
Design of Swarm Intelligence Control Based on Double-Layer Deep Reinforcement Learning


Abstract
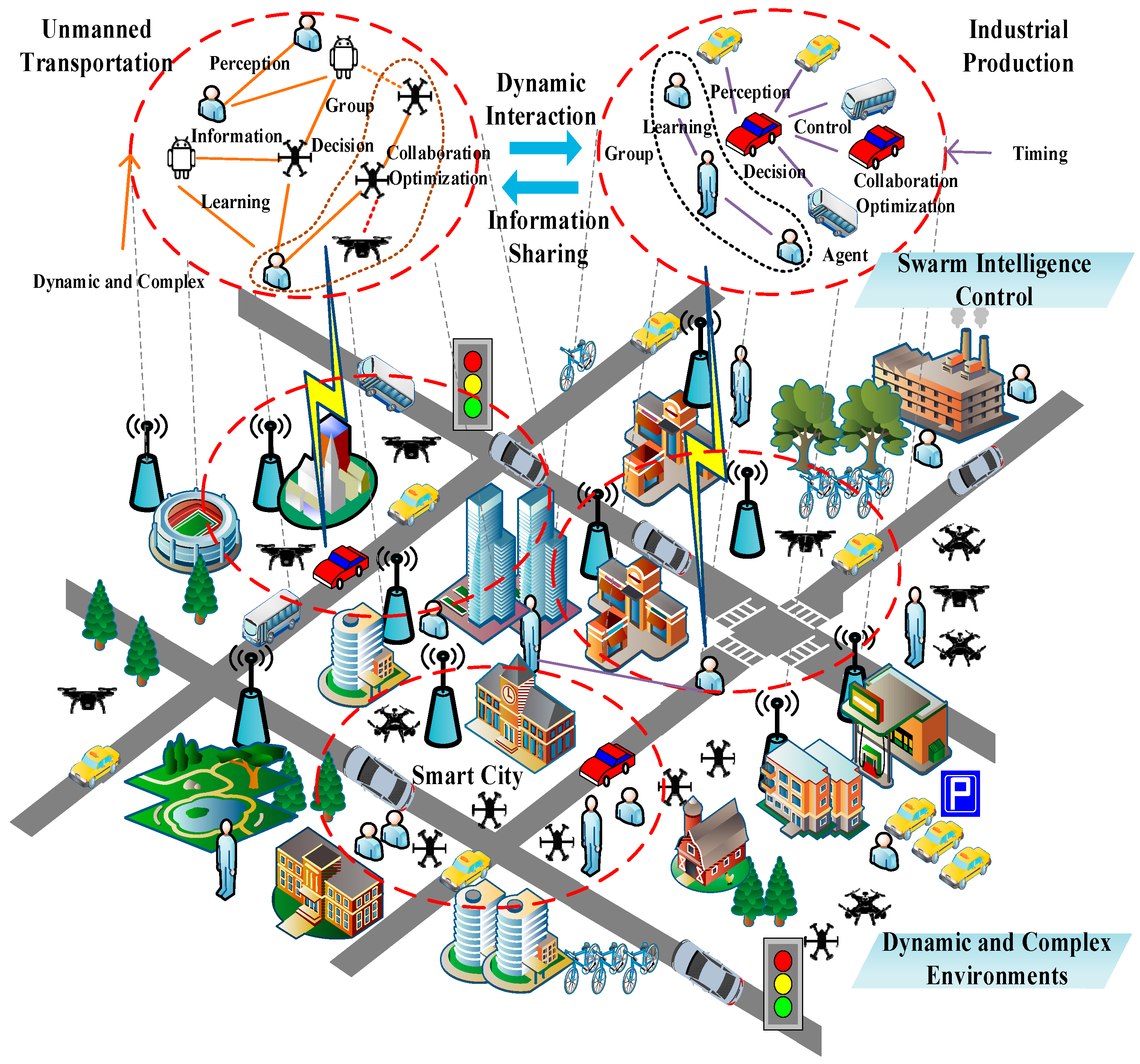
1. Introduction
2. Related Work
3. Double-Layer Deep Reinforcement Learning Design for Swarm Intelligence Control
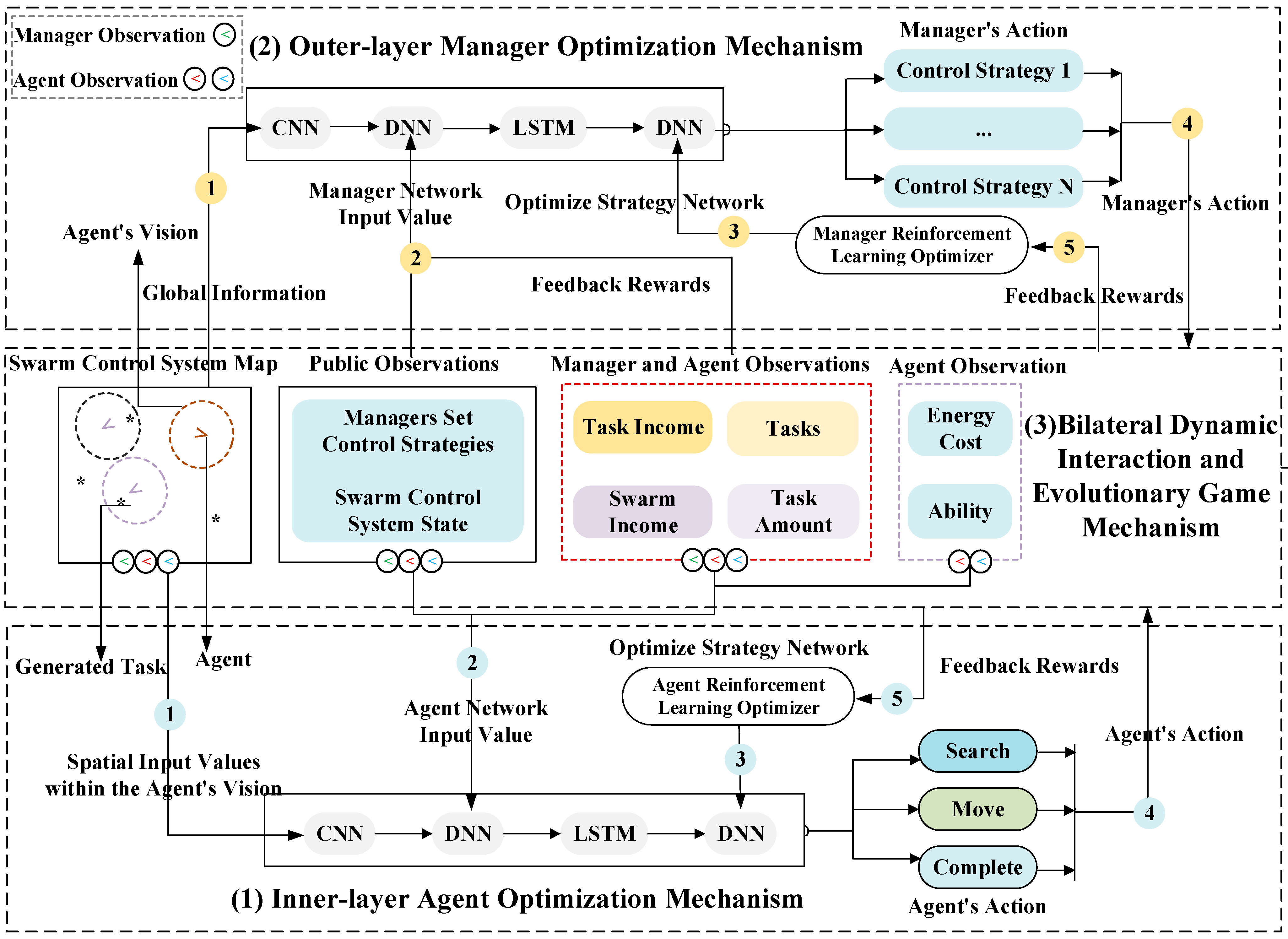
3.1. Overall Architecture of Double-Layer Deep Reinforcement Learning Framework
- (a)
- Input Information (labeled as 1 and 2):
- Each agent extracts spatial input values from the environment within its field of view. The input values are generated by the swarm control system map and represent local information, such as task location and environment status.
- The agent network input value consists of public observations, manager and agent observations, and agent observations. Public observations provide the swarm control system status and manager control strategy; manager and agent observations include task income, task amount, and swarm income; and agent observations include energy cost, ability, and local space information. This input integrates global and local information to provide a basis for optimization decisions for the policy network.
- (b)
- Optimizing Strategy Network (labeled as 3):
- These spatial inputs are processed through a Convolutional Neural Network (CNN) to extract spatial features. Extracted features are fed into a Deep Neural Network (DNN) and Long Short-Term Memory (LSTM) network for feature fusion and time-series prediction. This enables agents to optimize their decision-making processes.
- The Agent Reinforcement Learning Optimizer adjusts the action strategy based on the output of the policy optimization network.
- To enhance task efficiency, multi-agents share local information, enabling collaborative interactions.
- (c)
- Agent Actions (labeled as 4):
- The inner policy network finally outputs specific action instructions, such as search, move, complete tasks, etc. This behavior acts on the environment or task scenario.
- (d)
- Feedback Rewards (labeled as 5):
- When the agent performs an action, the environment provides a certain reward or penalty signal to update the parameters of the inner strategy and complete the closed loop of reinforcement learning.
- (a)
- Input Information (labeled as 1 and 2):
- The manager extracts global input values from the observation data of the environment and the agent, including the state of the environment, the distribution of tasks, and the action state of the agent. This information is integrated into the manager network input value as the input for subsequent feature extraction.
- The manager network input values include public, manager, and agent observations. Compared with the agent network input value, there is no agent observation. This input integrates manager observations, observed environmental states, global information, and agent observations, providing a basis for the optimization decision of the policy network.
- (b)
- Optimizing Strategy Network (labeled as 3):
- The manager comprehensively analyzes the environmental state, global information, and observable values of the agents. The CNN is used to extract features from the environment and agent distribution, followed by feature fusion and time series prediction using the DNN and LSTM to optimize resource allocation and control strategies.
- The manager reinforcement learning optimizer captures the dynamic changes in the swarm in both temporal and spatial dimensions. Based on this, it predicts swarm behavior trends, thereby enabling the efficient optimization of control strategies and resource allocation.
- (c)
- Manager Actions (labeled as 4):
- The manager generates multiple control strategies (e.g., strategy 1, strategy 2, …, strategy N) and selects the optimal one to guide agent behavior.
- (d)
- Feedback Rewards (labeled as 5):
- The manager also receives feedback rewards based on global performance indicators and multi-agent collaboration effects, thereby continuously optimizing its decision-making strategy.
- (a)
- Bilateral Dynamic Interaction:
- The manager formulates control strategies based on the global state to guide agents’ decision-making. After executing tasks, agents provide feedback on local states, influencing the manager’s strategy adjustments. Additionally, agents share information through local interactions to enhance collaborative effects.
- (b)
- Evolutionary Game Mechanism:
- Agents adjust their actions in dynamic environments based on reward maximization to adapt to optimal task allocation and resource utilization. The manager optimizes global strategies through reinforcement learning, guiding the swarm toward better solutions and ensuring overall performance improvement. By facilitating mutual learning and dynamic equilibrium between agents and the manager, a collaborative optimization of the swarm control system is achieved.
3.2. Inner-Layer Agent Optimization Mechanism for Individual and Group Control
3.3. Outer-Layer Manager Optimization Mechanism for System Control
3.4. Bi-Directional Dynamic Interaction Process and Evolutionary Game Mechanism
| Algorithm 1: Design of Swarm Intelligence Control Based on Double-layer Deep Reinforcement Learning |
| Input: Initial solution, sampling range , number of control policy change periods , stopping criteria for policy optimization , state, observation values, and hidden vectors |
| Output: Trained agent policy network weights , trained manager policy network |
|
|
4. A Case Study of Intelligence Control of Unmanned Aerial Vehicle Swarm
4.1. Design of Experimental System Scenarios
4.2. Experimental System Setting
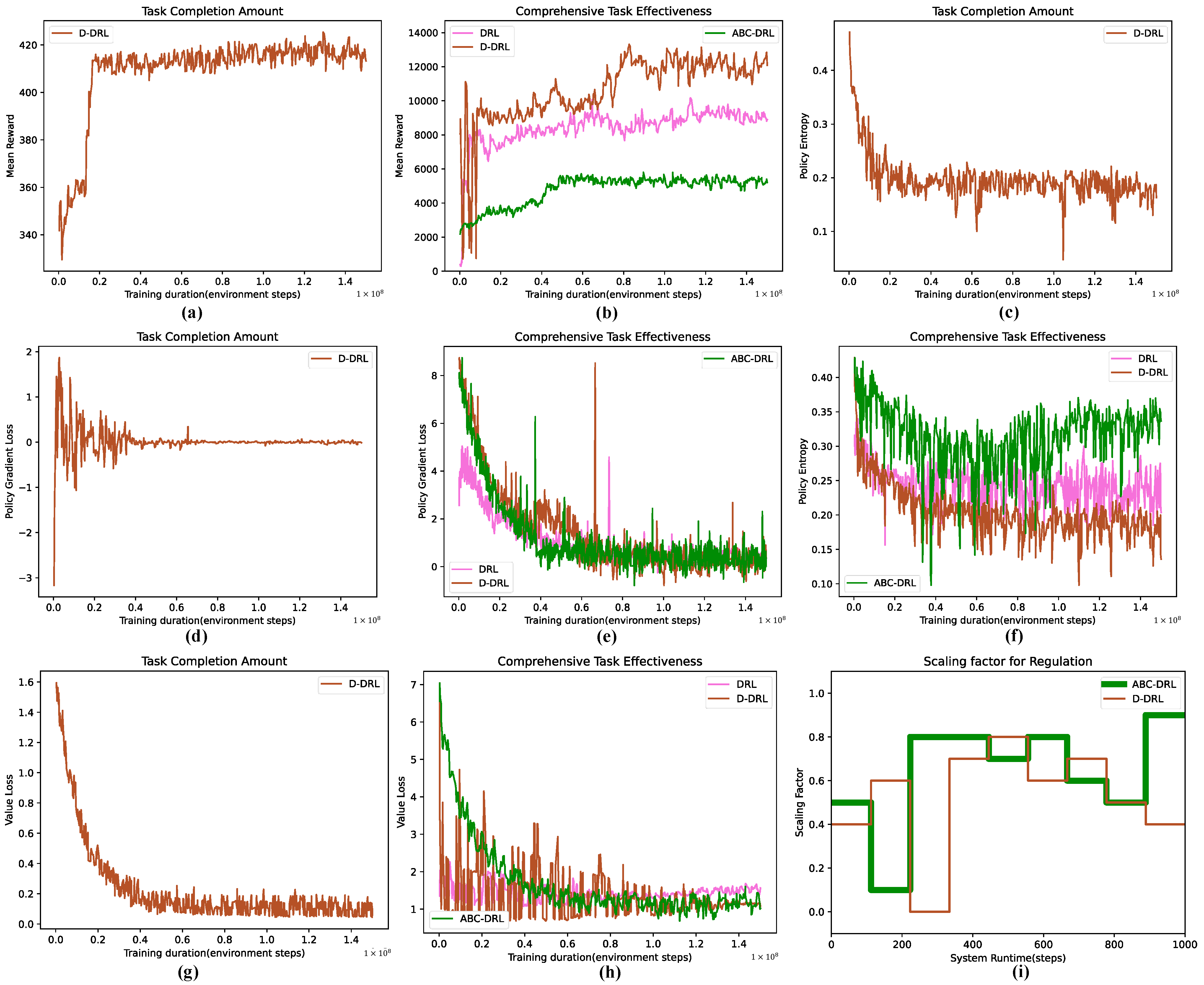
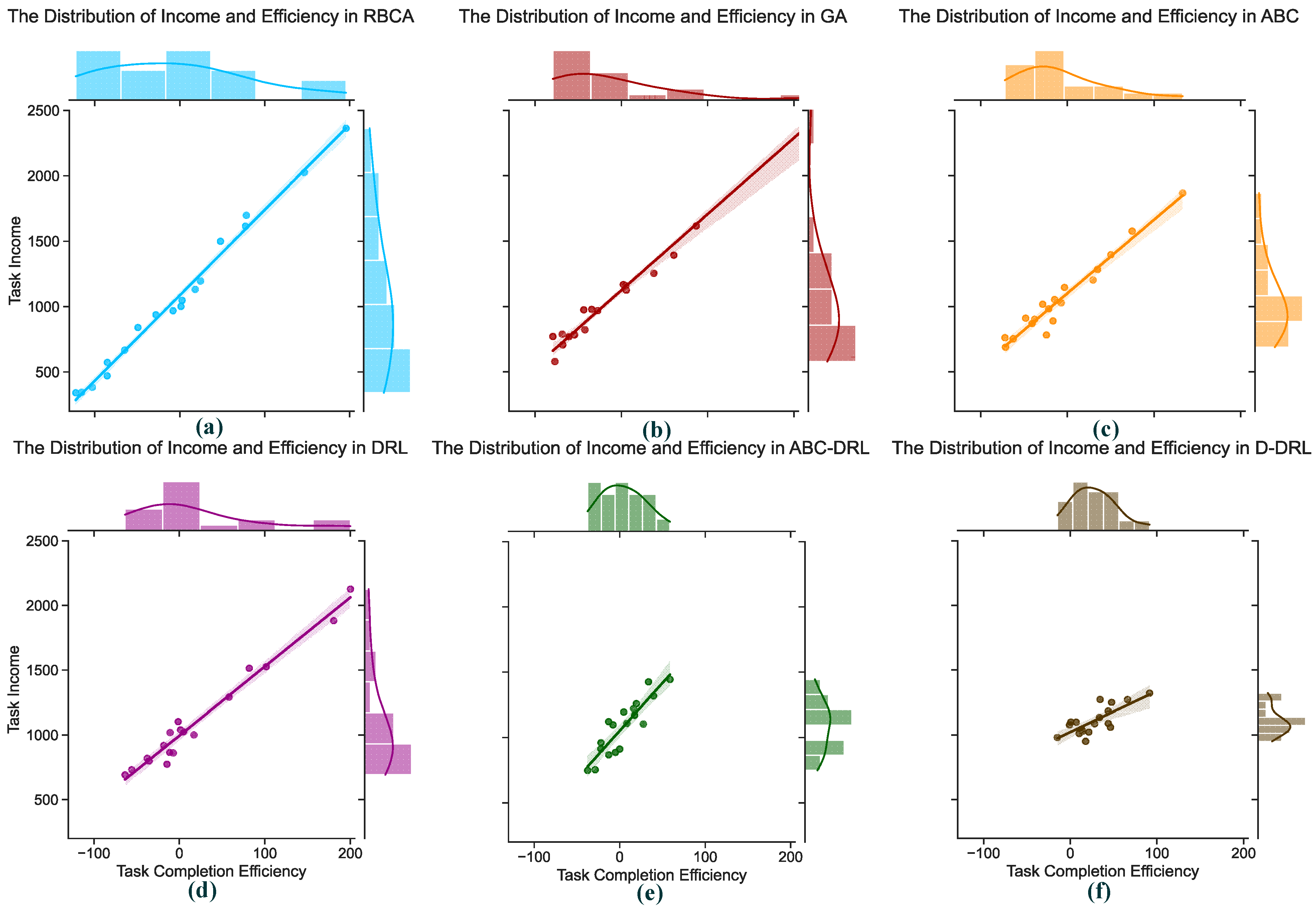
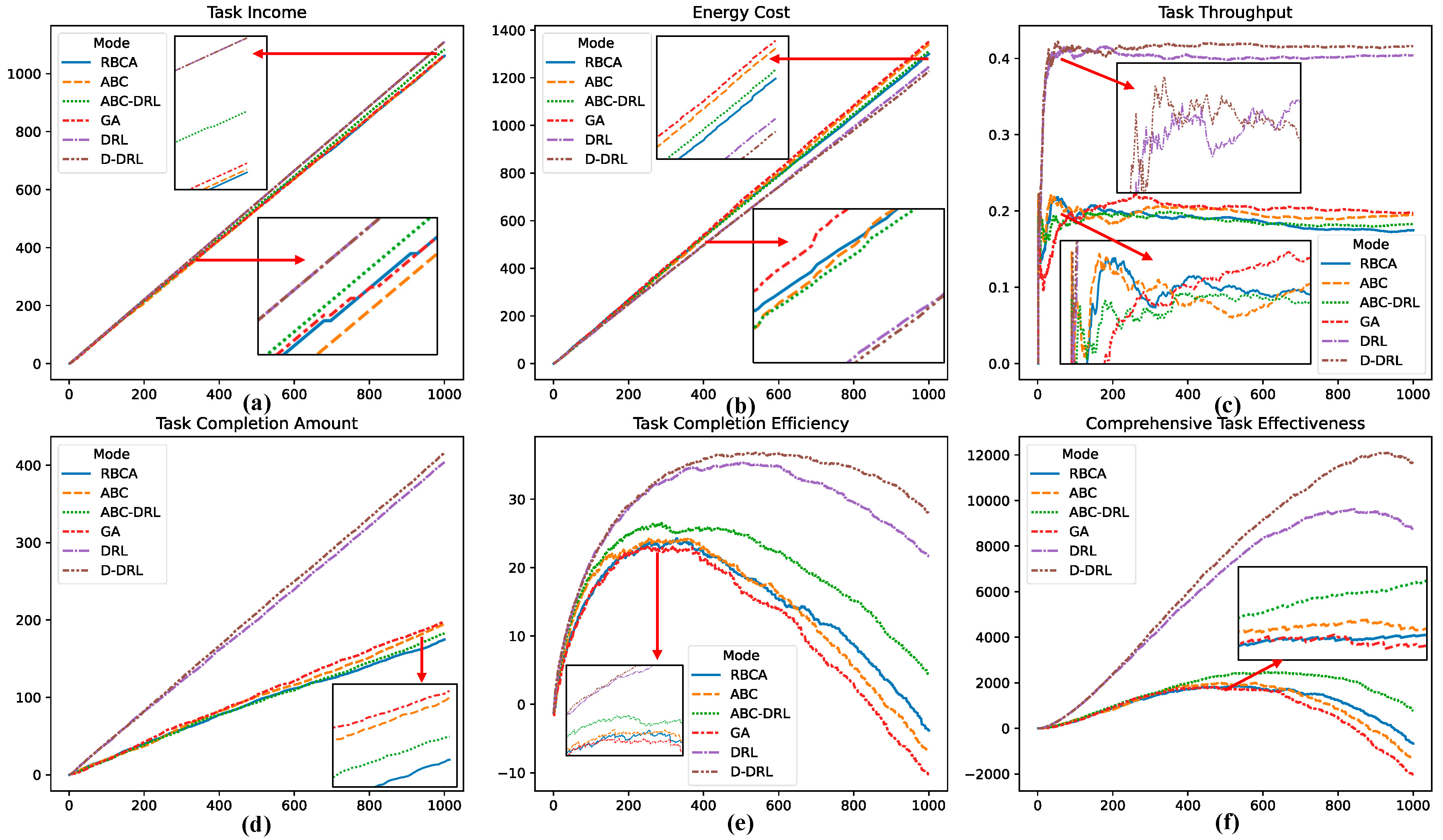
4.3. Experimental Results and Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Perez-Cerrolaza, J.; Abella, J.; Borg, M.; Donzella, C.; Cerquides, J.; Cazorla, F.J.; Englund, C.; Tauber, M.; Nikolakopoulos, G.; Flores, J.L. Artificial Intelligence for Safety-Critical Systems in Industrial and Transportation Domains: A Survey. ACM Comput. Surv. 2024, 56, 1–40. [Google Scholar] [CrossRef]
- Wang, G.-Y.; Cheng, D.-D.; Xia, D.-Y.; Jiang, H.-H. Swarm Intelligence Research: From Bio-Inspired Single-Population Swarm Intelligence to Human-Machine Hybrid Swarm Intelligence. Mach. Intell. Res. 2023, 20, 121–144. [Google Scholar] [CrossRef]
- Senapati, M.K.; Al Zaabi, O.; Al Hosani, K.; Al Jaafari, K.; Pradhan, C.; Ranjan Muduli, U. Advancing Electric Vehicle Charging Ecosystems with Intelligent Control of DC Microgrid Stability. IEEE Trans. Ind. Appl. 2024, 60, 7264–7278. [Google Scholar] [CrossRef]
- Wareham, T.; de Haan, R.; Vardy, A.; van Rooij, I. Swarm Control for Distributed Construction: A Computational Complexity Perspective. ACM Trans. Hum. Robot Interact. 2023, 12, 1–45. [Google Scholar] [CrossRef]
- Katal, A.; Dahiya, S.; Choudhury, T. Energy Efficiency in Cloud Computing Data Centers: A Survey on Software Technologies. Cluster Comput. 2023, 26, 1845–1875. [Google Scholar] [CrossRef]
- Qin, X.; Song, Z.; Hou, T.; Yu, W.; Wang, J.; Sun, X. Joint Optimization of Resource Allocation, Phase Shift, and UAV Trajectory for Energy-efficient RIS-assisted UAV-enabled MEC Systems. IEEE Trans. Green Commun. Netw. 2023, 7, 1778–1792. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, H.; Xie, L.; Liu, J.; Zhang, L.; Yu, J. Swarm Autonomy: From Agent Functionalization to Machine Intelligence. Adv. Mater. 2025, 37, 2312956. [Google Scholar] [CrossRef]
- Cetinsaya, B.; Reiners, D.; Cruz-Neira, C. From PID to Swarms: A Decade of Advancements in Drone Control and Path Planning—A Systematic Review (2013–2023). Swarm Evol. Comput. 2024, 89, 101626. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, J.; He, Z.; Li, Z.; Zhang, Q.; Ding, Z. A Survey of Multi-Agent Systems on Distributed Formation Control. Unmanned Syst. 2024, 12, 913–926. [Google Scholar] [CrossRef]
- Saha, D.; Bazmohammadi, N.; Vasquez, J.C.; Guerrero, J.M. Multiple Microgrids: A Review of Architectures and Operation and Control Strategies. Energies 2023, 16, 600. [Google Scholar] [CrossRef]
- Peng, F.; Zheng, L. Applications. Fuzzy Rule-based Neural Network for High-speed Train Manufacturing System Scheduling Problem. Neural Comput. Appl. 2023, 35, 2077–2088. [Google Scholar] [CrossRef]
- Hatata, A.Y.; Hasan, E.O.; Alghassab, M.A.; Sedhom, B.E. Centralized Control Method for Voltage Coordination Challenges with OLTC and D-STATCOM in Smart Distribution Networks based IoT Communication Protocol. IEEE Access 2023, 11, 11903–11922. [Google Scholar] [CrossRef]
- Meng, Q.; Hussain, S.; Luo, F.; Wang, Z.; Jin, X. An Online Reinforcement Learning-based Energy Management Strategy for Microgrids with Centralized Control. IEEE Trans. Ind. Appl. 2025, 61, 1501–1510. [Google Scholar] [CrossRef]
- Mostaani, A.; Vu, T.X.; Chatzinotas, S.; Ottersten, B. Task-effective Compression of Observations for the Centralized Control of a Multiagent System over Bit-budgeted Channels. IEEE Internet Things J. 2023, 11, 6131–6143. [Google Scholar] [CrossRef]
- Wang, Y.; Xing, L.; Wang, J.; Xie, T.; Chen, L. Multi-objective Rule System Based Control Model with Tunable Parameters for Swarm Robotic Control in Confined Environment. Complex Syst. Model. Simul. 2024, 4, 33–49. [Google Scholar] [CrossRef]
- Guo, F.; Huang, Z.; Wang, L.; Wang, Y. Distributed Event-Triggered Voltage Restoration and Optimal Power Sharing Control for an Islanded DC Microgrid. Int. J. Electr. Power Energy Syst. 2023, 153, 109308. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, Q.; Sun, P.; Feng, X. Distributed Adaptive Fault-Tolerant Control for High-Speed Trains Using Multi-Agent System Model. IEEE Trans. Veh. Technol. 2023, 73, 3277–3286. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Sun, J.; Wang, G.; Chen, J. Data-Driven Consensus Control of Fully Distributed Event-Triggered Multi-Agent Systems. Sci. China Inf. Sci. 2023, 66, 152202. [Google Scholar] [CrossRef]
- Zheng, J.; Ding, M.; Sun, L.; Liu, H. Distributed Stochastic Algorithm Based on Enhanced Genetic Algorithm for Path Planning of Multi-UAV Cooperative Area Search. IEEE Trans. Intell. Transp. Syst. 2023, 24, 8290–8303. [Google Scholar] [CrossRef]
- Han, Z.; Chen, M.; Shao, S.; Wu, Q. Improved Artificial Bee Colony Algorithm-Based Path Planning of Unmanned Autonomous Helicopter Using Multi-Strategy Evolutionary Learning. Aerosp. Sci. Technol. 2022, 122, 107374. [Google Scholar] [CrossRef]
- Song, Y.; Lim, S.; Myung, H.; Lee, H.; Jeong, J.; Lim, H.; Oh, H. Distributed Swarm System with Hybrid-Flocking Control for Small Fixed-Wing UAVs: Algorithms and Flight Experiments. Expert Syst. Appl. 2023, 229, 120457. [Google Scholar] [CrossRef]
- Ibrahim, A.-W.; Fang, Z.; Cai, J.; Hassan, M.H.F.; Imad, A.; Idriss, D.; Tarek, K.; Abdulrahman, A.A.-S.; Fahman, S. Fast DC-Link Voltage Control Based on Power Flow Management Using Linear ADRC Combined with Hybrid Salp Particle Swarm Algorithm for PV/Wind Energy Conversion System. Int. J. Hydrogen Energy 2024, 61, 688–709. [Google Scholar]
- Yakout, A.H.; Hasanien, H.M.; Turky, R.A.; Abu-Elanien, A.E.B. Improved Reinforcement Learning Strategy of Energy Storage Units for Frequency Control of Hybrid Power Systems. J. Energy Storage 2023, 72, 108248. [Google Scholar] [CrossRef]
- Liu, X.; Chai, Z.-Y.; Li, Y.-L.; Cheng, Y.-Y.; Zeng, Y. Multi-Objective Deep Reinforcement Learning for Computation Offloading in UAV-Assisted Multi-Access Edge Computing. Inf. Sci. 2023, 642, 119154. [Google Scholar] [CrossRef]
- Hou, Y.; Zhao, J.; Zhang, R.; Cheng, X.; Yang, L. UAV Swarm Cooperative Target Search: A Multi-Agent Reinforcement Learning Approach. IEEE Trans. Intell. Veh. 2024, 9, 568–578. [Google Scholar] [CrossRef]
- Chen, J.; Zhao, Y.; Wang, M.; Yang, K.; Ge, Y.; Wang, K.; Lin, H.; Pan, P.; Hu, H.; He, Z.; et al. Multi-Timescale Reward-Based DRL Energy Management for Regenerative Braking Energy Storage System. IEEE Trans. Transp. Electrif. 2025. [Google Scholar] [CrossRef]
- Cabuk, U.C.; Tosun, M.; Dagdeviren, O.; Ozturk, Y. Modeling Energy Consumption of Small Drones for Swarm Missions. IEEE Trans. Intell. Transp. Syst. 2024, 25, 10176–10189. [Google Scholar] [CrossRef]
- Laghari, A.A.; Jumani, A.K.; Laghari, R.A.; Nawaz, H. Unmanned aerial vehicles: A review. Cogn. Robot. 2023, 3, 8–22. [Google Scholar] [CrossRef]
- Horyna, J.; Baca, T.; Walter, V.; Albani, D.; Hert, D.; Ferrante, E.; Saska, M. Decentralized Swarms of Unmanned Aerial Vehicles for Search and Rescue Operations without Explicit Communication. Auton. Robot. 2023, 47, 77–93. [Google Scholar] [CrossRef]
- Javed, S.; Hassan, A.; Ahmad, R.; Ahmed, W.; Ahmed, R.; Saadat, A.; Guizani, M. State-of-the-Art and Future Research Challenges in UAV Swarms. IEEE Internet Things J. 2024, 11, 19023–19045. [Google Scholar] [CrossRef]
- Larkin, E.V.; Akimenko, T.A.; Bogomolov, A.V. The Swarm Hierarchical Control System. In International Conference on Swarm Intelligence; Lecture Notes in Computer Science; Springer Nature: Cham, Switzerland, 2023; pp. 30–39. ISBN 9783031366215. [Google Scholar]
- Gu, Y.; Cheng, Y.; Chen, C.L.P.; Wang, X. Proximal Policy Optimization with Policy Feedback. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 4600–4610. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. arXiv 2017, arXiv:1706.02275. [Google Scholar]
- Ye, M.; Han, Q.-L.; Ding, L.; Xu, S. Distributed Nash Equilibrium Seeking in Games with Partial Decision Information: A Survey. Proc. IEEE Inst. Electr. Electron. Eng. 2023, 111, 140–157. [Google Scholar] [CrossRef]
- Barman, S.; Khan, A.; Maiti, A.; Sawarni, A. Fairness and Welfare Quantification for Regret in Multi-Armed Bandits. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 6762–6769. [Google Scholar]
- Stein, A.; Salvioli, M.; Garjani, H.; Dubbeldam, J.; Viossat, Y.; Brown, J.S.; Staňková, K. Stackelberg Evolutionary Game Theory: How to Manage Evolving Systems. Philos. Trans. R. Soc. Lond. B Biol. Sci. 2023, 378, 20210495. [Google Scholar] [CrossRef]
- Liu, F.; Zhang, T.; Zhang, C.; Liu, L.; Wang, L.; Liu, B. A Review of the Evaluation System for Curriculum Learning. Electronics 2023, 12, 1676. [Google Scholar] [CrossRef]
- Makri, S.; Charalambous, P. Curriculum Based Reinforcement Learning for Traffic Simulations. Comput. Graph. 2023, 113, 32–42. [Google Scholar] [CrossRef]
- Bu, Y.; Yan, Y.; Yang, Y. Advancement Challenges in UAV Swarm Formation Control: A Comprehensive Review. Drones 2024, 8, 320. [Google Scholar] [CrossRef]
- Tang, J.; Duan, H.; Lao, S. Swarm Intelligence Algorithms for Multiple Unmanned Aerial Vehicles Collaboration: A Comprehensive Review. Artif. Intell. Rev. 2023, 56, 4295–4327. [Google Scholar] [CrossRef]
- Bai, Y.; Zhao, H.; Zhang, X.; Chang, Z.; Jäntti, R.; Yang, K. Toward Autonomous Multi-UAV Wireless Network: A Survey of Reinforcement Learning-Based Approaches. IEEE Commun. Surv. Tutor. 2023, 25, 3038–3067. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Category | Related Work | Strengths | Weaknesses | Comparison to This Work |
|---|---|---|---|---|
| Centralized Control | Peng et al. [11], Hatata et al. [12], Meng et al. [13], Mostaani et al. [14], Wang et al. [15] | Simplifies decision-making, achieves global optimization | Risk of insufficient optimization capability, single point failure, and processing capacity bottleneck | This work addresses the shortcomings of centralized control by decoupling local and global optimization, enhancing scalability and adaptability in complex scenarios |
| Distributed Control | Guo et al. [16], Guo et al. [17], Li et.al. [18], Zheng et al. [19], Han et al. [20] | Better fault tolerance and autonomy, increases agent decision-making capabilities | Increased decision complexity, load balancing issues, lack of effective information coordination | This work resolves the coordination problem in distributed control by introducing a double-layer architecture for better global optimization |
| Hybrid Control | Song et al. [21], Ibrahim et al. [22], Yakout et al. [23], Liu et al. [24], Hou et al. [25] | Combines the advantages of centralized and distributed control | Higher collaboration complexity, insufficient collaborative optimization capabilities, and reduced control flexibility | This work optimizes the balance between task completion and energy efficiency using a double-layer framework that improves both local and global optimization |
| Symbol | Meaning | Symbol | Meaning |
|---|---|---|---|
| Time | Agent indices | ||
| Agent policy weights | Task completion amount | ||
| Manager policy weights | Collision penalty weight | ||
| Agent action | Task completion efficiency | ||
| Manager action | Comprehensive task effectiveness | ||
| Agent state | Agent income | ||
| Manager state | Energy cost | ||
| Agent observation | Total funds | ||
| Manager observation | The ratio of basic income to performance incentive | ||
| Agent hidden state | The fraction of tasks completed relative to the total tasks | ||
| Manager hidden state | Sampling horizon | ||
| Agent reward | The number of agents | ||
| Manager reward | Degree of nonlinearity | ||
| Agent policy | Safety distance | ||
| Manager policy | Discount factor |
| Algorithm | Architecture | Optimization Goal | Double-Layer Structure | Characteristics/Performance Comparison |
|---|---|---|---|---|
| RBCA [15] | Centralized | Comprehensive task efficiency | Single layer | Suitable for coordinated tasks but lacks flexibility |
| GA [19] | Distributed | Comprehensive task efficiency | Single layer | High randomness, unsuitable for complex searches |
| ABC [20] | Distributed | Comprehensive task efficiency | Single layer | Efficient local search, weaker global optimization |
| DRL [25] | Hybrid | Comprehensive task efficiency | Single layer | Strong learning ability, but incomplete separation of individual and global optimization |
| ABC-DRL [20,26] | Hybrid | Inner: task completion amount; Outer: comprehensive task efficiency | Double layer | Good for individual optimization, but weak in global optimization |
| D-DRL | Hybrid | Inner: task completion amount; Outer: comprehensive task efficiency | Double layer | Combines individual and global optimization, superior performance |
| Category | Variable | Parameter Settings | Origin |
|---|---|---|---|
| Core | Number of UAVs (Region 1: Region 2: Region 3) | 6:6:6 | Industrial UAV system |
| UAV’s vision | |||
| Running Time | 1000 | ||
| UAV’s performance | |||
| Nonlinearity parameter of efficiency | |||
| Single-period revenue | |||
| Secondary | UAV’s energy cost for movement | is the movement distance | [27,28] |
| UAV’s exploration energy cost | [27,28] | ||
| UAV’s completion energy cost | [27,28] | ||
| Task value type | [28,29] | ||
| Task respawn probability | 0.1 | [29,30] | |
| Region 1 task generation rule | [30] | ||
| Region 2 task generation rule | [30] | ||
| Region 3 task generation rule | [30] |
| Category | Variable | Parameter Settings |
|---|---|---|
| General Settings | Reinforcement learning training algorithm | PPO |
| First-stage training steps: second-stage training steps (million) | 150:150 | |
| Training duration (million) | 150 | |
| Second-stage manager strategy annealing duration (million) | 37.5 | |
| Second-stage entropy regularization duration (million) | 70 | |
| Value/Policy networks share weights | False | |
| Discount factor | ||
| Generalized Advantage Estimation discount parameter | 0.98 | |
| GAE lambda | 0.98 | |
| Gradient clipping norm threshold | 10 | |
| Value function loss coefficient | 0.05 | |
| Whether the advantage is normalized | True | |
| SGD sequence length | 50 | |
| Number of parallel environment replicas | 60 | |
| Number of fully connected layers | 2 | |
| Sampling horizon (steps per replica) | 200 | |
| Episode length | 1000 | |
| Episodes | 12,000 | |
| Epochs | 1000 | |
| Activation function | Relu, Softmax | |
| CPU | 16 | |
| Agent Settings | Agent CNN dimension | 128 |
| Agent LSTM unit size | 128 | |
| Entropy regularization coefficient | 0.025 | |
| Agent learning rate | 0.0003 | |
| All agents share weights | True | |
| Number of convolutional layers | 2 | |
| Policy updates per horizon (agents) | 16 | |
| Agent SGD mini-batch size | 3000 | |
| Manager Settings | Policy updates per horizon (manager) | 4 |
| Manager CNN dimension | 256 | |
| Manager LSTM unit size | 256 | |
| Entropy regularization coefficient | 0.2 | |
| Manager learning rate | 0.0001 | |
| Manager SGD mini-batch size | 3000 | |
| Number of convolutional layers | 2 |
| Income | Amount | Cost | Throughput | Efficiency | Effectiveness | |
|---|---|---|---|---|---|---|
| D-DRL | 1111.11 ± 0.00 | 417.77 ± 4.98 | 1229.89 ± 6.29 | 0.42 ± 0.00 | 27.66 ± 1.31 | 11,650.87 ± 457.51 |
| ABC-DRL | 1082.61 ± 4.44 | 186.57 ± 9.27 | 1325.13 ± 20.69 | 0.19 ± 0.01 | 1.55 ± 3.77 | 268.73 ± 698.61 |
| DRL | 1111.11 ± 0.00 | 404.99 ± 2.25 | 1241.00 ± 9.55 | 0.40 ± 0.00 | 22.87 ± 2.20 | 9260.62 ± 884.89 |
| ABC | 1062.44 ± 13.93 | 192.68 ± 13.54 | 1341.52 ± 24.42 | 0.19 ± 0.01 | −8.39 ± 3.26 | −1629.32 ± 691.03 |
| GA | 1050.78 ± 13.85 | 48 ± 13.65 | 1321.32 ± 21.98 | 0.18 ± 0.01 | −6.87 ± 2.59 | −1269.14 ± 538.49 |
| RBCA | 1016.56 ± 14.43 | 159.19 ± 10.04 | 1283.91 ± 18.20 | 0.16 ± 0.01 | −4.24 ± 2.68 | −686.86 ± 453.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, X.; Yu, G.; Huang, G.; Zhou, R.; Hao, L. Design of Swarm Intelligence Control Based on Double-Layer Deep Reinforcement Learning. Appl. Sci. 2025, 15, 4337. https://doi.org/10.3390/app15084337
Yan X, Yu G, Huang G, Zhou R, Hao L. Design of Swarm Intelligence Control Based on Double-Layer Deep Reinforcement Learning. Applied Sciences. 2025; 15(8):4337. https://doi.org/10.3390/app15084337
Chicago/Turabian StyleYan, Xiangpei, Guorui Yu, Guoke Huang, Ruchuan Zhou, and Liu Hao. 2025. "Design of Swarm Intelligence Control Based on Double-Layer Deep Reinforcement Learning" Applied Sciences 15, no. 8: 4337. https://doi.org/10.3390/app15084337
APA StyleYan, X., Yu, G., Huang, G., Zhou, R., & Hao, L. (2025). Design of Swarm Intelligence Control Based on Double-Layer Deep Reinforcement Learning. Applied Sciences, 15(8), 4337. https://doi.org/10.3390/app15084337