1. Introduction
Using medical images to diagnose and treat diseases has always been the main development direction in the field of medical image processing. Deformable registration techniques for brain images have found many medical applications, such as brain tumor localization, neurosurgery assistance, and treatment response assessment. The aim of deformable registration is to establish a set of optimal spatial correspondence between a fixed image and a moving image in the same space, so that the difference regions between the two images tend to be aligned. According to different medical scenarios, it is possible to perform atlas-to-patient registration, patient-to-patient registration, multimodal image registration, multi-view image registration, etc. At the same time, the results of image registration can also be applied to many other medical image processing techniques, such as image segmentation, image fusion, etc. Recently, methods based on deep learning have been widely used in the field of image analysis and processing, and they have demonstrated advantages such as improved accuracy, faster processing speed, and the ability to handle complex deformations, surpassing traditional algorithms. Since AlexNet [
1] achieved outstanding performance, the convolutional neural network (CNN) has become one of the most successful models in deep learning. CNN has also made a major breakthrough in the field of medical image registration by virtue of its ability to efficiently process highly structured data. The CNN-based medical image registration methods can be divided into two categories: one is the iterative registration method using CNN for similarity prediction, and the other is the method of using CNN for transformation parameter prediction. The former can be called the method based on deep similarity, which mainly uses CNN to measure the similarity between multimodal images. Traditional intensity-based similarity measures such as cross-correlation (CC), square sum distance (SSD), and mean square distance (MSD) are very effective for the registration of single-modality images with the same intensity distribution. CC measures the linear correlation between two images, SSD calculates the sum of squared differences between corresponding pixels, and MSD is the average of squared differences, providing a robust measure of similarity. But for multimodal image registration, the performance of traditional similarity measures is not satisfactory. Consequently, some researchers have proposed using CNNs to measure the similarity between images, which has yielded promising results. However, these methods [
2,
3,
4] still rely on traditional image registration algorithms for iterative optimization, which results in lower registration efficiency. The second category includes both supervised [
5,
6,
7] and unsupervised [
8,
9] learning-based registration approaches. Unlike the methods based on deep similarity, the above two methods infer the transformation parameters at one time in the forward prediction (a direct inference process that predicts transformation parameters without iterative optimization), which greatly improves the registration efficiency. The difference between these two methods is that the supervised models need some label information during the training to help the model to learn. However, it is usually difficult to obtain these required real information or ground truth. These data often need to be manually marked by experts [
10] or generated by traditional registration algorithms [
11,
12] or by random transformation [
13]. The ground truth obtained by these methods may also be inconsistent with actual physiological changes, as it cannot always reflect real-world biological variability. In addition, these data will also limit the upper limit of registration. In contrast, unsupervised learning retains the benefits of supervised learning while not being constrained by the need for ground truth, making it increasingly favored by researchers. More and more studies have begun to explore how to use unsupervised methods to improve registration performance, such as the work by Zheng et al. [
14].
A key challenge in unsupervised learning for registration networks has been determining the appropriate loss function in the absence of supervised information. With the introduction of the space transformation network (STN) [
15], this problem was perfectly solved. As a differentiable module, STN can be arbitrarily inserted into any position of the neural network, and it can carry out gradient backpropagation along with the network as a whole. The insertion of the STN made it possible to warp the moving image to generate warped images during the training process, perform similarity calculations [
16] by applying STN to the field of medical images for the first time, and perform end-to-end registration of 2D cardiac cine MR scans, and it achieved comparable accuracy to traditional deformable registration methods and greatly shortened registration time. Later, Balakrishnan et al. [
17] proposed VoxelMorph, which is a deformable registration model based on an unsupervised full convolutional neural network. The model is trained by punishing the appearance difference between images and the spatial gradient of the deformation field. This model also achieves the same results as the most advanced traditional registration algorithm. Kuang et al. [
18] proposed a lightweight unsupervised registration model, FAIM, and strengthened the penalty for irreversible deformation. Later, Zhao et al. [
19] proposed a deep-learning framework VTN for unsupervised affine and deformable registration and used it for 3D cardiac cine MRI and 4D chest CT registration. The results showed that although the smoothness of deformation is a problem, the registration performance of this method exceeds that of traditional algorithms, such as Elastix [
20], and has achieved remarkable results in other aspects. In addition, Chen et al. [
21] introduced TransMorph, a hybrid Transformer ConvNet model for volume medical image registration.
Accurate patient-to-patient registration is extremely challenging due to the variability in brain structures across different individuals. In addition, voxel folding in the deformation field can significantly affect image topology and deformation authenticity. Voxel folding refers to the overlapping of voxels during deformation, leading to inaccuracies. In order to solve the above problems, the traditional registration algorithm can effectively deal with the problems of voxel folding and deformation smoothness based on mathematical models and optimization methods, especially in maintaining the local structure and overall consistency, but it has a slow registration speed in large-scale data or real-time applications, and low registration accuracy when dealing with complex deformation or nonlinear transformation. Deep-learning-based registration algorithms can achieve faster and more accurate registration by learning transformation patterns from large datasets. These algorithms perform better than traditional methods, especially when dealing with complex nonlinear deformations. However, they may still struggle with voxel folding and maintaining deformation smoothness. To enhance registration speed and accuracy, while also addressing voxel folding and deformation smoothness, we propose the multi-constraint cascaded attention network (MCANet). The network architecture consists of two identical subnets, one of which is the extended self-attention network (DSNet). This paper introduces an attention mechanism based on attention gates to the convolutional neural network. This improves the network’s sensitivity to regions with large differences between patient images by inhibiting feature activation in the alignment region. As a result, the network better adapts to inter-patient image variations, enhancing registration accuracy. By applying additional regularization constraints to reduce noise and discontinuities in the registration process, and to make the deformation results smoother and more realistic, our main contributions in this paper are as follows:
We have successfully applied the dilated convolution combination and attention mechanism to the registration of 3D brain MRI images, so that the network can expand the receptive field without adding too much computational cost and network parameters and obtain multi-scale features, and the network can better understand the global structure and local details of the image and improve the ability to accurately detect the deformed region.
Through the cascading network architecture, the deformation registration of the input image from coarse to fine is realized, which greatly improves the accuracy of registration. This method of step-by-step refinement of registration results can effectively improve the accuracy of registration results and can handle registration tasks of different scales and complexities. At the same time, the double regularization constraint is used to ensure the smoothness and authenticity of the image registration, avoid the excessive deformation and discontinuity of the registration results, and make the registration results more in line with the actual situation.
The proposed network model adopts an unsupervised end-to-end training method. It is not limited by ground-based facts and enables near-real-time brain MRI registration between patients.
Compared with traditional algorithms and existing deep-learning-based algorithms, the algorithm in this paper is able to perform alignment efficiently and accurately, and also promotes alignment smoothness and suppresses severe bending deformations under the constraints of dual regularization, which greatly improves the performance in all aspects.
2. Materials and Methods
2.1. Experimental Data
The data used for the brain MRI alignment experiments in this paper were obtained from the Mindboggle101 dataset [
22] and from the Neurite OASIS sample data, which is freely and publicly accessible, and which was derived from T1-weighted brain MR images from 101 participants. The Neurite OASIS [
23] sample data contains 413 brain MRI scans from multiple centers. These data were processed using FreeSurfer version 7.4.1 and the neuronal software package SAMSEG. Four data subsets from the Mindboggle101 dataset, including MMRR-21, NKI-RS-22, NKI-TRT-20, and OASIS-TRT-20, totaling 83 3D brain MR images, were initially used in this study. For image preprocessing, all images were subjected to a cranial stripping operation and strictly aligned to the MNI152 template space. Thirty-one cortical regions were manually labeled according to the Desikan–Killiany–Tourville (DKT) protocol. In the Mindboggle101 dataset, three subsets of MMRR-21, NKI-RS-22, and NKI-TRT-20 totaling 63 brain images (3906 pairs) were used as part of the training data. The test subset includes 20 images (380 pairs) from OASIS-TRT-20. In order to improve the generalization ability of the model, the study simultaneously used 413 3D brain MR images from Neurite OASIS and divided them into training, validation, and test sets in the ratio of 7:2:1. Specifically, 0.7 of the data (382 images) were used for training, 0.2 of the data (89 images) for validation, and 0.1 of the data (45 images) for testing. This strategy not only enlarges the size of the experimental data but also improves the adaptability of the model to different imaging protocols and population variations, thus enhancing the generalizability of the model in various clinical settings. In addition, in this study, the images were intensity normalized and the image size was cropped from the original 181 × 217 × 181 to 160 × 208 × 160 to make the images suitable for the proposed network. Also, linear affine alignment was performed on all images using the ANTs software version 2.4.3 package [
24]. The newly introduced validation set plays a crucial role in hyperparameter tuning and model selection to ensure optimal model performance while minimizing the risk of overfitting.
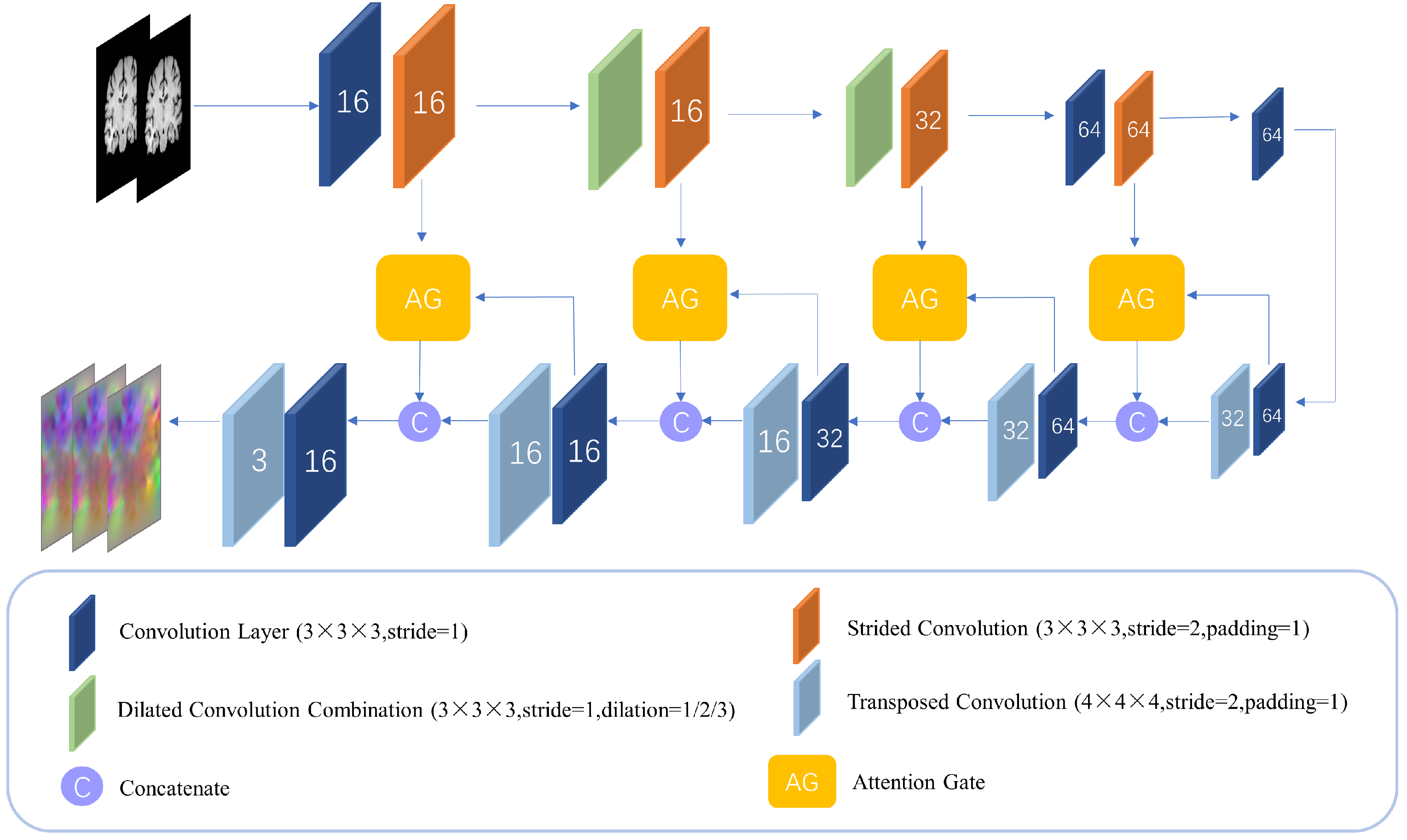
2.2. MCANet Network Structure
MCANet consists of two levels of identical registration subnet cascade, each of which incorporates an expanded self-attention design. Since the use of downsampling to enhance the receptive field of features will cause the deep feature map to lose the local detail information in the image, MCANet uses an expanded convolution group with different expansion rates to explicitly increase the receptive field without adding additional parameters, so that the network can capture more contextual information during the convolution process. The self-attention mechanism with the attention gate as the main form is added, and the shallow feature map is downsampled by step–step convolution, so that the size of the feature map is consistent with that of the gated feature map. Through the gating mechanism, the attention gate combines the attention-adjusted features with the original features, which can effectively increase the receptive field of the network without adding a large number of parameters, and at the same time inhibit the feature activity of the alignment region to improve the sensitivity of the network to the difference region and implicitly improve the deformation field smoothing problem. The transposed convolution is then used for upsampling to restore the obtained feature map to its original size in the input image. For the two-subnet cascade structure, double regularization constraints are explicitly applied to resolve the voxel folding problem, thereby comprehensively improving registration quality.
2.3. Cascade Network Registration Method
The input of the deformable image registration model is usually an image pair that has been affine aligned, where the image to be registered is called the fixed image and the image to be registered is called the moving image. For a pair of fixed image,
F, and moving image,
M, CNN can generate a displacement vector field (DVF)
for floating image warping by performing feature extraction and deformation prediction on them. In the registration task, the training process of CNN is the process of continuously updating the network parameters to obtain the optimal DVF. After obtaining the DVF, the STN can be used to perform trilinear interpolation on the floating image according to the deformation information in the DVF, thereby obtaining the deformed image. For the MCANet proposed in this paper, the floating image needs to go through two stages of deformation in total, as shown in
Figure 1.
In the first stage,
M and
F are passed into the registration subnet together as the initial input. After the deformation field
is generated by the registration subnet
, the first warping deformation is performed on
M to obtain a rough deformed image
. This stage can be expressed as Equation (
1):
After obtaining the deformed image
, it enters the second stage of registration. At this time,
is sent to the registration subnet
together with
F again as the moving image. After the prediction of
, the deformation field
between
F and
can be generated. According to the voxel displacement in
, rough deformed image
is warped again, and then we can obtain the fine deformed image
. This process can be expressed by Equation (
2):
Since is the moving image in the second stage, after the spatial transformation in the first stage, may lose part of the spatial information in the original moving image M. Therefore, in this study, the deformation field is input to the end of as auxiliary information to assist in the generation of . Through the above process, the network architecture completes the coarse-to-fine registration of the original input images.
2.4. Dilated Self-Attention Network
The deformable registration network in this paper is composed of two encoder–decoder networks with the same structure, which we call the dilated self-attention network (DSNet), as shown in
Figure 2. In this network, we use dilated convolutions to increase the receptive field of the convolutional layer and thereby improve the performance of the network. In the deep neural network, downsampling is often used to increase the receptive field. However, due to the limited number of downsampling in the shallow network, the receptive field of the low-level features cannot be effectively expanded. It is difficult for the extracted features to fully reflect the differences between the input images. Therefore, some studies [
25] have increased the receptive field of low-level features by adding Inception modules to the network. But for 3D convolution, especially in the shallow layer of the network (the size of the feature map is large at this time), the use of any large-scale convolution will bring huge memory and calculation consumption. But dilated convolution can bypass this problem. Dilated convolution can explicitly increase the receptive field of the feature map without adding additional parameters, enabling the network to capture more contextual information during the convolution process. At the same time, because there is no downsampling, the loss of detailed information in the image is avoided, and the ability of low-level features to perceive the difference in detail in the image is preserved. In computer vision, acquiring multi-scale features is crucial for object region detection. By adjusting the dilation rate of dilated convolutions, the size of the receptive field can be directly changed, and the network can capture features of different scales.
Previous research [
26] has elucidated that dilation convolution employs sparse sampling techniques, which, if a single dilation rate is used, can lead to a checkerboard pattern effect within the perceptual field of a pixel. In this case, voxels within the depth feature map can only perceive the underlying information in a checkerboard pattern, resulting in a large loss of local information. At the same time, the information correlation between voxels that are far away from each other is not strong, and the checkerboard effect reduces the coherence and consistency of the local information. For this reason, this study uses a cascade of three dilation convolutions with different dilation rates
and integrates them into one module. This cascade of dilation convolutions with different dilation rates is able to expand the sensory field of the output of each layer without increasing the number of parameters, which makes the parameter utilization more efficient in capturing the long-term dependence and global information in the input data, and thus simplifies the complexity of the model to a certain extent. In addition, the dilation convolution with different dilation rates is able to capture features at different scales, and by integrating these multi-scale features, information can be extracted more optimally, which in turn enhances the model’s representation of the input data. As the sequence of dilation rates is redesigned, this will further optimize the feature extraction process and enhance the model’s ability to recognize subtle features. This approach not only improves the model’s sensitivity to local features but also enhances its understanding of global features, thus achieving better performance in various visual tasks. In this way, the model is able to achieve the in-depth mining of multi-dimensional features of the input data while keeping the number of parameters constant, which is important for improving the generalization ability and adaptability of the model. Adopting the dilation convolution cascade strategy with different dilation rates can not only effectively solve the checkerboard grid problem caused by a single dilation rate but also further improve the feature extraction ability and expression ability of the model through the integration of multi-scale features, which provides new ideas and methods for the design of deep-learning models.
Attention gate has been shown to be successfully applied to dense prediction tasks for images [
27]. A network model trained with an attention gate can implicitly learn the ability to focus on task-relevant regions in an image and suppress responses to task-irrelevant features [
28]. This study incorporates attention gates into the design of the registration subnet DSNet.
Figure 3 shows the structure of the attention gate module. The attention gate uses feature maps of two adjacent scales as input; through the attention gate, the interrelated regions in the input image can be selectively learned, and the saliency of unrelated regions can be suppressed, which avoids the introduction of additional human supervision in the network construction process. The attention gates can enhance the model’s response to critical regions and improve the final registration accuracy. Among them, the deep feature map on the decoding path is input into the network as a gating signal, which contains rich context information; the attention gate can dynamically adjust the degree of attention of the model to the input features, which can be used to screen image features closely related to the registration task and determine key deformation areas in the image. For the gating feature map and the weighted feature map, this paper used the additive attention mechanism [
29] to calculate the attention weight. Compared with the multiplicative attention mechanism [
30], although the additive attention requires more computational cost, it will achieve better performance than the multiplicative attention. Therefore, this study used the additive attention mechanism to complete the calculation of attention weights. The attention mechanism helps the network identify salient features related to the task by continuously optimizing the attention weights. The calculation of the attention weight is:
where
and
represent the low-level feature map and the gated feature map of layer
j in the network, respectively.
represent the linear transformation parameters of convolution. The low-level feature map
is downsampled using strided convolution so that
has the same size as the gating feature map
.
and
are bias terms of the operation.
is the ReLU activation function, and
is the sigmoid activation function, which are used to enhance nonlinear expression. Afterwards, the attention weight coefficient
can be obtained by resampling
using trilinear interpolation. Finally, the attention weighted feature map
can be obtained by multiplying
and
element-wise.
By adding the attention gates to the skip connections of each scale, the multi-scale imaging information can be aggregated in the gating signal, which helps the network to achieve more accurate feature selection and weight assignment, thereby achieving better deformation prediction. In addition, the attention gate is also a differentiable module whose parameters can be updated in backpropagation.
2.5. Loss Function and Double Regularization Constraint
In this paper, we trained the two registration subnetworks as a whole and minimized the loss function in an end-to-end training manner to achieve the highest registration accuracy. The loss function usually consists of two parts: one is the similarity loss between the fixed image and the moving image, and the other is the regularization of the DVF. In this paper, normalized cross-correlation (NCC) [
31] was used to measure the similarity between the deformed image and the fixed image, and its negative value is taken as the similarity loss. The relevant calculation can be performed according to Equation (
6):
where
p represents the voxel point in the image and
represents the image domain.
and
denote the average voxel intensity within a local window centered at
p in the fixed and deformed images, respectively. In this paper, the window size is
.
If the network is optimized only with similarity loss, the network parameters are updated towards making the deformed image infinitely close to the fixed image. But at this time, the DVF predicted by CNN will be excessively warped, and even the voxels in the DVF will be folded. Therefore, it is necessary to carry out some spatial regularization on the DVF. Considering that the dual-subnetwork registration model used in this study may produce large deformation predictions, imposing a single regularization constraint is not enough to meet the smooth requirements of the deformation field, so double regularization constraints are implemented. The first regularization term is diffusion regularization, which penalizes the spatial gradient of the DVF:
The second regularization is the bending energy [
32], which penalizes severe bending deformation by applying a loss to the second derivative of the voxel displacement in the DVF. It is defined as:
The double regularization constraint in this paper can be expressed as:
where
and
represent the trade-off coefficients between the two regularization terms.
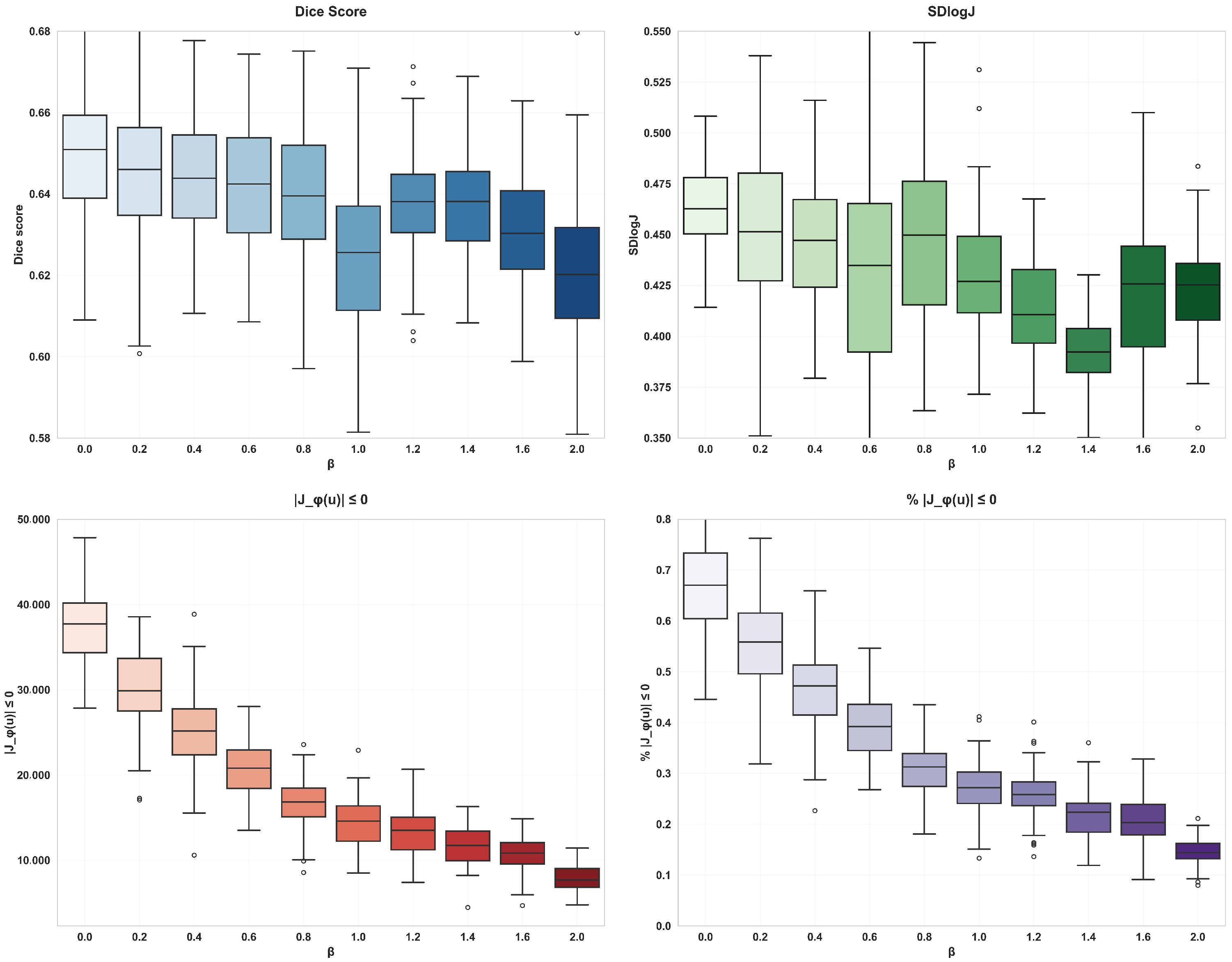
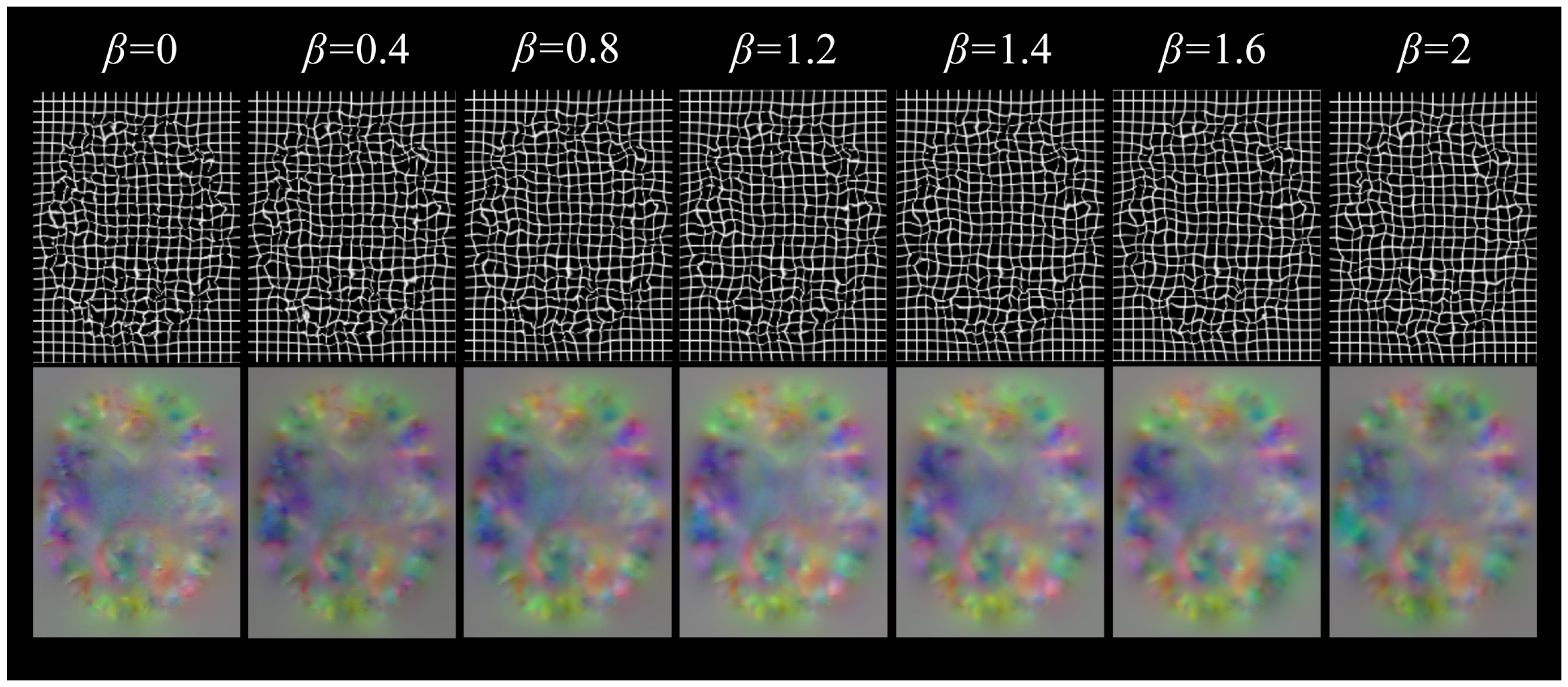
The diffusion regularization term is used to punish the spatial gradient of the displacement field, so as to promote the smoother displacement field, which helps to avoid overly complex local deformation and maintain the continuity of the overall deformation. The bending energy regularization term can not only promote the smoothness of the displacement field and inhibit the serious bending deformation at the same time but also effectively control the complexity of the model and reduce the risk of overfitting. With the increase of the of the weight coefficient of bending energy, the degree of voxel folding decreases significantly, but the Dice score also decreases, so when using double regularization constraints, the voxel folding problem can be effectively alleviated by adjusting the weight coefficient and ensuring smooth deformation.
2.6. Evaluation Method
In this paper, the Dice equation was used to calculate the volume overlap of the same anatomical tissues between the fixed image and the deformed image, and the Dice scores of all labeled tissues were averaged to quantitatively evaluate the registration accuracy. The calculation equation is as follows:
where
and
represent the corresponding brain anatomical tissues in the fixed image and the warped image, respectively. At the same time, in order to quantify the regularization of the DVF during registration, we also counted the number of folded voxels in the DVF, which was obtained by calculating the number of voxels with non-positive Jacobian determinant in the DVF (i.e.,
).
In order to better measure the smoothness of the deformation field, SDlogJ is also used in the study.
SDlogJ is an index used to evaluate the regularity of the deformation field, mainly to calculate the logarithmic standard deviation of the Jacobian determinant. The calculation formula is as follows:
In this formula,
N represents the total number of voxels.
denotes the absolute value of the Jacobian determinant for the
i-th voxel, and
is the mean of the logarithm of the Jacobian determinants across all voxels. Additionally, the study introduces Sensitivity to evaluate the model’s ability to detect positive samples. Sensitivity is calculated using the following formula:
where
is the number of true positive samples (correctly identified as positive) and
is the number of false negative samples (positive samples incorrectly classified as negative). This metric quantifies the proportion of actual positives that are correctly identified by the model.
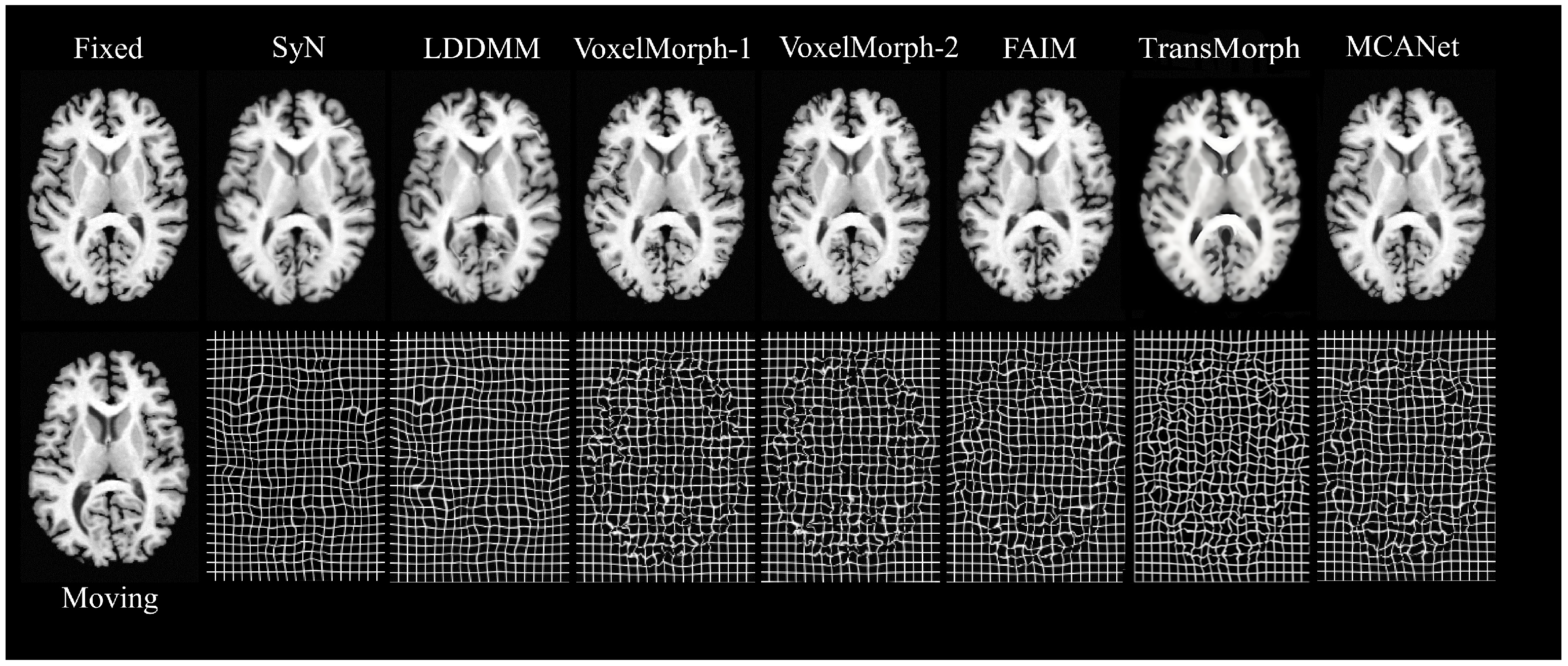
In order to intuitively demonstrate the performance of MCANet, this study introduced several other advanced registration methods as baselines, including SyN [
33], LDDMM [
34], VoxelMorph-1, VoxelMorph-2, FAIM, and Transmorph [
21] DIF-VM. SyN, as an excellent representative of traditional registration algorithms, has been proven to perform effective inter-patient brain registration. We used the ANTs software package to conduct SyN experiments with cross-correlation as the similarity measure and a gradient step size of 0.2. The second traditional algorithm baseline was LDDMM, which aimed to solve large deformation image registration and can handle inter-patient registration with varying brain structures very well. In our experiment, the mean square error (MSE) was used as the objective function, the smoothing kernel size was 5, the smoothing kernel power was 2, the matching item coefficient was 4, the regular item coefficient was 8, and the number of iterations was 500. Moreover, this paper also selected VoxelMorph based on unsupervised learning as the baseline. There were two variants of this model: VoxelMorph-1 and VoxelMorph-2. In this study, it was retrained according to the optimal parameters given in Ref. [
15], and the registration evaluation was completed on the test dataset of this paper. FAIM is a lightweight unsupervised registration model that can achieve high-precision registration with a small number of network parameters. In addition, FAIM also incorporates a regularization term that directly penalizes folded voxels during training. According to Ref. [
16], in this study, the weight coefficient of this regularization term was set to
to ensure the balance between the registration accuracy and the smoothness of the deformation field. In addition to the above methods, two baseline methods for deep learning have been chosen for this paper. DIF-VM is a probabilistic differential homography-based alignment method that uses CNNs to estimate the displacement vector field and diffusion regularization to ensure the smoothness of the deformation field. TransMorph, as a novel Transformer-based unsupervised alignment framework, effectively captures long-range spatial relations through a self-attention mechanism. In this study, the optimal parameters from Ref. [
21] are used for retraining, and the Adam optimizer is used during training with an initial learning rate of
, a batch size of 1, and a total number of iterations of 10,000. The loss function consists of similarity loss (negative mutual information) and regularization loss (bending energy) to ensure the smoothness and biomechanical soundness of the deformation field.
2.7. Implementation
The MCANet proposed in this paper was implemented using the deep-learning framework PyTorch version 1.12.0. All experiments were performed on a single NVIDIA Tesla P100 GPU from NVIDIA Corporation, Santa Clara, CA, USA and Intel Xeon Silver 4210 CPU from Intel Corporation, Santa Clara, CA, USA. All models were trained for 500 epochs (63,000 iterations) using the Adam gradient optimizer to minimize the training loss and update the network parameters, with a batch size of 1. In training, the initial learning rate was set to , and this decreased automatically with the increase of training times. The weight coefficient was set to 1 based on experimental experience.
4. Discussion
3D brain MRI alignment is important in observing structural brain lesions and performing brain health treatments. Traditional deformation alignment algorithms take a significant amount of time to align image pairs and require several manual adjustments of parameters to achieve optimal results. In addition, the optimal alignment parameters are different from one image to another, so the traditional methods are highly dependent on manual operation, which is both troublesome and time-consuming. With the improvement of hardware performance and the increase of network model size, the traditional methods gradually become unsatisfactory in terms of alignment time and accuracy. In contrast, the model proposed in this paper can learn the best parameters for predicting deformations through continuous optimization and can be directly applied to unseen images, completing the alignment at near real-time speed without human involvement. The network can automatically complete the deformation prediction based on the features of the input image, which is efficient and accurate. Although some traditional algorithms still have an advantage in deformation smoothing, FAIM and MCANet have made great strides in this area as well. When the weights of the regularization terms are large enough, they can achieve very smooth deformation without unnecessary sacrifices. While VoxelMorph has been a benchmark for unsupervised alignment due to its alignment accuracy, speed, and robustness, MCANet introduces several key architectural improvements. Specifically, MCANet incorporates attention gates to focus on critical anatomical regions and employs dilated convolutions to expand the receptive field without increasing computational complexity. These enhancements significantly improve deformation smoothness, reduce voxel folding, and enable more precise alignment of complex anatomical structures. Additionally, MCANet’s multi-scale context aggregation mechanism further refines the deformation field, making it particularly effective in scenarios requiring high-precision registration.When the model has a large receptive field and can focus on key areas of deformation, its deformation of deformed images will become more natural and accurate. As can be seen from the data of the ablation experiments in
Table 2, the addition of attention gates and regularization terms significantly reduces voxel folding, a common issue in learning-based methods. When combined with dilated convolutions, the proportion of folded voxels decreases by 0.3%, and the smoothness of the deformation field improves by 38%. Bending energy regularization further enhances these improvements by reducing voxel folding, though with a slight decrease in alignment accuracy (as shown in
Table 3). This trade-off is justified as it leads to more biologically plausible deformations, which are critical in medical imaging.
FAIM, a lightweight unsupervised network model that directly incorporates the value of a non-orthonormal comparable determinant as part of the loss function, has also made some progress. Although MCANet is larger than FAIM in terms of network architecture and number of parameters, it is significantly better than the latter in terms of alignment accuracy, which remains one of the most important metrics for evaluating models and algorithms. Compared to Transmorph, another advanced deep-learning-based registration method, MCANet demonstrates superior performance in deformation smoothness and voxel folding reduction. While Transmorph achieves competitive registration accuracy, MCANet excels in generating more natural and interpretable deformation fields, which is crucial for medical applications. MCANet’s ability to balance alignment precision with computational efficiency makes it a standout choice for image registration tasks, particularly in scenarios where high-precision and biologically plausible deformations are required. In summary, the model proposed in this paper has made progress in terms of alignment accuracy, speed, and robustness, and the advantages of the model are verified by ablation experiments and comparative analysis.
5. Conclusions
In this paper, we propose a multi-constraint cascade attention network (MCANet) based on unsupervised learning for deformable brain MRI registration. In the subnet design, we combine the expansion convolution combination and the attention mechanism strategy. These methods have played an active role in improving many factors that affect the registration effect. We tested MCANet using the Mindboggle101 and Neurite OASIS datasets, and calculated Dice scores and SDlogJ. The number of voxels folded and registration time were used to quantitatively evaluate the registration effect of 3D brain MRI. The experimental results show that, compared with several existing advanced registration methods (including traditional algorithms and learning based methods), MCANet achieves the highest level of registration accuracy and can smoothly deform moving images. This indicates that MCANet performs well in aligning two brain MR images, and this research has made substantial progress in this field. However, MCANet still has some limitations and needs further improvement in future research.
Although the network structure and regularization constraint mechanism of MCANet can theoretically solve the voxel folding problem and ensure smooth deformation, they still need to be further optimized in practical applications. In the future, we plan to further improve the smoothness and biological rationality of deformation by introducing more complex regularization strategies (such as deformation models based on physical constraints).
MCANet is currently mainly aimed at the registration task of brain MRI, but its applicability has not been verified in the 3D image registration of other organs. In the future, we plan to expand MCANet to other medical imaging fields, such as abdomen, chest, and other organ registration tasks, to verify its versatility and cross domain applicability.
The training process of MCANet relies on unsupervised learning. Although it avoids the need to annotate data, its performance may be affected by the quality and distribution of training data. In the future, we plan to explore semi-supervised learning or self-supervised learning methods to further improve the performance and robustness of the model.
In conclusion, MCANet has shown good performance in brain MRI registration tasks, but it still needs to be improved in data set size, network structure optimization, cross domain applicability, and experimental comparative analysis. We believe that through these improvements, MCANet will be able to play a greater role in the field of medical image registration and provide a valuable reference for related research.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}