1. Introduction
The growing number of remote sensing satellites and the miniaturization of remote sensing equipment in recent years have enhanced the flexibility of remote sensing data acquisition, enabling quicker and more targeted responses to specific areas [
1]. Among various remote sensing technologies, Hyperspectral Imagery (HSI) has attracted significant attention due to its capacity for capturing the distinct spectral properties of different objects in a scene. Hyperspectral sensors can provide hundreds of continuous spectral data across the electromagnetic spectrum, from the visible to the infrared (IR) bands. This enables the accurate observation of the reflection or emission characteristics of the object being tested [
2]. Therefore, hyperspectral is capable of a wide range of vision tasks, including image classification [
3], anomalous target detection [
4], target detection [
5], and change detection [
6]. Furthermore, it plays a pivotal role in numerous practical applications, including land cover classification [
7,
8], sea and land military target detection [
9], mineral resources exploration [
10], and crop pathology detection [
11], among others.
Hyperspectral Target Detection (HTD) identifies targets in complex backgrounds by exploiting subtle spectral differences between the targets and backgrounds in HSI. Because of impediments such as cloud cover and the poor spatial resolution of HSI, detected targets are often represented at a sub-pixel level, making the extraction process challenging. HTD methods are primarily divided into classical detection techniques and deep learning-based methods.
The classical HTD methods primarily include methods based on spectral angle detection [
12], hypothesis testing [
13], Constrained Energy Minimization (CEM) [
14], signal decomposition [
15] and sparse representation [
16]. Spectral angle detection methods measure spectral similarity through geometric or probabilistic metrics, such as Spectral Angle Mapper (SAM) [
12], Adaptive Coherence Estimator(ACE) [
17] and Spectral Information Divergence (SID) [
18].These methods are sensitive to spectral variations and often serve as pre- or post-processing steps due to their computational simplicity [
19].Hypothesis testing-based detectors, including Adaptive Spatial Detector (ASD) [
20] and Kernel-based Adaptive Subspace Detector (KASD) [
21], rely on statistical signal theory and likelihood ratio tests but face limitations from Gaussian distribution assumptions. The CEM detection algorithm [
14], minimizes background energy while enhancing target responses through linear filtering. Though simple, its linear nature struggles with nonlinear HSI features, prompting nonlinear extensions like hCEM [
22] and machine learning variants [
23,
24].The Signal Decomposition Detection method [
25,
26] separate targets from backgrounds using models like Orthogonal Subspace Projection (OSP) [
27] and Low-Rank and Sparse Matrix Decomposition (LRaSMD) [
28], yet require precise spectral modeling and suffer from high complexity.The sparse representation methods [
29,
30,
31] leverage sparse coefficients and dictionary learning (e.g., a dual sparsity constrained(DSC) [
32]) to enhance target-background discrimination. While effective, their performance depends heavily on dictionary completeness, limiting generalization.Most traditional detection algorithms rely on manually predefined assumptions (e.g., spectral matching criteria, energy minimization, or distribution models) and struggle to effectively handle the nonlinear characteristics inherent in complex real-world scenarios. This limitation has driven researchers to explore and adopt end-to-end deep learning models, leveraging data-driven approaches to reduce reliance on handcrafted feature engineering.
Recently, the rapid advancements in deep learning have revitalized HTD. Deep learning can capture complex and diverse nonlinear characteristics of HSI using multi-layered network structures. Deep learning-based HTD methods can be categorized into two main approaches. The first approach constructed an end-to-end network for HSI to enable target detection across all images. Freitas et al. [
33] developed a detection model using a 3D Convolutional Neural Network (CNN) for maritime HTD. Zhang et al. [
34] introduced HTD-Net, a method combining an Auto Encoder (AE) with CNN for HTD in scenarios with missing labels. Qin et al. [
35] introduced the HTD-ViT algorithm, which integrated spectral and spatial information for HTD. Jiao et al. [
36] combined Fourier transform with Transformer to develop a dual-branch Fourier hybrid transform network. Wang et al. [
37] innovatively enhanced spectral feature learning by integrating the momentum encoder with Transformer. Jiao et al. [
38] introduced a triplet spectral transformer method for HTD, excelling at capturing long-term dependencies in spectral features.
The second approach involved reconstructing hyperspectral data using generative deep learning, followed by target detection based on differences between the reconstructed target and background. These methods typically relied on learning from background samples generated after coarse detection. With advancements in generative networks, Generative Adversarial Networks (GAN) [
39], Variational Auto Encoders (VAE) [
40], and AEs have been widely applied in HTD. Xie et al. [
41] pioneered the field by proposing a target-constrained background GAN model, which relies on background learning based on target suppression constraint (BLTSC) for HTD. Xie et al. [
42] introduced an unsupervised algorithm leveraging a deep latent spectral representation model to adaptively map latent representations to optimal subset relationships. Ali et al. [
43] proposed a self-supervised background learning method by combining principal component analysis (PCA) with an adversarial autoencoder (AAE) network. Xie et al. [
44] proposed a Spectral Regularized Unsupervised Network (SRUN) to enhance the spectral representation capabilities of Autoencoder and Variational Autoencoder (VAE) models. The framework integrated spectral angular difference-driven feature selection and adaptive weighting mechanisms to generate discriminative detection maps. Tian et al. [
45] combined OSP theory with VAE and proposed the OS-VAE network framework, exploring new methods that fuse traditional methods with deep learning.In order to improve non-linear feature expression and physical interpretability, Shen et al. [
46] designed a subspace representation network for HTD. Shi et al. successively integrated AE with HTD to develop the DCSSAE network [
47] and 3DMMRAE network [
48].
Despite the significant success of deep learning-based HTD, several challenges remain:
Supervised deep learning often demands extensive labeled training data, which is challenging to obtain in practical scenarios, potentially undermining its robustness. Recently, self-supervised generative HTD has advanced significantly, but coarse detection often suffers from background-target misclassification. Improving coarse detection remains a critical challenge in generative HTD.
Effective background learning is crucial for enhancing algorithm performance through improved background representation. However, HSI is often underestimated in practical applications, with its relationship to prior spectra poorly understood, leading to inadequate suppression of specific targets.
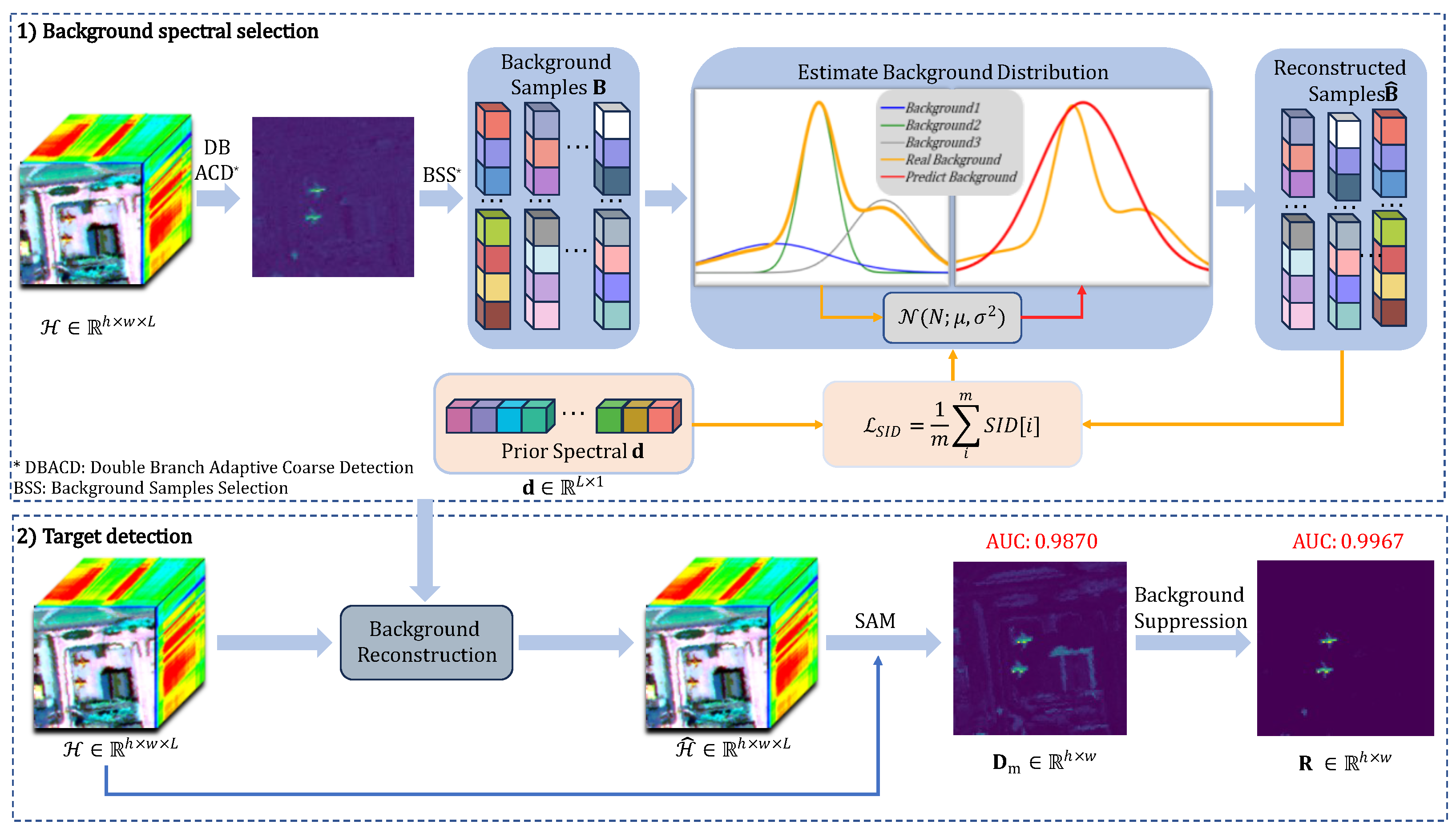
Based on the above considerations, this paper proposes a hyperspectral detection deep learning model based on Diffusion and target suppression constraints, with the intention of enhancing coarse detection’s efficiency and the ability to represent the background. The model is named by SID-DN. The main contributions of this paper are as follows:
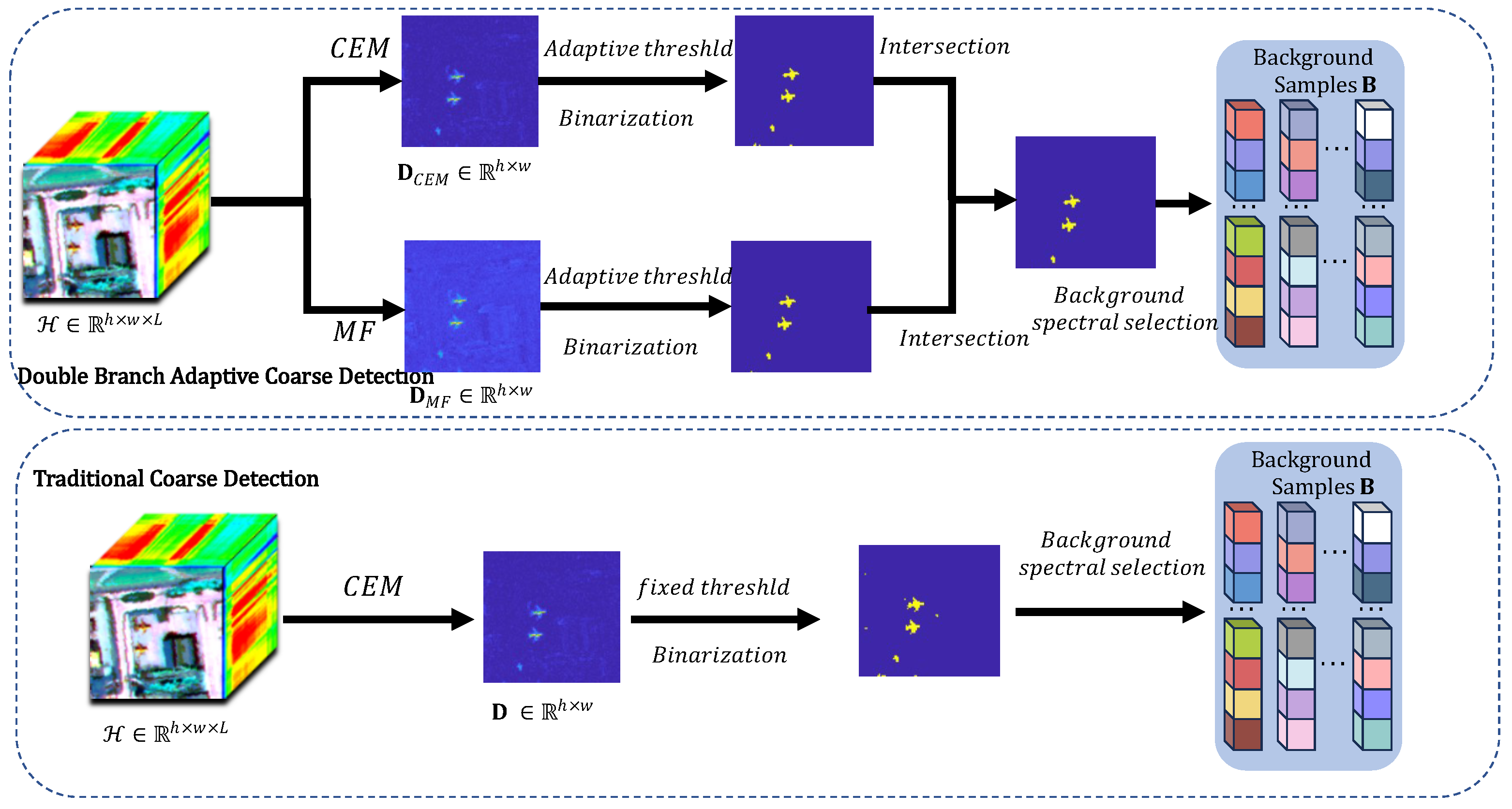
This paper proposes a two-stream adaptive coarse detection algorithm that enhances the coarse detection process and better distinguishes background samples from target samples.
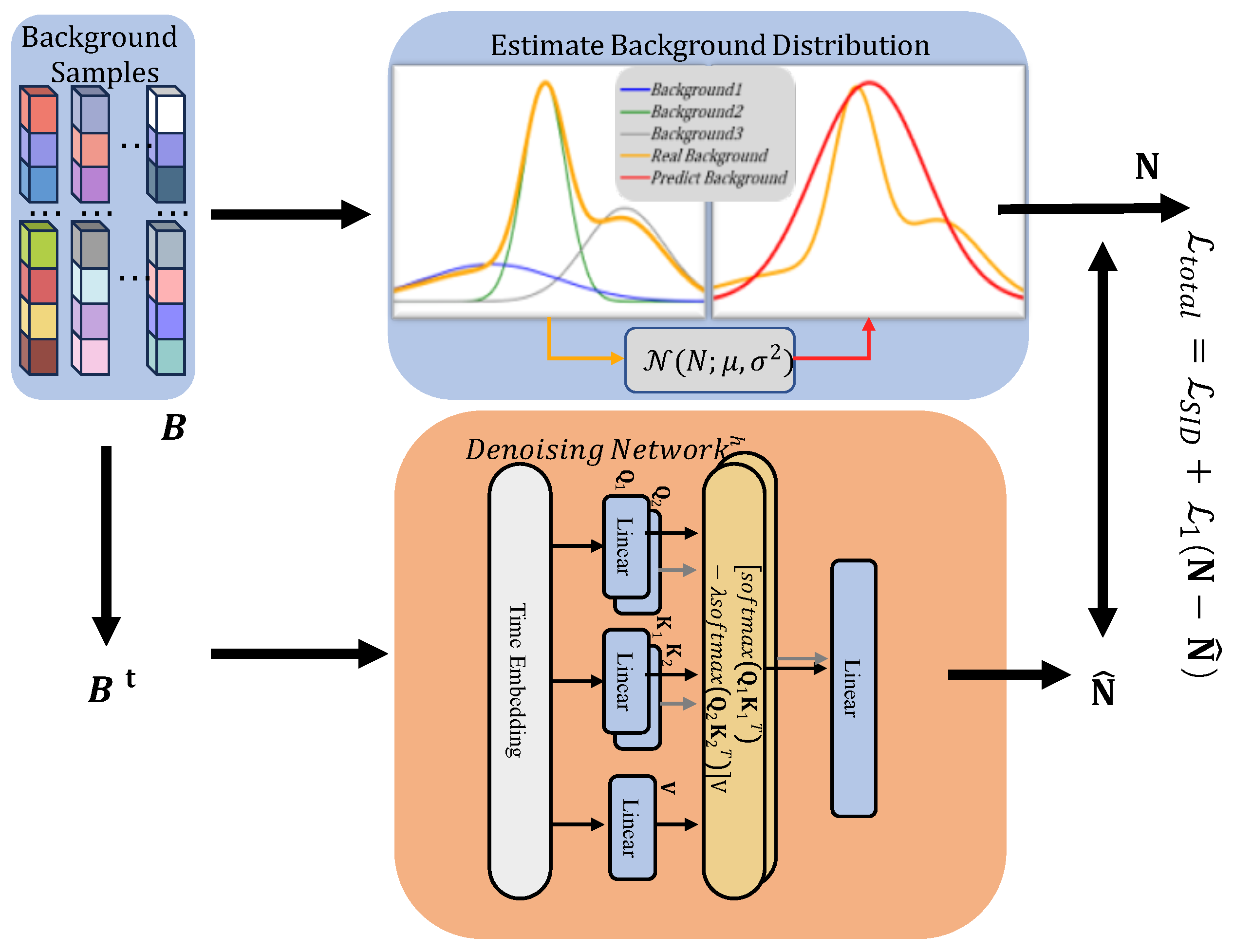
In order to enhance the learning of hyperspectral information by Diffusion, a SID-based Diffusion model is designed to optimize the loss of Diffusion. Compared with the traditional Diffusion, the performance of the algorithm is improved while using prior spectral information.
To verify the effectiveness of the method in this paper, the results are compared with the most advanced existing algorithms, which show that our model is superior to existing HTD algorithms.
The rest of this paper is organized as follows.
Section 2 reviews the necessary knowledge and related works.
Section 3 gives a detailed description of the proposed method.
Section 4 presents the experimental setup and results on the data set.
Section 5 analyses the experiments.
Section 6 concludes and summarizes the paper.
4. Results
This section begins with basic information about the test dataset, followed by the parameter and environment settings for both the proposed and state-of-the-art algorithms. Finally, the two algorithms are compared using objective and subjective metrics.
4.1. Description of Experimental Datasets
In this experiment, three real HTD datasets are selected to validate the proposed algorithm: the Gulfport dataset (part of the ABU dataset), the Los Angeles dataset, and the San Diego dataset. Their basic information is summarized in
Table 1. The Gulfport and Los Angeles datasets are derived from the ABU dataset collected by Kang et al. [
56], with aircraft as the detection objects. Low signal-to-noise spectra and spectra impacted by water vapor interference, including bands 1–6, 33–35, 97, 107–113, 153–166 and 221–224, are eliminated for the San Diego dataset. The remaining 189-dimensional spectra are used for experiments, with aircraft as the detection objects. The image sizes of the three datasets shown in
Table 1 represent cropped dimensions.
4.2. Evaluation Metrics
To comprehensively evaluate HTD performance, this paper uses the 2-D and 3-D Receiver Operating Characteristic Curves (ROC) and the target-background separation map as objective evaluation metrics.
The ROC curve illustrates the relationship between the detection rate
and the false alarm rate
as the classification threshold
varies. The corresponding formula is provided in Equations (
25) and (
26).
The detection rate
is defined as the proportion of positive cases correctly detected at a given threshold
, as described in Equation (
25). The false alarm rate
is the proportion of incorrectly detected positive cases relative to all negative cases at threshold
, as shown in Equation (
26). An ideal ROC curve approaches the upper left corner (0,1), indicating a high detection rate and a low false alarm rate.
By varying the threshold , 2D ROC curves and can be plotted. A faster rise in the 2D ROC curves indicates a higher detection rate, and a faster decline in the 2D ROC curves indicates a lower false alarm rate.
The Area Under the Curve (AUC) represents the area enclosed by the ROC curve and
, as defined in Equation (
27). A larger AUC value indicates a higher detection rate for the model.
To further evaluate the target detection performance of the model, Chang et al. [
57] proposed a 3D ROC curve detection method. The 3D ROC curve includes five key metrics:
,
,
,
. Calculated using Equations (
28) and (
29):
The value of is interpreted the same way as AUC: a larger value indicates better detection algorithm performance, with an optimal value of 1. represents the overall performance of the algorithm and is the most important metric. However, is interpreted differently: a smaller value signifies better performance, with the optimal value being 0. a smaller value reflects a lower false alarm rate and better background suppression. is a composite indicator calculated by weighting and summing the two AUC metrics. Consequently, a larger value indicates better detection algorithm performance, with the optimal value being 1. is inspired by the concept of Signal-to-Noise Ratio (SNR), where represents the signal and represents the noise. A larger value indicates better performance of the detection algorithm, with the optimal value being . The 3D ROC curve provides a three-dimensional visualization, allowing for intuitive assessment of the impact of threshold on the detection rate and the false alarm rate .
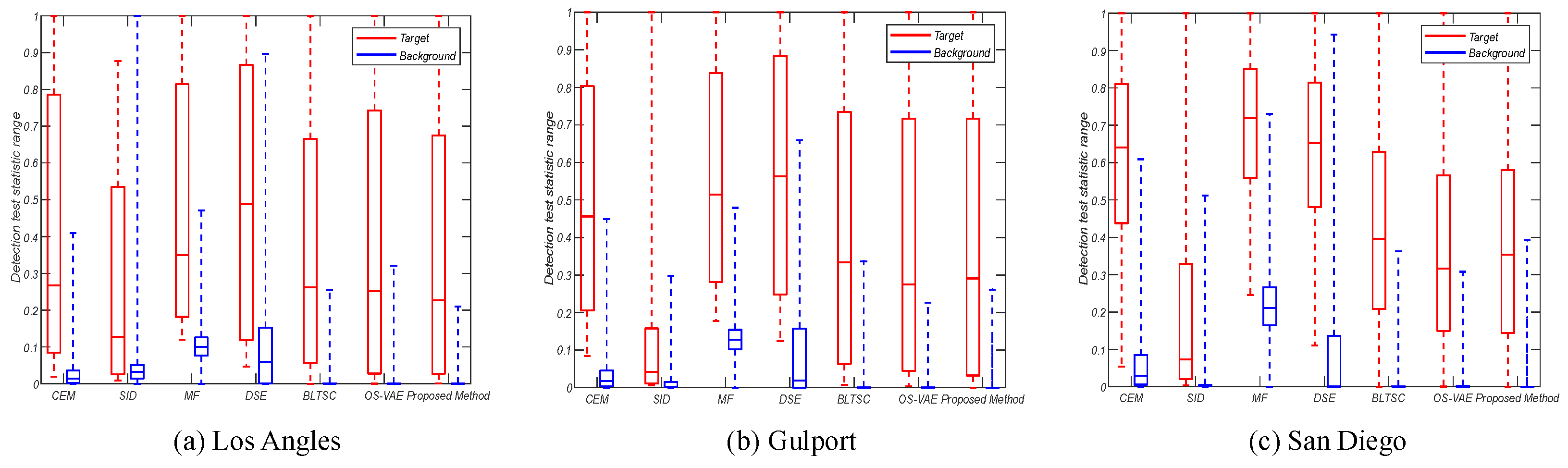
The target-background separation map, using the Box-Whisker method, analyzes the separation between target and background. There are two main criteria for evaluation. The first criterion is whether there is any overlap between the target box and the background box. If overlap exists, it indicates that the target and background are mixed during the detection process, making it difficult to distinguish them. The second criterion is based on the area of the background box. The upper and lower bounds of the box represent the 75th and 25th percentiles of the data, respectively. A smaller box indicates that the data are more concentrated, and background suppression is more effective.
4.3. Experimental Environment and Contrasting Models
The hardware used in this experiment includes an i7-12700K CPU, NVIDIA GTX 3090Ti 24 GB graphics card, and 128 GB RAM. The software environment comprises Windows Subsystem for Linux (WSL), PyTorch 1.11.0, and Python 3.8.
To evaluate the efficiency of the algorithms proposed in this paper, traditional target detection methods such as CEM [
14], SID [
18], MF [
54] and sparse representation method as DSE [
32], as well as deep learning models like BLTSC [
41] and OS-VAE [
45], were selected for comparison. All comparison algorithms were configured with the optimal parameters specified in the respective papers.
4.4. Comparative Results on HSI Target Detection
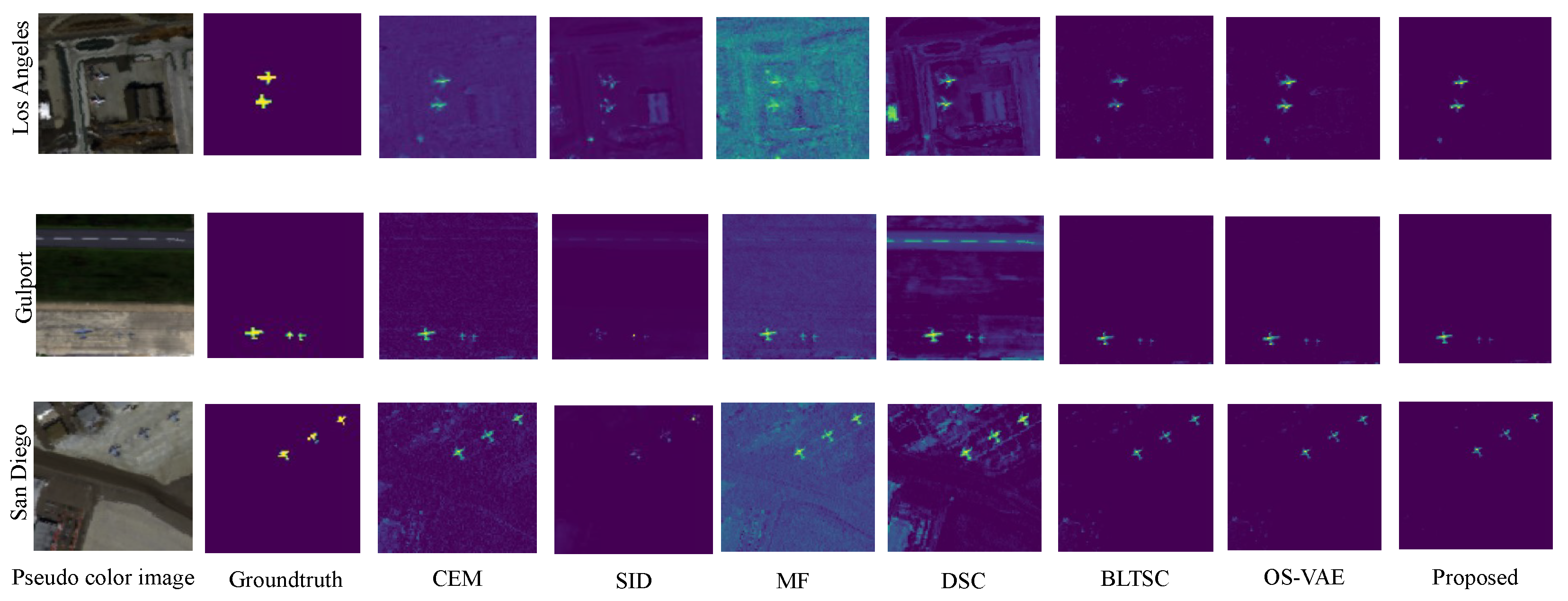
Figure 4 visualizes the detection maps generated by all comparison methods and the proposed method on three real datasets. The results demonstrate that the SID-DN method outperforms the other methods in both target detection and background suppression. Classical detection techniques like MF, CEM and SID exhibit high accuracy in target detection but struggle to filter extensive background information, resulting in insufficient background suppression. Likewise, the DSC method performs poorly in handling complex spectral scenarios, leading to increased false alarm targets. The SID-DN method excels in background suppression, effectively suppressing target-independent background information compared to recently proposed methods such as BLTSC and OS-VAE. BLTSC and OS-VAE, which are generative deep learning models that incorporate background generation representation, slightly lag behind the SID-DN algorithm in background suppression. This confirms the effectiveness of incorporating SID concepts into network design. Furthermore, using SID-DN, particularly on the Los Angeles dataset, the distinction between the target and background is highly evident, demonstrating that the reconstructed background closely resembles the real situation. Additionally, this paper enhances the coarse detection algorithm, significantly reducing target interference in the learning of background samples. The incorporation of SID concepts effectively eliminates potential bad samples, enabling accurate reconstruction of background samples. In summary, the SID-DN method proposed in this paper demonstrates competitive advantages in both target detection and background suppression.
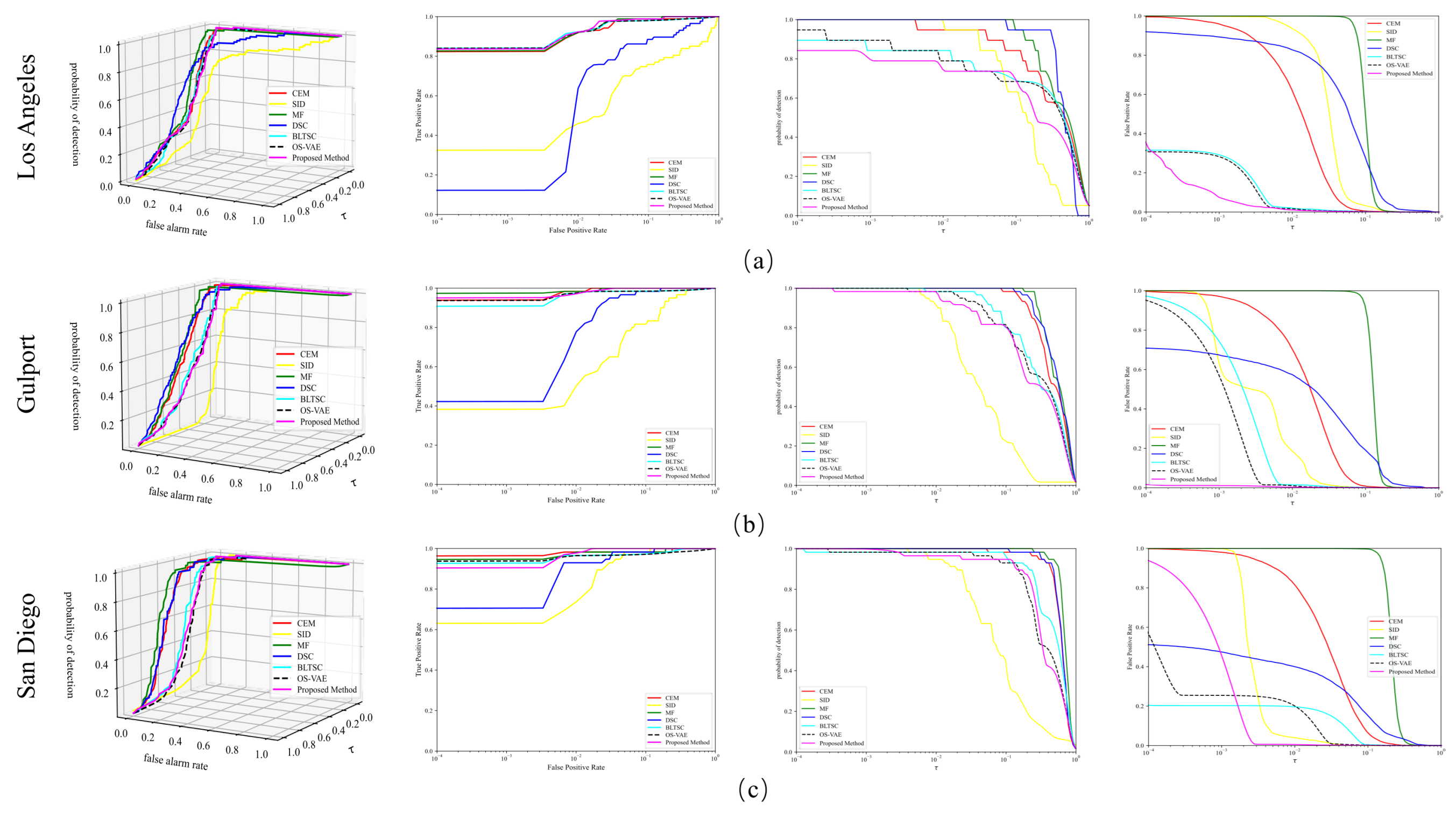
Figure 5 presents the 3D ROC curves corresponding to the above detection results. Compared to the other algorithms, SID-DN achieves results closer to the upper left corner of the test dataset in terms of the
metric. However, SID-DN performs slightly worse than DSE and MF in
. This is because SID-DN focuses on learning background features through reconstruction, but the target spectral reconstruction remains suboptimal, resulting in weaker target intensity in detection and impacting this metric. Conversely, SID-DN is closer to the bottom right corner in the
curve, indicating its superior background suppression capabilities compared to other methods. This observation highlights the importance of considering multiple metrics in evaluating algorithm performance. In summary, SID-DN achieves a highly advantageous average optimal detection rate across all three datasets.
While ROC curves visually represent the results, accurately assessing them can be challenging due to overlapping curves among the compared methods. Thus, the five AUC metrics across the three datasets are analyzed in detail in
Table 2,
Table 3 and
Table 4.
In
Table 2,
Table 3 and
Table 4, the best results are highlighted in bold. The proposed method achieves the best performance on the most critical metric,
demonstrating the superiority of the algorithm.
typically shows an inverse trend with
, where a large value of
corresponds to a small value of
, or vice versa. Due to limitations in background reconstruction, SID-DN does not achieve the best results in
. However, it achieves the highest average performance in
,
and
, strongly indicating its effectiveness in suppressing the complex backgrounds of HSI. In conclusion, the AUC scores from the comprehensive performance analysis highlight the sophistication and robustness of the proposed SID-DN algorithm.
This paper further evaluates the target-background separation performance of SID-DN compared to other methods across three datasets. As shown in
Figure 6, SID-DN achieves superior target-to-background separation ratios, better separation between target and background, and smaller overlapping regions across all datasets. Additionally, SID-DN effectively suppresses background interference, further demonstrating the algorithm’s effectiveness.
In conclusion, the proposed SID-DN method delivers outstanding performance in both subjective and objective metrics, including detection maps and 3D-ROC curves, while demonstrating superior target-background separation capability across multiple datasets.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}