Abstract
In the context of expensive constraint multi-objective problems, it is evident that the feasible domain shapes and sizes of different problems vary considerably. The difficulty in finding optimal solutions presents a significant challenge in ensuring the surrogate-assisted evolutionary algorithm’s feasibility, convergence, and diversity. To more effectively address the distinctive characteristics of the feasible domain and objective function across a range of problems, we have developed a Kriging-based surrogate-assisted evolutionary algorithm tailored to the current population’s preferences. The algorithm can optimize the population according to the current population’s requirements. Additionally, considering the varying degrees of accuracy observed in the surrogate models at different stages, this paper employs a dynamic approach to the number of surrogate model evaluations, contingent on the accuracy of the current surrogate model. Two types of Pareto frontier search are distinguished: unconstrained and constrained. Moreover, distinct fill sampling strategies are devised in accordance with the specific optimization requirements of the current population. After assessing the proposed solutions, the discrepancy between the actual fitness value and the surrogate model’s prediction is calculated.The discrepancy is used to modify the number of evaluations conducted on the surrogate model. In order to illustrate the algorithm’s efficacy, it is benchmarked against the current state-of-the-art algorithms on various test problems. The experimental results demonstrate that the proposed algorithm performs better than other advanced methods.
1. Introduction
Real-world engineering optimization problems often involve many conflicting objectives and some constraints [1]. A constrained multi-objective optimization problem (CMOP) with inequality constraints can be expressed as:
where is a d-dimensional decision variable, is the objective function to be optimized, and is the first inequality constraint. For CMOP, constraint violation (CV) can be computed in the following way:
A feasible solution refers to a solution whose CV value is less than or equal to 0. When a solution outperforms solution x on all objectives, dominates x. If is not dominated by other solutions, is called a non-dominated solution. The set of objective vectors formed by non-dominated solutions is called the constrained Pareto front. The goal of CMOP is to find the constrained Pareto front (CPF). There are a large number of constrained multi-objective problems in engineering problems in the real world. Some of these problems require expensive computational costs when being solved, such as fuel cell vehicle design [2], wire manufacturing [3], and space system design [4]. These types of problem are called expensive constrained multi-objective problems.
The ECMOP requires the algorithm to find the optimal solution under limited computational resources. However, the feasible domain is extremely narrow in MW1, which makes it difficult for the algorithm to find the feasible domain quickly. Meanwhile, the feasible domain of the problem is very broad for CF1 if the computational resources are heavily used in the constraint-value dominated search process, and the algorithm often falls into local convergence, making it difficult to approach the Pareto frontier. Therefore, the algorithm must use different search strategies for different feasible domains under different feasible domain conditions. In the case that the feasible domain is narrow and difficult to find, the algorithm needs to find the feasible domain with as few evaluations as possible, and in the case that there are already enough individuals in the feasible domain, it will not obtain good results if it pays too much attention to the convergence and feasibility. However, due to the limitation of computational resources, it is difficult for the algorithm to search for the optimal solution in a large decision space, requiring the algorithm to converge quickly to find the feasible domain. On the other hand, the complexity of CPF makes it difficult to explore the feasible domain with a limited number of solutions, which requires the algorithm to have good diversity.
Evolutionary algorithms are widely used in constrained multi-objective problems due to their advantages, such as simple implementation and strong search ability [5]. Constrained multi-objective evolutionary algorithms require using a large number of function evaluations to search the objective space to ensure the good performance of the algorithm. However, for ECMOPs, where the number of available function evaluations is limited, traditional constrained multi-objective evolutionary algorithms are not adept at generating solutions that meet the requirements [6].
In order to solve such problems, many researchers have used surrogate models instead of real evaluation functions to produce suitable solutions within a limited number of evaluations; this method is called surrogate-assisted MOEAs (SA-MOEAs). SA-MOEAs have become a promising direction in recent years [7] that has received increasing attention. Commonly used surrogate models in recent years include artificial neural networks and support vector machines [8,9], radial basis functions [10], and Gaussian regression (Kriging) [11]. The Kriging model is a stochastic model and, due to its good approximation ability to nonlinear functions with stochastic properties [12], it is one of the most representative and potential surrogate modeling methods in the field of surrogate-assisted evolutionary algorithms [13,14]. Surrogate-assisted evolutionary algorithms guide the search process of the algorithm by using existing solutions that have been evaluated with real functions to build surrogate models to predict the performance of the unevaluated ones. The use of surrogate models allows the algorithm to explore the decision space more fully within the constraints of a limited number of real evaluations and greatly reduces the amount of computation due to the computationally inexpensive nature of surrogate models.
SA-MOEA needs to find the optimal solution under the limitation of only a few evaluation times. Therefore, the strategy of the evolutionary algorithm needs to be improved to adapt to SA-MOEA [15]. The mainstream improvement directions can be divided into three types: offspring generation, surrogate model management, and fill sampling criteria. In terms of offspring generation, KTA2 [16] uses an archived population to generate multiple sets of candidate solutions to ensure the diversity and convergence of the population. In order to meet the preference requirements within a limited number of evaluations, K-RVEA [17] uses the angle penalty distance to balance the diversity and convergence of solutions in decision space and dynamically adjust the reference vector distribution simultaneously. In terms of surrogate model management. In order to improve the prediction accuracy of the surrogate model, MOEA/D-EGO [18] adopts the idea based on decomposition and uses the MOEA/D algorithm to decompose the multi-objective problem into multiple single-objective problems and establishes a surrogate model separately for each single-objective problem. K-RVEA utilized the uncertain information of the Kriging model to design the training data selection strategy for the Kriging model in order to improve the performance of Kriging. In terms of the fill sampling criterion, CSEA [8] uses the surrogate model to predict the dominant relationship between the candidate solution and the reference solution and selects the dominant solution for real function evaluation. ABSAEA [19] uses two fill sampling criteria; one of them selects the non-inferior solution to enhance the convergence of the population, and the other selects the solution with the maximum uncertainty to enhance the diversity of the population.
For ECMOPs, another problem that SAMOEA needs to solve is how to optimize the objectives under the premise of meeting the constraint conditions [20]. For SA-MOEA, predicting both the constraint values and the objective values simultaneously often leads to a large prediction error of the surrogate model [21], especially when there is an overlap between the constrained Pareto front and the unconstrained Pareto front. However, not predicting the constraint values often leads to the algorithm being unable to find the feasible region and making it difficult to search for effective feasible solutions. Therefore, SA-MOEA needs to use appropriate constraint handling techniques to balance the optimization of objective values and the satisfaction of constraint conditions.
In ECMOPs, the feasible domain of the problem may be extremely small, and then the algorithm needs to accelerate the convergence to ensure that the feasible domain can be found with limited computational resources; however, existing algorithms such as KTS [22] that only consider the correlation between the constraints and the objective values are unable to accelerate the convergence in this case. On the other hand, if the algorithm focuses too much on finding the feasible domain in the early stage, the algorithm may fall into localized convergence and fail to cross the feasible domain to converge to the CPF.
To solve the above problems, we propose a preference model-based surrogate-assisted constrained multi-objective evolutionary algorithm, which performs different offspring generation strategies based on the current difficulty of finding a feasible solution. In addition, a surrogate model management strategy is used to adjust the surrogate model evaluation strategy and the new offspring selection strategy according to the performance of the current surrogate model. Specifically, this paper’s contributions are as follows:
- To meet the optimization requirements of the population at different stages, we propose a multi-preference search model based on evolutionary demands. In the early stage of evolution, the waste of computing resources is reduced by rapidly converging to the feasible region. In the middle stage of evolution, for the feasibility search requirements of the population, a feasible solution archive and constrained preference strategy are used to help the population cross infeasible regions. For the diversity requirements of the population, the objective value preference algorithm is used to help the population get rid of local optima. In the later stage, the model balances diversity and convergence demands to facilitate the exploration and exploitation of feasible regions.
- In surrogate-assisted evolutionary algorithms, the accuracy of the surrogate model plays a crucial role in the algorithm’s performance. To better utilize the surrogate model for evaluating newly generated solutions, a strategy to modify the number of predictions of the surrogate model based on the prediction error of the current realistically evaluated solutions is proposed.
- Target constrained Pareto frontier search and unconstrained Pareto frontier search address the different optimization needs of populations. Convergence to the feasible domain is accelerated by auxiliary populations when the main population lacks feasible solutions and is converted to objective-value dominated to converge across the feasible domain to the unconstrained Pareto front (UPF) when there are sufficient feasible solutions.
2. Preliminaries
2.1. Kriging
In this study, we use the Kriging model to approximate the objective function and constraint functions. As a typical surrogate model, Kriging can effectively fit complex functions and provide uncertainty estimates for the prediction results. The dynamic evaluation strategy relies on the prediction accuracy and uncertainty information of the Kriging model. By monitoring the model prediction errors (such as the mean square error and the feasibility misclassification rate), it dynamically adjusts the usage frequency of the surrogate model. When the model reliability is low, the number of surrogate evaluations is reduced to prevent it from misleading the search direction. When the reliability is high, the number of surrogate evaluations is increased to save computational resources. The mathematical model of the Kriging model can be expressed as:
where is a uniformly distributed Gaussian noise and and are two constants independent of x.
Given the collected data and its corresponding output , for an unevaluated point , the estimated output , the mean , and the variance are calculated as follows:
Among others, X is the average vector of X, the mean vector of is the average vector of X, and is the vector of covariances between K, where K is the covariance matrix of X. The covariance matrix of two data points is measured using the squared exponential function as the covariance function of X and . The similarity between the two data points X and is given by:
Predicting the mean is directly used as , the predicted value, and the predicted variance represents the uncertainty. The hyperparameters in the covariance function can be obtained by maximizing the log-marginal likelihood function as follows:
2.2. Co-Evolution
In this study, we introduce the co-evolutionary algorithm into the multi-preference search mode based on evolutionary demand. Through the co-evolution of the main population and the auxiliary population, the overall optimization performance is enhanced. This collaborative mechanism enables the algorithm to dynamically balance feasibility and convergence at different stages of evolution. The cooperative co-evolutionary algorithm is an optimization method based on evolutionary algorithms. Its main aim is to decompose a complex problem into several relatively simple sub-problems, solve these sub-problems separately, and then combine their solutions to obtain the overall solution. During this process, the solutions of different sub-problems interact with each other through cooperation and competition, thereby optimizing the overall problem.
The basic steps of the co-evolutionary algorithm are as follows:
Problem decomposition: Decompose the original problem into multiple subproblems. These sub-problems should be relatively independent and can be solved relatively easily.
Individual representation: Designing a suitable individual representation for each subproblem, usually by encoding the solution of the subproblem as an individual.
Subproblem solving: Use evolutionary algorithms (e.g., Genetic Algorithm, Particle Swarm Algorithm, etc.) to solve each subproblem separately, and get the local optimal solution of each subproblem.
Merging and competition: Combining locally optimal solutions to individual subproblems and influencing each other competitively or collaboratively to further optimize those solutions.
Iterative optimization: The above steps are repeated until the stopping condition is reached (e.g., the maximum number of iterations is reached, the convergence condition is satisfied, etc.).
The advantage of the co-evolutionary algorithm is that it can deal with complex, high-dimensional problems and make full use of the structural information of the problem to improve the solution efficiency. It is often used in multi-objective optimization, large-scale optimization, and optimization problems with complex structures.
3. Proposed Methodology
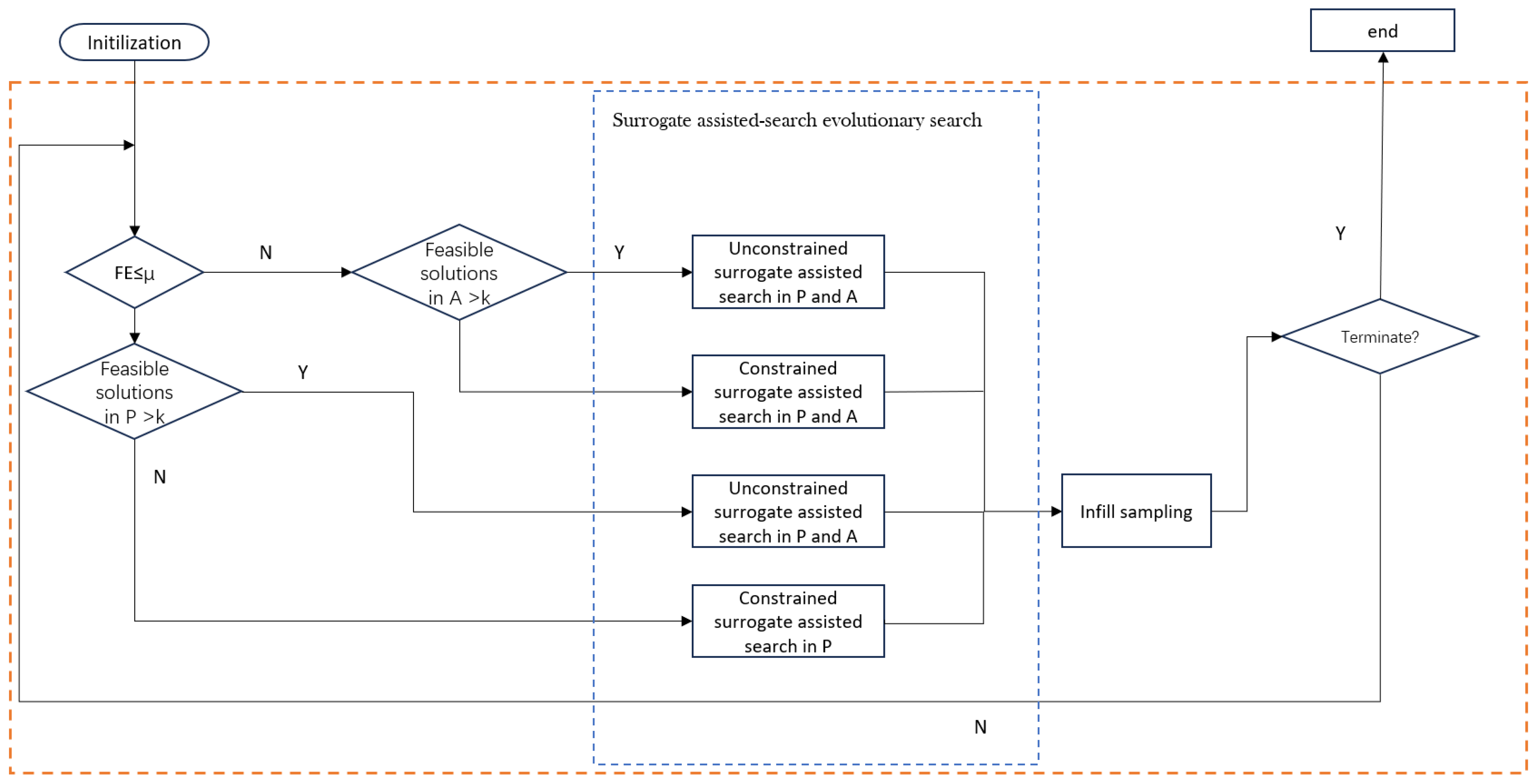
In this section, we propose a surrogate-assisted multi-preference constrained multi-objective evolutionary algorithm (SA-MPCMOEA) designed to address complex constrained multi-objective optimization problems (CMOPs). The primary goal of SA-MPCMOEA is to balance the evolution between feasible and infeasible solutions, facilitating the population to efficiently approach the constrained Pareto front while considering the trade-offs between objective values and constraint violations. Feng et al. [23] proposed the idea of a multi-preference model. This paper designs three different preference models according to the computational resources consumed by the algorithm and the ratio of diversity, convergence, and feasibility, as shown in Figure 1. It uses different offspring generation strategies for each model to guide the evolutionary direction of the population.
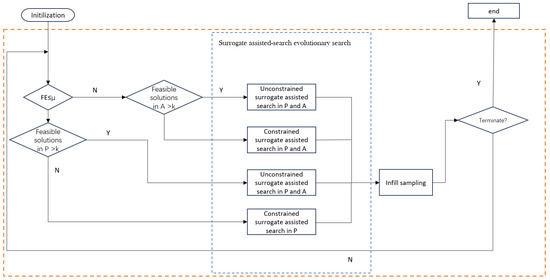
Figure 1.
The overall workflow of SA-MPCMOEA.
3.1. Overview of SA-MPCMOEA
Algorithm 1 summarizes the main procedure of SA-MPCMOEA. In the evolutionary process, SA-MPCMOEA relies on the following three key mechanisms:
- Multi-preference search mode based on evolutionary demand: To coordinate the trade-off between constraint feasibility and objective optimization across different stages of evolution, three preference-based search modes are proposed and switched adaptively based on population feedback. Mode 1 emphasizes the rapid discovery of feasible solutions. Mode 2 simultaneously guides the population toward both the constrained Pareto front and the unconstrained Pareto front. Mode 3 focuses on accelerating convergence when sufficient feasible solutions exist. This mechanism enhances the algorithm’s ability to balance feasibility and optimality across different evolution phases.
- Dynamic assessment strategy: In each generation: Candidate solutions are first evaluated by the surrogate models in terms of both objective and constraint functions. Their prediction confidence is then estimated based on model errors. When the surrogate prediction is reliable, more solutions are evaluated using the surrogate models to save computational resources. Otherwise, the proportion of real evaluations is increased to prevent misleading search directions.This strategy achieves a dynamic balance between solution accuracy and computational efficiency, improving overall optimization performance.
- Fill sampling strategy based on optimization requirements: During the population update phase: A hybrid sampling scheme is adopted, combining uncertainty maximization with potential promising solutions. The former enhances global model performance. The latter steers the population toward potentially optimal regions. Candidate solutions that are too close to the current population are excluded. This improves the diversity and spatial distribution of the population and avoids premature convergence.
These three components work in synergy throughout different stages of surrogate-assisted evolution, enabling SA-MPCMOEA to demonstrate enhanced adaptability and convergence performance on constrained multimodal multi-objective optimization problems.
| Algorithm 1 Pseudo-code for the proposed algorithm |
| Require: Population P; archive A Ensure: P; A; New samples O
|
3.2. Multi-Preference Search Mode Based on Evolutionary Demand
Constrained multi-objective optimization problems (CMOPs) often contain conflicting objectives and constraint satisfaction requirements. The algorithms’ different preferences for handling objective optimization and constraint optimization at different stages of population evolution directly affect the viability, diversity, and convergence of the population. It is challenging for CMOPs to maintain a balance between using objective information to accelerate convergence and locating feasible regions. Thus, to address the above challenges, we use a multi-preference model to rationalize the scheduling of offspring generation for populations. Based on the idea of the multi-preference model proposed by [24], this paper designs three different preference models according to the computational resources consumed by the algorithm and the ratio of diversity, convergence, and feasibility, as shown in Figure 1. Different offspring generation strategies are used for each model to guide the evolutionary direction of the population.
where FE represents the number of function evaluations currently used, maxFE represents the maximum number of function evaluations, is the threshold adjustment parameter, and feasible(·) represents the number of feasible solutions in the population.
3.2.1. Search Mode 1: Angle-Based Convergence Model for Feasible Domains
In Mode 1, the main population P is responsible for exploring the feasible domain, and the auxiliary population A is used to store the feasible solutions of P. A sampling strategy based on the direction of convergence is designed to enhance the convergence of P and feasible selection pressure. In the decision space, based on the solution , two convergence directions are formed by the lower bounds L and and the upper bound U and .
Afterwards, the solution is generated by sampling at different step sizes in the direction of convergence:
where and denote the step size, j and k denote the first j times and the k times sampling, and denotes the Euclidean distance.
3.2.2. Search Mode 2: Co-Evolutionary Search Model
In Mode 2, the main population and the auxiliary population are respectively used to explore the satisfaction demands of constraint conditions and the optimization demands of objective values. After the main population P and the auxiliary population A independently generate offspring solutions, the main population selects the solution with a lower CV value to approach the constrained Pareto front, and the auxiliary population selects the solution with a better objective value to approach the unconstrained Pareto front. In the population update operation, the main population P is first combined with the auxiliary population A. For updating P, feasible solutions are prioritized; if insufficient feasible solutions exist, the solution with the smallest CV value is selected. For updating A, non-dominated sorting and crowded distance are used to select individuals with better diversity and convergence to help the population cross the feasible region and improve diversity.
3.2.3. Search Mode 3: Feasible Domain-Assisted Exploration Search Model
Population P in Mode 3 continues to evolve, driven by feasibility criteria, and population A is designed to help the population explore unexplored areas of population P. The two mating parents are from population P and population A. The offspring are produced from population P and population A and are used to renew population P and population A.
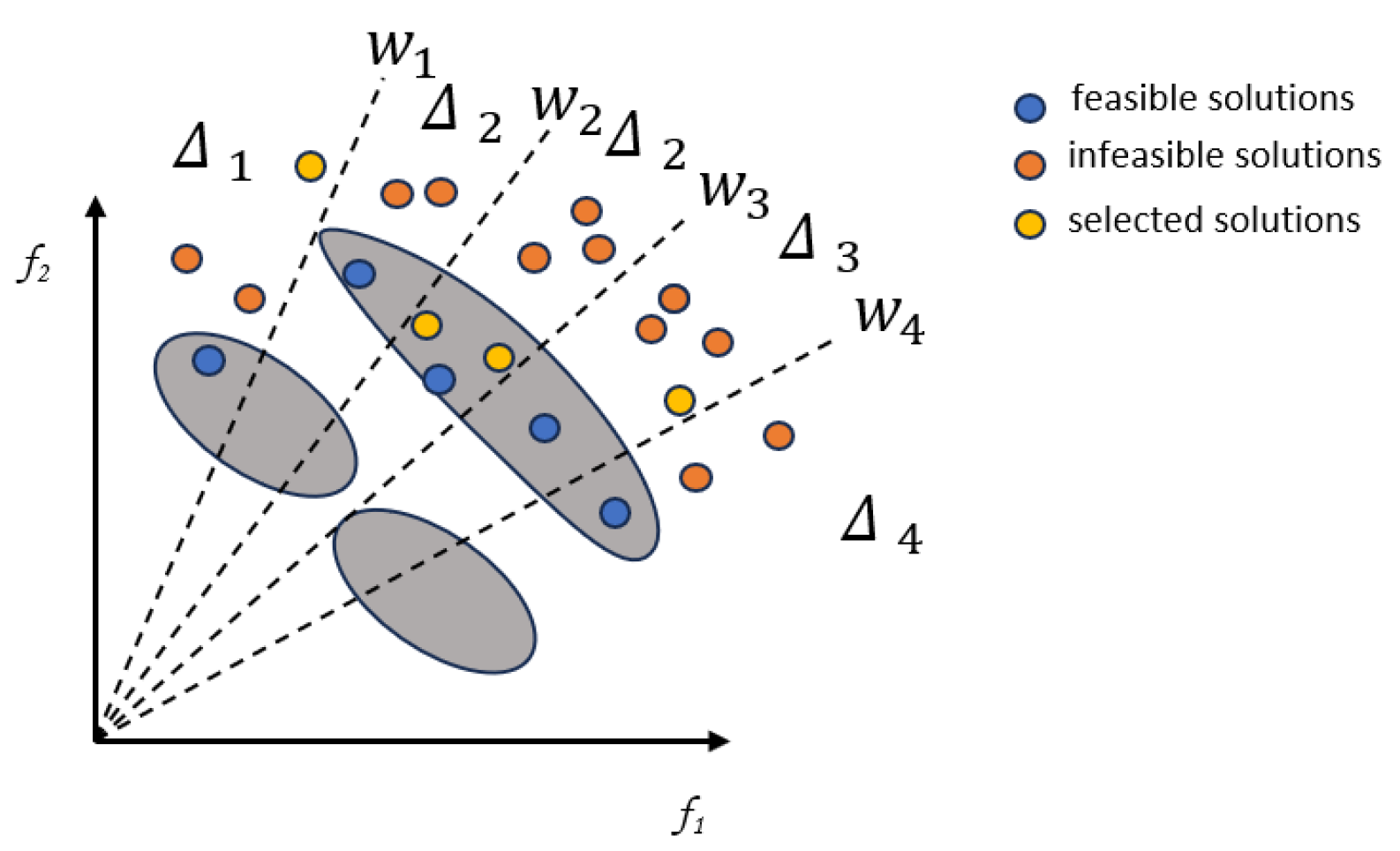
Population A does not consider constraint values and is driven by diversity and convergence information. Population A is mixed with child Q to generate a mixed population H. The solutions in population H and population P are then compared with a reference vector based on the reference vector of the subregion associated with them. For each subregion, if no solution exists in population P, the optimal non-dominated solution in H is selected in population A. The optimal non-dominated solution in H is then selected in population A.
Figure 2 illustrates the individual selection mechanism of Model 3. In the diagram, blue dots represent individuals selected by Population P, while yellow dots denote those selected by Population A.
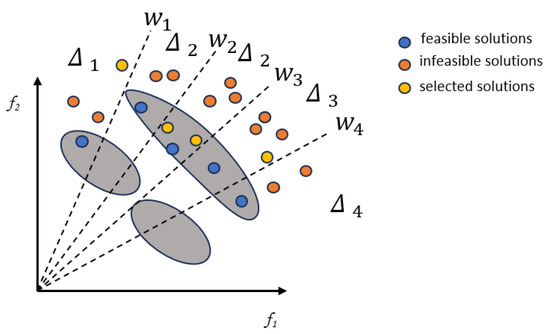
Figure 2.
Illustration of Model 3.
3.3. Dynamic Assessment Strategy
In expensive problems, due to limited computational resources, it is necessary to conserve computational resources by evaluating candidate solutions using surrogate models. The reliability of the surrogate model varies for different stages of the algorithm. When the reliability of the surrogate model is low, the objective values and constraint violations obtained by evaluating the candidate solutions using the surrogate model may have large errors with the real values, and it is difficult to truly reflect the superiority of a candidate solution among all the offspring solutions, which leads to the algorithm selecting a solution that cannot help the population to advance to the CPF, which results in a waste of real evaluation resources. Therefore, when the reliability of the surrogate model is low, the number of surrogate evaluations of the surrogate model should be reduced to avoid misleading the direction of population evolution. To this end, this paper dynamically adjusts the number of model evaluations according to the mean square error (MSE) of the surrogate model prediction results and the results of the real evaluation with the evaluation errors. The error bounds in Kriging models are determined by the MSE and the correlation index. The MSE is used to evaluate the prediction accuracy of the model, with a lower MSE indicating a better fit [25]. When the prediction error rate is high, the reliability of the surrogate model is considered to be low. At this point, the number of surrogate model evaluations is reduced, and when the surrogate model evaluation error rate is low, the number of surrogate model evaluations is increased. In [26], Song et al. proved that the change of will greatly affect the performance of the surrogate-assisted evolutionary algorithm.
where is the maximum number of evaluations of the surrogate model, S is the number of candidate solutions, and is the scaling factor.
3.4. Fill Sampling Strategy Based on Optimization Requirements
The newly generated solutions serve two purposes for the surrogate model-assisted evolutionary algorithm: (1) They can select candidate solutions with maximum uncertainty as training data to improve the accuracy of the surrogate model. (2) They can select candidate solutions that outperform the current evaluation under feasible rules, i.e., potentially good solutions, to find optimal solutions [16,17,27].
One of the advantages of the Kriging model is that it can provide not only a prediction of the unknown function but also an estimate of the error in the prediction. The solution with the largest error in the predicted value is the maximum uncertainty solution, indicating that the surrogate model has low confidence in its predictions around that solution. Sampling such solutions can improve the global accuracy of the surrogate model. Potentially good solutions are located around the approximate landscape [28]. Sampling such solutions can help the population find the optimal solution.
Based on the above considerations, the solution for true function evaluation in surrogate-assisted evolutionary algorithms should take both factors into account. To accelerate the speed of the population to find a feasible solution and avoid the population from falling into a local optimum, the solutions whose distance from the current population in the decision space is less than a set value are eliminated to optimize the distribution of the population in the decision space. The search for the optimal solution in this paper is measured by calculating the convergence information and diversity information of the solution. Among them, is used to solve the CPF search problem.
where denotes the number of individuals that x dominates, denotes the Euclidean distance between the solutions x and , and represents the diversity information of the solution x. After that, we divide the candidate solutions into k clusters using the k-nearest neighbor algorithm and select a solution with minimum fitness from each cluster for expensive evaluation.
For the UPF (Unconstrained Pareto Front) exploration, we give the objective function a higher priority and therefore do not consider the constraint values. Thus, in the diversity information, we multiply the distance by the difference of the constraint values.
4. Experimental Setup
In this paper, to demonstrate the ability of SA-MPCMOEA to solve expensive constrained multi-objective problems, two test suites, CF and LIRCMOP, are used to compare SA-MPCMOEA with the current state-of-the-art algorithms. The number of decision variables is set to 10 for all test instances. It is assumed that the evaluation of their objectives and constraints is expensive. The performance of the algorithms is evaluated using IGD metrics
where denotes the minimum Euclidean distance from x to and denotes the number of points in . A total of 10,000 reference points are used to compute the IGD values. Smaller IGD values indicate better convergence and diversity of the algorithm’s non-dominated set.
The hypervolume (HV) is a metric used to measure the volume of the objective space covered by a solution set relative to a reference point. A larger HV value indicates that the solution set obtained by the algorithm covers a wider range of the true Pareto front, demonstrating better solution quality and algorithm efficiency. The HV calculation method is shown in the following equation:
To ensure the fairness of the experiments, the parameter settings for all compared algorithms are configured as follows:
- All algorithms are independently executed 30 times.
- The maximum number of real function evaluations for each algorithm is set to 1000.
- The population size is uniformly set to 100 across all test problems.
4.1. Experiments Results
In this section, our algorithm SA-MPCMOEA is compared with the following state-of-the-art algorithms: The proposed SA-MPCMOEA was empirically compared with six state-of-the-art CMOEAs: CTAEA [29], RVEAa [30], ABSAEA, CCMO, and NSGA-II. to examine its performance.
All compared algorithms were implemented in MATLAB (R2023a) within the PlatEMO platform [31] and executed on a computer equipped with a 13th Gen Intel Core i5-13400 2.50 GHz CPU and the Microsoft Windows 10 operating system.
- CTAEA balances convergence, diversity, and feasibility by maintaining two collaborative archives: the convergence-oriented archive (CA) and the diversity-oriented archive (DA). By adaptively selecting individuals from these archives based on their distinct evolutionary states to generate offspring solutions, the algorithm achieves superior performance on constrained multi-objective optimization problems.
- RVEAa employs a reference vector regeneration strategy to address constrained many-objective optimization problems with irregular PFs (Pareto Fronts) and utilizes the angle-penalized distance to maintain a balance between convergence and diversity.
- ABSAEA employs an adaptive Bayesian surrogate-assisted evolutionary algorithm to address expensive multi-objective optimization problems, where the hyperparameters of the acquisition function are dynamically tuned to select candidate solutions for real function evaluations, thereby reducing the computational cost of evaluations.
- CMOEAD ensures the diversity of solutions by performing niching operations on individuals within the population. Through the adaptive updating of reference points, the CMOEAD algorithm can simultaneously search for multiple Pareto-optimal points in a single run to achieve efficient exploration.
- NSGA-II improves computational efficiency by utilizing fast non-dominated sorting and an enhanced dominance mechanism. Owing to its selection operator, which constructs the mating pool based on fitness and distribution characteristics, the algorithm achieves well-distributed solution sets across most optimization problems while demonstrating superior convergence performance near the true Pareto-optimal front in practical scenarios.
4.1.1. The Computational Complexity of SA-MPCMOEA
When using the Kriging model, the time complexity of the algorithm is mainly determined by the surrogate model training. The model training of Kriging requires the calculation of the inverse of the covariance matrix, and the time complexity is , where N is the population size. The independent modeling of each objective function increases the total training cost to (M is the dimension of the objective function). In each iteration, the surrogate prediction of the offspring individuals requires time (traversing M models, and the single prediction complexity of each model is ). The overall complexity is , where T is the number of iterations. As shown in Table 1, SA-MPCMOEA is compared with other algorithms on CF test problems and LIRCMOP test problems, respectively. Using 1000 evaluations, each algorithm is independently run once.

Table 1.
Runtime comparison.
4.1.2. Result on CF Test Suit
The comparative results of SA-MPCMOEA and other algorithms on the CF test problems [32] are presented in Table 2.
Table 2.
Performance comparison of different algorithms on CF problems.
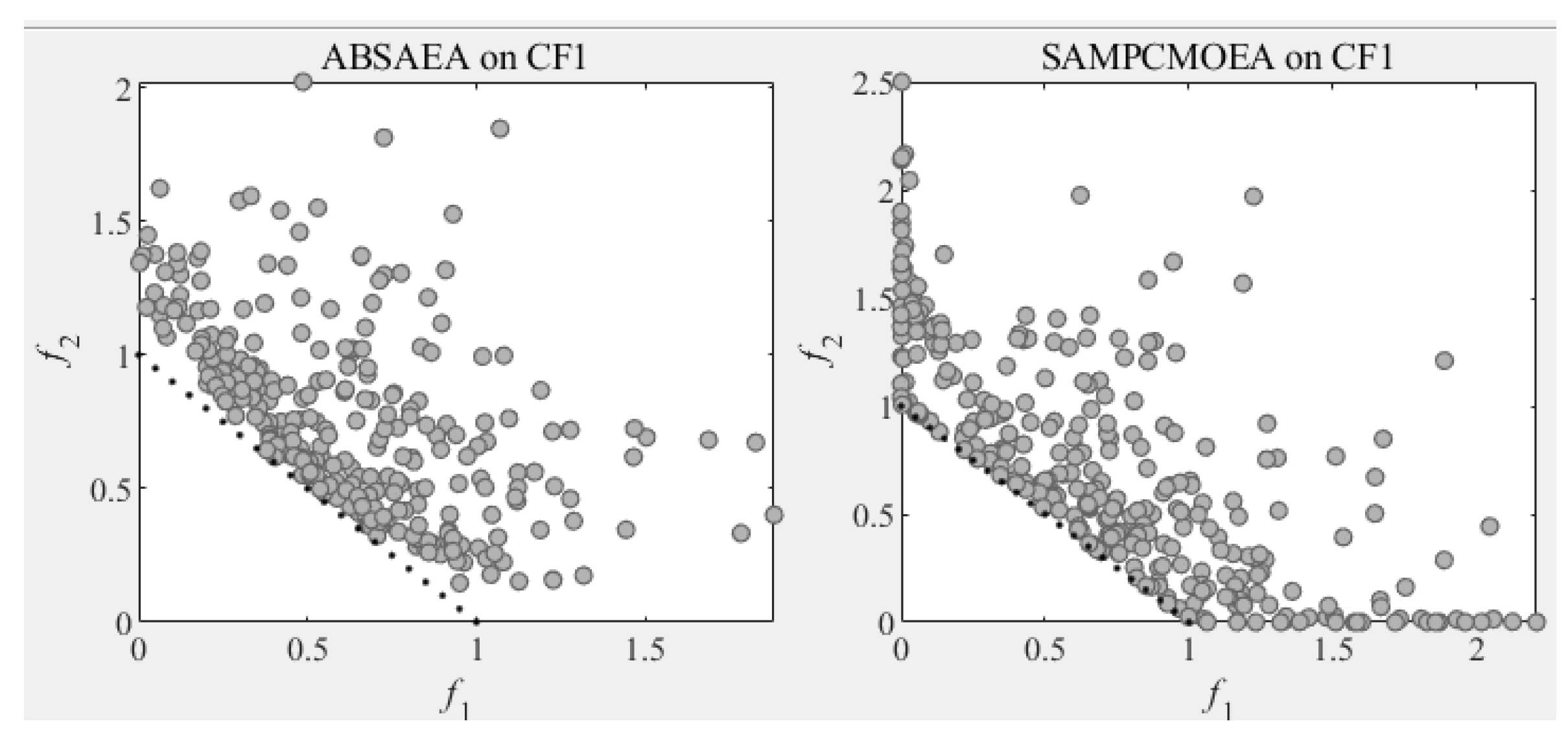
As shown in Table 2, the SA-MPCMOEA algorithm demonstrates a significant advantage across the CF benchmark problems. Among all compared algorithms, SA-MPCMOEA is only outperformed by ABSAEA on three problems (CF1, CF3, and CF10) in terms of IGD values because the feasible region of the problem is relatively large in CF1, CF3, and CF10. SA-MPCMOEA starts to focus on the diversity of the population after finding a sufficient number of feasible solutions, as shown in Figure 3, while maintaining superiority or equivalent performance on the remaining seven problems. Notably, SA-MPCMOEA exhibits exceptional performance on complex constrained problems (CF2, CF4, CF6, and CF7), particularly in the equality-constrained problem CF7, where it achieves the best results, highlighting its robust constraint-handling capability. In high-dimensional problems (CF8, CF9, and CF10), the infeasible regions disrupt the feasible domains, leading to the inferior performance of other algorithms compared to SA-MPCMOEA and ABSAEA. Benefiting from the angle-based convergence model for feasible domains, SA-MPCMOEA efficiently traverses complex and vast search spaces, rapidly crossing infeasible regions to locate feasible solutions.
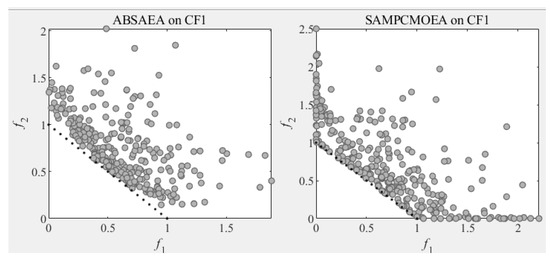
Figure 3.
The distribution of solutions by SA-MPCMOEA and ABSAEA in the CF1 problem.
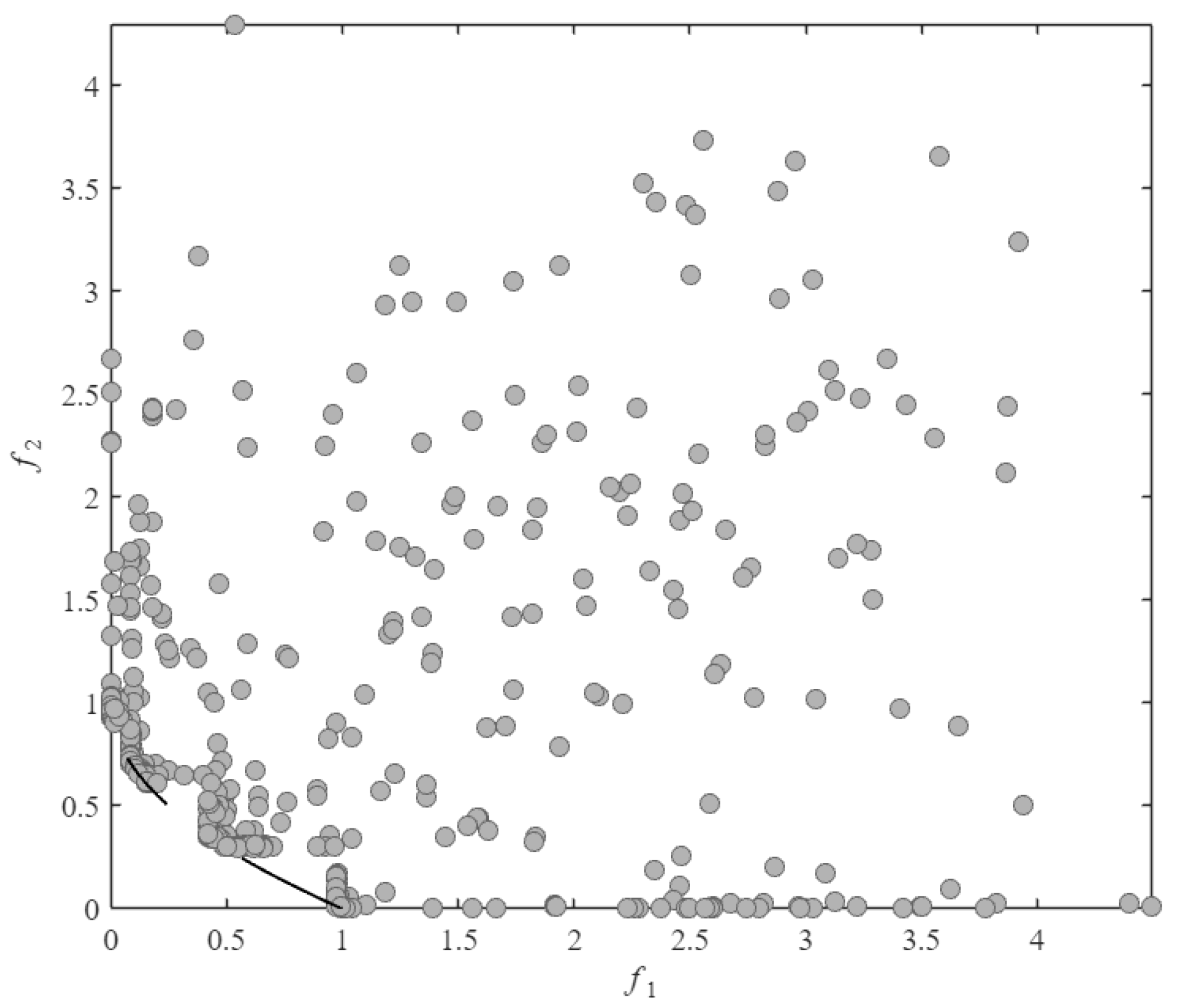
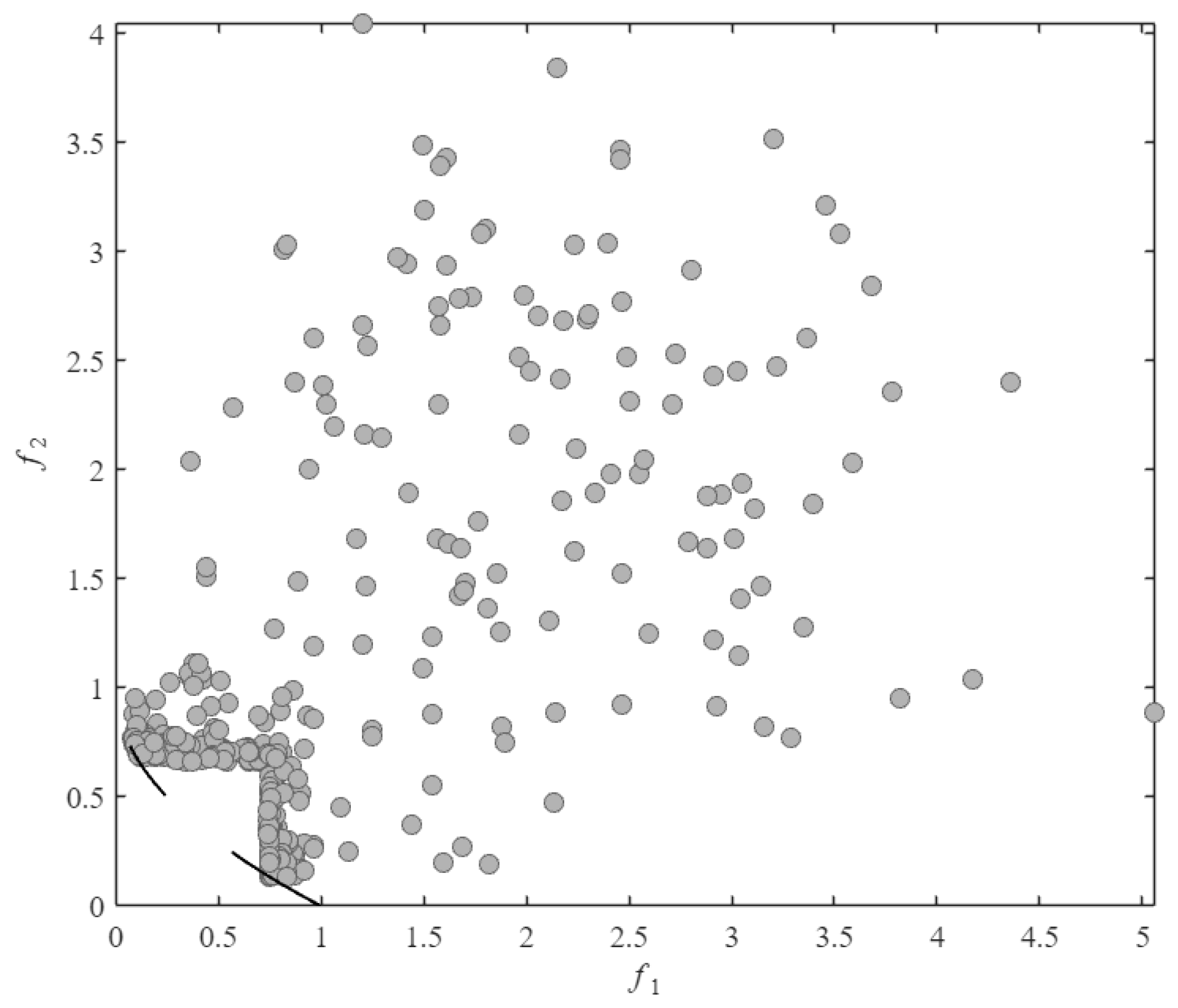
As observed in Figure 4 and Figure 5, SA-MPCMOEA effectively prevents population convergence toward CPF gap regions through its constraint-dominated exploration mechanism when handling problems with a discontinuous constrained Pareto front. Compared to ABSAEA, SA-MPCMOEA achieves more uniform distribution along the CPF, demonstrating superior diversity preservation capabilities in maintaining solution spread.
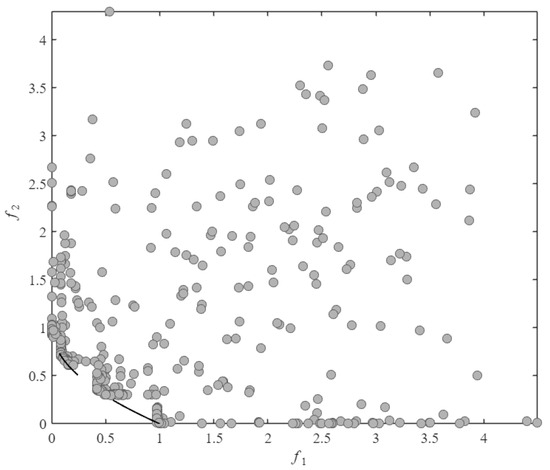
Figure 4.
The distribution of all solutions evaluated via real-function assessments by SA-MPCMOEA in the CF2 problem.
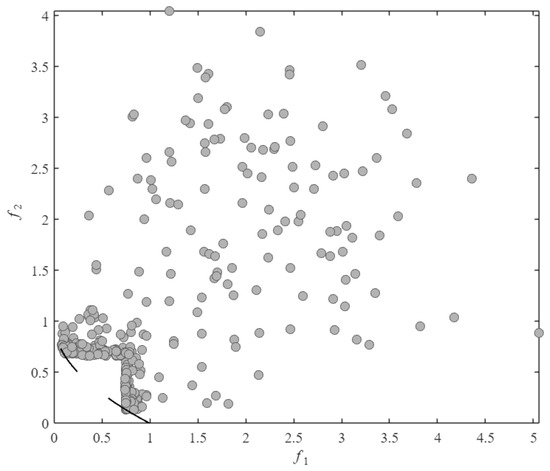
Figure 5.
The distribution of all solutions evaluated via real-function assessments by ABSAEA in the CF2 problem.
4.1.3. Result on LIRCMOP Test Suit
The comparative results of SA-MPCMOEA and other algorithms on the LIRCMOP [33] high-dimensional complex constrained multi-objective optimization problems are summarized in Table 3. As shown in LIRCMOP1–LIRCMOP4, where feasible regions are extremely limited, all compared algorithms fail to converge due to their inability to traverse infeasible regions before exhausting computational resources. In contrast, SA-MPCMOEA successfully obtains feasible solutions by leveraging its dynamic assessment strategy, which enables the surrogate model to efficiently screen candidate solutions and prioritize promising regions, thereby minimizing unnecessary real function evaluations and validating the robustness of its constraint-handling mechanism in extreme scenarios. For more complex problems (LIRCMOP5–LIRCMOP12), SA-MPCMOEA significantly outperforms conventional algorithms in most cases, although it slightly underperforms RVEAa on LIRCMOP5 and LIRCMOP6. These results highlight SA-MPCMOEA’s superior search efficiency in high-dimensional discontinuous feasible domains, particularly in balancing exploration–exploitation trade-offs under severe constraint conflicts.
Table 3.
Performance comparison of different algorithms on LIRCMOP problems.
4.1.4. Ablation Experiments
To verify the proposed methods in SA-MPCMOEA, this paper conducted ablation experiments for verification. The verification methods were divided into four algorithms: the SA-MPCMMOEA algorithm proposed in this paper; SA-MPCMOEA/MP without multi-preference modeling; SA-MPCMOEA/MP, which uses tournament selection [34] to generate offsprings; SA-MPCMOEA/FS without fill sampling strategy, which uses non-dominated sorting to select non-dominated candidate solutions for real function evaluation; SA-MPCMOEA/DA without dynamic assessment strategy, which uses a fixed of 20.
The four methods were run ten times independently on the CF test suit using the same random seeds. As shown in Table 4, among the 24 problems, SA-MPCMOEA achieved the optimal value or a value close to the optimal value.
Table 4.
Albation experiments.
In the experiments, SA-MPCMOEA/MP performed the worst because the control of search direction in ECMOPs has an important impact on the algorithm’s performance, generating offspring without considering the current evolutionary needs of the population, which leads to a waste of computational resources.
In the experiments, the performance of SA-MPCMOEA is better than that of SA-MPCMOEA/FS in 18 problems and is similar in 6 problems. The fill sampling strategy is responsible for selecting candidate solutions for real function evaluation. A good fill sampling strategy needs to select candidate solutions that can optimize the surrogate model and guide the population search. The fill sampling strategy based on optimization requirements effectively selects solutions with the greatest potential for evaluation, avoiding the population from getting trapped in local optima.
In the experiments, SA-MPCMOEA outperformed SA-MPCMOEA/DA in 16 problems, and the performance was similar in 6 problems. In surrogate-assisted evolutionary algorithms, a larger number of surrogate model evaluations means generating more candidate solutions to explore the decision space. However, as the number of surrogate model evaluations increases, the error of the approximate objective values obtained by evaluating the newly generated candidate solutions through the surrogate model also increases, which may mislead the population to evolve in the wrong direction.
4.1.5. Parameter Sensitivity Analysis Experiments
There are three parameters in SA-MPCMOEA: the threshold adjustment parameter (), the threshold number of feasible solutions in Populations P and A (k), and the scaling factor (). Different parameter values may affect the performance of SA-MPCMOEA. Therefore, we conduct experiments in the CF test suit to analyze the parameter sensitivity of SA-MPCMOEA.
In order to test the impact of different values on the algorithm performance, we set to 0.2, 0.25, 0.3, 0.35, and 0.4 respectively, with k = 30 and = 20.
As shown in Table 5, the performance is best when = 0.25, and the worst when = 0.4. This may be because, when = 0.4, the algorithm uses too many computational resources to meet the convergence condition, causing the algorithm to be prone to getting trapped in local optima.
Table 5.
Parameter analysis of .
After that, we adjust k to verify the influence of the threshold of the number of feasible solutions in the population. k is set to 10, 20, 30, 40, and 50, respectively, with = 0.25 and = 20. It can be seen in Table 6 that different k values will have an impact on the performance of SA-MPCMOEA. This may be because, when the feasible solution threshold k is too large, the algorithm fails to enter search mode 3 to explore the feasible region.
Table 6.
Parameter analysis of k.
Finally, we analyze the influence of the value of the scaling factor on the SA-MPCMOEA; we set to 10, 15, 20, 25, 30 respectively, with = 0.25 and k = 20. The value of controls the maximum number of evaluations that the surrogate model can use and affects the number of offspring solutions generated. As can be seen from Table 7, the effect is best when the value of is 20. This may be because, at this time, the algorithm can generate as many offspring solutions as possible under the condition of a relatively high surrogate model accuracy. When = 30, the performance of the algorithm begins to decline. This may be because the algorithm generates offspring solutions when the surrogate model has poor accuracy, which misleads the filling sampling strategy.
Table 7.
Parameter analysis of .
4.1.6. IGD Value Convergence Experiment
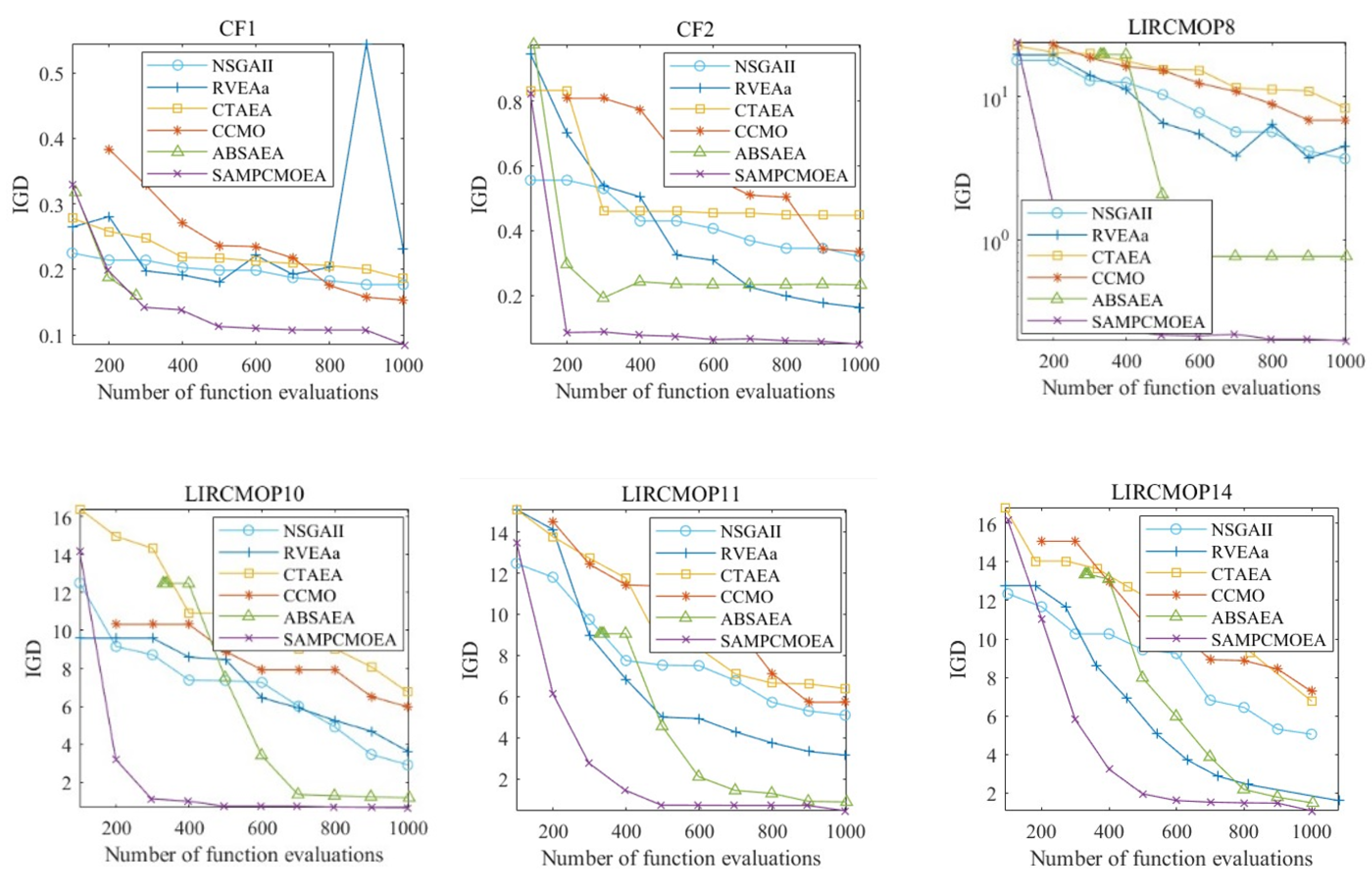
In order to demonstrate the convergence curves of the SA-MPCMOEA algorithm compared to other algorithms in terms of the IGD value, we conducted a convergence analysis in CF1, CF2, LIRCMOP8, LIRCMOP10, LIRCMOP11, and LIRCMOP14, respectively. For each test problem, we selected 6 values from 1000 function evaluations to show the convergence variation of the algorithm.
As can be seen in Figure 6, SA-MPCMOEA converges faster than other algorithms when in search mode 1, which demonstrates the effectiveness of the angle-based convergence model. This is mainly because, given limited computational resources, there are fewer individuals available to explore the feasible region. If the algorithm cannot converge quickly to reduce the search range, the population will spend some computational resources on ineffective exploration.
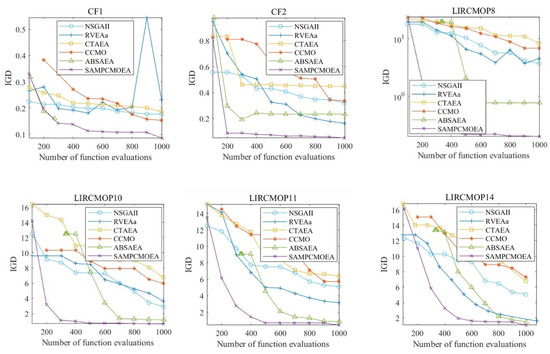
Figure 6.
IGD value convergence.
4.1.7. Real-World Case Study
In order to verify the ability of SA-MPCMOEA to solve practical application problems, we conduct verification respectively in RW1 (Pressure Vessel Design), RW2 (Simply Supported I-beam Design), RW3 (Cantilever Beam Design), RW4 (Crash Energy Management for High-speed Trains), and RW5 (Water Resources Management). The mathematical expressions of these five engineering design problems can be found in [35]. In each problem, it is necessary to find the minimum value of different objective functions.
From Table 8, it can be seen that SA-MPCMOEA has achieved the optimal solution or near-optimal solution in all practical engineering problems, demonstrating its applicability in solving practical engineering problems.
Table 8.
Performance comparison on RWMOP benchmark problems.
5. Conclusions
This paper proposes SA-MPCMOEA, a Kriging-assisted evolutionary algorithm based on a multi-preference model designed to address expensive, constrained multi-objective optimization problems. SA-MPCMOEA dynamically determines subsequent optimization operations by analyzing the current population distribution state. In Mode 1, the algorithm employs an angle-based convergence strategy to rapidly guide the population toward feasible regions using angular distribution information, thereby reducing computational resource waste. Mode 2 enhances convergence performance by driving the main population P and auxiliary population A to approximate the constrained Pareto front and the unconstrained Pareto front, respectively, achieving preference decoupling between objective functions and constraints. Under Mode 3, while maintaining the constraint compliance of population P, the auxiliary population A strengthens exploration capabilities in underdeveloped regions through constraint-free search mechanisms guided by diversity and convergence metrics coupled with hybrid update strategies. Additionally, the dynamic evaluation strategy and novel filling sampling criterion enable effective screening of high-quality candidate solutions, allowing the algorithm to allocate expensive evaluation resources to truly promising individuals. Collectively, SA-MPCMOEA achieves a balanced optimization between objective pursuit and constraint satisfaction in computationally expensive scenarios. The code for SA-MPCMOEA can be found at https://github.com/AMA123-sx/AMA (accessed on 28 March 2025).
Author Contributions
Conceptualization, Y.S.; data curation, Y.M.; resources, Y.S.; software, Y.S.; validation, Y.S. and Y.M.; visualization, Y.M.; writing—original draft, Y.M.; project administration, B.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China OF FUNDER grant number 61763002 and 62072124, Guangxi Major projects of science and technology OF FUNDER grant number 2020AA21077021, and the Foundation of Guangxi Experiment Center of Information Science OF FUNDER grant number KF1401.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all participants involved in the study.
Data Availability Statement
The data presented in this study are openly available in PlatEMO at [10.1109/MCI.2017.2742868], reference number [25].
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Habib, A.; Singh, H.K.; Chugh, T.; Ray, T.; Miettinen, K. A multiple surrogate assisted decomposition-based evolutionary algorithm for expensive multi/many-objective optimization. IEEE Trans. Evol. Comput. 2019, 23, 1000–1014. [Google Scholar] [CrossRef]
- Jie, H.; Shi, H.; Ding, J.; Wu, Y.; Yin, Q. A Metamodel-Based Global Algorithm for Mixed-Integer Nonlinear Optimization and the Application in Fuel Cell Vehicle Design. Comput. Model. Eng. Sci. 2015, 108, 193–214. [Google Scholar]
- Pandita, P.; Tsilifis, P.; Awalgaonkar, N.M.; Bilionis, I.; Panchal, J. Surrogate-Based Sequential Bayesian Experimental Design Using Non-Stationary Gaussian Processes. Comput. Methods Appl. Mech. Eng. 2021, 385, 114007. [Google Scholar] [CrossRef]
- Hebbal, A.; Brevault, L.; Balesdent, M.; Talbi, E.G.; Melab, N. Bayesian Optimization Using Deep Gaussian Processes with Applications to Aerospace System Design. Optim. Eng. 2021, 22, 321–361. [Google Scholar] [CrossRef]
- Ming, F.; Gong, W.; Jin, Y. Even Search in a Promising Region for Constrained Multi-Objective Optimization. IEEE/CAA J. Autom. Sin. 2024, 11, 474–486. [Google Scholar] [CrossRef]
- Liu, Q.; Cheng, R.; Jin, Y.; Heiderich, M.; Rodemann, T. Reference Vector-Assisted Adaptive Model Management for Surrogate-Assisted Many-Objective Optimization. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 7760–7773. [Google Scholar] [CrossRef]
- Hao, H.; Zhang, X.; Zhou, A. Enhancing SAEAs with unevaluated solutions: A case study of relation model for expensive optimization. Sci. China Inf. Sci. 2024, 67, 120103. [Google Scholar] [CrossRef]
- Pan, L.; He, C.; Tian, Y.; Wang, H.; Zhang, X.; Jin, Y. A Classification-Based Surrogate-Assisted Evolutionary Algorithm for Expensive Many-Objective Optimization. IEEE Trans. Evol. Comput. 2019, 23, 74–88. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory (COLT’92), Pittsburgh, PA, USA, 27–29 July 1992; Association for Computing Machinery: New York, NY, USA, 1992; pp. 144–152. [Google Scholar] [CrossRef]
- Broomhead, D.S.; Lowe, D. Multivariable functional interpolation and adaptive networks. Complex Syst. 1988, 2, 321–355. [Google Scholar]
- Krige, D.G. A statistical approach to some basic mine valuation problems on the Witwatersrand. J. S. Afr. Inst. Min. Metall. 1951, 52, 201–203. [Google Scholar]
- Zhao, H.; Yue, Z.; Liu, Y.; Gao, Z.; Zhang, Y. An efficient reliability method combining adaptive importance sampling and Kriging metamodel. Appl. Math. Model. 2015, 39, 1853–1866. [Google Scholar] [CrossRef]
- Jiang, P.; Zhang, Y.; Zhou, Q.; Shao, X.; Hu, J.; Shu, L. An adaptive sampling strategy for Kriging metamodel based on Delaunay triangulation and TOPSIS. Appl. Intell. 2018, 48, 1644–1656. [Google Scholar] [CrossRef]
- Fuhg, J.N.; Fau, A.; Nackenhorst, U. State-of-the-Art and Comparative Review of Adaptive Sampling Methods for Kriging. Arch. Comput. Methods Eng. 2021, 28, 2689–2747. [Google Scholar] [CrossRef]
- Song, Z.; Wang, H.; Jin, Y. A Surrogate-Assisted Evolutionary Framework with Regions of Interests-Based Data Selection for Expensive Constrained Optimization. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 6268–6280. [Google Scholar] [CrossRef]
- Song, Z.; Wang, H.; He, C.; Jin, Y. A Kriging-Assisted Two-Archive Evolutionary Algorithm for Expensive Many-Objective Optimization. IEEE Trans. Evol. Comput. 2021, 25, 1013–1027. [Google Scholar] [CrossRef]
- Chugh, T.; Jin, Y.; Miettinen, K.; Hakanen, J.; Sindhya, K. A Surrogate-Assisted Reference Vector Guided Evolutionary Algorithm for Computationally Expensive Many-Objective Optimization. IEEE Trans. Evol. Comput. 2018, 22, 129–142. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, W.; Tsang, E.; Virginas, B. Expensive Multiobjective Optimization by MOEA/D with Gaussian Process Model. IEEE Trans. Evol. Comput. 2010, 14, 456–474. [Google Scholar] [CrossRef]
- Wang, H.; Sun, C.; Xie, G.; Gao, X.Z.; Akhtar, F. A performance approximation assisted expensive many-objective evolutionary algorithm. Inf. Sci. 2023, 625, 20–35. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, J.; Jin, Y.; Li, F.; Zheng, T. A Surrogate-Assisted Two-Stage Differential Evolution for Expensive Constrained Optimization. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 715–730. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, H.; Tian, Y.; Ma, H.; Zhang, X. Multigranularity Surrogate Modeling for Evolutionary Multiobjective Optimization with Expensive Constraints. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 2956–2968. [Google Scholar] [CrossRef]
- Song, Z.; Wang, H.; Xue, B.; Zhang, M.; Jin, Y. Balancing Objective Optimization and Constraint Satisfaction in Expensive Constrained Evolutionary Multi-Objective Optimization. IEEE Trans. Evol. Comput. 2023, 28, 1286–1300. [Google Scholar] [CrossRef]
- Feng, X.; Ren, Z.; Pan, A.; Hong, J.; Tong, Y. A multi-preference-based constrained multi-objective optimization algorithm. Swarm Evol. Comput. 2023, 83, 101389. [Google Scholar] [CrossRef]
- Li, W.; Mai, R.; Ren, P.; Wang, Z.; Zhang, Q.; Xu, N.; Xu, B.; Fan, Z.; Hao, Z. A Surrogate-Ensemble Assisted Coevolutionary Algorithm for Expensive Constrained Multi-Objective Optimization Problems. In Proceedings of the 2023 IEEE Congress on Evolutionary Computation (CEC), Chicago, IL, USA, 1–5 July 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Wei, S.; Chen, Y.; Ding, H.; Chen, L. An improved interval model updating method via adaptive Kriging models. Appl. Math. Mech. (Engl. Ed.) 2024, 45, 497–514. [Google Scholar] [CrossRef]
- Huang, S.; Zhong, J.; Yu, W.-J. Surrogate-Assisted Evolutionary Framework with Adaptive Knowledge Transfer for Multi-Task Optimization. IEEE Trans. Emerg. Top. Comput. 2021, 9, 1930–1944. [Google Scholar] [CrossRef]
- Wang, Y.; Yin, D.Q.; Yang, S.; Sun, G. Global and Local Surrogate-Assisted Differential Evolution for Expensive Constrained Optimization Problems with Inequality Constraints. IEEE Trans. Cybern. 2019, 49, 142–149. [Google Scholar] [CrossRef]
- Jin, Y.; Wang, H.; Chugh, T.; Guo, D.; Miettinen, K. Data-Driven Evolutionary Optimization: An Overview and Case Studies. IEEE Trans. Evol. Comput. 2019, 23, 442–458. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhou, A.; Zhao, S. Multiobjective Optimization Test Instances for the CEC 2009 Special Session and Competition; Nanyang Technological University: Singapore, January 2008; Available online: https://www.al-roomi.org/multimedia/CEC_Database/CEC2009/MultiObjectiveEA/CEC2009_MultiObjectiveEA_TechnicalReport.pdf (accessed on 24 April 2025).
- Cheng, R.; Jin, Y.; Olhofer, M.; Sendhoff, B. A Reference Vector Guided Evolutionary Algorithm for Many-Objective Optimization. IEEE Trans. Evol. Comput. 2016, 20, 773–791. [Google Scholar] [CrossRef]
- Tian, Y.; Cheng, R.; Zhang, X.; Jin, Y. PlatEMO: A MATLAB platform for evolutionary multi-objective optimization [Educational Forum]. IEEE Comput. Intell. Mag. 2017, 12, 73–87. [Google Scholar] [CrossRef]
- Li, K.; Chen, R.; Fu, G.; Yao, X. Two-Archive Evolutionary Algorithm for Constrained Multiobjective Optimization. IEEE Trans. Evol. Comput. 2019, 23, 303–315. [Google Scholar] [CrossRef]
- Fan, Z.; Li, W.; Cai, X.; Huang, H.; Fang, Y.; You, Y.; Mo, J.; Wei, C.; Goodman, E. An improved epsilon constraint-handling method in MOEA/D for CMOPs with large infeasible regions. Soft Comput. 2019, 23, 12491–12510. [Google Scholar] [CrossRef]
- Fang, Y.; Li, J. A review of tournament selection in genetic programming. In Proceedings of the International Symposium on Intelligence Computation and Applications, Wuhan, China, 22–24 October 2010; pp. 181–192. [Google Scholar]
- Kumar, A.; Wu, G.; Ali, M.Z.; Luo, Q.; Mallipeddi, R.; Suganthan, P.N.; Das, S. A benchmark-suite of real-world constrained multi-objective optimization problems and some baseline results. Swarm Evol. Comput. 2021, 67, 100961. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).