

Multi-Grained Temporal Clip Transformer for Skeleton-Based Human Activity Recognition


Abstract
1. Introduction
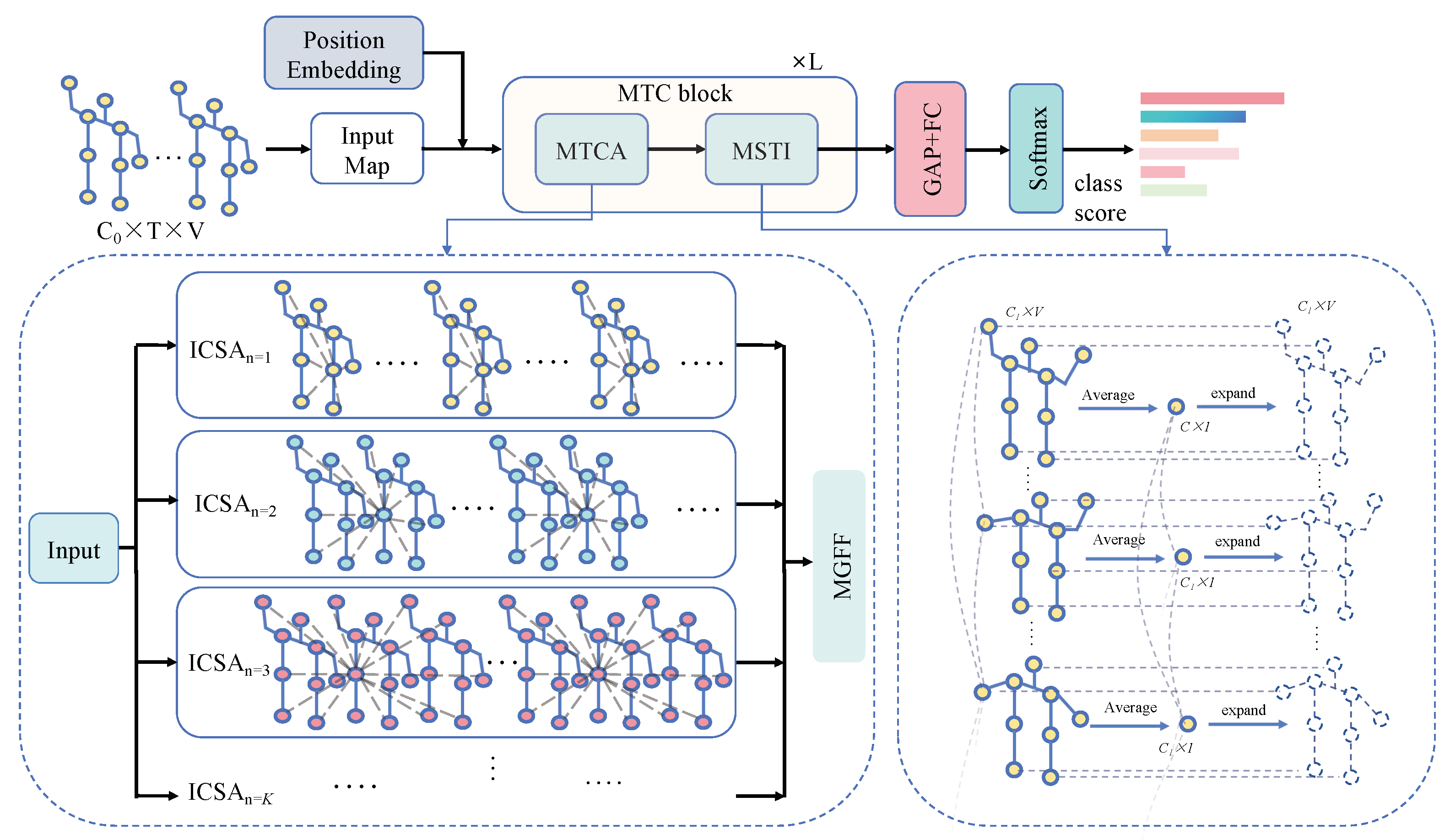
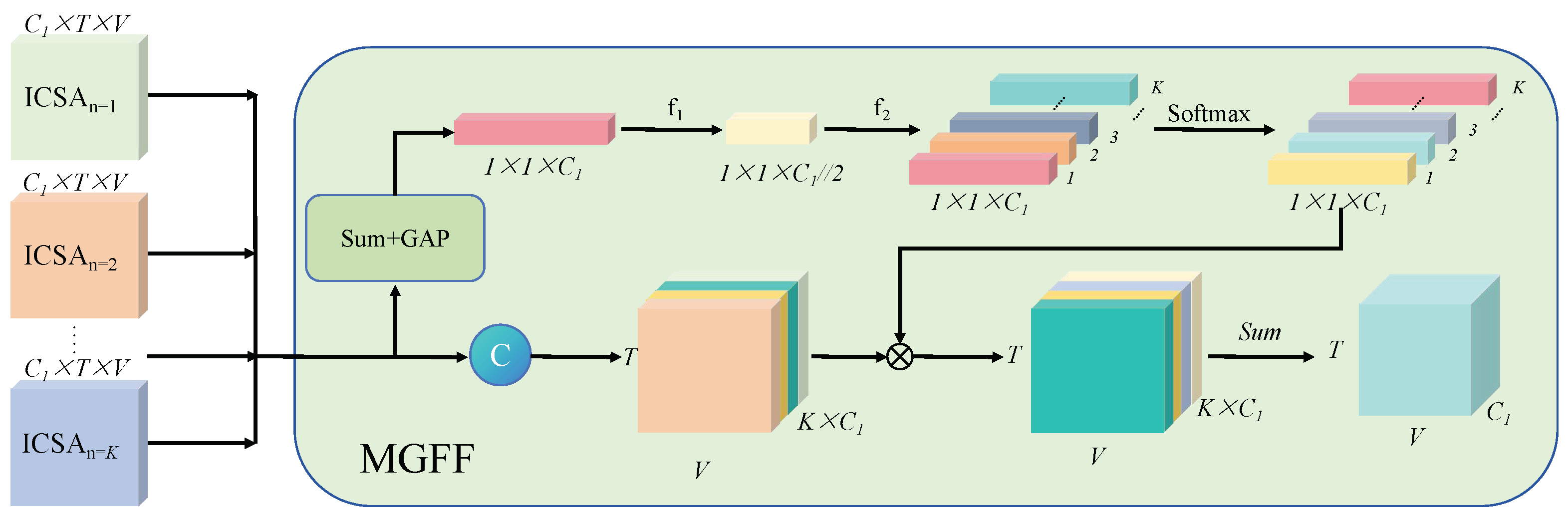
- A multi-grained temporal clip attention (MTCA) module is proposed to capture multi-granularity short-term action clip features. This module consists of several intra-clip self-attention (ICSA) modules and a multi-grained feature fusion (MGFF) module for multi-granularity feature extraction and fusion, respectively.
- Additionally, a multi-scale spatial–temporal feature interaction (MSTI) module is proposed to effectively capture long-term correlations between short action clips and enhance spatial information interaction between human skeleton joints.
- Extensive experiments were conducted on two large-scale datasets and an industrial scenario dataset, demonstrating the effectiveness and strong generalization of our method.
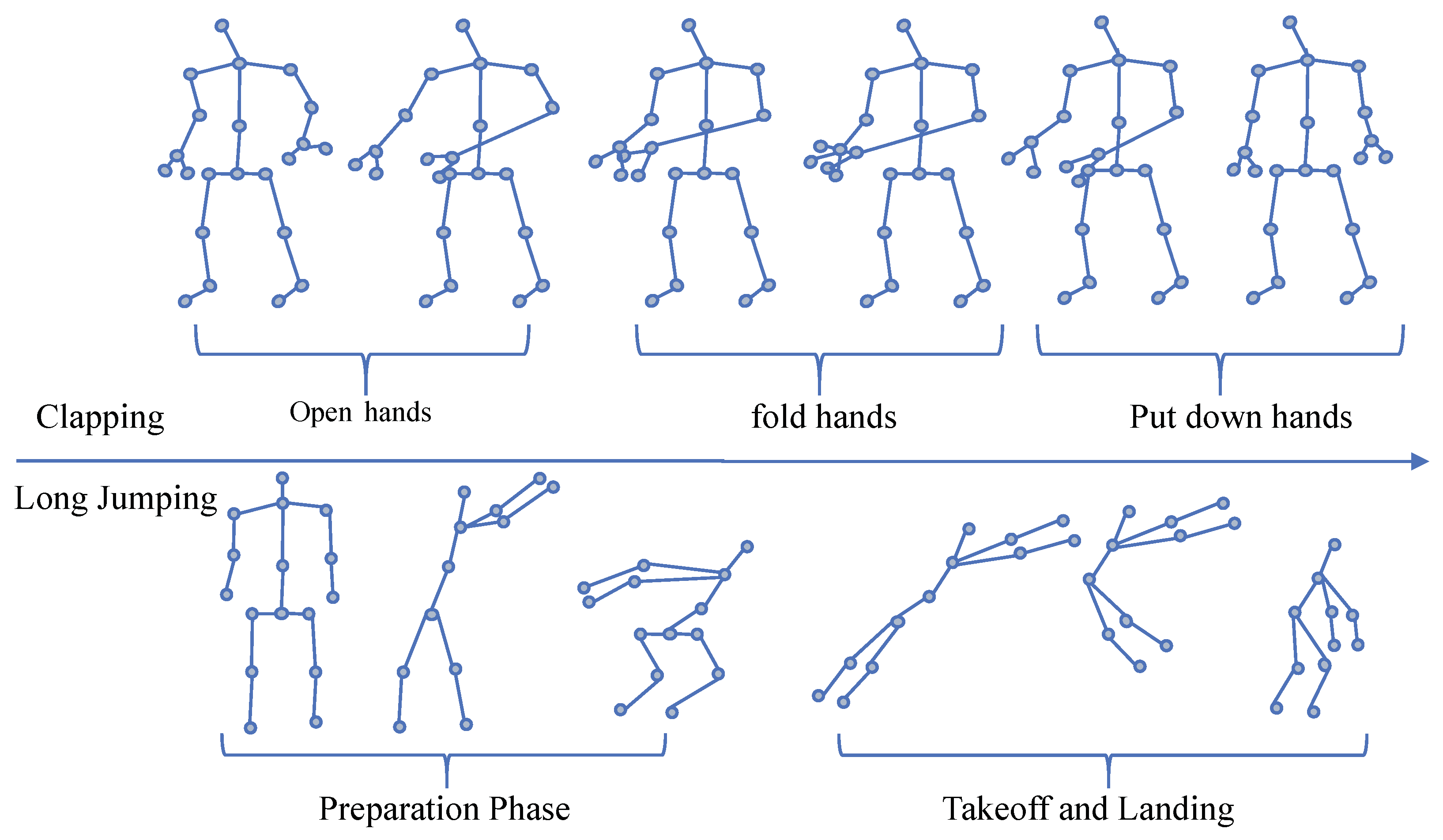
2. Related Works
2.1. Skeleton-Based Activity Recognition
2.2. Transformer for Skeleton-Based Activity Recognition
3. Method
3.1. Position Embedding
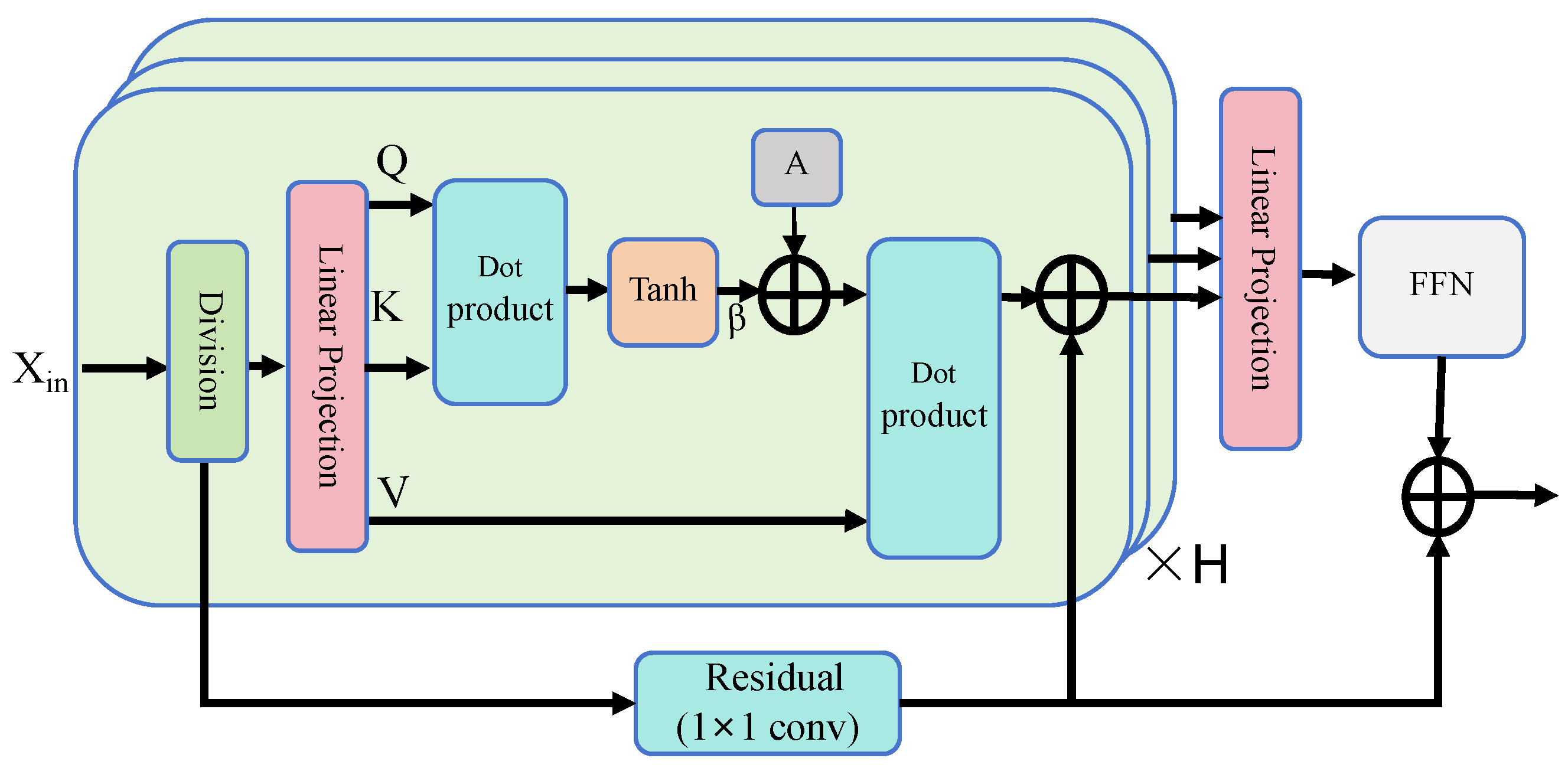
3.2. Intra-Clip Self-Attention
3.3. Multi-Grained Temporal Clip Attention Module
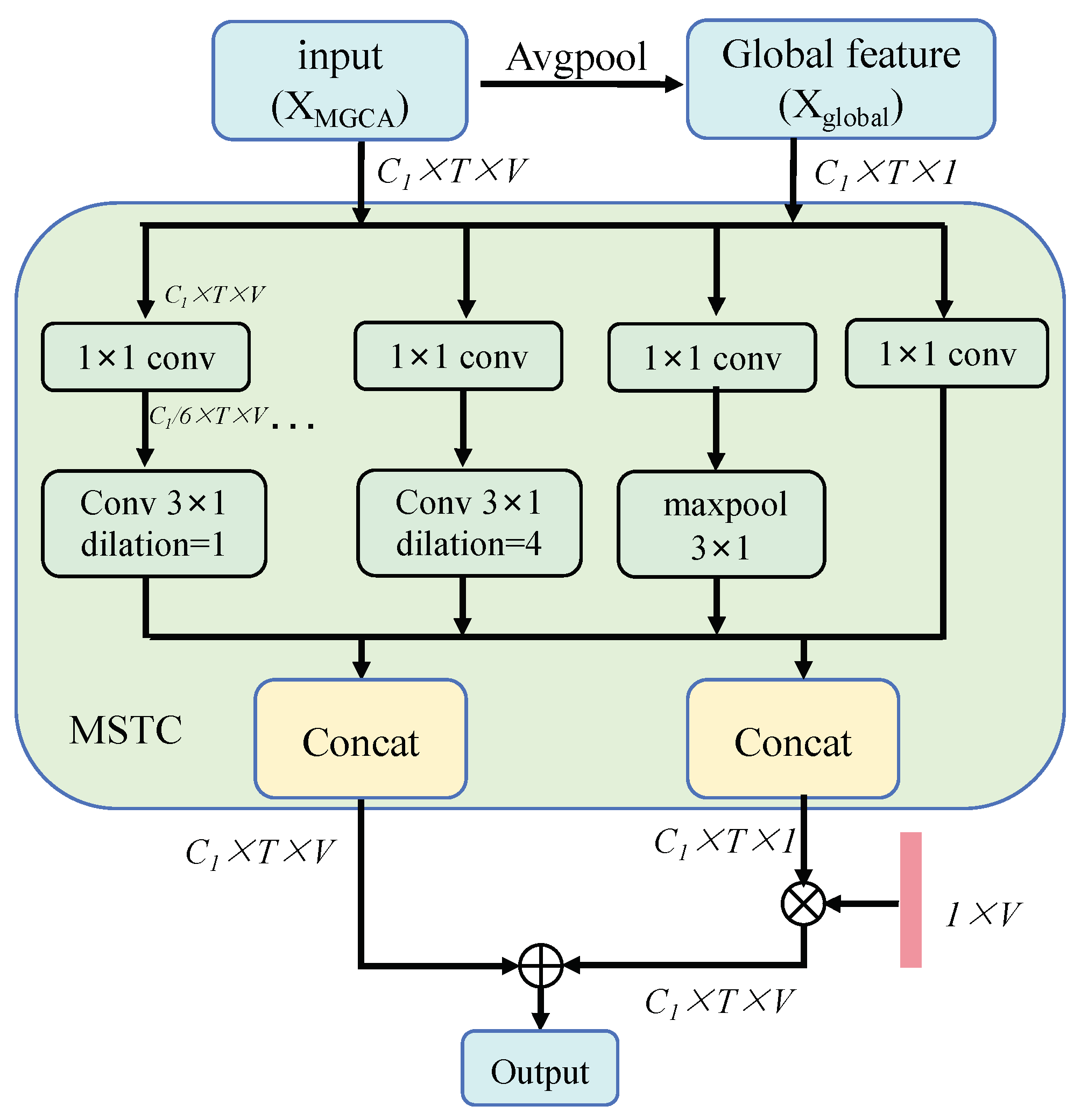
3.4. Multi-Scale Spatial–Temporal Feature Interaction (MSTI)
4. Experiments
4.1. Datasets
4.2. Experimental Setting
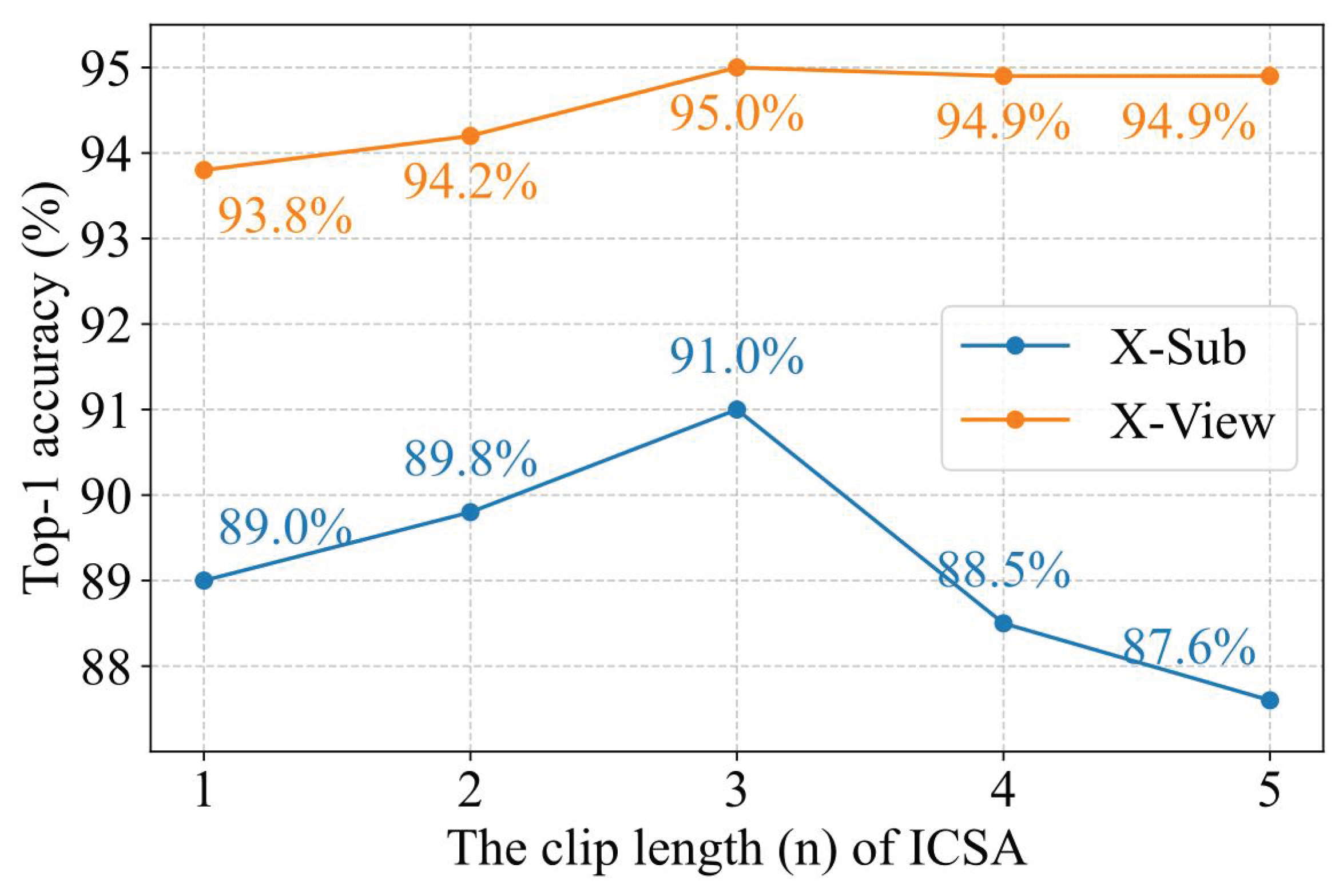
The Impact of Hyperparameters
4.3. Ablation Studies
4.3.1. Ablation Study of ICSA
4.3.2. Ablation Study of MSTI Module
4.3.3. Ablation Study of Fusion Strategy
4.3.4. Ablation Study of Multimodal Data
4.3.5. Per Class Accuracy
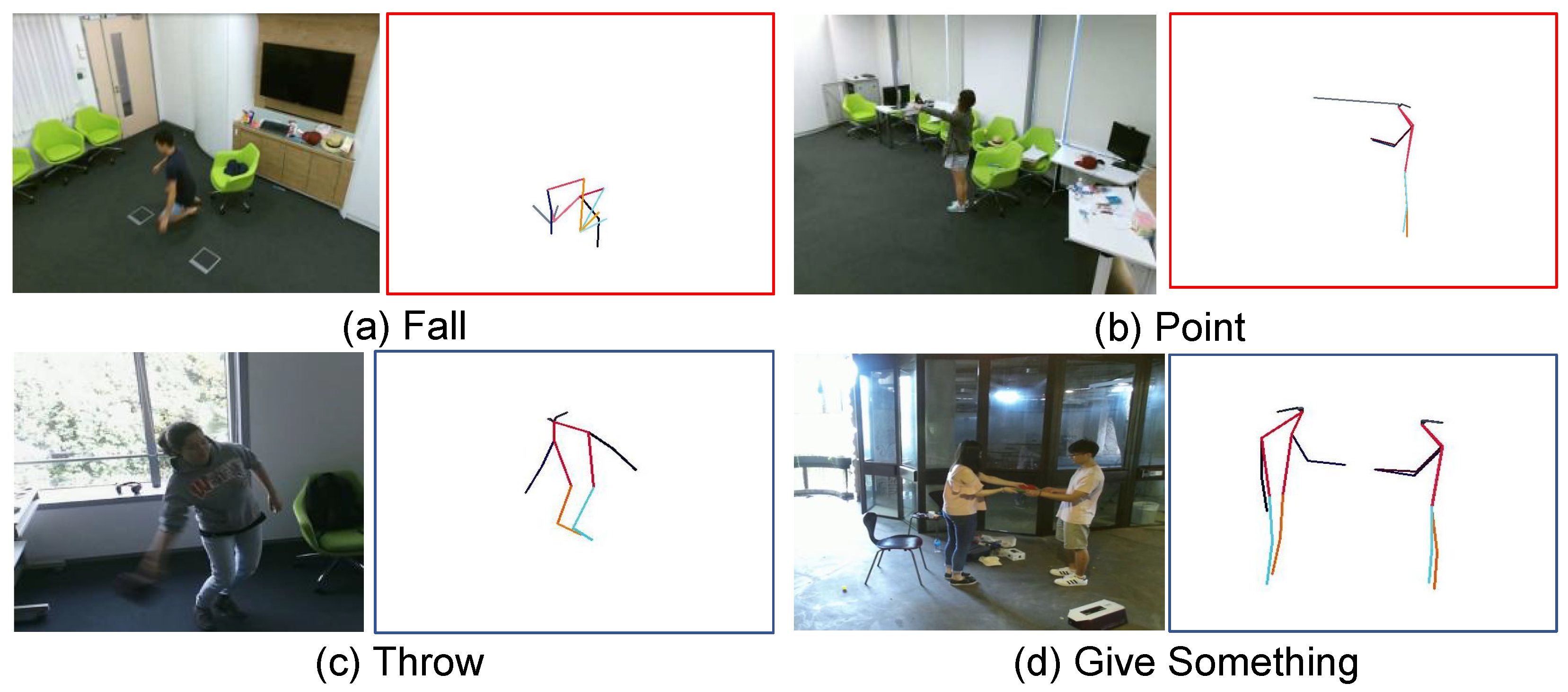
4.3.6. Visualizations
4.4. Comparison with State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sharma, R.; Sungheetha, A. An efficient dimension reduction based fusion of CNN and SVM model for detection of abnormal incident in video surveillance. J. Soft Comput. Paradig. (JSCP) 2021, 3, 55–69. [Google Scholar] [CrossRef]
- Li, S.; Zheng, P.; Fan, J.; Wang, L. Toward proactive human—Robot collaborative assembly: A multimodal transfer-learning-enabled action prediction approach. IEEE Trans. Ind. Electron. 2021, 69, 8579–8588. [Google Scholar] [CrossRef]
- Sumi, M. Simulation of artificial intelligence robots in dance action recognition and interaction process based on machine vision. Entertain. Comput. 2025, 52, 100773. [Google Scholar] [CrossRef]
- Pazhooman, H.; Alamri, M.S.; Pomeroy, R.L.; Cobb, S.C. Foot kinematics in runners with plantar heel pain during running gait. Gait Posture 2023, 104, 15–21. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Ke, Q.; Rahmani, H.; Bennamoun, M.; Wang, G.; Liu, J. Human action recognition from various data modalities: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3200–3225. [Google Scholar] [CrossRef]
- Zhang, J.; Li, W.; Ogunbona, P.O.; Wang, P.; Tang, C. RGB-D-based action recognition datasets: A survey. Pattern Recognit. 2016, 60, 86–105. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 143–152. [Google Scholar]
- Chen, Y.; Zhang, Z.; Yuan, C.; Li, B.; Deng, Y.; Hu, W. Channel-wise topology refinement graph convolution for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 13359–13368. [Google Scholar]
- Jang, S.; Lee, H.; Kim, W.J.; Lee, J.; Woo, S.; Lee, S. Multi-scale Structural Graph Convolutional Network for Skeleton-based Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 7244–7258. [Google Scholar] [CrossRef]
- Wu, Z.; Ding, Y.; Wan, L.; Li, T.; Nian, F. Local and global self-attention enhanced graph convolutional network for skeleton-based action recognition. Pattern Recognit. 2025, 159, 111106. [Google Scholar] [CrossRef]
- Lee, J.; Lee, M.; Lee, D.; Lee, S. Hierarchically decomposed graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 10444–10453. [Google Scholar]
- Plizzari, C.; Cannici, M.; Matteucci, M. Skeleton-based action recognition via spatial and temporal transformer networks. Comput. Vis. Image Underst. 2021, 208, 103219. [Google Scholar] [CrossRef]
- Wang, Q.; Shi, S.; He, J.; Peng, J.; Liu, T.; Weng, R. Iip-transformer: Intra-inter-part transformer for skeleton-based action recognition. In Proceedings of the 2023 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023; pp. 936–945. [Google Scholar]
- Qiu, H.; Hou, B.; Ren, B.; Zhang, X. Spatio-temporal segments attention for skeleton-based action recognition. Neurocomputing 2023, 518, 30–38. [Google Scholar] [CrossRef]
- Liu, H.; Liu, Y.; Chen, Y.; Yuan, C.; Li, B.; Hu, W. TranSkeleton: Hierarchical spatial-temporal transformer for skeleton-based action recognition. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4137–4148. [Google Scholar] [CrossRef]
- Cui, H.; Hayama, T. STSD: Spatial–temporal semantic decomposition transformer for skeleton-based action recognition. Multimed. Syst. 2024, 30, 43. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, Z.; Li, J.; Xie, X.; Chen, K.; Wang, X.; Shi, G. STDM-transformer: Space-time dual multi-scale transformer network for skeleton-based action recognition. Neurocomputing 2024, 563, 126903. [Google Scholar] [CrossRef]
- Liu, R.; Chen, Y.; Gai, F.; Liu, Y.; Miao, Q.; Wu, S. Local and Global Spatial-Temporal Transformer for skeleton-based action recognition. Neurocomputing 2025, 634, 129820. [Google Scholar] [CrossRef]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human action recognition by representing 3d skeletons as points in a lie group. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 588–595. [Google Scholar]
- Hou, Y.; Li, Z.; Wang, P.; Li, W. Skeleton optical spectra-based action recognition using convolutional neural networks. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 807–811. [Google Scholar] [CrossRef]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View adaptive recurrent neural networks for high performance human action recognition from skeleton data. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2117–2126. [Google Scholar]
- Zhu, W.; Lan, C.; Xing, J.; Zeng, W.; Li, Y.; Shen, L.; Xie, X. Co-occurrence feature learning for skeleton based action recognition using regularized deep LSTM networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Zhang, P.; Xue, J.; Lan, C.; Zeng, W.; Gao, Z.; Zheng, N. Adding attentiveness to the neurons in recurrent neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 135–151. [Google Scholar]
- Cai, D.; Kang, Y.; Yao, A.; Chen, Y. Ske2Grid: Skeleton-to-grid representation learning for action recognition. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 3431–3441. [Google Scholar]
- Liang, C.; Yang, J.; Du, R.; Hu, W.; Hou, N. Temporal-channel attention and convolution fusion for skeleton-based human action recognition. IEEE Access 2024, 12, 64937–64948. [Google Scholar] [CrossRef]
- Li, B.; Dai, Y.; Cheng, X.; Chen, H.; Lin, Y.; He, M. Skeleton based action recognition using translation-scale invariant image mapping and multi-scale deep CNN. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 601–604. [Google Scholar]
- Duan, H.; Wang, J.; Chen, K.; Lin, D. Dg-stgcn: Dynamic spatial-temporal modeling for skeleton-based action recognition. arXiv 2022, arXiv:2210.05895. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12026–12035. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1–11. [Google Scholar]
- Qiu, H.; Hou, B. Multi-grained clip focus for skeleton-based action recognition. Pattern Recognit. 2024, 148, 110188. [Google Scholar] [CrossRef]
- Lin, Z.; Gao, Y.; Li, D. Cross-Attention Multi-Scale Spatial Temporal Transformer for Skeleton-Based Action Recognition; Springer: Berlin/Heidelberg, Germany, 2023. [Google Scholar]
- Plizzari, C.; Cannici, M.; Matteucci, M. Spatial temporal transformer network for skeleton-based action recognition. In Proceedings of the Pattern Recognition. ICPR International Workshops and Challenges, Virtual Event, 10–15 January 2021; pp. 694–701. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Decoupled spatial-temporal attention network for skeleton-based action-gesture recognition. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Gao, Z.; Wang, P.; Lv, P.; Jiang, X.; Liu, Q.; Wang, P.; Xu, M.; Li, W. Focal and global spatial-temporal transformer for skeleton-based action recognition. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December 2022; pp. 382–398. [Google Scholar]
- Irani, H.; Metsis, V. Positional Encoding in Transformer-Based Time Series Models: A Survey. arXiv 2025, arXiv:2502.12370. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Davies, B. A review of “The Co-ordination and Regulation of Movements” By N. Bernstein. (Pergamon Press, 1967.) [Pp. xii+ 196.] 505. Ergonomics 1968, 11, 95–97. [Google Scholar] [CrossRef]
- Dallel, M.; Havard, V.; Baudry, D.; Savatier, X. InHARD—Industrial Human Action Recognition Dataset in the Context of Industrial Collaborative Robotics. In Proceedings of the 2020 IEEE International Conference on Human-Machine Systems (ICHMS), Rome, Italy, 7–9 September 2020; pp. 1–6. [Google Scholar]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. Learning clip representations for skeleton-based 3D action recognition. IEEE Trans. Image Process. 2018, 27, 2842–2855. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Ye, F.; Zhong, Q.; Xie, D. Topology-aware convolutional neural network for efficient skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 22 February–1 March 2022; Volume 36, pp. 2866–2874. [Google Scholar]
- Zhang, S.; Yin, J.; Dang, Y.; Fu, J. SiT-MLP: A simple MLP with point-wise topology feature learning for skeleton-based action recognition. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 8122–8134. [Google Scholar] [CrossRef]
- Zhou, H.; Liu, Q.; Wang, Y. Learning discriminative representations for skeleton based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 10608–10617. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3595–3603. [Google Scholar]
- Cheng, K.; Zhang, Y.; He, X.; Chen, W.; Cheng, J.; Lu, H. Skeleton-based action recognition with shift graph convolutional network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 183–192. [Google Scholar]
- Yin, X.; Zhong, J.; Lian, D.; Cao, W. Spatiotemporal progressive inward-outward aggregation network for skeleton-based action recognition. Pattern Recognit. 2024, 150, 110262. [Google Scholar] [CrossRef]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 20–36. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November; 2019; pp. 7083–7093. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding? In Proceedings of the ICML, Vienna, Austria, 18–24 July 2021; Volume 2, p. 4. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 3202–3211. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | X-Sub (%) | X-View (%) |
|---|---|---|
| MSTC-4 | 90.2 | 94.2 |
| MSTC-6 | 90.5 | 94.9 |
| MSTI-4 + fixed weight | 90.7 | 95.4 |
| MSTI-4 + dynamic weight | 90.8 | 95.4 |
| MSTI-6 + dynamic weight | 91.0 | 95.8 |
| Method | Fusion Strategy | X-Sub (%) | X-View (%) |
|---|---|---|---|
| Average | 90.8 | 95.6 | |
| Linear | 90.6 | 95.3 | |
| Dynamic Fusion | 91.0 | 95.8 |
| Methods | X-Sub (%) | X-View (%) |
|---|---|---|
| MTC-Former (joint) | 91.0 | 95.8 |
| MTC-Former (bone) | 91.2 | 95.2 |
| MTC-Former (joint motion) | 88.8 | 94.4 |
| MTC-Former (bone motion) | 88.3 | 92.9 |
| Fusion | 93.2 | 97.1 |
| Categories | Methods | Prams(M) | NTU RGB+D | NTU RGB+D 120 | ||
|---|---|---|---|---|---|---|
| X-Sub (%) | X-View (%) | X-Sub (%) | X-Set (%) | |||
| CNN | RotClips+MTCNN [43] | - | 81.1 | 87.4 | 62.2 | 61.8 |
| Ta-CNN+ [44] | 1.06 | 90.7 | 95.1 | 85.7 | 87.3 | |
| GCN | ST-GCN [10] | 3.1 | 81.5 | 88.3 | 70.7 | 73.2 |
| AS-GCN [47] | - | 86.8 | 94.2 | 78.3 | 79.8 | |
| 2s-AGCN [32] | 3.5 | 88.5 | 95.1 | 79.2 | 81.5 | |
| Shift-GCN [48] | 90.7 | 96.5 | 85.9 | 87.6 | ||
| MS-G3D [11] | 2.8 | 91.5 | 96.2 | 86.9 | 88.4 | |
| MSS-GCN [13] | - | 92.7 | 96.9 | 88.9 | 90.6 | |
| SPIA-Net [49] | 3.2 | 92.8 | 96.8 | 89.2 | 90.4 | |
| FR-Head [46] | 2.0 | 92.8 | 96.8 | 89.5 | 90.9 | |
| LG-SGNet [14] | 1.73 | 93.1 | 96.7 | 89.4 | 91.0 | |
| Transformer | ST-TR [16] | 12.1 | 89.9 | 96.1 | 82.7 | 84.7 |
| STSA-Net [18] | 1.9 | 92.7 | 96.7 | 88.5 | 90.7 | |
| TranSkeleton [19] | 2.2 | 92.8 | 97.0 | 89.4 | 90.5 | |
| LG-STFormer [22] | 10.1 | 92.8 | 96.7 | 88.6 | 90.4 | |
| MLP | SiT-MLP [45] | 0.6 | 92.3 | 96.8 | 89.0 | 90.5 |
| MTC-Former (ours) | 2.5 | 93.2 | 97.1 | 89.7 | 91.4 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, P.; Liang, C.; Liu, Y.; Jiang, S. Multi-Grained Temporal Clip Transformer for Skeleton-Based Human Activity Recognition. Appl. Sci. 2025, 15, 4768. https://doi.org/10.3390/app15094768
Zhu P, Liang C, Liu Y, Jiang S. Multi-Grained Temporal Clip Transformer for Skeleton-Based Human Activity Recognition. Applied Sciences. 2025; 15(9):4768. https://doi.org/10.3390/app15094768
Chicago/Turabian StyleZhu, Peiwang, Chengwu Liang, Yalong Liu, and Songqi Jiang. 2025. "Multi-Grained Temporal Clip Transformer for Skeleton-Based Human Activity Recognition" Applied Sciences 15, no. 9: 4768. https://doi.org/10.3390/app15094768
APA StyleZhu, P., Liang, C., Liu, Y., & Jiang, S. (2025). Multi-Grained Temporal Clip Transformer for Skeleton-Based Human Activity Recognition. Applied Sciences, 15(9), 4768. https://doi.org/10.3390/app15094768