1. Introduction
The last decades have been marked by the widespread use of bandwidth-hungry internet applications by multiple wireless users and cloud-network devices always connected online. This has led to an immense Internet expansion [
1], enabled by the rapid advances in photonic integration [
2] and optical transceiver technologies that achieve doubling of the optical transmission line-rates every year [
3]. Meanwhile, Internet topologies have strongly relied on resilient multi-homing techniques and on the Virtual Private Network (VPN) for enhanced network resiliency or security, necessitating additional physical or logical communication links [
4]. The insatiable interconnectivity demands have resulted in an enormous surge in the number of addressable end-points [
1,
4], even running up to the complete exhaustion of the unallocated IPv4 address pool [
5], enforcing the use of the next generation IPv6 protocol. IPv6 offers a higher availability for address space, but at the same time, quadruples the needs of Address Look-Up (AL), while scaling at a frantic annual growth rate of 90% [
6]. As a result, the Default Free Zone (DFZ) has been constantly expanding, with the Routing Information Base (RIB) of Internet core routers increasing up to 700 K prefix-entries [
7], requiring increasingly more search intensive operations to resolve the outgoing port of an incoming packet. Moreover, recent studies on the content centric nature of today’s internet usage have even inspired Content Centric Networking (CCN) [
8] that investigates a clean slate future internet, where packet forwarding will operate based on content addressing, instead of addressing the destination end-host, yet this would tremendously scale the respective name look-up requirements. As performance sensitive AL operations have to be performed at wire speed upon the arrival of the packet [
4], this has rendered software algorithmic search approaches with sequential access schemes to Random Access Memories (RAMs) as rather impractical since the early 2000s [
4], necessitating specialized electronic hardware AL-solutions [
9,
10].
Presently, routers rely on electronic Content Addressable Memories (CAMs) that facilitate AL table functionalities within one clock cycle [
10]. CAMs offer content-based addressing of the stored data, instead of location-based addressing, forming an alternative to conventional RAMs of computing architectures [
11,
12]. Specifically, upon the arrival of a packet, its destination address is inserted into a CAM-table for a fast parallel comparison across the AL memory contents, and upon a match, the outgoing port is obtained for next hop routing. In order to comply with the Classless Interdomain Routing (CIDR) [
13], CAMs have also been equipped with ternary features, to support wildcard bits of network subnets, that mask the stored RIB-prefixes at arbitrary bit-positions with a “logical
X” value [
10]. Early fast demonstrations of such Ternary CAM (T-CAM) devices built on 250 nm Complementary Metal–Oxide–Semiconductor (CMOS) nodes supported content comparisons at 260 MHz [
14], while similar T-CAMs at 180 nm [
15], 130 nm [
16], or 62 nm [
17] CMOS nodes achieved maximum frequencies of 210 MHz, 200 MHz, and 400 MHz, respectively. Despite the rich variety of optimization techniques of mature electronic technology, state of the art electronic CAMs are scaling at a slow growth rate [
18,
19], and even by shifting to advanced 28 nm CMOS Fully Depleted Silicon-On-Insulator (FD-SOI) [
20], only footprint and power reductions have been achieved, with frequencies still lying around 370 MHz. These results imply that electronic T-CAMs are hard-limited by the underlying interconnect network and can rarely reach the barrier of 1 Gb/s. This barrier was only recently broken using alternative non-optimal techniques that may use early predict/late-correct schemes [
21], which are yet known to be heavily dependent on data patterns [
17]. A second speed enhancement technique suggests inserting four T-CAM arrays performing in parallel at a slower rate of 4 × 400 MHz [
6], necessitating even more complex Application Specific Integrated Circuit (ASIC) for deserialization and further exacerbating the energy requirements of routers, which reached their rack-power density limits in 2005 [
4,
22,
23]. To this end, electronic CAM speeds seem inefficient to keep up with the frantic optical linerates of 100 Gb/s and beyond [
1]. This performance disparity has been placing an increasingly heavy load on the shoulders of electronic CAMs, enforcing energy-hungry, cost-expensive optoelectronic header conversions with subsequent data-rate down-conversion [
22,
23,
24], in order to perform AL searches in the MHz-regime. Furthermore, the migration towards Software Defined Networks (SDN) and OpenFlow networks enforces a dynamic operation with frequent updates of network topologies and multiple real time changes in the RIB-list [
25]. Internet routers are experiencing 100 updates per second and potentially reaching upwards of 1000 per second [
26], during which AL operations are stalled and the router remains idle, considerably limiting the performance. This, in-turn, requires fast Write operations to the CAM-table, with short latencies [
25,
26,
27,
28], to enable fast re-configurability of the network and rapid updating of the AL table.
Having detected the impact of slow-performing AL operations, optics have tried to circumvent the associated delays, mainly through the use of optical labeling and header processing schemes. These insert a bit-serial label in front of the payload or various multiplexing schemes, to route the data based on this label instead of the actual destination IP address [
29], yet they typically utilize lower label data-rates, hoping to retain compatibility with slow CAM speeds. At the same time, optical memories have undergone two decades of developments and are now on the verge of developing higher capacity [
30], programmable [
31], and/or non-volatile [
32] devices towards more practical memory sub-systems. Initially, optical memories were conceived as high bandwidth alternatives of electronic RAMs to overcome the “Memory Wall”, achieving multiple elementary Flip-Flops (FFs) with high speed and low power consumption credentials [
33,
34,
35,
36,
37,
38,
39,
40,
41], including coupled SOAs [
34], III-V-on-SOI microdisk lasers [
35], and polarization bistable Vertical Cavity Surface Emitting Laser (VCSEL) [
36], as well as coupled SOA-based Mach-Zehnder Interferometers (SOA-MZIs) [
33,
37]. Optical FFs, serving as optical storing units, were then combined with random access controlling gates, forming functional optical RAMs, so far demonstrated either as fully functional architectures using mature SOA-based devices [
37,
38,
39] or as discrete components based on photonic crystals [
40,
41]. These have both been experimentally shown to support speeds beyond 10 Gb/s, while in-depth frequency theoretical memory speed analyses [
42,
43] and validated time-domain SOA-based memory simulations [
43,
44] have revealed potential rates of up to 40 Gb/s. Furthermore, by combining optical Column/Row Address Selectors [
45,
46] and optical Tag Comparators [
47], the first designs of a complete optical cache memory architecture for high-performance computers revealed a 16 GHz operation via physical layer simulations [
48]. All of these have increased the maturity of optical memories towards penetrating the computing domain, where the use of electronics is so far undisputable, whereas in optical networks, optical FFs have been suggested for contention resolution [
49].
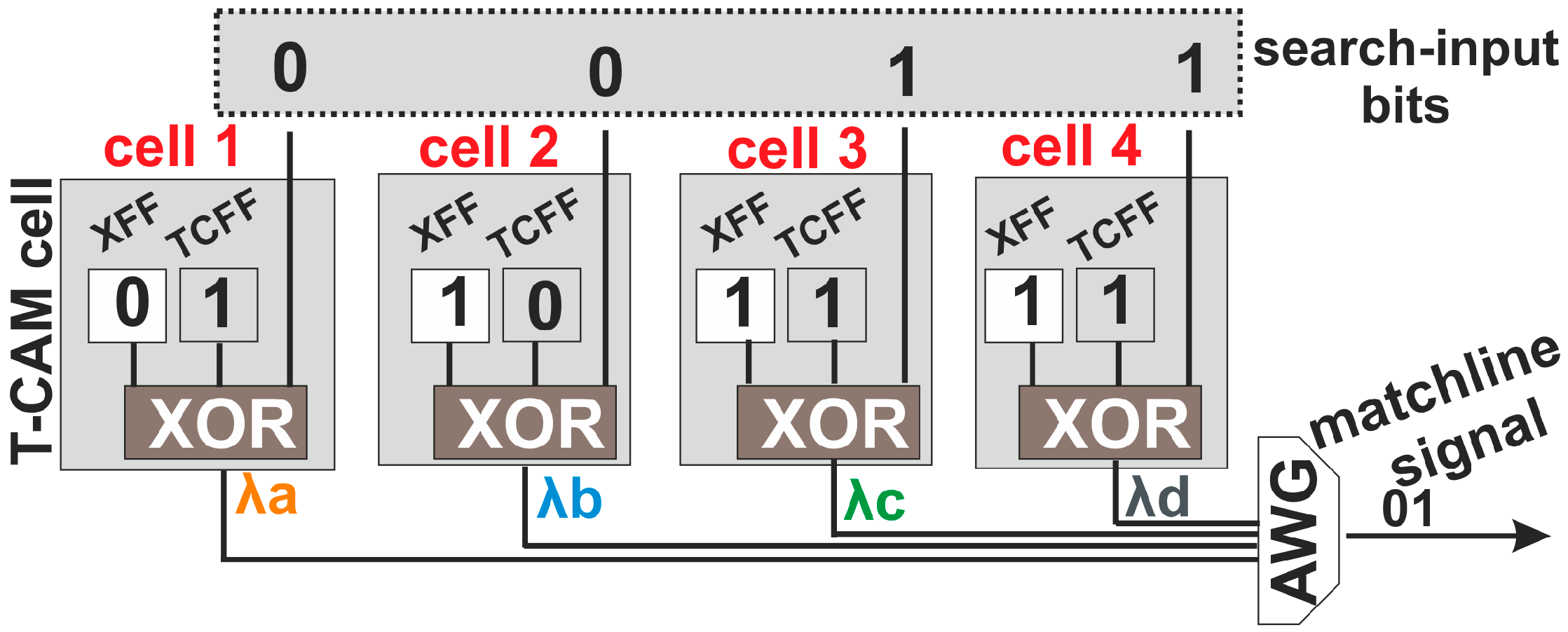
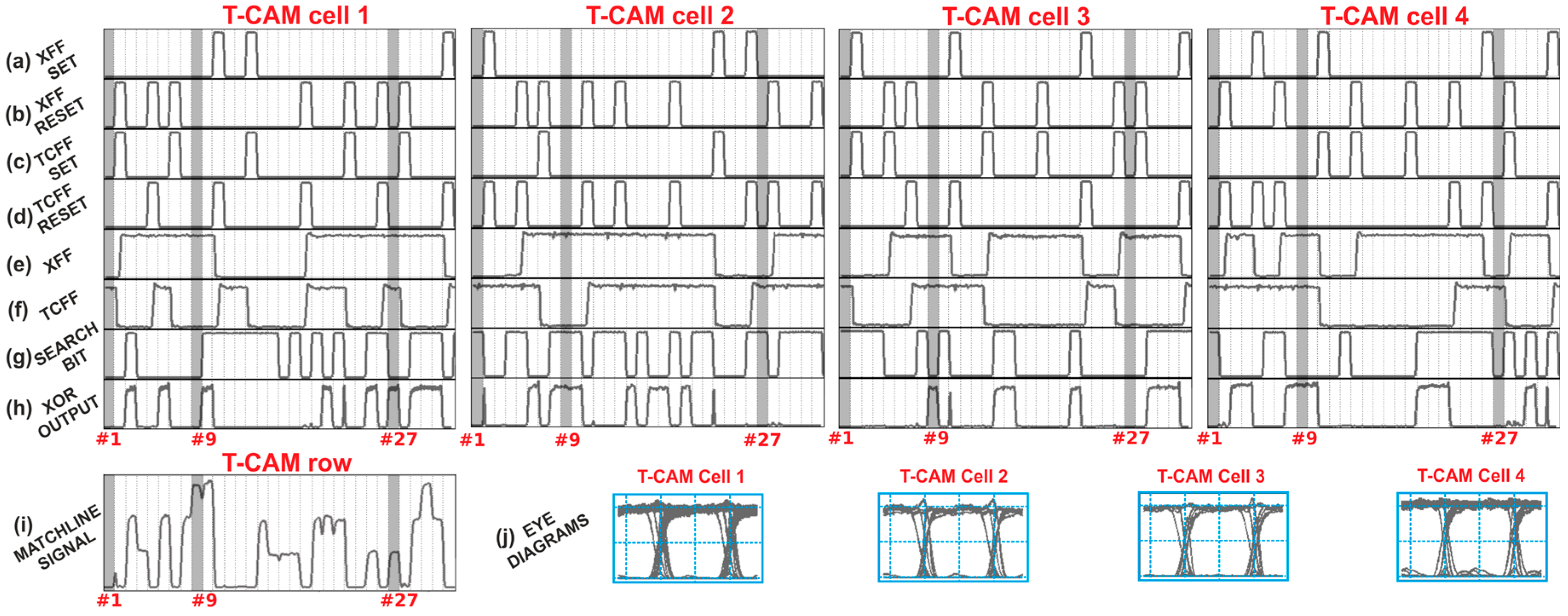
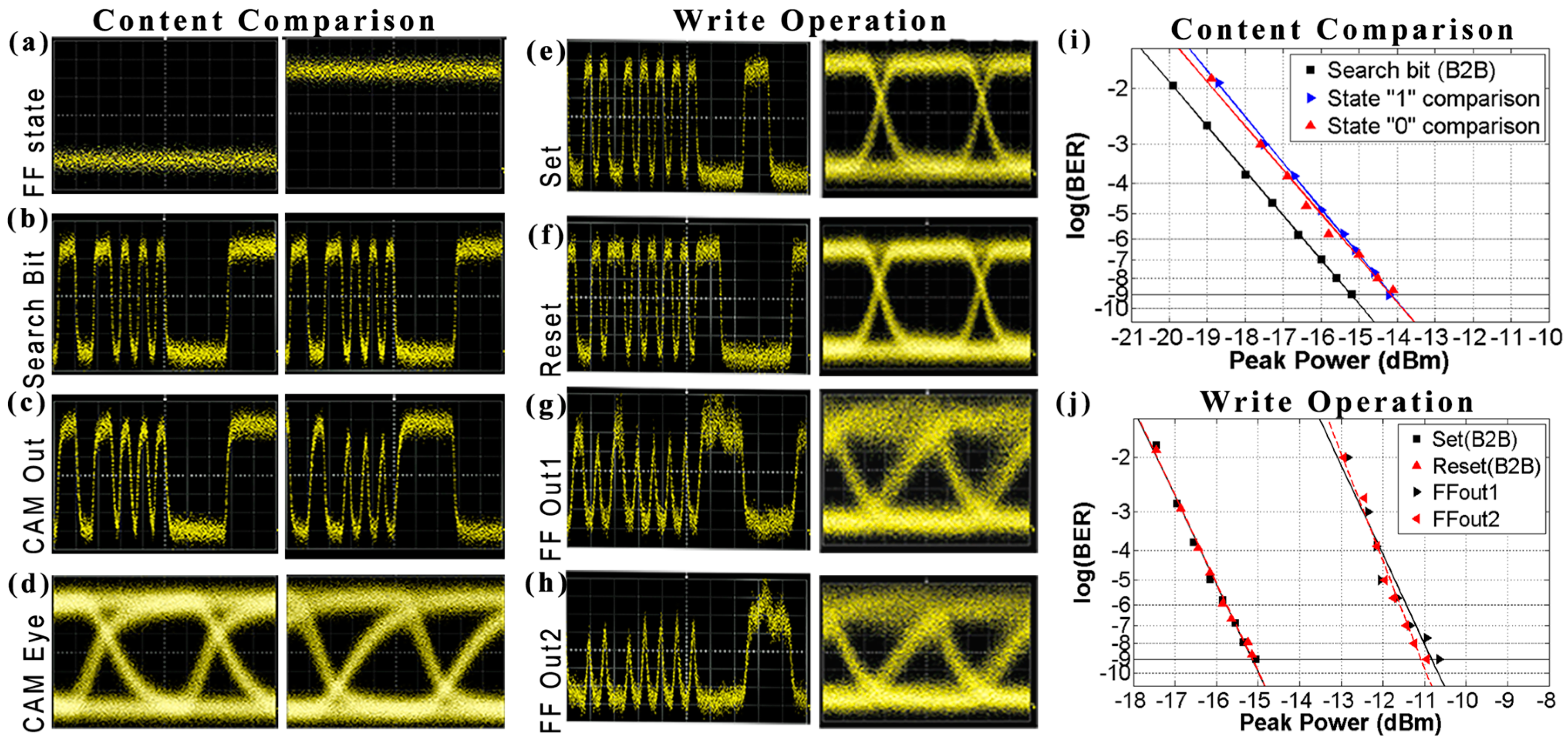
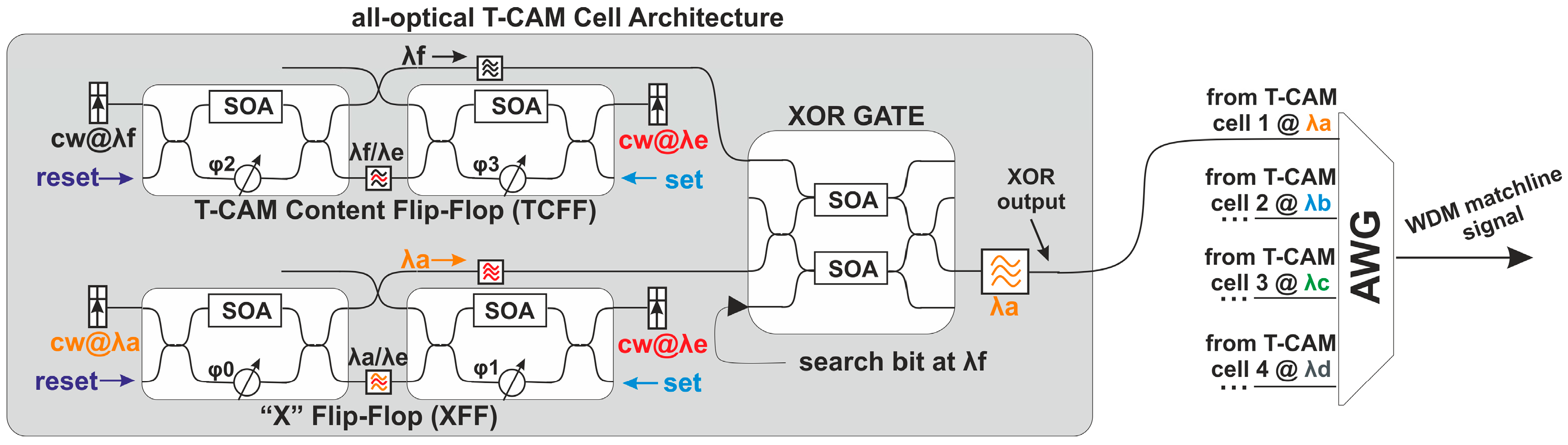
Following the paradigm of optical RAMs, optical alternatives of CAM architectures may facilitate similar advances and speed enhancements towards ultra-fast router AL memories in the high-end router domain. In this regime, some preliminary first steps, stemming from our group, have managed to develop the first photonic alternative CAM-based elements [
50,
51], which is the main focus of this paper. More specifically, in
Section 2, we initially discuss the architectures and main functional building blocks of electronic AL memories, followed by the development of monolithic photonic integration for optical FFs and RAM memories on a monolithic InP platform [
33,
39] in
Section 3. In
Section 4, we present the first experimental proof-of-principle of an all-optical Binary CAM (B-CAM) cell architecture at 10 Gb/s [
50]. This architecture is later extended in a more advanced all-optical (T-CAM configuration in
Section 4, directly supporting, for the first time, a wildcard bit operation of a logical “
X” value in the optical domain [
51]. By introducing Wavelength encoding in the search word, a 4-bit Matchline (ML) architecture is developed, capable of providing a unique identifying signal upon a match of the destination address with the stored prefix-entry [
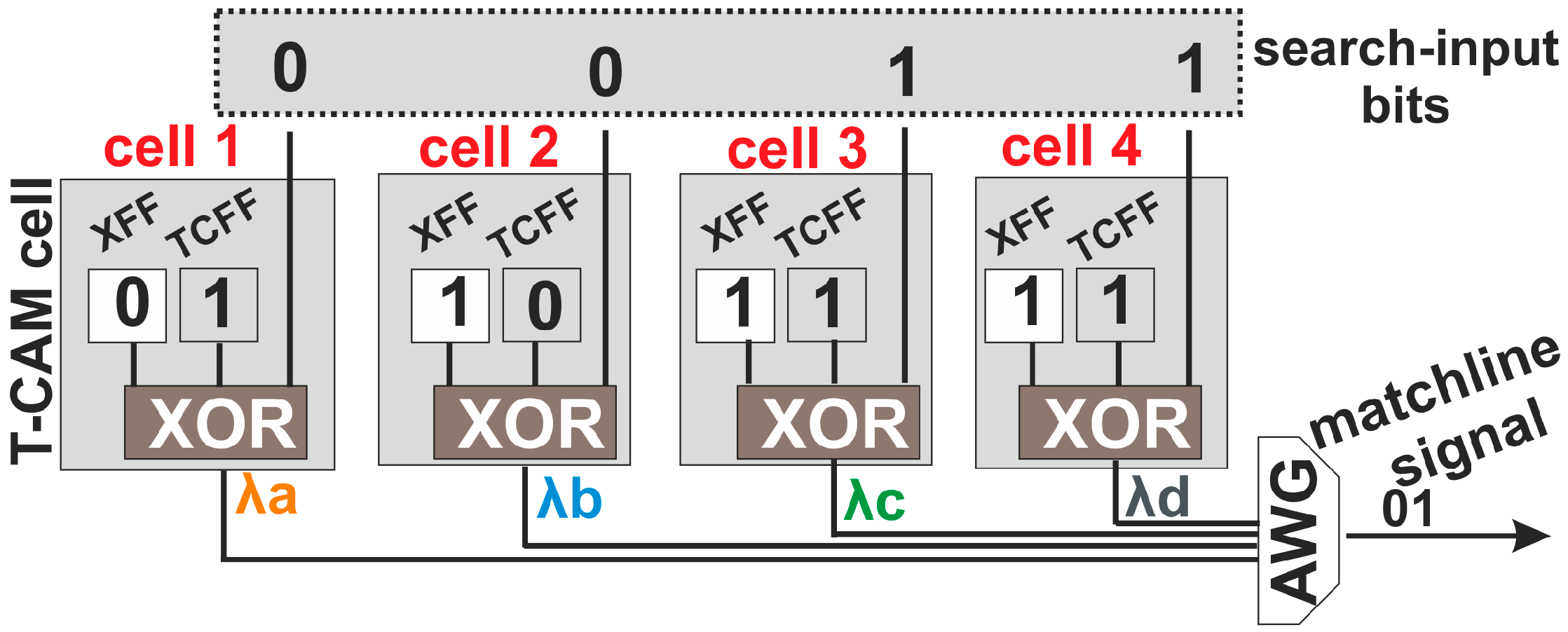
51]. Finally, we present a discussion on the future challenges that need to be addressed for migrating towards optical AL table architectures, bearing promises to directly resolve the AL in the optical domain that can significantly speed-up AL-speeds in high-end router architectures.
2. Electronic Address Look-Up Memory Architectures
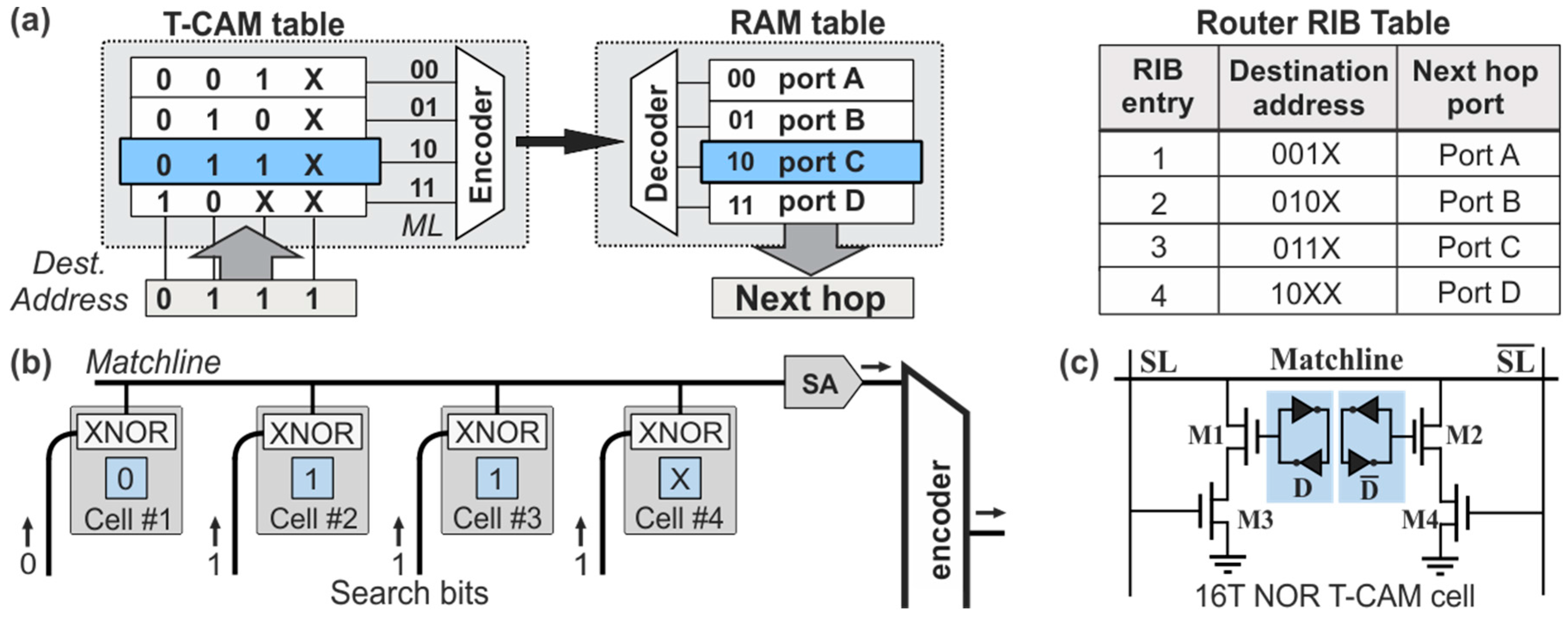
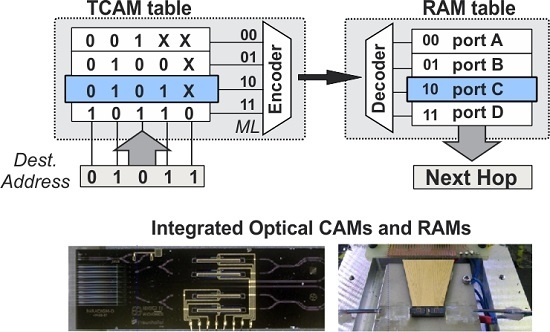
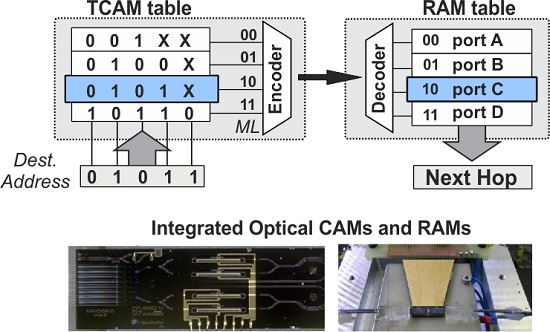
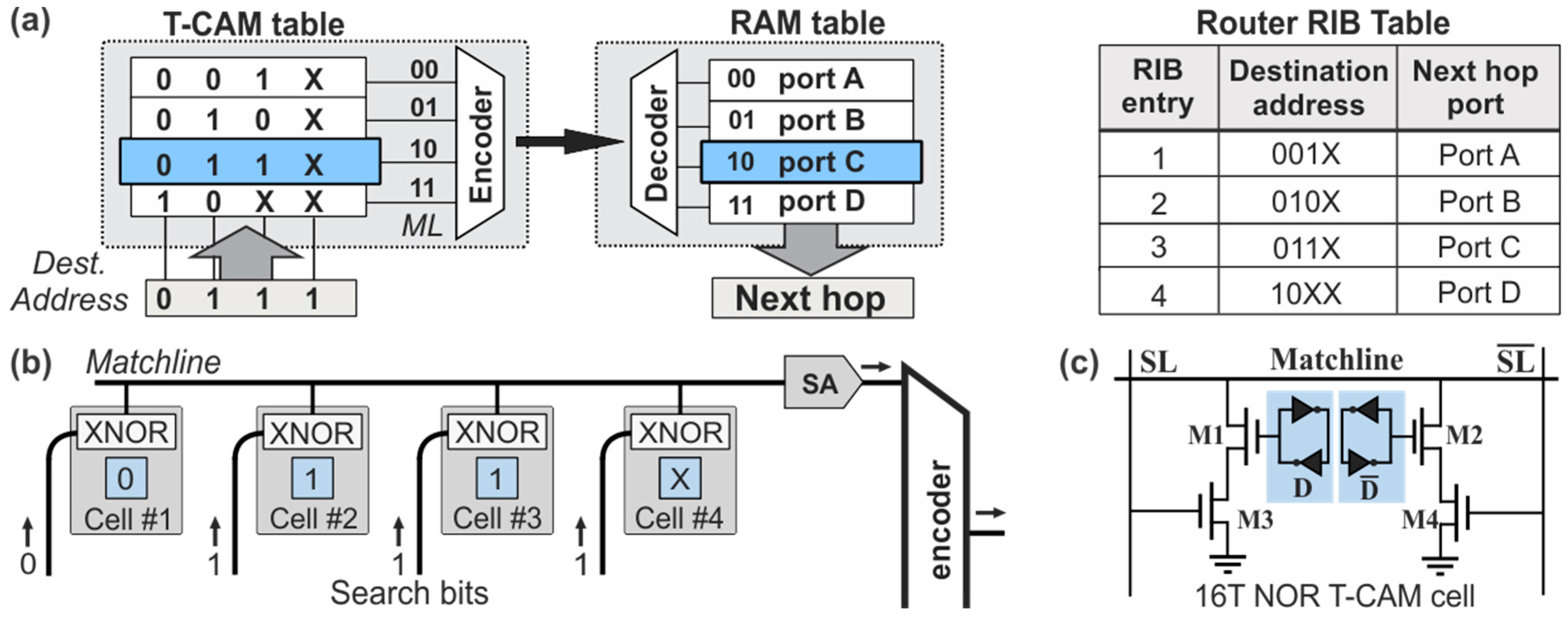
Internet routers forward the data packets of an incoming port to an outgoing port based on an AL comparison function of the destination address of the header. To achieve this, they are equipped with a hardware look-up table that maintains the RIB-list of the destination addresses and their associated outgoing ports for next-hop routing, as depicted in the AL memory table architecture of
Figure 1a. The architecture comprises a two dimensional CAM table inter-connected to a two dimensional RAM table. The CAM table stores the prefix-list with the destination addresses, while the RAM table maintains the outgoing port. Each entry of the RIB prefix-list is stored in a mutli-bit memory line, widely known as CAM ML. Upon the arrival of a packet, the header containing the destination address bits is broadcasted to all MLs of the CAM table, where it gets bitwise compared with the contents of the CAM cells. When the stored word of a specific ML matches the incoming search bits of the destination address, a match-signal is generated at the output of the ML, activating the specific line; otherwise, the CAM ML is not enabled. The activated CAM ML can then be mapped though the intermediate encoder-decoder network to the associated RAM table line, where the next-hop routing information is stored, so as to retrieve the outgoing port of the data packet. An example operation of the AL table is described by the RIB table shown at the right side of
Figure 1a, assuming an incoming packet designated with a destination address [0111] and an RIB-list with four entries, namely [001
X], [010
X], [011
X], and [10
XX]. By broadcasting and bit-wise comparing the destination address with all the RIB-entries, the third prefix of [011
X] matches the packet’s destination address. This matching will in turn activate the third line of the RAM forwarding table where port C is stored, indicating the next hop to which the incoming packet has to be forwarded.
A more detailed view of the block diagram describing the logical circuit operation of the 1 × 4 ML is shown in
Figure 1b, comprising four parallel CAM cells. The CAM cells have their outputs combined at an inline Sense Amplifier (SA) and are then inter-connected to the encoder/decoder network for communication with the RAM table. Every CAM cell stores a bit of a RIB prefix entry and bears a logical XNOR gate for comparison with the incoming search bits of the destination address. If the search bit and the stored bit are equal, the logic XNOR gate transmits a signal of logic “
1” value to the end of the respective ML. Equivalently, when all CAM cells of the line provide a logical match, the SA identifies the exact word match with the stored content and emits a proper signal towards the encoder. On the contrary, when there is a mismatch at any of the bits of the ML, the XNOR gate of the CAM cell provides a logical “
0” value at the output, and de-activates the SA and the ML, denoting that a mismatch between the incoming destination address and the stored prefix has occurred. At this point, it is worth noting that MLs consist of Ternary T-CAM cells, in order to support ternary features with masked wildcard bits of “logical
X”, as used in subnet masks, rather than simpler Binary CAM cells that store only bits of logical “
1” or “
0”.
The conventional architecture of the most typical 16T NOR-based electronic T-CAM cell is illustrated in
Figure 1c [
10], comprising two D-type flip-flops operating as storage cells and marked with a blue highlight. The first memory cell is responsible for storing the actual data-bit [0 or 1] and the second one stores the ternary state information for the “Care” or “Don’t Care” state of the logical “
X” value. Each memory cell is typically built on the configuration of two cross-coupled inverters, similar to 6T RAM cells [
11], while another two pairs of transistors, (M1, M3) and (M2, M4), form short–circuits to the ground. This configuration ensures that at least one pulldown path from the ML down to the ground exists at any time during a mismatch between the search word and the stored data. On the contrary, a match between the search word bit and the stored data disables both pulldown paths, disconnecting the ML from the ground and feeding its output to the SA. If this matching happens for all the cells of the ML, a NOR logic operation between all CAM outputs, performed at the SA, identifies the exact match of the packet’s destination address with the certain RIB prefix entry.
3. Monolithic Photonic Integration for Optical Memories
To this end, photonic integration processes have matured to the point where a wealth of optical FF and RAM memory configurations have been successfully demonstrated [
33,
34,
35,
36,
37,
38,
39,
40,
41], with most of these demonstrations relying on the mature SOA switching technology, owing to its high-gain, high-speed, and high-yield performance characteristics [
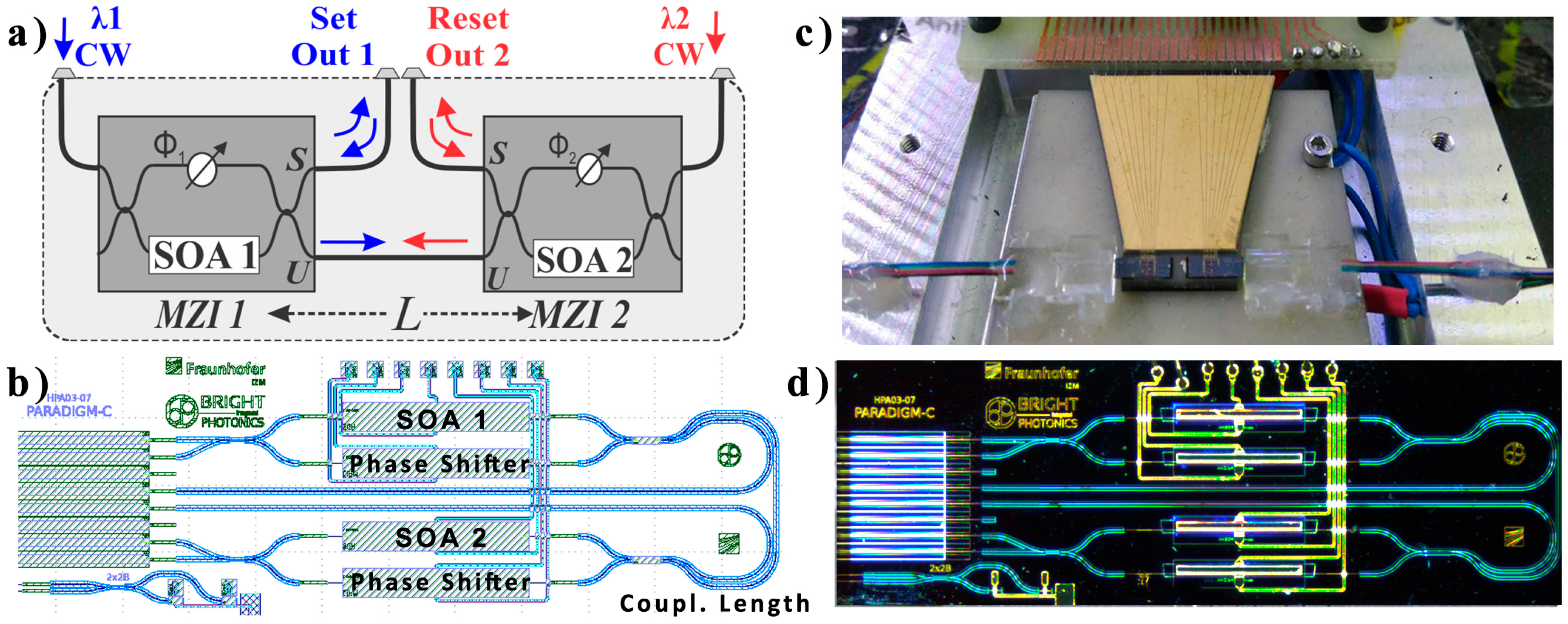
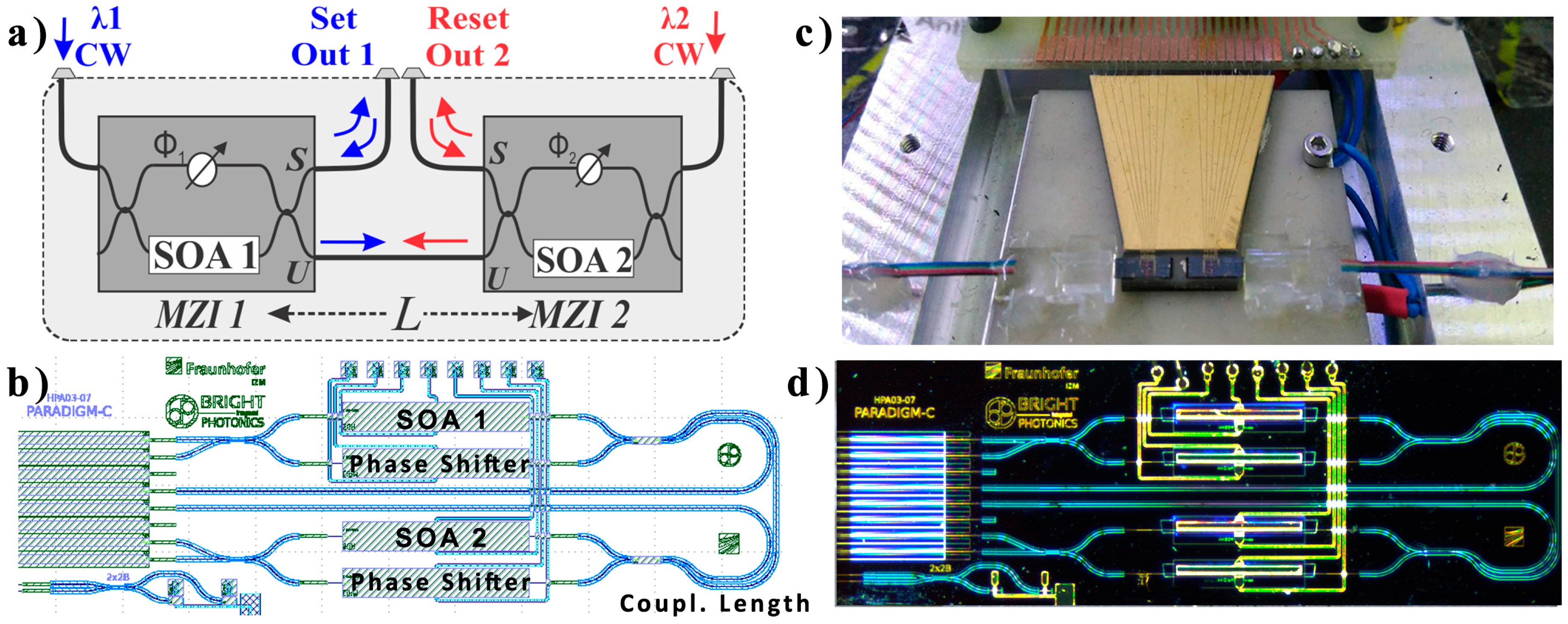
2]. In this paper, our analysis draws from the architecture of an FF memory with two cross-coupled asymmetric SOA-MZI switches, as illustrated in
Figure 2a, which was initially developed in [
37] and more recently theoretically investigated in the time and frequency domain in [
43]. Each SOA-MZI switch features one SOA (SOA1 and SOA2) at the lower branch and a phase shifting element (
Φ1 and
Φ2) at the upper branch for controlling the biasing conditions of the interferometer. The two SOA-MZIs (SOA-MZI1 and SOA-MZI2) are each powered by a weak Continuous Wavelength (CW) input signal at wavelengths
λ1 and
λ2, respectively, while their Unswitched output ports (U-ports) are interconnected through a common coupling waveguide path. This symmetric configuration of the two SOA-MZI switches allows for a master-slave operation with the U-output of the master switch controlling the operating condition of the opposite slave switch and blocking its transmission at the U-port. Owing to the symmetric configuration, the roles of the master and slave switch are interchangeable, allowing the FF state to be defined by the wavelength of the emitted signal outputs at either one of the Switched ports (S-ports). The FF state can be monitored through the respective FFOut1 and FFOut2 output ports in terms of high power levels of
λ1 and
λ2 optical signals, respectively.
The state of the FF can be optically controlled by external
Set/
Reset (SR) pulses fed through the S-ports of the SOA-MZIs. When a high
Set or
Reset pulse is injected at the master SOA-MZI, it will block its light-transmission and set it in the slave condition regardless of the previous state of the FF, allowing for the opposite SOA-MZI to recover and become the master. In this arrangement, the two logical values of the data-bit stored in the FF-memory, logical “
1” and “
0”, can be associated with the high optical power of the wavelength-signal emerging at the two outputs. The present FF memory configuration was initially demonstrated as a hybridly integrated module in [
37] with the use of silica-on-silicon integration technology, exhibiting a total footprint of 45 × 12 mm
2 and coupling length between the two SOAs of 2.5 cm, which was theoretically shown to be the main speed determining factor of the memory architecture [
42,
43].
Following the conclusions drawn by the underlying theory on the critical performance parameters [
42,
43], an integrated version of the SR FF was presented using library-based components of a generic monolithic InP platform [
33], to benefit from an integration technique that offers the possibility to fabricate multiple active and passive photonic components on a single chip at a close proximity. The two SOA-MZI switches were fitted in a die footprint-area of 6 × 2 mm
2 and cross-coupled together through a 5 mm-long coupling waveguide. In this configuration, the intra FF coupling waveguide was 5 mm-long, reducing the total footprint by two orders of magnitude, compared to the previous hybridly-integrated FF implementation [
37]. The mask file of the Photonic Integrated Chip (PIC) is illustrated in
Figure 2b. The input MMI couplers of the asymmetric MZIs featured a cross/through coupling ratio of 70/30, with respect to the SOA elements, and the MMIs between the two SOA-MZIs featured a coupling ratio of 50/50. The two SOAs featured an active length of 1 mm, while the biasing of the SOA-MZIs was achieved through the respective current injection phase shifters. Electrical routing of the metal wires connected the anodes and cathodes of the SOAs and the phase shifters to 100 × 100 μm
2 pads at the upper edge of the chip. The chip featured an array of eight zero-angled Spot Size Converters (SSC) with a pitch of 127 μm for optical I/O connectivity.
The monolithic InP FF-chip was fabricated by Fraunhofer Heinrich-Hertz-Institut (HHI) within a Multi-Project Wafer (MPW) run of the PARADIGM project funded by the European Commission and was later fully packaged in terms of the optical and electrical contacts for system level characterization. The chip was mounted on top of a ceramic sub-mount module, equipped with a thermistor and a Peltier element for temperature stability, while an 8-I/O fiber array was permanently glued to the I/O left facet of the chip. The metal pads of the chip were wire-bonded to the gold-plated ceramic mount, through gold wires, which also facilitated further connectivity with a Printed Circuit Board (PCB), where a 26-pin D-connector was mounted. The fully-packaged chip can be seen in
Figure 2c and a microscope image of the PIC is shown in
Figure 2d. The FF device was fully characterized in terms of its active components, i.e., the SOAs and the phase shifters, and was used to experimentally demonstrate a successful
Set-Reset FF operation at 10 Gb/s [
33], highlighting the potential to store and write data directly in the optical domain.
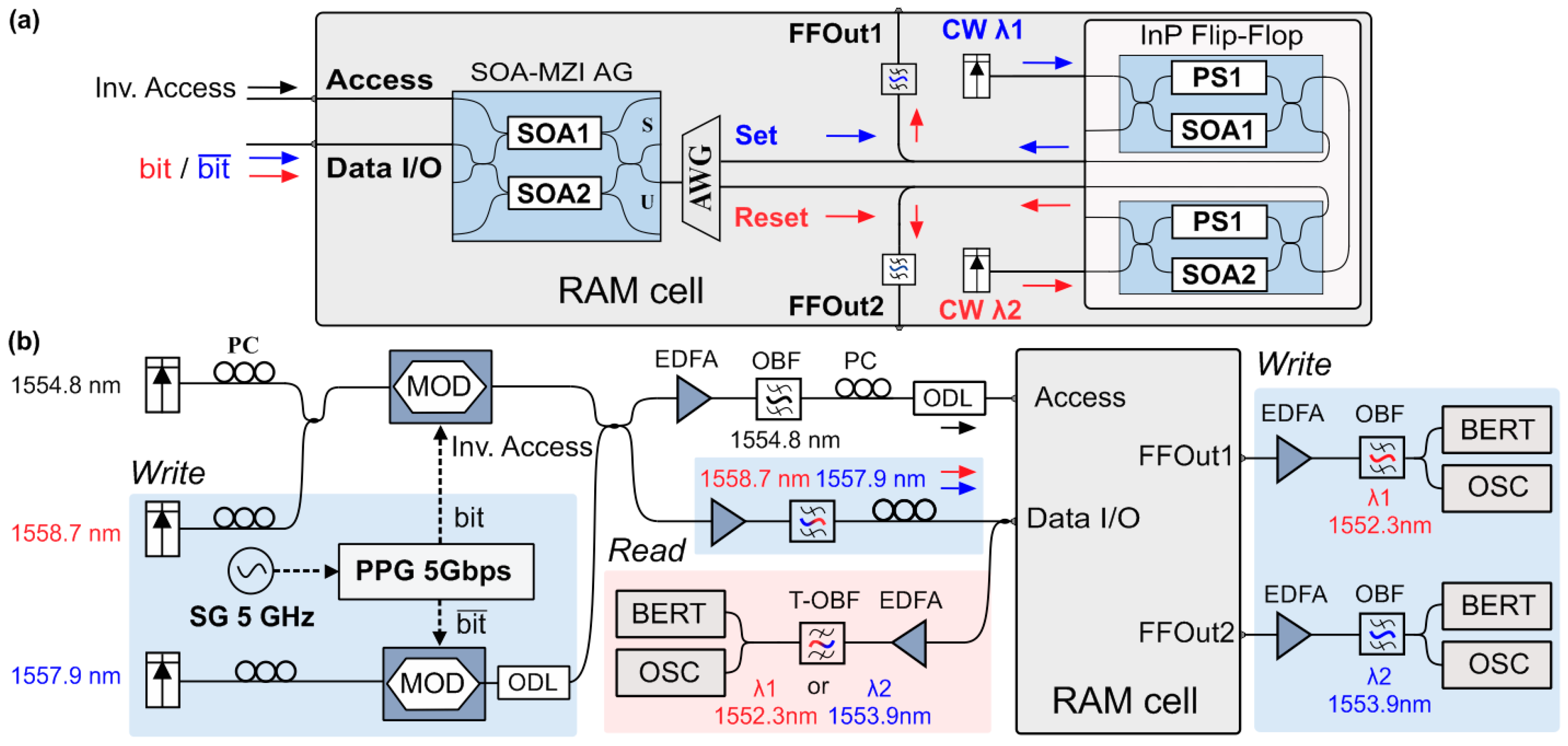
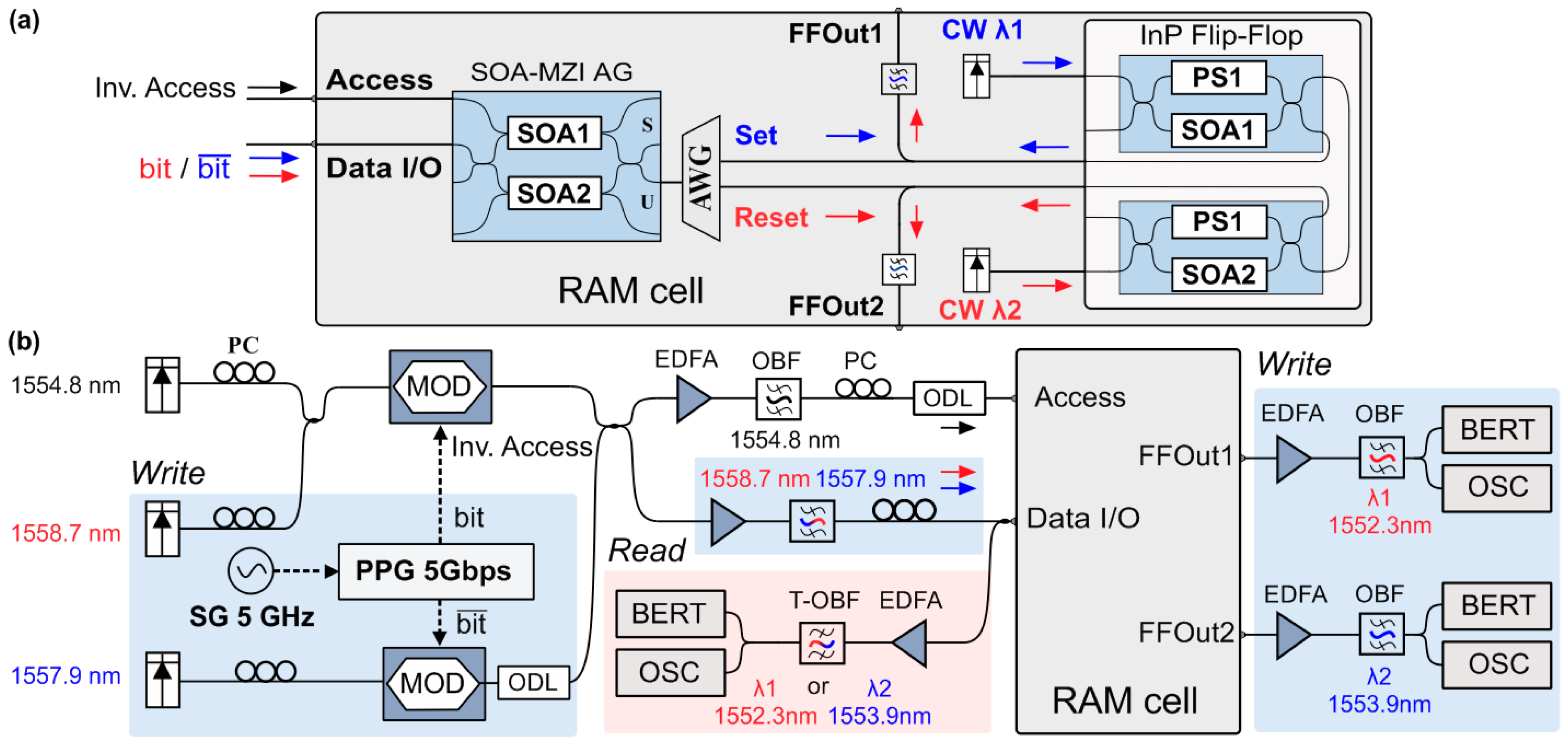
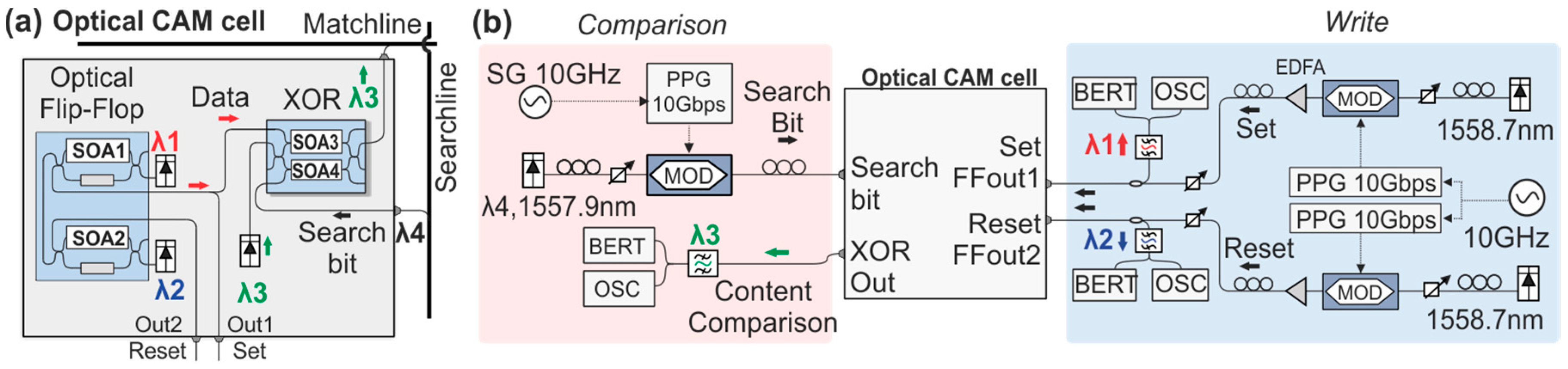
The present monolithic FF architecture served as the memory element of a more complex optical RAM cell configuration, capable delivering Read/Write and Block Access operations. To achieve this, the optical FF is combined with an SOA-MZI optical Access Gate (AG) in a cascade configuration, as shown in
Figure 3a. The AG is responsible for granting access to the RAM cell by allowing the data to be either written to or read from the FF each time. The input Data signals are connected to the input of the SOA-MZI AG, and subsequently to an Arrayed Waveguide Grating (AWG) demultiplexer that drives each wavelength to the input/output ports of the FF-memory. The control signal is fed to the upper branch of the SOA-MZI AG, to induce Cross-Phase Modulation (XPM) phenomena. This allows the
bit and
signals to pass through the AG switch and emerge at the U-port, when there is no control pulse present, or at the S-port when a control pulse is present. RAM cell operations are then defined based on the values of the logic pulses of the
Inverted Access signal and the
bit and
signals, which are fed to the RAM I/O Data port and Access port.
During the Write operation, when access is granted to the memory, the complementary bit and signals carry the incoming data word wavelength encoded on two different wavelengths, while the Inverted Access signal features a logical “0” pulse. Then, the external bit and signals pass through the AG U-port, and propagate towards the right side, where they are demultiplexed through the AWG and fed to the two inputs of the FF, acting as Set and Reset signals. During the Read operation, the Inverted Access signal again features a logical “0” pulse, while no external data are transmitted to the RAM cell. In this case, the complementary FF output signals, propagating from the FF towards the AG on the left side, are multiplexed in the AWG and fed to the AG through the U-port, so as to emerge at the output of the RAM cell. When access to the memory is blocked, the Inverted Access signal features a logical “1” pulse, which enters the SOA-MZI AG as the control signal, switching the complementary data signals to the S-port and blocking communication with the outer world, allowing for the FF-memory to retain its logic state and memory content.
The experimental setup used to evaluate the complete RAM functionalities is illustrated in
Figure 3b. A signal generator (SG) was used to drive a Programmable Pattern generator (PPG) at 5 GHz. The PPG drives two Ti: LiNbO
3 modulators using complementary bit-patterns in order to produce 5 Gb/s 2
7 − 1 Pseudorandom Binary Sequences (PRBS) Non-Return-to-Zero (NRZ) signals. One modulator is responsible for producing the
Inverted Access signal at 1554.8 nm and the
bit signal at 1558.7 nm, and the other is used for the
signal at 1557.9 nm. For the evaluation of the Write operation, the three signals were coupled together to form the complementary
bit and
pair and one access signal, while the two coupler outputs were amplified using erbium-doped fiber amplifiers (EDFA). The first branch incorporated a 0.6 nm 3 dB-bandwidth Optical Bandpass Filter (OBF) centered at 1554.8 nm to properly filter the
Inverted Access signal, while the second branch incorporated a 1 nm 3 dB-bandwidth OBF centered at 1558.3 nm, to filter the
bit and
pair. The AWG used has a 0.65 nm 3-dB channel bandwidth. The stored logical value of the FF and the
Set/
Reset signals could be monitored through the auxiliary ports FFOut1 and FFOut2 at any time of the experiment, which were amplified in respective EDFAs and filtered by suitable Optical Bandpass Filters (OBPFs), before being analyzed by a digital Optical Sampling Oscilloscope (OSC) and Bit Error Rate Tester (BERT). The blue-highlighted areas of the setup were only used during the evaluation of the Write operation, while the red-highlighted part of the setup was only used during the evaluation of the Read operation. To evaluate the READ operation, the FF was set to one of its logic memory states each time by properly adjusting the external CW signal power-levels, meaning that either only
λ1 or
λ2 was the dominant wavelength of the FF, providing a high FF output power level at either the FFOut1 or FFOut2 port, respectively. A monitor branch was connected at the Data I/O port of the RAM cell comprising an EDFA as a preamplifier and a 0.6 nm 3 dB-bandwidth Tunable OBPF (T-OBPF) that can be tuned at either one or two in order to evaluate one of the two wavelengths. Polarization controllers (PC) were used at several stages of the setup to control signal polarization. Variable optical attenuators (VOA) were also used to properly adjust the power levels of the optical signals, while optical delay lines (ODLs) were employed to ensure signal decorrelation and bit-level synchronization among the signals.
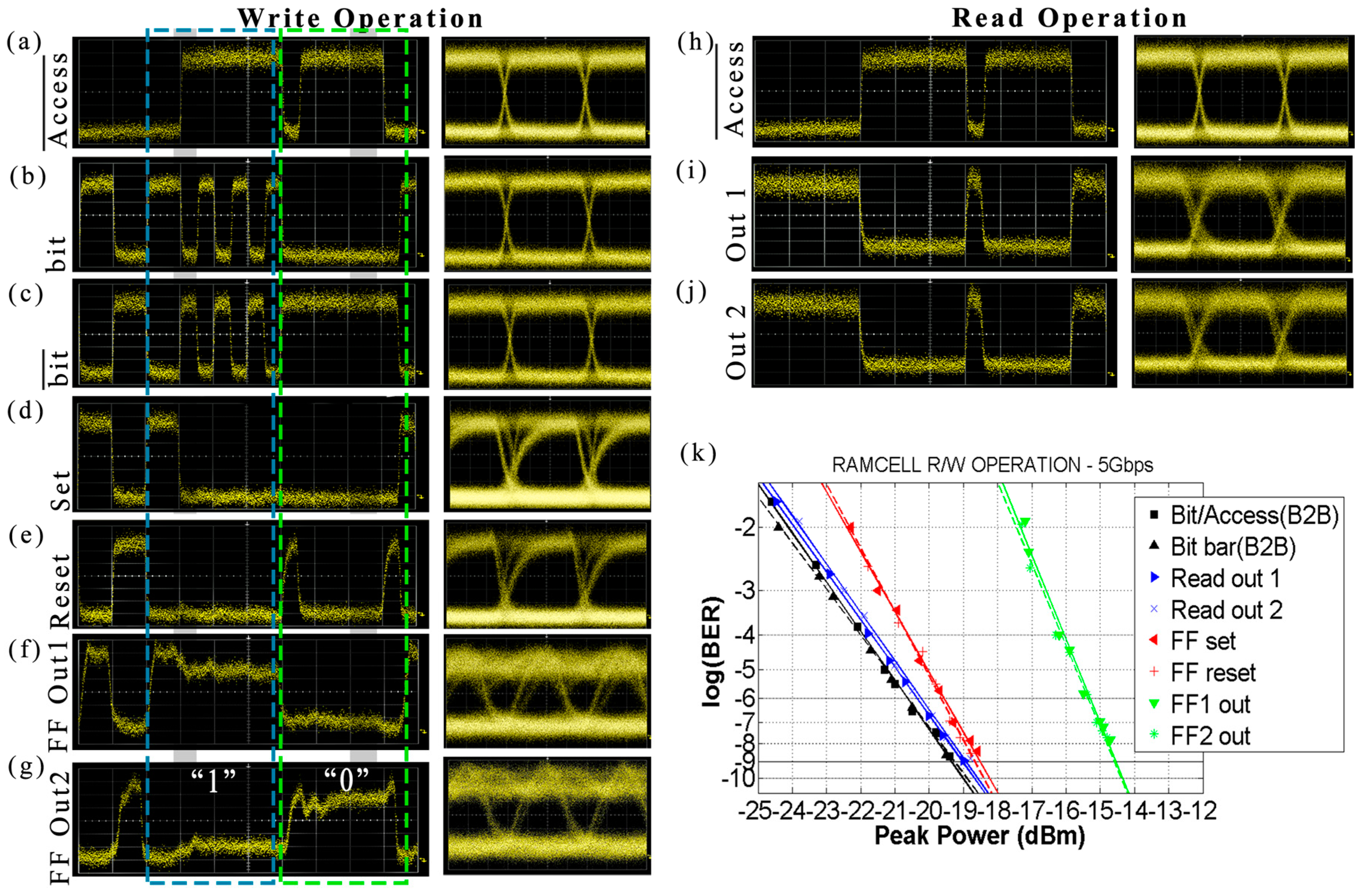
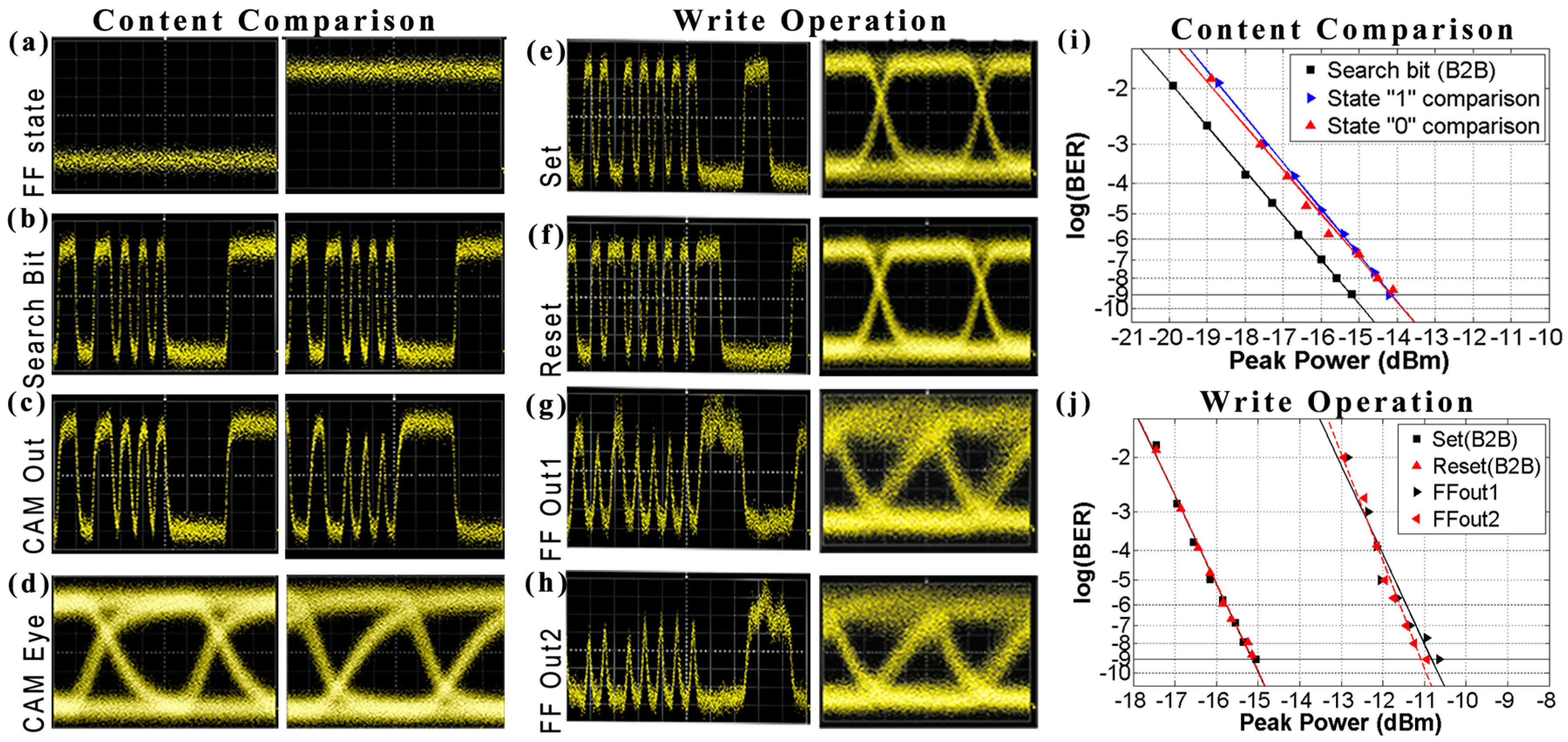
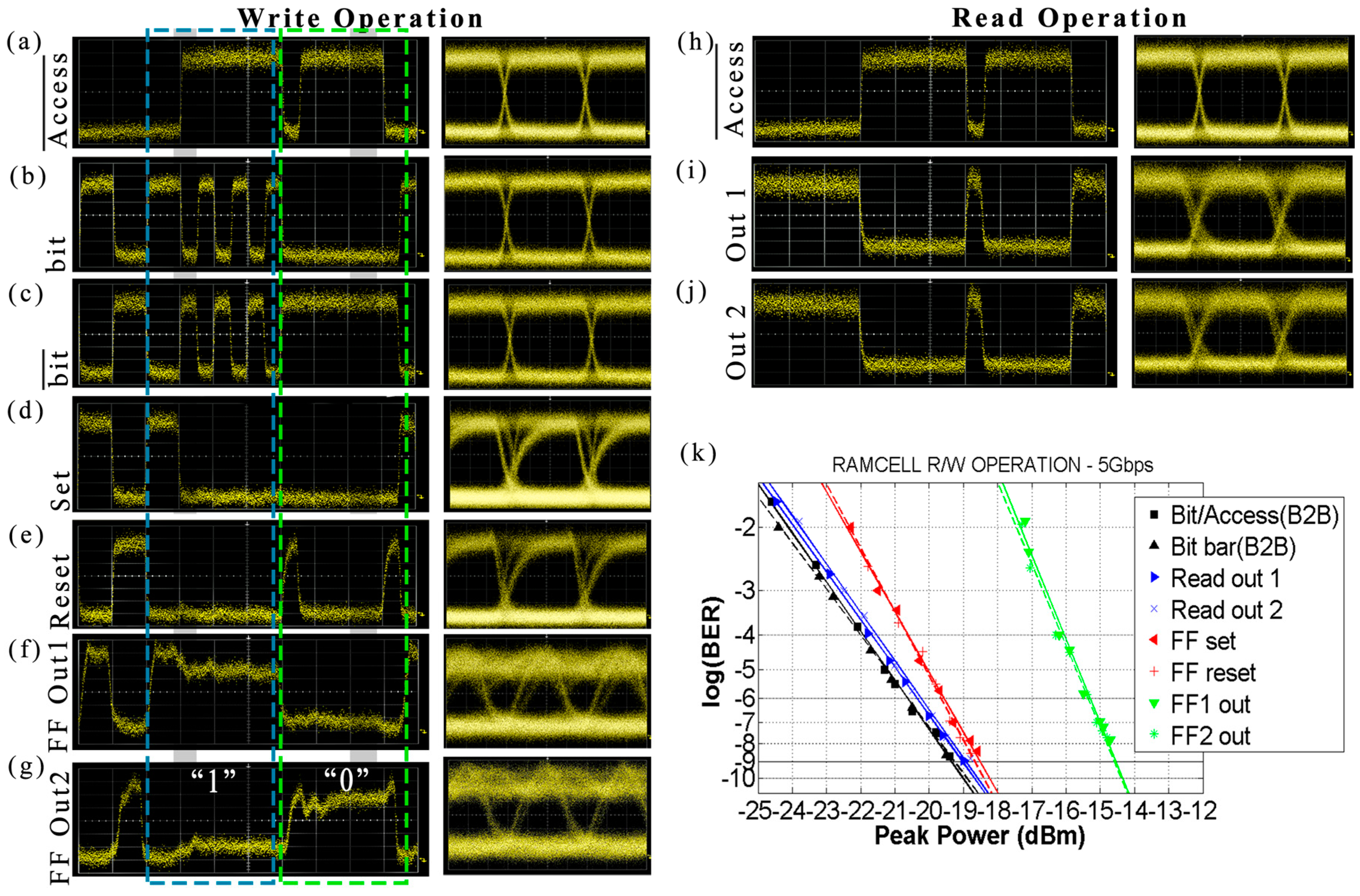
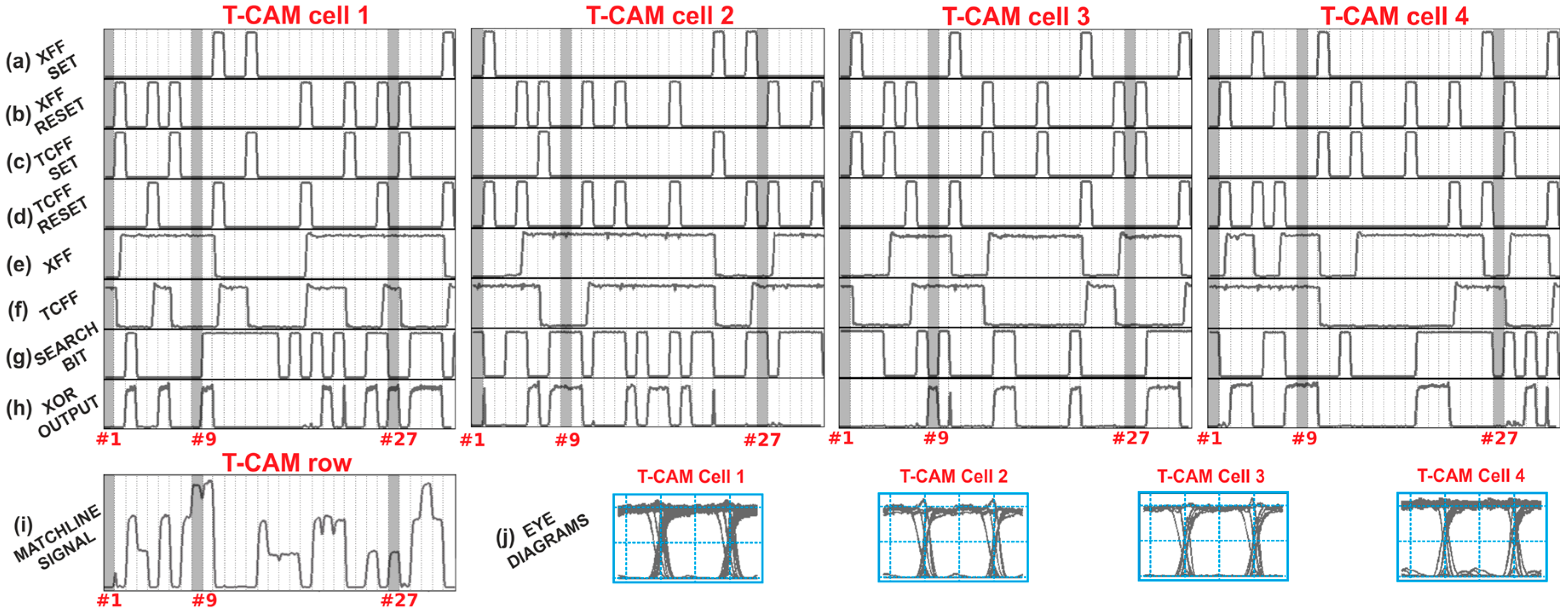
The experimental results obtained from the 5 Gb/s operation can be seen in
Figure 4.
Figure 4a–g depict synchronized time traces/eye diagrams of the Write operation.
Figure 4a shows the
Inverted Access signal and
Figure 4b,c show the
bit and
signals that were launched in the RAM cell, respectively.
Figure 4d,e illustrate the
Set/
Reset signals originating from the incoming
bit and
signals, after the access-controlling operation of the AG, where it is clear that they only imprint the logical “
1”
bit and
pulses, respectively, when there is no logical “
1” pulse at the
Inverted Access signal. The proof-of-principle of the Write operation is then verified by monitoring the FF stored content through the signals emerging at the respective FFOut1 and FFOut2 ports in
Figure 4f,g, where it can be seen that the FF changes its logic state when there is an incoming
Set or
Reset pulse and maintains its state until the next
Set/
Reset pulse arrival. The eye diagrams of the FF output signals feature a recovery time of 150 ps and an Extinction Ratio (ER) of 6 dB.
Figure 4h–j depict synchronized time traces and the respective eye diagrams for the Read operation. For this evaluation, the FF was set to one logic state and the data were then read by transmitting the
Inverted Access signal, shown in
Figure 4h.
Figure 4i,j illustrate the time traces of the RAM cell output signals, after the random access controlling operation of the AG for both of the FF logic states. A high output value is only obtained when there is no
Inverted Access signal pulse present, indicating that access is granted for the Read operation, while when there is a high optical power for the
Inverted Access signal, the RAM output of the RAM cell features a logical “
0” and access to the memory is thus blocked. The eye diagram of the read output features an ER of 9 dB.
Figure 4k shows the BER measurements obtained for both the Write and Read RAM cell functionalities, where, in all cases, error free operations are demonstrated. For the Write operation, the BER diagrams reveal a power penalty of 0.6 dB for the
Set and
Reset signals compared to the Back-to-Back measurements of the
bit and
signals, and in turn, 4.6 dB for the FFOut1 and FFOut2 signals of the data written to the RAM cell, while for the case of the Read operation, a power penalty of only 0.5 dB was obtained at the 10
−9 condition. The results were obtained with a current injection of around 250 mA for each SOA, while when relying on four SOAs operating at 5 Gb/s, the resulting energy efficiency per bit is 400 pJ/bit.
5. Future Challenges and Discussion
The presented multi-wavelength optical subsystems provide the necessary constituents for synthesizing a new design roadmap for a photonic AL memory architecture that can reap the unique benefits of a high-bandwidth and low-power consumption offered by optical technology. The use of discrete SOA-MZIs interconnected to fiber-pigtailed monolithic integrated FF-devices allows us to overcome the critical speed determining factor of the large intra-FF coupling distance [
42,
43] and facilitates the full characterization of each RAM cell and CAM cell independently, without any speed limitation, when unidirectional data-communication is employed. However, the latency of the fiber-network of the complete optical ML architecture introduces some latency in the overall destination address resolution, when the content comparison output of the CAM cell has to be propagated to the RAM cell for a Read operation. By reaping the benefits of mature photonic integration multiple photonic components per chip [
2], a fully integrated Matchline could enable studying all RAM and CAM functionalities simultaneously, with a shorter latency for the destination address resolution operation, which could be further improved by incorporating gain-accelerating techniques [
53]. Meanwhile, for a simultaneous synchronous write operation at the RAM cell and CAM cell of the envisioned optical ML, the write operation should be performed at 5 Gb/s due to the cascaded switching operation at the AG, which is already an order of magnitude faster than the respective electronic memory speed [
6,
54], while faster memory updates and network changes are subject to the use of higher speed SOAs. Drawing from our presented initial experimental timing tests with short rise/fall times of 90 ps, optical CAM memories can also significantly reduce the reconfiguration times towards enabling rapid updates of the RIB-memory.
Our proposed scheme has relied on power-hungry 1 mm-long SOAs of a generic foundry that necessitate external currents of 250 mA and a power consumption of 0.5 W for each SOA for proof-of-concept demonstration purposes, resulting in an optical multi-bit multi-wavelength ML architecture with a power efficiency of 300 pJ/bit per clock cycle when operating at 10 Gb/s. This value can be reduced by orders of magnitudes when shifting to more sophisticated low-power III/V-on-SOI photonic crystal technologies with nm-scale dimensions and power consumptions of a few mW [
55], towards energy efficiencies of a few fJ/bit, comparable to electronics [
6,
20,
21]. Meanwhile the use of the envisioned high-speed multi-bit optical ML architectures technology provides a possible path towards circumventing the use of power-hungry cost expensive power conversion at SERDES equipment, that can allocate up to half of the power consumption of a low power transceiver [
24]. Additional power consumption benefits may also be obtained, when shifting to higher bitrates beyond 10 Gb/s [
43] or even when exploiting the wavelength dimension for a single Access Gates shared among the multiplexed outputs of multiple optical RAMs [
45].
The use of optical AL memories can also benefit from the inherent support of WDM techniques for enhancing wavelength parallelism and reaping the advantages of a new multiplexing capability that is so far not feasible in electronic AL memories. Towards a more practical application of a fully integrated optical ML architecture suitable for handling IPv4 addresses, and considering the typical table sizes of electronic memories with 4K entries [
56], a row-capacity of 32-bit would be required, while for compatibility with next generation IPv6 addresses, a 128-bit memory would be required. In this case, the ML architecture will utilize 32 or 128 wavelengths, respectively, one per TCAM cell output, similar to the wavelength addressable large-scale photonic integrated photonic memories of 128-bits [
30] or the 128-wavelengths of the optically connected RAM architectures for High Performance Computers [
57], as well as an AWG with a similarly high channel count [
1]. The assignment of different wavelengths at the various T-CAM cells of an ML certainly adds an extra degree of freedom to system-designs for more efficient architectures, especially when considering multiple simultaneous WDM memory schemes with parallel wavelengths written to the T-CAM cells of an ML for fast memory updates. This can be of utter importance with the emergence of SDN and OpenFlow architectures that enforce a dynamic network operation with frequent updates of network topologies and multiple real time changes in the RIB-list [
25,
26]. Although the SDN controllers are increasingly optimized for swift policy updates, the T-CAM tables remain yet unoptimized for fast updates [
27,
28], which may trigger hundreds to thousands of table entry-moves and write-memory operations [
26]. Measurements on the timings of such AL-table updates have revealed a few hundreds of ms-long response times [
25,
26,
27,
28], as AL-updates need to be organized in electronic T-CAM tables with sequential time-multiplexed memory accesses through a memory-bus of a limited bandwidth. In this case, the optical nature of the proposed T-CAM may facilitate wavelength multiplexed memory access schemes in order to perform multiple simultaneous Write operations at 10 Gb/s, either when updating the prefix-list of the optical CAM-table or the outgoing ports stored in the optical RAM table, providing manifold improvements in the AL memory throughput.
When developing programmable low power optical AL-memory architectures, further system benefits could potentially be obtained by the introduction of the programmability of the optical memory content [
31] or the use of a non-volatile photonic integrated memory [
32]. However, apart from the optimization of the memory cell, additional developments are still required, as, e.g., the development of a proper input WDM interconnect network, capable delivering the input bit in vertical CAM-column arrangements, known as Searchlines, or the intermediate encoder/decoder interconnect network and peripheral sub-circuits that undertake the communication between the CAM-table and the RAM table, potentially taking into account the case of priority encoding, when multiple prefix matches are formed by the use of ternary bits. These next steps could potentially follow similar concepts as the ones suggested by the all-passive wavelength-based Column Address Selector [
45], the peripheral circuitry [
46], and/or the optical tag comparator [
47] of the more detailed studies in the area of optical RAM architectures.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}