
MWMOTE-FRIS-INFFC: An Improved Majority Weighted Minority Oversampling Technique for Solving Noisy and Imbalanced Classification Datasets


Abstract
1. Introduction
2. Materials and Methods
3. MWMOTE-FRIS-INFFC
3.1. Preliminaries
3.1.1. Majority Weighted Minority Oversampling Technique (MWMOTE)
| Algorithm 1. Majority Weighted Minority Oversampling Technique (MWMOTE) |
| Input: Minority sample and majority sample (Smin and Smaj) Procedure:
Output: The oversampled minority sets. |
3.1.2. Fuzzy-Rough Instance Selection (FRIS)
3.1.3. Iterative Noise Filter Based on the Fusion of Classifiers (INFFC)
3.2. The Proposed Method
| Algorithm 2. MWMOTE-FRIS-INFFC |
| Input: Set of D∈{min, maj}, where min means minority class and maj means majority class. Rmin:Rmaj means unbalanced sample target ratio. FC = SVM, 3-NN, C4.5, LR. Output: Balanced data set DBalanced Procedure:
|
4. Algorithm Testing and Discussion
4.1. Evaluation Criteria
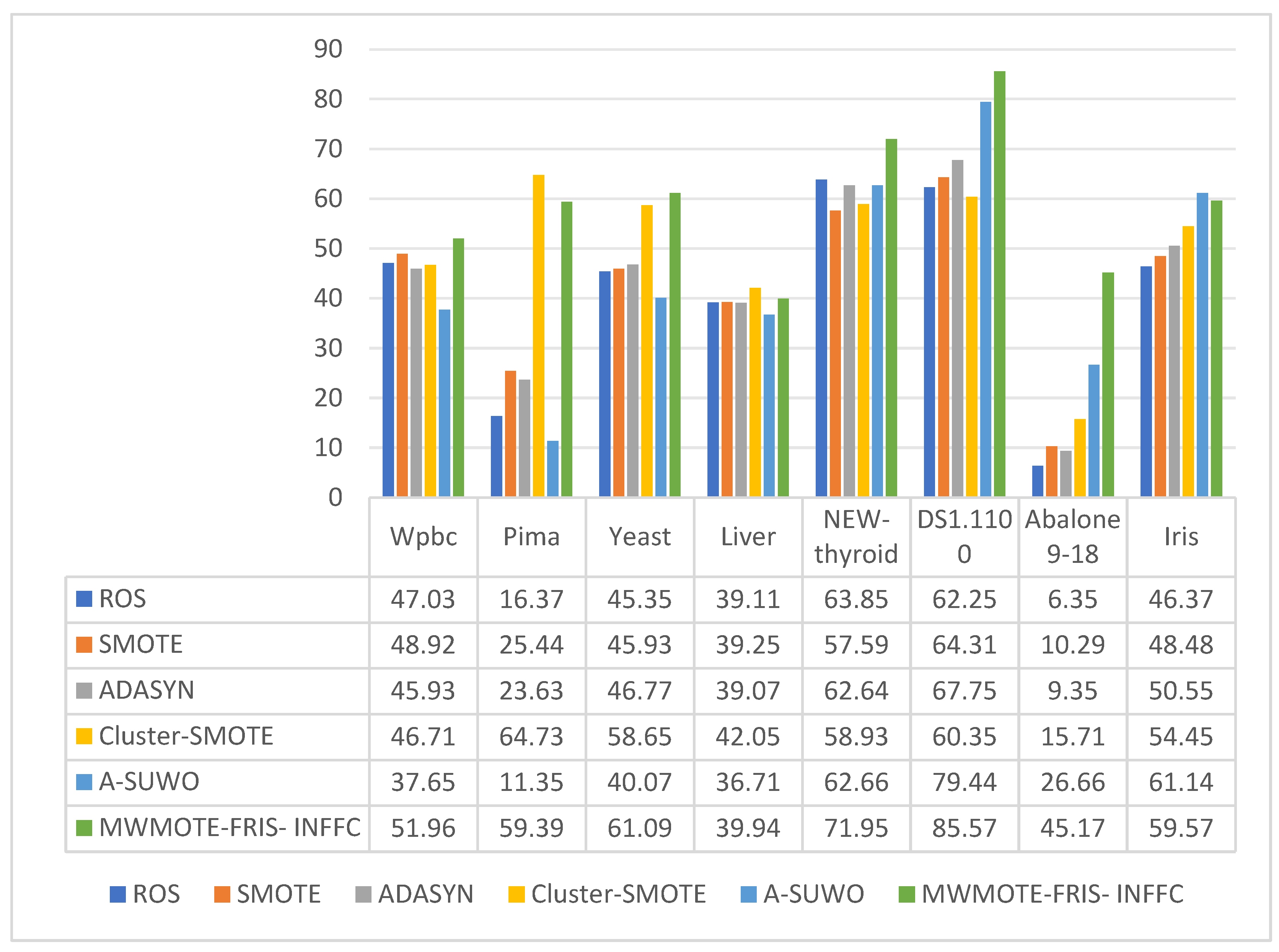
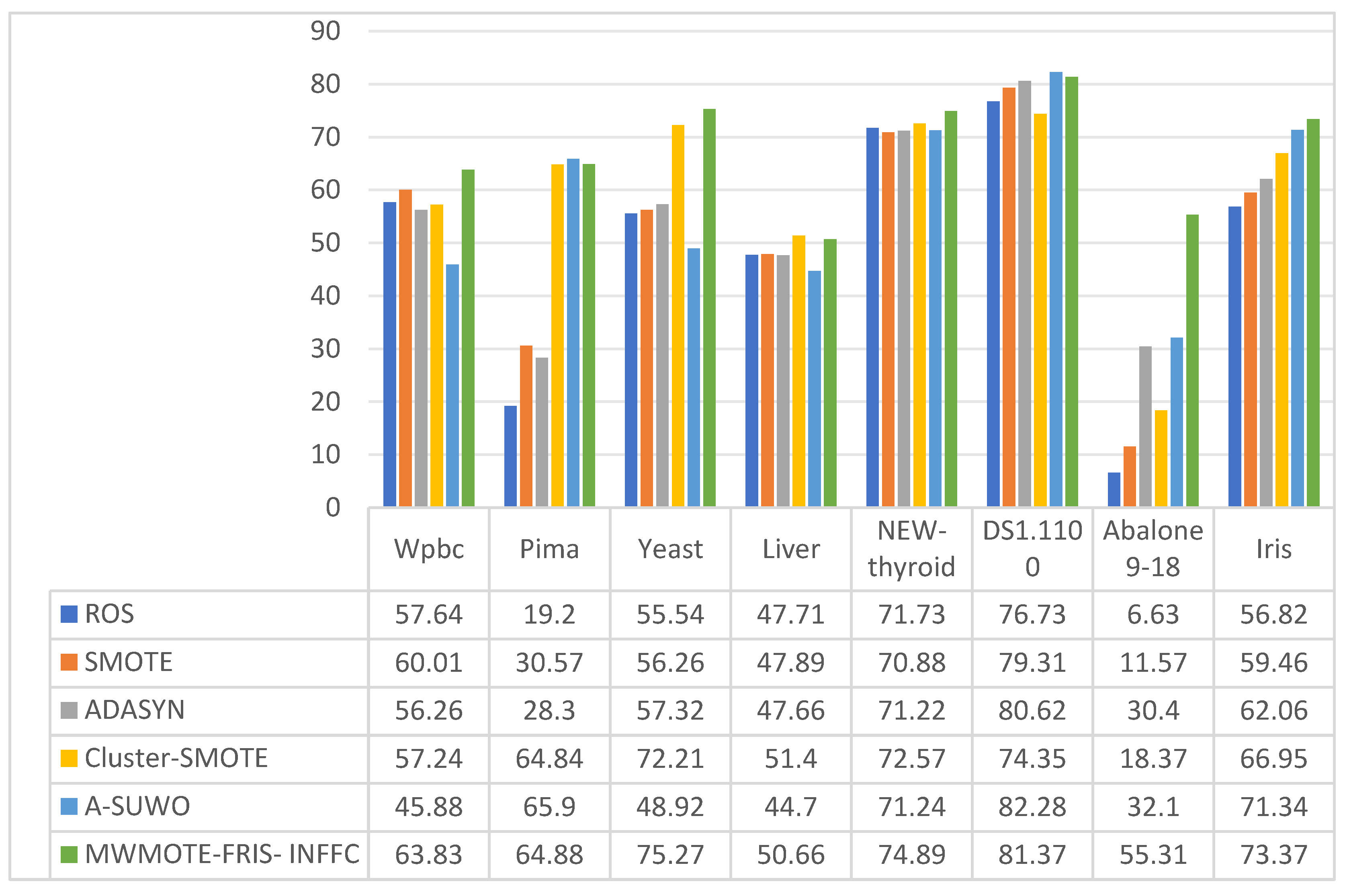
4.2. Comparison of Algorithm Evaluation Results
4.3. Comparison of Classification of Unbalanced Samples with High Noise
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Batuwita, R.; Palade, V. FSVM-CIL: Fuzzy Support Vector Machines for Class Imbalance Learning. IEEE Trans. Fuzzy Syst. 2010, 18, 558–571. [Google Scholar] [CrossRef]
- Berkmans, T.J.; Karthick, S. Credit Card Fraud Detection with Data Sampling. In Proceedings of the 2022 International Conference on Power, Energy, Control and Transmission Systems (ICPECTS), Chennai, India, 8–9 December 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Li, J. Oversampling framework based on sample subspace optimization with accelerated binary particle swarm optimization for imbalanced classification. Appl. Soft Comput. 2024, 162, 111708. [Google Scholar] [CrossRef]
- Li, Y.; Jia, X.; Wang, R.; Qi, J.; Jin, H.; Chu, X.; Mu, W. A new oversampling method and improved radial basis function classifier for customer consumption behavior prediction. Expert Syst. Appl. 2022, 199, 116982. [Google Scholar] [CrossRef]
- Li, R.; Xia, T.; Jiang, Y.; Wu, J.; Fang, X.; Gebraeel, N.; Xi, L. Deep Complex Wavelet Denoising Network for Interpretable Fault Diagnosis of Industrial Robots with Noise Interference and Imbalanced Data. IEEE Trans. Instrum. Meas. 2025, 74, 3508411. [Google Scholar] [CrossRef]
- Tzirakis, P.; Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.W.; Zafeiriou, S. End-to-End Multimodal Emotion Recognition using Deep Neural Networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 1301–1309. [Google Scholar] [CrossRef]
- Santos, M.S.; Abreu, P.H.; Japkowicz, N.; Fernández, A.; Santos, J. A unifying view of class overlap and imbalance: Key concepts, multi-view panorama, and open avenues for research. Inf. Fusion 2023, 89, 228–253. [Google Scholar] [CrossRef]
- Wei, J.; Huang, H.; Yao, L.; Hu, Y.; Fan, Q.; Huang, D. New imbalanced fault diagnosis framework based on Cluster-MWMOTE and MFO-optimized LS-SVM using limited and complex bearing data. Eng. Appl. Artif. Intell. 2020, 96, 103966. [Google Scholar] [CrossRef]
- Wang, C.; Shu, Z.; Yang, J.; Zhao, Z.; Jie, H.; Chang, Y.; Jiang, S.; See, K.Y. Learning to Imbalanced Open Set Generalize: A Meta-Learning Framework for Enhanced Mechanical Diagnosis. IEEE Trans. Cybern. 2025, 55, 1464–1475. [Google Scholar] [CrossRef]
- Dong, X.; Wang, J.; Liang, Y. A Novel Ensemble Classifier Selection Method for Software Defect Prediction. IEEE Access 2025, 13, 25578–25597. [Google Scholar] [CrossRef]
- Liu, Y.; Zhu, L.; Ding, L.; Sui, H.; Shang, W. A hybrid sampling method for highly imbalanced and overlapped data classification with complex distribution. Inf. Sci. 2024, 661, 120117. [Google Scholar] [CrossRef]
- Li, H.; Chen, G.; Wang, B.; Chen, Z.; Zhu, Y.; Hu, F.; Dai, J.; Wang, W. PFedKD: Personalized Federated Learning via Knowledge Distillation using Unlabeled Pseudo Data for Internet of Things. IEEE Internet Things J. 2025, 1, 1037–1042. [Google Scholar] [CrossRef]
- Noor, A.; Javaid, N.; Alrajeh, N.; Mansoor, B.; Khaqan, A.; Bouk, S.H. Heart Disease Prediction Using Stacking Model With Balancing Techniques and Dimensionality Reduction. IEEE Access 2023, 11, 116026–116045. [Google Scholar] [CrossRef]
- Lichman, M. Uci Machine Learning Repository. 2013. Available online: https://ergodicity.net/2013/07/ (accessed on 20 April 2025).
- Maalouf, M.; Siddiqi, M. Weighted logistic regression for large-scale imbalanced and rare events data. Knowl. Based Syst. 2014, 59, 142–148. [Google Scholar] [CrossRef]
- Liu, Q.; Xiao, Y.; Gui, Y.; Dai, G.; Li, H.; Zhou, X.; Ren, A.; Zhou, G.; Shen, J. MMF-RNN: A Multimodal Fusion Model for Precipitation Nowcasting Using Radar and Ground Station Data. IEEE Trans. Geosci. Remote Sens. 2025, 63, 4101416. [Google Scholar] [CrossRef]
- Vuttipittayamongkol, P.; Elyan, E. Neighbourhood-based undersampling approach for handling imbalanced and overlapped data. Inf. Sci. 2020, 509, 47–70. [Google Scholar] [CrossRef]
- Amiri, A.; Ghaffarnia, A.; Sakib, S.K.; Wu, D.; Liang, Y. FocalCA: A Hybrid-Convolutional-Attention Encoder for Intrusion Detection on UNSW-NB15 Achieving High Accuracy Without Data Balancing. In Proceedings of the 2025 IEEE 4th International Conference on AI in Cybersecurity (ICAIC), Houston, TX, USA, 5–7 February 2025; pp. 1–8. [Google Scholar] [CrossRef]
- Akter, S.; Ishika, I.; Das, P.R.; Nyne, M.J.; Farid, D.M. Boosting Oversampling Methods for Imbalanced Data Classification. In Proceedings of the 2023 26th International Conference on Computer and Information Technology (ICCIT), Cox’s Bazar, Bangladesh, 13–15 December 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Das, S.; Datta, S.; Chaudhuri, B.B. Handling data irregularities in classification: Foundations, trends, and future challenges. Pattern Recognit. 2018, 81, 674–693. [Google Scholar] [CrossRef]
- Sabha, S.U.; Assad, A.; Din, N.M.U.; Bhat, M.R. Comparative Analysis of Oversampling Techniques on Small and Imbalanced Datasets Using Deep Learning. In Proceedings of the 2023 3rd International conference on Artificial Intelligence and Signal Processing (AISP), Vijayawada, India, 18–20 March 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Shen, B.; Yao, L.; Jiang, X.; Yang, Z.; Zeng, J. Time Series Data Augmentation Classifier for Industrial Process Imbalanced Fault Diagnosis. In Proceedings of the 2023 IEEE 12th Data Driven Control and Learning Systems Conference (DDCLS), Xiangtan, China, 12–14 May 2023; pp. 1392–1397. [Google Scholar] [CrossRef]
- Sun, W.; Xu, G.; Li, S.; Feng, X. ISMOTE Oversampling Algorithm For Imbalanced Data Classification. In Proceedings of the 2024 IEEE 7th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 15–17 March 2024; pp. 1463–1468. [Google Scholar] [CrossRef]
- Vasighizaker, A.; Jalili, S. C-PUGP: A cluster-based positive unlabeled learning method for disease gene prediction and prioritization. Comput. Biol. Chem. 2018, 76, 23–31. [Google Scholar] [CrossRef]
- Azhar, N.A.; Pozi, M.S.M.; Din, A.M.; Jatowt, A. An Investigation of SMOTE Based Methods for Imbalanced Datasets With Data Complexity Analysis. IEEE Trans. Knowl. Data Eng. 2023, 35, 6651–6672. [Google Scholar] [CrossRef]
- Ayyannan, M. Accuracy Enhancement of Machine Learning Model by Handling Imbalance Data. In Proceedings of the 2024 International Conference on Expert Clouds and Applications (ICOECA), Bengaluru, India, 18–19 April 2024; pp. 593–599. [Google Scholar] [CrossRef]
- Nguyen, H.; Chang, J.M. Synthetic Information Toward Maximum Posterior Ratio for Deep Learning on Imbalanced Data. IEEE Trans. Artif. Intell. 2024, 5, 2790–2804. [Google Scholar] [CrossRef]
- Nekooeimehr, I.; Lai-Yuen, S.K. Adaptive semi-unsupervised weighted oversampling (A-SUWO) for imbalanced datasets. Expert Syst. Appl. 2016, 46, 405–416. [Google Scholar] [CrossRef]
- Wei, J.; Huang, H.; Yao, L.; Hu, Y.; Fan, Q.; Huang, D. NI-MWMOTE: An improving noise-immunity majority weighted minority oversampling technique for imbalanced classification problems. Expert Syst. Appl. 2020, 158, 113504. [Google Scholar] [CrossRef]
- Pendyala, V.S.; Kim, H. Analyzing and Addressing Data-driven Fairness Issues in Machine Learning Models used for Societal Problems. In Proceedings of the 2023 International Conference on Computer, Electrical & Communication Engineering (ICCECE), Kolkata, India, 20–21 January 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Mathew, J.; Luo, M.; Pang, C.K.; Chan, H.L. Kernel-based SMOTE for SVM classification of imbalanced datasets. In Proceedings of the IECON 2015-41st Annual Conference of the IEEE Industrial Electronics Society, Yokohama, Japan, 9–12 November 2015; IEEE: Yokohama, Japan, 2015. [Google Scholar] [CrossRef]
- Wei, J.; Wang, J.; Huang, H.; Jiao, W.; Yuan, Y.; Chen, H.; Wu, R.; Yi, J. Novel extended NI-MWMOTE-based fault diagnosis method for data-limited and noise-imbalanced scenarios. Expert Syst. Appl. 2024, 238, 22. [Google Scholar] [CrossRef]
- Cui, L.; Xia, Y.; Lang, L.; Hou, B.; Wang, L. The Dual Mahalanobis-kernel LSSVM for Semi-supervised Classification in Disease Diagnosis. Arab. J. Sci. Eng. 2024, 49, 12357–12375. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| NO. | NAME | Minority Class | Majority Class | Minority Quantity | Majority Quantity | Total Quantity | Imbalanced Ratios |
|---|---|---|---|---|---|---|---|
| 1 | Wpbc | N | R | 47 | 151 | 198 | 1/3.23 |
| 2 | Pima | 1 | 0 | 268 | 500 | 768 | 1/1.87 |
| 3 | Yeast | ME3/MEW/EXC/VAC/POX/ERL | Other | 304 | 1180 | 1484 | 1/3.88 |
| 4 | Liver | 1 | Other | 71 | 107 | 178 | 1/1.37 |
| 5 | NEW-thyroid | 2 | Other | 35 | 180 | 215 | 1/5.15 |
| 6 | DS1.1100 | 1 | 0 | 804 | 25,929 | 26,733 | 1/32.25 |
| 7 | Abalone9-18 | 18 | 9 | 42 | 689 | 731 | 1/16.41 |
| 8 | Iris | 2 | Other | 50 | 100 | 150 | 1/2 |
| Data Set (Noise Ratios) | Meas | ROS | SMOTE | ADASYN | Cluster-SMOTE | A-SUWO | MWMOTE-FRIS-INFFC |
|---|---|---|---|---|---|---|---|
| Ecoli3 (20.0%) | Precision | 0 | 0 | 0 | 1 | 0 | 4 |
| G-mean | 0 | 0 | 0 | 0 | 0 | 5 | |
| F-measure | 0 | 0 | 0 | 1 | 0 | 4 | |
| Ds1.100 (31.72%) | Precision | 0 | 0 | 1 | 0 | 0 | 4 |
| G-mean | 0 | 0 | 0 | 0 | 2 | 3 | |
| F-measure | 0 | 0 | 1 | 0 | 0 | 4 | |
| Haberman (24.69%) | Precision | 0 | 0 | 0 | 2 | 0 | 3 |
| G-mean | 0 | 0 | 0 | 1 | 0 | 4 | |
| F-measure | 0 | 0 | 0 | 1 | 0 | 4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, D.; Huang, X.; Li, G.; Kong, S.; Dong, L. MWMOTE-FRIS-INFFC: An Improved Majority Weighted Minority Oversampling Technique for Solving Noisy and Imbalanced Classification Datasets. Appl. Sci. 2025, 15, 4670. https://doi.org/10.3390/app15094670
Zhang D, Huang X, Li G, Kong S, Dong L. MWMOTE-FRIS-INFFC: An Improved Majority Weighted Minority Oversampling Technique for Solving Noisy and Imbalanced Classification Datasets. Applied Sciences. 2025; 15(9):4670. https://doi.org/10.3390/app15094670
Chicago/Turabian StyleZhang, Dong, Xiang Huang, Gen Li, Shengjie Kong, and Liang Dong. 2025. "MWMOTE-FRIS-INFFC: An Improved Majority Weighted Minority Oversampling Technique for Solving Noisy and Imbalanced Classification Datasets" Applied Sciences 15, no. 9: 4670. https://doi.org/10.3390/app15094670
APA StyleZhang, D., Huang, X., Li, G., Kong, S., & Dong, L. (2025). MWMOTE-FRIS-INFFC: An Improved Majority Weighted Minority Oversampling Technique for Solving Noisy and Imbalanced Classification Datasets. Applied Sciences, 15(9), 4670. https://doi.org/10.3390/app15094670