1. Introduction
Large language models (LLMs) such as GPT-4 have demonstrated remarkable capabilities across various natural language processing (NLP) tasks, including reasoning, instruction execution, and information retrieval (IR) [
1,
2,
3]. Their potential has led to increased interest in leveraging LLMs for IR applications, particularly in addressing challenges related to query-passage relevance evaluation. The quality of relevance evaluation in passage ranking is highly dependent on the effectiveness of the prompts used [
4,
5]. Therefore, designing optimal prompts for this task remains a crucial challenge.
Traditionally, prompt engineering has been performed manually, requiring extensive human effort and often leading to inconsistent results [
6,
7]. Manually designed prompts can introduce high variance in model performance, making them unreliable in practical IR systems [
6,
8]. As the reliance on LLM-based assessors grows, ensuring the quality and stability of prompts becomes increasingly critical for building dependable and scalable IR systems.
To address these issues, recent research has explored automated prompt optimization techniques, where LLMs themselves are used to iteratively refine prompts [
9,
10]. These methods generally fall into two categories: resampling-based approaches and reflection-based approaches.
Resampling-based methods, such as APE [
9], improve prompts by generating numerous semantically similar candidates and selecting the best-performing variant [
11]. While effective in exploring diverse prompt formulations, this approach incurs substantial computational costs due to the large number of LLM calls required at each optimization step.
Reflection-based methods, including APO [
10], refine prompts iteratively by analyzing previous errors and performance trajectories [
12,
13,
14,
15]. Although these methods enhance the consistency of prompt refinements and simulate human-like learning behaviors, they typically demand multiple rounds of error analysis and prompt updates, leading to high computational overhead. Furthermore, reflection-based techniques tend to focus primarily on correcting incorrect predictions, often neglecting insights from correctly predicted examples. This bias can result in suboptimal updates and overlooked opportunities for broader performance improvements.
Despite the progress made by these automated methods, two significant challenges remain unresolved: the high computational cost associated with prompt optimization, and the potential bias introduced by focusing solely on erroneous cases. These limitations hinder the practicality and scalability of LLM-based relevance evaluation systems, especially when applied to large-scale retrieval tasks in real-world environments.
Motivated by these challenges, we aim to develop a more efficient and balanced approach to prompt optimization for relevance evaluation. Specifically, we propose a novel confusion matrix-based method that systematically analyzes both correct and incorrect model predictions. By leveraging the full distribution of prediction outcomes, our method refines prompts through a single, targeted update, thereby reducing computational costs while maintaining or improving evaluation quality. For this purpose, we introduce APO-CF (Automatic Prompt Optimization via Confusion Feedback), a confusion matrix-guided prompt optimization framework designed for query-passage relevance evaluation. Our method minimizes the number of LLM calls required for optimization while enhancing robustness by considering the complete prediction landscape. To validate the effectiveness of APO-CF, we conduct experiments under realistic IR settings, measuring the alignment between human relevance judgments and ranking results obtained with optimized prompts. Our results demonstrate that APO-CF achieves competitive or superior performance compared to existing prompt optimization techniques, while significantly reducing computational resources.
Through this contribution, we offer a practical and scalable solution for deploying LLM-based assessors in real-world IR systems, addressing key obstacles in computational efficiency and balanced prompt refinement.
2. Related Works
Automated prompt optimization has become crucial for enhancing the performance and practicality of large language models (LLMs) in information retrieval (IR). This section reviews related literature in two areas closely tied to our work: relevance evaluation and prompt engineering.
2.1. Relevance Evaluation in Information Retrieval
Evaluating the relevance of retrieved passages to user queries has long been fundamental in information retrieval (IR). Traditionally, crowdsourced human assessors have been employed for this task [
16,
17]. However, human-based evaluations are time-consuming, costly, and often inconsistent due to the subjectivity of human judgment [
18,
19]. With advancements in machine learning, automated relevance judgment has increasingly gained traction [
20]. Transformer-based neural ranking models, such as BERT, have been widely adopted for relevance evaluation tasks [
21]. Nevertheless, balancing human-like precision with the scalability of automated methods remains a significant challenge.
Recent studies have begun exploring the use of LLMs, such as GPT-3, ChatGPT, and GPT-4, as relevance assessors. Wang et al. [
22] and Ding et al. [
23] evaluated GPT-3’s effectiveness in automated relevance annotation tasks. MacAvaney and Soldaini [
24] explored one-shot approaches for leveraging LLMs to assess document relevance, improving consistency in evaluations. Similarly, Thomas et al. [
5] demonstrated that LLMs could match human annotators’ accuracy at scale. Despite these promising results, concerns remain regarding the reliability and consistency of LLM-based judgments, as highlighted by Faggioli et al. [
25], who pointed out theoretical risks associated with fully replacing human assessors.
While existing studies have leveraged LLMs for relevance evaluation, they have generally overlooked the critical role of prompts. Given that prompt quality significantly influences the performance of LLMs, our work specifically addresses optimizing prompts to enhance the accuracy and efficiency of query-passage relevance evaluation.
2.2. Prompt Engineering
Prompt engineering, essential for maximizing the capabilities of LLMs, involves designing effective instructions to guide model behavior. Traditionally, prompt engineering has required extensive human effort, often leading to inconsistent and suboptimal outcomes due to variability in manual designs [
6,
8]. Since LLMs exhibit high sensitivity to prompt wording, even slight variations can significantly impact model performance [
8]. To mitigate these challenges, automated prompt optimization methods have been proposed, broadly categorized into resampling-based and reflection-based approaches.
Resampling-based methods, exemplified by Automated Prompt Engineering (APE) [
26], generate numerous semantically similar prompt variations and subsequently select the best-performing candidate [
9,
11]. Although effective in exploring diverse prompt formulations, this approach incurs substantial computational costs due to extensive sampling and lacks systematic error analysis capabilities, limiting its efficiency in precision-critical tasks.
Reflection-based methods, including Automatic Prompt Optimization (APO) [
10] and Optimization by Prompting (OPRO) [
27], iteratively refine prompts by analyzing past performance and error trajectories [
12,
13,
14,
15]. These methods simulate human-level trial-and-error feedback loops, enabling systematic prompt improvements. Explicit reflection-based methods provide structured feedback based on identified errors, whereas implicit methods leverage historical performance data to inform refinements [
27]. Despite their improved consistency, reflection-based methods typically demand multiple refinement iterations, significantly increasing computational overhead and reducing their practical applicability.
While these automated prompt optimization techniques have demonstrated effectiveness across various general-purpose NLP tasks, there has been limited exploration of their application to the specific challenge of relevance evaluation between queries and passages. In particular, adapting these methods to optimize prompts for query-passage relevance tasks, where precision and interpretability are critical, remains underexplored. In
Section 3, we describe how we adapt existing methods (APE, OPRO, and APO) to the relevance evaluation setting and introduce our proposed approach based on confusion matrix feedback.
3. Methodology
In this section, we describe our methodology for optimizing prompts in the task of query-passage relevance evaluation. We first adapt representative existing prompt optimization methods, namely, APE, OPRO, and APO, to the relevance evaluation setting, establishing strong baselines tailored for this task. Following this, we introduce our proposed method, APO-CF, which leverages confusion matrix feedback to achieve efficient and balanced prompt refinement. We begin by formally defining the problem setup.
3.1. Problem Definition
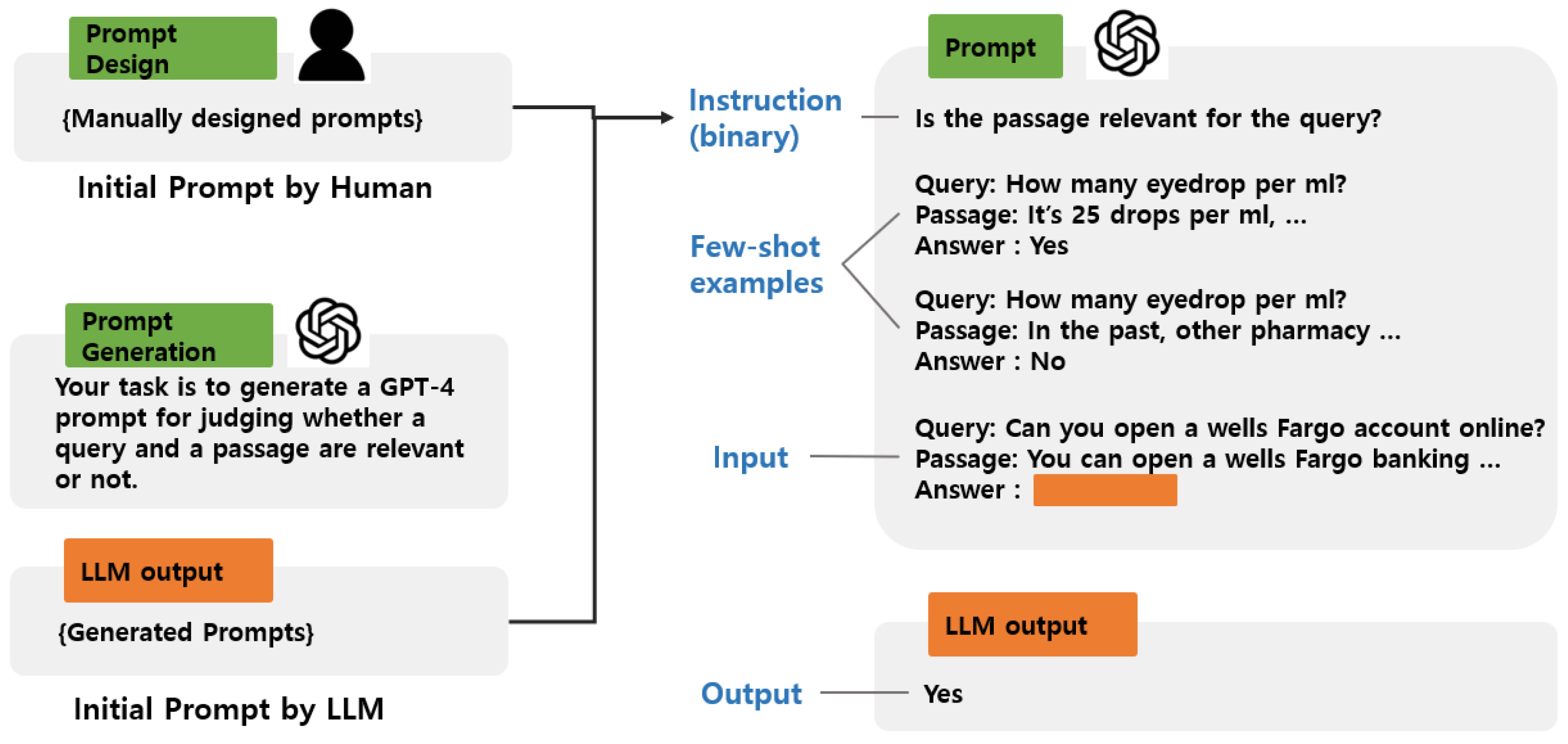
A prompt for evaluating the relevance between a query and a passage generally consists of three components: an instruction, few-shot examples, and an input, as shown in
Figure 1. The instruction is the most critical component, as it defines the behavior of the LLM and guides it in generating relevance judgments for the given input. The few-shot examples further clarify the instruction by providing context and demonstrating the expected output format. These examples help the LLM understand the relevance evaluation criteria more effectively. Depending on whether few-shot examples are included, the prompt can follow either a few-shot or zero-shot approach. We conduct experiments using only a zero-shot approach. The input consists of a query and a passage, where the LLM determines whether the passage is relevant to the query. The output is a binary label: “Yes” if the passage is relevant and “No” otherwise.
An initial prompt can be manually designed by humans or automatically generated by another LLM, as illustrated in
Figure 1. Human-designed prompts often leverage domain expertise to ensure clarity and reliability, while LLM-generated prompts can introduce diverse formulations that may improve generalization. We explore both approaches in our experiments.
By utilizing a prompt structured in this manner, an LLM can assess query-passage relevance effectively. In this study, we introduce a confusion matrix-based prompt optimization method, which enables the LLM to refine the prompt based on a systematic analysis of its own classification errors. In the next section, we review prior research on prompt optimization methods applicable to relevance evaluation.
3.2. Applying Existing Prompt Optimization Methods to Relevance Evaluation
To establish strong and representative baselines for our relevance evaluation task, we adopt three widely cited prompt optimization methods: APE, OPRO, and APO. These methods were originally developed for general prompt refinement tasks, but we adapt them to the specific context of query-passage relevance evaluation. They were selected to cover the two primary categories of automated prompt optimization: APE exemplifies resampling-based strategies, while APO and OPRO represent reflection-based approaches. This selection ensures a comprehensive and balanced comparison across different optimization paradigms. While these methods have shown effectiveness in various NLP settings, they face two notable limitations when applied to relevance evaluation.
First, they require a large number of LLM calls, making them computationally expensive. Many approaches iteratively modify prompts by generating multiple candidates and selecting the best-performing ones. Since each candidate requires evaluation with multiple sampled data points, the total number of LLM calls increases significantly, making real-world deployment impractical.
Second, reflection-based methods primarily focus on correcting wrong predictions without fully leveraging the entire distribution of training data. While identifying and correcting mistakes is important, this narrow focus can introduce biases, leading to degradation in the overall quality of prompt performance.
To quantitatively compare the computational efficiency of these methods, we follow the evaluation framework proposed by Ma et al. [
28], which provides a standardized methodology for estimating the number of LLM calls required during prompt optimization. Based on this framework, we calculate the minimum number of LLM calls for each method, assuming that each prompt evaluation involves 100 sampled examples to maintain consistency with prior studies.
Table 1 summarizes these results.
Iterative-APE [
26] follows a resampling-based strategy, where the LLM generates numerous similar prompt variations and selects the most effective candidate. Unlike true optimization methods, Iterative-APE does not refine a given prompt but instead searches for an effective one from a large candidate pool. This search process involves generating 100 new prompts at each step, with 50 prompts selected for the next iteration. Given that 10 iterations are performed, this results in at least 100,000 LLM calls, making it inefficient. The reliance on exploratory resampling without systematic improvements makes this approach costly and impractical for large-scale applications.
To adapt this method to our relevance evaluation task, we modified the base prompt used for paraphrasing so that it explicitly fits the binary decision setting of determining the relevance between a query and a passage.
OPRO [
27] adopts an implicit reflection-based strategy, where the LLM refines prompts by considering past optimization trajectories rather than explicitly analyzing errors. Unlike APO, OPRO does not provide structured error analysis but instead updates prompts based on previous performance patterns. However, this method still relies on extensive iterations (20+ steps), expanding the prompt set by a factor of 8 per iteration, leading to a total of 16,000 LLM calls. Since updates are made based only on past performance rather than the full dataset, optimization results can be unpredictable and inefficient.
In our implementation, the prompt generation process was guided by relevance-evaluation-specific instructions, ensuring that the synthesized prompts align with the binary decision objective.
APO [
10] employs an explicit reflection-based approach, where the LLM systematically analyzes reasons for prediction errors and modifies prompts accordingly. This structured feedback loop enables more interpretable improvements. However, APO still focuses only on wrong predictions, leading to biased updates that may not always improve overall model performance. Additionally, it requires 48 new prompts per iteration, with only 4 prompts retained in each of the 6 optimization steps. This results in at least 28,800 LLM calls, increasing computational cost.
To suit our evaluation setting, we adapted APO’s modification step to target specific aspects of the prompt related to the concept of “relevance”, ensuring that the model could learn from classification errors involving query-passage mismatches.
Overall, while these baseline methods provide valuable insights into prompt optimization, they remain computationally costly and may introduce biases when applied to relevance evaluation tasks. In the following section, we introduce our confusion matrix-based approach, which addresses these limitations by achieving efficient and balanced prompt refinement in a single update.
3.3. APO-CF: Automatic Prompt Optimization via Confusion Matrix Feedback
Relevance evaluation typically relies on simple prompts such as “Is the passage relevant for the query?”, as illustrated in
Figure 1. The key challenge in this task lies in interpreting the term “relevant”, which is inherently subjective [
29]. A broader interpretation increases false positives (FPs), while a narrower interpretation results in more false negatives (FNs). Since the accuracy of relevance evaluation depends on how this term is defined, learning an appropriate interpretation from training data is crucial for building reliable IR systems.
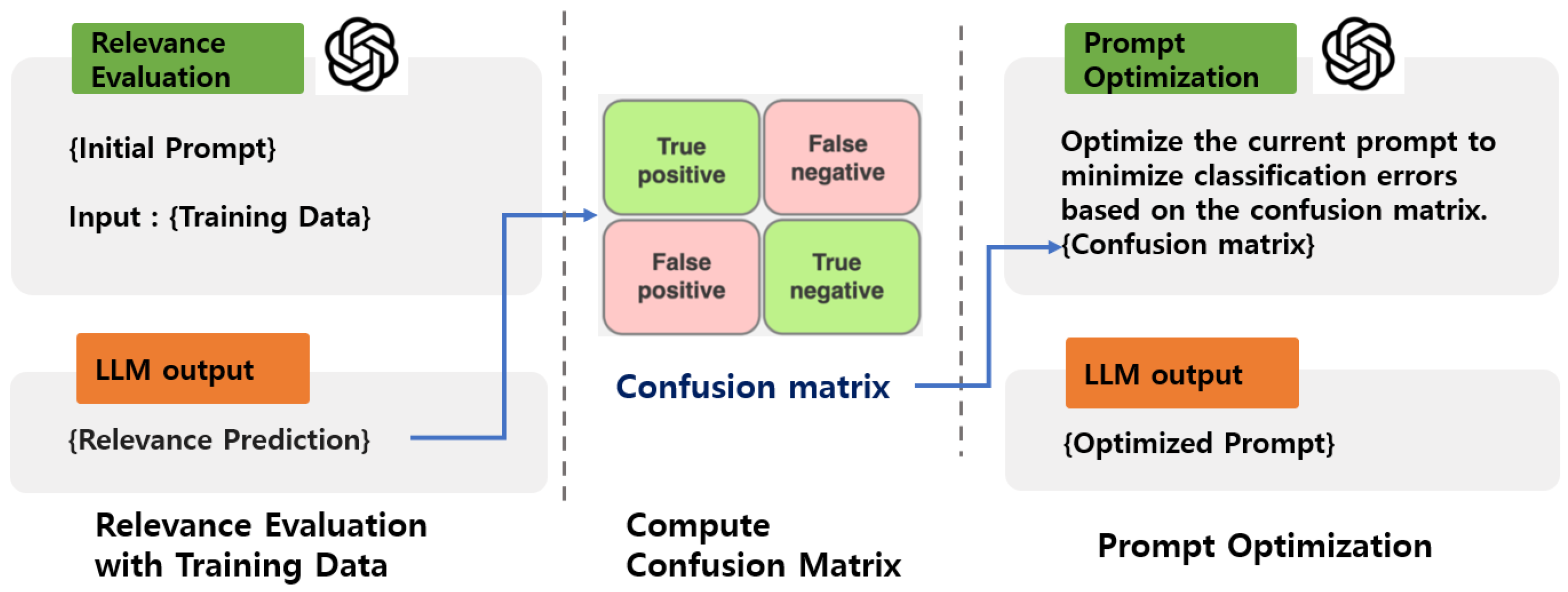
Our approach follows the reflection-based prompt optimization framework, similar to APO [
10], but enhances it by explicitly utilizing the confusion matrix. As illustrated in
Figure 2, we use training data annotated with human relevance judgments to compare the LLM-predicted outputs against the ground truth, generating a confusion matrix that categorizes predictions into true positives (TPs), true negatives (TNs), false positives (FPs), and false negatives (FNs).
To guide the optimization of prompts, we design a structured prompt template, shown in
Figure 3. This template presents the confusion matrix alongside the initial instruction and provides specific guidelines for refinement based on the observed classification errors. The instruction refinement strategy is determined according to the following four cases:
False positives (FPs) are high: The current instruction is too lenient, allowing irrelevant passages to be classified as relevant (“Yes”). The instruction is modified to adopt a stricter interpretation of “answering”, requiring passages to explicitly and directly address the query without ambiguity.
False negatives (FNs) are high: The current instruction is too restrictive, preventing relevant passages from being correctly classified. In this case, the instruction is revised to allow for more flexibility, such as accepting partial answers, inferred connections, or indirectly useful information as valid responses.
Both false positives (FPs) and false negatives (FNs) are high: The instruction is likely unclear or inconsistent, causing unstable classification behavior. To address this, the instruction is refined by explicitly defining the threshold for what constitutes a valid answer and improving the overall clarity and specificity.
Neither false positives nor false negatives are significantly high: The instruction is already well calibrated. However, slight optimizations, such as polishing phrasing or improving example demonstrations, may further enhance precision and recall balance without drastically altering the instruction’s intent.
Figure 3.
A structured prompt template for refining instructions based on the confusion matrix. The template provides the current instruction, classification results in the form of a confusion matrix, and refinement guidelines to adjust the instruction based on observed FP and FN rates. This structured approach ensures that the instruction is optimized to improve classification accuracy and balance precision and recall.
Figure 3.
A structured prompt template for refining instructions based on the confusion matrix. The template provides the current instruction, classification results in the form of a confusion matrix, and refinement guidelines to adjust the instruction based on observed FP and FN rates. This structured approach ensures that the instruction is optimized to improve classification accuracy and balance precision and recall.
This structured refinement ensures that prompts are updated in a systematic, data-driven manner based on actual model behavior observed through the confusion matrix. By leveraging the full distribution of prediction outcomes—including both correct and incorrect predictions—our method enables efficient and targeted prompt optimization.
A key advantage of our approach is that it achieves significant performance improvements with only a single update step, in contrast to iterative methods requiring multiple LLM calls. This is possible because the confusion matrix provides an explicit, structured guide for understanding and correcting model weaknesses. By learning the interpretation of “relevant” directly from training data, the model can optimize its prompt more effectively and scalably.
To implement this idea, we introduce APO-CF (Automatic Prompt Optimization via Confusion Matrix Feedback). Instead of relying on extensive iterative optimization cycles, APO-CF uses the confusion matrix as a structured feedback mechanism to refine the prompt in a single pass. As shown in
Table 1, this approach significantly reduces computational overhead while maintaining or improving the quality of relevance evaluation, making it highly practical for real-world IR applications.
4. Experimental Setup
Here, we describe the datasets, large language models (LLMs), evaluation metrics, and baseline methods used in our experiments. We also explain how we compare prompt performance and assess the utility of the optimized prompts in real-world-relevance ranking tasks.
4.1. Dataset and LLMs
As summarized in
Table 2, we sample 500 data points from each year’s dataset for evaluation, considering the computational cost of processing the full dataset. The 2019 dataset is used for training, while the 2021 dataset serves as the validation set, which is utilized when selecting the top-
k prompts after each expansion step. Since APO-CF performs a single update, it does not require validation data. For the test phase, we use the 2020 dataset to evaluate the final performance of optimized prompts. To ensure robustness and mitigate variance, we create three independent test samples of 500 data points each from the 2020 dataset. The final performance is reported as the average across these three test samples. While using full test sets would be ideal, it is computationally intensive. Therefore, we empirically validate that using three random samples of 500 points each yields results that closely match the full dataset results. This comparison is provided in
Appendix A.
The TREC DL 2019 dataset consists of 9260 query–passage pairs, with the relevance between each pair assessed by human evaluators. Similarly, the TREC DL 2020 and 2021 test sets follow the same format, comprising 11,386 and 10,828 query–passage pairs with relevance judgments, respectively.
Relevance in these pairs is rated on a 4-point scale: “Perfectly relevant”, “Highly relevant”, “Related”, and “Irrelevant”. For binary classification tasks, we simplify this 4-point relevance scale to a binary “Yes” or “No” judgment. Specifically, the categories of “Perfectly relevant” and “Highly relevant” are consolidated into a “Yes” category, while “Related” and “Irrelevant” are classified as “No”.
LLMs. For our experiments, we utilize GPT-4o, GPT-4o-mini, and DeepSeek-Chat as the large language models (LLMs). To access GPT-4o and GPT-4o-mini we use the OpenAI API (
https://openai.com/api/ (accessed on 15 February 2025)), while for DeepSeek-Chat we rely on the DeepSeek API (
https://api-docs.deepseek.com/ (accessed on 15 February 2025)). These APIs provide seamless access to the models’ capabilities while ensuring reproducibility in experimental settings. To minimize output variability, we set the temperature parameter to 0 across all API calls, ensuring deterministic outputs that simplify analysis and comparison across models.
We selected these models to represent a range of capacities and architectural backgrounds. GPT-4o is recognized for its reasoning capabilities and serves as a high-performance baseline. GPT-4o-mini, as a lightweight variant from the same model family, allows us to examine whether prompt optimization remains effective in smaller-capacity settings. DeepSeek-Chat, a recently released LLM with relatively limited comparisons against OpenAI models, is included to evaluate the generalizability of our method across different model architectures.
4.2. Prompt Performance Evaluation Metrics
To assess the effectiveness of a prompt, we evaluate how well the LLM’s relevance predictions align with human-labeled judgments. A prompt is considered effective if the LLM produces outputs that closely match human assessments. To measure this agreement quantitatively, we use Cohen’s kappa (
), which is a statistical measure of inter-rater reliability that accounts for agreement occurring by chance. This metric is particularly appropriate for our task, as it evaluates the degree to which LLM-generated labels replicate human judgments in a principled and chance-corrected manner. Cohen’s
has also been adopted in recent studies evaluating the reliability of LLM-based relevance judgments [
25].
Given that the LLM’s predicted relevance is denoted as
and the human-labeled ground-truth relevance as
, Cohen’s kappa is computed as follows:
where
represents the observed agreement between the LLM’s predictions and human labels, while
corresponds to the expected agreement that would occur by chance. To compute
, we measure the proportion of cases where the LLM’s prediction matches the human annotation. In a binary classification setting, this can be expressed as
where
is an indicator function that returns 1 if the LLM’s prediction matches the human label and 0 otherwise, and
N represents the total number of samples. The expected agreement
accounts for the probability that the LLM and human annotators agree by chance. This is computed based on the marginal distributions of the human and LLM predictions:
By utilizing Cohen’s kappa (), we evaluate how well a given prompt aligns the LLM’s responses with human judgments, where a higher value indicates stronger agreement and consequently a more effective prompt.
4.3. Baseline Comparison
Comparison models. We compare our method with APE [
9], OPRO [
27], and APO [
10], which are existing prompt optimization methods. APE generates refined prompts by paraphrasing the original prompt using LLMs. Instead of directly optimizing the prompt, APE searches for the most effective variation by generating multiple paraphrased candidates and selecting the best-performing one based on evaluation metrics. OPRO iteratively refines prompts using LLMs as optimizers, leveraging past optimization trajectories to generate better instructions. APO enables LLMs to directly modify prompts based on model-generated feedback. Instead of relying on human intervention or predefined templates, APO allows the LLM to iteratively refine prompts by analyzing its own responses and optimizing the wording accordingly.
Our proposed APO-CF utilizes confusion matrix-based feedback to refine prompts in a single step, eliminating the need for the refinement. Each baseline is evaluated under its respective default settings to ensure a fair comparison.
Initial prompt. For initial prompts, we incorporate both human-designed and LLM-generated instructions. Specifically, we select four prompts from the eight used in Choi [
30], ensuring a diverse range of starting points for optimization. The selected prompts include M1 and M2, which are human-designed prompts from previous research, and G1 and G2, which are GPT-4-generated prompts designed for binary classification.
Each initial prompt is evaluated independently, and performance results are averaged across all prompts to ensure robust conclusions.
Table 3 provides an overview of the prompt instructions used in our study.
4.4. Evaluation of Prompt Utility
We evaluate the utility of the prompts generated by APO-CF by assessing whether they can be used to determine the relevance between a query and a passage in place of human-annotated relevance labels. Specifically, we investigate whether relevance labels produced using APO-CF-generated prompts, combined with LLMs, can effectively substitute human-labeled data in passage-ranking evaluations.
To achieve this, we compare the performance of passage-ranking models using two different relevance label sets: one generated by APO-CF and another manually annotated by human evaluators. Ideally, both label sets should yield similar results across different passage-ranking models. First, we evaluate the performance of ranking models using the human-annotated relevance labels and establish a reference result. Then, we apply the APO-CF-generated labels to the same ranking models and compare the results.
To quantify the similarity between the two results, we compute Kendall’s coefficient, where a value close to 1.0 indicates a high degree of agreement between the rankings. If the rankings obtained using APO-CF-generated labels closely match those derived from human annotations, this suggests that APO-CF-generated prompts effectively capture relevance and that LLM-generated labels can potentially replace human-annotated relevance judgments.
For this evaluation, we use the MS MARCO passage-ranking leaderboard (
https://microsoft.github.io/MSMARCO-Passage-Ranking-Submissions/leaderboard/ (accessed on 15 February 2025)), which includes 59 different passage-ranking algorithms registered on the board. By leveraging this dataset, we assess the viability of using LLM-generated relevance labels in large-scale passage-ranking tasks.
5. Experimental Results
In this section, we present the experimental results of our proposed approach. We begin with a case study that illustrates how APO-CF refines prompts based on confusion matrix feedback. This is followed by a quantitative comparison of performance across different optimization methods, and finally an evaluation of how well APO-CF-generated prompts can replace human labels in practical ranking scenarios.
5.1. Case Study of Prompt Refinement via APO-CF
We examine how APO-CF refines prompts by analyzing training data and adjusting key semantic components to improve classification accuracy.
Table 4 presents an example where APO-CF is applied to the M1 prompt using GPT-4o. It summarizes the original and refined prompts, along with the confusion matrix derived from the training data prior to refinement.
The original prompt, “Does the passage answer the query? Respond with ‘Yes’ or ‘No”’, was found to have a high false negative (FN) rate of 22 in the training data, indicating that many valid responses were incorrectly classified as not answering the query. To address this issue, GPT-4o adjusted the prompt by introducing the phrase “partial response that logically infers the answer”. This modification broadens the interpretation of what constitutes an answer, effectively softening the rigid definition of the term “answer” in the original prompt. By allowing a passage that contains partial but inferable responses to be classified as “Yes”, the model adapts to better capture subtle but valid answer patterns.
This refinement process demonstrates that APO-CF actively examines training data to fine-tune prompt semantics, ensuring that terms such as “answer” are dynamically redefined in a way that improves classification accuracy. A similar case study for GPT-4o-mini can be found in
Appendix B, which provides additional insight into how the model-specific characteristics affect prompt refinement.
This example illustrates how a specific error pattern can be directly addressed through targeted semantic modifications in the prompt. The revised instruction enables the model to more flexibly interpret partially correct responses, reducing misclassifications. As shown in the next section, this single refinement leads to a measurable improvement in Cohen’s , confirming the practical effectiveness of the APO-CF approach.
5.2. Performance Comparison of Different Methods
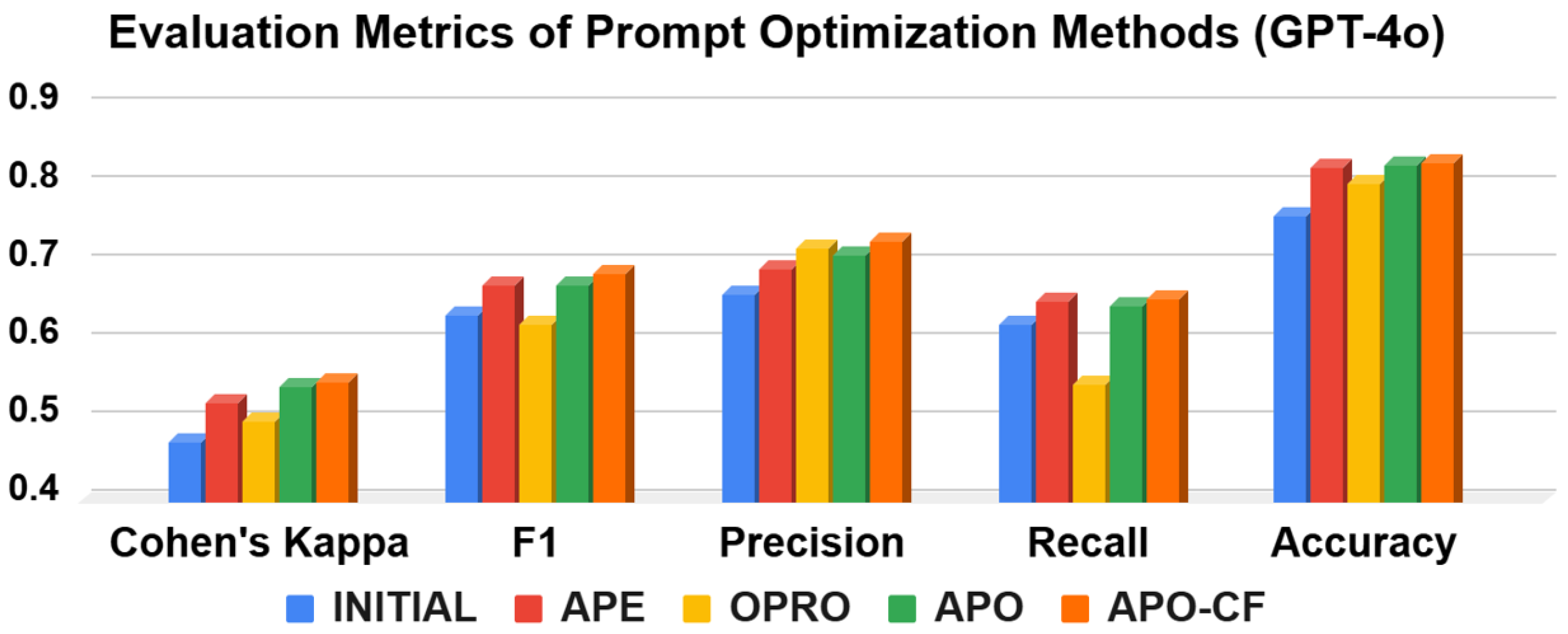
Table 5 and
Figure 4 provide a comprehensive comparison of prompt optimization methods across multiple evaluation metrics. The table reports the Cohen’s
and F1-score across three LLMs, while the figure focuses on GPT-4o and visualizes performance in terms of
, F1-score, precision, recall, and accuracy. Among all methods, APO-CF matches or outperforms existing approaches, demonstrating the effectiveness of our confusion matrix-guided prompt refinement strategy.
5.2.1. Initial Prompt Result
Examining the initial prompt results, we observe that although the four initial prompts (M1, M2, G1, G2) share similar intent, their performance varies significantly across models. This reinforces the critical role of prompt selection in optimizing LLM performance. The variation in Cohen’s across different initial prompts suggests that even slight changes in wording or structure can influence the model’s decision-making process.
Furthermore, no single prompt consistently outperforms others across all models. While M2 achieves the highest F1-score in GPT-4o (0.688) among the initial prompts, it does not maintain the lead in other models. Similarly, different prompts perform optimally depending on the model. This finding indicates that prompt selection should be model-dependent, as an effective prompt for one LLM may not generalize well to another.
5.2.2. Comparison of Automated Optimization Methods
Examining the results of automated prompt optimization methods, we observe that APO-CF achieves the highest Cohen’s score of 0.553 on GPT-4o-mini, demonstrating its strong ability to refine prompts effectively. On GPT-4o, APO-CF also achieves a notable improvement over initial prompts, reaching 0.548, although slightly lower than on GPT-4o-mini. More importantly, it outperforms all other automated methods, including APO, APE, and OPRO, indicating that our confusion matrix-based update process performs effectively, even with a single iteration. Notably, APO-CF performs better than APO while requiring significantly fewer LLM calls, proving that a single well-calibrated update can be more beneficial than multiple iterative updates.
However, when tested on DeepSeek-Chat, APO CF does not perform as well and, in fact, results in lower performance than some initial prompts. This suggests that the confusion matrix-based refinement process may not align well with DeepSeek-Chat’s interpretation of relevance. One possible explanation is that DeepSeek-Chat may not effectively utilize the confusion matrix for prompt refinement, leading to suboptimal adjustments. Further analysis of this issue is provided in the Discussion
Section 6.
Another intriguing result is that APE performs comparably to, and in some cases even better than, APO, which is counterintuitive given that APE does not allow the LLM to modify the prompt itself, only structuring it differently. The expectation was that direct LLM-driven updates (APO) would be superior, yet our findings challenge this assumption. This suggests that not all LLM-generated prompt modifications lead to improvements, and simpler structural refinements may sometimes be more effective than complex model-driven optimizations.
Additionally, OPRO does not perform as well as expected, showing that its approach of generating new prompts based on past iterations does not necessarily result in an optimal refinement. This aligns with our hypothesis that merely iterating over previously generated prompts without deeper analysis may not be an effective way to optimize prompts for relevance evaluation tasks.
Overall, our findings reinforce that confusion matrix-driven prompt updates are highly effective for relevance evaluation, as evidenced by APO-CF’s strong performance across GPT-based models. However, its lower performance on DeepSeek-Chat highlights the need for model-specific tuning in certain cases. Importantly, our results demonstrate that a single, well-informed update can outperform more iterative methods, offering an efficient approach to optimizing prompts with minimal LLM calls.
5.2.3. Analysis of Precision, Recall, and Accuracy on GPT-4o
Figure 4 presents a detailed comparison of prompt optimization methods on GPT-4o across five metrics, including precision, recall, and accuracy. The initial prompt, which represents the unoptimized instruction, performs the worst across all metrics, confirming the importance of optimization.
Among the methods, OPRO shows high precision but suffers from low recall, suggesting that it becomes overly conservative—correctly rejecting irrelevant passages but at the cost of missing many relevant ones. This imbalance leads to a lower Cohen’s , indicating weaker overall agreement. In contrast, APE appears to slightly favor higher recall, improving coverage of relevant passages but potentially increasing false positives.
APO improves both precision and recall to some extent, leading to better overall performance. However, APO-CF further improves both metrics simultaneously and achieves the highest accuracy among all methods. This balanced improvement can be attributed to APO-CF’s use of confusion matrix feedback, which allows the prompt to be adjusted in a more calibrated way by considering both false positives and false negatives. As a result, APO-CF demonstrates a more stable and effective classification pattern across the evaluated metrics.
5.3. Evaluating the Effectiveness and Practicality of APO-CF Prompts
We assess the reliability of the evaluation results generated using the prompts refined by APO-CF. Specifically, we compare human-annotated evaluations with those generated using APO-CF-enhanced prompts for the TREC DL 2020 test set. For this, we evaluated the 59 ranking systems described in
Section 4.4 using both types of test sets. The evaluation results are visualized in
Figure 5.
A particularly noteworthy observation is that the ranking consistency between human annotations and our LLM-generated evaluations is remarkably high, with Kendall’s values of 0.91 and 0.93. This suggests that LLM-generated evaluation results can serve as reliable alternatives to human judgments without significant discrepancies. Moreover, these results validate the effectiveness and utility of the prompts generated by APO-CF, demonstrating their potential to facilitate robust and scalable evaluation processes.
As mentioned in
Table 1, APO-CF achieves this level of reliability with less than 1% of the computational cost required by existing methods, highlighting its practicality and efficiency for real-world deployment.
6. Discussion
6.1. Why Did APO-CF Outperform Other Automated Methods?
Our experimental results demonstrate that APO-CF outperforms existing automated prompt optimization methods, including APO, APE, and OPRO. This superior performance can be attributed to two key factors: (1) its data-driven optimization strategy, and (2) its efficiency in achieving high performance with minimal LLM calls.
Unlike other methods, APO-CF directly utilizes the confusion matrix from the training data to guide prompt modifications. This approach allows it to explicitly address common misclassification patterns, such as reducing false negatives, rather than relying solely on LLM-generated refinements. In contrast, APO iteratively updates prompts through multiple LLM calls, but without directly referencing training data patterns, which can lead to less targeted improvements. Similarly, OPRO recombines past prompt variations without considering the underlying data distribution, limiting its effectiveness.
Moreover, APO-CF achieves these improvements with significantly fewer LLM calls than APO, demonstrating that a single well-informed, data-driven update can be more effective than multiple LLM-based refinements. This efficiency is particularly important in real-world applications, where API call costs and computational resources are constraints.
Finally, other methods fail to capture the overall characteristics of training data, as they focus primarily on structural modifications rather than data-driven refinements. APO-CF’s reliance on confusion matrix insights ensures that its prompt updates align more closely with actual model weaknesses, leading to a more reliable and scalable optimization approach.
These results underscore the importance of data-driven prompt optimization over purely LLM-driven iterative updates, positioning APO-CF as a promising and efficient alternative.
6.2. Why Did APO-CF Fail on DeepSeek-Chat?
While APO-CF improved performance on GPT-4o and GPT-4o-mini, it did not yield similar benefits on DeepSeek-Chat. As shown in
Table 6, the refined prompt became more rigid, requiring a passage to “directly and explicitly” provide a complete answer, while classifying partial or inferred responses as ‘No’. This adjustment, rather than improving accuracy, appears to have increased false negatives, suggesting that DeepSeek-Chat struggled to adapt to the stricter definition of relevance.
One possible explanation is that GPT-based models may be better at handling nuanced prompt refinements, especially when adjusting decision boundaries based on complex error patterns. Since APO-CF’s refinement relies on confusion matrix statistics rather than explicit linguistic understanding, its effectiveness may depend on how well an LLM interprets and generalizes prompt modifications. GPT-4o and GPT-4o-mini appear to adjust more flexibly to such refinements, while DeepSeek-Chat may require a different optimization strategy, potentially favoring more direct rather than abstract prompt adjustments.
This result suggests that not all LLMs process refined prompts in the same way, and that prompt optimization strategies should consider the model’s ability to generalize nuanced instructions. Further research could explore how different LLM architectures handle prompt modifications, especially in tasks requiring fine-grained relevance judgments.
6.3. Why Did APE Perform Surprisingly Well?
Our results indicate that APE occasionally outperforms APO and OPRO, despite being a simpler method. This aligns with findings from Ma et al. [
28], which suggest that LLM-based reflection-driven prompt optimization may not always be superior to resampling-based approaches.
One key limitation of APO is that it updates prompts based on individual error cases, leading to localized and potentially biased refinements. Since the updates are driven by specific misclassifications rather than a broader error distribution, this approach risks overfitting to particular cases rather than producing generalizable improvements.
Similarly, OPRO updates prompts based on previous iterations rather than a direct understanding of the data distribution, which can lead to a reinforcement of past patterns rather than true optimization. Because it lacks a structured way to incorporate overall error tendencies, it may fail to make meaningful global improvements.
In contrast, APE generates multiple paraphrased variations of a prompt, increasing the likelihood of producing an effective version purely by chance. While this method does not actively refine prompts based on error analysis, the large number of variations increases the probability that some reformulations will perform well, even if they are not intentionally optimized.
Our results confirm these characteristics: APO and OPRO struggle with targeted optimization, whereas APE benefits from its broader search space. However, APO-CF achieves the most effective updates by leveraging confusion matrix analysis, ensuring that modifications reflect the overall data distribution rather than being influenced by specific cases or past prompt iterations. This suggests that a structured, data-driven refinement process like APO-CF leads to more reliable and generalizable prompt optimizations.
7. Conclusions
In this work, we introduced APO-CF, a data-driven prompt optimization method that leverages confusion matrix analysis to refine prompts effectively. Unlike traditional LLM-based reflection methods, which rely on self-generated feedback that may not accurately diagnose errors, APO-CF updates prompts based on systematic patterns in the training data, leading to more reliable and generalizable improvements.
Our experimental results demonstrate that APO-CF outperforms existing automated prompt optimization methods, including APO, OPRO, and APE, across multiple LLMs. While APO tends to overfit to individual error cases and OPRO struggles to generalize beyond past prompt iterations, APE benefits from a broader search space but lacks targeted refinement. APO-CF, in contrast, effectively captures overall data characteristics, aiming to achieve balanced and meaningful updates that enhance model performance.
One of the key advantages of APO-CF is its efficiency in real-world applications. Unlike iterative methods such as APO, which require multiple LLM calls for refinement, APO-CF updates the prompt in a single step, significantly reducing computational cost and API usage. This makes it practically viable for large-scale applications, where excessive LLM calls can be prohibitively expensive. Despite using fewer LLM calls, APO-CF achieves comparable or superior results, demonstrating that a well-structured, data-driven update can be more effective than repeated refinements.
While our results confirm the potential of APO-CF in optimizing prompts for query-passage relevance evaluation, this study also has certain limitations. In particular, the method has been tested on a limited set of LLMs; namely, GPT-4o, GPT-4o-mini, and DeepSeek-Chat. Given the architectural and behavioral variability across LLMs, the performance and stability of APO-CF may differ when applied to other models. Therefore, the generalizability of our approach beyond the evaluated models remains an open question.
Future work should investigate how APO-CF performs across a broader spectrum of LLM architectures and tasks. Additionally, model-specific tuning strategies and adaptive feedback mechanisms can be explored to further improve prompt robustness and ensure adaptability across diverse application settings.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}