Performance of Fine-Tuning Techniques for Multilabel Classification of Surface Defects in Reinforced Concrete Bridges





Abstract
1. Introduction
2. Materials and Methods
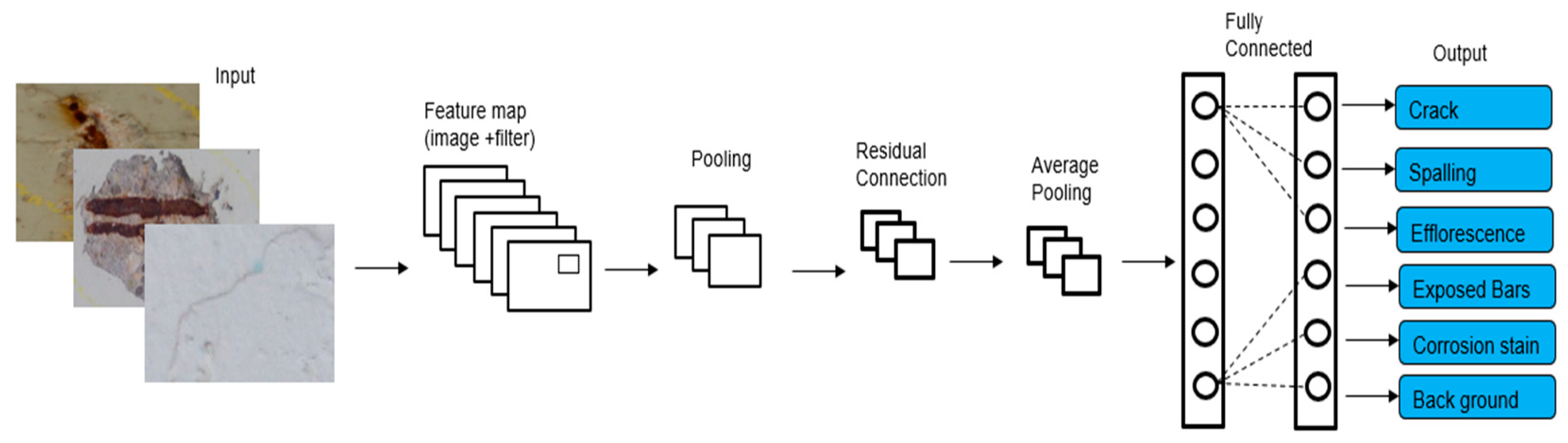
2.1. CNN Architecture
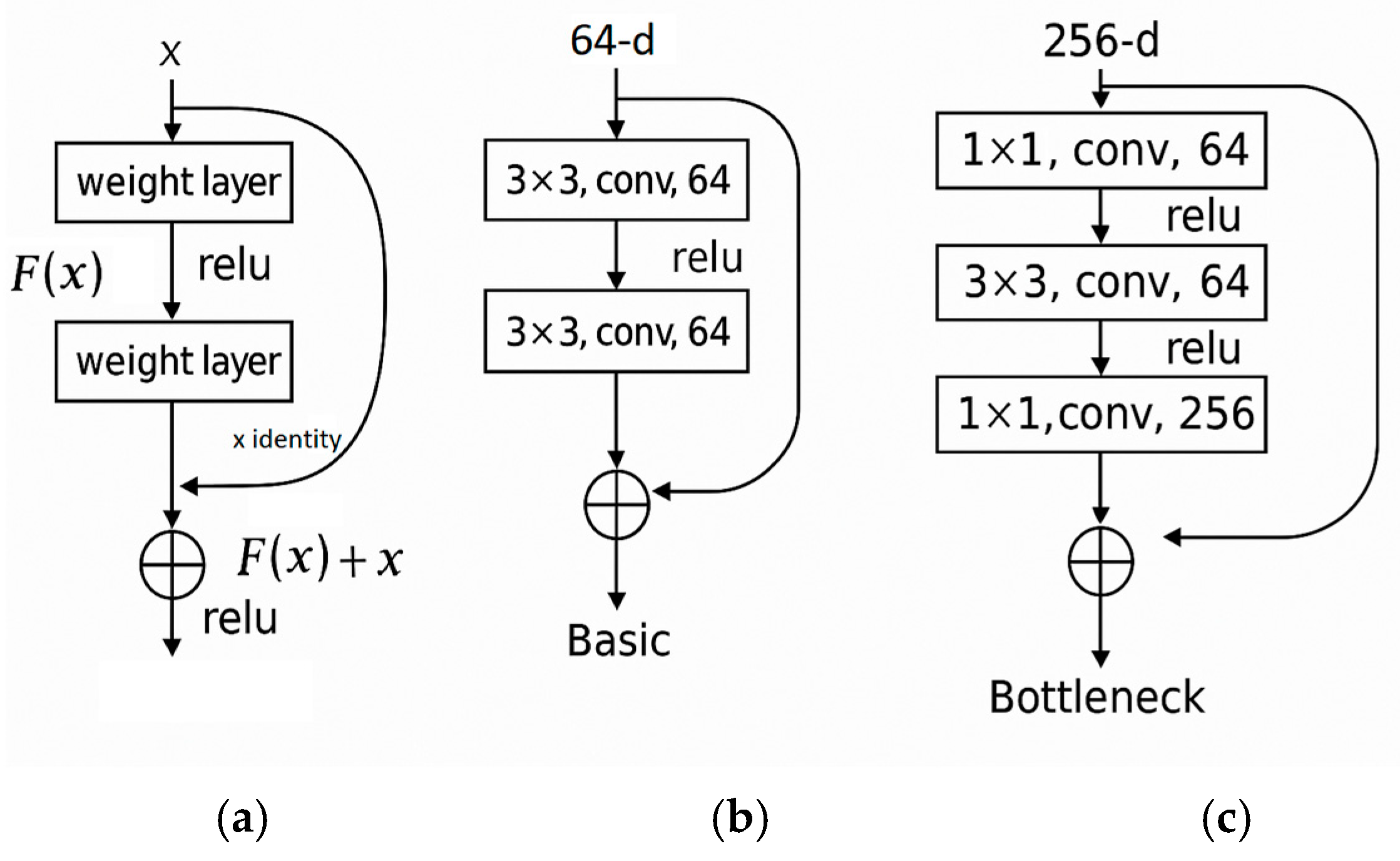
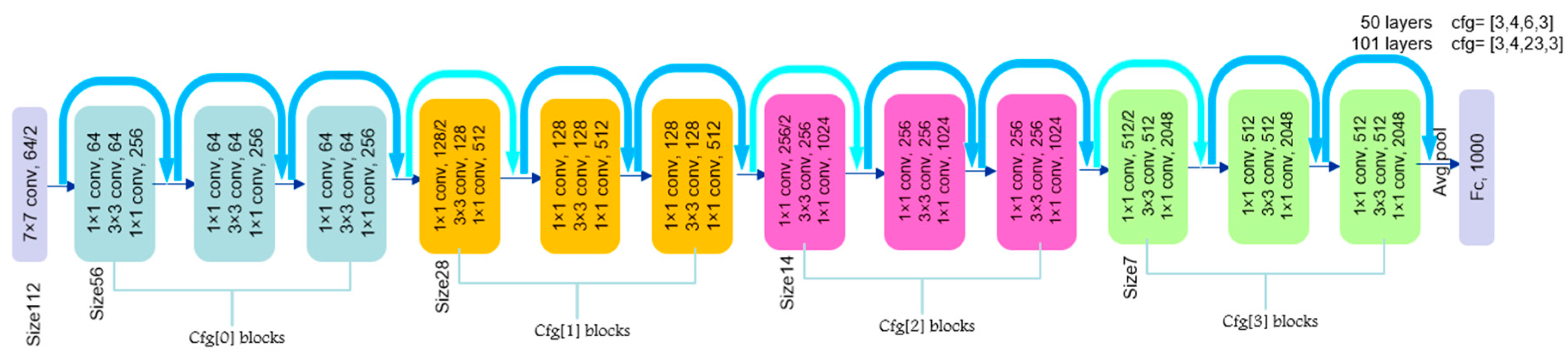
2.1.1. ResNet Network Architectures
2.1.2. ResNeXt Network Architectures
2.1.3. EfficientNet-B3 Network Architectures
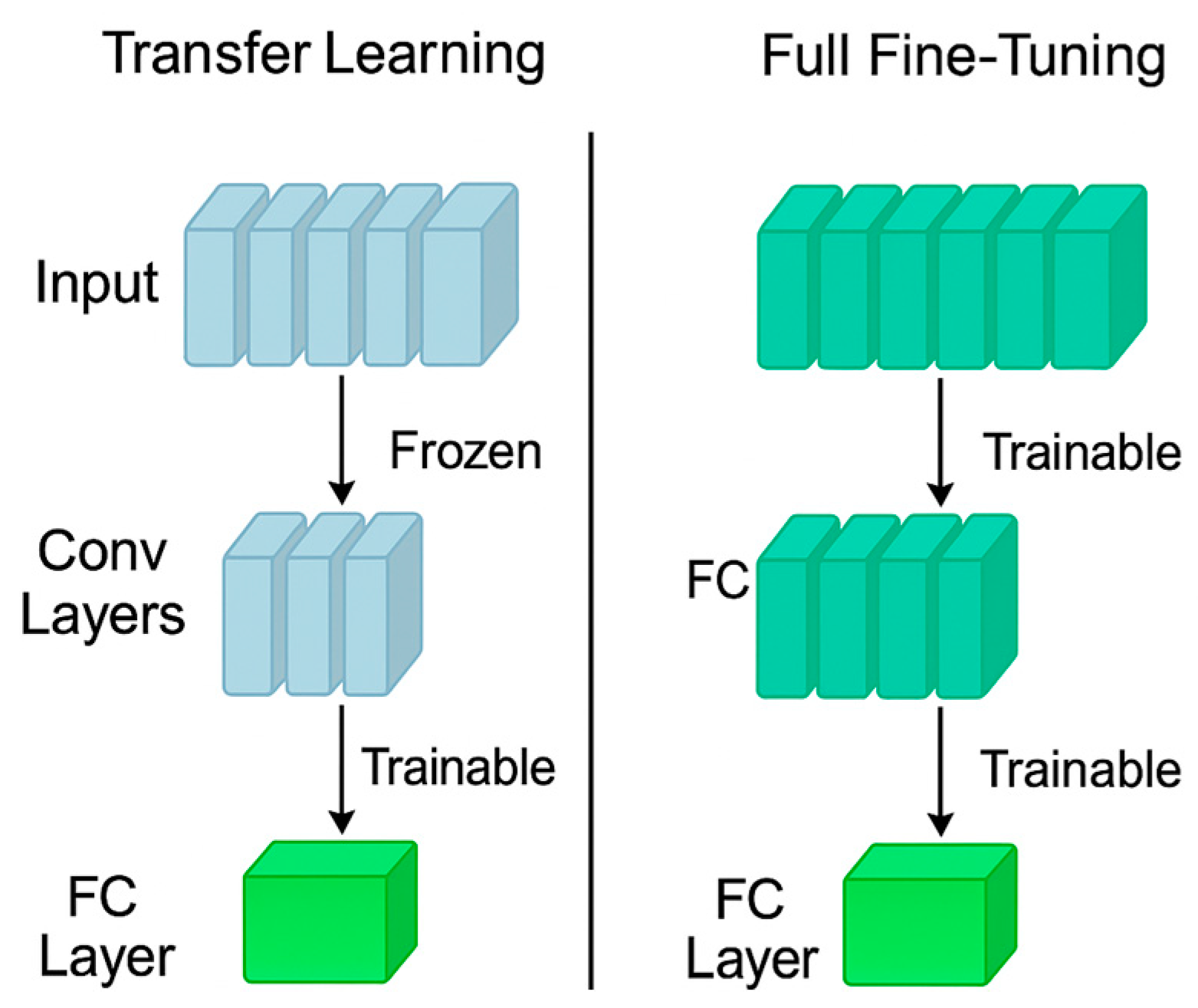
2.2. Fine-Tuning and Transfer Learning Strategies
3. Dataset
- Crack—visible linear fracture or separation in the concrete surface. Although cracks may exhibit various typologies such as hairline, vertical or diagonal cracks, the CODEBRIM dataset annotates all crack types under a single “crack” label. Consequently, our classification model is trained to recognize cracks as a general category.
- Spalling—surface flaking or detachment of concrete material.
- Efflorescence—white crystalline deposits resulting from salt leaching.
- Corrosion stain—discoloration due to rust formation, often near steel reinforcements.
- Exposed bars—visible steel reinforcement due to severe concrete loss.
4. Discussion
4.1. Training Results
4.2. Evaluation Metrics
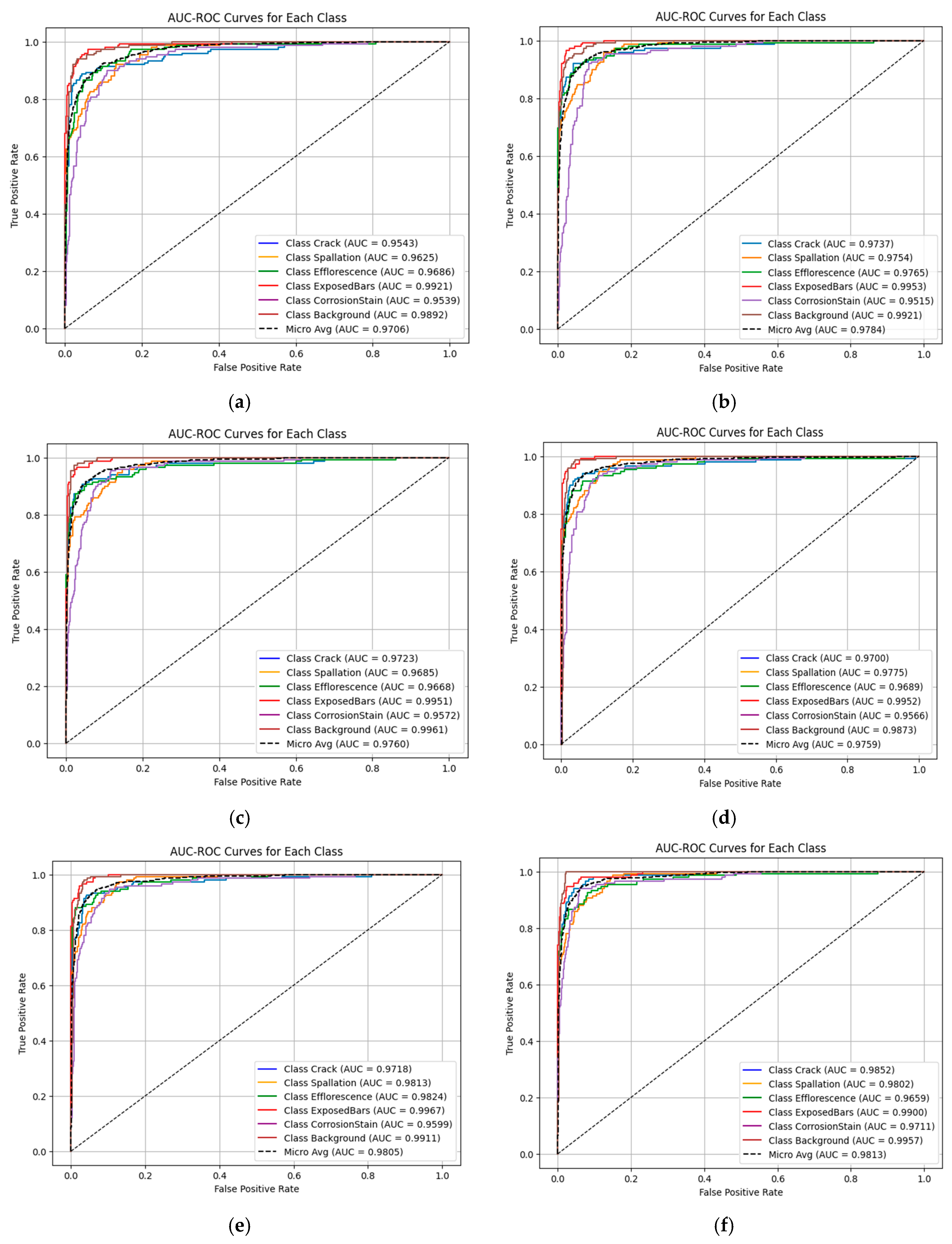
4.3. AUC-ROC Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Quirk, L.; Matos, J.; Murphy, J.; Pakrashi, V. Visual inspection and bridge management. Struct. Infrastruct. Eng. 2018, 14, 320–332. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuen, K.V. Review of artificial intelligence-based bridge damage detection. Adv. Mech. Eng. 2022, 14, 16878132221122770. [Google Scholar] [CrossRef]
- Han, X.; Zhao, Z.; Chen, L.; Hu, X.; Tian, Y.; Zhai, C.; Wang, L.; Huang, X. Structural damage-causing concrete cracking detection based on a deep-learning method. Constr. Build. Mater. 2022, 337, 127562. [Google Scholar] [CrossRef]
- Ali, L.; Harous, S.; Zaki, N.; Khan, W.; Alnajjar, F.; Al Jassmi, H. Performance evaluation of different algorithms for crack detection in concrete structures. In Proceedings of the 2nd International Conference on Computation, Automation and Knowledge Management (ICCAKM), Dubai, United Arab Emirates, 19–21 January 2021. [Google Scholar] [CrossRef]
- O’Byrne, M.; Ghosh, B.; Schoefs, F.; Pakrashi, V. Image-Based Damage Assessment for Underwater Inspections; Taylor & Francis: London, UK, 2018. [Google Scholar] [CrossRef]
- O’Byrne, M.; Ghosh, B.; Schoefs, F.; Pakrashi, V. Applications of virtual data in subsea inspections. J. Mar. Sci. Eng. 2020, 8, 328. [Google Scholar] [CrossRef]
- Ruggieri, S.; Cardellicchio, A.; Nettis, A.; Reno, V.; Uva, G. Using attention for improving defect detection in existing RC bridges. IEEE Access 2025, 13, 18994–19015. [Google Scholar] [CrossRef]
- Gostautas, R.; Tamutus, T. SHM of the Eyebars of the Old San Francisco Oakland Bay Bridge. In Structural Health Monitoring 2015; DEStech Publications, Inc.: Lancaster, PA, USA, 2015. [Google Scholar] [CrossRef]
- Calvi, G.M.; Moratti, M.; O’Reilly, G.J.; Scattarreggia, N.; Monteiro, R.; Malomo, D.; Calvi, P.M.; Pinho, R. Once upon a Time in Italy: The Tale of the Morandi Bridge. Struct. Eng. Int. 2019, 29, 198–217. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision: Algorithms and Applications, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Yang, W.; Zhao, J.; Li, J.; Chen, Z. Probabilistic machine learning approach to predict incompetent rock masses in TBM construction. Acta Geotech. 2023, 18, 4973–4991. [Google Scholar] [CrossRef]
- Yang, W.; Chen, Z.; Zhao, H.; Chen, S.; Shi, C. Feature fusion method for rock mass classification prediction and interpretable analysis based on TBM operating and cutter wear data. Tunn. Undergr. Space Technol. 2025, 157, 106351. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. SDNET2018: An annotated image dataset for non-contact concrete crack detection using deep convolutional neural networks. Data Brief 2018, 21, 1664–1668. [Google Scholar] [CrossRef]
- Mundt, M.; Majumder, S.; Murali, S.; Panetsos, P.; Ramesh, V. CODEBRIM: COncrete DEfect BRidge IMage Dataset. Zenodo 2019. [Google Scholar] [CrossRef]
- Pâques, M.; Law-Hine, D.; Hamedane, O.A.; Magnaval, G.; Allezard, N. Automatic Multi-label Classification of Bridge Components and Defects Based on Inspection Photographs. Ce/Papers 2023, 6, 1080–1086. [Google Scholar] [CrossRef]
- Özgenel, Ç.F. Concrete Crack Images for Classification. 2019. Available online: https://data.mendeley.com/datasets/5y9wdsg2zt/2 (accessed on 24 March 2025).
- Xu, H.; Su, X.; Wang, Y.; Cai, H.; Cui, K.; Chen, X. Automatic bridge crack detection using a convolutional neural network. Appl. Sci. 2019, 9, 2867. [Google Scholar] [CrossRef]
- Huethwohl, P. Cambridge Bridge Inspection Dataset. 2017. Available online: https://www.repository.cam.ac.uk/handle/1810/267902 (accessed on 24 March 2025).
- Li, S.; Zhao, X. Image-Based Concrete Crack Detection Using Convolutional Neural Network and Exhaustive Search Technique. Adv. Civ. Eng. 2019, 2019, 6520620. [Google Scholar] [CrossRef]
- Hüthwohl, P.; Lu, R.; Brilakis, I. Multi-classifier for reinforced concrete bridge defects. Autom. Constr. 2019, 105, 102824. [Google Scholar] [CrossRef]
- Bhattacharya, G.; Mandal, B.; Puhan, N.B. Interleaved Deep Artifacts-Aware Attention Mechanism for Concrete Structural Defect Classification. IEEE Trans. Image Process. 2021, 30, 6957–6969. [Google Scholar] [CrossRef]
- Su, C.; Wang, W. Concrete Cracks Detection Using Convolutional NeuralNetwork Based on Transfer Learning. Math. Probl. Eng. 2020, 2020, 1–10. [Google Scholar] [CrossRef]
- Mundt, M.; Majumder, S.; Murali, S.; Panetsos, P.; Ramesh, V. Meta-learning convolutional neural architectures for multi-target concrete defect classification with the concrete defect bridge image dataset. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Rajadurai, R.S.; Kang, S.T. Automated vision-based crack detection on concrete surfaces using deep learning. Appl. Sci. 2021, 11, 5229. [Google Scholar] [CrossRef]
- Ali, L.; Alnajjar, F.; Al Jassmi, H.; Gochoo, M.; Khan, W.; Serhani, M.A. Performance evaluation of deep CNN-based crack detection and localization techniques for concrete structures. Sensors 2021, 21, 1688. [Google Scholar] [CrossRef]
- Yang, Q.; Shi, W.; Chen, J.; Lin, W. Deep convolution neural network-based transfer learning method for civil infrastructure crack detection. Autom. Constr. 2020, 116, 103199. [Google Scholar] [CrossRef]
- Zhu, J.; Zhang, C.; Qi, H.; Lu, Z. Vision-based defects detection for bridges using transfer learning and convolutional neural networks. Struct. Infrastruct. Eng. 2020, 16, 1037–1049. [Google Scholar] [CrossRef]
- Zoubir, H.; Rguig, M.; El Aroussi, M.; Chehri, A.; Saadane, R.; Jeon, G. Concrete Bridge Defects Identification and Localization Based on Classification Deep Convolutional Neural Networks and Transfer Learning. Remote. Sens. 2022, 14, 4882. [Google Scholar] [CrossRef]
- Bukhsh, Z.A.; Jansen, N.; Saeed, A. Damage detection using in-domain and cross-domain transfer learning. Neural Comput. Appl. 2021, 33, 16921–16936. [Google Scholar] [CrossRef]
- Buckley, T.; Ghosh, B.; Pakrashi, V. A Feature Extraction & Selection Benchmark for Structural Health Monitoring. Struct. Heal. Monit. 2023, 22, 2082–2127. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. 2016. Available online: http://image-net.org/challenges/LSVRC/2015/ (accessed on 24 March 2025).
- Tan, G.; Yang, Z. Autonomous Bridge detection based on ResNet for multiple damage types. In Proceedings of the 2021 IEEE 11th Annual International Conference on CYBER Technology in Automation, Control, and In-telligent Systems (CYBER), Jiaxing, China, 27–31 July 2021. [Google Scholar] [CrossRef]
- Ramzan, F.; Khan, M.U.G.; Rehmat, A.; Iqbal, S.; Saba, T.; Rehman, A.; Mehmood, Z. A Deep Learning Approach for Automated Diagnosis and Multi-Class Classification of Alzheimer’s Disease Stages Using Resting-State fMRI and Residual Neural Networks. J. Med Syst. 2020, 44, 37. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K.; San Diego, U. Aggregated Residual Transformations for Deep Neural Networks. Available online: https://github.com/facebookresearch/ResNeXt (accessed on 24 March 2025).
- Soleimanipour, A.; Azadbakht, M.; Asl, A.R. Cultivar identification of pistachio nuts in bulk mode through EfficientNet deep learning model. J. Food Meas. Charact. 2022, 16, 2545–2555. [Google Scholar] [CrossRef]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Kandel, I.; Castelli, M. Transfer learning with convolutional neural networks for diabetic retinopathy image classification. A review. Appl. Sci. 2020, 10, 2021. [Google Scholar] [CrossRef]
- Valli, A.; Kumar, R. Review on the mechanism and mitigation of cracks in concrete. Appl. Eng. Sci. 2023, 16, 100154. [Google Scholar] [CrossRef]
- Amirkhani, D.; Allili, M.S.; Hebbache, L.; Hammouche, N.; Lapointe, J.F. Visual Concrete Bridge Defect Classification and Detection Using Deep Learning: A Systematic Review. IEEE Trans. Intell. Transp. Syst. 2024, 25, 10483–10505. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Total Images | Defect/Classes |
|---|---|---|
| ImageNet [13] | +15 M | Over 22,000 object classes |
| SDNET [14] | 230 High-resolution (56,092 images for all classes) | Concrete cracks from bridges, walls, pavement |
| CODEBRIM [15] | 1590 High-resolution (10,789 images for all classes) | Multi-label/Cracks, corrosion, spalling, etc. |
| SOFIA [16] | 139,455 (53,805 are labeled) | Bridge components and structural defects |
| METU [17] | 458 High-resolution (40,000 images for all classes) | Crack/No-crack |
| BCD [18] | 6069 | Bridge cracks/background |
| CDS [19] | 1028 | Surface damages in concrete bridges |
| ICCD [20] | 1455 | Cracks in bridges and towers |
| MCDS [21] | 3607 | Various concrete defects |
| Author | Model | Pre-Trained on | Dataset | Defect Type | Accuracy |
|---|---|---|---|---|---|
| Dorafshan et al. [14] | AlexNet | IMAGENET | SDNET | Binary Crack | 95.52% |
| Bhattacharya et al. [22] | Res2Net | - | CODEBRIM & SDNET | Multiple defects | 92.70% |
| Su and Wang [23] | EfficientNetB0 | IMAGENET | Li and Zhao & SDNET | Binary Crack | 99.11% |
| Páques et al. [16] | DINO ViT/8 | - | SOFIA | Multiple defects | 89.20% |
| Mundt et al. [24] | Meta-learned | - | CODEBRIM | Multiple defects | 72.19% |
| Rajadurai & Kang [25] | AlexNet | IMAGENET | Concrete Crack Images | Binary Crack | 89.00% |
| Ali et al. [26] | Customized CNN | IMAGENET | SDNET, METU | Binary Crack | 98.30% |
| Yang et al. [27] | VGG16 | IMAGENET | METU, SDNET, BCD | Binary Crack | 99.80% |
| Zhu et al. [28] | Inception-v3 | IMAGENET | Self-collected | Multiple defects | 97.80% |
| Zoubir et al. [29] | VGG16 | IMAGENET | Self-collected | Multiple defects | 97.10% |
| Bukhs et al. [30] | VGG16, Inception-v3, ResNet50 | IMAGENET | CDS, SDNETv1, BCD, ICCD, MCDS, CODEBRIM | Multiple defects | 90.00% |
| Stage | Output | ResNet-18 | ResNet-50 | ResNet-101 | ResNeXt-50 | ResNeXt-101 |
|---|---|---|---|---|---|---|
| conv1 | 112 × 112 | 7 × 7, 64, stride 2 | 7 × 7, 64, stride 2 | 7 × 7, 64, stride 2 | 7 × 7, 64, stride 2 | 7 × 7, 64, stride 2 |
| conv2 | 56 × 56 | 3 × 3 max pool, stride 2 | 3 × 3 max pool, stride 2 | 3 × 3 max pool, stride 2 | 3 × 3 max pool, stride 2 | 3 × 3 max pool, stride 2 |
| [3 × 3, 64] × 2 | × 3 | × 3 | × 3, C = 32 | × 3, C = 32 | ||
| conv3 | 28 × 28 | [3 × 3, 128] × 2 | × 4 | × 4 | × 4, C = 32 | × 4, C = 32 |
| conv4 | 14 × 14 | [3 × 3, 256] × 2 | × 6 | × 23 | × 6, C = 32 | × 23, C = 32 |
| conv5 | 7 × 7 | [3 × 3, 512] × 2 | × 3 | × 3 | × 3, C = 32 | × 3, C = 32 |
| fc | 1 × 1 | Global average pool 1000-d fc, softmax | Global average pool 1000-d fc, softmax | Global average pool 1000-d fc, softmax | Global average pool 1000-d fc, softmax | Global average pool 1000-d fc, softmax |
| # Params | 11.7 × 106 | 25.5 × 106 | 44.5 × 106 | 25.0 × 106 | 44.2 × 106 | |
| FLOPs | 1.8 × 109 | 4.1 × 109 | 7.6 × 109 | 4.2 × 109 | 8.0 × 109 |
| Class | Train Dataset | Validation Dataset | Test Dataset | Sum |
|---|---|---|---|---|
| Crack | 2208 | 149 | 150 | 2507 |
| Spalling | 1608 | 140 | 150 | 1898 |
| Efflorescence | 543 | 140 | 150 | 833 |
| Exposed Bars | 1215 | 142 | 150 | 1507 |
| Corrosion Stain | 1263 | 146 | 150 | 1559 |
| Background | 2185 | 150 | 150 | 2485 |
| Sum | 9022 | 867 | 900 | 10,789 |
| Class | ResNet-18 | ResNet-50 | ResNet-101 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Balanced Accuracy | Precision | Recall | F1-Score | Balanced Accuracy | Precision | Recall | F1-Score | Balanced Accuracy | |
| Crack | 0.760 | 0.907 | 0.827 | 0.909 | 0.777 | 0.927 | 0.845 | 0.922 | 0.803 | 0.927 | 0.861 | 0.928 |
| Spalling | 0.703 | 0.867 | 0.776 | 0.876 | 0.742 | 0.900 | 0.813 | 0.901 | 0.734 | 0.900 | 0.808 | 0.899 |
| Efflorescence | 0.849 | 0.832 | 0.841 | 0.893 | 0.894 | 0.846 | 0.869 | 0.907 | 0.909 | 0.872 | 0.890 | 0.923 |
| Exposed Bars | 0.897 | 0.933 | 0.915 | 0.950 | 0.965 | 0.913 | 0.938 | 0.951 | 0.946 | 0.933 | 0.940 | 0.958 |
| Corrosion Stain | 0.652 | 0.913 | 0.761 | 0.881 | 0.739 | 0.927 | 0.822 | 0.913 | 0.730 | 0.920 | 0.814 | 0.907 |
| Background | 0.865 | 0.940 | 0.901 | 0.947 | 0.898 | 0.940 | 0.919 | 0.953 | 0.918 | 0.973 | 0.945 | 0.973 |
| Overall | 0.778 | 0.899 | 0.834 | 0.909 | 0.826 | 0.909 | 0.865 | 0.925 | 0.831 | 0.921 | 0.874 | 0.931 |
| Class | ResNeXt-50 | ResNeXt-101 | EfficientNet-B3 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Balanced Accuracy | Precision | Recall | F1-Score | Balanced Accuracy | Precision | Recall | F1-Score | Balanced Accuracy | |
| Crack | 0.825 | 0.940 | 0.879 | 0.939 | 0.838 | 0.933 | 0.883 | 0.939 | 0.816 | 0.947 | 0.877 | 0.940 |
| Spalling | 0.756 | 0.907 | 0.824 | 0.908 | 0.771 | 0.900 | 0.831 | 0.909 | 0.729 | 0.913 | 0.811 | 0.904 |
| Efflorescence | 0.903 | 0.879 | 0.891 | 0.925 | 0.956 | 0.872 | 0.912 | 0.930 | 0.912 | 0.832 | 0.870 | 0.904 |
| Exposed Bars | 0.966 | 0.933 | 0.949 | 0.961 | 0.938 | 0.913 | 0.926 | 0.947 | 0.926 | 0.913 | 0.919 | 0.945 |
| Corrosion Stain | 0.758 | 0.920 | 0.831 | 0.914 | 0.765 | 0.913 | 0.833 | 0.913 | 0.828 | 0.933 | 0.878 | 0.937 |
| Background | 0.918 | 0.967 | 0.942 | 0.970 | 0.901 | 0.973 | 0.936 | 0.970 | 0.893 | 1.000 | 0.943 | 0.981 |
| Overall | 0.847 | 0.924 | 0.884 | 0.936 | 0.855 | 0.918 | 0.885 | 0.935 | 0.844 | 0.923 | 0.882 | 0.935 |
| Model | MetaQNN [24] | VGG16 [30] | Inception-V3 [30] | ResNet-50 [30] | Resnet-18 This Study |
|---|---|---|---|---|---|
| Accuracy% | 72.19% | 88.00% | 89.00% | 90.00% | 90.90% |
| Model | Resnet-50 This study | Resnet-101 This study | ResNeXt-50 This study | ResNeXt-101 This study | Efficient-B3 This study |
| Accuracy% | 92.50% | 93.10% | 93.60% | 93.50% | 93.50% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pooraskarparast, B.; Dang, S.N.; Pakrashi, V.; Matos, J.C. Performance of Fine-Tuning Techniques for Multilabel Classification of Surface Defects in Reinforced Concrete Bridges. Appl. Sci. 2025, 15, 4725. https://doi.org/10.3390/app15094725
Pooraskarparast B, Dang SN, Pakrashi V, Matos JC. Performance of Fine-Tuning Techniques for Multilabel Classification of Surface Defects in Reinforced Concrete Bridges. Applied Sciences. 2025; 15(9):4725. https://doi.org/10.3390/app15094725
Chicago/Turabian StylePooraskarparast, Benyamin, Son N. Dang, Vikram Pakrashi, and José C. Matos. 2025. "Performance of Fine-Tuning Techniques for Multilabel Classification of Surface Defects in Reinforced Concrete Bridges" Applied Sciences 15, no. 9: 4725. https://doi.org/10.3390/app15094725
APA StylePooraskarparast, B., Dang, S. N., Pakrashi, V., & Matos, J. C. (2025). Performance of Fine-Tuning Techniques for Multilabel Classification of Surface Defects in Reinforced Concrete Bridges. Applied Sciences, 15(9), 4725. https://doi.org/10.3390/app15094725