
An Evaluation of Mine Water Inrush Based on Data Expansion and Machine Learning


Abstract
1. Introduction
2. Materials and Methods
2.1. Natural Neighbor Theory
| Algorithm 1 Search for NaN (NaN-Search) |
| Input: Water inrush data set X |
| Output: natural neighbors feature λ, natural neighbors NaN, number of inverse neighbors of the sample nb |
| 1: Initialize the search round number r = 1, num = 0 (the number of xi with nb = 0), NNr(xi) = ∅, RNN(xi) = ∅ (xi’s inverse nearest neighbor), NaN(xi) = ⊘; |
| 2: Establish a k-dimensional tree on the water inrush data set X |
| 3: For each xi ∈ X, find its r-th neighbor xj by using k-d tree. Update nb(xj) = nb(xj) + 1, NNr(xi) = NNr(xi) ∪ {xj}, RNN(xj) = RNN(xj) ∪ {xi}; |
| 4: Compute the number num of xi with nb(xi) = 0; |
| 5: If num does not change λ = r; |
| 6: For each xi ∈ X, NaN(xi) = RNN(xi) ∩ NNr(xi); |
| 7: Otherwise r = r + 1, go to step 3; |
| 8: Return: λ, NaN, nb |
2.2. Coal Mine Water Inrush Prediction Model Based on Data Augmentation
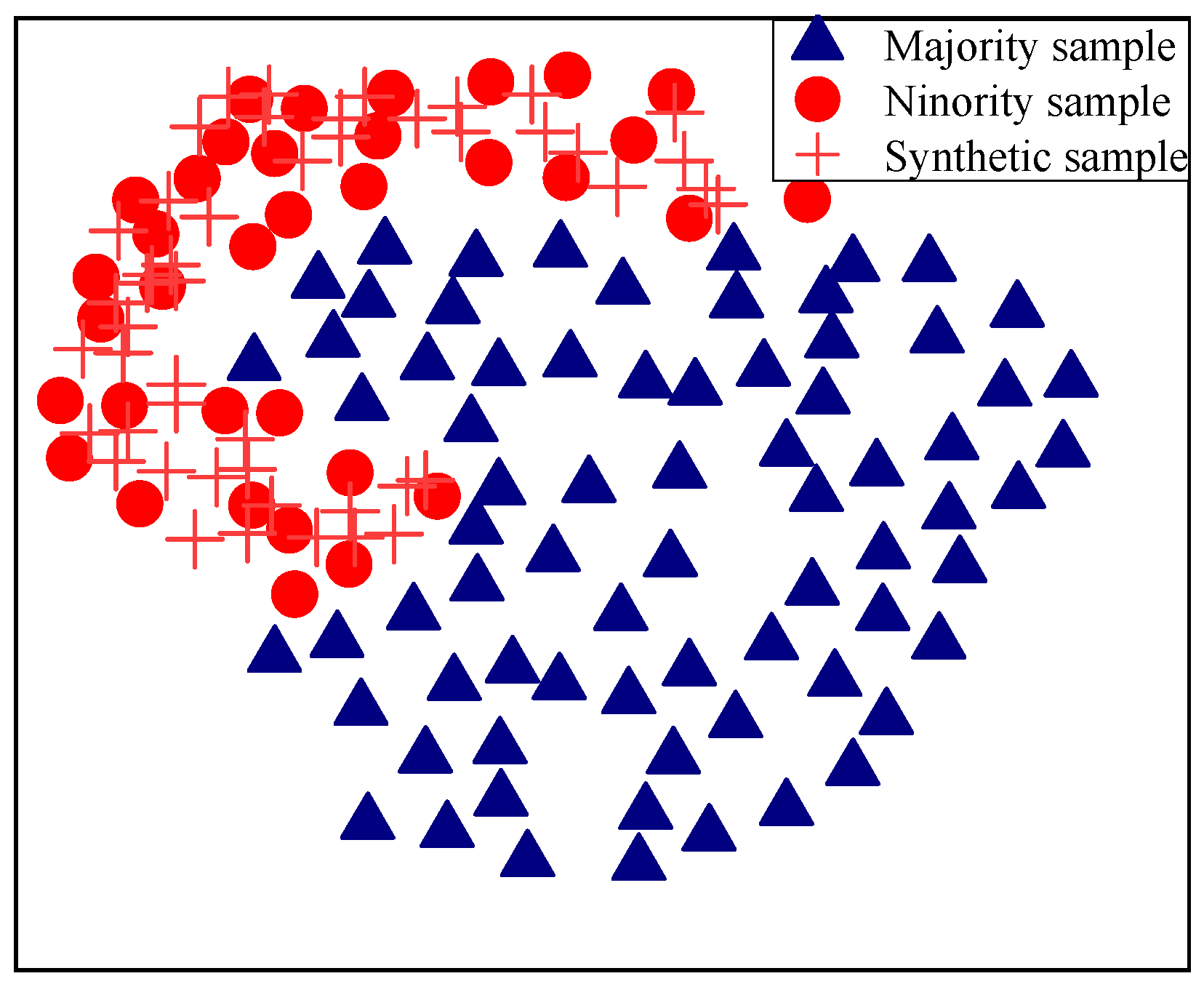
2.3. Natural Neighbor-Based Spatial Interpolation SMOTE
- Assuming that the minority class samples in the sample dataset are {S1, S2, …, Sn}, define K as the chosen hyperparameter (often the difference between the number of majority class data and the number of minority class data);
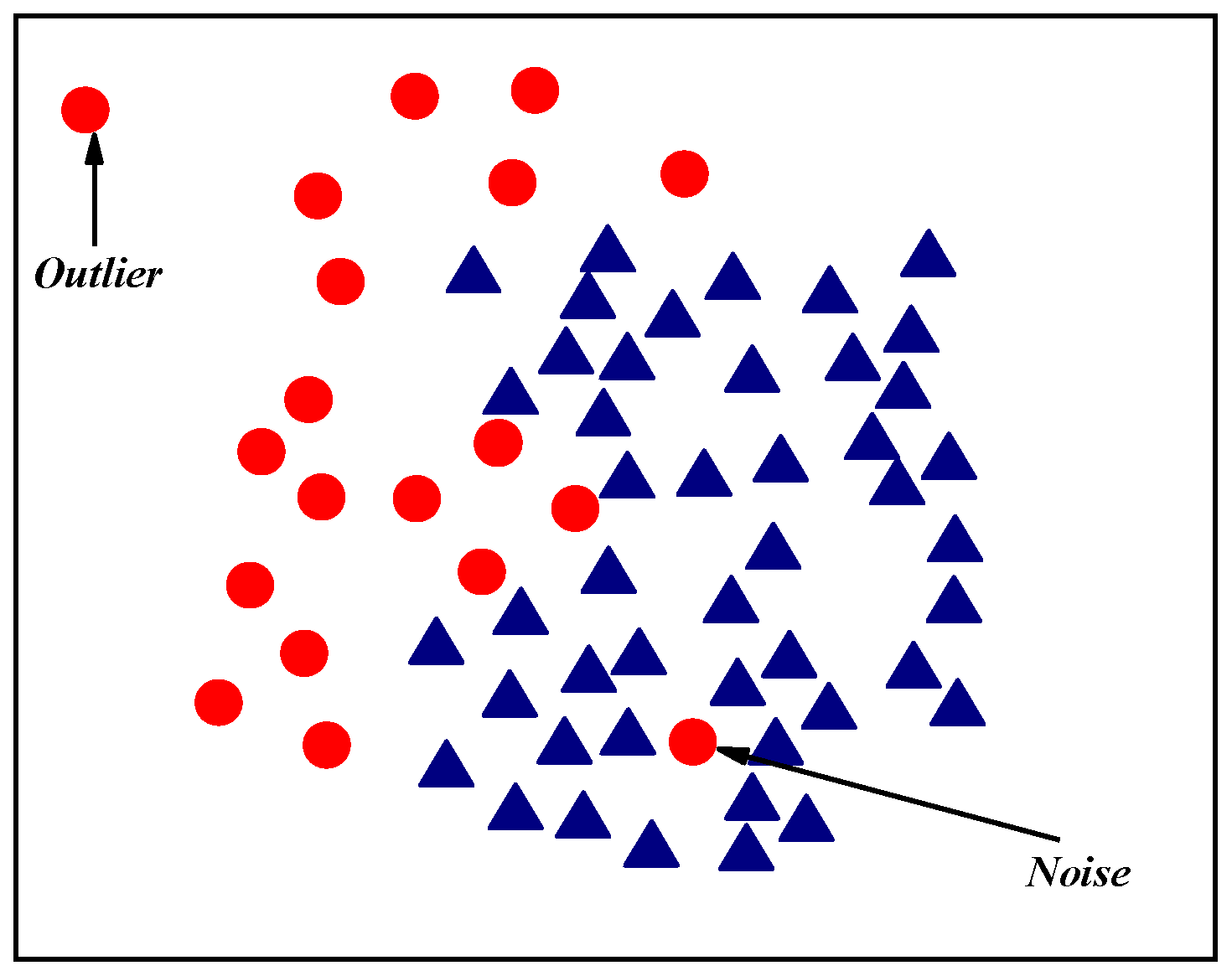
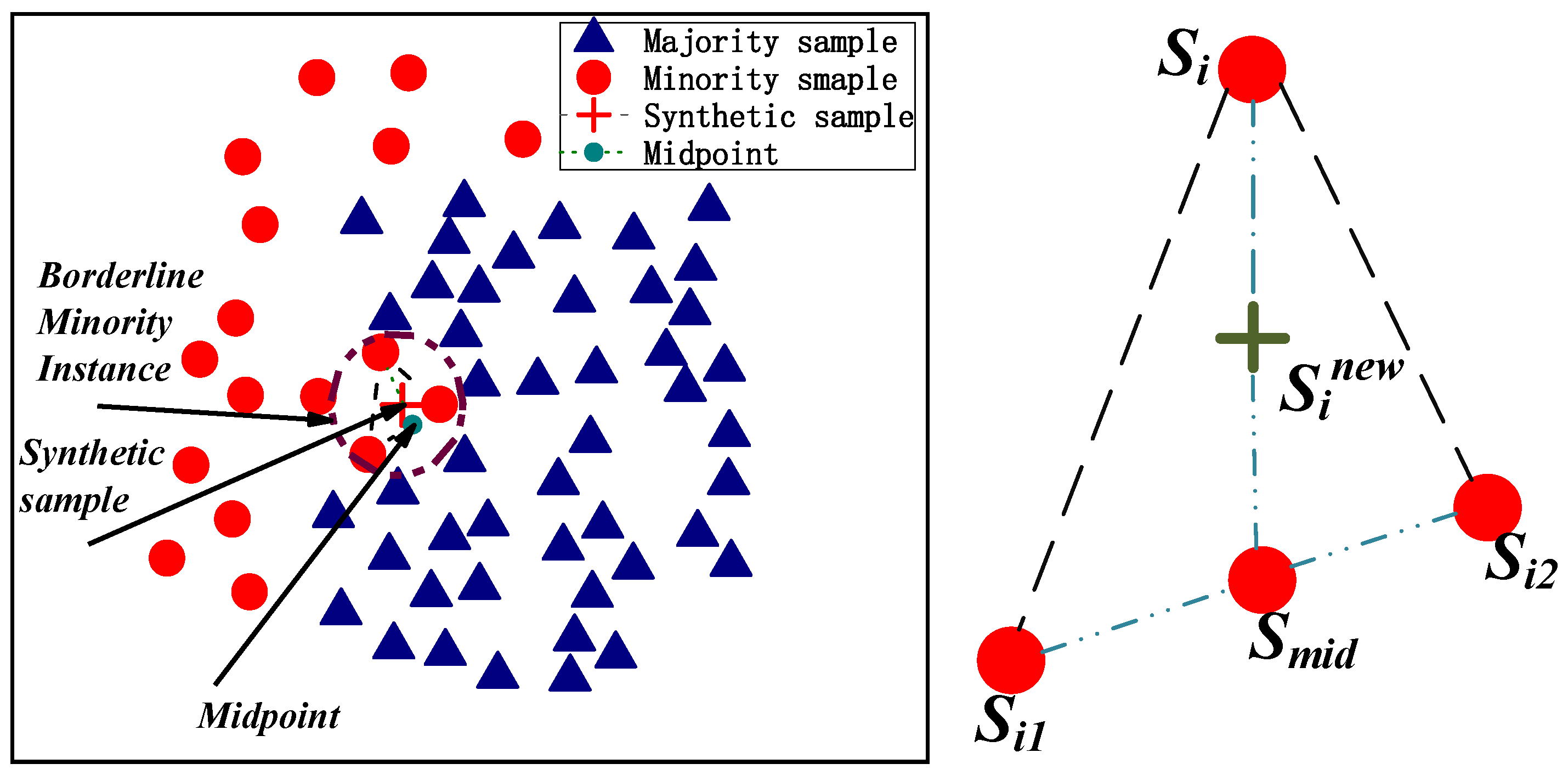
- Determine how many natural neighbors each sample has using the natural neighbor search technique, eliminate noise and outliers, separate a few samples into boundary and safe regions, and establish the edge sample set Si ∈ Danger and the safe sample set Si ∈ Safe;
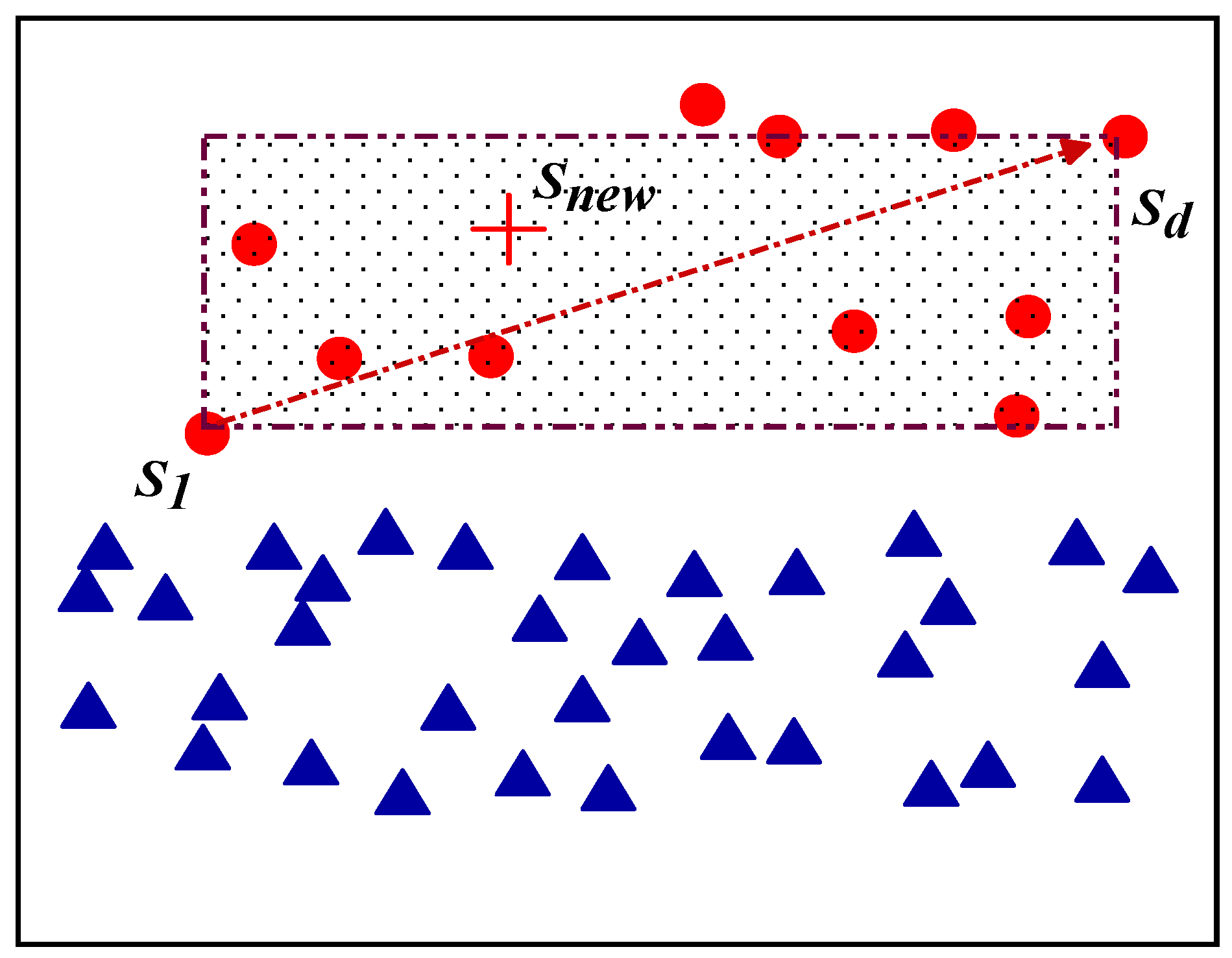
- The spatial interpolation sampling technique suggested in this paper is applied to oversample Si if Si ∈ Safe. If Si ∈ Danger, Si is sampled using the natural nearest intermediate point random interpolation suggested in this research, and a new sample Snew is created.
- Determine the average distance a and b between the majority and minority samples and the composite sample;
- Add the synthetic sample to the dataset if a < b, and remove it if a > b.
- If the number of iterations approaches K, the program terminates; if not, proceed to step (2).
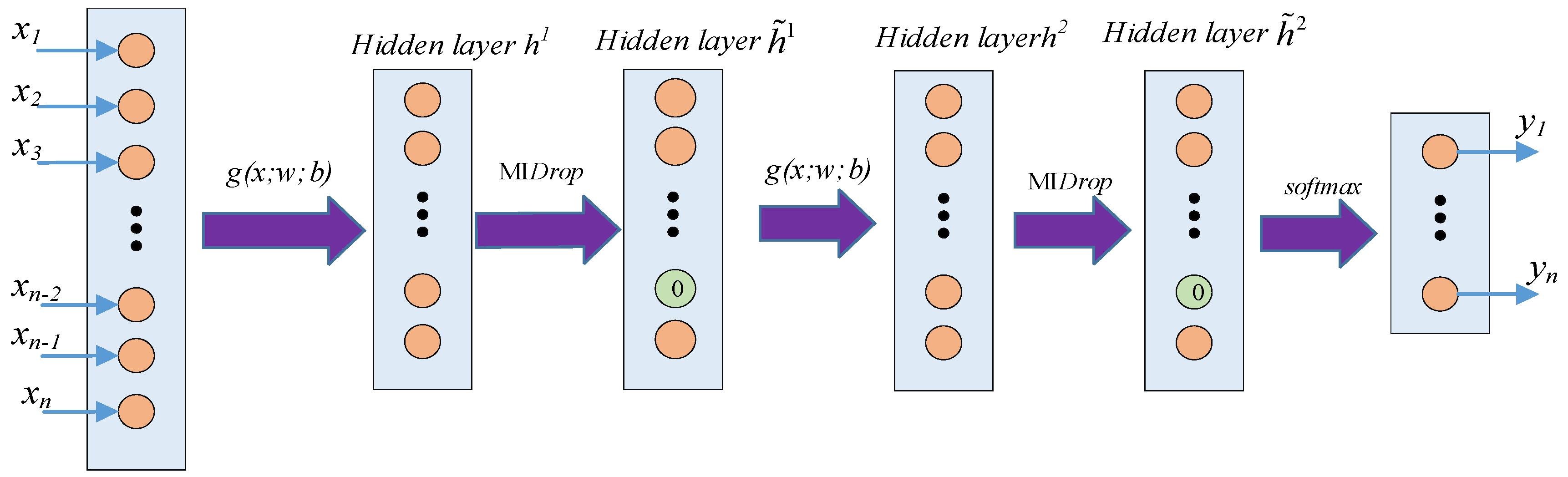
2.4. MISAE
- Feature extraction layer. An autoencoder is used as the feature extraction layer structure, which is defined as g(x; w; b), where x is the input function of the model and w and b are the interlayer weights and bias sizes, respectively, that need to be learned in the SAE model. G() is the feature extractor function constructed by the SAE, which is used to extract hidden features in water inrush data.
- The MI-Dropout layer. In this layer, the neurons in the hidden layer are sorted through mutual information, and a binary mask matrix is constructed to randomly deactivate the neurons in the hidden layer. The output vector of the mutual information drop layer is used as the input of the next feature extraction layer or combined with the softmax layer for model prediction.
- The softmax classification layer is defined as . The structure is shown in Figure 6.
| Algorithm 2 Oversampling Algorithm |
| Input: MISAE model, data set (x, y), oversampling factor N |
| Output: augmented data set |
| 1: Use the data set to train MISAE; |
| 2. Use the trained encoder to map x to the feature space, Z = Encoder(x); |
| 3. The natural neighbors algorithm traverses Z and calculates the number of natural neighbors of all samples in Z; |
| 4. Remove outliers and noise points, divide the remaining data points into center samples and borderline samples, and define the center sample set Safe and the borderline sample set Danger; |
| 5. If z ∈ Safe, use the spatial interpolation sampling method proposed in the article to oversample zi; if z ∈ Danger, use the random intermediate point interpolation proposed in the article to sample zi and synthesize N new samples Znew; |
| 6. Use the trained decoder to map [Z, Znew] to the original space, and the reconstructed sample set is ; |
| 7. Output the expanded water inrush sample set {} |
3. Results and Discussions
3.1. Water Inrush Dataset Experiment
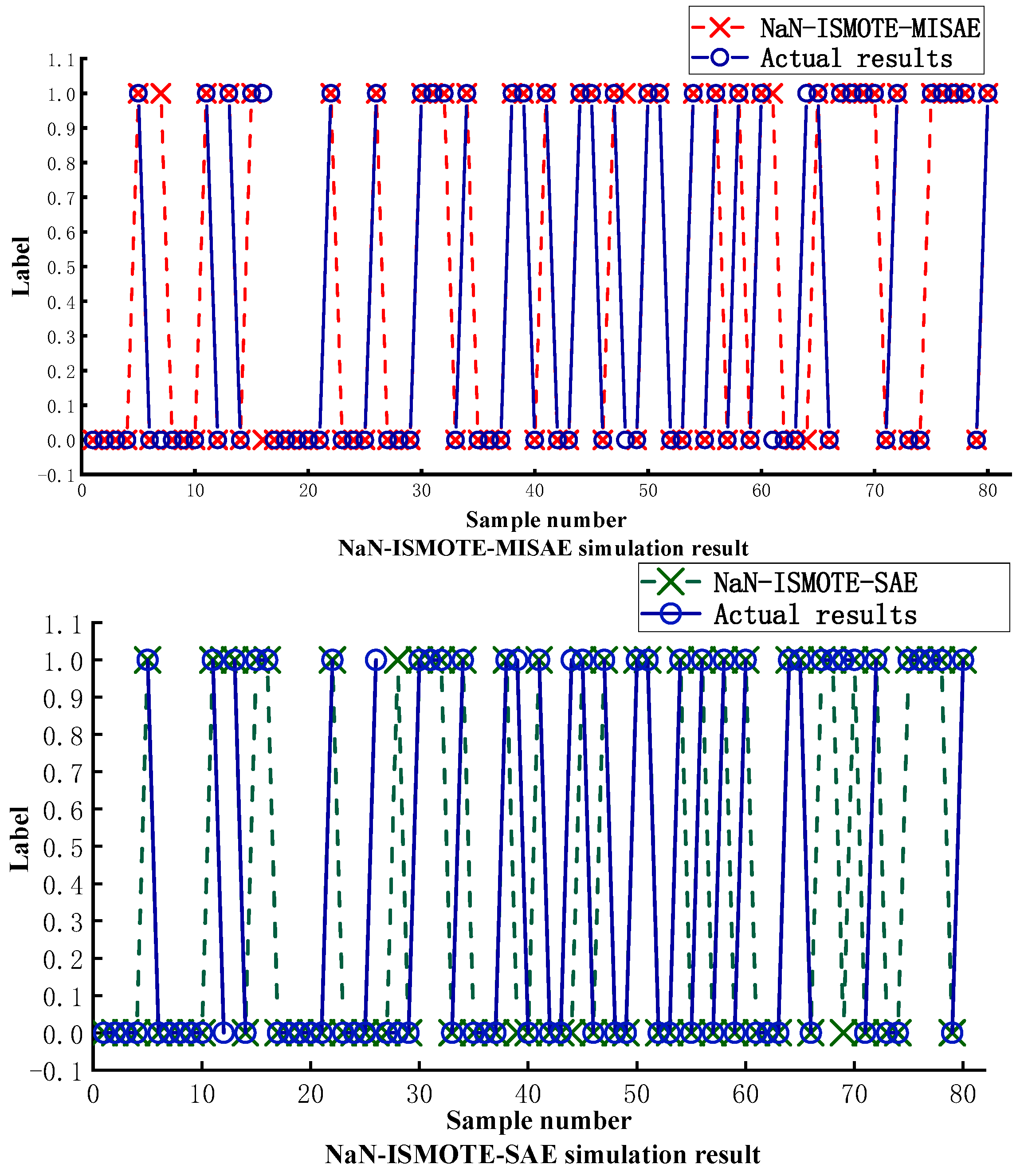
3.2. NaN-ISMOTE-MISAE Algorithm Ablation Experiment
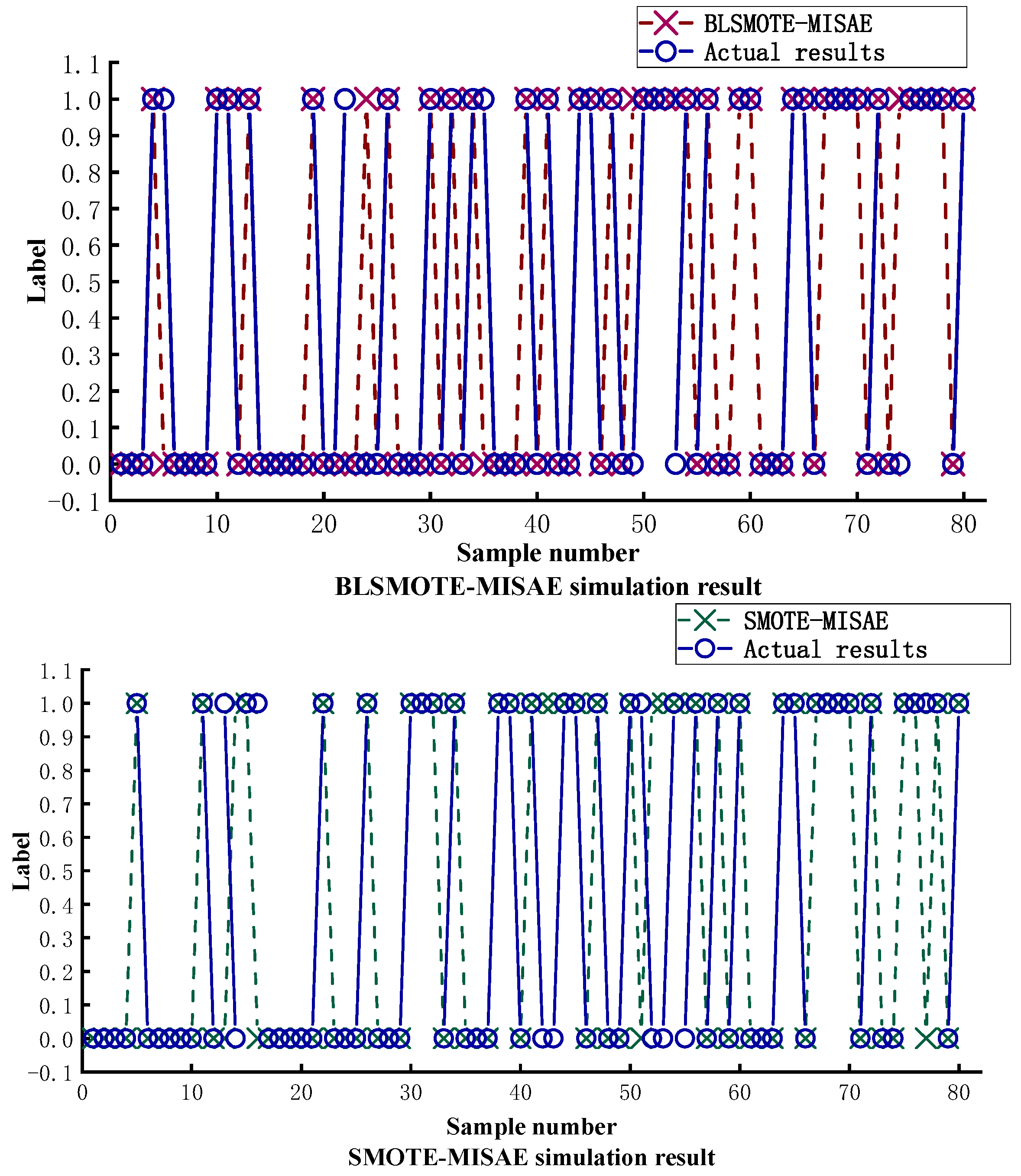
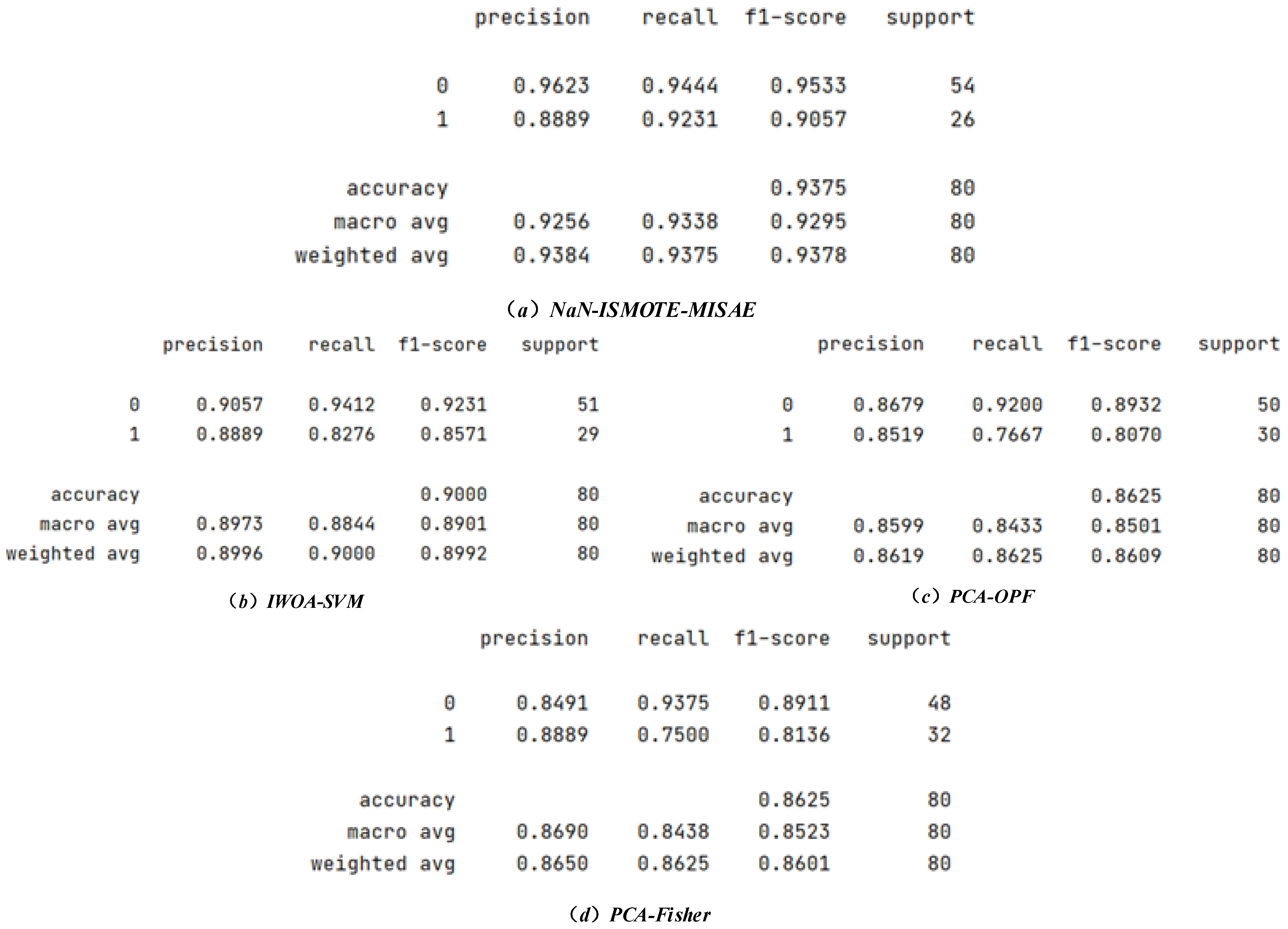
3.3. Comparison Between the NaN-ISMOTE-MISAE Algorithm and Water Inrush Prediction Algorithms in Recent Years
4. Conclusions
- The pseudo-label approach still has the flaw of having a fuzzy boundary between positive and negative data, as well as noise in the expansion of water-inrushing data. While this problem is somewhat resolved by the improved approach shown in this paper, it remains unresolved. In the subsequent research, the field of floor water inrush may be subjected to novel data-generating methods, such as GAN networks, and the data may undergo preprocessing and subsequent prediction.
- The majority of current data-based modeling techniques focus on static data and ignore the water inrush accident’s dynamic process. To improve the integrity and diversity of the floor water inrush dataset, future work must take into account the time dynamics of the data and collaborate with coal mines to collect time period series data of mine water inrush control factors during data collection.
- The control factors of water inrush in mine floor will change with the process of coal mining. The existing algorithms mainly focus on the study of constant weight statistics, and the model parameters can be updated in real time in future work through the variable weight mechanism.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shi, L.Q.; Han, J. Floor Water Inrush Mechanism and Prediction; China University of Mining and Technology Press: Xuzhou, China, 2004. [Google Scholar]
- Du, C.L.; Zhang, X.Y.; Li, F. Application of improved CART algorithm in prediction of water inrush from coal seam floor. Ind. Mine Autom. 2014, 40, 52–56. [Google Scholar] [CrossRef]
- Liu, W.T.; Liao, S.H.; Liu, S.L.; Liu, H. Principal component logistic regression analysis in application of water outbursts from coal seam floor. J. Liaoning Tech. Univ. 2015, 34, 905–909. [Google Scholar]
- Liu, Z.; Jin, D.; Liu, Q. Prediction of water inrush from seam floor based on binomial logistic regression model and CART tree. Coal Geol. Explor. 2009, 37, 56–61. [Google Scholar]
- Liu, Z.; Jin, D.; Liu, Q. Prediction of water inrush through coal floors based on data mining classification technique. Procedia Earth Planet. Sci. 2011, 3, 166–174. [Google Scholar] [CrossRef]
- Shi, L.; Gao, W.; Han, J.; Tan, X. A nonlinear risk evaluation method for water inrush through the seam floor. Mine Water Environ. 2017, 36, 597–605. [Google Scholar] [CrossRef]
- Cao, Q.K.; Zhao, F. Prediction of water inrush from coal floor based on genetic-support vector regression. J. Coal 2011, 36, 2097–2101. [Google Scholar]
- Yan, Z.G.; Bai, H.B.; Zhang, H.R. A novel SVM model for the analysis and prediction of water inrush from coal mine. China Saf. Sci. J. 2008, 18, 166–170. [Google Scholar] [CrossRef]
- Qiao, Y.F. Application Research of Genetic Algorithm and Artificial Neural Networks in the Prediction of Mine Water Gushing-out. Master’s Thesis, Xi’an University of Architecture and Technology, Xi’an, China, 2010. (In Chinese). [Google Scholar]
- Zhao, Z.; Hu, M. Multi-level forecasting model of coal mine water inrush based on self-adaptive evolutionary Extreme learning machine. Appl. Math. Inf. Sci. Lett. 2014, 2, 103–110. [Google Scholar] [CrossRef]
- Zhao, Z.; Li, P.; Xu, X. Forecasting model of coal mine water inrush based on extreme learning machine. Appl. Math. Inf. Sci. 2013, 7, 1243–1250. [Google Scholar] [CrossRef]
- Shi, L. Analysis of water inrush coefficient and its applicability. J. Shandong Univ. Sci. Technol. 2012, 31, 6–9. [Google Scholar] [CrossRef]
- Zhao, D.; Wu, Q.; Cui, F.; Xu, H.; Zeng, Y.; Cao, Y.; Du, Y. Using random forest for the risk assessment of coal-floor water inrush in Panjiayao Coal Mine, northern China. Hydrogeol. J. 2018, 26, 2327–2340. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Li, J.; Zhu, Q.; Wu, Q.; Fan, Z. A novel oversampling technique for class-imbalanced learning based on SMOTE and natural neighbors. Inf. Sci. 2021, 565, 438–455. [Google Scholar] [CrossRef]
- Leng, Q.; Guo, J.; Jiao, E.; Meng, X.; Wang, C. NanBDOS: Adaptive and parameter-free borderline oversampling via natural neighbor search for class-imbalance learning. Knowl.-Based Syst. 2023, 274, 110665. [Google Scholar] [CrossRef]
- Li, J.; Zhu, Q.; Wu, Q.; Zhang, Z.; Gong, Y.; He, Z.; Zhu, F. SMOTE-NaN-DE: Addressing the noisy and borderline examples problem in imbalanced classification by natural neighbors and differential evolution. Knowl.-Based Syst. 2021, 223, 107056. [Google Scholar] [CrossRef]
- Xu, Z.; Shen, D.; Kou, Y.; Nie, T. A synthetic minority oversampling technique based on Gaussian mixture model filtering for imbalanced data classification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 3740–3753. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F. Geometric smote a geometrically enhanced drop-in replacement for smote. Inf. Sci. 2019, 501, 118–135. [Google Scholar] [CrossRef]
- Susan, S.; Kumar, A. Ssomaj-smote-ssomin:Three-step intelligent pruning of majority and minority samples for learning from imbalanced datasets. Appl. Soft Comput. 2019, 78, 141–149. [Google Scholar] [CrossRef]
- Huang, H.; Wang, J.M. Research on water inrush from the blind fault of coal floor by physical experiment. J. North China Inst. Sci. Technol. 2015, 12, 11–16. [Google Scholar]
- Liu, D.; Zhong, S.; Lin, L.; Zhao, M.; Fu, X.; Liu, X. Deep attention SMOTE: Data augmentation with a learnable interpolation factor for imbalanced anomaly detection of gas turbines. Comput. Ind. 2023, 151, 103972. [Google Scholar] [CrossRef]
- Soltanzadeh, P.; Hashemzadeh, M. RCSMOTE: Range-controlled synthetic minority over-sampling technique for handling the class imbalance problem. Inf. Sci. 2021, 542, 92–111. [Google Scholar] [CrossRef]
- Wahid, A.; Annavarapu, C.S.R. NaNOD: A natural neighbour-based outlier detection algorithm. Neural Comput. Appl. 2020, 33, 2107–2123. [Google Scholar] [CrossRef]
- Elreedy, D.; Atiya, A.F. A comprehensive analysis of synthetic minority oversampling technique (SMOTE) for handling class imbalance. Inf. Sci. 2019, 505, 32–64. [Google Scholar] [CrossRef]
- Pan, T.; Zhao, J.; Wu, W.; Yang, J. Learning imbalanced datasets based on SMOTE and Gaussian distribution. Inf. Sci. 2020, 512, 1214–1233. [Google Scholar] [CrossRef]
- Chen, L.; Yuan, M.; Xiang, W. Application of Pca-Fisher Discriminant Model in Prediction of Water Inrush from Coal Seam Floor. J. Math. Pract. Theory 2021, 51, 9. [Google Scholar]
- Jiang, Z.H.; Yuan, Z.G.; Xie, D.H. Prediction of Coal Seam Floor Water Inrush Based on PCA-OPF Model. Miner. Eng. Res. 2021, 36, 6. [Google Scholar]
- Qiu, X.G.; Li, J. Prediction model of water inrush in coal mine based on IWOA-SVM. Ind. Min. Autom. 2022, 48, 7. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| First-Level Indicators | Secondary-Level Indicators |
|---|---|
| Aquifer conditions | Aquifer thickness |
| Aquifer water pressure | |
| Working surface distance | |
| Water barrier conditions | Muddy rock thickness |
| Sandy rock thickness | |
| Limestone section thickness | |
| Coal seam conditions | Coal seam thickness |
| Coal seam dip | |
| Construction conditions | Fault drop |
| Mining conditions | Mining area |
| Strike length | |
| Mining height |
| ISMOTE | SMOTE | B-SMOTE | ADASYN | |
|---|---|---|---|---|
| Ar1 | 0.8917 ± 0.015 | 0.8153 ± 0.0141 | 0.8424 ± 0.011 | 0.8601 ± 0.009 |
| Ar5 | 0.8818 ± 0.016 | 0.8251 ± 0.005 | 0.8478 ± 0.075 | 0.8798 ± 0.012 |
| Segment1 | 0.905 ± 0.004 | 0.895 ± 0.011 | 0.835 ± 0.030 | 0.870 ± 0.027 |
| Ecoli3 | 0.895 ± 0.003 | 0.8172 ± 0.044 | 0.8413 ± 0.004 | 0.8617 ± 0.023 |
| Ecoli4 | 0.892 ± 0.017 | 0.913 ± 0.001 | 0.906 ± 0.003 | 0.891 ± 0.005 |
| Year1-2-8-9v7 | 0.9127 ± 0.007 | 0.8687 ± 0.0015 | 0.8814 ± 0.0018 | 0.8958 ± 0.005 |
| Bank | 0.939 ± 0.021 | 0.8975 ± 0.014 | 0.906 ± 0.008 | 0.9204 ± 0.006 |
| Abalone5-19 | 0.9482 ± 0.02 | 0.8757 ± 0.017 | 0.909 ± 0.022 | 0.9226 ± 0.008 |
| Glass1 | 0.8531 ± 0.006 | 0.7226 ± 0.009 | 0.791 ± 0.033 | 0.837 ± 0.012 |
| Abalone19 | 0.9027 ± 0.002 | 0.8702 ± 0.017 | 0.873 ± 0.013 | 0.8937 ± 0.002 |
| NaN-ISMOTE-MISAE | NaN-ISMOTE-SAE | BLSMOTE-MISAE | SMOTE-MISAE | |
|---|---|---|---|---|
| Accuracy | 0.9375 | 0.9125 | 0.9 | 0.8750 |
| Recall | 0.9524 | 0.9259 | 0.9245 | 0.9057 |
| F1 Score | 0.9362 | 0.9346 | 0.9245 | 0.9057 |
| NaN-ISMOTE-MISAE | IWOA-SVM | PCA-OPF | PCA-Fisher | |
|---|---|---|---|---|
| Accuracy | 0.9375 | 0.9000 | 0.8625 | 0.8625 |
| Recall | 0.9444 | 0.9412 | 0.9200 | 0.9375 |
| F1 Score | 0.9533 | 0.9231 | 0.8932 | 0.8911 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Tang, S. An Evaluation of Mine Water Inrush Based on Data Expansion and Machine Learning. Appl. Sci. 2025, 15, 4229. https://doi.org/10.3390/app15084229
Zhang Y, Tang S. An Evaluation of Mine Water Inrush Based on Data Expansion and Machine Learning. Applied Sciences. 2025; 15(8):4229. https://doi.org/10.3390/app15084229
Chicago/Turabian StyleZhang, Ye, and Shoufeng Tang. 2025. "An Evaluation of Mine Water Inrush Based on Data Expansion and Machine Learning" Applied Sciences 15, no. 8: 4229. https://doi.org/10.3390/app15084229
APA StyleZhang, Y., & Tang, S. (2025). An Evaluation of Mine Water Inrush Based on Data Expansion and Machine Learning. Applied Sciences, 15(8), 4229. https://doi.org/10.3390/app15084229