1. Introduction
Indoor location-based services (LBS) such as indoor positioning, tracking and navigation, have been receiving a lot of attention in recent years [
1,
2]. However, it remains a challenge to provide the users with an accurate and robust location estimation. Global Positioning System (GPS) is the most widely used localization system and provides precise positioning in outdoor environments. However, due to the lack of sufficient signal strength in most of the indoor areas, GPS is not a reasonable solution for indoor environments. Therefore, various alternatives to GPS have been proposed for indoor localization. Examples include but are not limited to the methods using Ultra-Wideband, Ultrasound, Infrared and Radio Frequency signals [
2,
3,
4,
5,
6]. These alternatives provide a good localization accuracy for many applications, however, they require additional infrastructure that would be a disadvantage to their large-scale deployment.
With the growing deployment of WiFi access points in indoor environments and the widespread use of mobile devices such as smart phones, WiFi received signal strength (RSS)-based indoor localization methods are getting popular due to their low deployment cost and relatively high localization accuracy.
In general, there are two main categories of localization methods that use WiFi RSS readings. The first category comprises those methods that rely on the radio propagation model of the WiFi signal in indoor environments as well as the locations of the WiFi Access Points (AP). Specifically, the RSS readings from different access points are used to estimate the distance of a mobile device from those access points. Then a triangulation method is used to estimate the location of the mobile device. The next category includes those methods that are based on WiFi RSS fingerprints also known as fingerprint-based methods. Originally proposed by P. Bahl et al. [
7], various fingerprint-based localization systems have been designed and developed during the last decade [
7,
8,
9].
Typically, fingerprint-based methods consist of an offline phase followed by an online phase [
7]. In the offline phase, RSS values from different WiFi access points are measured at some known locations throughout the indoor area. These location are referred to as Reference Points (RP) and the measured RSS vector for each RP is called a
fingerprints. All fingerprints and their corresponding RPs are stored in a database called the
radio map. In the online phase, a user’s position can be estimated by comparing the RSS values measured by the user with the RSS fingerprints stored in the radio map.
A disadvantage to the offline phase of the fingerprint-based methods is the required time and labor to collect sufficient number of fingerprints throughout the indoor area. In addition, the RSS value of an AP at a certain location can change over time due to a number of reasons including but not limited to multipath fading, shadowing, moving objects and people [
10]. To mitigate these RSS fluctuations, a large number of RSS measurements are collected at every reference point in the offline training phase. However, collecting more RSS measurements at any location makes the offline phase even more time-consuming and labour-intensive. Several works have been proposed to reduce the workload of the offline phase [
11,
12,
13]. The crowdsourcing method has been shown to be a promising approach to solving this problem [
14,
15,
16]. In a crowdsourcing-based system, each user can contribute to the construction and updating of the radio map. Consequently, the number of RSS values collected in the offline training phase is greatly reduced. On the other hand, RSS measurements collected by the users moving in the environment are potentially more erroneous than those collected by the experts at the exact location of reference points.
One of the problems in the crowdsourcing localization system is that numerous of mobile devices are applied to build the radio map in the offline training phase and provide LBS for the device holders in the online phase. Due to the different WLAN adapter equipped in the mobile devices, the RSS values collected by the mobile device are subject to the difference of the WLAN adapter. As a result, different data collection devices may have different signal sensing capacities and yield different data distributions. Numerous studies show that, due to the hardware differences, the RSS differences collected by different devices exceeds more than 25 dB [
17,
18,
19]. Therefore, the localization accuracy is degraded significantly by the problem of RSS variations across different devices.
Another issue of indoor localization is the knowledge of the location of the access points. In most fingerprint-based methods, the location of the access points is considered to be unknown. This is a convenient simplifying assumption in many situations, especially when the signal strengths are measured in a passive mode. However, the knowledge of the location of the access points can enhance the localization accuracy. This is especially important since the location of an access point can be estimated using some signal processing techniques [
20]. The location of an access point can then be used to correlate the received signal strength across neighbouring locations, as will be discussed in this paper.
In this paper, in order to deal with the device diversity problem, the Linear Regression (LR) algorithm is used to mine the intrinsic relationship between different RSS values collected by different devices. Using the LR algorithm, the problem of device diversity will be solved automatically and the uniform RSS values are gotten, so as to ensure the application of the following algorithms. On the basis of graph-based semi-supervised learning (G-SSL) method, we propose RSS difference-aware G-SSL (RG-SSL) method and RSS difference-aware sparse graph SSL (RSG-SSL) method to smoothen the RSS values collected in the offline training phase and improve the localization results. Before smoothing RSS measurements using the G-SSL method, the locations of APs need to be known. Since the spatial distribution of the APs is sparse, the Compressed Sensing (CS)-based method of [
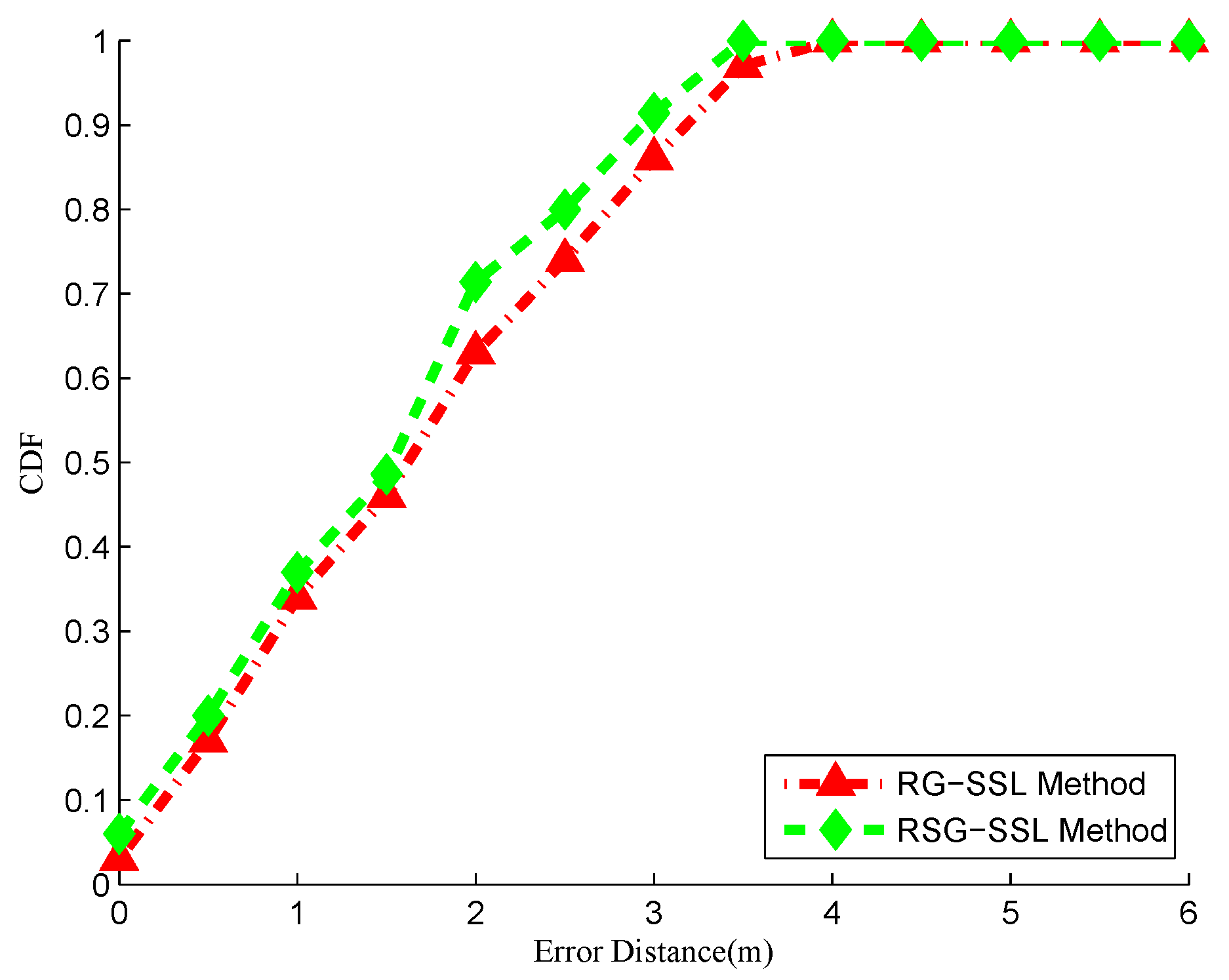
20] is proposed to precisely estimate the AP locations. Based on the signal propagation model, the RSS difference between two locations is calculated with respect to the locations of RPs and APs. Furthermore, RG-SSL method is proposed to smoothen the radio map in the offline training phase. By leveraging the RSS readings in the local neighbourhood, the effect of noise and erroneous measurements can be reduced to obtain a higher localization accuracy. Finally, the sparsity of the graph is discussed and RSG-SSL method is used to obtain a better RSS smoothing and localization result.
The rest of the paper is organized as follows. The related works are given and discussed in
Section 2.
Section 3 formulates the indoor localization problem. In
Section 4, the device diversity problem in crowdsourcing localization system is solved by linear regression method. The CS-based AP positioning method is explained in
Section 5.
Section 5 also explains some experiments with the proposed CS-based AP positioning method. In
Section 6, RG-SSL method is proposed with some experimental results. Finally, we explain the RSG-SSL method in
Section 7 and provide the localization results using RSG-SSL.
Section 8 concludes the paper.
2. Background and Related Works
C. Feng et al. in [
2] and J. J. Pan et al. in [
11] proposed the CS-based method and the G-SSL method respectively, to reduce the workload of the radio map construction in the offline phase. Both methods, aim to reduce the number of reference points (RP) and RSS measurements. Also, [
14,
15,
16] explore crowdsourcing-based methods to reduce the deployment workload by engaging the users to participate in radio map construction.
In [
21], an RSS pre-processing method called the “sliding correlation time window filter” (SCTW) is used to reduce the noise in the measured RSS values. Similarly, in this paper, a sliding time window is used to average the RSS values collected in every RP to improve the accuracy of RSS measurements. However, this filter only uses a small number of the RSS values in the radio map and most of the information in the radio map is abandoned.
M. Hasani et al. [
22] used a path-loss model to improve the reliability of the measured RSS values. In the offline phase of their method, a set of channel parameters are estimated for each access point. In the online phase, the user’s location is found based on the calculated RSS values using the stored channel parameters. Their method results in a reliable localization thanks to the stability of the estimated channel parameters. In [
23], S. Latif et al. proposed a D-model to estimate the radio signal strength in indoor areas. The experiments in their paper proved that the proposed D-model is capable of estimating the RSS values with a high accuracy. Also their method models the wall attenuation more accurately compared to the method of [
22]. Although the simulation result showed that the proposed method is fit for RFID positioning system, when this method is used in WiFi positioning system, the result is not satisfactory.
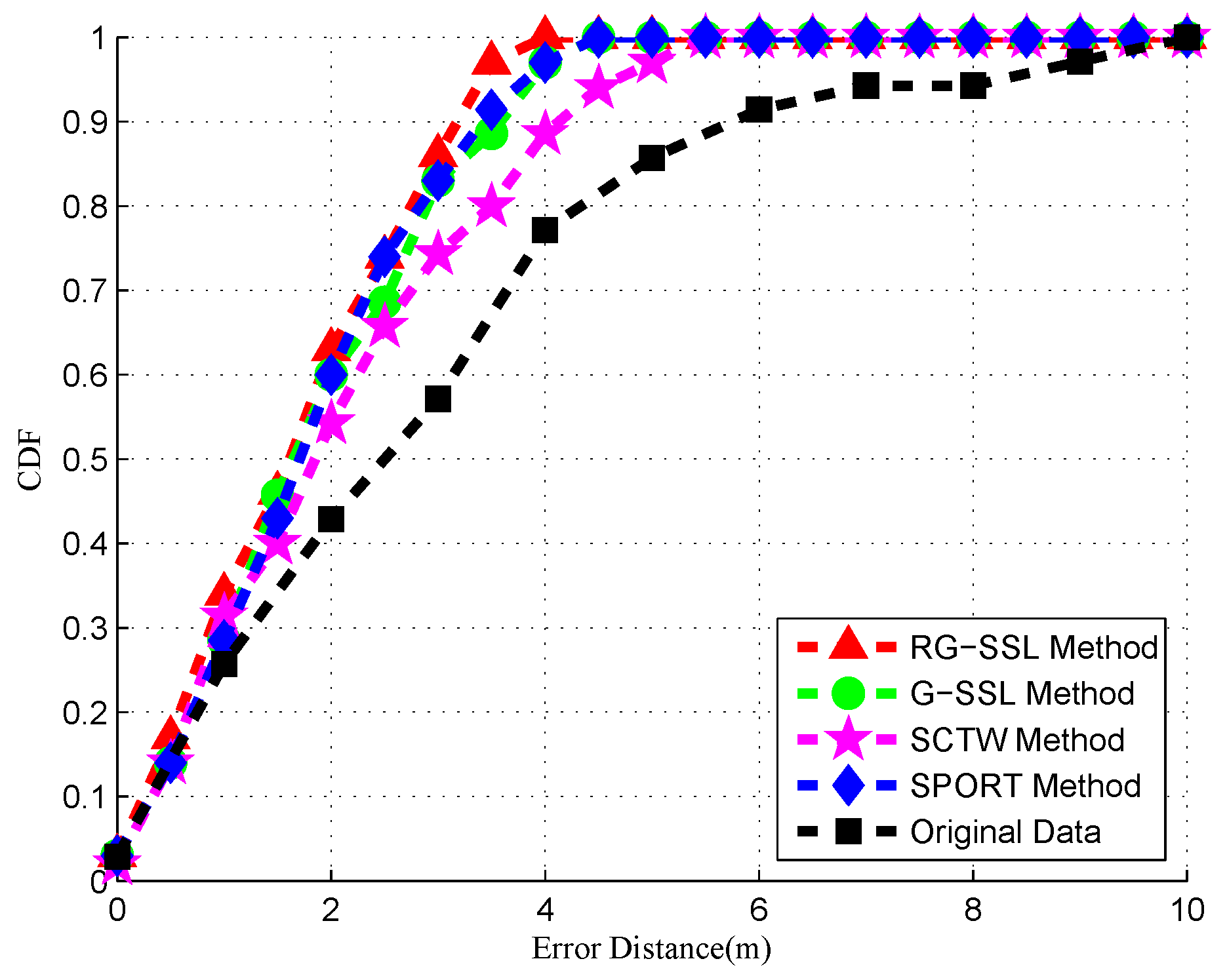
The signal propagation method gives us some inspiration, we proposed signal propagation-based outlier reduction technique (SPORT) to smooth the RSS collections in both the offline phase and the online phase and improve the localization accuracy [
24]. In this method, we investigate the relationship of RSS values between adjacent locations using a signal propagation model and show that the outliers can be corrected using a signal propagation model. Experimental results show that SPORT greatly smoothens the radio map and improves the location accuracy.
In order to minimize the fluctuation of RSS values, M. S. Rahman Sakib et al. [
25] developed a method using a Particle Filter (PF). Particle filters are used to perform non-linear and non-Gaussian estimations. However, in the online phase, a large number of particles have to be used in order to obtain a high positioning accuracy. Consequently, the computational cost is high which may be unacceptable for some indoor positioning applications.
L. Ma et al. [
26] proposed a method based on the singular value thresholding (SVT) to recover the missing RSS values both in offline and online phases. In that paper, the authors argued that the positioning performance degrades significantly when some of the APs are occasionally turned off such as in a green WLAN system. Therefore, they proposed an SVT-based method to estimate the missing RSS values both in the radio map and the online RSS readings. They showed that their SVT-based method could achieve an acceptable positioning performance.
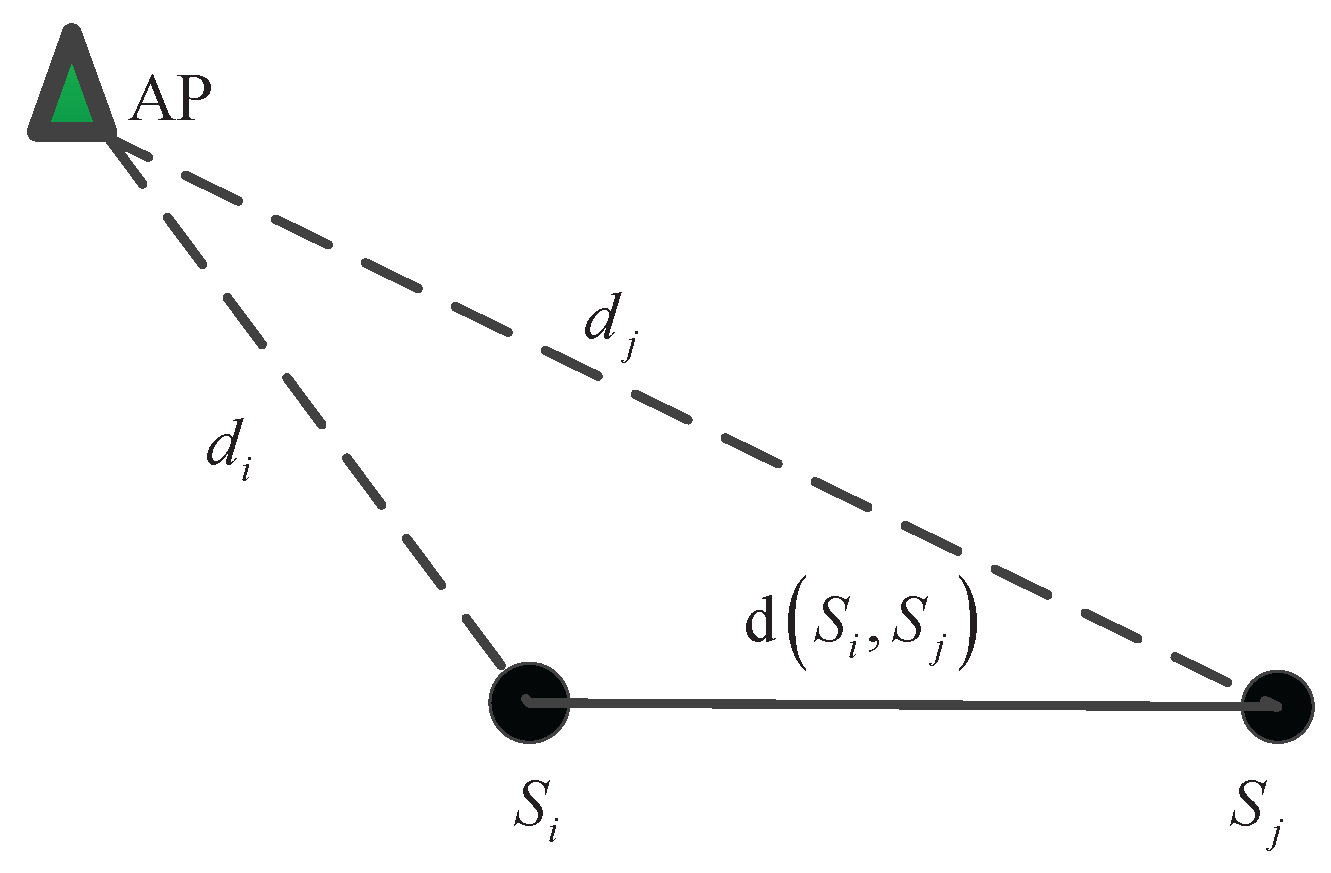
3. Problem Formulation
Suppose a set of ℓ RPs are selected throughout the indoor area and M APs are visible at each RP location. In the offline training phase, we collect the i-th fingerprint at RP , where is the geographical coordinates of and is an RSS vector. We refer to these fingerprints as labeled data. In the online phase, the user’s location can be estimated by comparing the RSS value collected at the unknown location of the user with the fingerprints in the radio map. If is similar to a particular , then we reason that user’s location must be close to RP location .
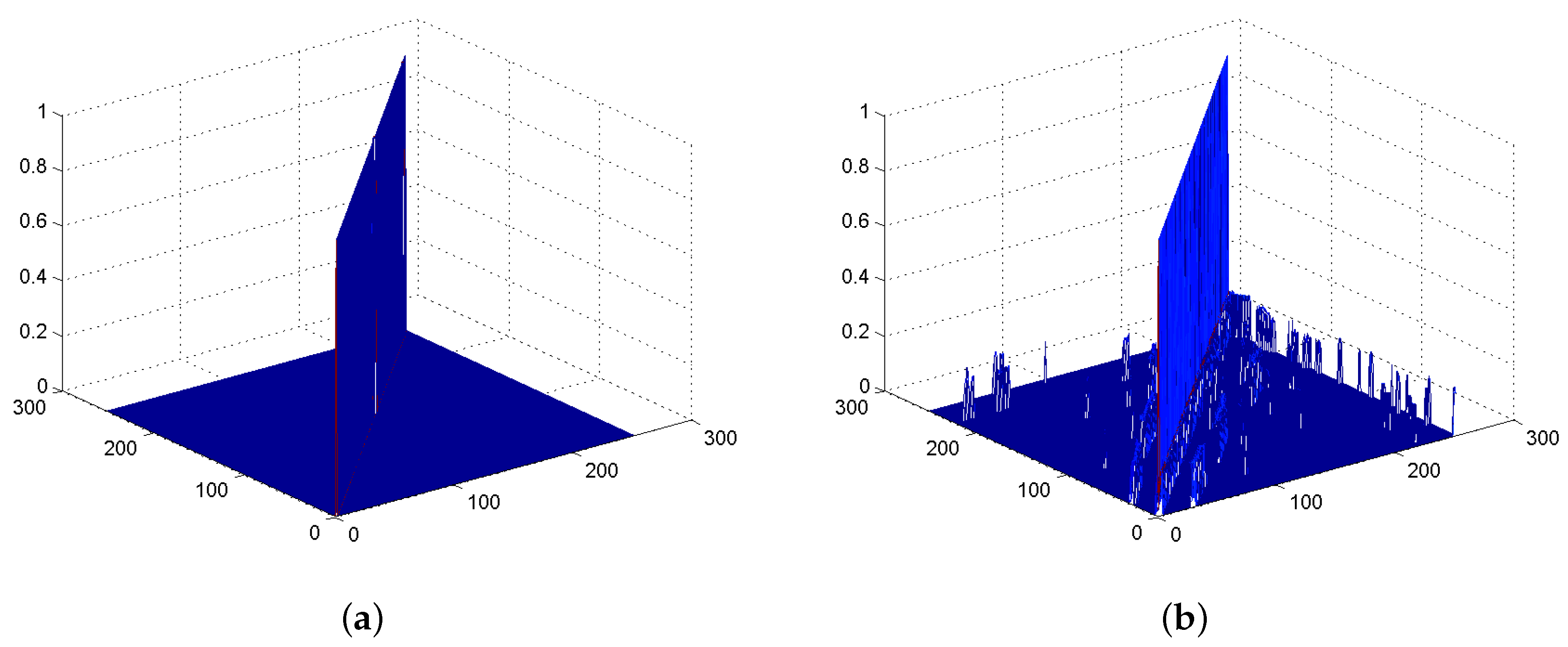
In practice, the RSS values measured by a mobile device are subject to multiple sources of noise, such as multi-path fading and shadowing.
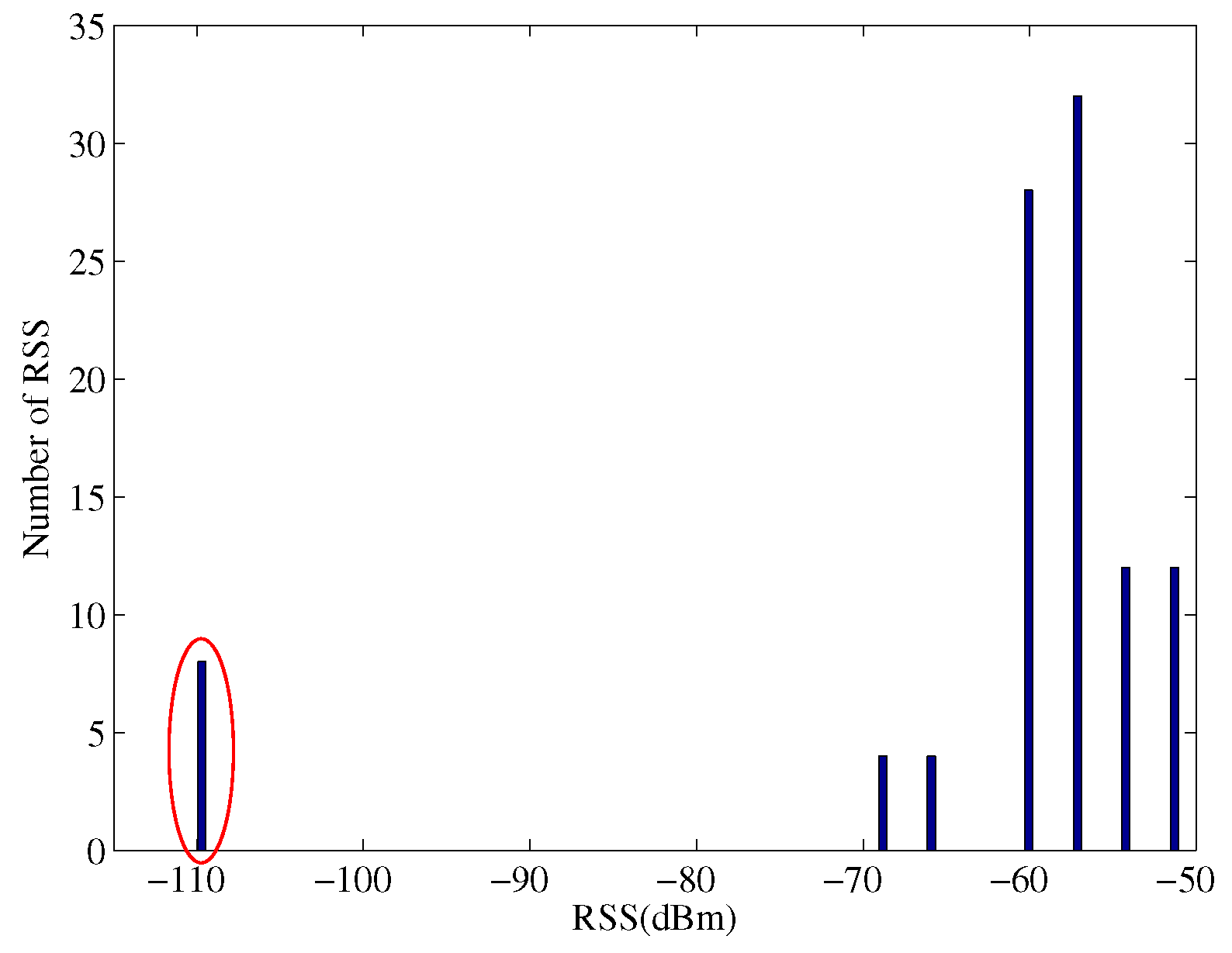
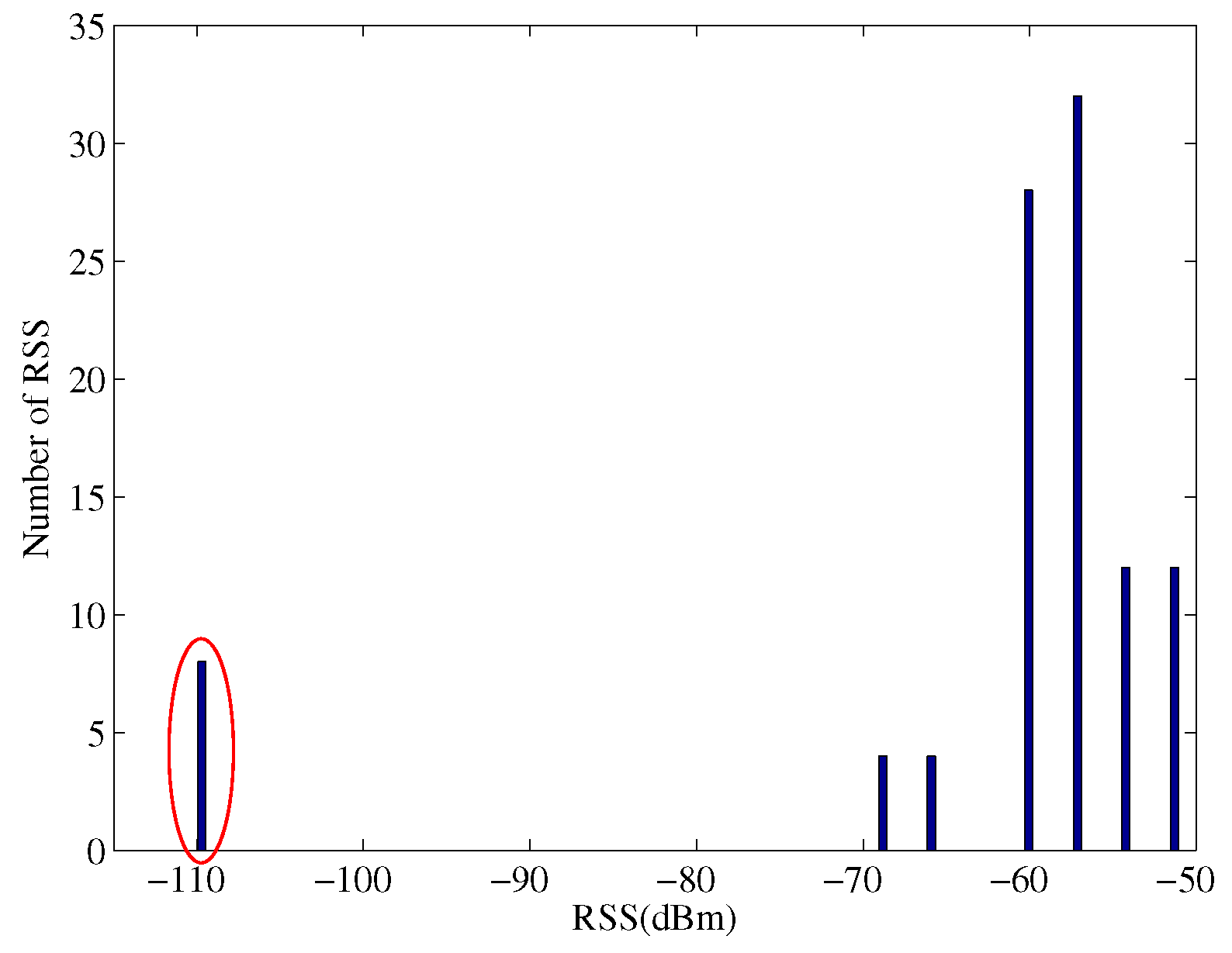
Figure 1 illustrates the histogram of 100 RSS values from a single AP at a particular location inside the Bahen Building at the University of Toronto. The RSS values are distributed in a wide range of
dBm to
dBm. Occasionally, we cannot receive any power from this AP and a value of
dBm is used to denote the missing RSS value.
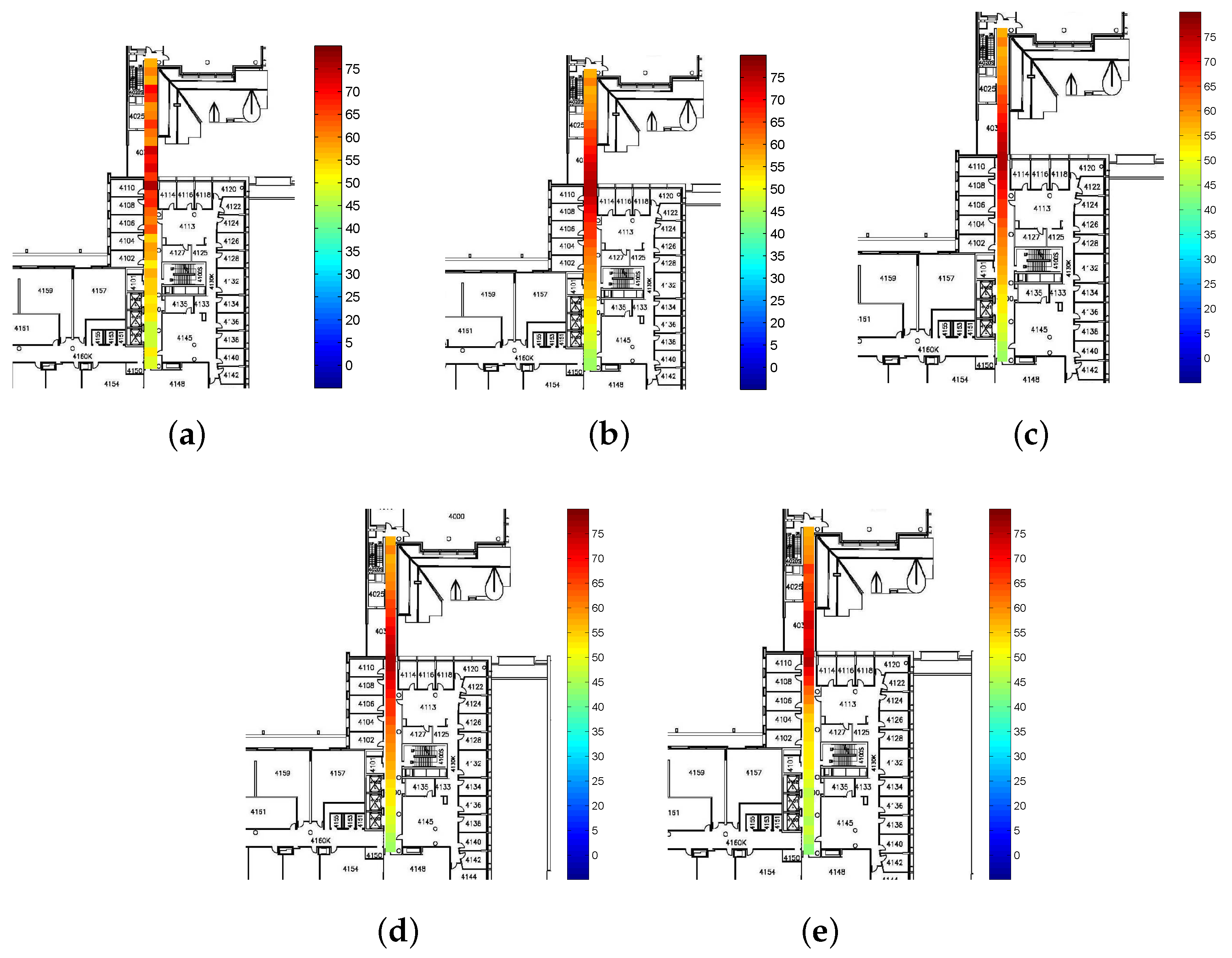
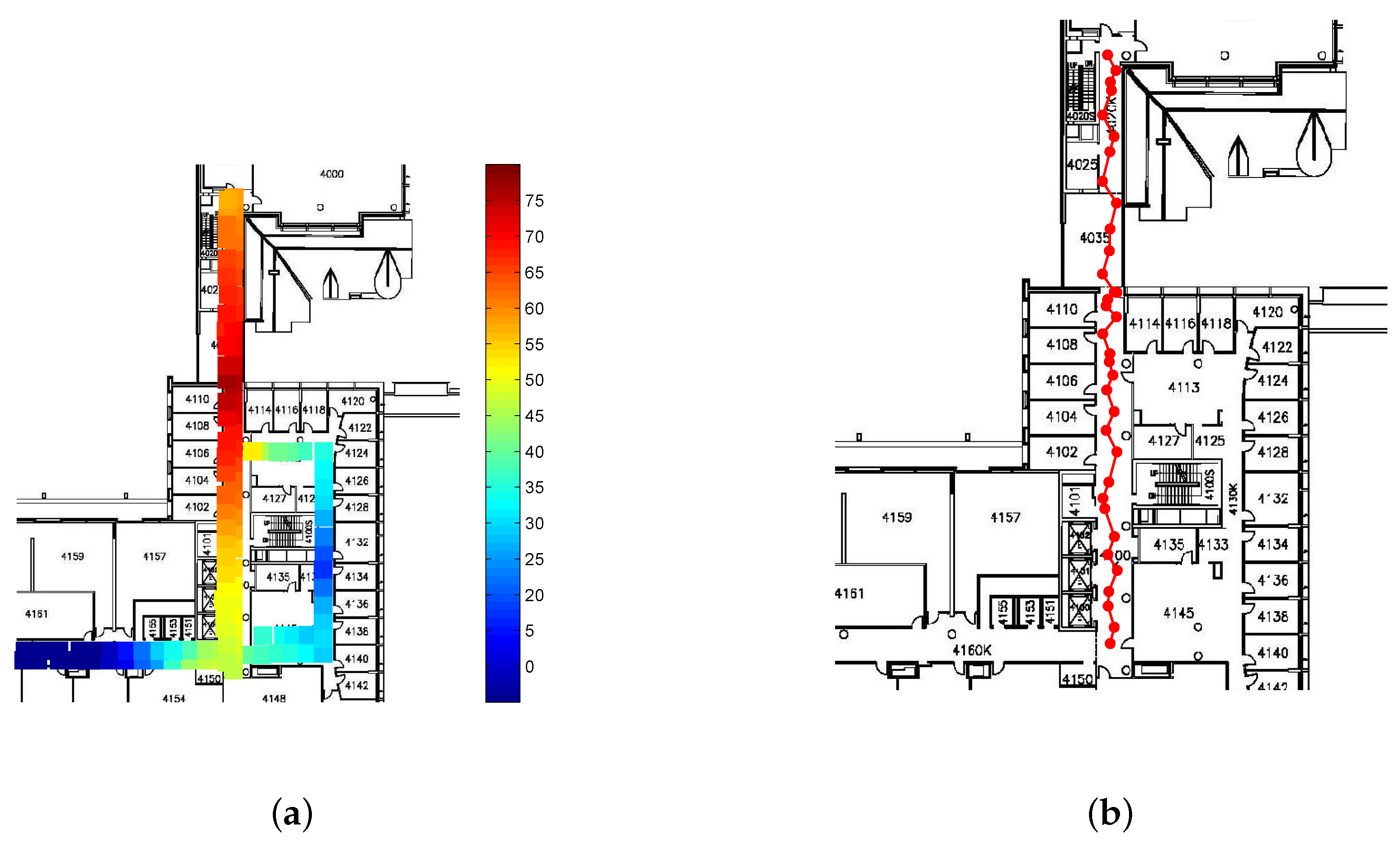
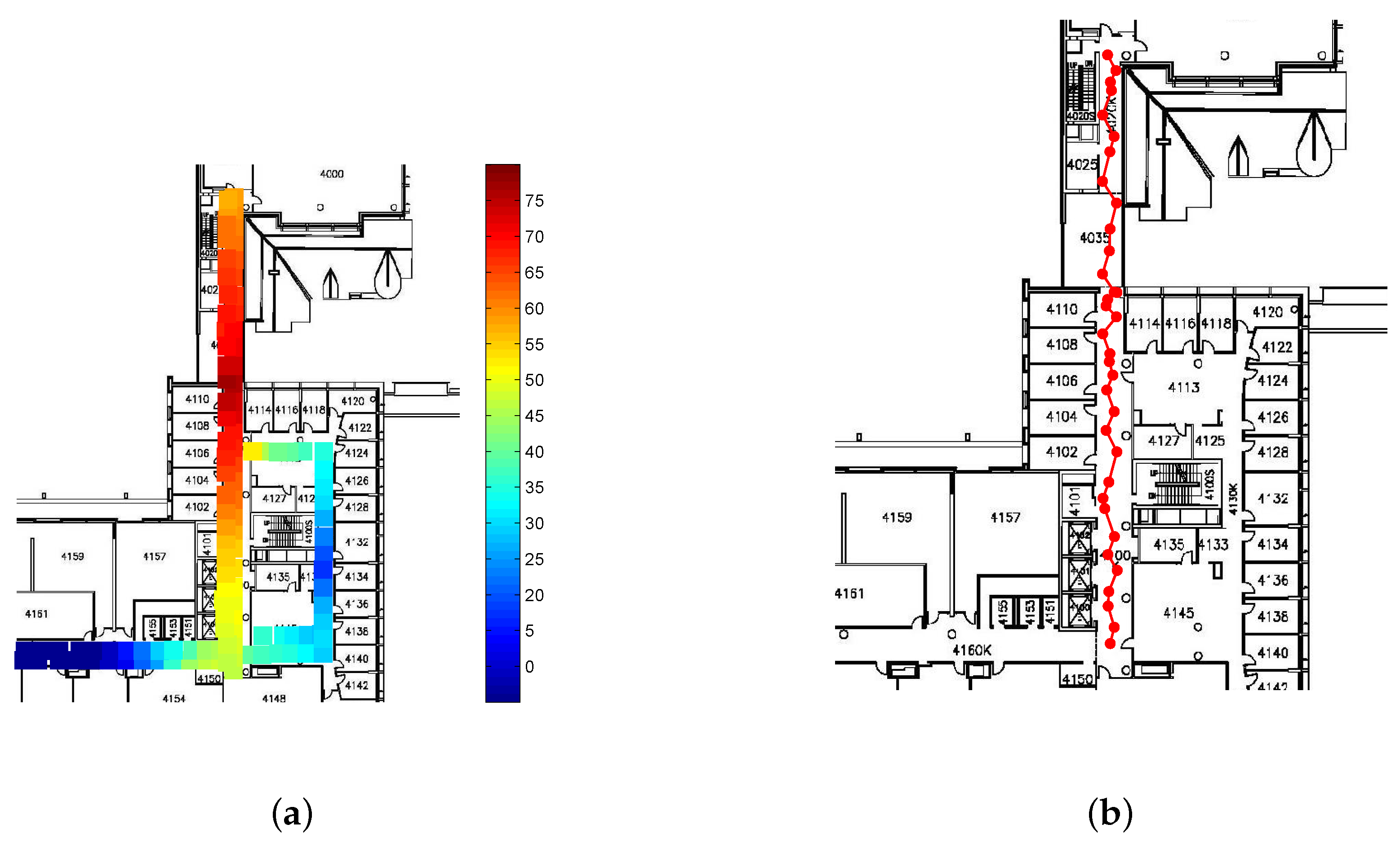
Figure 2 shows the RSS value from a single AP throughout the fourth floor of the Bahen Building after removing
dBm measurements and averaging over RSS values at each location.
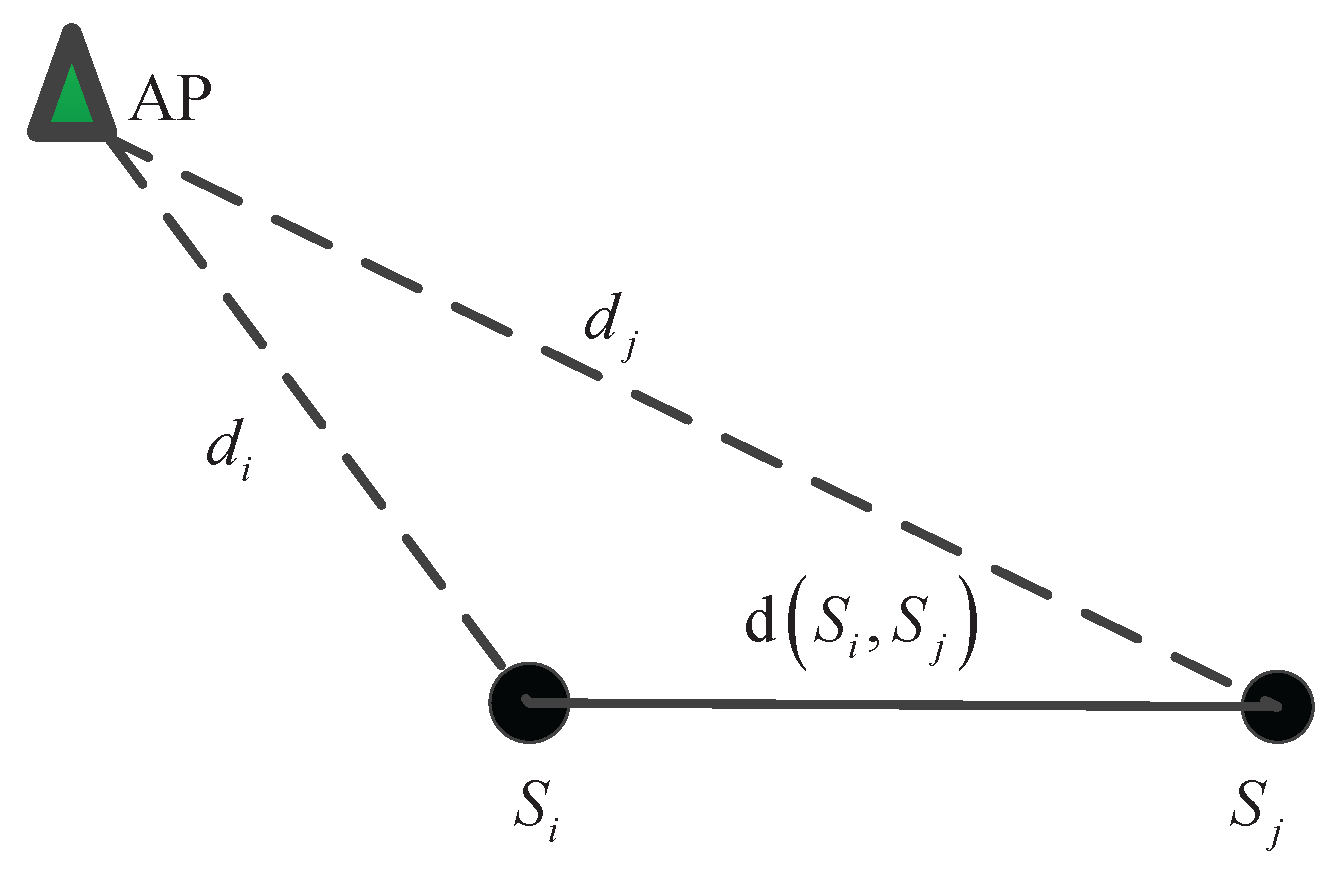
Next, we explain how we apply the G-SSL method to reduce the effect of noise in the radio map. Consider a set of u locations within the localization area that are not associated with RSS measurements hence we call them unlabelled data. In addition to these unlabelled locations, there are ℓ labelled RP locations as explained previously. Consequently, we have locations of labelled and unlabelled data. In the G-SSL method, a weighted graph is constructed using both labelled and unlabelled data. In this graph, the vertices represent the training data and all the vertices are connected by edges. The edge weight matrix, which is calculated by the training data, represents the relationship between vertices in the graph by assigning a weight to each edge connecting two vertices in the graph. Each vertex on the graph corresponds to a location and the weighted edges between vertices represent the relationship between both RSS values and locations corresponding to those vertices. As mentioned earlier in this section, measured RSS values in an indoor environment are affected by different types of noise. However, in the graph representation of the G-SSL method, any two vertices on the graph are related not only by the RSS values measured at those vertices but also by the physical locations corresponding to those vertices. Therefore, the G-SSL is able to reduce the effect of noise in the measured RSS value by incorporating both RSS and location information. Next, we will explain the G-SSL method with more details.
Suppose
denotes the graph of the G-SSL method. The vertices of the graph,
V, is defined as
where the first
ℓ elements are the location coordinates of the labelled data and the next
u elements are the location coordinates of the unlabelled data. For every edge between two vertices at
and
, we can calculate its weight
.
indicates the similarity between the two vertices and takes values in the range
with 0 indicating no similarity between the vertices. The result is an
weight matrix
containing all the calculated weights. The graph edges are usually undirected, so the edge
(weighted by
) and the edge
(weighted by
) are the same edge in the graph, which means
. In addition, the edge
does not exist, therefore, there are
edges in the graph. In summary, only the corresponding number of graph weights are calculated which makes the weight matrix
a symmetric matrix. To calculate the weights, here we use the well-known
heat-kernel function:
where
is the square of the Euclidean distance between location
and
and
is a parameter based on the application which controls how quickly the weight decreases.
The G-SSL uses
to estimate the labels of the unlabelled data using the relationship between different vertices in the graph. The result is a set of estimated labels
for
. If
is close to
, the estimated label
is close to the given label
for all
. The estimated labels
have to satisfy two conditions. First, for the labelled data, since the labels are already known, the estimated labels
must be close to the real labels. For the labelled data
, we should have
. This condition is enforced by minimizing the following loss function
where
is the
matrix of all estimated RSS values and
is the Euclidean distance.
The second condition is that the graph should be smooth. The smoothness of the graph comes from the fact that data points which are close to each other should have similar labels. To satisfy the smoothness condition, the estimated labels
and
should meet the following loss function
If and are close to each other, the weight would be large, and the labels and must be close in order for the whole term to be minimized. On the other hand, if and are far away from each other, the weight would be very small and the choice of the labels does not have much effect on the minimization.
Hence, the estimated labels that satisfy both conditions above can be estimated using:
where
is a the weight of the smoothness term based on the application.
is a design parameter used to enforce which term is of higher importance. In conclusion, the first term of the Equation (
4) penalizes the difference between the actual labels and the estimated labels and the second term ensures the smoothness of the graph.
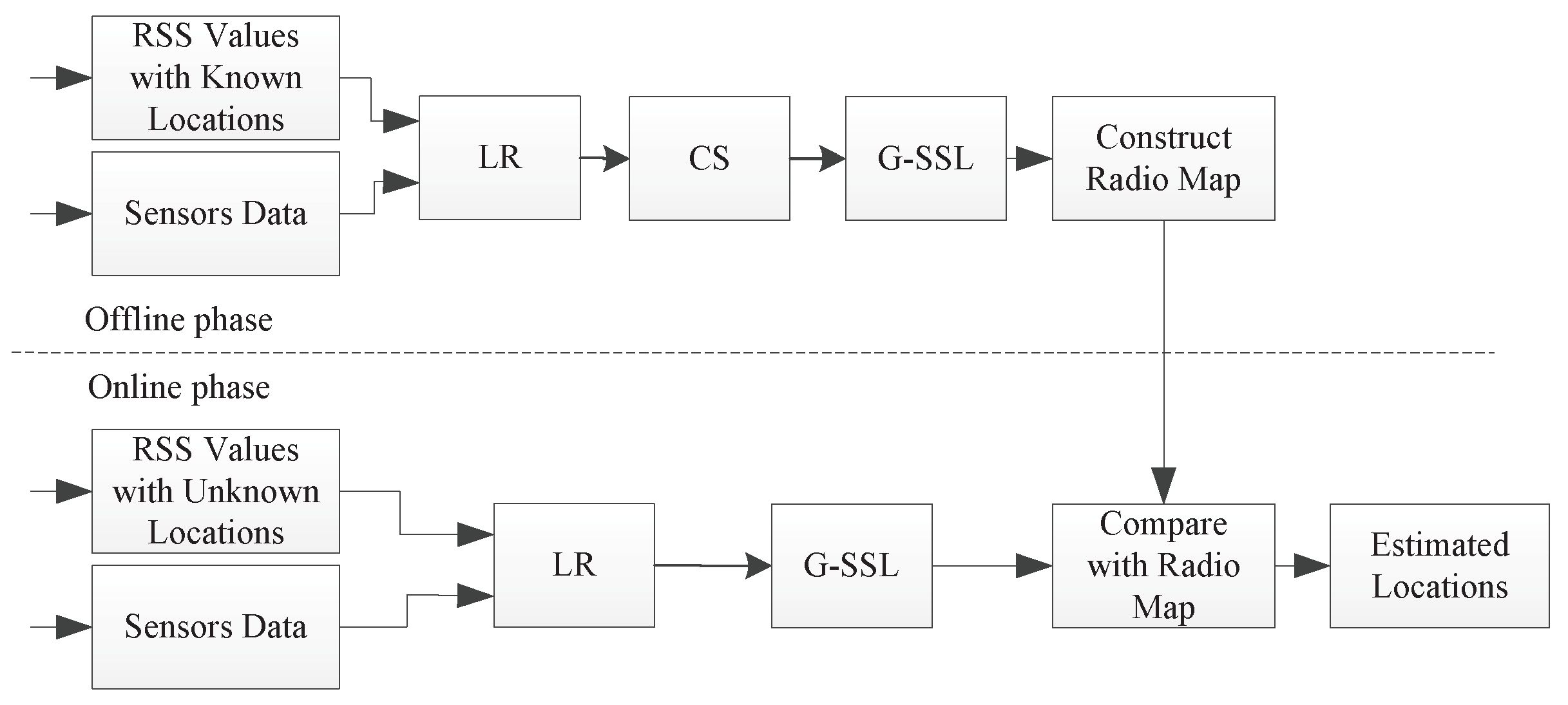
The proposed G-SSL-based RSS smoothing method for crowdsourcing is summarized in the system diagram shown in
Figure 3. In the offline phase, since the actual coordinates of
and
are already known, the LR algorithm is used to obtain the uniform RSS values. Then the locations’ APs are calculated by CS method. At last the RSS values can be smoothed by G-SSL method. In the online phase, the data collected simultaneously from sensors on the mobile device can be used to estimate the relative displacement between
and
, that is, the distance
. Then the collected RSS values are processed by the LR method. After that, the RSS values can be smoothed using the calculated distance
. Finally, we get a more accurate positioning result.
4. Linear Regression Algorithm against Device Diversity Problem
In the existing experimental systems, the same device is used to collect the RSS values in both the offline phase and the online phase. However, when the crowdsourcing method is widely applied to the indoor localization systems, a large number of different mobile devices have been used in the establishment of the radio map. In the online phase, a variety of mobile devices are also used by the users which are different from the device used to build the radio map. In this section, the linear regression (LR) algorithm is proposed to solve the device diversity problem in RSS-based crowdsourcing localization system.
We define
and
are the signal space of different devices. Assume that the fingerprint
belongs to
is the nearest neighbor to the online point
belongs to
. As described above, although they were collected at close physical locations, the RSS values have obvious difference. In order to solve the device diversity problem, the relationship between different devices has to be studied. Therefore, these RSS values collected by different devices could be processed to make the
in closer to
. Mathematically
By learning
f, the radio map build by the training device could be used to localize any other devices.
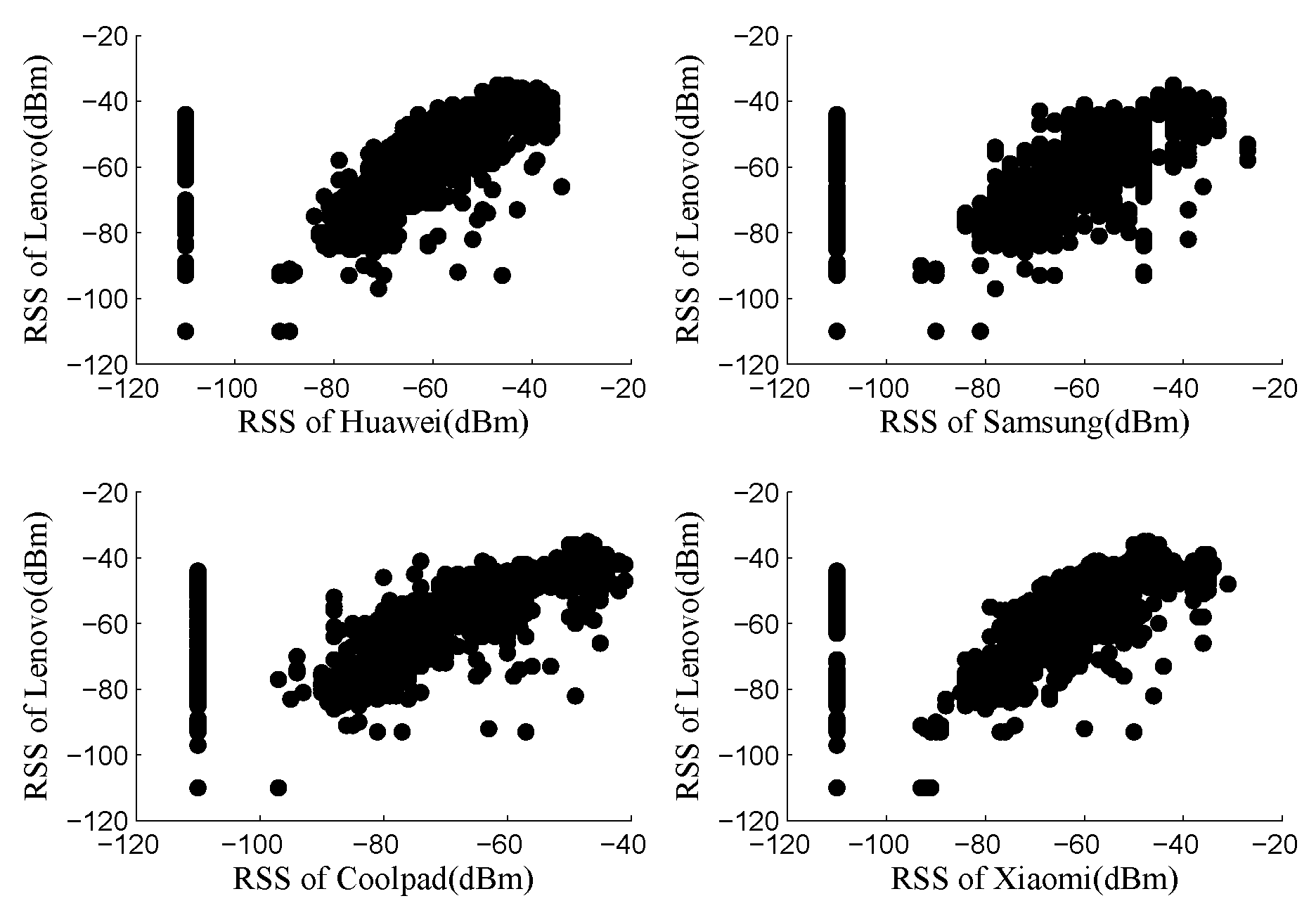
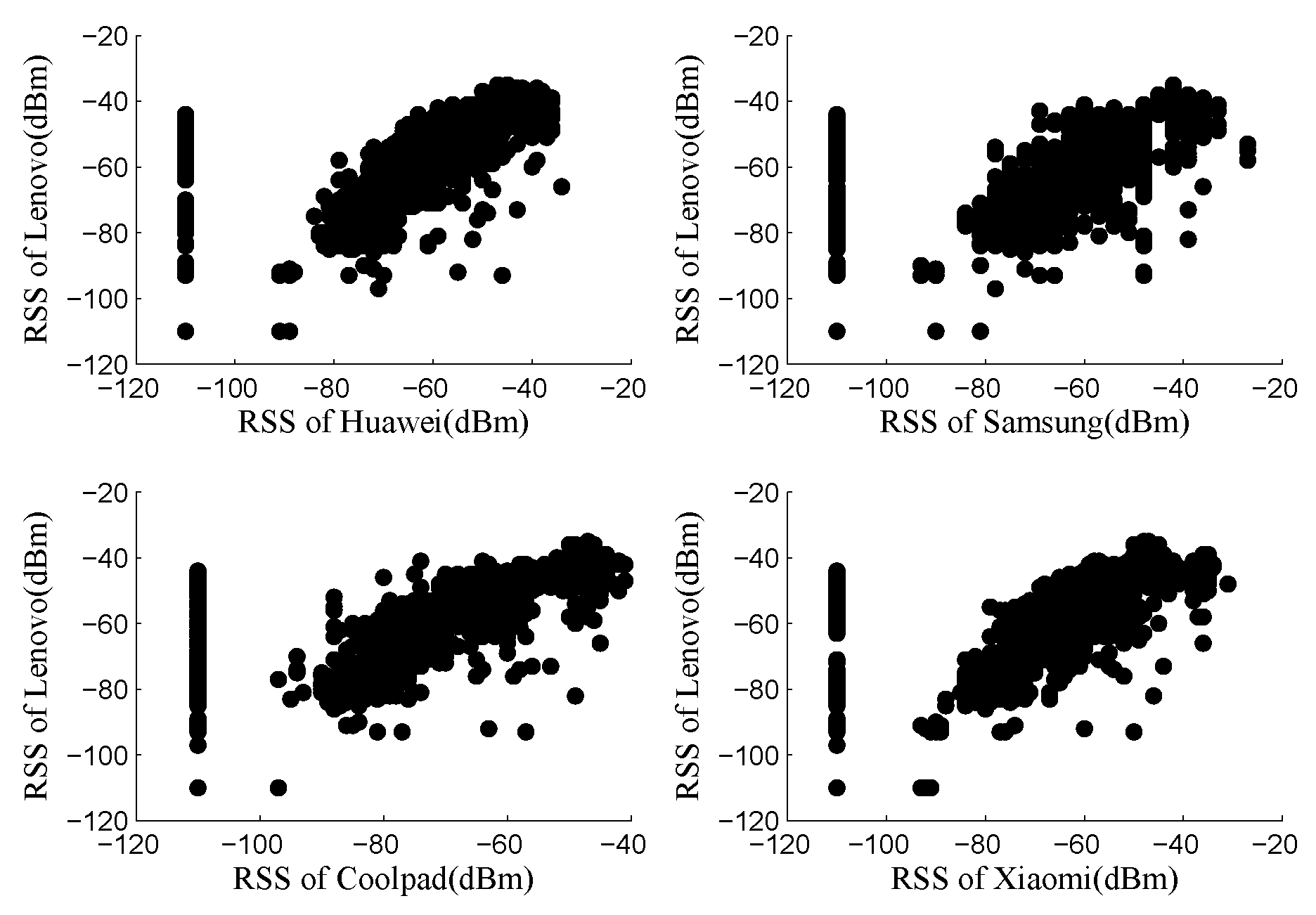
Aiming to explore the mapping function between RSS values collected by distinct devices, the comparison results of RSS values across different training/tracking devices are plotted in
Figure 4. Every point on the figure represents RSS values from two different devices measured at the same location from the same AP at the same location. For example, the top right subplot in
Figure 4 represents the RSS values measured by Lenovo laptop and Huawei mobile device. From
Figure 4, we can get a linear correlation between the RSS values measured by different devices. Hence, the following linear regression method can be employed as the mapping function.
where
are the coefficients in the mapping function.
4.1. Pre-Processing of RSS Values
In the typical WLAN localization scenario, the RSS values collected by the mobile device are subject to multiple sources of noise, such as multi-path fading and shadowing. To mitigate these RSS fluctuations, a large number of RSS measurements are collected from each AP at every location. Let
be the set of RSS values collected at location
l from the
i-th AP. As shown in
Figure 4, if we cannot receive any power from the AP, a value of
dBm is used to denote the missing RSS value.
In order to obtain the high localization accuracy, the first step in localization system is to stabilize the collected RSS values prior to the localization process. Aiming to overcome the fluctuations, the average of the collected RSS values is calculated. In the calculation of the average value, the filled RSS values of
could produce meaningless RSS values and will have a adverse impact. These filled RSS values could affect the localization process and produce erroneous location estimations. As a result, the average is calculated using the collected RSS values exclude the filled RSS values as the following equation:
where
is an indicator function.
The average value is used to build the radio map in offline training phase and estimate the current location in online localization phase.
4.2. Linear Regression Algorithm against Device Diversity Problem
Before using the linear regression method, the parameters
a and
b in Equation
6 should be computed. Since the outliers appear in the collected RSS values frequently and seriously affect the performance of the linear least squares (LLS) algorithm, the fast least trimmed squares (FAST-LTS) algorithm is used in this paper.
When the number of measured RSS values is
c, the FAST-LTS solution for linear regression with intercept is given by
where
,
and
is norm 2 of a vector,
are the ordered squared residuals:
.
Given the
h-subset
of all nearest neighbors, the
C-step is used to compute the
a and
b as follows [
27]:
compute and least squares regression estimator based on
compute the residuals for
sort the absolute values of these residuals,
arrange the absolute values of the residuals in ascending order, let be a subset consisting of the nearest neighbors corresponding to the first h the absolute values of the residuals in the sequence
compute and least squares regression estimator based on
Repeating
C-step with numerous
, a lot of regression coefficients will be gotten. The approximate solution is the coefficient corresponding to the least
. After getting the regression coefficient
a and
b,
is transformed as follows
where
. As a result, both
and
belong to the same signal space, and a uniform radio map could be built using
and
in the offline training phase and a higher positioning accuracy could be obtained in online phase.
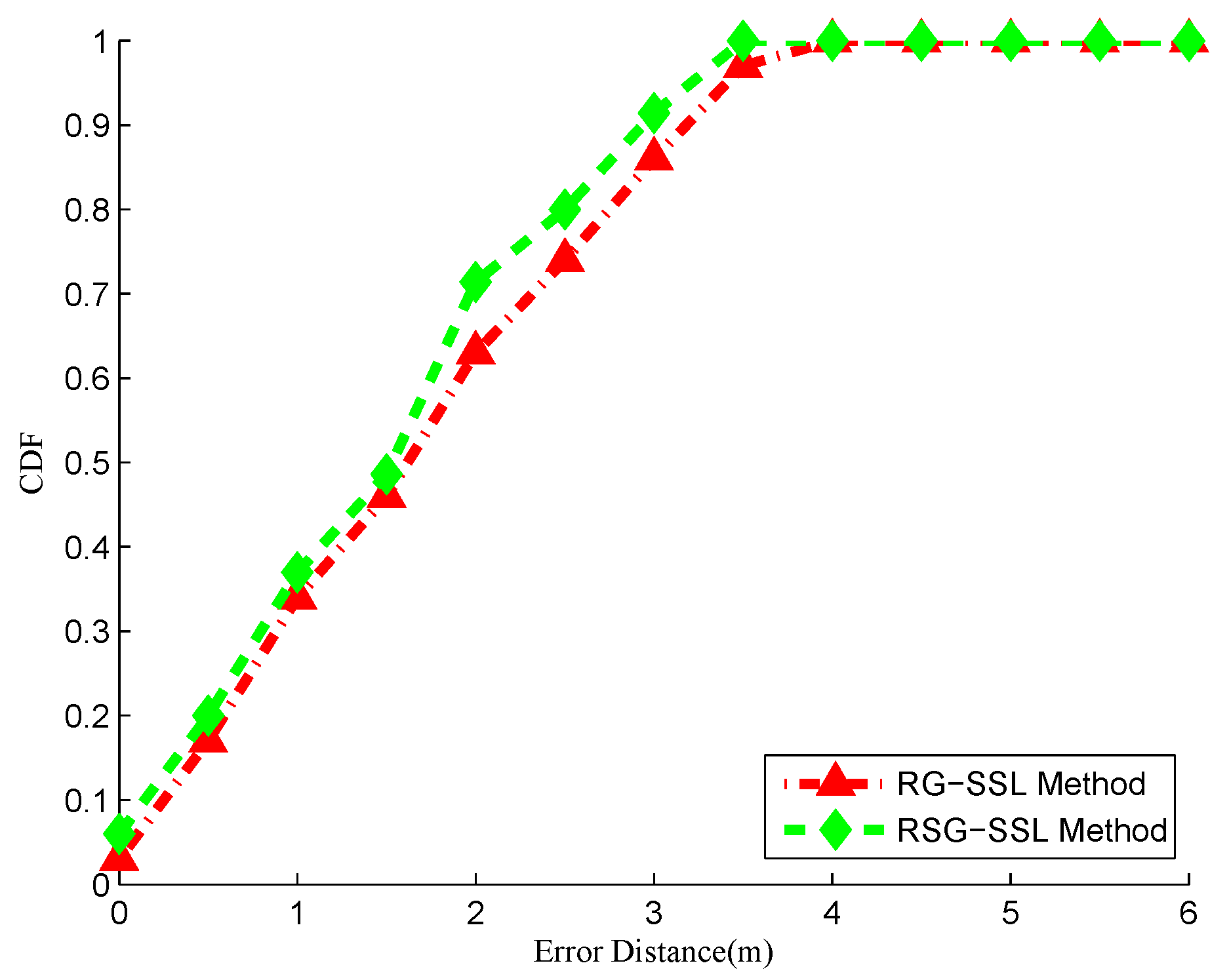
To verify the LR method, five distinct devices, namely Lenovo, Huawei, Samsung, Xiaomi and Coolpad, are used to collect RSS values at all RPs and the linear regression coefficients could be calculated based on the measured RSS values and the corresponding coordinates. When the regression coefficients are gotten, all the RSS values could be mapped into the same signal space by LR method and a uniform radio map could be built. Using the processed radio map, the user’s location will be estimated with a high accuracy in online phase.
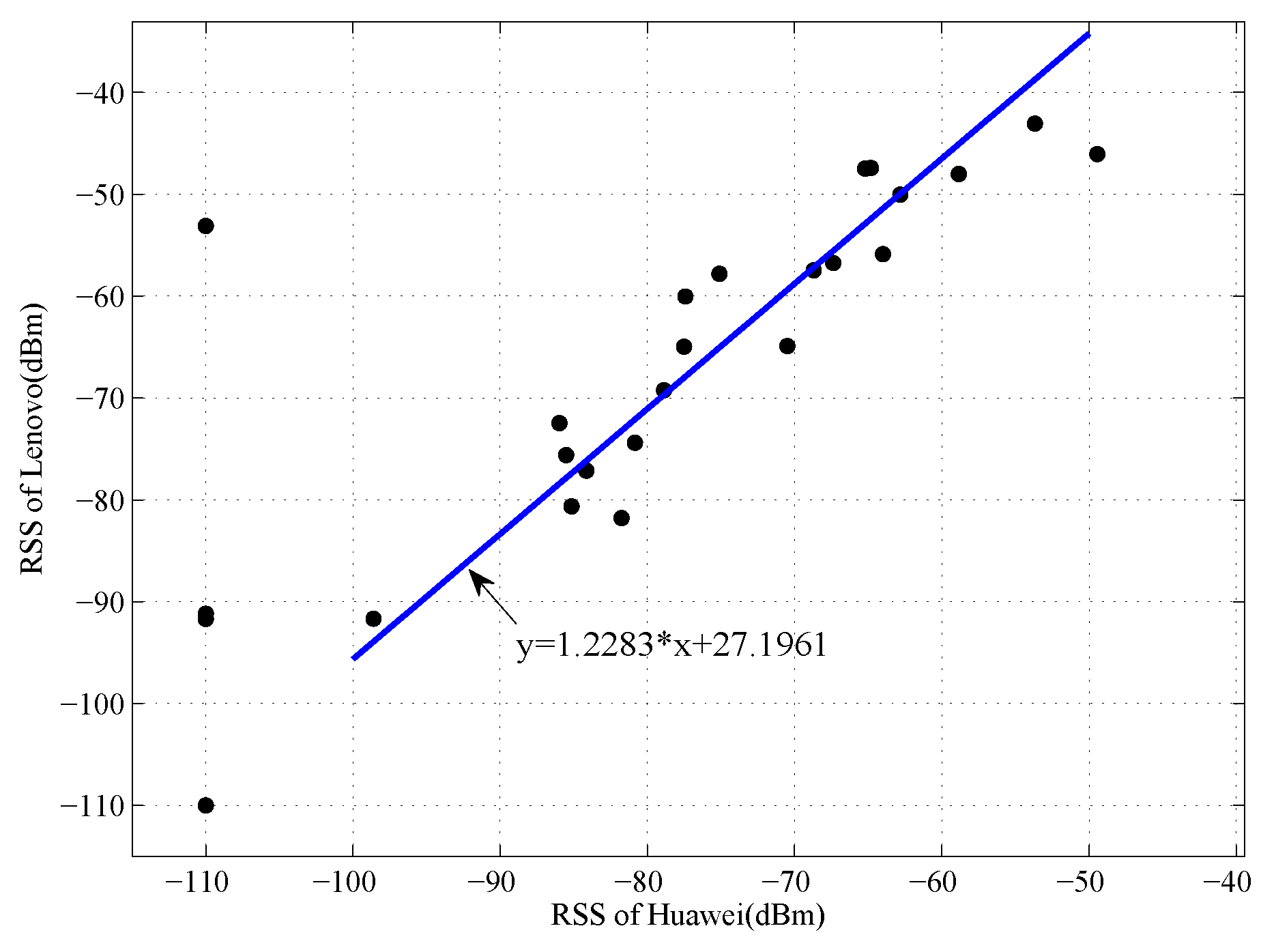
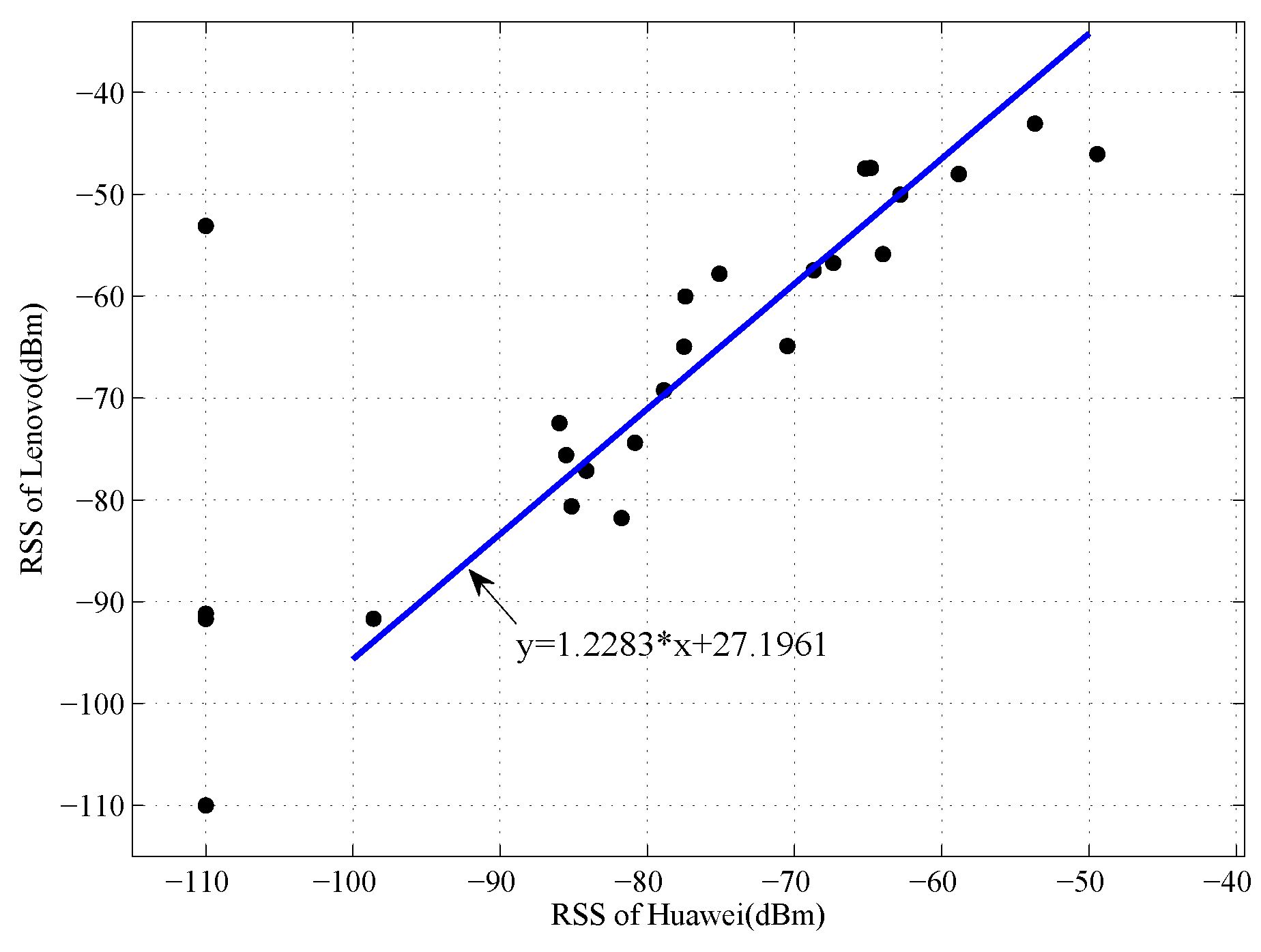
In our localization systems, we use the Lenovo device as the standard device, and all the RSS values collected by other devices are mapped into the signal space of Lenovo device. We take the (Huawei, Lenovo) pair as an example. As shown in
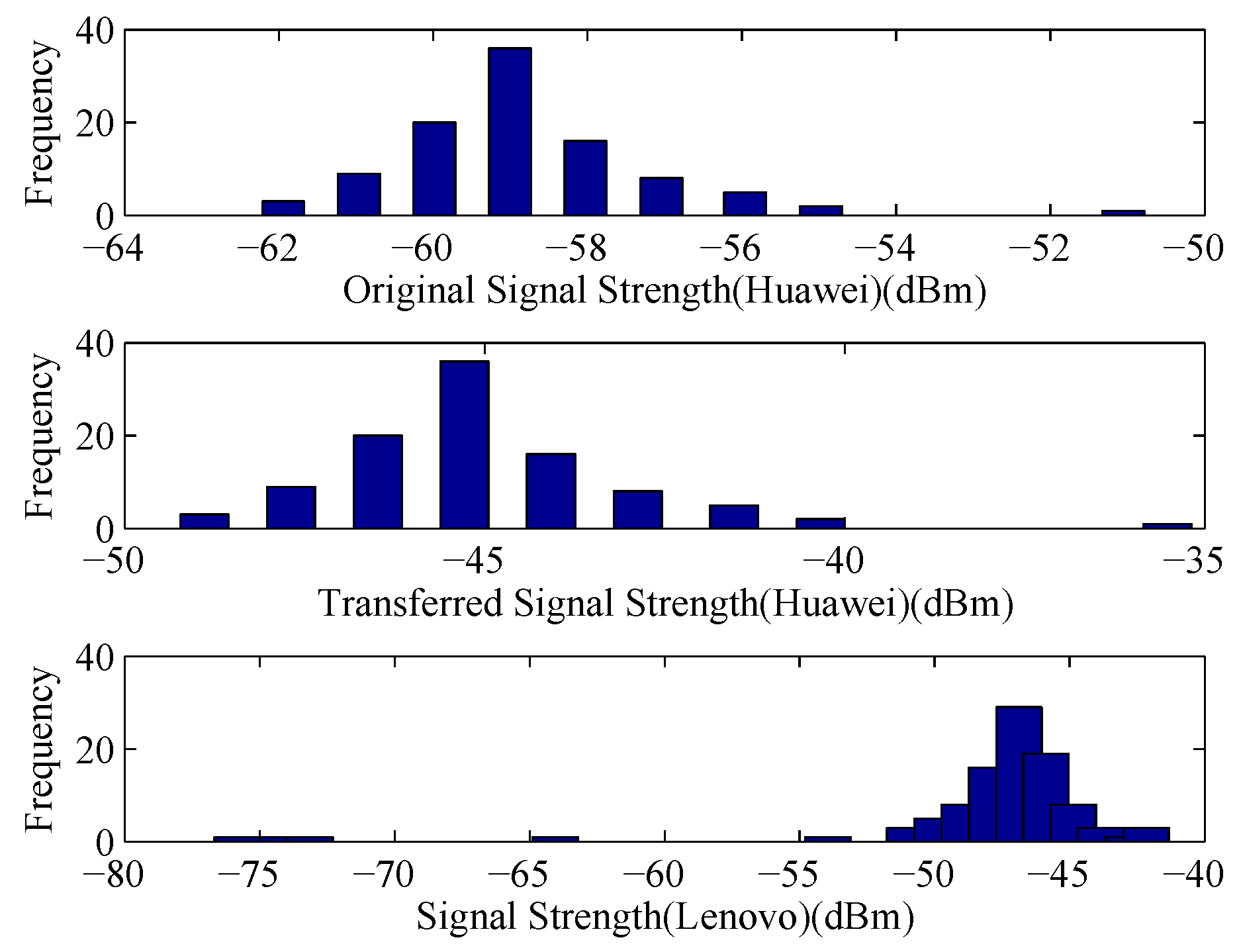
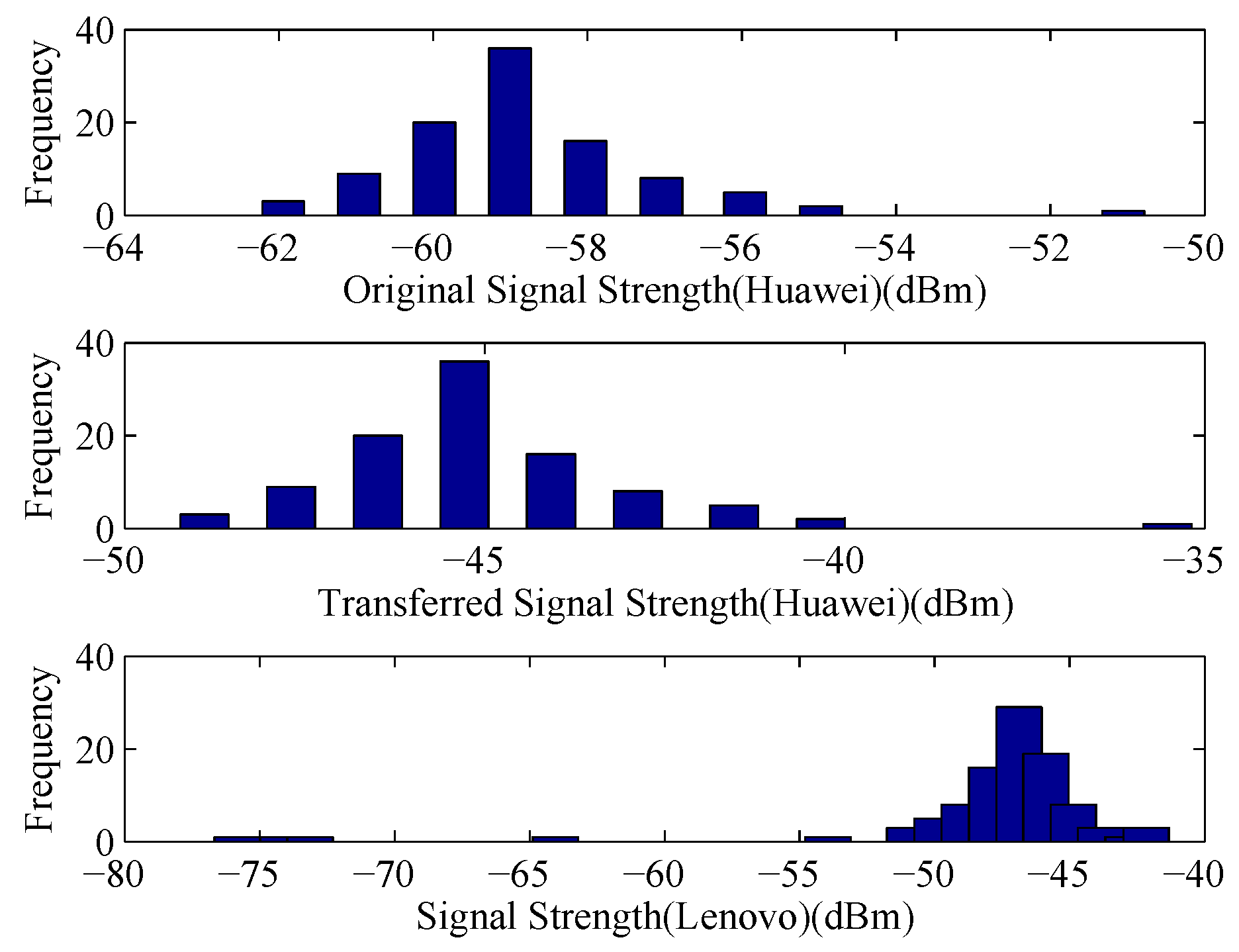
Figure 5, the collected data are more stable after pre-processing of RSS values, and the linear regression coefficients could be calculated by LTS method. Using the coefficients, the RSS values collected by Huawei device could be mapped into the signal space of Lenovo device. We compare the original RSS values and the transferred RSS values collected by Lenovo device with the RSS values collected by the Lenovo device, the comparison result is shown in
Figure 6. From the figure, we can see that the difference of signal distribution between different devices is reduced significantly. Accordingly, a uniform radio map can be built in the offline phase and the positioning performance could be improved in the online phase.
4.3. Automatic Device-Transparent Algorithm for Crowdsourcing Indoor Localization System
Based on the LR method, the device diversity problem can be solved. However, the LR method is applied to the premise that the coordinates of the RSS values are same. In offline training phase, the RSS values used to build the radio map have been labeled, so these RSS values meet the prerequisites for the LR method and the device diversity problem could be solved automatically. In online localization phase, the coordinates of the RSS values are unknown, which means the LR method cannot be used directly. Therefore, we use the correlation ratio computed from the Pearson Product-moment correlation coefficient to roughly label the RSS values collected by an unknown device.
where
m is the number of APs,
and
are the RSS values measured from the
k-th AP,
is the average of the RSS values from the tracking device and
is the mean of RSS values measured by the training device in a fingerprint.
The range of the absolute value of Pearson correlation ratio is
where 1 indicates the highest linear correlation between RSS values and 0 indicates the least similarity. In the online phase, when the RSS vector
is acquired, the similarity between the online point and all fingerprints
in
can be obtained by
t. Given a threshold
, we can get the set of nearest neighbor fingerprints in radio map
for
.
Based on the nearest neighbors in Equation (12), the RSS data collected in the online phase can be labeled roughly and the LR method proposed in the previous section is used to train the mapping function.
In summary, in the offline phase, because the coordinates of the collected RSS data are already known, the LR algorithm can be used to eliminate the device diversity problem directly. As a result, a uniform radio map can be built in the offline phase. In the online phase, the RSS values collected by the unknown device could be localized roughly by the Pearson correlation coefficient at the beginning. Then the RSS values can be mapped into the signal space of radio map using the LR algorithm. Finally, we can get a more accurate positioning result.
5. AP Localization Using Compressed Sensing Method
Typically, fingerprint-based localization methods do not rely on the location of the APs. In other words, the AP locations are assumed to be unknown. Nonetheless, better localization can be achieved if one could estimate the AP locations. Next, we discuss a compressed-sensing (CS)-based approach to estimate the AP locations.
Consider a set of N discrete locations throughout the indoor area. Suppose a set of M access points can be seen at each location. It is a practical assumption that the number of grid points is much larger than the number of access point in the indoor area i.e., . We will use this assumption to apply a CS-based method to recover the location of the APs.
Compressed Sensing is a signal processing technique that can efficiently reconstruct a signal by exploiting the
sparsity and
incoherence properties of the signal [
28,
29,
30]. Assume corresponding to the
i-th AP, we define a vector
of size
N.
is a vector that shows the location of the AP by assigning a one to one the
N element and zero for the rest of the element. For example, if
then the location of the
i-th AP is estimated to be the location of the
n-th grid point in the indoor area. Concatenating all such vectors for all
M APs results in a so-called index matrix,
as,
According to the CS theory, rather than measuring the
M-sparse signal or its sparse representation
directly, compressive noisy RSS measurements in an
ℓ-dimensional space are used. These compressive measurements are obtained by multiplying a random matrix by the original signal,
where
are the compressive noisy RSS measurements.
is the measurement matrix. Each row in this matrix represents the location of one RP, with an element of 1 to indicate the grid point at which the RP is located. Thus, only a few of RSS values are collected on the locations of RPs instead of measuring all the RSS values on the overall grid, which reduces the workload in the offline phase.
is the sparsity basis on which the measured signals have sparse coefficients
. In this matrix,
indicates the RSS values collected at grid point
i from the AP located at grip point
j, for all
and
. Assume that the transmition power of an AP is
. Then
is calculated based on the empirical indoor propagation model of [
20]:
where
d is the physical distance from the transmitter (AP) to the receiver.
is the measurement noise.
The locations of the APs can be recovered by the following
-minimization:
Unfortunately, solving (
16) is both numerically unstable and NP-hard. Therefore,
-minimization is used to recover the AP locations:
This is a convex optimization problem and various methods have been proposed to find the solution such as BP [
31], OMP [
32] and SP [
33]. In this paper, we use OMP algorithm.
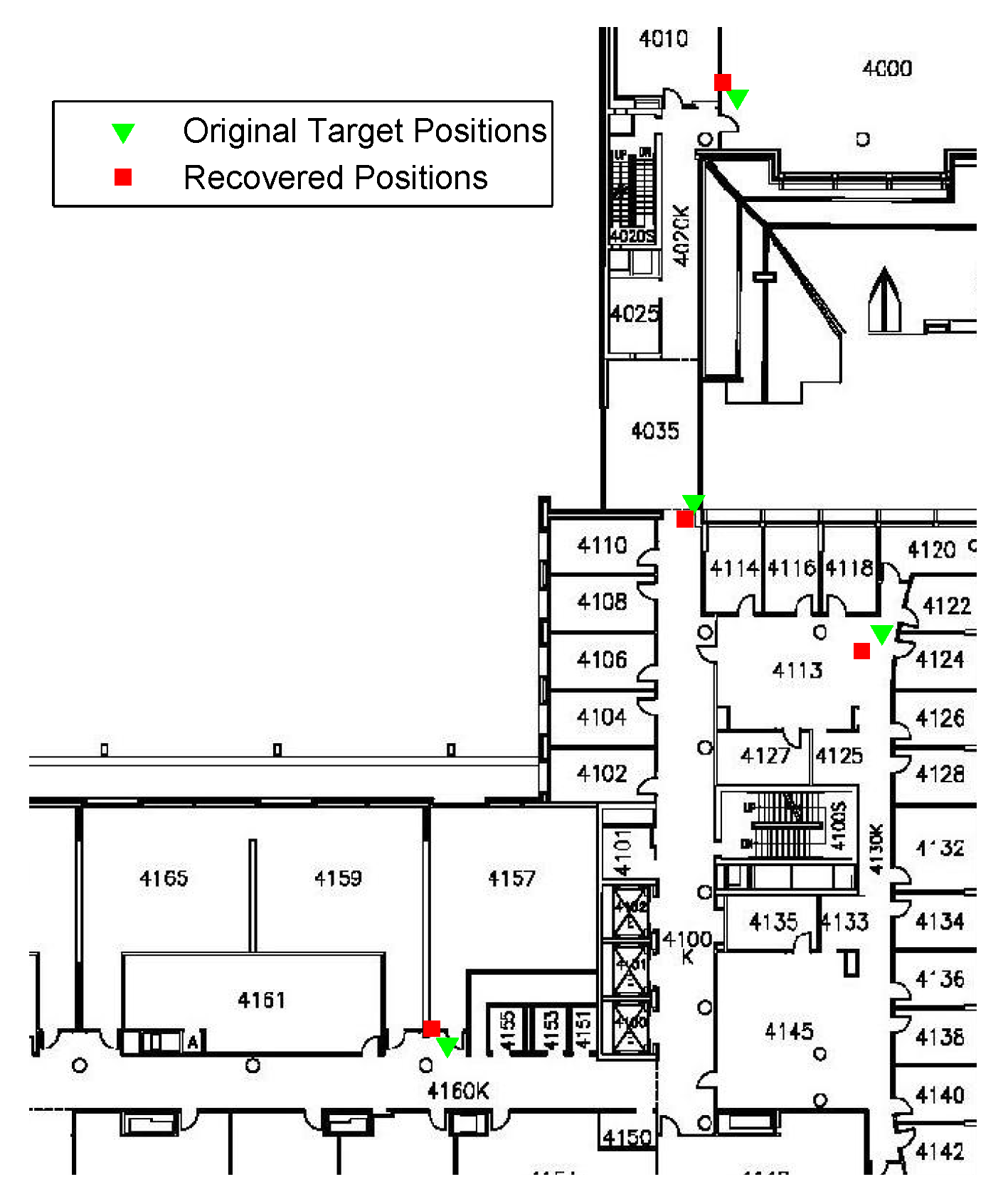
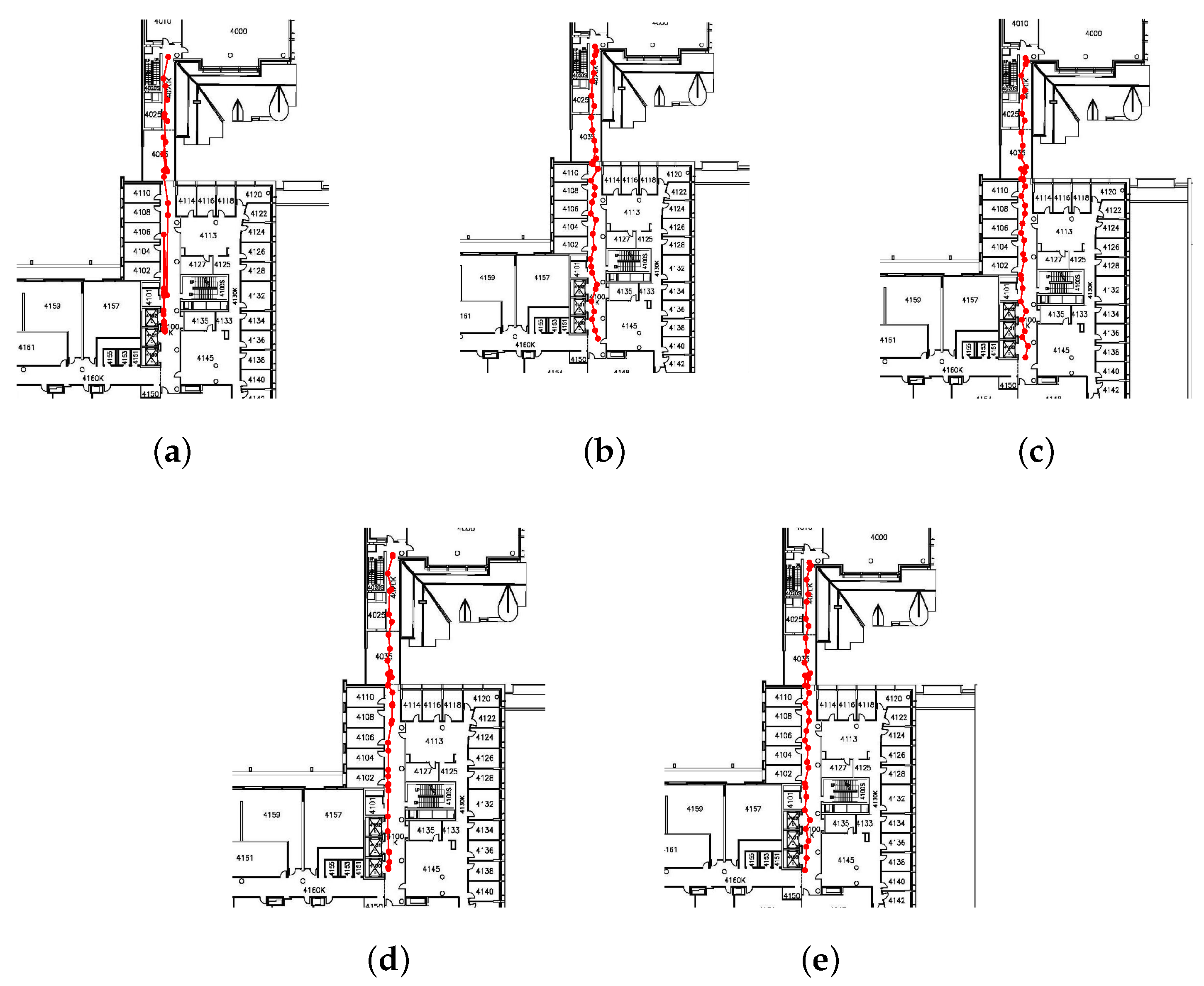
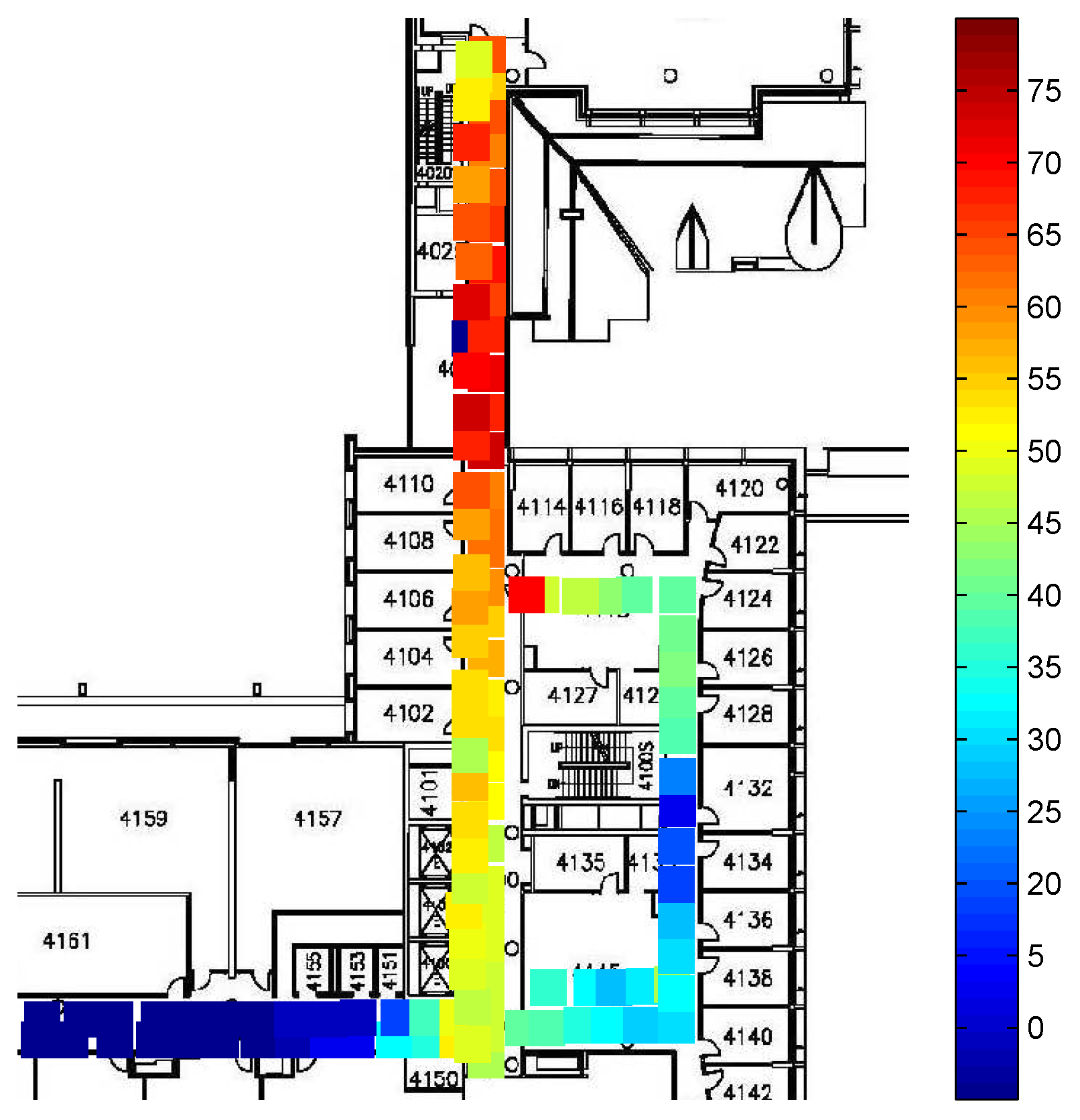
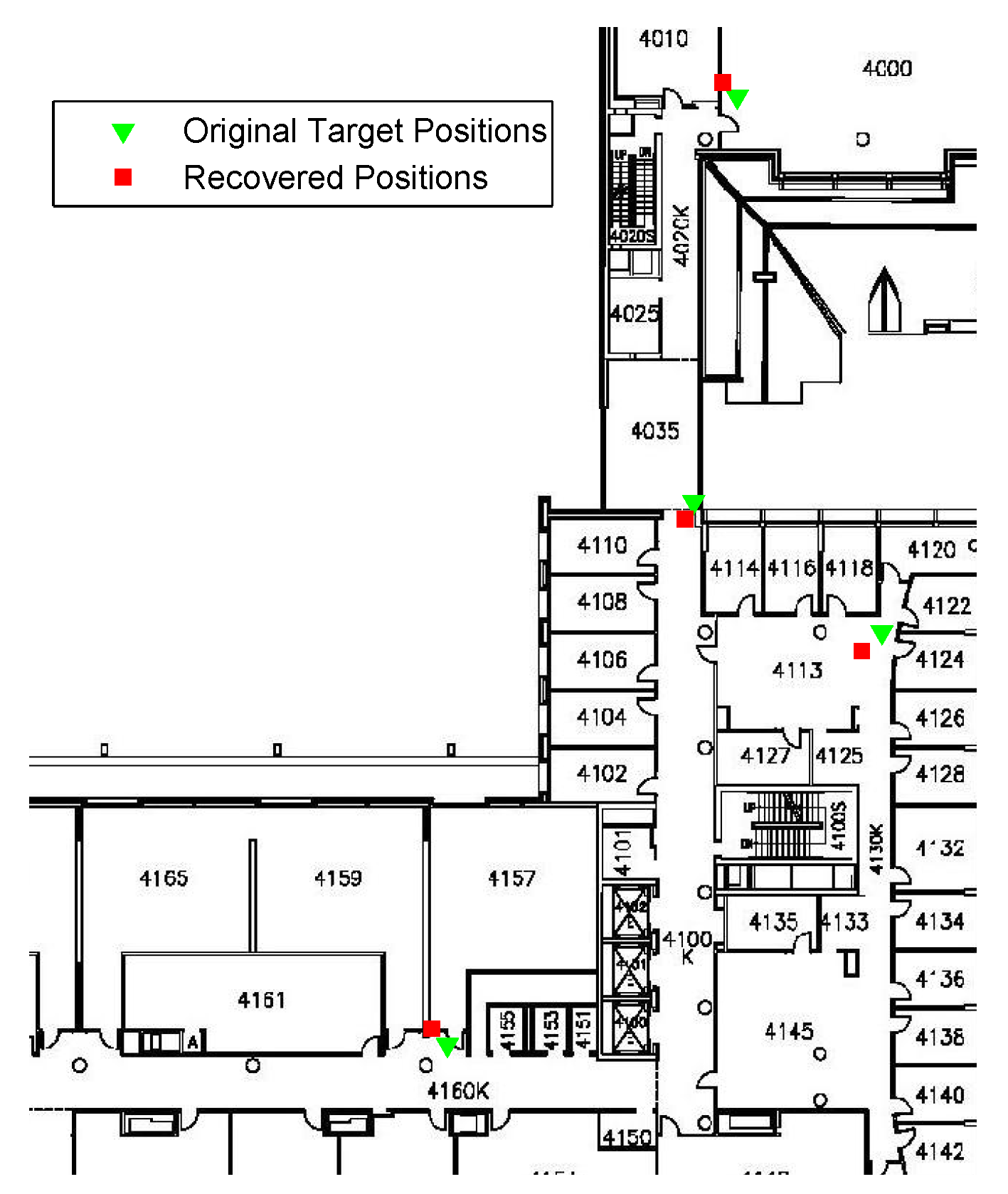
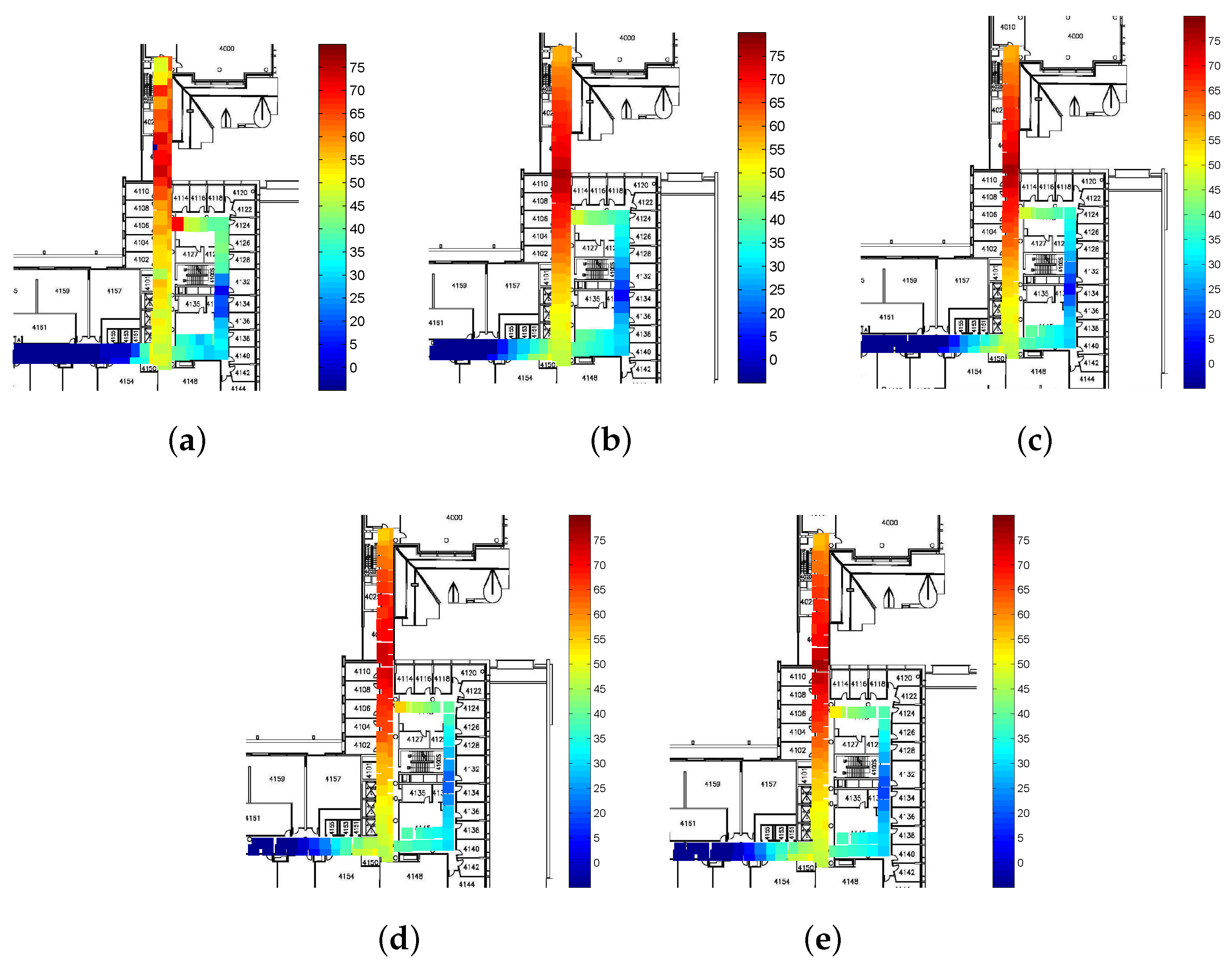
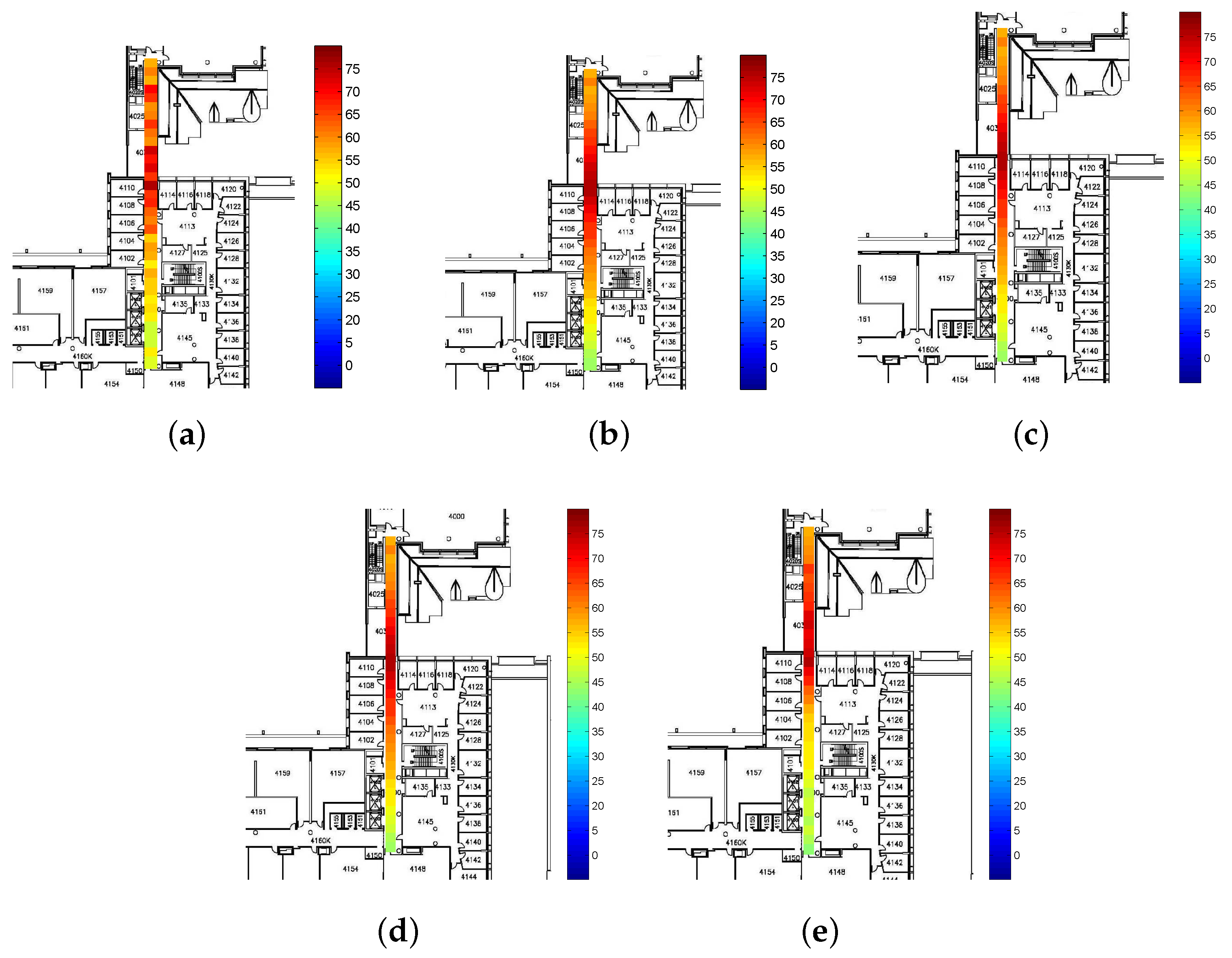
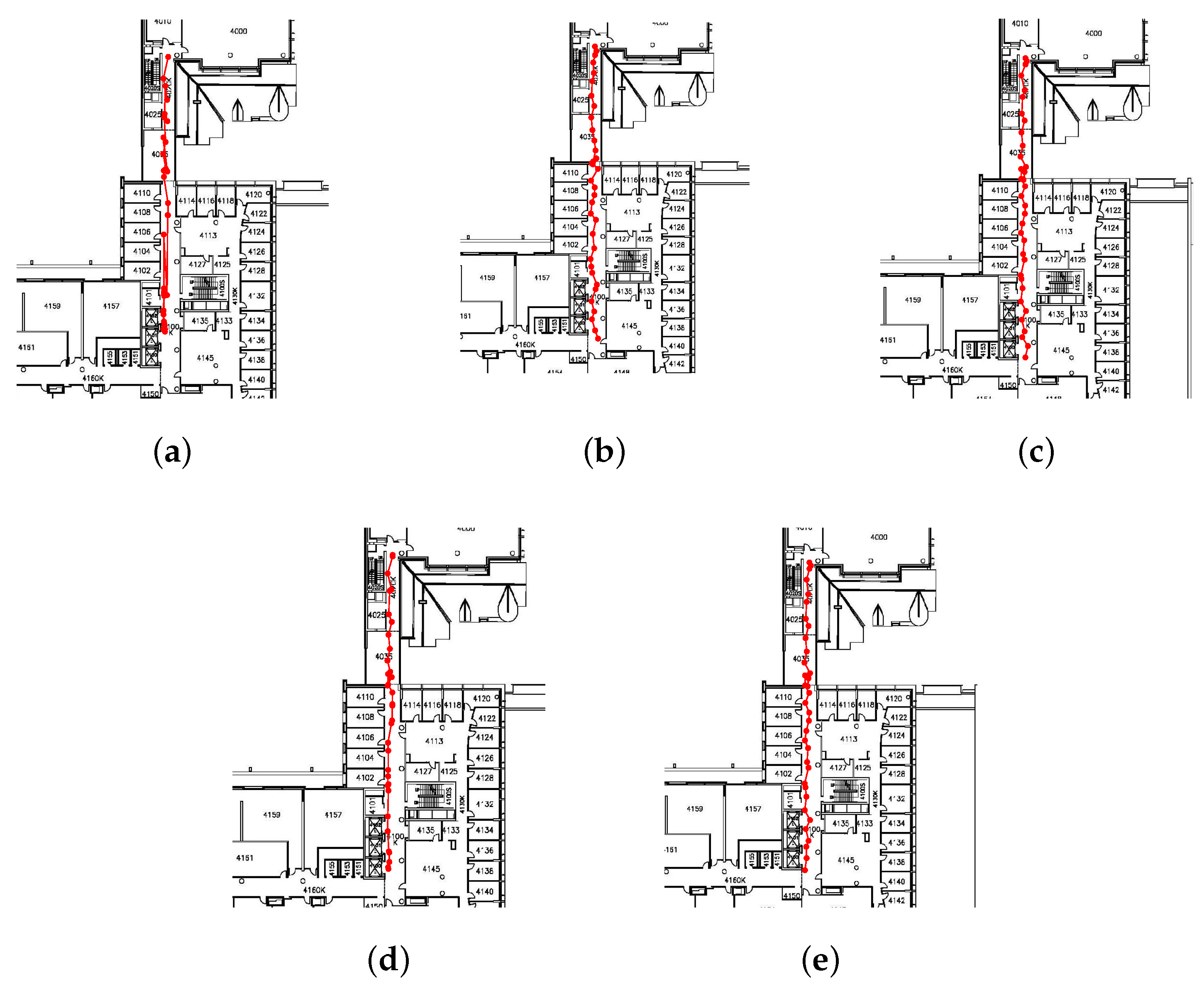
To evaluate the performance of the proposed CS-based AP localization algorithm, a few number of APs on the fourth floor of the Bahen Building at the University of Toronto have been localized.
Figure 7 shows the AP localization results. As seen in the figure, all the AP locations are estimated with a high level of accuracy. Although the localization results contain some errors, it brings limited effect to our RSS smoothing method proposed later.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}