1. Introduction
The Japanese writing system stands as one of the most intricate in the world, composed of three distinct character sets: hiragana, katakana, and kanji. Hiragana and katakana each include 46 basic characters, serving different linguistic functions—hiragana for native Japanese words and grammatical particles and katakana for foreign loanwords. However, it is kanji, adapted from Chinese, that introduces the greatest complexity. With tens of thousands of kanji in existence, even native speakers rely on the standardized Joyo kanji list, consisting of 2136 characters, deemed as sufficient for reading newspapers, legal documents, and other official materials. Additionally, the Jinmeiyo kanji list, with 863 characters, is designated for use in proper names. Despite these efforts to systematize the writing system, the sheer volume and complexity of kanji continue to pose challenges, particularly for non-native speakers striving to engage with Japanese culture and literature.
As technology advances, artificial intelligence has made remarkable strides in tackling tasks that once required human cognition. From image recognition to natural language processing, AI systems now handle many functions previously thought to be the exclusive domain of humans. However, certain challenges remain, particularly when it comes to nuanced, highly variable tasks. Handwritten kanji recognition is one such problem that has yet to be solved with a high degree of accuracy. Although printed kanji recognition has mostly been mastered, the transition to handwritten forms introduces a range of complexities that continue to challenge modern machine-learning models.
The difficulties arise from the inherent variability in human handwriting. Kanji characters are composed of radicals formed by specific strokes, and although there are established rules for stroke order and composition, these are frequently disregarded in everyday writing. This leads to subtle or sometimes significant variations in the final form of the character. Strokes that should connect may be slightly separated, merged unintentionally, or even cross each other in ways that deviate from standard forms. Additionally, writers often use shorthand, omitting or simplifying radicals, which further complicates the recognition process.
The variability does not end there. Differences in handwriting styles mean that stroke thickness, pressure, and continuity can vary significantly, influenced by writing speed or the physical characteristics of the writing instrument. Radicals within a kanji character may appear distorted—misaligned, resized, or tilted—affecting the overall structure and making the kanji difficult to recognize. These inconsistencies create a significant challenge for machine-learning models tasked with accurate handwritten kanji recognition.
This paper addresses this complex problem by implementing a Preact ResNet-18 model tailored for handwritten kanji recognition. The main contributions of this paper can be summarized as follows:
We have implemented the Preact ResNet-18 model tailored for handwritten kanji recognition with and without data augmentation and explored the efficiency of this architecture and the data augmentation’s impact on the kanji recognition task;
We have designed a new model for handwritten kanji recognition based on the concept of cross-language transfer learning using a Preact ResNet-18 architecture, where the designed model is originally trained in the Chinese dataset and then fine-tuned in the Japanese dataset;
We have adapted two training algorithms for the designed model, where the first one is based on the freezing of all the weights during the fine-tuning process, except for the weights of the last, fully connected layer, which leads to reductions in the training time and resource consumption, and the second one is based on the unfreezing of all the weights during the fine-tuning process, which leads to an improvement in the model’s performance;
We investigated the effectiveness of the developed model when solving the multiclass classification task for 150, 200, and 300 classes and showed an improvement in the recognition accuracy and an enhancement in a number of recognizable kanji with the proposed model compared to those of the existing methods.
The strategy of employing cross-language transfer learning, specifically by pretraining the model on Chinese characters before fine-tuning it on Japanese kanji, is justified by strong theoretical and historical connections that extend beyond a mere superficial visual resemblance. The fundamental rationale lies in the shared etymological roots and the consequent deep structural congruity between the two writing systems.
Elaborating on this historical connection, Japanese kanji are directly derived from Chinese characters through a centuries-long process of adoption and adaptation. This shared lineage means that a vast number of characters bear strong structural relationships. Consequently, the visual representations encode fundamentally similar information regarding character construction.
This deep structural congruity is evident in shared core elements. For instance, a significant portion of the radicals is common to both writing systems. Pretraining on Chinese characters, thus, allows the model to learn robust representations of these recurring substructures, which serve as essential building blocks for a large percentage of characters in both languages. Recognizing these shared components is vital for recognizing complex characters.
Furthermore, this structural commonality extends to the principles of character construction. Although specific calligraphic styles may exhibit variations, the foundational principles governing the stroke types, their relative positions, and conventional sequences (stroke order) are mostly conserved or systematically related between Chinese characters and kanji. A model pretrained on Chinese characters implicitly learns these low-level features, forming a valuable inductive bias for interpreting kanji strokes.
Consequently, by pretraining on Chinese characters, the model develops hierarchical feature extractors attuned not just to generic visual patterns but specifically to the shared strokes, radicals, and compositional rules pertinent to this script family. This learned knowledge provides a significantly more effective initialization for the kanji recognition task, facilitating faster convergence and achieving higher accuracy during the fine-tuning phase by leveraging the deeply ingrained structural commonalities inherited from their shared historical origin.
The structure of the paper is as follows: The
Section 2 presents the results of a review and a critical analysis of existing works on Chinese and Japanese character recognition.
Section 3 presents the mathematical basis of ResNet-18 and Preact ResNet-18, with four training approaches explained. The
Section 4 contains the information about the used datasets, metrics, and numerical results of the implemented Preact ResNet-18 architecture with the new cross-language transfer-learning concept to solve a multiclass handwritten character recognition task. The
Section 5 compares the implemented model with the existing one. The conclusions are presented in the
Section 6.
2. State-of-the-Art Methods
In this section, we have described the unique challenges of handwritten kanji recognition and the current state of the research in the field. As deep-learning approaches, like ResNet architectures, have shown promising results in various image classification tasks, including medical imaging [
1], we will focus on deep-learning methods. The journey began with an exploration of the history of Chinese character recognition [
2], where we reviewed early methods and the foundational assumptions that influenced future advancements. This historical perspective highlighted the evolution of techniques and underscored the complexities involved in character recognition.
One notable study [
3] focused on Chinese character recognition based on similarity, introducing an innovative approach accounting for character clarity/quality. This specificity provided new insights into how subtle visual differences impact recognition accuracy.
Another significant contribution was a real-time handwritten kanji recognition system [
4], which utilized SVG files and a step-by-step kanji-writing process. This solution combined a robust model with a tree-structured dictionary for kanji definitions, enabling efficient real-time recognition.
Further, we examined a straightforward CNN-based solution for handwritten Chinese character recognition that incorporated a median filter [
5] to effectively handle speckled noise and salt-and-pepper noise, common issues in image data. This approach demonstrated the importance of preprocessing in enhancing the model’s performance.
Addressing the challenge of classifying a large number of classes, we explored the label-mapping (LM) method [
6], which outperformed a similar well-known ECOC method [
7]. LM improves model predictions in N-class classification tasks, especially when the penultimate layer of the model has fewer dimensions than N-1. This method offers a strategic approach for managing the complexity inherent in multiclass classification.
We also reviewed the current state-of-the-art solution in image classification, known as model soups [
8]. This technique involves combining several pretrained models, fine-tuned in different datasets or with varying hyperparameter configurations, by averaging their weights. Model soups have demonstrated superior performances, highlighting the potential of ensemble approaches in achieving high accuracy rates in character recognition.
The advent of transformers has also spurred innovation in sequence modeling for text recognition, moving beyond traditional recurrent architectures. For example, the PARSeq model [
9] leverages features from vision transformers (like ViT or DeiT) but introduces a novel permutation-based autoregressive decoder. This approach allows for the parallel decoding of character sequences, significantly improving efficiency compared to that of purely sequential methods while achieving strong performance in challenging-scene text recognition benchmarks, demonstrating the versatility of transformer components in different sequence-processing paradigms for OCR tasks.
Further exploration into transformer variants has also yielded promising results, particularly for complex scripts, like handwritten Chinese characters. For instance, adaptations of the Swin transformer architecture have been proposed to address the challenges specific to offline handwritten Chinese character recognition (HCCR) [
10]. One such approach involved simplifying the hierarchical structure of the standard Swin transformer and adjusting window attention mechanisms to create a more parameter-efficient model (S-Swin) specifically tailored for HCCR, achieving competitive recognition accuracy while reducing computational demands compared to those of the original architecture.
Another notable contribution is the work by Thakur et al. [
11], who developed a vision-transformer-based model for plant disease classification. Their model effectively identifies various plant diseases by analyzing leaf images, demonstrating the capability of transformer architectures in handling complex image classification tasks. The study’s findings indicate that transformer-based models can be adapted for OCR applications, particularly in scenarios requiring the recognition of intricate patterns.
Finally, a more advanced solution involved a CNN ensemble for handwritten kanji recognition [
12], which serves as a baseline for this research. This study not only set a benchmark but also highlighted the Preact ResNet-18 architecture, which was chosen for the present work. Preact ResNet-18 strikes a balance between resource efficiency and high performance, making it ideal for processing small images without compromising accuracy.
Although transformer-based models [
9,
10,
11] excel at capturing global dependencies, their computational costs can be higher, and convolutional architectures, like ResNet, remain highly effective and efficient for image classification tasks, particularly character recognition, where local features are crucial.
Although our focus is on recognizing static handwritten characters derived from hand movements, related research addresses the complexities of interpreting the dynamic hand activity itself, such as real-time pose estimation or gesture recognition, often for human–computer interaction or robotic applications. These tasks frequently rely on multisensor fusion techniques to achieve robustness against challenges like sensor noise or occlusion. For instance, Ref. [
13] developed an adaptive sensor fusion method using Kalman filters and multiple leap motion controllers for stable hand pose estimation, even during occlusion. Similarly, Ref. [
14] tackled hand gesture recognition for robotic teleoperation using multisensor fusion guided by an LSTM-based recurrent neural network to handle interference and classify dynamic gestures. These approaches, leveraging temporal modeling (Kalman filters and RNNs) and different sensor modalities for dynamic tracking and gesture classification, represent a distinct but related area compared to our work on classifying static character images using convolutional architectures.
Considering the unique challenges of handwritten kanji recognition and the insights gained from these studies, this work aims to develop an artificial intelligence model capable of recognizing handwritten kanji with an accuracy rate exceeding 96.43% and supporting more than 150 distinct kanji characters.
3. Materials and Methods
3.1. Preact ResNet Model’s Description
During the process of selecting an appropriate model for solving the task, we examined models that have shown strong performance in classification tasks across popular datasets with similar image characteristics, such as CIFAR-10, CIFAR-100, and ImageNet. As shown in ref. [
15], among the existing modern architectures, the most promising for the task of handwritten character recognition is ResNet because of its efficiency in handling small images while maintaining strong feature extraction capabilities. Its residual connections help to mitigate vanishing gradients, ensuring stable training, even with a large number of classes. Additionally, its relatively lightweight architecture balances computational efficiency and accuracy, making it practical for large-scale classification tasks. Thus, we implemented a Preact ResNet-18 architecture (
Table 1).
ResNets (deep residual networks) are composed of numerous stacked “residual units”, also known as “residual blocks”. These blocks can be expressed in the following general form [
16]:
where
—the input of the ith residual block;
—the output of the ith residual block;
—the residual function;
—the identity function;
=
—the set of weights and biases for the residual block (K—the number of layers in the residual block);
—the operation after element-wise addition (usually an activation function).
The success of deep residual networks lies in their depth, as indicated by their name. The ResNet family includes several architectures beyond ResNet-18, such as ResNet-34, ResNet-50, ResNet-101, ResNet-152, and ResNet-1001. The primary difference among these variants is the number of residual blocks per layer. Additionally, the architectures of ResNet-50’s and deeper residual blocks differ slightly from that of ResNet-18, as illustrated in
Table 2.
Equations (1) and (2) represent the original residual block’s structure. However, using this structure as-is can lead to overfitting and the vanishing gradient problem [
17] in very deep neural networks. To mitigate these issues, we can apply identity mappings [
18] to
and
, resulting in
and
. This leads us to the following [
18]:
In addition, is utilized within residual blocks to reduce feature map sizes and increase dimensions, but in this case, only three such blocks are used, limiting their exponential impact.
Recursively,
, leading to the following [
18]:
for any deeper block (
) and any shallower block (
).
Equation (4) reveals several beneficial properties. First, for any deeper block (), its feature () can be expressed as the feature () of any shallower block () plus a residual function in the form of . This indicates a residual dependency between any units () and (). Second, examining , it becomes evident that the output feature of block is the summation of and residual functions, contrasting with the simple matrix–vector products found in a “plain network”.
The principal advantage of Equation (4) is that it facilitates effective backpropagation. Denoting the loss function as
, and applying the chain rule of backpropagation, we obtain the following [
18]:
Equation (5) shows that the gradient comprises two additive terms: one term () that propagates information directly without regard to weight layers and another term () that propagates through the weight layers. The additive term of ensures information is directly backpropagated to any shallower block (). Assuming is not consistently −1 across all the samples in a mini-batch, the probability of the gradient being canceled out is extremely low. This property ensures that the layer’s gradient remains intact, even when the weights are very low.
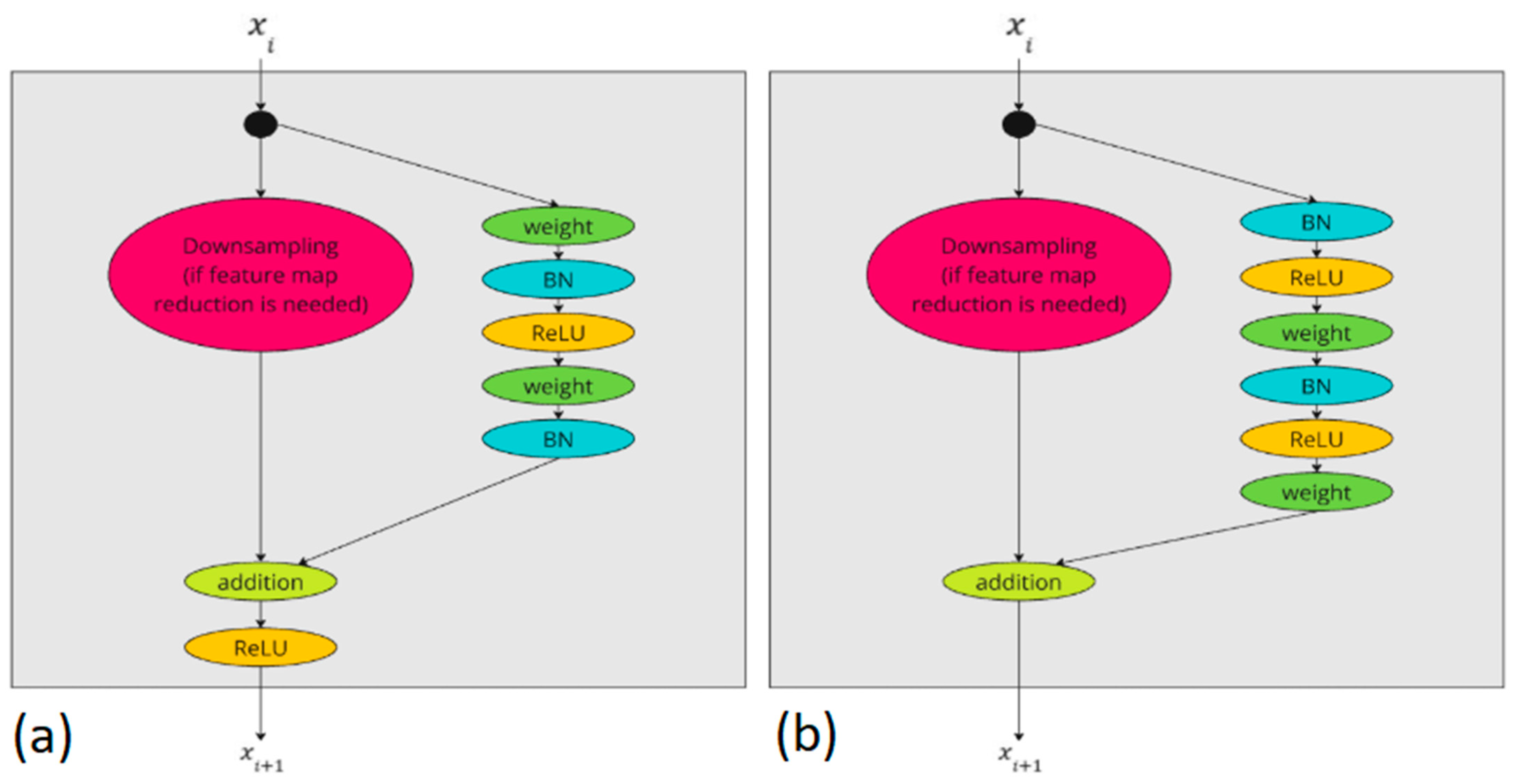
A crucial requirement for the validity of Equations (4) and (5) is the ability for signals to propagate directly between units, both forward and backward. This requirement is met through two conditions: , the identity skip connection, and , the identity mapping.
To achieve these conditions, we employ the concept of preactivation (see
Figure 1), which involves placing batch normalization and the activation function (ReLU [
19]) inside the residual block.
Batch normalization (BN) [
20] stabilizes learning by normalizing each layer’s input. BN adjusts each mini-batch’s mean and variance, keeping input values within a specific range. This leads to faster convergence by reducing the number of epochs needed, allows for higher learning rates, and can sometimes act as regularization, thereby reducing overfitting. The primary benefit is improved accuracy, particularly in large datasets. However, BN has drawbacks, including noisy mean and variance estimates for small batches and added computational complexity.
The ReLU activation function introduces nonlinearity and is defined by the following formula [
19]:
3.2. Model-Training Approaches
As stated at the beginning of this document, the primary objective of this work is to develop a machine-learning model capable of recognizing handwritten kanji from images. To achieve this, we explored four distinct training strategies using the selected architecture (ResNet-18 with a preactivation block). All the models were trained and evaluated in the Kuzushiji-Kanji dataset, except for one additional model trained in the CASIA-HWDB dataset to obtain the initial weights for cross-language transfer learning. Although Chinese characters and Japanese kanji are often visually identical, differing primarily in meaning and pronunciation, to the best of our knowledge, no prior research has explored cross-language transfer learning between them specifically for this task. We therefore tested the feasibility of this approach.
3.2.1. Training the Vanilla Preact ResNet-18 Model
The most straightforward approach for the training of the Vanilla Preact ResNet-18 model (
Figure 2) involved initializing the model with random weights and training it from scratch. This method not only served the primary task but also provided baseline weights for subsequent transfer-learning experiments.
3.2.2. Training the Preact ResNet-18 Model with Data Augmentation
Building upon the previous approach, this strategy (
Figure 3) incorporated data augmentation, a widely used technique in image recognition tasks. Although the base model remained the same, the input images were augmented slightly because any abnormal rotation or translation can transform one kanji to another. Specifically, the applied augmentations included random rotations within a narrow range (±15 degrees), minor horizontal and vertical translations (of up to 10% of the image’s dimension), random cropping combined with subtle resizing (scaling between 95% and 105% of the original area before resizing to the target 64 × 64 resolution), and slight shear transformations (up to 0.05). These carefully controlled transformations aimed to simulate minor variations in the writing angle, position, scale, and slant often encountered in handwritten characters, without introducing distortions severe enough to fundamentally alter the kanji’s identity.
3.2.3. Training the Preact ResNet-18 via Cross-Language Transfer Learning with the Last Layer Unfrozen (Algorithm 1)
One of the possible approaches for training the Preact ResNet-18 model involves using the “Transfer Learning with the Last Layer Unfrozen” algorithm [
21]. In this method, all the layers of the network are frozen except for the fully connected layer, which is fine-tuned in the target dataset. A simplified illustration of this approach is shown in
Figure 4. However, its main drawback is that it fails to achieve sufficient recognition accuracy for multiclass classification tasks, especially when dealing with a large number of classes.
Therefore, this paper proposes a slightly different approach, which is based on the concept of cross-language transfer learning with the last layer unfrozen. The main idea is to obtain the initial weights with the dataset that contains Chinese handwritten characters and fine-tuning the main model with the dataset that contains Japanese handwritten kanji (Algorithm 1). Similar to traditional transfer learning with only the last layer unfrozen, our adapted algorithm (Algorithm 1) reduces the training time and resource consumption (excluding the time spent obtaining the initial weights). However, the use of cross-language transfer learning with the last layer unfrozen allows us to find the initial weights that are closer to the deeper loss basin with deeper local minima; it leads to a better performance.
3.2.4. Training the Preact ResNet-18 Model via Cross-Language Transfer Learning with the Last Layer Unfrozen (Algorithm 2)
The previous approach, which is traditional transfer learning with the last layer unfrozen, often fails in approaching close enough to the loss’s local minimum, which leads to insufficient kanji recognition accuracy. Therefore, an alternative training approach, known as transfer learning with all the layers unfrozen [
22], is also considered. Similar to the previous algorithm, this strategy also employed transfer learning but took it a step further by unfreezing all the layers (
Figure 5). Although this approach demands more computational resources and time in comparison with those of Algorithm 1, it allows the model to fine-tune all the parameters, potentially leading to a better performance.
Similar to Algorithm 1, Algorithm 2 also presents an adaptation of transfer learning with all the layers unfrozen, incorporating the concept of cross-language transfer learning. The main idea is that, identical to the previous case (Algorithm 1), this algorithm (Algorithm 2) helps us to obtain the initial weights that are positioned closer to a deeper loss basin with a more stable local minimum, leading to a better model performance.
4. Modeling and Results
4.1. Datasets Used for Modeling
To effectively train a model capable of recognizing handwritten Japanese kanji, we utilized two distinct datasets: CASIA-HWDB and Kuzushiji Kanji. Each dataset offers unique characteristics that contribute to different stages of the training process.
4.1.1. CASIA-HWDB
The CASIA-HWDB dataset consists of handwritten Chinese characters, alphanumeric symbols, and whole Chinese texts, widely used in various research studies focused on character and text recognition [
23,
24,
25,
26,
27,
28]. This dataset is publicly available in [
29]. For this work, we specifically employed the subset containing individual characters. The dataset is divided into the following three parts:
HWDB1.0: Contains 3866 Chinese characters along with 171 alphanumeric and special symbols. Among these, 3740 characters belong to the GB2312-80 level 1 set (which contains a total of 3755 characters). Each class includes roughly 420 samples, amounting to a total of 1,609,136 images;
HWDB1.1: Includes 3755 GB2312-80 level 1 Chinese characters and 171 additional symbols. Approximately 300 samples represent each class, summing up to 1,121,749 images;
HWDB1.2: Features 3319 Chinese characters distinct from those in HWDB1.0, alongside 171 alphanumeric and special symbols. Each class contains about 300 samples, with a total of 990,989 images.
When combined, HWDB1.0 and HWDB1.2 offer 7185 unique characters, covering all 6763 Chinese characters in the GB2312 standard. For training purposes, only these 6763 classes were utilized. An 80/20 split was applied for training and testing (which is ~240/~60 or ~580/~140 samples for different characters).
Preprocessing involved inverting the image colors (to match the format of the Kuzushiji-Kanji dataset, where kanji are white on a black background), resizing all the images to 64 × 64 pixels, and converting them to tensors compatible with PyTorch 2.7. The images were then normalized to ensure the pixel values ranged between −1 and 1.
4.1.2. Kuzushiji Kanji
The Kuzushiji-Kanji dataset comprises 140,426 grayscale images of handwritten Japanese kanji in the cursive kuzushiji style. Each image is 64 × 64 pixels, maintaining a consistent size for training. This dataset is publicly available in Ref. [
30]. The dataset is notably unbalanced, with class distributions ranging from 1766 samples to only a single example per class. In this research, three subsets were created, containing the one hundred fifty, two hundred, and three hundred most-sampled classes. This dataset does not initially include a train/test split. Therefore, consistent with previous research [
12] using this dataset, a 70/30 train/test split was applied.
Prior to training, the images underwent the following preprocessing similar to the images in the CASIA-HWDB dataset: conversion to tensor format and normalization to scale pixel values between −1 and 1. This ensured compatibility with the training pipeline and helped to maintain consistency across the datasets.
4.1.3. Dataset Generalization
Utilizing both the CASIA-HWDB and Kuzushiji-Kanji datasets provided distinct advantages. CASIA-HWDB served as an excellent source for pretraining, leveraging its extensive and balanced dataset to develop the initial weights, especially beneficial for transfer learning. Kuzushiji Kanji, though smaller and imbalanced, offered authentic Japanese kanji samples, essential for fine-tuning and evaluating the model’s performance in the target task. The main differences between the CASIA-HWDB and Kuzushiji-Kanji datasets are represented below (in
Table 3 and
Figure 6).
Utilizing both datasets, the training process harnessed the robustness of CASIA-HWDB and the specificity of Kuzushiji Kanji, enhancing the model’s accuracy in recognizing handwritten kanji.
4.2. Metrics
The model’s assessment is one of the main parts of the implementation of AI solutions. Without this step, there is no way to understand if the task that was set at the beginning is fulfilled or not. In order to evaluate the performance of the model, appropriate metrics must be picked according to the model’s task and its specialties. In our research, we chose the following three metrics: accuracy [
31], mAP (mean average precision), and mAA (mean average accuracy).
4.2.1. Accuracy
One of the most well-known and basic metrics for binary and multiclass classifications is accuracy. It offers a direct measure of the proportion of correctly classified samples relative to the total number of inputs, serving as a primary indicator of the overall model performance.
This metric is easy to interpret and compute. The accuracy score reflects the percentage of the inputs that the model correctly classifies. So, a higher value suggests a better performance. The model’s accuracy can be obtained using the following formula:
The accuracy is typically employed in tasks where the dataset is balanced (meaning that each class is represented equally) and where the cost of the misclassification is uniform across the categories. However, this metric can be deceptive in situations involving class imbalance, and our situation is one of those. In such cases, a model might achieve a high degree of recognition accuracy simply by favoring the majority class, thereby masking a poor performance in underrepresented categories. Consequently, we do not solely rely on this metric; it is primarily used here for comparison with the previous SOTA solution.
4.2.2. MAP
MAP [
32] is a comprehensive metric widely used in classification and information retrieval tasks, particularly when evaluating models in contexts with imbalanced datasets or in multilabel scenarios. Unlike accuracy, which considers only correct predictions, mAP provides a deeper insight into the quality of the model’s ranking and its ability to distinguish between classes. However, it is more complex to compute and interpret compared to simpler metrics, like accuracy, and it is computationally intensive for large datasets or multiclass problems.
MAP measures the area under the precision–recall curve, which plots precision against recall. By considering both precision (the proportion of true positive predictions among all the positive predictions) and recall (the proportion of true positives identified out of all the actual positives), mAP provides a balanced view of the model’s performance. Thus, the higher the mAP value, the better the model’s performance is. The process for calculating mAP involves several steps, as follows:
- (1)
Calculating precision [
33] and recall [
34] for each class;
- (2)
Using the computed values to plot the precision–recall curve [
35] for each class;
- (3)
Determining the area under each precision–recall curve, representing the average precision for that class;
- (4)
Finally, calculating the mean of all the average precision values across all the classes.
Considering that mAP is commonly applied in multiclass classification tasks and scenarios with a high degree of class imbalance, we used it for the models’ assessment in our research, as one of the main metrics.
4.2.3. MAA
MAA [
36] is a straightforward yet insightful metric, particularly valuable in multiclass classification tasks, where class imbalance can distort the interpretation of the global classification accuracy. By focusing on the per-class performance and then averaging the results, mAA offers a clearer understanding of how well the model performs across all the classes, independent of their distribution. As well as the accuracy metric, a higher value suggests a better performance. This metric is computed in the following two steps:
- (1)
For each class, divide the number of correctly predicted samples by the total number of samples in that class;
- (2)
Calculate the mean of all the per-class accuracy scores to derive the final mAA.
MAA is used in similar situations to those where mAP is used. Both of them are powerful metrics for the model’s assessment. However, mAP is slightly better, because mAA emphasizes the per-class correctness, measuring how often the model predicts each class correctly, and gives a balanced view of the model’s performance across all the classes, treating each class equally, regardless of its frequency. MAP, on the other hand, centers on the ranking quality, evaluates the model’s precision–recall tradeoff, and captures how well the model ranks correct predictions higher than incorrect ones, so it handles class imbalance more robustly, focusing on precision and recall.
Furthermore, mAA is easier to compute and interpret and is less computationally intensive. Therefore, mAA was employed along with mAP as one of the main metrics.
4.3. Results
In order to comprehensively evaluate the effectiveness of the developed model and its training algorithms, a series of experimental studies was conducted. These experiments involved using the following models and algorithms:
Vanilla Preact ResNet-18;
Preact ResNet-18 with Data Augmentation;
Algorithm 1 (training Preact ResNet-18 via cross-language transfer learning with the last layer unfrozen);
Algorithm 2 (training Preact ResNet-18 via cross-language transfer learning with all the layers unfrozen).
To address the handwritten kanji recognition task for different class counts, 150, 200, and 300, the evaluations were performed based on the previously described metrics for all the examined approaches. Additionally, the recognition accuracy of each individual character was analyzed. Let us now take a closer look at the results of these experiments.
4.3.1. Pretraining the Performance Baseline in the CASIA-HWDB Dataset
Before conducting the aforementioned experiments, it is essential to first train the Vanilla Preact ResNet-18 model in the CASIA-HWDB dataset, as this step is crucial for implementing the cross-language transfer-learning concept proposed in this paper. This dataset, recognized for its extensive collection of handwritten Chinese character images, serves as an ideal basis for pretraining. Specifically, a Preact ResNet-18 architecture, chosen for its proven performance in image recognition tasks, was trained from scratch.
Figure A1 illustrates the training dynamics (accuracy and loss curves) achieved by the Vanilla Preact ResNet-18 model for CASIA-HWDB class recognition. The curves show the initial volatility within the first ~10 epochs, common during early learning phases in large datasets, followed by stabilization and convergence toward the optimal performance, which was observed at around the 14th epoch.
The performance metrics achieved during this initial training phase are detailed in
Table 4, providing a baseline for subsequent transfer-learning experiments.
As can be seen from
Table 4, the Vanilla Preact ResNet-18 model provided a satisfactory solution, which allowed us to use its weights for the transfer-learning approach. The deeper analysis of the obtained results showed that the minimal and maximal character-specific recognition accuracies varied significantly. The character 囗 had the lowest recognition accuracy, at 41.67%, while 乾 and dozens of other Chinese characters achieved a perfect recognition accuracy of 100%.
4.3.2. Experiment 1: Handwritten Kanji Recognition (150 Classes)
The first experiment evaluated the performances of the four proposed training approaches (Vanilla Preact ResNet-18, Preact ResNet-18 with data augmentation, Algorithm 1, and Algorithm 2) in the multiclass classification task involving the 150 most-sampled handwritten kanji characters from the Kuzushiji-Kanji dataset. It should be noted that this experiment corresponds to the research conducted in [
12].
Figure A2,
Figure A3,
Figure A4 and
Figure A5 in
Appendix A illustrate the accuracies and losses achieved using the proposed approaches. These figures generally show rapid initial convergences for all the approaches within the first 2–4 epochs, characterized by sharp increases in accuracy and decreases in loss. Subsequently, the models exhibit more gradual refinements. Notably, Algorithm 2 consistently converges to the lowest loss values among the methods. The results, based on various performance metrics for all the described approaches, are presented in
Table 5. This table highlights that Algorithm 2 achieved the highest performance metrics for the 150-class task, notably 97.94% accuracy.
An in-depth evaluation of the separate kanji recognition performances showed the highest and lowest accuracy rates for the different training strategies, which are presented below:
Vanilla Preact ResNet-18: The lowest accuracy rate for 来 (77.14%) and the highest for 気 and some others (100%);
Preact ResNet-18 with data augmentation: The lowest accuracy rate for 来 (70%) and the highest for 京 and some others (100%);
Algorithm 1: The lowest accuracy rate for 來 (70.51%) and the highest for 卵 and some others (100%);
Algorithm 2: The lowest accuracy rate for 來 (76.92%) and the highest for 何 and some others (100%).
4.3.3. Experiment 2: Handwritten Kanji Recognition (200 Classes)
According to the promising results from our previous experiment (
Section 4.3.2), we expanded our evaluation to include 200 kanji classes (
Table 6).
Figure A6,
Figure A7,
Figure A8 and
Figure A9 in
Appendix A demonstrate the accuracy and loss measurements obtained through our proposed approaches. Similar convergence patterns are observed for the 200-class task (
Figure A6,
Figure A7,
Figure A8 and
Figure A9). Fast initial learning is followed by stabilization, with Algorithm 2 again demonstrating convergence to superior loss minima compared to those of the other approaches.
An in-depth evaluation of the separate kanji recognition performances showed the highest and lowest accuracy rates for the different training strategies, which are presented below:
Vanilla Preact ResNet-18: The lowest accuracy rate for 来 (77.14%) and the highest for 十 and some others (100%);
Preact ResNet-18 with data augmentation: The lowest accuracy rate for 来 (77.14%) and the highest for 内 and some others (100%);
Algorithm 1: The lowest accuracy rate for 來 (71.80%) and the highest for 奥 and some others (100%);
Algorithm 2: The lowest accuracy rate for 来 (80%) and the highest for 七 and some others (100%).
4.3.4. Experiment 3: Handwritten Kanji Recognition (300 Classes)
The next experiment focused on evaluating the effectiveness of all the examined approaches for recognizing 300 kanji classes.
Figure A10,
Figure A11,
Figure A12 and
Figure A13 in
Appendix A illustrate the accuracies and losses achieved using the proposed approaches. The training dynamics for the 300-class experiment (
Figure A10,
Figure A11,
Figure A12 and
Figure A13) reinforce the observed trends. Rapid initial convergence occurs across the methods, but Algorithm 2 maintains its advantage in achieving a lower loss and a higher accuracy rate upon stabilization. It should be noted that in this experiment, we doubled the number of kanji classes compared to those in the studies conducted in [
12]. The results of this investigation are presented in
Table 7.
An in-depth evaluation of the kanji recognition performance uncovered the highest and lowest accuracy rates for the different training strategies, which are presented below:
Vanilla Preact ResNet-18: The lowest accuracy rate for 衞 (65.63%) and the highest for 似 and some others (100%);
Preact ResNet-18 with data augmentation: The lowest accuracy rate for 来 (69.01%) and the highest for 似 and some others (100%);
Algorithm 1: The lowest accuracy rate for 來 (62.82%) and the highest for 代 and some others (100%);
Algorithm 2: The lowest accuracy rate for 来 (67.61%) and the highest for 一 and some others (100%).
4.3.5. Statistical Significance of Performance Improvements
The statistical significance of our accuracy improvements compared to those of previous state-of-the-art methods was evaluated using binomial tests. Because our methodology involves fine-tuning pretrained models, precluding variance estimation through repeated runs from random initializations, the binomial test serves as a suitable alternative. This test allows for comparing the final accuracy scores based on the respective test set sizes to determine if observed differences are statistically significant [
37].
Performing the binomial test for the model trained with Algorithm 2 in the task of recognizing 150 kanji resulted in an extremely low p-value (approximately ). This value falls well below typical significance thresholds (e.g., ), strongly indicating the statistical significance of the achieved results.
Additionally, we calculated approximate 95% confidence intervals for our accuracy measurements using the Agresti–Coull method [
38], which is well suited for proportions, like accuracy.
The non-overlapping confidence intervals shown in
Table 8 further support that our improvements are statistically significant, confirming that our cross-language transfer-learning approach provides meaningful enhancements in kanji recognition accuracy.
5. Comparison and Discussion
To evaluate the performances of all the investigated approaches, we employed accuracy, as used in the baseline study [
12], allowing for a direct comparison of the results. Beyond this metric, which shows the overall accuracy of the model, we also calculated the accuracy for each individual kanji character to identify potential patterns or anomalies in the models’ performance.
Figure 7,
Figure 8 and
Figure 9 provide a comparison of all the examined approaches alongside the baseline method from [
12] across all three cases:
Classification task for 150 classes (
Figure 7);
Classification task for 200 classes (
Figure 8);
Classification task for 300 classes (
Figure 9).
These figures visually confirm the superior accuracy of Algorithm 2 compared to those of all the other methods. The analysis of the training curves across all the Kuzushiji-Kanji fine-tuning experiments (
Appendix A,
Figure A2,
Figure A3,
Figure A4,
Figure A5,
Figure A6,
Figure A7,
Figure A8,
Figure A9,
Figure A10,
Figure A11,
Figure A12 and
Figure A13) reveals consistent convergence behaviors. The approaches involving full network training (Vanilla, Vanilla + Aug, and Algorithm 2) typically displayed rapid performance gains within the initial 2–4 epochs, followed by a period of gradual fine-tuning. This indicates that the models quickly learned the foundational features relevant to the target task. Algorithm 2, benefiting from relevant pretrained weights, consistently converged to lower loss values and higher final accuracies compared to those of the Vanilla models trained from scratch, suggesting that it reached a more optimal local minimum in the loss landscape. Algorithm 1 also converged quickly but plateaued earlier at significantly higher loss and lower accuracy levels, highlighting the limitations of only fine-tuning the final layer for this complex task.
A critical tradeoff exists between the fine-tuning strategies concerning the computational efficiency and performance. Algorithm 1 (freezing convolutional layers) offered substantially reduced training times and computational demands (memory and processing power) per epoch, as the gradients only needed to be computed and applied to the final classification layer. This makes it a potentially attractive option for resource-constrained environments or rapid prototyping. However, as demonstrated by the results (
Table 5,
Table 6 and
Table 7), this efficiency was achieved at the significant cost of lower recognition accuracies across all the class counts. Conversely, Algorithm 2, requiring gradient computation and weight updates throughout the entire network, demanded considerably more computational resources and longer training durations. Yet, this investment consistently yielded statistically significant improvements and the overall best performance. The Vanilla models, also requiring full network training, represent an intermediate computational load but generally needed more epochs to reach their optimal performances compared to that of the pretrained Algorithm 2, which started closer to a good solution.
It is important to note that the baseline solution from [
12] was designed specifically for the recognition of 150 classes; therefore, its results are not included in
Figure 8 and
Figure 9.
The process for obtaining the initial weights through training in the CASIA-HWDB dataset yielded surprisingly strong results. Despite the discrepancy between the 512 output units in the penultimate layer of RESNET-18 and the 6763 classes in CASIA-HWDB, the model’s performance was respectable. A noticeable trend in the training process was the rapid ups and downs during the first 10 epochs, after which the model approached a local minimum. The optimal results were achieved at around the 14th epoch.
An intriguing observation was that the lowest accuracy rate was recorded for one of the simplest Chinese characters, consisting of just four strokes. Similarly, other characters with low recognition accuracy rates tended to be simple and had few strokes. In contrast, the highest accuracy rates were achieved for more complex characters with over 10, 15, or even 20 strokes. Although this phenomenon could be attributed to the model’s architecture and capacity, a deeper investigation was beyond the scope of this study, as this phase primarily aimed to generate the initial weights.
When analyzing the results of the handwritten kanji recognition models, several consistent patterns emerged as follows:
Regardless of the number of classes, the models typically approached a local minimum within 2–4 epochs, followed by gradual refinement over 14–40 epochs. A recurring issue was the lower accuracy rate for the visually similar kanji 来 and 來;
Across all the experiments, the pretrained RESNET-18 model with all the layers unfrozen consistently delivered the best results, while the pretrained model with only the last layer unfrozen performed the worst. These findings support the hypothesis that pretraining in a large dataset of handwritten Chinese characters is beneficial because of their visual similarity to handwritten kanji. The pretrained weights likely begin closer to a favorable loss basin compared to those in a random initialization;
The underperformance of the pretrained model with only the last layer unfrozen was anticipated, as this approach prioritizes computational efficiency over the optimal performance. Despite its limitations, the model still achieved reasonable results;
The models trained from scratch, with and without data augmentation, exhibited comparable performances. For the 150-class recognition task, the non-augmented model slightly outperformed the augmented one across all the metrics. In the 200-class task, the augmented model led in every metric. For the 300-class task, the augmented model achieved a higher accuracy rate but lower mAP and MAA values. These results suggest that data augmentation does not consistently enhance the models’ performances, which explains its exclusion from the pretrained models’ training.
Notably, the non-pretrained models demonstrated significantly lower mAP scores compared to that of the pretrained model with all the layers unfrozen, underscoring the value of transfer learning.
When comparing our solutions to the previous state-of-the-art (SOTA) approach for recognizing 150 kanji, our best model—pretrained RESNET-18 with all the layers unfrozen—achieved a 1.51% improvement in accuracy, which is an accuracy rate of 97.94%. For the 300-kanji recognition task, which doubles the class count of the previous SOTA approach, our model surpassed its accuracy by 1.19%, which is an accuracy rate of 97.62%. To facilitate future research, we have also provided benchmark metrics for mAP and mAA, offering a more comprehensive evaluation framework for this complex multiclass classification task.
6. Conclusions
This study aimed to develop an effective machine-learning approach for recognizing handwritten Japanese kanji. The proposed methodology involved implementing the Preact ResNet-18 model for kanji recognition, both with and without data augmentation, to evaluate its effectiveness and the impact of the augmentation on the recognition performance. Furthermore, a novel model based on cross-language transfer learning was developed using the Preact ResNet-18 architecture. The model was initially trained in a Chinese dataset and then fine-tuned in a Japanese dataset to improve its kanji recognition accuracy.
Experiments were conducted for 150, 200, and 300 kanji classes, with evaluations based on key performance metrics, such as the recognition accuracy rate, mAP, and mAA. The results indicated that although data augmentation provided slight benefits in certain scenarios, particularly with larger class sets, it did not consistently enhance the recognition performance. This suggests that the primary variations in handwritten kanji lie less in simple geometric transformations (e.g., rotation and minor scaling/translation) and more in intrinsic aspects (e.g., stroke thickness, connection variations, and character-specific deformation) not fully captured by the applied data augmentation techniques. Several factors, such as stroke thickness variation, slight deviations in stroke order or connection, and character-specific deformations, might be more critical for robust recognition. The applied affine and cropping transforms might not fully represent these more intrinsic handwriting variations. Therefore, we suggest further experimentation with alternative augmentation strategies. Additionally, models trained from scratch underperformed compared to their pretrained counterparts, reinforcing the effectiveness of transfer learning in handling high-class-count classification tasks.
This study also highlighted the importance of fine-tuning strategies. Unfreezing all the layers during training yielded the best performance, whereas restricting training to only the final layer yielded suboptimal results. This finding aligns with the notion that deep feature representations learned during pretraining must be fully adapted to the new task for the optimal performance. Moreover, pretraining in a large, well-balanced dataset, such as CASIA-HWDB, proved to be highly beneficial. The model trained with Algorithm 2 consistently outperformed the other approaches, achieving state-of-the-art results, with a statistically significant 1.51% accuracy improvement for recognizing 150 kanji and a 1.19% improvement for recognizing 300 kanji over the previous benchmarks. These findings validate the hypothesis that leveraging visually similar handwritten Chinese characters provides a strong foundation for kanji recognition. Moreover, statistical analysis confirms that these improvements are statistically significant (p < 0.001 and non-overlapping confidence intervals), providing strong evidence for the effectiveness of our cross-language transfer-learning approach.
Overall, this research demonstrates that combining robust pretraining with appropriate fine-tuning strategies can significantly enhance kanji recognition models. The insights gained not only advance the state of handwritten kanji recognition but also offer valuable benchmarks and methodologies for future studies in multiclass classification. Future research will focus on further improving the best-performing model by refining metric scores and expanding the range of recognizable kanji. This will involve experimenting with alternative architectures and enhancing data preprocessing techniques, especially because data preprocessing is critical in computer vision tasks, as demonstrated by [
39]. Additionally, specific recognition challenges, such as the poor differentiation of visually similar kanji (e.g., 来 and 來 (see
Appendix B for details)) and unexpected underperformance for simpler characters, will be investigated further. Addressing these issues by enhancing the pretraining model should be a priority in subsequent research efforts.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}