
Lightweight Anomaly-Based Detection Using Cuckoo Search Algorithm and Decision Tree to Mitigate Man-in-the-Middle Attacks in DNS



Abstract
1. Introduction
2. Related Work
2.1. Anomaly-Based Detection System
2.2. Cuckoo Search Algorithm
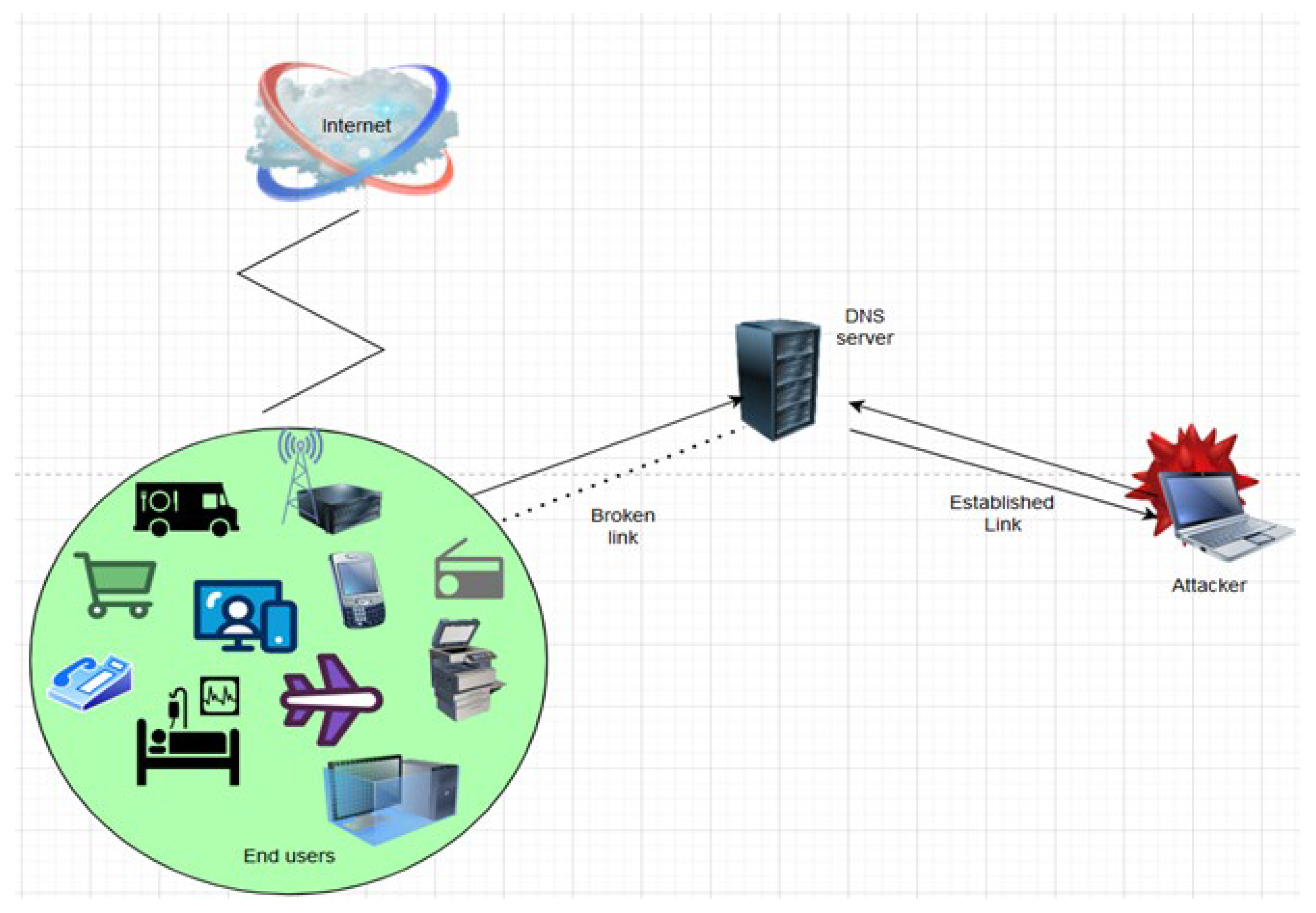
2.3. Man-in-the-Middle Attacks
2.4. Decision Tree-Related Works
3. Methodology
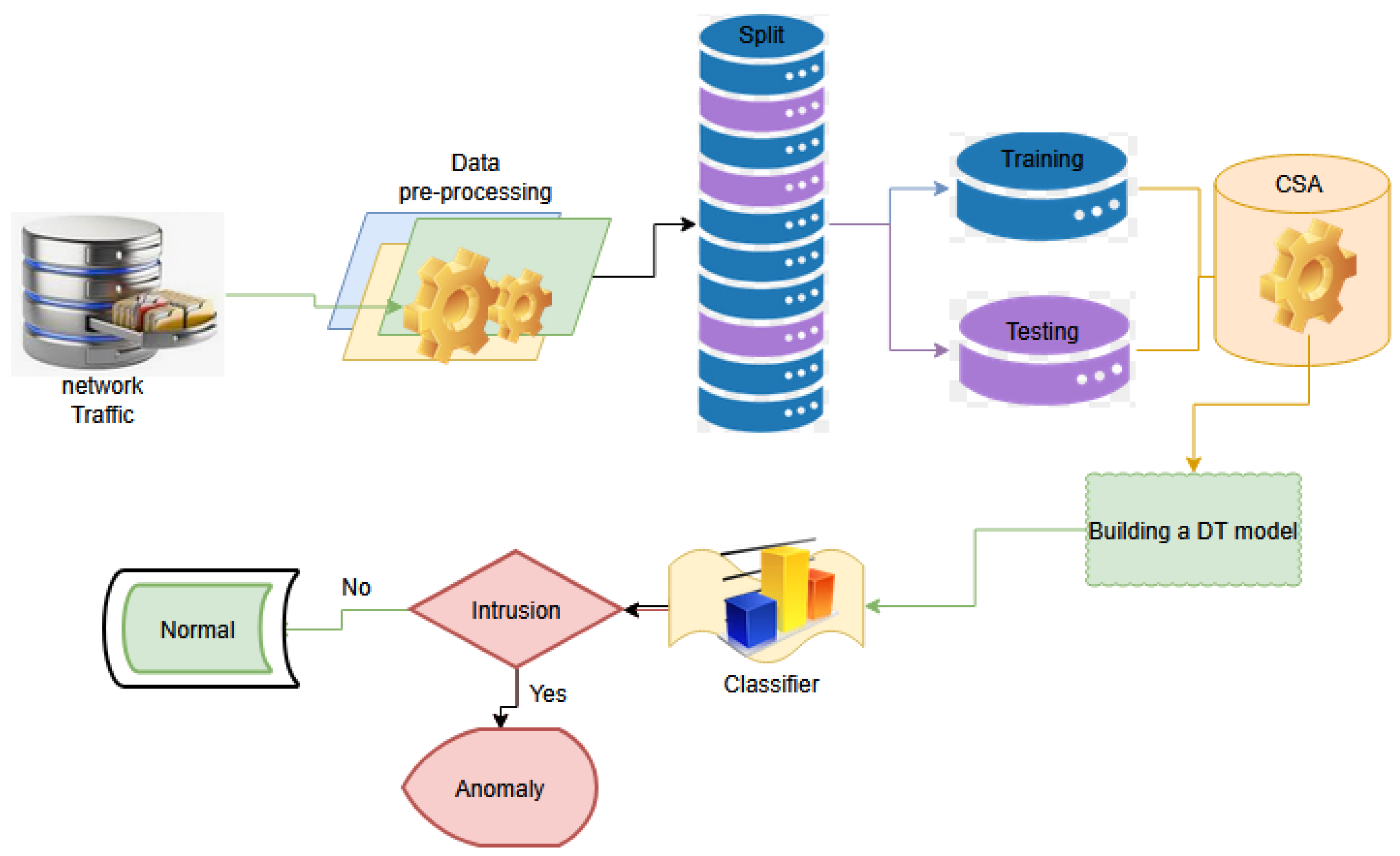
3.1. Research Design
3.2. Detection Algorithm
| Algorithm 1: Detection algorithm |
| 1 def detect (input_data, threshold): |
| 2 # Preprocess the input data |
| 3 preprocessed_data = preprocess(input_data) |
| 4 detection_results = [ ] |
| 5 |
| 6 # Iterate through each data point in the preprocessed data |
| 7 for data_point in preprocessed_data: |
| 8 if data_point > threshold: |
| 9 detection_results.append (True) |
| 10 else: |
| 11 detection_results.append (False) |
| 12 |
| 13 return detection_results |
| 14 |
| 15 def preprocess (input_data): |
| 16 # Add actual preprocessing steps here if needed |
| 17 return input_data |
| Algorithm 2: Cuckoo Search Algorithm |
| 1 Objective function f(x), x = ( x1, x2, …, xd)T |
| 2 Generate initial population of n host nests xi (i = 1, 2, …, n) |
| 3 while t < stop criteria do |
| 4 Get a cuckoo (say i) randomly by Levy distribution |
| 5 Evaluate its fitness Fi |
| 6 Choose a nest among n (say j) randomly |
| 7 Evaluate its fitness Fj |
| 8 if Fi > Fj then |
| 9 Replace j with the new solution |
| 10 end if |
| 11 A fraction of the worst nests are abandoned and replaced by new ones using Levy flight |
| 12 Keep the best solutions and continuously update the current best |
| 13 end while |
| 14 Repeat until the end |
3.3. Cuckoo Search Detection Scheme
| Algorithm 3: Cuckoo Search Detection Scheme |
| 1 Objective function (params, input_data, threshold): |
| 2 Detection results detects(input_data, threshold, params) |
| 3 Return evaluate_accuracy(detection_results) |
| 4 Detects (input_data, threshold, params): |
| 5 Preprocessed data preprocess(input_data, params) |
| 6 Returnpreprocessed_data] |
| 7 Preprocessed (input_data, params): |
| 8 Return input_data |
| 9 Cuckoo search (input_data, threshold, n − L, max_iter − n): |
| 10 Nests = np.random.rand(n, len(input_data)) |
| 11 best_nest = nests[0] |
| 12 best_fitness = objective_function(best_nest, input_data, threshold) |
| 13 for range (max_iter) do |
| 14 for range(n) do |
| 15 new_nest = nests[i] + levy_flight( ) |
| 16 new_fitness = objective_function(new_nest, input_data, threshold) |
| 17 j = np.random.randint(n) |
| 18 if new_fitness > objective_function(nests[j], input_data, threshold) |
| then |
| 19 nests[j] – new_nest |
| 20 end if |
| 21 if new_fitness > best_fitness then |
| 22 best_nest, best_fitness = new_nest, new fitness |
| 23 end if |
| 24 end for |
| 25 nests = abandon(nests) |
| 26 end for |
| 27 Return best_nest |
| 28 Levy flight ( ): |
| 29 Return np.random.randn( ) |
| 30 Abondon (nests): |
| 31 Return nests |
| 32 Evaluate accuracy (detection_results): |
| 33 Return np.random.rand( ) |
4. Proposed Model
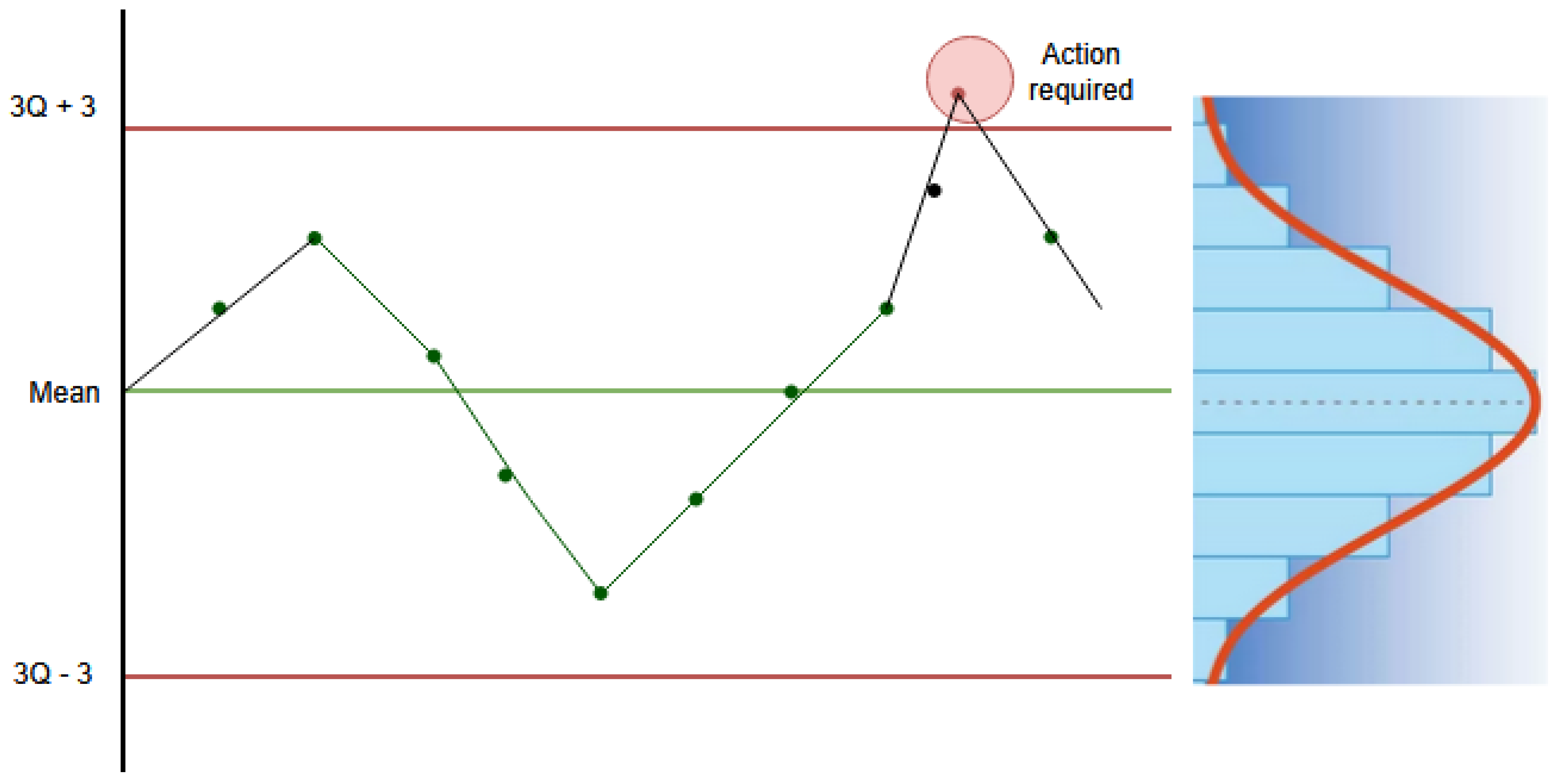
5. Objective Function
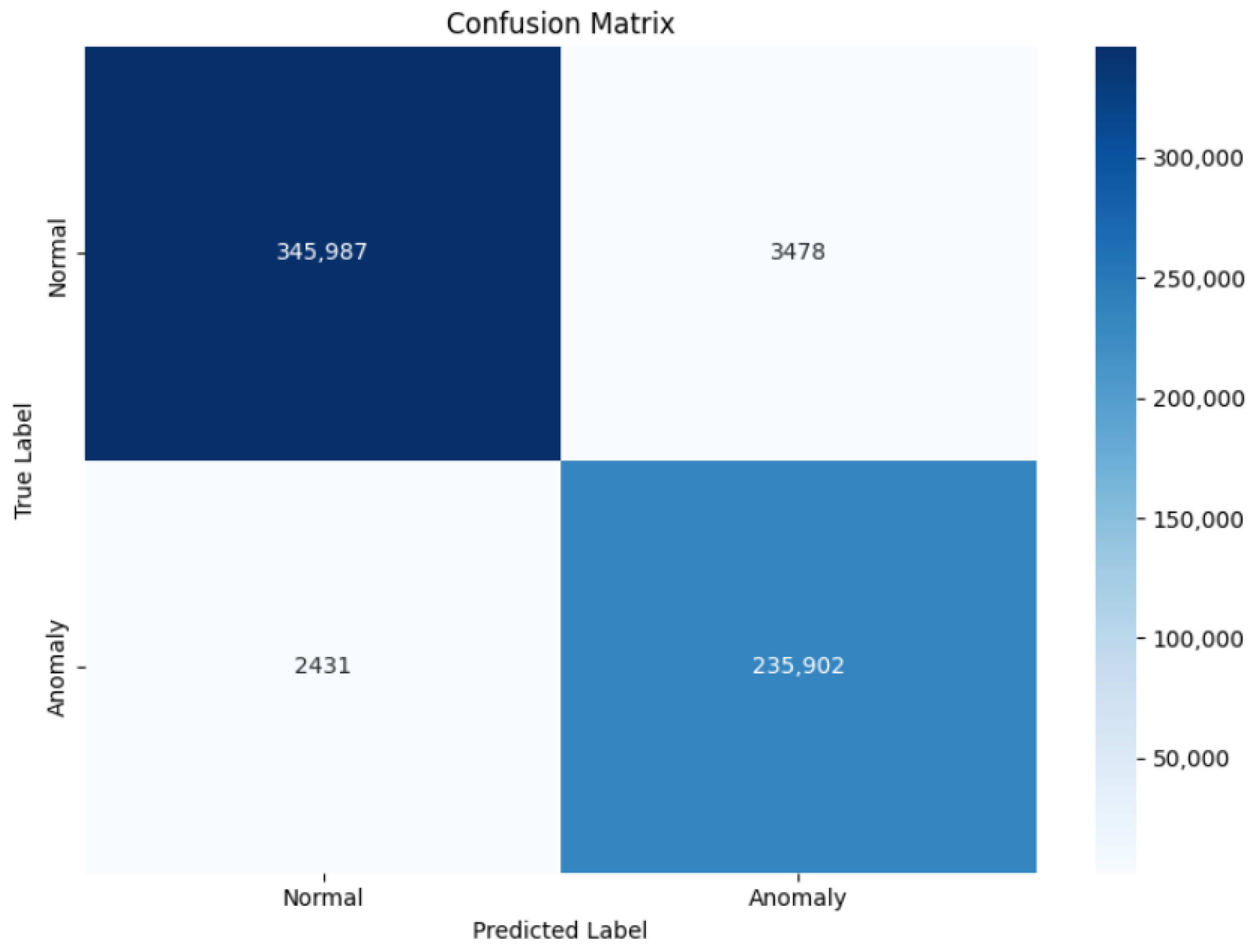
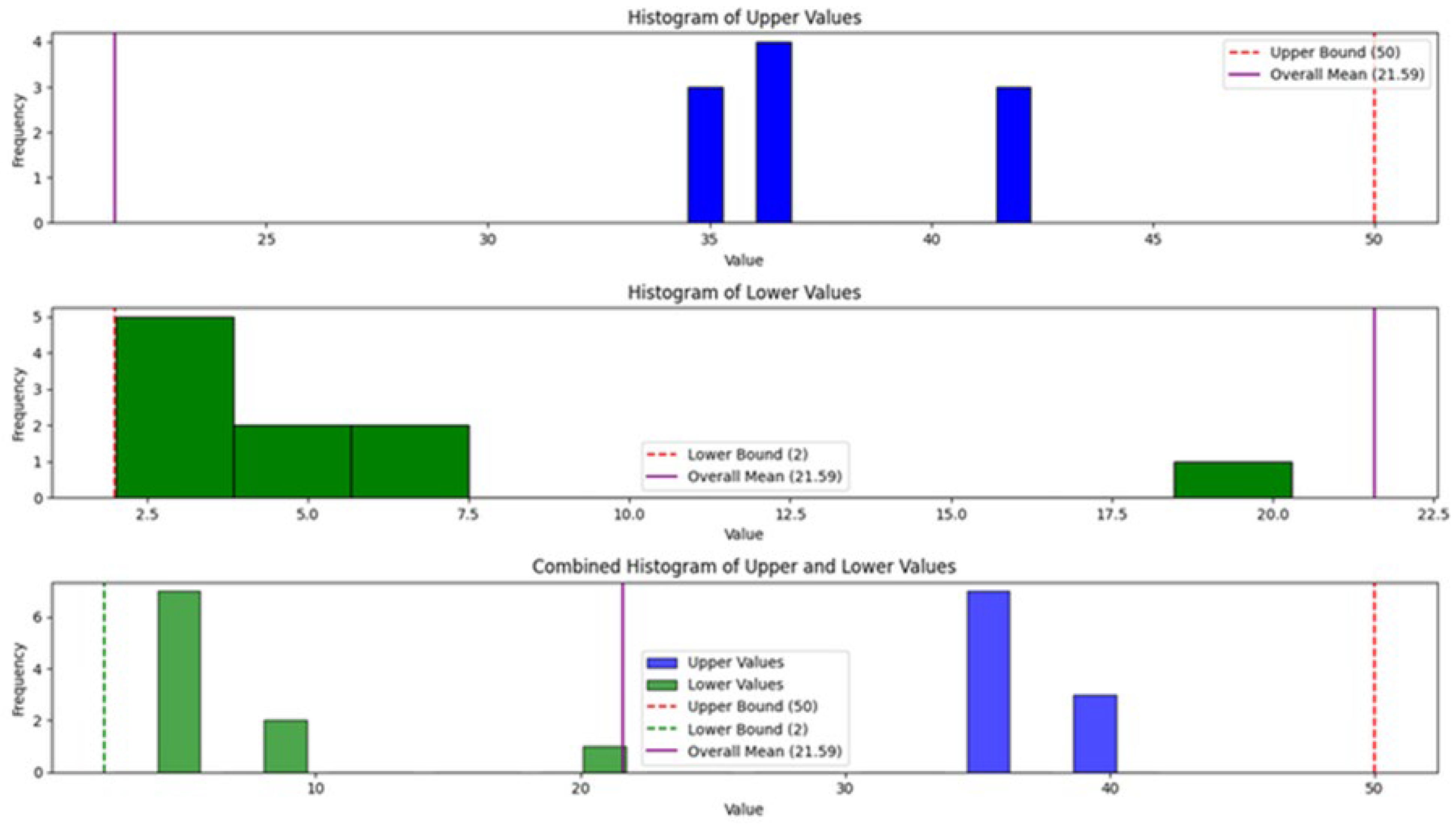
6. Experimental Simulation Results
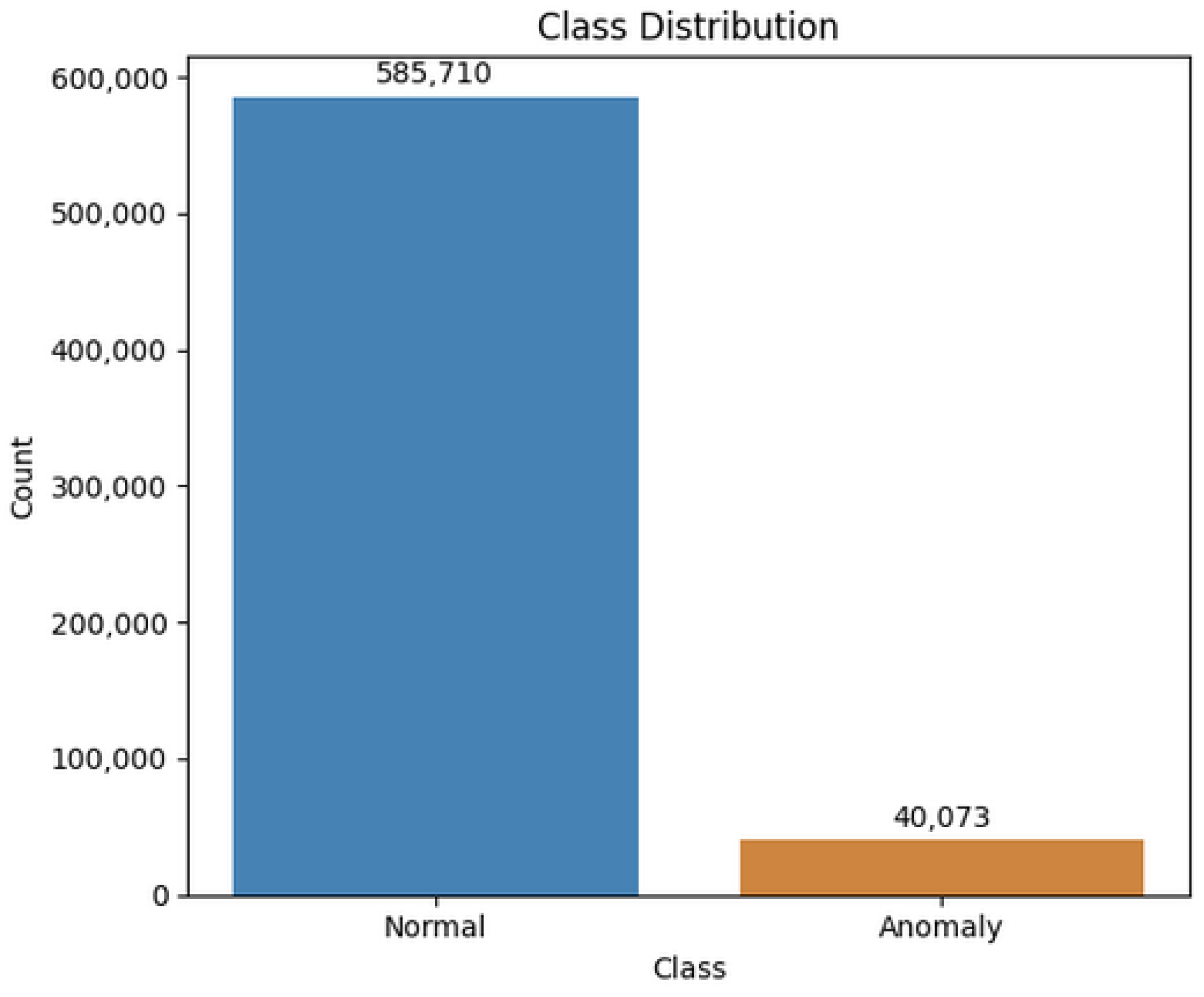
6.1. Dataset
Datasets Comparison
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Banu A, S.; Padmavathi, G. Hybrid Detection and Mitigation of DNS Protocol MITM attack based on Firefly algorithm with Elliptical Curve Cryptography. EAI Endorsed Trans. Pervasive Health Technol. 2022, 8, e3. [Google Scholar] [CrossRef]
- Xue, D.; Chi, Y.; Wu, B.; Zhao, L. APT Attack Detection Scheme Based on CK Sketch and DNS Traffic. Sensors 2023, 23, 2217. [Google Scholar] [CrossRef] [PubMed]
- Jahangeer, A.; Bazai, S.U.; Aslam, S.; Marjan, S.; Anas, M.; Hashemi, S.H. A Review on the Security of IoT Networks: From Network Layer’s Perspective. IEEE Access 2023, 11, 71073–71087. [Google Scholar] [CrossRef]
- Quezada, V.; Astudillo-Salinas, F.; Tello-Oquendo, L.; Bernal, P. Real-time bot infection detection system using DNS fingerprinting and machine-learning. Comput. Netw. 2023, 228, 109725. [Google Scholar] [CrossRef]
- Alem, S.; Espes, D.; Nana, L.; Martin, E.; De Lamotte, F. A novel bi-anomaly-based intrusion detection system approach for industry 4.0. Future Gener. Comput. Syst. 2023, 145, 267–283. [Google Scholar] [CrossRef]
- Muzammil, M.B.; Bilal, M.; Ajmal, S.; Shongwe, S.C.; Ghadi, Y.Y. Unveiling Vulnerabilities of Web Attacks Considering Man in the Middle Attack and Session Hijacking. IEEE Access 2024, 12, 6365–6375. [Google Scholar] [CrossRef]
- Imran, M.; Khan, S.; Hlavacs, H.; Khan, F.A.; Anwar, S. Intrusion detection in networks using cuckoo search optimization. Soft Comput. 2022, 26, 10651–10663. [Google Scholar] [CrossRef]
- Pliatsios, D.; Sarigiannidis, P.; Lagkas, T.; Sarigiannidis, A.G. A Survey on SCADA Systems: Secure Protocols, Incidents, Threats and Tactics. IEEE Commun. Surv. Tutor. 2020, 22, 1942–1976. [Google Scholar] [CrossRef]
- Sozol, M.S.; Saki, G.M.; Rahman, M.M. Anomaly Detection in Cybersecurity with Graph-Based Approaches. Int. J. Sci. Res. Eng. Manag. 2024, 8, 1–5. [Google Scholar] [CrossRef]
- Elrawy, M.F.; Hadjidemetriou, L.; Laoudias, C.; Michael, M.K. Detecting and classifying man-in-the-middle attacks in the private area network of smart grids. Sustain. Energy Grids Netw. 2023, 36, 101167. [Google Scholar] [CrossRef]
- Tidjon, L.N.; Frappier, M.; Mammar, A. Intrusion Detection Systems: A Cross-Domain Overview. IEEE Commun. Surv. Tutor. 2019, 21, 3639–3681. [Google Scholar] [CrossRef]
- Deivakani, M.; Sheela, M.S.; Priyadarsini, K.; Farhaoui, Y. An intelligent security mechanism in mobile Ad-Hoc networks using precision probability genetic algorithms (PPGA) and deep learning technique (Stacked LSTM). Sustain. Comput. Inform. Syst. 2024, 43, 101021. [Google Scholar] [CrossRef]
- Reddy, D.K.K.; Nayak, J.; Behera, H.S.; Shanmuganathan, V.; Viriyasitavat, W.; Dhiman, G. A Systematic Literature Review on Swarm Intelligence Based Intrusion Detection System: Past, Present and Future. Arch. Comput. Methods Eng. 2024, 31, 2717–2784. [Google Scholar] [CrossRef]
- Ramesh, B.; Bhandari, B.N.; Pothalaiah, S. A hybrid technique to provide effective allocation based on mac with UWSN for energy efficiency and effective communication. Multimed. Tools Appl. 2023, 82, 28977–28996. [Google Scholar] [CrossRef]
- Ismail, S.; Dawoud, D.W.; Reza, H. Securing Wireless Sensor Networks Using Machine Learning and Blockchain: A Review. Future Internet 2023, 15, 200. [Google Scholar] [CrossRef]
- Raja, D.J.S.; Sriranjani, R.; Arulmozhi, P.; Hemavathi, N. Unified Random Forest and Hybrid Bat Optimization Based Man-in-the-Middle Attack Detection in Advanced Metering Infrastructure. IEEE Trans. Instrum. Meas. 2024, 73, 1–12. [Google Scholar] [CrossRef]
- Cherian, M.M.; Varma, S.L. Mitigation of DDOS and MiTM Attacks using Belief Based Secure Correlation Approach in SDN-Based IoT Networks. Int. J. Comput. Netw. Inf. Secur. 2021, 14, 52–68. [Google Scholar] [CrossRef]
- Ma, T.; Xu, C.; Yang, S.; Huang, Y.; An, Q.; Kuang, X.; Grieco, L.A. A Mutation-Enabled Proactive Defense Against Service-Oriented Man-in-The-Middle Attack in Kubernetes. IEEE Trans. Comput. 2023, 72, 1843–1856. [Google Scholar] [CrossRef]
- Zukaib, U.; Cui, X.; Zheng, C.; Liang, D.; Din, S.U. Meta-Fed IDS: Meta-learning and Federated learning based fog-cloud approach to detect known and zero-day cyber attacks in IoMT networks. J. Parallel Distrib. Comput. 2024, 192, 104934. [Google Scholar] [CrossRef]
- Ullah, I.; Mahmoud, Q.H. A Scheme for Generating a Dataset for Anomalous Activity Detection in IoT Networks. In Advances in Artificial Intelligence; Goutte, C., Zhu, X., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; Volume 12109, pp. 508–520. [Google Scholar]
- Taştan, A.N.; Gönen, S.; Barışkan, M.A.; Kubat, C.; Kaplan, D.Y.; Pashaei, E. Detection of Man-in-the-Middle Attack Through Artificial Intelligence Algorithm. In Advances in Intelligent Manufacturing and Service System Informatics; Şen, Z., Uygun, Ö., Erden, C., Eds.; Lecture Notes in Mechanical Engineering; Springer Nature Singapore: Singapore, 2024; pp. 450–458. [Google Scholar]
- Bhavsar, M.; Roy, K.; Kelly, J.; Olusola, O. Anomaly-based intrusion detection system for IoT application. Discov. Internet Things 2023, 3, 5. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, R.; Mohammad, N.; Sallam, K.; Moustafa, N. An Adaptive Cuckoo Search-Based Optimization Model for Addressing Cyber-Physical Security Problems. Mathematics 2021, 9, 1140. [Google Scholar] [CrossRef]
- Al Nuaimi, T.; Al Zaabi, S.; Alyilieli, M.; AlMaskari, M.; Alblooshi, S.; Alhabsi, F.; Yusof, M.F.B.; Al Badawi, A. A comparative evaluation of intrusion detection systems on the edge-IIoT-2022 dataset. Intell. Syst. Appl. 2023, 20, 200298. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; El-Shahat, D.; Jameel, M.; Abouhawwash, M. Exponential distribution optimizer (EDO): A novel math-inspired algorithm for global optimization and engineering problems. Artif. Intell. Rev. 2023, 56, 9329–9400. [Google Scholar] [CrossRef]
- Tsai, Y.-T.; Wang, C.-H.; Chang, Y.-C.; Tong, L.-I. Using WPCA and EWMA Control Chart to Construct a Network Intrusion Detection Model. IET Inf. Secur. 2024, 2024, 3948341. [Google Scholar] [CrossRef]
- Dong, S.; Xia, Y.; Peng, T. Network Abnormal Traffic Detection Model Based on Semi-Supervised Deep Reinforcement Learning. IEEE Trans. Netw. Serv. Manag. 2021, 18, 4197–4212. [Google Scholar] [CrossRef]
- Maddaiah, P.N.; Narayanan, P.P. An Improved Cuckoo Search Algorithm for Optimization of Artificial Neural Network Training. Neural Process. Lett. 2023, 55, 12093–12120. [Google Scholar] [CrossRef]
- Xie, Y.; Zhu, C.; Hu, R.; Zhu, Z. A Coarse-to-Fine Approach for Intelligent Logging Lithology Identification with Extremely Randomized Trees. Math. Geosci. 2021, 53, 859–876. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Platform | Kaggle |
| Programming language | Python 3.10 |
| Algorithms | Decision Tree, CSA, SVM, LOF, CSA-ANN, CSA-DT |
| Datasets | IoTID20, Intrusion Detection Dataset (IDD) |
| Metrics | Precision, Recall, F1-score, Accuracy |
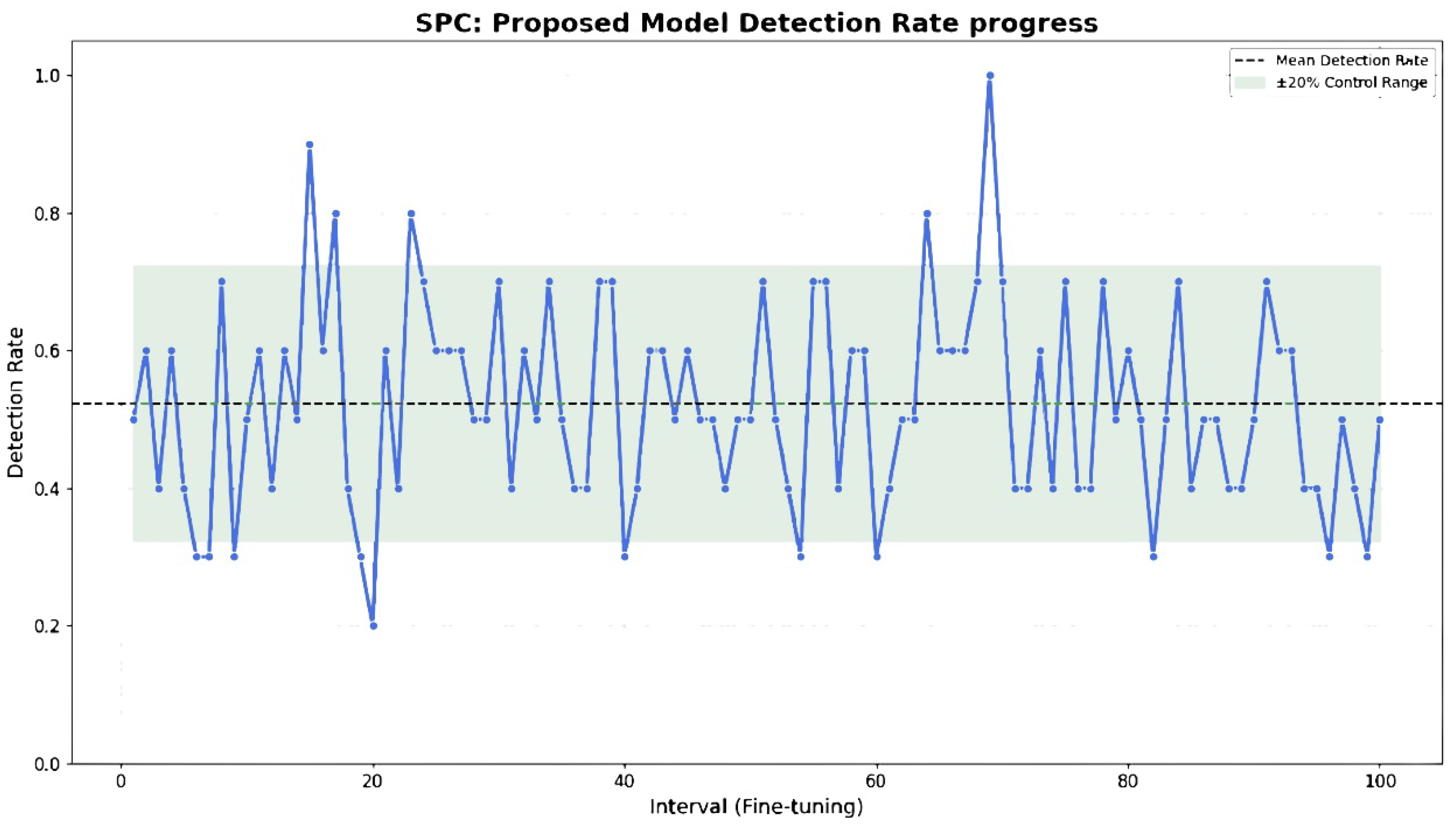
| Objective function | Statistical Process Control |
| Population size | 10–20 (nests) |
| Number of iterations | 20–50 |
| Discovery rate | 0.2–0.4 |
| Max_depth | 10–20 |
| Min_samples_split | 5–10 |
| Min_samples_leaf | 3–5 |
| Feature | Importance |
|---|---|
| Source IP | High |
| Destination IP | High |
| Source Port | Medium |
| Destination Port | Medium |
| Protocol | High |
| Flow Duration | High |
| Total Fwd Packets | Medium |
| Total Backward Packets | Medium |
| Fwd Packet Length Mean | High |
| Bwd Packet Length Mean | High |
| Flow Bytes/s | Medium |
| Flow Packets/s | Medium |
| Bwd IAT Mean | High |
| Fwd PSH Flags | Medium |
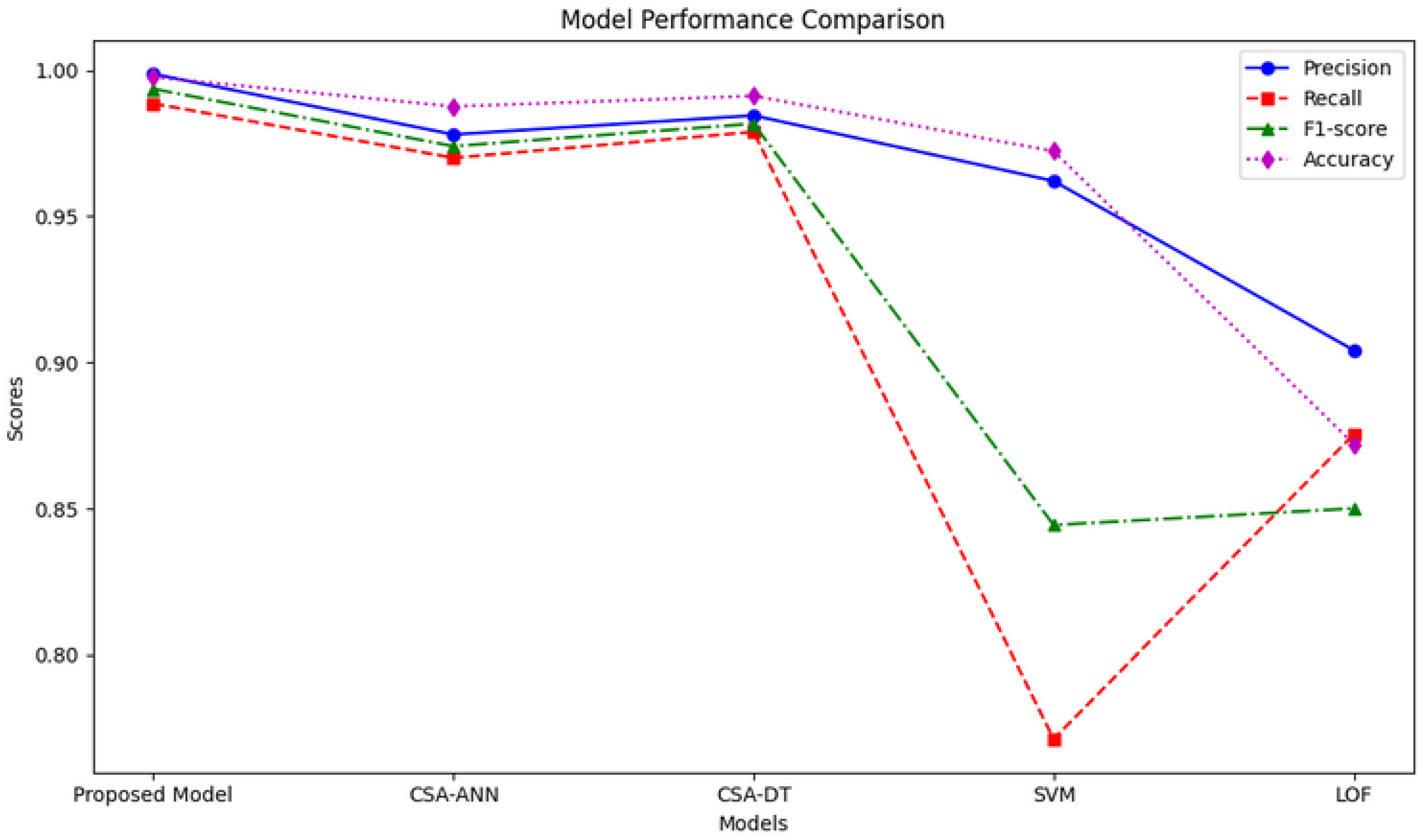
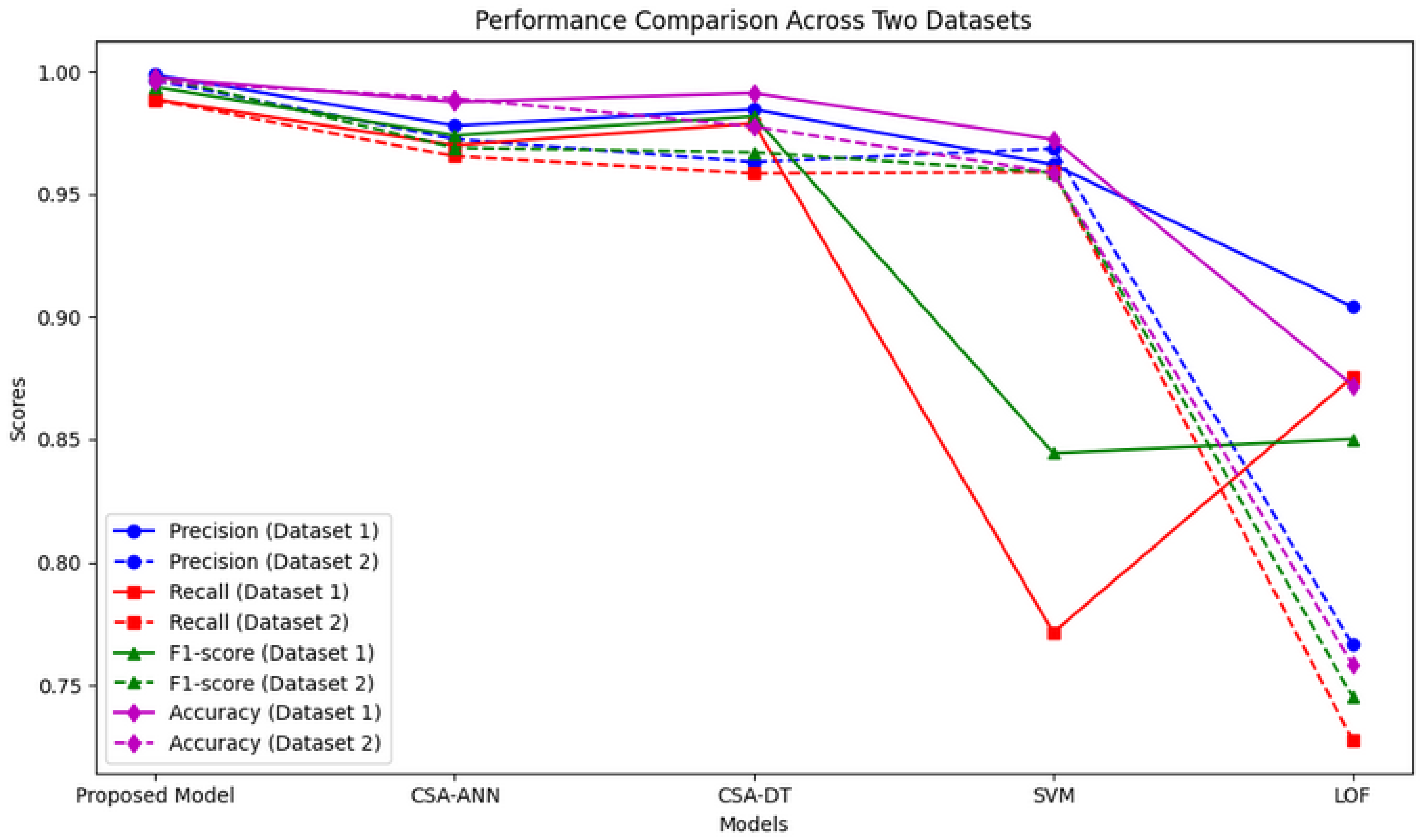
| Model | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| Proposed Model | 0.9987 | 0.9886 | 0.9936 | 0.9976 |
| CSA-ANN | 0.9780 | 0.9700 | 0.9740 | 0.9876 |
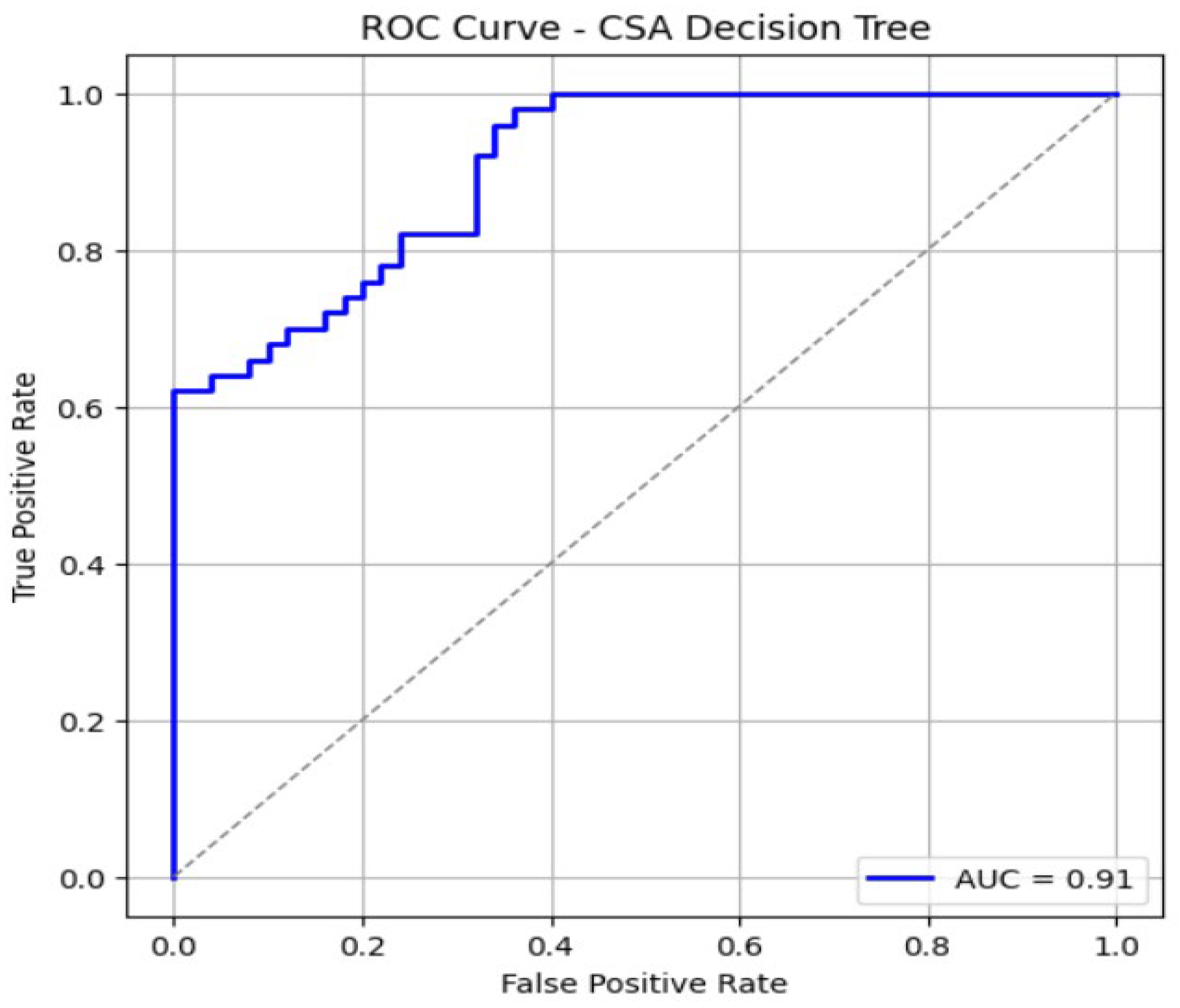
| CSA-DT | 0.9845 | 0.9789 | 0.9817 | 0.9912 |
| SVM | 0.9621 | 0.7713 | 0.8444 | 0.9723 |
| LOF | 0.9042 | 0.8754 | 0.8501 | 0.8721 |
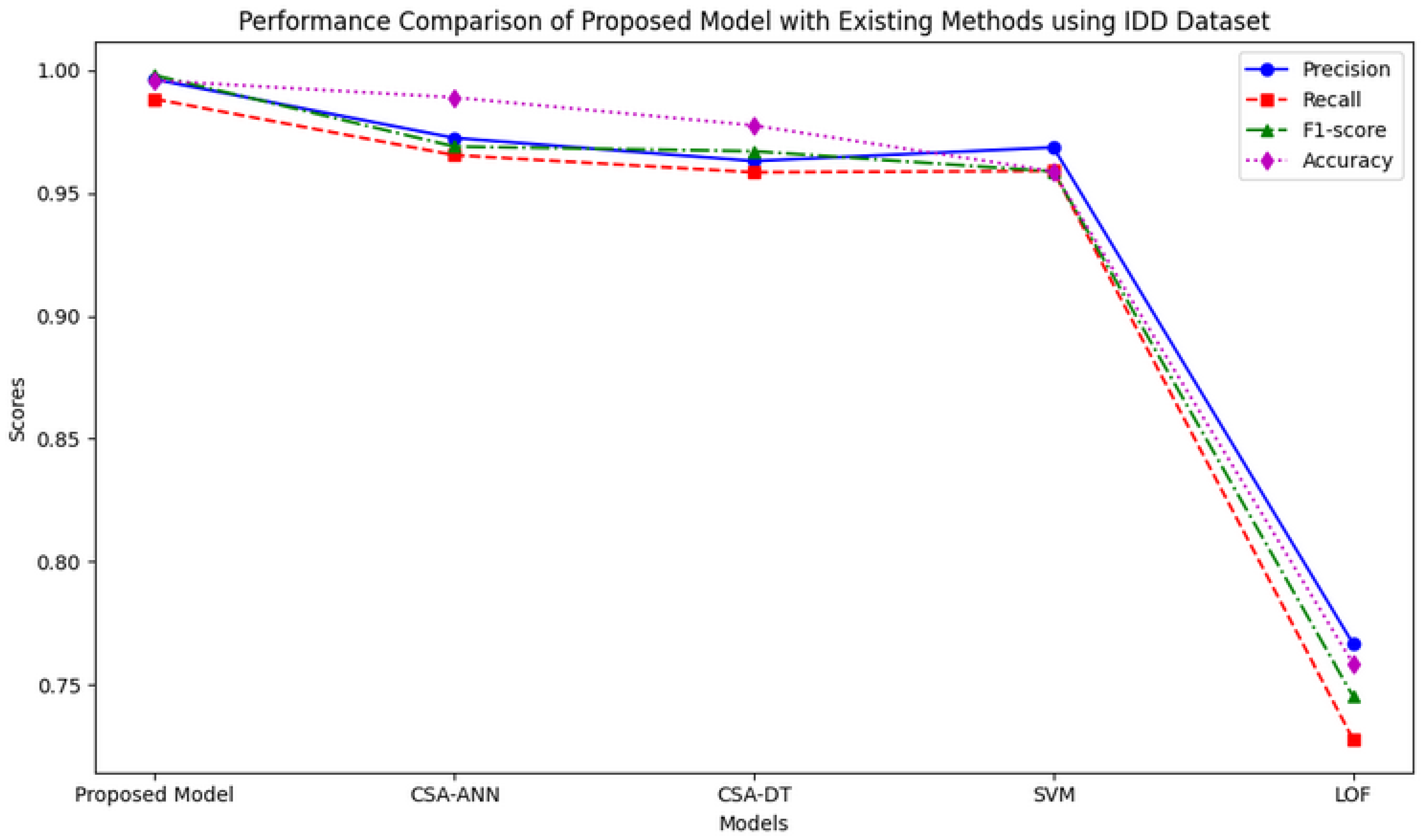
| Model | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| Proposed Model | 0.99631 | 0.98835 | 0.99801 | 0.99591 |
| CSA-ANN | 0.9725 | 0.9655 | 0.9690 | 0.9890 |
| CSA-DT | 0.9631 | 0.9585 | 0.9671 | 0.9776 |
| SVM | 0.96864 | 0.95905 | 0.95884 | 0.95889 |
| LOF | 0.76652 | 0.72774 | 0.74518 | 0.75844 |
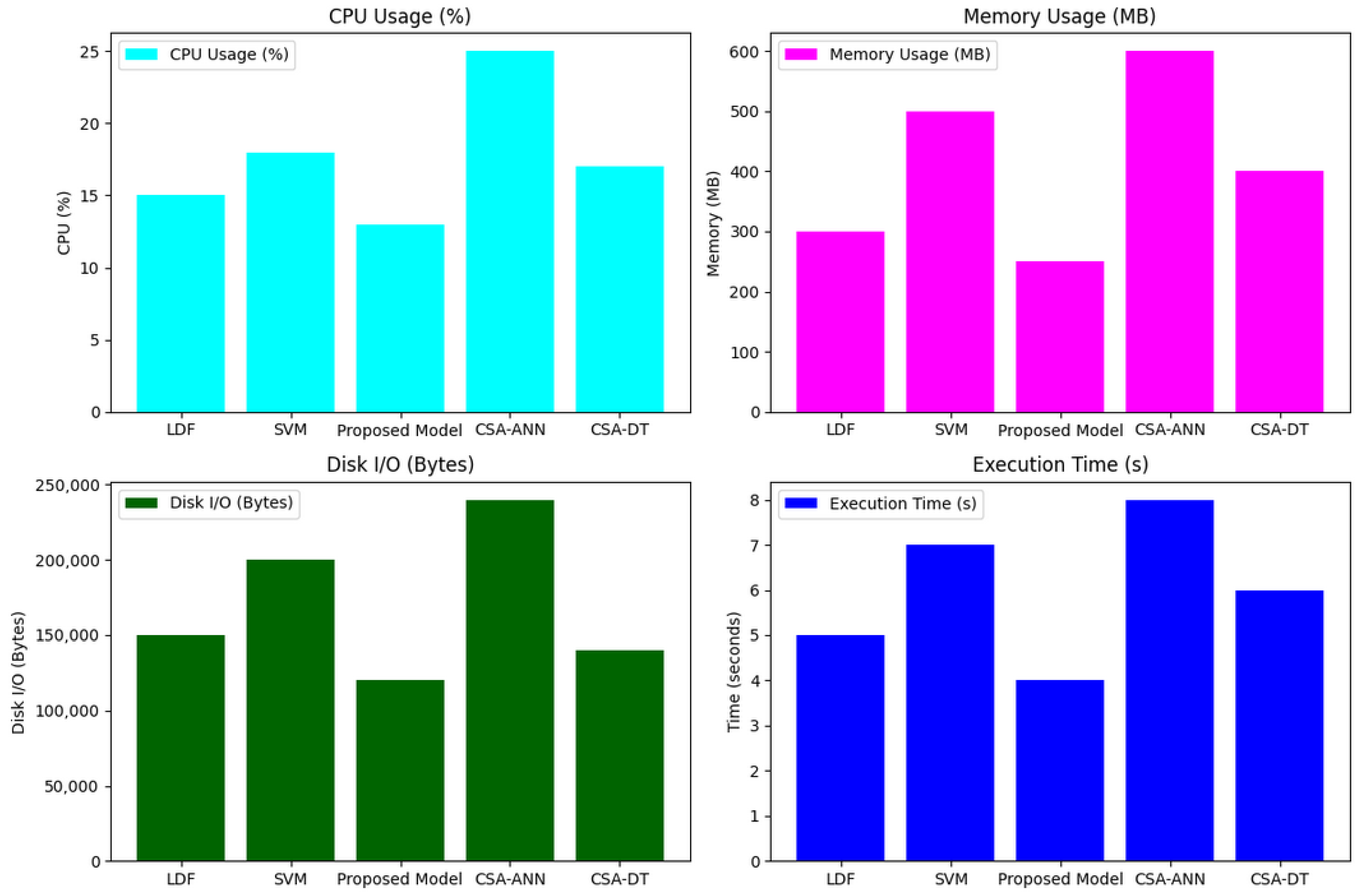
| Model | CPU Usage (%) | Memory (MB) | Disk I/O (Bytes) | Execution Time (s) |
|---|---|---|---|---|
| LOF | 14.0 | 320 | 110,000 | 3.5 |
| SVM | 17.5 | 480 | 190,000 | 4.6 |
| Proposed Model | 12.5 | 290 | 100,000 | 3.0 |
| CSA-ANN | 25 | 650 | 250,000 | 7.8 |
| CSA-DT | 15.6 | 350 | 125,000 | 4.5 |
| Aspect | Proposed Model | CSA-ANN [28] | DT-CSA [23] | Coarse Tree ABD Model [29] |
|---|---|---|---|---|
| Technique | Lightweight CSA-DT | CSA optimized ANN | Decision Tree optimized with CSA | Coarse Tree Algorithm-based model |
| Performance metrics | High accuracy and minimal execution time | High accuracy (R2 = 0.97) in prediction tasks | Reliable classification with reduced bias | Effective detection of unstructured cyberattacks |
| Novelty | Combines CSA with DT for lightweight anomaly detection in DNS | Combines CSA with ANN for enhanced prediction | Integrates CSA with DT for improved decision-making | Lightweight and tailored for process control networks |
| Application | Cybersecurity in Domain Name Server | Water quality prediction | Soil classification | Cybersecurity in oil and gas networks |
| Limitations | Struggles with datasets with high variability, affecting its effectiveness. | Lower sensitivity for minority classes | May exhibit reduced accuracy in complex datasets | Limited to specific types of cyber-attacks |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moila, R.L.; Velempini, M. Lightweight Anomaly-Based Detection Using Cuckoo Search Algorithm and Decision Tree to Mitigate Man-in-the-Middle Attacks in DNS. Appl. Sci. 2025, 15, 5017. https://doi.org/10.3390/app15095017
Moila RL, Velempini M. Lightweight Anomaly-Based Detection Using Cuckoo Search Algorithm and Decision Tree to Mitigate Man-in-the-Middle Attacks in DNS. Applied Sciences. 2025; 15(9):5017. https://doi.org/10.3390/app15095017
Chicago/Turabian StyleMoila, Ramahlapane Lerato, and Mthulisi Velempini. 2025. "Lightweight Anomaly-Based Detection Using Cuckoo Search Algorithm and Decision Tree to Mitigate Man-in-the-Middle Attacks in DNS" Applied Sciences 15, no. 9: 5017. https://doi.org/10.3390/app15095017
APA StyleMoila, R. L., & Velempini, M. (2025). Lightweight Anomaly-Based Detection Using Cuckoo Search Algorithm and Decision Tree to Mitigate Man-in-the-Middle Attacks in DNS. Applied Sciences, 15(9), 5017. https://doi.org/10.3390/app15095017