
The Data-Driven Optimization of Parcel Locker Locations in a Transit Co-Modal System with Ride-Pooling Last-Mile Delivery


Abstract
1. Introduction
- We develop an optimization framework based on random sampling to determine the optimal parcel locker locations in a transit co-modal system incorporating ride-pooling services to perform last-mile delivery;
- We propose a ranking-based classification for the candidate parcel locker locations, classifying the candidate locations into five types and offering policy implications;
- We discover that the average minimum detour distance of ride-pooling passengers can be positively affected by the density of ride-pooling demand and negatively impacted by the number of selected locations, thereby providing insights into the planning of parcel locker locations.
2. Literature Review
3. Scenario Design for the Ride-Pooling Services with Passenger–Parcel Integration
4. The p-Median Model for Planning Parcel Locker Locations
5. An Optimization Framework for Parcel Locker Locations with Randomly Sampled Passenger Trip Data
5.1. The Shenzhen Taxi Trip Data
- The anonymized taxi plate number;
- The start time of the trip;
- The longitude and the latitude (both in GPS coordinates) of the trip origin and destination.
5.2. The Candidate Parcel Locker Location Data
5.3. The Optimization Framework for Parcel Locker Locations
6. Numerical Experiments
6.1. Experimental Setup
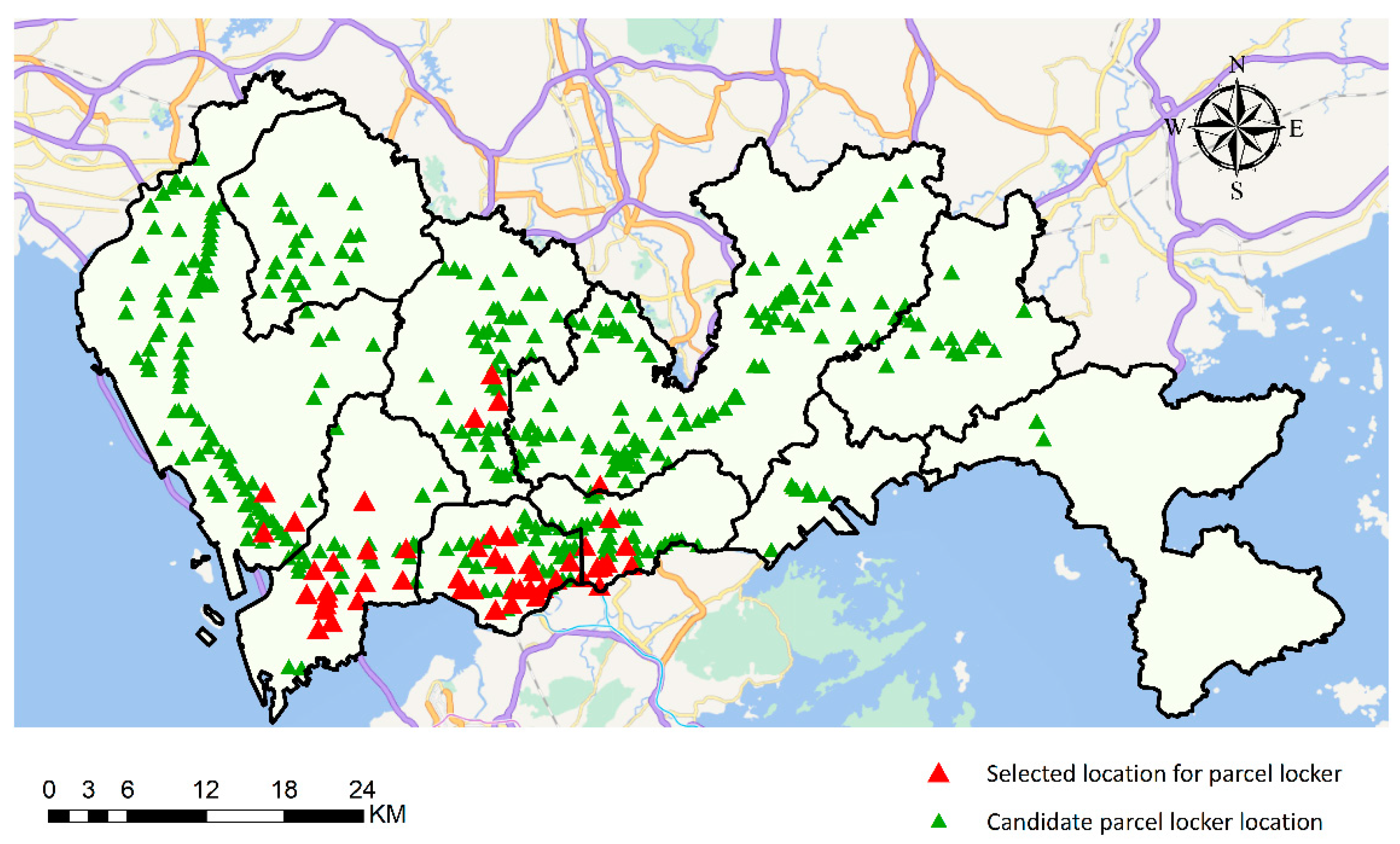
6.2. Illustrative Example of the Result of the Proposed Optimization Framework
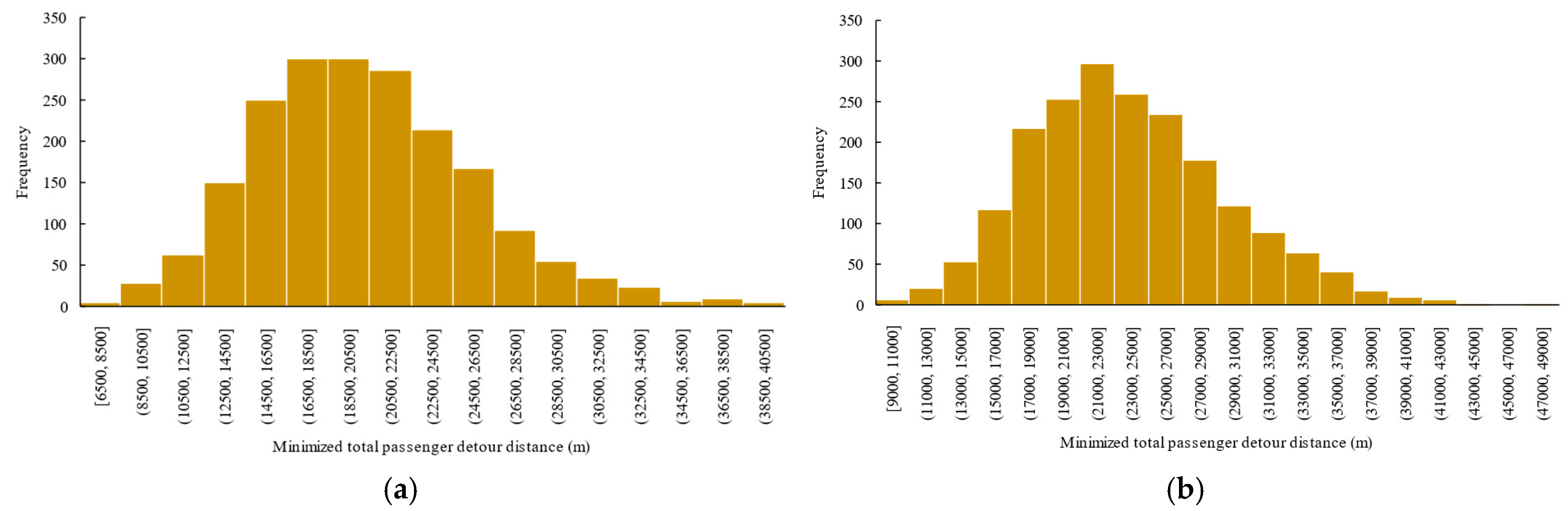
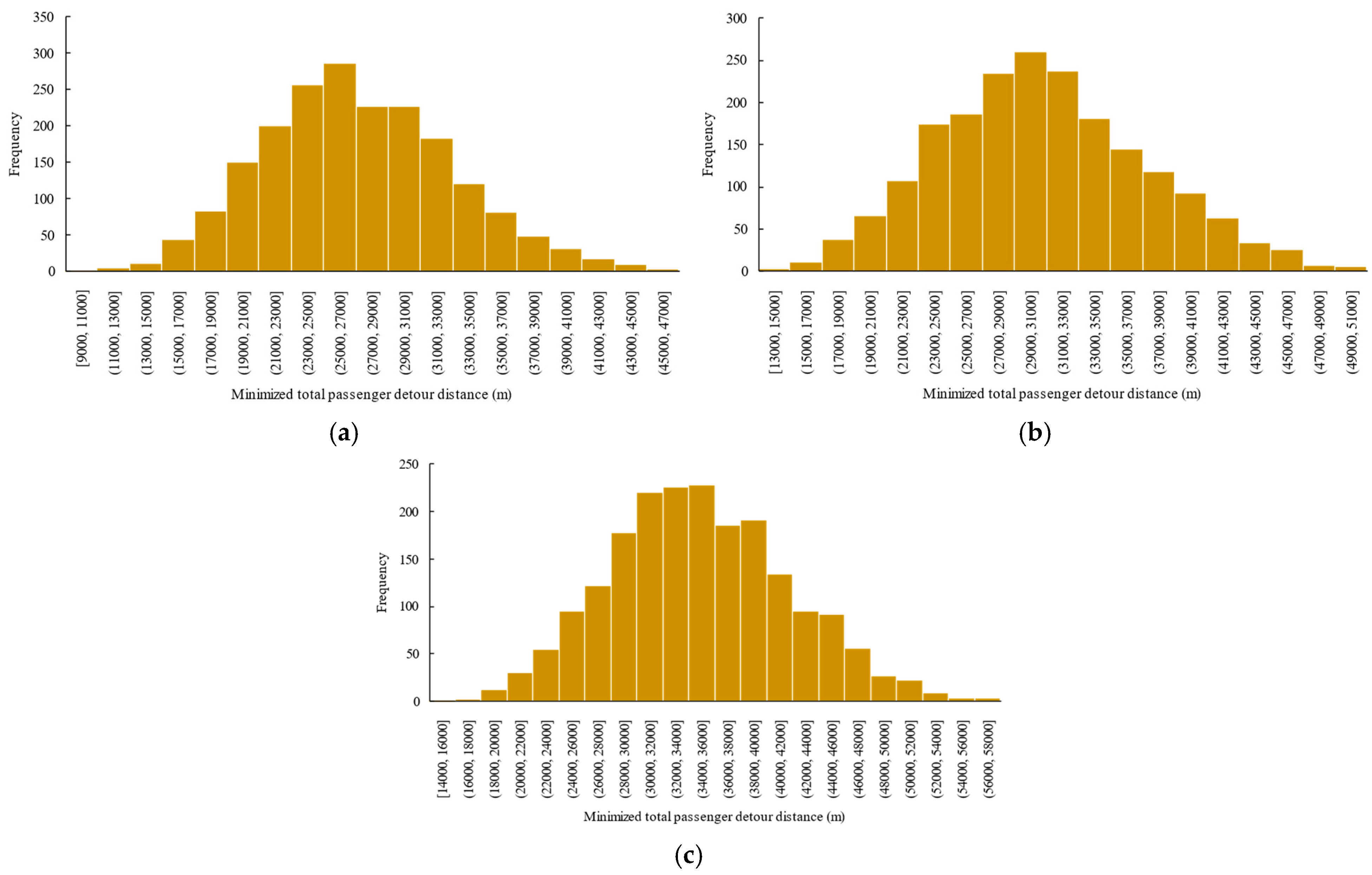
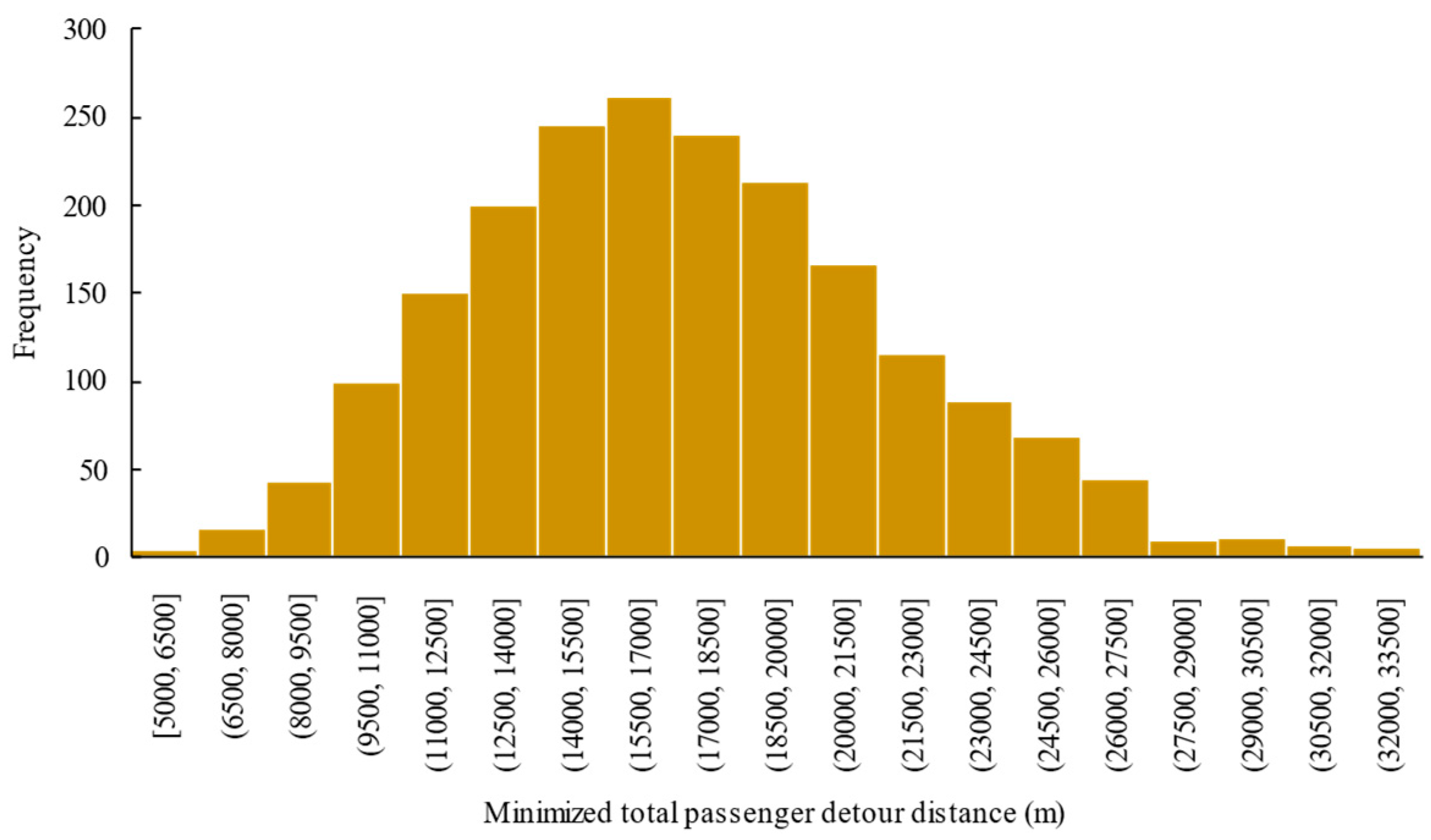
6.3. Effectiveness of the Proposed Optimization Framework
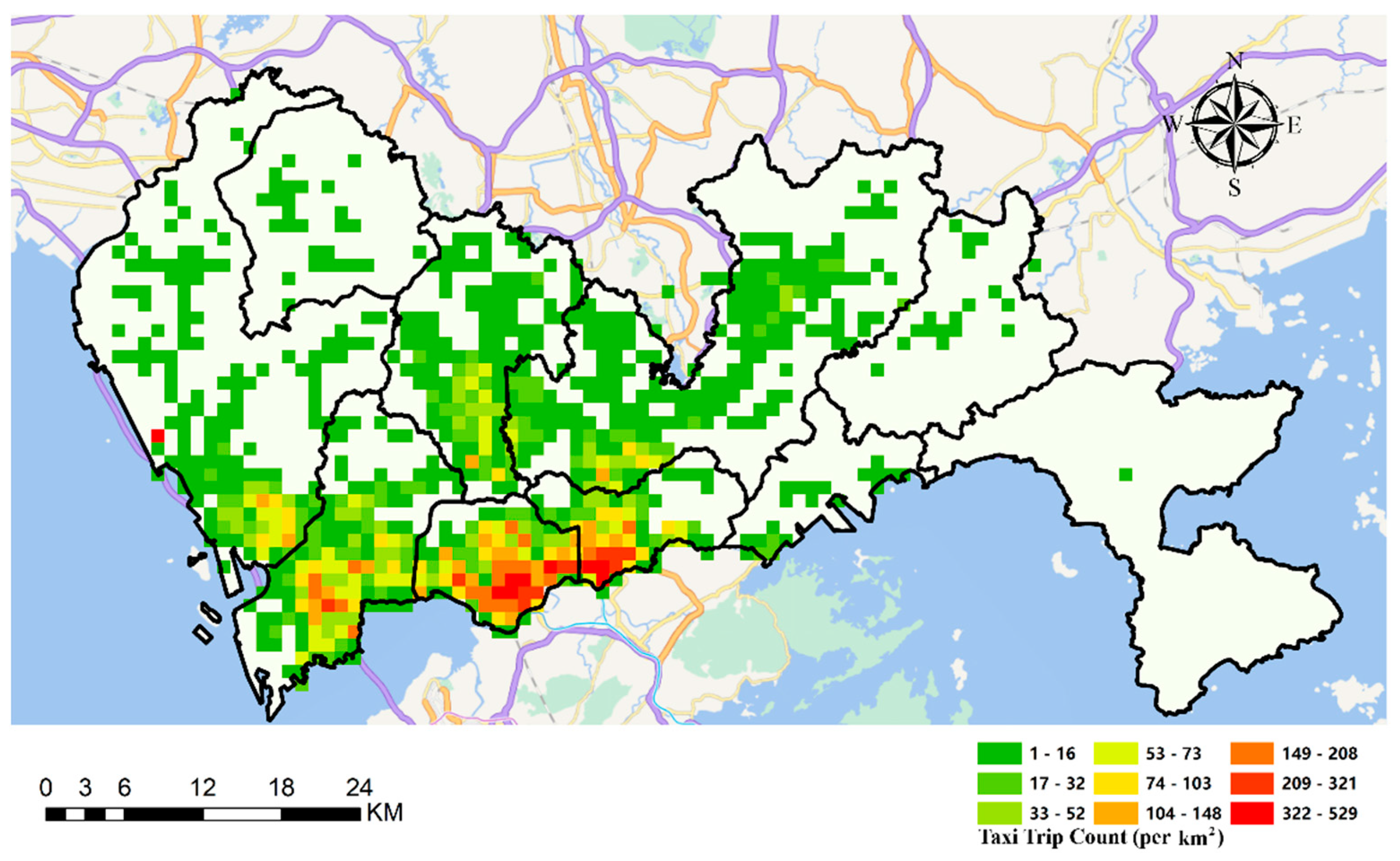
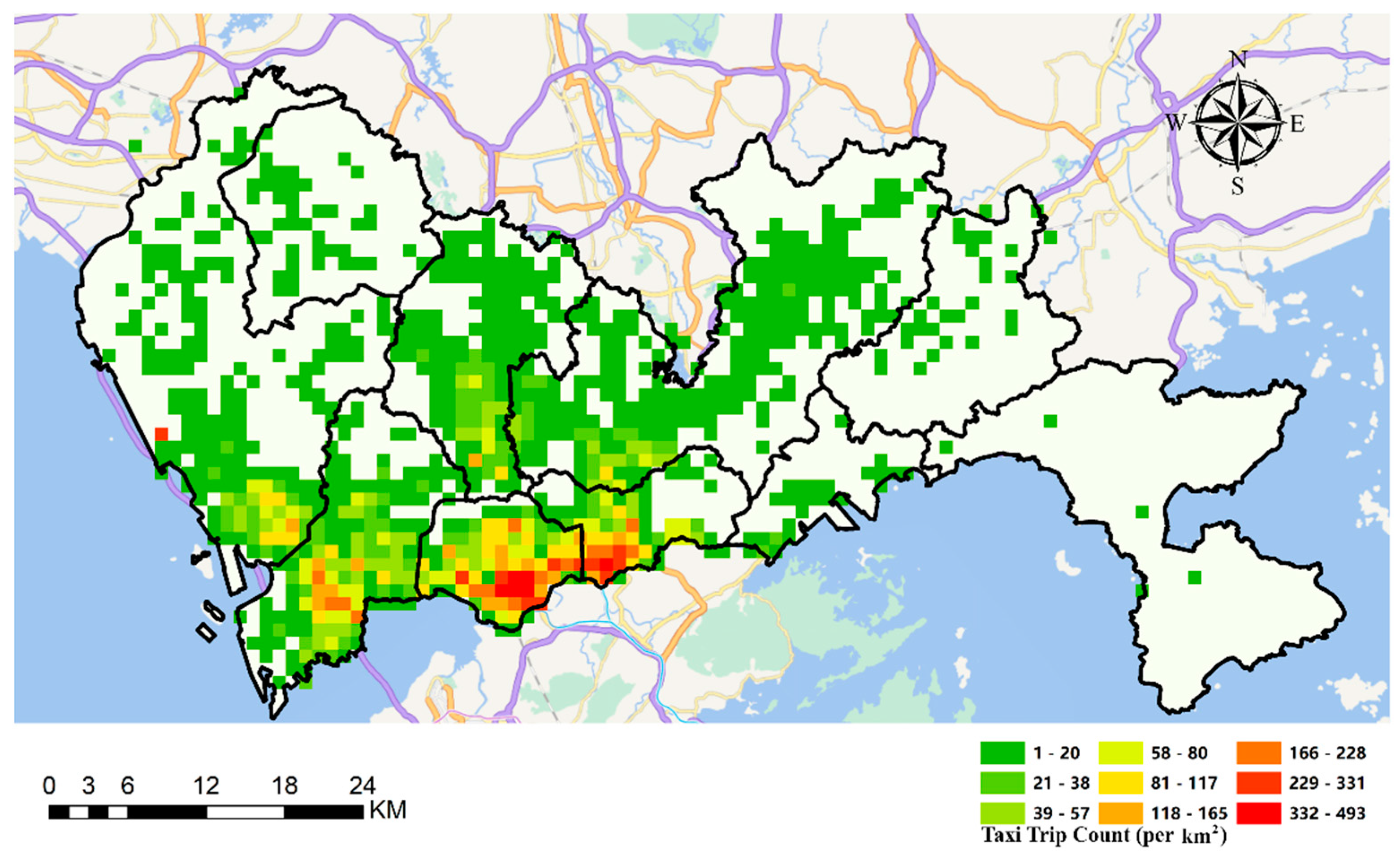
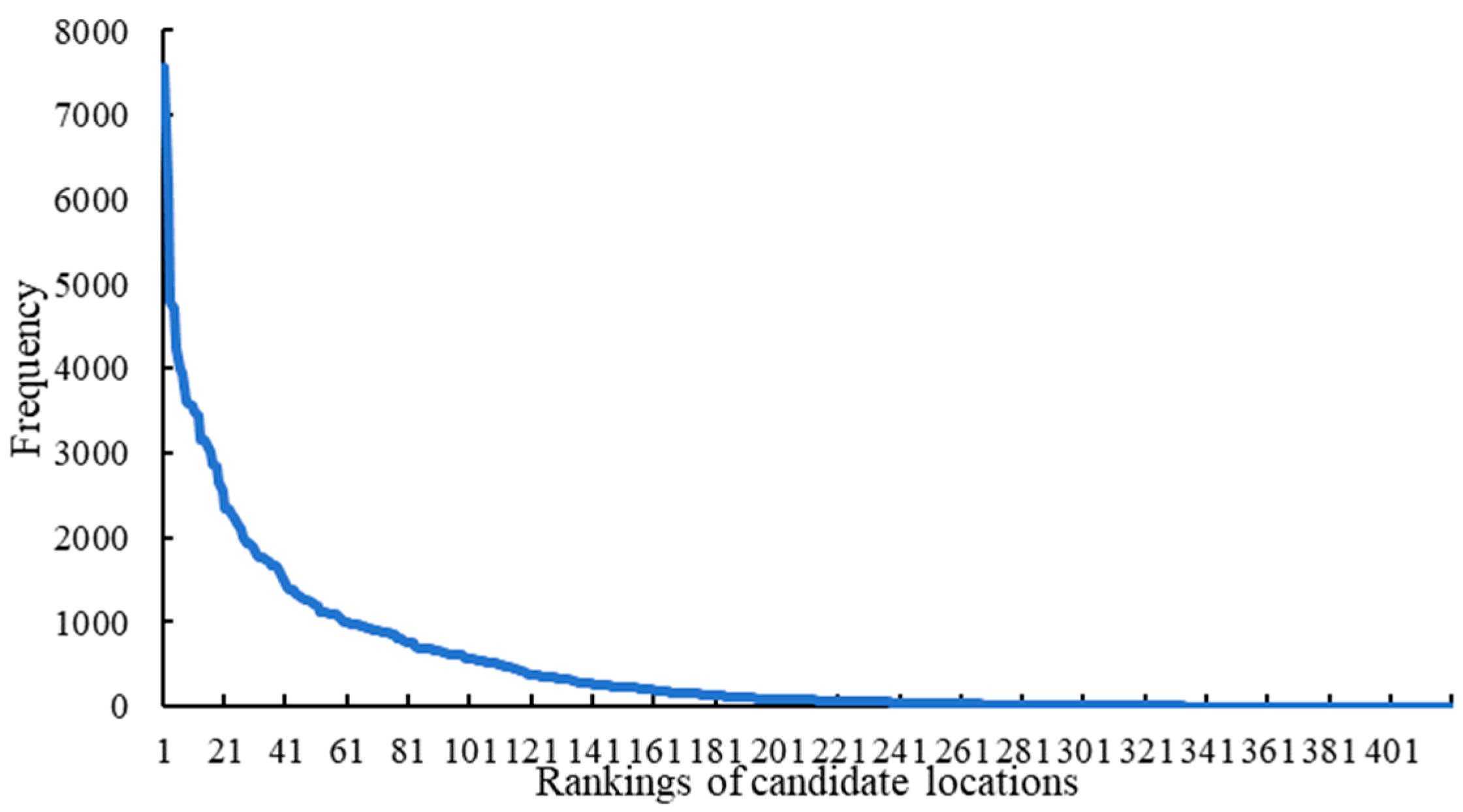
6.4. A Ranking-Based Classification of Candidate Parcel Locker Locations
6.5. Sensitivity Analyses
6.5.1. The Average Minimum Passenger Detour Distance
6.5.2. The Rankings of Candidate Locations
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kolmogorov–Smirnov Test | Shapiro-Wilk Test | |||
|---|---|---|---|---|
| Test Statistic | p-Value | Test Statistic | p-Value | |
| 50 | 0.033 | <0.001 | 0.990 | <0.001 |
| 60 | 0.033 | <0.001 | 0.984 | <0.001 |
| 70 | 0.043 | <0.001 | 0.985 | <0.001 |
| 80 | 0.034 | <0.001 | 0.994 | <0.001 |
| 90 | 0.028 | <0.001 | 0.994 | <0.001 |
| 100 | 0.028 | <0.001 | 0.996 | <0.001 |
References
- Taniguchi, E.; Thompson, R.G. City Logistics: Mapping the Future, 1st ed.; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Ronald, N.; Yang, J.; Thompson, R.G. Exploring Co-Modality Using On-Demand Transport Systems. Transp. Res. Procedia 2016, 12, 203–212. [Google Scholar] [CrossRef]
- Ma, M.; Zhang, F.; Liu, W.; Dixit, V. A game theoretical analysis of metro-integrated city logistics systems. Transp. Res. B 2022, 156, 14–27. [Google Scholar] [CrossRef]
- Ma, M.; Zhang, F.; Liu, W.; Dixit, V. Can urban co-modality benefit both users and operators? SSRN Electron. J. 2023. Available online: http://papers.ssrn.com/sol3/papers.cfm?abstract_id=4404702 (accessed on 14 April 2025). [CrossRef]
- Ma, M.; Zhang, F.; Liu, W.; Dixit, V. On urban co-modality: Non-cooperative and cooperative games among freight forwarder, carrier and transit operator. Transp. Res. C 2023, 153, 104243. [Google Scholar] [CrossRef]
- Kikuta, J.; Ito, T.; Tomiyama, I.; Yamamoto, S.; Yamada, T. New subway-integrated city logistics system. Procedia Soc. Behav. Sci. 2012, 39, 476–489. [Google Scholar] [CrossRef]
- De Langhe, K. The importance of external costs for assessing the potential of trams and trains for urban freight distribution. Res. Transp. Bus. Manag. 2017, 24, 114–122. [Google Scholar] [CrossRef]
- Bruzzone, F.; Cavallaro, F.; Nocera, S. The integration of passenger and freight transport for first-last mile operations. Transp. Policy 2021, 100, 31–48. [Google Scholar] [CrossRef]
- Zhu, S.; Bell, M.G.H.; Schulz, V.; Stokoe, M. Co-modality in city logistics: Sounds good, but how? Transp. Res. A 2023, 168, 103578. [Google Scholar] [CrossRef]
- Why Every Minute Matters for Efficient Last-Mile Logistics. Available online: https://www.moverlog.com/blog/every-minute-matters-efficient-last-mile-logistics (accessed on 10 April 2025).
- Making Every Step Count: Last-Mile Logistics for City Centres. Available online: https://urbact.eu/making-every-step-count-last-mile-logistics-city-centres (accessed on 10 April 2025).
- Daimler, Startup Design Drone-Facilitated Parcel Delivery Van. Available online: https://www.supplychaindive.com/news/daimler-drone-delivery-van/425982/ (accessed on 10 April 2025).
- Underground Express: The Quiet Rise of Subway Couriers in China. Available online: https://dialogue.earth/en/business/underground-express-the-quiet-rise-of-subway-couriers-in-china/ (accessed on 10 April 2025).
- Trentini, A.; Mahléné, N. Toward a shared urban transport system ensuring passengers & goods cohabitation. TeMA-J. Land Use Mobil. Environ. 2010, 3, 39–44. [Google Scholar]
- Arvidsson, N.; Givoni, M.; Woxenius, J. Exploring last mile synergies in passenger and freight transport. Built Environ. 2016, 42, 523–538. [Google Scholar] [CrossRef]
- Guo, X.; Wang, D.Z.; Wu, J.; Sun, H.; Zhou, L. Mining commuting behavior of urban rail transit network by using association rules. Phys. A 2020, 559, 125094. [Google Scholar] [CrossRef]
- Hu, W.; Dong, J.; Hwang, B.-G.; Ren, R.; Chen, Y.; Chen, Z. Using system dynamics to analyze the development of urban freight transportation system based on rail transit: A case study of Beijing. Sustain. Cities Soc. 2020, 53, 101923. [Google Scholar] [CrossRef]
- Van Duin, R.; Wiegmans, B.; Tavasszy, L.; Hendriks, B.; He, Y. Evaluating new participative city logistics concepts: The case of cargo hitching. Transp. Res. Procedia 2019, 39, 565–575. [Google Scholar] [CrossRef]
- What Is Last Mile? A Complete Guide to Last Mile Delivery & Logistics. Available online: https://fareye.com/what-is-last-mile-delivery (accessed on 10 April 2025).
- Wicaksono, S.; Lin, X.; Tavasszy, L.A. Market potential of bicycle crowdshipping: A two-sided acceptance analysis. Transp. Res. A 2022, 45, 100660. [Google Scholar] [CrossRef]
- Li, B.; Krushinsky, D.; Reijers, H.A.; Van Woensel, T. The share-a-ride problem: People and parcels sharing taxis. Eur. J. Oper. Res. 2014, 238, 31–40. [Google Scholar] [CrossRef]
- Beirigo, B.A.; Schulte, F.; Negenbor, R.R. Integrating people and freight transportation using shared autonomous vehicles with compartments. FAC-PapersOnLine 2018, 51, 392–397. [Google Scholar] [CrossRef]
- Van der Tholen, M.; Beirigo, B.A.; Jovanova, J.; Schulte, F. The share-a-ride problem with integrated routing and design decisions: The case of mixed-purpose shared autonomous vehicles. In Computational Logistics; Springer: Cham, Switzerland, 2021; pp. 347–361. [Google Scholar]
- Zhang, S.; Markos, C.; Yu, J.J.Q. Autonomous vehicle intelligent system: Joint ride-sharing and parcel delivery strategy. IEEE Trans. Intell. Transp. Syst. 2022, 23, 18466–18477. [Google Scholar] [CrossRef]
- Meinhardt, S.; Schlenther, T.; Martins-Turner, K.; Maciejewski, M. Simulation of on-demand vehicles that serve both person and freight transport. Procedia Comput. Sci. 2022, 201, 398–405. [Google Scholar] [CrossRef]
- Cheng, R.; Jiang, Y.; Nielsen, O.A. Integrated people-and-goods transportation systems: From a literature review to a general framework for future research. Transp. Rev. 2023, 45, 997–1020. [Google Scholar] [CrossRef]
- Derse, O.; Van Woensel, T. Integrated people and freight transportation: A literature review. Future Transp. 2024, 4, 1142–1160. [Google Scholar] [CrossRef]
- Dong, J.; Hu, W.; Yan, S.; Ren, R.; Zhao, X. Network planning method for capacitated metro-based underground logistics system. Adv. Civ. Eng. 2018, 2018, 6958086. [Google Scholar] [CrossRef]
- Zhao, L.; Li, H.; Li, M.; Sun, Y.; Hu, Q.; Mao, S.; Li, J.; Xue, J. Location selection of intra-city distribution hubs in the metro-integrated logistics system. Tunn. Undergr. Space Technol. 2018, 80, 246–256. [Google Scholar] [CrossRef]
- Ji, Y.; Zheng, Y.; Zhao, J.; Shen, Y.; Du, Y. A multimodal passenger-and-package sharing network for urban logistics. J. Adv. Transp. 2020, 2020, 6039032. [Google Scholar] [CrossRef]
- Azcuy, I.; Agatz, N.; Giesen, R. Designing integrated urban delivery systems using public transport. Transp. Res. E 2021, 156, 102525. [Google Scholar] [CrossRef]
- Kizil, K.U.; Yildiz, B. Public transport-based crowd-shipping with backup transfers. Transp. Sci. 2022, 57, 174–196. [Google Scholar] [CrossRef]
- Mourad, A.; Puchinger, J.; Chu, C. A survey of models and algorithms for optimizing shared mobility. Transp. Res. B 2019, 123, 323–346. [Google Scholar] [CrossRef]
- Manchella, K.; Umrawal, A.K.; Aggarwal, V. FlexPool: A distributed model-free deep reinforcement learning algorithm for joint passengers and goods transportation. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2035–2047. [Google Scholar] [CrossRef]
- Zhan, X.; Szeto, W.Y.; Wang, Y. The ride-hailing sharing problem with parcel transportation. Transp. Res. E 2023, 172, 103073. [Google Scholar] [CrossRef]
- Fehn, F.; Engelhardt, R.; Bogenberger, K. Ride-parcel-pooling—Assessment of the potential in combining on-demand mobility and city logistics. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference, Indianapolis, IN, USA, 19–22 September 2021. [Google Scholar]
- Fehn, F.; Engelhardt, R.; Dandl, F.; Bogenberger, K.; Busch, F. Integrating parcel deliveries into a ride-pooling service—An agent-based simulation study. Transp. Res. A 2023, 169, 103580. [Google Scholar] [CrossRef]
- Ji, Y.; Zhao, M.; Zheng, Y.; Shen, Y.; Du, Y. Urban passenger-and-package sharing transportation by e-hailing taxis: A simulation-based pricing analysis in Shanghai. Transp. Policy 2024, 156, 138–151. [Google Scholar] [CrossRef]
- Finding the Perfect Fit: Open vs. Closed Parcel Locker Networks. Available online: https://www.milytech.com/blog/open-vs-closed-parcel-locker-networks (accessed on 10 April 2025).
- Open or Closed Networks? Let’s Talk Parcel Lockers. Available online: https://www.ipc.be/services/markets-and-regulations/e-commerce-market-insights/e-commerce-articles/parcel-lockers-2022 (accessed on 10 April 2025).
- Hakimi, S.L. Optimum locations of switching centers and the absolute centers and medians of a graph. Oper. Res. 1964, 12, 450–459. [Google Scholar] [CrossRef]
- Hakimi, S.L. Optimum distribution of switching centers in a communication network and some related graph theoretic problems. Oper. Res. 1965, 13, 462–475. [Google Scholar] [CrossRef]
- Campell, J.F. Integer programming formulations of discrete hub location problems. Eur. J. Oper. Res. 1994, 72, 387–405. [Google Scholar] [CrossRef]
- Kara, B.Y.; Tansel, B.C. On the single-assignment p-hub center problem. Eur. J. Oper. Res. 2000, 125, 648–655. [Google Scholar] [CrossRef]
- Qu, B.; Weng, K. Path relinking approach for multiple allocation hub maximal covering problem. Comput. Math. Appl. 2009, 57, 1890–1894. [Google Scholar] [CrossRef]
- Shenzhen Statistical Yearbook. 2024. Available online: http://tjj.sz.gov.cn/ (accessed on 10 April 2025).
- List of Bus Lines and Stops in Shenzhen. Available online: http://jtys.sz.gov.cn/jtzx/wycx/gjcx/gjfw/content/post_11492052.html (accessed on 10 April 2025).
- Information of Shenzhen Metro Lines. Available online: http://jtys.sz.gov.cn/zwgk/ztzl/ggqsydw/jt/dt/ywxx/dtxlxx/content/post_11086812.html (accessed on 10 April 2025).
- Longitude and Latitude Query. Available online: https://api.map.baidu.com/lbsapi/getpoint/index.html (accessed on 10 April 2025).
- Ke, J.; Zheng, Z.; Yang, H.; Ye, J. Data-driven analysis on matching probability, routing distance and detour distance in ride-pooling services. Transp. Res. C 2021, 124, 102922. [Google Scholar] [CrossRef]




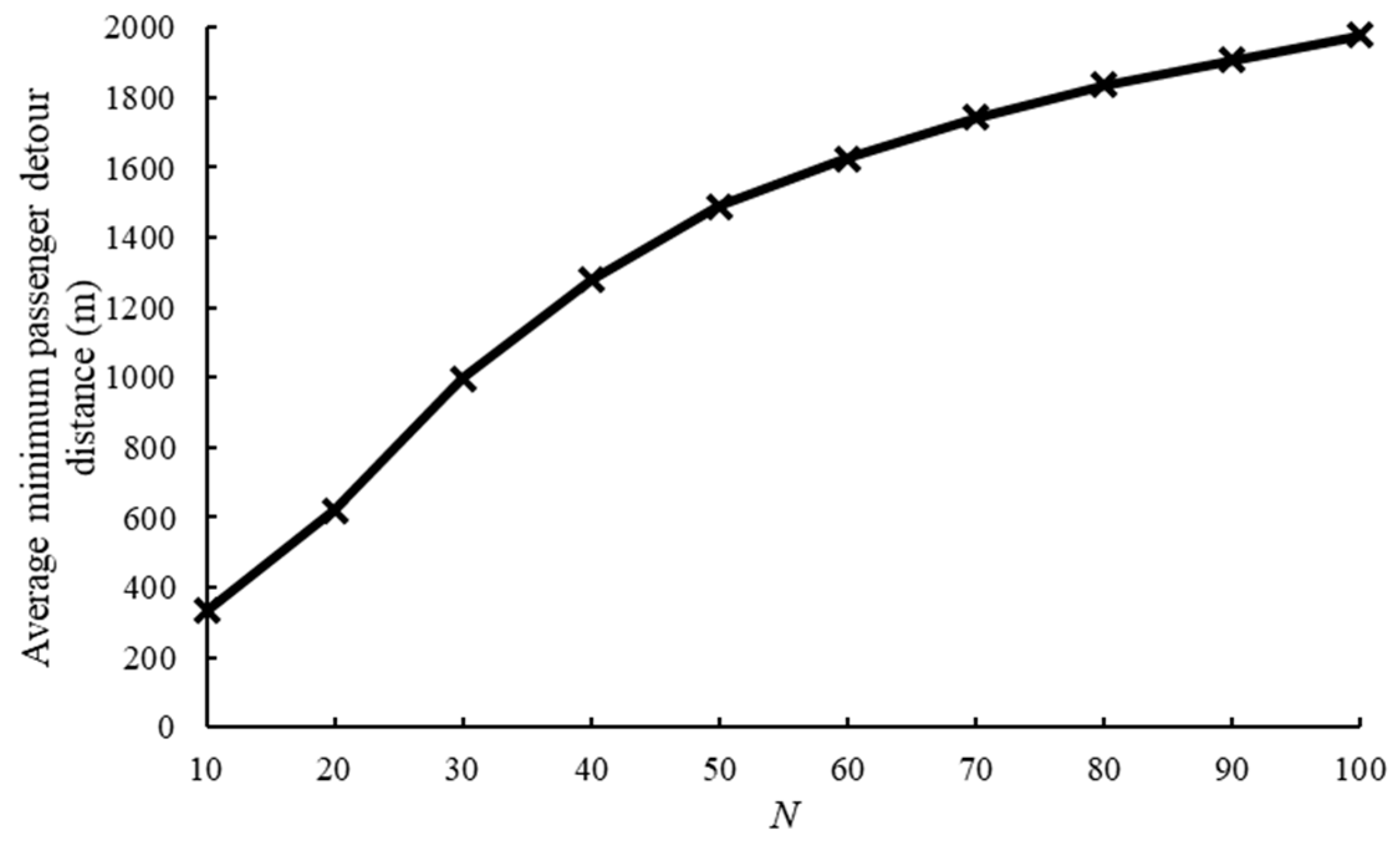
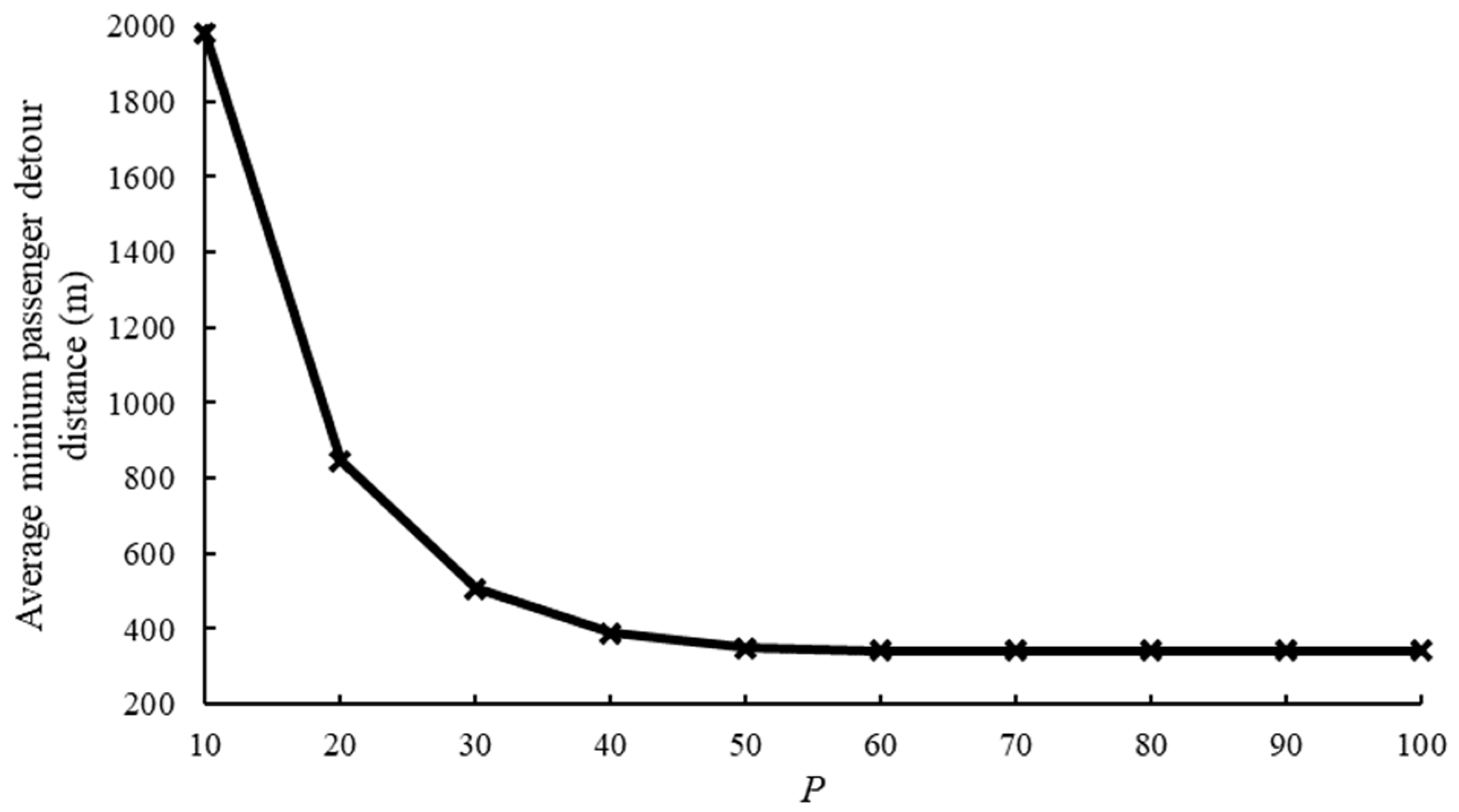
| Trip ID | Taxi Plate Number (Anonymized) | Start Time | Origin Longitude | Origin Latitude | Destination Longitude | Destination Latitude |
|---|---|---|---|---|---|---|
| 1 | ****** | 18:00:00 | 113.881195 | 22.56668 | 113.861404 | 22.603367 |
| 2 | ****** | 18:00:00 | 113.903885 | 22.516727 | 113.91072 | 22.539614 |
| 26,698 | ****** | 18:59:05 | 114.05342 | 22.5356 | 114.12182 | 22.567995 |
| The Optimization Framework for Parcel Locker Locations | |||
|---|---|---|---|
| Step 1: Initialization | |||
| Generate sample size , selection time , and the required number of parcel locker locations . | |||
| Step 2: Random sampling and optimization | |||
| For each selection : | |||
| Randomly choose ride requests from the trip dataset to form the passenger set ; | |||
| For each passenger : | |||
| Compute the detour distance for passenger if being pooled with candidate location ; | |||
| Looking for the optimal solution to the proposed PM model with and as model parameters, in which and are the vectors of optimized and , respectively. | |||
| Step 3: Output the optimal parcel locker locations | |||
| Define vector , sort the elements in in descending order and output the top elements and the corresponding candidate locations as the final locations for the parcel lockers. | |||
| Mean | Maximum | Minimum | Standard Deviation | |
|---|---|---|---|---|
| (50,20) | 0.313 | 0.600 | 0.050 | 0.081 |
| (60,30) | 0.296 | 0.500 | 0.067 | 0.061 |
| (70,30) | 0.395 | 0.667 | 0.167 | 0.069 |
| (80,40) | 0.459 | 0.650 | 0.250 | 0.060 |
| (90,40) | 0.459 | 0.650 | 0.275 | 0.060 |
| (100,50) | 0.512 | 0.680 | 0.340 | 0.053 |
| Candidate Index | P | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 | |
| Type I: Stable | ||||||||||
| 87 | 2 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 2 |
| 138 | 3 | 2 | 2 | 3 | 4 | 4 | 4 | 4 | 3 | 3 |
| Type II: Rising | ||||||||||
| 81 | 47 | 16 | 11 | 12 | 8 | 8 | 9 | 8 | 8 | 8 |
| 139 | 107 | 69 | 47 | 35 | 22 | 20 | 20 | 20 | 20 | 20 |
| Type III: Falling | ||||||||||
| 99 | 7 | 19 | 23 | 24 | 27 | 30 | 28 | 28 | 27 | 27 |
| 193 | 5 | 6 | 16 | 22 | 25 | 26 | 26 | 26 | 28 | 28 |
| Type IV: Concave | ||||||||||
| 146 | 52 | 17 | 21 | 25 | 33 | 42 | 42 | 42 | 42 | 42 |
| 194 | 19 | 10 | 8 | 7 | 11 | 16 | 16 | 16 | 15 | 15 |
| Type V: Convex | ||||||||||
| 137 | 8 | 21 | 20 | 16 | 14 | 14 | 14 | 14 | 14 | 14 |
| 158 | 79 | 129 | 104 | 95 | 78 | 73 | 73 | 72 | 73 | 70 |
| Candidate Index | R (km) | ||||
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | |
| P = 10 | |||||
| 80 | 1 | 1 | 1 | 1 | 2 |
| 87 | 2 | 2 | 2 | 9 | 36 |
| 138 | 3 | 3 | 3 | 3 | 6 |
| 140 | 4 | 4 | 4 | 2 | 1 |
| 193 | 5 | 5 | 5 | 4 | 4 |
| 47 | 6 | 6 | 6 | 6 | 9 |
| 99 | 7 | 7 | 7 | 5 | 7 |
| 137 | 8 | 8 | 8 | 7 | 3 |
| 167 | 9 | 9 | 9 | 12 | 10 |
| 141 | 10 | 10 | 10 | 8 | 8 |
| P = 50 | |||||
| 47 | 1 | 1 | 5 | 47 | 26 |
| 87 | 2 | 2 | 2 | 2 | 275 |
| 141 | 3 | 3 | 4 | 3 | 4 |
| 138 | 4 | 8 | 1 | 37 | 3 |
| 51 | 5 | 4 | 3 | 6 | 23 |
| 140 | 6 | 10 | 26 | 1 | 2 |
| 96 | 7 | 5 | 86 | 4 | 58 |
| 81 | 8 | 9 | 15 | 5 | 5 |
| 149 | 9 | 6 | 6 | 19 | 1 |
| 80 | 10 | 11 | 7 | 9 | 9 |
| P = 90 | |||||
| 47 | 1 | 1 | 2 | 30 | N/A |
| 87 | 2 | 2 | 2 | 4 | N/A |
| 138 | 3 | 7 | 1 | 143 | N/A |
| 141 | 4 | 3 | 4 | 10 | N/A |
| 51 | 5 | 4 | 3 | 2 | N/A |
| 96 | 6 | 5 | 86 | 12 | N/A |
| 140 | 7 | 10 | 27 | 1 | N/A |
| 81 | 8 | 9 | 16 | 51 | N/A |
| 149 | 9 | 6 | 6 | 85 | N/A |
| 95 | 10 | 25 | 88 | 27 | N/A |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Li, B. The Data-Driven Optimization of Parcel Locker Locations in a Transit Co-Modal System with Ride-Pooling Last-Mile Delivery. Appl. Sci. 2025, 15, 5217. https://doi.org/10.3390/app15095217
Li Z, Li B. The Data-Driven Optimization of Parcel Locker Locations in a Transit Co-Modal System with Ride-Pooling Last-Mile Delivery. Applied Sciences. 2025; 15(9):5217. https://doi.org/10.3390/app15095217
Chicago/Turabian StyleLi, Zhanxuan, and Baicheng Li. 2025. "The Data-Driven Optimization of Parcel Locker Locations in a Transit Co-Modal System with Ride-Pooling Last-Mile Delivery" Applied Sciences 15, no. 9: 5217. https://doi.org/10.3390/app15095217
APA StyleLi, Z., & Li, B. (2025). The Data-Driven Optimization of Parcel Locker Locations in a Transit Co-Modal System with Ride-Pooling Last-Mile Delivery. Applied Sciences, 15(9), 5217. https://doi.org/10.3390/app15095217