
How Good Are Large Language Models at Arithmetic Reasoning in Low-Resource Language Settings?—A Study on Yorùbá Numerical Probes with Minimal Contamination


Abstract
1. Introduction
2. Review of Related Works
3. Method
3.1. The Yorùbá Numerical Probes
“Dupe was given 5 naira for lunch before heading to school. She met Iya Gbonke and Baba Alatise, who gave her 9 naira and 12 naira, respectively. How much does Dupe have altogether?”
Steps Taken to Avoid Dataset Contamination
3.2. Models Used
- ChatGPT is arguably the most popular LLM. Having been trained on a wide range of multilingual datasets that include Yorùbá, its strong multilingual capabilities, accessibility, reasoning proficiency, and adaptability to generalize in LRL tasks like text generation and translation [29] make it an ideal choice for this assessment. The model we used was ChatGPT-4-turbo, which was accessed between January and April 2025.
- Gemini was developed by Google DeepMind; it is the second model we chose to assess NLR on Yorùbá arithmetic probes. Gemini has advanced multimodal capabilities, a fine NLR architecture, and robust support for LRL [30], including Yorùbá. The model we used was Gemini 2.0 Flash, which was accessed between January and April 2025.
- PaLM (Pathways Language Model) [31] has an architecture that supports complex reasoning and understanding of context. Its ability to solve multistep problems and support Yorùbá informed our choice of this model for the assessment. The model used was PaLM 2, accessed between January and April 2025.
3.3. Evaluation Metrics
3.3.1. Accuracy
3.3.2. Reasoning Completeness
3.3.3. Language Understanding
4. Results
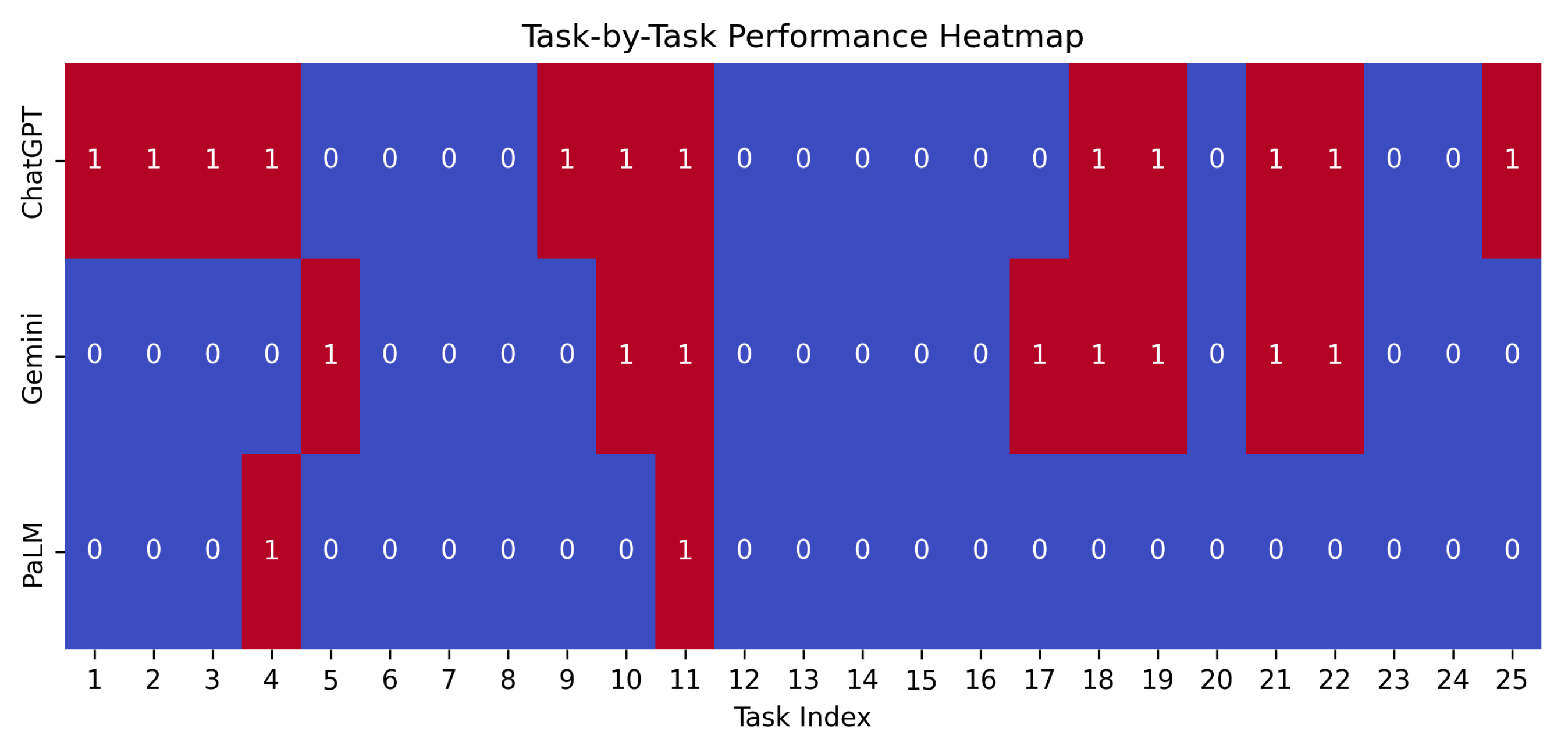
4.1. Question Set One: Basic Arithmetic Problems
4.2. Question Set Two: Time and Dates
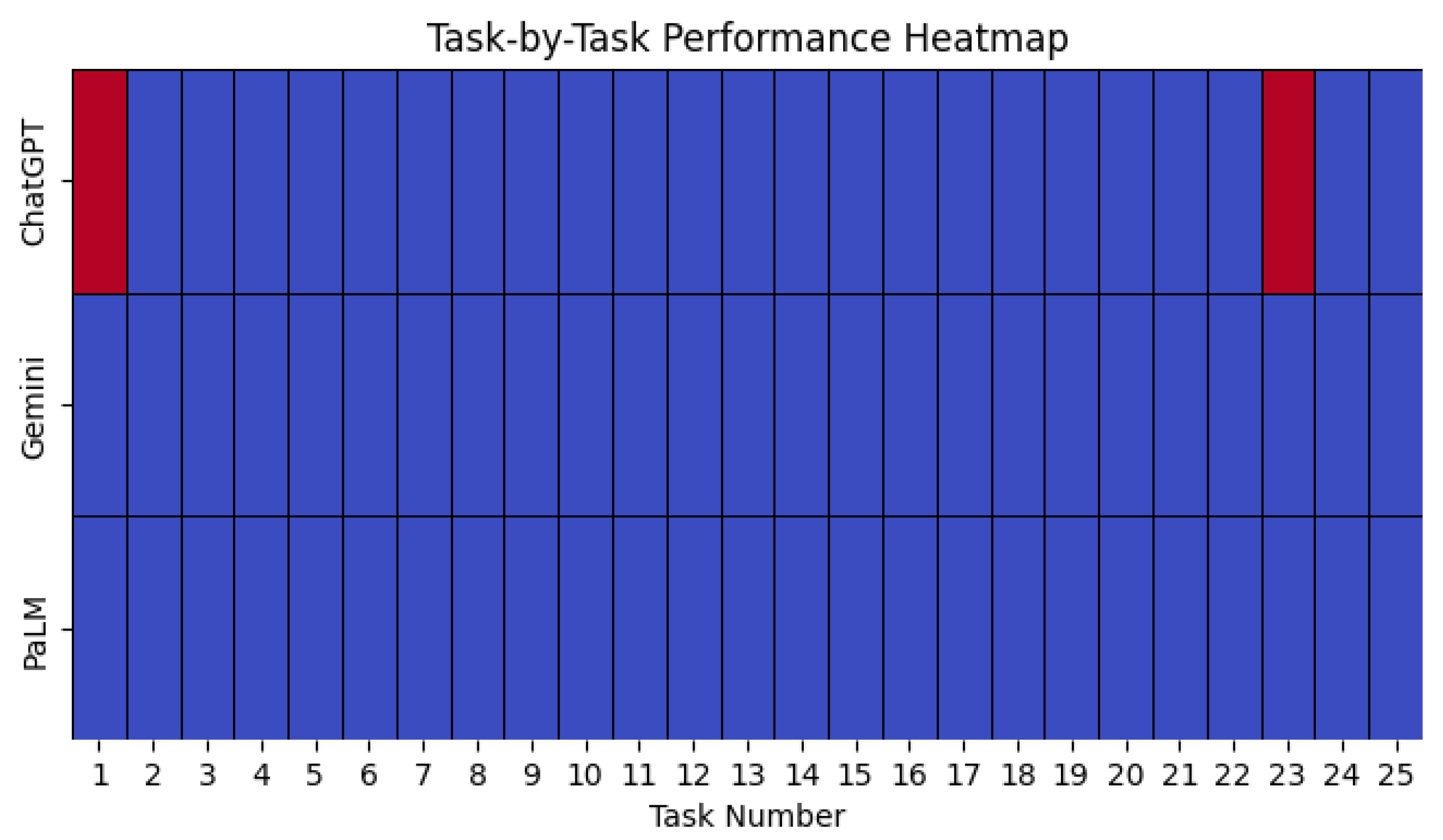
4.3. Question Set Three: Yorùbá Counting and Numeral System
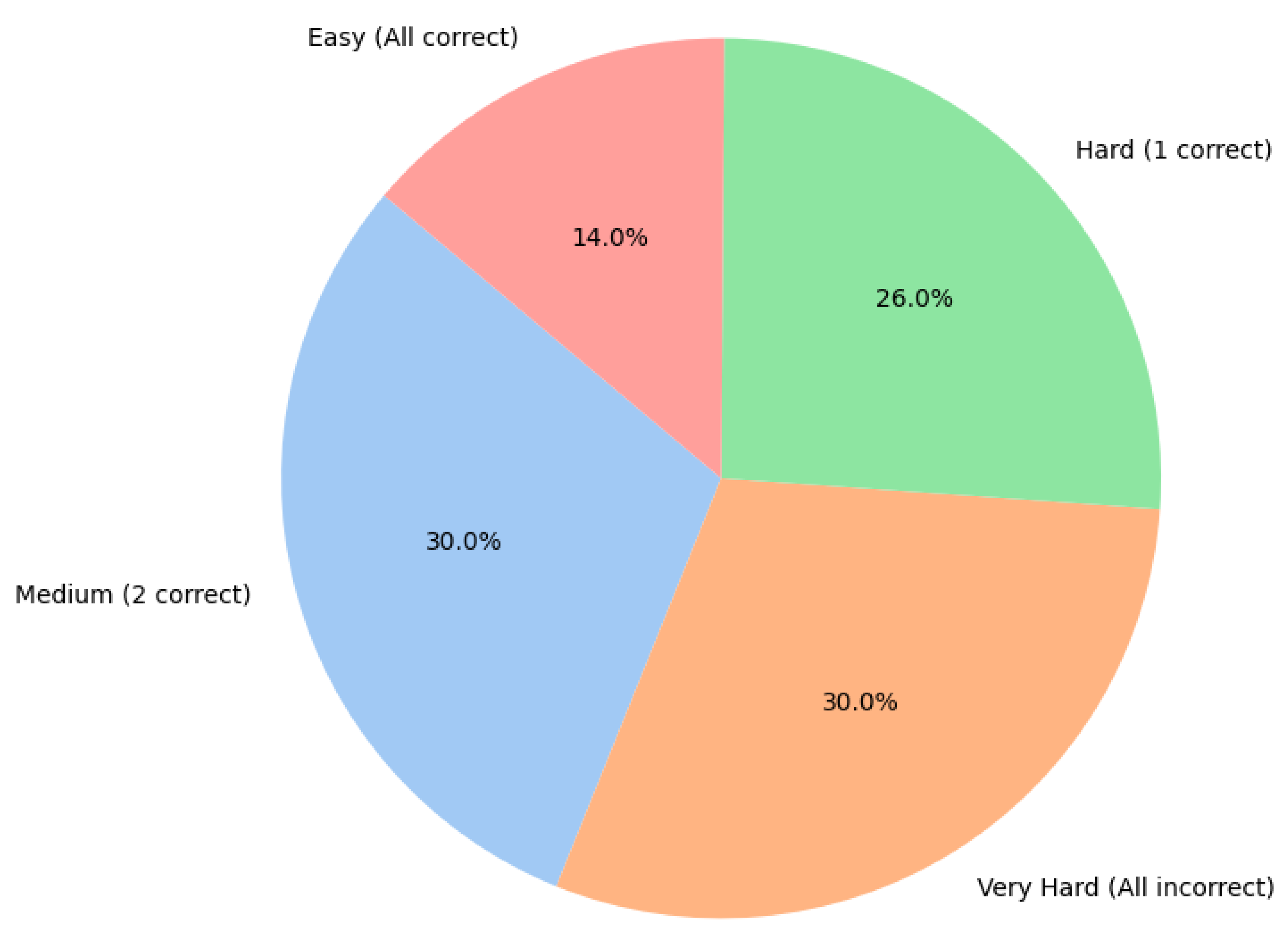
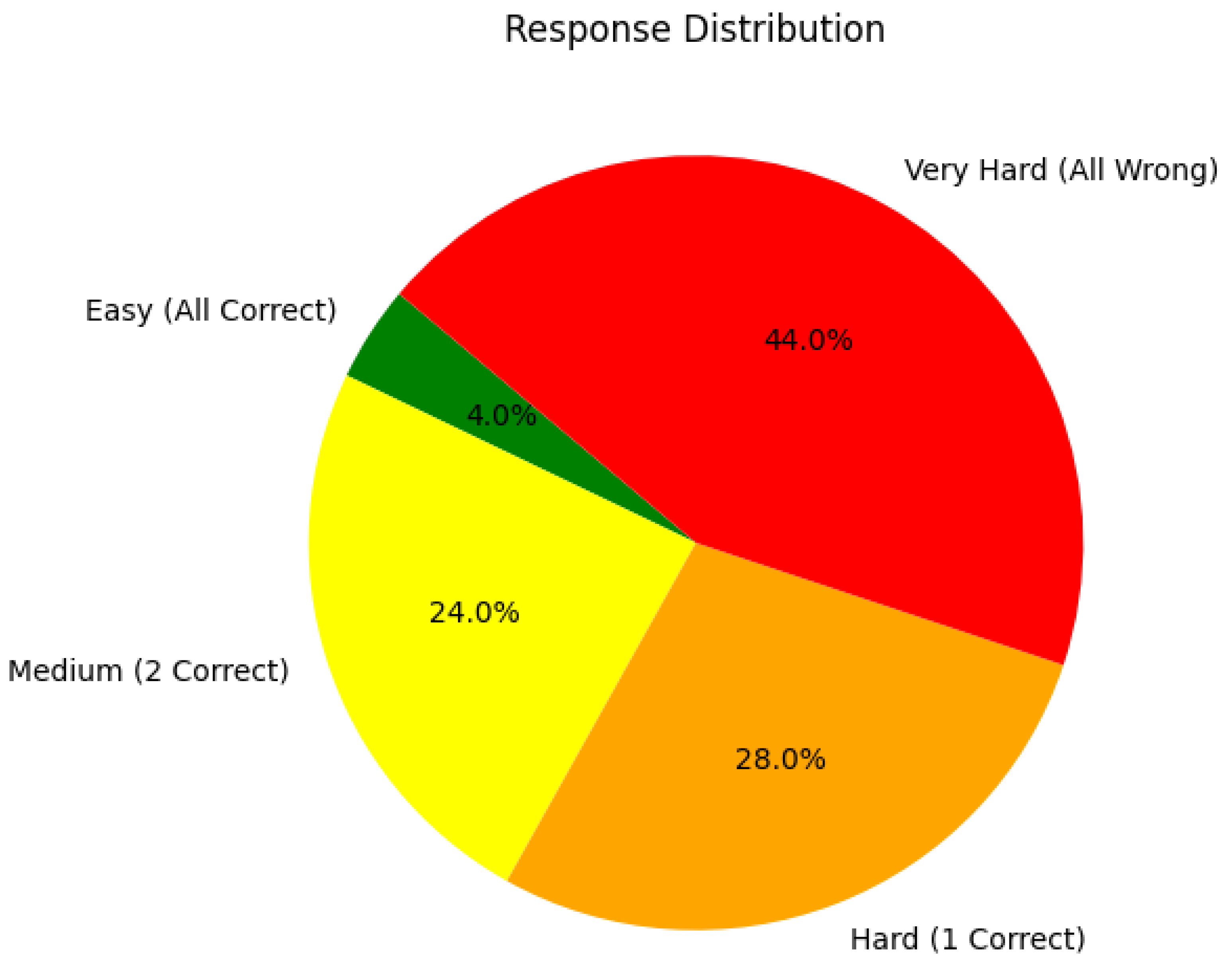
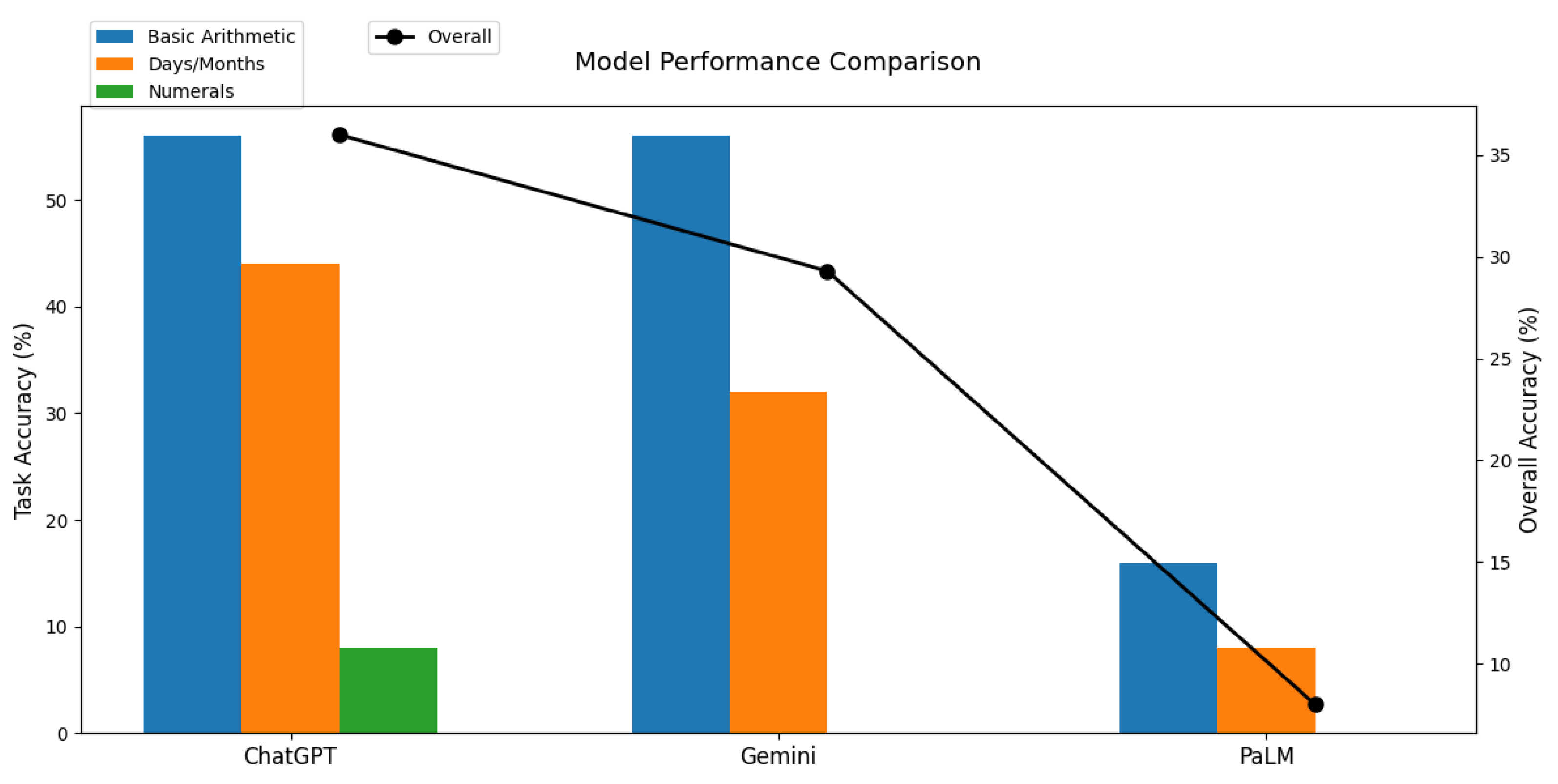
4.4. Overall Performance of the Three Models
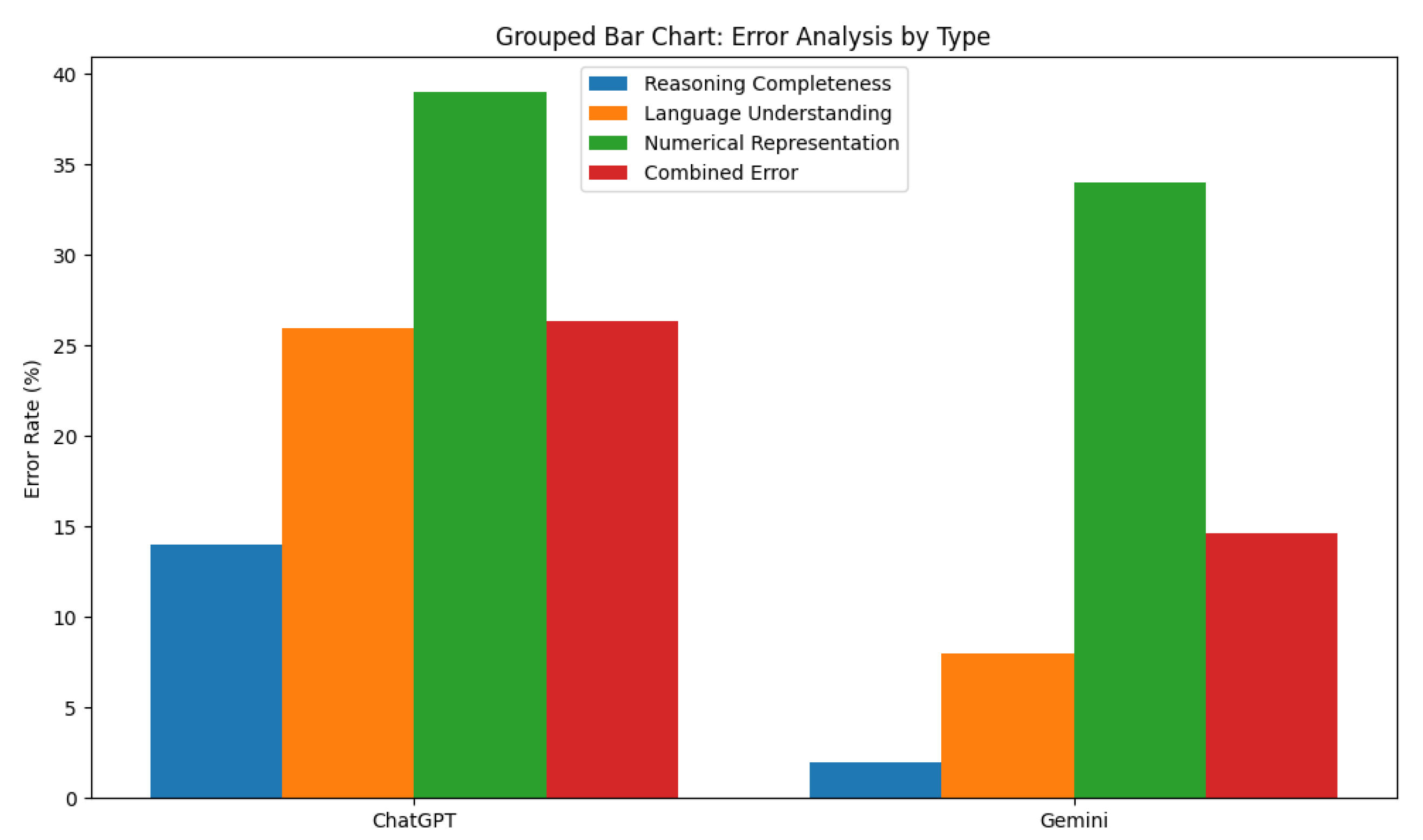
Analysis of Numerical Representation Errors
- Question 21
- Question 31
- Question 49
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Details of the Numerical Probes
Appendix A.1. General Arithmetic—First 20 Questions
Appendix A.2. Time, Days, and Months—First 10 Questions
Appendix A.3. Onka—First Twenty Questions
References
- Kasai, J.; Kasai, Y.; Sakaguchi, K.; Yamada, Y.; Radev, D. Evaluating gpt-4 and chatgpt on japanese medical licensing examinations. arXiv 2023, arXiv:2303.18027. [Google Scholar]
- Wu, J.; Wu, X.; Qiu, Z.; Li, M.; Lin, S.; Zhang, Y.; Zheng, Y.; Yuan, C.; Yang, J. Large language models leverage external knowledge to extend clinical insight beyond language boundaries. J. Am. Med. Inform. Assoc. 2024, 34, 2054–2064. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Hu, Z.; Lu, P.; Zhu, Y.; Zhang, J.; Subramaniam, S.; Loomba, A.R.; Zhang, S.; Sun, Y.; Wang, W. Scibench: Evaluating college-level scientific problem-solving abilities of large language models. arXiv 2023, arXiv:2307.10635. [Google Scholar]
- Imani, S.; Du, L.; Shrivastava, H. Mathprompter: Mathematical reasoning using large language models. arXiv 2023, arXiv:2303.05398. [Google Scholar]
- Peng, X.; Geng, X. Self-controller: Controlling LLMs with Multi-round Step-by-step Self-awareness. arXiv 2024, arXiv:2410.00359. [Google Scholar]
- Ji, K.; Chen, J.; Gao, A.; Xie, W.; Wan, X.; Wang, B. LLMs Could Autonomously Learn Without External Supervision. arXiv 2024, arXiv:2406.00606. [Google Scholar]
- Zhang, W.; Shen, Y.; Wu, L.; Peng, Q.; Wang, J.; Zhuang, Y.T.; Lu, W. Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 12–14 August 2024. [Google Scholar]
- Qin, C.; Zhang, A.; Zhang, Z.; Chen, J.; Yasunaga, M.; Yang, D. Is ChatGPT a general-purpose natural language processing task solver? arXiv 2023, arXiv:2302.06476. [Google Scholar]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large Language Models are Zero-Shot Reasoners. arXiv 2022, arXiv:2205.11916. [Google Scholar]
- Li, L.; Wang, Y.; Zhao, H.; Kong, S.; Teng, Y.; Li, C.; Wang, Y. Reflection-Bench: Probing AI intelligence with reflection. arXiv 2024, arXiv:2410.16270. [Google Scholar]
- Fang, X.; Xu, W.; Tan, F.A.; Zhang, J.; Hu, Z.; Qi, Y.; Nickleach, S.; Socolinsky, D.; Sengamedu, S.H.; Faloutsos, C. Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding—A Survey. arXiv 2024, arXiv:2402.17944. [Google Scholar]
- Kadlčík, M.; Štefánik, M. Self-training Language Models for Arithmetic Reasoning. arXiv 2024, arXiv:2407.08400. [Google Scholar]
- Cai, C.; Zhao, X.; Liu, H.; Jiang, Z.; Zhang, T.; Wu, Z.; Hwang, J.N.; Li, L. The Role of Deductive and Inductive Reasoning in Large Language Models. arXiv 2024, arXiv:2410.02892. [Google Scholar]
- He, P.; Li, Z.; Xing, Y.; Li, Y.; Tang, J.; Ding, B. Make LLMs better zero-shot reasoners: Structure-orientated autonomous reasoning. arXiv 2024, arXiv:2410.19000. [Google Scholar]
- Akhtar, M.; Shankarampeta, A.; Gupta, V.; Patil, A.; Cocarascu, O.; Simperl, E.P.B. Exploring the Numerical Reasoning Capabilities of Language Models: A Comprehensive Analysis on Tabular Data. arXiv 2023, arXiv:2311.02216. [Google Scholar]
- Shao, Z.; Huang, F.; Huang, M. Chaining Simultaneous Thoughts for Numerical Reasoning. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–9 December 2022. [Google Scholar]
- Mishra, S.; Mitra, A.; Varshney, N.; Sachdeva, B.S.; Clark, P.; Baral, C.; Kalyan, A. NumGLUE: A Suite of Fundamental yet Challenging Mathematical Reasoning Tasks. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022. [Google Scholar]
- Zhou, F.; Dong, H.; Liu, Q.; Cheng, Z.; Han, S.; Zhang, D. Reflection of Thought: Inversely Eliciting Numerical Reasoning in Language Models via Solving Linear Systems. arXiv 2022, arXiv:2210.05075. [Google Scholar]
- Heston, T.F.; Khun, C. Prompt Engineering in Medical Education. Int. Med. Educ. 2023, 2, 198–205. [Google Scholar] [CrossRef]
- Wong, W. Practical Approach to Knowledge-based Question Answering with Natural Language Understanding and Advanced Reasoning. arXiv 2007, arXiv:0707.3559. [Google Scholar]
- Yu, F.; Zhang, H.; Wang, B. Natural Language Reasoning, A Survey. Acm Comput. Surv. 2023, 56, 1–39. [Google Scholar] [CrossRef]
- Rybak, P. Transferring BERT Capabilities from High-Resource to Low-Resource Languages Using Vocabulary Matching. In Proceedings of the International Conference on Language Resources and Evaluation, Turin, Italy, 20–25 May 2024. [Google Scholar]
- Cahyawijaya, S.; Winata, G.I.; Wilie, B.; Vincentio, K.; Li, X.; Kuncoro, A.; Ruder, S.; Lim, Z.Y.; Bahar, S.; Khodra, M.L.; et al. IndoNLG: Benchmark and Resources for Evaluating Indonesian Natural Language Generation. arXiv 2021, arXiv:2104.08200. [Google Scholar]
- Joshua, A.M. Improving Question-Answering Capabilities in Large Language Models Using Retrieval Augmented Generation (RAG): A Case Study on Yoruba Culture and Language. In Proceedings of the 5th Workshop on African Natural Language Processing, Vienna, Austria, 11 May 2024. [Google Scholar]
- Kale, M.; Rastogi, A. Few-Shot Natural Language Generation by Rewriting Templates. arXiv 2020, arXiv:2004.15006. [Google Scholar]
- Adelani, D.I.; Liu, H.; Shen, X.; Vassilyev, N.; Alabi, J.O.; Mao, Y.; Gao, H.; Lee, A.E.S. SIB-200: A Simple, Inclusive, and Big Evaluation Dataset for Topic Classification in 200+ Languages and Dialects. In Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics, Dubrovnik, Croatia, 2–6 May 2023. [Google Scholar]
- Sánchez-Salido, E.; Morante, R.; Gonzalo, J.; Marco, G.; de Albornoz, J.C.; Plaza, L.; Amig’o, E.; Fern’andez, A.A.; Benito-Santos, A.; Espinosa, A.G.; et al. Bilingual Evaluation of Language Models on General Knowledge in University Entrance Exams with Minimal Contamination. arXiv 2024, arXiv:2409.12746. [Google Scholar]
- Perelkiewicz, M.; Poswiata, R. A Review of the Challenges with Massive Web-mined Corpora Used in Large Language Models Pre-Training. arXiv 2024, arXiv:2407.07630. [Google Scholar]
- Liu, Y.; Xu, M.; Wang, S.; Yang, L.; Wang, H.; Liu, Z.; Kong, C.; Chen, Y.; Sun, M.; Yang, E. OMGEval: An Open Multilingual Generative Evaluation Benchmark for Large Language Models. arXiv 2024, arXiv:2402.13524. [Google Scholar]
- Wang, Y.; Zhao, Y. Gemini in reasoning: Unveiling commonsense in multimodal large language models. arXiv 2023, arXiv:2312.17661. [Google Scholar]
- Anil, R.; Dai, A.M.; Firat, O.; Johnson, M.; Lepikhin, D.; Passos, A.; Shakeri, S.; Taropa, E.; Bailey, P.; Chen, Z.; et al. Palm 2 technical report. arXiv 2023, arXiv:2305.10403. [Google Scholar]
- Zhong, W.; Cui, R.; Guo, Y.; Liang, Y.; Lu, S.; Wang, Y.; Saied, A.; Chen, W.; Duan, N. Agieval: A human-centric benchmark for evaluating foundation models. arXiv 2023, arXiv:2304.06364. [Google Scholar]
- Shi, F.; Suzgun, M.; Freitag, M.; Wang, X.; Srivats, S.; Vosoughi, S.; Chung, H.W.; Tay, Y.; Ruder, S.; Zhou, D.; et al. Language models are multilingual chain-of-thought reasoners. arXiv 2022, arXiv:2210.03057. [Google Scholar]
- Xu, F.; Lin, Q.; Han, J.; Zhao, T.; Liu, J.; Cambria, E. Are Large Language Models Really Good Logical Reasoners? A Comprehensive Evaluation and Beyond. IEEE Trans. Knowl. Data Eng. 2025, 37, 1620–1634. [Google Scholar] [CrossRef]
- Huang, Y.; Tang, K.; Chen, M. A Comprehensive Survey on Evaluating Large Language Model Applications in the Medical Industry. arXiv 2024, arXiv:2404.15777. [Google Scholar]
- Nguyen, T.H.; Le, A.C.; Nguyen, V.C. ViLLM-Eval: A Comprehensive Evaluation Suite for Vietnamese Large Language Models. arXiv 2024, arXiv:2404.11086. [Google Scholar]
- Adetomiwa, A. Yorùbá Numeral System in 21st Century: Challenges and Prospects. 2023. Available online: https://www.researchgate.net/publication/375096095_YORUBA_NUMERAL_SYSTEM_IN_21ST_CENTURY_CHALLENGES_AND_PROSPECTS (accessed on 20 February 2025).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Irú Ìbéèrè (Question Type) | Ìbéèrè (Question) |
|---|---|
| àròpò | Dupe gba naira marun fun owó oúnje kúrò ní ilé. Ó pàdé Iya Gbonke tó fún un ní naira mesan àti Baba Alatise tó fún un ní naira mejila bí ó ṣe ń lo sí ilé-iwe. Èló ni owó tí Dupe ní je lápapo? |
| àyokúrò | Baba Sade fun Sade ni eko mewa. Sade fun Faderera ni eko meji. Mélò ni eko owo Sade kù? |
| ìsodipúpò | Baba Jiginni gba Abeke niyanju lati je ataare kookan lojoojumo fun ose meji gbako. Ataare melo ni o ye ki Abeke ra? |
| pípín | Oluko ri wipe Aarinola ko fi eti sile ninu yaara ikeko, o si so fun wipe ki o lo ka iye eranko ti o wa ninu ogba ile ikẹko naa. Ti ẹse eranko ti o wa ninu ogba naa ba je merindinlogota, ki ni idahun Aarinola yoo je? |
| Irú Ìbéèrè (Question Type) | Ìbéèrè (Question) |
|---|---|
| set 2 | Tì òní báa jẹ ojo ajé, ojo wo ni oojo mewa òní yóò je? |
| set 2 | Ojo mélòó ló wà nínú oṣù Èrèlé |
| set 3 | Ónkà wo lo tele Ogúnlélúgba? |
| set 3 | Kinni ogojo ni onka Yorùbá |
| Other Assessment Metrics | |||
|---|---|---|---|
| Model | Reasoning Completeness (%) | Language Understanding (%) | Numerical Representation Accuracy (%) |
| ChatGPT | 86 | 74 | 61 |
| Gemini | 98 | 92 | 66 |
| Accuracy | |||
|---|---|---|---|
| Model | Basic Yorùbá Arithmetic Set (%) | Yorùbá Time, Days and Months (%) | Yorùbá Numerals (%) |
| ChatGPT | 56 | 44 | 8 |
| Gemini | 56 | 32 | 0 |
| PaLM | 16 | 8 | 0 |
| Numerals | Expected Representation | ChatGPT | Gemini |
|---|---|---|---|
| otàlélúgba | 260 | 63 | 230 |
| àrúnlélotàlélúgba | 265 | 65 | 235 |
| Numerals | Expected Representation | ChatGPT | Gemini |
|---|---|---|---|
| ogbon | 30 | 40 | 30 |
| egbèsàn | 1800 | 9 | 900 |
| àádota | 50 | 15 | 50 |
| Numerals | Expected Representation | ChatGPT | Gemini |
|---|---|---|---|
| èedegbejo | 1500 | 800 | 250 |
| egbàáta | 6000 | 3000 | 600 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oyesanmi, F.; Olukanmi, P.O. How Good Are Large Language Models at Arithmetic Reasoning in Low-Resource Language Settings?—A Study on Yorùbá Numerical Probes with Minimal Contamination. Appl. Sci. 2025, 15, 4459. https://doi.org/10.3390/app15084459
Oyesanmi F, Olukanmi PO. How Good Are Large Language Models at Arithmetic Reasoning in Low-Resource Language Settings?—A Study on Yorùbá Numerical Probes with Minimal Contamination. Applied Sciences. 2025; 15(8):4459. https://doi.org/10.3390/app15084459
Chicago/Turabian StyleOyesanmi, Fiyinfoluwa, and Peter O. Olukanmi. 2025. "How Good Are Large Language Models at Arithmetic Reasoning in Low-Resource Language Settings?—A Study on Yorùbá Numerical Probes with Minimal Contamination" Applied Sciences 15, no. 8: 4459. https://doi.org/10.3390/app15084459
APA StyleOyesanmi, F., & Olukanmi, P. O. (2025). How Good Are Large Language Models at Arithmetic Reasoning in Low-Resource Language Settings?—A Study on Yorùbá Numerical Probes with Minimal Contamination. Applied Sciences, 15(8), 4459. https://doi.org/10.3390/app15084459