Abstract
Common visual simultaneous localization and mapping systems are built on the static environment hypothesis and fail to handle the substantial environmental dynamics. Particularly in highly dynamic environments, the pose estimation errors tend to accumulate rapidly, even causing the system to fail. To mitigate this limitation, we have developed DI-SLAM, an enhanced real-time SLAM system for dynamic indoor environments, extending the capabilities of ORB-SLAM3. DI-SLAM introduces a new parallel object detection thread, which employs an enhanced Yolov5s to extract semantic information in every input frame, enabling the filtering of dynamic features for initial tracking and localization. Additionally, we integrate multi-view geometry to further discriminate dynamic feature information, thereby increasing the precision and robustness of localization systems. Finally, experiments were executed on the TUM RGB-D dataset to prove the performance of the proposed algorithm. The results demonstrate strong performance on most datasets, showing a 97.06% improvement in localization accuracy over the original ORB-SLAM3 algorithm in indoor dynamic environments.
1. Introduction
Simultaneous localization and mapping (SLAM) technology, which estimates the camera’s pose and builds an environment map simultaneously during motion, is widely utilized in domains such as autonomous driving, augmented reality, robotics, and surveying [1]. Smith et al. [2] were the first to propose SLAM as a technique for determining a robot’s current pose without knowledge of its environment or motion. Today, visual SLAM systems have reached a high level of maturity, with notable algorithms such as ORB-SLAM3 [3], DS-SLAM [4], and DynaSLAM [5] achieving remarkable improvements in localization accuracy.
Current visual SLAM systems perform exceptionally well in static environments, stable lighting conditions, and ideal scenarios without external interference. However, in real-world applications, dynamic objects and continuous scene changes are inevitable. These dynamic factors frequently introduce substantial errors in camera pose computation, potentially leading to localization failure and adversely impacting map construction accuracy. Visual SLAM technology in dynamic environments still encounters numerous challenges, requiring further extensive research and enhancement.
Traditional SLAM systems frequently employ RANSAC’s outlier rejection mechanism to handle dynamic interference. However, in highly dynamic environments, this method may misclassify some genuine static features as outliers, leading to pose estimation errors. Recent studies have introduced various enhancements for such scenarios. For instance, ref. [6] proposes refining camera localization by filtering potential dynamic objects and constructing a static map, though excessive feature removal may destabilize SLAM tracking. Meanwhile, refs. [7,8,9] integrate semantic segmentation or scene flow to improve dynamic object detection. While these techniques boost perceptual precision, they also escalate computational demands.
To overcome these limitations, we propose DI-SLAM, a dynamic SLAM algorithm that extends ORB-SLAM3 through semantic–geometric collaboration. Our approach reliably distinguishes between static and dynamic features, ensuring that subsequent pose estimation is based solely on reliable static features, thereby improving the system’s localization accuracy and robustness in dynamic environments. The principal contributions of this research are summarized below:
- (1)
- We propose a visual SLAM system designed for indoor dynamic environments, significantly improving pose estimation accuracy and demonstrating enhanced robustness in dynamic indoor scenes.
- (2)
- We develop a dynamic feature filtering approach leveraging Yolov5s detection and multi-view geometry. This method effectively addresses the issues of false positives and false negatives in dynamic feature recognition through a dual-validation mechanism.
- (3)
- We evaluated our algorithm’s performance on the TUM RGB-D dataset. The results show that DI-SLAM effectively filters moving features and improves localization accuracy in highly dynamic scenarios.
The subsequent sections are structured accordingly: Section 2 provides the related work of dynamic SLAM approaches. The system framework and dynamic filtering strategy is detailed in the Section 3, highlighting the improved Yolov5s model and multi-view geometry method. Section 4 discusses the evaluation methodology and analyzes the experimental results of DI-SLAM. Finally, Section 5 wraps up the paper.
2. Related Works
To enhance visual SLAM performance in dynamic environments, experts in dynamic SLAM concentrate on two principal approaches: The first approach focuses on detecting and eliminating dynamic feature points to prevent their adverse effects on camera pose estimation. The second strategy jointly models dynamic objects and camera motion, achieving global optimization through multi-object tracking and motion constraints [10,11,12,13,14,15]. While the latter demonstrates superior perception and modeling capabilities in highly dynamic scenarios, it typically incurs substantial computational overhead and requires robust data association algorithms. This paper focuses on dynamic feature removal, which offers simpler implementation and faster computation while effectively mitigating dynamic interference. Existing removal methods can be broadly classified into three categories: motion segmentation-based filtering methods, semantic information-based approaches, and the fusion methods.
2.1. Methods Based on Motion Segmentation
Dynamic feature removal based on motion segmentation primarily includes three approaches: background–foreground initialization, optical flow methods, and geometric constraint methods. In terms of background–foreground initialization, ref. [16] establishes a rapid retrieval system by pre-storing SURF feature descriptors of dynamic objects [17], enabling efficient feature matching and motion region identification. Ref. [18] further improves dynamic feature filtering through a specialized template matching algorithm. For optical flow methods, ref. [19] presents an enhanced LK optical flow technique [20] that relaxes the grayscale consistency assumption, reducing gradient dependence while improving dynamic region detection accuracy. Ref. [21] implements a grid-based scene flow analysis combined with clustering algorithms to effectively separate dynamic and static features. Regarding geometric constraints, ref. [22] develops a point correlation segmentation method using motion consistency analysis, while ref. [23] constructs a geometric residual-based dynamic factor detection framework to enhance pose estimation. Ref. [24] optimizes computational efficiency through refined feature search ranges and outlier rejection strategies. Multi-view fusion approaches [25,26,27] demonstrate improved interference resistance, and ref. [28] introduces an innovative grid mapping technique employing probabilistic modeling for robust dynamic and static feature discrimination.
2.2. Methods Based on Semantic Information
Recent advancements in deep learning have significantly enhanced the environmental adaptability of visual SLAM systems. Several studies [29,30,31] leverage object detection algorithms to identify and eliminate dynamic objects, thereby improving localization accuracy in dynamic environments. Ref. [32] introduces a convolutional neural network (CNN)-based approach for feature extraction, generating compact yet distinctive image representations for improved loop closure detection. More sophisticated solutions [33,34] integrate instance segmentation networks into the SLAM system to eliminate potential moving objects in the scene, then use camera pose and epipolar constraints to filter out motion feature points, thus enhancing robustness in high-motion feature scenarios.
2.3. Methods Based on Fusion
Recent advancements in semantic-motion fusion for SLAM systems demonstrate significant improvements in computational efficiency and localization accuracy. Ref. [35] innovatively combines R-CNN instance segmentation with LK optical flow tracking, implementing a semantic-guided dynamic feature identification mechanism that reduces computational overhead while outperforming the original DSO algorithm. Building on this, ref. [36] develops an integrated framework combining instance-level segmentation with dense optical flow, enabling joint optimization of object motion tracking and camera pose estimation. Further developments by [37,38,39] employ semantic segmentation coupled with optical flow analysis to precisely eliminate interference features in highly dynamic environments, substantially enhancing system adaptability.
Inspired by the aforementioned research, we propose a visual–inertial SLAM algorithm that integrates semantic information with multi-view geometric constraints. First, we combine ORB features and Yolov5s to estimate a relatively rough camera pose (though not precise, this estimate still provides a useful reference for subsequent processing). Then, the localization system, using the association data between the current frame and the reference keyframe, applies semantic information and multi-view geometric methods to further identify and remove feature points related to dynamic targets in the current frame, ensuring they do not participate in subsequent pose estimation. This strategy reduces the system’s reliance on detection models, granting the SLAM algorithm better flexibility and scalability for different application scenarios. Compared to the existing dynamic SLAM algorithms, we significantly improve the pose estimation accuracy and demonstrate stronger robustness in indoor, highly dynamic environments.
3. System Introduction
In this section, we provide a detailed introduction to the DI-SLAM system. First, we describe the overall framework and the specific workflow of the system. Then, we focus on elaborating the methodology for dynamic feature filtering.
3.1. Framework of DI-SLAM
The DI-SLAM method is an improvement on ORB-SLAM3, a visual–inertial SLAM framework. ORB-SLAM3 is well known for its robustness in feature point-based localization and supports monocular, stereo, and RGB-D sensors. We focus on refining the RGB-D system by fully utilizing depth information to achieve higher localization precision.
ORB-SLAM3 is composed of four threads: tracking, local mapping, loop closing, and map merging. To enhance the system’s adaptability to dynamic scenes, as shown in Figure 1, DI-SLAM introduces a parallel object detection thread based on Yolov5s. This thread is used to extract semantic information from RGB images and generate dynamic masks to assist the tracking thread in filtering static features. Additionally, during the tracking phase, the localization system combines multi-view geometry methods with a semantic mask to remove dynamic features from the current frame. Notably, our proposed multi-view geometry strategy and object detection module maintain architectural independence, ensuring system robustness even in cases of detection failure.

Figure 1.
Framework of the DI-SLAM System. The orange section within the green box outlines the principal innovation of this study, and the remaining areas outlines the principal structure of ORB-SLAM3.
3.2. Dynamic Filtering Strategy
Our dynamic filtering strategy consists of three key components: dynamic feature point detection, object detection thread, and the multi-view geometry method. The first component detects dynamic features using epipolar constraints. Frame-to-frame correspondences are exploited to compute the fundamental matrix, and feature points violating epipolar line constraints are discarded as dynamic outliers. The second component is built on Yolov5s, which can extract semantic information from images in real time and generate a dynamic mask, denoted as , for subsequent dynamic feature removal in the image. The third component involves multi-view geometry, which, based on the association data between the current frame and the reference keyframe, generates another dynamic mask, . Finally, the two dynamic masks are then used together to identify dynamic features accurately.
3.2.1. Dynamic Feature Point Detection
ORB-SLAM3’s visual odometry relies on the feature points method for interframe pose estimation, providing reliable tracking even during high-speed camera motion. This paper introduces an algorithm built on ORB feature extraction, which is fast, stable, and capable of real-time representation of an image’s core features and can also quickly perform frame-to-frame matching through feature descriptors.
Building upon this, we further estimate the fundamental matrix using frame-to-frame matching of ORB feature points. Then, we apply epipolar constraints to filter out certain dynamic feature points in the scene.
- Estimation of the Fundamental Matrix
The fundamental matrix describes the geometric relationship between two cameras, and its decomposition provides their relative pose. By decomposing the known fundamental matrix, the relative pose between the two cameras can be determined. The following section details the process of solving the fundamental matrix using ORB feature points:
Initially, feature matching is conducted on two consecutive frames from the camera input, and a set of matched ORB feature points is obtained based on the feature descriptors, denoted as and , where and represent the matched feature points in the two frames. Subsequently, the fundamental matrix is computed by randomly selecting 8 pairs of matching points through RANSAC [40].
As shown in Figure 2, and represent the camera’s optical centers at two different locations. The epipolar plane is established by , , and . The baseline connecting and intersects the image planes at epipoles and . The intersection of the epipolar plane and the image planes and forms the epipolar lines and . According to the epipolar geometry constraint principle, the transformation relationship between each pair of feature points is described as
where represents the fundamental matrix. For a pair of matched points , set and . Substituting these into Equation (1), we obtain

Figure 2.
Epipolar geometry: the constraint for static scenes.
Set . After simplification, we derive
While the fundamental matrix can be derived with only 8 points through this method, RANSAC is employed to iteratively refine the selection of feature point pairs for precision. Additionally, by utilizing the geometric properties of epipolar lines, a cost function is constructed to further refine through optimization:
where measures the sum of squared polar line constraint errors for all matching point pairs in the two frames. During iteration, when reaches its minimum, the corresponding fundamental matrix is the optimal estimate.
- 2.
- Epipolar Constraint for Filtering Dynamic Features
With solved, the polar line is generated leveraging and coordinates of the feature points:
where and characterize the orientation vector of the epipolar line. That is, the mathematical representation of epipolar line takes the form , where represents the image coordinates.
To identify and eliminate anomalous dynamic feature points, the distance from to the polar line can be expressed as
Once the distance exceeds a predefined threshold, is recognized as a dynamic feature point.
Since the above method relies solely on adjacent frames to infer the fundamental matrix, its filtering capability has certain limitations in complex dynamic scenes with multiple target interactions. To address this, we augment the framework by incorporating semantic segmentation and multi-view geometry in Section 3.2.2 and Section 3.2.3, enabling more robust dynamic feature suppression.
3.2.2. Object Detection Thread
Object detection is a broad field that primarily utilizes neural networks to extract image features. These features are then used for calculations, and ultimately, the object is classified and localized in the form of a bounding box. Building on this foundation, we further process the detected dynamic object bounding boxes by merging them, generating a combined binary mask, , to represent potential dynamic regions in the image.
To balance real-time performance and computational efficiency, we select the Yolov5s neural network as the core of the object detection thread. Figure 3 illustrates the network architecture, which consists of four main components: input, backbone, neck, and prediction head. This structure allows for real-time object detection on each image frame, and the backbone is mainly composed of modules such as CBS, C3, and SPPF, which are used for efficiently extracting image features. For clarity, this subsection first provides a concise introduction to the fundamental modules highlighted in the purple region of Figure 3, including ConvBNSiLU, Bottleneck, and SPPF.

Figure 3.
Yolov5s framework diagram. The yellow and blue areas highlight the novel contributions of this work.
ConvBNSiLU, alternatively referred to as CBS, initially performs local feature extraction via a two-dimensional convolutional operation (Conv2d). Subsequently, it employs batch normalization (BatchNorm2d) for feature distribution standardization, followed by the application of a Sigmoid-weighted Linear Unit (SiLU) activation function to introduce nonlinear transformations, thereby enhancing the network’s expressive capability. The Bottleneck module adopts a “dimensionality reduction—convolution—dimensionality restoration” design: initially reducing channel dimensionality through 1 × 1 convolutions to minimize computational requirements, then performing spatial feature extraction via 3 × 3 convolutions and ultimately restoring the original channel dimensions through additional 1 × 1 convolutions. This architecture preserves feature fidelity while optimizing computational efficiency. The SPPF (Spatial Pyramid Pooling Fast) module concatenates feature maps with different receptive fields from multiple scales through maximum pooling layers and merges them to form a unified feature map, which enhances the network’s ability to recognize multi-scale objects at a relatively low computational cost.
To optimize the neural network processing efficiency, we strategically integrate the Convolutional Block Attention Module (CBAM) prior to the SPPF module in the backbone architecture. As illustrated in Figure 4, the SPPF module expands feature map receptive fields through its multi-scale max pooling operation, significantly enhancing multi-scale object detection performance. Meanwhile, CBAM combines channel attention with spatial attention, effectively strengthening the features of the target area while suppressing background interference. This structure helps reduce the model’s parameter count and computational complexity to some extent.

Figure 4.
CBAM network architecture diagram.
To more effectively enhance the feature representation capability of the neural network, we propose an enhanced version of the original C3 module in Yolov5s, designated as Nc2f. As depicted in Figure 5a, the baseline C3 module adopts a CSPNet-inspired architecture featuring, which divides the input features into two branches: one is processed only through the CBS module, and the other is processed through both CBS and the Bottleneck module. The features from both branches are then concatenated (Concat), followed by a CBS layer to restore the feature dimensions.

Figure 5.
Improvements of the C3 module. (a) The original C3 structure in YOLOv5s, inspired by CSPNet, splits the input into two branches for feature reuse and lightweight computation. (b) The enhanced version introduces a three-branch design with an additional residual path and element-wise addition to improve feature interaction and representation.
Although the original C3 module achieves a certain balance between speed and accuracy, there is still redundancy in the information flow in the Bottleneck path. To further improve feature utilization efficiency, this paper introduces a structural modification, as shown in Figure 5b. The improved C3 module adds three feature branches to the original structure. Two branches are still responsible for extracting information at different scales or depths, while the new branch retains the unprocessed features and performs an element-wise addition with the main path results. This structure enhances the interaction between the paths before fusion and creates a more expressive composite feature map after fusion.
Following the identification of potential dynamic regions and generation of the corresponding dynamic mask, the localization system employs this mask to perform preliminary filtering of extracted ORB features during the initial camera pose estimation phase. Subsequently, the remaining static features are utilized to compute a coarse initial estimate of the camera’s pose. During the tracking phase, the system further leverages this dynamic mask in combination with multi-view geometric constraints to jointly identify and eliminate dynamic features from the estimation process.
3.2.3. Multi-View Geometry Method
Although the object detection module can effectively identify potential dynamic feature points, its discriminative ability has two main limitations: On the one hand, it cannot accurately distinguish between actual dynamic objects and static objects, which can lead to misclassification (for example, a car parked on the side of the road should be considered a static object if it remains stationary). On the other hand, the system may fail to detect objects belonging to categories absent from the model’s training dataset. To overcome these limitations and achieve more precise dynamic feature identification, we compute another dynamic mask, , for the current image frame. This mask is then fused with the mask generated by object detection, , resulting in the final fused dynamic mask, .
Set:
The specific decision strategy is as follows:
Here, Condition 1 represents consensus cases where both detection methods agree on a dynamic status. Condition 2 resolves discordant cases by trusting geometric static results over detection-based dynamic calls, mitigating the misclassification of static regions as dynamic. Condition 3 conversely accepts geometric dynamic indications that override detection static labels, as the geometric method may have captured dynamic regions missed by the object detection. Finally, the three types of judgments are logically fused to obtain . The following will provide a detailed introduction to the multi-view geometric method used in this paper.
To start, we first select the keyframe that overlaps most with the current frame by calculating the rotation and descriptor distances of ORB feature points. Then, as shown in Figure 6, for each feature point in the keyframe , we calculate its corresponding projection point in the current frame, the reprojection angle between and , and the projection depth . If exceeds 30°, it indicates a significant viewpoint difference, and we classify this feature point as dynamic. If is less than 30°, we perform further analysis. In theory, the relation between and can be represented as
where and represent the projection depths of point on the two frames, and are the normalized coordinates of in the two frames, and is the camera pose calculated during the tracking step.

Figure 6.
Multi-view geometry: Once exceeds the threshold , (a) is part of a static object, (b) is part of a dynamic object, and is recognized as a dynamic feature.
Since our algorithm uses an RGB-D sensor, we can directly obtain the depth of . When considering the reprojection error, we compare with the projection depth of . If is greater than the threshold , we mark the point as a dynamic point.
By incorporating prior semantic insights with multi-view geometric methods, our SLAM system demonstrated strong performance in dynamic environments. Illustrated in Figure 7, across four different sequences, ORB-SLAM3 often includes dynamic features caused by moving objects, which compromise localization accuracy. In contrast, our method successfully filters out dynamic points, retaining only stable, static features and thereby significantly enhancing localization performance.


Figure 7.
Results of dynamic feature exclusion across four TUM RGB-D sequences: fr3_sitting_static, fr3_walking_halfsphere, fr3_walking_xyz, and fr3_walking_static. For each sequence, subfigures (a–e) represent five moments in time. The top row shows ORB features used by ORB-SLAM3, often affected by dynamic objects. The bottom row shows results from our method, where dynamic features are effectively removed, preserving only static keypoints for improved localization accuracy and robustness.
4. Experiments
4.1. Experiment Based on the Improved Yolov5s
To evaluate the performance of the improved Yolov5s object detection network, we used the VOC2007 + VOC2012 dataset, which includes 20 object categories split into training and validation sets in a 1:1 ratio. Data augmentation techniques such as random horizontal flipping, color jittering, and random cropping were applied to enhance the robustness.
In terms of network architecture, we reduced the model parameters by incorporating parameter sharing in the CBAM module and optimizing the C3 module, which also improved feature extraction. The improved Yolov5s reduced the parameters by 12.16% and increased the inference speed. During training, we used the Adam optimizer with an initial learning rate of 0.001, along with a cosine annealing learning rate scheduler, training for 150 epochs with early stopping to prevent overfitting.
The experiments were conducted on an NVIDIA RTX 3070 Ti GPU. As shown in Table 1, the results showed a 13.01% increase in inference speed and a 13.35% improvement in detection accuracy for the improved Yolov5s, demonstrating an effective balance between efficiency and accuracy.

Table 1.
Performance testing of object detection networks on a GPU.
4.2. Experimental Dataset
To validate the performance and robustness of the improved localization system, we carried out testing on the TUM RGB-D dataset [41], a popular resource for indoor scene analysis captured via a Kinect sensor. The dataset offers aligned RGB images and depth maps, ideal for appraising SLAM systems. We also evaluated our system by comparing it to ORB-SLAM3 and other progressive SLAM systems in an environment with moving objects.
Our experimental platform was a Dell laptop (Round Rock, TX, USA) equipped with an R7-6800H CPU operating at 3.3 GHz, an NVIDIA GeForce GTX 3070Ti GPU, and the Ubuntu 20.04 system.
4.3. Positioning Accuracy Analysis
To assess the effectiveness of our proposed algorithm, we first compared it with ORB-SLAM3, as our method extends the ORB-SLAM3 framework. We evaluated both systems using four sequences from the TUM dataset: sitting_static, walking_halfsphere, walking_xyz, and walking_static.
Figure 8a–i illustrate the comparison of the absolute trajectory error between the proposed algorithm (middle section), ORB-SLAM3 (upper section), and RDS-SLAM (lower section) on the datasets fr3_walking_halfsphere, fr3_walking_static, and fr3_walking_xyz. The black curve represents the ground truth of the camera’s movement path; the blue curve denotes the trajectory estimation from ORB-SLAM3, RDS-SLAM, or the proposed DI-SLAM algorithm; and the red line segments indicate the absolute error between the estimated and ground truth trajectories.
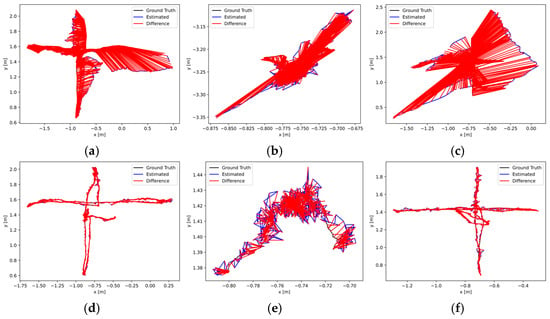

Figure 8.
Comparative evaluation of trajectory estimations in dynamic sequences between the proposed algorithm and ORB-SLAM3: (a) orb-slam3:fr3_w_half, (b) orb-slam3:fr3_w_static, (c) orb-slam3:fr3_w_xyz, (d) ours:fr3_w_half, (e) ours:fr3_w_static, (f) ours:fr3_w_xyz, (g) rds-slam:fr3_w_half, (h) rds-slam:fr3_w_static, and (i) rds-slam:fr3_w_xyz.
In our evaluation, we adopt three absolute trajectory error (ATE) metrics—RMSE, Mean, and Std—to measure the system’s localization accuracy. Additionally, to provide a more intuitive understanding of the experimental outcomes and to supplement the results presented in Figure 8, we illustrate the absolute pose errors of the proposed algorithm in comparison with two other methods in Figure 9a–i. The corresponding data comparing our method with the original ORB-SLAM3 are reported in Table 2, while the comparative results with the state-of-the-art RDS-SLAM are presented in Table 3.

Figure 9.
Comparative evaluation of trajectory estimations in dynamic sequences between the proposed algorithm and RDS-SLAM: (a) orb-slam3:fr3_w_half, (b) orb-slam3:fr3_w_static, (c) orb-slam3:fr3_w_xyz, (d) ours:fr3_w_half, (e) ours:fr3_w_static, (f) ours:fr3_w_xyz, (g) rds-slam:fr3_w_half, (h) rds-slam:fr3_w_static, and (i) rds-slam:fr3_w_xyz.
Table 2.
ATE comparison with the ORB-SLAM3 algorithms on 4 sequences.
Table 3.
ATE comparison with the RDS-SLAM algorithms on 4 sequences.
The results from the experiments indicate that it achieves significant improvements in pose estimation accuracy for highly dynamic scenarios when compared to the original ORB-SLAM3. In low dynamic scene dataset sequences, the RMSE of the absolute trajectory error demonstrates a 22.11% decrease relative to ORB-SLAM3. In high-dynamic scene datasets, the proposed algorithm reduces the RMSE of the absolute trajectory error by an average of 94.11% compared to ORB-SLAM3, which reveals that the DI-SLAM system proves to be more superior than ORB-SLAM3 in scenarios ranging from low to high dynamics, delivering significantly more precise trajectory estimates across the board.
Additionally, we compared our DI-SLAM system with the state-of-the-art dynamic SLAM algorithm, RDS-SLAM, and the experimental results are presented in Table 3. In static environments, both methods demonstrate reliable performance. However, as the presence of dynamic elements in the scene increases, trajectory errors also grow. Compared to RDS-SLAM, our method performs slightly better on the walking_xyz sequence. In other dynamic scenarios, although the estimation accuracy of both approaches is comparable, our method shows a marginally inferior overall performance. We attribute this discrepancy primarily to the semantic segmentation approach adopted by RDS-SLAM, which enables effective pixel-level separation of dynamic and static regions. Nevertheless, this segmentation method introduces additional image processing overhead. Furthermore, RDS-SLAM employs a mature dynamic–static data association strategy, granting it a notable advantage in tracking and handling outliers. In contrast, our method relies on multi-view geometry and object detection techniques for outlier filtering. While this approach may be slightly less effective in highly dynamic scenes, it does not significantly affect the overall system performance. Overall, the DI-SLAM system demonstrates clear advantages in specific scenarios (e.g., walking_xyz), and with further algorithmic refinement, it is expected to compete with—and potentially surpass—existing methods in a broader range of dynamic environments.
5. Conclusions
To improve SLAM precision in scenarios with moving elements, we proposed an enhanced SLAM system that integrates multi-view geometry and object detection techniques. Developed upon the ORB-SLAM3 framework, we implement a dynamic feature filtering thread using an improved object detection network to identify possible dynamic features. During the tracking process, dynamic feature points are filtered based on a combined dynamic mask generated from both multi-view geometry and object detection results, while static features are retained for pose estimation.
Extensive experiments on dynamic sequence datasets demonstrate that our approach significantly reduces visual localization errors caused by moving objects. For instance, on the walking_xyz sequence, our method reduces the RMSE from 0.6502 m (ORB-SLAM3) to 0.0191 m, achieving a 97.06% improvement. Compared to RDS-SLAM, it yields a further reduction of approximately 16.3%. Across all tested dynamic sequences, our method achieves an average RMSE improvement of 76.11% over ORB-SLAM3. Moreover, in highly dynamic indoor scenes such as walking_xyz and walking_half, our method significantly outperforms ORB-SLAM3 in both accuracy and robustness and demonstrates competitive performance compared to RDS-SLAM, in most cases.
However, the current evaluation is limited to indoor dynamic environments. Future works will focus on extending the proposed system to outdoor dynamic scenarios, where challenges such as scale variation, lighting changes, and complex motion patterns are expected to further test the adaptability and robustness of our approach.
Author Contributions
Conceptualization, W.W. and C.X.; Software, W.W.; Validation, C.X.; Data curation, J.H.; Writing—original draft, W.W.; Writing—review and editing, C.X.; Supervision, C.X. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partly supported by the National Natural Science Foundation of China under Grant 52272435.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
TUM dataset used in this paper is available at https://cvg.cit.tum.de/data/datasets/rgbd-dataset/download#, accessed on 3 March 2025.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SLAM | Simultaneous Localization and Mapping |
| ORB-SLAM3 | Oriented FAST and Rotated BRIEF-SLAM version 3 |
| DI-SLAM | SLAM For Dynamic Indoor Environments |
| TUM | Technical University of Munich |
| RANSAC | Random Sample Consensus |
| IMU | Inertial Measurement Unit |
| CBAM | Convolutional Block Attention Module |
| SPPF | Spatial Pyramid Pooling Feature |
| RDS-SLAM | RDS-SLAM: Real-Time Dynamic SLAM |
References
- Engel, J.; Schps, T.; Cremers, D. LSD-SLAM: Large-scale direct monocular SLAM. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Smith, R. On the representation of spatial uncertainty. Int. J. Robot. Res. 1986, 5, 56–68. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodriguez, J.J.G.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial, and Multimap SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Z.X.; Liu, X.J.; Xie, F.G.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments. In Proceedings of the 25th IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, Mapping, and Inpainting in Dynamic Scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Pan, Z.H.; Hou, J.Y.; Yu, L. Optimization RGB-D 3-D Reconstruction Algorithm Based on Dynamic SLAM. IEEE Trans. Instrum. Meas. 2023, 72, 13. [Google Scholar] [CrossRef]
- Fan, Y.C.; Zhang, Q.C.; Tang, Y.L.; Liu, S.F.; Han, H. Blitz-SLAM: A semantic SLAM in dynamic environments. Pattern Recognit. 2022, 121, 14. [Google Scholar] [CrossRef]
- Bescos, B.; Campos, C.; Tardós, J.D.; Neira, J. DynaSLAM II: Tightly-Coupled Multi-Object Tracking and SLAM. IEEE Robot. Autom. Lett. 2021, 6, 5191–5198. [Google Scholar] [CrossRef]
- Kochanov, D.; Osep, A.; Stückler, J.; Leibe, B. Scene Flow Propagation for Semantic Mapping and Object Discovery in Dynamic Street Scenes. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 1785–1792. [Google Scholar]
- Zhu, Y.; An, H.; Wang, H.D.; Xu, R.D.; Sun, Z.P.; Lu, K. DOT-SLAM: A Stereo Visual Simultaneous Localization and Mapping (SLAM) System with Dynamic Object Tracking Based on Graph Optimization. Sensors 2024, 24, 4676. [Google Scholar] [CrossRef] [PubMed]
- Henein, M.; Zhang, J.; Mahony, R.; Ila, V. Dynamic SLAM: The Need For Speed. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–15 June 2020; pp. 2123–2129. [Google Scholar]
- Qin, Y.; Yu, H.D. A review of visual SLAM with dynamic objects. Ind. Robot. 2023, 50, 1000–1010. [Google Scholar] [CrossRef]
- Long, R.; Rauch, C.; Zhang, T.W.; Ivan, V.; Vijayakumar, S. RigidFusion: Robot Localisation and Mapping in Environments With Large Dynamic Rigid Objects. IEEE Robot. Autom. Lett. 2021, 6, 3703–3710. [Google Scholar] [CrossRef]
- Bibby, C.; Reid, I.D. Simultaneous localisation and mapping in dynamic environments (SLAMIDE) with reversible data association. Proc. Robot. Sci. Syst. 2007, 66, 81. [Google Scholar]
- Saputra, M.R.U.; Markham, A.; Trigoni, N. Visual SLAM and Structure from Motion in Dynamic Environments: A Survey. ACM Comput. Surv. 2018, 51, 36. [Google Scholar] [CrossRef]
- Wang, Y.T.; Lin, M.C.; Ju, R.C. Visual SLAM and Moving-object Detection for a Small-size Humanoid Robot. Int. J. Adv. Robot. Syst. 2010, 7, 133–138. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Zhong, M.L.; Hong, C.Y.; Jia, Z.Q.; Wang, C.Y.; Wang, Z.G. DynaTM-SLAM: Fast filtering of dynamic feature points and object-based localization in dynamic indoor environments. Robot. Auton. Syst. 2024, 174, 10. [Google Scholar] [CrossRef]
- Fang, Y.H.; Xie, Z.J.; Chen, K.W.; Huang, G.Y.; Zarei, R.; Xie, Y.T. DYS-SLAM: A real-time RGBD SLAM combined with optical flow and semantic information in a dynamic environment. J. Intell. Fuzzy Syst. 2023, 45, 10349–10367. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application toStereo Vision. In Proceedings of the 7th International Joint Conference on ArtificialIntelligence, Nagoya, Japan, 23–29 August 1997. [Google Scholar]
- Long, F.; Ding, L.; Li, J.F. DGFlow-SLAM: A Novel Dynamic Environment RGB-D SLAM without Prior Semantic Knowledge Based on Grid Segmentation of Scene Flow. Biomimetics 2022, 7, 163. [Google Scholar] [CrossRef] [PubMed]
- Dai, W.C.; Zhang, Y.; Li, P.; Fang, Z.; Scherer, S. RGB-D SLAM in Dynamic Environments Using Point Correlations. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 373–389. [Google Scholar] [CrossRef]
- Lu, Q.; Pan, Y.; Hu, L.K.; He, J.S. A Method for Reconstructing Background from RGB-D SLAM in Indoor Dynamic Environments. Sensors 2023, 23, 3529. [Google Scholar] [CrossRef]
- Roussillon, C.; Gonzalez, A.; Solà, J.; Codol, J.M.; Mansard, N.; Lacroix, S.; Devy, M. RT-SLAM: A Generic and Real-Time Visual SLAM Implementation; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Huang, X.T.; Chen, X.B.; Zhang, N.; He, H.J.; Feng, S. ADM-SLAM: Accurate and Fast Dynamic Visual SLAM with Adaptive Feature Point Extraction, Deeplabv3pro, and Multi-View Geometry. Sensors 2024, 24, 3578. [Google Scholar] [CrossRef]
- Yang, H.W.; Jiang, P.L.; Wang, F. Multi-View-Based Pose Estimation and Its Applications on Intelligent Manufacturing. Sensors 2020, 20, 5072. [Google Scholar] [CrossRef]
- Zhang, Y.C.; Li, Y.M.; Chen, P.Z.; Xie, Y.L.; Zheng, S.Q.; Hu, Z.Z.; Wang, S.T. TSG-SLAM: SLAM Employing Tight Coupling of Instance Segmentation and Geometric Constraints in Complex Dynamic Environments. Sensors 2023, 23, 9807. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.F.; Cai, Z.X. Mobile robot mapping system and method in dynamic environments. In Proceedings of the International Conference on Informational Technology and Environmental System Science, Henan Polytechn Univ, Jiaozuo, China, 15–17 May 2008; pp. 1024–1029. [Google Scholar]
- Chang, Y.M.; Hu, J.; Xu, S.Y. OTE-SLAM: An Object Tracking Enhanced Visual SLAM System for Dynamic Environments. Sensors 2023, 23, 7921. [Google Scholar] [CrossRef]
- Cong, P.C.; Li, J.X.; Liu, J.J.; Xiao, Y.X.; Zhang, X. SEG-SLAM: Dynamic Indoor RGB-D Visual SLAM Integrating Geometric and YOLOv5-Based Semantic Information. Sensors 2024, 24, 2102. [Google Scholar] [CrossRef]
- Kan, X.K.; Shi, G.F.; Yang, X.R.; Hu, X.W. YPR-SLAM: A SLAM System Combining Object Detection and Geometric Constraints for Dynamic Scenes. Sensors 2024, 24, 6576. [Google Scholar] [CrossRef]
- Bai, D.D.; Wang, C.Q.; Zhang, B.; Yi, X.D.; Tang, Y.H. Matching-Range-Constrained Real-Time Loop Closure Detection with CNNs Features. In Proceedings of the IEEE International Conference on Real-Time Computing and Robotics (IEEE RCAR), Angkor Wat, Cambodia, 6–10 June 2016; pp. 70–75. [Google Scholar]
- Hu, X.; Lang, J.C. DOE-SLAM: Dynamic Object Enhanced Visual SLAM. Sensors 2021, 21, 3091. [Google Scholar] [CrossRef]
- Tian, L.Y.; Yan, Y.B.; Li, H.R. SVD-SLAM: Stereo Visual SLAM Algorithm Based on Dynamic Feature Filtering for Autonomous Driving. Electronics 2023, 12, 1883. [Google Scholar] [CrossRef]
- Yue, S.Z.; Wang, Z.J.; Zhang, X.N. DSOMF: A Dynamic Environment Simultaneous Localization and Mapping Technique Based on Machine Learning. Sensors 2024, 24, 3063. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Henein, M.; Mahony, R.; Ila, V. Robust Ego and Object 6-DoF Motion Estimation and Tracking. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 5017–5023. [Google Scholar]
- He, L.; Li, S.Y.; Qiu, J.T.; Zhang, C.H.M. DIO-SLAM: A Dynamic RGB-D SLAM Method Combining Instance Segmentation and Optical Flow. Sensors 2024, 24, 5929. [Google Scholar] [CrossRef] [PubMed]
- Lyu, L.; Ding, Y.; Yuan, Y.T.; Zhang, Y.T.; Liu, J.P.; Li, J.X. DOC-SLAM: Robust Stereo SLAM with Dynamic Object Culling. In Proceedings of the 7th International Conference on Automation, Robotics and Applications (ICARA), Prague, Czech Republic, 4–6 February 2021; pp. 258–262. [Google Scholar]
- Li, C.; Hu, Y.; Liu, J.Q.; Jin, J.H.; Sun, J. ISFM-SLAM: Dynamic visual SLAM with instance segmentation and feature matching. Front. Neurorobot. 2024, 18, 15. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).