


Machine-Learning-Based Integrated Mining Big Data and Multi-Dimensional Ore-Forming Prediction: A Case Study of Yanshan Iron Mine, Hebei, China



Abstract
1. Introduction
2. Study Area and Data
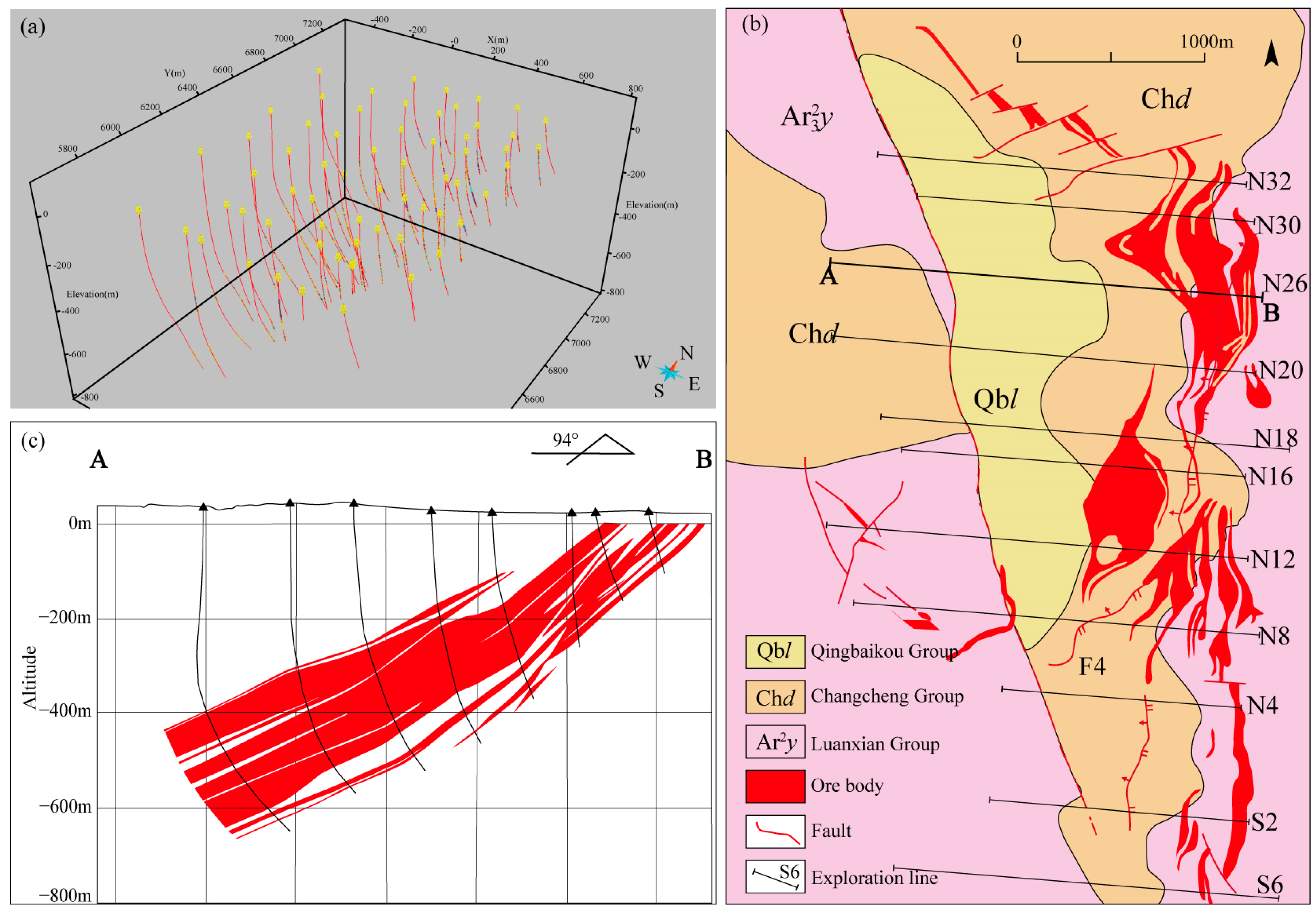
2.1. Geology Setting
2.2. Mine Big Data
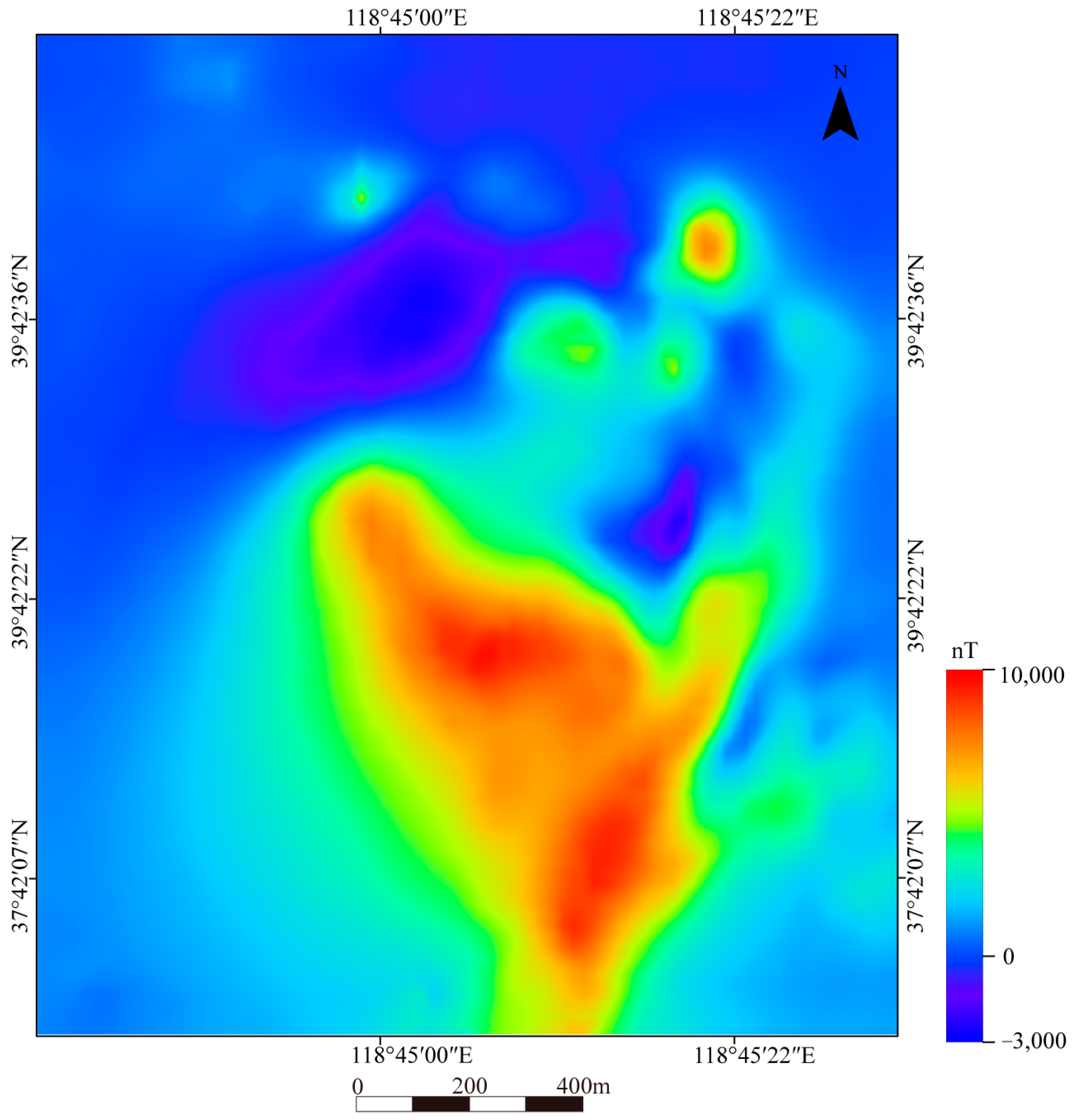
2.2.1. UAS Imagery—Multispectral, LiDAR, Aeromagnetic
2.2.2. Surface Sample Data—XRF, Spectroscopy, Susceptibility, Sampling
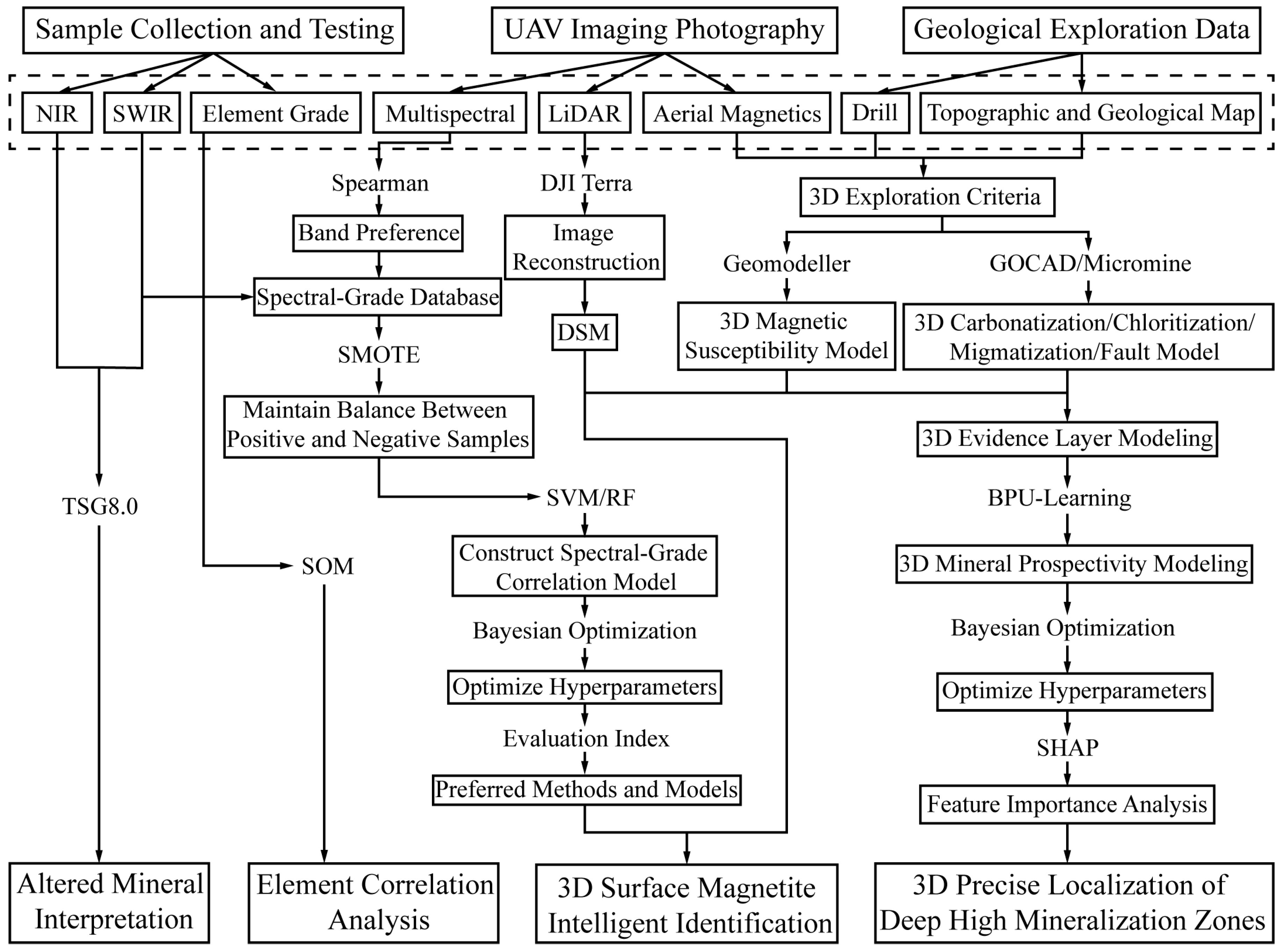
3. Methodologies
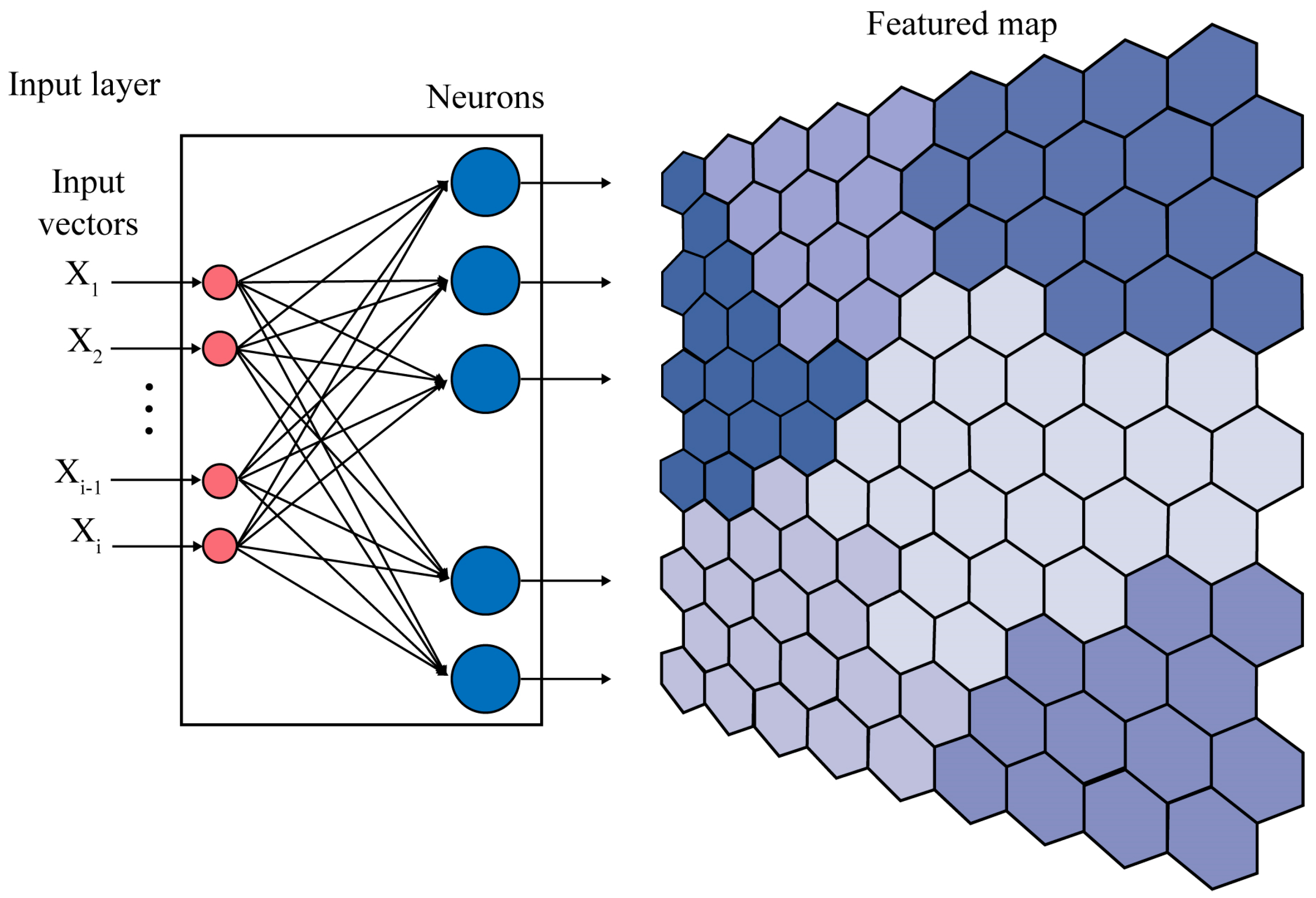
3.1. Self-Organizing Map
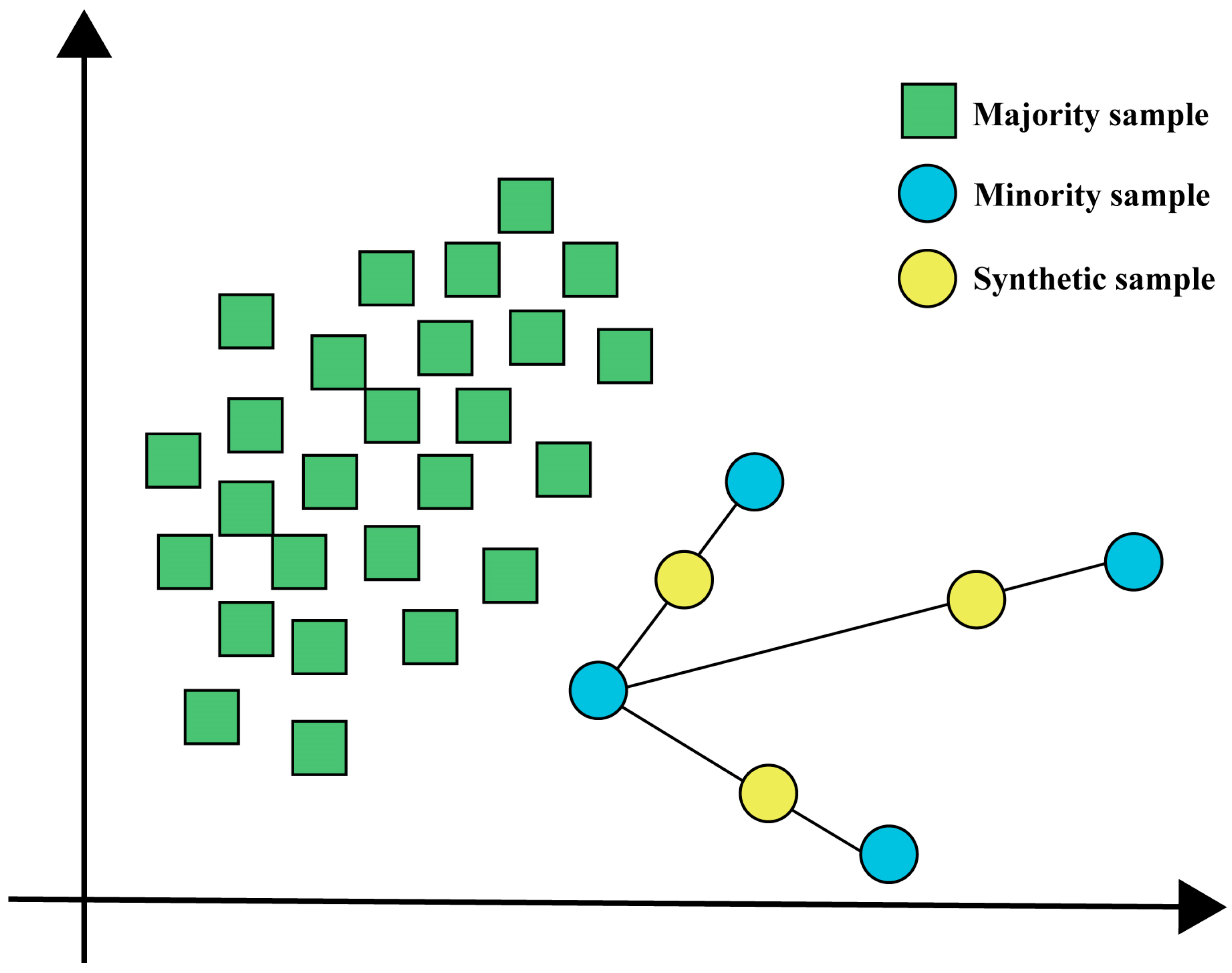
3.2. SMOTE
3.3. Support Vector Machine
3.4. Random Forest
3.5. Positive–Unlabeled Learning
3.6. Bayesian Optimization
- Search and obtain the locally optimal hyperparameters x* on the current surrogate model Mt−1 using the acquisition function.
- Calculate the actual loss value y of x*.
- Update x* and y into the experimental set H.
- Retrain the surrogate model using the updated H to obtain a new surrogate model Mt.
3.7. Model Evaluation Method
4. Results and Discussion
4.1. Sample Testing and Analysis
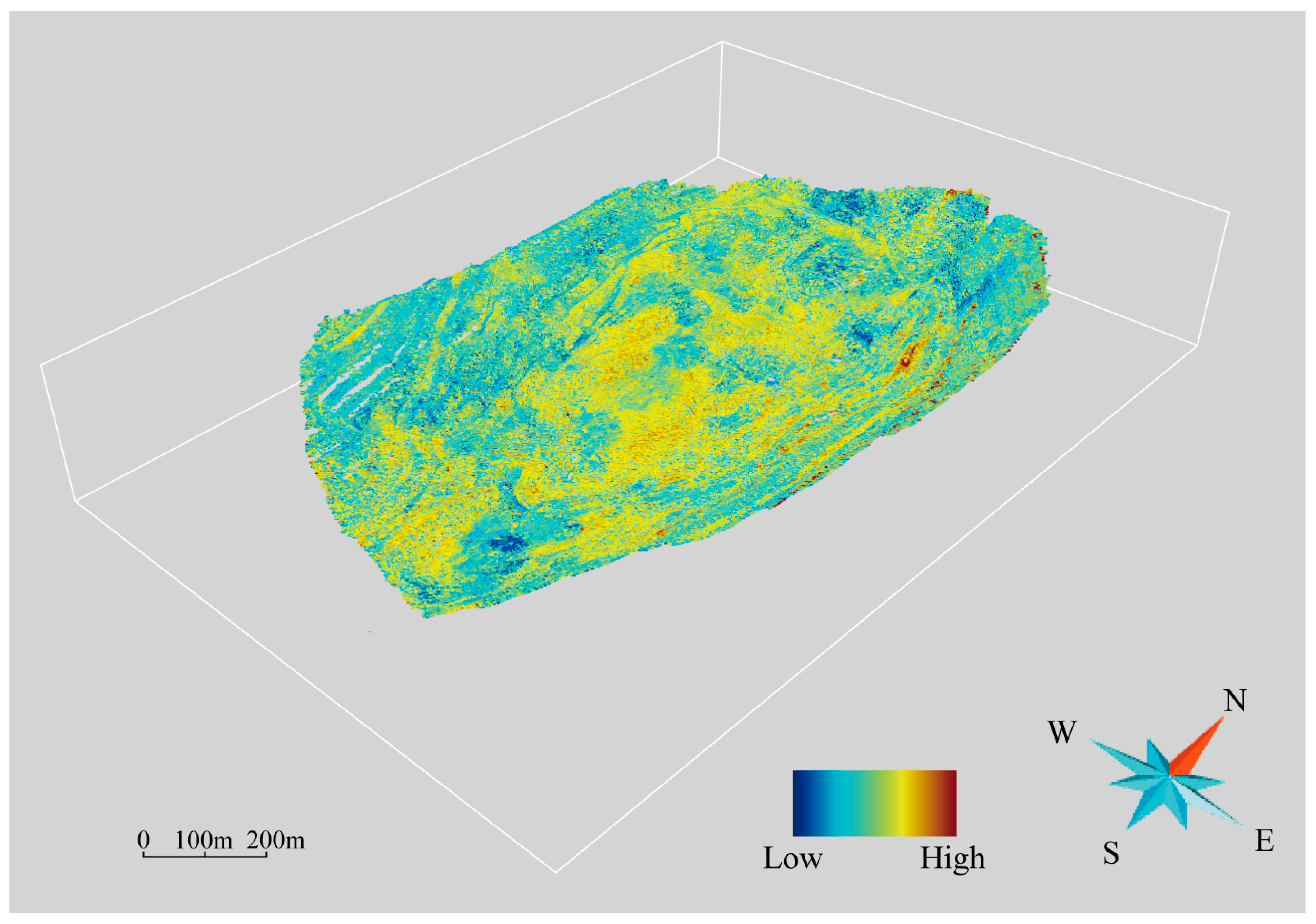
4.2. Intelligent Detection of UAV Images
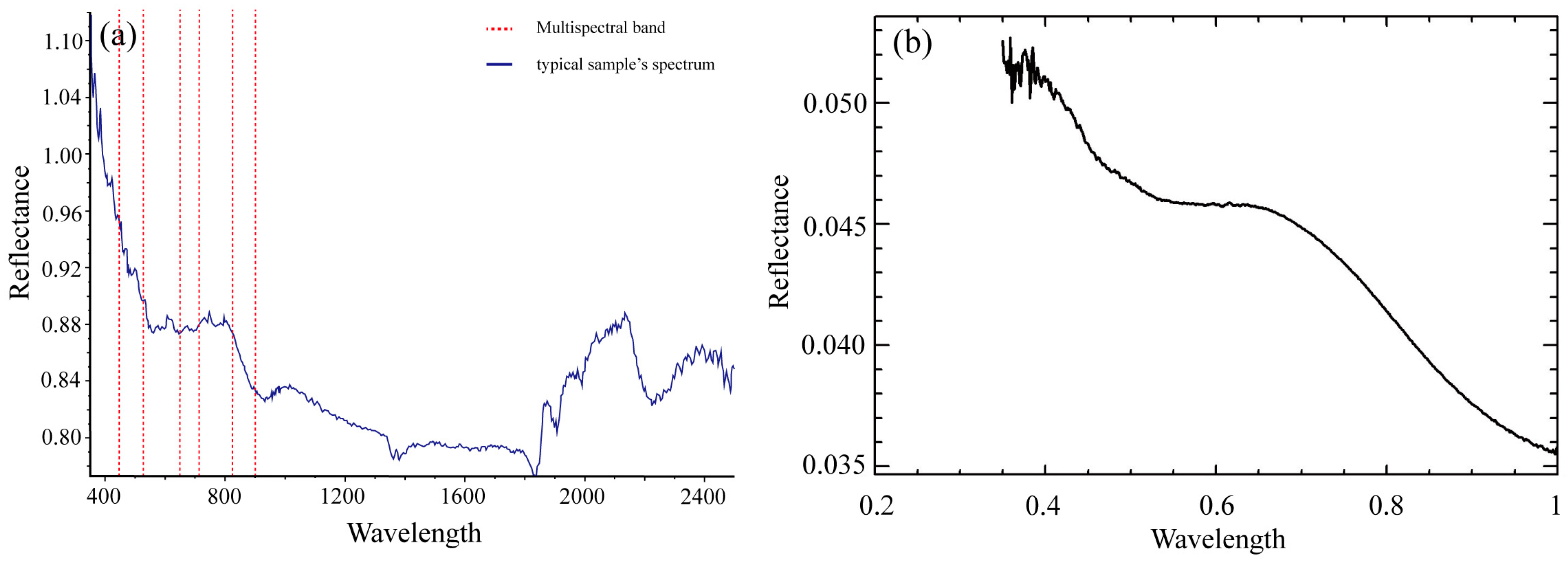
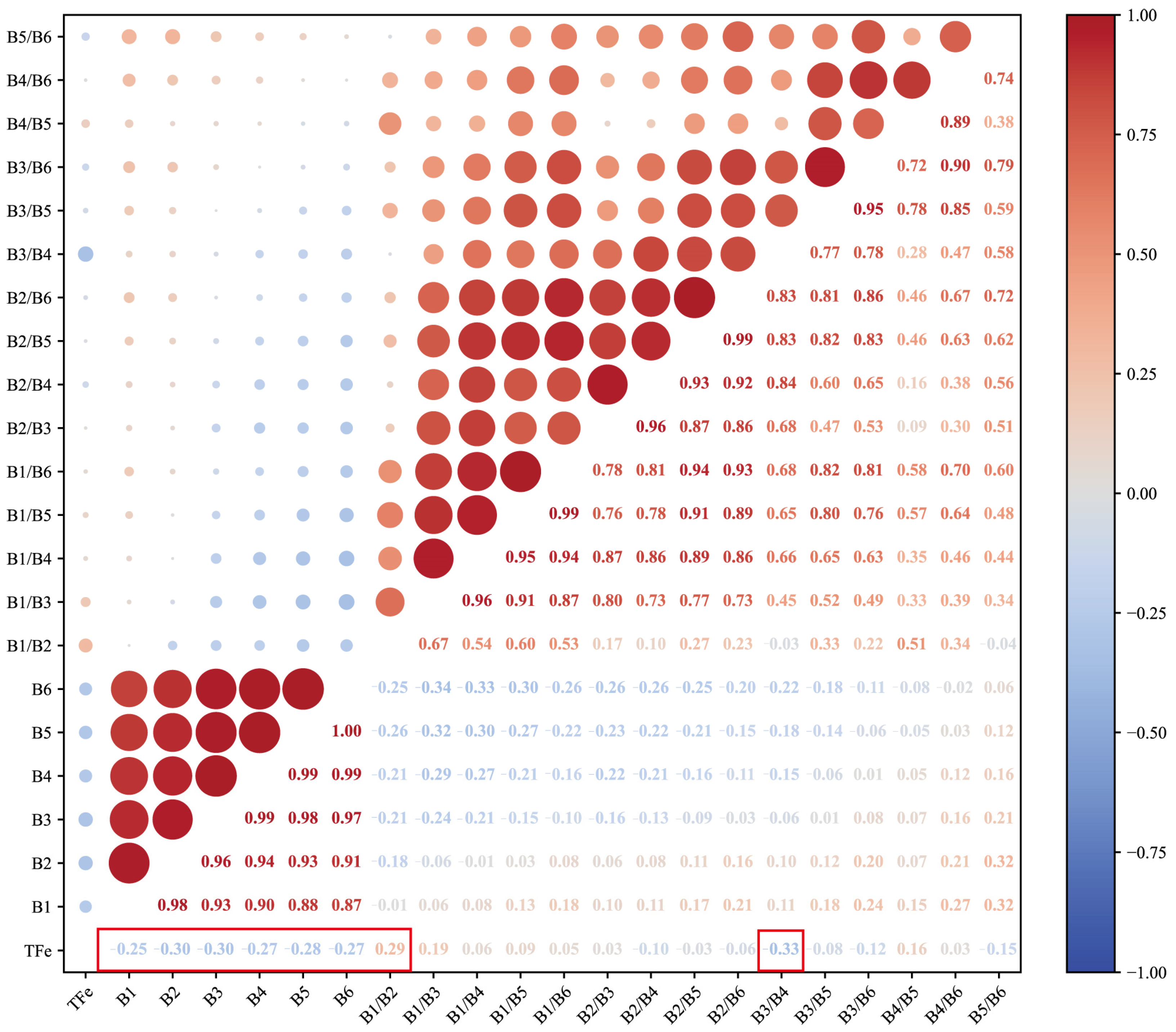
4.2.1. Band Preference
4.2.2. Magnetite Identification
4.3. Three-Dimensional Metallogenic Prediction
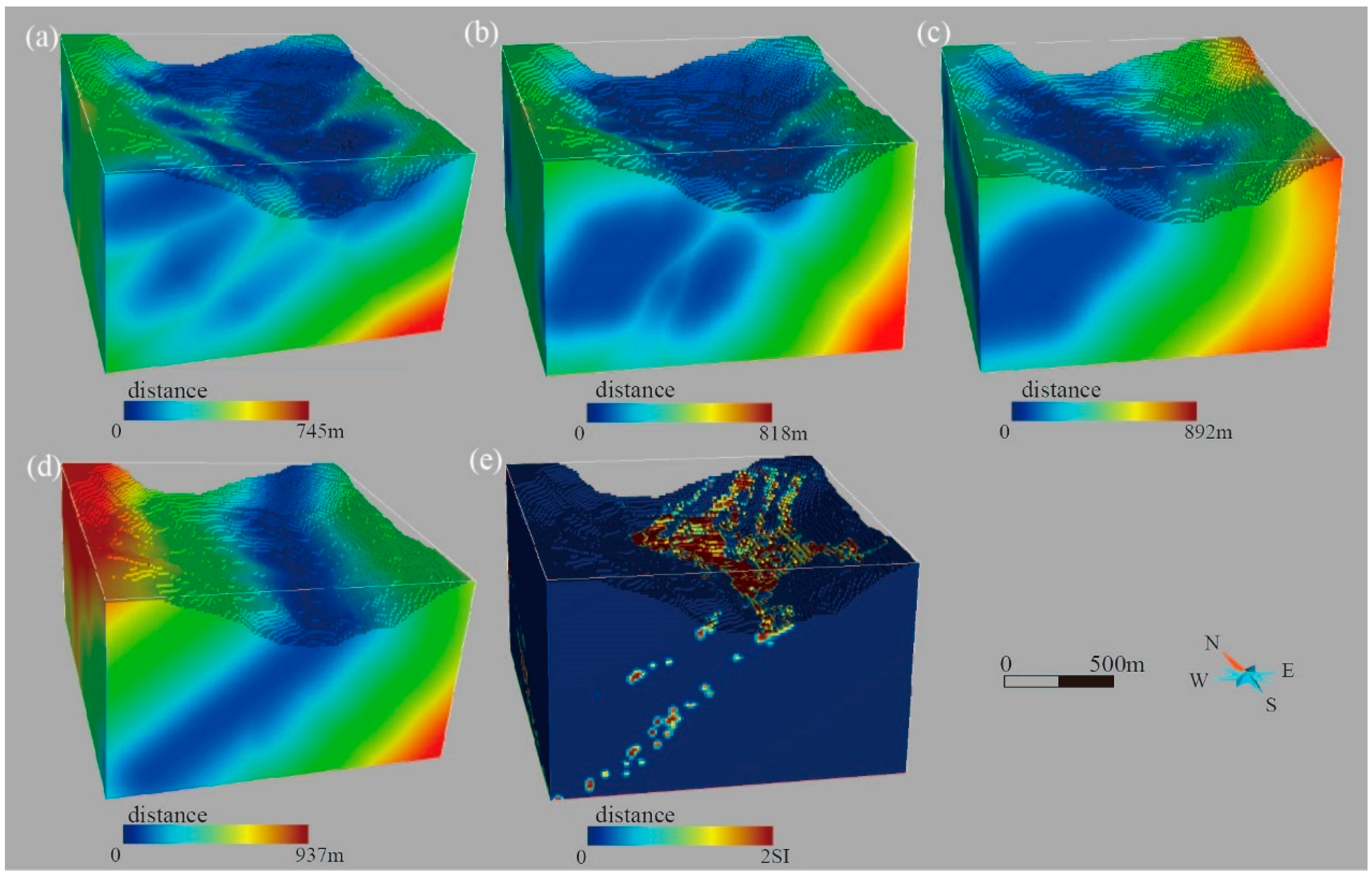
4.3.1. Three-Dimensional Exploration Criteria
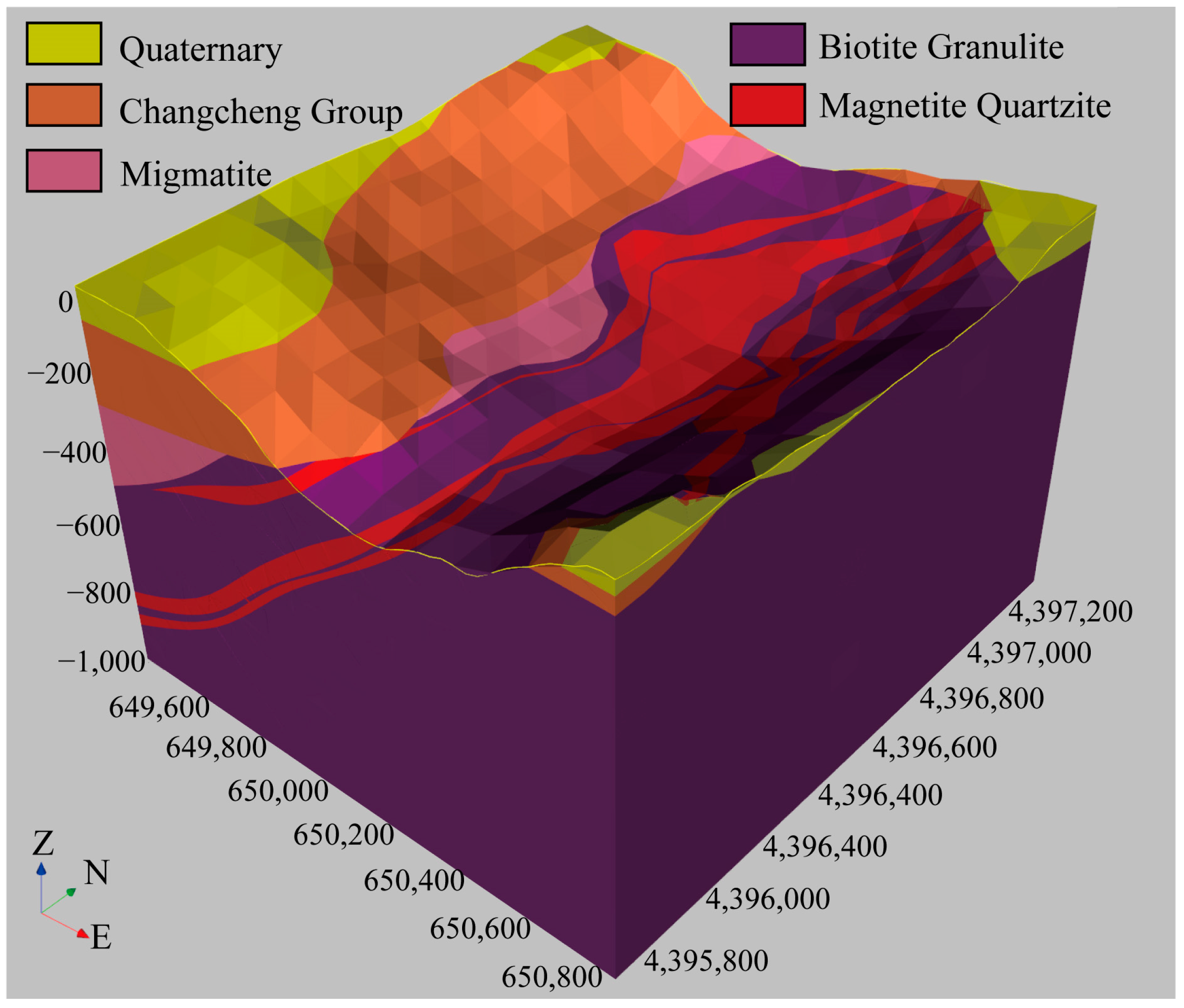
4.3.2. Three-Dimensional Geological-Geophysical Modeling
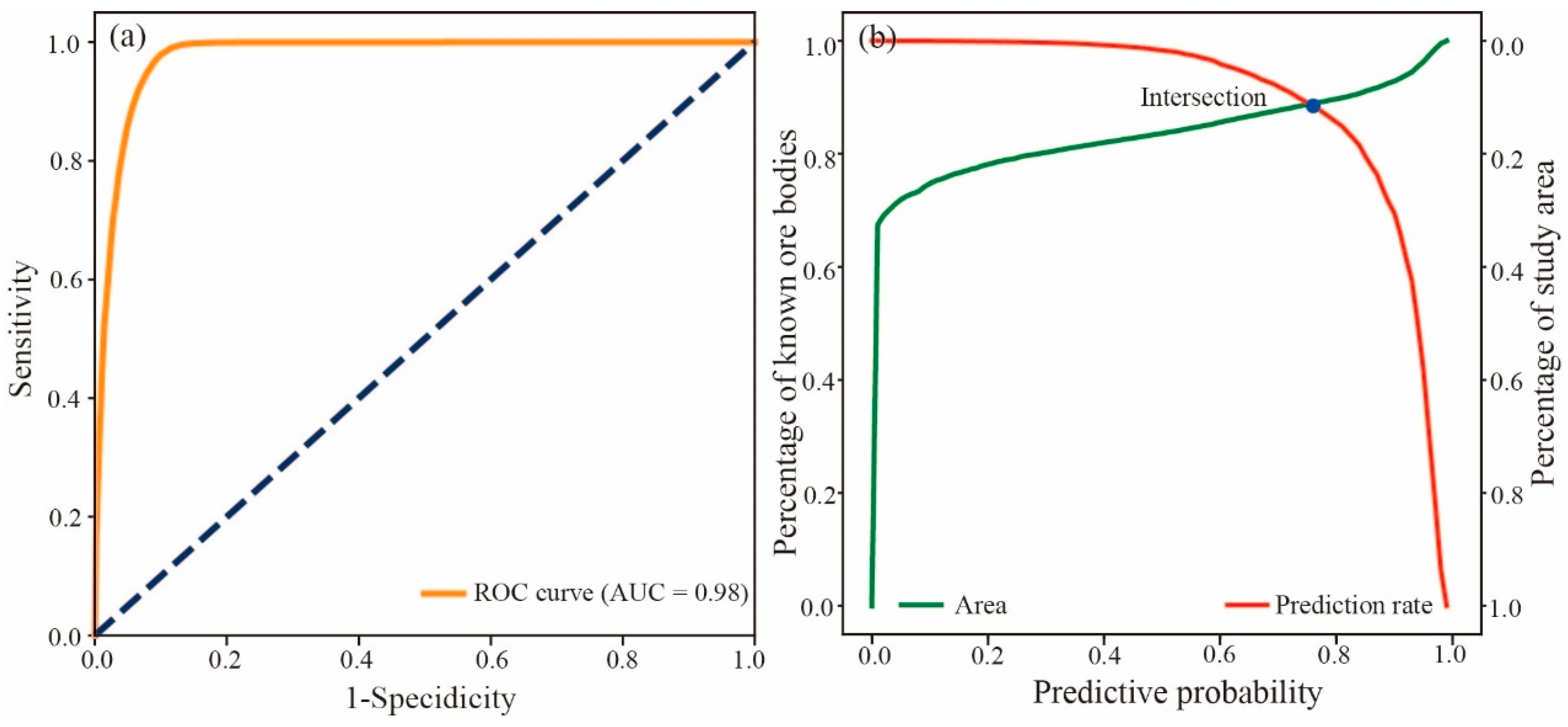
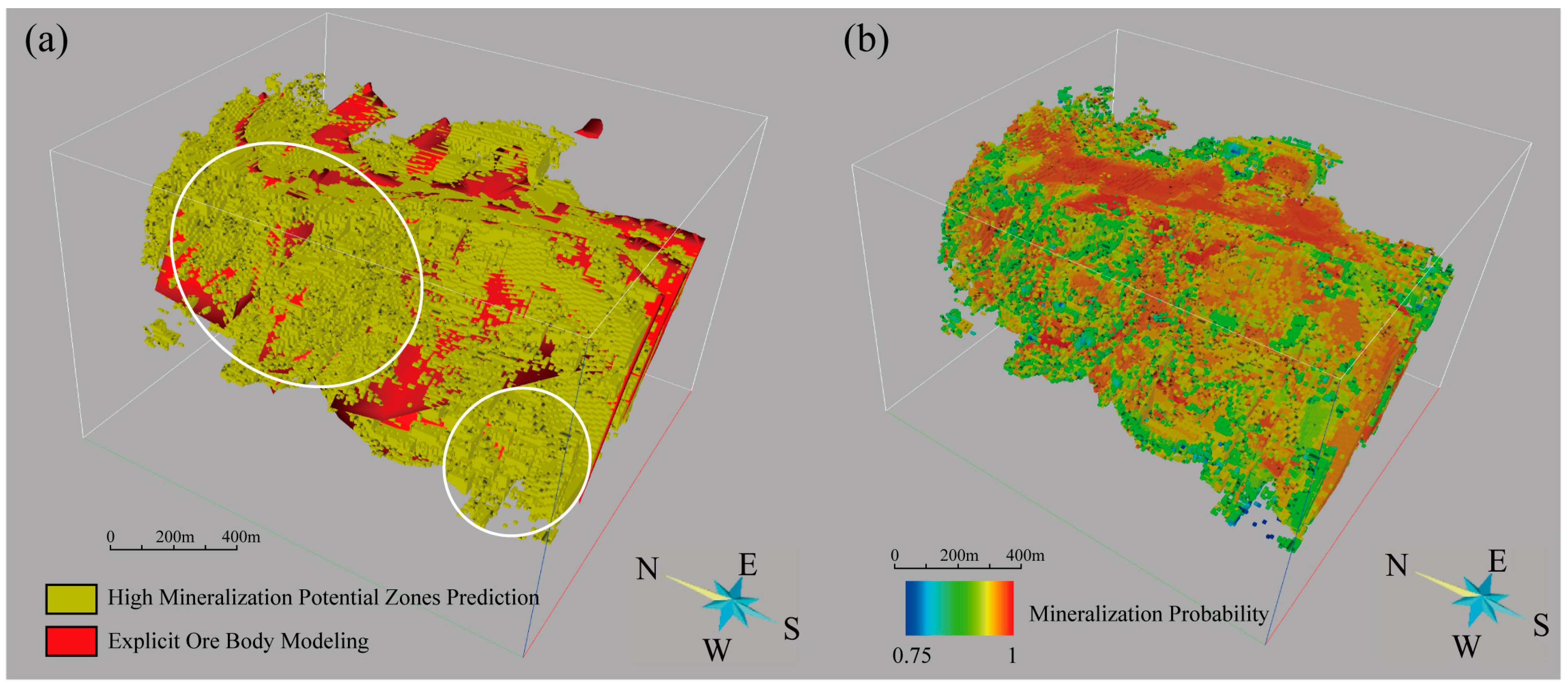
4.3.3. Three-Dimensional Prospectivity Mapping Based on BPUL
5. Conclusions
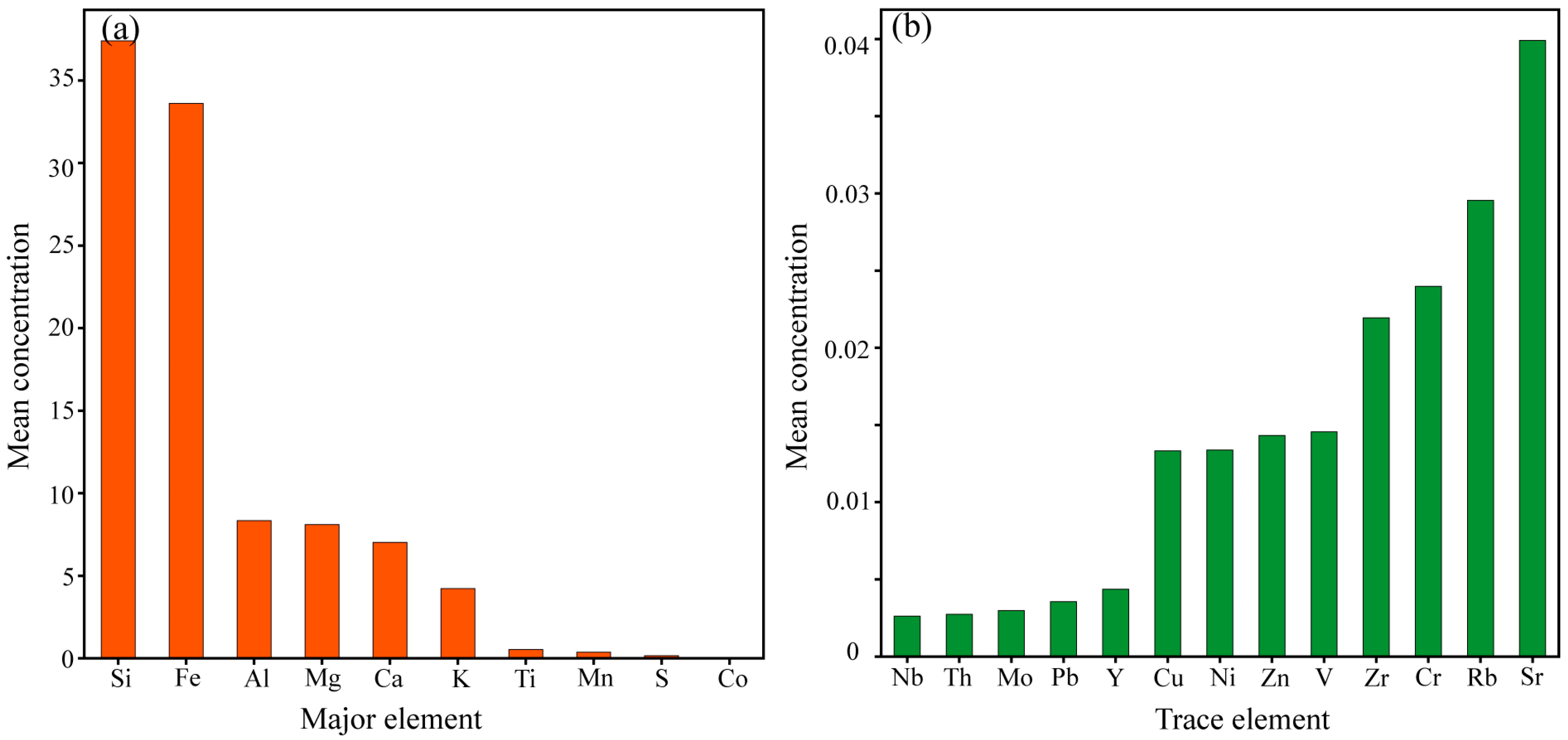
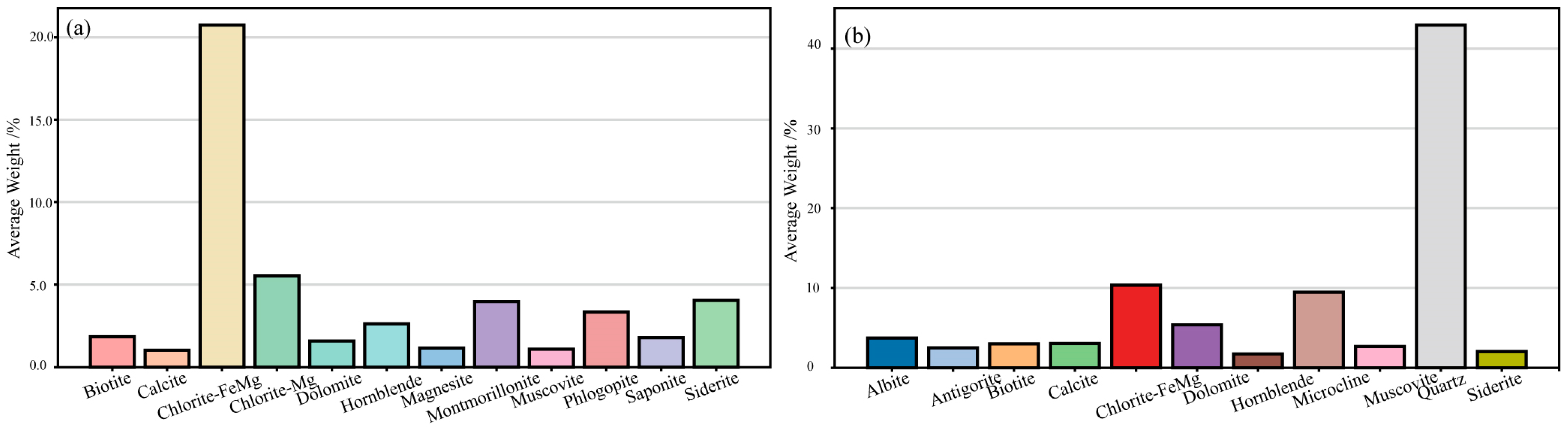
- Self-organizing map (SOM) clustering analysis of X-ray fluorescence (XRF) elemental data from 218 ore samples revealed that the samples from the study area could be divided into two clusters. In the first cluster, elements such as Mg, Al, Si, S, K, Ca, Mn, and Fe exhibited a very strong positive correlation, while Ti, Co, Zn, and Sr showed a weak positive correlation with Fe. Elements such as V, Cr, Ni, Cu, Y, Zr, Nb, Mo, and Pb displayed a negative correlation with Fe. The second cluster consisted of Rb and Th, which showed a positive correlation. Further analysis using TSG shortwave and thermal infrared hyperspectral rock data identified the main mineral types in the mining area, including chlorite, rhodochrosite, dolomite, amphibole, biotite, montmorillonite, quartz, and feldspar. Combined with the XRF results, it was concluded that the region is characterized by significant hydrothermal alteration, primarily chloritization and carbonation, closely related to mineralization. Mg, Al, Si, and Ca were identified as important indicator elements for further deep exploration.
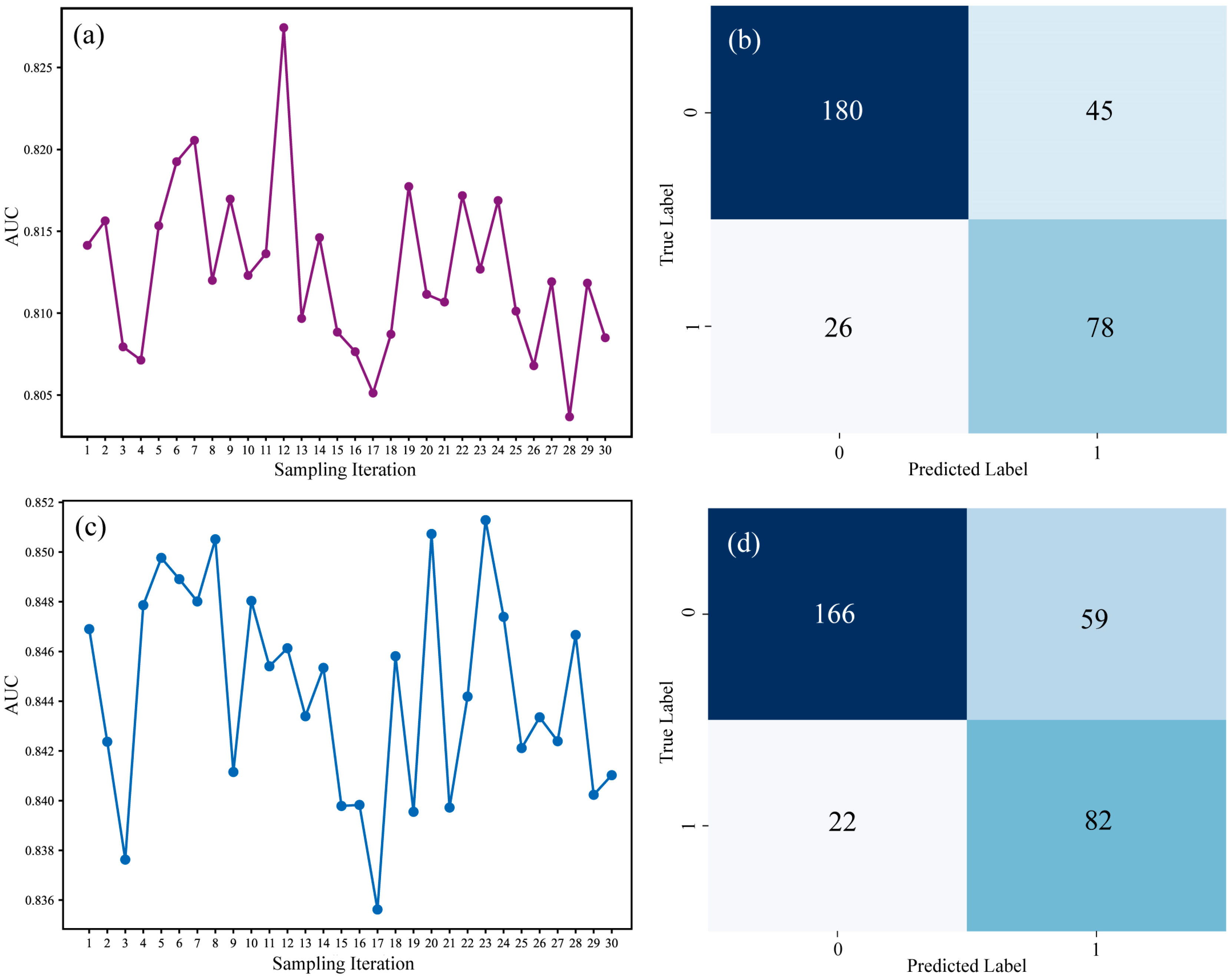
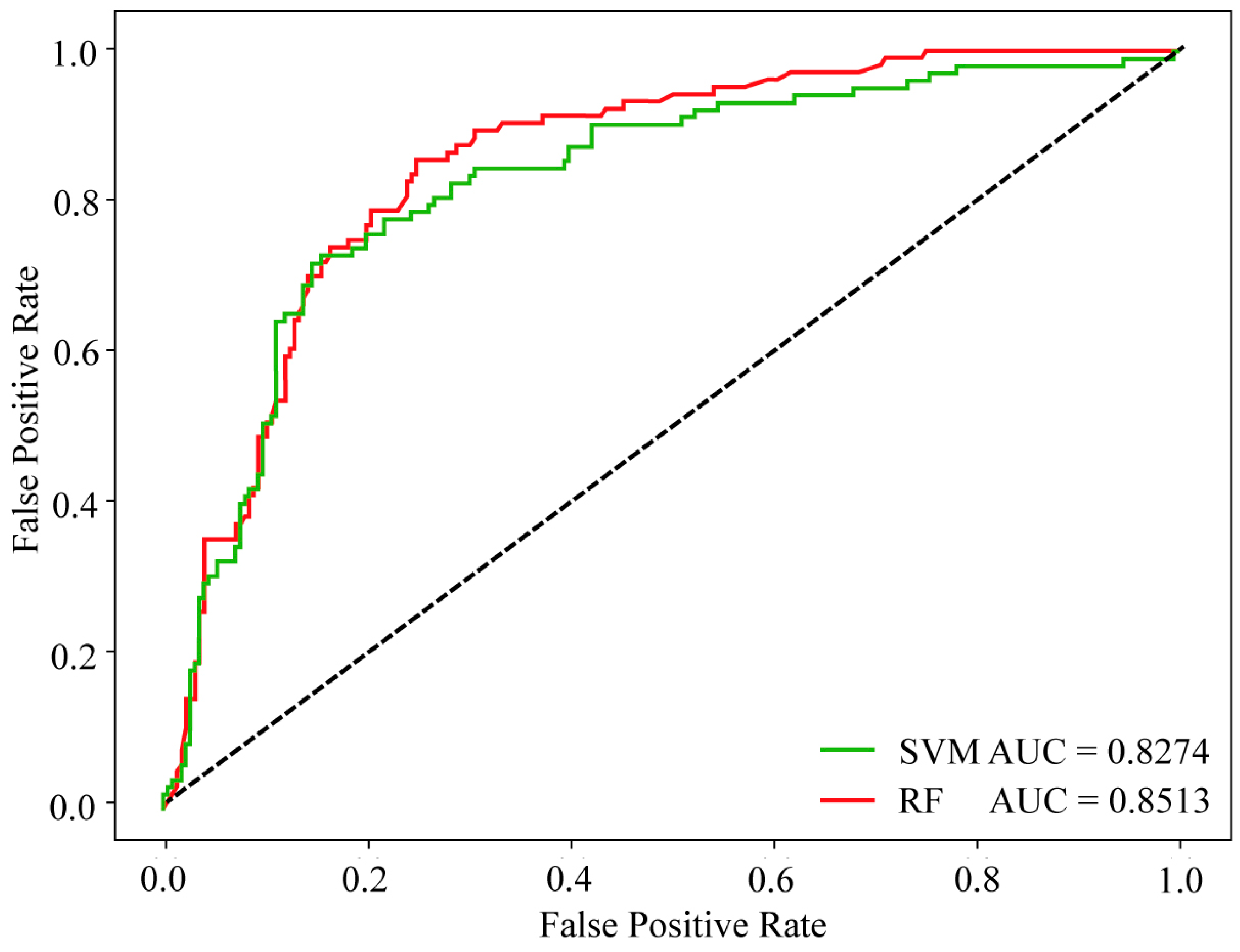
- Based on high-precision drone multispectral data and XRF sample grade data, an ore grade–spectrum correlation model was constructed using Random Forests, Support Vector Machine algorithms, and SMOTE algorithms. After evaluating multiple performance metrics, the RF23 model was selected as the optimal model for real-time prediction of the surface total iron grade in the mining area, with an ore body identification accuracy of 0.79. The model was applied to centimeter-level drone images, achieving high-precision intelligent identification of magnetite in the mining area. The drone multispectral image prediction clearly delineated the boundaries of rock minerals, aligning well with the grade distribution of measured samples, especially in the stope and blasted rock powder areas. Combined with LiDAR image elevation data, real-time monitoring of the three-dimensional surface mineralization information of the mining area was successfully realized, providing significant support for improving ore recovery rates and real-time detection in the mining area, demonstrating great practical application value.
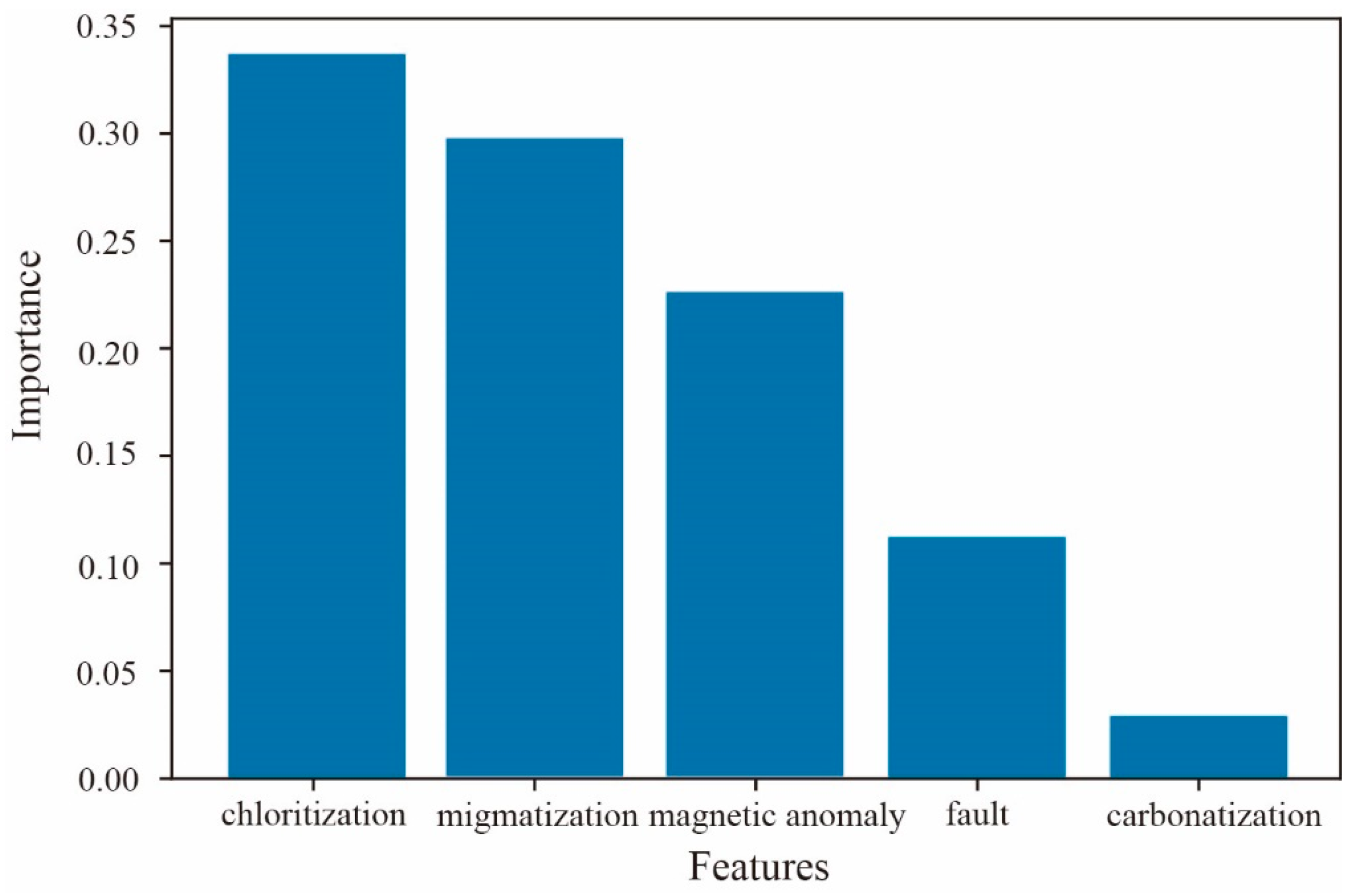
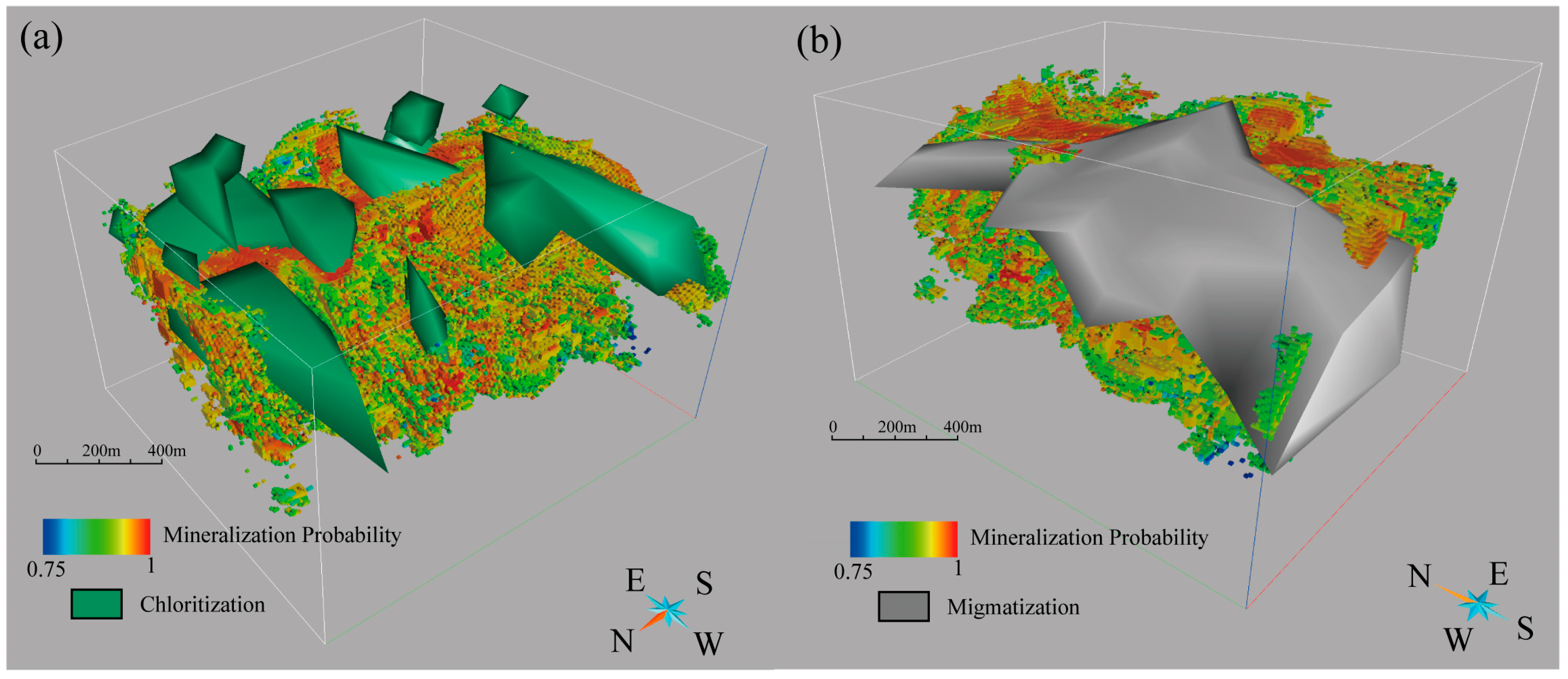
- A three-dimensional geological model was constructed to perform three-dimensional mineral resource potential evaluation (MPM). The results show that the BPUL algorithm can be effectively applied to deep mineral exploration prediction in the Yanshan Iron Mine. The predicted results closely aligned with the spatial location of high-grade mineralization zones. The P-V diagram analysis helped identify the high-mineralization areas at the scale of the mining area, pinpointing two potential exploration targets in the deep and northwest regions. SHAP values and the morphological features of different three-dimensional geological models indicated that chloritization, mixed rock alteration, and magnetic anomalies have significant contributions to ore body enrichment, while faults have some control over the morphological distribution of the Yanshan Iron Mine, but their contribution to the formation of high-grade ore bodies is relatively small.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, D.H. Study on Critical Mineral Resources: Significance of Research, Determination of Types, Attributes of Resources, Progress of Prospecting, Problems of Utilization, and Direction of Exploitation. Acta Geol. Sin. 2019, 93, 118–1209. [Google Scholar]
- Zhao, P. “Tri-Linked” Resource Quantitative Prediction and Evaluation: Discussion on Digital Prospecting Theory and Practice. Earth Sci. 2002, 5, 482–489, (In Chinese with English abstract). [Google Scholar]
- Zhao, P.; Chen, Y. Digital Geology and Digital Mineral Exploration. Earth Sci. Front. 2021, 28, 1–5+434–435, (In Chinese with English abstract). [Google Scholar]
- Zuo, R.; Xiong, Y. Geodata Science and Geochemical Mapping. J. Geochem. Explor. 2020, 209, 106431. [Google Scholar]
- Huang, J.; Mao, X.; Deng, H.; Liu, Z.; Chen, J.; Xiao, K. An Improved GWR Approach for Exploring the Anisotropic Influence of Ore-Controlling Factors on Mineralization in 3D Space. Nat. Resour. Res. 2022, 31, 2181–2196. [Google Scholar]
- Zhang, Z.; Wang, G.; Carranza, E.J.M.; Yang, S.; Zhao, K.; Yang, W.; Sha, D. Three-Dimensional Pseudo-Lithologic Modeling Via Adaptive Feature Weighted k-Means Algorithm from Multi-Source Geophysical Datasets, Qingchengzi Pb–Zn–Ag–Au District, China. Nat. Resour. Res. 2022, 31, 2163–2179. [Google Scholar]
- Sinaice, B.B.; Owada, N.; Ikeda, H.; Toriya, H.; Bagai, Z.; Shemang, E.; Adachi, T.; Kawamura, Y. Spectral Angle Mapping and AI Methods Applied in Automatic Identification of Placer Deposit Magnetite Using Multispectral Camera Mounted on UAV. Minerals 2022, 12, 268. [Google Scholar] [CrossRef]
- Zhang, G.; Chen, Q.; Zhao, Z.; Zhang, X.; Chao, J.; Zhou, D.; Chai, W.; Yang, H.; Lai, Z.; He, Y. Nickel Grade Inversion of Lateritic Nickel Ore Using WorldView-3 Data Incorporating Geospatial Location Information: A Case Study of North Konawe, Indonesia. Remote Sens. 2023, 15, 3660. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar]
- Jian, H.; Gong, W.; Li, Y.; Wang, L. Bayesian Inference of Fault Slip and Coupling Along the Tuosuo Lake Segment of the Kunlun Fault, China. Geophys. Res. Lett. 2022, 49, e2021GL096882. [Google Scholar]
- Yang, J.; Lu, R.; Tao, W.; Cai, M.; Liu, G.; Sun, X. MultiURNet for 3D Seismic Fault Attributes Fusion Detection Combined with PCA. J. Appl. Geophys. 2024, 221, 105296. [Google Scholar] [CrossRef]
- Yang, J.; Lu, R.; Tao, W.; Liu, G.; Guo, Z.; Yang, X.; Wang, K. Intelligent Identification of Sample-Adaptive Fracture Systems and Seismic Structure Analysis: A Case Study of the Hutubi Gas Storage Field in Xinjiang, China. Seismol. Res. Lett. 2025. [Google Scholar] [CrossRef]
- Asadzadeh, S.; Chabrillat, S.; Cudahy, T.; Rashidi, B.; De Souza Filho, C.R. Alteration Mineral Mapping of the Shadan Porphyry Cu-Au Deposit (Iran) Using Airborne Imaging Spectroscopic Data: Implications for Exploration Drilling. Econ. Geol. 2024, 119, 139–160. [Google Scholar] [CrossRef]
- Chen, Q.; Zhao, Z.; Zhou, J.; Zhu, R.; Xia, J.; Sun, T.; Zhao, X.; Chao, J. ASTER and GF-5 Satellite Data for Mapping Hydrothermal Alteration Minerals in the Longtoushan Pb-Zn Deposit, SW China. Remote Sens. 2022, 14, 1253. [Google Scholar] [CrossRef]
- Lyu, P.; He, L.; He, Z.; Liu, Y.; Deng, H.; Qu, R.; Wang, J.; Zhao, Y.; Wei, Y. Research on Remote Sensing Prospecting Technology Based on Multi-Source Data Fusion in Deep-Cutting Areas. Ore Geol. Rev. 2021, 138, 104359. [Google Scholar]
- Li, X.; Yuan, F.; Zhang, M.; Jowitt, S.M.; Ord, A.; Zhou, T.; Dai, W. 3D Computational Simulation-Based Mineral Prospectivity Modeling for Exploration for Concealed Fe–Cu Skarn-Type Mineralization within the Yueshan Orefield, Anqing District, Anhui Province, China. Ore Geol. Rev. 2019, 105, 1–17. [Google Scholar] [CrossRef]
- Huang, J.; Mao, X.; Chen, J.; Deng, H.; Dick, J.M.; Liu, Z. Exploring Spatially Non-Stationary Relationships in the Determinants of Mineralization in 3D Geological Space. Nat. Resour. Res. 2020, 29, 439–458. [Google Scholar] [CrossRef]
- Mao, X.; Su, Z.; Deng, H.; Liu, Z.; Li, L.; Wang, Y.; Wang, Y.; Wu, L. Three-Dimensional Mineral Prospectivity Modeling with Geometric Restoration: Application to the Jinchuan Ni–Cu–(PGE) Sulfide Deposit, Northwestern China. Nat. Resour. Res. 2024, 33, 75–105. [Google Scholar]
- Mao, X.; Wang, J.; Deng, H.; Liu, Z.; Chen, J.; Wang, C.; Liu, J. Bayesian Decomposition Modelling: An Interpretable Nonlinear Approach for Mineral Prospectivity Mapping. Math. Geosci. 2023, 55, 897–942. [Google Scholar] [CrossRef]
- Gao, M.; Wang, G.; Carranza, E.J.M.; Qi, S.; Zhang, W.; Pang, Z.; Li, X.; Xiao, F. 3D Au Targeting Using Machine Learning with Different Sample Combination and Return-Risk Analysis in the Sanshandao-Cangshang District, Shandong Province, China. Nat. Resour. Res. 2024, 33, 51–57. [Google Scholar] [CrossRef]
- Zhang, C.; Zuo, R. Recognition of Multivariate Geochemical Anomalies Associated with Mineralization Using an Improved Generative Adversarial Network. Ore Geol. Rev. 2021, 136, 104264. [Google Scholar] [CrossRef]
- Shi, L.; Xu, Y.; Zuo, R. A Heterogeneous Graph Construction Method for Mineral Prospectivity Mapping. Nat. Resour. Res. 2024, 33, 1365–1376. [Google Scholar]
- He, X.; Zhang, F.; Jim, C.Y.; Chan, N.W.; Tan, M.L.; Shi, J. A New Method to Extract Coal-Covered Area in Open-Pit Mine Based on Remote Sensing. Int. J. Remote Sens. 2024, 45, 5901–5916. [Google Scholar]
- Carranza, E.J.M.; Laborte, A.G. Random Forest Predictive Modeling of Mineral Prospectivity with Small Number of Prospects and Data with Missing Values in Abra (Philippines). Comput. Geosci. 2015, 74, 60–70. [Google Scholar]
- Chen, Y.; Wu, W. Application of One-Class Support Vector Machine to Quickly Identify Multivariate Anomalies from Geochemical Exploration Data. Geochem. Explor. Environ. Anal. 2017, 17, 231–238. [Google Scholar]
- Latifovic, R.; Pouliot, D.; Campbell, J. Assessment of Convolution Neural Networks for Surficial Geology Mapping in the South Rae Geological Region, Northwest Territories, Canada. Remote Sens. 2018, 10, 307. [Google Scholar] [CrossRef]
- Luo, Z.; Xiong, Y.; Zuo, R. Recognition of Geochemical Anomalies Using a Deep Variational Autoencoder Network. Appl. Geochem. 2020, 122, 104710. [Google Scholar] [CrossRef]
- Song, S.; Mukerji, T.; Hou, J. GANSim: Conditional Facies Simulation Using an Improved Progressive Growing of Generative Adversarial Networks (GANs). Math. Geosci. 2021, 53, 1413–1444. [Google Scholar] [CrossRef]
- Keykhay-Hosseinpoor, M.; Kohsary, A.-H.; Hossein-Morshedy, A.; Porwal, A. A Machine Learning-Based Approach to Exploration Targeting of Porphyry Cu-Au Deposits in the Dehsalm District, Eastern Iran. Ore Geol. Rev. 2020, 116, 103234. [Google Scholar]
- Li, T.; Zuo, R.; Zhao, X.; Zhao, K. Mapping Prospectivity for Regolith-Hosted REE Deposits via Convolutional Neural Network with Generative Adversarial Network Augmented Data. Ore Geol. Rev. 2022, 142, 104693. [Google Scholar]
- Luo, Z.; Zuo, R. Causal Discovery and Deep Learning Algorithms for Detecting Geochemical Patterns Associated with Gold-Polymetallic Mineralization: A Case Study of the Edongnan Region. Math. Geosci. 2025, 57, 193–220. [Google Scholar] [CrossRef]
- Deng, H.; Zheng, Y.; Chen, J.; Yu, S.; Xiao, K.; Mao, X. Learning 3D Mineral Prospectivity from 3D Geological Models Using Convolutional Neural Networks: Application to a Structure-Controlled Hydrothermal Gold Deposit. Comput. Geosci. 2022, 161, 105074. [Google Scholar] [CrossRef]
- Mou, N.; Carranza, E.J.M.; Wang, G.; Sun, X. A Framework for Data-Driven Mineral Prospectivity Mapping with Interpretable Machine Learning and Modulated Predictive Modeling. Nat. Resour. Res. 2023, 32, 2439–2462. [Google Scholar] [CrossRef]
- Wang, G.; Li, R.; Carranza, E.J.M.; Zhang, S.; Yan, C.; Zhu, Y.; Qu, J.; Hong, D.; Song, Y.; Han, J.; et al. 3D Geological Modeling for Prediction of Subsurface Mo Targets in the Luanchuan District, China. Ore Geol. Rev. 2015, 71, 592–610. [Google Scholar] [CrossRef]
- Lv, X.; Wang, G. GIS-Based Mineral Prospectivity Mapping Using Machine Learning Methods: A Case Study from Duobaoshan Ore District, Northeastern China. Ore Geol. Rev. 2024, 175, 106352. [Google Scholar] [CrossRef]
- Luo, Z.; Zuo, R.; Xiong, Y.; Zhou, B. Metallogenic-Factor Variational Autoencoder for Geochemical Anomaly Detection by Ad-Hoc and Post-Hoc Interpretability Algorithms. Nat. Resour. Res. 2023, 32, 835–853. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, G.; Carranza, E.J.M.; Liu, C.; Li, J.; Fu, C.; Liu, X.; Chen, C.; Fan, J.; Dong, Y. An Integrated Machine Learning Framework with Uncertainty Quantification for Three-Dimensional Lithological Modeling from Multi-Source Geophysical Data and Drilling Data. Eng. Geol. 2023, 324, 107255. [Google Scholar] [CrossRef]
- Zhao, G.; Wilde, S.A.; Cawood, P.A.; Lu, L. Thermal Evolution of Archean Basement Rocks from the Eastern Part of the North China Craton and Its Bearing on Tectonic Setting. Int. Geol. Rev. 1998, 40, 706–721. [Google Scholar] [CrossRef]
- Zhou, X.; Liu, N.; Tang, F.; Zhao, Y.; Qin, K.; Zhang, L.; Li, D. A Deep Manifold Learning Approach for Spatial-Spectral Classification with Limited Labeled Training Samples. Neurocomputing 2019, 331, 138–149. [Google Scholar]
- Li, H.; Zhang, Z.; Li, L.; Zhang, Z.; Chen, J.; Yao, T. Types and General Characteristics of the BIF-Related Iron Deposits in China. Ore Geol. Rev. 2014, 57, 264–287. [Google Scholar] [CrossRef]
- Zhang, Z.; Hou, T.; Santosh, M.; Li, H.; Li, J.; Zhang, Z.; Song, X.; Wang, M. Spatio-Temporal Distribution and Tectonic Settings of the Major Iron Deposits in China: An Overview. Ore Geol. Rev. 2014, 57, 247–263. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, L.; Gao, X.; Li, H.; Jia, D.; Li, L. Metallogenic conditions of high-grade ores in the Sijiaying sedimentary metamorphic iron deposit, Eastern Hebei Province. Geol. Explor. 2014, 50, 675–688, (In Chinese with English abstract). [Google Scholar]
- Zhang, T.; Zhang, W.; Wang, Z.; Zhang, F.; Li, B.; Yang, L. Characteristics of Gravity and Magnetic Anomalies in the Luanan Area of Eastern Hebei and Their Significance in Mineral Exploration. Geophys. Geochem. Explor. 2014, 38, 641–648, (In Chinese with English abstract). [Google Scholar]
- Xu, Y.; Zhang, L.; Li, H.; Li, L.; Gao, X.; Jia, D. The Exploration Model of the Sijiaying Sedimentary Metamorphic Iron Deposit in Eastern Hebei Province. Geol. Explor. 2015, 51, 23–35, (In Chinese with English abstract). [Google Scholar]
- Zhao, Y. Main genetic types and geological characteristics of iron-rich ore deposits in China. Miner. Depos. 2013, 32, 685–704, (In Chinese with English abstract). [Google Scholar]
- Gao, X.; Wang, D.; Huang, F.; Wang, Y.; Guo, W. Discussion on deep prospecting of the Sijiaying iron deposit in eastern Hebei Province. Acta Geol. Sin. 2022, 96, 2495–2505, (In Chinese with English abstract). [Google Scholar]
- Zhang, L.; Zhai, M.; Wan, Y.; Guo, J.; Dai, Y.; Wang, C.; Liu, L. Study of the Precambrian BF-iron depositsin the North China Craton: Progresses and questions. Acta Petrol. Sin. 2012, 28, 3431–3445, (In Chinese with English abstract). [Google Scholar]
- Li, W.; Dong, G.; Ding, F.; Cao, R.; Yang, L.; Fan, Y.; Liu, J.; Zheng, X. Mineralogical characteristics of typical ore from the BlF-type iron deposit at Sijiaying north mining district in eastern Hebei Province and their constraints on the metallogenic evolution. Acta Petrol. Mineral. 2025, 44, 68–86, (In Chinese with English abstract). [Google Scholar]
- Moreira, A.; Prats-Iraola, P.; Younis, M.; Krieger, G.; Hajnsek, I.; Papathanassiou, K.P. A Tutorial on Synthetic Aperture Radar. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–43. [Google Scholar]
- Jackisch, R.; Lorenz, S.; Kirsch, M.; Zimmermann, R.; Tusa, L.; Pirttijärvi, M.; Saartenoja, A.; Ugalde, H.; Madriz, Y.; Savolainen, M.; et al. Integrated Geological and Geophysical Mapping of a Carbonatite-Hosting Outcrop in Siilinjärvi, Finland, Using Unmanned Aerial Systems. Remote Sens. 2020, 12, 2998. [Google Scholar] [CrossRef]
- Li, B.; Peng, Y.; Zhao, X.; Liu, X.; Wang, G.; Jiang, H.; Wang, H.; Yang, Z. Combining 3D Geological Modeling and 3D Spectral Modeling for Deep Mineral Exploration in the Zhaoxian Gold Deposit, Shandong Province, China. Minerals 2022, 12, 1272. [Google Scholar] [CrossRef]
- Zuo, L.; Wang, G.; Carranza, E.J.M.; Zhai, D.; Pang, Z.; Cao, K.; Mou, N.; Huang, L. Short-Wavelength Infrared Spectral Analysis and 3D Vector Modeling for Deep Exploration in the Weilasituo Magmatic–Hydrothermal Li–Sn Polymetallic Deposit, Inner Mongolia, NE China. Nat. Resour. Res. 2022, 31, 3121–3153. [Google Scholar]
- Zuo, L.; Wang, G.; Carranza, E.J.M.; Pang, Z.; Ren, H.; Cao, K.; Liu, Z.; Gao, M. Deep Vector Exploration via Alteration Footprints and Thermal Infrared Scalars for the Weilasituo Magmatic–Hydrothermal Li–Sn Polymetallic Deposit, Inner Mongolia, NE China. Nat. Resour. Res. 2023, 32, 1871–1895. [Google Scholar]
- Shao, X.; Peng, Y.; Wang, G.; Zhao, X.; Tang, J.; Huang, L.; Liu, X.; Zhao, X. Application of Shortwave Infrared Spectroscopy, X-ray Fluorescence Spectroscopy, and Pyrite Thermoelectric Analysis in Deep Exploration of the Jincheng Gold Mine Field in Jiaodong. Earth Sci. Front. 2021, 28, 236–251, (In Chinese with English abstract). [Google Scholar]
- Kohonen, T. Self-Organized Formation of Topologically Correct Feature Maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar]
- Guo, G.; Li, K.; Zhang, D.; Lei, M. Quantitative Source Apportionment and Associated Driving Factor Identification for Soil Potential Toxicity Elements via Combining Receptor Models, SOM, and Geo-Detector Method. Sci. Total Environ. 2022, 830, 154721. [Google Scholar]
- Rahimi, H.; Abedi, M.; Yousefi, M.; Bahroudi, A.; Elyasi, G.-R. Supervised Mineral Exploration Targeting and the Challenges with the Selection of Deposit and Non-Deposit Sites Thereof. Appl. Geochem. 2021, 128, 104940. [Google Scholar] [CrossRef]
- Hazenfratz, R.; Munita, C.S.; Neves, E.G. Neural Networks (SOM) Applied to INAA Data of Chemical Elements in Archaeological Ceramics from Central Amazon. STAR: Sci. Technol. Archaeol. Res. 2017, 3, 334–340. [Google Scholar]
- Li, Y.; Wright, A.; Liu, H.; Wang, J.; Wang, G.; Wu, Y.; Dai, L. Land Use Pattern, Irrigation, and Fertilization Effects of Rice-Wheat Rotation on Water Quality of Ponds by Using Self-Organizing Map in Agricultural Watersheds. Agric. Ecosyst. Environ. 2019, 272, 155–164. [Google Scholar]
- Hariharan, S.; Tirodkar, S.; Porwal, A.; Bhattacharya, A.; Joly, A. Random Forest-Based Prospectivity Modelling of Greenfield Terrains Using Sparse Deposit Data: An Example from the Tanami Region, Western Australia. Nat. Resour. Res. 2017, 26, 489–507. [Google Scholar]
- Li, T.; Xia, Q.; Zhao, M.; Gui, Z.; Leng, S. Prospectivity Mapping for Tungsten Polymetallic Mineral Resources, Nanling Metallogenic Belt, South China: Use of Random Forest Algorithm from a Perspective of Data Imbalance. Nat. Resour. Res. 2020, 29, 203–227. [Google Scholar]
- Peng, Q.; Wang, Z.; Wang, G.; Zhang, W.; Chen, Z.; Liu, X. 3D Mineral Prospectivity Mapping from 3D Geological Models Using Return–Risk Analysis and Machine Learning on Imbalance Data. Minerals 2023, 13, 1384. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar]
- Ge, Y.-Z.; Zhang, Z.-J.; Cheng, Q.-M.; Wu, G.-P. Geological Mapping of Basalt Using Stream Sediment Geochemical Data: Case Study of Covered Areas in Jining, Inner Mongolia, China. J. Geochem. Explor. 2022, 232, 106888. [Google Scholar]
- Carranza, E.J.M.; Laborte, A.G. Data-Driven Predictive Mapping of Gold Prospectivity, Baguio District, Philippines: Application of Random Forests Algorithm. Ore Geol. Rev. 2015, 71, 777–787. [Google Scholar]
- Gao, M.; Wang, G.; Yang, W.; Zhang, Z.; Cai, D.; Xu, Y.; Yang, S. Bagging-Based Positive–Unlabeled Data Learning Algorithm with Base Learners Random Forest and XGBoost for 3D Exploration Targeting in the Kalatongke District, Xinjiang, China. Nat. Resour. Res. 2023, 32, 437–459. [Google Scholar]
- Jia, R.; Lv, Y.; Wang, G.; Carranza, E.J.M.; Chen, Y.; Wei, C.; Zhang, Z. A Stacking Methodology of Machine Learning for 3D Geological Modeling with Geological-Geophysical Datasets, Laochang Sn Camp, Gejiu (China). Comput. Geosci. 2021, 151, 104754. [Google Scholar]
- Mou, N.; Wang, G.; Sun, X. Identification of Geochemical Anomalies Related to Mineralization: A Case Study from Porphyry Copper Deposits in the Qulong-Jiama Mining District of Tibet, China. J. Geochem. Explor. 2023, 244, 107126. [Google Scholar]
- Zhang, Z.; Wang, G.; Liu, C.; Cheng, L.; Sha, D. Bagging-Based Positive-Unlabeled Learning Algorithm with Bayesian Hyperparameter Optimization for Three-Dimensional Mineral Potential Mapping. Comput. Geosci. 2021, 154, 104817. [Google Scholar]
- Zhang, W.; Wu, C.; Zhong, H.; Li, Y.; Wang, L. Prediction of Undrained Shear Strength Using Extreme Gradient Boosting and Random Forest Based on Bayesian Optimization. Geosci. Front. 2021, 12, 469–477. [Google Scholar] [CrossRef]
- Xia, Y.; Liu, C.; Li, Y.; Liu, N. A Boosted Decision Tree Approach Using Bayesian Hyper-Parameter Optimization for Credit Scoring. Expert Syst. Appl. 2017, 78, 225–241. [Google Scholar] [CrossRef]
- Wang, Z.; Yin, Z.; Caers, J.; Zuo, R. A Monte Carlo-Based Framework for Risk-Return Analysis in Mineral Prospectivity Mapping. Geosci. Front. 2020, 11, 2297–2308. [Google Scholar] [CrossRef]
- Bharti, J.P.; Mishra, P.; Moorthy, U.; Sathishkumar, V.E.; Cho, Y.; Samui, P. Slope Stability Analysis Using Rf, Gbm, Cart, Bt and Xgboost. Geotech. Geol. Eng. 2021, 39, 3741–3752. [Google Scholar] [CrossRef]
- Chen, G.; Huang, N.; Wu, G.; Luo, L.; Wang, D.; Cheng, Q. Mineral Prospectivity Mapping Based on Wavelet Neural Network and Monte Carlo Simulations in the Nanling W-Sn Metallogenic Province. Ore Geol. Rev. 2022, 143, 104765. [Google Scholar] [CrossRef]
- Xiong, Y.; Zuo, R. A Positive and Unlabeled Learning Algorithm for Mineral Prospectivity Mapping. Comput. Geosci. 2021, 147, 104667. [Google Scholar] [CrossRef]
- Yousefi, M.; Carranza, E.J.M. Prediction–Area (P–A) Plot and C–A Fractal Analysis to Classify and Evaluate Evidential Maps for Mineral Prospectivity Modeling. Comput. Geosci. 2015, 79, 69–81. [Google Scholar] [CrossRef]
- Xiao, F.; Chen, J.; Hou, W.; Wang, Z.; Zhou, Y.; Erten, O. A Spatially Weighted Singularity Mapping Method Applied to Identify Epithermal Ag and Pb-Zn Polymetallic Mineralization Associated Geochemical Anomaly in Northwest Zhejiang, China. J. Geochem. Explor. 2018, 189, 122–137. [Google Scholar] [CrossRef]
- Zuo, R. Identification of Weak Geochemical Anomalies Using Robust Neighborhood Statistics Coupled with GIS in Covered Areas. J. Geochem. Explor. 2014, 136, 93–101. [Google Scholar] [CrossRef]
- Xue, Q.; Wang, R.; Liu, S.; Shi, W.; Tong, X.; Li, Y.; Sun, F. Significance of Chlorite Hyperspectral and Geochemical Characteristics in Exploration: A Case Study of the Giant Qulong Porphyry Cu-Mo Deposit in Collisional Orogen, Southern Tibet. Ore Geol. Rev. 2021, 134, 104156. [Google Scholar] [CrossRef]
- Xiao, B.; Chu, G.; Feng, Y. Short-Wave Infrared (SWIR) Spectral and Geochemical Characteristics of Hydrothermal Alteration Minerals in the Laowangou Au Deposit: Implications for Ore Genesis and Vectoring. Ore Geol. Rev. 2021, 139, 104463. [Google Scholar] [CrossRef]
- Zhao, P. Characteristics of Geological Big Data and Its Rational Development and Utilization. Earth Sci. Front. 2019, 26, 1–5, (In Chinese with English abstract). [Google Scholar]
- Zhao, P. Big Data Era: Digital Prospecting and Quantitative Evaluation. Geol. Bull. 2015, 34, 1255–1259, (In Chinese with English abstract). [Google Scholar]
- Wang, C.; Wang, G.; Liu, J.; Zhang, D. 3D Geochemical Modeling for Subsurface Targets of Dashui Au Deposit in Western Qinling (China). J. Geochem. Explor. 2019, 203, 59–77. [Google Scholar]
- Gao, X.; Wang, D.; Huang, F.; Wang, Y.; Wang, C. Chronolgy and Geochemistry of the Sijiaying Iron Deposit in Eastern Hebei Province, North China Craton: Implications for the Genesis of High-Grade Iron Ores. Minerals 2023, 13, 775. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Description | Method |
|---|---|---|
| Previous Geological Survey Data | Regional geological maps, geomorphological geological maps, exploration line cross-sections (11), and drilling logs (70) | 3D geological modeling |
| Mineral Hyperspectral Data | SWIR hyperspectral data (395) and TIR hyperspectral data (134) | TSG interpretation |
| XRF | Major and trace elements (395) | SOM clustering |
| UAV Remote Sensing Imagery | LiDAR images, digital elevation data, visible light orthophotos, and multispectral imagery. | 3D surface modeling, 2D intelligent identification of magnetite |
| UAV Aeromagnetic Survey | 1:2000 UAV aeromagnetic data | Reduction to the pole, geophysical inversion |
| Strata/Lithology | Magnetic Susceptibility | |
|---|---|---|
| K (10−64ΠSI) | Jr (10−3 A/m) | |
| Quaternary | 0 | 0 |
| Changcheng Group | 0–300 | 0–200 |
| Migmatite | 0–500 | 0–200 |
| Biotite Granulite | 0–100 | 0–100 |
| Magnetite Quartzite | 30,000–150,000 | 5000–40,000 |
| MS600 Pro | LiDAR | QuSpin Rb OPM | |||
|---|---|---|---|---|---|
| Effective pixels | 1.2 million | Measuring range | 450 m@80%, 0 klx; 190 m@10%, 100 klx | Resolution | 0.1 nT |
| FOV | Horizontal: 49.6°; vertical: 38° | Ranging accuracy | ±2 cm (at 50 m) | Baseline error (200 Hz sampling) | 3 nT |
| Typical width | 110 m × 83 m@h = 120 m | Point cloud density | 240,000 points/s | Weight | 1.2 kg |
| Ground spatial resolution | 8.65 cm@h = 120 m | FOV | Horizontal: 70.4°; vertical: 4.5° | Power Consumption | <10 w |
| Band range | 450 nm@35 nm; 530 nm@27 nm; 650 nm@25 nm; 720 nm@10 nm; 840 nm@30 nm; 900 nm@35 nm | Positioning accuracy (IMU) | Horizontal: ~5 cm; Vertical: ~10 cm | ||
| Method | Parameters | Skopt Best Parameter | Search Range |
|---|---|---|---|
| SVM | C | 0.79 | [1 × 10−6, 1 × 106] (log-uniform) |
| kernel | rbf | [linear, rbf. Sigmoid] | |
| RF | n_estimators | 500 | [10, 500] |
| max_depth | 50 | [5, 50] | |
| min_samples_split | 2 | [2, 20] | |
| min_samples_leaf | 1 | [1, 20] | |
| criterion | gini | [gini, entropy] |
| Predictive Models | Recall | Precision | F1 Score |
|---|---|---|---|
| SVM12 | 0.75 | 0.78 | 0.76 |
| RF23 | 0.80 | 0.79 | 0.79 |
| Expression of Critical Processes | GIS-Based Targeting Criteria |
|---|---|
| The magnetic anomaly of the ore body is higher than that of the surrounding rock, and the magnetic anomaly significantly indicates the presence of rich ore. | Aeromagnetic anomaly |
| The fold structures provide migration pathways for hydrothermal activity, facilitating the formation of rich ore deposits. | Proximity to Sijiaying compound syncline; proximity to migmatization |
| Hydrothermal alteration is pronounced in areas near rich ore bodies. | Proximity to chloritization and carbonatization |
| Method | Parameters | Skopt Best Parameter | Search Range |
|---|---|---|---|
| RF | n_estimators | 35 | [1, 100] |
| max_depth | 481 | [1, 500] | |
| min_samples_split | 12 | [1, 20] |
| Predictive Model | Recall | Precision | F1 Score |
|---|---|---|---|
| BPUL | 0.98 | 0.98 | 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Wang, G.; Mou, N.; Huang, L.; Mei, R.; Zhang, M. Machine-Learning-Based Integrated Mining Big Data and Multi-Dimensional Ore-Forming Prediction: A Case Study of Yanshan Iron Mine, Hebei, China. Appl. Sci. 2025, 15, 4082. https://doi.org/10.3390/app15084082
Chen Y, Wang G, Mou N, Huang L, Mei R, Zhang M. Machine-Learning-Based Integrated Mining Big Data and Multi-Dimensional Ore-Forming Prediction: A Case Study of Yanshan Iron Mine, Hebei, China. Applied Sciences. 2025; 15(8):4082. https://doi.org/10.3390/app15084082
Chicago/Turabian StyleChen, Yuhao, Gongwen Wang, Nini Mou, Leilei Huang, Rong Mei, and Mingyuan Zhang. 2025. "Machine-Learning-Based Integrated Mining Big Data and Multi-Dimensional Ore-Forming Prediction: A Case Study of Yanshan Iron Mine, Hebei, China" Applied Sciences 15, no. 8: 4082. https://doi.org/10.3390/app15084082
APA StyleChen, Y., Wang, G., Mou, N., Huang, L., Mei, R., & Zhang, M. (2025). Machine-Learning-Based Integrated Mining Big Data and Multi-Dimensional Ore-Forming Prediction: A Case Study of Yanshan Iron Mine, Hebei, China. Applied Sciences, 15(8), 4082. https://doi.org/10.3390/app15084082