
Analysis of Demographic, Familial, and Social Determinants of Smoking Behavior Using Machine Learning Methods

 , , ,
, , ,  , and
, and 
Abstract
:1. Introduction
1.1. Physical and Prenatal Health Impacts
1.2. Social and Cultural Factors Shaping Smoking Behaviors
1.3. The Rise of E-Cigarettes and Technological Influence
1.4. Family Dynamics and Smoking Cessation
1.5. Long-Term Effects on Family Cohesion
2. Materials and Methods
2.1. Survey Instruments
2.2. Participant Recruitment
2.3. Data Collection
2.4. Statistical Analysis
2.5. Machine Learning Methods
3. Results
3.1. Statistical Analysis
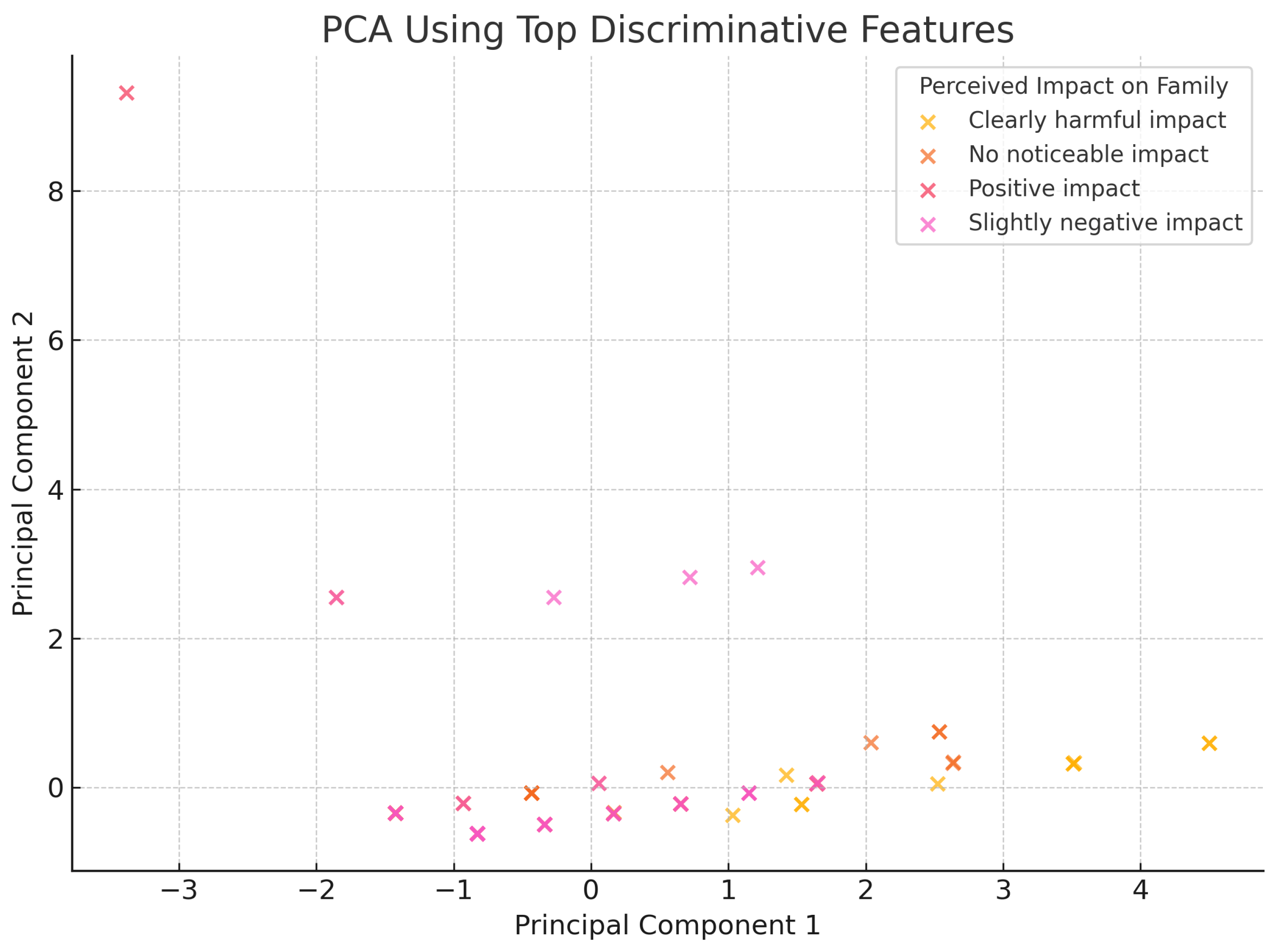
3.2. Machine Learning Analysis
- NumericImpactResponses—questions assessing the impact on family relationships;
- NumericConflictResponses—questions about family conflicts;
- NumericAcceptanceResponses—questions about family acceptance of smoking;
- NumericFamilySmoking—question whether anyone in the family smokes;
- CleanedSmokingFrequency—represents the individual’s smoking frequency.
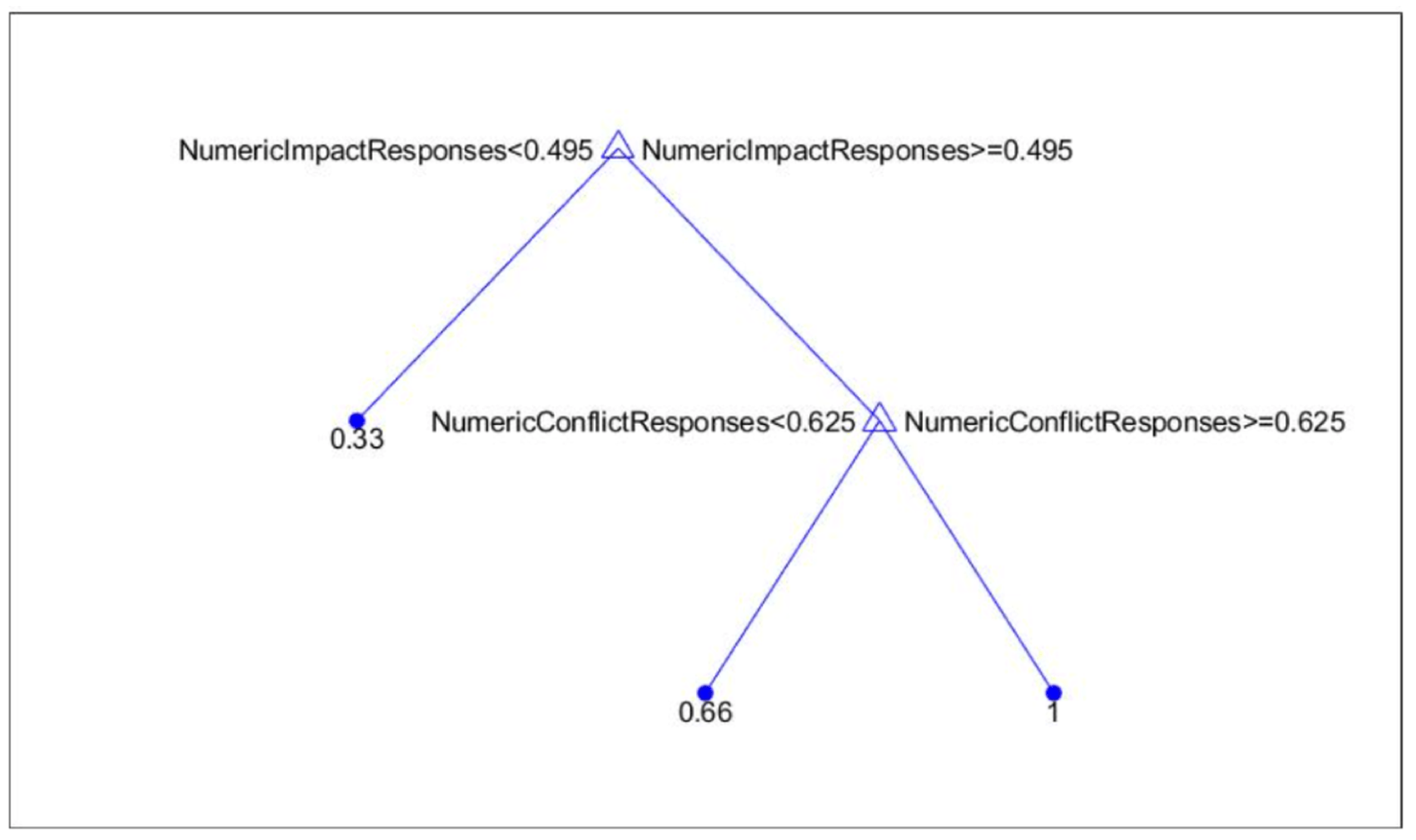
- When NumericImpactResponses is less than 0.495, the model predicts an outcome of 0.33.
- When NumericImpactResponses is greater than or equal to 0.495 and NumericConflictResponses is equal to or above 0.625, the predicted outcome is 1.
- When NumericImpactResponses is greater than or equal to 0.495 and NumericConflictResponses is below 0.625, the predicted outcome is 0.66.
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Thomas, P.A.; Liu, H.; Umberson, D. Family Relationships and Well-Being. Innov. Aging 2017, 1, igx025. [Google Scholar] [CrossRef] [PubMed]
- Ross, C.E.; Mirowsky, J. Family Relationships, Social Support and Subjective Life Expectancy. J. Health Soc. Behav. 2002, 43, 469. [Google Scholar] [CrossRef]
- McMahon, E.L.; Wallace, S.; Samuels, L.R.; Heerman, W.J. The relationships between resilience and child health behaviors in a national dataset. Pediatr. Res. 2024. [Google Scholar] [CrossRef] [PubMed]
- Kganyago Mphaphuli, L. The Impact of Dysfunctional Families on the Mental Health of Children. In Parenting in Modern Societies; IntechOpen: London, UK, 2023. [Google Scholar] [CrossRef]
- Steeger, C.M.; Bailey, J.A.; Epstein, M.; Hill, K.G. The link between parental smoking and youth externalizing behaviors: Effects of smoking, psychosocial factors, and family characteristics. Psychol. Addict. Behav. 2019, 33, 243–253. [Google Scholar] [CrossRef] [PubMed]
- Omasu, F.; Uemura, S.; Yukizane, S. The Impact of Family Relationships on the Smoking Habits of University Students. Open J. Prev. Med. 2015, 5, 14–22. [Google Scholar] [CrossRef]
- Wang, G.; Wu, L. Healthy People 2020: Social Determinants of Cigarette Smoking and Electronic Cigarette Smoking among Youth in the United States 2010–2018. Int. J. Environ. Res. Public Health 2020, 17, 7503. [Google Scholar] [CrossRef]
- Dietz, N.A.; Arheart, K.L.; Sly, D.F.; Lee, D.J.; McClure, L.A. Correlates of smoking among youth: The role of parents, friends, attitudes/beliefs, and demographics. Tob. Induc. Dis. 2016, 14, 9. [Google Scholar] [CrossRef]
- Mahabee-Gittens, E.M.; Harun, N.; Glover, M.; Folger, A.T.; Parikh, N.A.; Altaye, M.; Arnsperger, A.; Beiersdorfer, T.; Bridgewater, K.; Cahill, T.; et al. Prenatal tobacco smoke exposure and risk for cognitive delays in infants born very premature. Sci. Rep. 2024, 14, 1397. [Google Scholar] [CrossRef]
- McEvoy, C.T.; Spindel, E.R. Pulmonary Effects of Maternal Smoking on the Fetus and Child: Effects on Lung Development, Respiratory Morbidities, and Life Long Lung Health. Paediatr. Respir. Rev. 2017, 21, 27–33. [Google Scholar] [CrossRef]
- Barrington-Trimis, J.L.; Berhane, K.; Unger, J.B.; Cruz, T.B.; Urman, R.; Chou, C.P.; Howland, S.; Wang, K.; Pentz, M.A.; Gilreath, T.D.; et al. The E-cigarette Social Environment, E-cigarette Use, and Susceptibility to Cigarette Smoking. J. Adolesc. Health 2016, 59, 75–80. [Google Scholar] [CrossRef]
- Hubbard, G.; Gorely, T.; Ozakinci, G.; Polson, R.; Forbat, L. A systematic review and narrative summary of family-based smoking cessation interventions to help adults quit smoking. BMC Fam. Pract. 2016, 17, 73. [Google Scholar] [CrossRef]
- Srivastava, P.; Trinh, T.A. The effect of parental smoking on children’s cognitive and non-cognitive skills. Econ. Hum. Biol. 2021, 41, 100978. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Liu, D.y.; Wang, Y.j.; Huang, M.j.; Jiang, N.; Hou, Q.; Feng, B.; Wu, W.y.; Wu, Y.b.; Qi, F.; et al. Family functioning and nicotine dependence among smoking fathers: A cross-sectional study. BMC Public Health 2023, 23, 658. [Google Scholar] [CrossRef]
- Mohammadnezhad, M.; Tsourtos, G.; Wilson, C.; Ratcliffe, J.; Ward, P. Understanding Socio-cultural Influences on Smoking among Older Greek-Australian Smokers Aged 50 and over: Facilitators or Barriers? A Qualitative Study. Int. J. Environ. Res. Public Health 2015, 12, 2718–2734. [Google Scholar] [CrossRef] [PubMed]
- Egbe, C.O.; Petersen, I.; Meyer-Weitz, A.; Oppong Asante, K. An exploratory study of the socio-cultural risk influences for cigarette smoking among Southern Nigerian youth. BMC Public Health 2014, 14, 1204. [Google Scholar] [CrossRef] [PubMed]
- Wilkinson, A.V.; Shete, S.; Prokhorov, A.V. The moderating role of parental smoking on their children’s attitudes toward smoking among a predominantly minority sample: A cross-sectional analysis. Subst. Abus. Treat. Prev. Policy 2008, 3, 18. [Google Scholar] [CrossRef]
- Hiscock, R.; Dobbie, F.; Bauld, L. Smoking Cessation and Socioeconomic Status: An Update of Existing Evidence from a National Evaluation of English Stop Smoking Services. BioMed Res. Int. 2015, 2015, 274056. [Google Scholar] [CrossRef]
- Waters, A.; Kendzor, D.; Roys, M.; Stewart, S.; Copeland, A. Financial strain mediates the relationship between socioeconomic status and smoking. Tob. Prev. Cessat. 2019, 5, 3. [Google Scholar] [CrossRef]
- Pokhrel, P.; Herzog, T.A.; Muranaka, N.; Regmi, S.; Fagan, P. Contexts of cigarette and e-cigarette use among dual users: A qualitative study. BMC Public Health 2015, 15, 859. [Google Scholar] [CrossRef]
- Martinelli, T.; Candel, M.J.J.M.; de Vries, H.; Talhout, R.; Knapen, V.; van Schayck, C.P.; Nagelhout, G.E. Exploring the gateway hypothesis of e-cigarettes and tobacco: A prospective replication study among adolescents in the Netherlands and Flanders. Tob. Control 2021, 32, 170–178. [Google Scholar] [CrossRef]
- Wang, J.W.; Cao, S.S.; Hu, R.Y. Smoking by family members and friends and electroniccigarette use in adolescence: A systematic review and metaanalysis. Tob. Induc. Dis. 2018, 16, 5. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.; Palmer, P.H.; Sakuma, K.L.; Blake, J.; Johnson, C.A. The association between family structure and adolescent smoking among multicultural students in Hawaii. Prev. Med. Rep. 2015, 2, 206–212. [Google Scholar] [CrossRef]
- Eslava, D.; Martínez-Vispo, C.; Villanueva-Blasco, V.J.; Errasti-Pérez, J.M.; Al-Halabí, S. Family Conflict and the Use of Conventional and Electronic Cigarettes in Adolescence: The Role of Impulsivity Traits. Int. J. Ment. Health Addict. 2022, 21, 3885–3896. [Google Scholar] [CrossRef]
- Hill, K.G.; Hawkins, J.D.; Catalano, R.F.; Abbott, R.D.; Guo, J. Family influences on the risk of daily smoking initiation. J. Adolesc. Health 2005, 37, 202–210. [Google Scholar] [CrossRef] [PubMed]
- Foulds, J.; Veldheer, S.; Yingst, J.; Hrabovsky, S.; Wilson, S.J.; Nichols, T.T.; Eissenberg, T. Development of a Questionnaire for Assessing Dependence on Electronic Cigarettes Among a Large Sample of Ex-Smoking E-cigarette Users. Nicotine Tob. Res. 2014, 17, 186–192. [Google Scholar] [CrossRef]
- Children Whose Parents Smoke Are 4 Times as Likely to Take Up Smoking Themselves—gov.uk. Available online: https://www.gov.uk/government/news/children-whose-parents-smoke-are-four-times-as-likely-to-take-up-smoking-themselves (accessed on 2 April 2025).
- Alves, J.; Perelman, J.; Soto-Rojas, V.; Richter, M.; Rimpelä, A.; Loureiro, I.; Federico, B.; Kuipers, M.A.; Kunst, A.E.; Lorant, V. The role of parental smoking on adolescent smoking and its social patterning: A cross-sectional survey in six European cities. J. Public Health 2016, 39, 339–346. [Google Scholar] [CrossRef]
- Sanchez, S.; Kaufman, P.; Pelletier, H.; Baskerville, B.; Feng, P.; O’Connor, S.; Schwartz, R.; Chaiton, M. Is vaping cessation like smoking cessation? A qualitative study exploring the responses of youth and young adults who vape e-cigarettes. Addict. Behav. 2021, 113, 106687. [Google Scholar] [CrossRef]
- Kim, S.; Gil, M.; Kim-Godwin, Y. Development and Validation of the Family Relationship Assessment Scale in Korean College Students’ Families. Fam. Process 2020, 60, 586–601. [Google Scholar] [CrossRef]
- Yingst, J.; Foulds, J.; Hobkirk, A.L. Dependence and Use Characteristics of Adult JUUL Electronic Cigarette Users. Subst. Use Misuse 2020, 56, 61–66. [Google Scholar] [CrossRef]
- Glantz, S.A.; Bareham, D.W. E-Cigarettes: Use, Effects on Smoking, Risks, and Policy Implications. Annu. Rev. Public Health 2024, 39, 215–235. [Google Scholar] [CrossRef]
- Fidler, J.A.; West, R. Enjoyment of smoking and urges to smoke as predictors of attempts and success of attempts to stop smoking: A longitudinal study. Drug Alcohol Depend. 2011, 115, 30–34. [Google Scholar] [CrossRef] [PubMed]
- Sharma, R.; Martins, N.; Tripathi, A.; Caponnetto, P.; Garg, N.; Nepovimova, E.; Kuča, K.; Prajapati, P.K. Influence of Family Environment and Tobacco Addiction: A Short Report from a Post-Graduate Teaching Hospital, India. Int. J. Environ. Res. Public Health 2020, 17, 2868. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2000; pp. 1–15. [Google Scholar] [CrossRef]
- Chang, X. Comparative Analysis of Machine Learning, Decision Trees, and K-Nearest Neighbors for Heart Disease Prediction. Appl. Comput. Eng. 2024, 82, 188–192. [Google Scholar] [CrossRef]
- Guido, R.; Ferrisi, S.; Lofaro, D.; Conforti, D. An Overview on the Advancements of Support Vector Machine Models in Healthcare Applications: A Review. Information 2024, 15, 235. [Google Scholar] [CrossRef]
- Issabakhsh, M.; Sánchez-Romero, L.M.; Le, T.T.T.; Liber, A.C.; Tan, J.; Li, Y.; Meza, R.; Mendez, D.; Levy, D.T. Machine learning application for predicting smoking cessation among US adults: An analysis of waves 1–3 of the PATH study. PLoS ONE 2023, 18, e0286883. [Google Scholar] [CrossRef] [PubMed]
- Lai, C.C.; Huang, W.H.; Chang, B.C.C.; Hwang, L.C. Development of Machine Learning Models for Prediction of Smoking Cessation Outcome. Int. J. Environ. Res. Public Health 2021, 18, 2584. [Google Scholar] [CrossRef] [PubMed]
- Hummel, K.; Candel, M.J.J.M.; Nagelhout, G.E.; Brown, J.; van den Putte, B.; Kotz, D.; Willemsen, M.C.; Fong, G.T.; West, R.; de Vries, H. Construct and Predictive Validity of Three Measures of Intention to Quit Smoking: Findings from the International Tobacco Control (ITC) Netherlands Survey. Nicotine Tob. Res. 2017, 20, 1101–1108. [Google Scholar] [CrossRef]
- Gallus, S.; Cresci, C.; Rigamonti, V.; Lugo, A.; Bagnardi, V.; Fanucchi, T.; Cirone, D.; Ciaccheri, A.; Cardellicchio, S. Self-efficacy in predicting smoking cessation: A prospective study from Italy. Tob. Prev. Cessat. 2023, 9, 15. [Google Scholar] [CrossRef]
- Morrell, H.E.R.; Song, A.V.; Halpern-Felsher, B.L. Predicting adolescent perceptions of the risks and benefits of cigarette smoking: A longitudinal investigation. Health Psychol. 2010, 29, 610–617. [Google Scholar] [CrossRef]
- Kozlowski, L.T.; Porter, C.Q.; Orleans, C.; Pope, M.A.; Heatherton, T. Predicting smoking cessation with self-reported measures of nicotine dependence: FTQ, FTND, and HSI. Drug Alcohol Depend. 1994, 34, 211–216. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Categories | Frequency (%) |
|---|---|---|
| Gender | Male/Female/Other | 44/54/2 |
| Age | Mean (SD): 23.4 (4.6); Range: 18–39 | — |
| Living Environment | Rural/<50 k/50–150 k/150–500 k/>500 k | 12/9/15/30/34 |
| Educational Attainment | Primary/Lower Secondary/Vocational/Secondary/University | 2/6/12/42/38 |
| Smoking Behavior | Electronic/Traditional/Both | 43/21/36 |
| Category | Indicator | E-Cigarette Smokers | Traditional Smokers | Dual Users |
|---|---|---|---|---|
| Family Support (mean) | 4.22 | 3.50 | 3.67 | |
| FRAC | Family Conflict (mean) | 1.81 | 2.00 | 1.89 |
| Family Togetherness (mean) | 3.26 | 3.12 | 2.83 | |
| No Dependence (%) | 0.00 | 4.76 | 0.00 | |
| Low Dependence (%) | 21.05 | 33.33 | 16.67 | |
| PSECDI | Moderate Dependence (%) | 31.58 | 19.05 | 33.33 |
| High Dependence (%) | 47.37 | 42.86 | 50.00 | |
| PSECDI Score (mean) | 13.11 | 12.05 | 13.50 |
| Variables | Test | Results | p-Value | Interpretation |
|---|---|---|---|---|
| Participant age and type of smoking product | ANOVA | F = 8.79 | p < 0.001 | Significant differences in smoking products among age groups |
| Education level and type of smoking product | Chi-Square | = 6.41 | 0.601 | No significant association |
| Gender and type of smoking product | Chi-Square | = 10.63 | 0.031 | Significant differences between genders in smoking products used |
| Participant age and age of smoking initiation | Spearman Correlation | = 0.23 | 0.024 | Older participants started smoking at later ages |
| Place of residence and type of smoking product | Chi-Square | = 7.02 | 0.534 | No significant association |
| Family history of smoking and type of smoking product | Chi-Square | = 2.00 | 0.368 | No significant association |
| Perceived impact of smoking on relationships and number of cigarettes smoked | Spearman Correlation | = −0.15 | 0.135 | Weak negative correlation, not statistically significant |
| Smoking frequency and willingness to quit | Spearman Correlation | = −0.07 | 0.485 | Very weak negative correlation, not significant |
| Time to first cigarette after waking and willingness to quit | Spearman Correlation | = −0.31 | 0.002 | Moderate negative correlation, statistically significant |
| Family conflict score and willingness to quit | Chi-Square | = 5.15 | 0.272 | No significant association |
| Family support score and willingness to quit | Logistic Regression | Coefficients: 1.37, −0.18 | p = 0.058, p = 0.300 | Trend toward significance, but not significant |
| Family tension score and number of cigarettes smoked per day | Spearman Correlation | = 0.22–0.34 | 0.029–0.001 | Significant positive correlation |
| Family acceptance score and smoking frequency | Spearman Correlation | = −0.09 to −0.08 | 0.334–0.467 | No significant correlation |
| Quit attempts and urge to smoke | Chi-Square | = 5.15 | 0.272 | No significant correlation |
| Nocturnal smoking behavior and smoking frequency | Chi-Square | = 14.25 | 0.014 | Significant association |
| Current e-cigarette use and prior traditional cigarette use | Chi-Square | = 8.30 | p = 0.00396 | Statistically significant association between variables |
| Model | Accuracy (%) | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Decision Tree * | 83.33 | 0.79 | 0.70 | 0.74 |
| Ensemble Method * | 93.33 | 0.91 | 0.91 | 0.91 |
| SVM * | 80.00 | 0.60 | 0.75 | 0.67 |
| k-NN * | 90.00 | 0.90 | 0.82 | 0.86 |
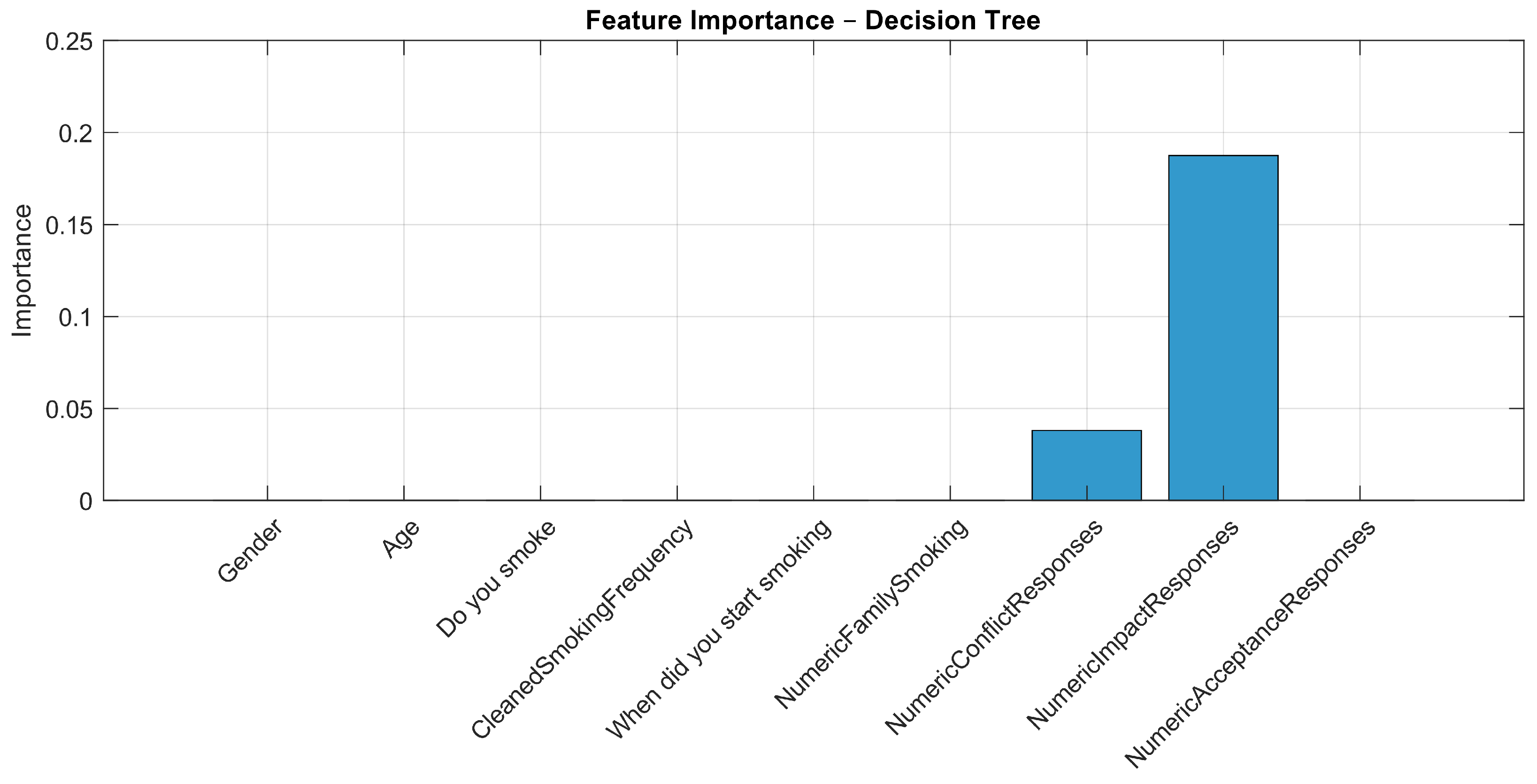
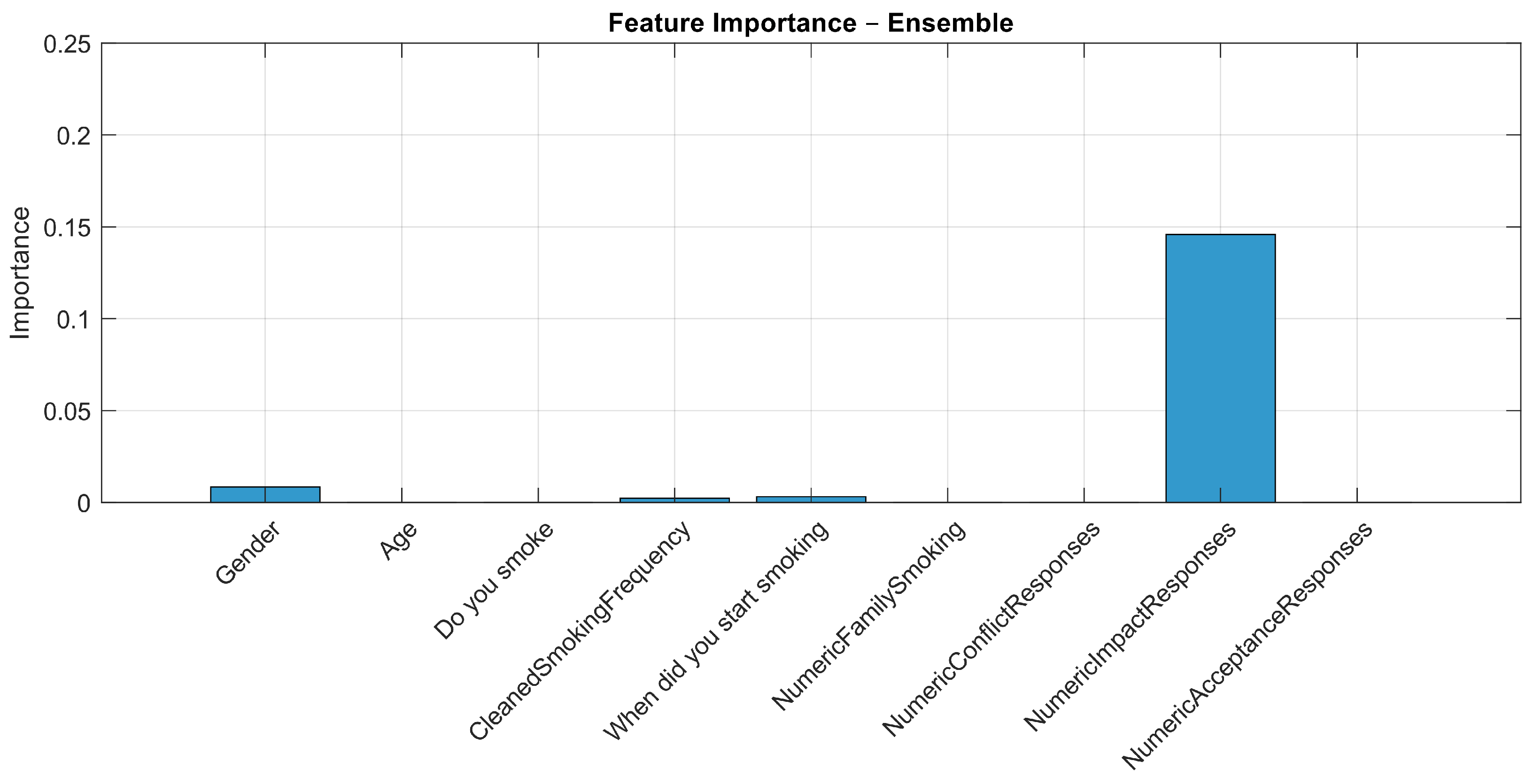
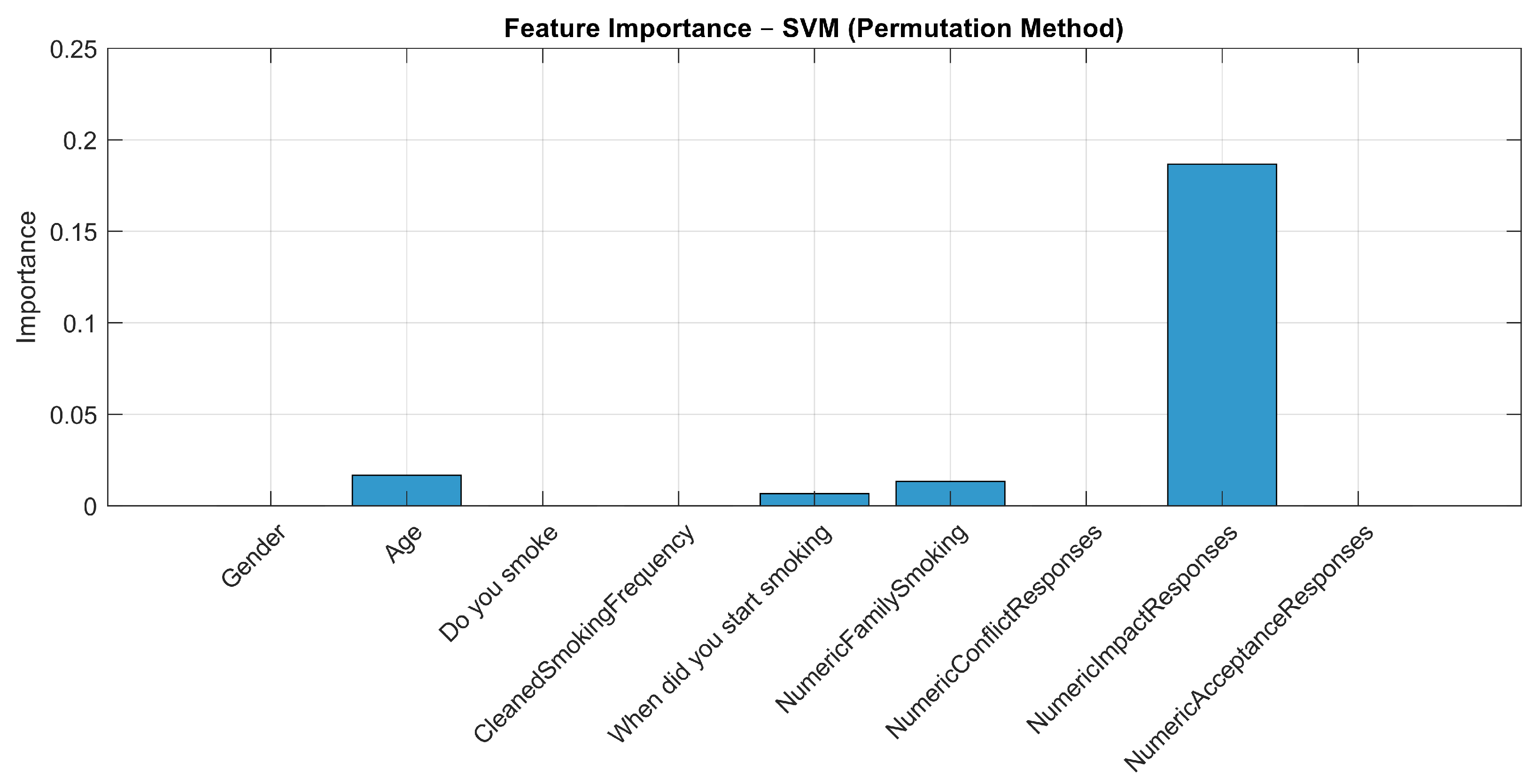
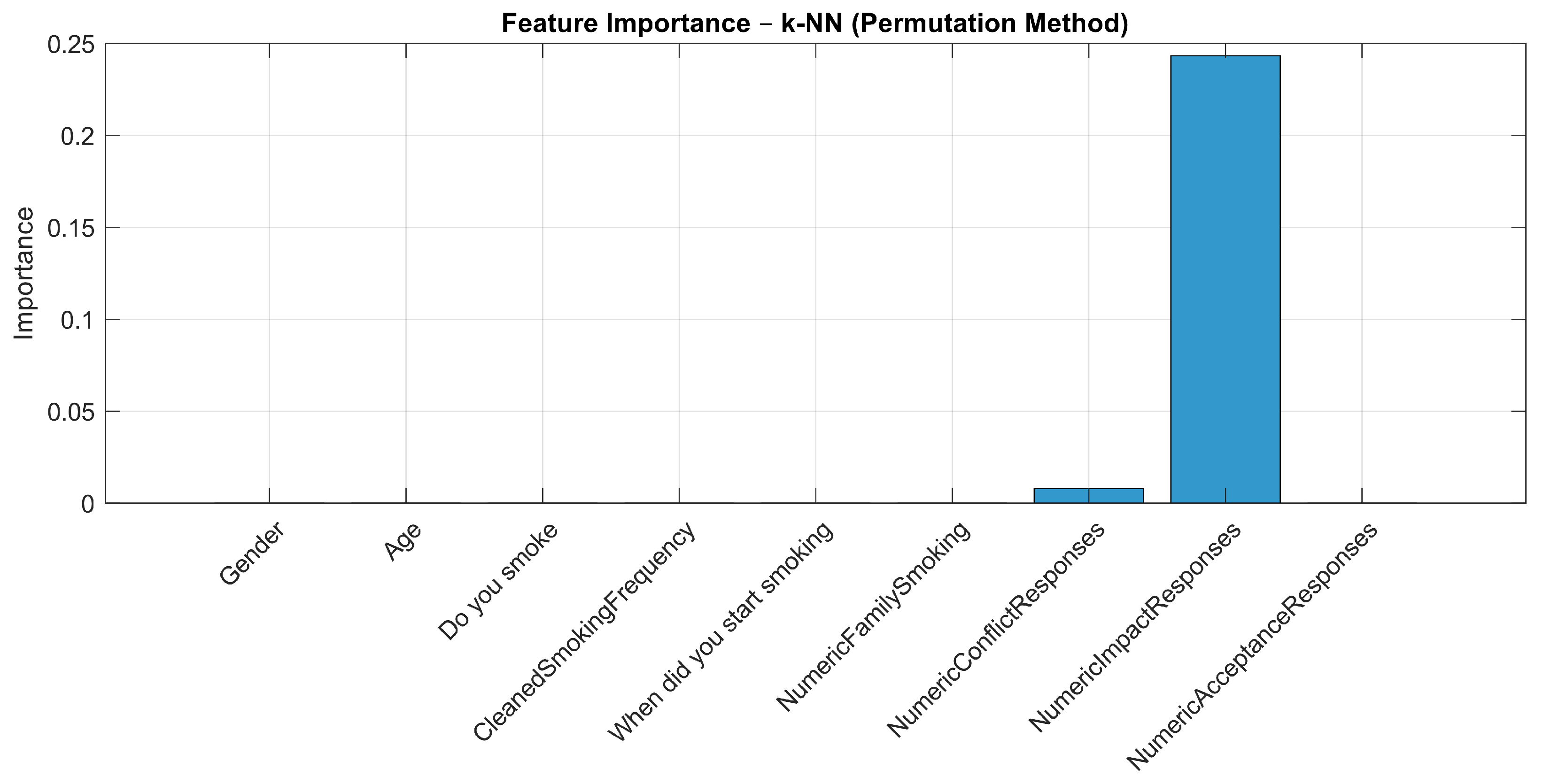
| Feature | Decision Tree | Ensemble | SVM | k-NN |
|---|---|---|---|---|
| Gender | 0.0000 | 0.0085 | 0.0000 | 0.0000 |
| Age | 0.0000 | 0.0000 | 0.0167 | 0.0000 |
| Do you smoke | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| CleanedSmokingFrequency | 0.0000 | 0.0023 | 0.0000 | 0.0000 |
| When did you start smoking | 0.0000 | 0.0031 | 0.0067 | 0.0000 |
| NumericFamilySmoking | 0.0000 | 0.0000 | 0.0133 | 0.0000 |
| NumericConflictResponses | 0.0381 | 0.0000 | 0.0000 | 0.0080 |
| NumericImpactResponses | 0.1875 | 0.1459 | 0.1867 | 0.2433 |
| NumericAcceptanceResponses | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chwał, J.; Kostka, M.; Kostka, P.S.; Dzik, R.; Filipowska, A.; Doniec, R.J. Analysis of Demographic, Familial, and Social Determinants of Smoking Behavior Using Machine Learning Methods. Appl. Sci. 2025, 15, 4442. https://doi.org/10.3390/app15084442
Chwał J, Kostka M, Kostka PS, Dzik R, Filipowska A, Doniec RJ. Analysis of Demographic, Familial, and Social Determinants of Smoking Behavior Using Machine Learning Methods. Applied Sciences. 2025; 15(8):4442. https://doi.org/10.3390/app15084442
Chicago/Turabian StyleChwał, Joanna, Małgorzata Kostka, Paweł Stanisław Kostka, Radosław Dzik, Anna Filipowska, and Rafał Jan Doniec. 2025. "Analysis of Demographic, Familial, and Social Determinants of Smoking Behavior Using Machine Learning Methods" Applied Sciences 15, no. 8: 4442. https://doi.org/10.3390/app15084442
APA StyleChwał, J., Kostka, M., Kostka, P. S., Dzik, R., Filipowska, A., & Doniec, R. J. (2025). Analysis of Demographic, Familial, and Social Determinants of Smoking Behavior Using Machine Learning Methods. Applied Sciences, 15(8), 4442. https://doi.org/10.3390/app15084442