
A Real-Time DAO-YOLO Model for Electric Power Operation Violation Recognition


Abstract
1. Introduction
- (1)
- The feature representation capability for objects with irregular shapes is insufficient. As shown in Figure 1a,b, the YOLOv8 model fails to detect hooks and cranes with irregular shapes.
- (2)
- The feature representation capability for multi-scale objects is insufficient. As shown in Figure 1a,b, the YOLOv8 model fails to detect smaller hooks and larger cranes.
- (3)
- The localization accuracy is insufficient. As shown in Figure 1b, the bounding box produced by the YOLOv8 model is too small for the operator.
- (4)
- The current datasets are not sufficient for EPOVR. The current datasets usually focus on safety helmets and reflective vests, as shown in Figure 2. These tasks are relatively less challenging, and existing studies are relatively mature in these tasks. However, many violations cannot be covered by the above object categories, such as personnel standing under lifted loads, workers throwing objects from height, and ladders without height restriction marking, etc.
- (1)
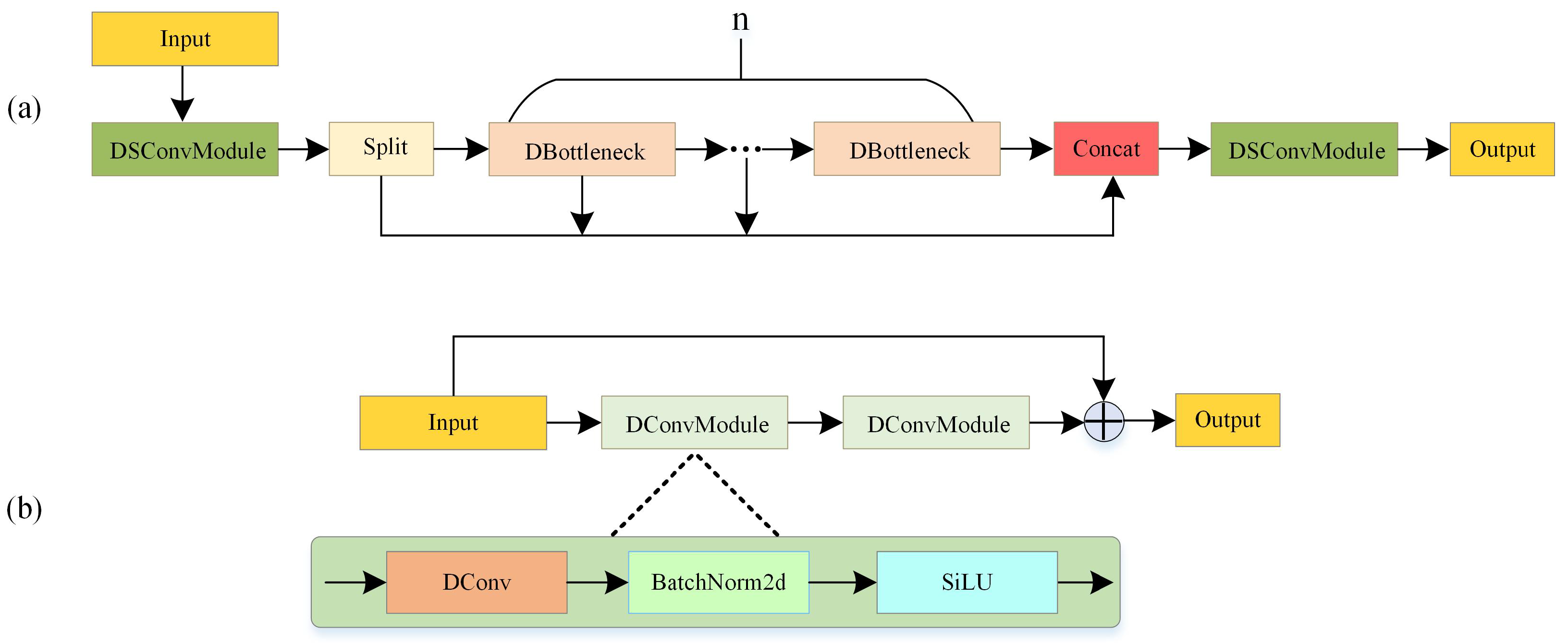
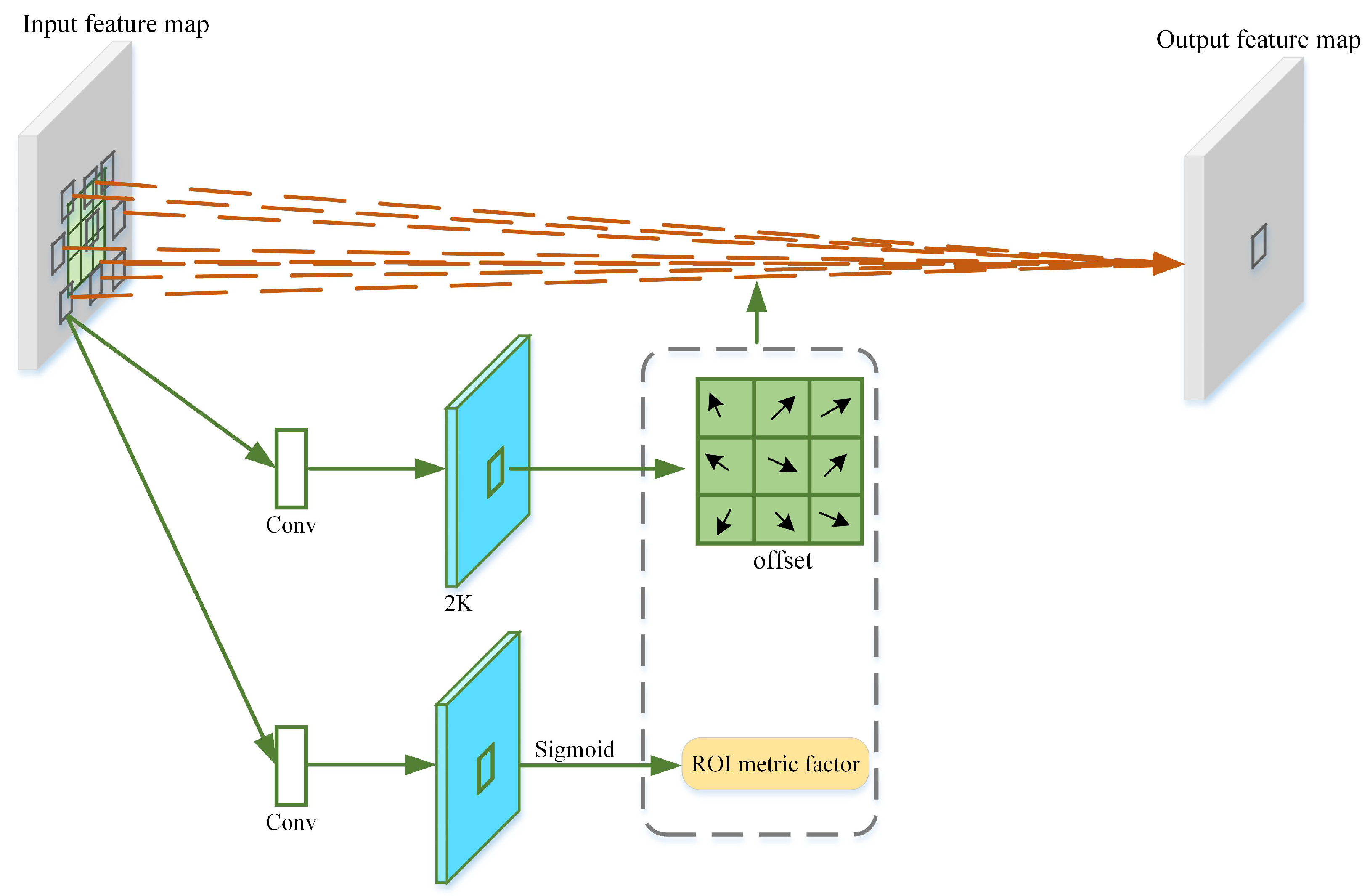
- To address the first challenge, a deformable C2f (DC2f) module is proposed and integrated into the backbone network. The DC2f module replaces the traditional convolutional operations with deformable convolution (DConv) and depthwise separable convolution operations. This approach reduces the number of parameters while providing more accurate feature representation for objects with irregular shapes.
- (2)
- To address the second challenge, an adaptive multi-scale feature enhancement (AMFE) module is proposed and integrated into the backbone network. The AMFE module combines multi-scale depthwise separable convolutions with an adaptive channel attention mechanism to better represent the characteristics of multi-scale objects.
- (3)
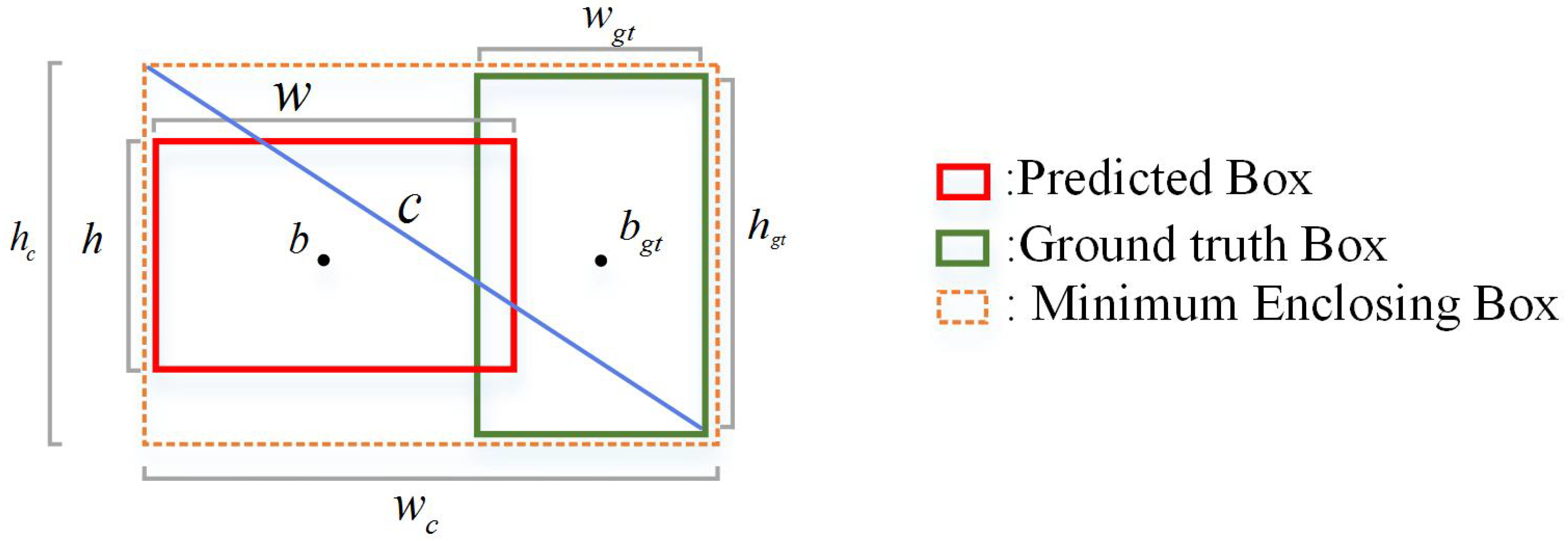
- To address the third challenge, an optimized CIoU (OCIoU) bounding box regression loss is proposed. The OCIoU loss enhances the CIoU (complete intersection over union) loss used in YOLOv8 by optimizing width and height separately instead of using aspect ratio optimization, thereby improving the localization accuracy.
- (4)
- To address the fourth challenge, a novel object detection dataset for EPOVR, named EPOVR-v1.0, is proposed in this paper. This dataset contains 1200 images covering eight common object categories in electric power operation scenarios. The training, validation, and testing sets consist of 840, 120, and 240 images, respectively.
2. Literature Review
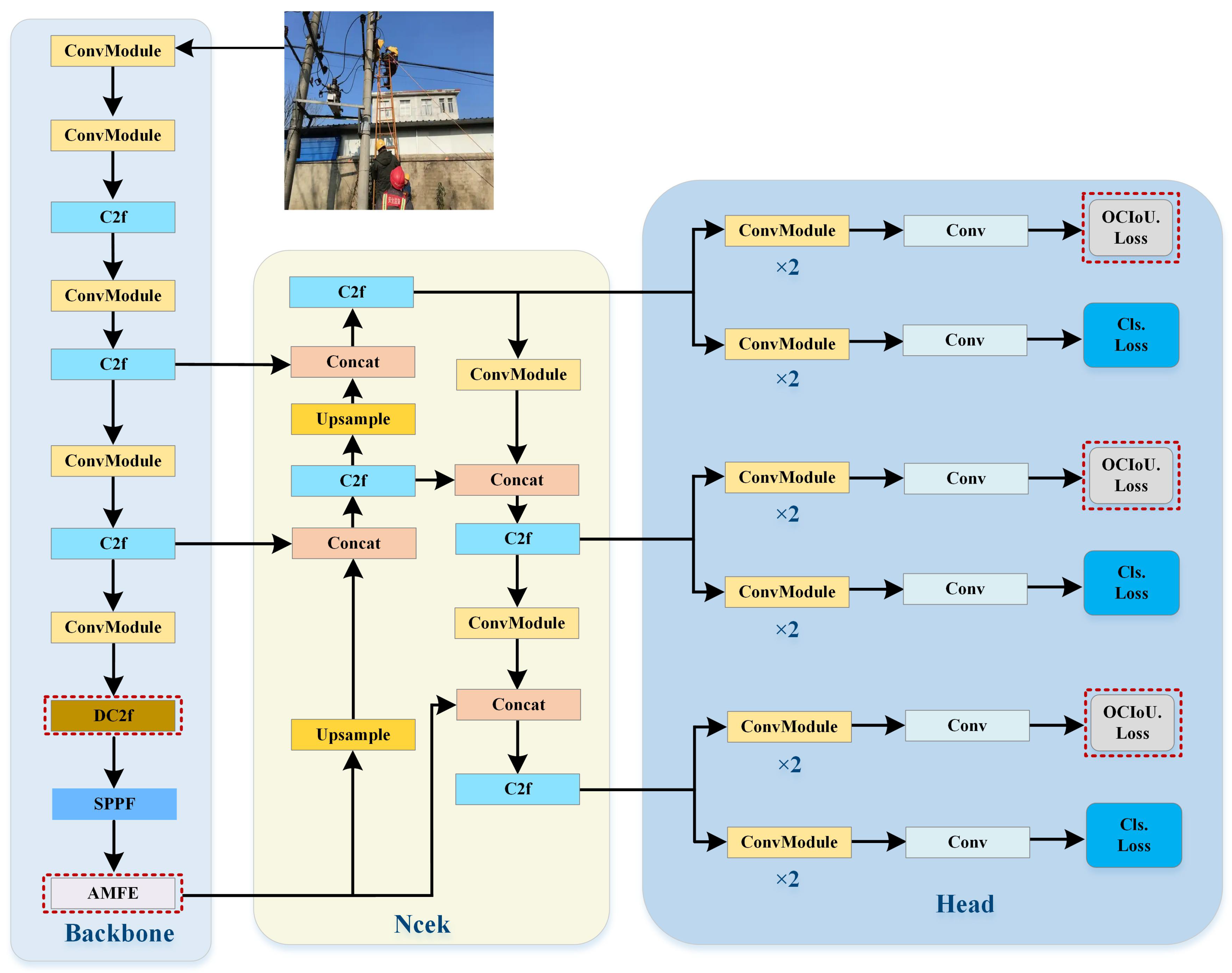
3. DAO-YOLO Model
3.1. Overview
3.2. DC2f Module
3.3. AMFE Module
3.4. OCIoU Bounding Box Regression Loss
3.5. Overall Loss Function
4. Experimental Results and Analysis
4.1. EPOVR-v1.0 Dataset
4.2. Experimental Setup
4.3. Evaluation Metrics
4.4. Ablation Study
4.5. Comprehensive Comparison with Other YOLO Models
4.6. Subjective Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DC2f | Deformable C2f |
| AMFE | Adaptive Multiscale Feature Enhancement |
| OCIoU | Optimized Complete Intersection over Union |
| EPOVR | Electric Power Operation Violation Recognition |
References
- Park, J.; Kang, D. Artificial Intelligence and Smart Technologies in Safety Management: A Comprehensive Analysis Across Multiple Industries. Appl. Sci. 2024, 14, 11934. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Qian, X.; Li, C.; Wang, W.; Yao, X.; Cheng, G. Semantic segmentation guided pseudo label mining and instance re-detection for weakly supervised object detection in remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2023, 119, 103301. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Qian, X.; Wang, C.; Wang, W.; Yao, X.; Cheng, G. Complete and invariant instance classifier refinement for weakly supervised object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5627713. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar]
- Qian, X.; Wu, B.; Cheng, G.; Yao, X.; Wang, W.; Han, J. Building a bridge of bounding box regression between oriented and horizontal object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5605209. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Qian, X.; Huo, Y.; Cheng, G.; Gao, C.; Yao, X.; Wang, W. Mining high-quality pseudoinstance soft labels for weakly supervised object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5607615. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016: Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Qian, X.; Zeng, Y.; Wang, W.; Zhang, Q. Co-saliency detection guided by group weakly supervised learning. IEEE Trans. Multimed. 2022, 25, 1810–1818. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Liu, W.; Meng, Q.; Li, Z.; Hu, X. Applications of computer vision in monitoring the unsafe behavior of construction workers: Current status and challenges. Buildings 2021, 11, 409. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Computer Vision and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1804, pp. 1–6. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ali, M.L.; Zhang, Z. The YOLO framework: A comprehensive review of evolution, applications, and benchmarks in object detection. Computers 2024, 13, 336. [Google Scholar] [CrossRef]
- njvisionpower. Safety Helmet Wearing Dataset (SHWD). 2019. Available online: https://github.com/njvisionpower/Safety-Helmet-Wearing-Dataset (accessed on 23 December 2020).
- Huang, M.-L.; Cheng, Y. Dataset of Personal Protective Equipment (PPE). Mendeley Data 2025, V2. [Google Scholar] [CrossRef]
- Wang, S.; Han, J. Automated detection of exterior cladding material in urban area from street view images using deep learning. J. Build. Eng. 2024, 96, 110466. [Google Scholar] [CrossRef]
- Zhang, M.; Zhao, Y. Algorithm for Identifying Violations in Electrical Power Operations by Integrating Spatial Attention Mechanism and YOLOv5. In Proceedings of the 2023 3rd International Conference on Electrical Engineering and Control Science (IC2ECS), Hangzhou, China, 29–31 December 2023; pp. 1710–1714. [Google Scholar]
- Liu, Q.; Xu, W.; Zhou, Y.; Li, R.; Wu, D.; Luo, Y.; Chen, L. Fusing PSA to Improve YOLOv5s Detection algorithm for Electric Power Operation Wearable devices. In International Conference on Mobile Networks and Management; Springer Nature: Cham, Switzerland, 2023; pp. 121–135. [Google Scholar]
- Sun, C.; Zhang, S.; Qu, P.; Wu, X.; Feng, P.; Tao, Z.; Zhang, J.; Wang, Y. MCA-YOLOV5-Light: A Faster, Stronger and Lighter Algorithm for Helmet-Wearing Detection. Appl. Sci. 2022, 12, 9697. [Google Scholar] [CrossRef]
- He, C.; Tan, S.; Zhao, J.; Ergu, D.; Liu, F.; Ma, B.; Li, J. Efficient and Lightweight Neural Network for Hard Hat Detection. Electronics 2024, 13, 2507. [Google Scholar] [CrossRef]
- Lian, Y.; Li, J.; Dong, S.; Li, X. HR-YOLO: A Multi-Branch Network Model for Helmet Detection Combined with High-Resolution Network and YOLOv5. Electronics 2024, 13, 2271. [Google Scholar] [CrossRef]
- Zhang, Y.; Qiu, Y.; Bai, H. FEFD-YOLOV5: A Helmet Detection Algorithm Combined with Feature Enhancement and Feature Denoising. Electronics 2023, 12, 2902. [Google Scholar] [CrossRef]
- Wang, Y.; Jiang, F.; Li, Y.; Zhang, H.; Wang, M.; Yan, S. Safety Helmet Detection Algorithm for Complex Scenarios Based on PConv-YOLOv8. In Proceedings of the 2023 International Conference on the Cognitive Computing and Complex Data (ICCD), Huaian, China, 21–22 October 2023; pp. 90–94. [Google Scholar]
- Bao, J.; Li, S.; Wang, G.; Xiong, J.; Li, S. Improved YOLOV8 network and application in safety helmet detection. J. Phys. Conf. Ser. 2023, 2632, 012012. [Google Scholar] [CrossRef]
- Di, B.; Xiang, L.; Daoqing, Y.; Kaimin, P. MARA-YOLO: An efficient method for multiclass personal protective equipment detection. IEEE Access 2024, 12, 24866–24878. [Google Scholar] [CrossRef]
- Park, S.; Kim, J.; Wang, S.; Kim, J. Effectiveness of Image Augmentation Techniques on Non-Protective Personal Equipment Detection Using YOLOv8. Appl. Sci. 2025, 15, 2631. [Google Scholar] [CrossRef]
- Yang, X.; Wang, J.; Dong, M. SDCB-YOLO: A High-Precision Model for Detecting Safety Helmets and Reflective Clothing in Complex Environments. Appl. Sci. 2024, 14, 7267. [Google Scholar] [CrossRef]
- Zhang, H.; Mu, C.; Ma, X.; Guo, X.; Hu, C. MEAG-YOLO: A Novel Approach for the Accurate Detection of Personal Protective Equipment in Substations. Appl. Sci. 2024, 14, 4766. [Google Scholar] [CrossRef]
- Han, D.; Ying, C.; Tian, Z.; Dong, Y.; Chen, L.; Wu, X.; Jiang, Z. YOLOv8s-SNC: An Improved Safety-Helmet-Wearing Detection Algorithm Based on YOLOv8. Buildings 2024, 14, 3883. [Google Scholar] [CrossRef]
- Wang, J.; Sang, B.; Zhang, B.; Liu, W. A Safety Helmet Detection Model Based on YOLOv8-ADSC in Complex Working Environments. Electronics 2024, 13, 4589. [Google Scholar] [CrossRef]
- Tang, P.; Xiao, B.; Su, Z.; Gao, F. Wearable Detection Application of Protective Equipment for Live Working Based on YOLOv9. In Proceedings of the IEEE 2024 8th International Conference on Smart Grid and Smart Cities (ICSGSC), Shanghai, China, 25–27 October 2024; pp. 406–411. [Google Scholar]
- Zhang, L.; Sun, Z.; Tao, H.; Wang, M.; Yi, W. Research on Mine-Personnel Helmet Detection Based on Multi-Strategy-Improved YOLOv11. Sensors 2024, 25, 170. [Google Scholar] [CrossRef]
- Eum, I.; Kim, J.; Wang, S.; Kim, J. Heavy Equipment Detection on Construction Sites Using You Only Look Once (YOLO-Version 10) with Transformer Architectures. Appl. Sci. 2025, 15, 2320. [Google Scholar] [CrossRef]
- Wang, S.; Hae, H.; Kim, J. Development of easily accessible electricity consumption model using open data and GA-SVR. Energies 2018, 11, 373. [Google Scholar] [CrossRef]
- Jia, X.; Zhou, X.; Shi, Z.; Xu, Q.; Zhang, G. GeoIoU-SEA-YOLO: An Advanced Model for Detecting Unsafe Behaviors on Construction Sites. Sensors 2025, 25, 1238. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J.; Ultralytics. YOLOv5. GitHub Repository. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 27 May 2020).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Jocher, G.; Chaurasia, A. Ultralytics. YOLOv8. GitHub Repository. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 January 2023).
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2024; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Violation Category | Object Category |
|---|---|---|
| 1 | Unattended operation site | operator, supervision |
| 2 | Personnel standing under lifted loads during crane operation | crane, operator |
| 3 | Workers throwing objects from height | throwing |
| 4 | Ladder without height restriction marking | ladder with height restriction marking (LHRM), ladder |
| 5 | Hooks of lever hoists, pulley hooks, or cranes lacking locking devices | locked-hook, unlocked-hook |
| Category | NTR | NVA | NTE |
|---|---|---|---|
| operator | 110 | 16 | 30 |
| supervision | 106 | 13 | 28 |
| crane | 103 | 15 | 31 |
| throwing | 104 | 15 | 30 |
| LHRM | 105 | 16 | 29 |
| ladder | 102 | 13 | 30 |
| locked-hook | 106 | 14 | 28 |
| unlocked-hook | 104 | 18 | 34 |
| Total | 840 | 120 | 240 |
| DC2f | AMFE | OCIoU | mAP@0.5(%) | mAP@0.5–0.95(%) | SDAP@0.5 | SDAP@0.5–0.95 | Parameters/M | GFLOPS | FPS |
|---|---|---|---|---|---|---|---|---|---|
| × | × | × | 85.0 | 59.5 | 0.104 | 0.120 | 3.0 | 8.1 | 86.2 |
| ✓ | × | × | 86.4 | 60.7 | 0.093 | 0.115 | 2.9 | 7.9 | 87.1 |
| × | ✓ | × | 86.6 | 61.0 | 0.089 | 0.112 | 3.0 | 8.1 | 85.7 |
| × | × | ✓ | 85.9 | 61.7 | 0.098 | 0.109 | 3.0 | 8.1 | 86.2 |
| ✓ | ✓ | × | 87.6 | 62.6 | 0.075 | 0.106 | 2.9 | 7.9 | 86.6 |
| ✓ | × | ✓ | 87.1 | 63.2 | 0.083 | 0.104 | 2.9 | 7.9 | 87.2 |
| × | ✓ | ✓ | 87.4 | 63.5 | 0.079 | 0.103 | 3.0 | 8.1 | 85.8 |
| ✓ | ✓ | ✓ | 88.2 | 63.9 | 0.070 | 0.101 | 2.9 | 7.9 | 86.7 |
| Method | mAP@0.5(%) | mAP@0.5–0.95(%) | SDAP@0.5 | SDAP@0.5–0.95 | Parameters/M | GFLOPS | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv5n | 83.2 | 57.3 | 0.133 | 0.137 | 2.5 | 7.1 | 88.7 |
| YOLOv6n | 82.5 | 56.9 | 0.159 | 0.141 | 4.2 | 12.1 | 83.3 |
| YOLOv7t | 84.3 | 58.5 | 0.119 | 0.129 | 6.0 | 13.1 | 79.6 |
| YOLOv8n | 85.0 | 59.5 | 0.104 | 0.120 | 3.0 | 8.1 | 86.2 |
| YOLOv9t | 82.3 | 57.7 | 0.144 | 0.136 | 2.0 | 7.7 | 87.8 |
| YOLOv10n | 81.9 | 56.8 | 0.162 | 0.151 | 2.3 | 6.5 | 89.7 |
| YOLOv11n | 84.3 | 59.0 | 0.117 | 0.125 | 2.6 | 6.3 | 90.3 |
| DAO-YOLO | 88.2 | 63.9 | 0.070 | 0.101 | 2.9 | 7.9 | 86.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qian, X.; Li, Y.; Ding, X.; Luo, L.; Guo, J.; Wang, W.; Xing, P. A Real-Time DAO-YOLO Model for Electric Power Operation Violation Recognition. Appl. Sci. 2025, 15, 4492. https://doi.org/10.3390/app15084492
Qian X, Li Y, Ding X, Luo L, Guo J, Wang W, Xing P. A Real-Time DAO-YOLO Model for Electric Power Operation Violation Recognition. Applied Sciences. 2025; 15(8):4492. https://doi.org/10.3390/app15084492
Chicago/Turabian StyleQian, Xiaoliang, Yang Li, Xinyu Ding, Longxiang Luo, Jinchao Guo, Wei Wang, and Peixu Xing. 2025. "A Real-Time DAO-YOLO Model for Electric Power Operation Violation Recognition" Applied Sciences 15, no. 8: 4492. https://doi.org/10.3390/app15084492
APA StyleQian, X., Li, Y., Ding, X., Luo, L., Guo, J., Wang, W., & Xing, P. (2025). A Real-Time DAO-YOLO Model for Electric Power Operation Violation Recognition. Applied Sciences, 15(8), 4492. https://doi.org/10.3390/app15084492