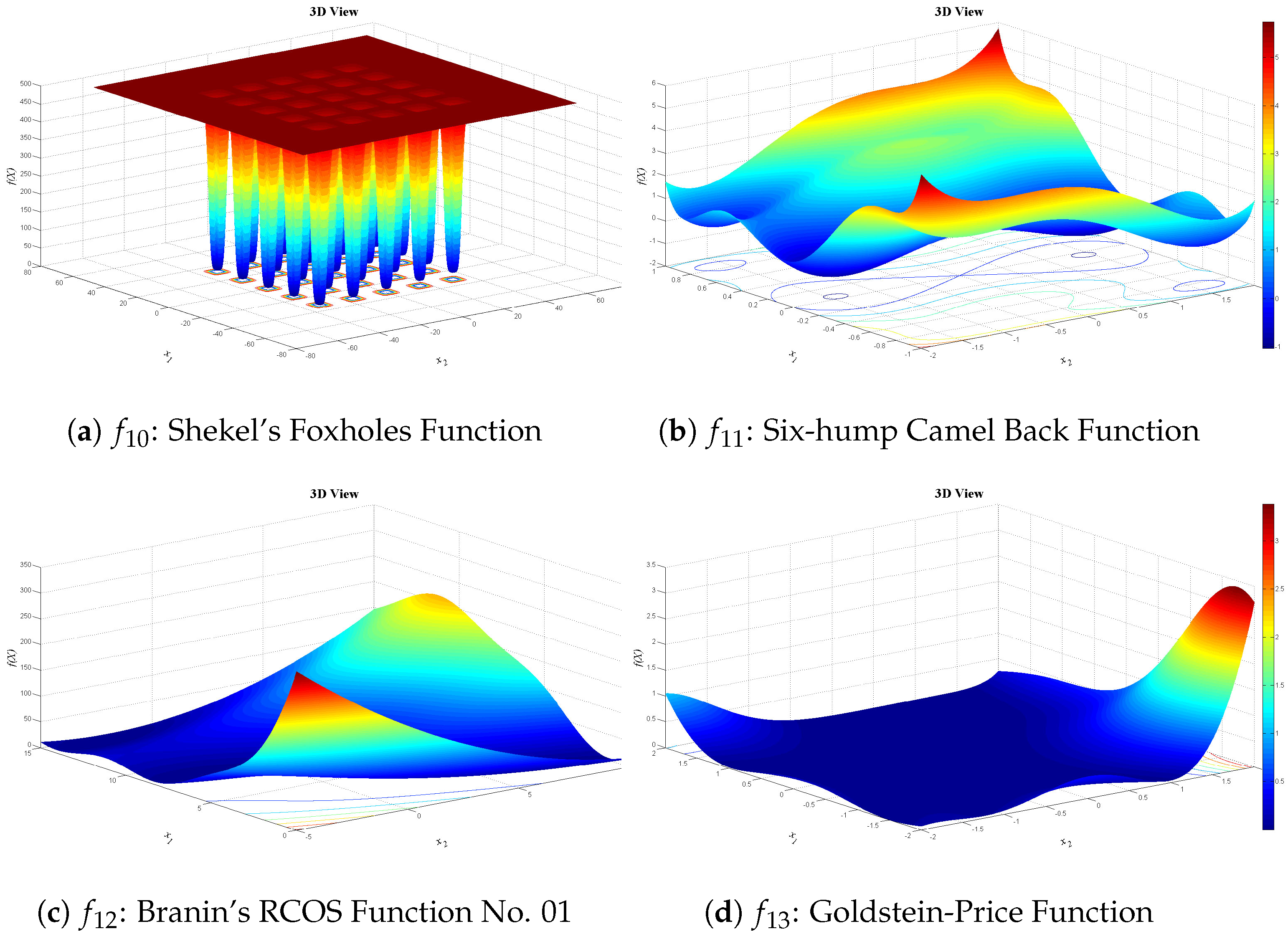
Figure 13,
Figure 14 and
Figure 15 show 3D views of the first set of benchmark functions utilized in our experiments.
Unimodal test functions:
Schwefel’s Function No. 2.22:
Schwefel’s Function No. 1.2:
Generalized Rosenbrock’s Function:
Multimodal test functions:
Generalized Schwefel’s Function No. 2.26:
Generalized Rastrigin’s Function:
Generalized Griewank’s Function:
Generalized Penalized Function:
where
is equal to
and
Multimodal test functions with fixed dimensions:
Shekel’s Foxholes Function:
where
Six-hump Camel Back Function:
Goldstein-Price Function:
Hartman’s Family Function:
where
,
and
, for
, i.e.,
, are given in
Table 4, and for
, i.e.,
, in
Table 5.
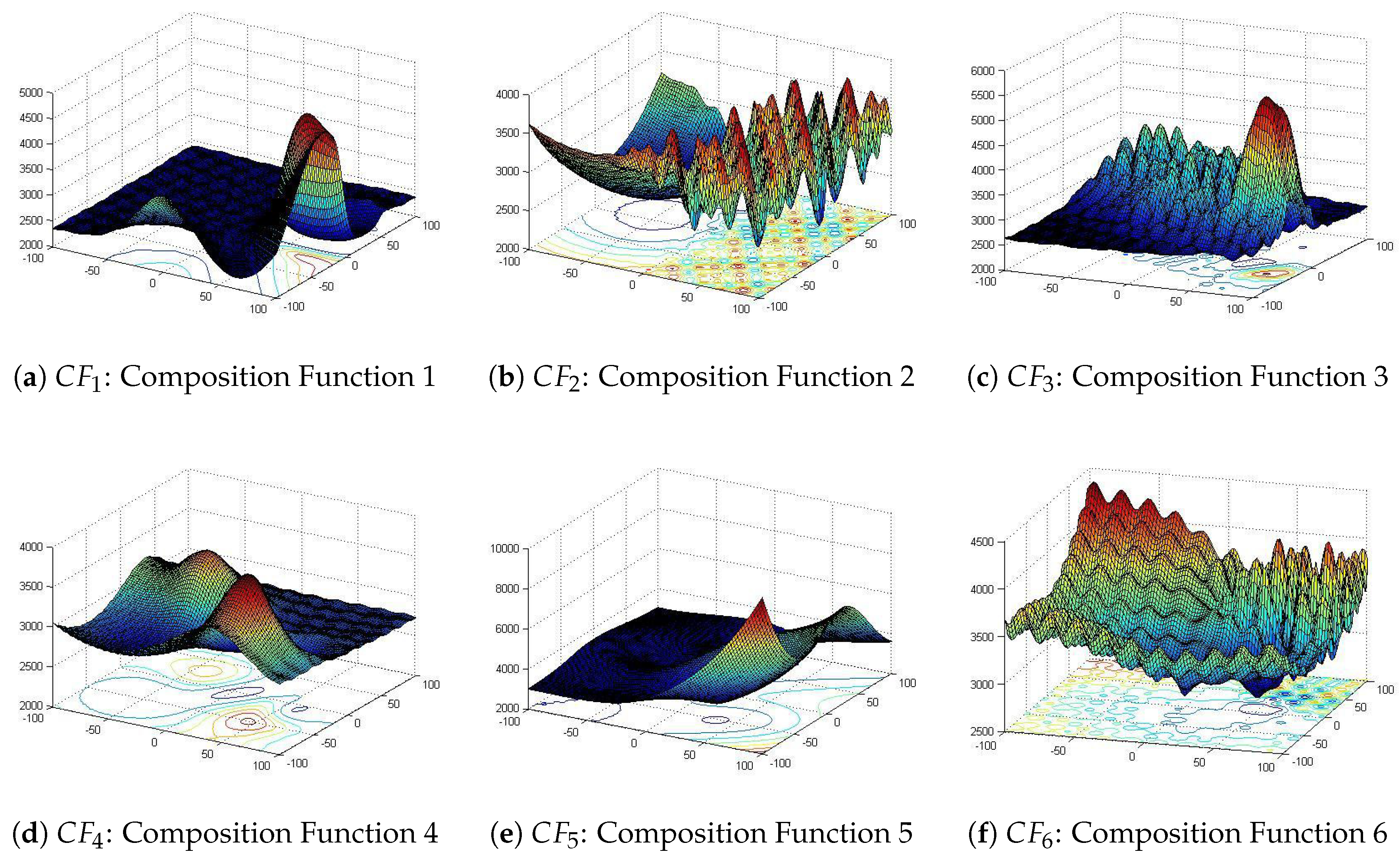
Regarding the second set of benchmark functions, all basic functions that have been used in the composition functions are shifted and rotated functions [
43]. In addition, all composite functions are multimodal, non-separable, asymmetrical and have different properties around different local optima [
43]. These properties create a high complexity in searching the optimum solution. Complete definitions of these functions are stated in the CEC 2017 Technical Report [
43]. The number of dimensions and the search subset or range (
) were
and
,
, respectively, for all composite functions utilized, as shown in
Table 6.
Figure 16 shows the 3D views of the benchmark composite functions chosen.
6.2. Results
Table 7 and
Table 8 show the statistical results obtained with the first set of benchmark functions as follows: the benchmark function (BenFun), the average value obtained with the benchmark function (Avg), the standard deviation (StdDev), the median (Med), the minimum value achieved (Min), the optimal value (Opt), the true percentage deviation (
, %) or the difference between the minimum value achieved, and the optimal value published
, the worst result obtained or maximum value reached (Max), the search subset (SeaSub), and the optimal location (OptLoc). Optimal locations found were rounded to the values indicated under the OptLoc column in
Table 8. For this set of functions, a total number of 1000 movements or 1000 restarts as the stop condition were considered for all the experiments, except in the experiments with functions f3, f4, f5 and f6; with those last functions, we use a maximum of 9000, 3000, 1500 and 4000, respectively. Very good results were obtained in 100.0% of the benchmark functions. Optimization results obtained by VLE were compared with the corresponding results reported for PSO [
24], GSA [
2], DE [
42], and WOA [
34], in [
29,
34]. All results obtained by VLE were rounded to four decimals. The results published for PSO, GSA, DE and WOA, were rounded in
Table 7 and
Table 9 to four decimals, using scientific notation, only for presentation purposes. However, all computations were realized using the reported decimals by their respective authors.
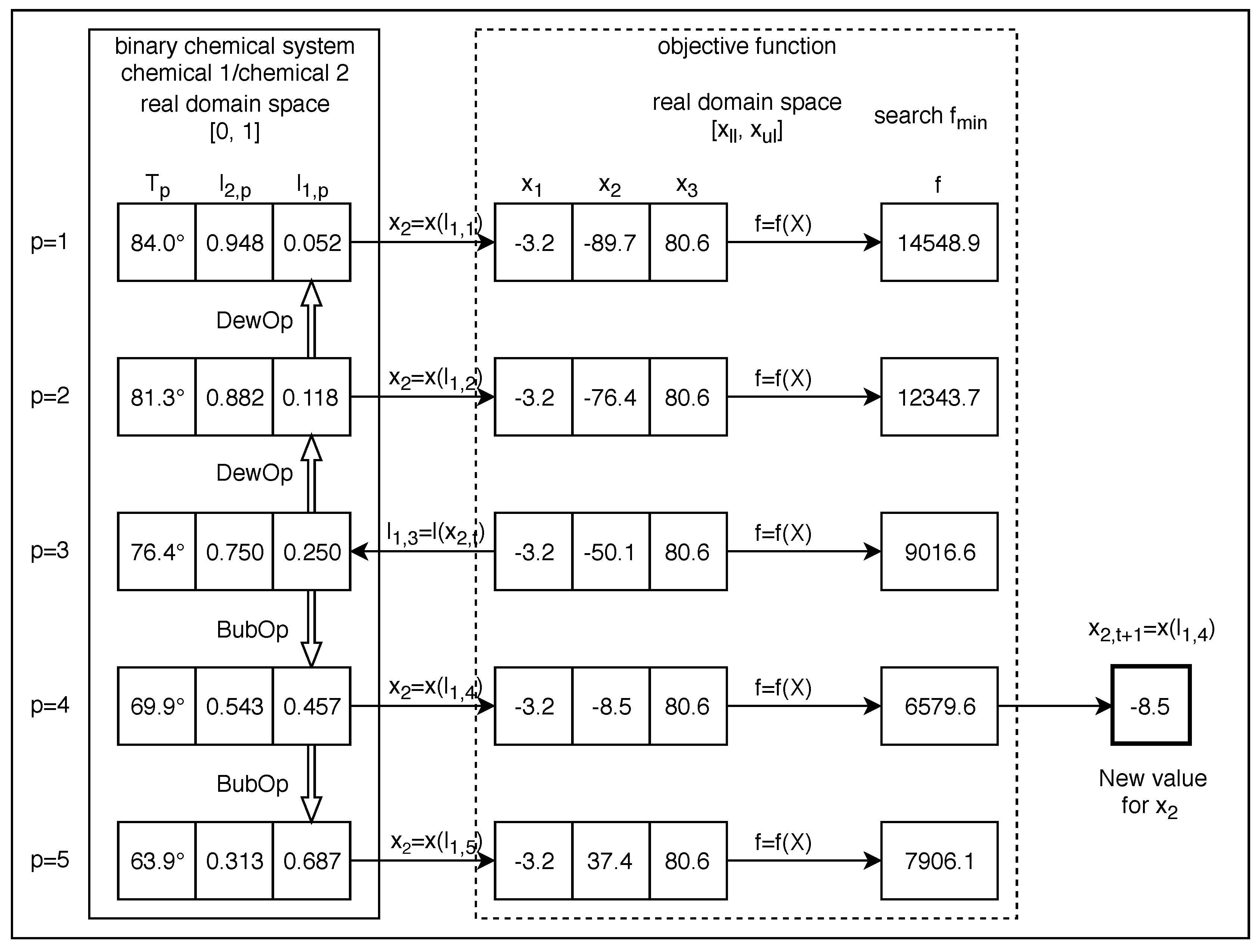
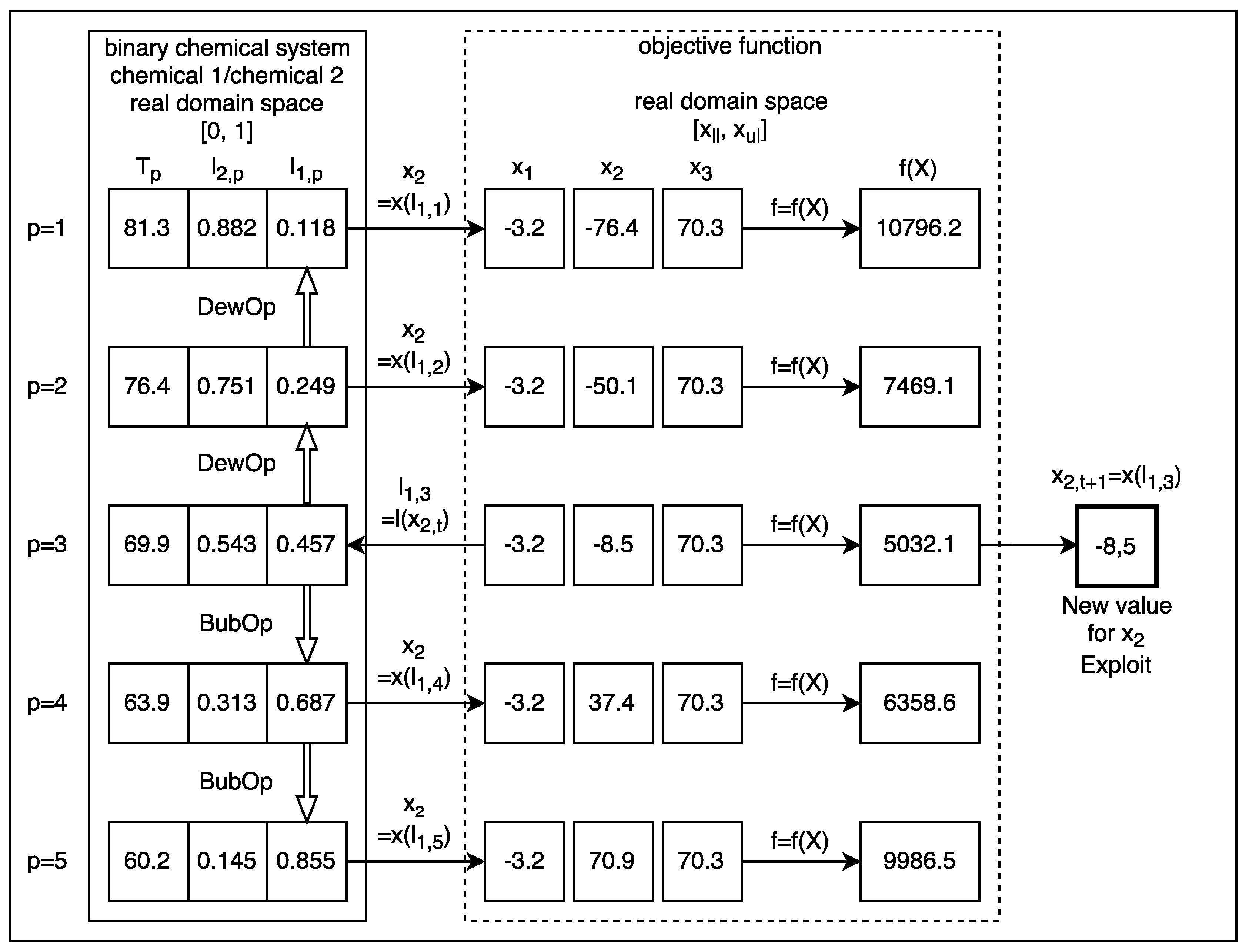
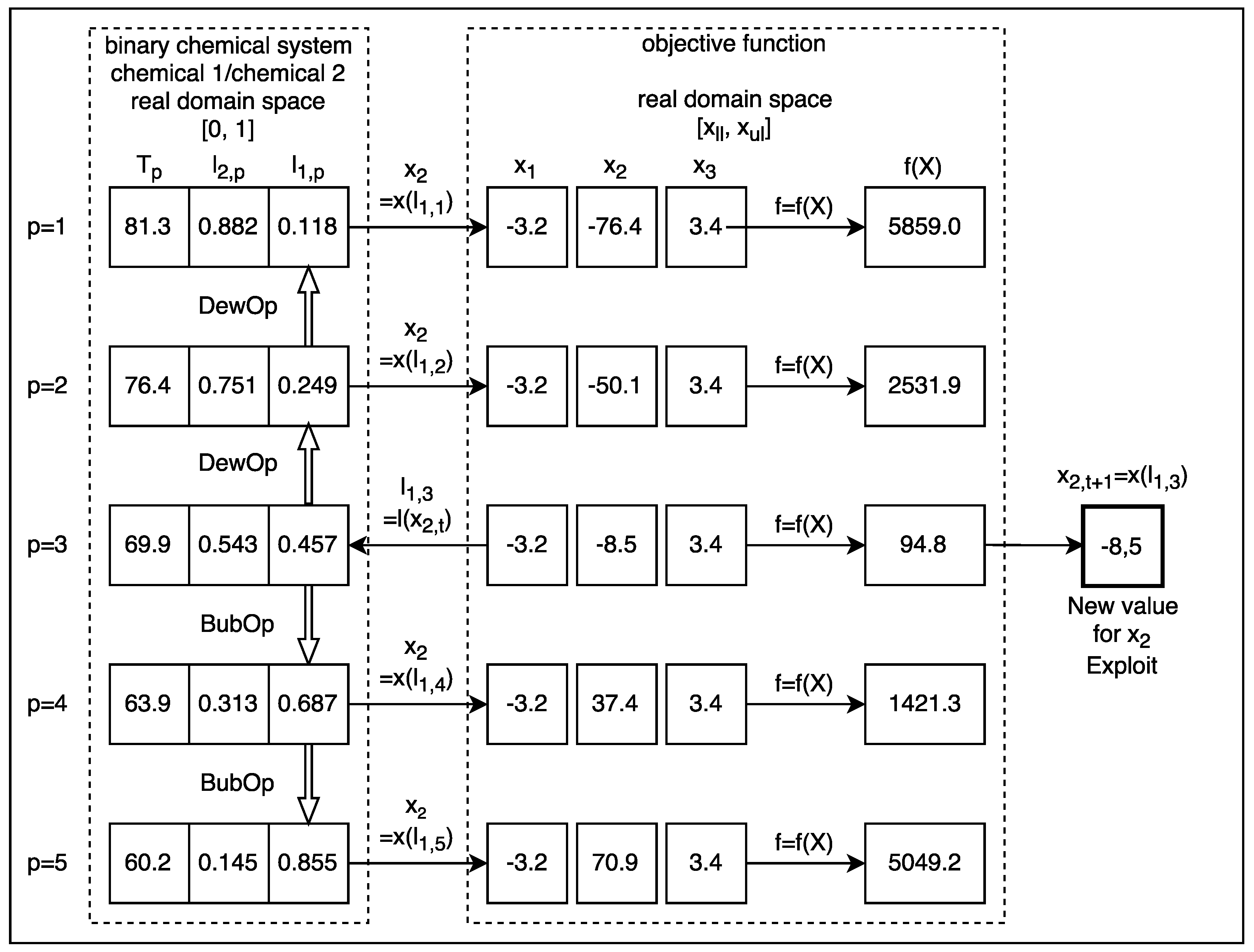
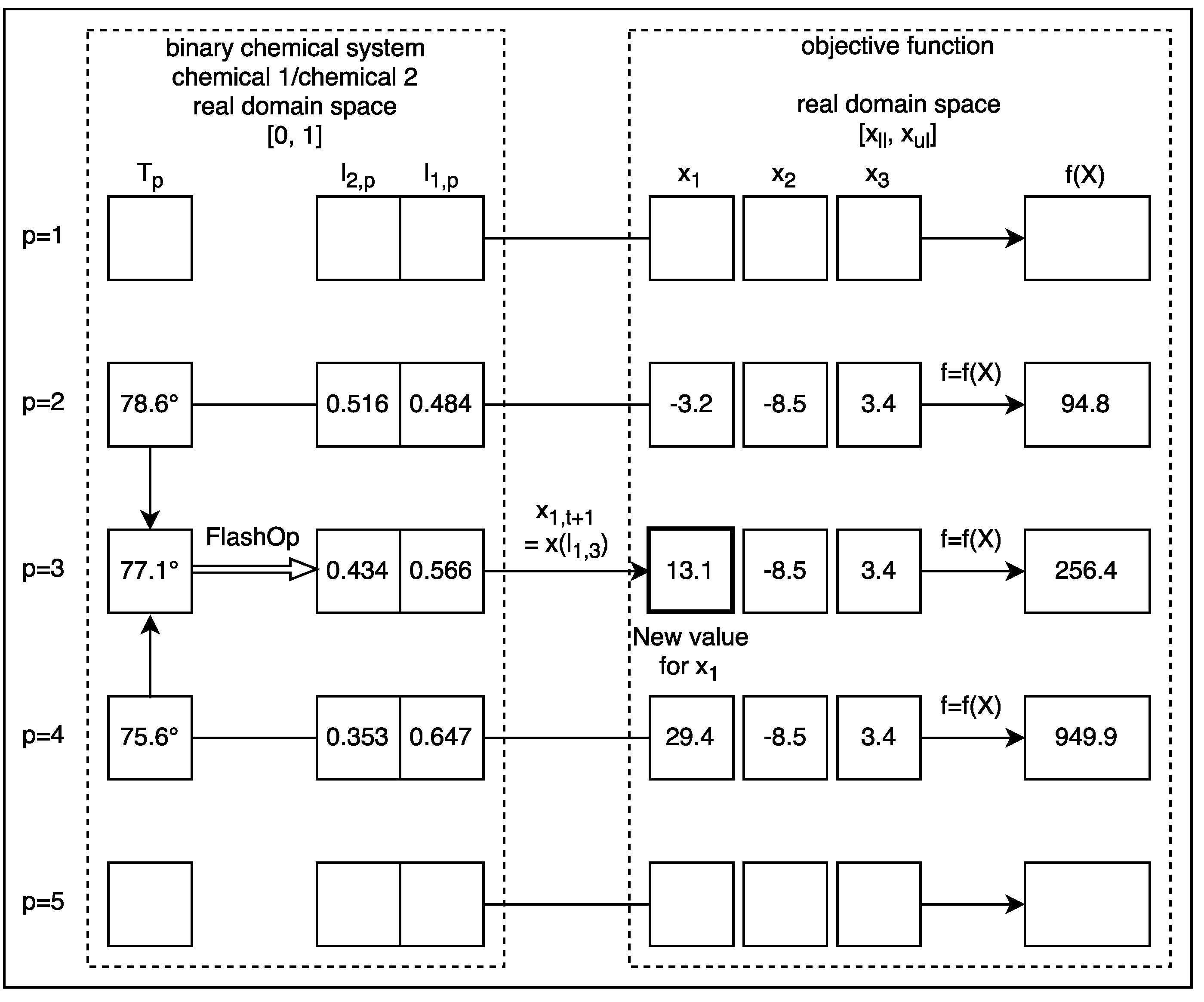
All experiments performed with VLE consisted of at least 31 executions with a certain set of VLE parameters. VLE parameters were tuned until a best possible solution was found. The technique for tuning was the parametric sweep. After this, the truncated mean was calculated by removing all possible strong outliers one by one. This process was done at 6.5% (, , and ), at 13.0% (, , , , and ) and at 20.0% (, , and ) depending on the number of strong outliers found. There were no outliers found with functions , , , and . All statistics reported for VLE in this work are presented according to this methodology. The reason for removing the strong outliers was to provide a measure of central tendency that was more representative of the distribution of the data obtained in each experiment.
A simple inspection of the values of the average fitness (Avg) of the objective function and of the corresponding standard deviation (StdDev), as it is shown in
Table 9, permits us to establish a priori that VLE can compete successfully with a considerable part of this type of optimization problem, which is the scope of the present research. In other words, it can been seen that the results obtained by VLE are competitive.
We define the true percentage deviation (
) (
34) as the measure of the search success. However, several of the benchmark functions tested have the optimal solutions as zero, and it is not possible to divide by zero. The (
) indicator was employed only for those functions whose optima (
) were different than zero. For the remaining functions, as the success indicator, we calculated the (
), the difference between the minimum achieved by VLE (
) and the optimal value published (
) (
35).
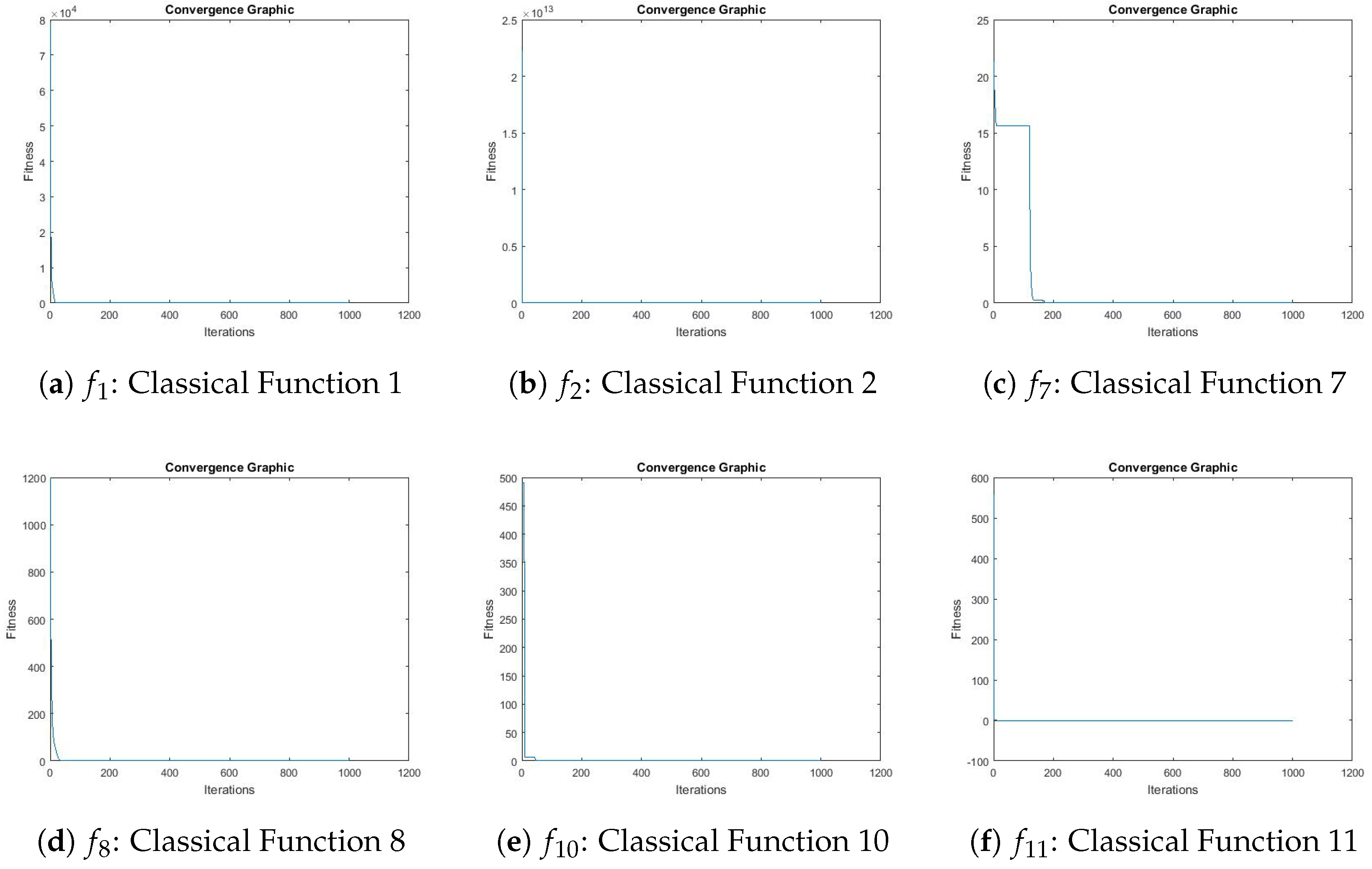
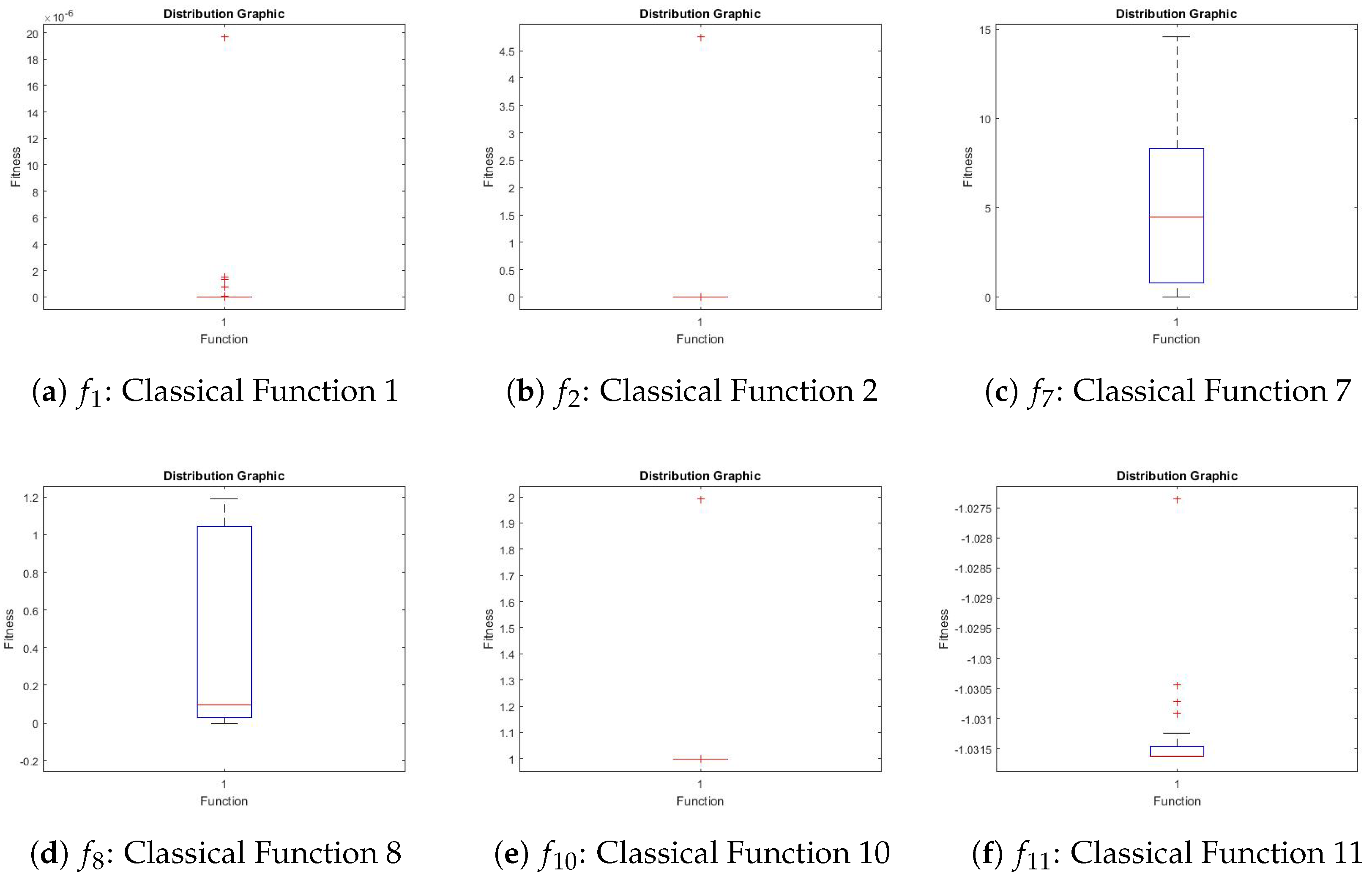
Figure 17 shows the convergence graphics obtained by VLE for benchmark functions
,
,
,
,
, and
.
Figure 18 shows the distribution graphics obtained by VLE for these functions.
The results were analysed from two points of view: (1) by making a thorough a comparative study of the mean values by function and metaheuristic; and (2) by using the root-mean-square error or RMSE. The comparative study allowed, in the first place, determining initially which VLE metaheuristic obtains a better result, and also determining the position of VLE on an evaluation scale of 1 to 5. In this evaluation scale, the number 1 is the best evaluation an algorithm can achieve. On the other hand, the use of the root-mean-square error, or RMSE, as a more robust statistic metric allowed the evaluation, in general terms, of which algorithm provided the averages that best fit the true optimum of the classical reference functions considered in this study.
Comparative study of the mean values:
Table 10 and
Table 11 show the result of the comparative analysis of the performance of VLE compared to that of PSO, GSA, DE and WOA before the 15 reference functions already indicated. The results in
Table 10 indicate that VLE shows a performance somewhat superior to that of PSO (60.00%), slightly higher than that of GSA (53.33%), and somewhat lower than that of WOA (40.00%). Since there is no information available for DE regarding functions
and
, if these functions are excluded, it can be seen that VLE has low performance compared to DE (23.08%). Based on these observations, and the benchmark functions considered, it can be stated that, in general, and qualitative terms, VLE presents a competitive performance among PSO, GSA, DE, and WOA.I In quantitative terms, this analysis allows us to affirm that VLE has a weighted average performance of 44.83% among this group of functions and algorithms. In other words, considering this group of algorithms, this means that, if we take a population of 100 benchmark functions, VLE will deliver the best average fitness in 45 of these functions. The results of
Table 11 show that, in general, the average performance of VLE is 2.6 on a scale of 1 to 5, with 1 being the best performance evaluation. This average global ranking considers that VLE reached first place 4 times, second place 2 times, third place 5 times, fourth place 4 times and that VLE never occupied fifth place. In addition to these results, it can be seen that the VLE ranking by type of benchmark function is 3.5 for the unimodal functions, 3.0 for the multimodal functions, and 2.0 for the multimodal test functions with a fixed number of dimensions. If functions
and
are excluded because there is no information available for DE, then the estimated global average performance of VLE is 2.85. In summary, if this indicator is rounded to the nearest integer, then VLE ranks third among the five metaheuristics considered and the 15 functions evaluated.
This comparative analysis allows us to corroborate that there is no metaheuristic that is capable of solving any optimization problem better than all the others. Some will work better than others for certain problems, while others will not perform as well [
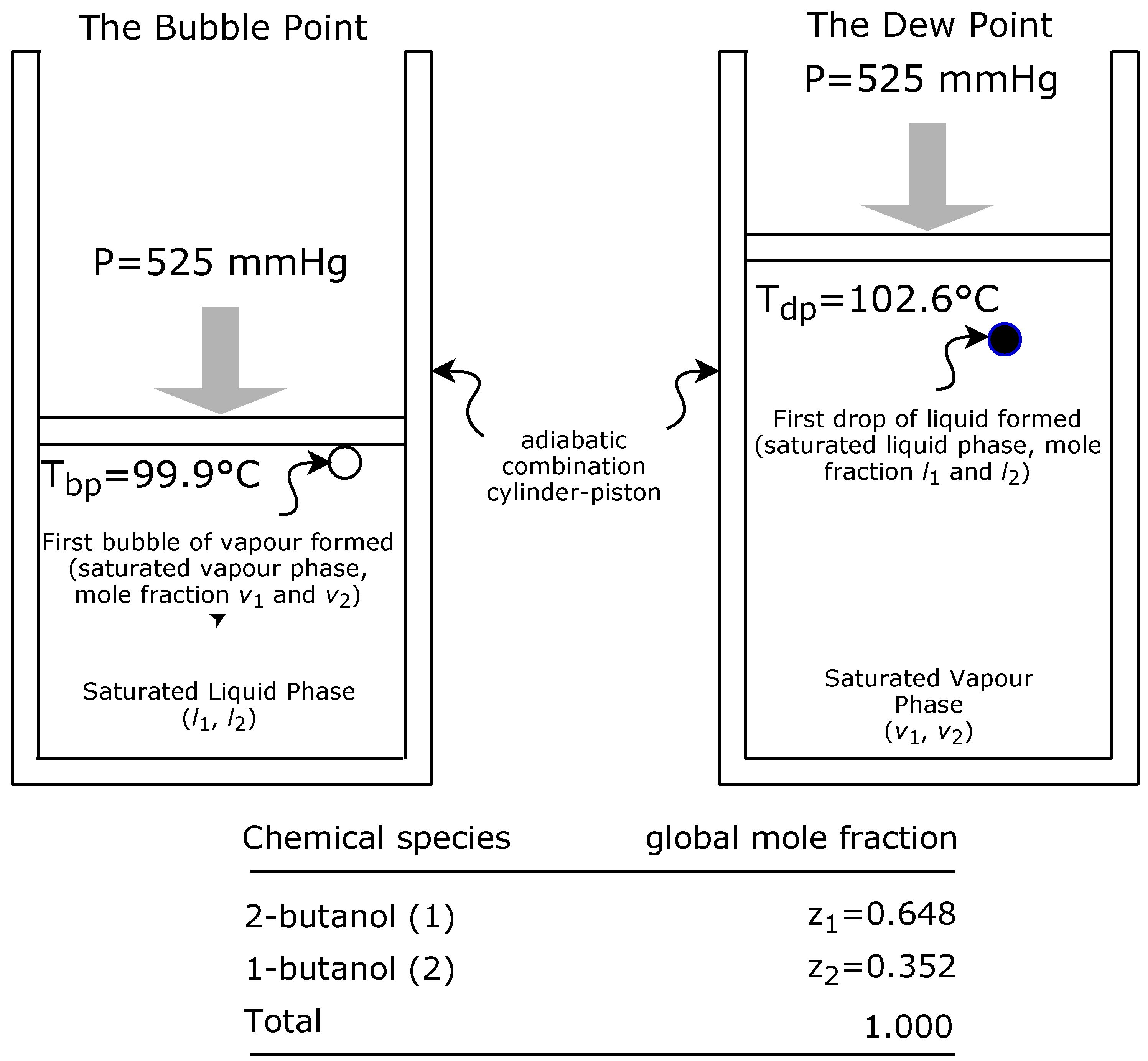
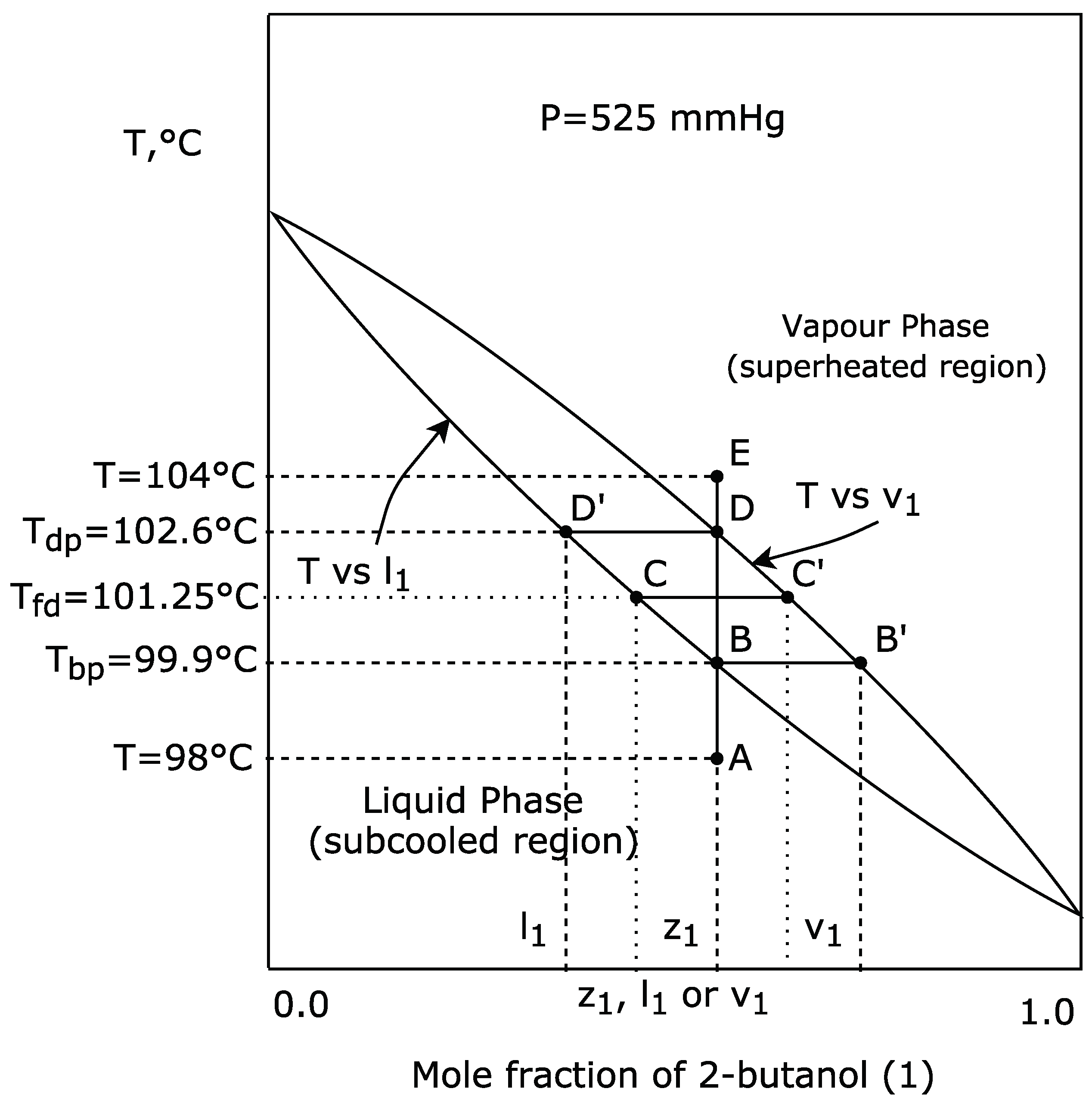
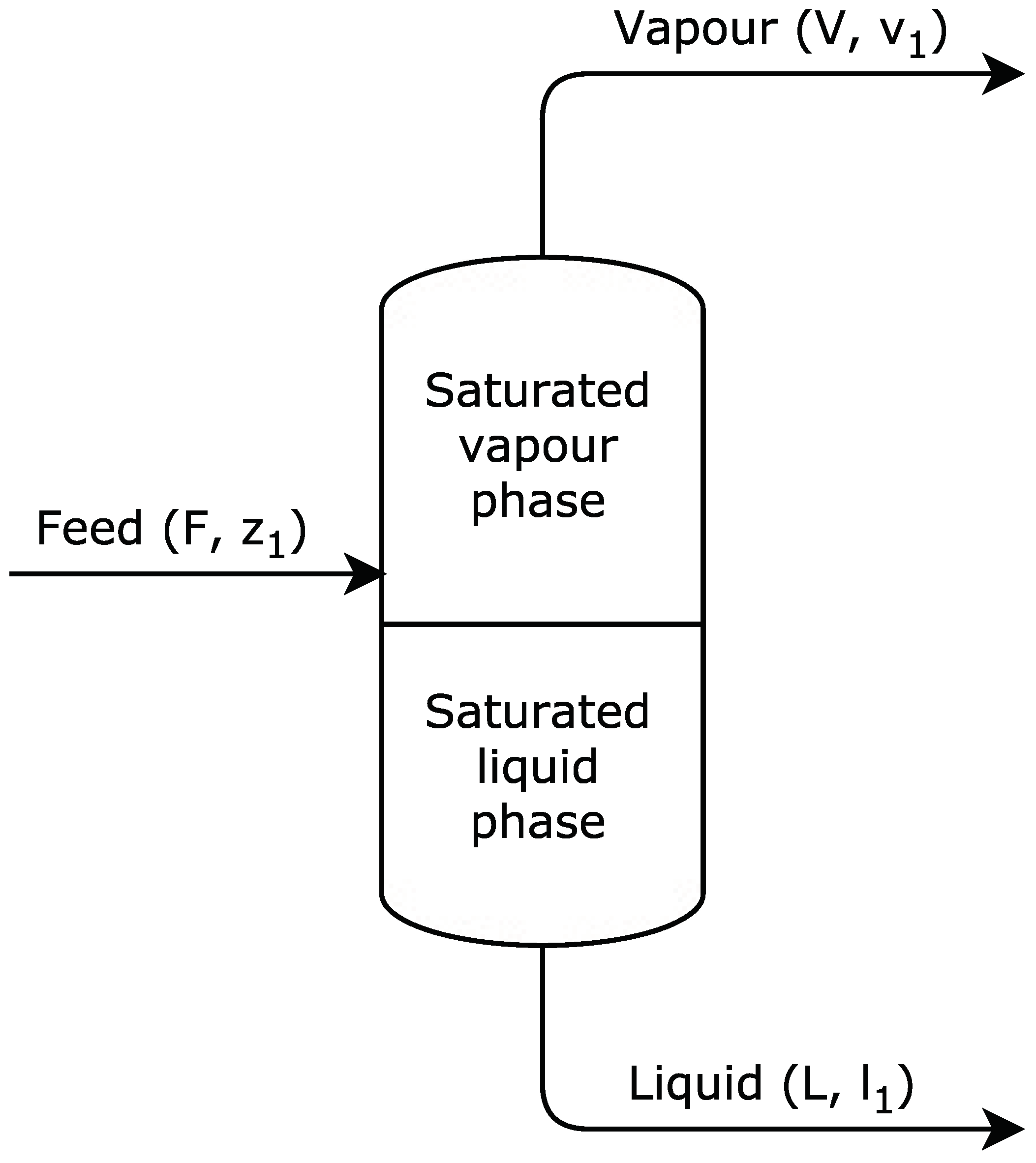
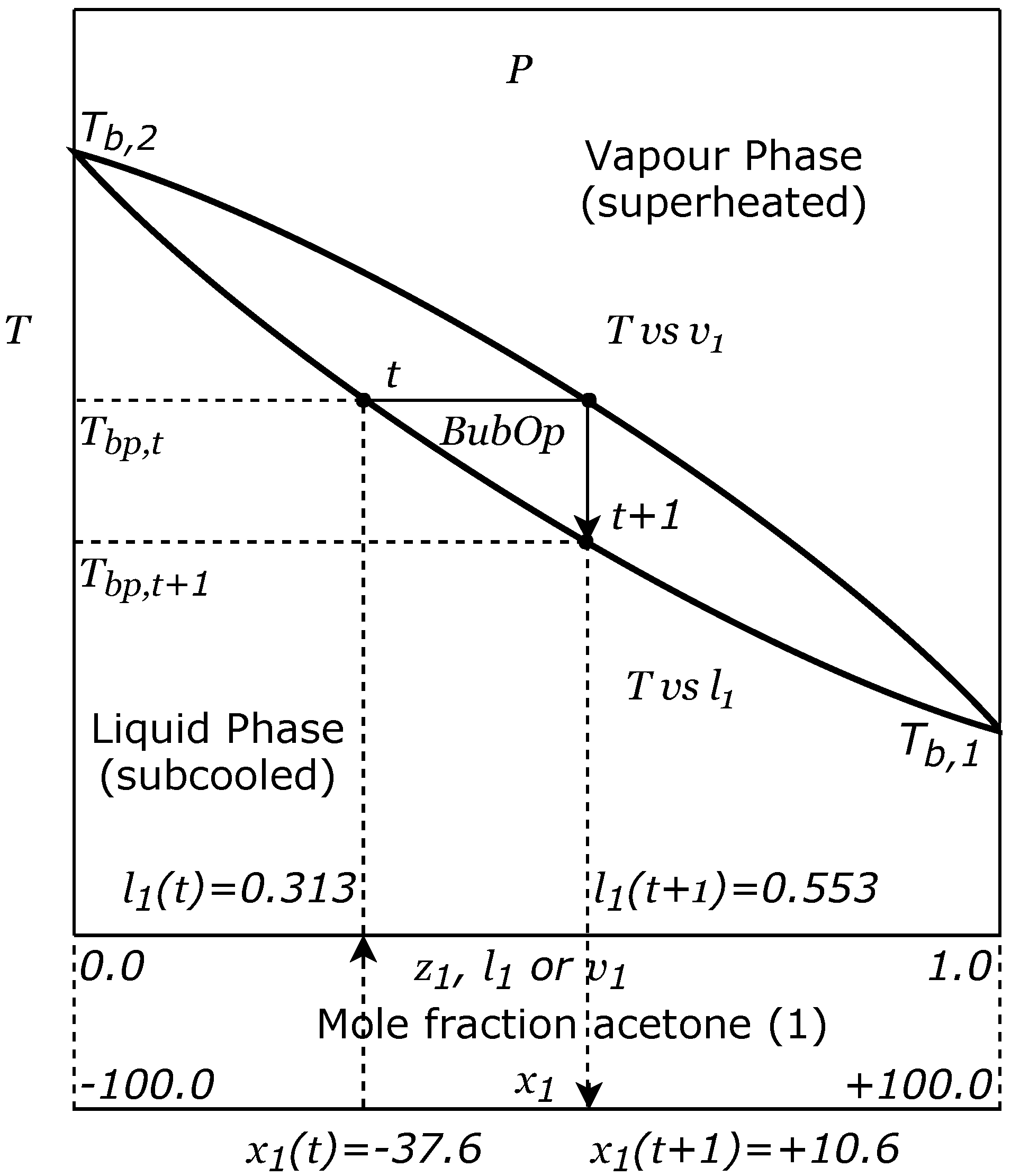
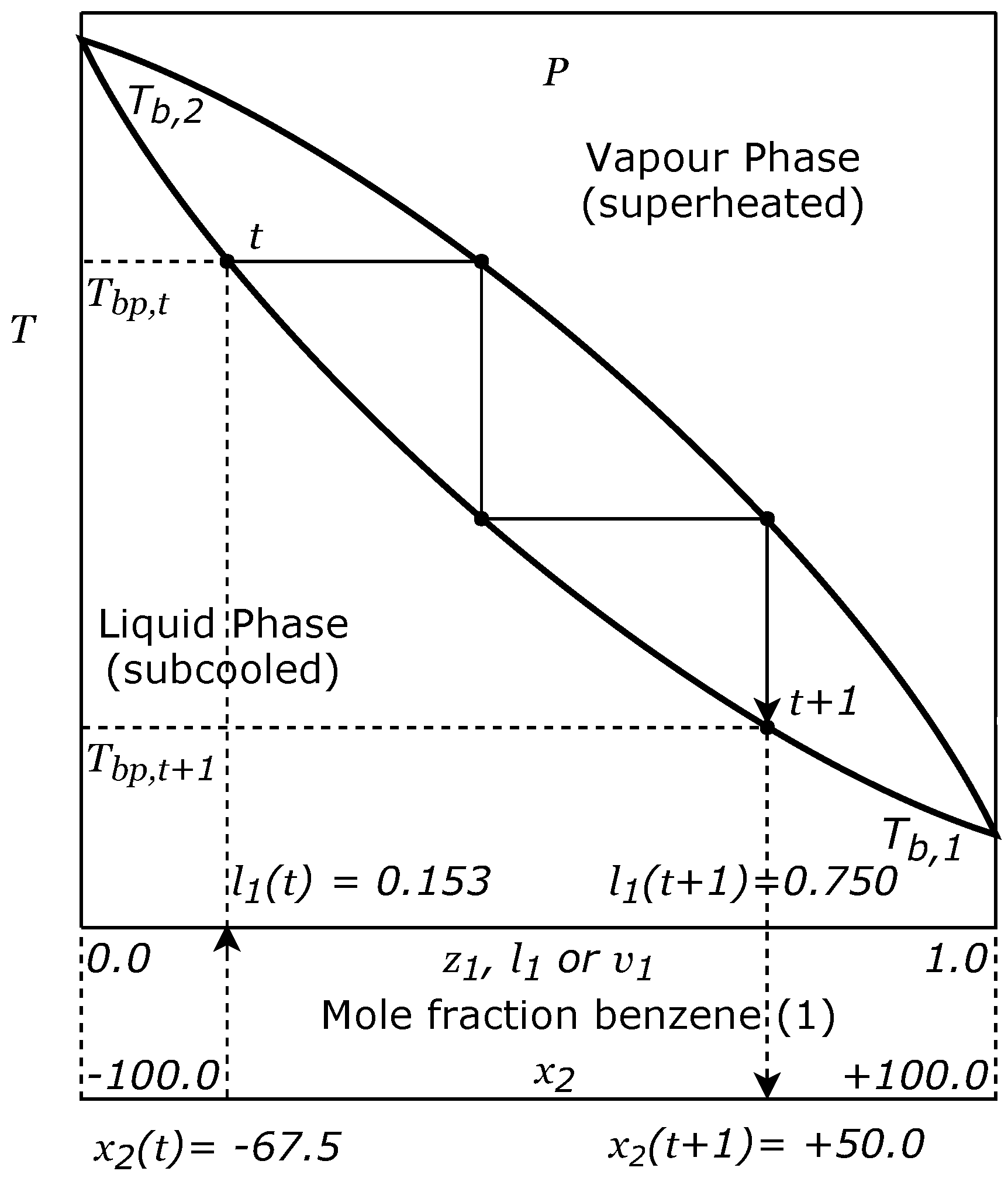
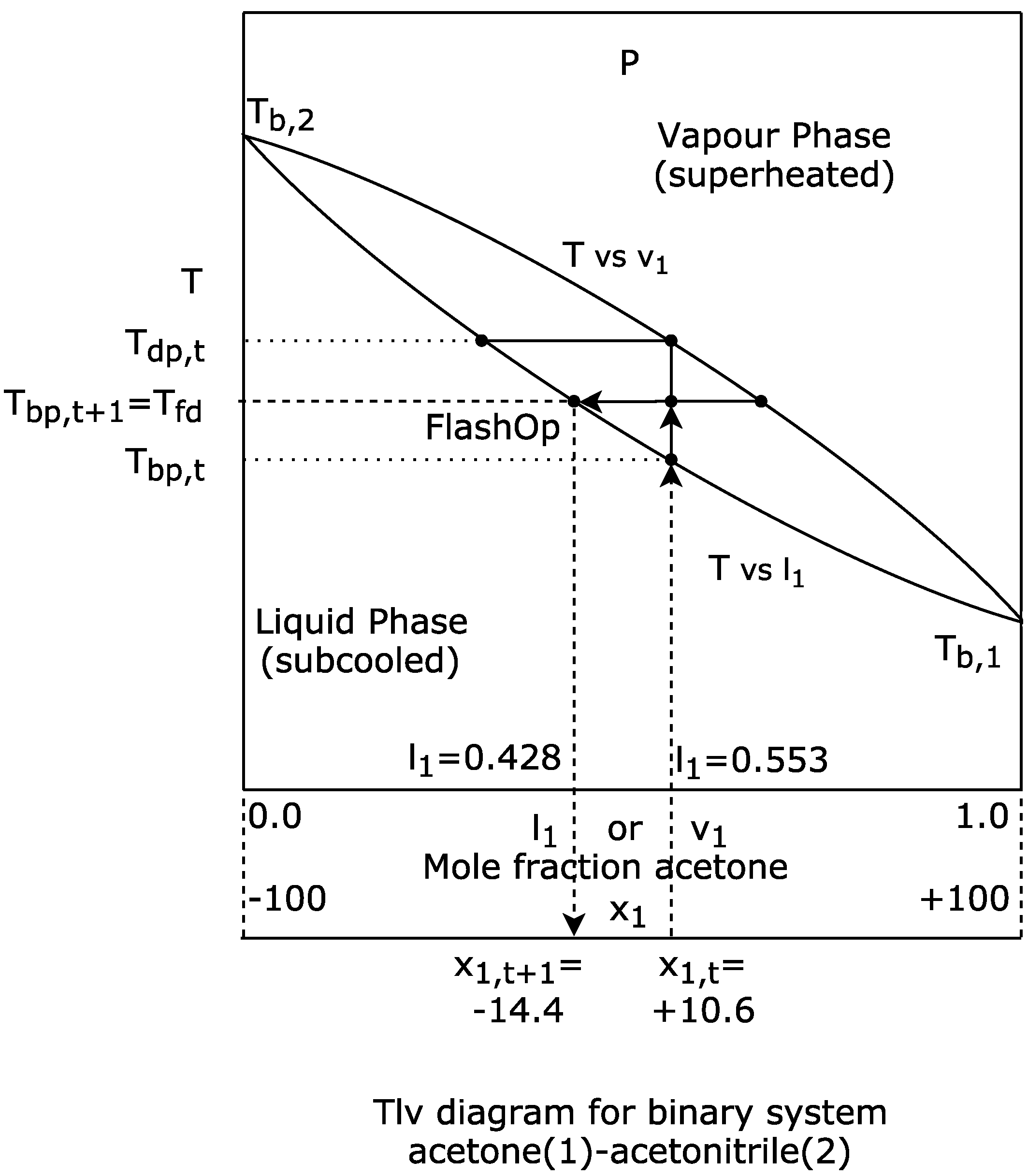
2]. In the case of VLE, this outcome may be due to the complexity of the algorithm, which simulates the physical-chemical process that served as inspiration. The real simulation restricts the potential capacity of the algorithm to reach more promising solutions with certain functions. For example, if a chemical species A and chemical species B are very similar to each other, the region enclosed between the saturation curves of the vapour-liquid equilibrium diagram will be very fine and will trend to be horizontal. This will produce more big steps around a good solution, than with a region of the same shape but with a greater incline, i.e., with a strong negative slope. In the limit, when chemical A is equal to chemical B, the system will be constituted by only one chemical species, i.e., will be a pure chemical species, so in this case, the binary diagram will be a horizontal straight line with no steps.
Root-mean-square error orRMSE:
Another general observation can be obtained if the root-mean-square error or
is used as shown in Equation (
36). The
measures the average of the squared errors, that is, the difference between the estimator and what is estimated. In this case, the estimator considered is the average of the fitness of the reference function, determined by the optimization algorithm, and what is estimated is the value of the true optimum of the reference function. In Equation (
36),
is any of the metaheuristics indicated, i.e., VLE, PSO, GSA, DE or WOA, and
F is the number of data considered.
Table 12 shows the
values calculated for the 15 classical functions and the five algorithms considered in this study.
Table 12 also presents the
values calculated for VLE and DE, excluding functions
and
due to lack of information for DE. With these results, it can be stated that, in general, the average fitness obtained by VLE is better adjusted to the true optimum of the reference functions than any of the published data sets for PSO, GSA, DE, and WOA. Considering the 15 classical functions, the
value for VLE is 22.388, for PSO it is 1995.7, for GSA it is 2527.7, and for WOA 1933.6. Excluding functions f14 and f15, the
values for VLE, PSO, GSA, DE and WOA are 24.048, 2143.7, 2715.2, 413.53 and 2077.0, respectively. According to this statistic metric, the
obtained by VLE under these circumstances is lower than that obtained by the other algorithms.
Similarly,
Table 13 shows the statistical results obtained with the second set of optimization problems, i.e., the composite functions, which are the following: the benchmark function (BenFun), the average value (Avg), the standard deviation (StdDev), the median (Med), the minimum value achieved (Min), the optimal value published (Opt), the difference between the minimum value achieved (Min) and the optimal value published (
), the true percentage deviation (
, %), and the maximum value reached (Max).
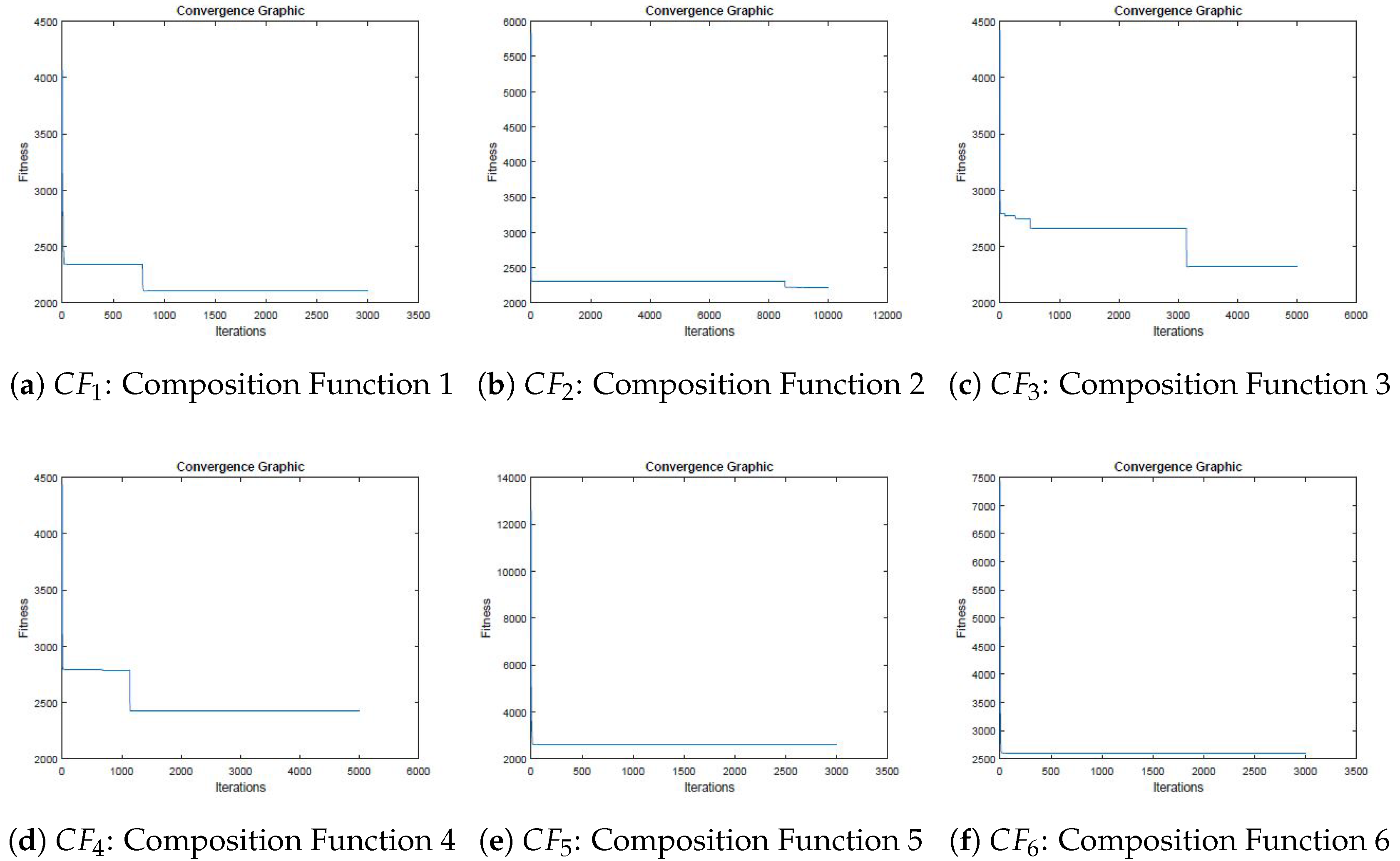
Figure 19 shows the convergence graphics obtained by VLE for these benchmark functions. The number of iterations was fixed at 1000, 3000, 5000 and 10000 for these functions.
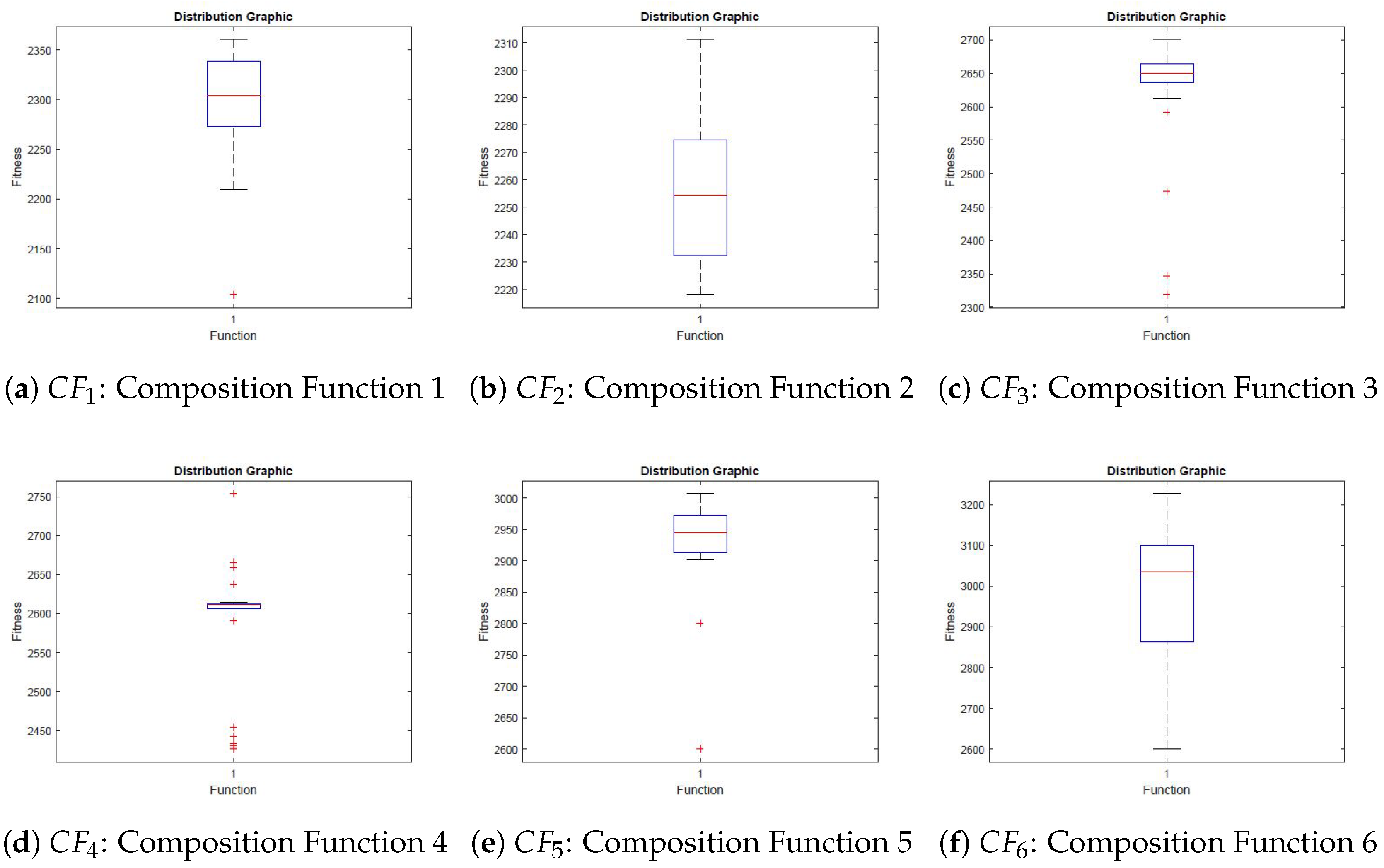
Figure 20 shows the distribution graphics obtained by VLE for the composite functions chosen. All experiments were repeated at least 31 times to guarantee a meaningful statistical analysis.


 ,
, 

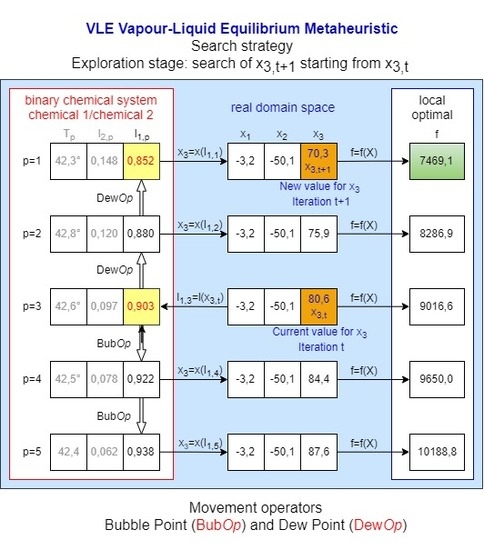






















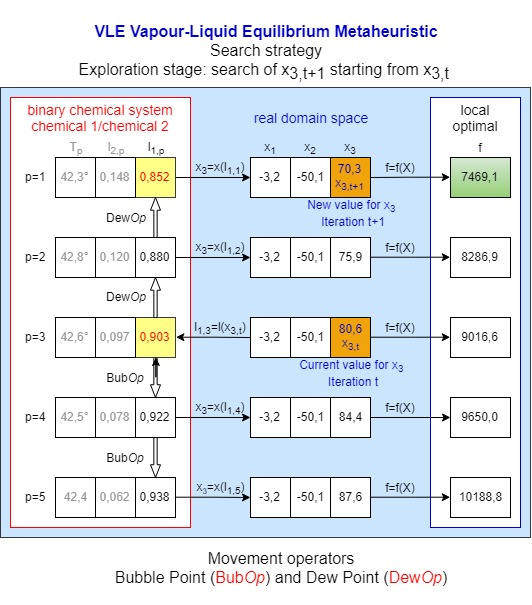{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}