
Research on Bearing Remaining Useful Life Prediction Method Based on Double Bidirectional Long Short-Term Memory


Abstract
1. Introduction
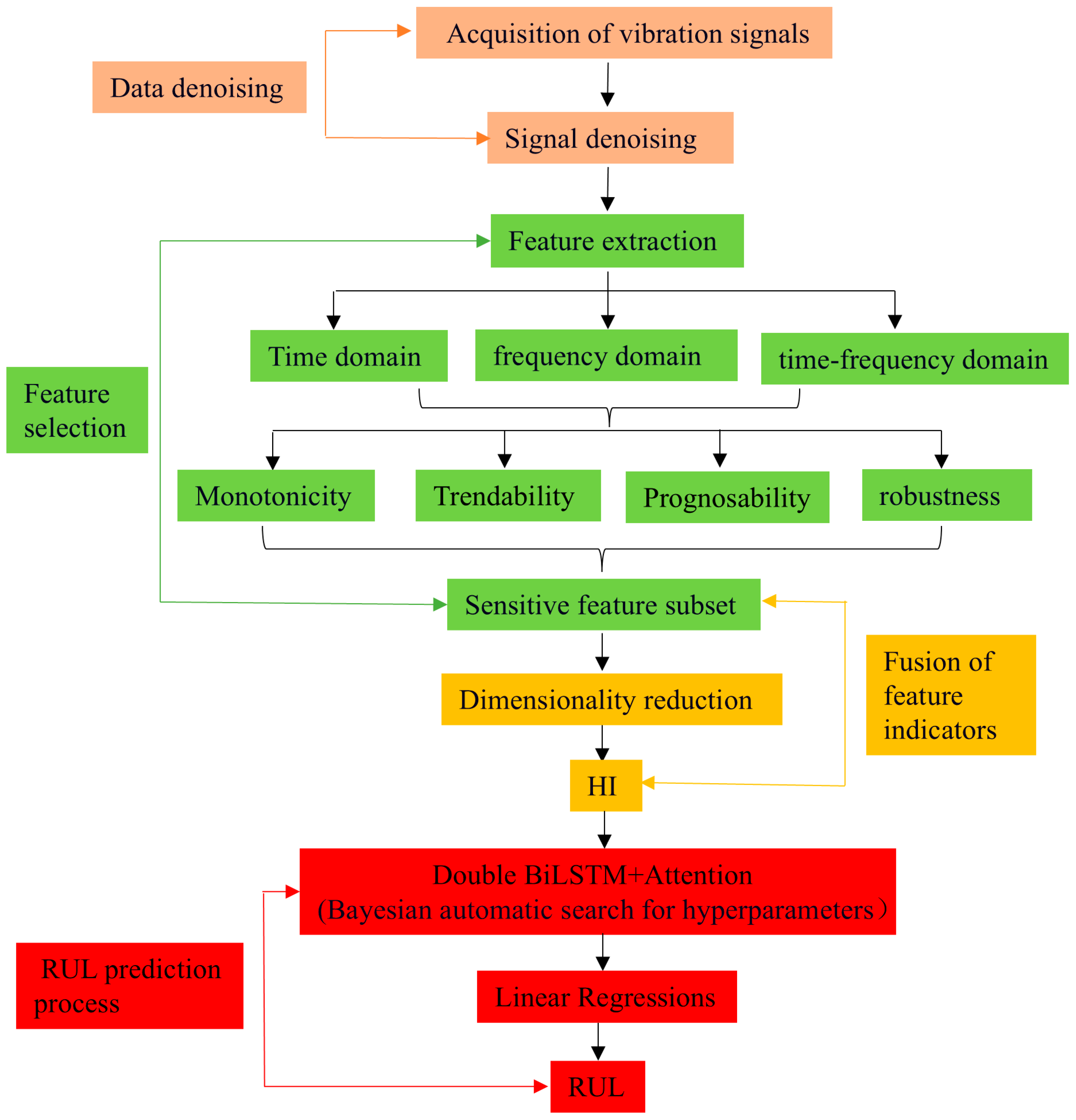
2. Vibration Signal Processing Methods
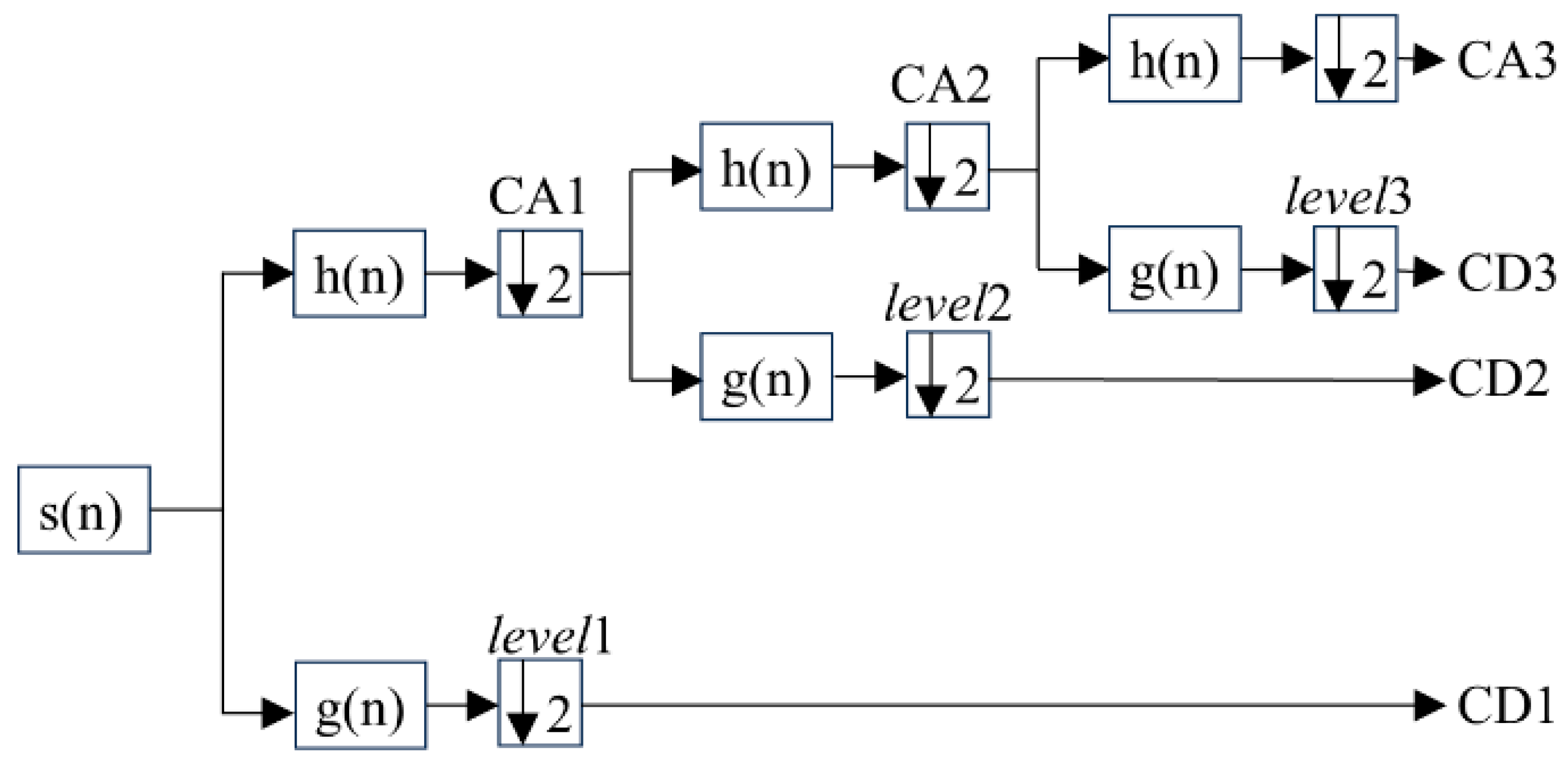
2.1. Signal Denoising Processing Methods
2.2. Multi-Domain Feature Extraction and Sensitive Feature Selection
2.2.1. Multi-Domain Feature Extraction
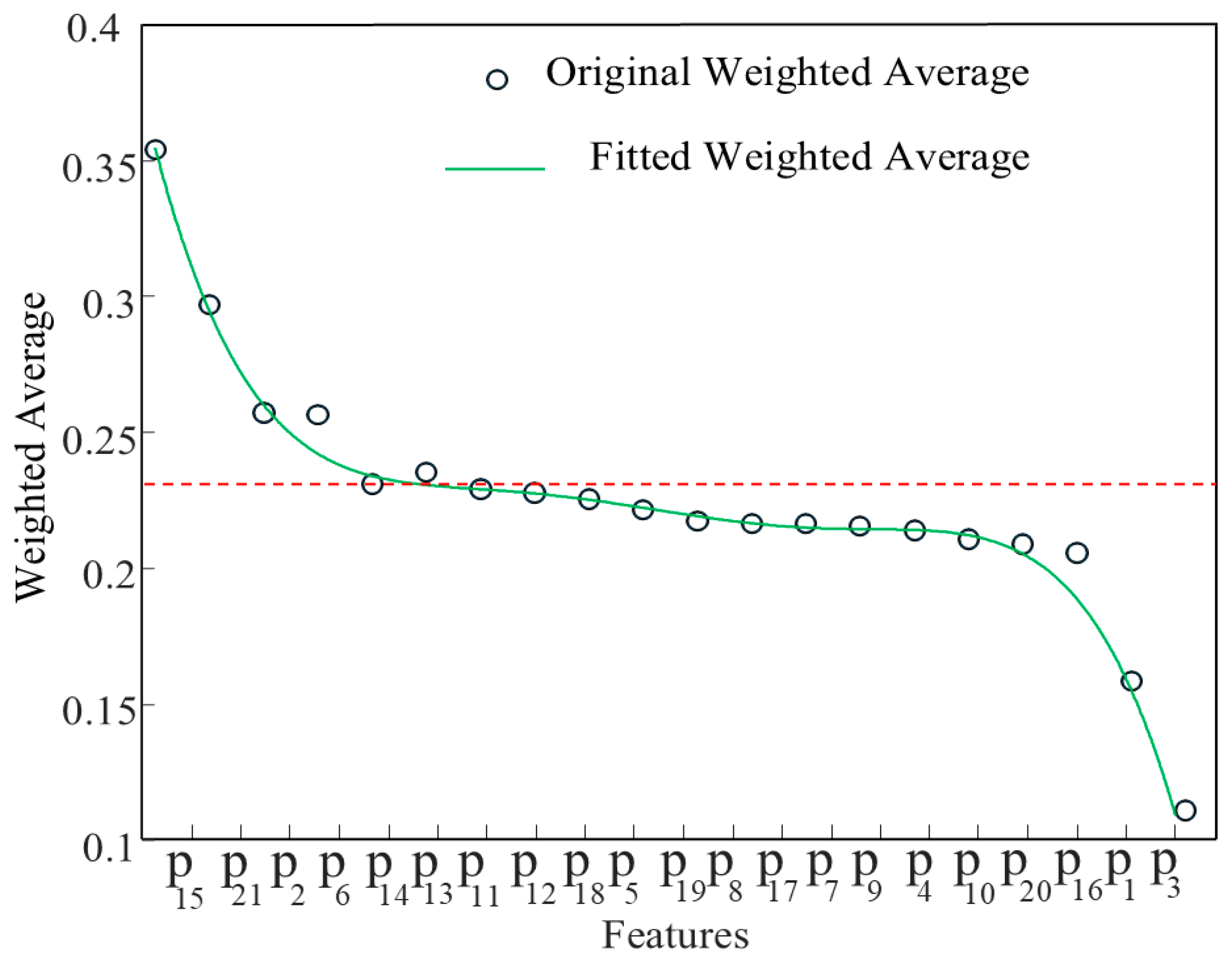
2.2.2. Sensitive Feature Selection
2.2.3. The Fusion of Sensitive Features
- (1)
- The sample matrix X, composed of feature vectors and b dimensions, is as follows [33]:where corresponds to the feature vector value of the vibration signal in the c-th row of the matrix.
- (2)
- Implement the mapping of X into the high–dimensional space , samples in the input space are transformed via Φ, denoted as , and become sample points within the high-dimensional feature space , where , satisfying the centrality condition [33]:The covariance matrix in is given by C [35]:where represents the feature sample in .
- (3)
- Calculate the eigenvalues and eigenvectors of the covariance matrix C. The eigenvectors thus obtained represent the principal component directions of the original sample space in the feature space [33]:where represents the eigenvalue of C, and v denotes the corresponding eigenvector in the feature space .
- (4)
- Define the matrix, , the normalized feature vector is represented as vg, (vg, vg) = 1, the expression for the f-th principal component S of the original sample is [33]:
- (5)
- (6)
- is an eigenvalue of matrix , the first l eigenvalues, whose contribution rates satisfy the following formula, are selected as principal components [33]:
3. Remaining Useful Life Prediction Algorithm Based on Double Bidirectional Long Short-Term Memory
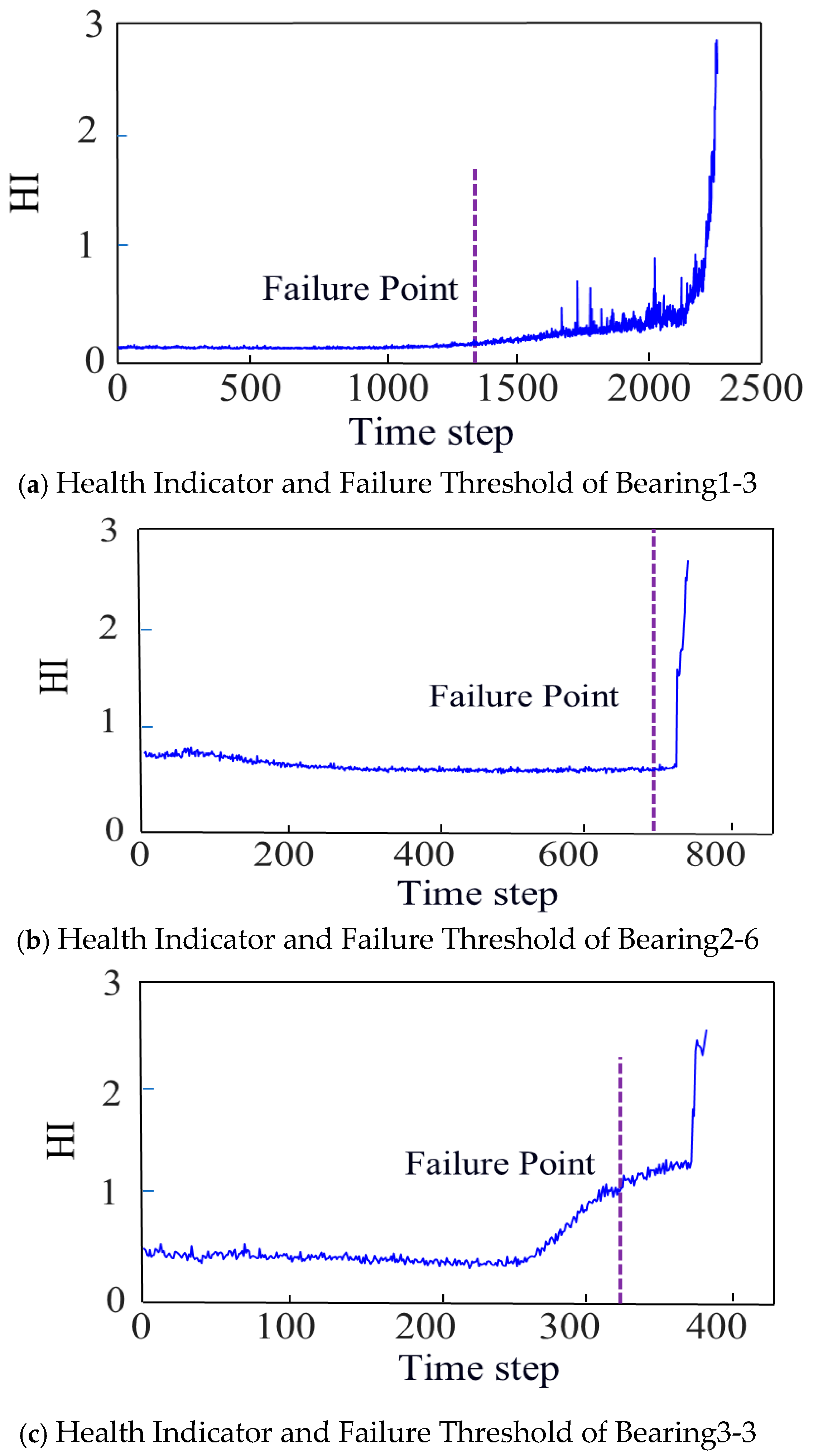
3.1. The Determination of Failure Thresholds
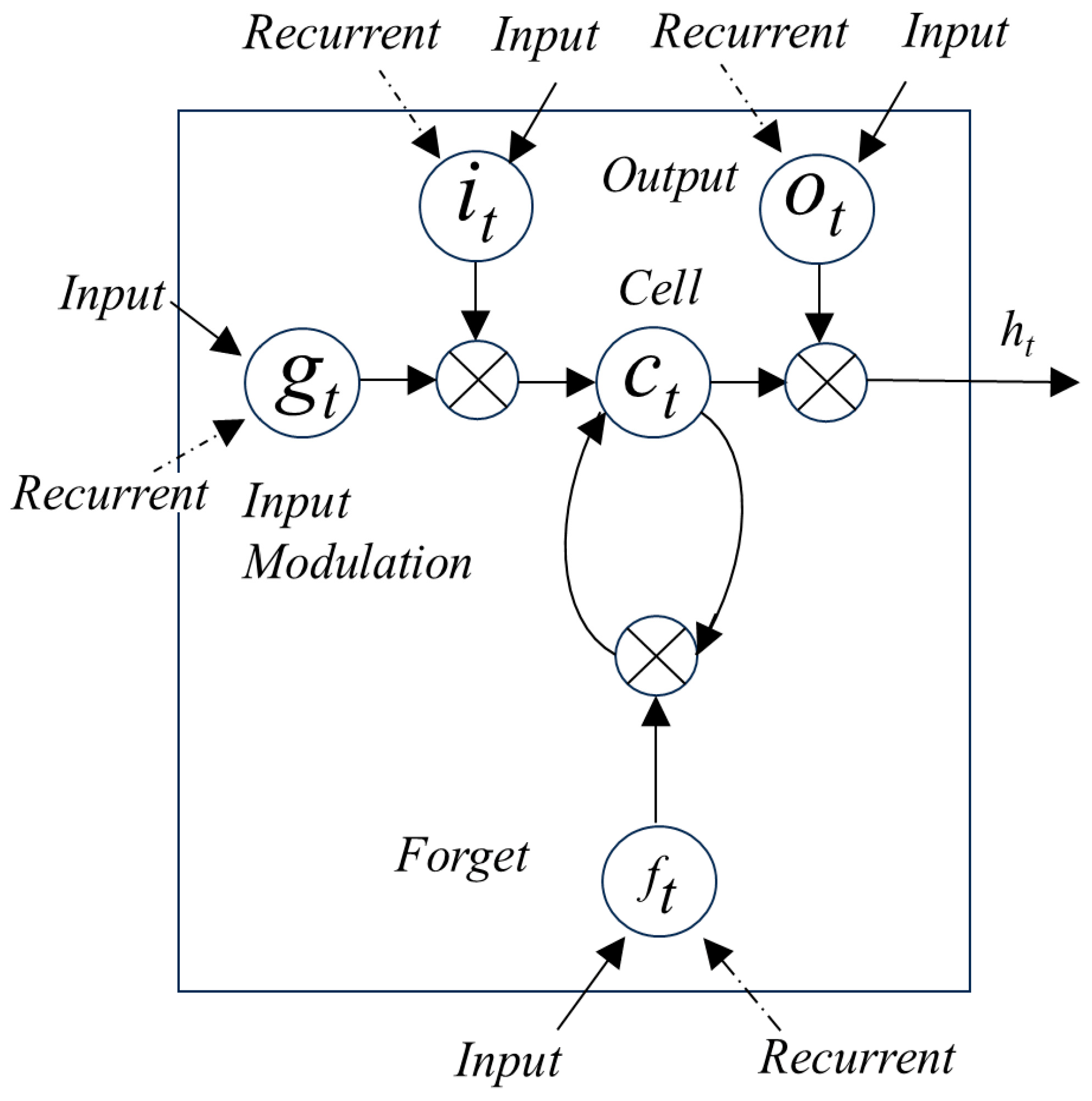
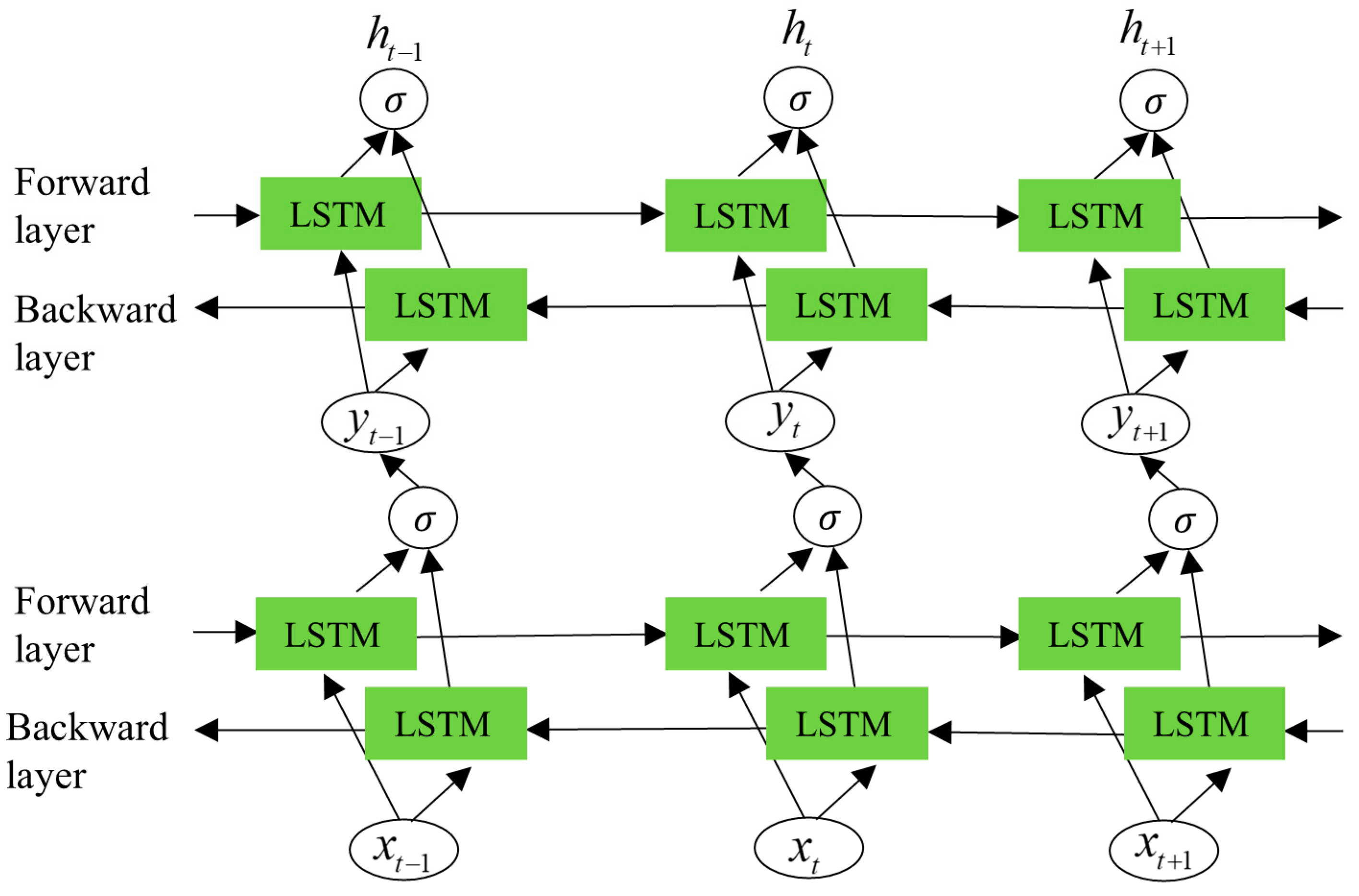
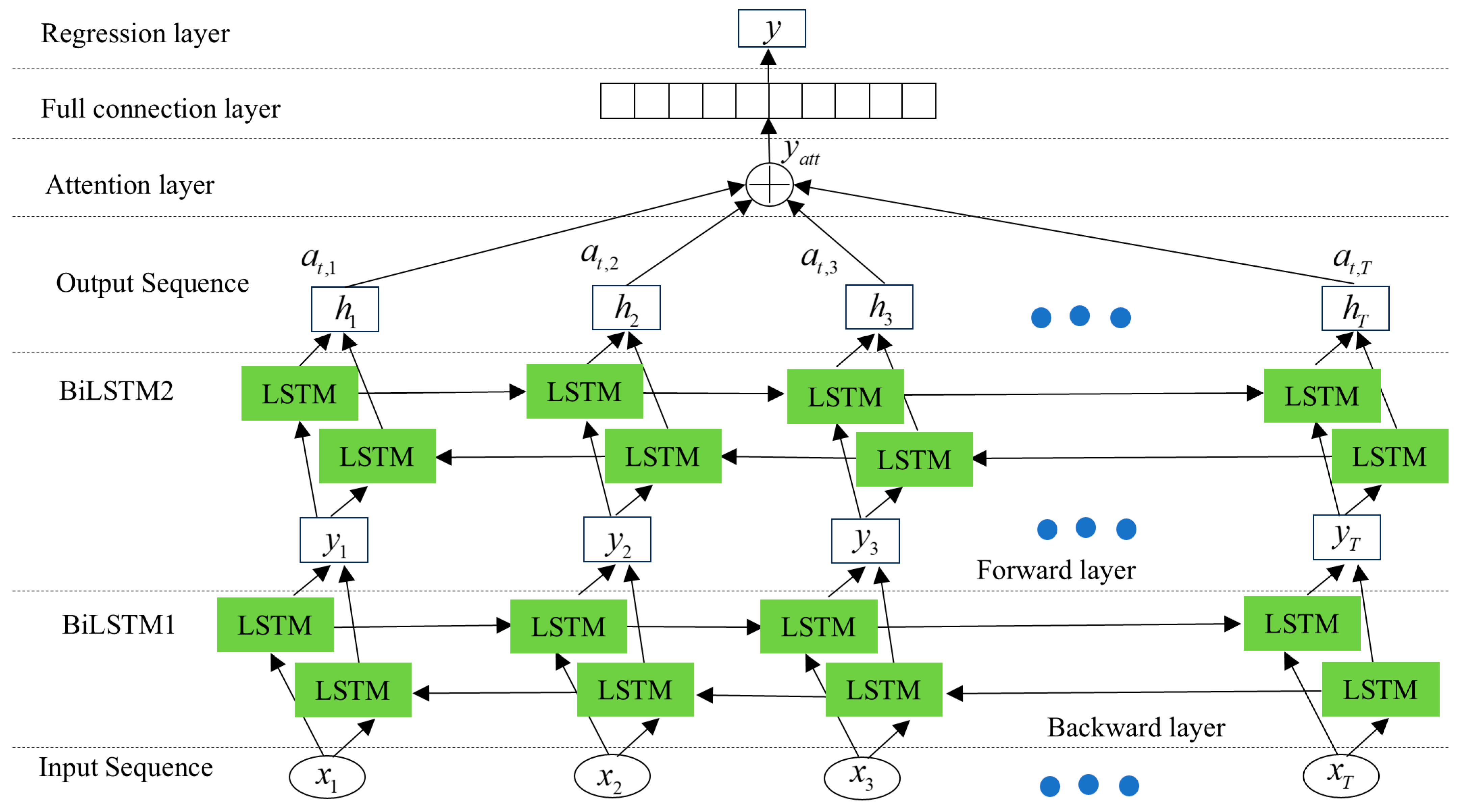
3.2. Principle of Double Bidirectional Long Short-Term Memory (DBiLSTM)
3.3. The Principle of Attention Mechanism Network
3.4. RUL Prediction Model
3.4.1. RUL Prediction Network Model Process
3.4.2. Bayesian Optimization for Hyperparameters
- (1)
- The objective search formula is designed as:where θ represents the combination of hyperparameters (learning rate, number of hidden layer neurons, batch size, dropout rate, and number of iterations).
- (2)
- Bayesian optimization models the objective function through a Gaussian process, with the assumption that:where m(θ) is the mean function (usually set to 0), and kh(θ,θ′) is the kernel function, whose formula is:
- (3)
- Given the observed data (where represents the number of samples in the test set, and ii = 1,2, …, ), the posterior distribution remains a Gaussian process, with its mean and variance given by:where is the vector of kernel function values between the new point θ and the observed points θii, is the kernel function matrix among the observed points, and is the variance of the observation noise.
- (4)
- An acquisition function is used to select the next evaluation point. The main formula is:Expected Improvement:where fbest is the current optimal value.Upper Confidence Bound:where κ controls the balance between exploration and exploitation and is the uncertainty coefficient.
4. Experimental Validation and Result Analysis
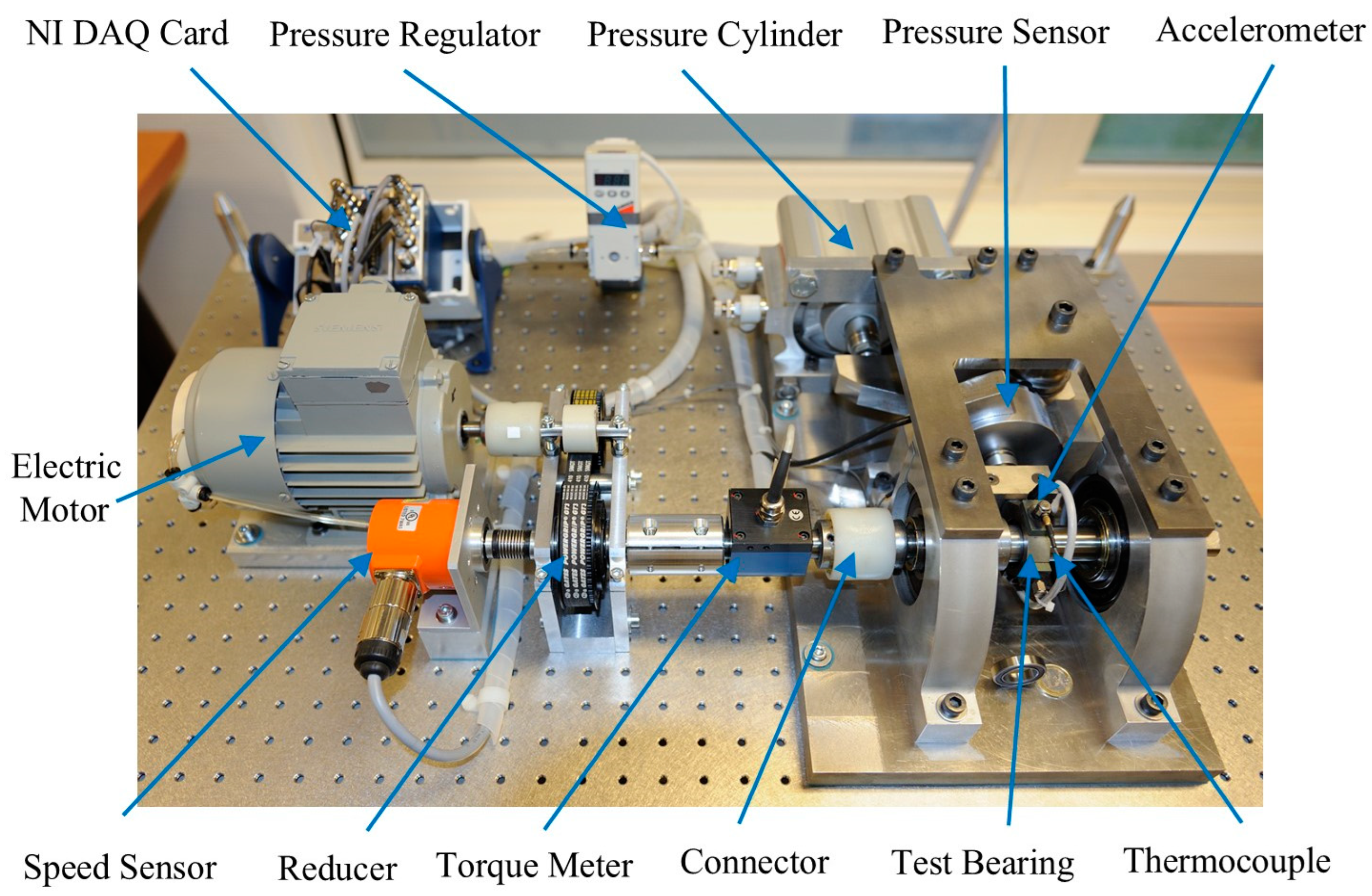
4.1. Processing of Experimental Data
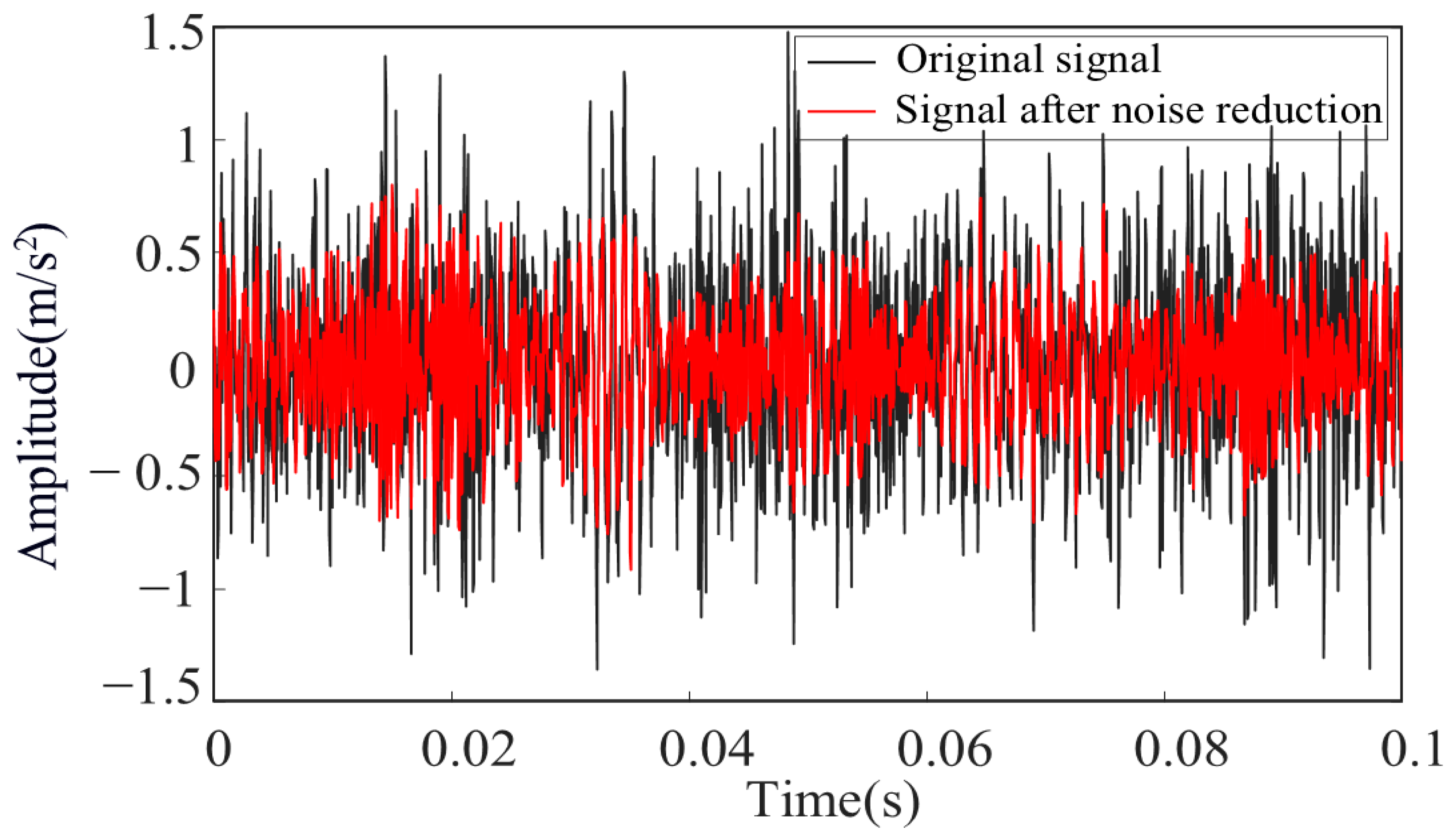
4.1.1. Result of Experimental Data Denoising
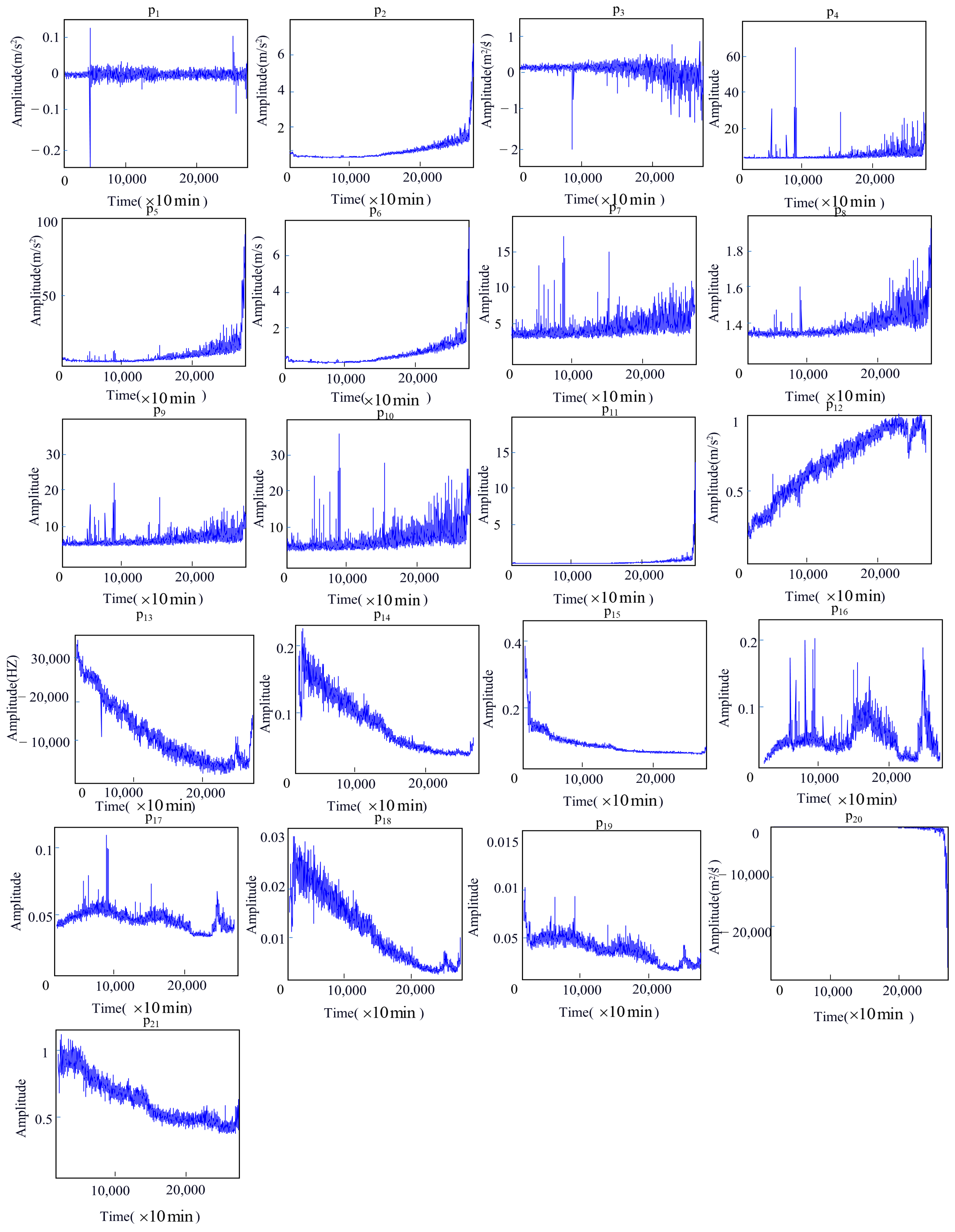
4.1.2. Sensitive Feature Selection Results
4.1.3. Feature Fusion and Failure Threshold
4.2. RUL Prediction Process and Result Analysis
4.2.1. RUL Prediction Process
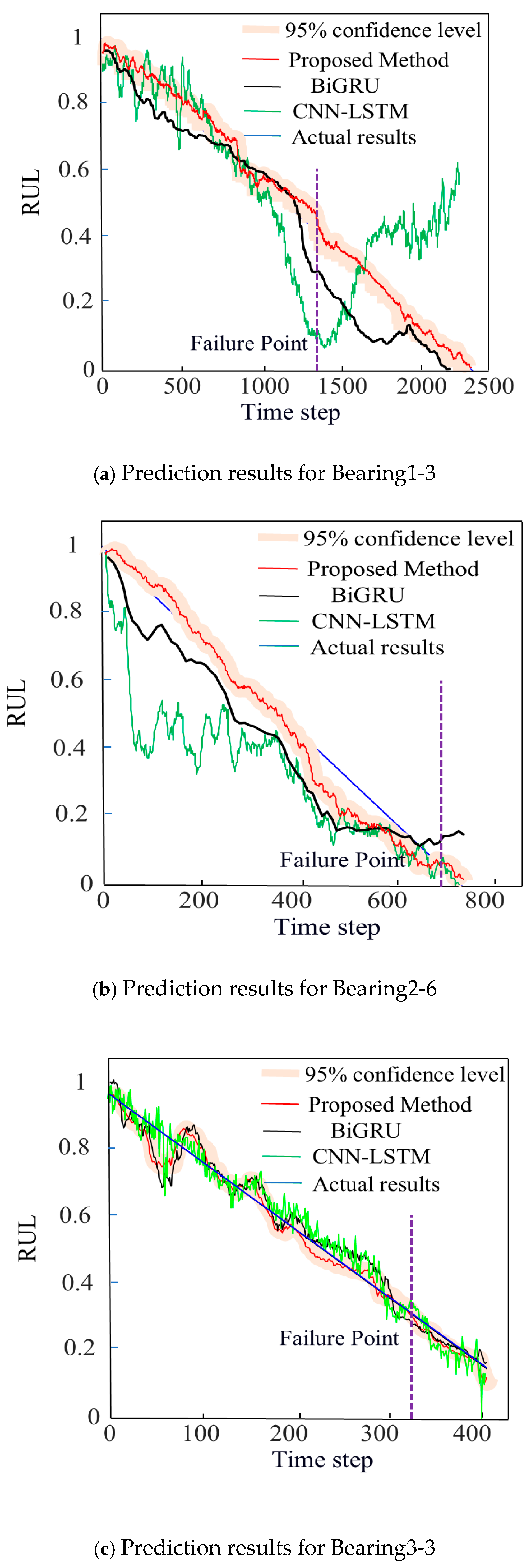
4.2.2. Prediction Result Analysis
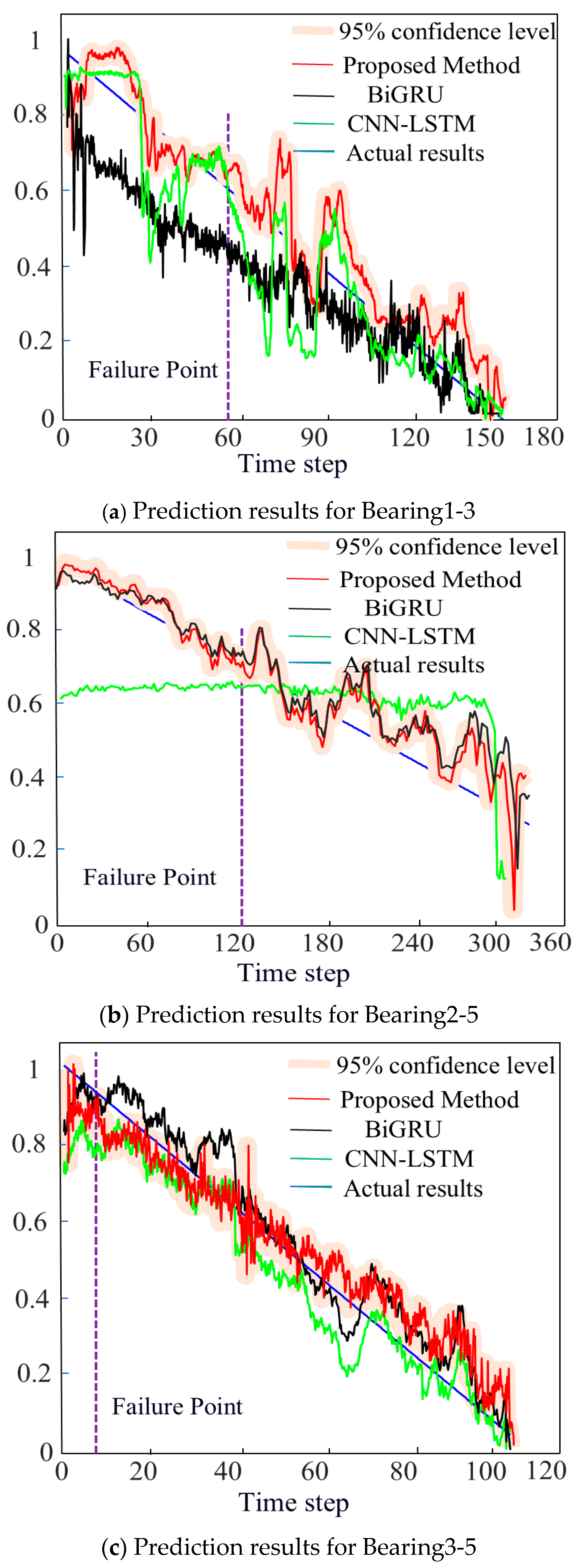
4.2.3. Validation of the Generalization Ability of the Prediction Model
5. Conclusions
- (1)
- After wavelet threshold denoising, the RMSE (Root Mean Square Error), RMS (Root Mean Square), and MAE (Mean Absolute Error) values of the signal are 0.0153, 0.123, and 0.00008, respectively. These values are all smaller than PSO-VMD method, which proves that this method has a strong denoising effect. The signal free from noise can provide a data foundation for bearing feature extraction and remaining life prediction. Different features exhibit varying degrees of sensitivity to bearing degradation, and not all features are rich in degradation information. By comprehensively evaluating the sensitivity of each bearing signal feature based on monotonicity, trend, predictability, and robustness, the optimal features that are more sensitive to bearing degradation can be screened out, and redundant signal features can be eliminated.
- (2)
- The failure threshold is an important parameter in bearing performance evaluation, marking the starting point where a bearing transitions from a normal state to a faulty state, and influencing the prediction of the bearing’s RUL. The failure times detected using the 3σ threshold method for the PHM dataset are 1330 min, 673 min, and 323 min, and this method detects the failure time of the bearing earlier than the comparative methods, and it can detect bearing failure earlier than the comparative method. Early detection of bearing failure time provides staff with sufficient time to formulate safety measures, thereby avoiding missed detections.
- (3)
- When establishing a network model that combines a Double-way Bidirectional Long Short-Term Memory network with an attention mechanism for predicting the RUL of bearings, when tested with the datasets Bearing1-3, Bearing2-6, and Bearing3-3 from PHM2012, the p-values between the prediction results of the proposed RUL method and those of the BiGRU prediction method are 0.0188, 0.0012, and 0.0234, respectively; the p-values between the prediction results of the proposed RUL method and those of the CNN-LSTM prediction method are also 0.0188, 0.0012, and 0.0234, respectively, with p < 0.05. When tested with the datasets Bearing1-3, Bearing2-5, and Bearing3-5 from XJTU-SY, the p-values between the prediction results of the proposed RUL method and those of the BiGRU prediction method are 0.0196, 0.0012, and 0.0241, respectively; the p-values between the prediction results of the proposed RUL method and those of the CNN-LSTM prediction method are 0.0001, 0.0083, and 0.0327, respectively, with p < 0.05. The prediction results from both datasets can demonstrate significant differences between the proposed method and the comparative methods. Therefore, the RUL prediction performance of the proposed method is higher. Moreover, the prediction curves for both datasets fall within the 95% confidence interval, which demonstrates the reliability of the prediction results obtained using the proposed model.
- (4)
- When compared with the BiGRU (Bidirectional Gated Recurrent Neural Network) method and the CNN-LSTM (Hybrid Model of Convolutional Neural Network and LSTM Network) method, the proposed prediction model, when validated using the PHM2012 dataset and the XJTU-SY dataset, yielded smaller RMSE and MAE values in the prediction results (Table 8 and Table 10) than the other two comparative methods. Although the other two methods could also predict RUL results, the RUL curves exhibited greater fluctuations. Generally speaking, smaller RMSE and MAE values indicate better model performance. The R2 value of the proposed prediction model is closer to 1, and the model’s fitting ability is also superior to that of the comparative methods. Therefore, the proposed model further enhances the performance of RUL prediction. Additionally, this also demonstrates that the proposed prediction model is less influenced by data variations and possesses strong generalization capabilities and practicality.
- (5)
- The proposed method performs well under different operating conditions and across various datasets; therefore the proposed method demonstrates higher effectiveness in predicting RUL. By employing this method for RUL prediction, potential bearing failures can be detected in a timely manner, providing sufficient time to prompt bearing repairs. It guides personnel in formulating comprehensive maintenance strategies, thereby preventing further deterioration of faults that could lead to equipment shutdown or damage, and reducing economic losses caused by fault-induced downtime.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shang, J.; Xu, D.; Qiu, H.; Jiang, C.; Gao, L. Domain generalization for rotating machinery real-time remaining useful life prediction via multi-domain orthogonal degradation feature exploration. Mech. Syst. Signal Process. 2025, 223, 111924. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, Z. Remaining useful life prediction of rolling bearing via composite multiscale permutation entropy and Elman neural network. Eng. Appl. Artif. Intell. 2024, 135, 108852. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, Y.; Miao, Q. An attention-based Multi-Scale Temporal Convolutional Network for Remaining Useful Life Prediction. Reliab. Eng. Syst. Saf. 2024, 250, 110288. [Google Scholar] [CrossRef]
- Chen, K.; Liu, J.; Guo, W.; Wang, X. A two-stage approach based on Bayesian deep learning for predicting remaining useful life of rolling element bearings. Comput. Electr. Eng. 2023, 109, 108745. [Google Scholar] [CrossRef]
- Cui, L.; Xiao, Y.; Liu, D.; Han, H. Digital twin-driven graph domain adaptation neural network for remaining useful life prediction of rolling bearing. Reliab. Eng. Syst. Saf. 2024, 245, 109991. [Google Scholar] [CrossRef]
- Saidi, L.; Ali, J.B.; Bechhoefer, E.; Benbouzid, M. Wind turbine high-speed shaft bearings health prognosis through a spectral Kurtosis-derived indices and SVR. Appl. Acoust. 2017, 120, 1–8. [Google Scholar] [CrossRef]
- Li, Q.; Yan, C.; Chen, G.; Wang, H.; Li, H.; Wu, L. Remaining Useful Life prediction of rolling bearings based on risk assessment and degradation state coefficient. ISA Trans. 2022, 129, 413–428. [Google Scholar] [CrossRef]
- Qin, Y.; Chen, D.; Xiang, S.; Zhu, C. Gated dual attention unit neural networks for remaining useful life prediction of rolling bearings. IEEE Trans. Ind. Inform. 2020, 17, 6438–6447. [Google Scholar] [CrossRef]
- Tang, G.; Liu, L.; Liu, Y.; Yi, C.; Hu, Y.; Xu, D.; Zhou, Q.; Lin, J. Unsupervised transfer learning for intelligent health status identification of bearing in adaptive input length selection. Eng. Appl. Artif. Intell. 2023, 126, 107051. [Google Scholar] [CrossRef]
- Wu, J.; Hu, K.; Cheng, Y.; Zhu, H.; Shao, X.; Wang, Y. Data-driven remaining useful life prediction via multiple sensor signals and deep long short-term memory neural network. ISA Trans. 2020, 97, 241–250. [Google Scholar] [CrossRef]
- Yu, W.; Shao, Y.; Xu, J.; Mechefske, C. An adaptive and generalized Wiener process model with a recursive filtering algorithm for remaining useful life estimation. Reliab. Eng. Syst. Saf. 2022, 217, 108099. [Google Scholar] [CrossRef]
- Lin, J.; Liao, G.; Chen, M.; Yin, H. Two-phase degradation modeling and remaining useful life prediction using nonlinear wiener process. Comput. Ind. Eng. 2021, 160, 107533. [Google Scholar] [CrossRef]
- Duan, F.; Wang, G. Bayesian analysis for the transformed exponential dispersion process with random effects. Reliab. Eng. Syst. Saf. 2022, 217, 108104. [Google Scholar] [CrossRef]
- Que, Z.; Jin, X.; Xu, Z. Remaining useful life prediction for bearings based on a gated recurrent unit. IEEE Trans. Instrum. Meas. 2021, 70, 3511411. [Google Scholar] [CrossRef]
- Berghout, T.; Mouss, L.-H.; Kadri, O.; Saïdi, L.; Benbouzid, M. Aircraft engines Remaining Useful Life prediction with an adaptive denoising online sequential Extreme Learning Machine. Eng. Appl. Artif. Intell. 2020, 96, 103936. [Google Scholar] [CrossRef]
- Xu, M.; Wang, J.; Liu, J.; Li, M.; Geng, J.; Wu, Y.; Song, Z. An improved hybrid modeling method based on extreme learning machine for gas turbine engine. Aerosp. Sci. Technol. 2020, 107, 106333. [Google Scholar] [CrossRef]
- Elforjani, M.; Shanbr, S. Prognosis of bearing acoustic emission signals using supervised machine learning. IEEE Trans. Ind. Electron. 2017, 65, 5864–5871. [Google Scholar] [CrossRef]
- Xie, G.; Jia, H.; Li, H.; Zhong, Y.; Du, W.; Dong, Y.; Wang, L.; Lv, J. A life prediction method of mechanical structures based on the phase field method and neural network. Appl. Math. Model. 2023, 119, 782–802. [Google Scholar] [CrossRef]
- Kankar, P.K.; Sharma, S.C.; Harsha, S.P. Vibration-based fault diagnosis of a rotor bearing system using artificial neural network and support vector machine. Int. J. Model. Ident. Control 2012, 15, 185–198. [Google Scholar] [CrossRef]
- Shi, L.; Su, S.; Wang, W.; Gao, S.; Chu, C. Bearing Fault Diagnosis Method Based on Deep Learning and Health State Division. Appl. Sci. 2023, 13, 7424. [Google Scholar] [CrossRef]
- Niu, G.; Wang, X.; Liu, E.; Zhang, B. Lebesgue sampling based deep belief network for lithium-ion battery diagnosis and prognosis. IEEE Trans. Ind. Electron. 2021, 69, 8481–8490. [Google Scholar] [CrossRef]
- Qin, Y.; Wang, X.; Zou, J. The optimized deep belief networks with improved logistic sigmoid units and their application in fault diagnosis for planetary gearboxes of wind turbines. IEEE Trans. Ind. Electron. 2018, 66, 3814–3824. [Google Scholar] [CrossRef]
- Qiu, H.; Niu, Y.; Shang, J.; Gao, L.; Xu, D. A piecewise method for bearing remaining useful life estimation using temporal convolutional networks. J. Manuf. Syst. 2023, 68, 227–241. [Google Scholar] [CrossRef]
- Mo, H.; Custode, L.L.; Iacca, G. Evolutionary neural architecture search for remaining useful life prediction. Appl. Soft Comput. 2021, 108, 107474. [Google Scholar] [CrossRef]
- Xia, M.; Zheng, X.; Imran, M.; Shoaib, M. Data-driven prognosis method using hybrid deep recurrent neural network. Appl. Soft Comput. 2020, 93, 106351. [Google Scholar] [CrossRef]
- Zhang, H.; Xi, X.; Pan, R. A two-stage data-driven approach to remaining useful life prediction via long short-term memory networks. Reliab. Eng. Syst. Saf. 2023, 237, 109332. [Google Scholar] [CrossRef]
- Ni, Q.; Ji, J.C.; Feng, K. Data-driven prognostic scheme for bearings based on a novel health indicator and gated recurrent unit network. IEEE Trans. Ind. Inform. 2022, 19, 1301–1311. [Google Scholar] [CrossRef]
- Yang, X.; Zheng, Y.; Zhang, Y.; Wong, D.S.-H.; Yang, W. Bearing remaining useful life prediction based on regression shapalet and graph neural network. IEEE Trans. Instrum. Meas. 2022, 71, 3505712. [Google Scholar] [CrossRef]
- Shang, X.; Li, W.; Yuan, F.; Zhi, H.; Gao, Z.; Guo, M.; Xin, B. Research on Fault Diagnosis of UAV Rotor Motor Bearings Based on WPT-CEEMD-CNN-LSTM. Machines 2025, 13, 287. [Google Scholar] [CrossRef]
- Matania, O.; Bachar, L.; Bechhoefer, E.; Bortman, J. Signal Processing for the Condition-Based Maintenance of Rotating Machines via Vibration Analysis: A Tutorial. Sensors 2024, 24, 454. [Google Scholar] [CrossRef]
- Randall, R.B. Vibration-Based Condition Monitoring: Industrial, Aerospace and Automotive Applications; John Wiley & Sons: Chichester, UK, 2011. [Google Scholar]
- Wu, Y.; Dai, J.; Yang, X.; Shao, F.; Gong, J.; Zhang, P.; Liu, S. The Fault Diagnosis of Rolling Bearings Based on FFT-SE-TCN-SVM. Actuators 2025, 14, 152. [Google Scholar] [CrossRef]
- Li, T.; Zhou, Z.; Li, S.; Sun, C.; Yan, R.; Chen, X. The emerging graph neural networks for intelligent fault diagnostics and prognostics: A guideline and a benchmark study. Mech. Syst. Signal Process. 2022, 168, 108653. [Google Scholar] [CrossRef]
- Yang, C.; Ma, J.; Wang, X.; Li, X.; Li, Z.; Luo, T. A novel based-performance degradation indicator remaining useful life prediction model and its application in rolling bearing. ISA Trans. 2022, 121, 349–364. [Google Scholar] [CrossRef]
- Kumar, P.S.; Kumaraswamidhas, L.; Laha, S. Selection of efficient degradation features for rolling element bearing prognosis using Gaussian Process Regression method. ISA Trans. 2020, 112, 386–401. [Google Scholar] [CrossRef] [PubMed]
- Qi, J.; Zhu, R.; Liu, C.; Mauricio, A.; Gryllias, K. Anomaly detection and multi-step estimation based remaining useful life prediction for rolling element bearings. Mech. Syst. Signal Process. 2024, 206, 110910. [Google Scholar] [CrossRef]
- Li, X.; Teng, W.; Peng, D.; Ma, T.; Wu, X.; Liu, Y. Feature fusion model based health indicator construction and self-constraint state-space estimator for remaining useful life prediction of bearings in wind turbines. Reliab. Eng. Syst. Saf. 2023, 233, 109124. [Google Scholar] [CrossRef]
- Lu, Q.; Li, M. Digital Twin-Driven Remaining Useful Life Prediction for Rolling Element Bearing. Machines 2023, 11, 678. [Google Scholar] [CrossRef]
- Li, J.; Huang, F.; Qin, H.; Pan, J. Research on Remaining Useful Life Prediction of Bearings Based on MBCNN-BiLSTM. Appl. Sci. 2023, 13, 7706. [Google Scholar] [CrossRef]
- Fan, Z.; Li, W.; Chang, K.-C. A Bidirectional Long Short-Term Memory Autoencoder Transformer for Remaining Useful Life Estimation. Mathematics 2023, 11, 4972. [Google Scholar] [CrossRef]
- Wang, L.; Zhu, Z.; Zhao, X. Dynamic predictive maintenance strategy for system remaining useful life prediction via deep learning ensemble method. Reliab. Eng. Syst. Saf. 2024, 245, 110012. [Google Scholar] [CrossRef]
- Gan, F.; Qin, Y.; Xia, B.; Mi, D.; Zhang, L. Remaining useful life prediction of aero-engine via temporal convolutional network with gated convolution and channel selection unit. Appl. Soft Comput. 2024, 167, 112325. [Google Scholar] [CrossRef]
- Zhao, X.; Yang, Y.; Huang, Q.; Fu, Q.; Wang, R.; Wang, L. Rolling bearing remaining useful life prediction method based on vibration signal and mechanism model. Appl. Acoust. 2025, 228, 110334. [Google Scholar] [CrossRef]
- Rathore, M.S.; Harsha, S. An attention-based stacked BiLSTM framework for predicting remaining useful life of rolling bearings. Appl. Soft Comput. 2022, 131, 109765. [Google Scholar] [CrossRef]
- Shang, Y.; Tang, X.; Zhao, G.; Jiang, P.; Lin, T.R. A remaining life prediction of rolling element bearings based on a bidirectional gate recurrent unit and convolution neural network. Measurement 2022, 202, 111893. [Google Scholar] [CrossRef]
- Jiang, L.; Zhang, T.; Lei, W.; Zhuang, K.; Li, Y. A new convolutional dual-channel Transformer network with time window concatenation for remaining useful life prediction of rolling bearings. Adv. Eng. Inform. 2023, 56, 101966. [Google Scholar] [CrossRef]
- Guo, K.; Ma, J.; Wu, J.; Xiong, X. Adaptive feature fusion and disturbance correction for accurate remaining useful life prediction of rolling bearings. Eng. Appl. Artif. Intell. 2024, 138, 109433. [Google Scholar] [CrossRef]
- Li, N.; Lei, Y.; Lin, J.; Ding, S.X. An improved exponential model for predicting remaining useful life of rolling element bearings. IEEE Trans. Ind. Electron. 2015, 62, 7762–7773. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, Y.; Zi, Y.; Jin, X.; Tsui, K.-L. A two-stage data-driven-based prognostic approach for bearing degradation problem. IEEE Trans. Ind. Inform. 2016, 12, 924–932. [Google Scholar] [CrossRef]
- Wen, J.; Gao, H.; Zhang, J. Bearing remaining useful life prediction based on a nonlinear wiener process model. Shock. Vib. 2018, 2018, 4068431. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, Y.; Ma, X. Remaining useful life prediction using a novel two-stage wiener process with stage correlation. IEEE Access 2018, 6, 65227–65238. [Google Scholar] [CrossRef]
- Wang, D.; Tsui, K.-L. Two novel mixed effects models for prognostics of rolling element bearings. Mech. Syst. Signal Process. 2018, 99, 1–13. [Google Scholar] [CrossRef]
- Li, J.; Fan, J.; Wang, Z.; Qiu, M.; Liu, X. A new method for change-point identification and RUL prediction of rolling bearings using SIC and incremental Kalman filtering. Measurement 2025, 250, 117150. [Google Scholar] [CrossRef]
- Matania, O.; Cohen, R.; Bechhoefer, E.; Bortman, J. Zero-fault-shot learning for bearing spall type classification by hybrid approach. Mech. Syst. Signal Process. 2025, 224, 112117. [Google Scholar] [CrossRef]
- Sheng, Z. Probability Theory and Mathematical Statistics, 3rd ed.; Higher Education Press: Beijing, China, 2001. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial Number | Name | Feature Expression |
|---|---|---|
| 1 | Mean | |
| 2 | Standard Deviation | |
| 3 | Variance | |
| 4 | Skewness | |
| 5 | Mean Square Root Value | |
| 6 | Root Mean Square Value | |
| 7 | Kurtosis | |
| 8 | Waveform | |
| 9 | Kurtosis | |
| 10 | Skewness | |
| 11 | Peak | |
| 12 | Mean Amplitude in Frequency Domain | |
| 13 | Root Mean Square Frequency |
| Conditions | Training Set | Testing Set |
|---|---|---|
| Condition 1 | Bearing 1-1~Bearing 1-2 | Bearing 1-3 |
| Condition 2 | Bearing 2-1~Bearing 2-2 | Bearing 2-6 |
| Condition 3 | Bearing 3-1~Bearing 3-2 | Bearing 3-5 |
| Evaluation Method | PSO-VMD | Wavelet Soft Thresholding |
|---|---|---|
| RMSE | 0.0153 | 0.032 |
| RMS | 0.123 | 0.179 |
| MAE | 0.00008 | 0.000012 |
| Feature | Monotonieity | Trendability | Prognosability | Robustness | J |
|---|---|---|---|---|---|
| p1 | 0.020 | 0.003 | 0.323 | 0.417 | 0.07 |
| p2 | 0.075 | 0.324 | 0.454 | 0.955 | 0.27 |
| p3 | 0.018 | 0.008 | 0.240 | 0.462 | 0.07 |
| p4 | 0.020 | 0.022 | 0.567 | 0.831 | 0.13 |
| p5 | 0.034 | 0.230 | 0.460 | 0.858 | 0.21 |
| p6 | 0.075 | 0.318 | 0.454 | 0.955 | 0.27 |
| p7 | 0.019 | 0.013 | 0.656 | 0.864 | 0.13 |
| p8 | 0.021 | 0.028 | 0.621 | 0.983 | 0.15 |
| p9 | 0.015 | 0.012 | 0.644 | 0.853 | 0.13 |
| p10 | 0.017 | 0.007 | 0.642 | 0.850 | 0.13 |
| p11 | 0.063 | 0.241 | 0.247 | 0.913 | 0.22 |
| p12 | 0.175 | 0.018 | 0.499 | 0.916 | 0.21 |
| p13 | 0.162 | 0.463 | 0.553 | 0.915 | 0.36 |
| p14 | 0.211 | 0.091 | 0.400 | 0.896 | 0.25 |
| p15 | 0.162 | 0.576 | 0.925 | 0.905 | 0.42 |
| p16 | 0.166 | 0.033 | 0.525 | 0.896 | 0.21 |
| p17 | 0.047 | 0.025 | 0.553 | 0.894 | 0.15 |
| p18 | 0.170 | 0.040 | 0.400 | 0.887 | 0.21 |
| p19 | 0.109 | 0.027 | 0.522 | 0.886 | 0.18 |
| p20 | 0.023 | 0.043 | 0.151 | 0.886 | 0.12 |
| p21 | 0.174 | 0.116 | 0.254 | 0.967 | 0.24 |
| Bearings | 3σ (Failure Points (min)) | RMS (Failure Points (min)) | Actual Operating (min) |
|---|---|---|---|
| 1-3 | 1330 | 1414 | 2311 |
| 2-6 | 673 | 688 | 701 |
| 3-3 | 323 | 328 | 434 |
| Model | Layer Name | Detailed Description |
|---|---|---|
| Prosed method | BiLSTM1, BiLSTM2, Fully connected layer, Regression layer | Number of hidden layer neurons: BiLSTM1 = 93, BiLSTM2 = 93; Fully connected layer: layer1 = 40, layer2 = 25, Output vector dimension:1; Learning rate: 0.0098; Batch size: 64; Number of iterations: 2000; Dropout rate: 0.147; Activation function: Relu. Regression layer = 1 |
| BiGRU | GRU, Fully connected layer, Regression layer | Number of hidden layer neurons: 240; Fully connected layer: 40; Output vector dimension: 1; Learning rate: 0.001; Batch size: 64; Number of iterations: 2000; Dropout rate: 0.15; Activation function: Relu. Regression layer = 1 |
| CNN-LSTM | 1DConv1, 1DConv1, LSTM, Fully connected layer, Regression layer | Number of hidden layer neurons: 128; Fully connected layer: layer1 = 40, layer2 = 25; Output vector dimension: 1; Pooling = {1*2}, Learning rate: 0.001; Batch size: 64; Number of iterations: 2000; Dropout rate: 0.015; Activation function: Relu. Regression layer = 1 |
| Bearings | The Proposed Method vs. BIGRU p-Value | The Proposed Method vs. CNN-LSTM. p-Value |
|---|---|---|
| 1-3 | p1-3 = 0.0188 | p1-3 = 0.0001 |
| 2-6 | p2-6 = 0.0012 | p2-6 = 0.0082 |
| 3-3 | p1-3 = 0.0234 | p3-3 = 0.0329 |
| Model | Bearings | RMSE | MAE | R2 |
|---|---|---|---|---|
| 1_3 | 0.1033 | 0.0729 | 0.8920 | |
| Prosed method | 2_6 | 0.1316 | 0.0975 | 0.9725 |
| 3_3 | 0.0406 | 0.0296 | 0.9802 | |
| 1_3 | 0.0503 | 0.4354 | 0.8298 | |
| BiGRU | 2_6 | 0.1368 | 0.1803 | 0.7753 |
| 3_3 | 0.0532 | 0.0422 | 0.9660 | |
| 1_3 | 0.0503 | 0.1733 | 0.8821 | |
| CNN-LSTM | 2_6 | 0.2216 | 0.1004 | 0.4372 |
| 3_3 | 0.0554 | 0.0429 | 0.9632 |
| Bearings | The Proposed Method vs. BIGRU p-Value | The Proposed Method vs. CNN-LSTM. p-Value |
|---|---|---|
| 1-3 | p1-3 = 0.0196 | p1-3 = 0.0001 |
| 2-6 | p2-5 = 0.0012 | p2-5 = 0.0083 |
| 3-3 | p3-5 = 0.0241 | p3-5 = 0.0327 |
| Model | Bearings | RMSE | MAE | R2 |
|---|---|---|---|---|
| 1_3 | 0.0682 | 0.0741 | 0.8743 | |
| Prosed method | 2_5 | 0.0811 | 0.0591 | 0.9211 |
| 3_5 | 0.0866 | 0.0533 | 0.9100 | |
| 1_3 | 0.0881 | 0.0567 | 0.8298 | |
| BiGRU | 2_5 | 0.0917 | 0.0763 | 0.9090 |
| 3_5 | 0.0899 | 0.0422 | 0.8570 | |
| 1_3 | 0.1255 | 0.0907 | 0.8538 | |
| CNN-LSTM | 2_5 | 0.1666 | 0.0914 | 0.8863 |
| 3_5 | 0.2166 | 0.4836 | 0.8782 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, Y.; Sun, W.; Wang, H.; Xu, T.; Wang, B. Research on Bearing Remaining Useful Life Prediction Method Based on Double Bidirectional Long Short-Term Memory. Appl. Sci. 2025, 15, 4441. https://doi.org/10.3390/app15084441
Zou Y, Sun W, Wang H, Xu T, Wang B. Research on Bearing Remaining Useful Life Prediction Method Based on Double Bidirectional Long Short-Term Memory. Applied Sciences. 2025; 15(8):4441. https://doi.org/10.3390/app15084441
Chicago/Turabian StyleZou, Yi, Wenlei Sun, Hongwei Wang, Tiantian Xu, and Bingkai Wang. 2025. "Research on Bearing Remaining Useful Life Prediction Method Based on Double Bidirectional Long Short-Term Memory" Applied Sciences 15, no. 8: 4441. https://doi.org/10.3390/app15084441
APA StyleZou, Y., Sun, W., Wang, H., Xu, T., & Wang, B. (2025). Research on Bearing Remaining Useful Life Prediction Method Based on Double Bidirectional Long Short-Term Memory. Applied Sciences, 15(8), 4441. https://doi.org/10.3390/app15084441