

Mobile-AI-Based Docent System: Navigation and Localization for Visually Impaired Gallery Visitors



Abstract
1. Introduction
- Integrated assistance service: Our service unifies multiple assistive functionalities, overcoming the compartmentalization prevalent in conventional solutions that separately provide directional guidance, hazard detection, or audio descriptions. Instead, this approach integrates navigational assistance and in-depth audio interpretation within a single cohesive platform, ensuring consistent and convenient user engagement throughout the museum experience.
- Adaptive information provision: Utilizing real-time behavioral analysis algorithms, the system monitors visitor engagement patterns—including proximity to exhibits, dwell time, departure cues, and ambulatory velocity—to dynamically adjust content delivery. This approach mitigates the passive information delivery and unnecessary repeated information characteristic of existing solutions, thereby providing visually impaired visitors with a more immersive and enriched experience beyond superficial descriptions.
- Real-time obstacle detection and alerts: Utilizing an on-device object detection model, our system actively identifies obstacles in real-time and promptly alerts users, enhancing visitor safety and facilitating a secure and comfortable museum environment.
- Accurate and reliable positioning: The solution employs a dual-method positioning approach that synthesizes BLE beacon technology with continuous analysis of movement trajectories. This integration effectively mitigates the localization inaccuracies inherent in conventional indoor positioning systems, particularly those resulting from signal interference or unpredictable movement patterns.
2. Background of Analysis
2.1. Navigation Service

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technology Type | Specific Technology | Benefits & Features | Limitations & Challenges | Refs. |
|---|---|---|---|---|
| Wireless Communication | Wi-Fi + Lateration | - Uses existing APs - No line-of-sight required - Low setup cost | - Low distance accuracy - Sensitive to signal reflections | [10] |
| Wi-Fi + RSS fingerprinting | - Higher accuracy in mapped areas - No special setup on user devices | - Time-consuming offline mapping - Performance varies with environment - Hard to scale in large spaces | [10] | |
| BLE beacon + Neural networks | - Enhanced Localization Accuracy - Adaptability to Environmental Variations - Performance Enhancement | - Intrinsic Limitations of BLE Signals - Data and Training Requirements - Device and Environment Dependency | [12,13,14] | |
| BLE beacon + Filtering | - Accuracy improvement and error reduction - Noise and variability handling | - Implementation and computational complexity - Intrinsic limitations of BLE signals | [6,10] | |
| UWD | - High accuracy - Robust signal penetration - Extended range | - Infrastructure costs - Energy consumption | [10,15] | |
| Sensor | GPS + Transformer or ML | - Outdoor precision - Enhanced portability and usability - Improved accessibility | - Limited positional accuracy - Inaccurate distance estimation | [16,17] |
| RGB-D camera + ML | - Data fusion - Provision of enriched environmental information - Real-time processing | - Data noise and distortion - External environmental constraints | [15,18] | |
| IMU | - Posture estimation - Motion tracking | - Cumulative drift error | [11,16,18] | |
| Marker-based | Two-dimensional code | - High positioning accuracy - Low cost - Fast information retrieval | - Low distance estimation accuracy - Requires environmental installation | [19,20,21] |
2.2. Guide Service
3. Material and Methods
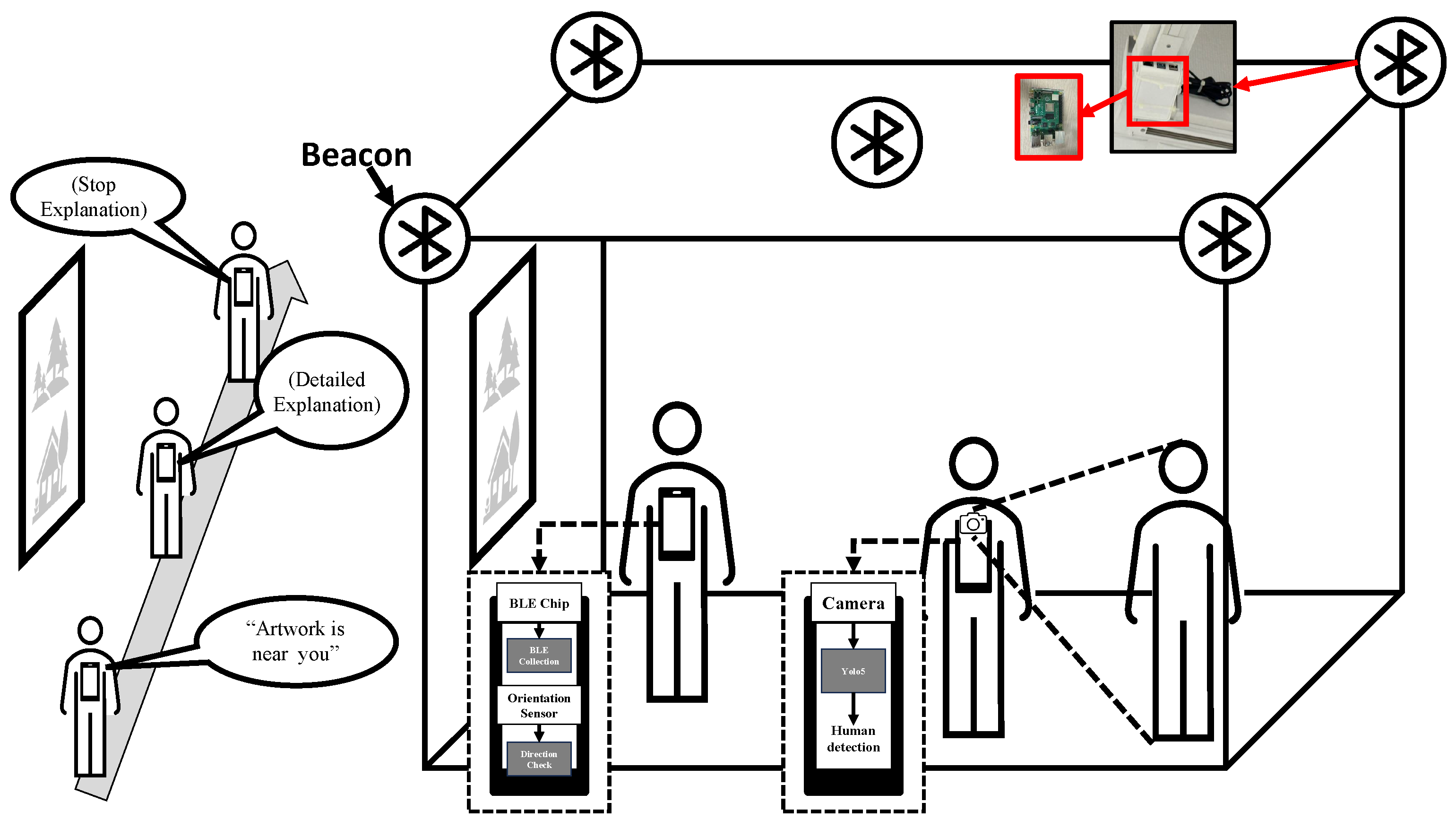
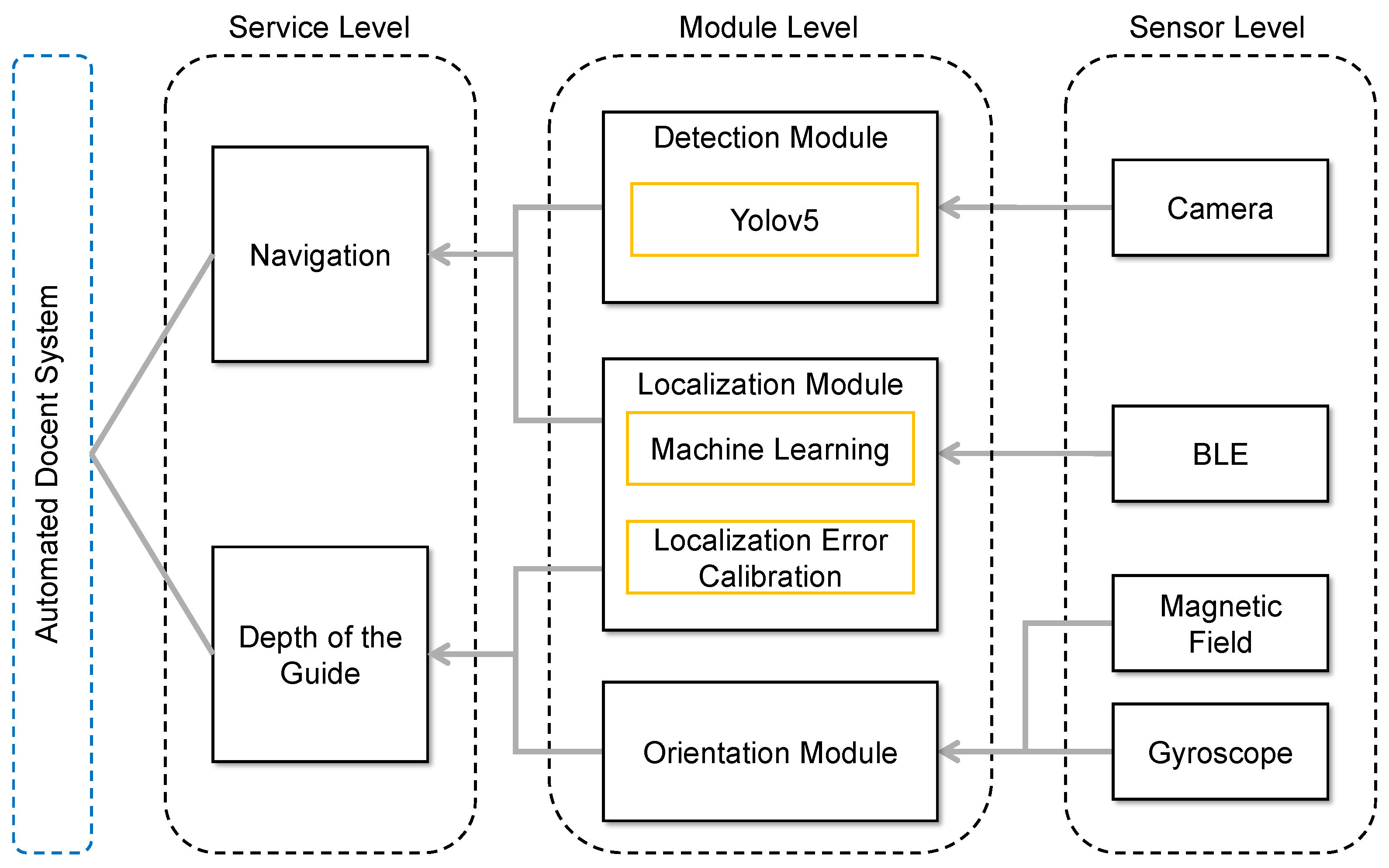
3.1. System Design
| Algorithm 1 Audio guide algorithm of navigation service with localization error calibration |
|
3.2. Experiment Environment
4. Research and Analysis
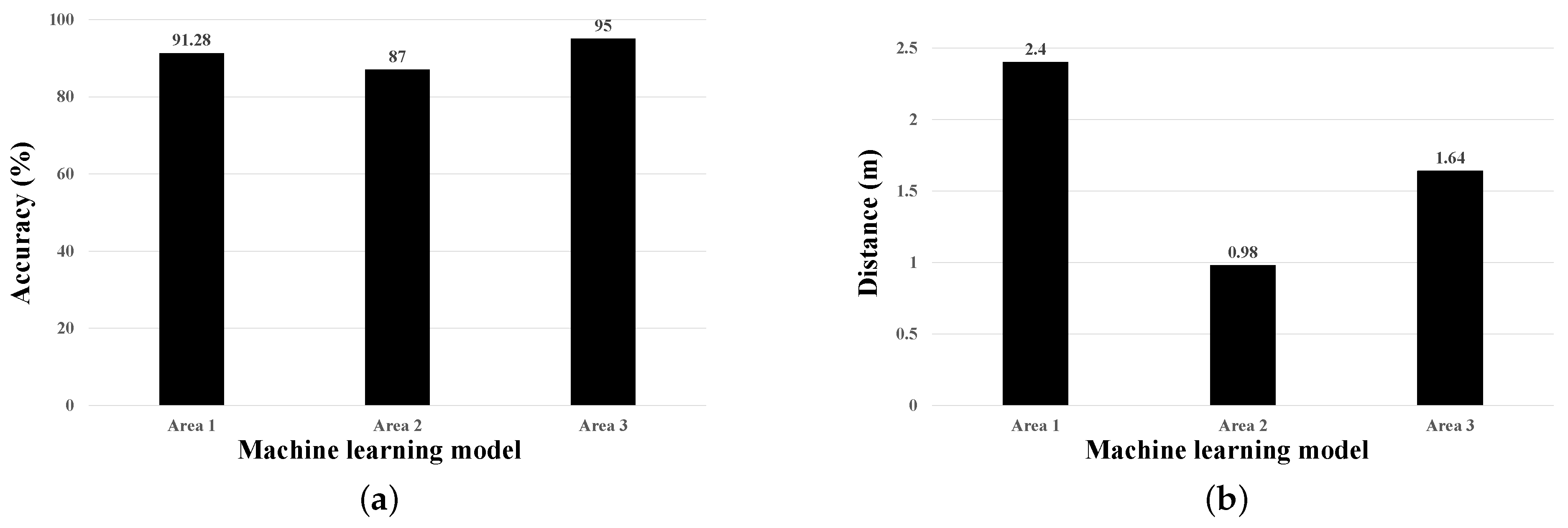
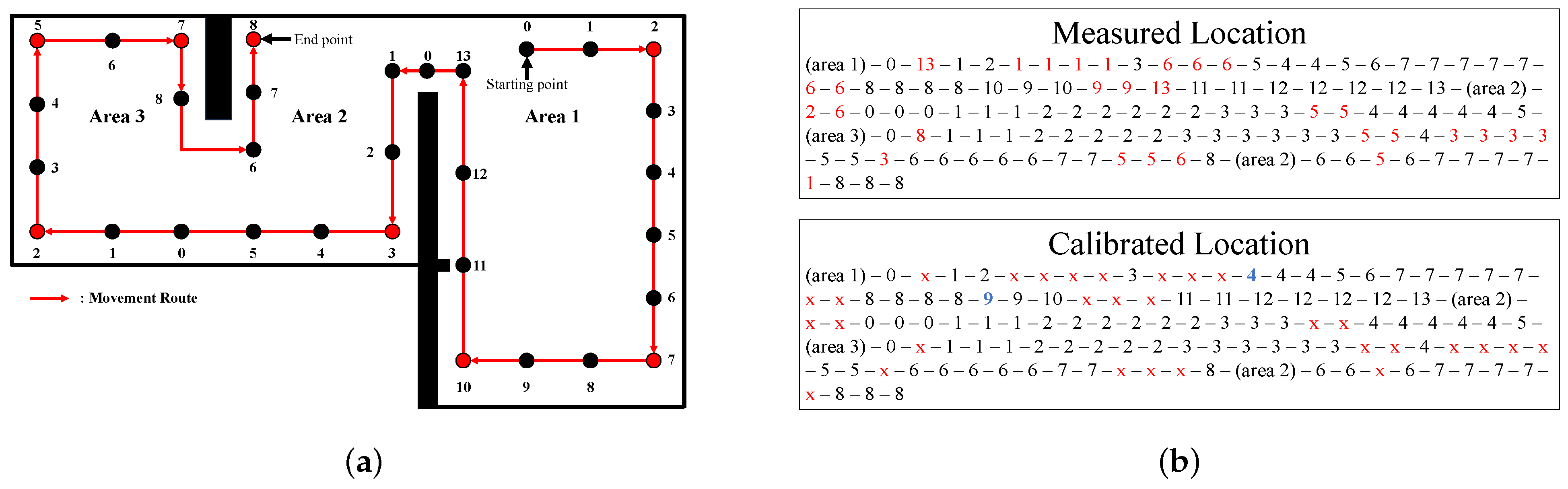
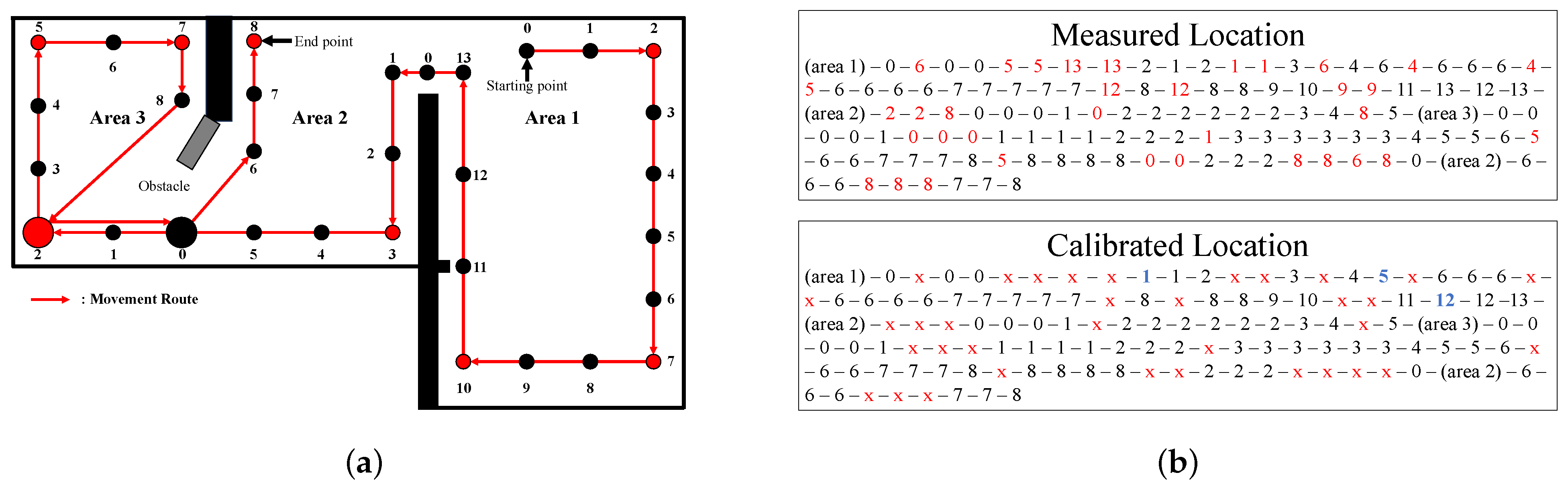
4.1. Localization
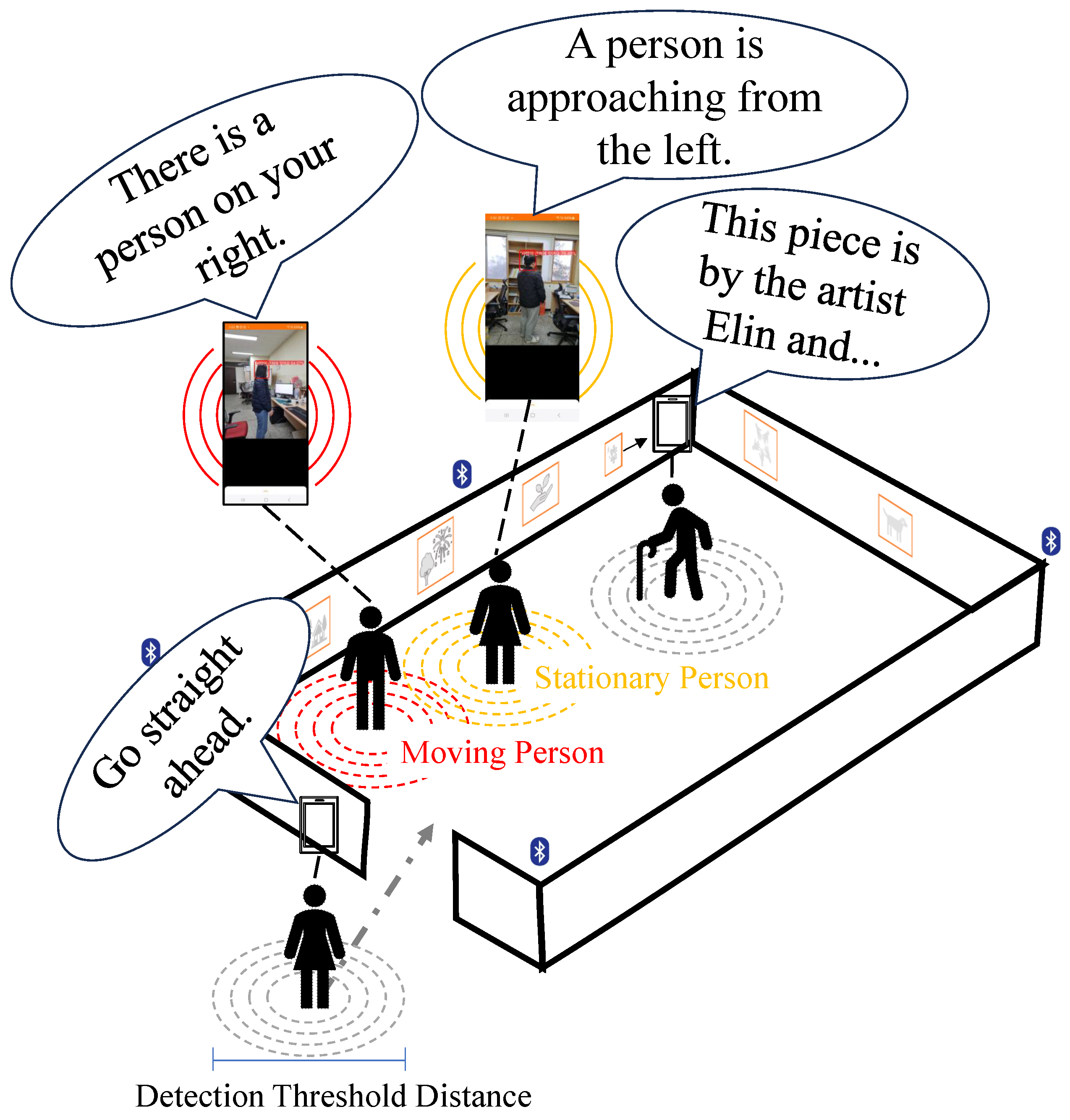
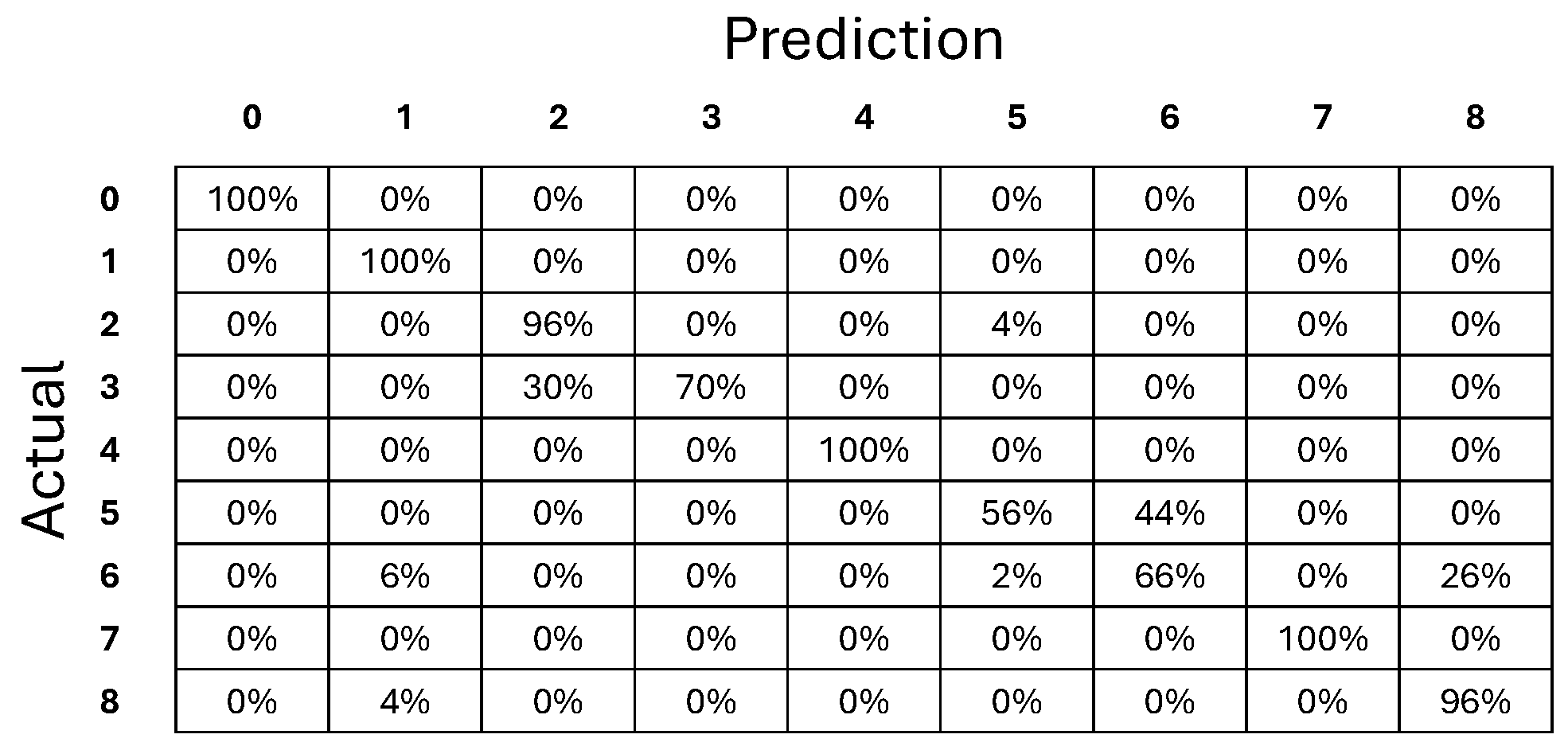
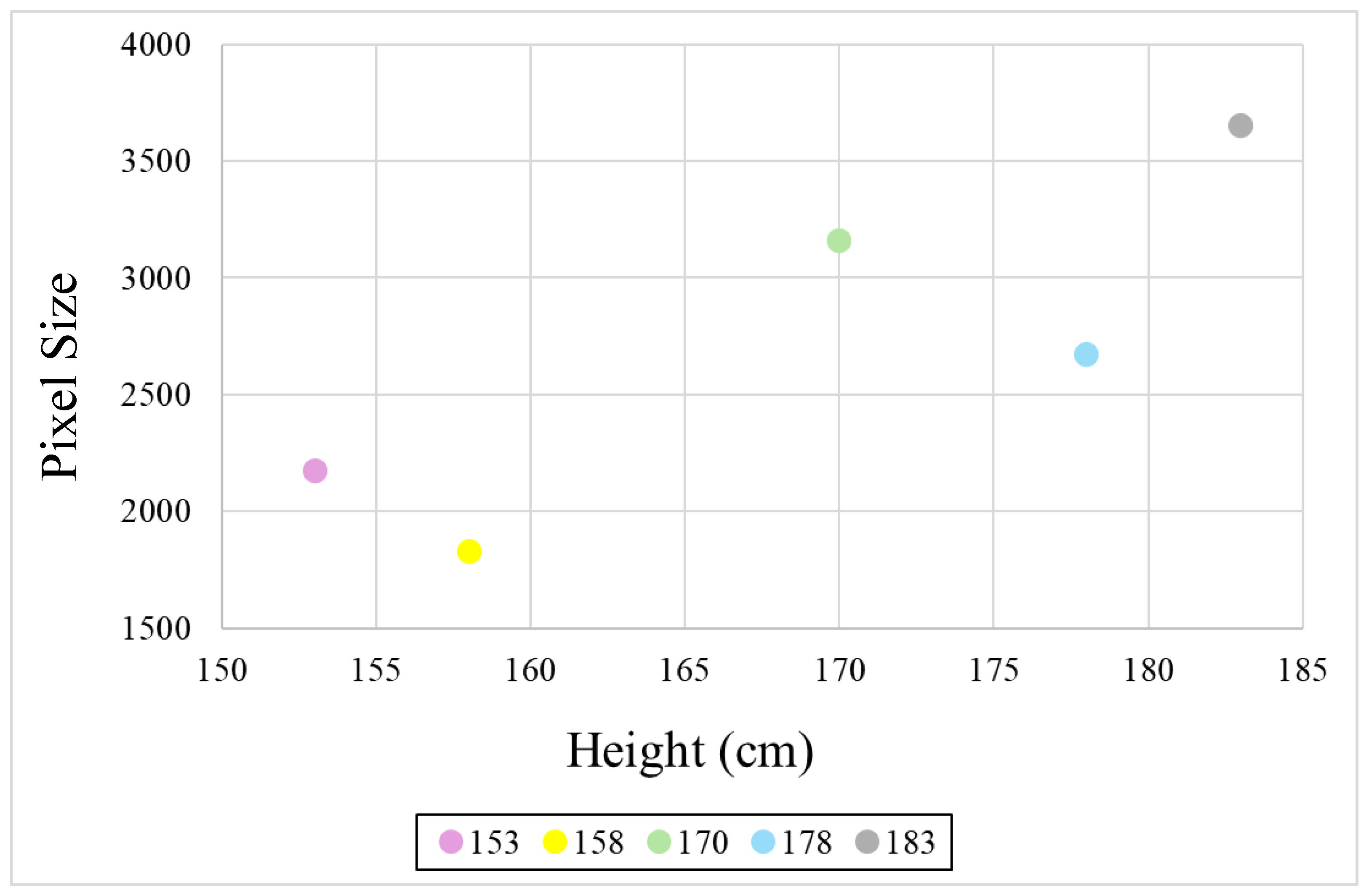
4.2. Human Detection
4.3. Comparison of Object Detection Performance
4.4. Quality of User Experience
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kaif, M.; Chauhan, U.; Chauhan, R.; Rana, R.; Chauhan, P. Designing Sensor Based Smart Stick for Handicapped Person. In Proceedings of the 2022 4th ICAC3N, Greater Noida, India, 16–17 December 2022; pp. 1399–1402. [Google Scholar]
- Quero, L.C.; Bartolomé, J.I.; Cho, J. Accessible visual artworks for blind and visually impaired people: Comparing a multimodal approach with tactile graphics. Electronics 2021, 10, 297. [Google Scholar] [CrossRef]
- Vaz, R.; Freitas, D.; Coelho, A. Blind and visually impaired visitors’ experiences in museums: Increasing accessibility through assistive technologies. Int. J. Incl. Mus. 2020, 13, 57–80. [Google Scholar] [CrossRef]
- Bai, J.; Lian, S.; Liu, Z.; Wang, K.; Liu, D. Virtual-Blind-Road Following-Based Wearable Navigation Device for Blind People. IEEE Trans. Consum. Electron. 2018, 64, 136–143. [Google Scholar] [CrossRef]
- Li, B.; Munoz, J.P.; Rong, X.; Chen, Q.; Xiao, J.; Tian, Y.; Arditi, A.; Yousuf, M. Vision-Based Mobile Indoor Assistive Navigation Aid for Blind People. IEEE Trans. Mob. Comput. 2019, 18, 702–714. [Google Scholar] [CrossRef] [PubMed]
- Spachos, P.; Plataniotis, K.N. BLE Beacons for Indoor Positioning at an Interactive IoT-Based Smart Museum. IEEE Syst. J. 2020, 14, 3483–3493. [Google Scholar] [CrossRef]
- Ahriz, I.; Douin, J.-M.; Lemoine, F. Location-based Service Sharing for Smart Museum. In Proceedings of the 2019 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 19–21 September 2019; pp. 1–6. [Google Scholar]
- Alletto, S.; Cucchiara, R.; Del Fiore, G.; Mainetti, L.; Mighali, V.; Patrono, L.; Serra, G. An Indoor Location-Aware System for an IoT-Based Smart Museum. IEEE Internet Things J. 2016, 3, 244–253. [Google Scholar] [CrossRef]
- Tyagi, N.; Sharma, D.; Singh, J.; Sharma, B.; Narang, S. Assistive Navigation System for Visually Impaired and Blind People: A Review. In Proceedings of the 2021 AIMV, Gandhinagar, India, 24–26 September 2021; pp. 1–5. [Google Scholar]
- Ayaz, Z. Digital Advertising and Customer Movement Analysis Using BLE Beacon Technology and Smart Shopping Carts in Retail. J. Theor. Appl. Electron. Commer. Res. 2025, 20, 55. [Google Scholar] [CrossRef]
- Feghali, J.M.; Feng, C.; Majumdar, A.; Ochieng, W.Y. Comprehensive Review: High-Performance Positioning Systems for Navigation and Wayfinding for Visually Impaired People. Sensors 2024, 24, 7020. [Google Scholar] [CrossRef]
- Barsocchi, P.; Girolami, M.; La Rosa, D. Detecting proximity with bluetooth low energy beacons for cultural heritage. Sensors 2021, 21, 7089. [Google Scholar] [CrossRef]
- Verde, D.; Romero, L.; Faria, P.M.; Paiva, S. Indoor content delivery solution for a museum based on BLE beacons. Sensors 2023, 23, 7403. [Google Scholar] [CrossRef]
- Girolami, M.; La Rosa, D.; Barsocchi, P. Bluetooth dataset for proximity detection in indoor environments collected with smartphones. Data Brief 2024, 53, 110215. [Google Scholar] [CrossRef]
- Abidi, M.H.; Siddiquee, A.N.; Alkhalefah, H.; Srivastava, V. A comprehensive review of navigation systems for visually impaired individuals. Heliyon 2024, 10, e31825. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Shangguan, Z.; Zhang, J.; Bar, G.; Boyd, M.; Ohn-Bar, E. Assister: Assistive navigation via conditional instruction generation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 271–289. [Google Scholar]
- Okolo, G.I.; Althobaiti, T.; Ramzan, N. Smart Assistive Navigation System for Visually Impaired People. J. Disabil. Res. 2025, 4, 20240086. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, X.; Kojima, M.; Huang, Q.; Arai, T. A wearable navigation device for visually impaired people based on the real-time semantic visual SLAM system. Sensors 2021, 21, 1536. [Google Scholar] [CrossRef] [PubMed]
- Zhou, C.; Liu, X. The Study of Applying the AGV Navigation System Based on Two Dimensional Bar Code. In Proceedings of the 2016 International Conference on Industrial Informatics—Computing Technology, Intelligent Technology, Industrial Information Integration (ICIICII), Wuhan, China, 3–4 December 2016; pp. 206–209. [Google Scholar]
- Liu, D.; Zhang, W.; Qi, Y.; Liu, F.; Liu, J.; Ren, J.; Wang, Y.; Wang, Z. Auxiliary Smart Glasses for Visually Impaired People Based on Two-dimensional Code Positioning. In Proceedings of the 2021 7th IEEE International Conference on Network Intelligence and Digital Content (IC-NIDC), Beijing, China, 17–19 November 2021; pp. 279–283. [Google Scholar]
- Lv, H.; Feng, L.; Yang, A.; Lin, B.; Huang, H.; Chen, S. Two-Dimensional Code-Based Indoor Positioning System With Feature Graphics. IEEE Photonics J. 2018, 11, 1–15. [Google Scholar] [CrossRef]
- Arifando, R.; Eto, S.; Wada, C. Improved YOLOv5-based lightweight object detection algorithm for people with visual impairment to detect buses. Appl. Sci. 2023, 13, 5802. [Google Scholar] [CrossRef]
- Khan, S.; Nazir, S.; Khan, H.U. Analysis of navigation assistants for blind and visually impaired people: A systematic review. IEEE Access 2021, 9, 26712–26734. [Google Scholar] [CrossRef]
- Dilli, H.; Katragadda, K.; Sang, V.M. Smart Blind Stick Using Node MCU with Voice Alert. In Proceedings of the 2022 OTCON, Raigarh, Chhattisgarh, India, 8–10 February 2023; pp. 1–6. [Google Scholar]
- Wang, H.; Song, C.; Li, H. Application of social media communication for museum based on the deep mediatization and artificial intelligence. Sci. Rep. 2024, 14, 28661. [Google Scholar] [CrossRef]
- Costales, J.A.; Vida, A.K.S.; Albino, M.G. Mobile Based Navigation System for Visually Impaired Person Using Image Detection with Voice Translation. In Proceedings of the 2023 3rd ICICSE, Chongqing, China, 7–9 April 2023; pp. 32–36. [Google Scholar]
- Birmingham Museum of Art. Smart Guide. Available online: https://www.artsbma.org/art/smartguide/ (accessed on 10 March 2024).
- Siwalette, R.; Suyoto. IoT-Based Smart Gallery to Promote Museum in Ambon. In Proceedings of the 2020 Fourth World Conference on Smart Trends in Systems, Security and Sustainability (WorldS4), London, UK, 27–28 July 2020; pp. 528–532. [Google Scholar]
- Ng, P.C.; She, J.; Park, S. Notify-and-interact: A beacon-smartphone interaction for user engagement in galleries. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 1069–1074. [Google Scholar]
- Hussain, M. Yolov5, yolov8 and yolov10: The go-to detectors for real-time vision. arXiv 2024, arXiv:2407.02988. [Google Scholar]
- Geetha, A.S.; Hussain, M. A comparative analysis of yolov5, yolov8, and yolov10 in kitchen safety. arXiv 2024, arXiv:2407.20872. [Google Scholar]
- Gebru, K.; Rapelli, M.; Rusca, R.; Casetti, C.; Chiasserini, C.F.; Giaccone, P. Edge-based passive crowd monitoring through WiFi Beacons. Comput. Commun. 2022, 192, 163–170. [Google Scholar] [CrossRef]
- De Brouwer, R.; Torres-Sospedra, J.; Trilles-Oliver, S.; Berkvens, R. Optimal Receivers Location for Passive Indoor Positioning Based on BLE. In Proceedings of the IPIN-WiP, Lloret de Mar, Spain, 29 November–2 December 2021. [Google Scholar]
- Saghafi, S.; Kiarashi, Y.; Rodriguez, A.D.; Levey, A.I.; Kwon, H.; Clifford, G.D. Indoor Localization Using Multi-Bluetooth Beacon Deployment in a Sparse Edge Computing Environment. Digit. Twins Appl. 2025, 2, e70001. [Google Scholar] [CrossRef]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. CrowdHuman: A Benchmark for Detecting Human in a Crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar]
- Baume, R.M.; Buschang, P.H.; Weinstein, S. Stature, head height, and growth of the vertical face. Am. J. Orthod. 1983, 83, 477–484. [Google Scholar] [CrossRef]
- Zuckerman, M.; Kolberg, E. Distance Estimation to Image Objects Using Adapted Scale. Int. J. Eng. Sci. 2017, 6, 39–50. [Google Scholar] [CrossRef]

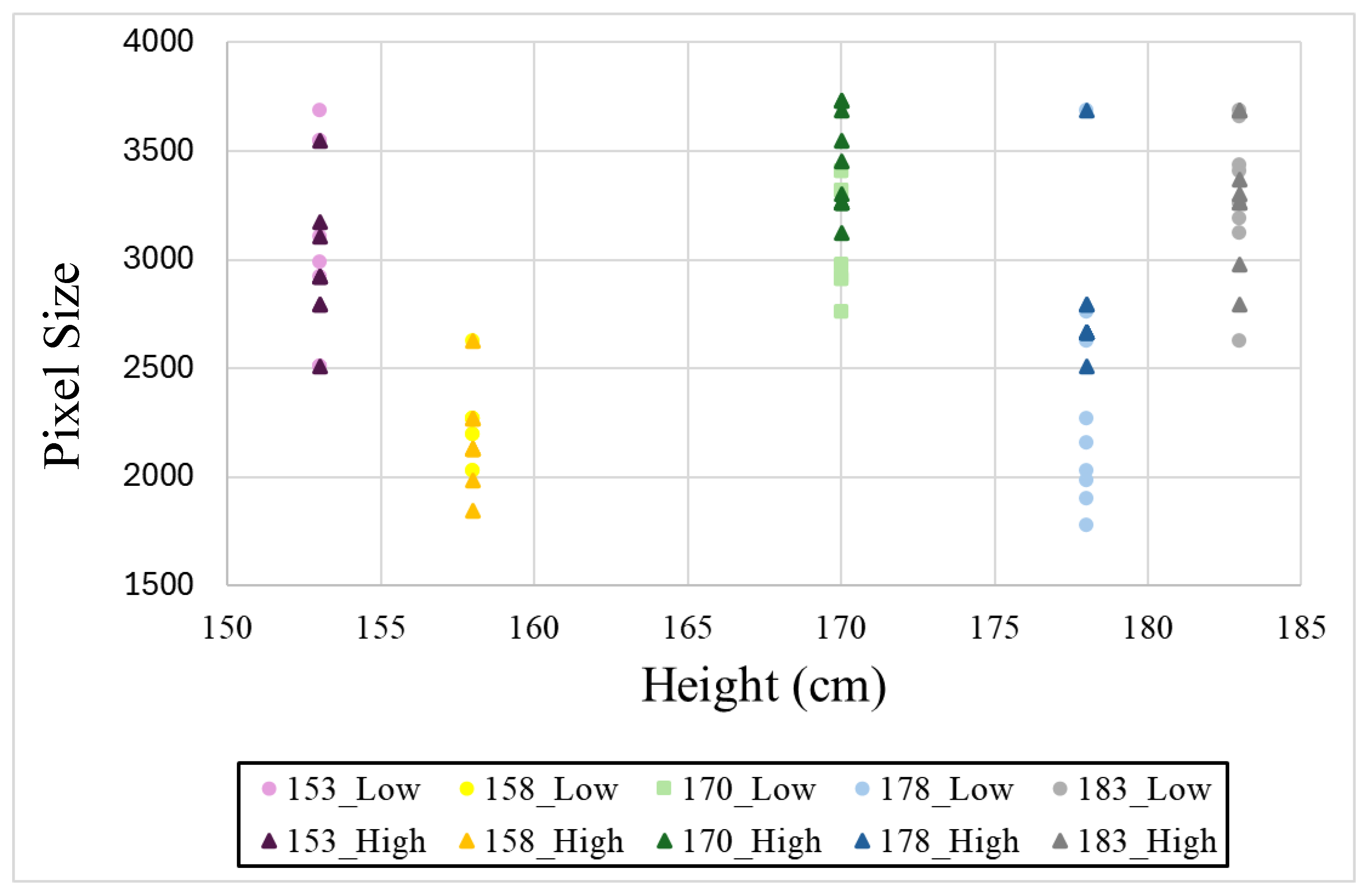
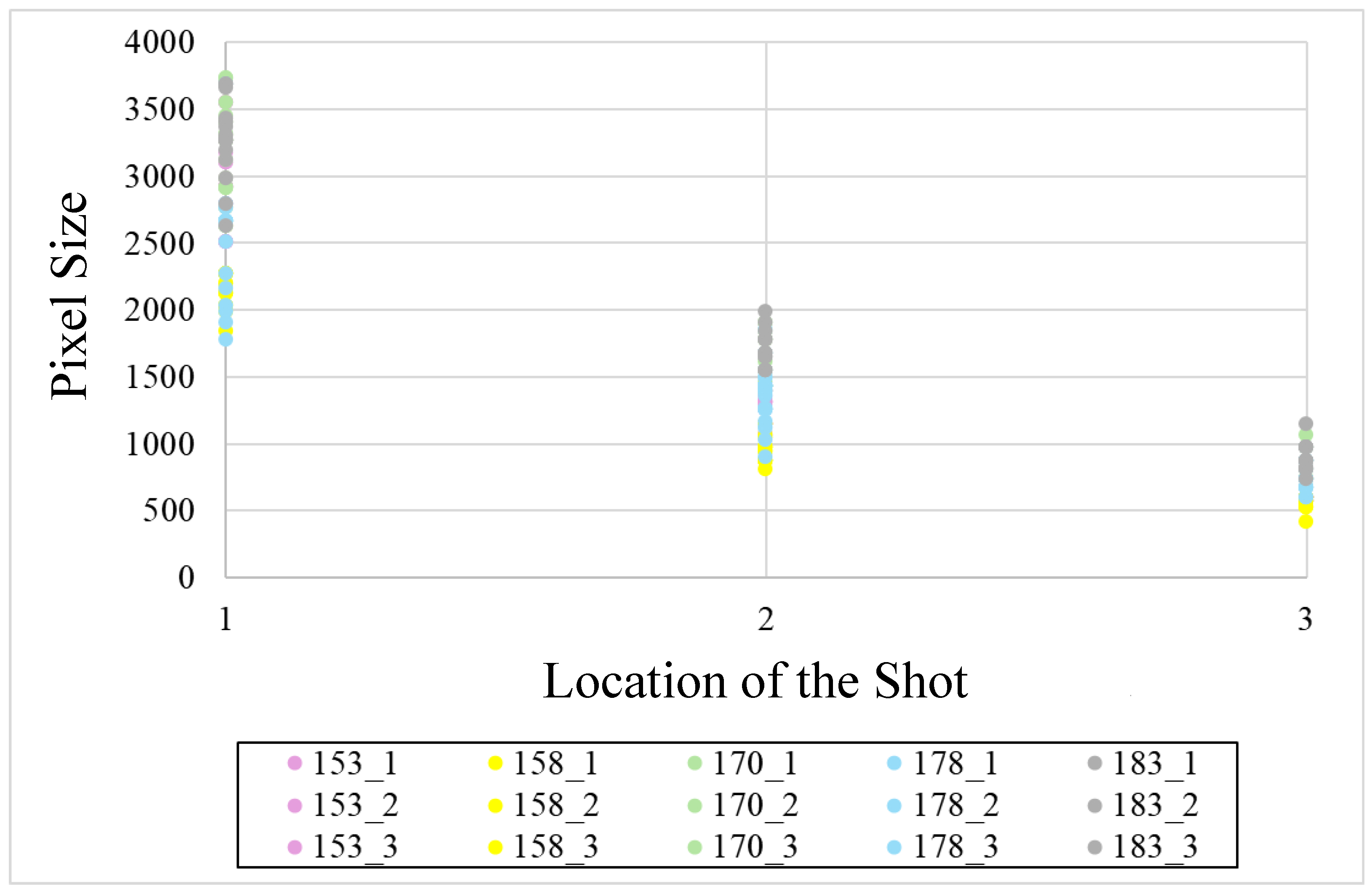

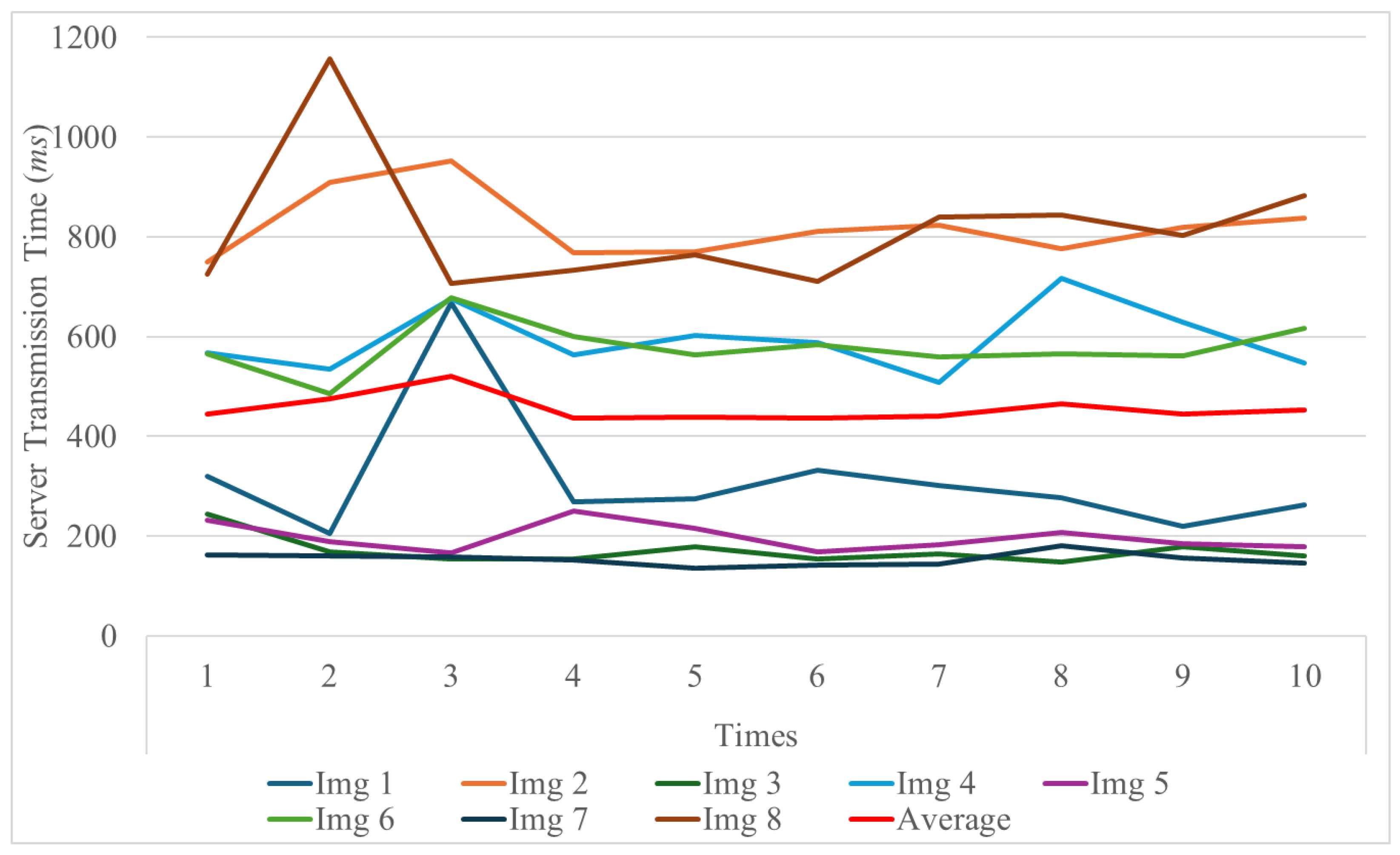
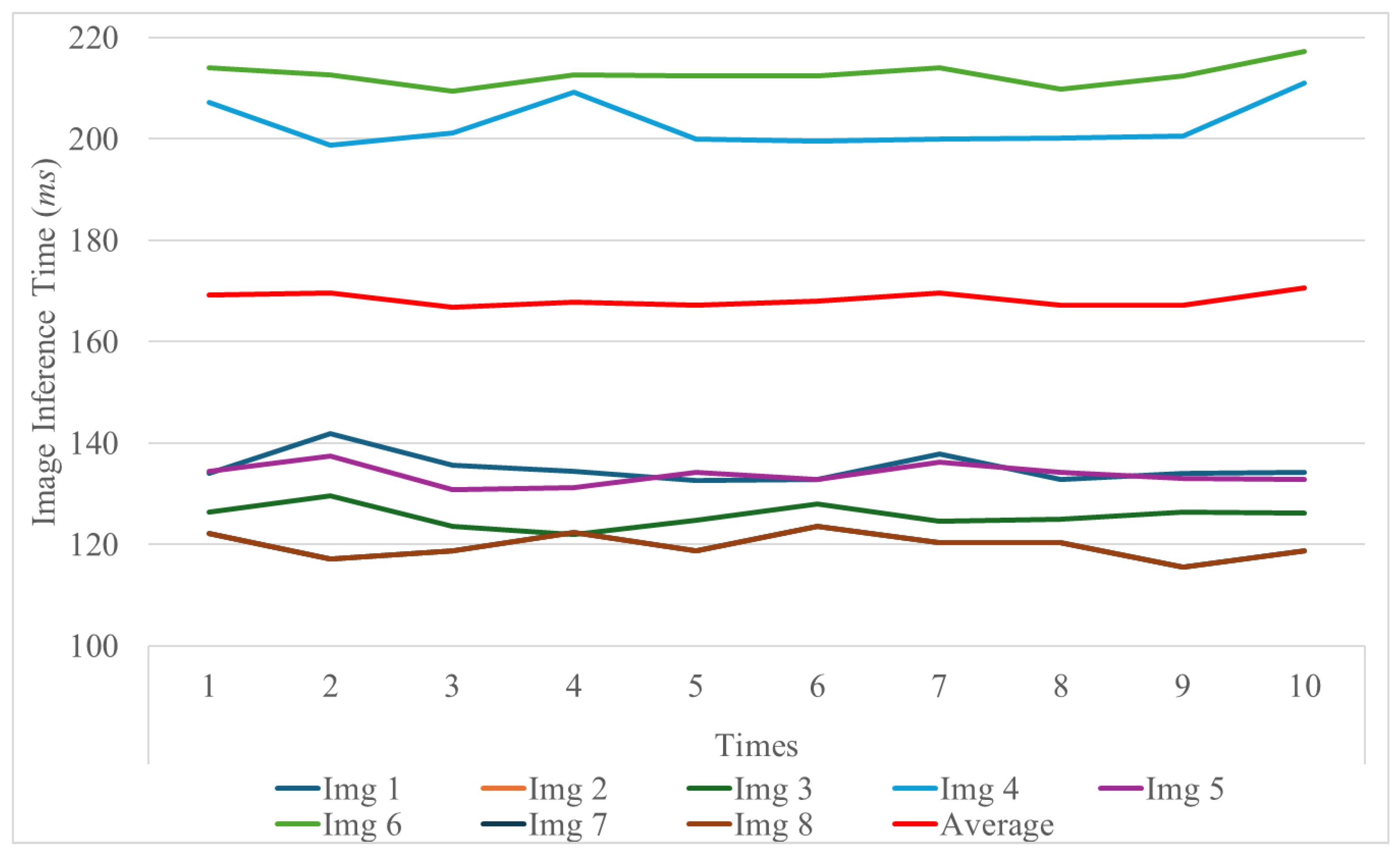

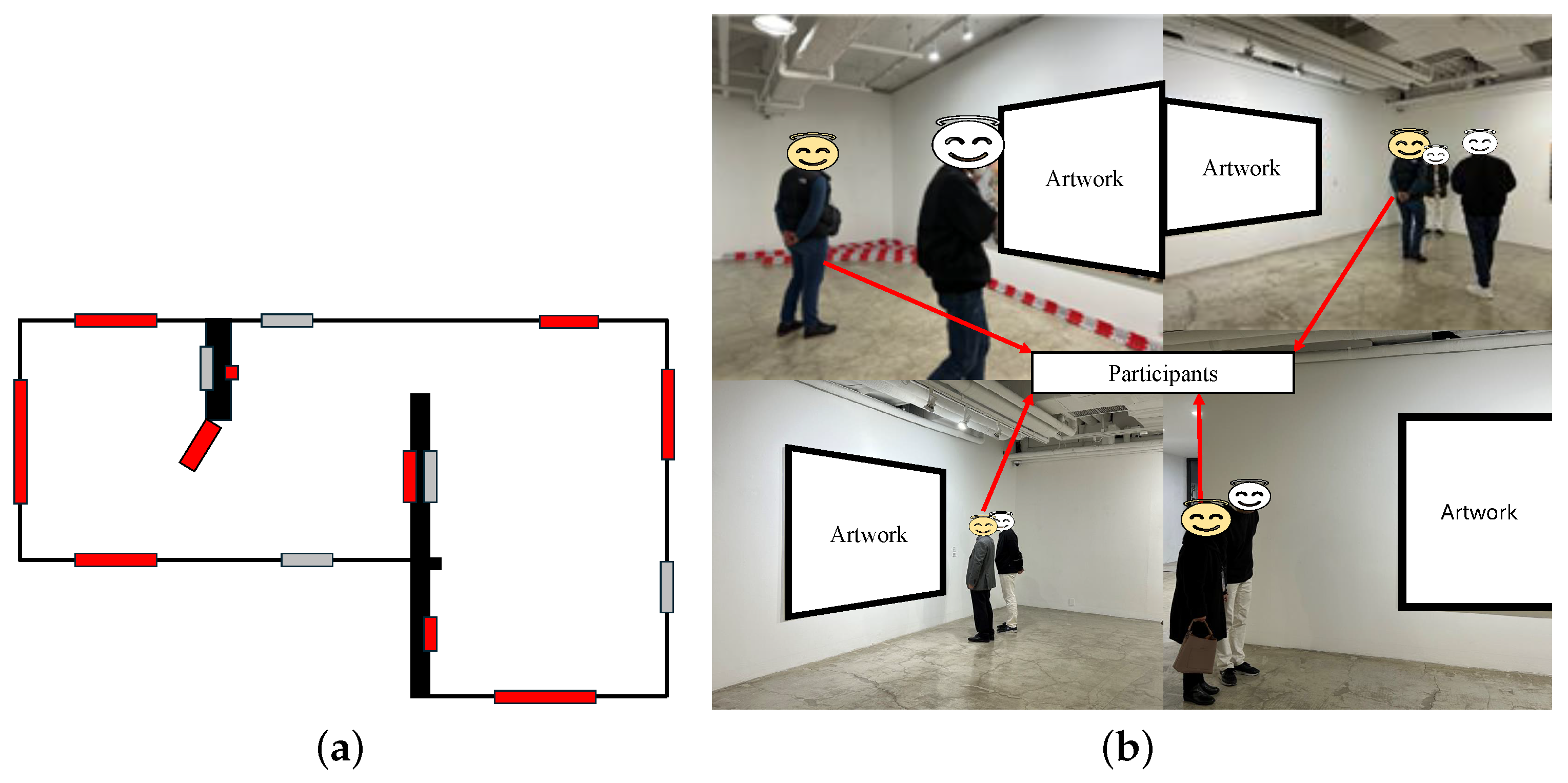
| Category | Component | Details |
|---|---|---|
| Hardware | BLE beacons | Raspberry Pi 4B unit |
| Mobile device | Galaxy S21 smartphone | |
| GPU (training) | NVIDIA GeForce RTX 3070 GPU | |
| Software | YOLOv5 | YOLOv5m architecture - Epochs: 128 - Batch size: 4 - Image resolution: 416 × 416 pixels - Dataset: CrowdHuman dataset |
| Python | Version: 3.9.17 | |
| Library | TFLite, TensorFlow |
| Height (cm) | Location (cm) | ||
|---|---|---|---|
| 180 | 270 | 360 | |
| 153 | 2968.451 | 1275.108 | 600.8036 |
| 158 | 2179.694 | 959 | 559.5476 |
| 170 | 3261.687 | 1612.492 | 814.3333 |
| 178 | 2478.534 | 1338.682 | 762.1111 |
| 183 | 3269.375 | 1717.545 | 900.9821 |
| Image ID | Image Properties | ||
|---|---|---|---|
| Dimensions | Resolution (MP) | File Size (MB) | |
| Img1 | 3024 × 4032 | 12.00 | 4.08 |
| Img2 | 6936 × 9248 | 64.00 | 17.23 |
| Img3 | 2268 × 4032 | 9.00 | 2.56 |
| Img4 | 5204 × 9248 | 48.00 | 12.29 |
| Img5 | 3024 × 3024 | 9.00 | 2.63 |
| Img6 | 6928 × 6928 | 48.00 | 12.27 |
| Img7 | 1816 × 4032 | 7.00 | 2.35 |
| Img8 | 4164 × 9248 | 39.00 | 11.20 |
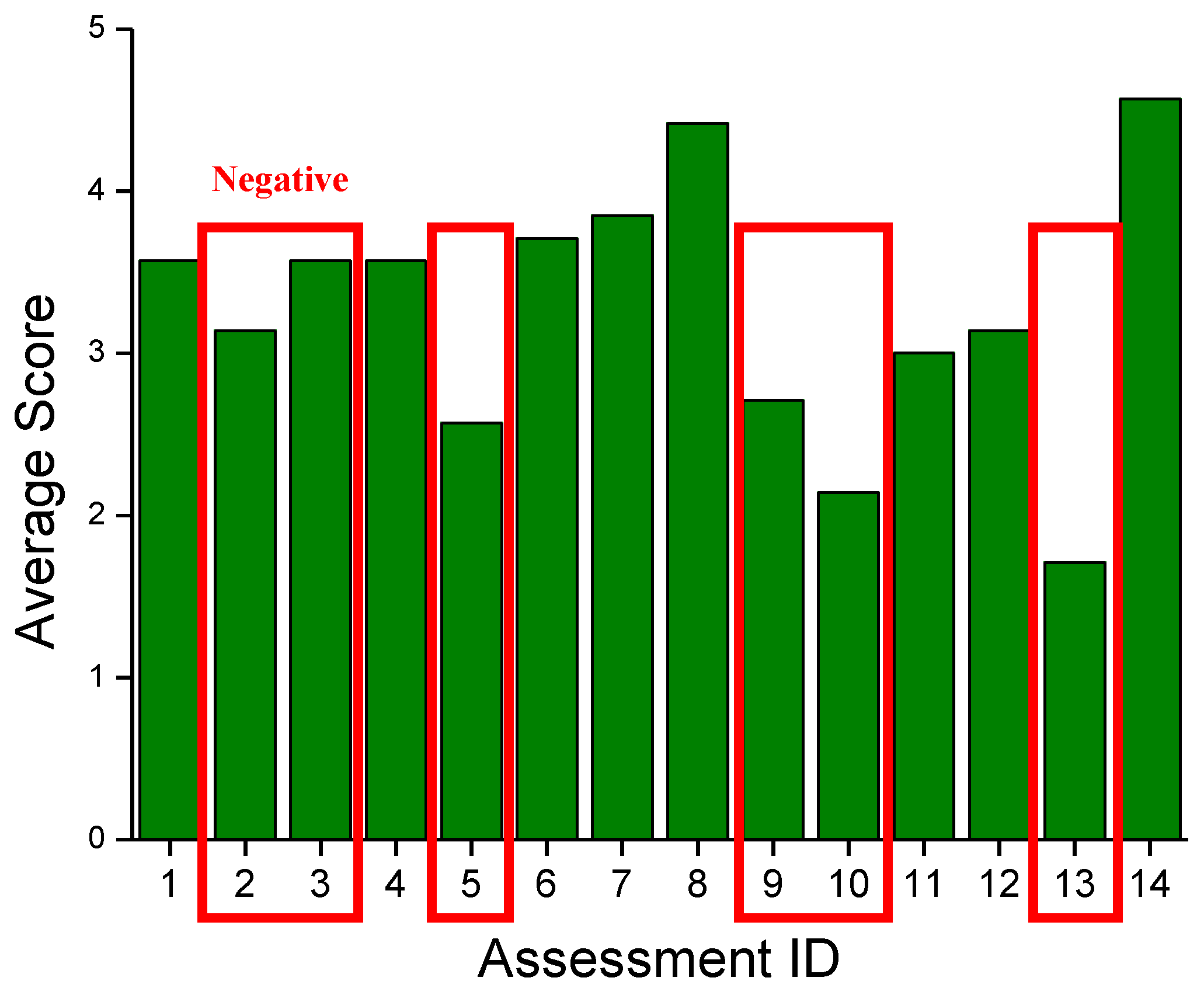
| ID | Assessment | Type |
|---|---|---|
| 1 | Was a smartphone suitable as a device to provide a system? | P |
| 2 | Was the system complicated to use? | N |
| 3 | Were the navigation inaccurate? | N |
| 4 | Was the location of the artwork recognized by the system suitable for listening to information about it? | P |
| 5 | Were you dissatisfied with traveling along the recommended route? | N |
| 6 | Were the audio navigation helpful when touring the museum? | P |
| 7 | Was it convenient to have information provided when looking in the direction of the artwork? | P |
| 8 | Was the audio guide for the artwork adequate for obtaining information about the artwork? | P |
| 9 | Was it inconvenient because an obstacle detection alarm was provided while providing information about artwork? | N |
| 10 | Had you found the frequency of obstacle detection alarms once per second to be too slow and inconvenient? | N |
| 11 | Did you feel that obstacle detection was working well? | P |
| 12 | Did the obstacle detection service give you psychological stability while moving around the art gallery? | P |
| 13 | Were you dissatisfied with using the system at the art gallery? | N |
| 14 | Would you consider using the system again when you return to the art gallery? | P |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
An, H.; Park, W.; Liu, P.; Park, S. Mobile-AI-Based Docent System: Navigation and Localization for Visually Impaired Gallery Visitors. Appl. Sci. 2025, 15, 5161. https://doi.org/10.3390/app15095161
An H, Park W, Liu P, Park S. Mobile-AI-Based Docent System: Navigation and Localization for Visually Impaired Gallery Visitors. Applied Sciences. 2025; 15(9):5161. https://doi.org/10.3390/app15095161
Chicago/Turabian StyleAn, Hyeyoung, Woojin Park, Philip Liu, and Soochang Park. 2025. "Mobile-AI-Based Docent System: Navigation and Localization for Visually Impaired Gallery Visitors" Applied Sciences 15, no. 9: 5161. https://doi.org/10.3390/app15095161
APA StyleAn, H., Park, W., Liu, P., & Park, S. (2025). Mobile-AI-Based Docent System: Navigation and Localization for Visually Impaired Gallery Visitors. Applied Sciences, 15(9), 5161. https://doi.org/10.3390/app15095161