1. Introduction
Instagram users upload over 95 million photos and videos every day, with an average of 65,000 images posted per minute [
1]. Pinterest hosts over 240 billion pins across 5 billion boards, providing a vast repository of user-generated and shared images [
2]. These massive volumes of digital content are easily copied, modified, and shared through high-speed internet and mobile networks, leading to a rapid increase in unauthorized content, from copyright violations to the non-consensual distribution of intimate recordings captured through covert cameras [
3,
4].
To mitigate the spread of such unlawful digital content, social media platforms require filtering mechanisms at various stages involving media creators, service providers, and consumers. Automated filtering techniques leveraging AI are widely adopted to identify and block illegal content, including pornography [
5,
6]. However, the filtering systems discussed in this study specifically target predefined unauthorized or unlawful data, such as content violating personal portrait rights or non-consensual imagery. Failure to effectively filter such content can lead to its rapid spread online, causing significant harm to individuals [
7,
8]. Although traditional research in digital rights management (DRM) has tackled similar issues [
9], the growing sophistication of data manipulation techniques to evade filtering presents new challenges.
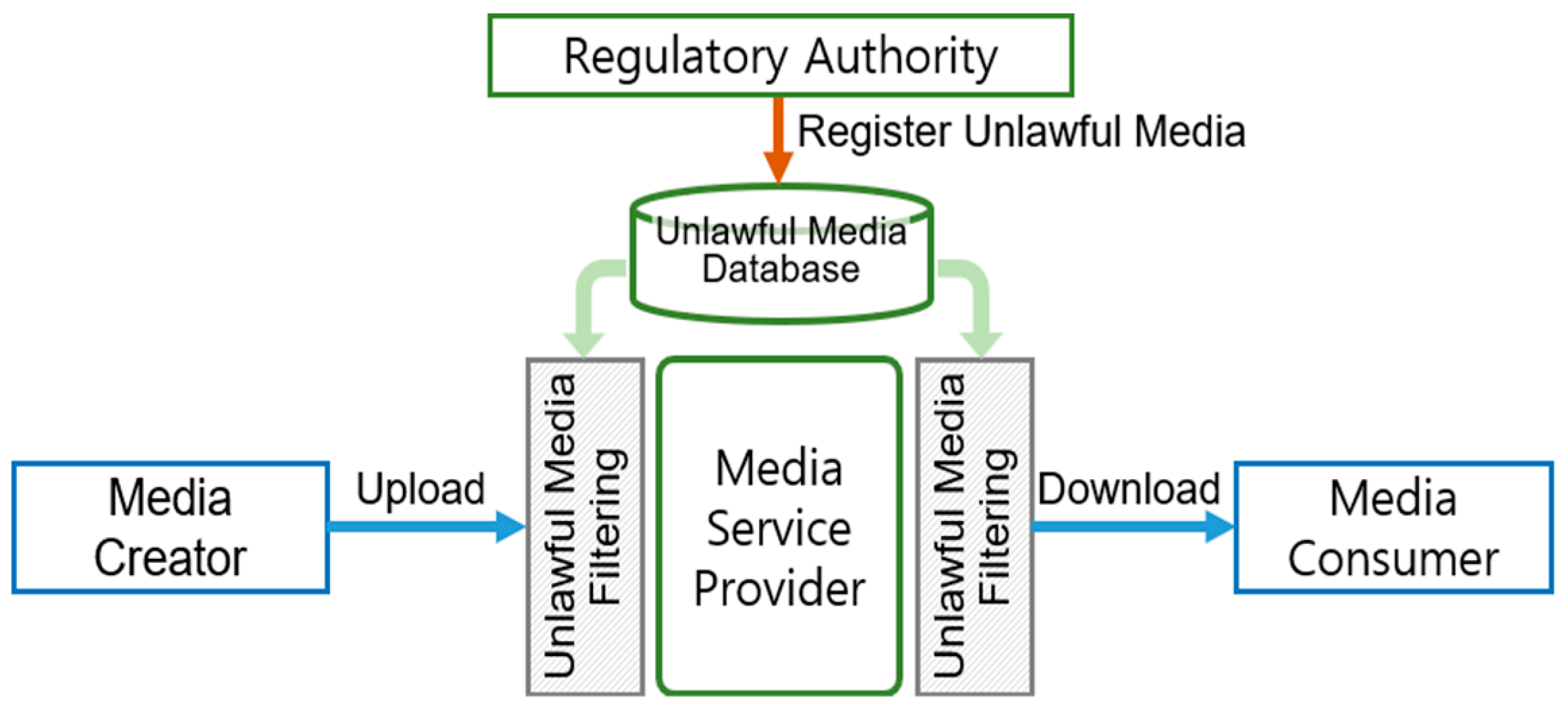
Figure 1 illustrates the structure of the filtering system discussed in this paper. Service providers manage a database of known unauthorized data, periodically updated by regulatory authorities. When media data are uploaded by creators or downloaded by consumers, the system verifies whether the content is unauthorized and blocks it if necessary. The effectiveness of a filtering system depends on how accurately and quickly it can identify illegal data while avoiding excessive false positives. High false positive rates require manual intervention by administrators, increasing operational costs and excessively restricting users from uploading legitimate images.
Due to the inherent nature of digital data, it is trivial to modify original content, such as changing file formats or altering image properties. Consequently, filtering systems must not only detect exact matches but also identify derivative data generated through transformations. This study focuses on filtering techniques for images, aiming to provide a quantitative analysis of methods for detecting modified or derivative images based on the original. Video data, being a temporal sequence of multiple images, could be extended using the techniques discussed in this paper.
Traditionally, fingerprint techniques, a specific method within ICD (Image Copy Detection), have been used to uniquely identify digital data, generating unique identifiers akin to human fingerprints [
10]. Recently, these techniques have expanded into the concept of image DNA, which extracts features in more diverse ways. This study adopts the term “image DNA”, which ensures that transformed images produce similar DNA values while distinct images yield dissimilar DNA. Thus, the extent to which DNA similarity reflects image transformation becomes the key metric for evaluating the effectiveness of image DNA techniques.
1.1. Problem Definition
Filtering systems for image services must distinguish between an image derived from an original and a visually similar but non-derivative image, as incorrectly filtering out unrelated yet similar-looking images can lead to frequent false positives. To address this, we introduce the concept of image equivalence, which distinguishes transformation-derived images from those that are merely similar in appearance.
Definition 1. Two images, A1 and A2, are equivalent if and only if A2 can be generated by applying a transformation to A1.
Equivalent images encompass not only exact copies of the original but also images that have undergone various transformations, such as format conversion, caption addition, resizing, color adjustment, facial mosaicking, and other modifications. Most Image Copy Detection (ICD) techniques focus on identifying equivalent images with high precision and recall.
In contrast, images that may appear visually similar but are not transformation-derived are classified as similar images rather than equivalent images. To formalize this distinction, we define image DNA as a unique descriptor, ensuring that equivalent images exhibit similar DNA values, whereas visually similar but non-equivalent images possess distinct DNA characteristics.
Definition 2. The image DNA of an image must satisfy the following two properties:
If images A and B are equivalent images, then their DNA representations, DNA(A) and DNA(B), should have a small distance under a predefined similarity metric dist, i.e.,where τ1 is a threshold ensuring that small variations from transformations do not disrupt equivalence. If images A and B are not equivalent images, then their DNA representations should have a large distance under the same metric, i.e.,where τ2 is a threshold ensuring that visually similar but non-equivalent images remain distinguishable.
A robust image DNA technique, in this context, is one that consistently upholds these properties, ensuring clear differentiation between equivalent and non-equivalent images. The core challenge addressed in this study is the real-time verification of uploaded images in large-scale social media or content service platforms. This process requires computing the image DNA upon upload and instantly comparing it against a database of stored images to determine equivalence.
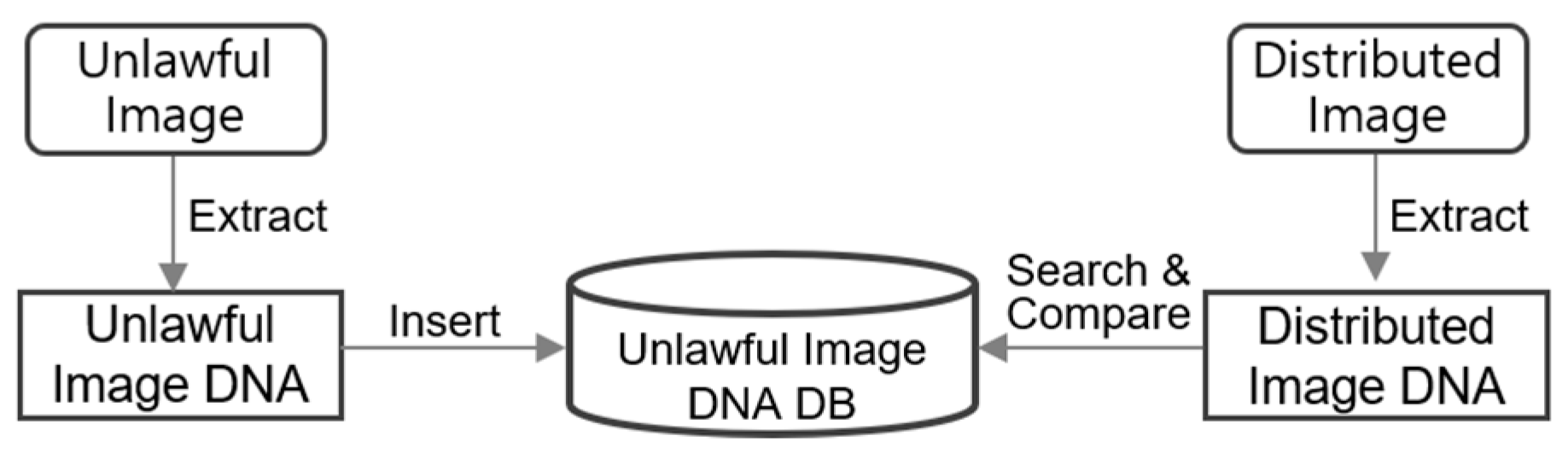
The process of filtering unauthorized images involves the steps illustrated in
Figure 2. First, DNA is extracted from the filtering target images and stored in a searchable DNA database. This database can either be prepopulated with unauthorized images or updated incrementally as needed. For filtering, the DNA of distributed images is extracted, compared against the database, and analyzed for similarity to detect unauthorized content.
For image DNA techniques to be practical in real-world scenarios, several requirements must be satisfied. First, the overhead for DNA generation and search must remain within acceptable limits. Search overhead is particularly critical as the database grows, potentially impacting real-time upload and download performance. Second, the false positive rate must be kept low to avoid mistakenly restricting legitimate uploads and downloads, which would impose additional manual verification costs on operators. Third, the system must achieve high detection rates for equivalent images to effectively block the spread of unauthorized content.
1.2. Main Findings
Image DNA techniques have been studied across three categories: bitmap-based, image processing-based, and deep learning-based methods. Each category demonstrates distinct trade-offs between performance and detection accuracy, making the choice of technique dependent on factors like service scale, user base, and detection accuracy requirements. However, no comprehensive quantitative comparison of these techniques has been conducted. We formalize the notion of image equivalence and define the requirements for image DNA techniques, particularly the real-time verification of uploaded images on large-scale social media and content service platforms. From this perspective, the originality of this study lies in its comprehensive, quantitative comparison of three existing categories, thoroughly analyzing their performance across varying datasets and conditions while evaluating their ability to meet these requirements.
The main findings of this study are as follows:
Each DNA technique is sensitive to threshold settings, which significantly impact its performance in detecting equivalent images, necessitating careful optimization of threshold values.
Bitmap-based methods offer fast DNA extraction and search with minimal computational requirements, demonstrating practical advantages for field deployment.
Image processing-based methods, particularly ORB (Oriented FAST and Rotated BRIEF) [
11], provide superior detection accuracy due to their use of multiple feature vectors as DNA while maintaining reasonable overhead for DNA generation and search.
Deep learning-based methods perform poorly in both speed and detection accuracy, highlighting their limitations in addressing image equivalence compared to their strengths in classification and similarity tasks.
Our findings indicate that DNA DB build and search times depend heavily on DNA extraction time, emphasizing the need to prioritize extraction efficiency in practical large-scale filtering systems with high processing demands and frequent DB updates.
These findings provide valuable insights into the strengths and limitations of current techniques and contribute to the design of effective image filtering systems for large-scale content platforms.
1.3. Paper Structure
The remainder of this paper is organized as follows.
Section 2 provides a detailed explanation of the three categories of image DNA techniques.
Section 3 describes the experimental methodology used for the quantitative analysis of these techniques.
Section 4 presents the results of comparative experiments on DNA extraction, insertion into the DNA database, search performance, and detection rates. Finally,
Section 5 concludes this paper.
3. Strategies for Analyzing Image DNA Techniques
3.1. Performance Metrics for Image DNA
Evaluating the performance of image DNA techniques requires well-defined metrics from the perspective of the DNA database. These metrics are essential for understanding the strengths and limitations of different techniques and ensuring their practical applicability in real-world scenarios. They can be categorized into two primary aspects: execution time and detection accuracy.
Execution time metrics are further divided into DNA build time and DNA search time. DNA build time refers to the time required to extract DNA from target images and insert it into the database. DNA search time is the time needed to determine the presence of similar DNA within the database, which includes both DNA extraction and similarity computation. DNA extraction time, common to both the build and search processes, is influenced by the computational complexity of generating image DNA. The size of DNA generated by each technique varies, and larger DNA data typically contain more detailed image features but increase storage costs and negatively impact extraction and search performance.
Detection accuracy is evaluated through two complementary metrics: the true detection rate (TDR) and the false detection rate (FDR). TDR measures the ability to correctly identify derivative images as equivalent to the original, while FDR quantifies the rate of incorrectly identifying distinct images as equivalent. These rates depend on the similarity threshold used to determine equivalence based on DNA similarity. A tighter threshold leads to a simultaneous decrease in both TDR and FDR.
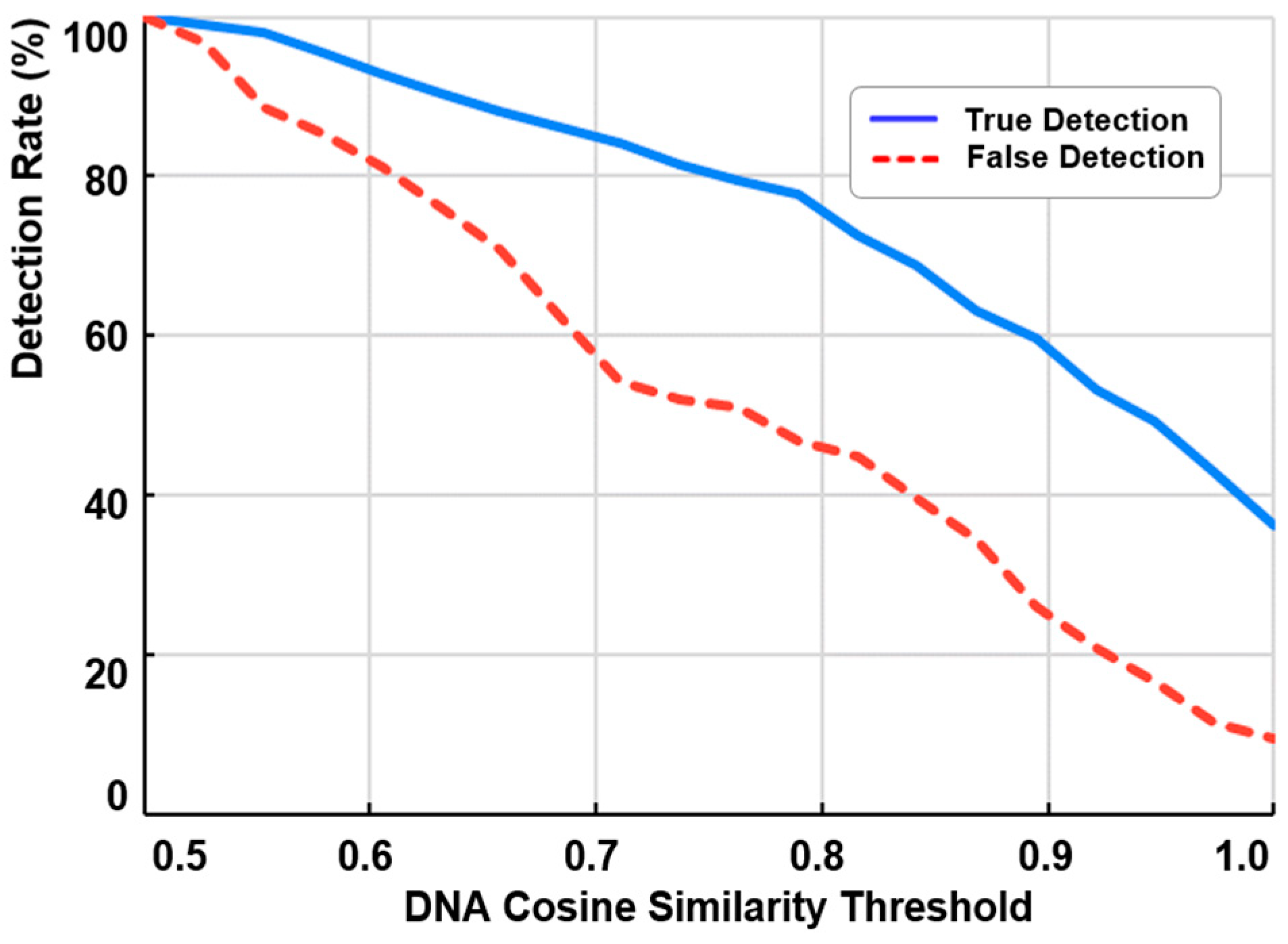
Figure 4 illustrates the average detection rates of 17 different image DNA techniques applied to 53 image pairs selected from a Kaggle dataset [
27]. In the figure, the blue line represents the “true detection rate” (TDR), which indicates the proportion of correctly identified equivalent images as the threshold
τ1 in Definition 2 varies. Conversely, the dashed red line represents the “false detection rate” (FDR), which measures the proportion of correctly identified non-equivalent images as the threshold
τ2 varies. Cosine similarity was used as the measure of DNA similarity in this experiment, with the threshold ranging from 0.5 to 1.
A lower threshold improves TDR, approaching 1, but also increases FDR, highlighting the importance of selecting an appropriate threshold. Even at thresholds close to 1, 9 out of 96 non-equivalent test images were misclassified as equivalent, underscoring the frequent occurrence of false detections. These results indicate the importance of fine-tuning τ1 and τ2 to optimize filtering performance. However, optimal thresholds depend heavily on image characteristics, DNA techniques, and distance metrics, requiring extensive environment-specific optimization. As such, fine-tuning falls beyond the scope of this study; we instead conduct a comparative analysis using empirically optimized threshold values to ensure a fair evaluation of each method’s effectiveness for the given dataset.
3.2. Image DNA DB
The DNA of target images stored in the DNA database consists of real-valued vector data, making exact matching infeasible and incompatible with traditional indexing techniques. Filtering decisions based on metrics such as Euclidean distance or cosine similarity often requires computing the similarity between a query DNA and every DNA stored in the database. While these calculations are independent and can be parallelized to reduce processing time, the computational cost scales linearly with the size of the DNA database.
Recent advances in vector database (VDB) technologies [
28] provide a way to significantly reduce DNA similarity computation time. Approximate indexing techniques, commonly used in VDBs, enable probabilistic similarity calculations that address the inefficiencies of brute-force methods. In this study, we utilize FAISS [
29], a VDB supporting incremental updates, with the HNSW (Hierarchical Navigable Small World) [
30] indexing technique to construct the DNA database.
Image processing-based DNA techniques generate a large and variable number of 128-dimensional feature vectors per image, often reaching hundreds, depending on image complexity. Consequently, their DNA databases are significantly larger than those of other methods and require additional overhead for managing the mapping information for individual vectors. Moreover, the similarity between the DNA must be calculated based on the ratio of matched vectors between the query DNA and stored DNA, rather than simple pairwise comparisons, further complicating the computation process. This ratio is referred to as the Matched Vector Ratio (MVR).
For our experiments with Nabla DNA, we configured different resolutions and depths for storage DNA and indexing DNA to evaluate their performance. Specifically, the notation x8d4x16 indicates that vector indexing is performed with a resolution of 8 and a depth of 4, while storage DNA is created with a resolution of 16 and a default depth of 8. Such configurations allow us to analyze the impact of varying DNA parameters on indexing and retrieval performance.
3.3. Experimental Data Setup
To compare the performance of image DNA techniques, experiments were conducted using two datasets: a small-scale Kaggle dataset [
27] and the COCO dataset (2014 version) [
31]. The Kaggle dataset contains 1752 images, excluding exact duplicates, of which 34 image pairs deemed equivalent were used for experimentation. This dataset includes images that appear visually similar but are inherently different, as well as transformed versions of the same image, making it ideal for testing equivalence detection while ensuring sufficient diversity.
The COCO dataset comprises 164,062 images with no equivalent pairs. For equivalence experiments, 20 types of transformations were performed as detailed in
Table 2. For performance evaluation, only the large-scale COCO dataset was used, considering that the smaller Kaggle dataset exhibited significant speed fluctuations and that extraction and search time generally scale with dataset size.
3.4. Limitations of the Study
Despite the promising results, this study has several limitations that should be addressed. First, while the COCO dataset is widely used in image-based deep learning research, its size and diversity may not be sufficient to fully represent real-world scenarios. As a result, the model’s performance in highly variable or complex environments remains uncertain. Nevertheless, the dataset serves as a reasonable benchmark for performance comparisons, providing a foundational reference for evaluating different approaches.
Additionally, although various editing methods were applied to the original images, the study did not incorporate manually augmented datasets. More extensive manual augmentation could have further enriched the dataset, enhancing the robustness of the model. Moreover, future research could benefit from employing advanced data augmentation techniques to improve dataset diversity and generalization. Finally, while this study primarily focused on autoencoders and classification-based deep learning models pretrained on ImageNet, it did not evaluate models that directly learn transformation methods. Exploring such models could provide further insights into optimizing image DNA-based techniques.
4. Experiment Results
In this section, we conduct a quantitative analysis of three different types of image DNA techniques using various performance metrics through experiments. For the bitmap-based methods, two configurations of the Nabla DNA technique were used: low-resolution Nabla (x8d4x8) and high-resolution Nabla (x8d8x16). The image processing-based methods included SIFT and ORB, while the deep learning-based methods consisted of Autoencoder, MobileNet, and VGG.
Table 3 summarizes the image DNA techniques employed in this study. The code and datasets used for the experiments are publicly available on GitHub [
13], versioned at commit 0ca06ef.
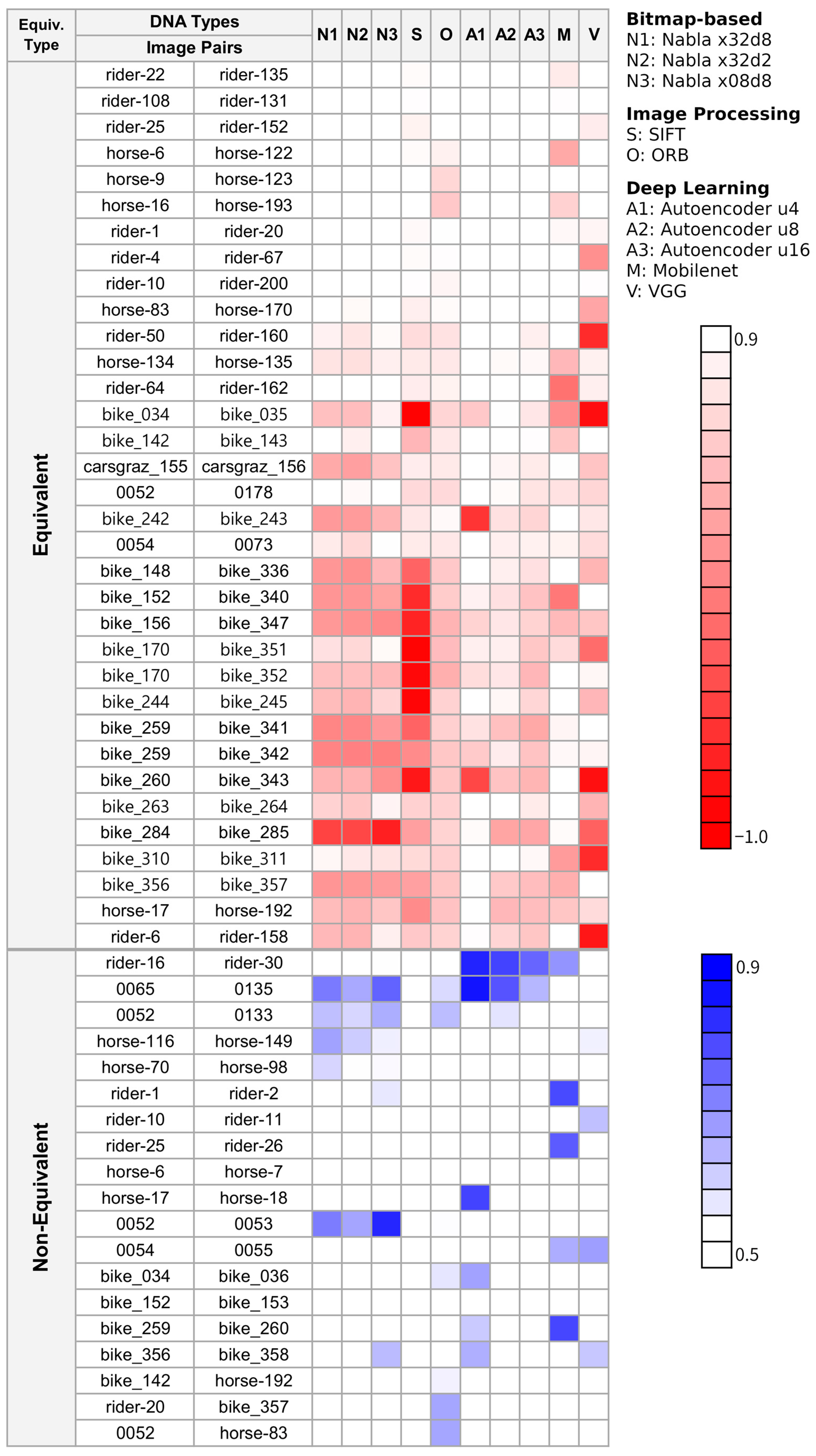
Figure 5 illustrates a heatmap of DNA similarities for the Kaggle dataset, which comprises 34 equivalent image pairs and 19 non-equivalent image pairs. Cosine similarity was used to measure DNA similarity. For equivalent image pairs, similarities below 0.9 (to −1) are represented with a gradient of red, while for non-equivalent pairs, similarities from 0.5 to 1 are shown in blue. Darker red indicates low DNA similarity for equivalent images, signifying poor true detection rates, while darker blue indicates high DNA similarity for non-equivalent pairs, signifying elevated false detection rates. The closer the colors are to white, the better the performance.
As shown in
Figure 5, ORB and Autoencoder (u16) achieved relatively good overall results. However, none of the methods could perfectly detect image equivalence. Many equivalent image pairs exhibited low cosine similarity across all techniques, likely due to the nature of the dataset. The Kaggle equivalent image pairs often included the same object photographed from different angles or heavily cropped images, resulting in low similarity for bitmap-based and image processing-based methods. Deep learning-based DNA techniques, which excel at distinguishing image classification and similarity, generally demonstrate higher cosine similarity. In particular, the Autoencoder trained on a limited dataset achieves a notably high true detection rate. However, apart from SIFT, all other methods show relatively high DNA similarity for non-equivalent image pairs, indicating a higher likelihood of incorrectly judging image equivalence.
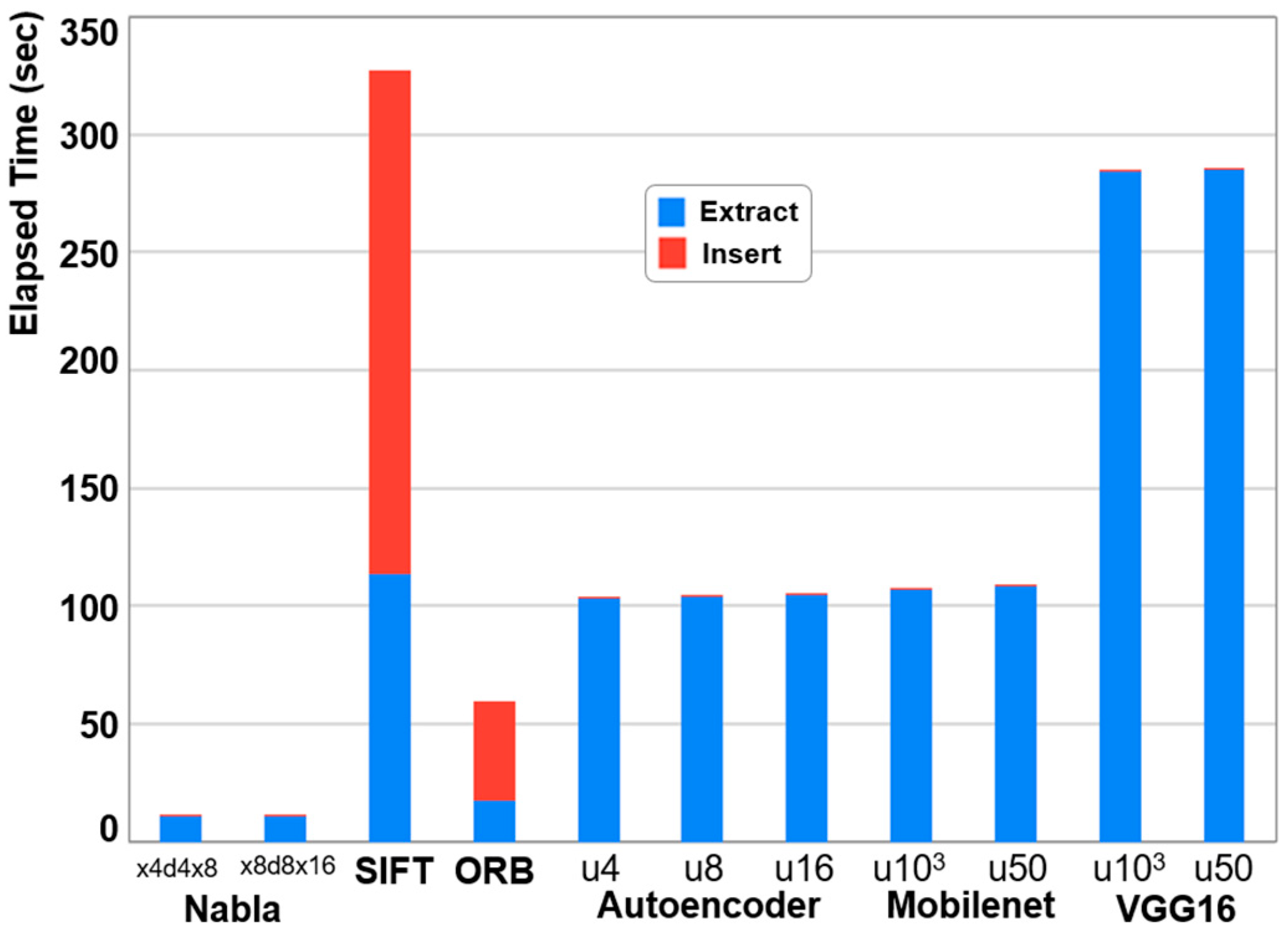
Figure 6 illustrates the time required to construct DNA databases for each technique, using 3000 randomly selected images from the COCO dataset as the filtering target. The database construction time is composed of DNA extraction time and the time to insert the DNA into the VDB. DNA extraction time in our experiments excludes I/O delays, as image files are read from the buffer cache instead of secondary storage [
32].
As shown in the figure, the bitmap-based Nabla method outperformed other techniques, achieving speeds that were 5.6 to 30.5 times faster. This superior performance is attributed to its reduced DNA extraction time and smaller DNA size, which collectively contribute to faster processing. When separating DNA extraction and database insertion times, the insertion time for bitmap-based and deep learning-based methods is negligible. In contrast, image processing-based methods incurred significant insertion delays, taking 1.5 to 2 times longer than DNA extraction. This is because image processing-based methods generate hundreds of high-dimensional feature vectors per DNA. To mitigate this limitation, enhancing parallelism for database insertion in image processing-based methods is essential. By contrast, the extraction process is embarrassingly parallel for filtering target images, giving all techniques the potential for performance improvements.
For the Autoencoder method, training time was excluded from the measurement. Including training would add several hours to the overall build time. Even when comparing DNA extraction times alone, the bitmap-based method demonstrated the best performance. Image processing methods and some lightweight deep learning methods (e.g., Autoencoder, MobileNet) also achieved reasonable overheads of less than 100 s. However, the VGG method required nearly 300 s, due to its deep network architecture with numerous layers, which increases computational demand for DNA extraction.
In summary, for environments where database insertion time is critical, bitmap-based and deep learning-based methods impose minimal overhead and are thus more suitable. Conversely, image processing-based methods exhibit considerable overhead during insertion. For scenarios prioritizing DNA extraction speed, bitmap-based and image processing-based methods outperform deep learning techniques.
Notably, the bitmap-based Nabla method required only 3.5 ms per image for DNA extraction, even when additional DNA was generated for vector indexing. Similarly, the image processing-based ORB method achieved an extraction time of approximately 5.9 ms per image. However, when accounting for the large number of feature vectors generated per DNA, the total time, including database insertion, increased to approximately 20 ms.
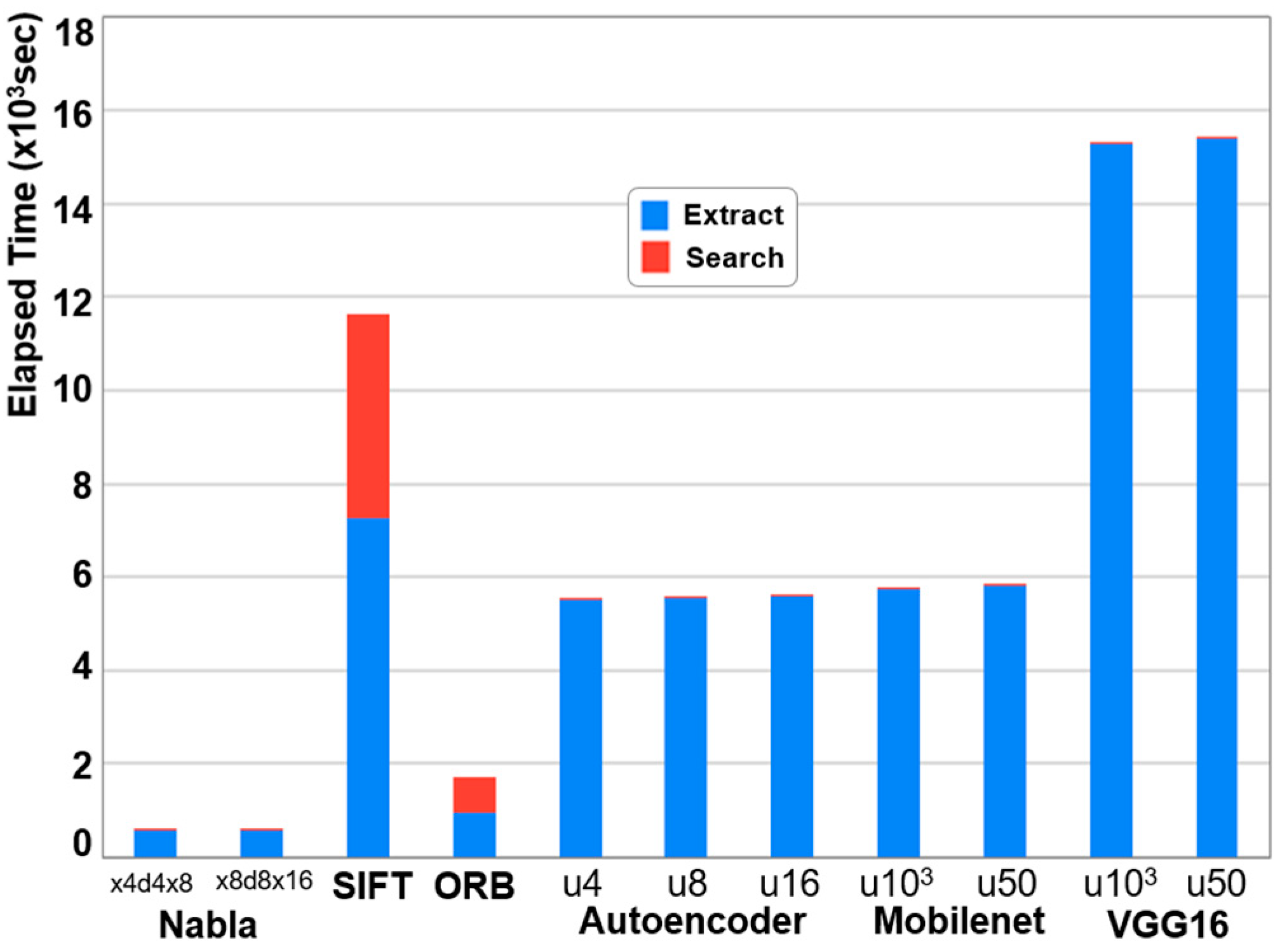
The DNA search time consists of both DNA extraction time and database query time.
Figure 7 illustrates the total search time for 161,062 images from the COCO dataset, excluding the 3000 filtering target images used to construct the DNA database. As shown in the figure, the search time trends are consistent with those observed during DNA database construction. Except for image processing-based methods, the database query time is negligible compared to the DNA extraction time.
The bitmap-based Nabla method achieved a search time of approximately 3.5 ms per image, making it 3 to 27 times faster than other techniques. This superior performance stems from the crucial role of DNA extraction time in search efficiency. Since Nabla significantly reduces DNA extraction time, it directly accelerates the overall search process. For image processing-based methods such as SIFT and ORB, the search time accounted for 60% and 83%, respectively, of the DNA extraction time. This is because these methods generate hundreds of high-dimensional feature vectors per DNA, increasing the computational cost of database queries.
Deep learning-based methods exhibited higher DNA extraction times, with VGG being the slowest due to its deep network architecture. Notably, the size of the DNA itself, regardless of whether it is derived from deep learning- or bitmap-based methods, had minimal impact on the extraction speed.
To quantitatively compare the detection accuracy of each technique, the detection rates were evaluated using 20 transformed images from the COCO dataset.
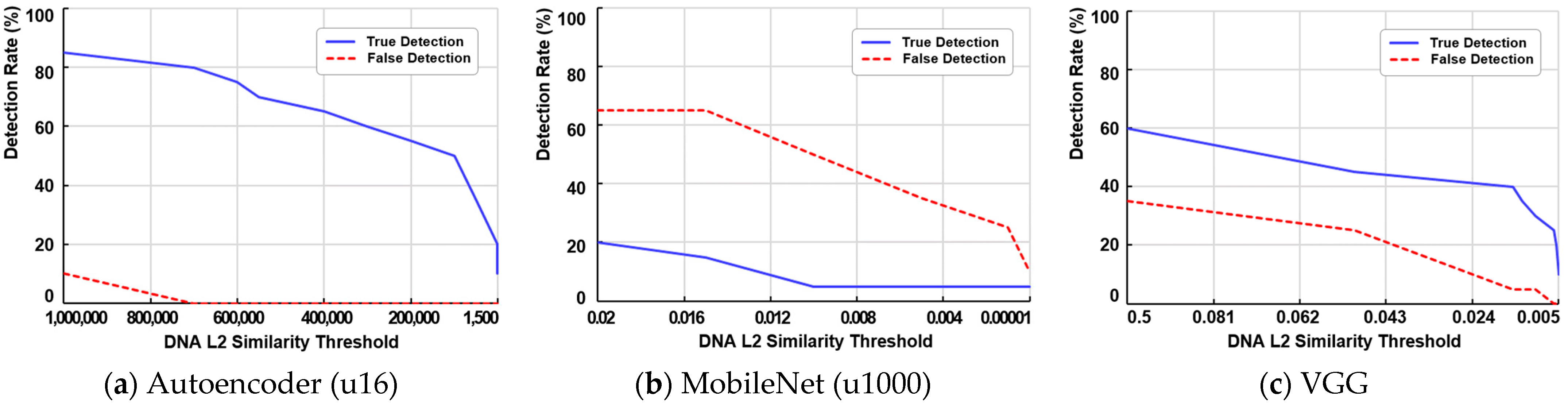
Figure 8 plots the true detection rate (TDR) and false detection rate (FDR) for the bitmap-based Nabla method as a function of the cosine similarity threshold between DNA vectors. The results show that increasing the threshold reduces both the TDR and FDR.
For the bitmap-based method, certain equivalent images fail to be detected even at thresholds close to zero, indicating that its ability to distinguish image features is weaker compared to image processing-based methods. However, the TDR decreases more gradually compared to other techniques, resulting in a broader effective threshold range. Notably, when the DNA resolution is high, the gap between the TDR and FDR widens, making it easier to determine an optimal threshold.
Figure 9 shows the trends in the True Detection Ratio (TDR) and False Detection Ratio (FDR) for the image processing-based methods SIFT and ORB. Both methods used the Matched Vector Ratio (MVR) to determine thresholds, and the results indicate that FDR remained exceptionally low across all threshold values. This is because image processing-based methods generate hundreds of feature vectors per DNA, and the likelihood of feature vectors from non-equivalent DNA matching those of transformed DNA is extremely rare. However, compared to bitmap-based methods, the TDR for image processing-based methods decreases more sharply as the threshold increases, making it relatively more challenging to determine an optimal threshold for deployment.
Figure 10 depicts the TDR and FDR for deep learning-based methods. The thresholds on the
x-axis are based on L2 distances. Among the methods, Autoencoder performed well in detecting the 20 transformed images it was specifically trained on. However, overall TDR was lower than that of other approaches, and the lightweight MobileNet model exhibited a higher FDR than TDR, making it impractical for real-world use. Although VGG achieved higher detection rates compared to MobileNet, its performance was inadequate for practical equivalence detection. This limitation is attributed to its dependence on class-probability vectors, which are specifically designed for image classification tasks. These results indicate that deep learning models have significant room for improvement in addressing the image equivalence detection problem, particularly for untrained arbitrary images, by shifting the focus from similarity detection to equivalence detection.
The poor performance of deep learning approaches can largely be attributed to the architecture itself. While current deep learning architectures demonstrate strong performance in terms of “image similarity”, they are less effective in determining “image equivalence”. If a model were trained on a sufficiently diverse dataset of entirely distinct images, it could establish an appropriate threshold while maintaining a low false negative rate. However, training on a limited dataset may perform well in image classification problems but remains less effective in distinguishing whether an image is a derivative of another.
Figure 10 clearly illustrates that a well-trained Autoencoder, which learns a compact representation of the data, achieves a higher detection rate than classification-based models such as MobileNet or VGG.
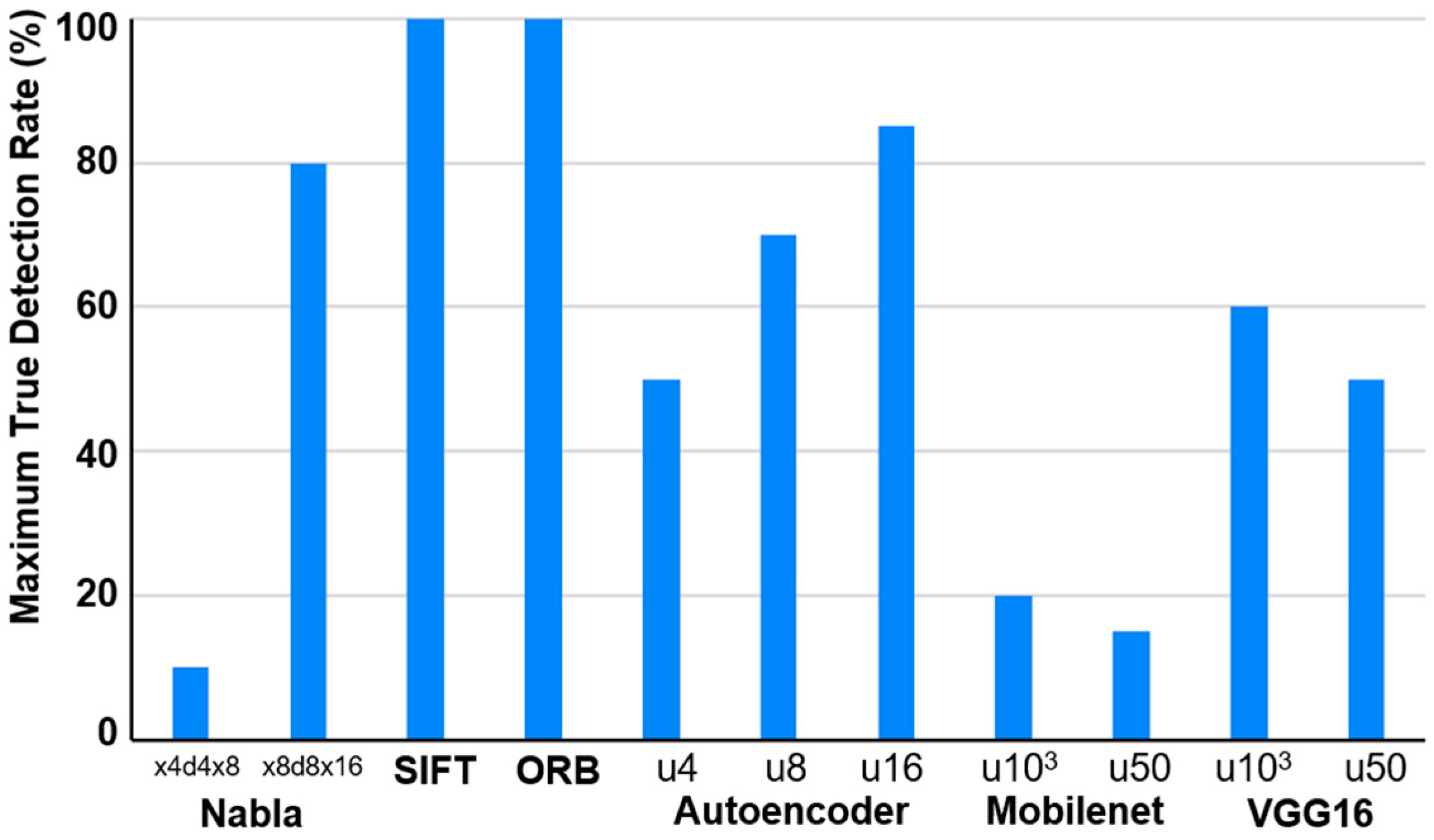
Figure 11 illustrates the maximum achievable TDR for each method across the 20 types of image transformations in
Table 2. As shown in the figure, image processing-based methods achieved the highest detection rates for all image cases we considered. In contrast, low-resolution Nabla (x4d4x8) and the lightweight MobileNet network achieved TDRs below 20%, making them unsuitable for filtering systems. However, high-resolution Nabla (x8d8x16) achieved a TDR of 80%, demonstrating the potential of bitmap-based methods despite their simplicity.
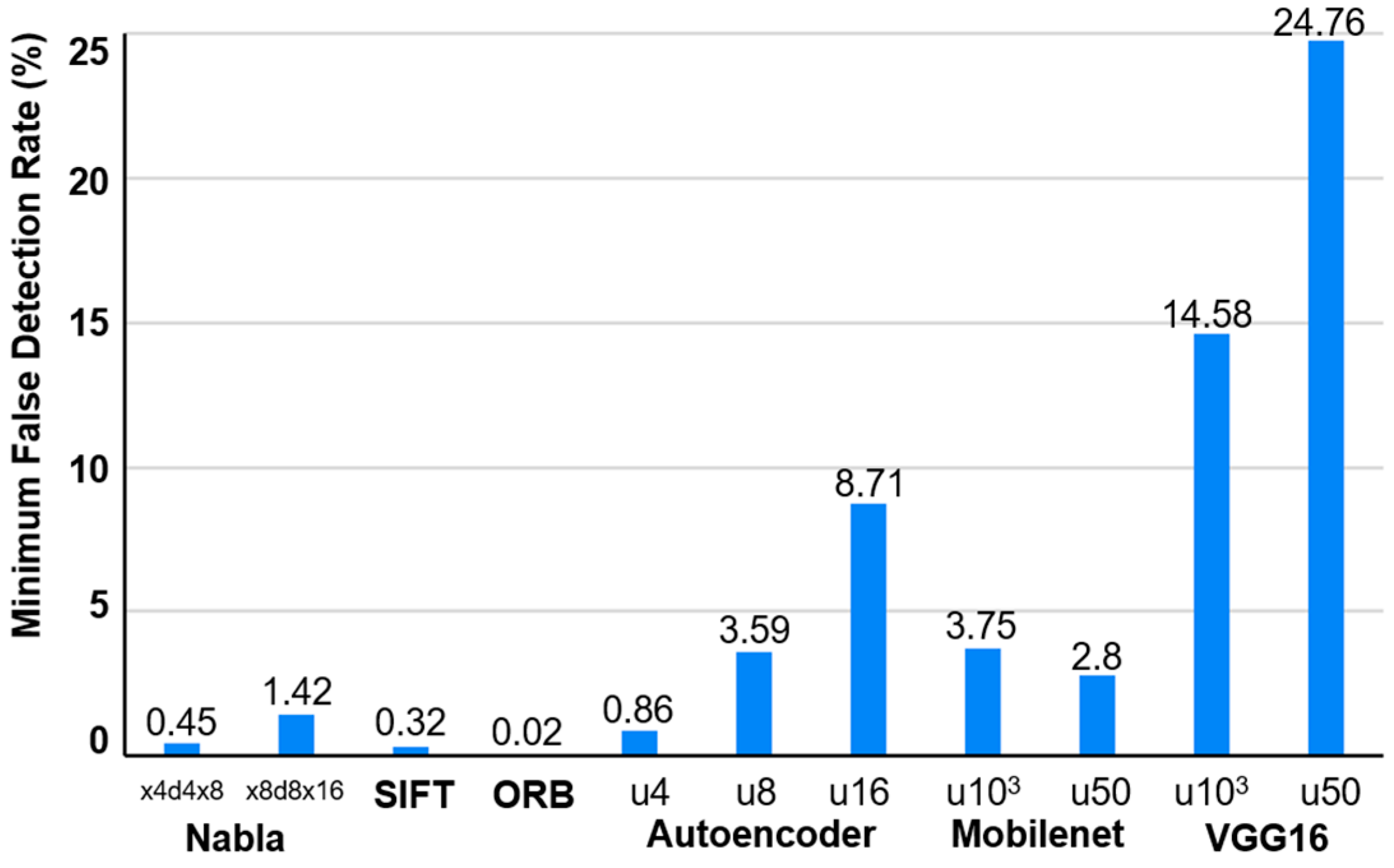
Figure 12 compares the minimum FDR across 161,062 non-equivalent images. As shown, the image processing-based ORB method exhibited the lowest FDR among all techniques. The extraction of hundreds of 128-dimensional feature vectors in image processing-based methods minimizes the likelihood of non-equivalent DNA vectors matching, resulting in consistently low FDRs. In contrast, FDRs exceeding 2–3% impose substantial costs on system operators due to the manual effort required to manage false positives, making deep learning-based methods less suitable for practical deployment. These results suggest that deep learning techniques, while effective for image classification and similarity detection, are less robust for image equivalence detection.
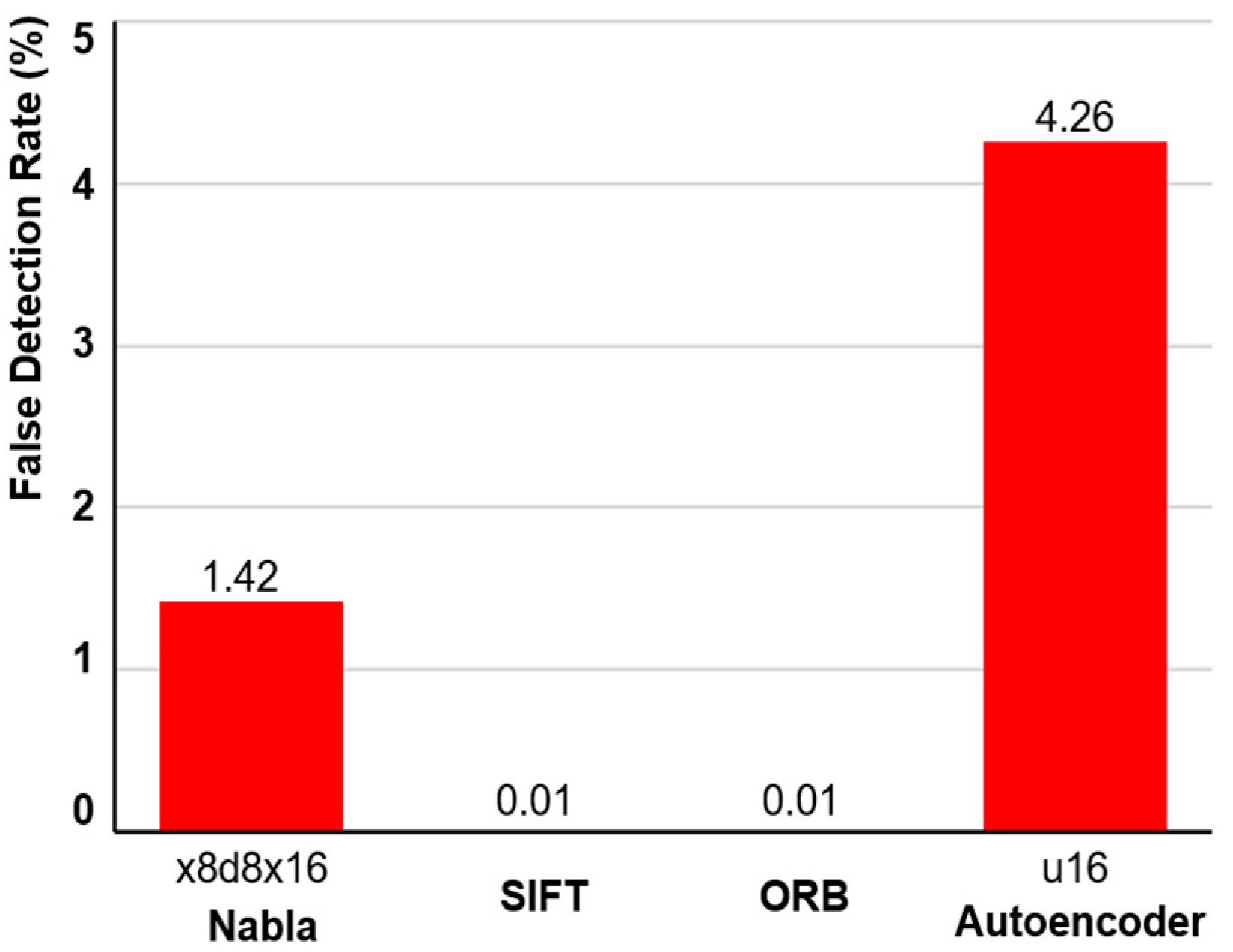
Given the trade-off between the TDR and FDR,
Figure 13 evaluates the FDR for each method when the TDR is fixed at 80%. Only four methods achieved a TDR of 80%, and their results are presented. Despite being a bitmap-based method, Nabla (x8d8x16) achieved an acceptable FDR at minimal cost. While Autoencoder demonstrated a low FDR for the limited dataset, it showed a higher tendency for false detections when handling untrained images, resulting in higher FDRs compared to other methods.
5. Related Works
Image copy detection (ICD) is a well-known research area focused on detecting transformed versions of images. One of the earliest approaches to image copy detection involves perceptual hashing. Techniques such as Average Hashing (aHash) [
33], Difference Hashing (dHash) [
34], and the more robust Perceptual Hashing (pHash) [
35] generate compact representations of images, enabling efficient comparison and duplicate detection. Microsoft PhotoDNA [
36] is another significant development in this field, designed to detect and identify altered images through robust hashing techniques. These methods are computationally efficient but may struggle with highly transformed copies, such as those subjected to geometric distortions or heavy compression.
More recent research has leveraged deep learning to improve robustness against complex transformations. Convolutional Neural Networks (CNNs) [
18] have been widely used to learn high-level feature representations that remain invariant to various image manipulations. Models such as ResNet [
21] and VGG [
19] have been fine-tuned on large-scale datasets to enhance their discriminative power in detecting copied images. Siamese and triplet networks have also been employed to learn similarity metrics for matching transformed versions of the same image.
Hybrid approaches combining traditional and deep learning methods have also been explored to achieve better accuracy and robustness. Some studies [
37,
38] integrate handcrafted features with CNN-extracted embeddings, leveraging both low-level texture patterns and deep feature representations to enhance detection performance. Others [
39,
40] utilize transformer-based architectures, capturing spatial and geometric relationships between image regions through self-attention mechanisms, enabling more effective copy detection.
While deep learning-based ICD methods perform well in controlled laboratory environments, they often struggle in large-scale production settings. DISC2021 [
41] introduced a large-scale dataset comprising one million images to better reflect real-world workloads. This dataset simulates query conditions by including numerous distractor images that are not equivalent to the target images. However, it does not sufficiently address hard negative cases, which are crucial for distinguishing near-duplicates from true copies. To overcome this limitation, NDEC [
42] has focused on developing benchmark datasets that explicitly incorporate hard negative cases, enabling more robust evaluation and adaptation to real-world scenarios.
6. Conclusions
Filtering systems are essential in large-scale content service platforms to prevent the dissemination of unauthorized media data. However, given the ease with which digital content can be manipulated, such systems are rendered ineffective if they cannot detect derivatives of unauthorized content. This study conducted a comprehensive quantitative performance evaluation of various DNA techniques designed to identify manipulated and derivative image data. To this end, four key performance metrics were defined from the perspective of image equivalence: database build time, database search time, true detection rate (TDR), and false detection rate (FDR). The analysis categorized image DNA techniques into three groups—bitmap-based, image processing-based, and deep learning-based—and evaluated them using extensive experiments.
The results highlight the distinct advantages and limitations of each approach. Bitmap-based techniques, with minimal computational requirements, demonstrated detection rates suitable for practical deployment, along with the fastest extraction and search speeds. Deep learning-based techniques, such as Autoencoder and VGG, excel in identifying similar images and image classification tasks but underperform in detecting image equivalence, with additional drawbacks in execution speed. For scenarios demanding extremely high detection rates and sufficient computational resources, the image processing-based ORB method emerged as the most effective choice. The findings of this study are expected to offer valuable insights for designing efficient and reliable filtering systems for large-scale content platforms.
This study proposed three classification methods based on image DNA for detecting image transformations. Future research could explore an additional classification approach using image quality metrics such as SSIM (Structural Similarity Index Measure) and PSNR (Peak Signal-to-Noise Ratio), enabling a comparative analysis of the proposed method and quality-based metrics, particularly in low-computational environments. Furthermore, validating our experimental results using widely accepted benchmarks [
32,
33] would enhance the reliability of our findings and provide a standardized comparison with existing approaches in the field. Another direction for future research is to explore the feasibility of integrating fuzzy logic into image DNA-based filtering techniques and to compare its performance with the current threshold-based method.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}