A 3D Human Skeletonization Algorithm for a Single Monocular Camera Based on Spatial–Temporal Discrete Shadow Integration

Abstract
:1. Introduction
- (1)
- The 3D human skeletonization is realized with a normal monocular camera based on the proposed SSSE method.
- (2)
- The proposed SSSE method achieves 3D human skeletonization in a large-scale outdoor scene.
- (3)
- The proposed SSSE method deploys the aggregation of temporal–spatial discrete two-dimensional (2D) shadow information in a 3D human skeletonization procedure
2. Basic Theory
2.1. Skeleton Simulation in Multi-Light-Source Scenarios
- (1)
- human contour shape.
- (2)
- positional relationship between the light source and the human.
2.1.1. 3D Scenario Reproduction
Plane-to-Plane Projection Transformation
- Rotation transformation. Most surveillance cameras are not precisely set up at the horizontal angle which is parallel with the ground surface. The non-horizontal installation attitude brings a rotated field of view. The rotation transformation is introduced to calibrate the rotated field of view, ensuring the calibrated field of view parallel with the ground surface.
- Scale transformation. The coordinate system of the ground surface plane is measured in centimeters. However, pixel is the basic unit of measurement in the image coordinate plane. Thus the scale transformation is introduced to bridge two different units of measurement, extracting ground surface plane coordinates from the pixel coordinates.
- Translation transformation. For the image coordinate plane, the origin of the coordinate system is fixed at the bottom left corner. For each captured frame, the origin of the coordinate system on the ground surface plane does not necessarily coincide with the origin of image coordinate plane. The translation transformation is introduced to calibrate the translation between two coordinate systems. The detailed parameters for translation transformation are given in parameter matrix T.
- Perspective transformation. Instead of the flat view, a perspective view is captured by each monocular surveillance camera in each frame. Thus, the perspective transformation is introduced to recover the flat ground surface plane from the captured perspective view. The detailed perspective transformation parameters are given in parameter matrix P.
Block Matrix-Based Projection Transformation Parameter Calculation
Block-Matrix Based Projection Transformation Deployment
| Algorithm 1: Block matrix based projection transformation deployment Algorithm |
| Input: : coordinates set of marker positions for sub-block ; : corresponding pixel coordinates set of on image coordinate plane ; : image coordinates of captured pixel in human shadow silhouette Output: : corresponding real-world coordinates of  |
- The positions of markers can be reused to simplify the scenario set up. For a scenario containing a square meter area, the number of markers is reduced from to .
- Parallel sub-transformations on different sub-blocks can be processed synchronously to accelerate the overall projection transformation procedure.
- Only when the position of camera is moved or the ground surfaced is repaved, will partial recalibration work be necessary for the affected sub-block .
2.1.2. Silhouette Information Extraction
Human Shadow Silhouette Contour Preprocess
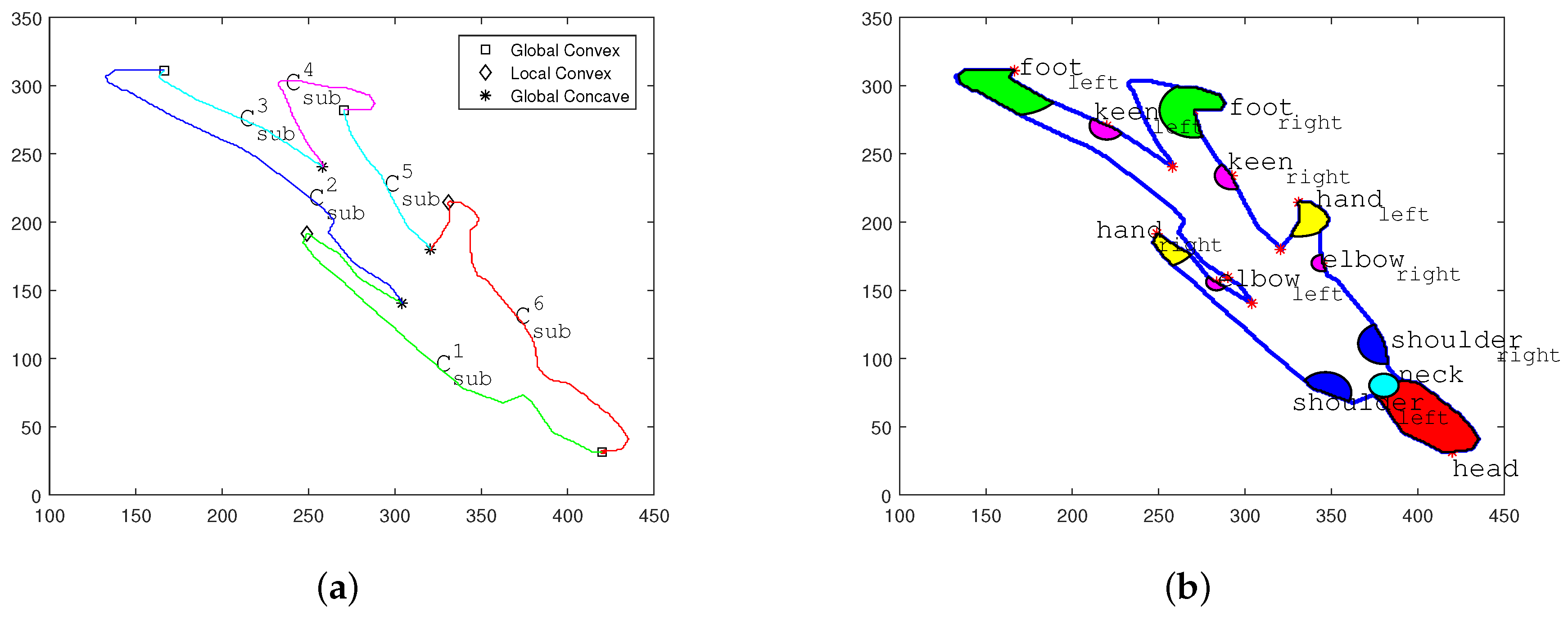
Localization of Major Joint Positions on Human Shadow Silhouette Contour
- (1)
- Localization of Global Convex Areas
- (2)
- Localization of Auxiliary Anchor Points
- The sub-curve between two feet joints contains the position of hip center at the local nadir position.
- The sub-curves between the head position and two feet positions contain positions of two oxters at local nadir positions, respectively.
- (3)
- Localization of Remaining Major Joint Positions
- Sub-curves and cover the contour ranges of left arm and right arm. Thus the local peak positions of these two sub-curves are hand positions. Their local nadir positions are located between the cervical vertebra position and two shoulders.
- The local peak positions of and indicate the positions of two keens and in the shadow area.
- Similarly, the nadir positions of and can assist the positioning of both keens and .
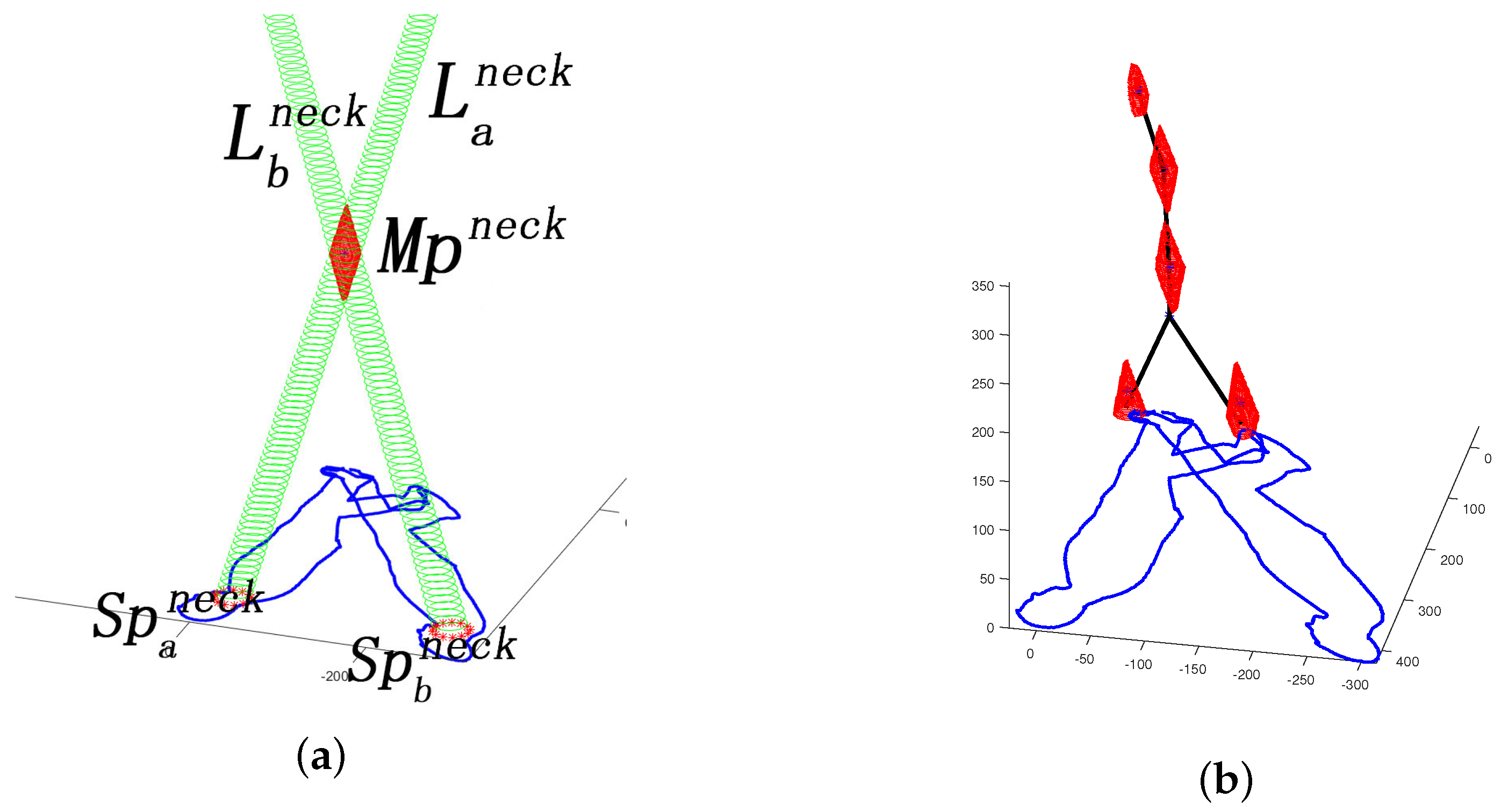
2.1.3. 3D Joint Position Estimation and Skeleton Synthesis
- Condition (1) Two or more light sources are required in the scene.
- Condition (2) Relative angular positions between human body and different light sources should be different.
| Algorithm 2: Human skeleton synthesis procedure under multiple light source scenario |
| Input: : 2D human shadow contour on the ground surface. : 3D positions of multiple light sources . Output: : 3D human skeleton synthesis based on seven major joint positions.  |
2.2. Skeleton Simulation in Single-Light-Source Scenario
2.2.1. Theoretic Proof of the Extension Solution in a Single Light Source Scenario
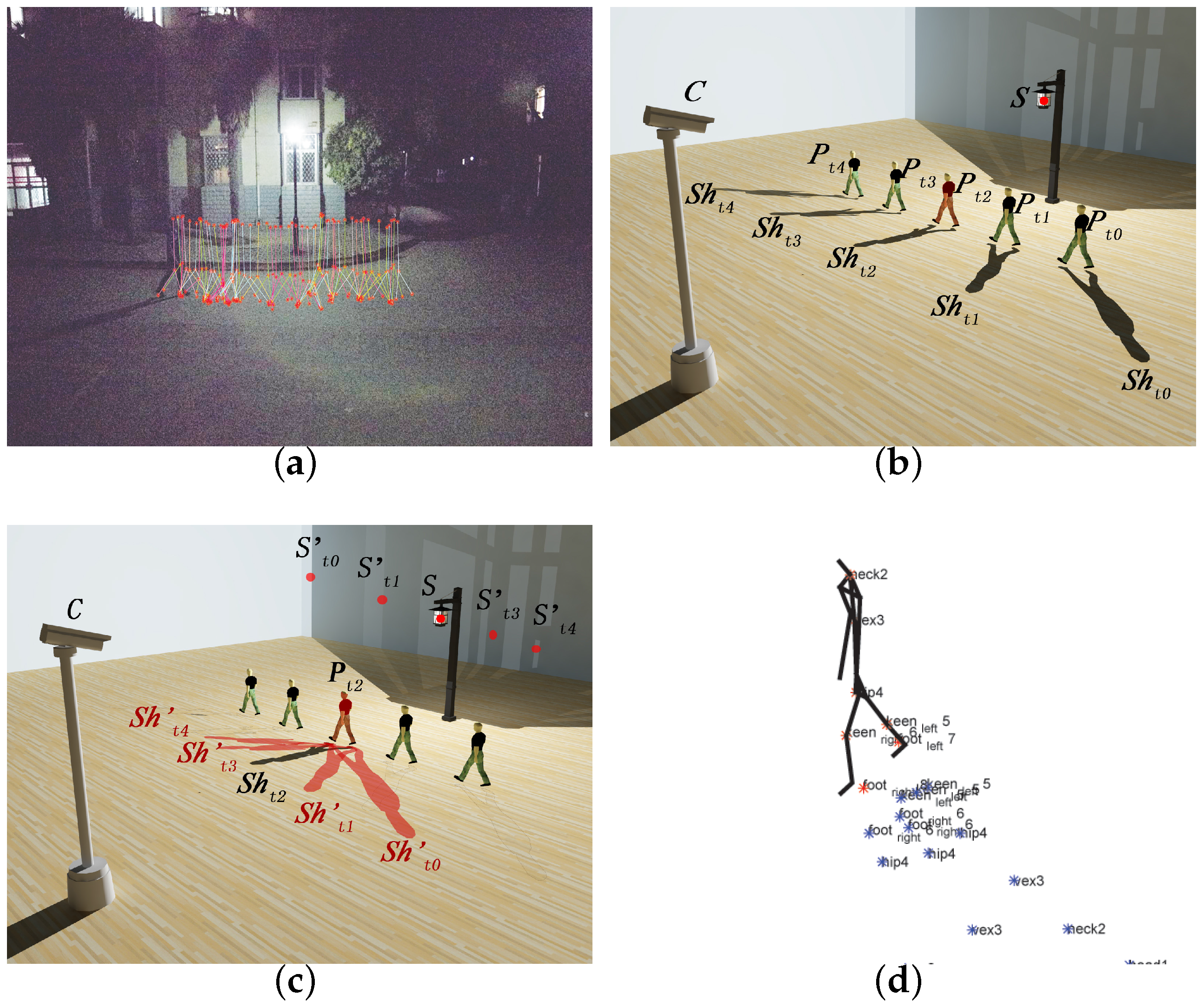
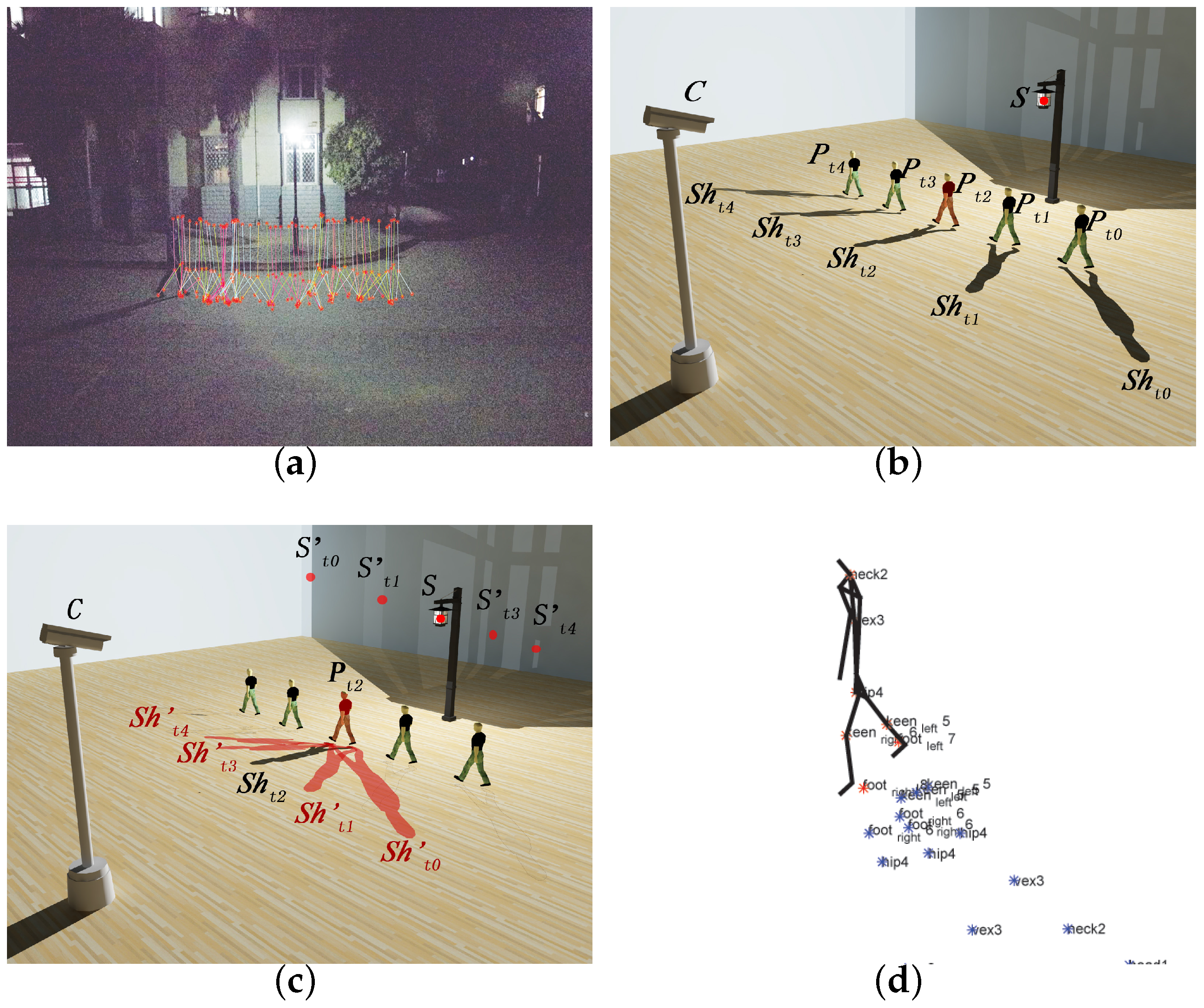
Temporal Distinguished Relative Position between Light Source and Human Body
Temporal Discrete Shadows for Same Human Pose
2.2.2. Temporal–Spatial Aggregation Method
Human Pose Classification
Temporal–Spatial Shadow Aggregation
| Algorithm 3: Temporal–spatial aggregation procedure |
| Input: : time coordinate for each frame; :human shadow on the ground surface in frame ; : human pose in frame ; S: light source position; : joint position set of the central pose on the aggregation destination; Output: : integrated human shadow in the simulated scenario. : integrated light source position in correspondence with .  |
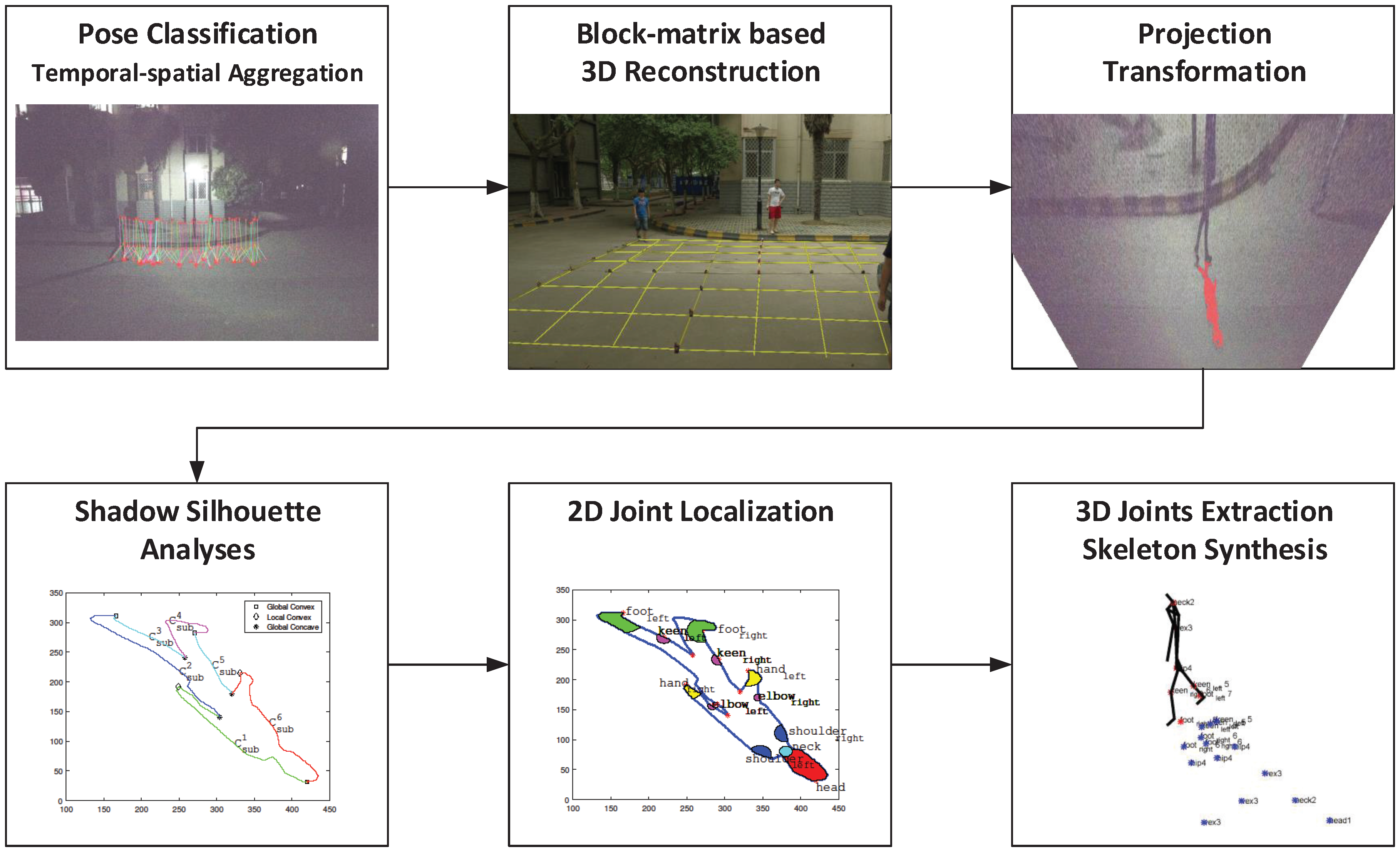
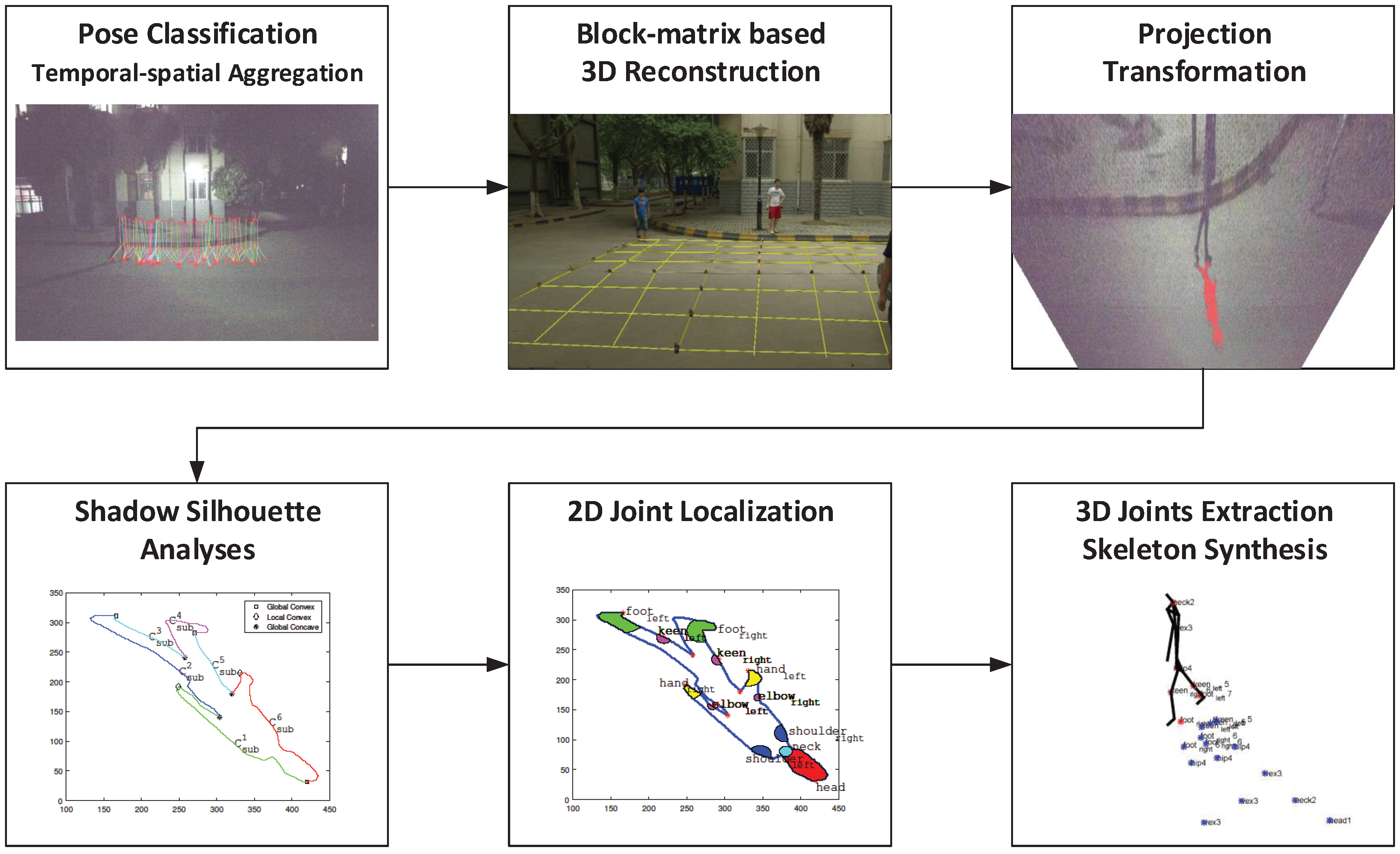
3. Proposed Method
| Algorithm 4: Skeleton synthesis procedure |
| Input: : time coordinate for each frame; :captured human shadow in frame ; : human pose in frame ; S: light source position; : the set of sub-blocks on the ground surface plane S : the marker position coordinate sets for sub-block on S; : the pixel coordinates set of on the image coordinate plane. Output: : 3D human skeleton corresponding to at time coordinate  |
Pose Classification
Preprocess
Temporal–Spatial Aggregation
Joint Position Estimation and Skeleton Synthesis
Frame Integration
4. Experimental Validation
4.1. Data Source Description and Experimental Settings
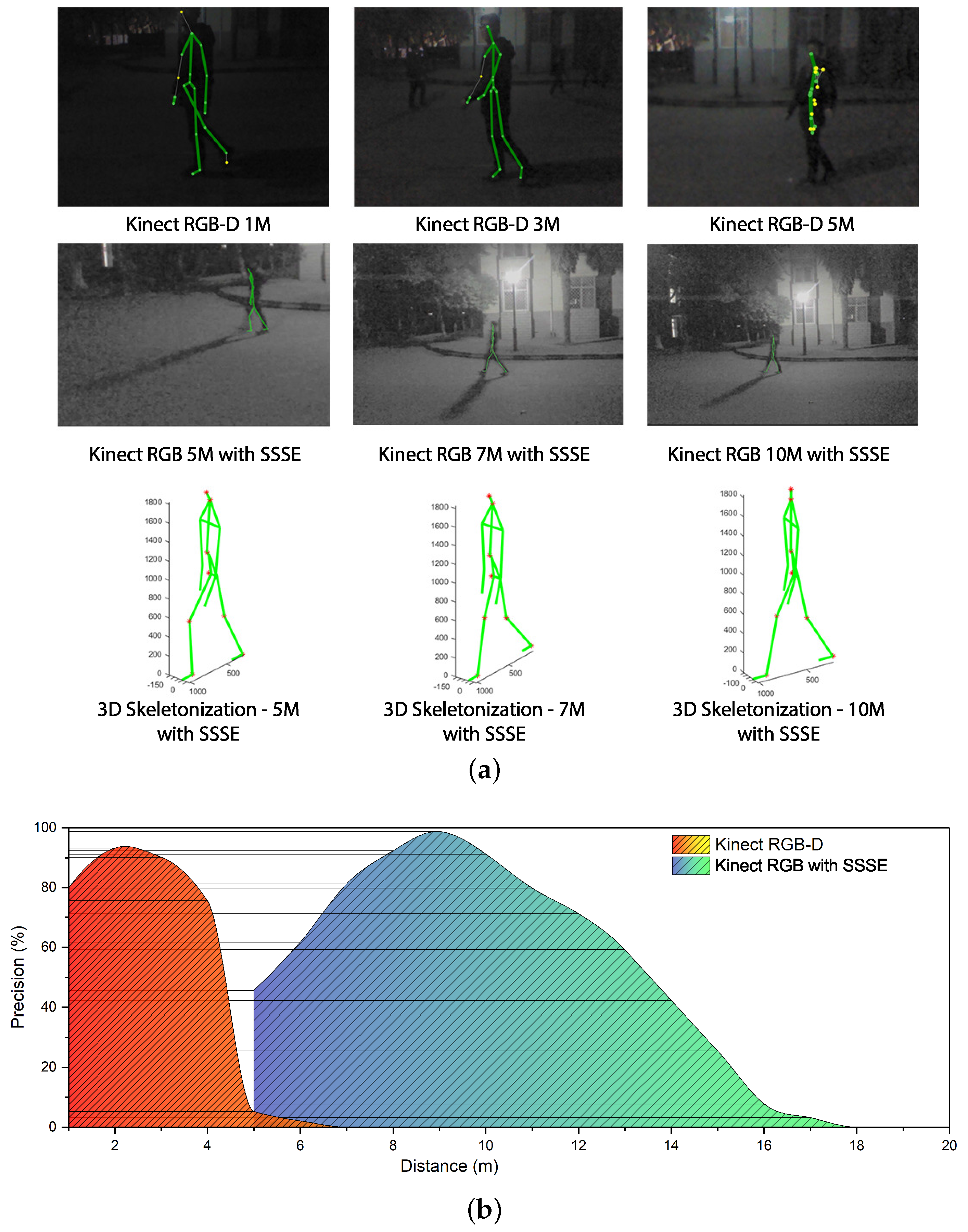
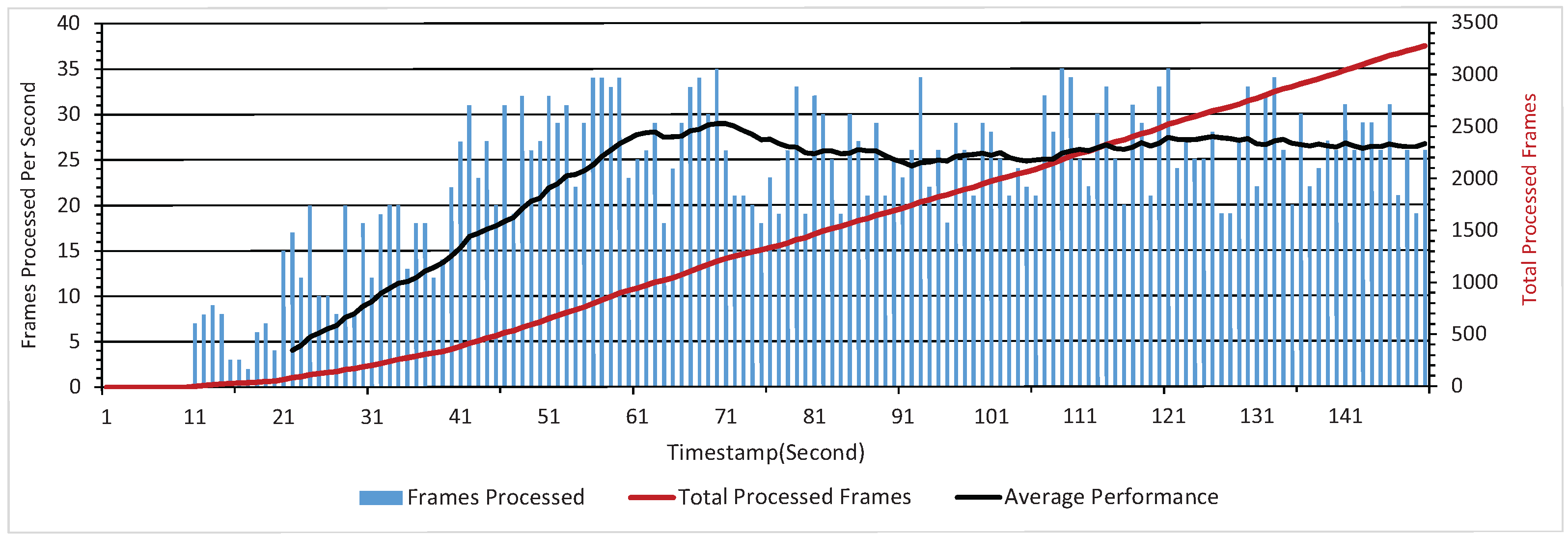
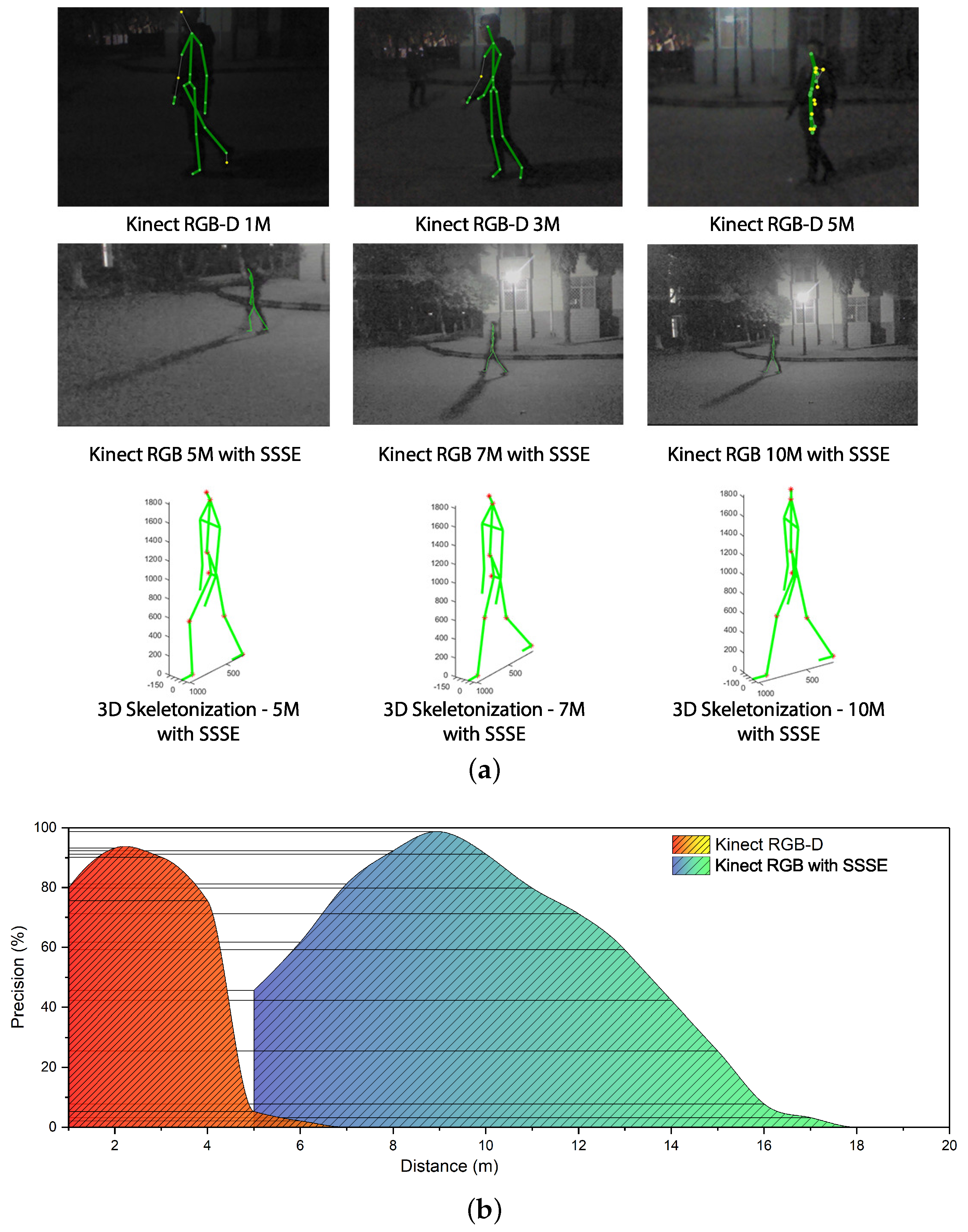
4.2. Effective Range and Precision Analyses
Effective Range
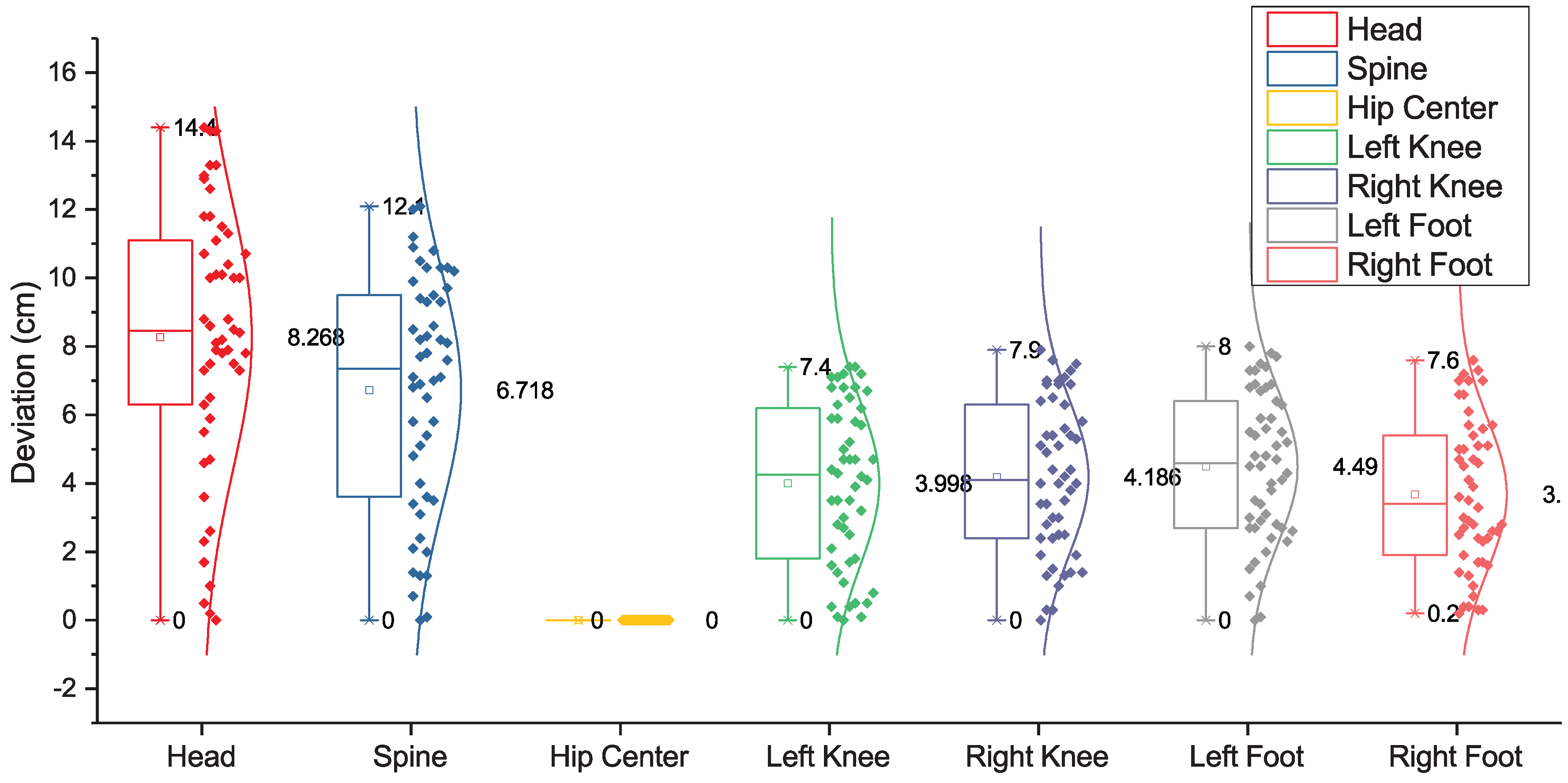
Precision Evaluation
5. Discussion
5.1. Reliable Joint Percentage Enhancement
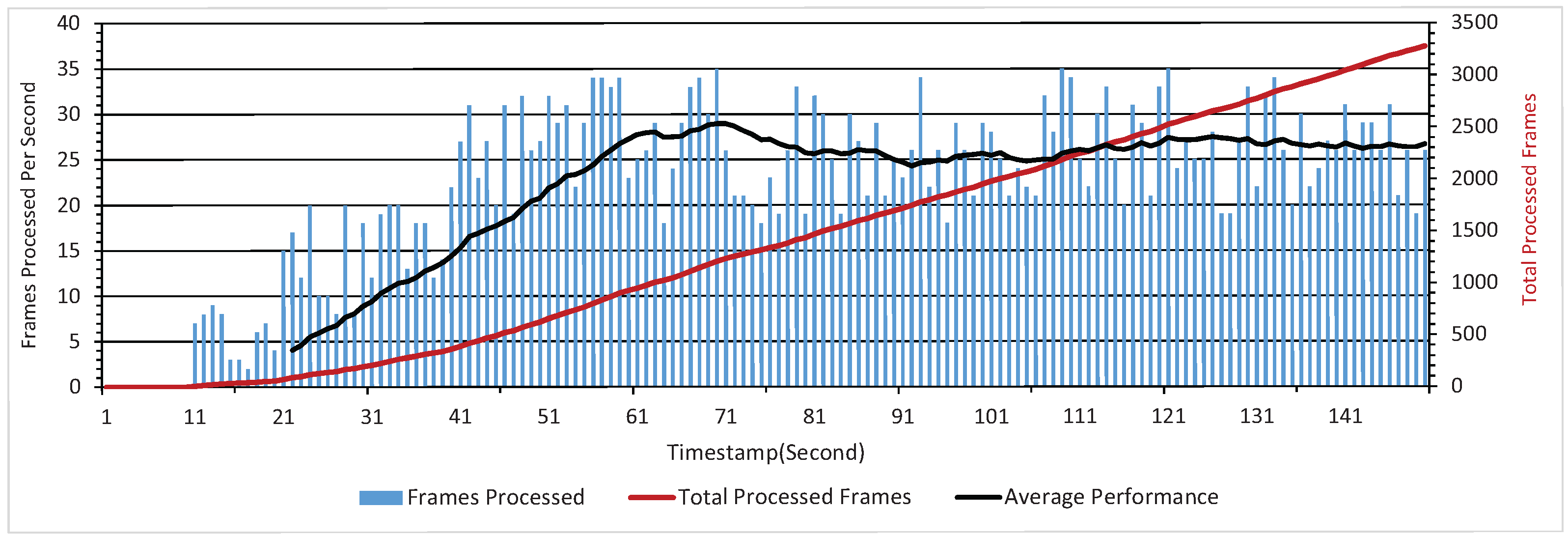
5.2. Computational Cost Evaluation
6. Conclusions
- (1)
- A block matrix-based projection transformation is proposed, allowing the reconstruction of precise shadow silhouette information from human shadow captured by monocular camera.
- (2)
- A silhouette shadow-based human skeleton extraction method is proposed. The proposed SSSE method extracts 3D positions of seven major joints in the human skeleton based on the reconstructed human shadow silhouette information and light source position.
- (3)
- A temporal–spatial integration algorithm for discrete shadow silhouette information is proposed, empowering the SSSE-based human skeletonization in single light source scenario.
- (1)
- The SSSE method can be deployed in large-scale outdoor scenarios where traditional 3D human skeletonization algorithms are not effective.
- (2)
- the SSSE method is capable of extracting human skeleton from frames shot by any normal monocular camera.
- (3)
- The SSSE method can be deployed in stretching the effective range of traditional RGB-D skeletonization method in the fusion application.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Zhang, Z. Microsoft kinect sensor and its effect. IEEE Multimedia 2012, 19, 4–10. [Google Scholar] [CrossRef]
- Xia, L.; Aggarwal, J. Spatio–temporal depth cuboid similarity feature for activity recognition using depth camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2834–2841. [Google Scholar]
- Zhang, X.; Gao, Y. Heterogeneous specular and diffuse 3-D surface approximation for face recognition across pose. IEEE Trans. Inf. Forensics Secur. 2012, 7, 506–517. [Google Scholar] [CrossRef]
- Zhang, Y.; Mu, Z.; Yuan, L.; Zeng, H.; Chen, L. 3D Ear Normalization and Recognition Based on Local Surface Variation. Appl. Sci. 2017, 7, 104. [Google Scholar] [CrossRef]
- Lay, Y.L.; Yang, H.J.; Lin, C.S.; Chen, W.Y. 3D face recognition by shadow moiré. Opt. Laser Technol. 2012, 44, 148–152. [Google Scholar] [CrossRef]
- Yang, T.; Zhang, Y.; Li, M.; Shao, D.; Zhang, X. A multi-camera network system for markerless 3d human body voxel reconstruction. In Proceedings of the 2009 IEEE Fifth International Conference on Image and Graphics, Xi’an, China, 20–23 September 2009; pp. 706–711. [Google Scholar]
- Chen, L.C.; Hoang, D.C.; Lin, H.I.; Nguyen, T.H. Innovative methodology for multi-view point cloud registration in robotic 3D object scanning and reconstruction. Appl. Sci. 2016, 6, 132. [Google Scholar] [CrossRef]
- Gouiaa, R.; Meunier, J. 3D reconstruction by fusioning shadow and silhouette information. In Proceedings of the IEEE 2014 Canadian Conference on Computer and Robot Vision (CRV), Montreal, QC, Canada, 6–9 May 2014; pp. 378–384. [Google Scholar]
- Wang, Y.; Huang, K.; Tan, T. Human activity recognition based on r transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Chen, C.C.; Aggarwal, J. Recognizing human action from a far field of view. In Proceedings of the 2009 IEEE Workshop on Motion and Video Computing, Snowbird, UT, USA, 8–9 December 2009; pp. 1–7. [Google Scholar]
- Jin, X.; Kim, J. A 3D Skeletonization Algorithm for 3D Mesh Models Using a Partial Parallel 3D Thinning Algorithm and 3D Skeleton Correcting Algorithm. Appl. Sci. 2017, 7, 139. [Google Scholar] [CrossRef]
- Shotton, J.; Girshick, R.; Fitzgibbon, A.; Sharp, T.; Cook, M.; Finocchio, M.; Moore, R.; Kohli, P.; Criminisi, A.; Kipman, A.; et al. Efficient human pose estimation from single depth images. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2821–2840. [Google Scholar] [CrossRef] [PubMed]
- Shotton, J.; Sharp, T.; Kipman, A.; Fitzgibbon, A.; Finocchio, M.; Blake, A.; Cook, M.; Moore, R. Real-time human pose recognition in parts from single depth images. Commun. ACM 2013, 56, 116–124. [Google Scholar] [CrossRef]
- Song, Y.; Liu, S.; Tang, J. Describing trajectory of surface patch for human action recognition on RGB and depth videos. IEEE Signal Proc. Lett. 2015, 22, 426–429. [Google Scholar] [CrossRef]
- Han, J.; Shao, L.; Xu, D.; Shotton, J. Enhanced computer vision with microsoft kinect sensor: A review. IEEE Trans. Cybern. 2013, 43, 1318–1334. [Google Scholar] [PubMed]
- Jafari, O.H.; Mitzel, D.; Leibe, B. Real-time RGB-D based people detection and tracking for mobile robots and head-worn cameras. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 5636–5643. [Google Scholar]
- Juang, C.F.; Chang, C.M.; Wu, J.R.; Lee, D. Computer vision-based human body segmentation and posture estimation. IEEE Trans. Syst. Man Cybern. A Syst. Hum. 2009, 39, 119–133. [Google Scholar] [CrossRef]
- Hsieh, J.W.; Hsu, Y.T.; Liao, H.Y.M.; Chen, C.C. Video-based human movement analysis and its application to surveillance systems. IEEE Trans. Multimedia 2008, 10, 372–384. [Google Scholar] [CrossRef]
- Yuan, X.; Yang, X. A robust human action recognition system using single camera. In Proceedings of the 2009 International Conference on Computational Intelligence and Software Engineering, Wuhan, China, 11–13 December 2009; pp. 1–4. [Google Scholar]
- Hu, M.C.; Chen, C.W.; Cheng, W.H.; Chang, C.H.; Lai, J.H.; Wu, J.L. Real-time human movement retrieval and assessment with Kinect sensor. IEEE Trans. Cybern. 2015, 45, 742–753. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Set | Joints | Frames | ||||||
|---|---|---|---|---|---|---|---|---|
| Set No. | ||||||||
| 1 | 0.8644 | 1221 | 1111 | 56 | 0.7923 | 1385 | 1291 | 194 |
| 2 | 0.8554 | 1666 | 1516 | 91 | 0.7943 | 1218 | 1125 | 158 |
| 3 | 0.8357 | 1654 | 1519 | 137 | 0.8603 | 1293 | 1236 | 124 |
| 4 | 0.8636 | 1632 | 1532 | 123 | 0.8410 | 1377 | 1316 | 158 |
| 5 | 0.8391 | 1913 | 1764 | 159 | 0.7705 | 1176 | 1066 | 160 |
| 6 | 0.8929 | 1404 | 1348 | 94 | 0.7606 | 1198 | 1072 | 161 |
| 7 | 0.8816 | 1985 | 1842 | 92 | 0.8170 | 1048 | 973 | 117 |
| 8 | 0.8303 | 1254 | 1096 | 55 | 0.8189 | 1383 | 1287 | 154 |
| 9 | 0.8476 | 1907 | 1796 | 180 | 0.8264 | 1346 | 1236 | 124 |
| 10 | 0.8374 | 1516 | 1395 | 126 | 0.7877 | 1132 | 1049 | 157 |
| 11 | 0.7664 | 1944 | 1817 | 327 | 0.7190 | 1228 | 1132 | 249 |
| 12 | 0.7254 | 1135 | 992 | 169 | 0.7209 | 1063 | 970 | 204 |
| 13 | 0.7480 | 1446 | 1319 | 237 | 0.7092 | 1242 | 1159 | 278 |
| 14 | 0.7234 | 1129 | 996 | 179 | 0.6987 | 1037 | 941 | 216 |
| 15 | 0.7282 | 1076 | 944 | 160 | 0.7419 | 1247 | 1171 | 246 |
| 16 | 0.8029 | 1561 | 1492 | 239 | 0.7348 | 1269 | 1211 | 279 |
| 17 | 0.8113 | 1959 | 1892 | 303 | 0.7542 | 1414 | 1333 | 267 |
| 18 | 0.7999 | 1562 | 1470 | 221 | 0.6861 | 1138 | 1041 | 260 |
| 19 | 0.7806 | 1599 | 1486 | 238 | 0.6800 | 1039 | 942 | 236 |
| 20 | 0.7849 | 1589 | 1521 | 274 | 0.7445 | 1182 | 1100 | 220 |
| Total | 0.8149 | 31152 | 28848 | 3460 | 0.7655 | 24415 | 22651 | 3962 |
| Methods | Device Requirement | Effective Range | Output Format | Joint Numbers |
|---|---|---|---|---|
| SSSE | Single RGB Camera | 7.0 m < < 10 m | Human Skeleton | 7 |
| Traditional RGB-D Method [20] | RGB-D Camera | 0.8 m < < 3.5 m | Human Skeleton | 20 |
| SSSE and RGB-D Fusion | RGB-D Camera | 0.8 m < < 10 m | Human Skeleton | 7 to 20 |
| Jafari’s RGB-D method [16] | RGB-D Camera | Not Available (N/A) | Human Voxel | 0 |
| Yang’s mono-RGB method [6] | Multiple RGB Cameras | N/A | Partial Voxels | 0 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, J.; Guo, B.; He, W.; Wu, J. A 3D Human Skeletonization Algorithm for a Single Monocular Camera Based on Spatial–Temporal Discrete Shadow Integration. Appl. Sci. 2017, 7, 685. https://doi.org/10.3390/app7070685
Hou J, Guo B, He W, Wu J. A 3D Human Skeletonization Algorithm for a Single Monocular Camera Based on Spatial–Temporal Discrete Shadow Integration. Applied Sciences. 2017; 7(7):685. https://doi.org/10.3390/app7070685
Chicago/Turabian StyleHou, Jie, Baolong Guo, Wangpeng He, and Jinfu Wu. 2017. "A 3D Human Skeletonization Algorithm for a Single Monocular Camera Based on Spatial–Temporal Discrete Shadow Integration" Applied Sciences 7, no. 7: 685. https://doi.org/10.3390/app7070685
APA StyleHou, J., Guo, B., He, W., & Wu, J. (2017). A 3D Human Skeletonization Algorithm for a Single Monocular Camera Based on Spatial–Temporal Discrete Shadow Integration. Applied Sciences, 7(7), 685. https://doi.org/10.3390/app7070685