
Deep Reinforcement Learning-Based Uncalibrated Visual Servoing Control of Manipulators with FOV Constraints



Abstract
1. Introduction
- (1)
- A novel uncalibrated IBVS framework is proposed to address the feature constraint problem in the manipulator’s visual servoing task under unknown noise environments. The framework effectively mitigates the motion randomness caused by errors in the estimation of the feature–motion mapping matrix.
- (2)
- Base on DQN, the offline FOV feature mapping mechanism further is designed. Additionally, a camera FOV-based reward and punishment mechanism is established to train the visual feature agent to perform the uncalibrated visual servoing task with FOV constraints.
- (3)
- The new DQN-based uncalibrated visual servoing scheme achieves the auxiliary positioning task for 6-DOF manipulators, directly utilizing the feature states from 2D images to enforce visual feature constraints. This ensures the operational flexibility and stability of the uncalibrated visual servoing task in unknown noisy environments, making it more suitable for industrial robot applications.
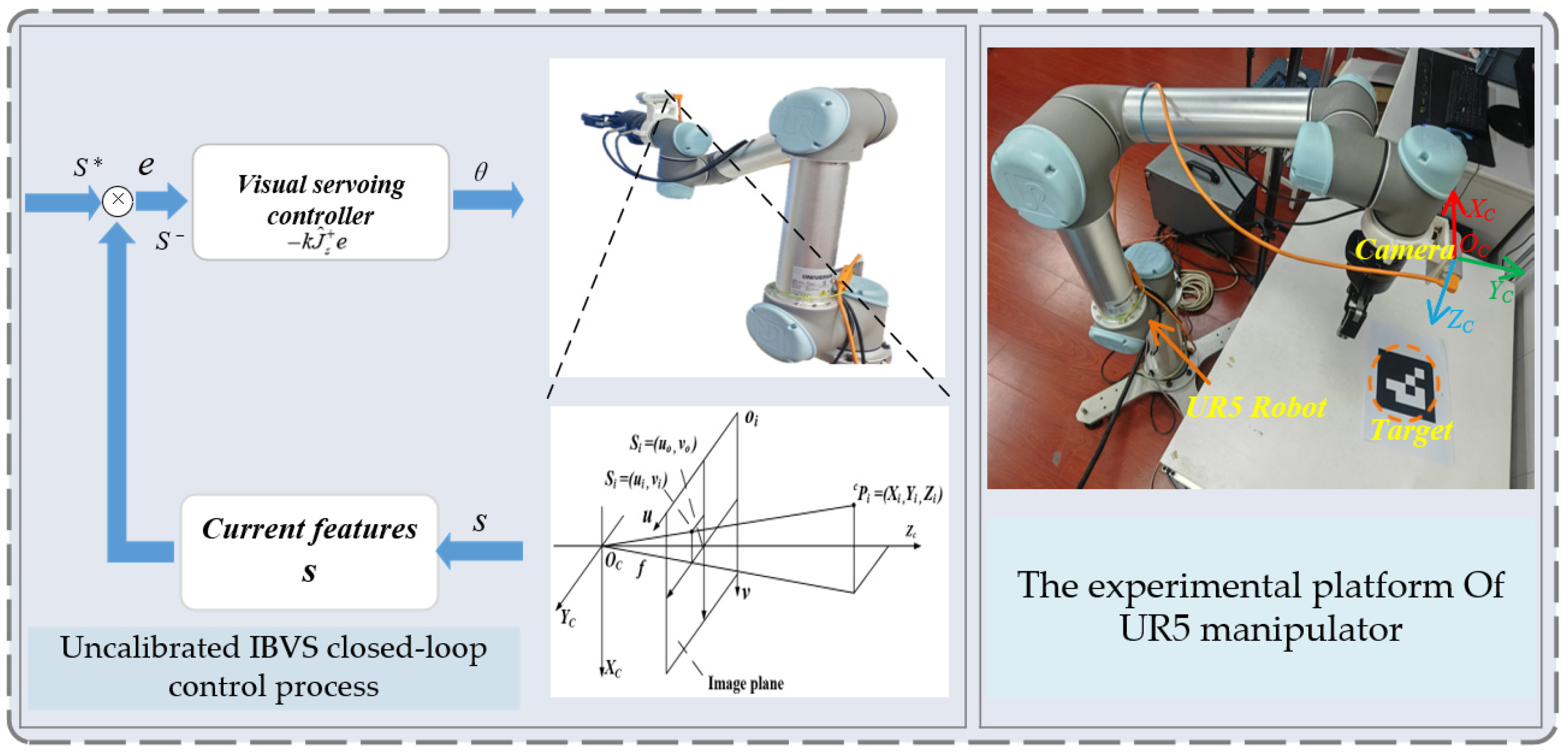
2. Theoretical Description of Uncalibrated IBVS
3. Design and Training Methods for DQN Feature Constrained Control
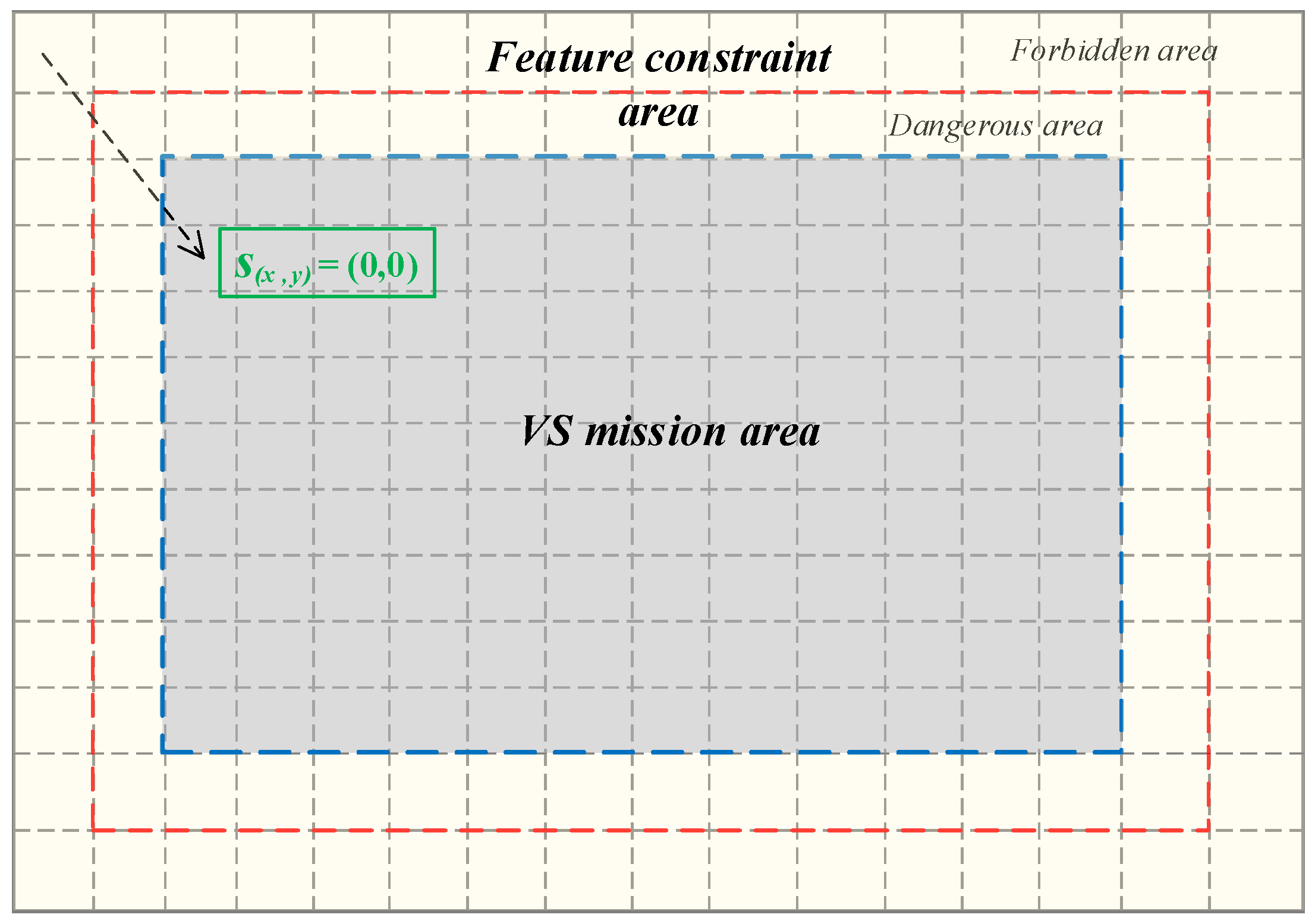
3.1. Definition and Division of State Space
3.2. The Definition of Action Space
- (1)
- Action1: , camera FOV shifted down (features shifted upward);
- (2)
- Action2: , camera FOV shifted upward (features shifted down);
- (3)
- Action3: , camera FOV left shifted (features right shifted);
- (4)
- Action4: , camera FOV right shifted (features left shifted);
- (5)
- Action5: camera FOV does not move (action5, features do not move): .
3.3. Design of the Reward Function
3.4. Training Method and Result
| Algorithm 1: Q-Network Training |
| Define the camera FOV environment, state space S, action space A, and r reward functions; Set up and initialize Q-network (primary network) and target network parameter ; Initialize learning rate α, discount factor γ, exploration rate ϵ; for episode = 1, …, n do Randomly initialize the feature’s state (positions) in the camera FOV and observe the initial state ; for t = 1, …, m do Acquire state and select actions from A based on ε-greedy policy; Get reward and reach new state ; Store sample into the replay buffer D; if is located in VS area then break; if D is full then Extract N samples from D according to Equations (8)–(11) Update network Q-network and target network parameters ; end if end for end for Optimal action value function Q based on FOV feature constraints (trained Q-network) |
4. DQN-Based Visual Servoing with FOV Feature Constraints
5. Experimental Results
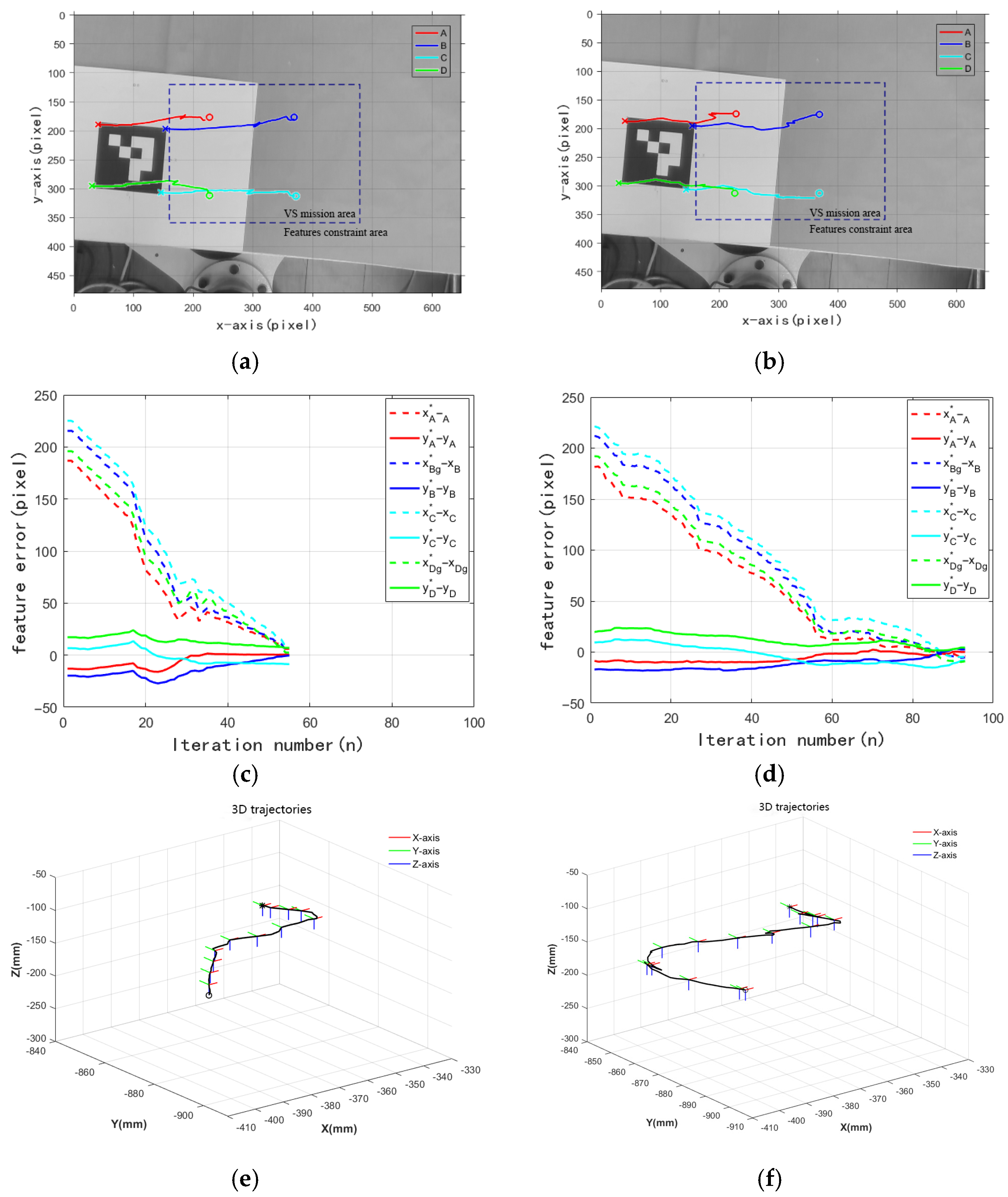
5.1. Features Constraint Validation
5.2. Comparison Experiment
5.3. Ablation Study and Real Application
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tsuchida, S.; Lu, H.; Kamiya, T.; Serikawa, S. Characteristics Based Visual Servo for 6DOF Robot Arm Control. Cogn. Cogn. Robot. 2021, 1, 76–82. [Google Scholar] [CrossRef]
- Reyes, R.; Murrieta-Cid, R. An approach integrating planning and image-based visual servo control for road following and moving obstacles avoidance. Int. J. Control 2020, 93, 2442–2456. [Google Scholar] [CrossRef]
- Liu, H.; Zhu, W.; Dong, H.; Ke, Y. Hybrid visual servoing for rivet-in-hole insertion based on super-twisting sliding mode control. Int. J. Control Autom. Syst. 2020, 18, 2145–2156. [Google Scholar] [CrossRef]
- Madhusanka, B.G.D.A.; Jayasekara, A.G.B.P. Design and development of adaptive vision attentive robot eye for service robot in domestic environment. In Proceedings of the IEEE International Conference on Information and Automation for Sustainability, Celle, Sri Lanka, 16–19 December 2016; pp. 1–6. [Google Scholar]
- Cai, K.; Chi, W.; Meng, M. A Vision-Based Road Surface Slope Estimation Algorithm for Mobile Service Robots in Indoor Environments. In Proceedings of the 2018 IEEE International Conference on Informatics, Electronics and Vision (ICIEV), Dhaka, Bangladesh, 17–19 May 2018; pp. 1–6. [Google Scholar]
- Allibert, G.; Hua, M.; Krupínski, S.; Hamel, T. Pipeline following by visual servoing for autonomous underwater vehicles. Control Eng. Pract. 2019, 82, 151–160. [Google Scholar] [CrossRef]
- Shu, T.; Gharaaty, S.; Xie, W.; Joubair, A.; Bonev, I. Dynamic path tracking of industrial robots with high accuracy using photogrammetry sensor. IEEE/ASME Trans. Mechatron. 2018, 23, 1159–1170. [Google Scholar] [CrossRef]
- Janabi-Sharifi, F.; Deng, L.; Wilson, W.J. Comparison of Basic Visual Servoing Methods. IEEE/ASME Trans. Mechatron. 2010, 16, 967–983. [Google Scholar] [CrossRef]
- Wu, J.; Jin, Z.; Liu, A.; Yu, L. Non-linear model predictive control for visual servoing systems incorporating iterative linear quadratic Gaussian. IET Control Theory Appl. 2020, 14, 1989–1994. [Google Scholar] [CrossRef]
- Malis, E.; Chaumette, F.; Boudet, S. 2 1/2 D visual servoing. IEEE Trans. Robot. Autom. 1999, 15, 238–250. [Google Scholar] [CrossRef]
- Tang, Z.; Cunha, R.; Cabecinhas, D.; Hamel, T.; Silvestre, C. Quadrotor going through a window and landing: An image-based visual servo control approach. Control Eng. Pract. 2021, 112, 104827. [Google Scholar] [CrossRef]
- Chaumette, F.; Hutchinson, S. Visual servo control. I. Basic approaches. IEEE Robot. Autom. Mag. 2006, 13, 82–90. [Google Scholar] [CrossRef]
- Siradjuddin, I.; Behera, L.; McGinnity, T.; Coleman, S. Image-based visual servoing of a 7-DOF robot manipulator using an adaptive distributed fuzzy PD controller. IEEE/ASME Trans. Mechatron. 2013, 19, 512–523. [Google Scholar] [CrossRef]
- Ahmadi, B.; Xie, W.-F.; Zakeri, E. Robust cascade vision/force control of industrial robots utilizing continuous integral sliding-mode control method. IEEE/ASME Trans. Mechatron. 2022, 27, 524–536. [Google Scholar] [CrossRef]
- Gao, J.; Proctor, A.A.; Shi, Y.; Bradley, C. Hierarchical model predictive image-based visual servoing of underwater vehicles with adaptive neural network dynamic control. IEEE Trans. Cybern. 2016, 46, 2323–2334. [Google Scholar] [CrossRef]
- Li, Z.; Yang, C.; Su, C.; Deng, J.; Zhang, W. Vision-based model predictive control for steering of a nonholonomic mobile robot. IEEE Trans. Control Syst. Technol. 2016, 24, 553–564. [Google Scholar] [CrossRef]
- Maniatopoulos, S.; Panagou, D.; Kyriakopoulos, K.J. Model Predictive Control for the Navigation of a Nonholonomic Vehicle with Field-of-View Constraints. In Proceedings of the 2013 American Control Conference, Washington, DC, USA, 17–19 June 2013; pp. 3967–3972. [Google Scholar]
- Huang, X.; Houshangi, N. A Vision-Based Autonomous Lane Following System for a Mobile Robot. In Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics, San Antonio, TX, USA, 11–14 October 2009; pp. 2344–2349. [Google Scholar]
- Wang, R.; Zhang, X.; Fang, Y.; Li, B. Virtual-goal-guided RRT for visual servoing of mobile robots with FOV constraint. IEEE Trans. Syst. Man Cybern. Syst. 2021, 52, 2073–2083. [Google Scholar] [CrossRef]
- Heshmati-Alamdari, S.; Karras, G.C.; Eqtami, A.; Kyriakopoulos, K.J. A Robust Self-Triggered Image-Based Visual Servoing Model Predictive Control Scheme for Small Autonomous Robots. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September 28–2 October 2015; pp. 5492–5497. [Google Scholar]
- Chesi, G. Visual Servoing Path Planning via Homogeneous Forms and LMI Optimizations. IEEE Trans. Robot. 2009, 25, 281–291. [Google Scholar] [CrossRef]
- Kazemi, M.; Gupta, K.; Mehrandezh, M. Global Path Planning for Robust Visual Servoing in Complex Environments. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 326–332. [Google Scholar]
- Corke, P.I.; Hutchinson, S. A New Partitioned Approach to Image-Based Visual Servo Control. IEEE Trans. Robot. Autom. 2001, 17, 507–515. [Google Scholar] [CrossRef]
- Chen, J.; Dawson, D.M.; Dixon, W.E.; Chitrakaran, V.K. Navigation Function-Based Visual Servo Control. Automatica 2007, 43, 1165–1177. [Google Scholar] [CrossRef]
- Cowan, N.J.; Weingarten, J.D.; Koditschek, D.E. Visual Servoing via Navigation Functions. IEEE Trans. Robot. Autom. 2002, 18, 521–533. [Google Scholar] [CrossRef]
- Zheng, D.; Wang, H.; Wang, J.; Zhang, X.; Chen, W. Toward visibility guaranteed visual servoing control of quadrotor UAVs. IEEE/ASME Trans. Mechatron. 2019, 24, 1087–1095. [Google Scholar] [CrossRef]
- Hajiloo, A.; Keshmiri, M.; Xie, W.F.; Wang, T.T. Robust Online Model Predictive Control for a Constrained Image-Based Visual. Servoing. IEEE Trans. Ind. Electron. 2016, 63, 2242–2250. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Wang, Y.; Lang, H.; De Silva, C.W. A Hybrid Visual Servo Controller for Robust Grasping by Wheeled Mobile Robots. IEEE/ASME Trans. Mechatron. 2010, 15, 757–769. [Google Scholar] [CrossRef]
- Wu, J.; Jin, Z.; Liu, A.; Yu, L.; Yang, F. A Hybrid Deep-Q-Network and Model Predictive Control for Point Stabilization of Visual Servoing Systems. Control. Eng. Pract. 2022, 128, 105314. [Google Scholar] [CrossRef]
- Shi, H.; Li, X.; Hwang, K.S.; Pan, W.; Xu, G. Decoupled Visual Servoing with Fuzzy Q-Learning. IEEE Trans. Ind. Inform. 2018, 14, 241–252. [Google Scholar] [CrossRef]
- Shi, H.; Shi, L.; Sun, G.; Hwang, K.S. Adaptive Image-Based Visual Servoing for Hovering Control of Quad-Rotor. IEEE Trans. Cogn. Dev. Syst. 2020, 12, 417–426. [Google Scholar] [CrossRef]
- Jin, Z.; Wu, J.; Liu, A.; Zhang, W.A.; Yu, L. Policy-based deep reinforcement learning for visual servoing control of mobile robots with visibility constraints. IEEE Trans. Ind. Electron. 2021, 69, 1898–1908. [Google Scholar] [CrossRef]
- Xiaolin, R.; Hongwen, L. Uncalibrated image-based visual servoing control with maximum correntropy Kalman filter. IFAC-PapersOnLine 2020, 53, 560–565. [Google Scholar] [CrossRef]
- Jiao, J.; Li, Z.; Xia, G.; Xin, J.; Wang, G.; Chen, Y. An uncalibrated visual servo control method of manipulator for multiple peg-in-hole assembly based on projective homography. J. Frankl. Inst. 2025, 362, 1234–1249. [Google Scholar] [CrossRef]
- Zhong, X.; Zhong, X.; Peng, X. Robots visual servo control with features constraint employing Kalman-neural-network filtering scheme. Neurocomputing 2015, 151, 268–277. [Google Scholar] [CrossRef]
- Chaumette, F. Potential problems of stability and convergence in image-based and position-based visual servoing. In The Confluence of Vision and Control; Springer: London, UK, 2007; pp. 66–78. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Controlled Object | Main Contributions | FOV Constraint |
|---|---|---|---|
| [19] | Nonholonomic mobile robots | Combining the RRT algorithm with virtual goal-guided constraint planning increases the computational burden and may affect real-time performance. | √ |
| [21,22] | 6-DOF robot arm | In 3D space, trajectories that satisfy field-of-view constraints rely on accurate environment and system modeling. | √ |
| [23] | 6-DOF robot manipulator | The potential function approach may suffer from the problem of local minima, which may cause the control system to stagnate at a local optimum. | × |
| [26] | Quadrotor | The behavior of the system is constrained by the visible set, which is limited by a control barrier function. | √ |
| [27] | 6-DOF robot manipulator | Actuator limitations and visibility constraints can be addressed using the MPC strategy while considering computational complexity. | √ |
| [29] | WMRs | The Q-learning controller was designed for the simple movements of wheeled robots. | × |
| [31,32] | Quadrotor | Designing adaptive servo gains with Q-learning can improve control without considering FOV. | × |
| [33] | WMRs | Designing adaptive servo gains with DDPG can improve control without considering FOV, and DDPG requires extensive data interactions and training, which can result in high computational cost and time overhead. | √ |
| Ours | 6-DOF robot manipulator | In the case where the system model is unknown and FOV feature constraints are considered, the DQN directly enforces the feature constraints using the mapped states of the camera FOV image features. | √ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, X.; Zhou, Q.; Sun, Y.; Kang, S.; Hu, H. Deep Reinforcement Learning-Based Uncalibrated Visual Servoing Control of Manipulators with FOV Constraints. Appl. Sci. 2025, 15, 4447. https://doi.org/10.3390/app15084447
Zhong X, Zhou Q, Sun Y, Kang S, Hu H. Deep Reinforcement Learning-Based Uncalibrated Visual Servoing Control of Manipulators with FOV Constraints. Applied Sciences. 2025; 15(8):4447. https://doi.org/10.3390/app15084447
Chicago/Turabian StyleZhong, Xungao, Qiao Zhou, Yuan Sun, Shaobo Kang, and Huosheng Hu. 2025. "Deep Reinforcement Learning-Based Uncalibrated Visual Servoing Control of Manipulators with FOV Constraints" Applied Sciences 15, no. 8: 4447. https://doi.org/10.3390/app15084447
APA StyleZhong, X., Zhou, Q., Sun, Y., Kang, S., & Hu, H. (2025). Deep Reinforcement Learning-Based Uncalibrated Visual Servoing Control of Manipulators with FOV Constraints. Applied Sciences, 15(8), 4447. https://doi.org/10.3390/app15084447