Learning Word Embeddings with Chi-Square Weights for Healthcare Tweet Classification


Abstract
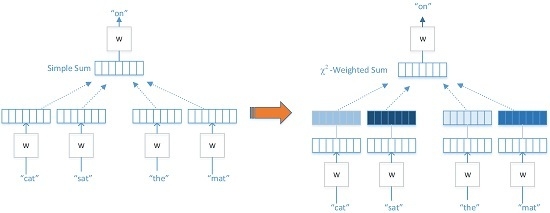
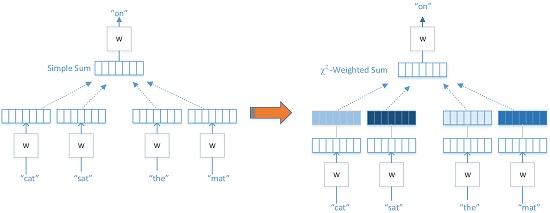
:
1. Introduction
- 1.
- Worried about swine flu? Here are 10 things you need to know: Since it first emerged in April, the global swine ..
- 2.
- Swine Flu - How worried are you? - Take our poll now and check out how others feel!
- 3.
- Missed getting a FREE FLU SHOT at Central last night? You’ve got three more “shots” at it.
- 4.
- feels icky. I think I’m getting the flu...not necessarily THE flu, but a flu.
- 5.
- Resting 2day ad my mthly blood test last 1 ok got apoint 4 flu jab being lky so far not getting swine flu thats something
- 6.
- 38 degrees is possible swine flu watching the thermometer go up. at 36.9 right now im scared :/
- We are the first to propose to use the statistic to weight the context in the CBOW model to enhance the contribution of the useful semantic words for the classification task and limit the noise brought by comparatively unimportant words.
- We propose two algorithms to train word embeddings using on the task of healthcare tweet classification for the purpose of identification of truly health-related tweets from healthcare-noise data collected from a keyword-based approach.
- We evaluate our learned word embeddings for each of the proposed algorithms on two healthcare-related twitter corpora.
2. Related Work
3. Algorithms
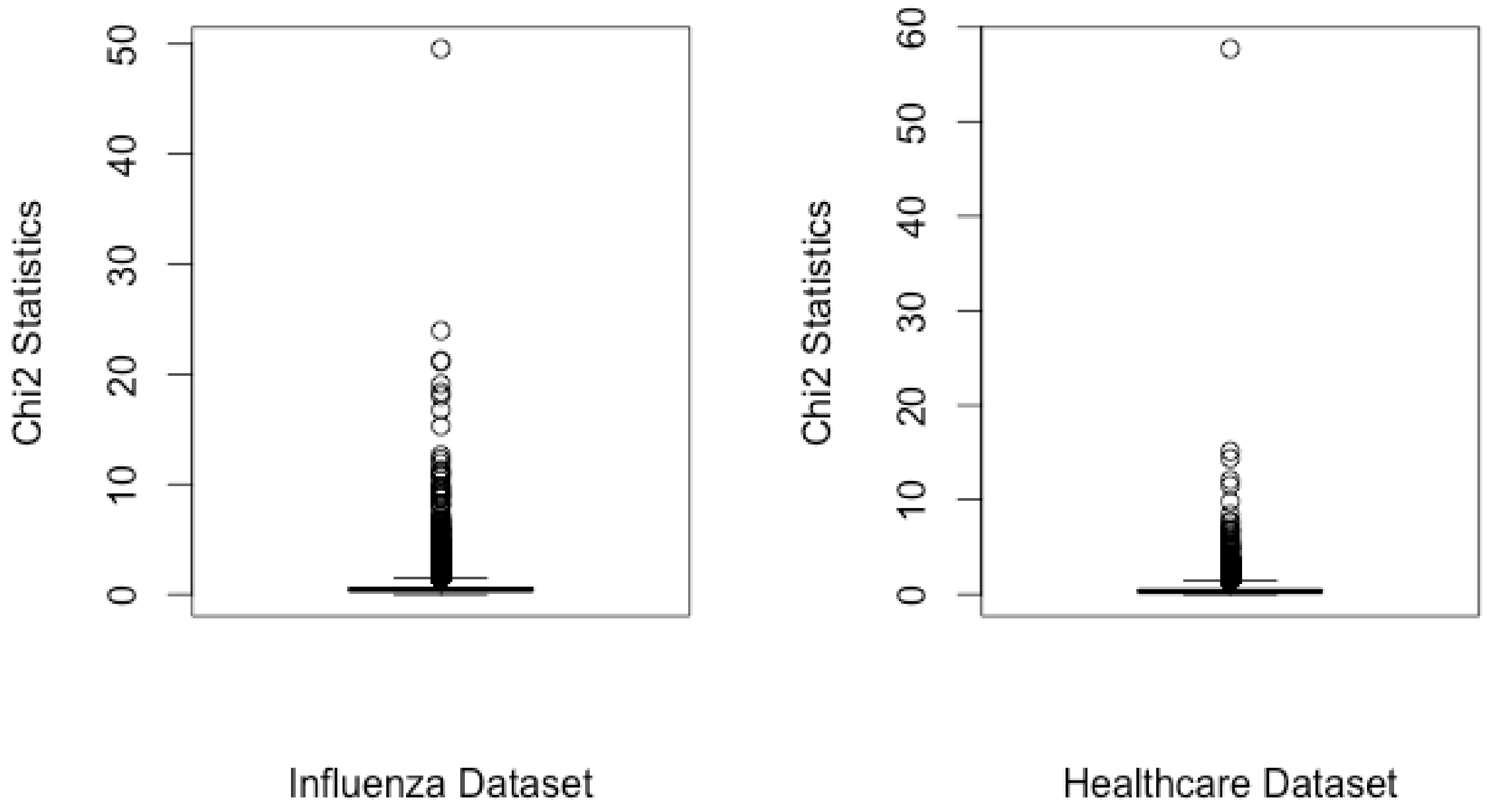
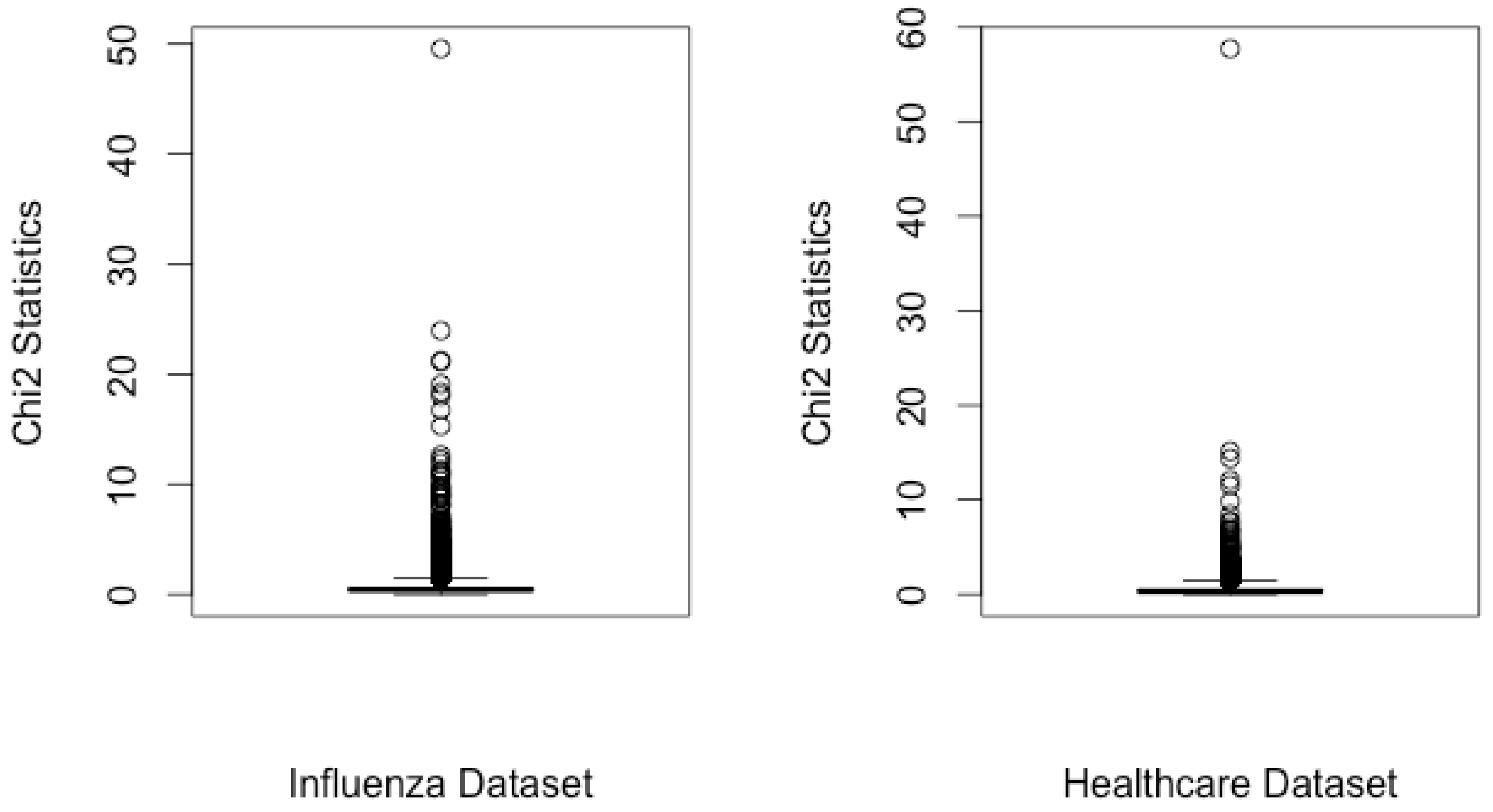
3.1. Chi-Square Statistical Test
3.2. Continuous Bag-of-Words Model (CBOW)
3.3. Algorithm I
3.4. Algorithm II
4. Experimental Method
4.1. Datasets
4.2. Baselines
- skip-gram + CNN: we train Mikolov et al.’s skip-gram model on the training set for both datasets. We learn the word embedding for each word in the corpus to use as features and train a convolutional neural network model (CNN) for classification [42].
- CBOW + CNN: we train the original CBOW model and learn the word embeddings for the word in the corpus as a feature and train a convolutional neural network model (CNN) for classification [42].
4.3. Experimental Setup
4.4. Evaluation and Results
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Ginsberg, J.; Mohebbi, M.H.; Patel, R.S.; Brammer, L.; Smolinski, M.S.; Brilliant, L. Detecting influenza epidemics using search engine query data. Nature 2009, 457, 1012–1014. [Google Scholar] [CrossRef] [PubMed]
- Butler, D. When Google got flu wrong. Nature 2013, 494, 155. [Google Scholar] [CrossRef] [PubMed]
- Lamb, A.; Paul, M.J.; Dredze, M. Separating Fact from Fear: Tracking Flu Infections on Twitter. In Proceedings of the HLT-NAACL, Atlanta, GA, USA, 9–15 June 2013; pp. 789–795. [Google Scholar]
- Wang, T.; Brede, M.; Ianni, A.; Mentzakis, E. Detecting and Characterizing Eating-Disorder Communities on Social Media. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining (WSDM), Cambridge, UK, 6–10 February 2017; pp. 91–100. [Google Scholar]
- Signorini, A.; Segre, A.M.; Polgreen, P.M. The use of Twitter to track levels of disease activity and public concern in the US during the influenza A H1N1 pandemic. PLoS ONE 2011, 6, e19467. [Google Scholar] [CrossRef] [PubMed]
- Paul, M.J.; Dredze, M. You are what you Tweet: Analyzing Twitter for public health. In Proceedings of the AAAI International Conference on Weblogs and Social Media (ICWSM), Barcelona, Spain, 17–21 July 2011; Volume 20, pp. 265–272. [Google Scholar]
- Huang, X.; Smith, M.C.; Paul, M.J.; Ryzhkov, D.; Quinn, S.C.; Broniatowski, D.A.; Dredze, M. Examining Patterns of Influenza Vaccination in Social Media. In Proceedings of the AAAI Joint Workshop on Health Intelligence (W3PHIAI), San Francisco, CA, USA, 4–5 February 2017. [Google Scholar]
- Ali, A.; Magdy, W.; Vogel, S. A tool for monitoring and analyzing healthcare tweets. In Proceedings of the ACM SIGIR Workshop on Health Search & Discovery, Dublin, Ireland, 28 July–1 August 2013; p. 23. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Liu, Q.; Ling, Z.H.; Jiang, H.; Hu, Y. Part-of-Speech Relevance Weights for Learning Word Embeddings. arXiv, 2016; arXiv:1603.07695. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Tang, D.; Wei, F.; Yang, N.; Zhou, M.; Liu, T.; Qin, B. Learning Sentiment-Specific Word Embedding for Twitter Sentiment Classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 23–25 June 2014. [Google Scholar]
- Ling, W.; Dyer, C.; Black, A.; Trancoso, I. Two/too simple adaptations of word2vec for syntax problems. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; pp. 1299–1304. [Google Scholar]
- Chen, Y.; Perozzi, B.; Al-Rfou, R.; Skiena, S. The Expressive Power of Word Embeddings. In Proceedings of the ICML 2013 Workshop on Deep Learning for Audio, Speech, and Language Processing, Atlanta, GA, USA, 16 June 2013. [Google Scholar]
- Levy, O.; Goldberg, Y. Dependency-Based Word Embeddings. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 23–25 June 2014; Volume 2, pp. 302–308. [Google Scholar]
- Qiu, L.; Cao, Y.; Nie, Z.; Yu, Y.; Rui, Y. Learning Word Representation Considering Proximity and Ambiguity. In Proceedings of the AAAI, Québec City, QC, Canada, 27–31 July 2014; pp. 1572–1578. [Google Scholar]
- Gamallo, P. Comparing explicit and predictive distributional semantic models endowed with syntactic contexts. Lang. Resour. Eval. 2016, 51, 727–743. [Google Scholar] [CrossRef]
- Howell, D.C. Chi-square test: Analysis of contingency tables. In International Encyclopedia of Statistical Science; Springer: Berlin, Germany, 2011; pp. 250–252. [Google Scholar]
- Paul, M.J.; Dredze, M. A model for mining public health topics from Twitter. Health 2012, 11, 16–26. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Harris, Z.S. Distributional structure. Word 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Firth, J.R. A synopsis of linguistic theory 1930–1955. In Studies in Linguistic Analysis (Special Volume of the Philological Society); Blackwell: Oxford, UK, 1957; pp. 1–32. [Google Scholar]
- Clark, S. Vector space models of lexical meaning. In Handbook of Contemporary Semantics; University of Cambridge Computer Laboratory: Cambridge, UK, 2014; pp. 1–43. [Google Scholar]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by Latent Semantic Analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Landauer, T.K.; Dumais, S.T. A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychol. Rev. 1997, 104, 211. [Google Scholar] [CrossRef]
- Golub, G.H.; Reinsch, C. Singular value decomposition and least squares solutions. Numer. Math. 1970, 14, 403–420. [Google Scholar] [CrossRef]
- Turney, P.D. Similarity of semantic relations. Comput. Linguist. 2006, 32, 379–416. [Google Scholar] [CrossRef]
- Padó, S.; Lapata, M. Dependency-based construction of semantic space models. Comput. Linguist. 2007, 33, 161–199. [Google Scholar] [CrossRef]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Tian, F.; Dai, H.; Bian, J.; Gao, B.; Zhang, R.; Chen, E.; Liu, T.Y. A Probabilistic Model for Learning Multi-Prototype Word Embeddings. In Proceedings of the 25th Annual Conference on Computational Linguistics (COLING), Dublin, Ireland, 23–29 August 2014; pp. 151–160. [Google Scholar]
- Finkelstein, L.; Gabrilovich, E.; Matias, Y.; Rivlin, E.; Solan, Z.; Wolfman, G.; Ruppin, E. Placing search in context: The concept revisited. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; ACM: New York, NY, USA, 2011; pp. 406–414. [Google Scholar]
- Trask, A.; Michalak, P.; Liu, J. Sense2vec—A Fast and Accurate Method for Word Sense Disambiguation in Neural Word Embeddings. arXiv, 2015; arXiv:1511.06388. [Google Scholar]
- Zhang, Z.; Brewster, C.; Ciravegna, F. A Comparative Evaluation of Term Recognition Algorithms. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC 2008), Marrakech, Morocco, 28–30 May 2008; pp. 28–31. [Google Scholar]
- Kholghi, M.; Vine, L.D.; Sitbon, L.; Zuccon, G.; Nguyen, A.N. The Benefits of Word Embeddings Features for Active Learning in Clinical Information Extraction. In Proceedings of the Australasian Language Technology Association Workshop 2016, Caulfield, Australia, 5–7 December 2016; pp. 25–34. [Google Scholar]
- Choi, Y.; Chiu, C.Y.I.; Sontag, D. Learning low-dimensional representations of medical concepts. In Proceedings of the AMIA Summits on Translational Science, San Francisco, CA, USA, 21–24 March 2016; American Medical Informatics Association: Bethesda, MD, USA, 2016; p. 41. [Google Scholar]
- Pearson, K. On the Criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. In Breakthroughs in Statistics: Methodology and Distribution; Kotz, S., Johnson, N.L., Eds.; Springer: New York, NY, USA, 1992; pp. 11–28. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.J.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Robertson, S. Understanding inverse document frequency: On theoretical arguments for IDF. J. Doc. 2004, 60, 503–520. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Fan, R.E.; Chang, K.W.; Hsieh, C.J.; Wang, X.R.; Lin, C.J. LIBLINEAR: A library for large linear classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 16 June 2017).
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the scikit-learn project. In Proceedings of the ECML/PKDD Workshop: Languages for Data Mining and Machine Learning, Prague, Czech Republic, 23–27 September 2013; pp. 108–122. [Google Scholar]

{kind=link}
{kind=link}
| Data | Healthcare-Related | Healthcare-Unrelated | Total |
|---|---|---|---|
| Train | 868 | 1301 | 2169 |
| Test | 217 | 325 | 532 |
| Data | Influenza-Related | Influenza-Unrelated | Total |
|---|---|---|---|
| Train | 2148 | 1609 | 3757 |
| Test | 537 | 402 | 939 |
| Healthcare Dataset | Influenza Dataset | |
|---|---|---|
| 1 | headache | sick |
| 2 | sick | vaccine |
| 3 | allergies | throat |
| 4 | feeling | fear |
| 5 | flu | news |
| 6 | surgery | swineflu |
| 7 | cramps | bird |
| 8 | throat | shot |
| Method | Healthcare Dataset | Influenza Dataset |
|---|---|---|
| tf-idf + SVM baseline | 59.96 | 57.18 |
| Skip-gram + CNN baseline | 66.61 | 66.99 |
| CBOW + CNN baseline | 69.00 | 66.67 |
| Algorithm I + CNN | 69.19 | 72.31 |
| Algorithm II + CNN | 69.93 | 72.84 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuang, S.; Davison, B.D. Learning Word Embeddings with Chi-Square Weights for Healthcare Tweet Classification. Appl. Sci. 2017, 7, 846. https://doi.org/10.3390/app7080846
Kuang S, Davison BD. Learning Word Embeddings with Chi-Square Weights for Healthcare Tweet Classification. Applied Sciences. 2017; 7(8):846. https://doi.org/10.3390/app7080846
Chicago/Turabian StyleKuang, Sicong, and Brian D. Davison. 2017. "Learning Word Embeddings with Chi-Square Weights for Healthcare Tweet Classification" Applied Sciences 7, no. 8: 846. https://doi.org/10.3390/app7080846
APA StyleKuang, S., & Davison, B. D. (2017). Learning Word Embeddings with Chi-Square Weights for Healthcare Tweet Classification. Applied Sciences, 7(8), 846. https://doi.org/10.3390/app7080846