1. Introduction
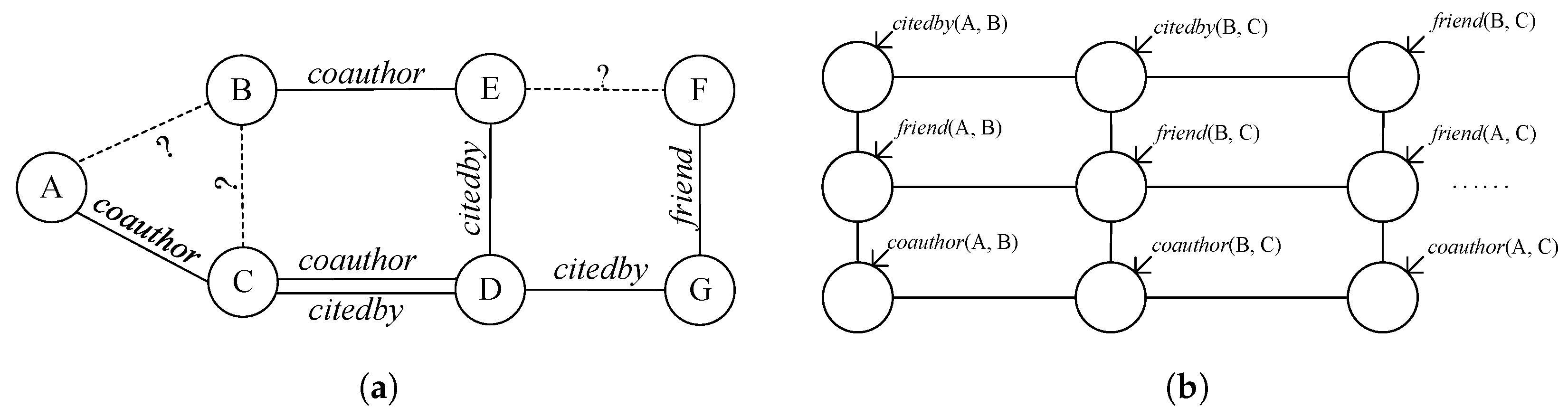
Link prediction (LP) in heterogeneous networks (also known as multi-relational LP) [
1] aims to forecast multi-type connections between objects in networks. This field has recently garnered significant interest due to its diverse applications in social networks [
2], knowledge graph completion [
3], community discovery [
4], item recommendation [
5], etc. For instance, in a heterogeneous academic social network with entities like authors A, B, and C and link types such as
coauthor and
citedby, as illustrated in
Figure 1a, the LP task involves determining the validity of links like
coauthor (A, B),
citedby (A, B), and
citedby (B, C). Notably, these diverse link types mutually influence each other’s existence, such as
citedby (C, D) impacting
coauthor (C, D). Moreover, the scarcity of observed links compared to potential links results in the link sparsity challenge.
LP in heterogeneous networks faces two primary challenges. Firstly, nodes in such networks often exhibit multiple relationship types, necessitating the creation of a unified metric space that captures the inter-dependencies among these diverse links [
6]. Current approaches [
7,
8] typically extract and merge type-specific features into distinct metric spaces, aiming to enhance prediction performance through transfer learning or algebraic space integration. However, these methods often neglect dependencies across various link types, leading to decreased accuracy. For instance, the presence of a
coauthor link between C and D might influence
citedby. Secondly, real-world networks exhibit sparsity, with numerous pairs of unconnected nodes. LP tasks, akin to supervised learning on non-relational data, involve predicting relational facts using known facts as supervision. This setup results in inadequate supervision and reduced accuracy in LP tasks. Addressing these challenges is crucial for effective multi-relational LP.
Multi-type relations could be encompassed into logical formulas for inter-dependency calculation. Markov logic networks (MLNs) offer an intuitive methodology for delineating network relationships through logical formulas, garnering increasing acclaim in the domain of multi-relational link prediction [
9]. MLNs permit deviations from formulas with a penalizing mechanism rather than outright failure, which aligns with the inherent uncertainty prevalent in real-world relationships among entities. The magnitude of the penalty is regulated by weights assigned to individual formulas, with higher weights denoting a more robust endorsement of the associated patterns.
For instance, propositions such as “coauthors are likely to be friends” () and “if one author cites another, they might develop a friendly relationship” () elucidate the interplay between different relations. By designing these formulas and employing grounding techniques, we can transform the information like into grounded predicates, which serve as nodes in the MLN structure. The inter-dependency between different relations can be represented through the weights of formulas, which are calculated using MLN’s learning methods based on the values of MLN nodes. Similarly, the values of unknown nodes indicating link facts can be calculated through MLN’s inference methods using these learned weights.
In particular, LP in heterogeneous networks can be reformulated as an inference problem in MLNs and traditionally solved using Statistical Relational Learning (SRL) methods [
10]. This approach predicts unknown links by inferring node labels in the MLN, using observed links as evidence, facing two major challenges for multi-relational LP: (1) the sparsity of observed links leads to numerous unobserved MLN nodes, and (2) the computational complexity of inference in large MLNs.
Traditional SRL inference methods for MLNs struggle with these challenges due to their inability to efficiently handle latent variables in sparse network settings. The variational expectation maximization (VEM) algorithm [
10] addresses these limitations by introducing a principled framework for reasoning with latent variables. VEM enhances MLN inference for LP tasks in two key ways: first, by treating unobserved nodes as latent variables, it provides a systematic approach to handle network sparsity. Second, by approximating complex posterior distributions through variational inference, it significantly reduces the computational burden of exact inference in large-scale networks. Specifically, VEM iteratively updates variational and true posterior distributions to maximize the Evidence Lower Bound (ELBO) [
11], thereby approximating the posterior distribution of node labels while maintaining computational tractability. This optimization process effectively balances inference accuracy with computational efficiency, making it particularly suitable for large heterogeneous networks.
To tackle the first challenge, we develop a substructure-based approach that iteratively partitions the MLN by selecting neighbors of unobserved nodes (seed nodes) corresponding to unknown links. The neighbor selection follows the 2-hop enclosing subgraph principle [
12], balancing computational efficiency with prediction accuracy. Seed nodes are progressively selected based on VEM results from previous substructures, leading to an efficient MLN-based link prediction algorithm.
For the second challenge, we enhance the VEM framework by incorporating both neighboring node labels and MLN structural features. We leverage graph convolutional networks (GCNs) [
13] to capture label dependencies and network topology. Specifically, we model the variational distribution of unobserved node labels as a categorical distribution and use GCNs to learn MLN structure representations, using neighboring node label distributions as feature matrices. This approach effectively captures the complex dependencies between different relationship types in the network.
Generally, the contributions of this paper are as follows:
We introduce the concept of transforming multi-relational LP tasks into inferences in MLN, wherein LP is viewed as the estimation of node labels in MLN, with known links in a heterogeneous network considered as observed nodes in MLN.
We propose a method to partition the MLN into distinct substructures to address the complexity of large MLN structures. Additionally, we present a VEM-based approach for calculating the distribution of node labels by incorporating formula features and the MLN structure.
We define a termination condition for computing label distributions in MLN substructures and provide an algorithm for MLN-based LP.
Extensive experiments demonstrate that our method surpasses both traditional and state-of-the-art (SOTA) approaches in terms of the accuracy of LP tasks.
The rest of this paper is organized as follows. We introduce related work, preliminaries, and the overview of our framework in
Section 2. We elaborate our proposed inference framework of MLN for LP in
Section 3. In
Section 4, we report experimental results and performance studies. Lastly, we conclude and discuss future work in
Section 5.
2. Related Work
In this section, we provide a comprehensive review of existing research on LP in both homogeneous and heterogeneous networks, along with an examination of inferences within MLN.
LP on homogeneous network. Heuristic and learning-based methods represent recent trends in LP research on homogeneous networks. Heuristic methods, such as utilizing common neighbors [
14,
15], are employed to infer link existence. Recent advancements in LP research have shown that learning-based methods like matrix factorization and network embedding techniques are more effective in acquiring node embeddings [
16]. For instance, MHGCN+ [
17] and HL-GNN [
18] aggregate node embeddings through heterogeneous meta-path interaction and intra-layer propagation with inter-layer connections, respectively, to learn node embeddings. Moreover, ensemble methods [
9,
19] enhance LP tasks by combining the outcomes of heuristic and learning-based methods, leading to improved robustness at the expense of efficiency. These approaches construct classifier features through network embedding but struggle to achieve a unified representation of multiplex edges, prevalent in real-world heterogeneous network scenarios.
LP on heterogeneous network. Deep neural network-based methods have garnered significant attention for their adept feature extraction in LP tasks on heterogeneous networks [
20,
21]. These methods primarily focus on mining type-specific features to optimize prediction performance and subsequently combine relation embeddings through algebraic or transferable operations, as discussed in studies such as [
7,
8]. However, effectively capturing inter-dependencies among different types of links remains a challenge. Various techniques have been suggested to create link prediction models that minimize the loss associated with the representation of multi-type links. For instance, HRMNN [
22] integrates a relational graph generator that leverages the topological attributes of heterogeneous graphs and combines object-level aggregation with a multi-head attention mechanism to produce more comprehensive node representations. MTTM [
2] consists of a generative predictor and a discriminative classifier for link representations, enabling the discrimination of links and leveraging an adversarial neural network to maintain robustness against type differences. While these methods improve the representation of multiplex edges, challenges related to limited observed links and complex network architectures persist.
Researchers have endeavored to employ probabilistic graphical models (PGMs) to represent multi-type links in a unified manner, as discussed in [
23]. First-order logic formulas have been utilized to model multi-relational databases with Bayesian network (BN), as outlined in [
24], and the first-order BN serves as a statistical relational model capturing database frequencies.
As MLN formulas conclude predicates indicating various link types, inter-dependencies among various link types could be captured by the weights of formulas [
25]. Meanwhile, MLN, acting as a PGM incorporating first-order logic rules, has been applied for representing relational data [
26]. By converting heterogeneous networks into MLN and leveraging formulas, it enables a unified expression for multiplex edges. Nonetheless, optimization using SRL methods, as discussed in [
27], is found to be non-scalable for LP tasks, primarily due to its inefficiency. Furthermore, the extensive structure of MLN leads to a vast search space and necessitates a costly inference process.
Inference in MLN. Efforts have been undertaken to enhance the efficiency and scalability of inferences in MLN for LP across diverse scenarios. For instance, QNMLN [
25] expands on the formulas, while MCLA [
28] refines its parameter updates for a range of practical tasks. The VEM algorithm [
29] serves as the inference framework for MLN, with graph neural networks (GNNs) utilized in the E-step to capture the features of target relation nodes. ExpressGNN [
30] utilizes GNN for node representation integration with formulas. On the other hand, PlogicNet [
11] infers embeddings based on the local dependency of target nodes, yet overlooks their interactions. Pgat [
26] optimizes the representations by employing graph attention neural network-based node embeddings. These methods use SRL to update parameters in the M-step by exploring the complete MLN, leading to challenges in generating precise embeddings for unlabeled nodes in efficient multi-relational LP. In contrast, our study in this paper utilizes GNNs to encapsulate the features of MLN and formulas in the M-step, and propose substituting the complete MLN with substructures to significantly decrease the search space of inferences.
3. Preliminaries
Consider a heterogeneous network with the following components: represents the set of entities (e.g., papers, authors), denotes the set of edges representing relationships, and is the set of attributes associated with entities. We distinguish between observed and unobserved relationships where represents the set of observed relations and represents the set of unobserved relations.
Definition 1. A heterogeneous network is defined as , , where = and + > 2.
To transform our heterogeneous network into an MLN, we first represent relationships as logical predicates. Each relationship becomes a predicate , where r is a relation type from , and and are entities from .
These predicates form the building blocks of logical formulas that capture patterns in our data. When we ground these formulas (replace variables with actual entities), we create fact nodes in MLN. For example, in the academic citation network like in
Figure 1a, we might observe that when author A cites both authors B and C, authors B and C are likely to be related. This pattern can be encoded as a logical formula:
citedby (A, B) ∧
citedby (A, C) →
citedby (B, C), in which
(A, B),
(A, C) and
(A, B) become concrete nodes in MLN.
Let V represent all fact nodes in our MLN, consisting of and , which denote the observed predicates (known relationships), and unobserved predicates (relationships to be inferred), respectively.
Definition 2. An MLN is defined as , where the following are denoted:
is an undirected graph where V is the set of fact nodes following Bernoulli distribution, E is the set of edges derived from logical formulas .
The joint probability distribution over G is defined by where is the partition function, is the weight of formula f, and counts true groundings of f.
The parameters
of an MLN can be learned through discriminative learning by maximizing the pseudo-likelihood of
[
10]:
where
represents the label of node
n, and MB(
n) refers to the Markov blanket of
n [
31], encompassing its direct parents, direct children, and other parents of its direct children within the MLN.
The joint distribution
can be computed using maximum a posteriori (MAP) inference [
26]:
In this paper, we aim to address the multi-relational LP task within
G, by transforming
H into
G and calculating
, where
is corresponding to unknown links in
H, and
represents the joint probability distribution. For the transformation, we firstly build
G by establishing
m formulas and the corresponding grounding. To address the efficiency bottleneck, we partition
G into substructures
, where
denotes the unobserved nodes in
. To calculate
efficiently, we propose the VEM-based inference method to update
by Equation (
1) and calculate
by Equation (
2) in each substructure
. Moreover, we introduce a termination condition to determine the necessity of computations in
. Consequently, we frame the inference of
into the computation of
,
,
…,
.
The key notations, abbreviations, and their descriptions are summarized in
Table 1 and
Table 2.
4. Proposed Method
The inference framework for efficient LP tasks is depicted in
Figure 2, comprising the following three components.
MLN substructure construction is proposed to construct MLN substructures to avoid the massive search space of the entire MLN, as presented in
Section 4.1.
VEM-based inference is proposed to calculate the joint distributions of nodes by extending the VEM with GCN, as presented in
Section 4.2.
MLN-based LP is proposed with the termination condition to fulfill LP by inferences in MLN, as presented in
Section 4.3.
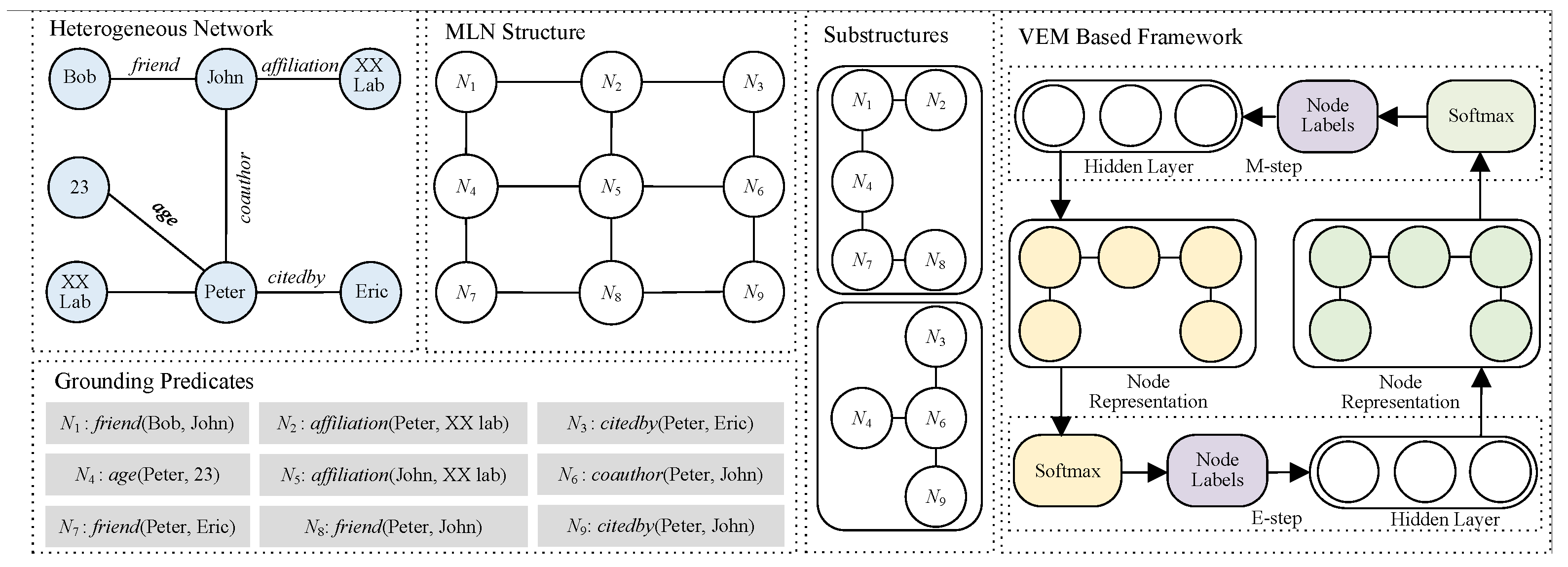
Figure 2.
Overview of the proposed framework.
Figure 2.
Overview of the proposed framework.
Our method initiates by transforming knowledge graph triples into grounded predicates to construct the MLN structure. Subsequently, we partition this MLN structure into coherent substructures. Finally, we apply VEM-based inference independently on each substructure, enabling efficient LP tasks on KGs.
4.1. MLN Substructure Construction
To compute the joint distribution efficiently without navigating the extensive MLN search space, we divide G into k substructures, labeled as . Constructing involves choosing unobserved nodes neighboring in (labeled as ) and progressively expanding through neighboring nodes in the MLN hop by hop, until adequate information is collected for label computation.
Viewed from a heterogeneous network perspective, the 2-hop enclosing subgraph
has been validated as containing adequate information for LP between entities
u and
v in the heterogeneous network
H, with minimal approximation errors [
12]. This validation guarantees the rationale to leverage the 2-hop enclosing subgraph principle for the expansive refinement of
within
G, which encompasses the links in
H. To achieve this, we map
to corresponding fact nodes in MLN. Assuming that
includes
predicates for facts like
, the analogous nodes in
G to
in
H are denoted as follows:
where
is the MLN node corresponding to the link between
u and
v in
H.
In the context of MLN, Equation (
3) comprises ample information for the calculation of node labels for
, guiding the exploration of
’s neighbors through successive expansion hops. For convenience of expression, we use
n and
to denote
and its neighbors in MLN, reached through
h expansion hops, respectively. In particular, the expansion of the
h-th hop is fulfilled by adding the neighbors of all the nodes in
iteratively. The expansion of
halts when all generated neighbors encompass the nodes specified in Equation (
3).
Note that without substructure construction, the interpretability of the entire MLN with respect to can be calculated based on . While our approach partitions the computation process, the substructure construction is specifically designed for the efficient estimation of . Consequently, despite this division, the weights can still be derived through conditional probability calculations, thus preserving the inherent interpretability of the original MLN.
By this procedure of substructure construction, we could transform into , , …, () with minimal approximation errors. Consequently, this partition strategy reduces computational complexity from to , where for typical sparse KGs. We summarize the steps of substructure construction in Algorithm 1 with time complexity , where denotes the average number of fact nodes in substructures.
4.2. VEM-Based Inference
In this section, we present a method to augment the VEM algorithm with GCNs to compute the labels of unobserved relation nodes.
4.2.1. Variational Distribution
To enhance LP efficiency in MLN, we propose computing the true posterior distribution
within the EM algorithm by treating the labels of
as latent variables. Given the challenge posed by a large number of unobserved fact nodes in MLN for directly calculating
, we approximate this distribution with a variational distribution
. Consequently, we derive
from
by minimizing their KL divergence:
where
represents the expectation with respect to
Q.
By swapping the term
in Equation (
4), we have
| Algorithm 1 MLN Substructure Construction |
- Input:
observed nodes , unobserved nodes , MLN structure , number of substructures k - Output:
set of substructures
- 1:
- 2:
- 3:
for to k do - 4:
- 5:
for each node n in do - 6:
Obtain using Equation ( 3) - 7:
- 8:
while do // expansion - 9:
- 10:
- 11:
- 12:
end while - 13:
in G - 14:
// the i-th substructure of G - 15:
end for - 16:
// update observed nodes - 17:
// add substructure to - 18:
end for - 19:
return
|
As is non-negative, we define as the ELBO of . Since is a constant with respect to , we transform the minimization of into the ELBO maximization by iterative executions of variational E-steps and M-steps.
4.2.2. Argumentation of VEM
Variational E-step. According to the mean-field theory [
32], the variational distribution
of all unobserved fact nodes is formed by the independent fact node
:
To calculate
in Equation (
6), we adopt the GCN-based representation with Softmax function as the distribution of
n. For this purpose, we take the labels of neighbors of
n as the feature vector
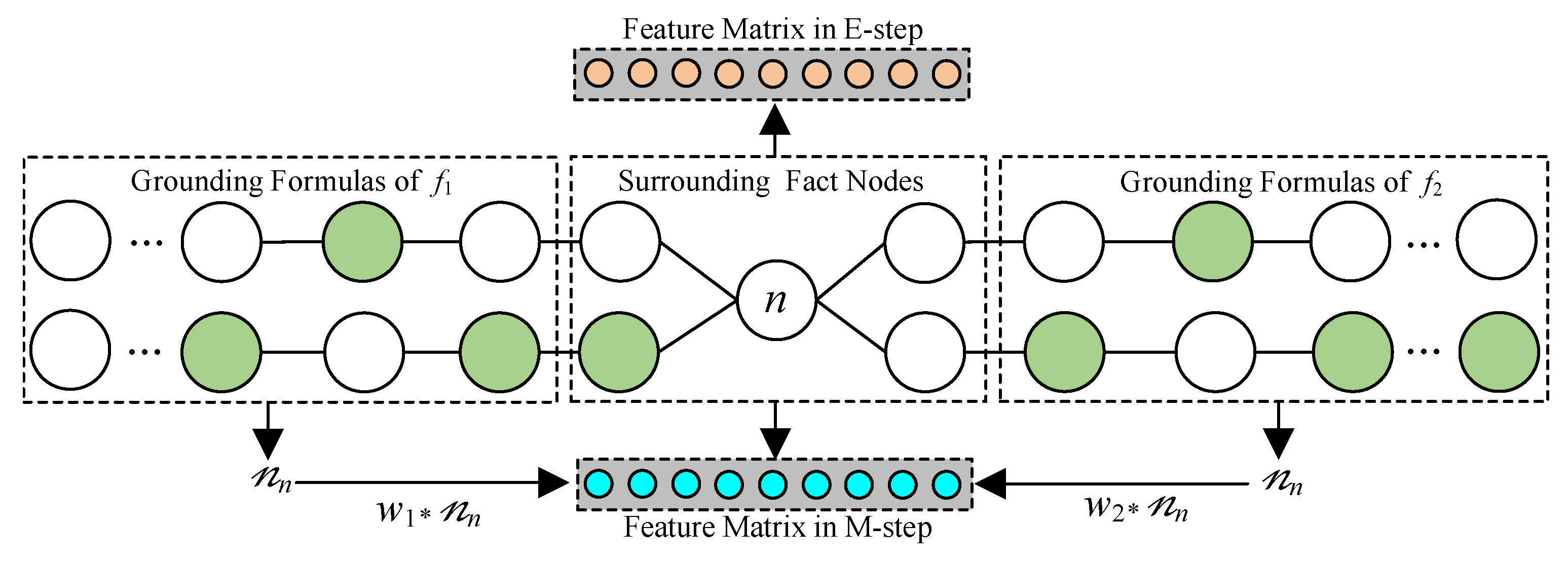
. The labels of the observed and unobserved fact nodes are 1 and 0, respectively. As shown in
Figure 3, the labels of the fact nodes surrounding
n form its feature vector. Thus, the feature matrix
could be constructed, and the distribution of
n is
where Cat denotes the categorical distribution,
is the adjacency matrix corresponding to the graph structure, and
is the weight matrix. Since
could be optimized by observed nodes, we divide the optimization of
into the following two parts:
For unobserved fact nodes
, we update
by maximizing
where
is the distribution of unobserved fact nodes in the previous iteration round. Since both unobserved and observed fact nodes follow the same distribution, we initialize
to
in the first round of iteration.
For the observed fact nodes
, we use the cross-entropy loss to make the GCN fit the true labels:
where
is the label of
n in
, and
is the probability that
n is predicted as true.
Thus, we sum Equations (
8) and (
9) as the following training loss of GCN to obtain the variational distribution
:
M-step. To maximize the expectation of
,
, we use a similar method as Equation (
6) to formulate
. Then, we leverage another GCN to obtain the node representations for categorical distribution:
Due to the same structure of these two GCNs in the same iteration round, the adjacency matrix
in Equation (
11) is the same with that in Equation (
7). An element in
represents the feature vector
of
n in
and the value of
is determined by the
m formulas and corresponding weights
. Let
denote the number of truth-value nodes linked with each formula
, respectively. Let
be the weight of
. Then, we multiply the weight and number of truth-value nodes to achieve the feature
. As shown in
Figure 3, we construct the feature matrix
in the M-step by the numbers of nodes in grounding formulas of
and
, as well as their weights
and
.
Let
and
be the real and expected numbers of true groundings of formulas, respectively. We use their difference as the gradient of
with the previous iteration round:
where
is the joint distribution of
calculated by the E-step in the previous iteration round.
Additionally, if the fact node is not grounded from any predicate in the j-th formula (i.e., the node is not linked to this formula), we set the corresponding weight to 0.
Then, we design the following predicate loss to update
by maximizing
:
where
is the label of
n.
Thus, could be maximized by the optimal in the current iteration, and the distribution of unobserved fact nodes could be approximated efficiently.
4.2.3. Inference Algorithm
To calculate the joint distribution of fact nodes in each substructure, we use the VEM-based inference to update the parameters of GCNs in the variational E-steps and M-steps given the observed fact nodes.
We first initialize
with a normal distribution for training
with
in the M-step. Then, in the variational E-step, we optimize the variational distribution
with the output
. In the M-step, we optimize the posterior distribution
with
calculated by Equation (
7). Then, we alternatively optimize
and
until their KL divergence is less than the given threshold or the given maximal iteration number is reached.
We summarize the above ideas in Algorithm 2. In the worst case, the time complexity is
, where
is the maximal iteration number of steps 7∼13,
is the average number of edges in each substructure, and
is the number of layers in GCN.
| Algorithm 2 VEM-based inference |
- Input:
the threshold of KL divergence, the MLN substructure , the observed fact nodes , the weights , the unobserved fact nodes - Output:
posterior distribution
- 1:
Initialize and - 2:
Obtain with by Equation ( 12) - 3:
Obtain by edges of - 4:
Optimize by Equation ( 13) - 5:
// by Equation ( 11) - 6:
- 7:
while do - 8:
Update in E-step by Equation ( 10) - 9:
Optimize by Equation ( 7) - 10:
Update in M-step by Equation ( 13) - 11:
Optimize by Equation ( 11) - 12:
- 13:
end while - 14:
- 15:
return
|
4.3. MLN-Based LP
The labels of fact nodes in could be determined through logical inference based on formulas rather than the VEM inference method. For instance, a grounding formula with a non-zero weight such as can create a true relation-node , if both and hold. By iteratively obtaining the joint distribution of unobserved node labels using Algorithm 2 based on the observed fact nodes in the substructures, more observed nodes can be acquired. A comparison with the joint distribution derived from logical formulas reveals an increasing discrepancy in VEM-based inferences as more unobserved fact nodes are updated to observed. Consequently, we opt to halt the iterative inferences when the difference surpasses a specified threshold, enabling the calculation of the joint distribution of for LP tasks.
Without loss of generality, we establish the KL divergence-based termination condition to determine whether further calculation should proceed by measuring the difference between the distribution of fact node labels obtained through logical evaluation and VEM-based methods:
Here, denotes the observed fact nodes in , U represents the sole unobserved node in each formula, which can be evaluated logically as 1 or 0, corresponding to true or false, respectively. signifies the value of U given through logical evaluation, while denotes the joint distribution from VEM-based inferences. A smaller KL divergence indicates that the two joint distributions calculated by VEM-based inferences and logical evaluations are more consistent.
To calculate
, we utilize Equation (
12) to compute
, deriving the nonzero-weight formulas
(
). Subsequently, we construct
U using the fact nodes, whose labels could be logically inferred as true by
. Therefore,
could be redefined as
. As
could be calculated using Algorithm 2 as
, we transform Equation (
14) into
Equation (
15) serves as the termination criterion, indicating that if it falls below a specified threshold, the computation in
continues. By this pause mechanism, we could prevent noisy data from causing significant error impacts. These concepts are consolidated in Algorithm 3. Within each substructure
, the time complexity of step 4 is
, where
denotes the average number of nodes in
. Step 5’s time complexity is
as per Algorithm 2, with
representing the average edge count in
. The time complexity of steps 6 through 7 is
). Hence, in a scenario where
substructures are constructed, the time complexity of Algorithm 3 amounts to
, where
and
are considerably smaller than
and
, respectively. Specifically, the time complexity of substructure construction is
, while the VEM-GCN integration exhibits a time complexity of
, respectively.
| Algorithm 3 MLN-based LP |
- Input:
the set of initial observed fact nodes , the set of formulas , the threshold of KL divergence between and - Output:
joint distribution
- 1:
- 2:
- 3:
while do - 4:
Obtain with by Algorithm 1 - 5:
Obtain by Algorithm 2 - 6:
Obtain with by Equation ( 12) - 7:
Obtain U via by logical way - 8:
- 9:
- 10:
end while - 11:
- 12:
return
|
5. Experiments
Our proposed method is evaluated based on the following inquiries:
Comparing the accuracy of our method for multi-relational LP tasks with that of competitors.
Assessing how our VEM-based inference method enhances the efficiency of MLN-based LP.
Investigating the impact of parameters on the accuracy of the LP.
5.1. Experiment Settings
Datasets. Our experiments were carried out on five heterogeneous networks: the academic network, Aminer; the network of relatives, Kinship [
30]; the medical relation network, UMLS [
11]; the word net WN18RR [
29]; and the social knowledge base Freebase15k-237 [
33]. The dataset statistics are presented in
Table 3.
Formulas. Logical formulas for multi-relational LP tasks were devised for each dataset and translated into inferences within MLN. Specific formulas for each dataset are delineated in
Table 4.
Comparison methods. We compared two types of methods: deep learning-based methods including SEAL [
12] and Matrix Factorization (MF) [
16], and MLN-based methods including ExpressGNN [
30], PlogicNet [
11], Pgat [
26], RNNlogic [
29], and MLN [
10]. The latter category employs MLN to model heterogeneous networks, facilitating learning and inferences for diverse downstream tasks. They are summarized as follows:
SEAL adopts GNN for node representation by learning the structural information.
MF transforms the representation matrix into multiplication of matrices to enhance node representation.
ExpressGNN uses a GNN variant to conduct the variational inference in MLN structures.
PlogicNet uses GNN to embed the graphical structures and incorporates the weights of formulas by VEM.
Pgat incorporates graph attention network embeddings to infer the relations.
RNNlogic leverages recurrent neural networks to generate high-quality formulas for inferences in MLN.
MLN uses SRL-based methods to generate posterior distributions of nodes in MLN.
Implementation. We utilized accuracy to evaluate the efficacy of our proposed method, defined as the ratio of correct predictions generated by the LP methods. Efficiency was assessed through execution time, encompassing the overall time for parameter updates and link predictions.
For the learning-based methods, we treated the evidence nodes in MLN and their labels as the training and test sets, respectively. To execute multi-relational LP using MLN, we formulated the MLN structure for each dataset. In the case of the Aminer dataset, we randomly selected subsets by varying the sizes from 10,000, 5000, 2000, to 1000 individuals. SEAL and MF were applied to the datasets for each link type, with the average accuracy serving as the LP outcome. For robust evaluation, we repeated each experiment 5 times with different random seeds and reported the mean performance along with standard deviation. For each experimental configuration, the training and testing processes were executed independently, maintaining consistent hyperparameter settings across all runs to ensure fairness.
Our experiments were conducted on a machine equipped with a 6000Ada GPU, 128 GB of memory, and an i9-9900K CPU. All implementations were carried out using Python 3.7. We primarily used PyTorch v1.12.1 and ProbCoG libraries.
5.2. Experimental Results
Accuracy. We assessed the efficacy of our method by comparing its accuracy with various other methods. To ensure fairness in the experiments, we maintained consistent links in the test set. For discerning accuracy across different scales, we segmented the Aminer dataset into subsets: Aminer-10000, Aminer-5000, Aminer-2000, and Aminer-1000, containing 12,601, 3591, 2384, and 1189 relations, respectively. Two types of links were designated for prediction, with an 8/2 ratio between training and testing data. Furthermore, we examined the outcomes of combinations with varying numbers of link types and ratios, specifically (3 types, 8/2) and (2 types, 7/3), to analyze the impact of these factors on results. The accuracy comparisons are detailed and summarized in
Table 5,
Table 6 and
Table 7. In cases where a model failed to operate due to memory constraints, this is denoted by `-’. Our findings suggest the following:
Across 2-type and 3-type links at different train–test ratios, our method attains an average accuracy of 94.87%, which stands as the highest accuracy across all dataset sizes. Notably, our method enhances accuracy by approximately 3.7%, 2.9%, 0.5%, 6.0%, and 11.5% compared to the highest accuracy achieved by the comparison methods, respectively.
Across varying sizes of the Aminer datasets, our method consistently surpasses all competitors, showcasing enhanced robustness. Notably, our method boosts accuracy by 3.7%, 3.1%, 5.3%, and 1.8% compared to the second-highest performing model on Aminer with 10,000, 5000, 2000, and 1000 individuals, respectively.
The MLN-based methods (ExpressGNN, MLN, PlogicNet, Pgat, RNNlogic, and our method) attain average accuracies of 85.71%, 82.81%, 41.52%, 34.4%, and 72.66% on the Aminer, Kinship, UMLS, WN18RR, and FB15k-237 datasets, respectively, surpassing the learning-based methods (SEAL and MF) by 8.3%, 0.1%, 171.55%, 140.1%, and 6.2%, respectively. Our method achieves accuracies of 72.66%, 76.7%, 79.48%, and 81.75%, outperforming the second-highest model by an average of 3.65% on the Aminer datasets with 10,000, 5000, 2000, and 1000 individuals, respectively.
Also, we conducted experiments on different missing link ratios to evaluate the robustness of our method. We randomly removed 10%, 30%, and 50% of the Kinship, UMLS, WN18RR, and FB15k-237 datasets, respectively, and various sizes of Aminer. The accuracy comparisons are detailed in
Table 8. Our findings suggest the following:
When 10% of the edges are removed, the performance of the model shows a slight overall decline, with more pronounced decreases in the sparse datasets such as WN18RR and FB15k-237, reaching 5% and 6%, respectively. In other datasets, the performance degradation is relatively smaller, approximately 3.5–4%.
As the edge removal increases to 30%, performance degradation becomes more significant. The FB15k-237 dataset is most affected, with a 20% reduction, while WN18RR shows a 15% decrease. Kinship, UMLS, and the Aminer series datasets experience reductions between 11 and 13%.
When 50% of edges are removed, all datasets undergo substantial performance deterioration. The FB15k-237 dataset remains the most severely impacted, with a 35% decrease; WN18RR declines by 30%; Kinship decreases by 25%; UMLS exhibits the smallest relative reduction at 23%; and all Aminer series datasets uniformly experience a 26% decrease.
Overall, sparser graph structures (e.g., WN18RR and FB15k-237) demonstrate higher sensitivity to edge removal, whereas denser relationship graphs (e.g., UMLS and Kinship) display better robustness. The Aminer series datasets, regardless of size, show similar patterns of performance degradation.
The accuracy enhancements observed in multi-relational LP validate the efficacy and robustness of our method through the integration of the VEM-based inference framework.
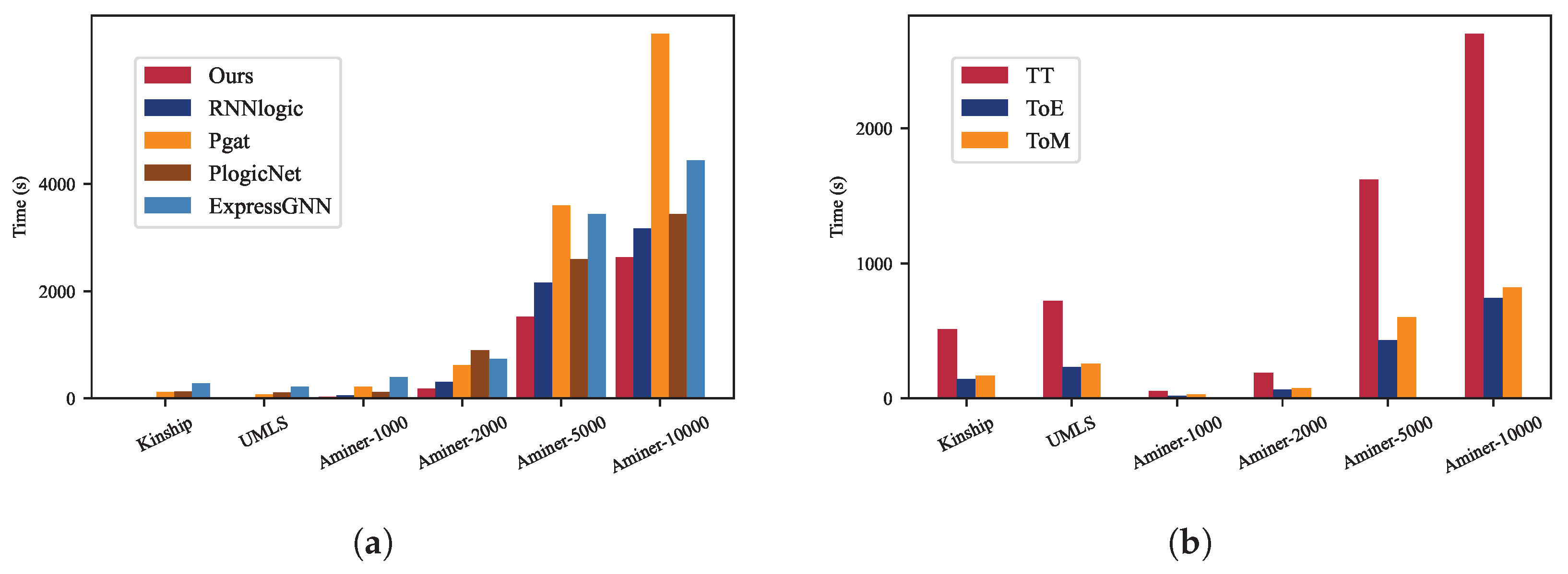
Efficiency. Efficiency evaluation of our method involved comparing its execution time with various MLN-based methods in multi-relational LP on the benchmarks WN18RR, FB15k-237, and Aminer datasets. The total execution time (TT), time for the E-step (ToE), and time for the M-step (ToM) are illustrated in
Figure 4. It is noteworthy that the execution times of MLN and NMLN are not included due to their significantly longer durations compared to the listed methods. Our observations reveal the following:
On WN18RR and FB15k-237 datasets, each containing over 10,000 entities, our method demonstrates the shortest processing time and surpasses the second-fastest model by an average of 42.37%.
When compared to pgat, RNNlogic, ExpressGNN, and PlogicNet on FB15k-237, our method reduces the total execution time (TT) by 40%, 56.82%, 63.3%, and 69.7%, respectively. On WN18RR, our method outperforms pgat, RNNlogic, ExpressGNN, and PlogicNet by 19.09%, 42.86%, 49.14%, and 55.5%, respectively.
In terms of the E-step (ToE) and M-step (ToM), our method achieves average improvements of 57.85% and 21.15% on WN18RR, and 71.96% and 37.41% on FB15k-237, respectively.
These results illustrated in
Figure 4 denote that our method demonstrates efficiency advancements on TT, ToE, and ToM, on the datasets with more than 10,000 entities.
Moreover, to assess efficiency across datasets of different sizes, we compared the total execution time (TT) on UMLS, Kinship, Aminer-10000, Aminer-5000, Aminer-2000, and Aminer-1000, each comprising fewer than 10,000 entities, as depicted in
Figure 5a. Furthermore,
Figure 5b presents the TT, time for the E-step (ToE), and time for the M-step (ToM) of our method, showcasing the execution durations of these steps across various dataset sizes. Our analysis indicates the following:
As depicted in
Figure 5a, our method exhibits the shortest total execution time among the datasets containing fewer than 10,000 entities, surpassing RNNlogic, Pgat, and PlogicNet. On average, our model consumes 33.2% less time than the second-fastest model in each dataset.
As illustrated in
Figure 5b, the execution time for the M-step (ToM) in our method averages 26% more than that for the E-step (ToE) across different datasets. Furthermore, the total time (TT) of our model demonstrates exponential growth with increasing data size, whereas both ToE and ToM exhibit nearly linear growth.
Impacts of parameters. We assessed the influence of experimental variables on the efficacy of LP by examining the accuracy of different methods while altering the number of formulas on Aminer-10000, FB15k-237, and Kinship datasets with more than 3 formulas, as detailed in
Table 9. Our analysis indicates that:
Our method attains average accuracies of 81.03%, 91.54%, and 44.39% on Aminer-10000, FB15k-237, and Kinship, respectively, surpassing the second-best competitors by 3.75%, 2.87%, and 11.55% on average. This underscores the robustness of our approach.
Accuracy shows a slight increment with an increase in logical formulas, suggesting that more formulas lead to improved accuracy. Conversely, a higher number of formulas results in a substantially larger grounded MLN structure, introducing more unlabeled nodes in MLN that could potentially impact accuracy negatively. Notably, as depicted in
Table 9, the accuracy on PlogicNet decreases by an average of 1.34% with the increase in formulas.
Ablation study. We conducted ablation experiments on the distinct contributions of each component in our proposed framework, the results of which are shown in
Table 10. The base MLN with SRL establishes a foundation but shows limitations on larger, complex datasets like FB15k and WN18RR. The VEM-GCN integration substantially enhances performance with a 7–12% across all datasets. Substructure condition (SC) presents an intriguing efficiency–accuracy trade-off. While moderately impacting accuracy with a reduction of only 1–2%, SC substantially enhances computational efficiency, delivering processing speeds up to 3.5x faster on larger datasets. Most significantly, the termination condition (TC) mechanism provides the most substantial accuracy gains, boosting performance by 4–6% when combined with SC across all datasets. The optimal configuration with all components except SRL achieves the highest accuracy.
In conclusion, based on the diverse experimental conditions and datasets examined, our method demonstrates the highest average accuracy in multi-relational LP across various datasets and link types, surpassing competitors by over 30% in efficiency.
6. Conclusions
First, we establish a perspective by transforming multi-relational LP into a node label estimation problem within MLN, treating known links as observed nodes. This transformation provides a principled probabilistic foundation for handling the inherent complexity of heterogeneous networks. Second, our substructure construction method partitions significantly enhance computational efficiency while preserving semantic relationships. Complementing this, our VEM-based framework strikes a balance between precision and computational feasibility. Third, the proposed terminating computation ensures both accuracy and efficiency in practical applications, making our approach viable for real-world heterogeneous networks. Finally, the experimental results demonstrate our method’s advantages in terms of efficiency, robustness, and accuracy. In all, our approach indeed bridges the critical gap between unknown links in heterogeneous networks and unobserved nodes in MLN, establishing a hybrid approach to link prediction that combines the strengths of both machine learning techniques and logical deduction.
Efficient inferences heavily depend on the MLN structure size, shaped by the formulated formulas for diverse multi-relational LP tasks. In future research, we aim to explore automatic formula selection to strike a balance between efficiency and efficacy. Furthermore, the combined VEM-GCN architecture possesses robust capacity for capturing temporal dynamics, strengthening MLN-based LP performance. Thus, we aim to extend our approach to dynamic graph-based applications such as sequential node classification using MLN-based inferences.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}