1. Introduction
A growing number of researchers are directing their attention towards the field of object classification due to its excellent potential for practical applications. Autonomous driving [
1], for instance, facilitates vehicles in making accurate driving decisions through the detection and classification of traffic signs. Image retrieval [
2] is enhanced by identifying and classifying image content, resulting in improved retrieval efficiency. Security monitoring [
3] involves the process of detecting, recognizing, and categorizing individuals or items that are deemed suspicious to ensure public safety. Medical imaging [
4] is used by clinicians to classify and diagnose lesions. Agricultural applications [
5] involve the identification and classification of field crops, as well as the detection of the growth of crops.
With the continuous development of machine learning, single-modal target classification technologies have also advanced rapidly. Deep learning has revolutionized the field of target classification through its end-to-end feature learning mechanism. In image classification, Convolutional Neural Networks (CNNs) [
6] automatically extract hierarchical features (from edge textures to semantic information) through multiple layers of non-linear transformations. Models such as ResNet [
7], EfficientNet [
8], and VGG [
9] have surpassed human classification accuracy on the ImageNet dataset, significantly improving classification efficiency. In the field of sound classification, end-to-end models based on Recurrent Neural Networks (RNNs) and Transformers (such as WaveNet [
10]) can directly learn the temporal dependencies from raw audio signals, exhibiting stronger capabilities in sound classification. The core breakthrough of deep learning lies in eliminating the bottleneck of manual feature design by obtaining more essential feature representations through data-driven methods and improving overall performance by jointly optimizing feature extraction and classification processes. However, single-modal deep learning target classification has significant limitations. First, its semantic representation is incomplete, as a single modality can only capture partial attributes of the target. Second, it is highly sensitive to the environment, with a single modality being susceptible to interference from other data sources (e.g., visual models affected by lighting changes, speech models sensitive to background noise). Third, it has weak generalization with small sample sizes, and model performance significantly degrades when data for a single modality is scarce.
The rapid development of multimodal fusion technology [
11,
12,
13] can be attributed to several key factors. First, multimodal fusion technology enables a more accurate description of the same entity through different modalities. Second, multimodal fusion technology can fully utilize the correlated information between modalities when classifying objects, thus complementing each other to classify the same object. Third, in multimodal fusion technology, if one modality’s information is missing or incomplete, the robust nature of multimodal fusion ensures that the system remains stable and operates without being affected. Multimodal fusion effectively overcomes the bottleneck of single-modal classification by leveraging the synergistic complementarity of heterogeneous data. Firstly, joint learning of vision and hearing can mutually correct environmental interference (e.g., using emotional features to compensate for noise in speech classification [
14]). Secondly, multimodal pre-training constructs a unified semantic space through cross-modal alignment, enhancing fine-grained classification capabilities (e.g., combining pathological images and clinical text to improve disease diagnosis accuracy [
15]). Moreover, through feature sharing between modalities (e.g., fusion of infrared and visible light images [
16]), the reliance on labeled data from a single modality is reduced.
Despite the widespread application of multimodal fusion classification technologies [
17,
18,
19,
20,
21], during the complementary process of cross-modal data fusion, the heterogeneity generated due to the distinct semantic characteristics of each modality can lead to insufficient feature information in the fused data. To address the heterogeneity issue in multimodal data fusion, this paper proposes an audiovisual fusion-based target classification framework. The innovations of this paper are as follows.
(1) The transformation method is used to convert the one-dimensional sequence of sound, which is transformed into a two-dimensional discrete sound spectrogram. This process visually visualizes the sound and obtains a more stable sound signal. Additionally, it solves the problem of the ineffective fusion of one-dimensional sound sequence and two-dimensional image sequence, enhances the complementary ability of sound and image, and improves the accuracy of object classification.
(2) Under the condition of dual-channel input of sound and images, this study combines Convolutional Neural Networks (CNNs) with feature-level fusion. To address the misalignment issue between spectrograms and images during the fusion process, this paper introduces a self-attention mechanism module during feature fusion. This approach utilizes a weighted method to resolve the heterogeneity between the spectrogram and image fusion.
2. Related Work
2.1. Single-Modal Target Classification
Image classification, as a popular research topic in the field of computer vision, has developed rapidly in recent years. It employs a series of complex algorithms and models to deeply analyze various features in images, such as color, texture, shape, and edges, thereby accurately extracting the core information of the image. This information is then processed and transformed into a form that machines can understand and process. For example, in the ImageNet challenge in 2012, the introduction of the AlexNet model [
22] achieved an overwhelming victory. Its network structure significantly improved the accuracy of image classification and solved the problems of gradient vanishing and overfitting during model training in deep learning. Subsequently, the introduction of GoogLeNet [
23], VGG [
9], and ResNet [
7] accelerated progress in the field of image classification. They all optimized the network structure to enhance the model’s ability to process images and improve its classification accuracy. In 2020, Google proposed Vision Transformer (ViT) [
24], which achieved end-to-end modeling of high-resolution images through a global attention mechanism, significantly enhancing the performance of image classification tasks. In 2025, YJ Ban [
25] introduced the DINOv2 model, which employs self-supervised learning strategies to extract universal visual features without labeled data, significantly improving the adaptability of cross-domain image classification.
Sound classification, another research hotspot in the field of target classification, has also been widely explored by researchers. Sound signals possess unique spatiotemporal features that can provide effective information in complex environments. Therefore, extracting and analyzing these features has become the key to research. Deep learning models, trained on large-scale data, can learn more robust feature representations, thereby demonstrating higher robustness in complex environments with noise, accents, and varying speech rates. In 2019, Qiuqiang Kong [
26] and others proposed a large-scale pre-trained audio neural network (PANNS) for audio pattern classification. This method introduced the Wavegram–Log-Mel–CNN architecture, which combines log-mel spectrograms and waveforms as input features, significantly enhancing the performance of audio pattern classification. In 2020, Benjamin Desplanques [
27] and others proposed the ECAPA_TDNN method, which introduced the Squeeze-and-Excitation (SE) module to enhance the model’s ability to focus on important feature channels and aggregate features from multiple layers. By leveraging complementary information from different levels, this method improved the model’s feature representation capability and enhanced sound classification performance.
Despite the significant breakthroughs achieved in sound classification through deep learning, monomodal sound classification exhibits poor robustness in complex environments. Moreover, under the interference of noise, deep learning-based sound classification techniques may fail to classify targets. In the field of deep learning-based image classification, reliance on large-scale data annotation and extensive model training is significant. Additionally, under conditions of varying lighting and target occlusion, robustness tends to decline, leading to a substantial decrease in the accuracy of image target classification. Therefore, to enhance classification robustness, it is necessary to introduce other modalities to assist in target classification.
2.2. Multimodal Target Classification
Multimodal fusion object detection (Multi-modal Fusion Object Detection) is a direction based on the fusion of multimodal data. It is one of the important research directions in the field of computer vision in recent years [
28]. With the continuous improvement of computing power and sensor technology, multimodal data processing has progressed from monomodal object classification to multimodal object classification in the current environment. Multimodal fusion object detection technology can combine different data structures, fully utilize the complementary relationship between data, better understand the environment comprehensively, and improve the accuracy and robustness of object classification.
In recent years, deep learning has played a key role in multimodal fusion object detection. In 2021, Xu et al. proposed a multimodal fusion framework based on Transformer, which effectively fused image and LiDAR data through self-attention mechanisms [
29]. This method performed excellently in object detection tasks in autonomous driving scenarios, significantly improving classification accuracy and speed. Aligning and fusing cross-modal features is one of the core challenges in multimodal fusion object detection. In 2024, K. Islam et al. proposed a joint enhancement method for multimodal data [
30], which reduced the information loss between different modalities through collaborative enhancement at the data level. This method performed particularly well in complex environments such as low light and occlusion. In 2025, Chen et al. further improved the Transformer model [
31] and proposed a multi-scale multimodal fusion network (Multi-scale Multi-modal Fusion Network, MMFN). This network can perform feature fusion at different scales, thereby better capturing the details and contextual information of objects.
Despite the progress made in multimodal fusion object detection in the above cases, there are still problems to be solved in object detection. For example, when describing the same object, different modalities often have significant semantic differences due to differences in sensor working principles, imaging mechanisms, and data representation methods. This semantic gap is not only reflected in the mismatch of features between different modalities but also in the inconsistency of descriptions of the same object. Therefore, how to solve the semantic gap between features of different modalities is the key to achieving efficient and accurate multimodal fusion object detection.
In response to the above problems, this research starts from the task of using audio to assist image classification, aiming to transfer image features from training set samples (containing known categories) to test set samples (containing unknown categories) through shared semantic features. In this process, this paper explores the mapping mechanism of semantic feature space to image feature space and its generalization ability. Meanwhile, to address the semantic gap between different modal features, this paper introduces a feature matching mechanism in the multimodal information fusion process. Through this mechanism, this paper can effectively align the feature representations of different modalities, thereby reducing their heterogeneity differences.
3. Proposed Method
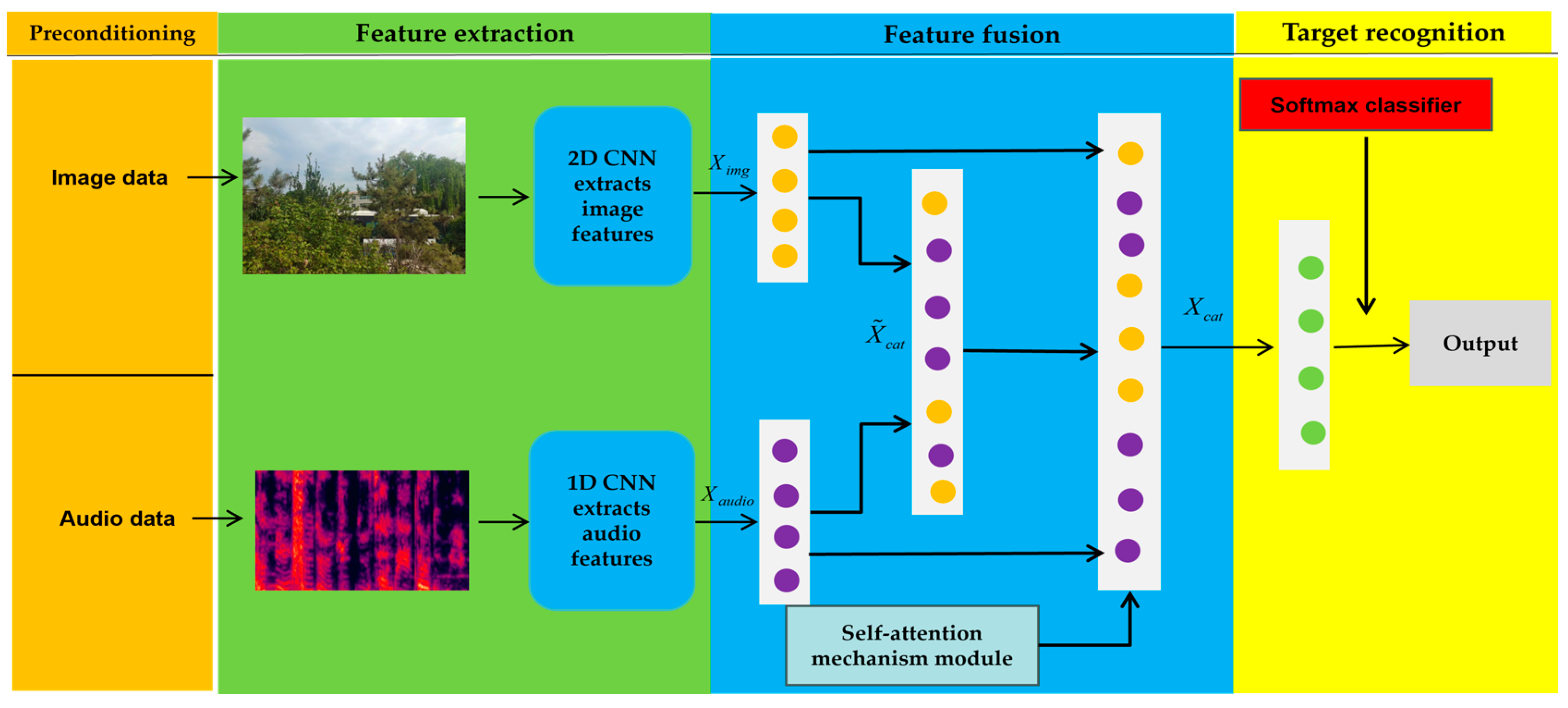
3.1. Audio-Visual Fusion Network Model
Figure 1 illustrates the architecture of M-AVFA. To address the issue of cross-modal fusion between audio and visual data, we explored a novel approach. First, since audio signals are one-dimensional temporal signals, we leveraged the relationship between the time domain and the frequency domain. By applying the Fast Fourier Transform (FFT), we converted the temporal information into frequency information. Subsequently, we extracted audio features through a series of operations, including triangular filters and discrete cosine transforms, and transformed them into corresponding audio feature spectrograms.
To fully exploit the semantic correlations between auditory and visual modalities, we designed a dual-stream network architecture. The audio spectrogram and target image are independently processed through a 1D CNN and 2D CNN, respectively, to extract modality-specific features (denoted as audio feature and visual feature ). These unimodal features are then fused through cross-modal interaction to generate a joint semantic representation . To preserve modality-specific discriminability while enhancing complementary information, both the original features ( and ) and the fused representation are adaptively integrated via a self-attention-based feature fusion module, producing the final unified semantic embedding . This hierarchical fusion mechanism ensures the retention of critical unimodal patterns while capturing cross-modal dependencies. The resulting embedding is subsequently fed into a Softmax classifier to accomplish unified target classification.
3.2. The Conversion of the Spectrogram (Audio Preprocessing)
Considering that the acquisition process of sound will be affected by some environmental factors, and the acquisition of sound characteristics will be affected by large noise, we use multiple microphone arrays in terms of hardware and can use beamforming technology to lock the direction of sound, which has a good signal-to-noise ratio.
The sound captured by the microphone array is a one-dimensional time series signal. First, we will send the sound signal via a high-pass filter, specifically Equation (1):
Among them, the filter coefficient is set to 0.95, t represents the time of the sound signal, represents the input signal, and represents the output signal. In this manner, we complete the pre-emphasis processing of the input sound signal and compensate for the high-frequency part of the speech signal that was suppressed by the pronunciation signal system.
Nevertheless, the sound signal exhibits stationary characteristics over a brief period of time, allowing us to simply apply a framing operation to the output sound signal produced by the high-pass filter. To enhance the signal’s smoothness, we multiply each frame of the sound signal by a hamming window, thereby increasing the continuity from the left end of the frame to the right end. Suppose that the signal after framing is
,
= 0, 1, 2, …, N − 1, where N is the length of the window. Hamming window makes the edge of the signal gradually weaken by weighting the signal, reducing the leakage of signal energy into the adjacent frequency components, that is, reducing the aliasing between different frequency components, thus suppressing the influence of noise. The signal of each frame is multiplied by the Hamming window, denoted as Equation (2):
Among them,
represents a sub-frame defined by
and
is a Hamming window, whose form is defined by Equation (3):
where
represents the weight value of the signal at the nth discrete time point of the window,
L represents the length of the window, and
n represents the sample index of the window.
The energy distribution in the frequency domain observes its characteristics, and distinct speech characteristics can be distinct through different energy distributions in the frequency domain. We perform an
N-point FFT on each frame of the frame windowed signal to calculate the spectrum. Equation (4) is as follows:
where
represents the input frame data,
refers to the Hamming window function,
N is the number of Fourier transform points, and
denotes the frequency domain expression of the input audio signal. The absolute values of the Fourier transform results are used to obtain the spectral amplitude.
The spectral amplitude of each time frame is arranged into a two-dimensional matrix according to Equation (5):
where
i represents the index of the time frame,
k represents the index of the frequency, and
is a two-dimensional matrix. This is the spectrogram of sound that we need.
Therefore, this paper completes the conversion of one-dimensional acoustic signal to two-dimensional spectrogram signal.
Figure 2 shows the spectrum diagram.
3.3. Feature Extraction
3.3.1. Sound Feature Extraction
In
Section 3.2, preprocessing operations were applied to the audio data. This paper employs Mel-Frequency Cepstral Coefficients (MFCC) to extract features of sound targets in complex environments. The principle behind MFCC extraction is based on the spectrogram of the sound. However, when fusing these features with image features, MFCC is unable to capture higher-level phonetic information from the sound. Therefore, this paper further extracts the semantic information of the sound using a one-dimensional convolutional neural network (1D CNN). During the extraction process, the sound features are used as the input, denoted as
. As shown in Equation (6),
Among them, represents the semantic features of the sound, conv denotes the convolution operation, and represents the size of the convolution kernel.
3.3.2. Image Feature Extraction
In the design of this paper, a 2D CNN is specifically selected to process image data because of its proficiency in capturing spatial features of images. The designed 2D CNN consists of multiple convolutional layers, pooling layers, and fully connected layers. Convolutional layers extract local features from images using different convolution kernels, while pooling layers are used to reduce the dimensionality of feature maps, decrease computational load, and retain important features. Fully connected layers map the extracted features to the target category space, providing a basis for subsequent feature fusion and target classification. This section uses the image features obtained from the aforementioned image as input, denoted as
. As shown in Equation (7),
Among them, represents the semantic features of the target image, conv denotes the convolution operation, H and W represent the height and width of the image, and C represents the number of channels in the image.
3.4. Mode Fusion
When fusing audio and visual data, it is essential to ensure alignment between the modalities. The data collected in this study consists of 10 s videos, from which the visual and audio data are separated. The visual data have a sampling rate of 24 frames per second, while the audio data are sampled at 24 Hz. By matching each frame of the video with its corresponding audio segment, this study achieves alignment between the audio and visual modalities. The visual modality contains rich detail information, while the audio modality provides complementary auditory details to the visual modality.
As discussed in
Section 3.3.1 and
Section 3.3.2, this study represents the high-level semantic features of images and sounds as
and
, respectively. A multimodal fusion network structure is constructed to fuse these features. The high-level semantic features extracted from images and sounds using the CNN are mapped into a shared semantic subspace through a joint architecture for feature fusion, resulting in the fused high-level semantic feature
, as shown in Equation (8):
After obtaining the fused high-level semantic feature
in the feature fusion stage, this paper introduces a Self-Attention module (SA module) to learn the representations of image features and audio features. The high-level semantic feature
, the image features extracted by the 2D CNN
, and the audio features extracted by the 1D CNN
are passed through a self-channel attention module and ultimately weighted to obtain the result. The optimized high-level semantic feature
, the optimized image feature
, and the optimized audio feature
are then fused. The attention weights
,
, and
between each modality are calculated for
,
, and
, respectively, as shown in Equation (9):
Among them, and .
In this study, self-attention weights were used to carry out weighted fusion of each modal feature, and finally, the final high-level semantic information
was obtained through modal fusion, as shown in Equation (10):
In order to effectively complete the task of target classification, Softmax function is used to normalize and achieve the probability distribution of classification. Sofatamx’s formula is shown in (11):
The audiovisual fusion network proposed in this paper can gradually enhance the matching degree and fusion effect between sound visual features. In the iterative process, the network adjusts and optimizes the feature extraction and fusion methods of each mode according to the current feature representation and interaction weights, so as to obtain the high-level semantic information of the final fusion. This cross-modal interaction and fusion method not only improves the robustness and generalization ability of feature representation but also solves the problem of data heterogeneity among modes. It makes full use of the complementarity between different modes and provides strong support for the subsequent classification output.
5. Conclusions
Traditional monomodal recognition systems, due to their inherent limitations in data representation and sensitivity to environmental conditions, are increasingly unable to meet the robustness requirements for target recognition. Faced with significant technical challenges, such as the difficulty in aligning heterogeneous modality features and the substantial semantic gap across modalities, this study proposes a multimodal fusion framework based on audio-visual fusion. The network architecture employs a 2D CNN and a 1D CNN to extract semantic features from images and sounds, respectively, thereby providing high-quality modality-specific feature representations for subsequent fusion.
To address the heterogeneity issues in modality fusion and to solve the problem of heterogeneity among modes, a feature fusion strategy based on self-attention mechanism is proposed in this paper. Comparison with the latest multimodal fusion recognition methods: Compared with the PCTDF method, the proposed method increases the average recognition rate by 2.6%. Compared with the STNet method, the recognition accuracy of the proposed method is increased by 2.4%. Compared with the AFT-SAM method, the proposed method increases the average recognition rate by 1.2%. Compared with the PSFMMA method, the recognition accuracy of the proposed method is increased by 0.9%. These results demonstrate that the proposed M-AVFA algorithm has significant advantages in multimodal fusion, effectively integrating audio and visual information to enhance target recognition performance in complex environments.
The current multimodal fusion-based target classification in this study is primarily proposed based on convolutional neural networks (CNNs). Future research will attempt to explore deeper network architectures, such as ResNet structures. Future work will prioritize validating the proposed methods through classification experiments in complex outdoor environments. Additionally, further modifications to the current audio-visual fusion approach to achieve target classification under extreme weather conditions remain an area for future investigation.






{kind=link}
{kind=link}
{kind=link}