1. Introduction
The growing population of elderly people is becoming a pressing issue worldwide, especially in developed countries. In Europe, the official projections indicate that the elderly population is expected to grow rapidly by 58 million between 2004 and 2050 [
1]. In the United States,
of the population is expected to be elderly by 2030, while in 1994, the percentage of elderly people was only one in eight Americans [
2,
3]. In fact, falls are among the major threats to the health of elderly people, particularly those who live by themselves. According to [
4], the percentage of elderly people who fall each year is more than
. Falls can lead to both physiological and psychological problems for elderly people [
5]. Moreover, in the case of falls that do not lead to immediate injuries, around one half of the non-injured elderly fallers require assistance to get up, and hence, delayed assistance can result in long immobile periods, which might affect the faller’s health [
5,
6]. Therefore, accurate and efficient fall detection systems are crucial to improve the safety of elderly people.
Recently, several fall detection systems have been proposed to detect fall incidents. Among these systems, wearable and non-wearable sensor-based systems are the most commonly used [
7]. Wearable sensor-based systems employ sensors that are attached to the subject to continuously monitor the subject’s activities. For example, several fall detection systems utilize wearable devices that are equipped with gyroscope and accelerometer sensors in order to identify fall incidents [
8,
9,
10]. One limitation of wearable sensor-based fall detection systems is the requirement of wearing sensing devices all of the time. Such a requirement might be impractical and inconvenient, especially that wearable sensing devices need to be recharged on a regular basis. The second group of commonly-used fall detection systems is based on using non-wearable sensing devices, such as vision and motion tracking systems, to identify human activities [
11,
12,
13]. RGB video cameras (2D cameras) and motion-capturing systems are among the most widely-used non-wearable sensing devices for fall detection [
14,
15]. Fall detection systems that are based on analyzing RGB videos recorded by 2D cameras are highly affected by several factors, such as occlusions, illumination, complex background and camera view-angle. Such factors can reduce the accuracy of fall detection. Utilizing motion-capturing systems for fall detection can be a remedy for the aforementioned factors. However, the high cost of the motion-capturing systems and the need to mount markers on the subjects to track their motions might limit the practical application of motion-capturing systems for fall detection.
Recently, Microsoft (Microsoft Corporation, Redmond, WA, USA) has introduced a low-cost RGB-D sensor, called the Kinect sensor, which comprises both an RGB camera and a depth sensor. The depth sensor of Kinect enables the recording of depth-map video sequences that preserve the privacy of the subjects. This privacy feature makes the Kinect sensor a non-intrusive sensor compared with the 2D cameras that reveal the identity of the subjects. Furthermore, the capability of the Kinect sensor to detect and track the 3D positions of skeletal joints has attracted several researchers to utilize the Kinect sensor to track human activities and detect falls by analyzing depth-map videos.
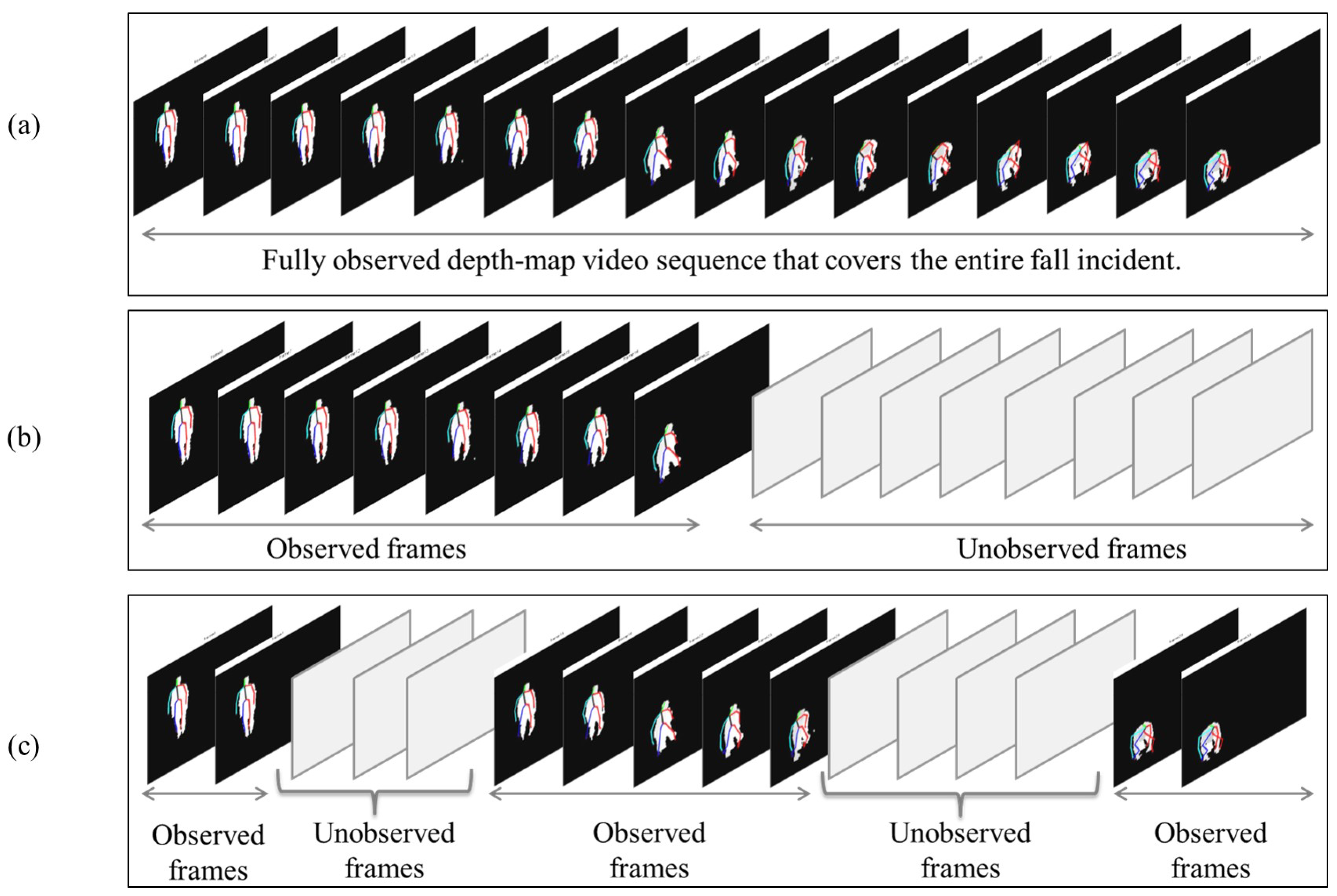
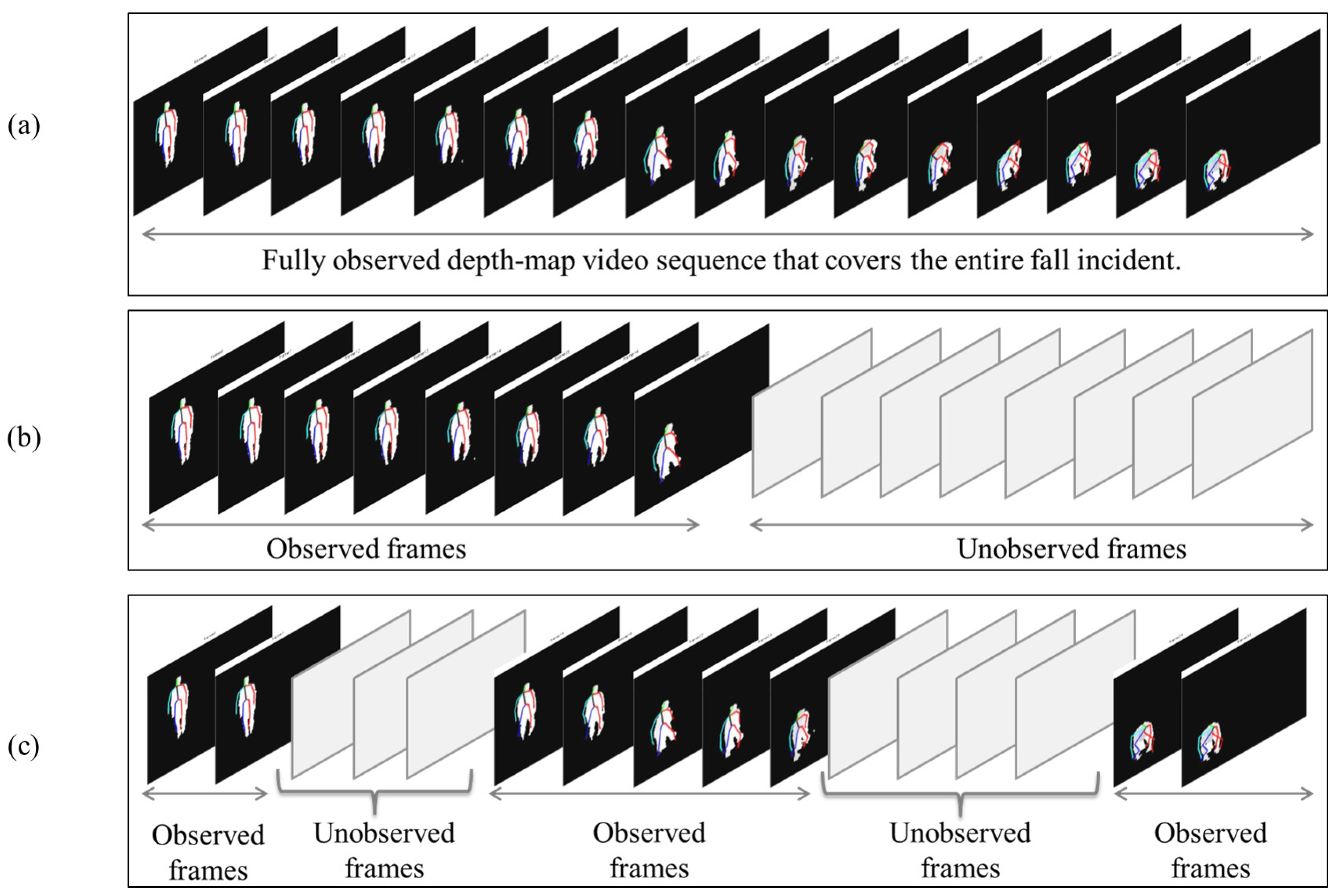
The literature reveals that the majority of fall detection systems that employ depth-map video sequences are focused on detecting falls by analyzing the frames of a complete video sequence that covers the entire fall incident [
16,
17,
18,
19,
20,
21,
22,
23,
24,
25], as illustrated in
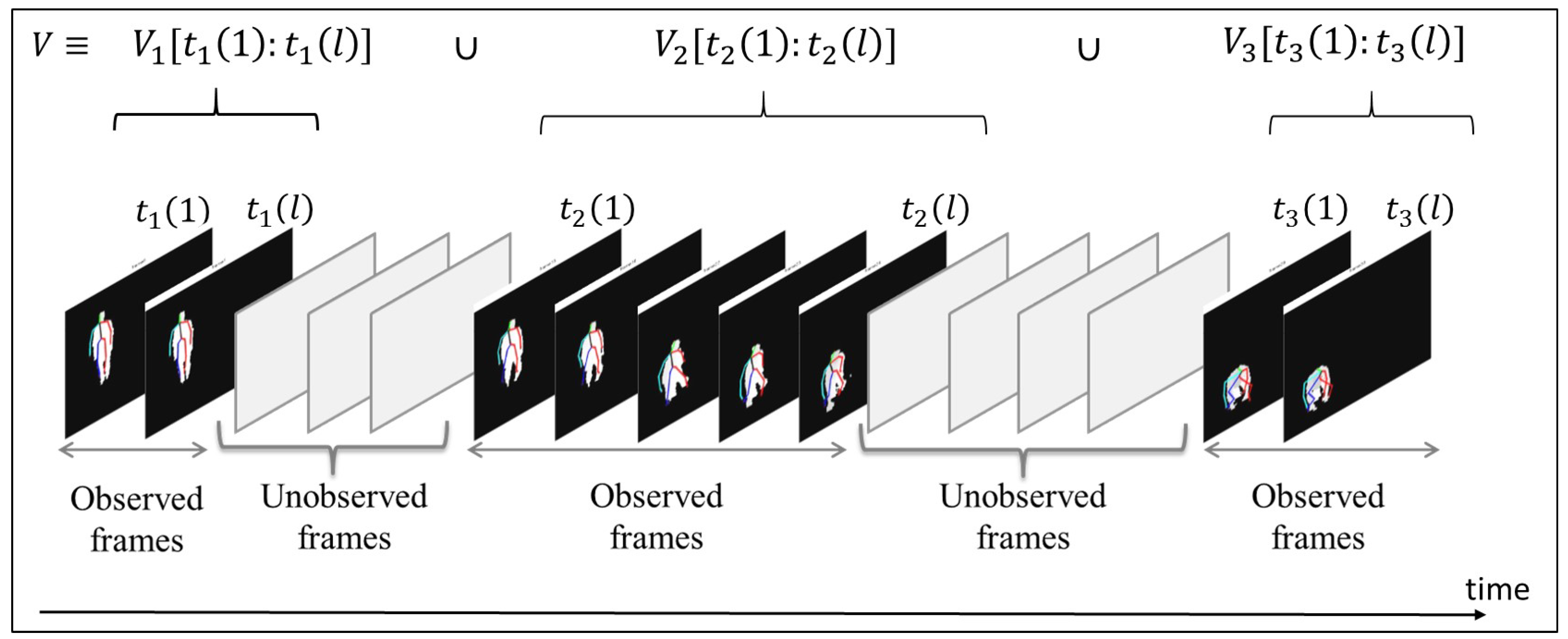
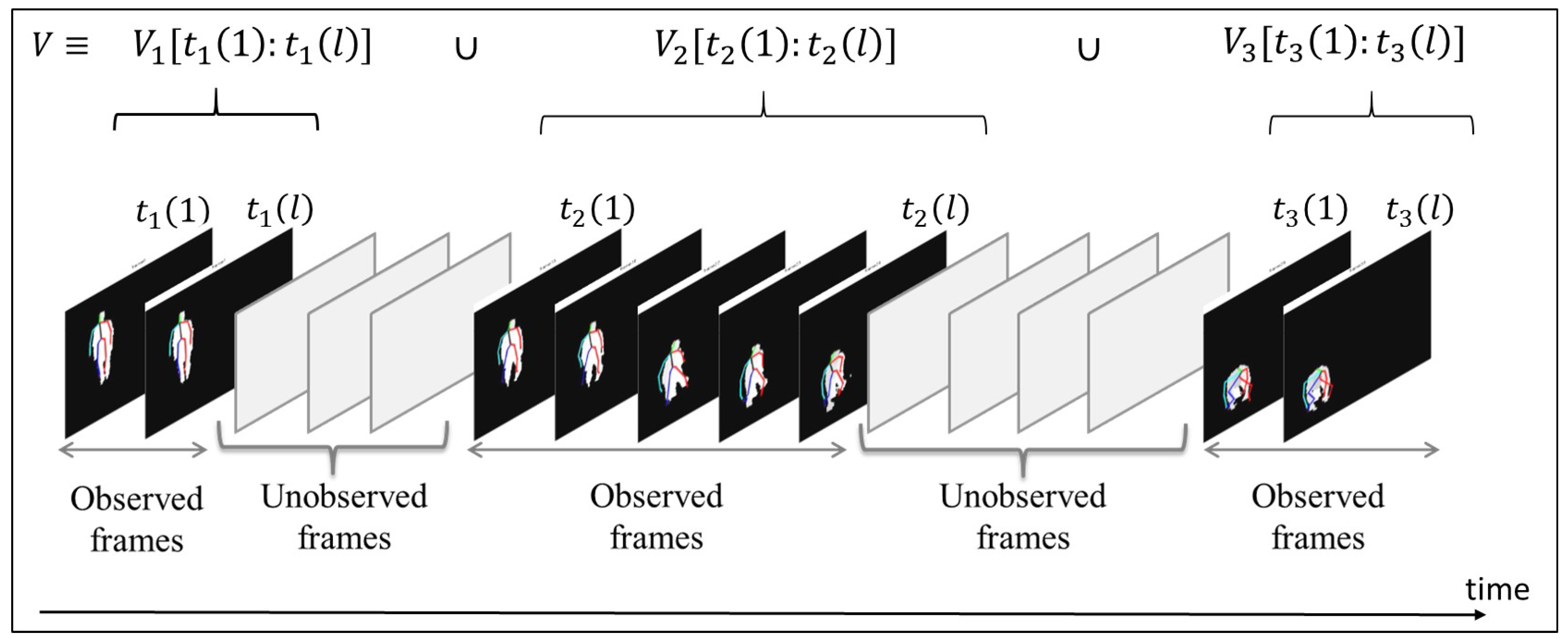
Figure 1a. Nonetheless, in real-life scenarios, the fall incident might be partially observed due to the presence of an occlusion that blocks the view of the camera or occludes the subject of interest. Moreover, power disconnections may result in missing some video segments, which in turns can lead to partially-observed videos. Fall detection based on partially-observed videos is considered challenging due to the fact that the unobserved subsequences of video frames might be of different lengths and can occur at any time during video recording. To address this challenge, researchers have recently attempted to predict falls using incomplete depth-map video sequences [
26,
27]. Specifically, fall prediction aims to predict the falling event by analyzing an incomplete depth-map video sequence in which a subset of frames that covers only the beginning of the fall is observed, as depicted in
Figure 1b. In fact, fall prediction can be viewed as a special case of the general scenario of fall detection based on partially-observed videos, in which the fall is identified by analyzing a video sequence that includes unobserved subsequences of video frames having different durations and occurring at any time.
Figure 1c illustrates the general scenario of fall detection based on partially-observed videos.
Recently, several approaches have been proposed to detect falls under occluded conditions based on analyzing the depth images acquired using the Kinect sensor. For example, Gasparrini et al. [
23] proposed a Kinect-based approach for detecting falls in indoor environments. The approach analyzes the depth images acquired from the Kinect sensor using anthropometric relationships and features to identify depth blobs that represent humans. Then, a fall is detected if the depth blob associated with a human is near the floor. Stone and Skubic [
28] proposed a two-stage fall detection approach to identify three fall-related positions, including: standing, sitting and lying down. The first stage of their approach analyzes the depth images acquired from a Kinect sensor to identify the vertical characteristics of each person and identify on-ground events based on the computed vertical state information of the subject over time. Then, the second stage employs an ensemble of decision trees classifier to identify falls in the on-ground events. Rougier et al. [
24] proposed a Kinect-based system to detect falls under occlusion conditions. Their system employs two features for fall detection, including the subject’s centroid to measure the distance from the floor, as well as the body velocity. A fall is detected when the velocity is larger than a certain threshold, while the distance from the ground to the subject’s centroid is smaller than a specific threshold value.
Unlike the aforementioned approaches, in which fall-related activities were recognized while the subject is partially occluded based on depth images, Cao et al. [
29] proposed an approach for recognizing human activities from partially-observed videos based on sparse coding analysis. The reported experimental results in [
29] show limited recognition accuracy, which might not be suitable for real-world applications. Moreover, the approach employed in [
29] considered only RGB videos that include a single unobserved subsequence of video frames. As discussed previously, the use of depth sensors, such as the Microsoft Kinect sensor, for fall detection provides several advantages over the RGB cameras, including subject privacy preservation and the capability to acquire the 3D positions of skeletal joints at interactive rates. To the best of our knowledge, the general scenario of fall detection from partially-observed depth-map video sequences based on utilizing the 3D skeletal joint positions has not been investigated in the literature.
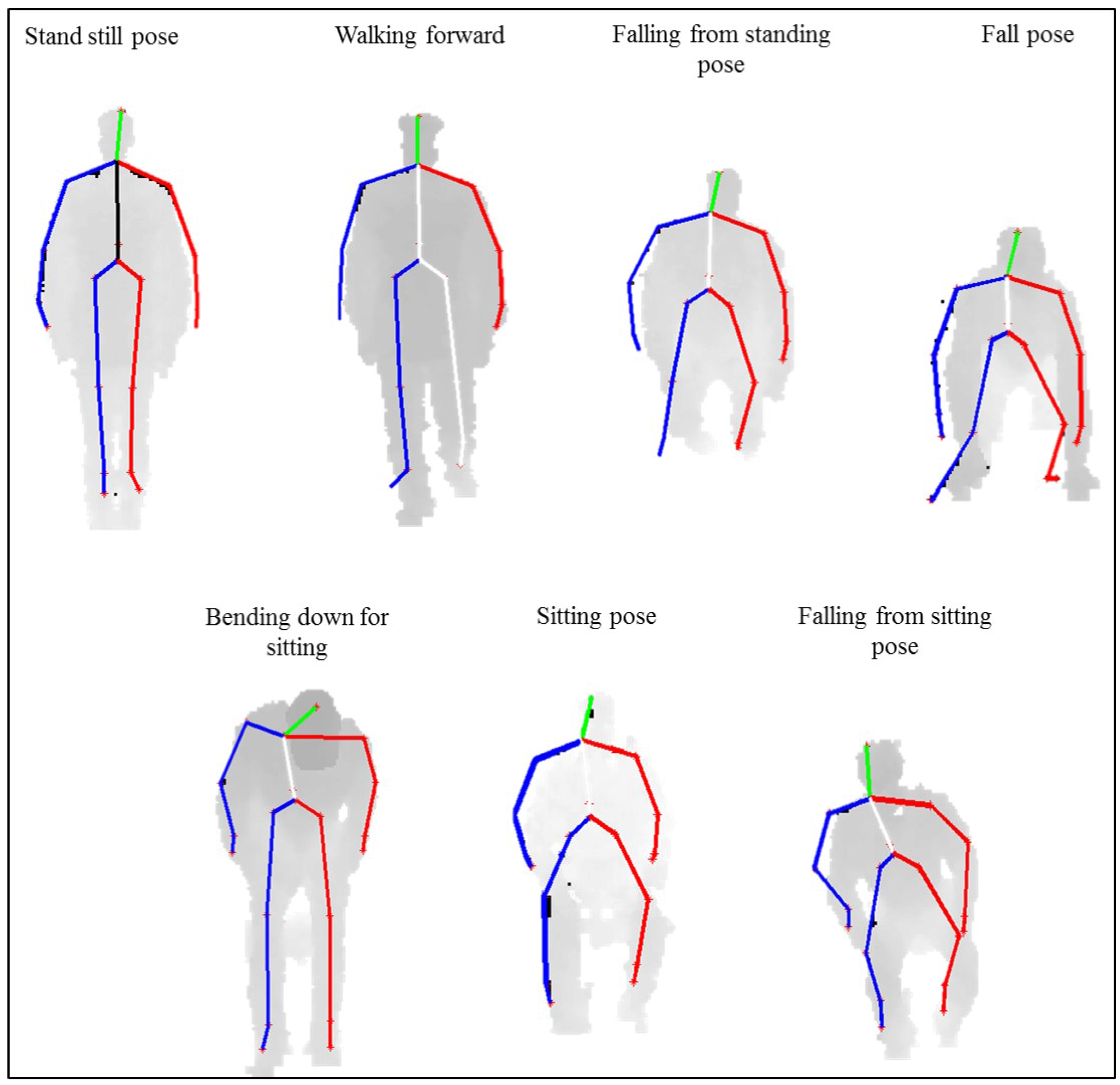
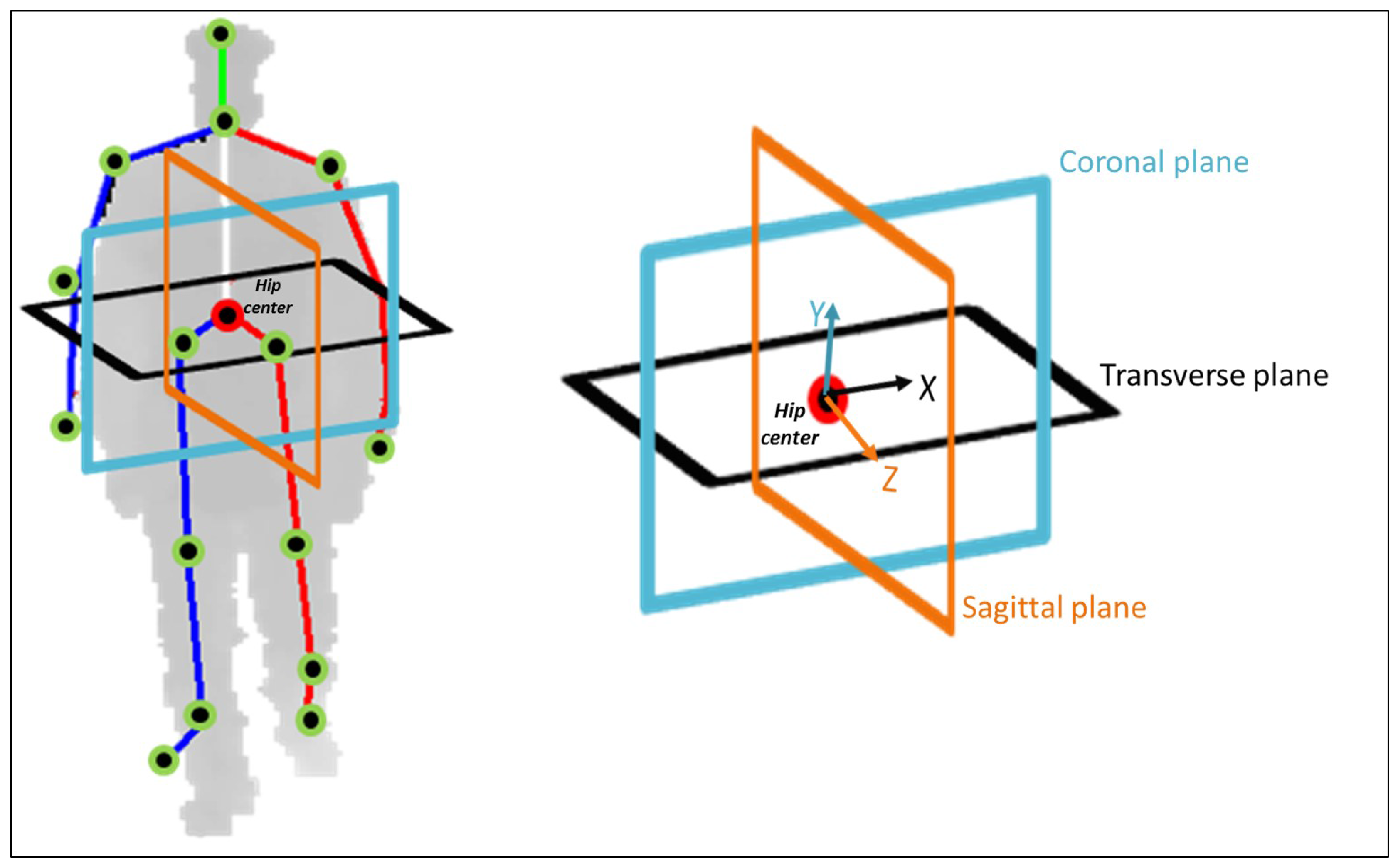
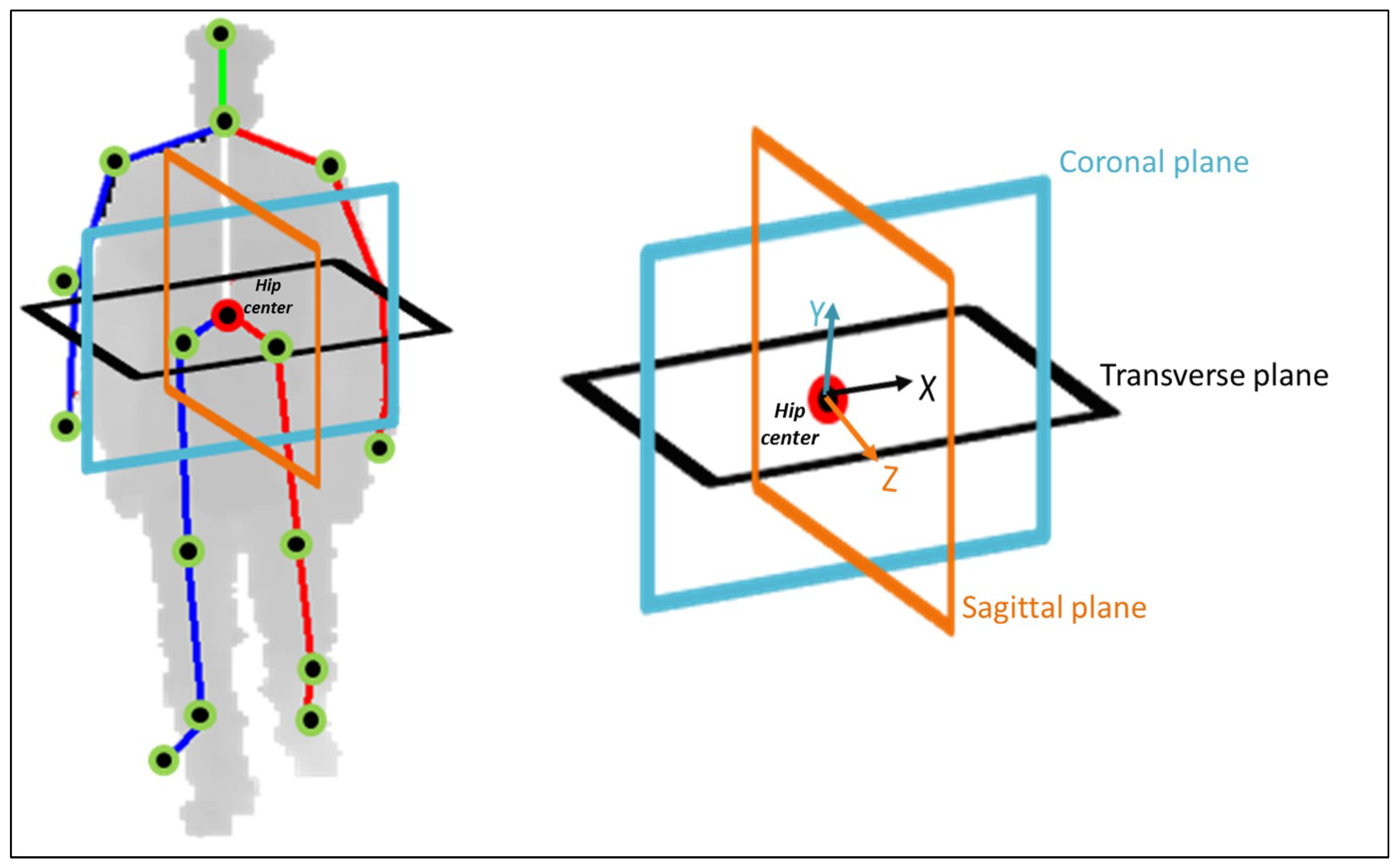
In this paper, we propose an approach for detecting falls from partially-observed depth-map video sequences based on the 3D skeletal joint positions provided by the Kinect sensor. The proposed approach utilizes the anatomical planes concept [
31] to construct a human representation that can capture both the poses and motions of the human body parts during fall-related activities. In particular, we adopt and expand our earlier work [
30,
32] in which a motion pose geometric descriptor (MPGD) was proposed for analyzing human-human interactions and elderly fall detection using complete depth-map video sequences. The MPGD consists of two profiles, namely motion and pose profiles. These profiles enable effective capturing of the semantic context of human activities being performed at each video frame. In this work, we expand the motion and pose profiles in the MPGD by introducing a new set of geometrical relational-based features, to better describe fall-related activities. In order to detect falls in partially-observed depth-map video sequences, we segment fully-observed training video sequences into overlapping segments. Then, we construct a histogram-based representation (HBR) of the MPGDs for the video frames of each segment. The HBR describes the distribution of the MPGDs within each video segment and captures the spatiotemporal configurations encapsulated within the activities of an elderly person during each video segment. Using the computed HBRs of MPGDs, we train a support vector machine (SVM) classifier with a probabilistic output [
33] to predict the class of the performed activity in a given video segment. For any new video with unobserved frames subsequences, we compute the HBR of the MPGDs that are associated with video frames in each observed video subsequence. Then, for each observed video subsequence, we utilize the learned SVM model to compute the class posteriori probability of the observed subsequence given its HBR. Finally, to predict the class of the performed activity in the given partially-observed video, we combine the obtained posteriori probabilities from all observed subsequences to obtain an overall posteriori probability estimation for the partially-observed video.
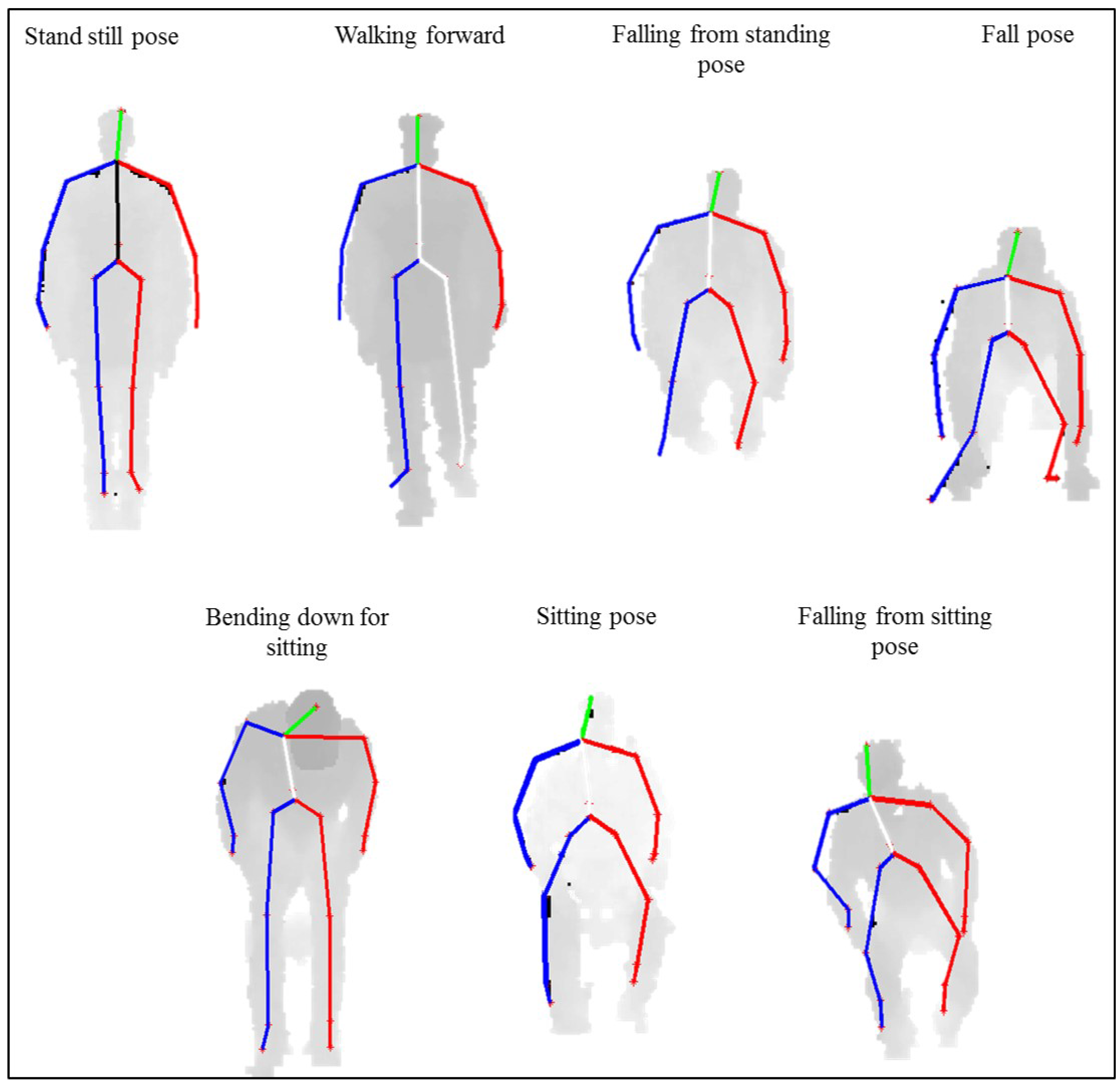
In order to evaluate the proposed fall detection approach, we have utilized the Microsoft Kinect sensor to record a dataset of depth-map video sequences that simulates fall-related activities of elderly people. The recorded activities include: walking, sitting, falling form standing and falling from sitting. Three evaluation procedures are developed to quantify the performance of the proposed approach at various configurations, including: fully-observed video sequence, partially-observed video sequence that includes one unobserved video subsequence of random length and partially-observed video sequence that includes two unobserved video subsequences of random lengths. The experimental results reported in this study demonstrate the feasibility of employing the proposed approach for detecting falls based on partially-observed videos.
The remainder of this paper is organized as follows. In
Section 2, we describe the collected dataset of fall-related activities, the modified MPGD and HBR for human activities and the proposed fall detection approach based on partially-observed depth-map videos.
Section 3 presents the experimental results and discussion. Finally, conclusions are presented in
Section 4.
3. Experimental Results and Discussion
In order to evaluate the performance of the proposed approach, we utilize the collected dataset, described in
Section 2.1, to develop three evaluation scenarios based on the number of unobserved video subsequences in the testing videos, including: fully-observed video sequences, single unobserved video subsequence with random length and two unobserved video subsequences with random lengths. Moreover, we utilize the LOVSO-CV procedure to evaluate the performance of each scenario. In particular, the classifiers in each scenario are trained using all of the video sequences except one video sequence that is used for testing. This evaluation scheme is repeated for all possible combinations, and the overall result is computed by averaging the results obtained from each repetition. For all evaluation scenarios, the window size
W and the overlap size
O of the motion profile are selected experimentally and are equal to three frames and one frame, respectively. In order to train the SVM classifiers in the second and third evaluation scenarios, we divided each video sequence into overlapping segments. The size of each segment is equal to
of the total number of frames in the video sequence, and the overlap between any two consecutive segments is equal to
. Moreover, as the lengths of the unobserved video sequences are random, we evaluate the performance of the proposed approach for the second and third evaluation scenarios by repeating the LOVSO-CV procedure ten times, such that in each repetition, we generate unobserved video subsequences with different random lengths in the testing sequences. Then, the average values of the recognition accuracy, precision, recall and F1-measure are computed as performance evaluation metrics over the ten LOVSO-CV train-test repetitions. These metrics are defined as follows:
where
is the number of true positive cases,
is the number of true negative cases,
is the number of false positive cases and
is the number of false negative cases. Next, we discuss the results of our proposed approach for each evaluation scenario.
3.1. Evaluation on the Fully-Observed Video Sequences Scenario
In this section, we evaluate the performance of the proposed approach in recognizing the four fall-related activities from fully-observed video sequences. Specifically, in this evaluation scenario, the video sequences are fully observed as described in
Figure 1a. For the purpose of this evaluation scenario, we have trained a multi-class SVM classifier using the HBRs obtained from unsegmented training video sequences. In particular, for each training video
of length
N frames, we construct the HBR of the video frames with indices between one and
N. Using the obtained HBR from each training video sequence, we train the multi-class SVM classifier to identify the four fall-related activities in our dataset.
In order to classify a testing video sequence
of length
T, we construct the HBR of the video frames with indices between one and
T in the video
, namely
. Then, using the trained multi-class SVM classifier, the class of
can be determined by rewriting Equation (22) as follows:
Table 3 shows the results of recognizing the four fall-related activities expressed using the precision, recall and F1-measure as an evaluation metric. The average recognition accuracy of fully-observed video sequences is
. The results demonstrate the capability of the proposed approach to detect falls from fully-observed video sequences.
In comparison, the Kinect-based approach proposed by Marzahl et al. [
35], which was evaluated using 55 fall depth-map videos, achieved an average fall classification accuracy of
. Similarly, the Kinect-based system introduced by Planinc and Kampel [
36] achieved fall detection accuracies between
and
based on a dataset that includes 40 falls and 32 non-falls depth-map videos. In fact, the results reported in our study for the fully-observed depth-map video sequences are comparable to the results reported in the previous approaches. It is worth noting that the main focus of our work is to detect falls form partially-observed depth-map video sequences, which has not been investigated in previous studies. The following subsections provide the performance evaluation results obtained by our approach for the partially-observed depth-map video sequences.
3.2. Evaluation on the Single Unobserved Video Subsequence with Random Length Scenarios
In this section, we evaluate the performance of the proposed approach in recognizing the four fall-related activities from partially-observed video sequences. In particular, we have constructed partially-observed video sequences by generating temporal gaps with random lengths at the beginning, end and middle of the testing video sequences. Next, we discuss the evaluation results of our proposed approach for each temporal gap configuration.
3.2.1. Evaluation Results When the Temporal Gap Is at the Beginning of the Video Sequences
In this evaluation scenario, we aim at evaluating the performance of the proposed approach in recognizing the four fall-related activities when the unobserved video subsequence is happening at the beginning of the video sequence. In particular, we have investigated the scenario in which the temporal gap is mainly affecting the video frames belonging to the first sub-activity and a subset of the second sub-activity in each of the four fall-related activities. Hence, our assumption is that the majority of the observed video frames belong to the last sub-activity. To achieve this goal, we have set the temporal gap interval to
, where
is a random integer that is larger than one and less than
of the total length of the video sequence.
Table 4 shows the results of recognizing the four fall-related activities expressed in terms of the precision, recall and F1-measure as an evaluation metric. In addition,
Table 4 provides the average length of the temporal gaps introduced in the testing video sequences for each activity over the 10 repetitions of the LOVSO-CV procedure. The proposed approach achieved an average recognition accuracy of
in identifying the four fall-related activities from partially-observed video sequences.
The results in
Table 4 indicate that the average recognition accuracy has been reduced to
compared to
that was obtained in the fully-observed scenario. This can be attributed to the fact that the ratio of the average length of the introduced temporal gaps across the four activities in this scenario, which is equal to 35 frames, to the average sequence length in our dataset, which is equal to 84 frames, is approximately
. The relatively high lengths of the introduced temporal gaps can generate unobserved subsequences that represent multiple sub-activities, which in turn reduces the recognition accuracy. For example, when the unobserved video subsequence is spanning the first two sub-activities in the falling from sitting and falling from standing activities, the remaining sub-activity represents the falling pose, which is common to both activities. This can reduce the ability of the proposed approach to distinguish between different activities that involve fall-related events.
3.2.2. Evaluation Results When the Temporal Gap Is at the End of the Video Sequences
In this evaluation scenario, we aim at evaluating the performance of the proposed approach in recognizing the four fall-related activities when the unobserved video subsequence is happening at the end of the video sequence. This is similar to the prediction scenario illustrated in
Figure 1b. In particular, we have investigated the scenario in which the temporal gap is mainly affecting the video frames belonging to the last sub-activity and a subset of the second sub-activity in each of the four fall-related activities. Hence, our assumption is that the majority of the observed video frames belong to the first sub-activity. To achieve this goal, we have set the temporal gap interval to
, where
is a random integer in the range
.
Table 5 provides the recognition results of the four fall-related activities expressed in terms of the precision, recall and F1-measure as an evaluation metric. In addition,
Table 5 provides the average length of the temporal gaps introduced in the testing video sequences for each activity over the 10 repetitions of the LOVSO-CV procedure. The proposed approach achieved an average recognition accuracy of
in recognizing the four fall-related activities from partially-observed video sequences.
Recognizing human activities from partially-observed video sequences with the unobserved video subsequence at the end of the video is considered challenging. The reason behind that is the absence of some key sub-activities that can distinguish different activities from each other. For example, when the sub-activity that represents the falling pose is unobserved, distinguishing between sitting and falling from sitting activities becomes challenging, especially when the duration of the falling from sitting pose sub-activity is short. Similarly, the absent of the fall pose increases the difficulty in distinguishing between the walking and falling from standing activities. This explain the reduction in the average recognition accuracy between this evaluation scenario and the previously described scenario in
Section 3.2.1.
3.2.3. Evaluation Results When the Temporal Gap Is at the Middle of the Video Sequences
In this evaluation scenario, we aim at evaluating the performance of the proposed approach in recognizing the four fall-related activities when the unobserved video subsequence is happening at the middle of the video sequence. In particular, we have investigated the scenario in which the temporal gap is mainly affecting the video frames belonging to the second sub-activity, along with a subset of the frames that belong to the first and last sub-activities in the four fall-related activities. Hence, our assumption is that the majority of the observed video frames are belonging to the first and last sub-activities. To achieve this goal, we have set the temporal gap interval to
, where
and
are random integers that satisfy
. The scenario in this section can be viewed as a simplified version of the scenario described in
Figure 1c, as it consists of a single unobserved subsequence of frames.
Table 6 presents the recognition results of the four fall-related activities expressed in terms of the precision, recall and F1-measure as an evaluation metric. The last column in
Table 4 provides the average length of the temporal gaps introduced in the testing video sequences for each activity over the 10 repetitions of the LOVSO-CV procedure. The proposed approach achieved an average recognition accuracy of
in recognizing the four fall-related activities from partially-observed video sequences.
The results in
Table 6 show that the proposed approach achieved a better recognition accuracy in comparison with the results obtained when the unobserved video subsequences were at the end of the video sequences, as described in
Section 3.2.2. This can be attributed to the fact that, in this scenario, we observe two video subsequences from each testing video. These observed video subsequences comprise the starting and ending sub-activities of each activity. Furthermore, the observed video subsequences might contain subsets of the video frames that belong to the intermediate sub-activities in each activity. This in turn can enhance the recognition accuracy as depicted in
Table 6.
3.3. Evaluation of the Two Unobserved Video Subsequences with Random Lengths Scenarios
In this section, we evaluate the performance of the proposed approach in recognizing the four fall-related activities from partially-observed video sequences with two unobserved frame subsequences. In particular, we consider two configurations for the locations of the two unobserved frames subsequences. In the first configuration, we construct partially-observed video sequences by generating two temporal gaps with random lengths at the beginning and the end of the testing video sequences. In the second configuration, we generate two temporal gaps with random lengths between the beginning and the end of the testing video sequences. Next we discuss the evaluation results of our proposed approach for the aforementioned two configurations.
3.3.1. Evaluation Results When the Two Temporal Gaps Are at the Beginning and the End of the Video Sequences
In this evaluation scenario, we aim at evaluating the performance of the proposed approach in recognizing the four fall-related activities when the unobserved video subsequences are at the beginning and the end of the video sequence. To achieve that, we created two temporal gaps. The first temporal gap spans a subset of video frames that belong to the first and second sub-activities; while the second gap spans video frames that belong to the second and last sub-activities. Hence, the majority of the remaining frames belong to the second sub-activity. To achieve this goal, we have set the intervals of the two temporal gaps to
and
, where
and
are two random integers in the ranges of
and
, respectively.
Table 7 presents the recognition results of the four fall-related activities expressed in terms of the precision, recall and F1-measure as an evaluation metric. The last two columns in
Table 7 provide the average lengths of the two temporal gaps introduced in the testing video sequences of each activity over the 10 repetitions of the LOVSO-CV procedure. The proposed approach achieved an average recognition accuracy of
in identifying the four fall-related activities from partially-observed video sequences.
Table 7 shows that the recognition results have been reduced drastically compared with the results of the previous evaluation scenarios. This reduction in the recognition accuracy is due to the large amount of unobserved video frames, which are mainly frames from the first and the last sub-activities of each activity. These sub-activities have a key role in distinguishing between different fall-related activities, such as sitting and falling from sitting activities.
3.3.2. Evaluation Results When the Two Temporal Gaps Are between the Beginning and the End of the Video Sequences
In this evaluation scenario, we aim at evaluating the performance of the proposed approach in recognizing the four fall-related activities; the unobserved video subsequences are at random locations between the beginning and the end of the video sequence, which is similar to the scenario described in
Figure 1c. To achieve that, we created two temporal gaps. The first gap spans a subset of the video frames that belong to the first and second sub-activities. While the second gap spans a subset of the video frames that belong to the second and last sub-activities. Hence, the remaining frames are sparsely distributed between the first, second and last sub-activities. To implement the temporal gaps in this evaluation scenario, we have set the intervals of the two temporal gaps to
and
, where
,
,
and
are random integers that satisfy the two conditions:
and
.
Table 8 provides the recognition results of the four fall-related activities expressed in terms of the precision, recall and F1-measure as an evaluation metrics. The last two columns in
Table 8 provide the average lengths of the two temporal gaps introduced in the testing video sequences of each activity over the 10 repetitions of the LOVSO-CV procedure. The proposed approach achieved an average recognition accuracy of
in identifying the four fall-related activities from partially-observed video sequences.
The results in
Table 8 show that, in this evaluation scenario, the proposed approach achieved a better recognition accuracy compared with the results obtained when the two temporal gaps were at the beginning and the end of the testing video sequences, as described in
Section 3.3.1. This can be justified by observing that each testing video consists of three observed video subsequences after creating the temporal gaps. The first observed video subsequence is at the beginning of the testing video and consists of video frames from the first sub-activity. The second observed video subsequence is at the middle of the testing video and might contain frames from more than one sub-activity depending on the lengths of the temporal gaps. The third observed video subsequence is at the end of the testing video and consists of video frames from the last sub-activity. This implies that the observed video subsequences are comprising video frames from the different sub-activities of an activity in a given testing video, which can enhance the recognition accuracy.
4. Conclusions
In this paper, we proposed an approach for fall detection from partially-observed depth-map video sequences. The proposed approach utilizes the Microsoft Kinect sensor to build a view-invariant descriptor for human activities, namely the motion-pose geometric descriptor (MPGD). To detect falls in the partially-observed depth-map video sequence, we segmented fully-observed training video sequences into overlapping video segments. Then, we constructed an HBR of the MPGDs extracted from the video frames within each segment. Using the computed HBRs, we trained an SVM classifier with a probabilistic output to predict the class of the performed activity in a given partially-observed video. To classify a new video with unobserved frames subsequences, we utilized the trained SVM models to compute the class posteriori probability of each observed subsequence. Then, we combined the computed posteriori probabilities from all observed subsequences to obtain an overall class posteriori probability for the partially-observed video. In order to evaluate the performance of the proposed approach, we utilized the Kinect sensor to record a dataset of depth-map video sequences that simulates four fall-related activities of elderly people, namely walking, sitting, falling form standing and falling from sitting. Furthermore, using the collected dataset, we have developed three evaluation scenarios based on the number of unobserved video subsequence in the testing videos. Experimental results show the potential of the proposed approach to detect falls from partially-observed videos efficiently.
In the future, we intend to extend our approach to utilize multiple Kinect sensors to overcome the distance limitation of the Kinect sensor, the subject occlusion problem and the requirement of having the subject in the frontal or near-frontal view with respect to the Kinect sensor. Such an extension can also enhance the accuracy of localizing the 3D skeletal joint positions. Furthermore, we plan to extend our dataset to evaluate the performance of the proposed approach in recognizing a larger number of human activities in partially-observed depth-map video sequences. Moreover, we plan to evaluate the proposed approach using more complex datasets that comprise activities of more than one person. In addition, for each examined human activity, a higher number of evaluation trails will be employed that include various configurations, such as different lengths and locations of the induced temporal gaps.




{kind=link}
{kind=link}
{kind=link}
{kind=link}