1. Introduction
Computer network security plays a vital role in many organizations today. Business services heavily depend on the reliability of the network. Especially, for companies who provide 24/7 services across the globe, network security plays a core role in the business. The Internet acts as a backbone to these networks. The open architectural nature of the Internet opens inevitable security vulnerabilities to the connected networks and devices.
Over the last few decades, researchers have focused on automating the process of network security management [
1]. One of the main problems with the current research approach is addressing network security based on heuristics. To address this issue, recently, there has been a growing body of research focused on systematic analysis of network security using game theory. Game theory provides a systematic method to analyze and predict complex attack-defense scenarios.
It is important for security researchers to keep pace with the rapidly evolving threats and the continuous development of networking technology. The technological advances both complement, as well as hinder, network security since they act as new tools for wrongdoers. Network security involves securing more than one aspect to the network, such as confidentiality, integrity, and availability. Multi-objective optimization in network security have been widely employed to reflect this need. And can be applied to threatening similar security problems arise such as of Internet of Things [
2,
3,
4,
5]. Especially, in the case that the mobile nodes, e.g., normal nodes and not the malicious ones, form coalitions in order to achieve a common goal. It is of great interest to research the damage imposed by the attacker and how the proposed framework can provide solution in such types of problems. Multi-objective optimization has attracted many mathematicians and several approaches have been proposed to increase the efficiency and accuracy of the optimal solutions. There is an emerging growth of research interest in the study that uses multi-objective optimization on stochastic game theoretic models. One of the key problems in multi-objective optimization is choosing optimal solutions from a set of solutions. Among other approaches, the most natural and popular method among researchers is scalarization of an objective vector [
6].
In this paper, we compare three different types of scalarization approaches with Reinforcement Learning in the context of strategic defense action selection for a defender during interactive attack scenarios. We assume that the defender does not know what move the attacker will make, but must instead respond to previous attack moves.
In recent years, Reinforcement Learning (RL) has received growing attention in the research community. Our work is an extension of our previous work on network defense strategy selection with Reinforcement Learning and Pareto Optimization [
7], in which we combined Pareto optimization with Q-learning to find an optimal solution.
The usage of Reinforcement Learning allows for the creation of an offline system that improves over time. The algorithm retains the contribution of every attack-defense interaction and will eventually outperform algorithms that start every new interaction from scratch.
The Pareto-Q-learning approach presents several problems, which we aim to resolve with this study. First is how to choose a solution from the remaining Pareto optimal fronts. As previously indicated, many researchers use scalarization of an objective vector. We examine the efficiency and effectiveness of several scalarization methods. The second problem is the efficiency of the Pareto-Q-learning approach. Previous researches show that direct application and calculation of Pareto fronts for every step in the Q-learning process is onerous and inefficient. Our research explores if the usage of a scalarization algorithm can provide us with a more efficient solution. Finally, our previous game model lacked real-world application. We have updated the model to represent an abstracted DDOS attack.
Single-objective optimization often fails to reflect the variety of complex real-world scenarios [
8]. Most of the problems in real life involving decision-making depends on multiple objectives [
9,
10]. Multi-objective decision-making has been a widely explored area [
11]. Multi-objective problems are also known as multi-criteria optimization, or vector minimization [
12]. Traditional methods, such as linear programing and gradient descent, are too complex for solving multi-objective Pareto-optimal fronts [
13,
14]. Multi-Objective Reinforcement Learning has been actively researched in various fields [
11]. In traditional reinforcement learning an agent learns and takes action based on receiving a scalar reward from the dynamic environment. The quality of estimate improves over time as the agent tries to maximize the cumulative reward [
15]. Sutton’s [
15] reward hypothesis states that goals and purposes can be thought of as maximization of the cumulative single scalar reward. Thus, a single scalarized reward is adequate to represent multiple objectives [
11]. Since traditional RL focuses on a single objective, the algorithm requires a modification to accommodate multi-objective problems. The most common approach to deal with multi-objective problems is scalarization.
Scalarization of multi-objective RL involves two steps. First, we specify the scalarization function
, such that the
state value vector is projected into a scalar value
, where
is the weight vector parametrizing
. Then, we define an objective function with an additive scalar return, such that for all policies
and states
, the expected return equals the scalarized value of
. The simplest and most popular, as well as, historically, the first proposed scalarization technique, is linear scalarization [
16]. In linear scalarization,
represents the relative weight of the objectives. Since it is a convex combination of all objectives, linear scalarization lacks the ability to find all solutions in a non-convex Pareto set [
17]. Lizotte et al. [
12] proposed an offline algorithm that uses linear function approximation. Although the method reduces the asymptotic space and complexity of the bootstrapping rule, generalizing the concept into higher dimensions is not straightforward. Commonly known non-linear scalarization, among others, includes the Hiriart-Urruty function [
18] and Gerstewitz functions [
19].
Another class of algorithm for solving multi-objective problems are evolutionary algorithms (EA). Multi-objective EA (MOEA) uses an evolving population of solutions to solve the Pareto fronts in a single run. Deb and Srinavas [
20] proposed non-dominated sorting in a genetic algorithm (NSGA) to solve multi-objective problems. Despite NSGA being able to capture several solutions simultaneously, it has several shortcomings, such as high computation complexity, lack of elitism, and specification of sharing parameters. NSGA-II improves by addressing these issues [
21]. Other EA algorithms includes Pareto-archived evolution strategy (PAES) [
20] and strength Pareto EA (SPEA). For a thorough survey of multi-objective evolutionary algorithms, the interested reader is referred to [
22].
In [
23], Miettinen and Mäkelä studied two categories of scalarization functions: classification and reference point-based scalarization functions. In classification, the current solution is compared to the desired value, whereas in reference point-based scalarization functions a reference point is used to represent the aspiration level of the decision-maker (DM) and can be specified irrespective of the current solution.
Benayoun et al. [
24] used a step method (STEM) in which the DM classifies the current solution points into two classes,
and
. The DM defines the ideal upper bounds for each objective function. This method requires global ideal and nadir points. Non-differentiable Interactive Multi-Objective Bundle-based optimization System (NIMBUS) is another method that asks the DM to classify objective functions [
25]. Additionally, this method requires a corresponding aspirational level and upper bounds.
Since MORL has different optimal policies with respect to different objectives, different optimal criteria can be used. Some of these include lexicographical ordering [
26] and linear preference ordering [
27]. However, the most common optimal criterion is Pareto optimality [
28].
In this paper, we compare the performance of our implementation of Pareto-Q-learning with different reference point-based scalarization methods. We limited our study to three well-known methods: linear scalarization, the satisficing trade-off method (STOM), and the Guess method.
The rest of the paper is organized as follows: In the next section, the related works and background of the different scalarization techniques are covered. In
Section 3, we detail the theory and experimental design. Before the conclusion, the experimental results are analyzed in
Section 4.
Section 5 concluded in this paper.
4. Experiment
This section contains the implementation and discussion of an experiment comparing Pareto based MORL to three different scalarization approaches. The Pareto-Q-learning implementation, developed by Sun et al. in [
7], was shown to be superior to a basic Q-learning implementation. The implementation had two major drawbacks: (1) calculating Pareto fronts is an inefficient process (see the complexity analysis); and (2) the algorithm used linear scalarization when selecting an action (see the Multi-Objective Reinforcement Learning section).
4.1. Problem Statement
In the theory section, we discussed why we believe that the scalarization approach is the best method for selecting a solution from a set of non-dominated Pareto fronts. In the Game Model section, we described a game model that representative of a basic DDOS attack. This section brings those elements together to answer the last problem presented in our introduction, namely the inefficiency of the Pareto-Q-learning approach.
The experiment aims to show that we can improve on the MORL approach used by Sun et al., by replacing the Pareto Optimal linear scalarization with a reference point based scalarization approach. The reference point based approaches tend to choose moves that are both (a) Pareto-Optimal, (b) in line with the value judgment of the Decision Maker, and (c) more efficient than the Sun et al.’s Pareto-Q-learning approach. The experiment, thus, gives us the resolution of three specific problems:
- (1)
Do the selected scalarization approaches lead to moves that are Pareto Optimal?
- (2)
Do the selected scalarization approaches lead to game results that reflect the decision-maker’s value judgment (as represented by weights)?
- (3)
Are the selected scalarization implementations more efficient than calculating the Pareto fronts?
As indicated in the section on the game model, we chose to use chaotic goal functions as those are likely to lead to a convex Pareto Front. We expect, and the experiment does show, that linear scalarization tends to lead to results that do not reflect the value judgment of the decision-maker.
4.2. Experiment Planning
We deemed it unnecessary to implement the experiment under different network configurations, as our previous research on Pareto-Q-learning has shown the approach to perform comparably under different network configurations [
7]. We focused on a configuration of 50 nodes running three services.
For this experiment, we chose to keep the players relatively unintelligent. Rather than build complex autonomous agents with sensors and underlying sub-goals, we have chosen to have an attacker that always randomly chooses an action and a defender that always follows the advice of the given algorithm.
The players were given 10 moves per player. This was deemed to lead to sufficiently long games to expose the players to a variety of possible game states, while not having the game last unnecessarily long. We chose to have the game conclude after 10 moves, because in large networks the players would have to play extremely long games to meet any other winning conditions. In our network of 50 nodes, the attacker would have to make a minimum of 50 × 3 = 150 moves to bring down all the services, or 50 × 3 = 150 moves to infect all the nodes, and that is assuming that the defender does nothing to hinder the attacker’s progress. Allowing for games with “infinite” game points led to games that were thousands of moves long.
Our network consists of 50 nodes. Each node in the network has three services and can be flooded or exhausted. Ten percent of the possible services have been turned off (meaning that the service cannot be contacted, but also cannot be compromised). Likewise, 10% of the nodes require negligible CPU resources. Twenty percent of the nodes are high-value devices (app servers, sensitive equipment, etc.) and 80% of the nodes are low-value devices (client machines, mobile phones, etc.).
The exact cost of flooding or exhausting a service is randomly calculated when creating a network.
Table 1 contains the ranges for those values.
Table 1 also details the rest of the network configuration values. The game does not require the attacker and defender to have the same value judgment allowing for different scalarization weights for the attacker and defender.
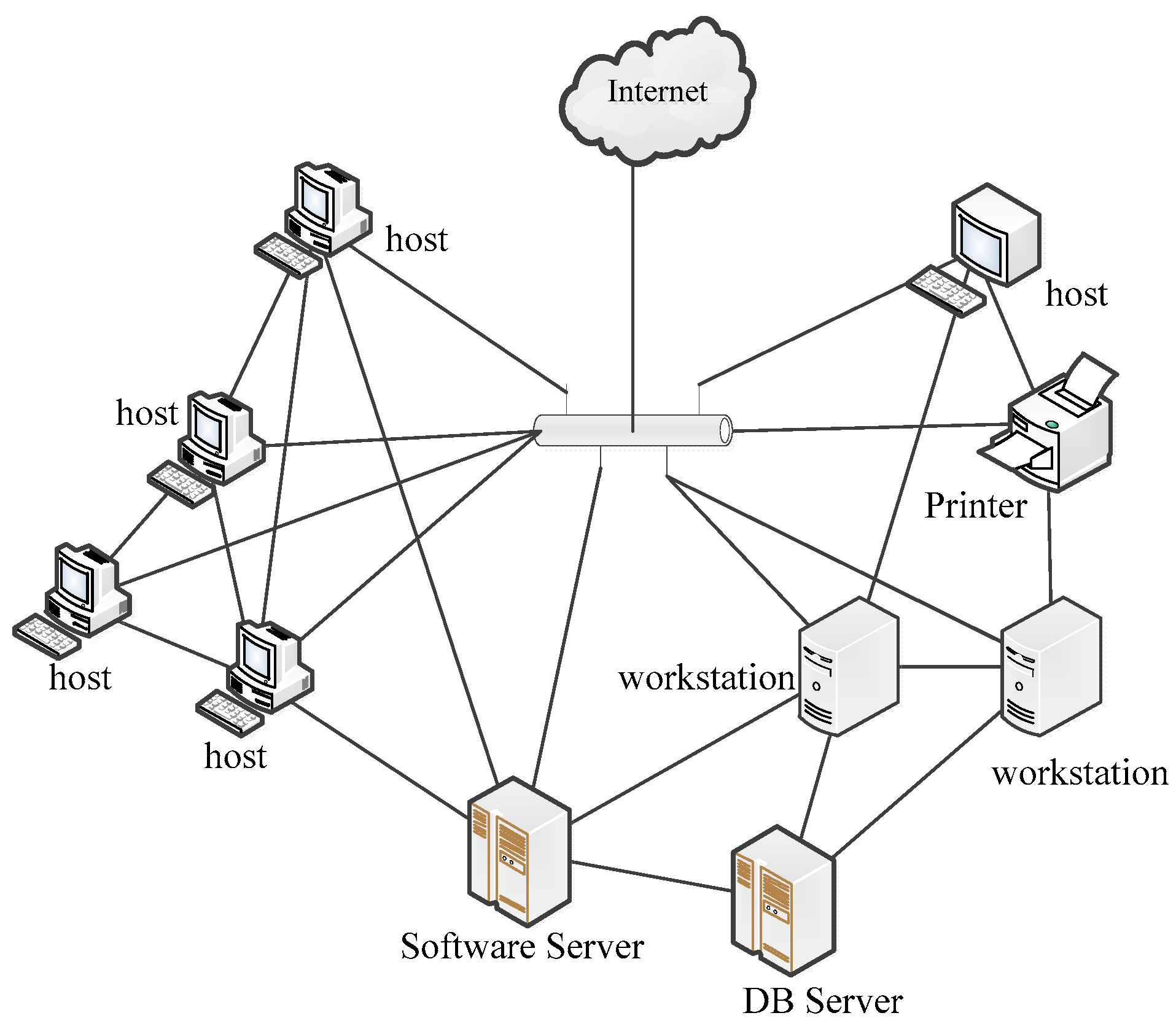
The starting game network is randomly generated. Nodes are randomly connected with a number of edges given by the sparsity, where |edges| = sparsity × |nodes| × (|nodes| − 1).
Figure 1 shows an example of what the actual network may look like. Note that this figure contains just 10 nodes, and that there exists a path between all the nodes of the graph, but that the graph is not fully connected.
4.3. Experiment Operation
In order to give the Q-learning algorithm sufficient data to learn, we ran the game 200 times with ε starting at 0 and increasing to 0.8 by the 150th run. The starting game network was the same for each algorithm. The following algorithms were used:
- (1)
Random strategy: The defender uses a random strategy;
- (2)
Pareto-Q-Learning: The defender uses the combined Pareto-Q-learning algorithm;
- (3)
Linear Scalarization: The defender uses linear scalarization (does not calculate the Pareto fronts);
- (4)
STOM: The defender uses STOM (does not calculate Pareto fronts); and
- (5)
GUESS: The defender uses the naïve scalarization method (does not calculate Pareto fronts).
The complete setup (five algorithms for 200 iterations with the same starting network) was then repeated for 50 different starting networks. The data of those repetitions should show us if there is a statistical difference between the results gained from the five different algorithms.
The experiment was implemented in Python, with the numpy library. The experiment was run on a MacBook Pro 2016 model machine (Macintosh OS Sierra Version 10.12.6) with an Intel Core i5 (dual-core 3.1 GHz) CPU and 8 GB RAM. The program consists of a Game object in charge of the Q-learning part of the implementation and a State object in charge of storing the game state and calculating the Pareto front and scalarization methods.
4.4. Results and Analysis
4.4.1. Single Game Analysis
The results are consistent with what would we should expect from MORL. The final reward for a game increases as the defender learns with each iteration.
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
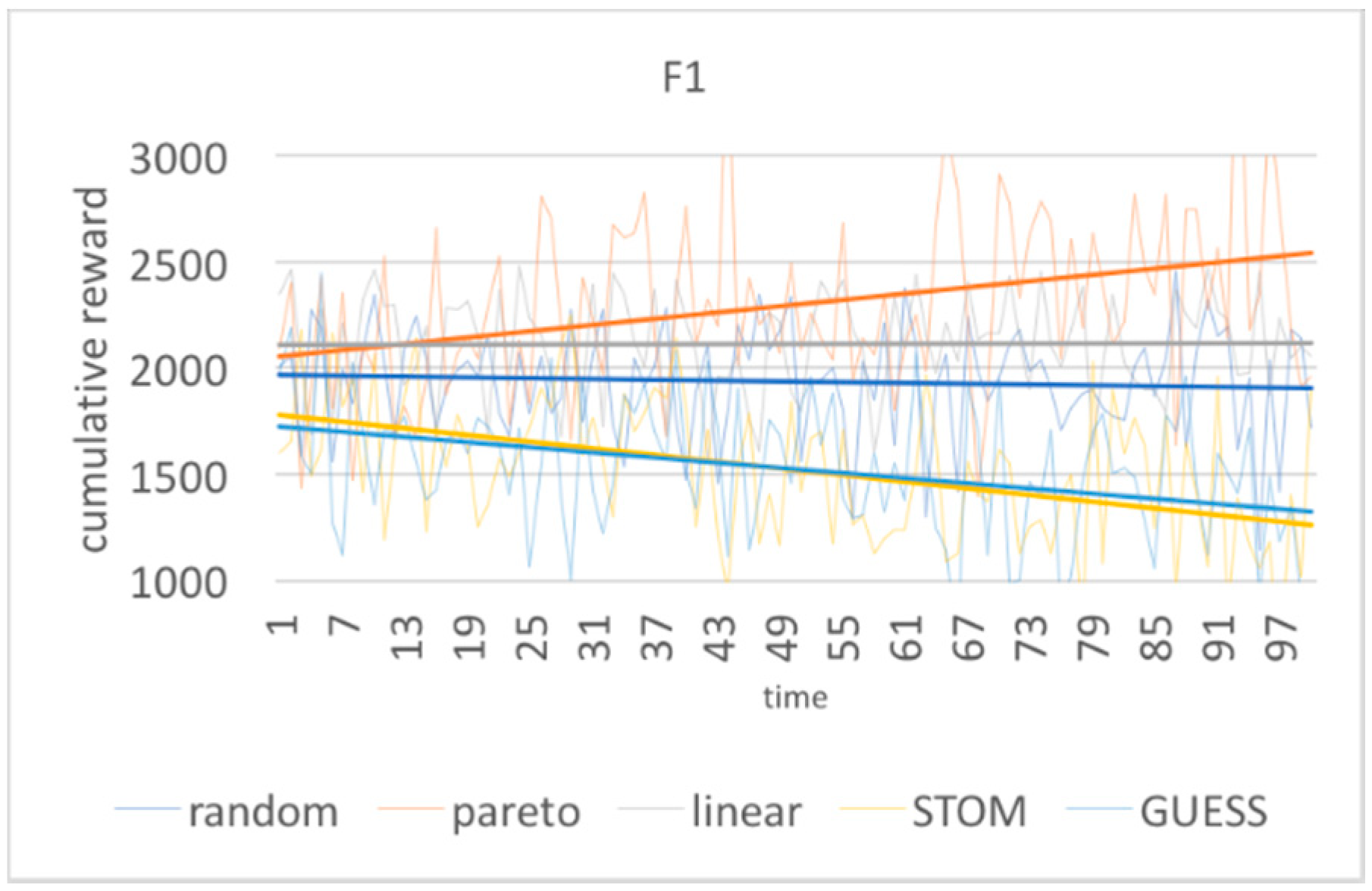
Figure 6 show the results over time for one starting network. From
Figure 2, it is clear that not all the optimization approaches outperform a random strategy. Linear scalarization and the Pareto-Q-learning approach lead to better results over time, while the STOM and GUESS method do not lead to better results. Both STOM and GUESS prioritize fitting the goal prioritization over improving the results of the interaction.
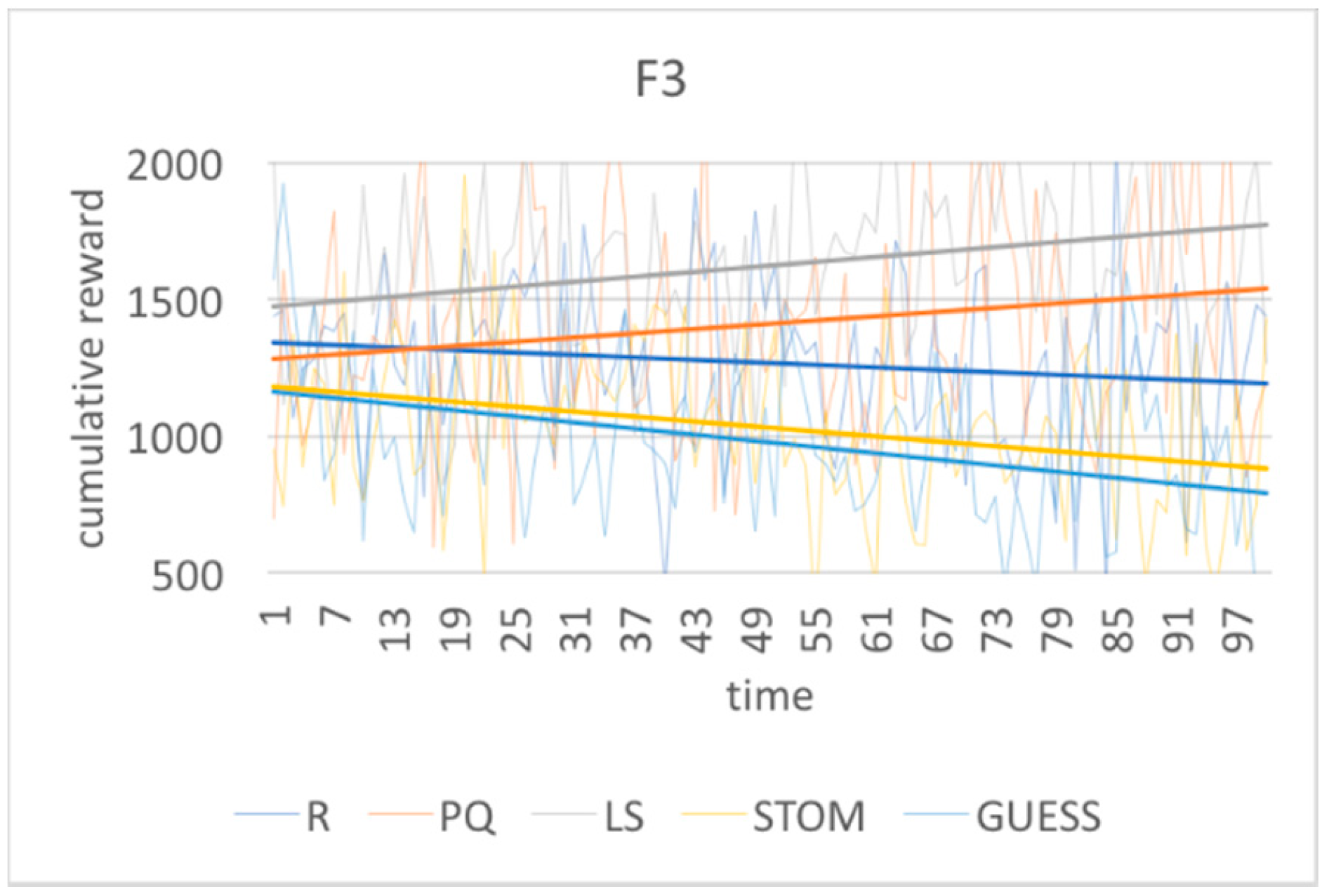
From
Figure 3,
Figure 4 and
Figure 5, we can see that all the algorithms start with an unfavorable distribution of the goals. Both STOM and GUESS aggressively react by decreasing the results for goals
f(1) and
f(3) and increasing the result for
f(2), until the algorithm reaches a goal distribution that matches the set goal prioritization of 3:7:2. The GUESS method slightly outperforms the STOM method.
The Pareto-Q-learning approach attempts increase the result for all goals. It does so by focusing on increasing the contribution of f(2), while not to decreasing the results of f(1) and f(3). Due to this, the goal distribution of Pareto-Q-learning falls well short of the desired 3:7:2 goal prioritization. The linear scalarization approach indiscriminately focuses on increasing the final scalarized result. This leads to a goal distribution which is lower than that of the Pareto-Q-learning approach, but still reasonably high, as the scalarization weights are the exact same as the goal prioritization.
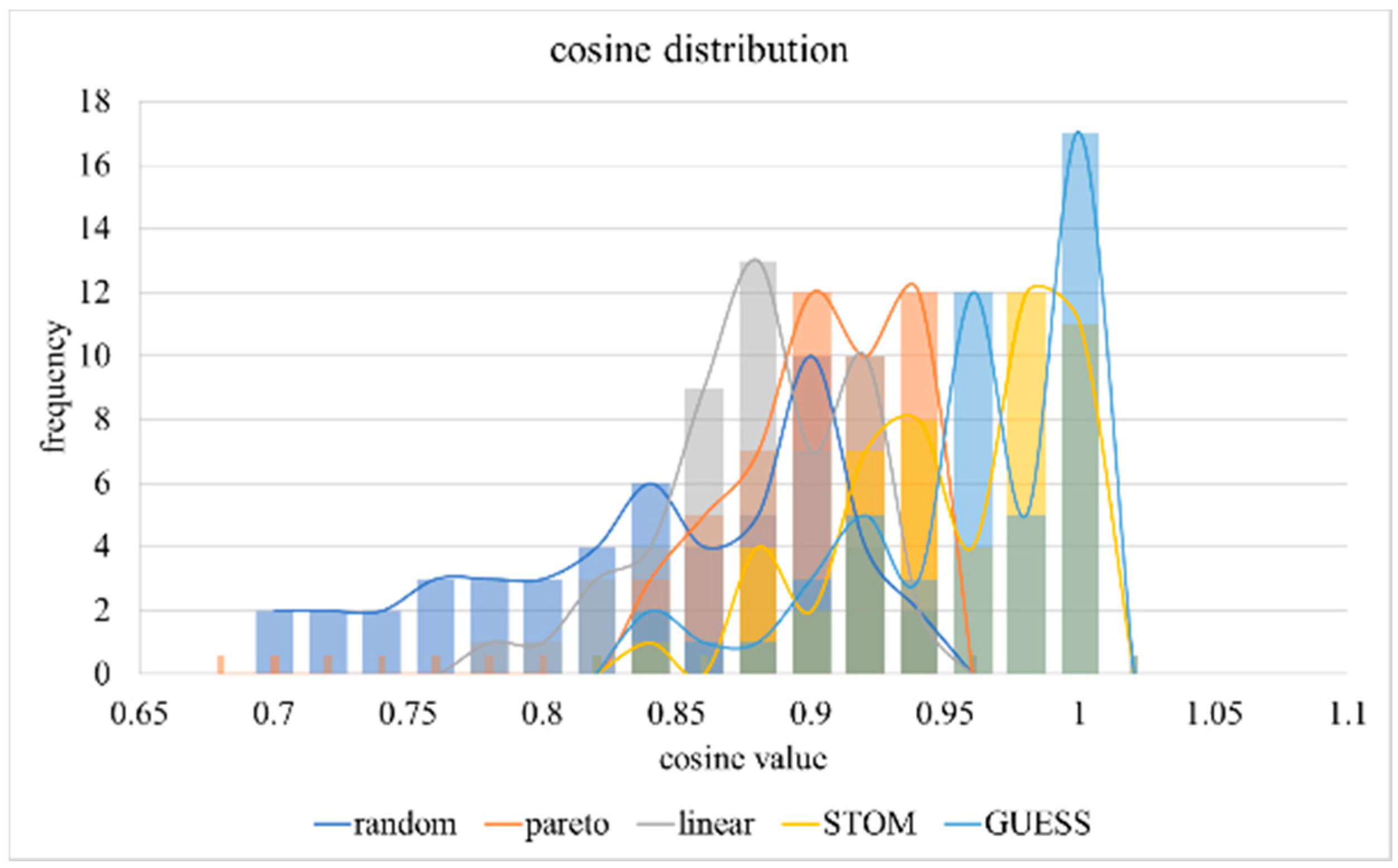
Figure 6 shows the cosine of the angle between the goal prioritization vector (3:7:2) and the result vector over time. This is according to Equation (25). A result vector parallel to the goal prioritization vector will have a cosine value of 1 and a result vector perpendicular to the goal prioritization vector will have a cosine value of 0. The results in
Figure 6 make it obvious that the GUESS method is a superior approach for goal prioritization. With the exception of random choice, linear scalarization performs the worst.
These results show a single game network. Different starting conditions may have different results.
4.4.2. Multiple Game Analysis
We determined if these results exist across starting conditions by mapping out the rewards over 50 different starting networks and statistically analyzing the resulting reward distribution.
Table 2 shows the mean, standard deviation, and 99% confidence interval for the scalarization of the cumulative game rewards and the cosine value of the game rewards. The table also includes the result of a
t-test comparing the game rewards of the Pareto-Q-learning with that of the other approaches; and the results of a
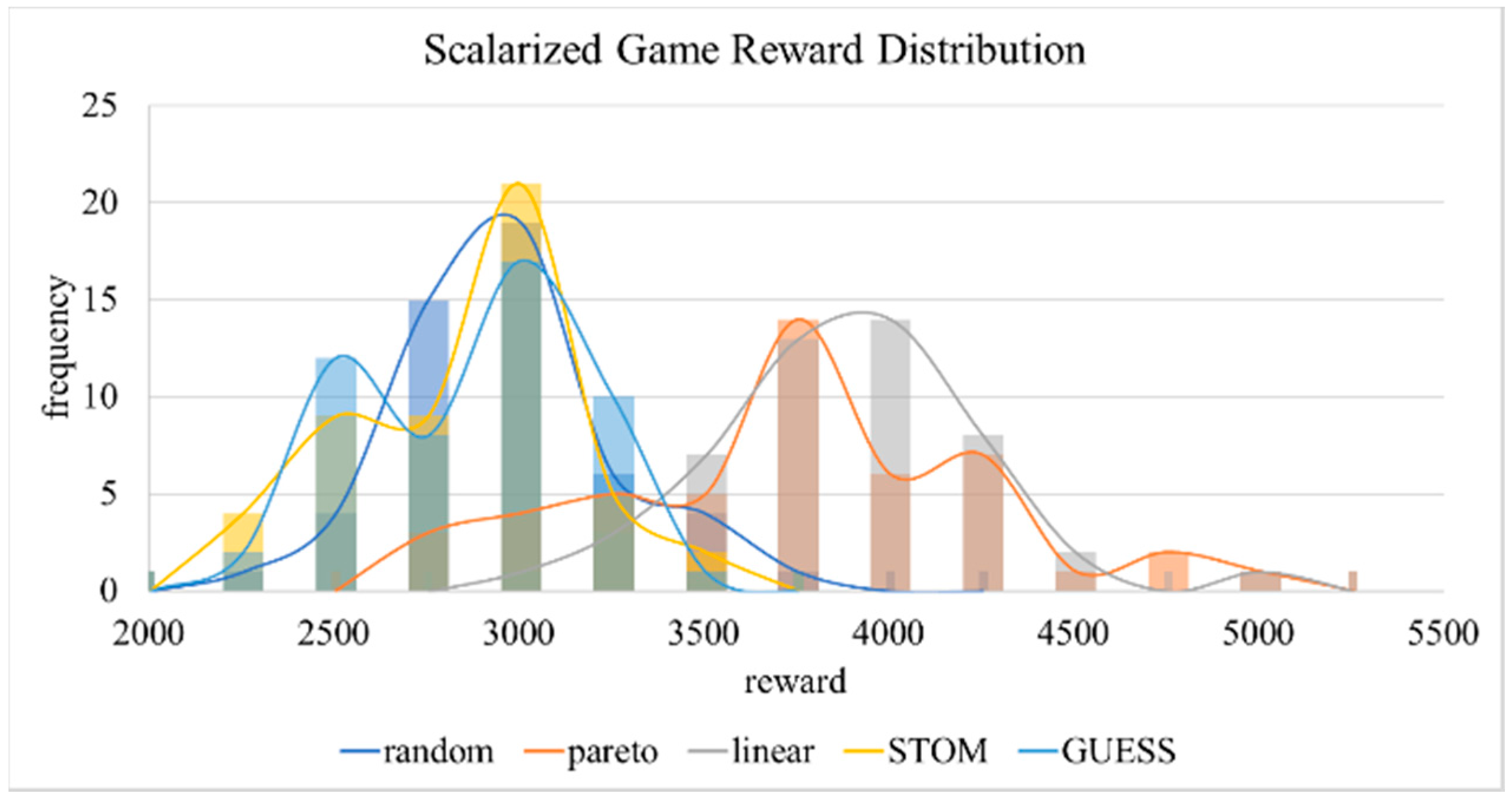
t-test comparing the cosine value of each approach to the desired value of 1. A graphical representation of these distributions is visible in
Figure 7 and
Figure 8.
The results show that Pareto-Q-learning and linear scalarization consistently outperform the other approaches for the cumulative rewards. A standard t-test, with a p-value of 0.05, confirms this difference. Linear scalarization performs comparable to Pareto-Q-learning with a t-statistic of 0.853. STOM and GUESS perform very poorly with results comparable to a random strategy selection. If the defender aims to merely maximize the game rewards, regardless of which goals are prioritized, the Pareto-Q-learning approach or linear scalarization give the best results.
The cosine results, however, show that Pareto-Q-learning and linear scalarization achieve this high cumulative result by ignoring the defender’s desired goal prioritization. The STOM and GUESS approaches meanwhile result in a goal distribution which is close to the optimum. The GUESS distribution is statistically not different from the desired goal prioritization. The standard t-test confirms this with GUESS t-statistic of 0.057, being the only one to exceed the p-value of 0.05. It is noteworthy that the STOM method led to a ratio that was still close to the desired goal prioritization, while the other approaches were nowhere near the distribution.
The results clearly show that if the defender wishes to have control over goal prioritization, the GUESS approach is the best. However the fairer distribution of rewards may not be worth the loss in cumulative rewards. The Pareto-Q-learning approach still appears to strike the best balance between the conflicting goals, with a high cumulative reward and a respectable goal distribution.
4.4.3. Complexity Analysis
We use the method proposed in [
39] to calculate the Pareto fronts. The best-case complexity is
and the worst-case complexity is
. The worst-case complexity linear scalarization is
.
We tested the algorithm efficiency by recording the running time of just the optimization algorithm for each of 50 starting network conditions. The resulting time for 2000 operations is listed in
Table 3.
Figure 9 shows the distribution of the running times. It is clear from the results that the Pareto-Q-learning is the most inefficient approach. By contrast, linear scalarization is the most efficient and runs 760 times faster than Pareto-Q-learning approach and two times faster than the other two scalarization approaches. Of the two algorithms in the middle, the STOM approach performs significantly better than the GUESS approach. These results confirm our assumption that the scalarization approaches outperform the Pareto-Q-Learning approach.
4.4.4. PDSSS System Analysis
We have researched and developed a Pareto Defense Strategy Selection Simulator (PDSSS) system for assisting network administrators on decision-making, specifically, on defense strategy selection.
The objective of the system is to develop a system that addresses the multi-criteria decision making using Pareto efficiency. The purpose is to assist network security managers in choosing a defense strategy to mitigate the damage to the business by an attack.
Our system is developed by specifically focusing on one specific type of attack, the network flooding attack. However, with slight changes the system should work with any attack that has multiple objectives. The goals, tasks, and solutions of PDSSS are listed below in
Table 4.
The GUI (Graphical User Interface) layout is visible in the wireframe in
Figure 10, which consists of five sections:
- -
The configuration panel
Here the user can choose the input configuration of the model. There are three models, each of which has a different set of goal functions.
- -
The goal function before the application of optimization
Here the user can see the solution space for the goal functions before we implement the algorithm (i.e., the results from selecting a strategy as defined by the model).
- -
The goal function after the application of optimization
Here the user can see the solution space for the goal functions after we implement the algorithm (i.e., the results from selecting a strategy as defined by the model).
- -
The results
Here the user sees a summary of what the optimization algorithm has done for a single step.
- -
The command buttons
Here the user interacts with the GUI by generating a new model with the given configuration or by loading an existing model from a csv (Comma-Separated Values) file.
In order to validate the proposed models using simulated results, we use the SNAP email-EU-core network dataset to extract the network topology. The network dataset in
Table 5 contains email data from a large European research institution. The edge (u, v) represents the existence of an email communication between two users. The primary reason we use this data is that it has the properties of a peer-to-peer network presented in the models. Additionally, the higher clustering coefficient and higher number of triangles in the network allows us to easily extract smaller subgraphs to perform simplified versions of the simulations. Moreover, data contains a ‘ground-truth’ community membership of the nodes. Each node can only belong to one of the 42 departments. This makes it easy for us to classify nodes into high-value nodes and low-value nodes based on the department number. In addition to this, email services are often the victims of real-world DDOS attacks, which makes the dataset a relevant representation of the network model. The following tables detail the dataset.
Note that the dataset does not contain all the necessary information for the models in the simulations. The missing configuration data has been auto-generated.
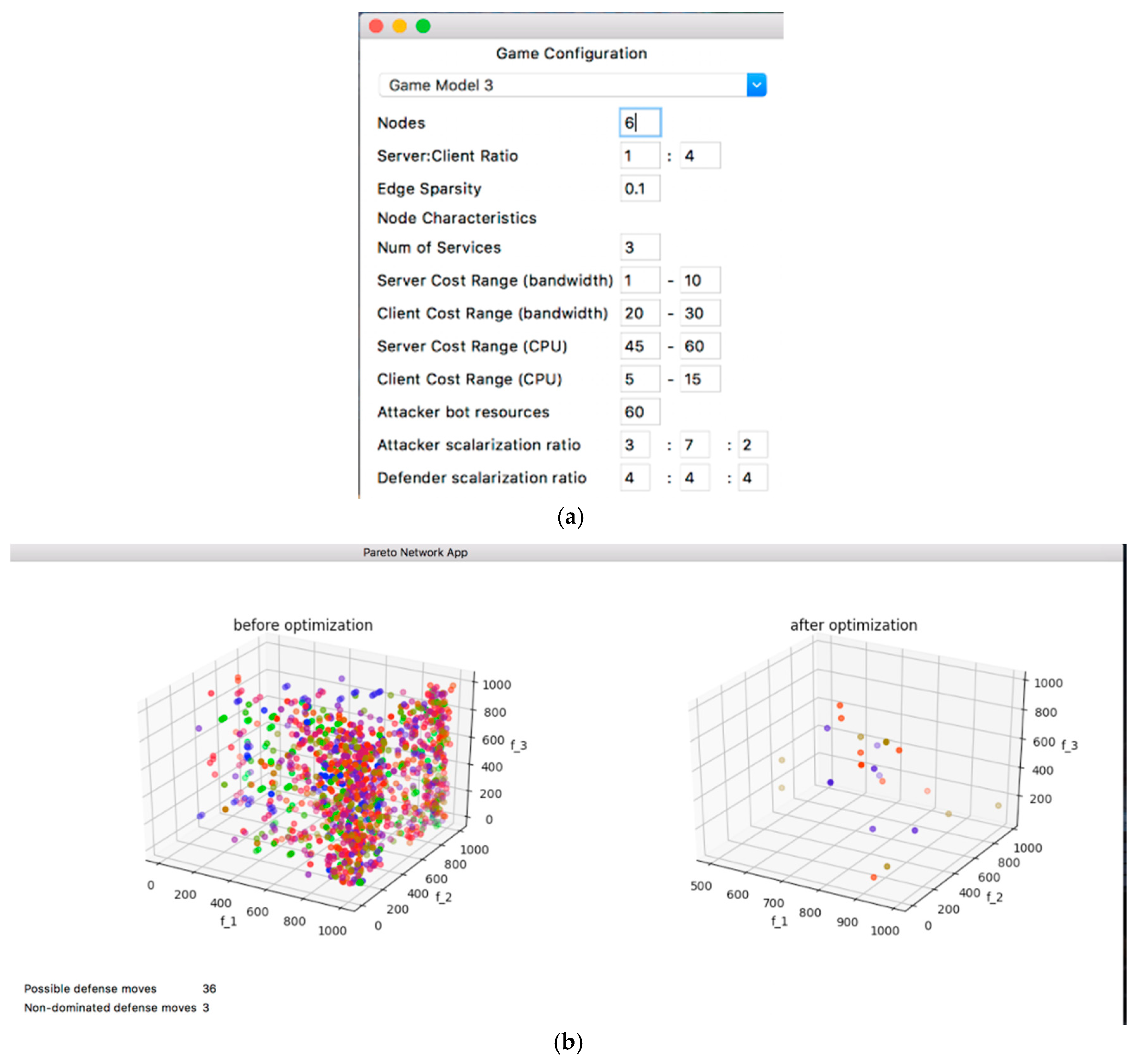
The PDSS system overview is shown in
Figure 11, which is under the configuration of
Table 6, and the user can select the regular network graph definition features: the number of nodes and server-client ratio. The user can select the model specific graph definition features: edge sparsity and cost ranges for bandwidth and CPU resources. The user can select the model features: attack resources and the scalarization ratios for the attacker and defender. The number of possible strategies is determined by the model. This model has a 3-D solution space.
In the first graph in
Figure 11, it is difficult to visually identify the best strategies from the initial graph as most of the colors are spread across the graph. However, there is a noticeable concentration at the top-right corner of the graph.
On the second graph, the optimal values are much easier to interpret. The orange (~600, ~950, <650) and blue points are much more vivid than the khaki points, indicating higher scores in the goal functions. The orange and blue points are diagonally oriented from the inner upper left corner to the outer bottom right corner. This explains why these colors are brighter at the center. The other optimal values scattered near the walls are faint, indicating they score very low in one of the goals, although they are in the optimal set.
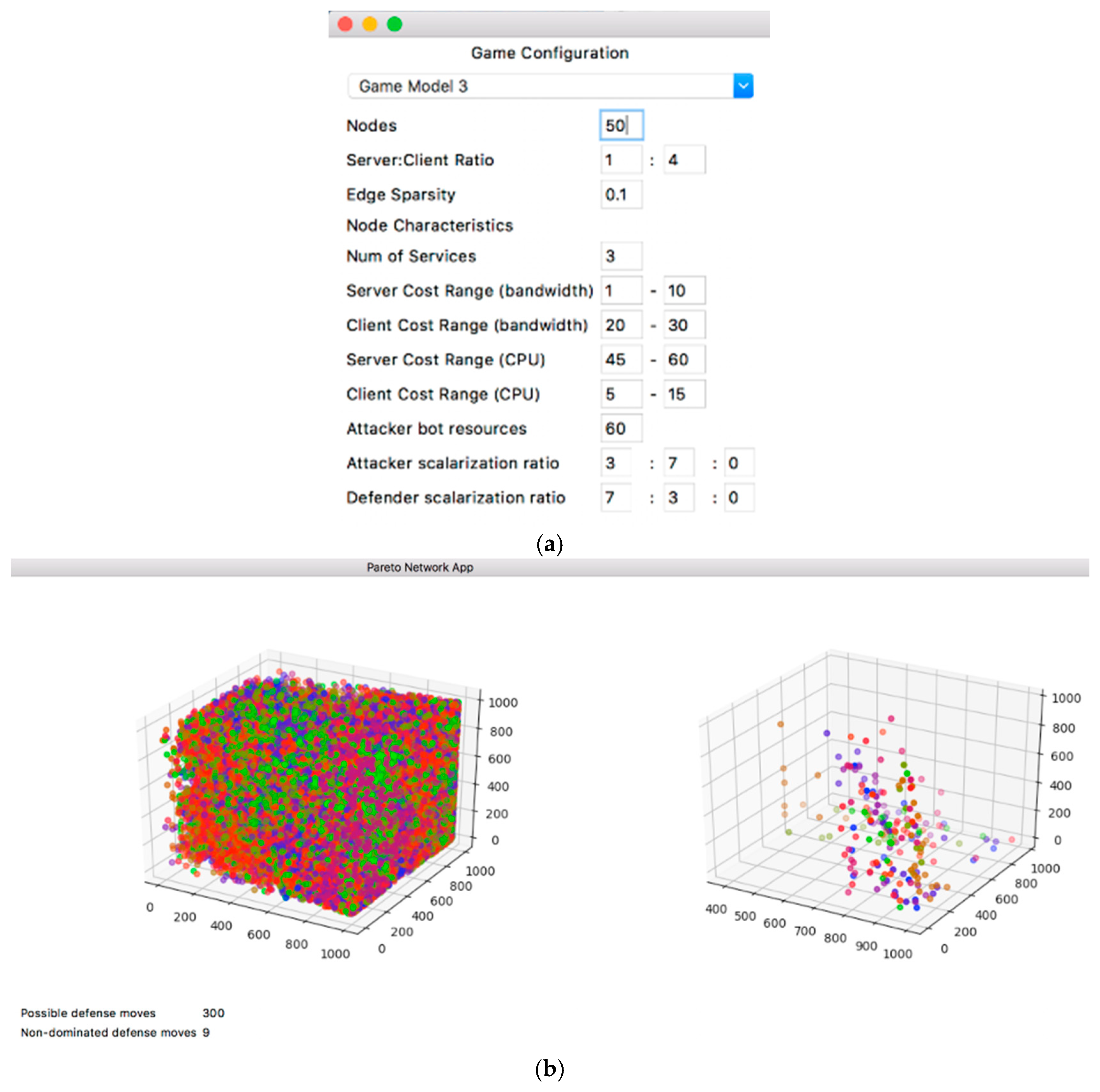
Figure 12 shows the PDSS system with a more realistic network size with configuration in
Table 7. As is visible from the image, the graphical representation of the results is no longer useful. The algorithm also took much longer to graph the results. For the actual running of the experiments (which includes many repetitions), we opted not to use the GUI and instead ran the code from the command line.
In the first graph in the above figure, the initial strategies are cramped into the plot making it nearly impossible make an inference solely from the graph. However, the second graph shows the optimal non-dominated strategies. It is much easier for a DM to make a decision in this case just by referring to the second graph: all of the unnecessary dominated strategies have been removed. It seems green is the most distributed strategy, while blue and orange have fewer options.
5. Conclusions
This article shows that in network defense games, the Pareto-Q-learning approach suggested by Sun et al. leads to higher game rewards than scalarization approaches. However, those higher rewards are achieved by choosing actions that do not fully adhere to the defender’s desired goal distribution. It is possible to obtain a better goal distribution by choosing a scalarization approach that prioritizes the goal distribution over the final game reward.
The conducted experiment shows that for an abstract DDOS attack represented in the game model, this approach allows decision-makers to learn how best to allocate scarce resources to avoid a loss of service availability. The abstract DDOS model can be implemented with a decision-maker specific goal function. Various decision-makers can, thus, use the model to create a goal prioritization strategy specific to their network.
Our research in multi-criteria decision-making techniques has shown that scalarization is more efficient and less dependent on qualitative analysis than other options, such as the Analytical Hierarchy Process or the Tabular method. The experiment also shows that Pareto optimization may be computationally too expensive for real-time monitoring and response. However, the effectiveness of the algorithm can be significantly increased by the use of a scalarization function.
The usage of a reinforcement learning algorithm is also very apparent, as the algorithm produces better results over time. This means that the algorithm is very suited for offline learning. By gathering data on previous attacks, we can teach the algorithm to perform better than non-learning algorithms which cannot leverage that information.
We suggest that network defense games that wish to find an optimal solution via a MORL use the STOM approach, as this method leads to results that are within one standard deviation of the Pareto-Q-learning approach, while adhering closely to the desired goal distribution. The STOM method is also significantly more efficient than the Pareto-Q-learning approach.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}