
Maize Seed Variety Classification Using the Integration of Spectral and Image Features Combined with Feature Transformation Based on Hyperspectral Imaging

Abstract
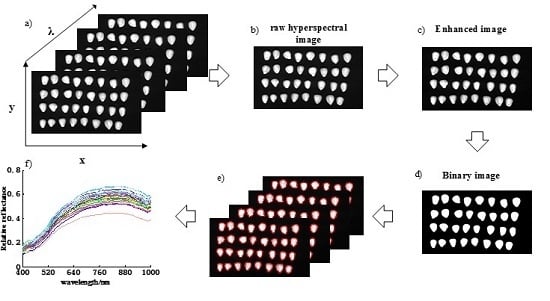
:
1. Introduction
2. Materials and Methods
2.1. Maize Seeds
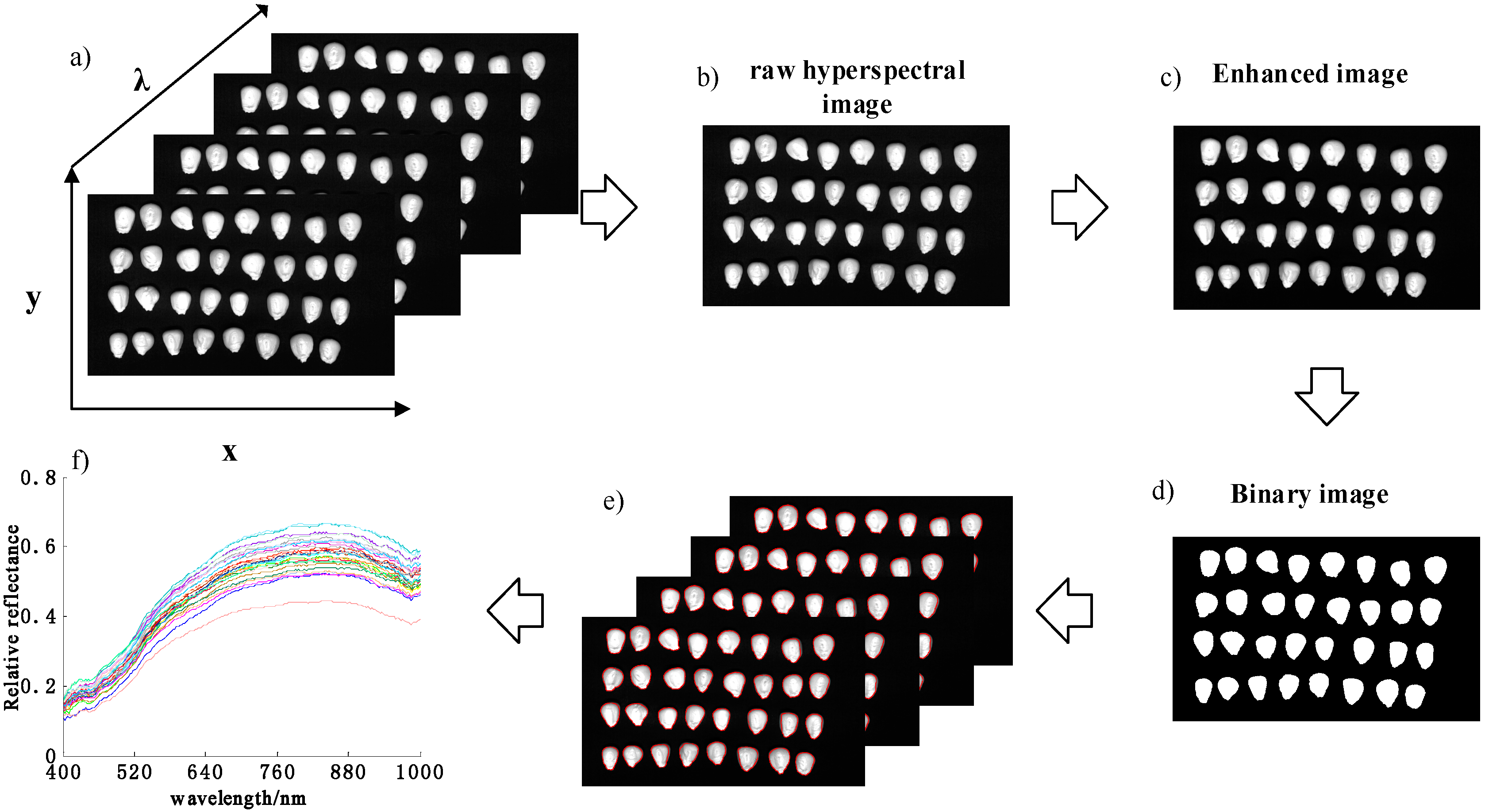
2.2. Hyperspectral Reflectance Imaging Ccquisition and Correction
2.3. Spectral and Image Feature Extraction
2.3.1. Image Segmentation and Spectral Feature Extraction
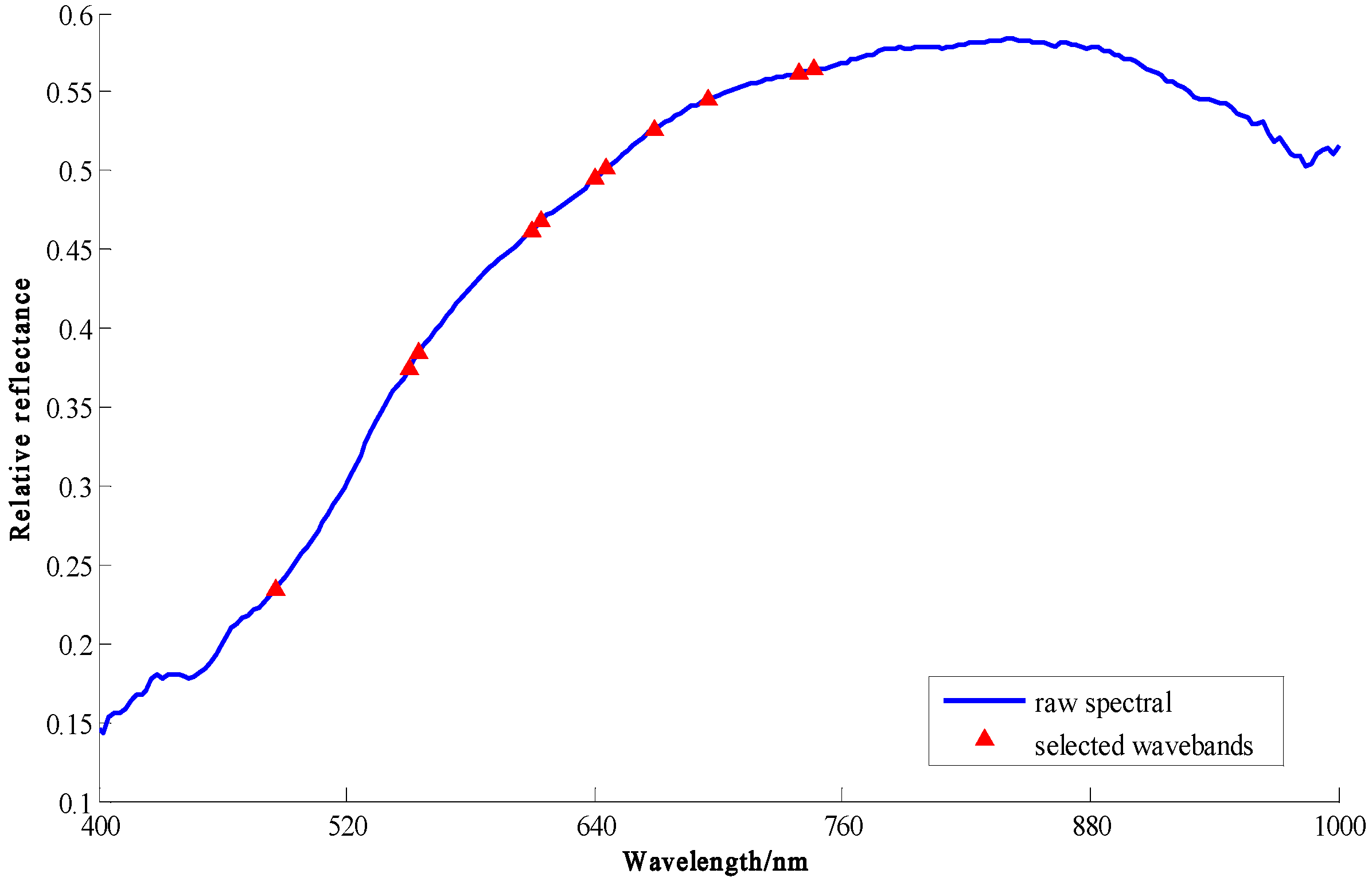
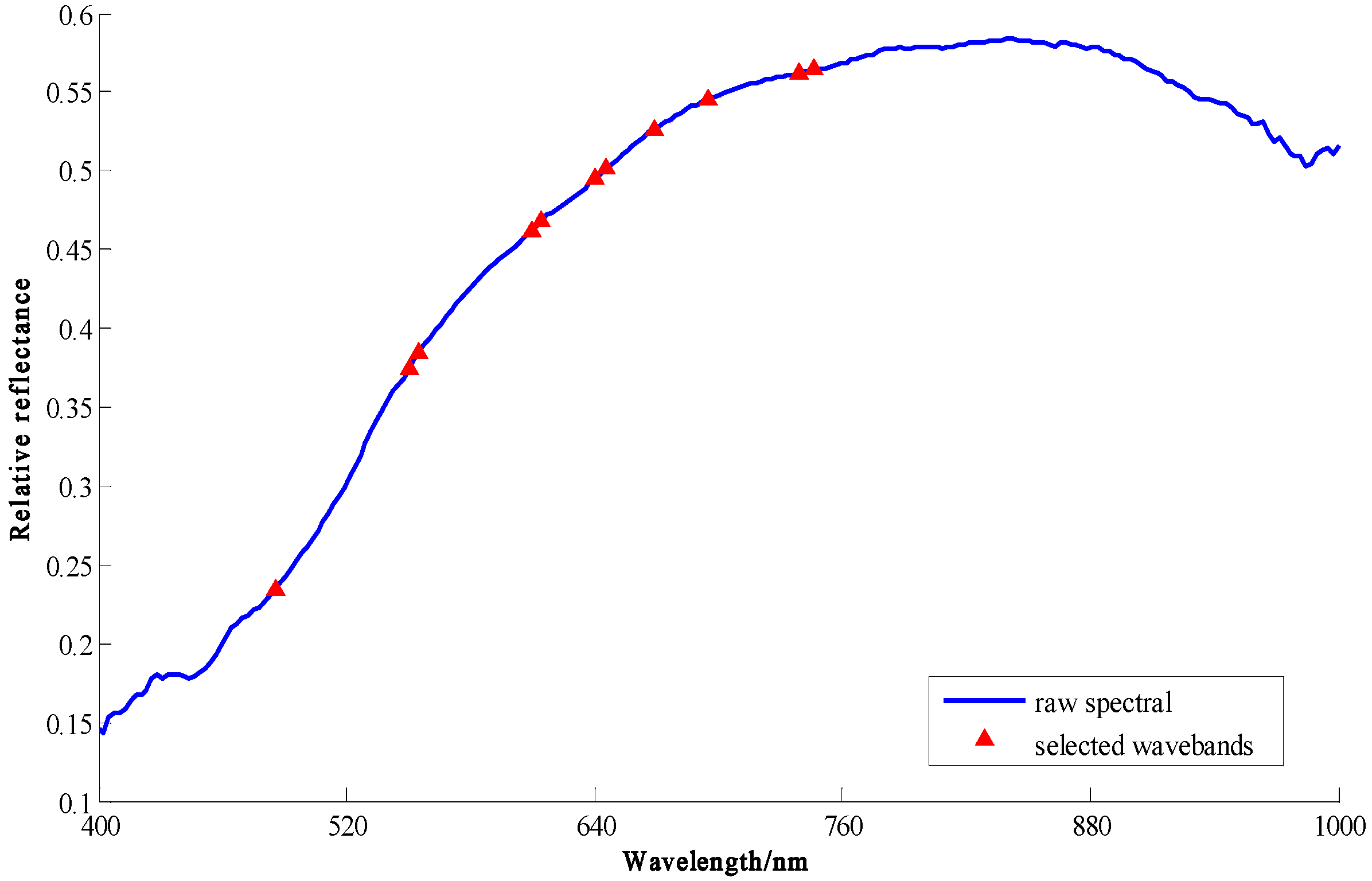
2.3.2. Optimal Wavelength Selection
2.3.3. Image Feature Extraction
2.4. Feature Integration and Transformation/Reduction
2.5. Developing Classification Models Based on LS–SVM
3. Results
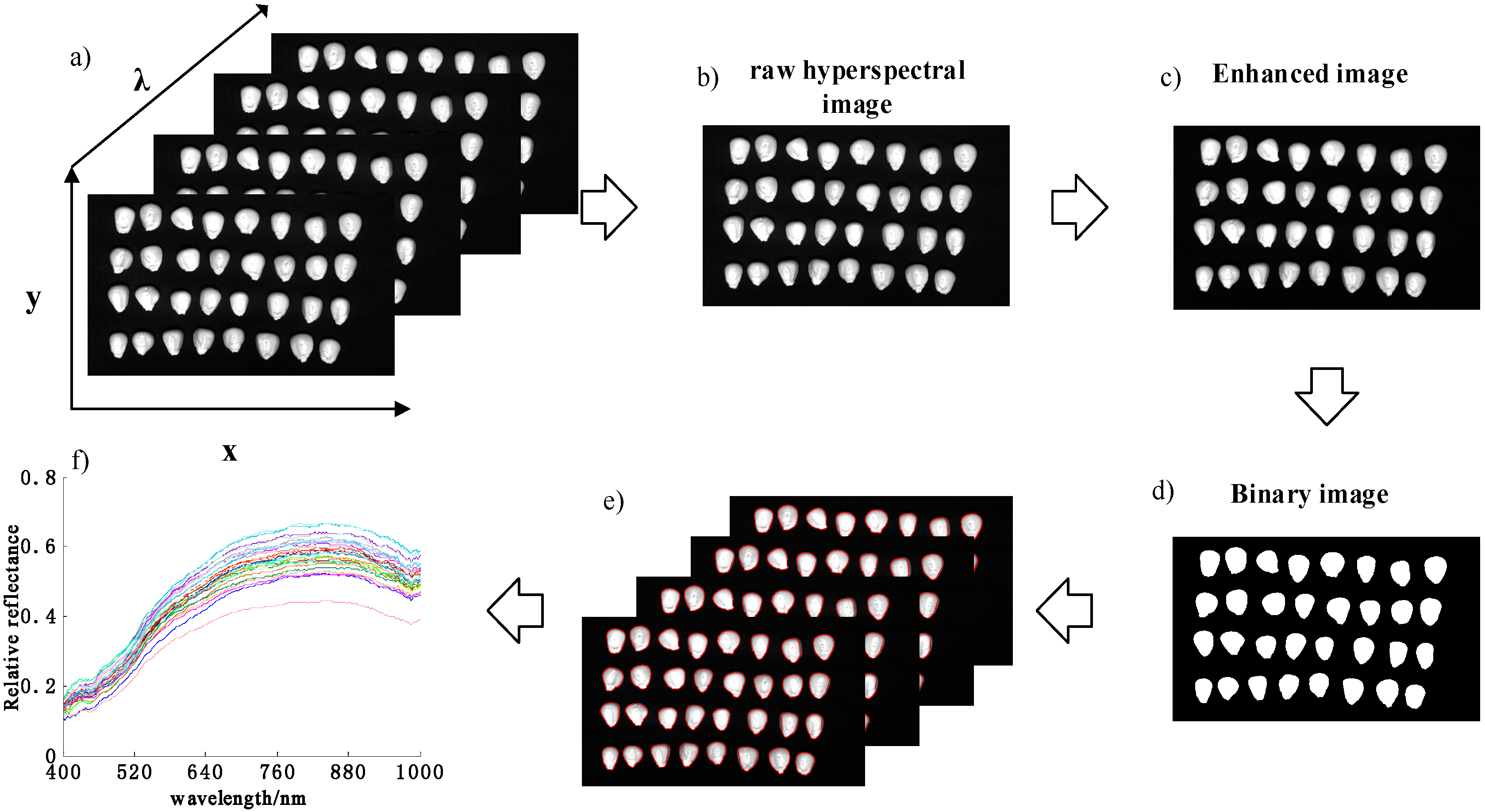
3.1. Characteristics of the Spectral Features of Maize Seeds
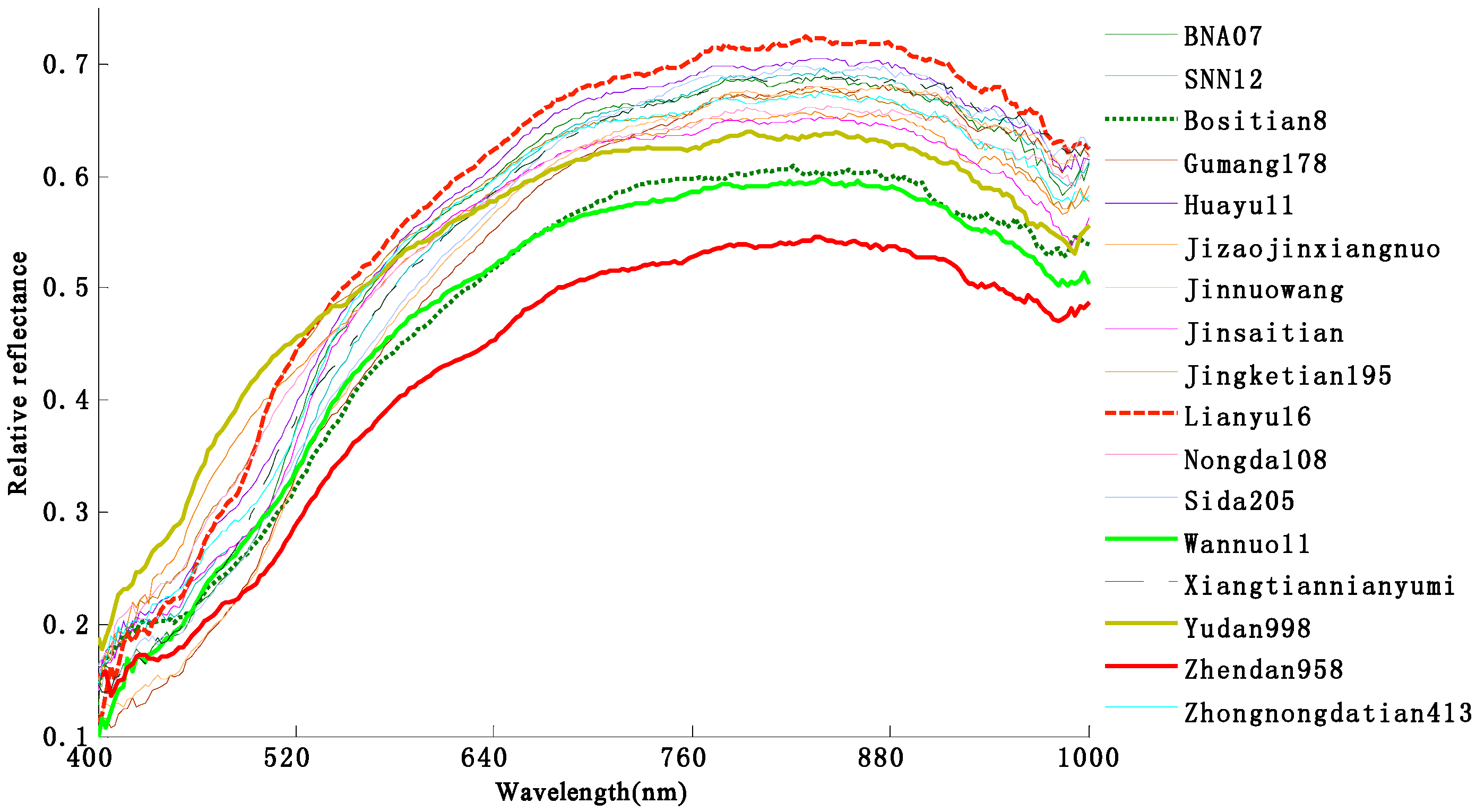
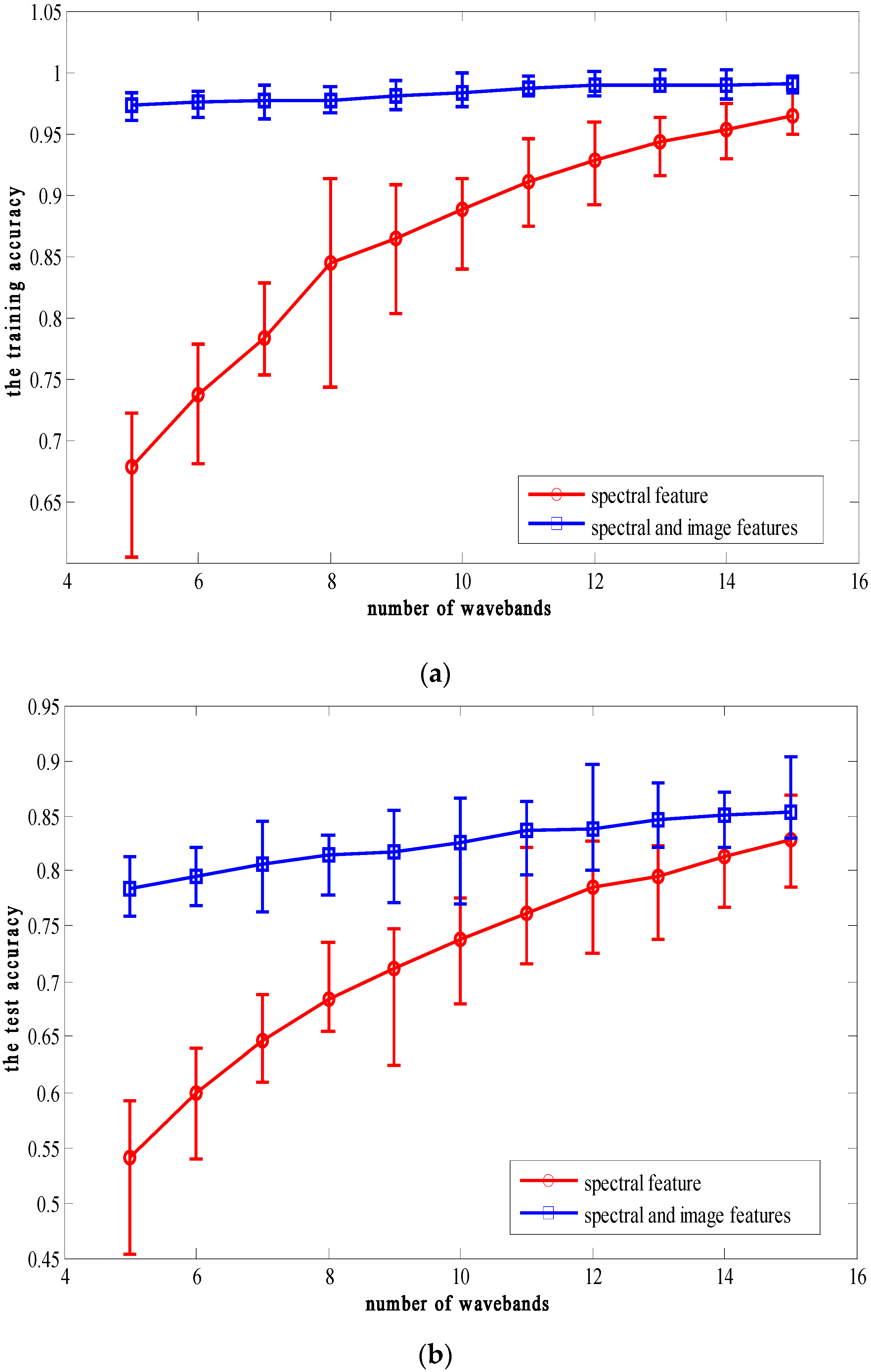
3.2. Classification Results Using the Integration of Spectral and Image Features Based on the Optimal Wavelengths
3.3. Classification Results Using the Integration of Spectral and Image Features Combined with the Feature Transformation/Reduction Method
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Tenaillon, M.I.; Charcosset, A. A European perspective on maize history. C. R. Biol. 2011, 334, 221–228. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Wang, Y. Brief analysis of maize seed purity electrophoresis identification. Seed World 2000, 1, 21. [Google Scholar]
- Zhu, D.; Wang, C.; Pang, B.; Shan, F.; Wu, Q.; Zhao, C. Identification of wheat cultivars based on the hyperspectral image of single seed. J. Nanoelectron. Optoe. 2012, 7, 167–172. [Google Scholar] [CrossRef]
- Su, Q.; Wu, W.; Wang, H.; Wang, K.; An, D. Fast discrimination of varieties of corn based on near infrared spectra and biomimetic pattern recognition. Spectrosc. Spectr. Anal. 2009, 29, 2413–2416. [Google Scholar]
- Zhang, Y.; Zhang, L.; Bai, Q.; Chen, S. Nondestructive identification of different oil content maize kernels by near-infrared spectra. Spectrosc. Spectr. Anal. 2009, 29, 686–689. [Google Scholar]
- Dana, W.; Ivo, W. Computer image analysis of seed shape and seed color for flax cultivar description. Comput. Electron. Agr. 2008, 61, 126–135. [Google Scholar] [CrossRef]
- Khatchatourian, O.; Padilha, F.R.R. Soybean varieties recognition through the digital image processing using artificial neural network. Eng. Agric. 2008, 28, 759–769. [Google Scholar]
- Hadzli, H.; Fairul, N.O.; Syed, A.M.J.; Muhammad, A.H.; Hajar, M.S. An Intelligent Classification Model for Rubber Seed Clones Based on Shape Features through Imaging Techniques. In Proceeding of the International Conference on Intelligent Systems, Modelling and Simulation, Liverpool, UK, 27–29 January 2010.
- Wang, Y.; Liu, X.; Su, Q.; Wang, C. Maize seeds varieties identification based on multi-object feature extraction and optimized neural network. Trans. CSAE 2010, 26, 199–204. [Google Scholar]
- Lu, R.; Park, B. Hyperspectral Imaging Technology in Food and Agriculture; Springer, Food Engineering Series: New York, NY, USA, 2015. [Google Scholar]
- Mahesh, S.; Manickavasagan, A.; Jayas, D.S.; Paliwal, J.; White, N.D.G. Feasibility of near-infrared hyperspectral imaging to differentiate Canadian wheat classes. Biosyst. Eng. 2008, 101, 50–57. [Google Scholar] [CrossRef]
- Serranti, S.; Cesare, D.; Marini, F.; Bonifazi, G. Classification of oat and groat kernels using NIR hyperspectral imaging. Talanta 2013, 103, 276–284. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Q.; Feng, Z.; Huang, M.; Zhu, X. Maize seed identification using hyperspectral imaging and SVDD algorithm. Spectrosc. Spectr. Anal. 2013, 33, 517–521. [Google Scholar]
- Huang, M.; Tang, J.; Yang, B.; Zhu, Q. Classification of maize seeds of different years based on hyperspectral imaging and model updating. Comput. Electron. Agric. 2016, 122, 139–145. [Google Scholar] [CrossRef]
- Wang, L.; Sun, D.; Pu, H.; Zhu, Z. Application of Hyperspectral Imaging to Discriminate the Variety of Maize Seeds. Food Anal. Methods 2016, 9, 225–234. [Google Scholar] [CrossRef]
- Yang, X.; Hong, H.; You, Z.; Cheng, F. Spectral and Image Integrated Analysis of Hyperspectral Data for Waxy Corn Seed Variety Classification. Sensors 2015, 15, 15578–15594. [Google Scholar] [CrossRef] [PubMed]
- Gerrit, P.; Gerie, W.A.M.; van der Heijden, L.C.; Paul, K.; Ian, T.Y. Calibration and characterization of imaging spectrographs. J. Near Infrared Spec. 2003, 11, 193–210. [Google Scholar]
- Sezgin, M.; Sankur, B. Survey over image thresholding techniques and quantitative performance evaluation. J. Electron. Imaging 2004, 13, 146–165. [Google Scholar]
- Araújo, M.C.U.; Saldanha, T.C.B.; Galvão, R.K.H.; Yoneyama, T.; Chame, H.C.; Visani, V. The successive projections algorithm for variable selection in spectroscopic multicomponent analysis. Chemometr. Intell. Lab. Syst. 2001, 57, 65–73. [Google Scholar] [CrossRef]
- Galvão, R.K.H.; Araujo, M.C.U.; José, G.E.; Pontes, M.J.C.; Silva, E.C.; Saldanha, T.C.B. A method for calibration and validation subset partitioning. Talanta 2005, 67, 736–740. [Google Scholar] [CrossRef] [PubMed]
- Galvao, R.K.H.; Araujo, M.C.U.; Fragoso, W.D.; Silva, E.C.; Jose, G.E.; Soares, S.F.C.; Paiva, H.M. A variable elimination method to improve the parsimony of MLR models using the successive projections algorithm. Chemometr. Intell. Lab. Syst. 2008, 92, 83–91. [Google Scholar] [CrossRef]
- Battiti, R. Using mutual information for selecting features in supervised neural net learning. ITNN 1994, 5, 537–550. [Google Scholar] [CrossRef] [PubMed]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min-redundancy. ITPAM 2005, 27, 1226–1238. [Google Scholar]
- Paliwal, J.; Visen, N.; Jayas, D. Evaluation of neural network architectures for cereal grain classification using morphological features. J. Agric. Eng. Res. 2001, 79, 361–370. [Google Scholar] [CrossRef]
- Liu, Z.; Cheng, F.; Ying, Y.; Rao, X. Identification of rice seed varieties using neural network. J. Zhejiang Univ. Sci. B. 2005, 6, 1095–1100. [Google Scholar] [CrossRef] [PubMed]
- Mery, D.; Pedreschi, F.; Soto, A. Automated design of a computer vision system for visual food quality evaluation. Food. Bioprocess. Tech. 2012, 6, 2093–2108. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417–441. [Google Scholar] [CrossRef]
- Cox, T.; Cox, M. Multidimensional scaling; Chapman and Hall: London, UK, 1994. [Google Scholar]
- Vapnik, V.N. Statistical Learning Theory; John Wiley and Sons: Hoboken, NJ, USA, 1998. [Google Scholar]
- Suykens, J.A.K.; Brabanter, J.D.; Lukas, L.; Vandewalle, J. Weighted least squares support vector machines: Robustness and sparse approximation. Neurocomputing 2002, 48, 85–105. [Google Scholar] [CrossRef]
- Wu, D.; He, Y.; Feng, S. Short-wave near-infrared spectroscopy analysis of major compounds in milk powder and wavelength assignment. Anal. Chim. Acta 2008, 610, 232–242. [Google Scholar] [CrossRef] [PubMed]
- Drochioiu, G.; Ciobanu, C.I.; Bancila, S.; Ion, L.; Petre, B.A.; Andries, C.; Gradinaru, R.V.; Murariu, M. Ultrasound-based protein determination in maize seeds. Ultrason. Sonochem. 2016, 29, 93–103. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variety | The Training Accuracy | The Test Accuracy | ||||
|---|---|---|---|---|---|---|
| None | PCA | MDS | None | PCA | MDS | |
| BNA07 | 99.06% | 99.84% | 100% | 87.82% | 95.00% | 94.69% |
| SNN12 | 97.97% | 99.84% | 99.69% | 76.88% | 91.54% | 92.19% |
| Bositian8 | 98.28% | 100% | 100% | 74.38% | 86.56% | 85.00% |
| Gumang178 | 100% | 100% | 100% | 95.32% | 97.82% | 98.44% |
| Huayu11 | 99.38% | 100% | 100% | 77.81% | 94.07% | 95.63% |
| Jizaojinxiangnuo | 100% | 100% | 100% | 91.57% | 95.94% | 95.00% |
| Jinnuowang | 96.88% | 100% | 100% | 86.25% | 94.07% | 94.69% |
| Jinsaitian | 98.13% | 99.53% | 99.53% | 81.25% | 92.50% | 89.38% |
| Jingketian195 | 97.97% | 99.69% | 99.53% | 84.06% | 83.75% | 84.38% |
| Lianyu16 | 97.50% | 99.69% | 99.84% | 83.44% | 94.69% | 93.44% |
| Nongda108 | 98.13% | 99.69% | 99.68% | 85.32% | 94.07% | 94.69% |
| Sida205 | 98.75% | 100% | 100% | 85.00% | 85.32% | 85.63% |
| Wannuo11 | 97.50% | 100% | 99.84% | 78.75% | 91.25% | 90.32% |
| Xiangtiannianyumi | 99.06% | 99.53% | 99.69% | 71.88% | 90.63% | 91.56% |
| Yudan998 | 99.84% | 99.84% | 100% | 95.94% | 97.81% | 96.88% |
| Zhendan958 | 99.06% | 100% | 100% | 92.50% | 99.38% | 98.13% |
| Zhongnongdatian413 | 98.59% | 99.84% | 100% | 74.38% | 90.94% | 87.19% |
| Average | 98.69% | 99.85% | 99.87% | 83.68% | 92.65% | 92.19% |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, M.; He, C.; Zhu, Q.; Qin, J. Maize Seed Variety Classification Using the Integration of Spectral and Image Features Combined with Feature Transformation Based on Hyperspectral Imaging. Appl. Sci. 2016, 6, 183. https://doi.org/10.3390/app6060183
Huang M, He C, Zhu Q, Qin J. Maize Seed Variety Classification Using the Integration of Spectral and Image Features Combined with Feature Transformation Based on Hyperspectral Imaging. Applied Sciences. 2016; 6(6):183. https://doi.org/10.3390/app6060183
Chicago/Turabian StyleHuang, Min, Chujie He, Qibing Zhu, and Jianwei Qin. 2016. "Maize Seed Variety Classification Using the Integration of Spectral and Image Features Combined with Feature Transformation Based on Hyperspectral Imaging" Applied Sciences 6, no. 6: 183. https://doi.org/10.3390/app6060183
APA StyleHuang, M., He, C., Zhu, Q., & Qin, J. (2016). Maize Seed Variety Classification Using the Integration of Spectral and Image Features Combined with Feature Transformation Based on Hyperspectral Imaging. Applied Sciences, 6(6), 183. https://doi.org/10.3390/app6060183