
A Genetic Regulatory Network-Based Method for Dynamic Hybrid Flow Shop Scheduling with Uncertain Processing Times


Abstract
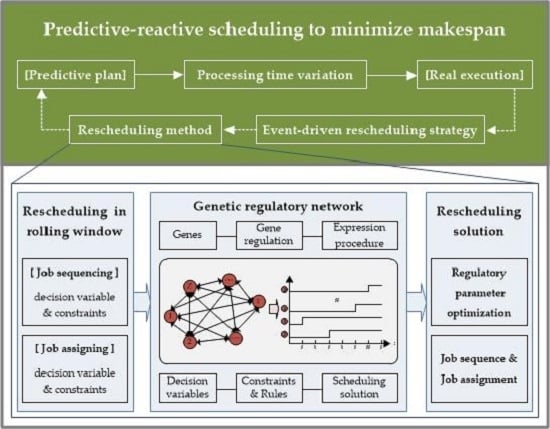
:
1. Introduction
2. Hybrid Flow Shop Dynamic Scheduling Problem
- Each job and each machine are available at the initial time.
- Each job passes through multiple production stages to complete operations.
- One or more parallel machines are available at each stage.
- Parallel machines require different processing times for the same operation.
- Each machine is not able to process more than one job at the same time, and cannot be interrupted until the operation on this job has been completed.
- A job can enter the next stage if its operation at current stage has been accomplished.
- Processing times are uncertain, and their actual values may be different from the expected ones.
- A machine requires changeover time if it needs to process two jobs of different types consecutively.
- Operations of a job have no effect on those of other jobs.
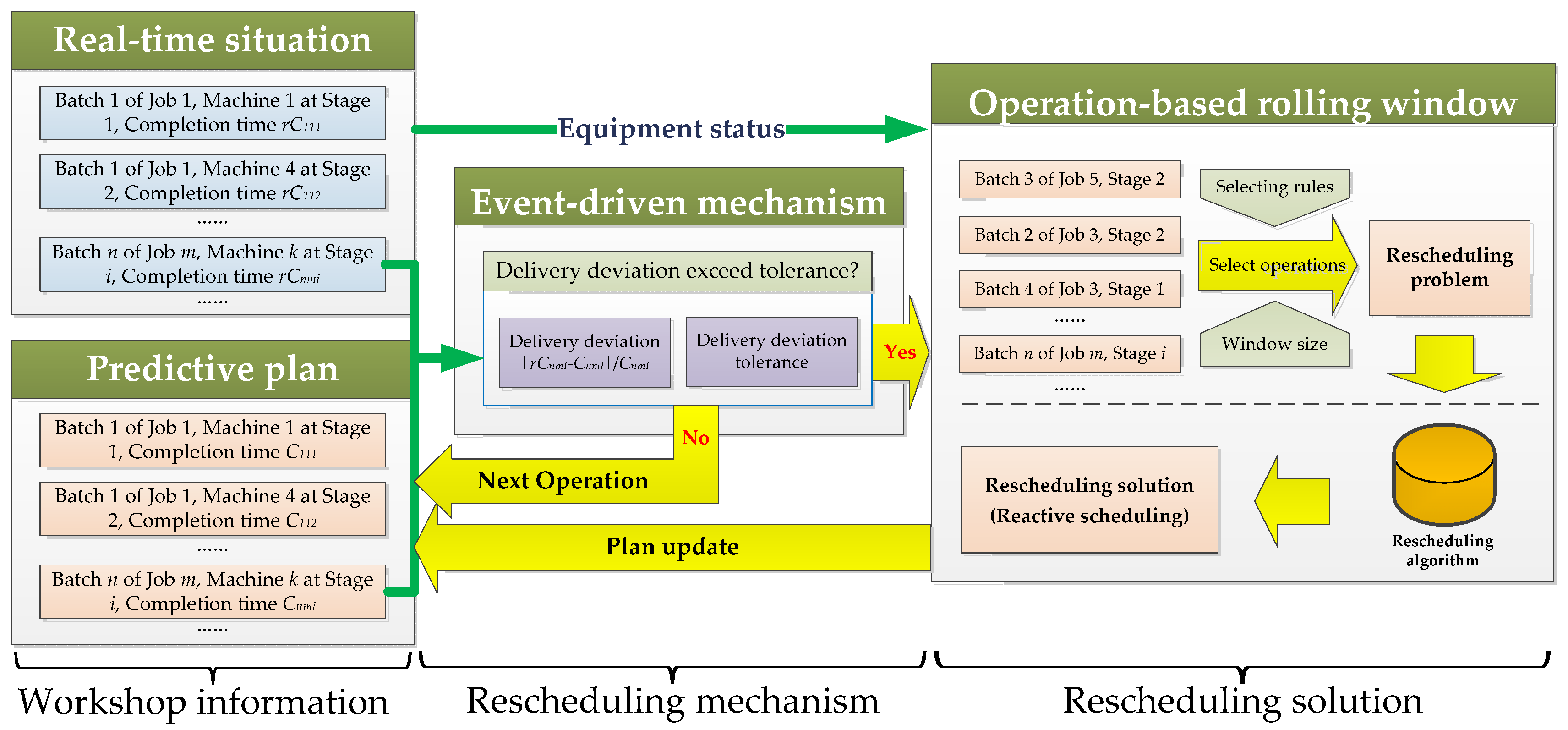
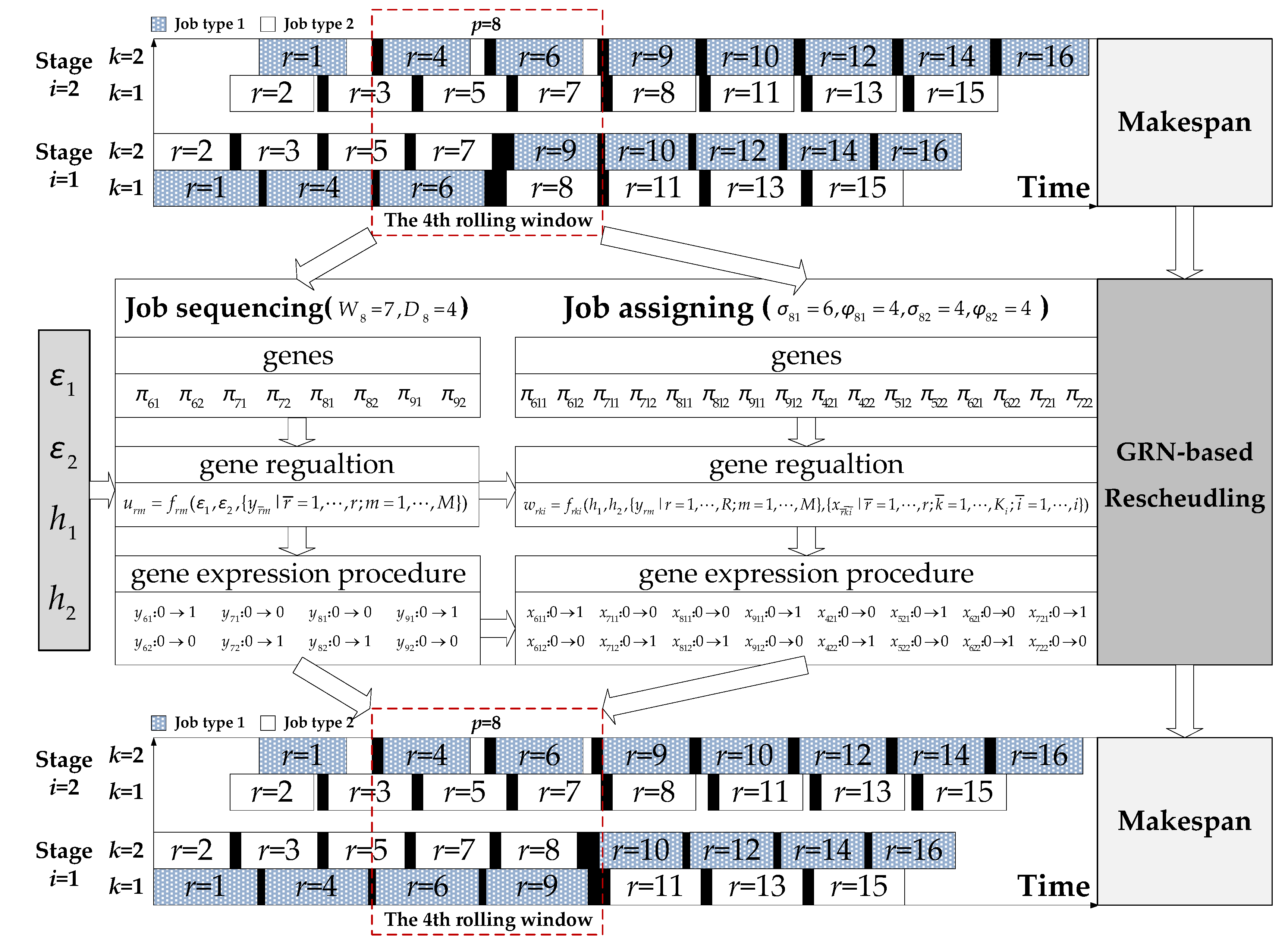
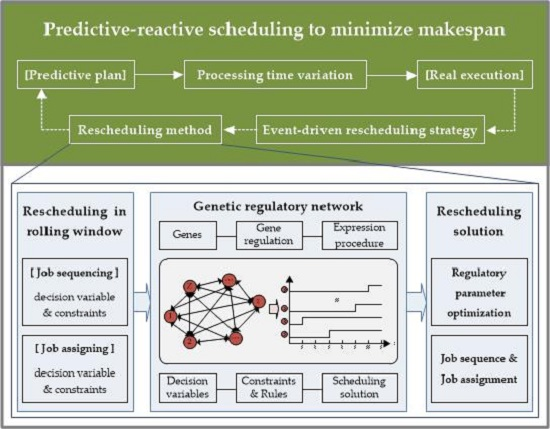
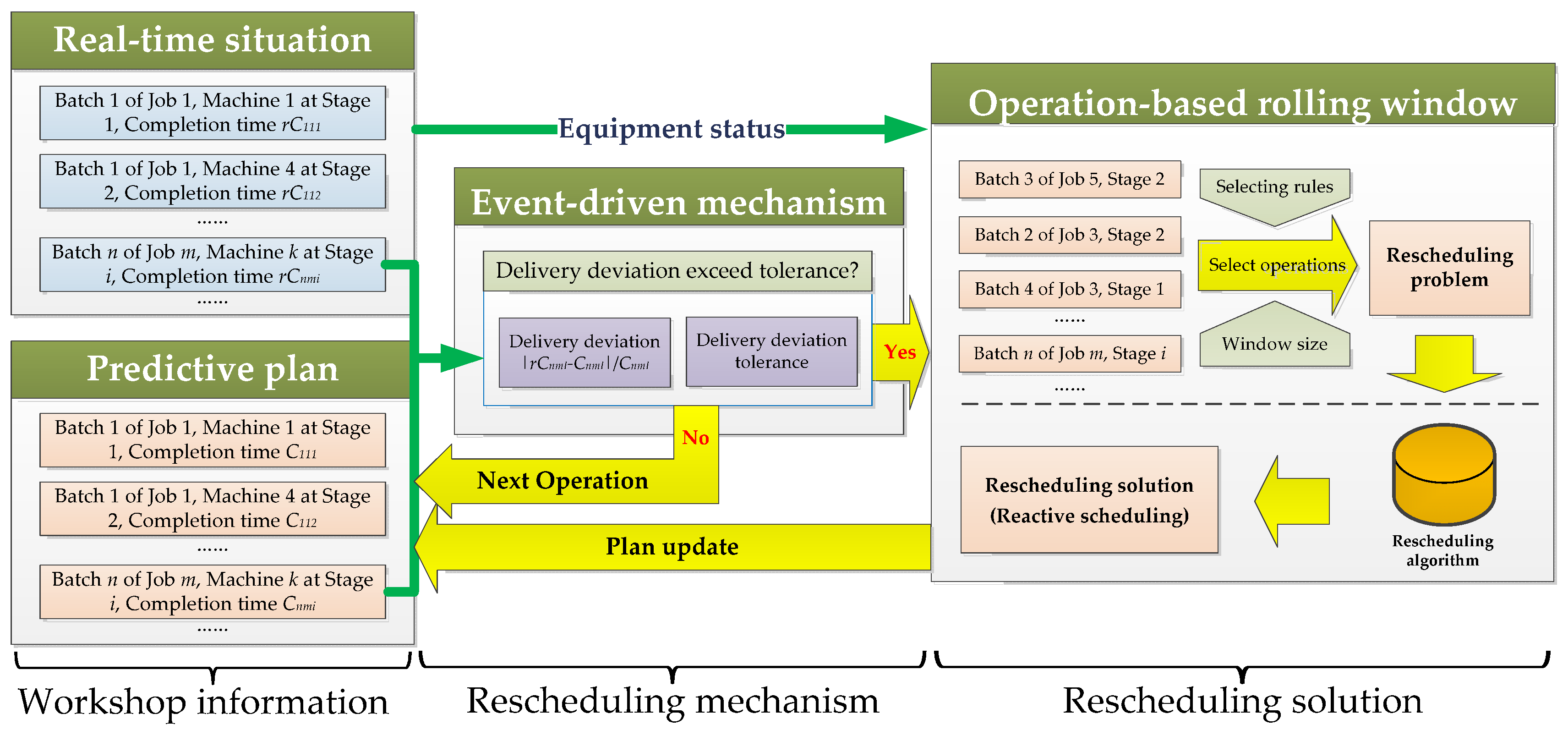
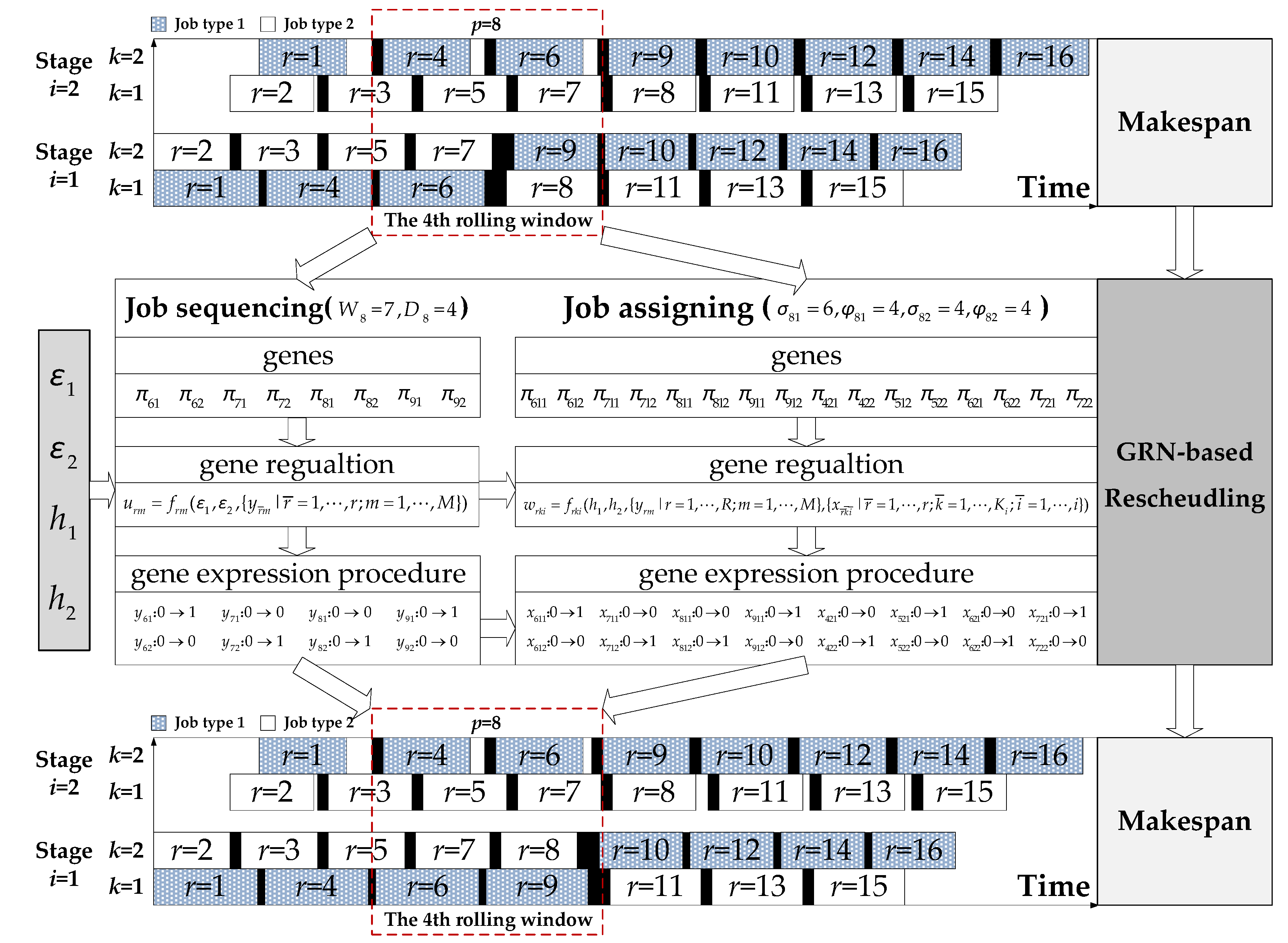
3. Event-Driven Rescheduling Strategy
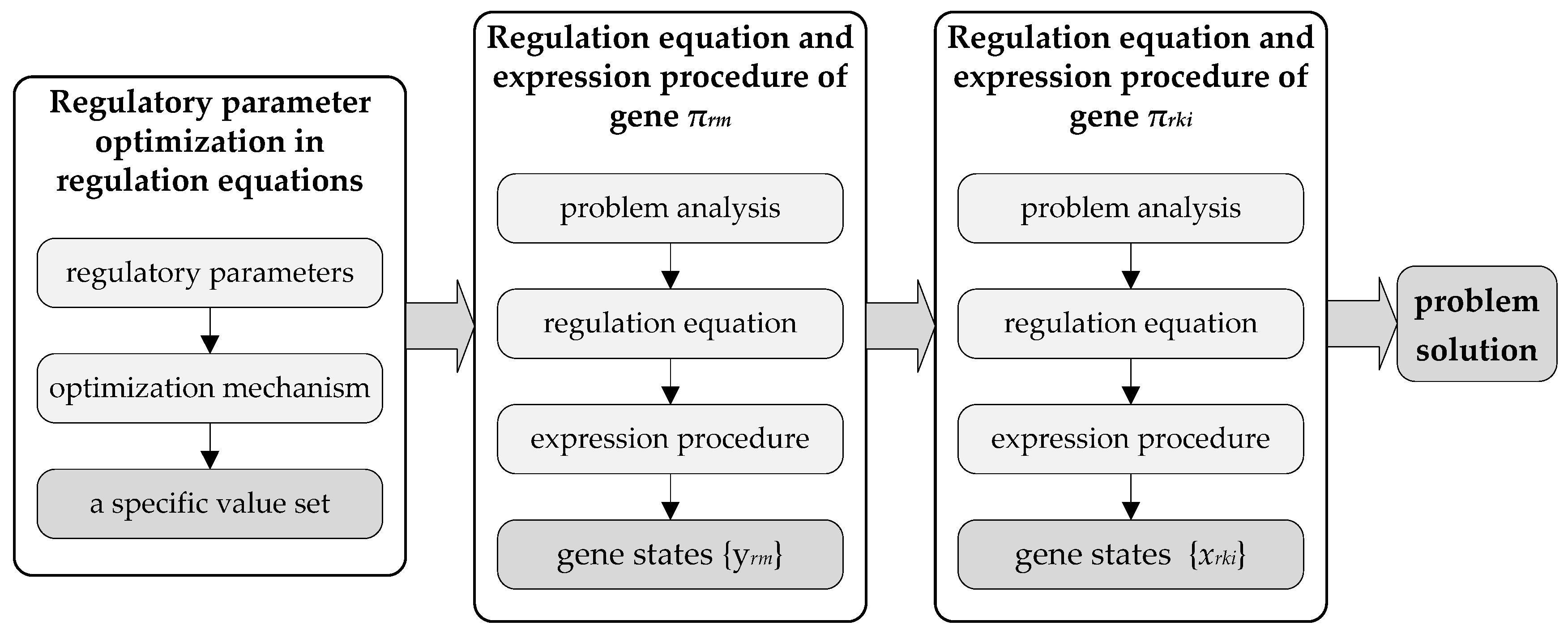
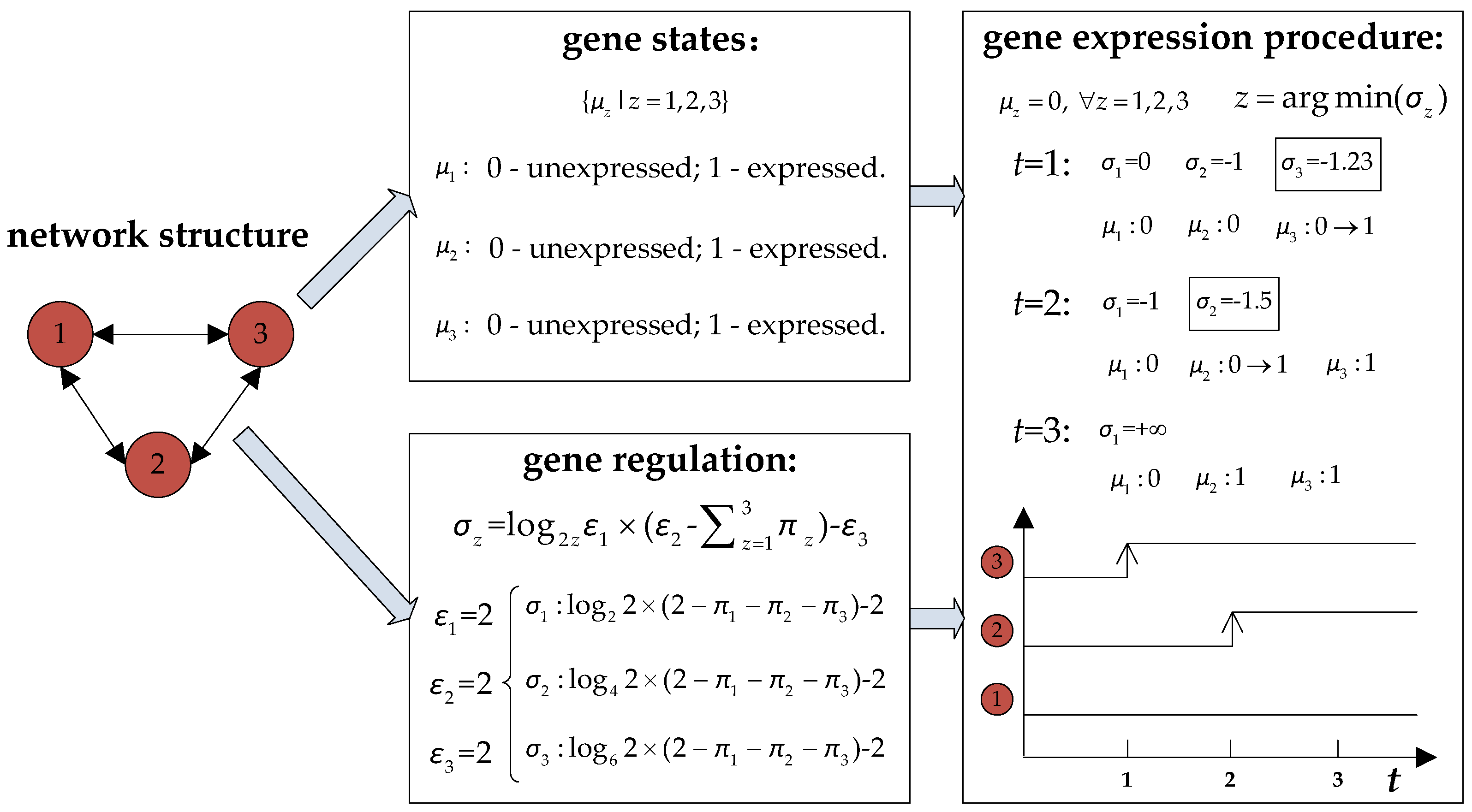
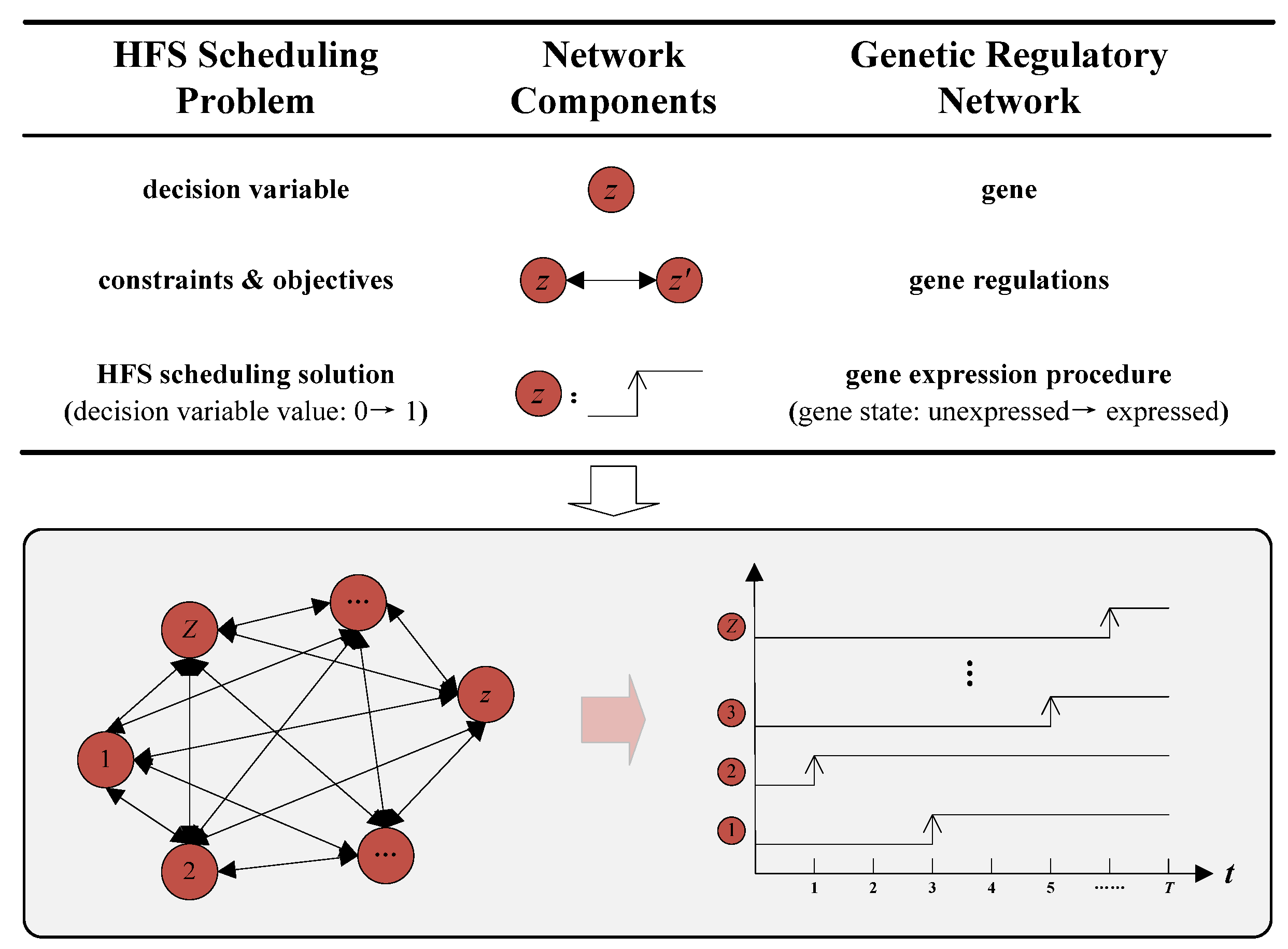
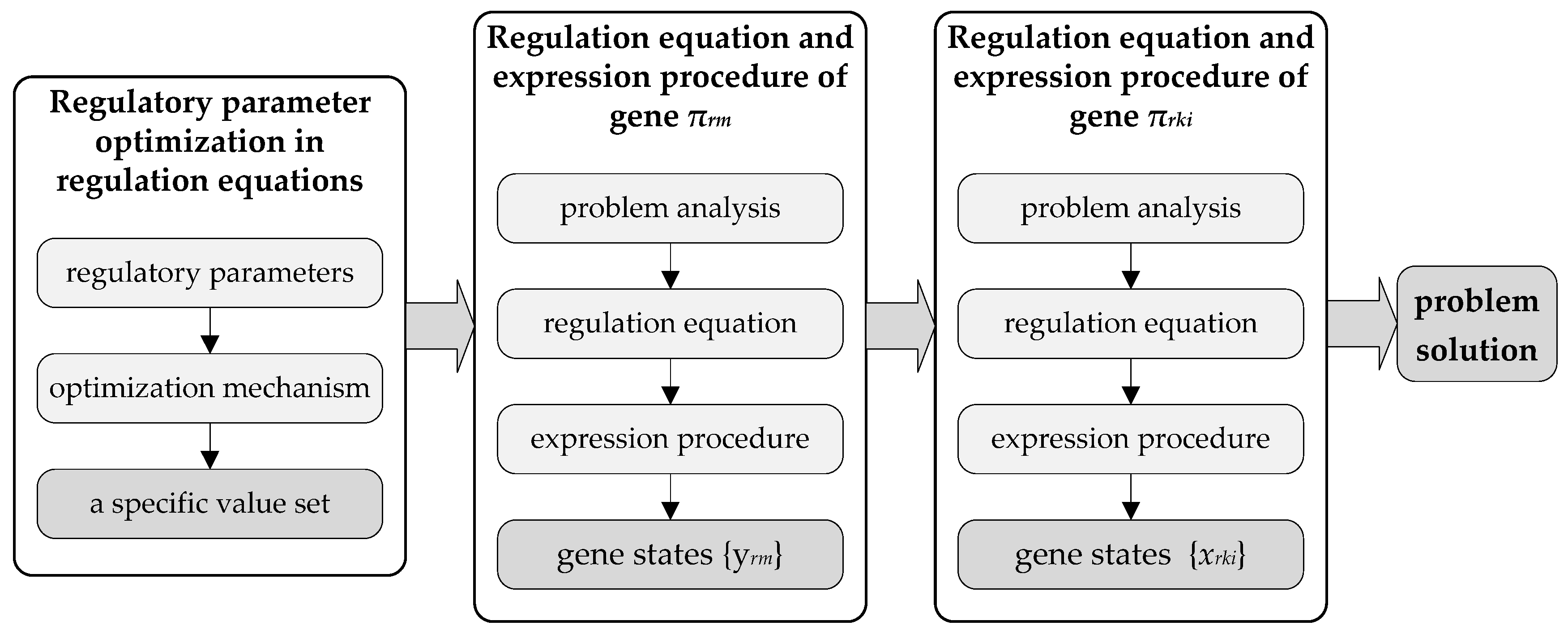
4. Genetic Regulatory Network-Based Rescheduling Method
- Step (1)
- Genes are generated to represent the decision variables. In terms of decision variables yrm and xrki in Table 1, two kinds of genes (i.e., and ) are generated. The gene denotes that the th job entering the HFS belongs to job type , whereas the gene denotes that the th job entering the HFS is processed on the th machine at the th production stage.
- Step (2)
- Regulation equations are developed to describe the constraints and objectives:where represents the number of genes in a GRN, is a binary variable that is equal to 1 if gene is in the expressed state at the th iteration, otherwise, is equal to 0, is the inhibition coefficient that describes the inhibitory effects on gene quantitatively; are regulatory parameters; and is a nonlinear function related to workshop conditions.
- Step (3)
- Gene expression procedures are designed to determine solutions. At the beginning of such a procedure, the set of related genes is first confirmed based on operations within the rolling window. If a reactive scheduling is necessary, all these genes are initialized to the unexpressed state. At each iteration (i.e., ), some of these genes are converted to the expressed state based on the regulation equations. When , genes in the expressed state are confirmed, and their corresponding decision variable values are equal to 1 in the rescheduling solution.
- Step (4)
- Regulatory parameters are optimized to minimize the makespan. A near-optimal solution is obtained by gene states and that are decided by the optimized regulation equations.
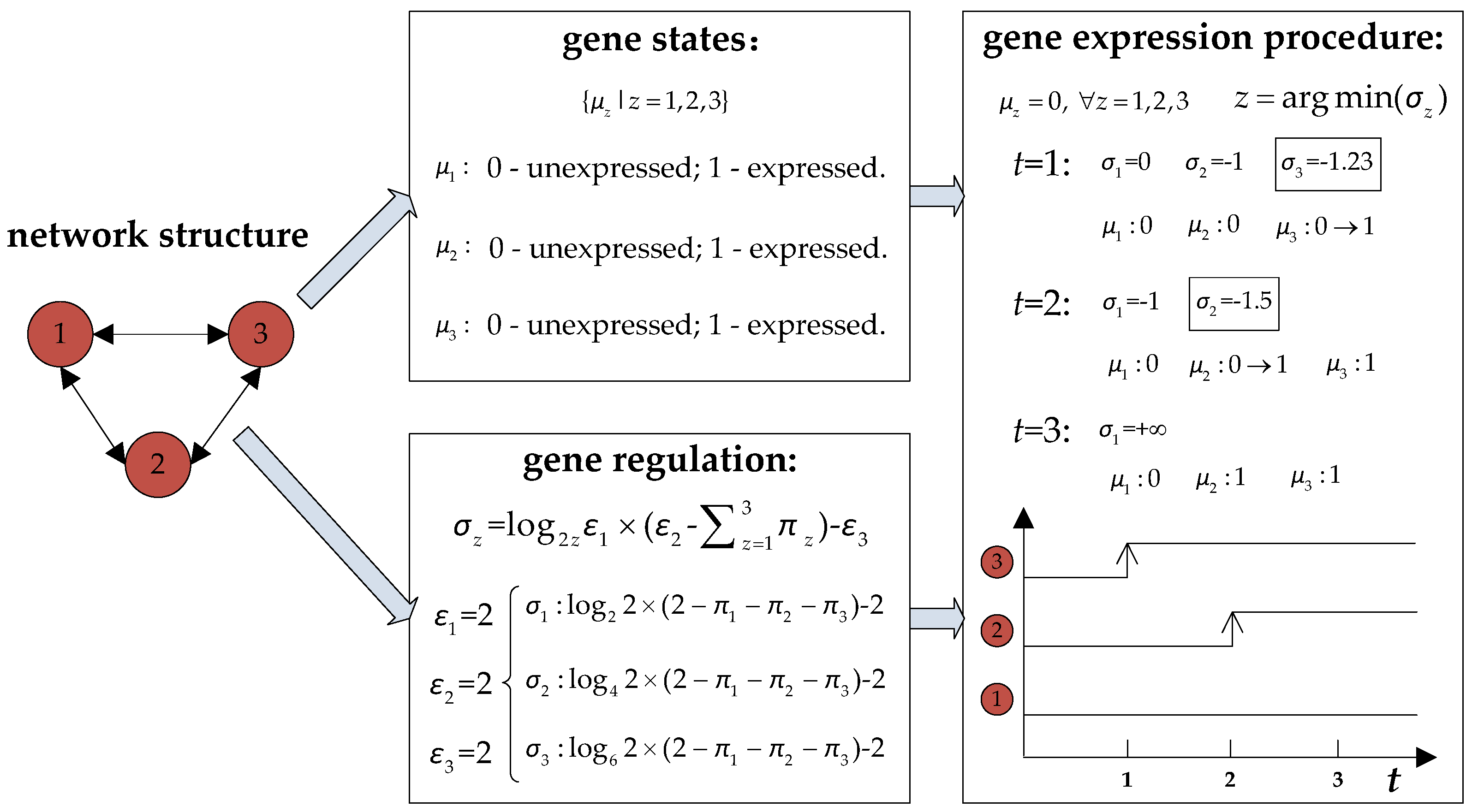
4.1. Regulation Equation and Expression Procedure of Gene
- A job type cannot be selected if its cycle of entering the HFS is not accord with the number of parallel machines at each stage;
- A job type cannot be selected if its production ratio differs from its demand ratio.
4.2. Regulation Equation and Expression Procedure of Gene
- A machine cannot be selected if the waiting time of a job on this machine is longer than that on another machine.
- A machine cannot be selected if it requires setup time for a job.
4.3. Regulatory Parameter Optimization
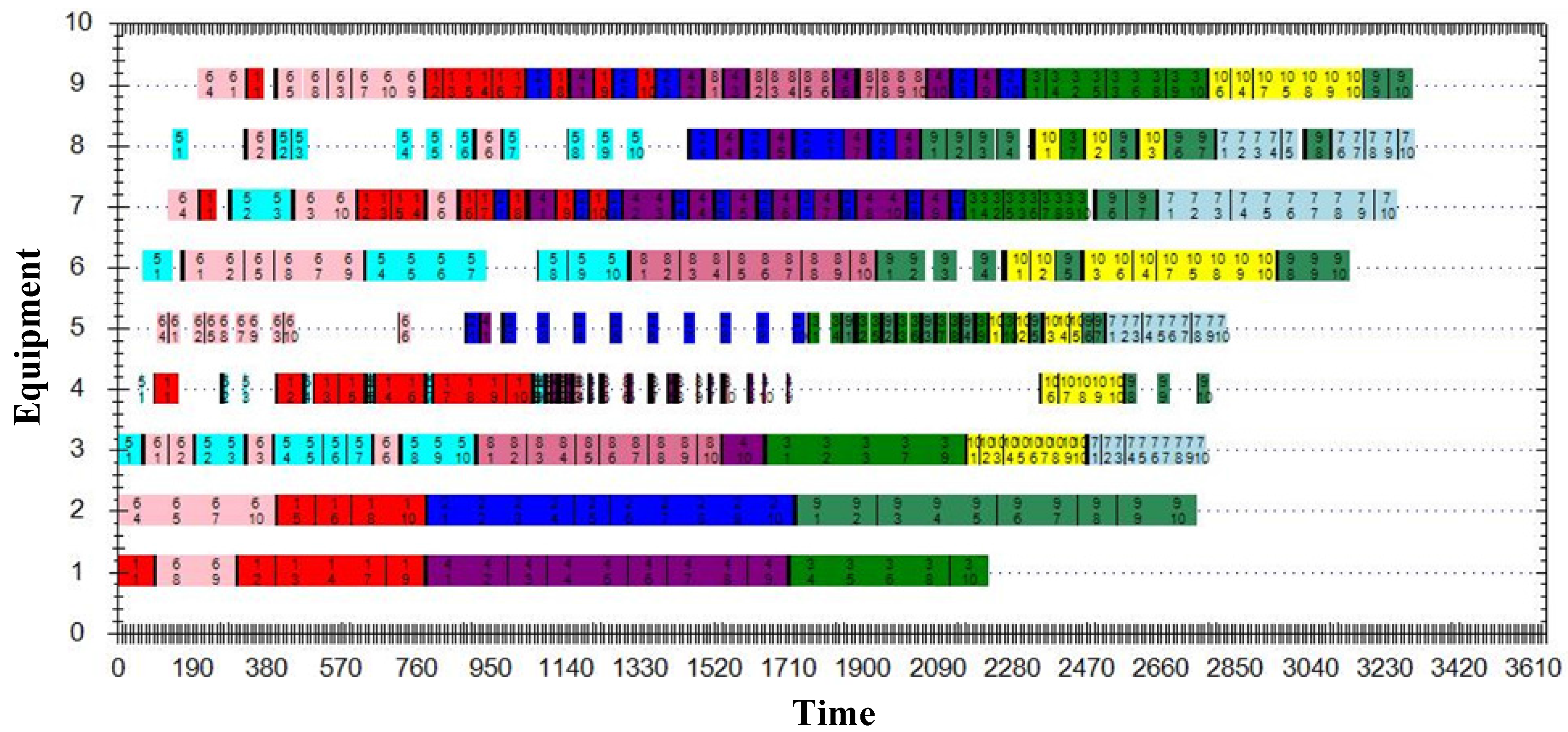
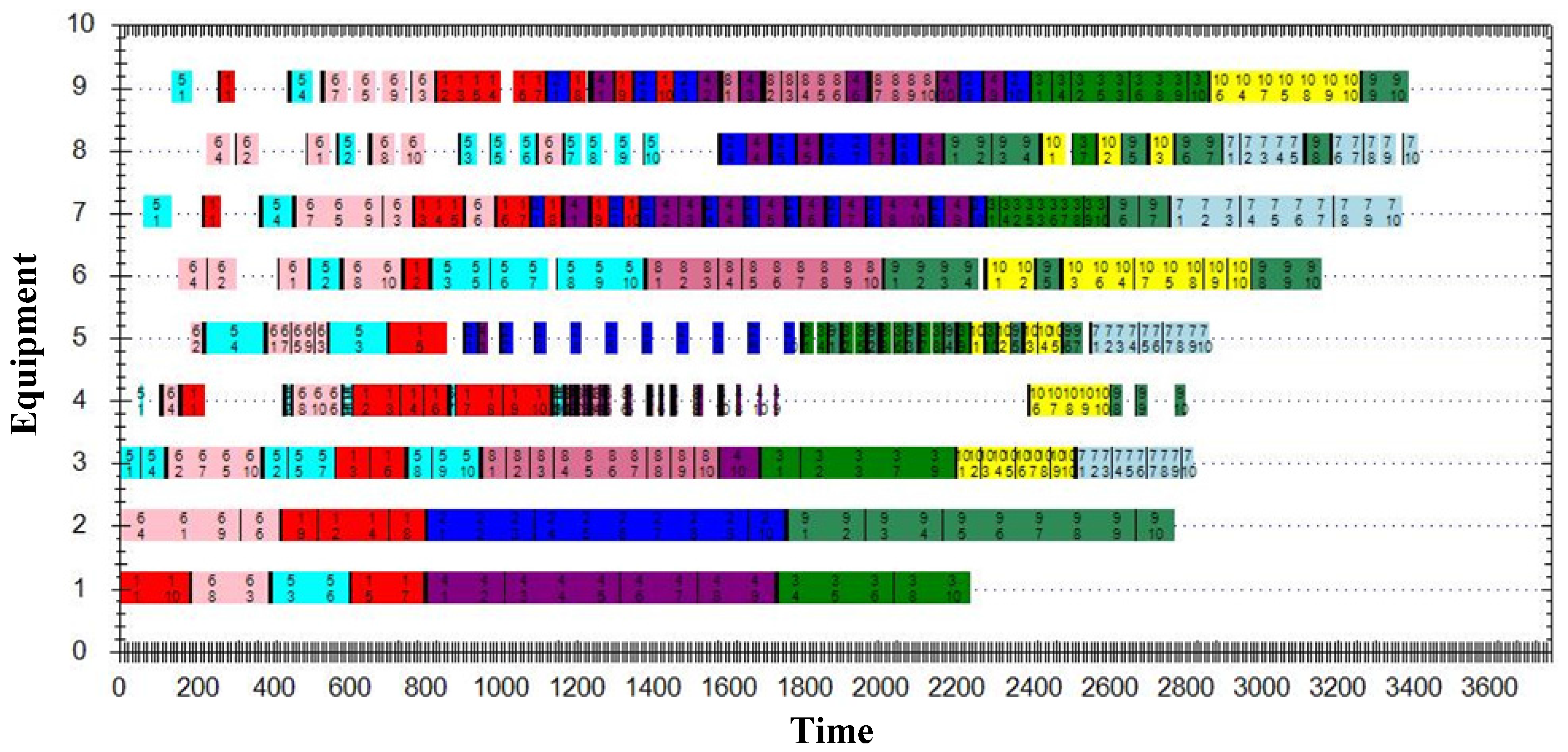
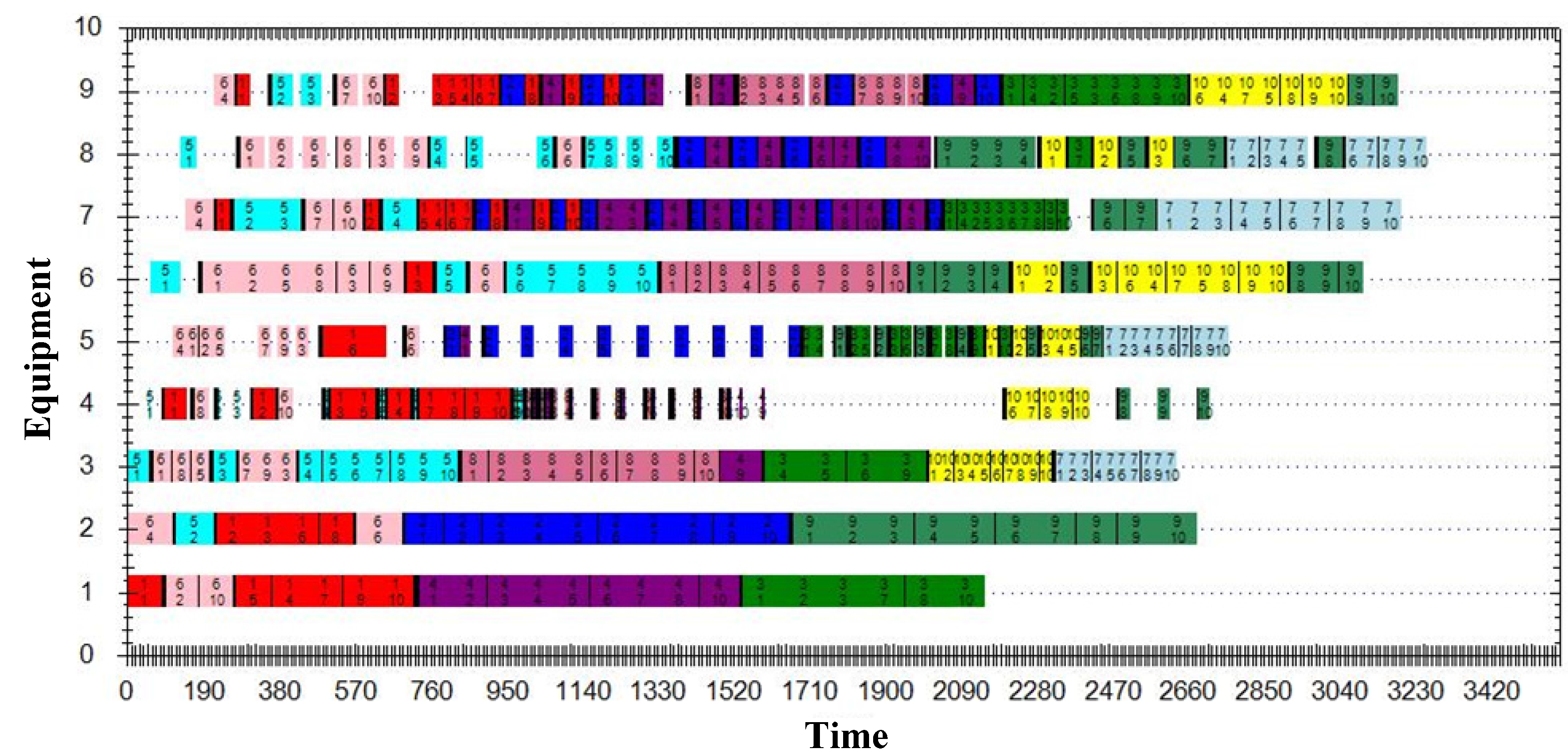
5. Numerical Results
5.1. Strategy Parameter Analysis
5.2. Comparative Experiments
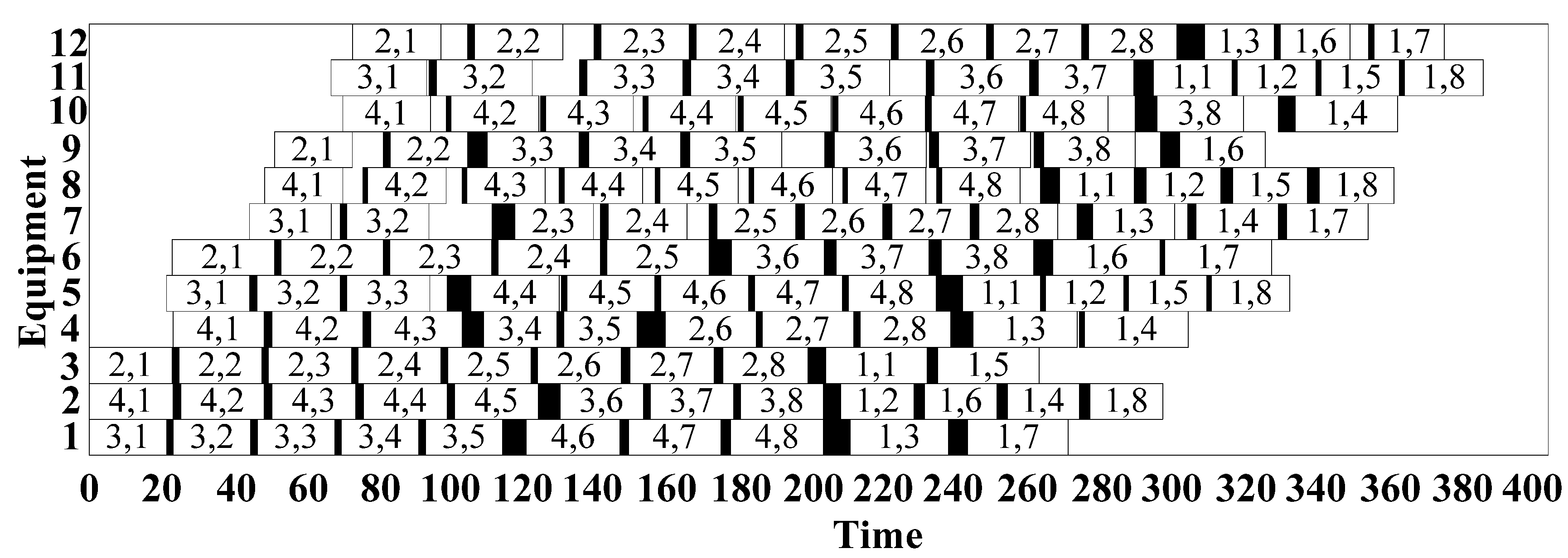
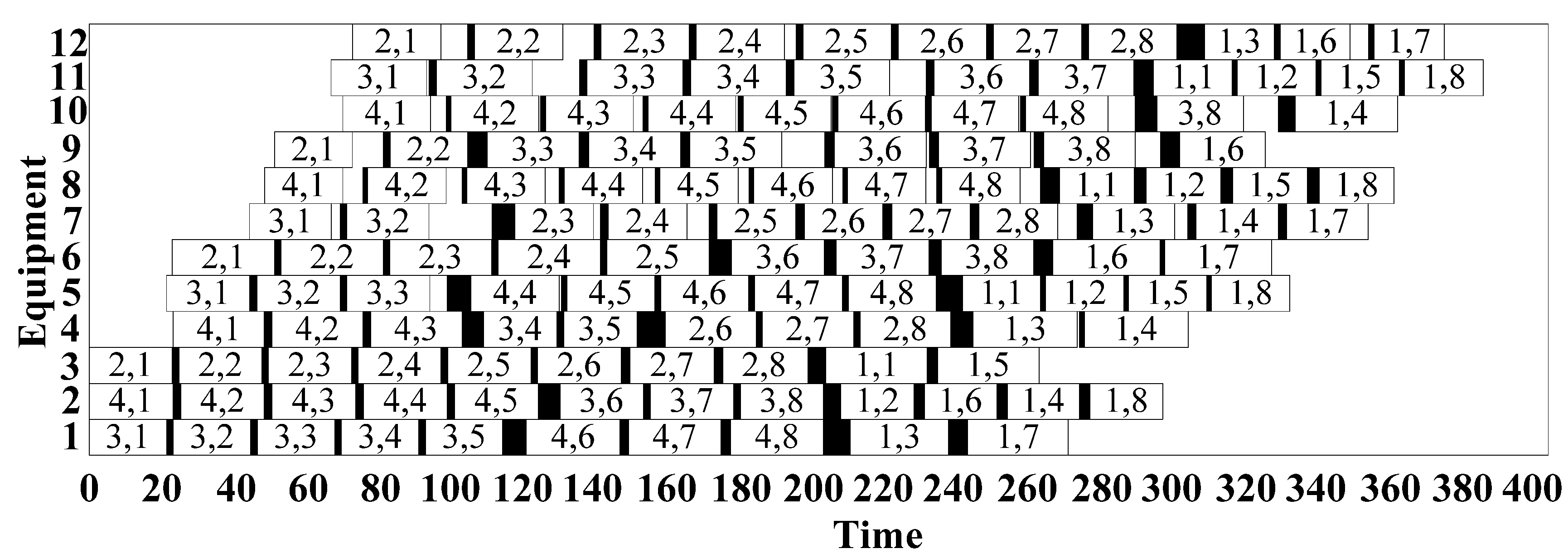
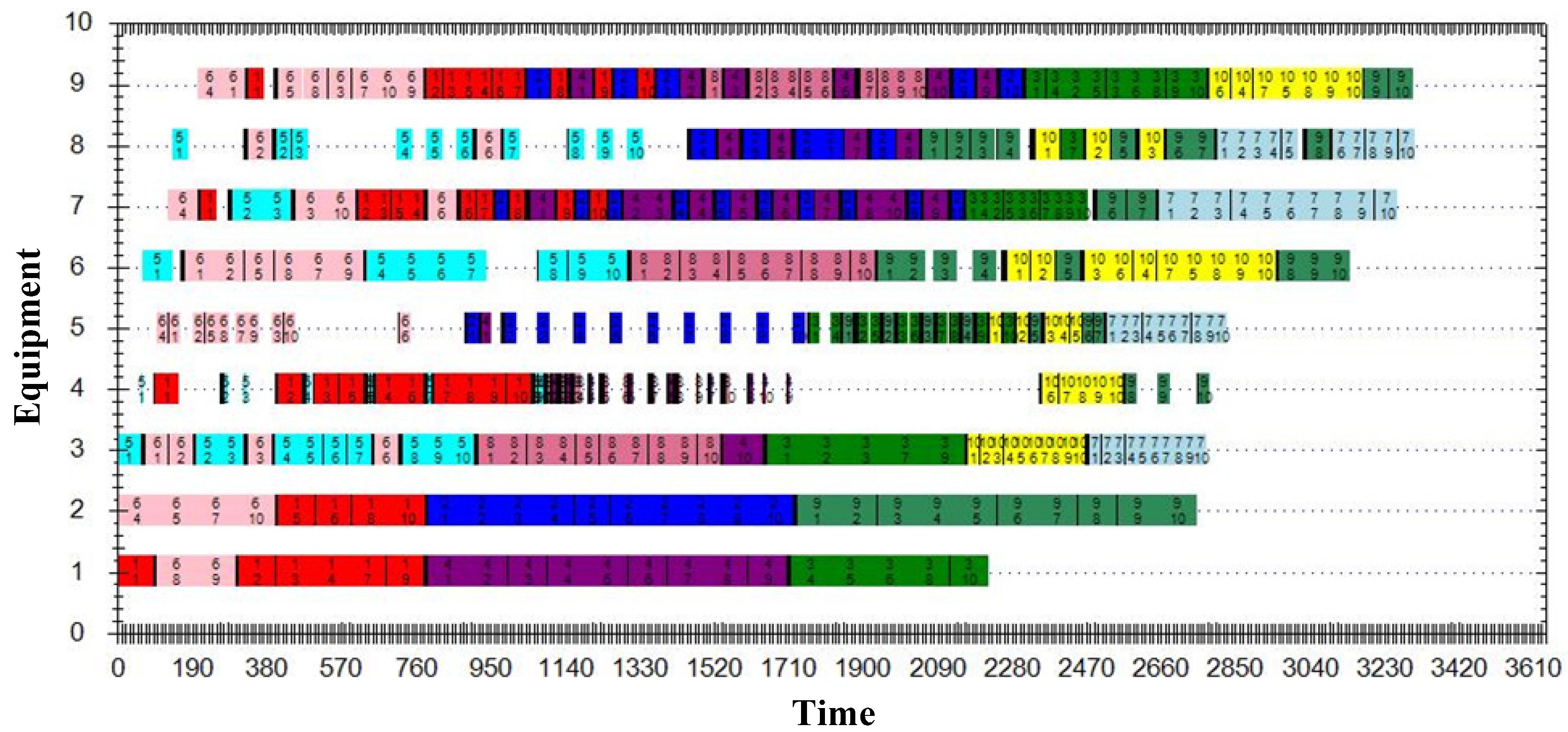
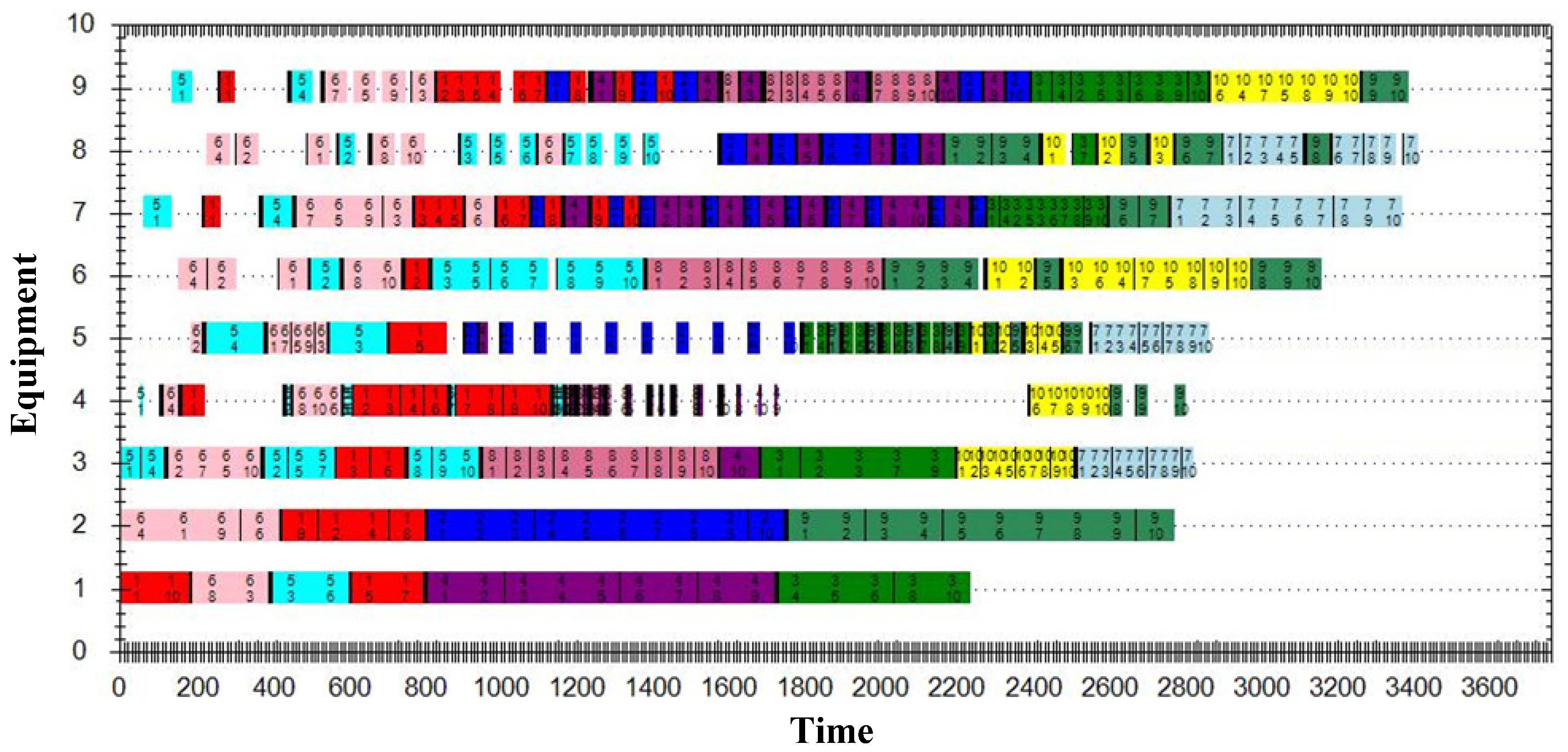
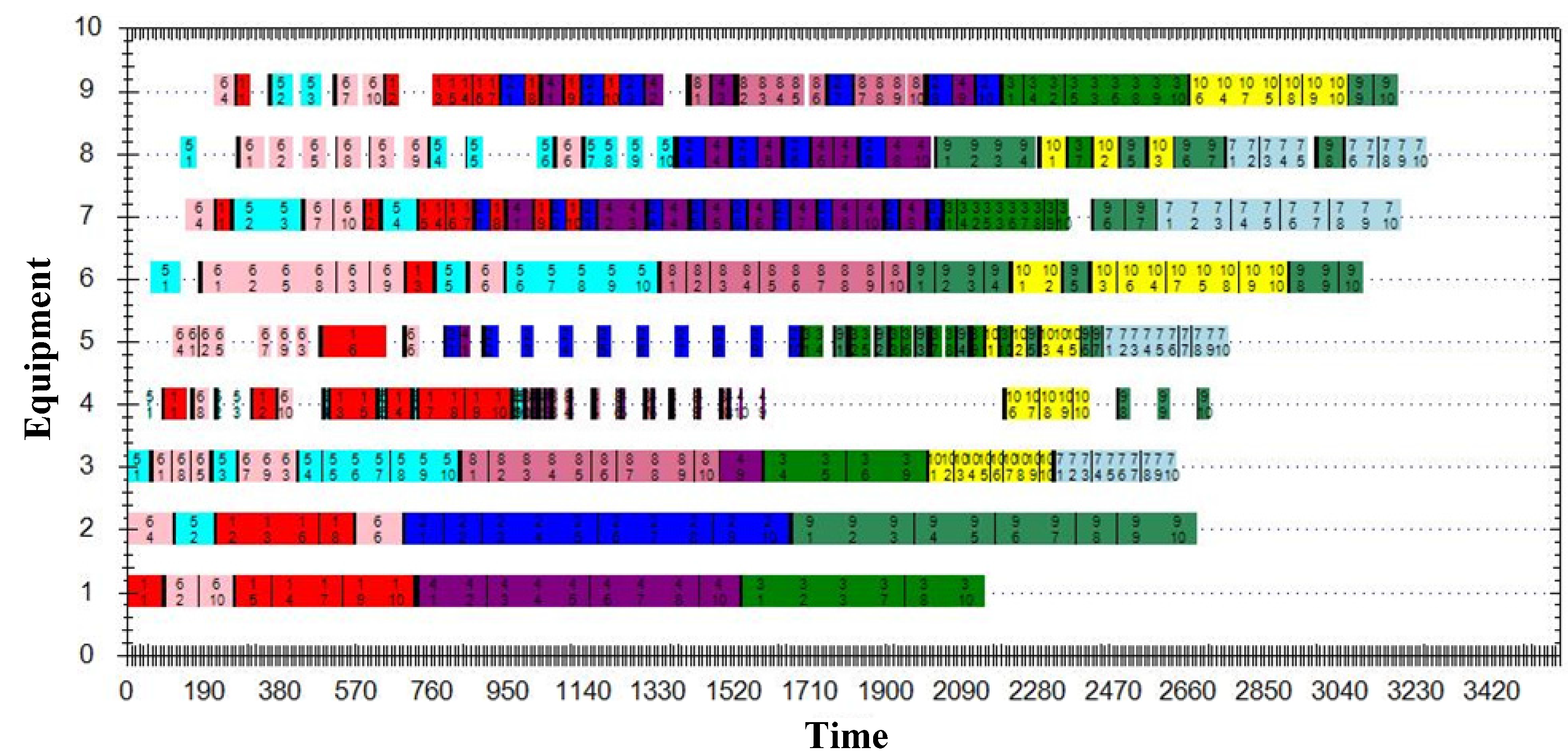
5.3. Case Study
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
| Pseudo codes of expression procedure of gene : |
| //initialization of genes related to the th window |
| for to do |
| for to do |
| //all genes are in the unexpressed state |
| next; |
| next; |
| //expression circulation |
| for to do |
| , |
| //current iteration |
| for to do |
| calculate in Equation (4) //inhibition coefficient of current gene |
| if then |
| //update index of the gene with minimum |
| //update the minimum |
| end if; |
| next; |
| //convert the gene with minimum to the expressed state |
| next. |
Appendix B
| Pseudo codes of expression procedure of gene : |
| //initialization of genes related to the th window |
| for to do |
| for to do |
| for to do |
| //all genes are in the unexpressed state |
| next; |
| next; |
| next; |
| //real-time shop information |
| for to do |
| for to do |
| get and |
| next; |
| next; |
| //expression circulation |
| for to do |
| for to do |
| , |
| for to do //current iteration |
| calculate in Equation (4) //inhibition coefficient of current gene |
| if then |
| //index of the gene with minimum |
| //the minimum |
| end if; |
| next; |
| //convert the gene with minimum to the expressed state |
| for to do |
| calculate in Equation (5) //update shop information |
| calculate in Equation (6) //update shop information |
| next; |
| next; |
| next. |
References
- Gholami, M.; Zandieh, M.; Alem-Tabriz, A. Scheduling hybrid flow shop with sequence-dependent setup times and machines with random breakdowns. Int. J. Adv. Manuf. Technol. 2009, 42, 189–201. [Google Scholar] [CrossRef]
- Chou, F. Der Particle swarm optimization with cocktail decoding method for hybrid flow shop scheduling problems with multiprocessor tasks. Int. J. Prod. Econ. 2013, 141, 137–145. [Google Scholar] [CrossRef]
- Yan, H.S.; Jiang, T.H.; Xiong, F.L. A hybrid electromagnetism-like algorithm for a mixed-model assembly line sequencing problem. Int. J. Ind. Eng. Theory Appl. Pract. 2014, 21, 153–167. [Google Scholar]
- Arnaout, J.P.; Rabadi, G.; Musa, R. A two-stage Ant Colony Optimization algorithm to minimize the makespan on unrelated parallel machines with sequence-dependent setup times. J. Intell. Manuf. 2010, 21, 693–701. [Google Scholar] [CrossRef]
- Lamothe, J.; Marmier, F.; Dupuy, M.; Gaborit, P.; Dupont, L. Scheduling rules to minimize total tardiness in a parallel machine problem with setup and calendar constraints. Comput. Oper. Res. 2012, 39, 1236–1244. [Google Scholar] [CrossRef]
- Grabowski, J.; Pempera, J. Sequencing of jobs in some production system. Eur. J. Oper. Res. 2000, 125, 535–550. [Google Scholar] [CrossRef]
- Sawik, T.J. Mixed integer programming for scheduling surface mount technology lines. Int. J. Prod. Res. 2001, 39, 3219–3235. [Google Scholar] [CrossRef]
- Wong, T.C.; Chan, F.T.S.; Chan, L.Y. A resource-constrained assembly job shop scheduling problem with Lot Streaming technique. Comput. Ind. Eng. 2009, 57, 983–995. [Google Scholar] [CrossRef]
- Yalaoui, N.; Ouazene, Y.; Yalaoui, F.; Amodeo, L.; Mahdi, H. Fuzzy-metaheuristic methods to solve a hybrid flow shop scheduling problem with pre-assignment. Int. J. Prod. Res. 2013, 51, 3609–3624. [Google Scholar] [CrossRef]
- Salvador, M.S. A solution to a special class of flow shop scheduling problems. In Symposium on the Theory of Scheduling and Its Applications, 1st ed.; Elmaghraby, S.E., Ed.; Springer: Berlin, Germany, 1973; pp. 83–91. [Google Scholar]
- Yan, H.S.; Xia, Q.F.; Zhu, M.R.; Liu, X.L.; Guo, Z.M. Integrated Production Planning and Scheduling on Automobile Assembly Lines. IIE Trans. 2003, 35, 711–725. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, C.; Gao, L.; Wang, X. Multi-objective optimization algorithms for flow shop scheduling problem: A review and prospects. Int. J. Adv. Manuf. Technol. 2011, 55, 723–739. [Google Scholar] [CrossRef]
- Rossi, A.; Puppato, A.; Lanzetta, M. Heuristics for scheduling a two-stage hybrid flow shop with parallel batching machines: Application at a hospital sterilisation plant. Int. J. Prod. Res. 2013, 51, 2363–2376. [Google Scholar] [CrossRef]
- Chan, F.T.S.; Wang, Z. Robust production control policy for a multiple machines and multiple product-types manufacturing system with inventory inaccuracy. Int. J. Prod. Res. 2014, 52, 4803–4819. [Google Scholar] [CrossRef]
- Kis, T.; Pesch, E. A review of exact solution methods for the non-preemptive multiprocessor flowshop problem. Eur. J. Oper. Res. 2005, 164, 592–608. [Google Scholar] [CrossRef]
- Ruiz, R.; Vázquez-rodríguez, J.A. The hybrid flow shop scheduling problem. Eur. J. Oper. Res. 2010, 205, 1–18. [Google Scholar] [CrossRef]
- Pan, Q.K.; Wang, L.; Gao, L. A chaotic harmony search algorithm for the flow shop scheduling problem with limited buffers. Appl. Soft Comput. 2011, 11, 5270–5280. [Google Scholar] [CrossRef]
- Wang, H.; Chou, F.; Wu, F. A simulated annealing for hybrid flow shop scheduling with multiprocessor tasks to minimize makespan. Int. J. Adv. Manuf. Technol. 2011, 53, 761–776. [Google Scholar] [CrossRef]
- Yang, J. Minimizing total completion time in a two-stage hybrid flow shop with dedicated machines at the first stage. Comput. Oper. Res. 2015, 58, 1–8. [Google Scholar] [CrossRef]
- Mirsanei, H.S.; Zandieh, M.; Moayed, M.J.; Khabbazi, M.R. A simulated annealing algorithm approach to hybrid flow shop scheduling with sequence-dependent setup times. J. Intell. Manuf. 2011, 22, 965–978. [Google Scholar] [CrossRef]
- Wang, I.L.; Yang, T.; Chang, Y.B. Scheduling two-stage hybrid flow shops with parallel batch, release time, and machine eligibility constraints. J. Intell. Manuf. 2012, 23, 2271–2280. [Google Scholar] [CrossRef]
- Wang, S.; Liu, M.; Chu, C. A branch-and-bound algorithm for two-stage no-wait hybrid flow-shop scheduling. Int. J. Prod. Res. 2015, 53, 1143–1167. [Google Scholar] [CrossRef]
- Komaki, G.M.; Teymourian, E.; Kayvanfar, V. Minimising makespan in the two-stage assembly hybrid flow shop scheduling problem using artificial immune systems. Int. J. Prod. Res. 2015, 7543, 1–21. [Google Scholar] [CrossRef]
- Sun, L.; Yu, S. Scheduling a real-world hybrid flow shop with variable processing times using Lagrangian relaxation. Int. J. Adv. Manuf. Technol. 2015, 78, 1961–1970. [Google Scholar] [CrossRef]
- Tang, L.; Liu, W.; Liu, J. A neural network model and algorithm for the hybrid flow shop scheduling problem in a dynamic environment. J. Intell. Manuf. 2005, 16, 361–370. [Google Scholar] [CrossRef]
- Chryssolouris, G. Manufacturing Systems: Theory and Practice, 2nd ed.; Springer Science & Business Media: New York, NY, USA, 2006; pp. 465–597. [Google Scholar]
- Mehta, S.V.; Uzsoy, R.M. Predictable scheduling of a job shop subject to breakdowns. IEEE Trans. Robot. Autom. 1998, 14, 365–378. [Google Scholar] [CrossRef]
- Yao, F.S.; Zhao, M.; Zhang, H. Two-stage hybrid flow shop scheduling with dynamic job arrivals. Comput. Oper. Res. 2012, 39, 1701–1712. [Google Scholar] [CrossRef]
- Feng, X.; Zheng, F.; Xu, Y. Robust scheduling of a two-stage hybrid flow shop with uncertain interval processing times. Int. J. Prod. Res. 2016, 54, 3706–3717. [Google Scholar] [CrossRef]
- Chryssolouris, G.; Velusamy, S. Dynamic scheduling of manufacturing job shops using genetic algorithms. J. Intell. Manuf. 2001, 12, 281–293. [Google Scholar] [CrossRef]
- Gourgand, M.; Grangeon, N.; Norre, S. A review of the static stochastic flow-shop scheduling problem. J. Decis. Syst. 2000, 9, 1–31. [Google Scholar] [CrossRef]
- Joo, B.J.; Choi, Y.C.; Xirouchakis, P. Dispatching rule-based algorithms for a dynamic flexible flow shop scheduling problem with time-dependent process defect rate and quality feedback. Procedia CIRP 2013, 7, 163–168. [Google Scholar] [CrossRef]
- Wang, K.; Choi, S.H.; Qin, H.; Huang, Y. A cluster-based scheduling model using SPT and SA for dynamic hybrid flow shop problems. Int. J. Adv. Manuf. Technol. 2013, 67, 2243–2258. [Google Scholar] [CrossRef]
- Chryssolouris, G.; Dicke, K.; Lee, M. An approach to real-time flexible scheduling. Int. J. Flex. Manuf. Syst. 1994, 6, 235–253. [Google Scholar] [CrossRef]
- Rahmani, D.; Ramezanian, R. A stable reactive approach in dynamic flexible flow shop scheduling with unexpected disruptions: A case study. Comput. Ind. Eng. 2016, 98, 360–372. [Google Scholar] [CrossRef]
- Michalos, G.; Makris, S.; Mourtzis, D. A web based tool for dynamic job rotation scheduling using multiple criteria. CIRP Ann. Manuf. Technol. 2011, 60, 453–456. [Google Scholar] [CrossRef]
- Sahin, F.; Narayanan, A.; Robinson, E.P. Rolling horizon planning in supply chains: Review, implications and directions for future research. Int. J. Prod. Res. 2013, 51, 5413–5436. [Google Scholar] [CrossRef]
- Sun, Y.; Feng, G.; Cao, J. Stochastic stability of Markovian switching genetic regulatory networks. Phys. Lett. A 2009, 373, 1646–1652. [Google Scholar] [CrossRef]
- Jong, H.D. Modeling and simulation of genetic regulatory systems: A literature review. J. Comput. Biol. 2002, 9, 67–103. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, Z.; Liang, J.; Li, Y.; Du, M. Synchronization of stochastic genetic oscillator networks with time delays and Markovian jumping parameters. Neurocomputing 2010, 73, 2532–2539. [Google Scholar] [CrossRef]
- Wahde, M.; Hertz, J. Coarse-grained reverse engineering of genetic regulatory networks. Biosystems 2000, 55, 129–136. [Google Scholar] [CrossRef]
- Shan, R.; Zhao, Z.S.; Chen, P.F.; Liu, W.J.; Xiao, S.Y.; Hou, Y.H.; Wang, Z. Network modeling and assessment of ecosystem health by a multi-population swarm optimized neural network ensemble. Appl. Sci. 2016, 6, 175. [Google Scholar] [CrossRef]
- Quan, G.Z.; Zhang, Z.H.; Zhang, L.; Liu, Q. Numerical Descriptions of Hot Flow Behaviors across β Transus for as-Forged Ti–10V–2Fe–3Al Alloy by LHS-SVR and GA-SVR and Improvement in Forming Simulation Accuracy. Appl. Sci. 2016, 8, 210. [Google Scholar] [CrossRef]
- Qin, W.; Zhang, J.; Song, D. An improved ant colony algorithm for dynamic hybrid flow shop scheduling with uncertain processing time. J. Intell. Manuf. 2015. [Google Scholar] [CrossRef]

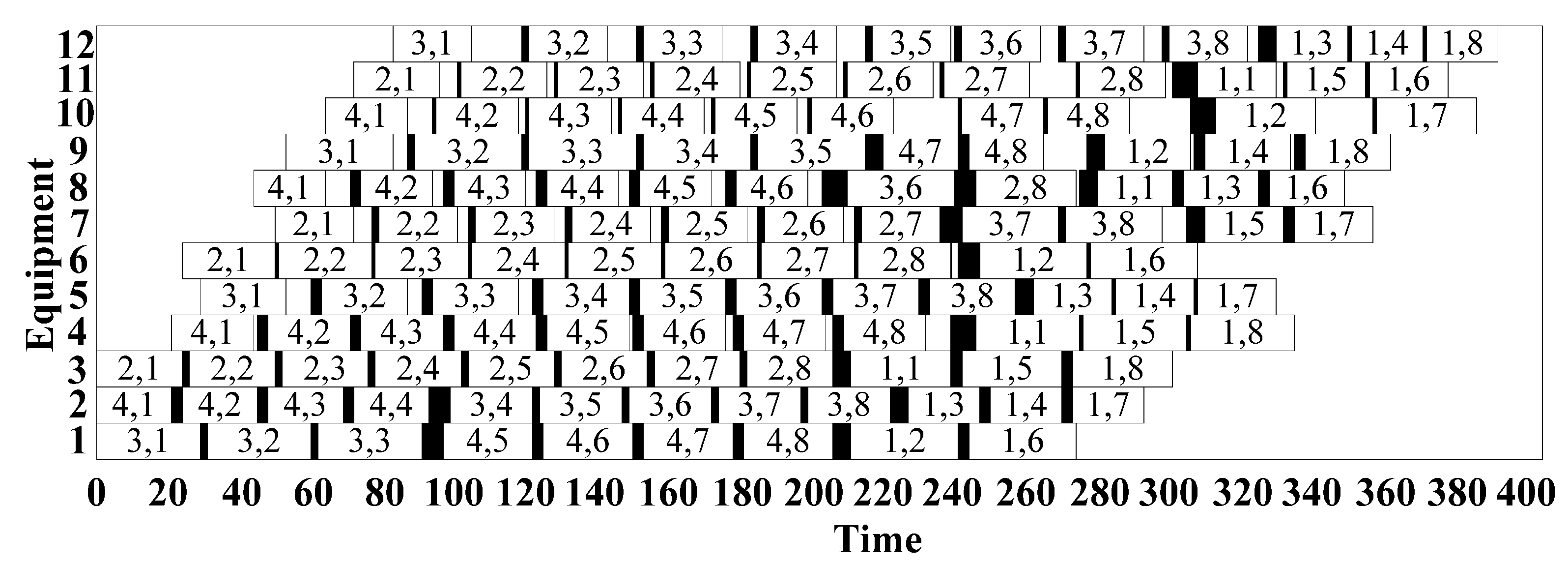

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
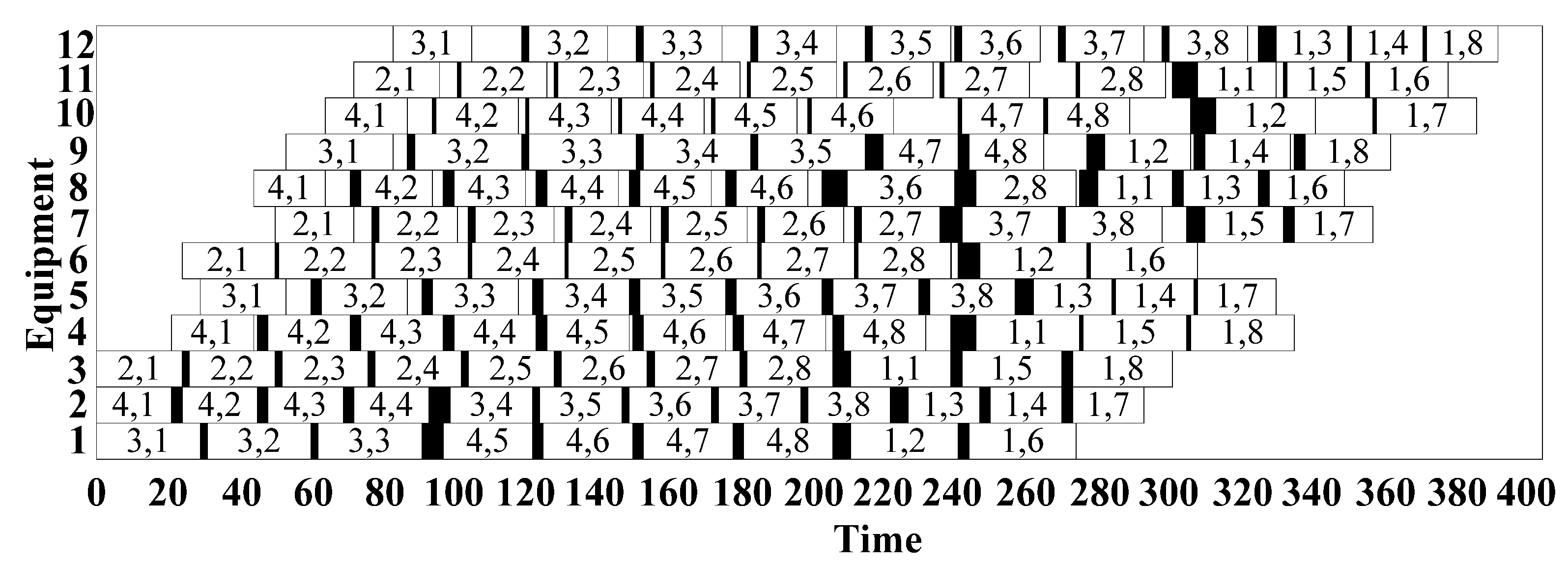{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Definitions |
|---|---|
| Sets | |
| Set of job types | |
| Set of production stages | |
| Set of parallel machines at stage | |
| Set of waiting processing jobs | |
| Parameters | |
| Operation processing time of job type on the th machine at stage | |
| Changeover time required by the th machine at stage to operate on job type after job type | |
| Production volume of job type , | |
| Variables | |
| Binary variable: 1, if the th job entering the first production stage belongs to job type ; 0, otherwise | |
| Binary variable: 1, if the th job entering the first production stage is processed on the th machine at stage ; 0, otherwise | |
| The time instant the th machine of production stage to be available for the th job | |
| The job type processed by the th machine of production stage before | |
| Problem Parameter | Numerical Range |
|---|---|
| Number of production stages (I) | 4 |
| Number of parallel machines at each stage (Ki) | U[2, 4] |
| Number of job types (M) | 4 |
| Production volume of each job type (dm) | 8 |
| Processing time (tmki) (s) | U[20, 30] |
| Changeover time between same job types (cmmki) (s) | U[1, 3] |
| Changeover time between different job types (cmm′ki) (s) | U[5, 7.5] |
| Delivery Time Deviation Tolerance | Makespan (s) | Rescheduling Times | Computational Time (ms) |
|---|---|---|---|
| 0.025 | 408.08 | 39 | 65,708 |
| 0.05 | 400.55 | 15 | 23,842 |
| 0.075 | 401.03 | 7 | 11,346 |
| 0.1 | 407.20 | 5 | 7245 |
| 0.125 | 394.34 | 2 | 3243 |
| 0.15 | 394.93 | 2 | 3193 |
| 0.2 | 395.22 | 1 | 1602 |
| 0.25 | 395.22 | 1 | 1602 |
| 0.3 | 439.46 | 0 | 16 |
| 0.35 | 439.46 | 0 | 19 |
| 0.4 | 439.46 | 0 | 18 |
| 0.45 | 439.46 | 0 | 21 |
| 0.5 | 439.46 | 0 | 19 |
| Rolling Window Size (Operation) | Makespan (s) | Rescheduling Times | Computational Time (ms) |
|---|---|---|---|
| 13 | 394.54 | 2 | 3216 |
| 26 | 397.55 | 3 | 4997 |
| 39 | 400.78 | 4 | 7914 |
| 51 | 394.56 | 4 | 9305 |
| 64 | 398.19 | 3 | 7219 |
| 77 | 386.78 | 4 | 13,006 |
| 90 | 390.33 | 2 | 6363 |
| 102 | 393.33 | 2 | 7519 |
| 115 | 389.03 | 4 | 18,545 |
| 128 | 390.54 | 2 | 10,400 |
| Benchmark | Number of Jobs | Number of Stages | Number of Machines at Each Stage | Processing Times (s) | Setup Times (s) (Same Jobs) | Setup Times (s) (Different Jobs) |
|---|---|---|---|---|---|---|
| 6 × 2 | 6 | 2 | U[1, 5] | U[50, 70] | U[3, 5] | U[12, 24] |
| 30 × 2 | 30 | 2 | U[1, 5] | U[50, 70] | U[3, 5] | U[12, 24] |
| 100 × 2 | 100 | 2 | U[1, 5] | U[50, 70] | U[3, 5] | U[12, 24] |
| 6 × 4 | 6 | 4 | U[1, 5] | U[50, 70] | U[3, 5] | U[12, 24] |
| 30 × 4 | 30 | 4 | U[1, 5] | U[50, 70] | U[3, 5] | U[12, 24] |
| 100 × 4 | 100 | 4 | U[1, 5] | U[50, 70] | U[3, 5] | U[12, 24] |
| 6 × 8 | 6 | 8 | U[1, 5] | U[50, 70] | U[3, 5] | U[12, 24] |
| 30 × 8 | 30 | 8 | U[1, 5] | U[50, 70] | U[3, 5] | U[12, 24] |
| 100 × 8 | 100 | 8 | U[1, 5] | U[50, 70] | U[3, 5] | U[12, 24] |
| Benchmark Name | GRN-Based Method | IACO Method | ||||
|---|---|---|---|---|---|---|
| Makespan (s) | Rescheduling Times | CPU Time (ms) | Makespan (s) | Rescheduling Times | CPU Time (ms) | |
| 6 × 2 | 256.27 | 2.3 | 13.3 | 252.79 | 1.15 | 164.5 |
| 30 × 2 | 573.58 | 4.25 | 48.6 | 568.45 | 1.6 | 580.3 |
| 100 × 2 | 886.23 | 1.35 | 354.5 | 855.01 | 1.9 | 8130.5 |
| 6 × 4 | 1071.56 | 1.2 | 26.0 | 1098.29 | 1.85 | 365.2 |
| 30 × 4 | 2249.04 | 2.35 | 67.5 | 2314.21 | 1.2 | 3906.2 |
| 100 × 4 | 2532.37 | 3.15 | 498.4 | 2761.85 | 1.35 | 33,538.3 |
| 6 × 8 | 3471.06 | 1.3 | 51.7 | 3536.51 | 1.55 | 921.4 |
| 30 × 8 | 6859.97 | 1.9 | 97.6 | 6978.14 | 1.9 | 13,641.4 |
| 100 × 8 | 7396.41 | 5.1 | 3055.2 | 7646.71 | 1.85 | 21,9613.3 |
| PCB Type | S1 | S2 | S3 | M1 | M2 | A1 | A2 | T1 | T2 |
|---|---|---|---|---|---|---|---|---|---|
| 3ET0321AF | 4.615 | 1 | 1.2 | 0.3 | 0.24 | 0.6 | 0.75 | 0.6 | 0.6 |
| 3ET0322AF | 4.615 | 1 | 0.293 | 0.4 | 0.3 | 0.6 | 0.75 | 0.6 | 0.55 |
| 3ET0100CET | 1 | 1 | 0.6 | 0.06 | 1.5 | 0.75 | 0.75 | 0.4 | 0.55 |
| 3ET0141CET | 1 | 1.428 | 1 | 0.4 | 0.24 | 0.6 | 0.3 | 0.55 | 0.5 |
| 3ET0349CET | 1 | 1 | 0.6 | 0.4 | 0.3 | 0.75 | 0.75 | 0.6 | 0.6 |
| 3ET0630CET | 1 | 1 | 1 | 0.06 | 0.24 | 0.75 | 0.6 | 0.55 | 0.5 |
| 3ET0631CET | 1 | 1 | 0.6 | 0.06 | 0.3 | 0.6 | 0.75 | 0.55 | 0.4 |
| 3ET0741CET | 1 | 4.615 | 0.293 | 0.6 | 0.3 | 0.75 | 0.6 | 0.4 | 0.4 |
| 3ET0374TEK | 1.428 | 0.923 | 1.2 | 0.4 | 0.3 | 0.6 | 0.3 | 0.6 | 0.55 |
| 3ET0435TEK | 0.923 | 0.923 | 0.882 | 0.6 | 1.5 | 0.6 | 0.4 | 0.6 | 0.4 |
| PCB Type | 3ET0 321AF | 3ET0 322AF | 3ET0 100CET | 3ET0 141CET | 3ET0 349CET | 3ET0 630CET | 3ET0 631CET | 3ET0 741CET | 3ET0 374TEK | 3ET0 435TEK |
|---|---|---|---|---|---|---|---|---|---|---|
| 3ET0321AF | 1.56 | 12.58 | 8.37 | 13.12 | 10.83 | 7.28 | 8.37 | 7.1 | 9.51 | 9.2 |
| 3ET0322AF | 5.73 | 1.32 | 9.64 | 7.3 | 9.53 | 10.57 | 5.77 | 10.67 | 12.13 | 9.82 |
| 3ET0100CET | 9.81 | 7.23 | 1.23 | 6.34 | 11.22 | 14.63 | 12.2 | 11.09 | 12.98 | 6.54 |
| 3ET0141CET | 8.93 | 8.27 | 11.62 | 1.28 | 12.96 | 5.97 | 8.6 | 5.69 | 9.95 | 8.02 |
| 3ET0349CET | 14.12 | 10.73 | 10.05 | 7.79 | 1.32 | 14.26 | 9.83 | 14.6 | 7.07 | 9.29 |
| 3ET0630CET | 8.93 | 10.83 | 10.36 | 10.79 | 14.15 | 1.56 | 14.95 | 11.8 | 10.88 | 10.12 |
| 3ET0631CET | 9.14 | 12.32 | 14.64 | 9.99 | 9.37 | 7.51 | 1.75 | 10.37 | 13.43 | 5.48 |
| 3ET0741CET | 12.19 | 9.81 | 14.22 | 8.99 | 9.52 | 14.33 | 14.43 | 1.22 | 14.09 | 11.83 |
| 3ET0374TEK | 13.17 | 7.75 | 14.34 | 10.12 | 7.54 | 5.85 | 8.44 | 6.82 | 1.38 | 5.03 |
| 3ET0435TEK | 6.44 | 7.89 | 12.52 | 13.34 | 10.28 | 13.01 | 10.72 | 6.14 | 7.85 | 1.52 |
© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, Y.; Zhang, J.; Qin, W. A Genetic Regulatory Network-Based Method for Dynamic Hybrid Flow Shop Scheduling with Uncertain Processing Times. Appl. Sci. 2017, 7, 23. https://doi.org/10.3390/app7010023
Lv Y, Zhang J, Qin W. A Genetic Regulatory Network-Based Method for Dynamic Hybrid Flow Shop Scheduling with Uncertain Processing Times. Applied Sciences. 2017; 7(1):23. https://doi.org/10.3390/app7010023
Chicago/Turabian StyleLv, Youlong, Jie Zhang, and Wei Qin. 2017. "A Genetic Regulatory Network-Based Method for Dynamic Hybrid Flow Shop Scheduling with Uncertain Processing Times" Applied Sciences 7, no. 1: 23. https://doi.org/10.3390/app7010023
APA StyleLv, Y., Zhang, J., & Qin, W. (2017). A Genetic Regulatory Network-Based Method for Dynamic Hybrid Flow Shop Scheduling with Uncertain Processing Times. Applied Sciences, 7(1), 23. https://doi.org/10.3390/app7010023